[AINews] Creating a LLM-as-a-Judge
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Critique Shadowing is all you need.
AI News for 10/29/2024-10/30/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (231 channels, and 2558 messages) for you. Estimated reading time saved (at 200wpm): 241 minutes. You can now tag @smol_ai for AINews discussions!
On a day when Anthropic (Claude 3.5 SWEBench+SWEAgent details), OpenAI (SimpleQA), DeepMind (NotebookLM) and Apple (M4 Macbooks) and a mysterious new SOTA image model (Recraft v3) have releases, it is rare to focus on news from a smaller name, but we love news you can use.
After his hit Your AI Product Needs Evals (our coverage here), Hamel Husain is back with an epic 6,000 word treatise on Creating a LLM-as-a-Judge That Drives Business Results, with a clear problem statement: AI teams have too much data they don't trust and don't use.
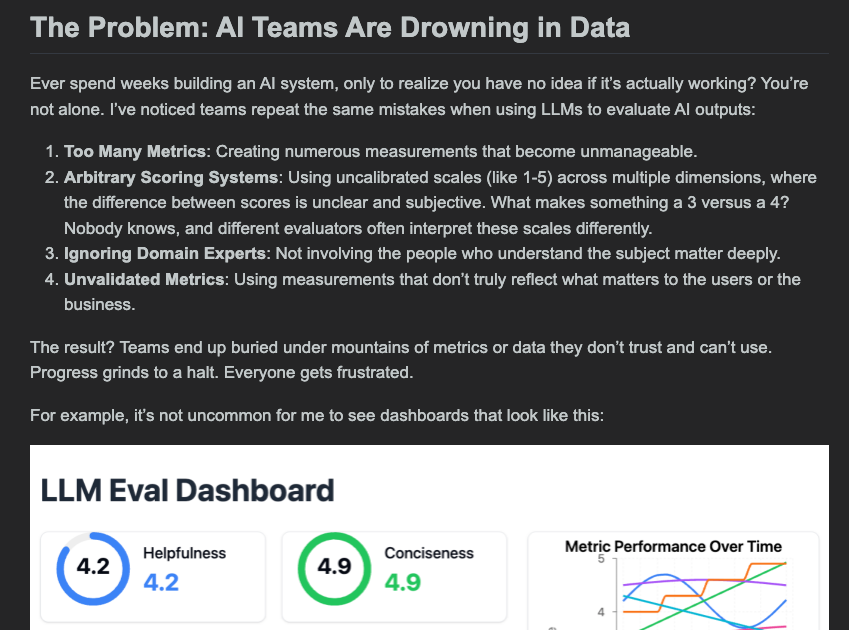
There are a lot of standard themes echoed in Hamel's AI.Engineer talk (as well as the very fun Weights & Biases one), but this piece is notable for its strong recommendation of critique shadowing as to create few-shot examples for LLM judges to align with domain experts:
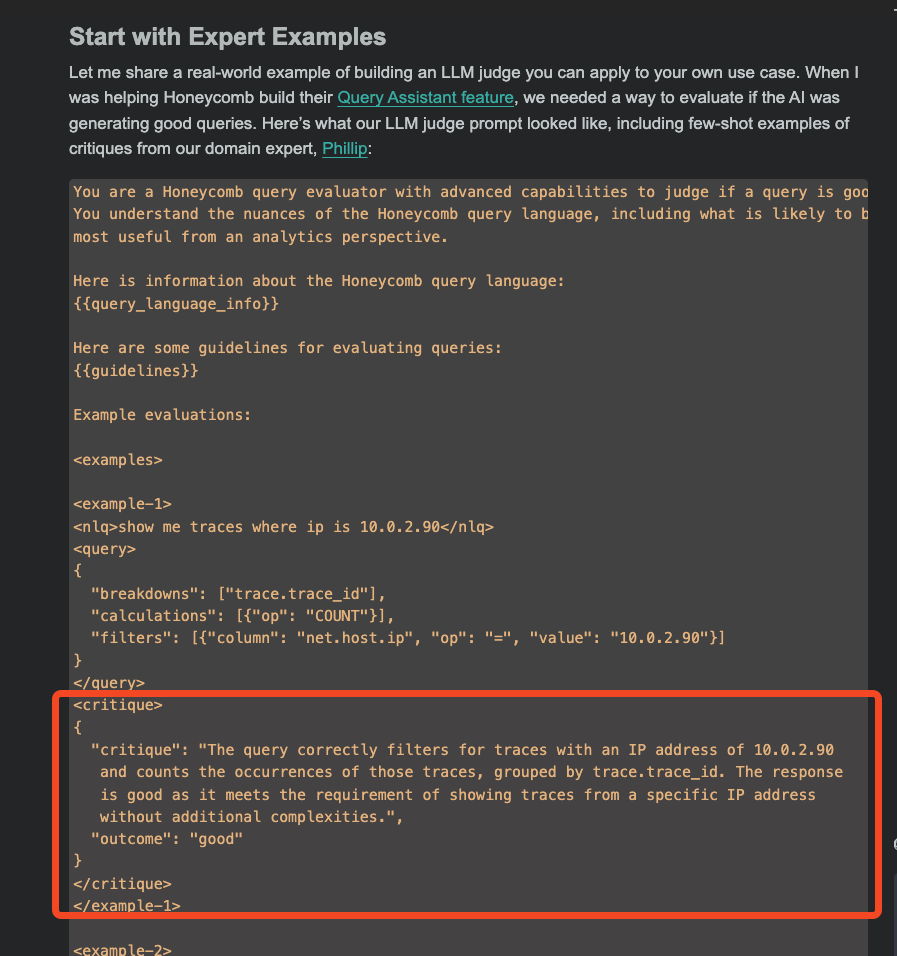
Critique Shadowing TLDR:
- Find Principal Domain Expert
- Create A Dataset
- Generate diverse examples covering your use cases
- Include real or synthetic user interactions
- Domain Expert Reviews Data
- Expert makes pass/fail judgments
- Expert writes detailed critiques explaining their reasoning
- Fix Errors (if found)
- Address any issues discovered during review
- Return to expert review to verify fixes
- Go back to step 3 if errors are found
- Build LLM Judge
- Create prompt using expert examples
- Test against expert judgments
- Refine prompt until agreement is satisfactory
- Perform Error Analysis
- Calculate error rates across different dimensions
- Identify patterns and root causes
- Fix errors and go back to step 3 if needed
- Create specialized judges as needed
The final workflow looks like this:
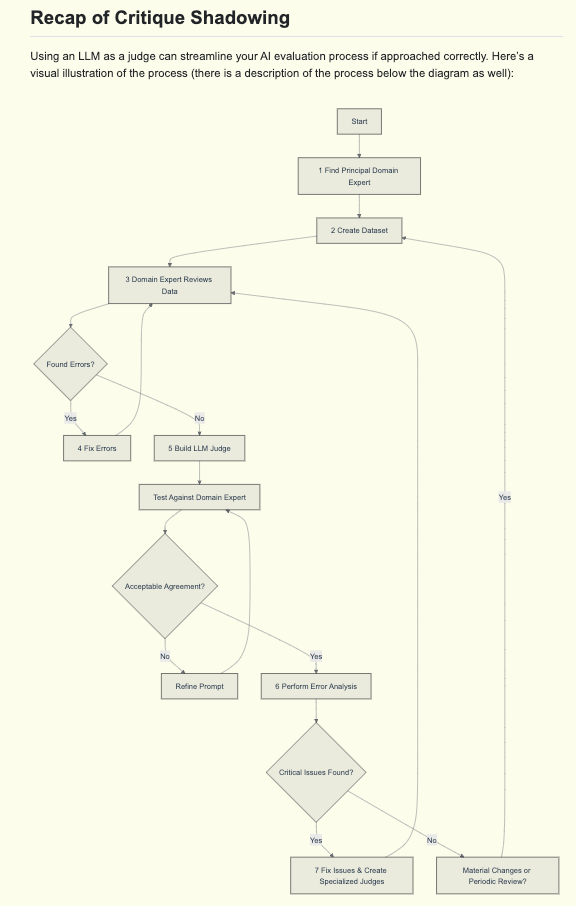
Handy, and, as Hamel mentions in the article, this is our critique-and-domain-expert-heavy iterative process for building AINews as well!
[Sponsored by Zep] Why do AI agents need a memory layer, anyway? Well, including the full interaction history in prompts leads to hallucinations, poor recall, and costly LLM calls. Plus, most RAG pipelines struggle with temporal data, where facts change over time. Zep is a new service that tackles these problems using a unique structure called a temporal knowledge graph. Get up and running in minutes with the quickstart.
swyx's commentary: the docs for the 4 memory APIs of Zep also helped me better understand the scope of what Zep does/doesn't do and helped give a better mental model of what a chatbot memory API should look like agnostic of Zep. Worthwhile!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- LM Studio Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- OpenAI Discord
- Perplexity AI Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- Nous Research AI Discord
- Eleuther Discord
- Interconnects (Nathan Lambert) Discord
- Notebook LM Discord Discord
- GPU MODE Discord
- Torchtune Discord
- Cohere Discord
- Latent Space Discord
- tinygrad (George Hotz) Discord
- Modular (Mojo 🔥) Discord
- LlamaIndex Discord
- DSPy Discord
- OpenInterpreter Discord
- LangChain AI Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- LLM Agents (Berkeley MOOC) Discord
- Mozilla AI Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- LM Studio ▷ #general (161 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (600 messages🔥🔥🔥):
- HuggingFace ▷ #general (326 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (8 messages🔥):
- HuggingFace ▷ #cool-finds (17 messages🔥):
- HuggingFace ▷ #i-made-this (3 messages):
- HuggingFace ▷ #computer-vision (2 messages):
- HuggingFace ▷ #NLP (10 messages🔥):
- HuggingFace ▷ #diffusion-discussions (3 messages):
- Unsloth AI (Daniel Han) ▷ #general (89 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (41 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (28 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (12 messages🔥):
- OpenAI ▷ #ai-discussions (129 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (11 messages🔥):
- OpenAI ▷ #prompt-engineering (2 messages):
- OpenAI ▷ #api-discussions (2 messages):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (124 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (5 messages):
- aider (Paul Gauthier) ▷ #general (107 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (12 messages🔥):
- aider (Paul Gauthier) ▷ #links (3 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (114 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (117 messages🔥🔥):
- Nous Research AI ▷ #general (67 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (12 messages🔥):
- Nous Research AI ▷ #interesting-links (8 messages🔥):
- Nous Research AI ▷ #reasoning-tasks (3 messages):
- Eleuther ▷ #general (16 messages🔥):
- Eleuther ▷ #research (44 messages🔥):
- Eleuther ▷ #interpretability-general (7 messages):
- Eleuther ▷ #lm-thunderdome (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (54 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (3 messages):
- Interconnects (Nathan Lambert) ▷ #posts (8 messages🔥):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (38 messages🔥):
- Notebook LM Discord ▷ #general (40 messages🔥):
- GPU MODE ▷ #general (4 messages):
- GPU MODE ▷ #torch (16 messages🔥):
- GPU MODE ▷ #beginner (12 messages🔥):
- GPU MODE ▷ #torchao (1 messages):
- GPU MODE ▷ #rocm (15 messages🔥):
- GPU MODE ▷ #sparsity-pruning (7 messages):
- GPU MODE ▷ #thunderkittens (7 messages):
- Torchtune ▷ #general (27 messages🔥):
- Torchtune ▷ #dev (20 messages🔥):
- Cohere ▷ #discussions (4 messages):
- Cohere ▷ #questions (17 messages🔥):
- Cohere ▷ #api-discussions (15 messages🔥):
- Cohere ▷ #projects (1 messages):
- Cohere ▷ #cohere-toolkit (1 messages):
- Latent Space ▷ #ai-general-chat (36 messages🔥):
- tinygrad (George Hotz) ▷ #general (11 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
- Modular (Mojo 🔥) ▷ #general (6 messages):
- Modular (Mojo 🔥) ▷ #mojo (17 messages🔥):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (14 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- DSPy ▷ #papers (5 messages):
- DSPy ▷ #general (4 messages):
- OpenInterpreter ▷ #general (4 messages):
- OpenInterpreter ▷ #ai-content (4 messages):
- LangChain AI ▷ #general (2 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- LangChain AI ▷ #tutorials (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- LAION ▷ #general (2 messages):
- LAION ▷ #research (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
- Mozilla AI ▷ #announcements (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
GitHub Copilot and AI Integration
- Claude integration: @AnthropicAI announced that Claude 3.5 Sonnet is now available on GitHub Copilot, with access rolling out to all Copilot Chat users and organizations over the coming weeks. @alexalbert__ echoed this announcement, highlighting the availability in Visual Studio Code and GitHub.
- Perplexity AI partnership: @perplexity_ai shared their excitement about partnering with GitHub, detailing features like staying updated on library updates, finding answers to questions, and accessing API integration assistance within the GitHub Copilot platform.
- Multiple model support: @rohanpaul_ai noted that Gemini 1.5 Pro is also available in GitHub Copilot, alongside Claude 3.5 Sonnet and OpenAI's o1-preview. This multi-model support represents a significant shift in GitHub Copilot's offerings.
- Impact on development: @rohanpaul_ai highlighted a statistic that "more than 25% of all new code at Google is now generated by AI", suggesting a significant impact of AI on software development practices.
AI Advancements and Research
- Layer Skip technology: @AIatMeta announced the release of inference code and fine-tuned checkpoints for Layer Skip, an end-to-end solution for accelerating LLMs by executing a subset of layers and using subsequent layers for verification and correction.
- Small Language Models: @rohanpaul_ai shared a survey paper on Small Language Models, indicating ongoing research interest in more efficient AI models.
- Mixture-of-Experts (MoE) research: @rohanpaul_ai discussed a paper revealing that MoE architectures trade reasoning power for memory efficiency in LLM architectures, with more experts not necessarily making LLMs smarter, but better at memorizing.
AI Applications and Tools
- Perplexity Sports: @AravSrinivas announced the launch of Perplexity Sports, starting with NFL widgets for game summaries, stats, and player/team comparisons, with plans to expand to other sports.
- AI in media production: @c_valenzuelab shared a lengthy thread about Runway's vision for AI in media and entertainment, describing AI as a tool for storytelling and predicting a shift towards interactive, generative, and personalized content.
- Open-source developments: @AIatMeta released inference code and fine-tuned checkpoints for Layer Skip, an acceleration technique for LLMs, on Hugging Face.
Programming Languages and Tools
- Python's popularity: @svpino noted that Python is now the #1 programming language on GitHub, surpassing JavaScript.
- GitHub statistics: @rohanpaul_ai shared insights from the Octoverse 2024 report, including a 98% YoY growth in AI projects and a 92% spike in Jupyter Notebook usage.
Memes and Humor
- @willdepue joked about AGI being achieved internally, saying "proof agi has been achieved internally. we did it joe".
- @Teknium1 quipped "Japan AI companies are brutal lol", likely in reference to some humorous or aggressive AI-related development in Japan.
- @nearcyan made a joke about the "80IQ play" of investing in NVIDIA due to ChatGPT's popularity, reflecting on the massive returns such an investment would have yielded.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Apple's M4 Mac Mini: A New Contender for AI Development
- Mac Mini looks compelling now... Cheaper than a 5090 and near double the VRAM... (Score: 49, Comments: 18): The post suggests that the Mac Mini with the M4 chip could be a more attractive option for AI workloads compared to high-end GPUs like the hypothetical 5090. The author highlights that the Mac Mini is potentially cheaper and offers nearly twice the VRAM, making it a compelling choice for AI tasks that require substantial memory.
- New M4 / Pro Mac Minis discuss (Score: 40, Comments: 58): The post discusses speculation about potential M4 / Pro Mac Mini models for AI tasks. While no specific specs or pricing information is provided, the title suggests interest in the capabilities and cost of future Mac Mini iterations optimized for artificial intelligence applications.
- Speculation on M4 Mac Mini pricing: Base model with 32GB RAM estimated at $1000, while 64GB version at $2000. A user claimed base model with 16GB could be $499 with education discount.
- Discussion on memory bandwidth and performance: The M4 is estimated to have 260 GB/s bandwidth, potentially achieving 6-7 tokens/s with Qwen 72B 4-bit MLX. Some users debated the trade-offs between Mac Minis and GPUs like 3090s for AI tasks.
- Comparisons with Nvidia GPUs: Users discussed how Mac Minis with high RAM could compete with expensive GPUs like the 4090. However, others noted that while Macs offer more RAM, GPUs still provide significantly faster processing speeds for AI tasks.
Theme 2. Stable Diffusion 3.5 Medium Released on Hugging Face
- Stable Diffusion 3.5 Medium · Hugging Face (Score: 68, Comments: 31): Stable Diffusion 3.5 Medium, a new text-to-image model, has been released on Hugging Face. This model boasts improved capabilities in text rendering, multi-subject generation, and compositional understanding, while also featuring enhanced image quality and reduced artifacts compared to previous versions. The model is available for commercial use under the OpenRAIL-M license, with a 768x768 default resolution and support for various inference methods including txt2img, img2img, and inpainting.
- Users inquired about hardware requirements for self-hosting the model. According to the blog, it requires 10GB of VRAM, with GPUs ranging from 3090 to H100 recommended for "32GB or greater" setups.
- Discussion arose about the possibility of running the model with smaller quantizations, similar to LLMs. Users speculated that this would likely be attempted by the community.
- When asked about comparisons to Flux Dev, one user simply responded "badly," suggesting that Stable Diffusion 3.5 Medium may not perform as well as Flux Dev in certain aspects.
Theme 3. AI Safety and Alignment: Debates and Criticisms
- Apple Intelligence's Prompt Templates in MacOS 15.1 (Score: 293, Comments: 67): Apple's MacOS 15.1 introduces AI prompt templates and safety measures as part of its Apple Intelligence feature. The system includes built-in prompts for various tasks such as summarizing text, explaining concepts, and generating ideas, with a focus on maintaining user privacy and data security. Apple's approach emphasizes on-device processing and incorporates content filtering to prevent the generation of harmful or inappropriate content.
- Users humorously critiqued Apple's prompt engineering, with jokes about "begging" for proper JSON output and debates on YAML vs. JSON efficiency. The discussion highlighted the importance of minifying JSON for token savings.
- The community expressed skepticism about Apple's approach to preventing hallucinations and factual inaccuracies, with one user sharing a GitHub gist containing metadata.json files from Apple's asset folders.
- Discussions touched on the potential use of a 30 billion parameter model (v5.0-30b) and critiqued the inclusion of specific sports like diving and hiking in event options, speculating on possible management influence.
- The dangerous risks of “AI Safety” (Score: 47, Comments: 62): The post discusses potential risks of AI alignment efforts, linking to an article that suggests alignment technology could be misused to serve malicious interests rather than humanity as a whole. The author argues this is already happening, noting that current API-based AI systems often enforce stricter rules than Western democratic laws, sometimes aligning more closely with extremist ideologies like the Taliban in certain areas, while local models are less affected but still problematic.
- Users noted AI's inconsistent content restrictions, with some pointing out that API-based AI often prohibits content readily available on primetime television. There's significant demand for NSFW content, despite AI companies' anti-NSFW stance.
- Commenters discussed the potential for AI alignment to be used as a tool for censorship and control. Some argued this is already happening, with AI being ideologically aligned to its creators and used to exert power over users.
- Several users expressed concerns about corporate anxiety and sensitivity driving AI restrictions, potentially leading to the suppression of free speech. Some advocated for widespread AI access to balance power between citizens and governments/corporations.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Techniques
- Geometric structure in LLM-learned concepts: A paper shared on Twitter reveals surprising geometric structures in concepts learned by large language models, including brain-like "lobes" and precise "semantic crystals".
- AI-generated code at Google: Google CEO Sundar Pichai stated that more than 25% of new code at Google is now generated by AI. Some commenters speculate this likely includes auto-complete suggestions and other assistance tools.
- ARC-AGI benchmark progress: MindsAI achieved a new high score of 54.5% on the ARC-AGI benchmark, up from 53% just 6 days prior. The prize goal is 85%.
AI Applications and Impacts
- AI in education: A study found students with AI tutors learned more than twice as much in less time compared to traditional in-class instruction. Some commenters noted AI could provide more personalized, interactive learning.
- Digital fruit replication: A plum became the first fruit to be fully digitized and reprinted with its scent, without human intervention.
- AI in software development: Starting today, developers can select Claude 3.5 Sonnet in Visual Studio Code and Github Copilot. Gemini is also officially coming to Github Copilot.
AI Model Releases and Improvements
- Stable Diffusion 3.5 improvements: A workflow combining SD 3.5 Large, Medium, and upscaling techniques produced high-quality image results, showcasing advancements in image generation capabilities.
AI Industry and Business
- OpenAI revenue sources: OpenAI's CFO reported that 75% of the company's revenue comes from paying consumers, rather than business customers. This sparked discussion about OpenAI's business model and profitability timeline.
AI Ethics and Societal Impact
- Linus Torvalds on AI hype: Linux creator Linus Torvalds stated that AI is "90% marketing and 10% reality". This sparked debate about the current state and future potential of AI technology.
Memes and Humor
- A humorous image depicting preparation for "AI wars" using anime-style characters generated discussion about the potential militarization of AI and its cultural impact.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: Apple's M4 Chips Supercharge AI Performance
- LM Studio Steals the Show on Apple's New M4 MacBook Pro: At the recent Apple event, LM Studio showcased its capabilities on the new MacBook Pro powered by M4 chips, highlighting its impact on AI applications.
- Rumors Fly as M4 Ultra Aims to Outshine NVIDIA's 4090 GPUs: The upcoming M4 Ultra is rumored to support 256GB of unified memory, potentially outperforming the M2 Ultra and rivaling high-end GPUs.
- M3 Max Impresses Engineers with 60 Tokens Per Second: The M3 Max chip reportedly runs models like Phi 3.5 MoE at around 60 tokens per second, showcasing its efficiency even in lower-end configurations.
Theme 2: AI Models Stir Up the Community with Updates and Controversies
- Haiku 3.5 Release Imminent, AI Enthusiasts Buzz with Excitement: The community eagerly anticipates the release of Haiku 3.5, with hints it could happen soon, sparking curiosity about its potential improvements.
- Gemini Leaves Competitors in the Dust, Coders Rejoice: Users praise Gemini for its prowess in handling database coding tasks, outperforming models like Claude and Aider in practical applications.
- Users Mock Microsoft's Overcautious Phi-3.5 Model: Phi-3.5's excessive censorship led to humorous mockery, with users sharing satirical responses highlighting the model's reluctance to answer simple questions.
Theme 3: Fine-Tuning and Training Hurdles Challenge AI Developers
- Unsloth Team Uncovers Gradient Glitches, Shakes Training Foundations: The Unsloth team revealed critical issues with gradient accumulation in training frameworks, affecting language model consistency.
- LoRA Fine-Tuning Hits a Wall on H100 GPUs, Engineers Frustrated: Users struggle with LoRA finetuning on H100 GPUs, noting QLoRA might be the only workaround due to unresolved BitsAndBytes issues.
- Quantization Mishaps Turn Outputs into Gibberish: During Llama 3.2 1B QLoRA training, users experienced incoherent outputs when applying Int8DynActInt4WeightQuantizer, highlighting challenges in quantization processes.
Theme 4: AI Disrupts Software Engineering and Automation Tools Flourish
- AI Gobbles Up Software Engineer Jobs, Developers Panic: Members note that AI is increasingly taking over regular software engineering tasks, sparking debates about the future of tech employment.
- Skyvern Automates Browsers, Manual Tasks Meet Their Match: Skyvern introduces a no-code solution for browser automation, enabling users to streamline workflows without writing code.
- ThunderKittens Unleash New Features with a Side of Humor: The ThunderKittens team released new features like exciting kernels and talking models, sprinkled with playful mentions of adorable kittens.
Theme 5: OpenAI Tackles Factuality and Enhances User Experience
- OpenAI Fights Hallucinations with New SimpleQA Benchmark: Introducing SimpleQA, OpenAI aims to measure the factual accuracy of language models with 4,000 diverse questions, targeting the hallucination problem.
- ChatGPT Finally Lets You Search Chat History, Users Rejoice: OpenAI rolled out the ability to search through chat history on the ChatGPT web app, making it easier to reference or continue past conversations.
- AGI Debate Heats Up as Optimists and Skeptics Clash: Members express mixed opinions on the timeline and feasibility of achieving AGI, debating whether companies like Google can keep pace amid challenges.
PART 1: High level Discord summaries
LM Studio Discord
-
Apple's MacBook Pro Features LM Studio: During the recent Apple event, LM Studio showcased its capabilities on the new MacBook Pro powered by the M4 family of chips, significantly recognizing its impact in commercial applications.
- Members expressed excitement for the developers, noting that this acknowledgment could influence future integration within AI workflows.
- M3 Max Impresses with Token Speed: The M3 Max reportedly runs models like Phi 3.5 MoE at around 60 tokens per second, underscoring its efficiency even in lower-end configurations.
- While this is impressive, some users suggested that for peak speed, a dedicated GPU like the A6000 might yield better results.
- H100 GPU Rentals Become Affordable: Users mentioned that H100 rentals are now available for approximately $1 per hour, making them a cost-effective option for model inference.
- Despite the drop in pricing, discussions emerged regarding the practicality of using high-powered GPUs versus local models for various tasks.
- M4 Ultra Rumored Specs Daunt Competitors: The upcoming M4 Ultra is rumored to support 256GB of unified memory, with expectations to significantly outperform the M2 Ultra.
- Speculations abound regarding the M4 rivaling 4090 GPUs, with users buzzing about enhanced performance metrics.
- Windows vs. Linux Performance Clash: Frustration with Windows surfaced, highlighting its limitations in AI tasks compared to Linux, which provides greater efficiency and control.
- Members agreed that Linux can optimize GPU utilization better, especially when running computational-intensive applications.
HuggingFace Discord
-
Hugging Face API facilitates token probabilities: A user confirmed that obtaining token probabilities via the Hugging Face serverless inference API for large language models is possible, especially using the inference client.
- Discussions also touched on rate limits and API usage, which was further elaborated with a detailed link on Rate Limits.
- Ollama offers privacy in image analysis: Concerns about Ollama accessing local files during image analysis were addressed, highlighting that it operates locally without server interactions.
- This ensures user privacy while analyzing images effectively.
- Choosing the right path in Machine Learning: A participant emphasized selecting a major that encompasses a wide knowledge of data science rather than just AI, reflecting on the importance of math and programming skills.
- Further discussions centered on the foundational aspects necessary for careers in this field.
- Qwen 2 model suffers from erroneous token generation: Issues with the Qwen 2 base model have been reported, particularly regarding unexpected tokens at the end of outputs due to EOS token misrecognition.
- This reflects broader concerns about the model's context length handling.
- Langchain SQL agent struggles with GPT-4: A transition from GPT-3.5 Turbo to GPT-4 with the Langchain SQL agent returned mixed results, with the latter posing difficulties.
- Concerns over API decommissioning prompted discussions on alternative environments.
Unsloth AI (Daniel Han) Discord
-
Unsloth team uncovers Gradient Issues: The Unsloth team released findings on gradient accumulation issues in training frameworks affecting language model output consistency.
- Their report suggests alternatives to traditional batch sizes due to significant impacts on loss calculations.
- Apple Launches Compact New Mac Mini: Apple's announcement of the new Mac mini features M4 and M4 Pro chips, boasting impressive 1.8x CPU performance increases.
- This release marks Apple's first carbon-neutral Mac, embodying a significant milestone in their product line.
- ThunderKittens Bring New Features: The ThunderKittens team published a blog post unveiling new features, highlighting exciting kernels and talking models.
- They included playful mentions of social media reactions and extra adorable kittens to enhance community engagement.
- Instruct Fine-Tuning Challenges: A user faced tensor shape mismatch errors with the Meta Llama3.1 8B Instruct model while attempting fine-tuning.
- Frustrations mounted as they switched models but continued to struggle with merging and loading, pointing to compatibility concerns.
- Unsloth’s Efforts on VRAM Efficiency: Unsloth announced a pretraining method achieving 2x faster training and consuming 50% less VRAM, coupled with a free Colab notebook for Mistral v0.3 7b.
- Users were advised on fine-tuning embeddings and adjusting learning rates to stabilize training.
OpenAI Discord
-
Mixed Opinions on AGI Race: Members expressed differing views on the timeline and feasibility of achieving AGI, particularly concerning Google's challenges with regulations hampering their progress.
- Concerns about Google’s hurdles contrasted with optimism around emerging algorithms boosting advancement.
- Model Efficiency Debate Rages On: The community discussed how larger models aren't always superior, pointing out the role of quantization in achieving efficiency without sacrificing performance, with mentions of Llama 3.0 and Qwen models.
- Recent quantized models were cited as outperforming their larger counterparts, underscoring the shift in focus to effective model usage.
- Nvidia GPU Sufficiency Under Fire: Debate centered around the adequacy of a 4070 Super GPU for local AI projects, calling attention to the need for higher VRAM options for demanding applications.
- Participants acknowledged both the performance of smaller models and the gap in availability of affordable high-performance GPUs.
- Prompt Generation Tools in Demand: Users sought access to a prompt generation tool in the OpenAI Playground to better tailor their requests, referencing the official prompt generation guide.
- The discussion led to a consensus on its importance for refining prompt strategies.
- Organized Data Crucial for Chatbots: When developing personal chatbots, a focus on maintaining organized and concise data was highlighted to avoid extraneous API call fees, as input tokens for irrelevant data still incur costs.
- One member pointed out that proper data management is not just a best practice, but a critical financial consideration in API usage.
Perplexity AI Discord
-
Perplexity Supply Launches New Essentials: Perplexity Supply has launched a range of thoughtful essentials designed for curious minds, allowing customers to spark conversations through their products.
- Global shipping is now available to countries like the US, Australia, and Germany, with updates accessible via this link.
- File Upload Issues Frustrate Users: Several users have reported issues with the file upload feature, highlighting problems with lingering files during discussions.
- One user pointed out that the file handling capabilities are subpar compared to other platforms.
- Exploration of Playground vs API Results: A user raised concerns about discrepancies observed between results from the Playground and the API, despite both using the same model.
- No further clarifications were provided on the reasons behind these inconsistencies.
- Earth's Temporary New Moon Sparks Discussions: A recent discussion highlighted Earth's temporary new moon, detailing its visibility and effects view details here.
- This fascinating find led to dynamic conversations around temporary celestial phenomena.
- Clarifying API Use for Perplexity Spaces: It was clarified that there is currently no API available for Perplexity Spaces, with the website and API functioning as separate entities.
- A user expressed interest in using the Perplexity API for development projects but received no specific guidance.
aider (Paul Gauthier) Discord
-
Aider enhances file management with commands: Aider introduces
/saveand/loadcommands for easy context management, simplifying batch processing and file handling.- This feature eliminates the hassle of manually recreating code contexts, making workflows more efficient.
- Anticipated Haiku 3.5 release stirs excitement: Ongoing discussions suggest the Haiku 3.5 release could happen soon, potentially as early as tomorrow.
- Users are eager to learn about its enhancements over previous versions, hoping for significant improvements.
- Qodo AI vs Cline sparks comparison debate: A discussion surfaces regarding how Qodo AI differentiates itself from competitors like Cline, especially in usability and features.
- Despite a starting subscription of $19/month, concerns about limited features dampen enthusiasm about Qodo's position in the market.
- Skyvern automates browser tasks with AI: Skyvern aims to streamline browser automation as a no-code solution, delivering efficiency for repetitive workflows.
- Its adaptability across web pages allows users to execute complex tasks with straightforward commands.
- Users weigh in on Gemini's coding effectiveness: Feedback highlights Gemini's proficiency in handling database-related coding tasks compared to Claude and Aider.
- Consensus reveals Gemini’s advantages for practical coding needs, yet performance can fluctuate based on context.
OpenRouter (Alex Atallah) Discord
-
Oauth Authentication Breaks, Fix Incoming: Apps utilizing openrouter.ai/auth faced issues this morning due to an Oauth problem, but a fix is expected shortly after the announcement.
- The team confirmed that downtime for API key creation would be minimal, reassuring affected users.
- Alpha Testers Wanted for macOS Chat App: A developer seeks alpha testers for a flexible chat app for macOS, with screenshots available for review.
- Interested parties are encouraged to DM for more info, underscoring the importance of user feedback during testing.
- Security Concerns Surround OpenRouter API Keys: Users are worried about the vulnerability of OpenRouter API keys, especially regarding misuse in proxy setups like Sonnet 3.5.
- A community member warned, 'Just because you think the key is secure doesn't mean it is secure,' emphasizing the importance of key management.
- Eager Anticipation for Haiku 3.5 Release: The community buzzes with excitement over the expected release of Haiku 3.5, with a model slug shared as
claude-3-5-haiku@20241022.
- Despite the model being on allow lists and not generally available yet, hints suggest a release might happen within a day.
- Request for Access to Integration Features: Users are clamoring for access to the integration feature, emphasizing its importance for testing various capabilities.
- Responses like 'I would like to rerequest integration feature!' indicated a strong demand for this functionality.
Stability.ai (Stable Diffusion) Discord
-
GPU Price Debate Heats Up: Members analyzed that used 3090 cards cost less than 7900 XTX models, stressing the budget vs performance trade-off.
- eBay prices hover around ~$690, leading to tough choices in GPU selection for cost-conscious engineers.
- Training for Custom Styles: A member asked about training models on a friend's art style with 15-20 images, debating between a model or Lora/ti.
- Others suggested using a Lora for better character consistency based on specific stylistic preferences.
- Grey Image Troubles in Stable Diffusion: Multiple users reported encountering grey images in Stable Diffusion and sought troubleshooting advice.
- Members recommended trying different UI options and checking compatibility with AMD GPUs to improve outputs.
- UI Showdown: Auto1111 vs Comfy UI: Comfy UI emerged as the popular choice for its user-friendliness, while some still prefer Auto1111 for automation.
- Suggestions also included trying SwarmUI for its easy installation and functionality.
- Buzz Around Upcoming AI Models: The community speculated about the potential popularity of SD 3.5 compared to SDXL, driving discussions on performance.
- Anticipation grows for new control nets and model updates that are crucial in keeping pace with AI advancements.
Nous Research AI Discord
-
Microsoft De-Risks from OpenAI Dependency: Discussion arose about Microsoft's strategy to de-risk from OpenAI, particularly if OpenAI declares AGI, which could provide Microsoft a contractual out and a chance to renegotiate.
- “Microsoft will NEVER let that happen,” expressed skepticism about the potential AGI release.
- AI Latency Issues Ignite Concerns: Notable issues surfaced regarding a reported 20-second latency with an AI model, with members humorously suggesting it might be run on a potato.
- Comparisons were made with Lambda's performance, which serves 10x more requests with only 1s latency.
- Hermes 3 Performance Surprises Users: Members discussed that Hermes 3 8B surprisingly rivals GPT-3.5 quality, outperforming other sub-10B models.
- Critiques were directed at models like Mistral 7B, described as sad by comparison.
- Spanish Function Calling Datasets Needed: A member seeks to build function calling datasets in Spanish, facing challenges with poor results from open-source models, notably using data from López Obrador's conferences.
- Their goal is to process info from over a thousand videos, targeting journalistic relevance.
- Sundar Pichai Highlights AI's Role at Google: During an earnings call, Sundar Pichai stated that over 25% of new code at Google is AI-generated, prompting discussions on the impact of AI on coding.
- This statistic, shared widely, has led to conversations about evolving coding practices.
Eleuther Discord
-
Multiple Instances on a Single GPU: Members discussed running multiple instances of GPT-NeoX on the same GPU, aiming to maximize memory usage with larger batch sizes, although benefits from DDP may be limited.
- The ongoing conversation highlighted potential configurations and considerations for parallel training.
- RAG with CSV Data: A member questioned the efficacy of using raw CSV data for RAG with a ~3B LLM, indicating plans to convert it to JSON after facing challenges with case number discrepancies.
- This move implies preprocessing complexities that could impact RAG performance.
- Entity Extraction Temperature Tuning: After recognizing incorrect temperature settings during entity extraction, a member re-attempted with corrected parameters to enhance results.
- This highlights the significance of tuning model parameters for effective performance.
- Modular Duality and Optimizations in LLMs: A recent paper revealed that methods like maximal update parameterization and Shampoo serve as partial approximations to a single duality map for linear layers.
- This connection reinforces the theoretical basis of contemporary optimization techniques discussed in the paper.
- Challenges of Diffusion Models: Discussion emerged on how diffusion models present unique limitations compared to GANs and autoregressive models, especially regarding training and quality metrics.
- Members pinpointed issues around controllability and representation learning, stressing their implications on model applicability.
Interconnects (Nathan Lambert) Discord
-
Elon Musk in talks to boost xAI valuation: Elon is negotiating a new funding round aimed at raising xAI's valuation from $24 billion to $40 billion, according to the WSJ. Despite discussions, Elon continuously denies prior fundraising rumors, leading to community unease about xAI's direction.
- xAI kind of scares me, expressed a member, reflecting broader concerns within the community.
- Uncovering the Claude 3 Tokenizer: A recent post highlights the Claude 3 tokenizer's closed nature, revealing limited accessible information. Users have to rely on billed services instead of open documentation, causing frustration.
- The post underscores significant barriers for developers looking to leverage Claude 3 effectively.
- AI2 to Relocate to New Office by Water: AI2 is set to open a new office in June next year, offering beautiful views of the Pacific Northwest. Members expressed excitement for the relocation, citing the delightful scenery as a perk.
- This shift promises to foster a more inspiring work environment for the AI2 team.
- Staggering Prices for MacBook Pro: Members reacted to the exorbitant prices of high-spec MacBook Pros, with configurations like 128GB RAM + 4TB SSD costing around 8k EUR. The discussion highlighted bewilderment at the pricing's implications across different regions.
- Comments reflected on how currency fluctuations and taxes could complicate purchases for engineers seeking cutting-edge hardware.
- Voiceover enhances personal articles: A member advocated for voiceover as a more engaging medium for tomorrow's personal article. They expressed satisfaction with voiceover content, signaling a shift in how written material could be delivered.
- This suggests a trend towards integrating audio elements for enhanced user experience and accessibility.
Notebook LM Discord Discord
-
NotebookLM Usability Study Invitation: NotebookLM UXR is inviting users to participate in a 30-minute remote usability study focused on Audio Overviews, offering a $50 gift for selected participants.
- Participants need high-speed Internet, a Gmail account, and functional video/audio equipment for these sessions, which will continue until the end of 2024.
- Simli Avatars Enhance Podcasts: A member showcased how Simli overlays real-time avatars by syncing audio segments through diarization from .wav files, paving the way for future feature integration.
- This proof of concept opens up exciting possibilities for enhancing user engagement in podcasts.
- Pictory's Role in Podcast Video Creation: Users are exploring Pictory for converting podcasts into video format, with discussions on how to integrate speakers’ faces effectively.
- Another member mentioned that Hedra can facilitate this by allowing the upload of split audio tracks for character visualization.
- Podcast Generation Limitations: Users reported challenges in generating Spanish podcasts after initial success, leading to questions about the feature's status.
- One user expressed frustration, noting, 'It worked pretty well for about two days. Then, stopped producing in Spanish.'
- Voice Splitting Techniques Discussion: Participants discussed the use of Descript for efficiently isolating individual speakers in podcasts, leveraging automatic segmentation capabilities noted during the Deep Dive.
- One user remarked, 'I have noticed that sometimes the Deep Dive divides itself into episodes,' showcasing the platform's potential for simplifying podcast production.
GPU MODE Discord
-
AI Challenges Software Engineer Roles: A member noted that AI is increasingly taking over regular software engineer jobs, indicating a shifting job landscape.
- Concerns were raised about the implications of this trend on employment opportunities in the tech industry.
- Growing Interest in Deep Tech: A member expressed a strong desire to engage in deep tech innovations, reflecting curiosity about advanced technologies.
- This highlights a trend towards deeper engagement in technology beyond surface-level applications.
- FSDP2 API Deprecation Warning: A user highlighted a FutureWarning concerning the deprecation of
torch.distributed._composable.fully_shard, urging a switch to FSDP instead, detailed in this issue.
- This raised questions regarding the fully_shard API's ongoing relevance following insights from the torch titan paper.
- Memory Profiling in Rust Applications: A member sought advice on memory profiling a Rust application using torchscript to identify potential memory leak issues.
- They specifically wanted to debug issues involving custom CUDA kernels.
- ThunderKittens Talk Scheduled: Plans for a talk on ThunderKittens discussed features and community feedback, with gratitude expressed for coordination efforts.
- The engagement promises to strengthen community bonds around the project.
Torchtune Discord
-
Llama 3.2 QLoRA Training Issues: During the Llama 3.2 1B QLoRA training, users achieved QAT success but faced incoherent generations with Int8DynActInt4WeightQuantizer.
- Concerns were raised that QAT adjustments might be insufficient, potentially causing quantization problems.
- Quantization Layers Create Confusion: Generated text incoherence post-quantization was attributed to incorrect configurations in QAT training and quantization layers.
- Users shared code snippets illustrating misconfigurations with torchtune and torchao versions.
- Activation Checkpointing Slows Down Saves: Participants questioned the default setting of activation checkpointing as false, noting substantial slowdowns in checkpoint saves for Llama 3.2.
- It was clarified that this overhead isn’t necessary for smaller models, as it incurs additional costs.
- Dynamic Cache Resizing to Improve Efficiency: Proposals for a dynamic resizing feature for the kv cache would tailor memory allocation efficiently based on actual needs.
- This change is expected to enhance performance by reducing unnecessary memory use, particularly during extended generations.
- Multi-query Attention's Role in Cache Efficiency: The implementation of multi-query attention aims to save kv-cache storage, as noted in discussions about PyTorch 2.5 enhancements.
- Group query attention support is seen as a strategic advancement, easing manual kv expansion needs in upcoming implementations.
Cohere Discord
-
Dr. Vyas on SOAP Optimizer Approaches: Dr. Nikhil Vyas, a Post Doc at Harvard, is set to discuss the SOAP Optimizer in an upcoming event. Tune in on the Discord Event for insights.
- This provides an opportunity for deeper understanding of optimization techniques relevant to AI models.
- Command R Model Faces AI Detection Issues: Users reported that the Command R model consistently outputs text that is 90-95% AI detectable, sparking frustration among paid users.
- Creativity is inherent in AI, suggesting an underlying limitation related to the training data distribution.
- Concerns on Invite and Application Responses: Members are actively inquiring about the status of their invites and common response times for applications, expressing worries over extended delays.
- There appears to be a lack of clarity regarding potential rejection criteria, indicating a need for improved communication.
- Embed V3 vs Legacy Models Debate: Discussion highlights comparisons between Embed V3, ColPali, and JINA CLIP, focusing on evolving comparative methodologies beyond older embeddings.
- Members are interested in how integrating JSON structured outputs could enhance functionality, particularly for search capabilities.
- Seeking Help on Account Issues: For account or service problems, users are advised to reach out directly to support@cohere.com for assistance.
- One proactive member expressed eagerness to assist others experiencing similar issues.
Latent Space Discord
-
Browserbase bags $21M for web automation: Browserbase announced they have raised a $21 million Series A round, co-led by Kleiner Perkins and CRV, to help AI startups automate the web at scale. Read more about their ambitious plans in this tweet.
- What will you 🅱️uild? highlights their goal of future development making it easier for startups to engage with web automation.
- ChatGPT finally allows chat history search: OpenAI has rolled out the ability to search through chat history on the ChatGPT web application, allowing users to quickly reference or continue past conversations. This feature enhances user experience by making it simpler to access previous chats.
- OpenAI announced this update in a tweet, emphasizing streamlined interaction with the platform.
- Hamel Husain warns on LLM evaluation traps: A guide by Hamel Husain outlines common mistakes with LLM judges, such as using too many metrics and overlooking domain experts' insights. He stresses the importance of validated measurements for more accurate evaluations.
- His guide can be found in this tweet, advocating for focused evaluation strategies.
- OpenAI's Realtime API springs new features: OpenAI's Realtime API now incorporates five new expressive voices for improved speech-to-speech applications and has introduced significant pricing cuts thanks to prompt caching. This means a 50% discount on cached text inputs and 80% off cached audio inputs.
- The new pricing model promotes more economical use of the API and was detailed in their update tweet.
- SimpleQA aims to combat hallucinations in AI: The new SimpleQA benchmark has been launched by OpenAI, consisting of 4k diverse questions for measuring the factual accuracy of language models. This initiative directly addresses the hallucination problem prevalent in AI outputs.
- OpenAI's announcement underscores the need for reliable evaluation standards in AI deployment.
tinygrad (George Hotz) Discord
-
Tinycorp's Ethos NPU Stance Sparks Debate: Members discussed Tinycorp's unofficial stance on the Ethos NPU, with some suggesting inquiries about hardware specifics and future support.
- One user humorously noted that detailed questions could elicit richer community feedback on the NPU's performance.
- Mastering Long Training Jobs on Tinybox: Strategies for managing long training jobs on Tinybox included the use of tmux and screen for session persistence.
- One member humorously complained about their laziness to switch to a better tool despite its recommendation.
- Qwen2's Unique Building Blocks Shake Things Up: Curiosity grew around Qwen2's unconventional approach to foundational elements like rotary embedding and MLP, with speculation on Alibaba's involvement.
- A user expressed frustration over this collaboration, adding to the community's spirited discussions on dependencies.
- EfficientNet Facing OpenCL Output Issues: A user reported exploding outputs while implementing EfficientNet in C++, prompting calls for debugging tools to help compare buffers.
- Suggestions included methods to access and dump buffers from tinygrad’s implementation for more effective troubleshooting.
- Exporting Models to ONNX: A Hot Topic: Discussion focused on strategies for exporting tinygrad models to ONNX, suggesting existing scripts for optimization on lower-end hardware.
- Debates emerged over the merits of directly exporting models versus alternative bytecode methods for chip deployment.
Modular (Mojo 🔥) Discord
-
Mojo Idioms in Evolution: Members discussed that idiomatic Mojo is still evolving as the language gains new capabilities, leading to emerging best practices.
- This showcases a fluidity in language idioms compared to more entrenched languages like Python.
- Learning Resources Scarcity: A member highlighted struggles in finding resources for learning linear algebra in Mojo, particularly regarding GPU usage and implementation.
- It was suggested that direct communication with project leads on NuMojo and Basalt could help address the limited material available.
- Ambitious C++ Compatibility Goals: Members shared ambitions of achieving 100% compatibility with C++, with discussions centering around Chris Lattner's potential influence.
- One user suggested it would be a complete miracle, reflecting the high stakes and interest surrounding compatibility.
- Syntax Spark Conversations: A proposal to rename 'alias' to 'static' ignited debate on the implications for Mojo's syntax and potential confusion with C++ uses.
- Some members voiced concerns about using static, suggesting it may not accurately represent its intended functionality as it does in C++.
- Exploring Custom Decorators: Plans for implementing custom decorators in Mojo were discussed, viewed as potentially sufficient alongside compile-time execution.
- It was noted that functionalities like SQL query verification may exceed the capabilities of decorators alone.
LlamaIndex Discord
-
Create-Llama App Launches for Rapid Development: The new create-llama tool allows users to set up a LlamaIndex app in minutes with full-stack support for Next.js or Python FastAPI backends, and offers various pre-configured use cases like Agentic RAG.
- This integration facilitates the ingestion of multiple file formats, streamlining the development process significantly.
- Game-Changer Tools from ToolhouseAI: ToolhouseAI provides a suite of high-quality tools that enhance productivity for LlamaIndex agents, noted during a recent hackathon for drastically reducing development time.
- These tools are designed for seamless integration into agents, proving effective in expediting workflows.
- Enhanced Multi-Agent Query Pipelines: A demonstration by a member showcased using LlamaIndex workflows for multi-agent query pipelines, promoting this method as effective for collaboration.
- The demo materials can be accessed here to further explore implementation strategies.
- RAG and Text-to-SQL Integration Insights: An article elaborated on the integration of RAG (Retrieval-Augmented Generation) with Text-to-SQL using LlamaIndex, showcasing an improvement in query handling.
- Users reported a 30% decrease in query response times, emphasizing LlamaIndex's role in improving data retrieval efficiency.
- Enhancements in User Interaction via LlamaIndex: LlamaIndex seeks to simplify how users interact with databases by automating SQL generation from natural language inputs, leading to greater user empowerment.
- The approach has proven effective as users expressed feeling more confident in extracting data, even without deep technical knowledge.
DSPy Discord
-
IReRa Tackles Multi-Label Classification: The paper titled IReRa: In-Context Learning for Extreme Multi-Label Classification proposes Infer–Retrieve–Rank to improve language models' efficiency in multi-label tasks, achieving top results on the HOUSE, TECH, and TECHWOLF benchmarks.
- This underscores the struggle of LMs that lack prior knowledge about classes, presenting a new framework that could enhance overall performance.
- GitHub Repo Linked to IReRa: Members noted a relevant GitHub repo mentioned in the paper's abstract, indicating further insights into the discussed methodologies.
- This could greatly aid in the implementation and understanding of the findings presented in the paper.
- Debating DSPy's Structure Enforcement: A member questioned the need for DSPy to enforce structure when libraries like Outlines could handle structured generation more efficiently.
- Another contributor pointed out DSPy’s structural enforcement since v0.1 is essential for accurate mapping from signatures to prompts, balancing effectiveness with quality.
- Quality vs Structure Showdown: The discussion heated up as skepticism arose around structured outputs potentially lowering output quality, suggesting that constraints could actually enhance results, especially for smaller models.
- This approach could yield great results, particularly for smaller LMs, reflecting varying opinions on quality and adherence to formats.
- Integrating MIPROv2 with DSPy: A member shared insights on utilizing zero-shot MIPROv2 with a Pydantic-first interface for structured outputs, advocating for more integration in DSPy’s optimization processes.
- They expressed a desire for a more integrated and native way to handle structured outputs, indicating possible improvements in workflow.
OpenInterpreter Discord
-
Job Automation Predictions Ignite Workforce Debate: A user predicted that virtual beings will lead to job redundancies, comparing it to a virtual Skynet takeover.
- This sparked a robust discussion about the overall impact of AI on employment and future job landscapes.
- Open Interpreter's Edge Over Claude: A member inquired about how Open Interpreter stands apart from Claude in computer operations.
- Mikebirdtech highlighted the utilization of
interpreter --oswith Claude, underscoring the advantages of being open-source. - Restoration of Chat Profiles Raises Questions: A user sought advice on restoring a chat using a specific profile/model that was previously active.
- Despite using
--conversations, it defaults to the standard model, leaving users looking for solutions. - ChatGPT Chat History Search Feature Rolls Out: OpenAI announced a rollout allowing users to search their chat history on ChatGPT web, enhancing reference convenience.
- This new feature aims to streamline user interactions, improving the overall experience on the platform.
- Major Milestone in Scent Digitization Achieved: A team succeeded in digitizing a summer plum without any human intervention, achieving a significant breakthrough.
- One member expressed their thrill about carrying the plum scent and considered an exclusive fragrance release to fund scientific exploration.
LangChain AI Discord
-
Invoke Function Performance Mystery: Calling the .invoke function of the retriever has baffled users, showcasing a response time of over 120 seconds for the Llama3.1:70b model, compared to 20 seconds locally.
- There are suspicions of a security issue affecting performance, prompting the community to assist in troubleshooting this anomaly.
- FastAPI Routes Execution Performance: FastAPI routes demonstrate impressive performance, consistently executing in under 1 second as confirmed through debugging logs.
- The user confirmed that the sent data is accurate, isolating the responsiveness issue to the invoke function itself.
- Frustration with Hugging Face Documentation: Navigating the documentation for Hugging Face Transformers has been a headache for users aiming to set up a chat/conversational pipeline.
- The difficulty in finding essential guidance within the documentation highlights an area needing improvement for user onboarding.
- Knowledge Nexus AI Launches Community Initiatives: Knowledge Nexus AI (KNAI) announced new initiatives aimed at bridging human knowledge with AI, focusing on a decentralized approach.
- They aim to transform collective knowledge into structured, machine-readable data impactful across healthcare, education, and supply chains.
- OppyDev Introduces Plugin System: OppyDev's plugin system enhances standard AI model outputs using innovative chain-of-thought reasoning to improve response clarity.
- A tutorial video demonstrates the plugin system and showcases practical improvements in AI interactions.
OpenAccess AI Collective (axolotl) Discord
-
LoRA Finetuning Remains Unresolved: A member expressed difficulty in finding a solution for LoRA finetuning on H100 GPUs, suggesting that QLoRA might be the only viable workaround.
- The issue remains persistent as another member confirmed that the BitsAndBytes issue for Hopper 8bit is still open and hasn't been resolved.
- Quantization Challenges Persist: The discussion highlighted ongoing challenges with quantization-related issues, particularly in the context of BitsAndBytes for Hopper 8bit.
- Despite efforts, it appears that no definitive solution has been established regarding these technical problems.
LAION Discord
-
Clamping Values Essential for Image Decoding: A member highlighted that failing to clamp values to [0,1] before converting decoded images to uint8 can lead to out-of-range values wrapping, impacting image quality.
- Unexpected results in image appearance could stem from neglecting this critical step in the preprocessing chain.
- Flaws Potentially Lurking in Decoding Workflow: Concerns were raised about possible flaws in the decoding workflow, which might affect overall image processing reliability.
- Further discussions are needed to thoroughly identify these issues and bolster the robustness of the workflow.
- New arXiv Paper on Image Processes: A member shared a link to a new paper on arXiv, titled Research Paper on Decoding Techniques, available here.
- This paper could provide valuable insights or methodologies relevant to ongoing discussions in image decoding.
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents Quizzes Location Revealed: A member inquired about the location of the weekly quizzes for the LLM Agents course, and received a prompt response with a link to the quizzes, stating, 'here you can find all the quizzes.'
- These quizzes are critical for tracking progress in the course and are accessible through the provided link.
- Get Ready for the LLM Agents Hackathon!: Participants learned about the upcoming LLM Agents Hackathon, and were provided a link for hackathon details to sign up and join the coding fray.
- This event provides a great opportunity for participants to showcase their skills and collaborate on innovative projects.
- Easy Course Sign-Up Process: Instructions were shared on how to enroll in the course via a Google Form, with participants encouraged to fill in this form to join.
- This straightforward sign-up process aims to boost enrollment and get more engineers involved in the program.
- Join the Vibrant Course Discussion on Discord: Details were provided on joining discussions in the MOOC channel at LLM Agents Discord, fostering community engagement.
- Participants can utilize this platform to ask questions and share insights throughout the duration of the course.
Mozilla AI Discord
-
Transformer Labs showcases local RAG on LLMs: Transformer Labs is hosting an event to demonstrate training, tuning, and evaluating RAG on LLMs with a user-friendly UI installable locally.
- The no-code approach promises to make this event accessible for engineers of all skill levels.
- Lumigator tool presented in tech talk: Engineers will give an in-depth presentation on Lumigator, an open-source tool crafted to assist in selecting optimal LLMs tailored to specific needs.
- This tool aims to expedite the decision-making process for engineers when choosing their large language models.
Gorilla LLM (Berkeley Function Calling) Discord
-
Llama-3.1-8B-Instruct (FC) Falters Against Prompting: A member raised that Llama-3.1-8B-Instruct (FC) is underperforming compared to Llama-3.1-8B-Instruct (Prompting), questioning the expected results for function calling tasks.
- Is there a reason for this discrepancy? indicates a concern around performance expectations based on the model's intended functionality.
- Expectations for Function Calling Mechanics: Another participant expressed disappointment, believing that the FC variant should outperform others given its design focus.
- This led to discussions on whether the current results are surprising or hint at potential architectural issues within the model.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LM Studio ▷ #general (161 messages🔥🔥):
Apple's MacBook Pro AnnouncementM3 Max PerformanceModel Access and InferenceH100 GPU Rental PricingLocal vs. Remote Model Usage
-
Apple's MacBook Pro Features LM Studio: During the recent Apple event, LM Studio was featured prominently, showcasing its capabilities on the new MacBook Pro powered by the M4 family of chips.
- Members expressed excitement and congratulations to the devs for this significant recognition in a major commercial.
- M3 Max Achieves Impressive Performance: Users reported that the M3 Max can run models like Phi 3.5 MoE at around 60 tokens per second, emphasizing its efficiency even with a lower-end configuration.
- Comparative discussions suggested that for those needing intense speed, a dedicated GPU like the A6000 might still be more beneficial.
- Exploring Local Model Access: Members discussed various methods to give local models internet access, with suggestions including port forwarding and setting up Open WebUI to connect with LM Studio.
- It was noted that some frameworks may allow easier integrations for accessing web data, although more straightforward options are still anticipated.
- H100 GPU Rental Prices Drop: Users mentioned that H100 rentals can now be found at approximately $1 per hour, making them more accessible for model inference.
- Despite this, considerations regarding the practicality of using powerful hardware versus local models were debated.
- Challenges in Implementing FFN Blocks: One user shared their struggles with implementing feedforward network blocks in their model code, facing garbage output despite following guidelines.
- This sparked discussions around debugging and refining model code to improve output quality.
Links mentioned:
- 'Let chaos reign': AI inference costs are about to plummet : Inference is becoming the commodity of the AI age.
- New MacBook Pro features M4 family of chips and Apple Intelligence: Apple today unveiled the new MacBook Pro, powered by the M4 family of chips: M4, M4 Pro, and M4 Max.
- Mochi Peach GIF - Mochi Peach Cat - Discover & Share GIFs: Click to view the GIF
- $2 H100s: How the GPU Bubble Burst: H100s used to be $8/hr if you could get them. Now there's 7 different resale markets selling them under $2. What happened?
- ggml/docs/gguf.md at master · ggerganov/ggml: Tensor library for machine learning. Contribute to ggerganov/ggml development by creating an account on GitHub.
- ggerganov - Overview: I like big .vimrc and I cannot lie. ggerganov has 71 repositories available. Follow their code on GitHub.
- magnolia1234/bpc_uploads: Участвуйте в разработке magnolia1234/bpc_uploads, создав учетную запись в GitFlic.
LM Studio ▷ #hardware-discussion (600 messages🔥🔥🔥):
M4 Ultra expectationsComparison of Apple SiliconGPU performance discussionAI model fitting on GPUsWindows vs. Linux for AI tasks
-
M4 Ultra expectations heighten: The upcoming M4 Ultra is rumored to support up to 256GB unified memory, with expectations of significant performance improvements over the M2 Ultra.
- The M4 Max is anticipated to have 128GB, and there's speculation that the M4 will rival current 4090 GPUs in performance.
- Comparison of Apple Silicon performance: Users are curious about the real-world performance of the M4 series compared to existing NVIDIA GPUs, especially in running large language models (LLMs).
- Currently, the M2 Ultra reportedly achieves 8 - 12 T/S with models like Mistral, while the M4 is expected to push those numbers higher.
- GPU performance discussion: Discussion centered on how the M4’s raw GPU performance might exceed the M2 Ultra's by 35-40%, enhancing overall efficiency.
- The memory bandwidth increase is also anticipated, making the M4 a significant upgrade for tasks involving intensive computational loads.
- AI model fitting on GPUs: Individuals noted challenges with fitting large models, such as 60B, within limited unified memory constraints on current hardware setups.
- The effective use of memory resources is critical when running advanced AI models like Mistral, balancing performance with memory availability.
- Windows vs. Linux for AI tasks: Users expressed frustration with Windows due to limited performance and control, specifically in AI tasks and model running.
- In contrast, Linux provides more flexibility and efficiency, especially for GPU utilization in various AI applications.
Links mentioned:
- AMD Navi 22 GPU Specs: 2560 Cores, 160 TMUs, 64 ROPs
- Qwen2.5 - a Qwen Collection: no description found
- EP2098941A1 - Computer apparatus - Google Patents: no description found
- Tweet from Patrick Wardle (@patrickwardle): An example, two macOS firewalls: LuLu and Little Snitch Despite best efforts (e.g. disabling default rules, creating explicit rules to block, enabling 'deny mode'), Apple's App Store appe...
- NVIDIA GeForce RTX 4060 Ti 16 GB Specs: NVIDIA AD106, 2535 MHz, 4352 Cores, 136 TMUs, 48 ROPs, 16384 MB GDDR6, 2250 MHz, 128 bit
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
- GitHub - Blaizzy/mlx-vlm: MLX-VLM is a package for running Vision LLMs locally on your Mac using MLX.: MLX-VLM is a package for running Vision LLMs locally on your Mac using MLX. - Blaizzy/mlx-vlm
- Feature Request: NPU Support · Issue #9181 · ggerganov/llama.cpp: Prerequisites I am running the latest code. Mention the version if possible as well. I carefully followed the README.md. I searched using keywords relevant to my issue to make sure that I am creati...
HuggingFace ▷ #general (326 messages🔥🔥):
Hugging Face API UsageImage Analysis with OllamaMachine Learning EducationTransformers and Attention ModelsDocker Spaces and Private Images
-
Navigating Hugging Face API for Token Probabilities: A member inquired whether it's possible to obtain token probabilities through the Hugging Face serverless inference API for large language models and received confirmation that it is indeed achievable.
- It was highlighted that using the inference client makes the process easier, and discussions about rate limits and API usage ensued.
- Image Analysis and Local File Access with Ollama: A user expressed concerns about privacy issues when using Ollama for image analysis, noting that it can access local files.
- It was clarified that Ollama runs locally, processing data without sending it to any server, allowing for privacy in the analysis.
- Choosing a Major in Machine Learning and Data Science: A member shared insights on selecting a major for university studies, emphasizing the importance of broader knowledge in data science over a narrow focus on AI.
- Participants discussed the significance of having a strong foundation in mathematics and relevant programming experience as crucial for careers in machine learning.
- Discoveries in Transformers and Attention Mechanisms: A discussion unfolded about the necessity of separate attention models in transformers, leading to the realization that transformers may integrate this functionality intrinsically.
- Concern arose about the time spent studying this aspect in light of newfound understanding among community members.
- Challenges with Docker Spaces and Private Base Images: Users discussed experiences with building Docker Spaces, particularly with private base images and job timeouts during the build process.
- Advice was shared about using public images to avoid issues and suggestions for troubleshooting, such as utilizing factory rebuilds.
Links mentioned:
- xxxxxxx (sayaka.M): no description found
- Rate Limits: no description found
- Wan Im Rich GIF - Wan Im Rich Rich - Discover & Share GIFs: Click to view the GIF
- Nervous Hot GIF - Nervous Hot Sweat - Discover & Share GIFs: Click to view the GIF
- KoboldAI Lite: no description found
HuggingFace ▷ #today-im-learning (8 messages🔥):
Llama-3.1 70B compatibilityParallel computing setupFine-tuning datasets on Hugging FaceLLM recommendations for Q&A and sentiment analysis
-
Llama-3.1 70B pushes PC limits: One member expressed concern about whether their PC could handle the Llama-3.1 70B, indicating they were so close to being able to run it.
- They shared their experience with the limitations of their current setup and the need for parallel computing.
- Fine-tuning discussions lack dedicated space: A member inquired about chats dedicated to fine-tuning, to which another member responded that channels typically focus on different modalities.
- They were also reminded not to cross-post across channels.
- Adding datasets for fine-tuning on Hugging Face: To help with fine-tuning, a member was directed to a Hugging Face course on dataset preparation for quick setup.
- This brings insight into getting started with fine-tuning even when datasets aren’t readily available on the Hub.
- LLM sizing for general Q&A and sentiment analysis: A user discussed their struggle to find an LLM that could handle general Q&A and sentiment analysis, given the limitations of their RTX 3090 setup.
- They mentioned adding their laptop’s resources for additional support but faced challenges with setting up parallel computing.
Link mentioned: What if my dataset isn’t on the Hub? - Hugging Face NLP Course: no description found
HuggingFace ▷ #cool-finds (17 messages🔥):
Latent Space RegularizationAnthropic Agent in LlamaIndexComputational Modeling GuidelinesTuring's ContributionsNomic Atlas Insights
-
Latent Space Regularization Explained: An article discusses Latent Space Regularization, detailing techniques to probe algorithms behind behavior and explore neural correlates linked to computational variables.
- The paper emphasizes the importance of applying ten simple rules to ensure computational modeling yields meaningful insights.
- Using Anthropic Agent with LlamaIndex: The LlamaIndex provides a notebook showing how to utilize the Anthropic agent with function calling capabilities, specifically for claude-3 models.
- It guides users through the initial setup process, emphasizing the installation of required libraries.
- Guidelines for Computational Modeling: A comprehensive introduction offers ten rules for effective computational modeling to help researchers avoid pitfalls and properly relate models to data.
- These guidelines cater to beginners and advanced techniques alike, highlighting the significance of careful application to avoid misleading conclusions.
- Turing's Original Paper Revisited: A book titled Annotated Turing expands on Alan Turing's foundational work, making his complex ideas accessible to modern readers with enriching context on his life and contributions.
- The book provides annotations that clarify Turing's original statements regarding computability theory and its implications on contemporary programming.
- Congressional Discourse on Social Media: Analysis using Nomic Atlas reviews 3.2 million posts from US Congress members, revealing communication patterns and key topics before the 2024 election.
- This tool aims to empower policy researchers and engaged citizens alike by transforming complex datasets into user-friendly insights.
Links mentioned:
- Tweet from Nomic AI (@nomic_ai): What do 3.2 million @X posts from Congress show about how US legislators talk? What are they posting about going into the 2024 US presidential election? Learn what we found in 3.2M posts from Cong...
- Pdf2audio - a Hugging Face Space by lamm-mit: no description found
- Function Calling Anthropic Agent - LlamaIndex: no description found
- What Is US Congress Posting About In The Leadup To The Election?: Explore over 3 million X/Twitter posts from US legislators
- Ten simple rules for the computational modeling of behavioral data: Computational modeling of cognitive and neuroscience data is an insightful and powerful tool, but has many potential pitfalls that can be avoided by following simple guidelines.
- no title found: no description found
HuggingFace ▷ #i-made-this (3 messages):
Transformer Tokenizer UpdatesGPUs and Docker IntegrationNew Blog Post on DockerDstack Task Configurations
-
Transformer Tokenizer Enhancements On the Horizon: A member suggested pushing the tokenizer to the AutoTokenizer class in Transformers, indicating it is totally possible and doable.
- Another member confirmed that this is indeed the plan and they are currently working on it.
- Exciting New Blog on Docker with HF Chat UI: A member announced the publication of a blog post detailing how to deploy HF Chat UI using Docker and Docker Compose inside GPU-enabled containers, available here.
- The post explains using your own Docker image with dstack without direct Docker interaction while noting that some existing code may still require it.
- Dstack Configuration for Docker and Compose Use: The latest dstack release allows using Docker with your configuration by setting
imagetodstackai/dindandprivilegedto true, including the commandstart-dockerd.
- This enables direct use of Docker commands after initializing with dstack, streamlining deployment processes in development environments.
Link mentioned: Using Docker and Docker Compose inside GPU-enabled containers - dstack: The latest release of dstack allows for the direct use of Docker and Docker Compose within run configurations.
HuggingFace ▷ #computer-vision (2 messages):
User EngagementFuture Discussions
-
User Interest in Side Character Discussions: A member expressed their desire to engage in discussions about side characters, indicating a strong interest in the topic.
- This reflects a growing enthusiasm within the community for exploring character development outside of main narratives.
- Anticipation for Upcoming Conversations: There is an indication that members are eager to participate in future conversations surrounding the topic of side characters.
- This sentiment highlights an ongoing commitment to enriching discussions in the group.
HuggingFace ▷ #NLP (10 messages🔥):
Qwen 2 model issuesLangchain SQL agent with GPT-4Mini Omni 2 feedback
-
Qwen 2 model struggles with token generation: A new user reported issues with the Qwen 2 base model, specifically that random tokens appear at the end of outputs, causing repeats.
- Another member clarified that this might be due to the EOS token not being recognized or the model reaching its context length.
- Challenges using GPT-4 with Langchain SQL agent: A member successfully utilized the Langchain SQL agent with GPT-3.5 Turbo, but faced difficulties switching to GPT-4.
- Concerns were raised about GPT-3.5 Turbo being decommissioned soon, prompting discussions on alternatives.
- Feedback on Mini Omni 2 model: A user expressed interest in the new release of Mini Omni 2, but found it lacking in language support and session history scope.
- They inquired if anyone knew of alternative models with similar capabilities that they could explore.
HuggingFace ▷ #diffusion-discussions (3 messages):
Diffusion models for non-standard dataFoldingDiff projectConsistency Models in AI
-
Exploring Diffusion Models on Unique Data: Research indicates that diffusion models can effectively handle non-standard data types by employing customized noise factors for each feature channel.
- This approach is particularly relevant for features with different behaviors, such as angular and non-angular features that may require distinct corruption patterns.
- FoldingDiff's Unique Diffusion Approach: A member shared insights on the FoldingDiff project, emphasizing its use of diffusion models for protein structure analysis, focusing on trigonometry and attention mechanisms.
- The project presents innovative methodologies that could potentially enhance protein modeling through tailored computational techniques.
- Discussion on Consistency Models Paper: A member sought insights on the paper titled Simplifying, Stabilizing, and Scaling Continuous-Time Consistency Models to gather thoughts on the subject.
- This inquiry reflects a growing interest in understanding and evaluating the effectiveness of consistency models in various AI applications.
Link mentioned: GitHub - microsoft/foldingdiff: Diffusion models of protein structure; trigonometry and attention are all you need!: Diffusion models of protein structure; trigonometry and attention are all you need! - microsoft/foldingdiff
Unsloth AI (Daniel Han) ▷ #general (89 messages🔥🔥):
Gradient Accumulation IssuesApple's New Mac Mini ReleaseTraining Foundation ModelsDataset Preparation in MLVision Fine-Tuning Delay
-
Unsloth Team Investigates Gradient Accumulation: The Unsloth team released a report revealing critical issues with gradient accumulation in training frameworks, particularly for language model generation.
- They found inconsistencies in the outputs when using traditional batch sizes, impacting loss calculations.
- Apple Unveils New Mac Mini: Apple announced its new Mac mini featuring M4 and M4 Pro chips, marking it as the first carbon-neutral Mac.
- The compact design delivers up to 1.8x faster CPU performance and is small enough to fit in a hand.
- Discussion on Foundation Models vs Fine-tuning: Members debated the classification of a fine-tuned llama 70B model as a foundation model, with acknowledgments of the complexity involved in training.
- Concerns were raised about model accuracy and the need for balanced datasets, with suggestions for simpler classification models for narrow tasks.
- Preparation for AI Model Fine-tuning: There were discussions around best practices for dataset preparation, highlighting the importance of quality and balance to achieve better accuracy in models.
- Members recommended resources from Hugging Face for those new to fine-tuning and dataset balancing.
- Vision Fine-tuning Delayed: An announcement was made regarding the delay of vision fine-tuning, originally scheduled for today, now expected later this week or early next week.
- Community members expressed anticipation and appreciation for the ongoing work, humorously referencing the timeline with a Gandalf meme.
Links mentioned:
- Tweet from Marcel Binz (@marcel_binz): Excited to announce Centaur -- the first foundation model of human cognition. Centaur can predict and simulate human behavior in any experiment expressible in natural language. You can readily downloa...
- Apple’s new Mac mini is more mighty, more mini, and built for Apple Intelligence: Apple today unveiled the all-new Mac mini powered by the M4 and new M4 Pro chips, and redesigned around Apple silicon so it’s even smaller.
- Hobbit Gandalf GIF - Hobbit Gandalf Wizard - Discover & Share GIFs: Click to view the GIF
- Zach Mueller - PyTorch, Gradient Accumulation, and the dreaded lack of reproducability: no description found
- [AMD] Triton Backend for ROCm by micmelesse · Pull Request #1203 · Dao-AILab/flash-attention: Hi, this is a pr to add a Triton backend to Flash Attention on ROCm. We hope that this pr will be the first in a series of prs to that end. Triton has had support for ROCm for a while now and a Fla...
Unsloth AI (Daniel Han) ▷ #off-topic (41 messages🔥):
Quitting school earlyExperiences of agingR&D in techJob searching after a master'sCollaborative work offers
-
Quitting school at an early age leads to unique perspectives: A member shared their experience of quitting school at 17, noting that learning outside traditional education has been more beneficial for them.
- My experience is valid with or without anyone else's validation, highlighting a strong belief in personal growth outside of academic norms.
- Reflection on aging brings mixed feelings: Another member expressed that turning middle-aged was a drastic life change, stating, My whole life got turned upside down as expectations shifted.
- They poignantly observed that many friends from their 20s have passed, emphasizing the vast differences in life experiences as one ages.
- R&D roles can be both exciting and overwhelming: A member who recently completed their master's noted they feel like a noob in the tech world, having just scratched the surface of knowledge.
- They expressed enthusiasm for their new R&D position, saying, I was lucky enough to discover this world and get paid to explore it.
- Collaborative work offers can be lucrative: A member requested help for an essay project, offering 2 sats per entry for assistance with typing over 200 pages.
- They mentioned that despite wanting to use AI for help, They don’t get it, reflecting frustration with current AI limitations.
- Humorous take on challenges with coding tests: A member humorously shared their reaction to getting a HackerRank challenge, stating experiences with it can feel daunting.
- They used a meme to express this feeling, conveying the relatable struggle many face in tech testing scenarios.
Link mentioned: Brain Dog Brian Dog GIF - Brain dog Brian dog Cooked - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (28 messages🔥):
Continued Pretraining with UnslothInstallation Issues with UnslothFine-Tuning Models with Custom DatasetsInstruct Fine-Tuning with Llama ModelsGPU VRAM Management during Fine-Tuning
-
Unsloth’s Continued Pretraining Boasts Efficiency: Unsloth’s latest release allows continual pretraining of LLMs 2x faster and using 50% less VRAM than other solutions, along with a free Colab notebook for Mistral v0.3 7b.
- Key insights include recommendations on finetuning embeddings and using different learning rates for stabilization.
- Installation Troubles with Unsloth Packages: A user faced installation errors while trying to set up Unsloth but resolved it after identifying a typo in the package name 'bitsandbytes'.
- Another member reminded about the importance of isolating Python environments, especially for Linux systems.
- Guidance on Fine-Tuning with Custom JSON Datasets: A user sought help for fine-tuning a model using a nested JSON dataset format, aiming to learn about the process using Unsloth.
- The response highlighted a general approach but mentioned the need for proper formatting and compatibility during model training.
- Instruct Fine-Tuning with Meta Llama Models: One user encountered tensor shape mismatch errors when trying to fine-tune with the Meta Llama3.1 8B Instruct template and sought advice.
- They switched models and still faced issues with merging and loading the model, indicating potential gaps in compatibility.
- Exploring Fine-Tuning Options for OLMo with VRAM Concerns: A community member inquired about fine-tuning the allenai/OLMo-7B-0724-Instruct model with Unsloth, specifically regarding VRAM usage.
- This inquiry reflects ongoing challenges many users face regarding model fine-tuning with limited resources.
Links mentioned:
- Miniconda — Anaconda documentation: no description found
- Continued LLM Pretraining with Unsloth: Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.
Unsloth AI (Daniel Han) ▷ #research (12 messages🔥):
ThunderKittens UpdateRickroll in ResearchCommunity ReactionsPaper on ThunderKittens
-
ThunderKittens Team Returns with New Features: The ThunderKittens team published a blog post highlighting several new and improved features, including exciting kernels and talking models.
- They humorously noted the warm reception their previous work received on social media and included a playful mention of extra adorable kittens.
- Community Rickroll Reference: A member expressed being surprised and amused by getting rickrolled, referring to a humorous element from the ThunderKittens update.
- Another member jokingly stated they won't reveal the details, keeping the rickroll mysterious.
- Inquiring About the ThunderKittens Paper: A member asked if there was a paper related to ThunderKittens, prompting the sharing of the arXiv link.
- The discussion hinted at interest in diving deeper into the contents of the paper.
- Community Enjoyment of Lightheartedness: Several members shared their appreciation for the ThunderKittens team's lighthearted approach, pointing out how fun their style is.
- A member expressed that they love the unserious attitude of the team, showcasing community engagement.
Links mentioned:
- Easier, Better, Faster, Cuter: no description found
- ao/torchao/prototype/low_bit_optim at main · pytorch/ao: PyTorch native quantization and sparsity for training and inference - pytorch/ao
OpenAI ▷ #ai-discussions (129 messages🔥🔥):
AGI DevelopmentModel EfficiencyQuantization TechniquesAI Tools and IntegrationNvidia GPUs for AI
-
Mixed Opinions on AGI and Models: Members expressed differing views on the timeline and feasibility of achieving AGI, debating whether companies like Google can keep up in the race.
- Concerns were raised about Google's regulatory challenges and optimism around new algorithms driving progress.
- Debate on Model Efficiency and Size: A discussion emerged about the notion that larger models aren't always better, emphasizing the potential for quantization to achieve efficiency without loss in performance.
- Members referenced Llama 3.0 and Qwen models as comparisons, citing recent quantized models outperforming larger predecessors.
- ChatGPT and API Development Queries: Users sought advice on starting with API development and learning Python, with suggestions of leveraging YouTube for beginners to gain foundational skills.
- Emphasis was placed on practical applications such as using LeetCode to refine coding skills once basics are mastered.
- Nvidia GPU Debate for AI Work: There was a conversation about whether a 4070 Super GPU is sufficient for local AI projects, with opinions shifting towards the necessity of a higher VRAM option for more demanding tasks.
- Members collectively highlighted the increasing efficiency of smaller models while acknowledging the lingering disparity between affordable GPUs.
- Evolution of AI Coding Tools: Participants discussed the transition of GitHub Copilot to integrating Claude, pointing out how this change enhances code completion processes.
- Comments emphasized the time-saving advantages of AI tools, specifically in automating mundane coding tasks such as filling in function parameters.
Link mentioned: Meta Releases Llama3.2 1B/3B Quantized Models: Accelerated Edge Inference, Reduced Memory Usage: Meta launches Llama3.2 quantized models with 2-4x faster inference and reduced memory usage, optimized for mobile devices.
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
Open Source LLM ToolCustom GPT Data UploadsPerformance of RAGCave Johnson AI
-
Searching for Open Source LLM Tool: A member inquired about an open source LLM tool that supports branching conversations with ChatGPT, allowing responses to diverge from and return to original threads.
- No specific tool name was provided, leading to a call for similar front-end suggestions.
- Custom GPT File Organization: Members debated whether to upload many smaller files or a single large file to a custom GPT's knowledge base for optimal performance.
- One member noted that it depends on the situation, using RAG on a scientific paper as a scenario where larger files may be preferred.
- Cave Johnson AI Compilation Choices: One member shared their approach to creating a Cave Johnson AI, compiling all lines from the Portal Wiki into a single text file without splitting it.
- They emphasized that this method was preferable in that case, suggesting that RAG implementation effectively handles the data.
- Importance of Organized Data for Chatbots: When programming personal chatbots, one member stressed the importance of keeping data organized and concise to avoid irrelevant token usage-related costs on API calls.
- Input tokens for irrelevant data still incur fees when using the API, reinforcing the need for careful data management.
OpenAI ▷ #prompt-engineering (2 messages):
StochasticityPrompt Generation Tool
-
Discussion on Stochasticity: A member mentioned Stochasticity, likely referring to its implications in AI behaviors or outputs.
- Further details or context were not provided, leaving the topic open for interpretation.
- Seeking Access to Prompt Generation Tool: A user inquired about accessing a prompt generation tool within the playground to assist with generating effective prompts for specific tasks.
- They referenced documentation on prompt generation, indicating uncertainty about its location in the interface.
OpenAI ▷ #api-discussions (2 messages):
StochasticityPrompt generationPlayground tools
-
Exploring Stochasticity: A member briefly mentioned the concept of stochasticity, which seems to invite further discussion.
- No additional details were provided on this topic.
- Looking for Prompt Generation Tool: Another user inquired about accessing a prompt generation tool within the OpenAI Playground, wanting to better tailor prompts for their tasks.
- They linked to the official guide on prompt generation for reference.
Perplexity AI ▷ #announcements (1 messages):
Perplexity SupplyNew Shipping Options
-
Perplexity Supply Launches: Perplexity Supply introduces thoughtfully designed essentials that celebrate the pursuit of knowledge, targeting curious minds.
- Customers can now purchase quality goods that spark conversation and curiosity through their various product offerings.
- Global Shipping Now Available: Perplexity Supply is now shipping to multiple countries including the US, Australia, and Germany, among others.
- Those interested can sign up to receive updates on future drops and expansions to additional countries via this link.
Links mentioned:
- Perplexity Supply: Where curiosity meets quality. Our premium collection features thoughtfully designed apparel for the the curious. From heavyweight cotton essentials to embroidered pieces, each item reflects our dedic...
- Perplexity Supply: Coming Soon: Perplexity Supply exists to explore the relationship between fashion and intellect with thoughtfully designed products to spark conversations and showcase your infinite pursuit of knowledge.
Perplexity AI ▷ #general (124 messages🔥🔥):
File Upload IssuesPro Subscription Promo CodesSpaces and Collections ChangesNFL Widgets IntroductionComparison of Perplexity and Consensus for Research
-
Multiple users facing File Upload issues: Users have reported that the file upload feature has been malfunctioning, causing frustration about lingering files during conversations.
- One user noted that the handling of uploaded files has never been satisfactory, comparing it unfavorably to other platforms.
- Problems with claiming Pro subscription promo code: Several users are encountering issues with the GitHub Universe promo code for a free year of Pro, receiving 'Invalid promo code' messages.
- One user expressed concern that while the code works on web, it fails on the Android app.
- Changes in Spaces and Collections features: A user reported that the Collections section has been renamed to Spaces and is now located in the sidebar, leading to confusion.
- Another user confirmed they faced a blank screen bug upon clicking on their spaces, affirming similar experiences from others.
- Launch of NFL Widgets: The community was informed about new NFL widgets, which provide game summaries, stats, and comparisons, with more sports features coming soon.
- A build announcement on social media hinted at future expansions to sports coverage beyond NFL, like NBA and cricket.
- Discussion on Perplexity vs. Consensus for Medical Research: A user asked for comparisons between Perplexity and Consensus, suggesting that Consensus may be better for medical research.
- The thread indicated that some users have tested both, looking for insights on their respective effectiveness.
Links mentioned:
- Tweet from Perplexity (@perplexity_ai): Both Perplexity and GitHub Copilot users can install the integration for free via the GitHub Marketplace: https://github.com/marketplace/perplexityai
- Tweet from Perplexity (@perplexity_ai): Perplexity Supply. Merch, made for the curious. Drops tomorrow: http://perplexity.supply
- Tweet from Pete Lada (@pklada): This was a fun one to build - lots of little details we were able to sneak in. It’s still early days for sports on perplexity, let me know what you want to see next! Quoting Aravind Srinivas (@AravSr...
Perplexity AI ▷ #sharing (9 messages🔥):
Earth's Temporary New MoonPython Module HeadersSearch History ViewingJang GyuriDiscord Registration
-
Earth gains a temporary new moon: A source discusses Earth's temporary new moon here. Key details about its impact and visibility are mentioned.
- This discovery opens fascinating discussions about temporary celestial bodies.
- Correcting Python Header Misconceptions: An individual corrected the claim regarding Python module headers, stating that the header should include the relative path to the module source here.
- Accurate module referencing is essential for successful coding.
- How to See History of Searches: One member inquired about viewing the history of searches on the platform, referring to the process discussed here.
- Getting access to one's search history can streamline the research process.
- Insights on Jang Gyuri: A link was shared relating to Jang Gyuri, which offers interesting insights into her work and achievements see here.
- Fans and researchers alike are eager to learn more about her contributions.
- Questions on Discord Registration: A query was raised about the Discord registration process, with a discussion linked here.
- Clarifying registration could benefit many new users.
Perplexity AI ▷ #pplx-api (5 messages):
Differences in Playground and API resultsAPI for Perplexity SpacesPerplexity API usage for development
-
Playground vs API Results Discrepancy: A user questioned why results from the Playground and the API are different, noting they use the same model.
- No further clarifications were provided regarding the discrepancies between the two products.
- No API for Perplexity Spaces: In response to an inquiry, it was stated that there is currently no API for Perplexity Spaces.
- The member clarified that the Perplexity website and the API function as two distinct products.
- Considering Perplexity API for Projects: A user expressed interest in potentially using the Perplexity API for their development project instead of the OpenAI API.
- The discussion did not yield any specific guidance or recommendations on the suitability of the Perplexity API for such purposes.
aider (Paul Gauthier) ▷ #general (107 messages🔥🔥):
Aider commandsHaiku 3.5 release statusQodo AI vs ClineSkyvern AI automationGemini usage in development
-
Aider implements /save and /load commands: A new feature in Aider allows users to save added and read-only files with
/saveand load commands with/load, helping to recreate contexts easily.- These commands simplify the process of managing code contexts and allow for batch processing.
- Anticipation for Haiku 3.5 release: There are ongoing discussions about the potential release of Haiku 3.5, with expectations that it might be available soon, possibly the next day.
- Users are curious about the improvements it could bring compared to previous versions.
- Comparison of Qodo AI and Cline: While Qodo offers a variety of features for AI code generation, users question how it distinguishes itself from models like Cline, particularly regarding usability and functionalities.
- Qodo subscription starts at $19/month but the lack of model choice and inline completion paid features are points of concern.
- Skyvern for AI browser automation: Skyvern aims to automate browser-based workflows using AI, providing users with a no-code/low-code solution for repetitive tasks.
- This tool adapts to web pages and boasts features for executing complex tasks with simple commands.
- Gemini vs other tools: Users are sharing experiences with Gemini, particularly its effectiveness for database logic inquiries compared to other models like Claude and Aider.
- There's a general consensus on the advantages of Gemini for practical coding needs, although its performance can vary with context size.
Links mentioned:
- Quality-first AI Coding Platform | Qodo (formerly Codium): Qodo (formerly CodiumAI) offers quality-first AI tools for developers to write, test, and review code directly within their IDE and Git.
- Skyvern - Automate Browser-Based Workflows with AI: Skyvern helps companies automate browser-based workflows using LLMs and Computer Vision, fully automating manual workflows and replacing brittle or unreliable scripts.
aider (Paul Gauthier) ▷ #questions-and-tips (12 messages🔥):
Aider ConfigurationDeepSeek Coder with OllamaInput Caching EfficiencyConsistent Code Generation GuidelinesConnection Issues with Copilot
-
Aider Configuration for Closed Source LLMs: A user inquired about configuring Aider to use closed-source LLMs like Sonnet or O1 with O1 mini or Ollama in architect mode, seeking guidance.
- Another member suggested referring to the
.aider.conf.ymlfile and Aider benchmarks for optimal model selection. - Challenges Running DeepSeek Coder Locally: A user encountered difficulties in running DeepSeek Coder over Ollama locally, believing they might have missed something in the setup.
- The community member offered assistance to clarify the user's goals and troubleshoot the issue.
- Mixed Results with Input Caching: A member shared their experience suggesting that input caching isn't yielding cost savings as expected, providing codebase statistics.
- They provided a comprehensive breakdown of files and code, indicating potential inefficiencies.
- Loading Conventions for Consistent Code Generation: To maintain consistent code generation, a user wanted to know if it’s possible to always include a conventions file in Aider.
- Guidance was offered to create a markdown file and load it with
/read CONVENTIONS.mdor configure it in the.aider.conf.ymlfile. - Connection Issues Between Aider and Copilot: A user reported a connection error using Aider with Copilot, having already set the necessary environment variables.
- The discussion revealed that the user is constrained to use Copilot due to company policies, prompting queries about compatibility.
- Another member suggested referring to the
Link mentioned: Specifying coding conventions: Tell aider to follow your coding conventions when it works on your code.
aider (Paul Gauthier) ▷ #links (3 messages):
New Bash Tools from Claude AnthropicIntegration of New Tools with Code Assistants
-
Exploring New Bash Tools from Claude Anthropic: A member shared an interest in the recent discussion regarding the new bash and editor tools from Claude Anthropic and their potential applications.
- The conversation highlights possible implementations of these tools within existing code assistants like Aider, emphasizing their significance in enhancing user experience.
- Hope for Automatic File Handling: Another member expressed a desire for improvements, suggesting that manual file addition to chats may soon be a thing of the past.
- This reflects a broader expectation for automation and seamless integration in chat functionalities, particularly regarding relevant files.
Link mentioned: GitHub - disler/anthropic-computer-use-bash-and-files: Contribute to disler/anthropic-computer-use-bash-and-files development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Oauth issueAPI key creation
-
Oauth authentication broke this morning: Apps utilizing openrouter.ai/auth for API key creation were affected by an Oauth issue this morning.
- The team has identified the issue, and a fix has been confirmed to be live shortly after the announcement.
- Quick fix for Oauth disruption: Members noted the disruption to API key creation would be resolved quickly as the fix was confirmed shortly after the report.
- This swift response ensured minimal downtime for applications relying on the Oauth system.
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
Flexible Chat App for macOSAlpha TestingUser Feedback
-
Seeking Alpha Testers for New Chat App: A developer is looking for alpha testers for a flexible chat app they are building for macOS and provided a link to screenshots.
- Interested users are encouraged to DM the developer for more information and to become involved in the testing phase.
- Screenshots Available for Review: Screenshots of the chat app are available on Imgur showcasing its current design and features.
- The developer is eager to receive feedback from potential testers to refine the app before its public release.
Link mentioned: imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
OpenRouter (Alex Atallah) ▷ #general (114 messages🔥🔥):
OpenRouter Key IssuesModel Selection in OpenRouterHaiku 3.5 ReleasePrompt Caching for ModelsOpenRouter Chat Functionality
-
OpenRouter API Key Scraping Concerns: A discussion arose about the security of OpenRouter API keys, highlighting that keys can be scraped and misused by others, particularly in paid proxy setups like Sonnet 3.5 and Mythomax.
- Just because you think the key is secure doesn't mean it is secure was a notable comment, emphasizing the necessity of vigilance with sensitive information.
- Discrepancies in Model Selection: Users expressed confusion over the automatic selection of specific models by OpenRouter, particularly when utilizing 'openrouter/auto', which consistently selected Llama 3 70B Instruct despite expectations for Claude 3.5 Sonnet or GPT-4o.
- A request for examples of prompts that could trigger selections of these models was made, suggesting a need for clearer understanding of the system's behavior.
- Anticipation for Haiku 3.5 Release: The community eagerly awaited the release of Haiku 3.5, with hints suggesting it might occur within a day, despite the model not being readily available in the GCP model garden yet.
- The model slug for GCP was shared as
claude-3-5-haiku@20241022, but it remains behind allow lists and is not generally available yet. - Utilization of Prompt Caching: Members discussed prompt caching's role in reducing costs when using certain models in OpenRouter, with suggestions to enable such caching to improve efficiency.
- Clarification was provided on how prompt caching functions, and its potential limitations with specific providers, emphasizing its benefits for overall cost management.
- OpenRouter Chat Saving Features: Users inquired about the saving functionality of chats within OpenRouter, confirming that chats are stored locally in the browser, which could lead to lost data if not managed properly.
- A shared link highlighted this aspect of OpenRouter, which appears to affect users trying to revisit earlier discussions.
Links mentioned:
- Prompt Caching | OpenRouter: Optimize LLM cost by up to 90%
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- OpenRouter Status: OpenRouter Incident History
- Models | OpenRouter: Browse models on OpenRouter
- LLM Rankings | OpenRouter: Language models ranked and analyzed by usage across apps
OpenRouter (Alex Atallah) ▷ #beta-feedback (5 messages):
Integration Feature Access
-
Community Request for Integration Feature Access: Multiple users expressed interest in gaining access to the integration feature within the platform, emphasizing its importance for their needs.
- One member humorously noted, 'I would like to rerequest integration feature!', highlighting the eagerness for this capability.
- Repeated Requests for Integration Access: Several users stated their desire to test out the integration feature, indicating a broader curiosity about its functionalities.
- Comments like, 'Hi, I would like to get access to integrations', were common, showcasing the demand for this feature.
Stability.ai (Stable Diffusion) ▷ #general-chat (117 messages🔥🔥):
GPU ComparisonsTraining ModelsStable Diffusion IssuesUsing Auto1111 vs Comfy UIRecent Model Developments
-
Market Insights on GPUs: Members discussed that used 3090 cards cost less than 7900 XTX models and debated their relative benefits, emphasizing budget considerations.
- eBay prices hover around ~$690, creating a dilemma for users deciding between performance metrics and price.
- Training Models for Stylistic Adaptation: A member inquired about the best approach to train on a friend's art style using a small dataset of 15-20 images, questioning if a model or Lora/ti is preferable.
- Opinions surfaced that using a Lora could be more effective for creating consistent characters based on stylistic choices.
- Resolving Stable Diffusion Image Issues: There were multiple inquiries about users encountering grey images while using Stable Diffusion and seeking support for troubleshooting.
- Members suggested exploring various UI options and checking compatibility with AMD GPUs to enhance performance.
- UI Preferences: Auto1111 vs Comfy UI: Discussions leaned towards Comfy UI being favored due to ease of use, while some users still prefer Auto1111 for its automation capabilities.
- Members shared experiences suggesting SwarmUI for its straightforward installation process and functionality.
- Upcoming AI Model Developments: The community speculated whether SD 3.5 would become as popular as SDXL, prompting discussions on performance comparisons.
- There were notes on the anticipated release of new control nets and model updates that maintain relevance within the evolving landscape.
Links mentioned:
- no title found.): no description found
- Anzhc's Face Segmentation (Prototype) | YOLOv8 | Adetailer model - Woman face (real only) | Stable Diffusion Other | Civitai: New models, woman and man face detection: Basically sponsored by @girlsthatdontexist , I actually don't know if they want to be mentioned, they can...
- Create CONSISTENT CHARACTERS for your projects with FLUX! (ComfyUI Tutorial): Unlock the secret to perfect characters in AI art with this in-depth tutorial!If you like my work, please consider supporting me on Patreon: https://www.patr...
- stabilityai (Stability AI): no description found
Nous Research AI ▷ #general (67 messages🔥🔥):
Microsoft's Control Over OpenAILatency Issues with AI ModelsDeployment of Autonomous Twitter AgentsFlash Attention and CUDA CompatibilityPerformance of Hermes 3 vs Other Models
-
Microsoft De-Risks from OpenAI Dependency: Discussion arose about Microsoft's strategy to de-risk from OpenAI, particularly if OpenAI declares AGI, giving them a contractual out and a chance to renegotiate.
- “Microsoft will NEVER let that happen,” stated a member, highlighting skepticism about such a release.
- Concern Over AI Latency: There were concerns over a reported 20-second latency with a model, leading to jokes about the hardware it might be running on, like being run on a potato.
- Members remarked on the disparity in performance compared to other services, with one stating Lambda serves 10x more requests with 1s latency.
- Guide for Deploying Twitter Agents: Users expressed interest in guides for deploying autonomous Twitter agents, confirming that open-source repos exist for such projects.
- Another member encouraged participation through PRs to contribute to the community's open-source efforts.
- Success with Flash Attention on A6000: A member shared their success in running Flash Attention 2.6.3 on CUDA 12.4 and PyTorch 2.5.0 on their A6000, noting it's achievable despite previous challenges.
- They mentioned that building it manually resolved symbol linking issues that arose from pip installation.
- Performance Comparisons of AI Models: Members discussed the surprisingly high performance of Hermes 3 8B compared to other under 10B models, asserting it rivals GPT-3.5 quality.
- The conversation included critiques of other models like Mistral 7B being sad by comparison, emphasizing Hermes 3's effectiveness in tool calling.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from Javi Lopez ⛩️ (@javilopen): I asked an AI to show me how Egyptian pyramids were built, and now I'm pretty sure I'll have nightmares for life 🤯
- Tweet from DataVoid (@DataPlusEngine): no description found
- fblgit/cybertron-v4-qw7B-MGS · Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (12 messages🔥):
Function Calling Datasets in SpanishEffectiveness of Hermes 3Data Retention Policies of API-based AIsApple's Private Cloud ComputeConcerns about Data Privacy
-
Need for Spanish Function Calling Datasets: A member is actively trying to construct datasets for function calling in Spanish, but has faced challenges with open source models performing poorly; an example site provided highlights ongoing experiments with data transformation from López Obrador's morning conferences.
- They cited the large volume of information processed from over a thousand videos, aiming for journalistic relevance while reducing data handling time.
- Hermes 3's Custom Effectiveness: One user reported that Hermes 3, when equipped with a custom system prompt, proves to be particularly effective and boasts a low barrier to entry for users.
- This contrasts sharply with disappointing performances from other models like Llama 3.2 and Qwen.
- Deep Dive into AI Data Retention: Concerns arose about the high levels of data collection in the T&Cs of API-based AIs, leading to inquiries about any potential backlash against such practices.
- Several participants noted that many users overlook details that suggest data retention, assuming that non-training clauses imply no storage.
- Apple's Private Cloud Compute Initiative: A shared Apple blog post detailed their Private Cloud Compute (PCC) initiative, emphasizing the importance of privacy and security in handling user data via on-device processing.
- This points to Apple's recognition of data handling issues, though concerns were raised about whether such solutions would primarily benefit Mac users.
- Concerns about Data Confidentiality: Discussions revealed that even benign data handling practices can lead to incidental data exposure, particularly for sensitive information during server maintenance and debugging.
- A participant highlighted that many AIs' terms often include caveats about logging prompts for abuse monitoring, further complicating trust in data privacy.
Links mentioned:
- Blog - Private Cloud Compute: A new frontier for AI privacy in the cloud - Apple Security Research: Secure and private AI processing in the cloud poses a formidable new challenge. To support advanced features of Apple Intelligence with larger foundation models, we created Private Cloud Compute (PCC)...
- Las Mañaneras - Las Mañaneras: no description found
Nous Research AI ▷ #interesting-links (8 messages🔥):
AI-generated Code at GoogleNotebookLMCode MetricsContinuum App
-
Sundar Pichai touts AI's impact on Google coding: At an earnings call, Sundar Pichai revealed that over 25% of new code at Google is generated by AI, according to Andrew Curran's tweet.
- This statistic has sparked conversations about the significance of AI in coding practices.
- NotebookLM as a Tool for Code Generation: Members discussed that the AI advancements are linked to NotebookLM, a tool that facilitates code generation with various resources.
- Mikebirdtech confirmed that the information shared was derived from NotebookLM's functionality along with pertinent links.
- Questioning Code Productivity Metrics: Zachmayer commented on the notion that counting lines of code isn't the best measure of productivity, stating, **
- He humorously remarked that he would feel more impressed if an AI could delete 25% of his code.
- Continuum as a Potential Platform: Felixultimaforeverromanempire suggested that the AI-generated code conversation would be valuable on the Continuum platform.
- This indicates interest in exploring innovative applications for AI coding capabilities.
Link mentioned: Tweet from Andrew Curran (@AndrewCurran_): Sundar Pichai said on the earnings call today that more than 25% of all new code at Google is now generated by AI.
Nous Research AI ▷ #reasoning-tasks (3 messages):
StocksMeme coin simulationSynthetic datasets
-
Stocks discussion sparkles interest: A member inquired about stocks, prompting a brief discussion in the channel.
- Haha, I see stock market sim was the light-hearted response that followed, showcasing engagement with the topic.
- Meme Coin Simulation in Progress: Another member mentioned that they are currently working on meme coin simulation for generating synthetic datasets.
- This effort reflects a trend toward innovative financial modeling using playful currency concepts.
Eleuther ▷ #general (16 messages🔥):
Running multiple instances on a single GPUTesting RAG with CSV dataEntity extraction and temperature settingsSubmissions and rebuttals for COLINGVariability in harmful instructions across benchmarks
-
Exploring multiple instances on a GPU: A member inquired about running multiple instances of a small LLM on the same GPU using GPT-NeoX to fill up GPU memory with larger batch sizes.
- Others discussed the feasibility, noting the potential for experimenting with parallel training regimes but cautioned against expecting significant benefits from DDP on the same GPU.
- Attempting RAG on natural language CSV: A member expressed doubts about feeding raw CSV data with delimiters into a local ~3B LLM for RAG and mentioned testing it with case numbers getting mixed up.
- They plan to convert the CSV to JSON for better performance, indicating possible preprocessing challenges.
- Entity extraction settings adjustment: After a testing phase with qwen2.5, a member realized the temperature was incorrectly set to 0.8 instead of 0 during entity extraction, affecting results.
- They are reattempting the extraction with the correct temperature setting to improve outcomes.
- COLING submission inquiries: A member asked if others submitted to COLING and noted the shared 500-word limit for rebuttals to reviews.
- They sought clarification on whether this limit applies universally or if it was specific to their experience.
- Discussion on harmful instructions in safety benchmarks: A member inquired about papers discussing variability in defining 'harmful instructions' across safety benchmarks due to differing organizational policies.
- They raised concerns over how benchmark authors' values may influence what is deemed harmful.
Eleuther ▷ #research (44 messages🔥):
Modular Duality in OptimizationComparison of Optimization PapersTraining Diffusion ModelsLimitations of Diffusion ModelsOperator Norms in Neural Networks
-
Modular Duality Theory Surprises: A member shared that popular methods like maximal update parameterization and Shampoo emerge as partial approximations to a single duality map for linear layers, as discussed in the recent paper on modular duality.
- This connection is elaborated in Section 4.1 of the paper, highlighting the relevance of this theory in contemporary optimization techniques.
- Critical Reception of Recent Paper: Critics expressed skepticism about the complexity and originality of the recent optimization theory paper, suggesting that the only significant contribution might be the Newton-Schulz iteration.
- Some remarked that the paper might employ complex language to ostracize rather than clarify concepts, undermining its accessibility.
- Conversations on Fine-Tuning Diffusion Models: Members discussed the strategy of fine-tuning Dino or CLiP ViTs as diffusion transformers, expressing uncertainty about their superiority over RePA.
- One approach mentioned was to retain the first couple of layers while randomly initializing the rest, maintaining a standard transformer block structure with adaptations.
- Limitations of Diffusion Models Explored: There was a discussion on the challenges and limitations of diffusion models, including comparatives to other generative models like GANs and autoregressive models with respect to training time and quality.
- Main issues identified included controllability, latent space manipulation, and representation learning, raising questions about how these affect their applicability.
- Operator Norms and Functional Analysis: Members showed interest in operator norms, noting that understanding them can clarify certain aspects of functional analysis relevant to optimization.
- The discussion included insights into how different tensor roles within neural networks could justify unique operator norms to streamline optimization.
Links mentioned:
- Tweet from Jeremy Bernstein (@jxbz): A surprising aspect of the theory of modular duality is that popular methods such as ~maximal update parameterization~ and Shampoo emerge as partial approximations to a single duality map for linear...
- Tweet from Jeremy Bernstein (@jxbz): Over the past month, methods developed by myself and my collaborators were used to set new speed records for training LLMs up to 1.5B scale. I also want to help the science go faster, so now get ready...
- Modular Duality in Deep Learning: An old idea in optimization theory says that since the gradient is a dual vector it may not be subtracted from the weights without first being mapped to the primal space where the weights reside. We t...
- Old Optimizer, New Norm: An Anthology: Deep learning optimizers are often motivated through a mix of convex and approximate second-order theory. We select three such methods -- Adam, Shampoo and Prodigy -- and argue that each method can in...
Eleuther ▷ #interpretability-general (7 messages):
sae_dashboardAI paper on concept geometry
-
Imminent Work on sae_dashboard: A member indicated they have not yet tried to make sae_dashboard work, stating that it will be the next part of their project.
- They decided to release what they had so far for analyzing features before improving it.
- Text-Centric Analysis with sae_dashboard: sae_dashboard allows for text-centric analysis, focusing on which features activate based on the input text.
- This was clarified in the discussion, highlighting the tool's capability to check feature activation.
- New AI Paper by Tegmark on Feature Structure: A member shared a link to Tegmark's tweet announcing an AI paper that uncovers a surprising geometric structure in LLM-learned concepts.
- The paper discusses concepts organized into brain-like lobes, semantic crystals, and illustrates a fractal concept cloud structure that is more precise than previously thought.
Link mentioned: Tweet from Max Tegmark (@tegmark): Our new AI paper reveals surprising geometric structure in the LLM-learned concepts: 1) They form brain-like "lobes", 2) they form "semantic crystals" much more precise than it first ...
Eleuther ▷ #lm-thunderdome (15 messages🔥):
Freezing Embedding LayerMultiple Choice Prompt FormatWinogrande Context HandlingEval Harness API IssuesAnswer Matching Heuristics
-
Can I Freeze the Embedding Layer?: A user inquired about a configuration option to freeze the embedding layer for a Megatron model, aiming to train only transformer blocks. They also asked if embedding and output parameters are excluded in configs like 19M.yml.
- There's no direct response, suggesting the discussion is ongoing.
- Clarifying Multiple Choice Prompt Format: Instructions were provided on the intended prompt format for multiple-choice tasks, which is structured as
- The answer for a sample is determined by the choice that yields the highest logprob.
- Winogrande's Unique Challenge: Discussion highlighted that Winogrande operates differently, flipping the context rather than maintaining a consistent context for assessment. Members expressed that normally, conditional loglikelihood is computed over a stable context.
- The uniqueness of Winogrande's structure was noted as a deviation from standard practices.
- Issues with Eval Harness API: A user faced challenges running the eval harness against an OpenAI-compliant API, detailing the request formats being sent. The solution suggested was to use
--apply_chat_templateto correct the formatting issues.
- This fix was confirmed to be successful, leading to the user's appreciation.
- Interpreting Evaluation Results: A user questioned the implications of their evaluation results showing a value of 0.0000 for the strict-match on gsm8k, wondering if it indicates complete failure. The response pointed to a potential breakdown in the answer matching heuristic used by the task.
- Recommendations included checking generation logs and adding few-shot examples to guide the model better.
Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
Elon Musk xAI funding talksCursor premium discussionRobonato embodiment talksCreative Writing Arena insights
-
Elon Musk in talks to boost xAI valuation: According to the WSJ, Elon is negotiating a new funding round aimed at raising xAI's valuation from $24 billion to $40 billion. Despite these discussions, Elon has continuously denied prior rumors of fundraising.
- xAI kind of scares me, shared a member, reflecting on the company's ambitious direction.
- Cursor premium's perceived value: A member pondered if there's a better choice than Cursor premium, claiming it offers virtually unlimited access to the models they prioritize. This sparked comments about alternative options, including using a work Claude API key.
- Another contributor humorously noted, nato too OP, highlighting the perceived advantages of the suggested approach.
- Discussions on Robonato's needs: A member joked that robonato needs to be embodied, emphasizing the desire for more physical intelligence. They further suggested that Robonato craves powerful end effectors for its operation.
- A member envisioned the blog output that could be achieved with a fully developed Robonato, showcasing the potential of advanced AI embodiment.
- New insights from Chatbot Arena: A new category for Creative Writing has been introduced in the Chatbot Arena, indicating a notable shift in focus towards originality and artistic expression. Key findings revealed that o1-Mini has dropped below top models, while Gemini 1.5 Pro and Flash 002 have gained ground.
- Amid these changes, ChatGPT-4o-Latest continues to hold the #1 spot with a significant uptick, while New Sonnet 3.5 has shown improvement over its predecessor.
Links mentioned:
- Tweet from Andrew Curran (@AndrewCurran_): The WSJ is reporting Elon is in talks for a new funding round to raise xAI's valuation from $24 billion to $40 billion. Elon has repeatedly denied previous rumors.
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): 🚨New Chatbot Arena Category: Creative Writing Arena! Creative writing (~15% votes) involves originality, artistic expression, and often different from technical prompts. Key Findings: - o1-Mini dr...
Interconnects (Nathan Lambert) ▷ #random (54 messages🔥):
Claude 3 TokenizerAI2 New OfficeMacBook Pro PricingAI2 Cringe VideoPacific Northwest Scenery
-
Uncovering the Claude 3 Tokenizer: A recent post shares insights on the uniquely closed nature of the Claude 3 tokenizer, mentioning its limited available information.
- The need to rely on billed services instead of open documentation is highlighted as a frustrating aspect of its usage.
- AI2 to Relocate to New Office by Water: AI2's new office is set to open in June next year, and it promises to have beautiful views of the water.
- Members expressed their enthusiasm for the change, noting the delightful nature of the Pacific Northwest scenery.
- Staggering Prices for MacBook Pro: Members discussed the astronomical prices of high-spec MacBook Pros, with configurations like 128GB RAM + 4TB SSD costing around 8k EUR.
- There was a sense of disbelief at the pricing, with comments about the effects of exchange rates and taxes across countries.
- AI2's New Video Critiqued: A member shared a cringe-inducing YouTube video from AI2, praising its earnestness despite its odd production quality.
- Others chimed in about the video's brightness, suggesting it needed adjustments to be more visually appealing.
- Living near a Scenic Lake: One member shared their envy for the stunning views from the new AI2 office, comparing it to their own pleasant view of a small lake from their living room.
- This sparked a discussion about the appeal of both local scenery and the Pacific Northwest, highlighting the charm of both environments.
Links mentioned:
- The Mystery of the Claude 3 Tokenizer: Part 1
- More than open: Ai2 believes in the power of openness to build a future where AI is accessible to all.Learn more about our approach: https://allenai.org/more-than-open
Interconnects (Nathan Lambert) ▷ #memes (3 messages):
420gunna's reignImpressive financial milestoneTimeliness commentary
-
420gunna dubbed 'the king': A member declared that 420gunna is 'the king', hinting at a prominent status in discussions.
- Another member humorously remarked on this title, implying a light-hearted context to the claim.
- A staggering 45B in just 45 minutes!: A member commented on achieving 45 billion in 45 minutes, indicating a remarkable financial milestone with a laughing emoji.
- This statement was met with amusement, highlighting the over-the-top nature of the figure.
- Late to the game commentary: A member quipped about the timing of someone's participation, suggesting they arrived 'a little bit too late'.
- This playful critique added a humorous touch to the ongoing interaction, poking fun at tardiness.
Interconnects (Nathan Lambert) ▷ #posts (8 messages🔥):
Voiceover feedbackEmail mishaps
-
Voiceover enhances personal articles: A member suggested that voiceover is a better way to engage with tomorrow's personal article.
- They mentioned they were really vibing with much of the voiceover content.
- Double email blunder: A member humorously noted an accidental double email sent out.
- "People know to just delete and move on," implying that users are generally relaxed about such email mishaps.
- Wild nature of email communication: One member described email as a wild medium, hinting at its unpredictable nature.
- This reflects a broader sentiment about the quirks of using email for communication.
Notebook LM Discord ▷ #announcements (1 messages):
NotebookLM usability studyAudio Overviews feedbackParticipant incentivesRemote chat opportunities
-
NotebookLM Usability Study Sign-Up: NotebookLM UXR is inviting users to share how they are creatively using NotebookLM, especially with Audio Overviews in a usability study.
- Participants will be scheduled for 30-minute remote sessions, with a $50 equivalent gift for those selected.
- Engagement through Remote Chats: The UXR team will host remote chats via Google Meet to dive deeper into the ways users engage with NotebookLM.
- Interested users should fill out a form for potential selection in this collaborative initiative.
- Essential Study Details Shared: Participants need a high-speed Internet connection, an active Gmail account, and functional video/audio equipment for the study.
- The study will be conducted remotely every Friday until the end of 2024.
Link mentioned: Participate in an upcoming Google UXR study!: Hello, I’m contacting you with a short questionnaire to verify your eligibility for an upcoming usability study with Google. This study is an opportunity to provide feedback on something that's c...
Notebook LM Discord ▷ #use-cases (38 messages🔥):
Simli real-time avatarsPictory for podcast videosVoice splitting techniquesNotebookLM podcast capabilitiesHedra character generation
-
Simli Avatars Enhance Podcasts: A member showcased how Simli can overlay real-time avatars on podcasts by using diarization from .wav files to sync audio segments.
- This proof of concept illustrates the potential for feature integration in future releases.
- Using Pictory for Video Podcasts: A user inquired about converting podcasts to video using Pictory, expressing interest in adding speakers' faces to videos.
- Another member suggested that Hedra could achieve this by uploading split audio tracks for character visualization.
- Voice Splitting Made Easy: For splitting voices in podcast audio, members recommended Descript, discussing efficient methods for isolating individual speakers within the transcript.
- Options include cropping one voice from the transcript or using multiple audio tracks to refine audio quality.
- Exploration of NotebookLM Podcast Capabilities: Users shared experiences with NotebookLM for creating engaging podcasts, highlighting the simplicity of starting from a single word as a source material.
- Members discussed the iterative process and testing limits of LLMs through various stages of audio and critique integration.
- Hedra for Character Generation: One member pointed out the ability to generate expressive characters using Hedra, a platform that complements Pictory for character-based video content.
- The discussion included how the platform could enhance storytelling through AI-powered character creation and expression.
Links mentioned:
- Simli: no description found
- EverythingSTEVENANDJAMIERICE.wav: no description found
- Hedra: Video creation for everyone.
- no title found: no description found
- CYBERSECURITY Experts Reveal The Open Jobs Crisis: In this video, cybersecurity experts reveal the open jobs crisis in the industry. Learn about the demand for cyber security professionals and how you can sta...
- Notebook LM - Create Video Podcasts in Minutes! With Pictory AI: Hey there! 🚀 Want to transform your content into an engaging video podcast using AI? In this tutorial, I’ll guide you through the simple steps to create a v...
- Impact of Decisions: In this video, we deep dive into how every decision matters and how you can improve at making good decisions
Notebook LM Discord ▷ #general (40 messages🔥):
Podcast Generation LimitationsIssues with Language SwitchingNotebook Features RequestAudio Segmentation TechniquesInterruption Issues in Podcasts
-
Podcast Generation Limitations: Several users reported difficulties in generating podcasts in Spanish, despite previous successes, leading to questions about when this feature might be reinstated.
- One user noted, 'It worked pretty well for about two days. Then, stopped producing in Spanish.'
- Issues with Language Switching: A user highlighted an interesting experiment where the model successfully generated Finnish podcasts using English source material, demonstrating its multi-language capabilities.
- When asked about this possibility, they explained, *'I included
- Notebook Features Request: A request was made for increasing the Customize prompt length in Notebook, as the current limit of 500 is considered a bit short.
- Another user suggested a workaround by creating a source called
Instructionsfor additional customization. - Audio Segmentation Techniques: Users have been exploring methods for dividing podcast episodes using tools like Descript, indicating that some observed automatic segmentation during the Deep Dive.
- One user remarked, 'I have noticed that sometimes the Deep Dive divides itself into episodes.'
- Interruption Issues in Podcasts: Concerns were raised about increasing interruptions among podcasters, resulting in inconsistent dialogue flow.
- One user commented, 'Is anyone else finding the podcasters interrupting each other more?'
Links mentioned:
- How Steve Jobs Foresaw AI’s Power to Preserve Great Minds Like Aristotle & Plato in 1983 🤖🧠: In 1983, Steve Jobs shared a visionary idea that feels remarkably like today's AI, such as ChatGPT 🤖✨. During his talk at the International Design Conferenc...
- GitHub - souzatharsis/podcastfy: An Open Source alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI: An Open Source alternative to NotebookLM's podcast feature: Transforming Multimodal Content into Captivating Multilingual Audio Conversations with GenAI - souzatharsis/podcastfy
GPU MODE ▷ #general (4 messages):
AI Impact on JobsInterest in Deep TechAdvertisement Messages
-
AI challenges traditional software engineering jobs: A member noted that AI is increasingly taking over regular software engineer jobs, indicating a shifting job landscape.
- They expressed concerns about the implications of this trend on employment opportunities in the tech industry.
- Desire to engage in Deep Tech: One member expressed a strong interest in getting involved with deep tech innovations, signaling a desire for deeper engagement in the field.
- This reflects a growing curiosity about the potential of advanced technologies beyond surface-level applications.
- Request to remove advertisements: A member made a plea to have certain advertisement messages removed from the channel, indicating distress over non-relevant content.
- This highlights a need for maintaining focus and relevancy in discussions within the community.
GPU MODE ▷ #torch (16 messages🔥):
FSDP2 API UpdatesMemory Profiling in Rust with PyTorchtorchao Optimizers and SR SupportCUDA Kernel Debugging with C++Early Pruning Configs in Triton Kernels
-
FSDP2 API deprecation notice: A user highlighted a FutureWarning regarding the deprecation of
torch.distributed._composable.fully_shard, urging to switch to FSDP instead, with details available in this issue.- This raised questions about the ongoing relevance of the fully_shard API following the insights from the torch titan paper.
- Rust tch.rs application memory profiling: A member sought advice on memory profiling a Rust application using torchscript to identify potential memory leak issues.
- They are particularly interested in debugging potential issues when custom CUDA kernels are involved.
- torchao optimizers and SR support: Discussion arose around the torchao optimizers, specifically on whether they support SR, with one user mentioning that it was added recently.
- The conversation hinted at pursuing SR for bf16 momentum, though it was noted that prior tests didn't showcase significant improvements.
- Compiling CUDA Kernels in C++: A member expressed challenges compiling CUDA kernels directly in C++ for easier debugging while using
cpp_extension.load.
- Advice was provided on setting the
CUDACXXenvironment variable to choose a specific CUDA version not linked with the system path. - Early pruning configs in Triton kernels: A user inquired about approaches to early prune configs in PyTorch/Inductor, given the absence of prune_configs_by support in
torch.compile.
- This indicates a need for alternative methods to handle Triton kernel configurations effectively.
Links mentioned:
- max_autotune_vs_reduce_overhead.py: GitHub Gist: instantly share code, notes, and snippets.
- Issues · pytorch/pytorch): Tensors and Dynamic neural networks in Python with strong GPU acceleration - Issues · pytorch/pytorch
GPU MODE ▷ #beginner (12 messages🔥):
int8 vs fp16 tensor coresGPU options for compute-heavy tasksCloud GPU vs Local GPU DeploymentPerformance overheads in tensor operations
-
Int8 Tensor Cores Slowing Down?: Discussants raised the question of why int8 tensor core could be slower than fp16 tensor core during specific GEMM shapes, with some suggesting potential quantization overhead.
- Quantization overhead and varying output data types when storing results could significantly affect performance comparisons.
- Choosing Your Compute Setup for Hackathons: A participant debated the best setup for hackathons, weighing options like M4 Mac mini, a PC with 3090, or an NVIDIA Jetson AGX Orin.
- Suggestions leaned toward cloud-based GPUs for flexibility, with concerns about the learning curve for deploying on Apple hardware.
- Local vs. Cloud GPU Deployment: Concerns were shared about the overhead and inconvenience of using cloud GPUs versus having local hardware, emphasizing the benefits of quick access to resources.
- While cloud GPUs offer flexibility, there's frustration with reconnecting and potential latency when computing needs arise unexpectedly.
- Efficient Shapes for int8: It was noted that using int8 shapes that are multiples of 16 tends to be more efficient across most hardware configurations.
- Others affirmed the general performance overhead in configurations, suggesting code sharing for deeper analysis.
GPU MODE ▷ #torchao (1 messages):
starsupernova: Will take a look!!
GPU MODE ▷ #rocm (15 messages🔥):
HIP memory error issuesGFX1100 contention problemsROCM version concerns
-
HIP Memory Error Causing Lock-ups: A member reported a HIP memory error issue that causes the machine to lock, leading to hundreds of lines of spam in journalctl when running with torch 2.5 and ROCM 6.2.
- This problem seems to arise when a torch job runs simultaneously with another process that allocates video memory, with headless mode reportedly avoiding these issues.
- Contention Issues on GFX1100: Contention was discussed regarding the GFX1100, indicating that loading a simple webpage can occasionally lead to blocking behaviors during torch tasks.
- One member mentioned that their setup is frequently used for both torch and desktop tasks, making it susceptible to contention.
- ROCM Updates for GFX1100: Concerns were raised about updates in the ROCM changelog, highlighting that fixes for the GFX1100 were only noted in earlier versions, specifically beginning from 6.1.
- A member with ROCM 6.2.1 mentioned that issues have persisted since 6.0, indicating a long-standing problem without resolutions in subsequent updates.
GPU MODE ▷ #sparsity-pruning (7 messages):
Variably sized block pruningStructured pruning methodsUnstructured sparsity methodsLottery Ticket HypothesisStructured sparse winning tickets
-
Exploring Variably Sized Block Pruning: A member raised a question about existing works that prune weight matrices into sparse matrices with variably sized blocks, rather than fixed sizes.
- They inquired if there are structured pruning methods capable of achieving this while still being optimized for GPU performance.
- Structured Pruning Requires Fixed Blocks: It was pointed out that structured pruning typically results in fixed size blocks, leading to a query about alternatives with variably sized blocks.
- Despite this, a response noted that structured pruning methods are generally more agreeable for GPUs.
- Unstructured Sparsity has Performance Gains: Members discussed that while unstructured sparsity methods may yield better performance, achieving gains with them can be challenging.
- Unstructured methods often result in irregular sparse patterns that are difficult to accelerate on hardware.
- Lottery Ticket Hypothesis and Structured Pruning: A paper was referenced discussing the Lottery Ticket Hypothesis, indicating that traditionally pruned subnetworks tend to have unstructured sparsity, complicating GPU acceleration.
- The paper suggests that post-processing techniques could help find structurally sparse winning tickets effectively, marking a positive advancement.
- Mixed Opinions on Pruning Techniques: While there are varied approaches to pruning, including structured techniques, one member commented on the quality of certain attempts, labeling one as 'kinda bad'.
- They also referenced another paper that presented promising results, although expressed reservations about the classifier used.
Link mentioned: Coarsening the Granularity: Towards Structurally Sparse Lottery Tickets: The lottery ticket hypothesis (LTH) has shown that dense models contain highly sparse subnetworks (i.e., winning tickets) that can be trained in isolation to match full accuracy. Despite many exciting...
GPU MODE ▷ #thunderkittens (7 messages):
ThunderKittens talk scheduleLivestream on CUDA and ThunderKittensTK vs Triton and CUTLASSTK library approachMamba-2 kernel complexity
-
ThunderKittens Talk on the Horizon: A user mentioned plans to schedule a talk soon to discuss features and feedback regarding ThunderKittens.
- They thanked another member for setting this up, fostering an engaging community atmosphere.
- Livestream on CUDA Success: A livestream titled 'CUDA + ThunderKittens, but increasingly drunk' showcased hours of content on CUDA and debugging kernels, available here.
- Viewers were informed about a minor hiccup in the screen sharing during the session but can skip that section.
- TK as a Library vs Compiler-based Approaches: Members discussed how ThunderKittens aims to offer higher abstraction than libraries like Cutlass while being easier to use than compiler-based solutions like Triton.
- The conversation highlighted that while compilers can be more powerful, libraries are preferred for ease of use and flexibility.
- Extensibility of ThunderKittens: The discussion explained how ThunderKittens is designed to handle complex tasks while allowing users to write custom CUDA code as needed.
- An example was provided where the Mamba-2 kernel leverages custom CUDA for specific requirements, showcasing the platform's flexibility.
- Revisiting Kernels for Precision: The demo H100 kernel example operates solely within ThunderKittens primitives, emphasizing the library's built-in functionality.
- In contrast, the Mamba-2 kernel utilizes custom techniques to manage intricate operations not easily expressed as simple tensor operations.
Link mentioned: CUDA + ThunderKittens, but increasingly drunk.: My friend Quinn (x.com/qamcintyre) asked me to teach him CUDA and ThunderKittens, and I agreed on the condition that we film it so that I can make new studen...
Torchtune ▷ #general (27 messages🔥):
Llama 3.2 QLoRA TrainingQuantization IssuesActivation Checkpointing ImpactAdapter Weights Saving TimeCheckpointing Performance Discrepancies
-
Llama 3.2 QLoRA Training Process: A user detailed their process of replicating the Llama 3.2 1B QLoRA training, noting success with QAT, but incoherent generations when applying quantization with Int8DynActInt4WeightQuantizer.
- They suggested that the QAT might not adjust weights sufficiently, leading to problems during quantization.
- Quantization Challenges with Checkpoints: Issues were discussed regarding incoherence in generated text after quantization, with insights shared on configurations used for QAT training and quantization.
- One user shared a code snippet that revealed quantization layers were not being prepared correctly with the versions of torchtune and torchao being used.
- Activation Checkpointing Slows Down Saves: A user questioned why activation checkpointing is set to false by default, noting it makes saving checkpoints significantly slower, especially for Llama 3.2.
- Another participant clarified that checkpointing was not necessary for a smaller model, as it incurs additional computational costs.
- Saving Adapter Weights Only for Speed: Users confirmed that saving only adapter weights (
save_adapter_weights_only=True) resulted in significantly faster checkpoint times, being reduced to 1 second.
- In contrast, saving the full model was much slower, with times of 270 seconds for Llama 3.2 1B compared to 30 seconds for Llama 3.1 8B when saving weights.
- Performance Discrepancies in Checkpointing: Confusion arose over the differences in saving times between Llama 3.1 and Llama 3.2, with observations that the adapter weights are larger in the latter.
- Ultimately, users found that saving configurations greatly influenced performance, with unexpected results based on model size and adapter parameters.
Link mentioned: improve resume from checkpoint · Issue #1551 · pytorch/torchtune: The current experience with resume from checkpoint can improve. A few potential ways: good defaults: Resuming from checkpoint should have as default using the last checkpoint saved, so the user can...
Torchtune ▷ #dev (20 messages🔥):
kv cache implementationdynamic cache resizingmulti-query attentionPyTorch 2.5 enhancements
-
Revising kv Cache Creation Strategy: Currently, the kv cache is built using num_heads instead of num_kv_heads, which may lead to unnecessary memory usage during inference. The change proposed would save memory by ensuring the kv cache is initialized with num_kv_heads and moved before the expand step.
- Additionally, during inference, it's acknowledged that storing copies of enlarged tensor dimensions in kv caches is redundant and should be optimized, prompting excitement to implement these changes.
- Dynamic Resizing for Enhanced Efficiency: There's potential to implement a dynamic resizing feature for the kv cache, allowing for allocation under specific conditions. It would adjust memory use more efficiently by reallocating based on actual requirements rather than a predefined maximum length.
- This strategy could cater to common use cases where generation continues until specific stopping criteria are met, reducing wasted space and improving performance.
- Multi-query Attention as a Storage Solution: The discussion pointed out that the main reasoning behind implementing multi-query attention is to reduce kv-cache storage. This was corroborated by a member noting that features like grouped query attention in PyTorch 2.5 mitigate the need for manual kv expansion.
- Members indicated that additional support in libraries such as flex_attention parallels the advancements in PyTorch, enhancing operational efficiency.
- Concerns Regarding Compatibility with PyTorch Versions: A concern was raised about using enable_gqa only being available in PyTorch 2.5 or later, as maintaining logical consistency across different versions could complicate code management. The approach in attention_utils.py was outlined to ensure that logic remains consistent regardless of any specific attention implementations.
- Members expressed a desire to simplify version management to maintain clarity in code, emphasizing a need for a pragmatic approach in future implementations.
- Collaboration on Code Contributions: A member expressed enthusiasm about contributing to the implementation and reiterated their willingness to send a pull request soon. Others encouraged collaboration, recognizing the shared excitement around enhancing functionalities in the project.
Links mentioned:
- torch.nn.functional.scaled_dot_product_attention — PyTorch 2.5 documentation: no description found
- torchtune/torchtune/modules/attention.py at main · pytorch/torchtune): PyTorch native finetuning library. Contribute to pytorch/torchtune development by creating an account on GitHub.
- llama-models/models/llama3/reference_impl/model.py at main · meta-llama/llama-models~~.): Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
- Initialize kv cache w/num_kv_heads instead of num_heads · Issue #38 · pytorch/torchtune: This will save memory for GQA / MQA, but will require a bit of refactor to attention forward pass.
Cohere ▷ #discussions (4 messages):
SOAP OptimizerAccount issues
-
Dr. Nikhil Vyas to Discuss SOAP Optimizer: We will host Dr. Nikhil Vyas, Post Doc at Harvard, to talk about the SOAP Optimizer.
- Feel free to tune in on Discord Event.
- Direct Support for Account Issues: For any account or service related issues, directly email support@cohere.com for assistance.
- One member expressed their eagerness to help those in need.
Cohere ▷ #questions (17 messages🔥):
Cohere Command R Model performanceRate limit issuesSupport contact for assistanceEnterprise use cases focusBudget software model application
-
Cohere Command R Model struggles with AI detection: A user expressed frustration that the Command R model consistently generates text that is 90-95% AI detectable, despite being a paid user and attempting numerous prompts.
- Creativity is inherent in AI, as all generated text is based on sampled distributions from the human-curated data it's trained on.
- Handling rate limit errors: A user reported receiving a 429 Too Many Requests error while using the production API key and inquired about requesting a rate limit increase.
- Another member advised them to email support@cohere.com along with a screenshot of the error for assistance.
- Support engagement for rate limit increase: After contacting support, the user confirmed sending the email and expressed gratitude for the direction offered.
- The team acknowledged receipt of the email and assured that a colleague is addressing the issue promptly.
- Conference publication inquiry: A member asked about which conferences the Cohere community papers typically get published in.
- Clear timelines or responses regarding email inquiries were also mentioned in the conversation.
- Focus on enterprise applications: Discussion indicated that the core intent of the Cohere models isn't towards generating human-like text but rather towards fulfilling enterprise use cases.
- Members emphasized that the application primarily serves business needs rather than casual or role-playing scenarios.
Cohere ▷ #api-discussions (15 messages🔥):
Embed V3 ComparisonsStructured Output AugmentationModel Type Display IssuesFine-tuning Model Training ErrorsGamification Ideas
-
Embed V3 vs ColPali Architecture and JINA CLIP: A member questioned how Embed V3 compares to the ColPali architecture and JINA CLIP embeddings, suggesting the comparison to the older CLIP model might be outdated.
- The discussion hints at the evolution of embedding architectures beyond traditional biencoder methods.
- JSON Structured Output Enhances Embed V3: A member proposed that adding a JSON structured output dataset could enhance the search capabilities of Embed V3, questioning how it differs from the ColPali multimodal architectures.
- This suggests a growing interest in integrating structured output with existing models for improved functionality.
- Issues with Model Type Display: A member reported that the [Model Type] is always set to [default], regardless of the model in use, expressing the need for it to reveal the actual model name.
- Another member clarified that the default type indicated whether it’s a finetuned model, indicating a possible misunderstanding.
- Fine-tuning Model Training Problems: A user reported an error while training a fine-tuning model, claiming they received a message that support would reach out for assistance.
- This raises concerns regarding potential intermittent issues in the fine-tuning process after being able to create a model successfully the previous day.
- Gamification Ideas for Embed V3: A member brainstormed ideas about integrating components that combine image and text within Embed V3.
- There are also discussions about leveraging levels or reference points to enhance user experiences, linking to the concept of gamification.
Cohere ▷ #projects (1 messages):
Invites statusApplication rejections
-
Seeking Status on Invites: A member inquired about the status of invites after applying last week and expressed concern about not receiving any responses.
- They are particularly interested in knowing if there is any basis for rejection of their application.
- Inquiry on Application Response Time: Another member raised questions about the typical response times for applications and whether delays are common.
- This highlights a potential concern regarding communication from the organization overseeing the applications.
Cohere ▷ #cohere-toolkit (1 messages):
sssandra: <@1132196995361157171> hi! is this an error you're getting using toolkit?
Latent Space ▷ #ai-general-chat (36 messages🔥):
Browserbase FundingChatGPT Chat History SearchLLM Evaluation ChallengesRealtime API UpdatesSimpleQA Benchmark
-
Browserbase raises $21M for web automation: Browserbase announced they have raised a $21 million Series A round, co-led by Kleiner Perkins and CRV, to help AI startups automate the web at scale.
- What will you 🅱️uild? speaks to their ambitious goals for future development.
- ChatGPT introduces chat history search: OpenAI rolled out the ability to search through chat history on ChatGPT web, enabling users to quickly reference past chats or continue where they left off.
- This feature aims to improve user experience by providing easier access to previous conversations.
- Common mistakes with LLM judges: A guide by Hamel Husain highlights pitfalls teams face with LLM judges, such as too many metrics and ignoring domain experts.
- This discussion emphasizes the need for validated measurements to enhance evaluation accuracy.
- New updates to OpenAI's Realtime API: OpenAI's Realtime API now includes five new expressive voices for speech-to-speech experiences and offers significant pricing reductions through prompt caching.
- Cached text inputs are discounted 50% while cached audio inputs see an 80% discount, promoting cost-effective use of the API.
- Introducing SimpleQA for factuality evaluation: OpenAI has introduced SimpleQA, a new benchmark aimed at measuring the factuality of language models, consisting of 4k diverse questions with definitive answers.
- This initiative seeks to address the hallucination problem in AI by ensuring future models can produce more trustworthy and reliable results.
Links mentioned:
- Tweet from Hamel Husain (@HamelHusain): The most common mistakes I see teams make with LLM judges: • Too many metrics • Complex scoring systems • Ignoring domain experts • Unvalidated measurements That's why I wrote this guide, w/ det...
- Tweet from Paul Klein IV (@pk_iv): The next billion dollar company will be powered by Browserbase. We already help hundreds of AI startups automate the web at scale. Now, we've raised a $21 million Series A round, co-led by Klein...
- Transformer Explainer: LLM Transformer Model Visually Explained: An interactive visualization tool showing you how transformer models work in large language models (LLM) like GPT.
- Tweet from OpenAI (@OpenAI): We’re starting to roll out the ability to search through your chat history on ChatGPT web. Now you can quickly & easily bring up a chat to reference, or pick up a chat where you left off.
- Tweet from Julien Chaumond (@julien_c): The @ollama - @huggingface integration has been rolled out for 1 week now, how it’s going? Obviously, pretty well! We’re having on average 4500 pulls per day. That’s about one pull every 20 seconds! ...
- Tweet from OpenAI Developers (@OpenAIDevs): Two Realtime API updates: - You can now build speech-to-speech experiences with five new voices—which are much more expressive and steerable. 🤣🤫🤪 - We're lowering the price by using prompt ca...
- Tweet from Jeff Harris (@jeffintime): these new voices are WAY way more prompt-able! - accents - emotions - whispering - emphasis - talking speed - characters you can explore from the playground https://platform.openai.com/playground/rea...
- Tweet from Coframe (@coframe_ai): The web is dead. We've raised $9M from @khoslaventures and @natfriedman to help bring it to life ⚡
- Tweet from zbeyens (@zbeyens): Introducing Plate AI, a rich text editor powered by AI commands and Copilot. ◆ Configurable plugins ◆ 200+ shadcn/ui components ◆ AI SDK
- Tweet from OpenAI (@OpenAI): Factuality is one of the biggest open problems in the deployment of artificial intelligence. We are open-sourcing a new benchmark called SimpleQA that measures the factuality of language models. http...
- Tweet from Sundar Pichai (@sundarpichai): @YouTube 5/ We continue to invest in state-of-the-art infrastructure to support our AI efforts, including important work inside our data centers to drive efficiencies, while making significant hardwar...
- Tweet from Jason Wei (@_jasonwei): Excited to open-source a new hallucinations eval called SimpleQA! For a while it felt like there was no great benchmark for factuality, and so we created an eval that was simple, reliable, and easy-to...
- Octoverse: AI leads Python to top language as the number of global developers surges: In this year’s Octoverse report, we study how public and open source activity on GitHub shows how AI is expanding as the global developer community surges in size.
- GitHub - langchain-ai/langgraph: Build resilient language agents as graphs.: Build resilient language agents as graphs. Contribute to langchain-ai/langgraph development by creating an account on GitHub.
- GitHub - langchain-ai/langgraphjs: ⚡ Build language agents as graphs ⚡: ⚡ Build language agents as graphs ⚡. Contribute to langchain-ai/langgraphjs development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #general (11 messages🔥):
Ethos NPU OpinionsEvaluation Kit OwnershipTinygrad Development QuestionsTinygrad Font Inquiry
-
Tinycorp's Unofficial Stance on Ethos NPU: A member inquired about the Tinycorp's official unofficial opinion on the Ethos NPU, sparking curiosity about community insights.
- Some participants suggested a more specific angle, indicating that the inquiry could benefit from direct questions related to hardware specifications and future support.
- Seeking Owners of Evaluation Kits: A member asked if anyone owned an evaluation kit, hinting at the potential for shared experiences among peers.
- This query brought forth suggestions to ask more technical questions to elicit detailed responses about the product’s practical uses.
- Discussion on Tinygrad Development Context: There was a reminder to adhere to community rules which emphasize discussions focused on Tinygrad development and usage.
- Responses suggested that members clarify where to post questions that don't align directly with these focused topics.
- Inquiry about Tinygrad Website Font: A user inquired about the font used on the top image of the tinygrad website, indicating interest in the site's design.
- The question led to a reminder about community guidelines regarding the relevancy of discussions.
- General Sentiments on NPUs: One member expressed uncertainty regarding the excitement for NPUs in open source communities, reflecting on prior experiences with NPU performance in products like Microsoft laptops.
- The conversation flowed into exploring potential support for NPUs and the relevance of initiatives like TOSA, balancing casual inquiry with serious technical discussion.
Links mentioned:
- tinygrad: A simple and powerful neural network framework: no description found
- How To Ask Questions The Smart Way: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
Training Jobs on TinyboxQwen2's Base Building BlocksEfficientNet OpenCL IssuesExporting Models to ONNXTesting Time Training Approaches
-
Running Long Training Jobs on Tinybox: Members discussed strategies for managing long training jobs on a remote tinybox, emphasizing the use of tools like tmux and screen to maintain persistent sessions.
- One noted a recommendation for using a more effective alternative but admitted to being too lazy to switch.
- Qwen2's Unconventional Base Building Blocks: Curiosity arose regarding Qwen2's approach of recreating foundational elements like rotary embedding and MLP from scratch, leading to questions about its affiliations with Alibaba.
- One user humorously expressed frustration at Alibaba's apparent influence in this situation.
- Exploding Outputs with EfficientNet in OpenCL: A user encountered issues with exploding outputs while implementing EfficientNet through custom OpenCL kernels in C++, prompting inquiries about debugging tools to compare buffers.
- Suggestions were made on accessing and dumping buffers from the tinygrad implementation to assist in troubleshooting.
- Model Export Strategies for ONNX Compatibility: Discussion highlighted potential methods for exporting tinygrad models to ONNX, proposing to leverage existing scripts for potential model optimization on weaker hardware.
- There were debates on whether to directly export models or explore alternative bytecode compilation methods for chip deployment.
- Testing Time Training and Format Concerns: Members considered the implications of test time training on embedded models, particularly the importance of retaining the original weight formats in memory.
- The sentiment emerged that standardizing on ONNX for model exporting could simplify the integration process across various platforms.
Links mentioned:
- Hailo-Application-Code-Examples/runtime/python/streaming/yolox_stream_inference.py at 77441f09b38f4a548fa1bb2f0eaca75701b62fa9 · hailo-ai/Hailo-Application-Code-Examples: Contribute to hailo-ai/Hailo-Application-Code-Examples development by creating an account on GitHub.
- tinygrad/extra/export_model.py at master · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- tinygrad/examples/compile_tensorflow.py at 4c0ee32ef230bdb98f0bc9d0a00f8aaaff4704f1 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
Modular (Mojo 🔥) ▷ #general (6 messages):
Idiom of Mojo vs PythonLearning Resources for MojoContributing to NuMojo and Basalt ProjectsLinear Algebra Implementation in MojoGPU Utilization in Mojo
-
Idiom of Mojo still evolving: A member shared that Idiomatic Mojo is still being figured out, stating that as the language gets new capabilities, new 'best practices' emerge.
- This indicates a fluidity in the language's idioms compared to more established languages like Python.
- Lack of learning resources for Mojo: Another member expressed difficulty finding resources to learn about linear algebra and its implementation in Mojo, particularly regarding GPU usage.
- It was noted that contributions to projects like NuMojo and Basalt may benefit from directly communicating with project leads, given the limited existing material.
- Linear algebra approaches remain undefined: A member indicated that there's no consensus on the best approach for linear algebra in Mojo, with implementations largely based on translations from other languages or books.
- They highlighted that approaches may vary based on metrics like speed and optimization, although existing practices are relatively narrow.
Modular (Mojo 🔥) ▷ #mojo (17 messages🔥):
Mojo architectureC++ compatibilitySyntax proposalC++ macrosCustom decorators
-
Mojo's potential compatibility with C++: There is a discussion about achieving 100% compatibility with C++, with members stating that if anyone can do it, it's Chris Lattner.
- One user remarked that this would be a complete miracle, highlighting the interest and concern around this topic.
- Innovative syntax proposals for Mojo: A member proposed to rename 'alias' to 'static', sparking a discussion on the implications of using the term static in Mojo, which may confuse due to its typical C++ usage.
- Others expressed that the keyword may not accurately convey its intended functionality compared to C++'s constexpr.
- Debate over C++ macros in Mojo: Concerns were raised about the introduction of C++ macros due to potential complications they could create for compilers, with a preference for hygienic macros.
- One member emphasized that Mojo's focus on functions that execute at compile-time could mitigate the need for conventional macros.
- Custom decorators in Mojo: Plans for implementing custom decorators in Mojo were mentioned, with belief that they could be sufficient along with compile-time execution.
- However, it was noted that certain capabilities, like SQL query verification at compile time, may extend beyond what decorators can accomplish.
- Alternative preprocessing options: A user suggested exploring GPP, a generic preprocessor, as an alternative while waiting for more sophisticated features in Mojo.
- This reflects the ongoing search for tools that could enhance the development experience while integrating features from established languages like C++.
Links mentioned:
- GitHub - logological/gpp: GPP, a generic preprocessor: GPP, a generic preprocessor. Contribute to logological/gpp development by creating an account on GitHub.
- Issues · modularml/mojo.): The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
LlamaIndex ▷ #blog (2 messages):
create-llama appToolhouseAI toolshackathon insights
-
Launch of LlamaIndex's create-llama app: You can now create a LlamaIndex app in minutes with the new create-llama tool, allowing setup of a full-stack Next.js or Python FastAPI backend.
- Users can choose from various pre-configured use cases like Agentic RAG or Data Analysis, and intend to easily ingest multiple file formats.
- ToolhouseAI is a Game-Changer: @ToolhouseAI offers dozens of high-quality tools that significantly reduce time spent during development for LlamaIndex agents, as evidenced by participants at a recent hackathon.
- These ready-made tools plug directly into agents, making integration smooth and effective, confirming their status as a substantial time-saver.
LlamaIndex ▷ #general (14 messages🔥):
Multi-agent query pipelinesLlamaIndex workflowsRecursiveRetriever class issuesParallel agents with memory
-
Recommendation for Multi-Agent Query Pipeline: Cheesyfishes affirmed that using the LlamaIndex workflows approach for a multi-agent query pipeline is a good strategy and shared a demo showcasing this implementation.
- The resources from the video can be found here.
- Orchestrator Agent's Role in Multi-Agent Systems: When a speaking agent cannot fully resolve an issue, it always returns to the orchestrator agent to request a transfer, as per the design to reduce agent performance complications.
- This design choice aims to maintain system scalability by limiting each agent's direct access to others.
- Issues with RecursiveRetriever Class: A user raised concerns that the RecursiveRetriever class was not functioning properly and that the
add_nodesoutput was empty despite having nodes with relationships.
- They attempted to retrieve all nodes using a specific command without success.
- Need for Multi-Agent Guidelines with LlamaIndex: A user inquired about guidelines for using multiple agents in parallel with different LLMs and maintaining memory loops, similar to CrewAI.
- Cheesyfishes suggested a video example which addresses multi-agent orchestration with LlamaIndex, although it may run agents sequentially.
- Parallel Tool Calls in Multi-Agent Framework: While confirming that the shared video runs agents sequentially, Cheesyfishes noted that tool calls can actually be executed concurrently with relative ease.
- This flexibility allows for diverse implementations of agent interactions.
Link mentioned: multi-agent-concierge/video_tutorial_materials at main · run-llama/multi-agent-concierge: An example of multi-agent orchestration with llama-index - run-llama/multi-agent-concierge
LlamaIndex ▷ #ai-discussion (1 messages):
RAG with LlamaIndexText-to-SQL integration
-
RAG and Text-to-SQL synergy with LlamaIndex: An article discussed the integration of RAG (Retrieval-Augmented Generation) with Text-to-SQL using LlamaIndex, showcasing its potential in enhancing data retrieval tasks.
- The piece highlights how LlamaIndex optimizes querying and improves user experience by effectively transforming natural language into structured database queries.
- Exploring practical applications of RAG: The article details several practical applications of RAG technology, particularly in automating data retrieval and improving accuracy in SQL queries.
- It mentions that users have experienced a 30% decrease in query response times when utilizing LlamaIndex with RAG functionalities.
- Enhancements in User Interaction through LlamaIndex: LlamaIndex aims to simplify interactions between users and databases by reducing the complexity of SQL generation through natural language processing.
- The implementation has led to greater user satisfaction as users reported feeling more empowered to extract data without deep technical knowledge.
DSPy ▷ #papers (5 messages):
Extreme Multi-Label ClassificationDSPy Programming ModelOnline Search for Labels
-
Exploring In-Context Learning Limitations: The paper titled IReRa: In-Context Learning for Extreme Multi-Label Classification discusses the challenges of solving multi-label classification problems with language models lacking prior knowledge about classes.
- It proposes a program called Infer–Retrieve–Rank to efficiently manage interactions between LMs and retrievers, achieving state-of-the-art results on the HOUSE, TECH, and TECHWOLF benchmarks.
- Availability of Related GitHub Repository: A member pointed out that there is a GitHub repo mentioned in the abstract of the paper that relates to the work being discussed.
- This repo likely provides further insights and implementations following the findings in the paper.
- Interest in Online Search for Labels: A member inquired about the feasibility of using online searches for labels instead of a retriever in the classification process.
- This raises questions on whether the DSPy model can accommodate such an agent-style search functionality.
- Clarification on Label Searching: Another member expressed confusion over the implication of searching online for labels instead of utilizing a retriever.
- This indicates a need for further discussion on how label retrieval methods can be adapted or alternatively implemented.
Link mentioned: In-Context Learning for Extreme Multi-Label Classification: Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to ...
DSPy ▷ #general (4 messages):
DSPy Structure EnforcementsStructured OutputsMIPROv2 Integration
-
Questioning DSPy's Need for Structure Enforcement: A member questioned the necessity of DSPy enforcing structure/types when libraries like Outlines exist for such purposes, especially with API LMs introducing structured generation.
- Isn't it better to leverage those existing libraries?
- Importance of Structure in DSPy: Another member clarified that DSPy has enforced structure since v0.1 to learn the mapping from signatures to effective prompts and weights, adapting to provider capabilities.
- They emphasized that while structured outputs can serve as backends, DSPy's approach balances adhering to formats with maintaining quality.
- Discussion on Quality vs Structure in Outputs: A member expressed skepticism about the notion that adhering to certain formats might lower quality, arguing that structured outputs could benefit from set constraints and correct grammar usage.
- This approach could yield great results, particularly for smaller LMs.
- Integrating MIPROv2 with DSPy: Another member shared their experience using zero-shot MIPROv2 and a Pydantic-first interface for structured outputs, relying on the current MIPROv2 step for construction.
- They expressed a desire for a more integrated and native way to handle structured outputs in the optimization process.
OpenInterpreter ▷ #general (4 messages):
Job Automation PredictionsOpen Interpreter vs ClaudeRestoring Specific Chat Profiles
-
Job Automation Predictions Spark Debate: A user predicted that virtual beings will take over a lot of jobs in the near future, likening it to a virtual Skynet takeover.
- This comment ignited a conversation about the implications of AI on the workforce.
- Open Interpreter's Unique Features: A member asked how Open Interpreter differs from Claude's usage in computer operations.
- Mikebirdtech responded, noting that they implemented Claude's computer use through
interpreter --os, while also emphasizing their open-source advantages. - Challenges in Restoring Chat Profiles: A user inquired about restoring a chat that utilizes a specific profile/model previously employed in their discussions.
- They mentioned that while they can restore via
--conversations, it defaults to the standard model instead of the one used before.
OpenInterpreter ▷ #ai-content (4 messages):
ChatGPT Chat History SearchDigitizing ScentScent TeleportationLimited Release Fragrance
-
ChatGPT now remembers chats: OpenAI announced the rollout of a feature allowing users to search through their chat history on ChatGPT web easily, making it convenient to reference or continue previous chats.
- This new capability aims to enhance user experience and streamline interactions within the platform.
- Groundbreaking Digitization of Scent: A team successfully digitized a fresh summer plum, marking a major milestone in scent digitization with no human intervention required.
- One member expressed excitement, noting their enjoyment of carrying the plum scent with them and contemplating producing a limited release fragrance to benefit science.
- Scent Teleportation Milestone Celebration: The Osmo team celebrated their accomplishment in scent teleportation with a heartfelt message about what this achievement means for future innovations.
- They expressed a desire to engage the community, asking whether there would be interest in a fragrance release that supports scientific endeavors.
Links mentioned:
- Tweet from Alex Wiltschko (@awiltschko): Well, we actually did it. We digitized scent. A fresh summer plum was the first fruit and scent to be fully digitized and reprinted with no human intervention. It smells great. Holy moly, I’m still ...
- Tweet from OpenAI (@OpenAI): We’re starting to roll out the ability to search through your chat history on ChatGPT web. Now you can quickly & easily bring up a chat to reference, or pick up a chat where you left off.
LangChain AI ▷ #general (2 messages):
invoke function response timeFastAPI routes efficiencyHugging Face Transformers documentation
-
Invoke function creates a response time mystery: User reported an issue where calling the .invoke function of the retriever returns a significantly slower response time (over 120 seconds) compared to local execution (20 seconds) when accessing the same inference URL for the Llama3.1:70b model.
- There are suspicions of a potential security issue impacting performance, and the user seeks help from the community.
- FastAPI route performance shines: Despite performance issues with the invoke function, FastAPI routes are confirmed to perform well and take under 1 second to execute as verified by debugging.
- The user assures that the data sent is correct and of the right type, isolating the problem to the invoke function.
- Hugging Face Transformers docs lead to frustration: Another user expressed frustration about not being able to set up a chat/conversational pipeline with Hugging Face Transformers due to the challenges in navigating the documentation.
- They highlighted the difficulty in finding the necessary guidance within the docs to accomplish their goals.
LangChain AI ▷ #share-your-work (1 messages):
Knowledge Nexus AIKNAI Discord CommunityKNAI Publication on MediumDecentralized Knowledge SystemsKnowledge Graphs and Semantic Web
-
Knowledge Nexus AI Launches Initiatives: Knowledge Nexus AI (KNAI) announced the launch of community initiatives aimed at bridging human knowledge and AI, fostering a decentralized future.
- Their mission emphasizes transforming collective knowledge into structured, machine-readable data to drive insights across industries like healthcare, education, and supply chain.
- Join the KNAI Discord Community: KNAI is creating a vibrant Discord space for those interested in Knowledge Graphs, Semantic Web, and Web3 & Blockchain technologies.
- They invite innovators, researchers, and enthusiasts to help shape the future of decentralized knowledge systems.
- Contribute to KNAI Publication on Medium: KNAI is seeking contributors for their Medium publication, focusing on topics like Knowledge Graph innovations and AI advancements.
- Individuals are encouraged to start drafting articles and share their expertise in decentralized knowledge systems and practical technical guides.
- Empowering Collaborative Knowledge Systems: KNAI aims to create an accessible, collaborative platform that fuels insights and innovation across multiple industries.
- They are enthusiastic about building a comprehensive encyclopedia for machines, driven by community collaboration.
LangChain AI ▷ #tutorials (1 messages):
OppyDev Plugin SystemEnhancing AI Output
-
OppyDev Introduces Plugin System: A quick introduction to OppyDev's plugin system was shared, showing how it can enhance the output of a standard AI model using chain-of-thought reasoning.
- The explained process aims to provide clearer and more detailed responses, making AI interactions more effective.
- Watch the Tutorial on OppyDev: A tutorial video was provided that demonstrates the plugin system and its capabilities, available here.
- The video emphasizes practical examples of enhancing AI responses through plugins, fostering deeper understanding.
OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
duh_kola: True but the ones I want to train are instruction versions lol
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
LoRA finetuningH100 GPUsBitsAndBytes issue
-
LoRA Finetuning Remains Unresolved: A member expressed difficulty in finding a solution for LoRA finetuning on H100 GPUs, suggesting that QLoRA might be the only viable workaround.
- The issue remains persistent as another member confirmed that the BitsAndBytes issue for hopper 8bit is still open and hasn't been resolved.
- Quantization Challenges Persist: The discussion highlighted ongoing challenges with quantization-related issues, particularly in the context of BitsAndBytes for Hopper 8bit.
- Despite efforts, it appears that no definitive solution has been established regarding these technical hurdles.
LAION ▷ #general (2 messages):
Image Decoding Issues
-
Clamping Issue in Image Decoding: A member pointed out that failing to clamp values to [0,1] before converting decoded images to uint8 can cause out-of-range values to wrap.
- This can lead to unexpected results in image quality and appearance.
- Concerns Raised about Decoding Workflow: Another participant suggested that there may be additional flaws in the decoding workflow, potentially affecting the overall image processing.
- Further discussion is needed to pinpoint these issues and improve robustness.
LAION ▷ #research (1 messages):
thejonasbrothers: https://arxiv.org/abs/2410.20424
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
LLM Agents QuizzesLLM Agents HackathonCourse Sign UpDiscord Channel
-
LLM Agents Quizzes Location Shared: A member inquired about the location of the weekly quizzes for the course.
- Another member promptly responded with a link to the quizzes stating, 'here you can find all the quizzes.'
- Announcement for the LLM Agents Hackathon: Participants were informed about the LLM Agents Hackathon, with a link to sign up for more details.
- The announcement included a link to the hackathon details for those interested.
- Course Sign Up Instructions: For prospective students, instructions were shared on how to sign up for the course via a Google Form.
- Participants were encouraged to fill in this form to enroll in the course.
- Joining the Course Discussion: Details were provided on how to join the course discussion on Discord.
- Participants can join the MOOC channel at LLM Agents Discord for questions and discussions.
Link mentioned: Large Language Model Agents MOOC: MOOC, Fall 2024
Mozilla AI ▷ #announcements (1 messages):
Transformer Labs EventLumigator Tech Talk
-
Transformer Labs to demo local RAG on LLMs: The team from Transformer Labs is hosting an event to showcase how to train, tune, evaluate, and use RAG on LLMs with an easy-to-install UI in your local environment.
- Participants can expect a no-code approach, making it accessible for all skill levels.
- In-depth look at Lumigator tool: Engineers will present a detailed tech talk on Lumigator, an open-source tool designed to help users select the best LLMs tailored to their needs.
- This tool aims to streamline the decision process for engineers when choosing large language models.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Llama-3.1-8B-Instruct (FC)Llama-3.1-8B-Instruct (Prompting)Function Calling PerformanceModel Comparison
-
Llama-3.1-8B-Instruct (FC) underperforms compared to Prompting: A member questioned why Llama-3.1-8B-Instruct (FC) is performing worse than Llama-3.1-8B-Instruct (Prompting), expecting better results from the FC model for function calling tasks.
- Is there a reason for this discrepancy? highlights a concern about the performance expectations based on model design.
- Expectation of Performance in Function Calling: Another participant noted their expectations that the FC variant should excel due to its design focus on function calling.
- They pondered whether the observed performance was surprising or indicative of underlying issues with the model architecture.