[AINews] Contextual Position Encoding (CoPE)
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Just one more RoPE variant bro just one more
AI News for 5/29/2024-5/30/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (391 channels, and 4383 messages) for you. Estimated reading time saved (at 200wpm): 478 minutes.
A quiet day, but the CoPE paper got some buzz: so we're talking about it.
Traditional LLMs have known issues with simple algorithmic tasks like counting and copying. This is likely an artefact of their positional encoding strategy.
Jason Weston of Meta AI released his paper on CoPE, a new positional encoding method for transformers that takes into account context, creating "gates" with learnable indices.
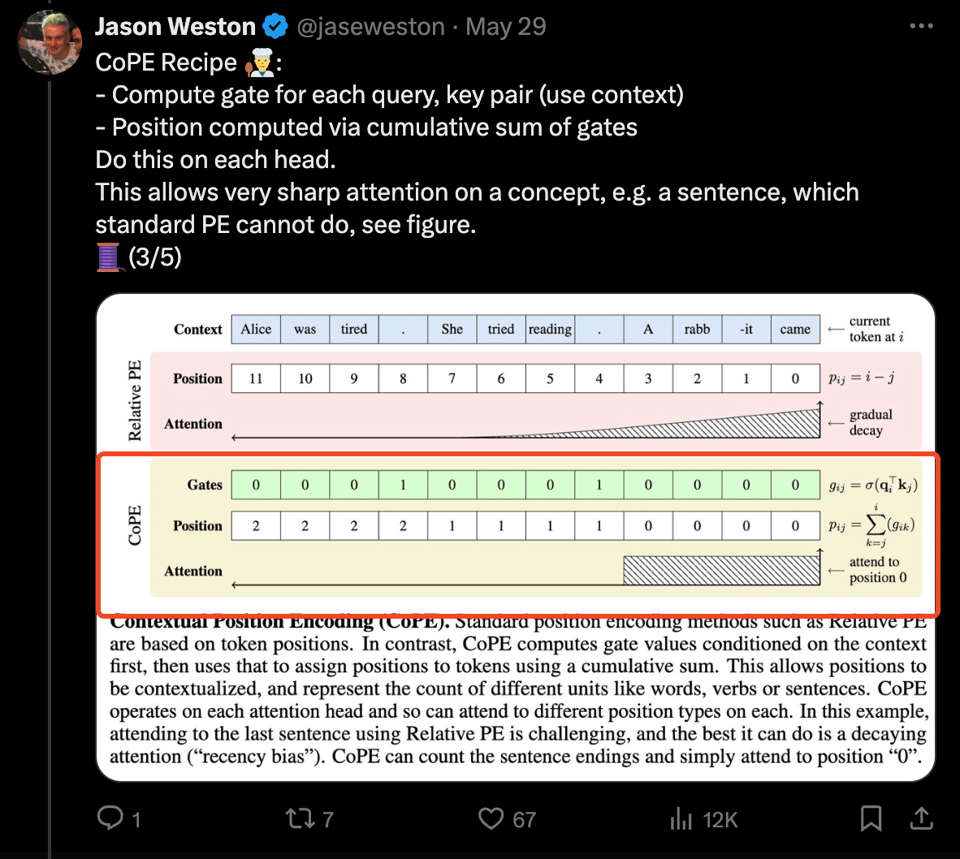
Using this, a CoPE LLM can:
- "count" distances per head dependent on need, e.g. i-th sentence or paragraph, words, verbs, etc. Not just tokens.
- solve counting & copy tasks that standard transformers cannot.
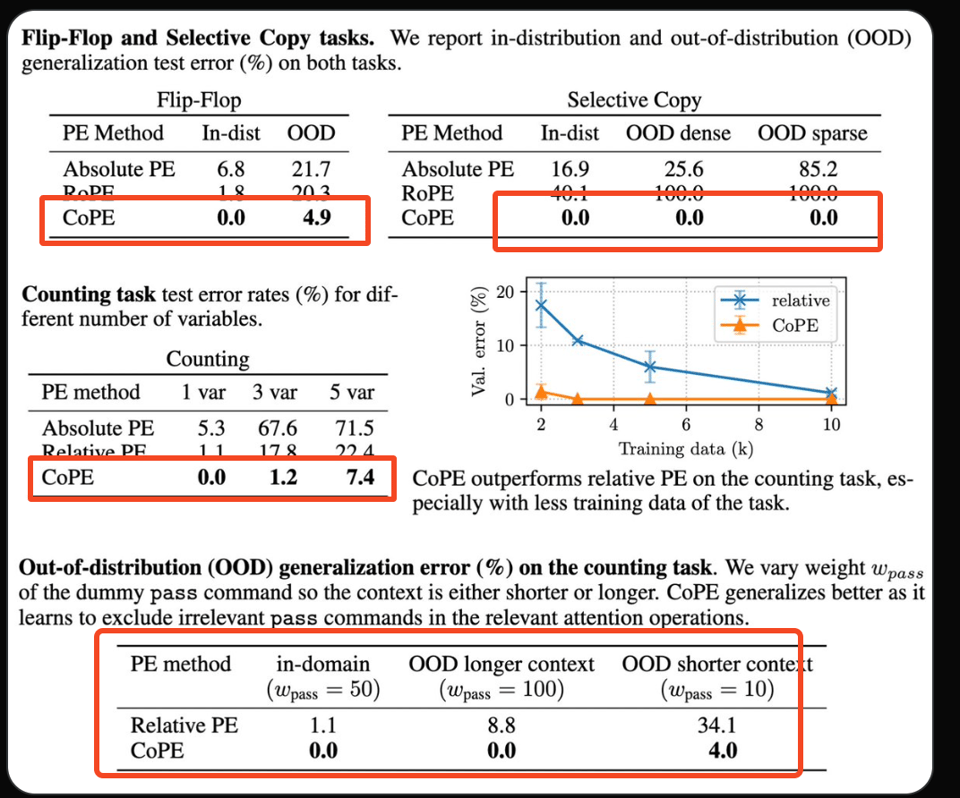
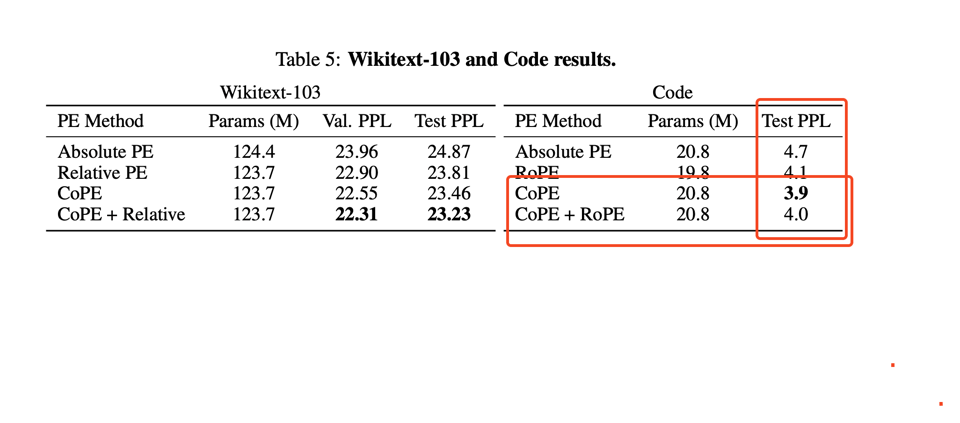
- Better PPL on language modeling + coding tasks.
You could even modify this concept to use external memory, not merely local context, to calculate the gates.
As Lucas Beyer notes, the raft of position encoding variants this year is perhaps a richer source of research because "Linear attention was about removing capacity from the model, which didn’t make sense long term. Position embedding is about adding missing capabilities to the model, which makes a lot more sense."
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
New AI Models and Benchmarks
- Contextual Position Encoding (CoPE): @jaseweston introduced CoPE, a new positional encoding method for transformers that takes context into account, enabling them to solve counting & copy tasks and improving performance on language modeling and coding.
- SEAL Leaderboards: @alexandr_wang launched SEAL Leaderboards for private, expert evaluations of frontier models that are unexploitable and continuously updated.
- Gemini 1.5 models: @GoogleDeepMind released Gemini 1.5 Flash and Pro models on their API, with Flash designed for fast, efficient inference at 1000 requests per minute.
- Claude with tool use: @AnthropicAI announced general availability of tool use for Claude, enabling intelligent selection and orchestration of tools for complex tasks.
Advancements in AI Applications and Platforms
- ChatGPT Free upgrades: @gdb noted ChatGPT Free tier is providing widespread access to cutting-edge AI features.
- Claude Tool Use GA: @AnthropicAI made tool use generally available for Claude, allowing it to intelligently select and orchestrate tools to solve complex tasks end-to-end.
- GPT3 Birthday: @karpathy reflected on the 4th anniversary of GPT-3 and how it showed that models would improve on practical tasks just by training bigger ones, making better algorithms a bonus rather than a necessity for AGI progress. He noted if given a 10X bigger computer now, he would know exactly what to do with it.
- Perplexity Pages: @perplexity_ai launched Perplexity Pages, allowing users to turn research into visually appealing articles with formatted images and sections. @AravSrinivas described Perplexity's mission to cater to the world's curiosity with Pages as "AI Wikipedia", allowing the effort of analyzing sources and synthesizing a readable page with a simple "one-click convert".
- Milvus Lite: @LangChainAI partnered with Milvus to simplify creating powerful GenAI apps by combining their capabilities.
- Property Graph Index: @llama_index launched the Property Graph Index, providing a high-level API for constructing and querying knowledge graphs using LLMs.
- Repetitions in LangSmith: @LangChainAI added support for running multiple repetitions of experiments in LangSmith to smooth out noise from variability.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Technology Developments and Partnerships
- OpenAI partnerships: OpenAI announced partnerships with The Atlantic, Vox Media, and WAN-IFRA to help news publishers explore AI integration. They also appear to have closed a deal with Apple. Discussions in /r/OpenAI centered around how people are using ChatGPT daily.
- Google Gemini models: Google doubled the output price of Gemini 1.5 Flash. Their updated Gemini 1.5 0514 models are rated well on Chatbot Arena leaderboard considering the API costs.
- Mistral AI's Codestral: Mistral AI debuted Codestral, a 22B open-weight code model licensed under the Mistral AI Non-Production License. The Verge covered the Codestral launch.
- Groq speeds up Llama 3: Groq announced Llama 3 running at 1200+ tokens per second on their systems.
Model Benchmarks and Evaluations
- AutoCoder beats GPT-4: AutoCoder, a new code generation model, surpassed GPT-4 Turbo and GPT-4o in pass@1 on the HumanEval benchmark. It also offers a more versatile code interpreter.
- Scale AI's SEAL Leaderboards: Scale AI introduced SEAL Leaderboards with private datasets and paid annotators for fairer, higher quality expert evaluations of frontier models. An infographic explains the SEAL approach.
- GPT-4 bar exam claims challenged: An MIT study found GPT-4 did not really score 90th percentile on the bar exam as previously claimed.
- TimeGPT-1 tops time series benchmarks: TimeGPT-1 ranked first in accuracy and speed vs other foundation time series models like TimesFM, Chronos, Moirai and Lag-Llama in a 30,000+ time series benchmark.
AI Hardware & Performance
- AI training compute scaling 4-5x per year: The amount of compute used in AI training is scaling up 4-5x per year, highlighting rapid progress. (1)
- Groq updates LLama 3 performance to 1200+ tokens/sec: Groq updates LLama 3 performance to 1200+ tokens per second on their hardware.
- Qualcomm releases Snapdragon X Plus/Elite benchmarks: Qualcomm releases Snapdragon X Plus and X Elite benchmarks showing 45 TOPS performance for the Hexagon NPU, enabling efficient on-device AI.
- Sambanova sets speed record of 1000 tokens/sec on Llama 3: Sambanova system reaches 1000 tokens per second on Llama 3 8B, setting a new speed record.
AI Discord Recap
A summary of Summaries of Summaries
1. New AI Model Releases and Benchmarks:
- The Yuan2.0-M32 model with 40B parameters outperformed Llama 3 70B on Math/ARC tasks using only 3.7B active parameters during generation.
- Codestral Model Release and Integration: Mistral AI released Codestral-22B-v0.1, a code-generating model supporting 80+ programming languages. It excels at code instruction and Fill in the Middle (FIM) tasks, with more details in their blog post. LlamaIndex provides day 0 support and a tutorial notebook for Codestral, and it's also compatible with Ollama for local execution with direct LlamaIndex support.
- K2, a fully open-source model, outperformed Llama 2 70B using 35% less compute, showcasing efficient AI engineering.
2. Optimizations and Advancements in AI Systems:
- Whisper Model Optimization Yields 6.3x Speedup: A community member successfully optimized the Whisper model using techniques like static cache, HQQ quantization, torchao 4-bit kernel, and torch.compile with fullgraph. This combination resulted in a substantial 6.3x speed increase. A detailed blog post is forthcoming to share insights from this optimization process.
- Discussions covered templating block sizes like
blockDim.xfor significant CUDA kernel performance boosts, especially in fused classifiers. - Cloudflare R2 was suggested to replace Python dependencies and internal S3 for sharing large datasets, optimizing costs and avoiding ancillary fees.
3. AI Model Fine-tuning and Customization:
- Members explored ideal strategies for fine-tuning LLMs like Llava for image and video understanding tasks, debating the merits of Direct Preference Optimization (DPO) over Supervised Fine-Tuning (SFT).
- Anti-prompts were discussed as a technique to guide conversation flow by halting generation at predefined words, allowing user interjection before resuming model output.
- Advice was shared on fine-tuning Llama3 base models and using DPO over instruction models for creating bespoke roles like historical figures or characters.
4. Competitions and Open Initiatives:
- A Model Merging competition at NeurIPS was announced, offering an $8K prize pool to revolutionize model selection and merging techniques for creating optimal LLMs.
- LAION called for community contributions to build an open GPT-4-Omni model with large-scale multi-modal capabilities, providing datasets, tutorials, and guidance.
- The Le Tigre project, a multimodal variant based on Mistral 7B inspired by GPT-4-V's architecture, was showcased from a recent hackathon.
PART 1: High level Discord summaries
Perplexity AI Discord
Perplexity Pages Pioneers Prettier Posts: Perplexity AI has unveiled Perplexity Pages, a tool for transforming research into curated articles, creating an AI Wikipedia. The feature is currently available to Pro users, with expectations to open to more users, and elaborated upon in their blog post.
Grok Woes Lead to Search Superiority Strive: Community member sneakyf1shy strives to build an improved model over Grok, aiming to enhance the search functionality within Perplexity's web application. The community also debated the efficacies of existing models, APIs, and indexed data, citing limitations and envisioning enhancements.
Pages Feedback: The Good, the Bad, the Ugly: Users experimenting with Perplexity Pages shared mixed feedback; some praised its utility while others faced issues, such as missing content sections. The community's pulse ranged from skepticism about Perplexity's indexing to excitement about the feature, with a how-to guide circulating for those interested.
API Angst and Google vs. OpenAI Grudge Match: Technical discussions delved into the challenges of user-friendly API scalability and multi-step reasoning improvements. Meanwhile, the Google-OpenAI rivalry captured attention, sparking debate over their strategic AI moves with speculation around AGI progress and market influence.
AI Ethics and Physics Explored by the Curious: The sharing channel highlighted member contributions on the ethical and physical dimensions of perplexing topics. Links to discussions on consciousness, LLM functionalities, and a supposed pro/con analysis indicate a community engaged in substantive and diverse AI-related themes.
LLM Finetuning (Hamel + Dan) Discord
- Google's Gemini Gaffe: Confusion arose over the inconsistency in Google's Vertex AI pricing, with concerns about billing per character on Vertex AI versus per token on Google's direct AI services, which led to a discussion thread.
- LLM Fine-Tuning Finesse: The community shared knowledge and experiences in fine-tuning Large Language Models (LLMs), specifically focusing on deterministic tool calling in multi-agent systems and the successful use of state machine logic from repositories like robocorp/llmstatemachine. Another focal point was the improvement of fine-tuning LLMs with custom data using the GGUF format, backed by an active Hugging Face Pull Request providing easier conversion from HF to GGUF (source).
- Embracing Modal's Multifaceted Mechanisms: Debates and troubleshooting of Modal task executions were rampant, highlighting issues like dataset paths and config settings. The community responded with insights on WANDB integration, sharing config files, and directing users to Modal's documentation for further learning.
- Expanded Learning Through Papers and Bundles: An array of learning resources surfaced, including a Meta paper on vLLM, a collection of LLM resources on GitHub, and details of an AI-coding Humble Bundle. Additionally, a paper on expanding LLama3's context window piqued interest (source).
- Global Gatherings and Events: There's a buzz around upcoming AI events such as the Global AI Hackathon from June 7 to 9 in Singapore, Sydney, and San Francisco, which is backed by top AI builders, aiming to explore "AI for a better world" – interested attendees can RSVP via this link. Meanwhile, on Discord, members across the U.S. coasts and European regions voiced enthusiasm for local meetups and shared venues.
OpenAI Discord
- Freebies for ChatGPT Users: ChatGPT Free users received a substantial upgrade with access to browsing, vision, data analysis, file uploads, and GPTs, which opens up new avenues for experimentation and development.
- OpenAI Empowers Nonprofits: OpenAI launched OpenAI for Nonprofits, offering greater accessibility to their tools for charitable organizations, marking a strategic move to support social good through advanced AI applications. Further details were discussed, including strategies to counteract deceptive AI uses.
- GPT-4 Availability and Performance Discourse: The community engaged in lively discussions around GPT-4's availability and performance, noting that free users might experience automatic model switching and raised concerns about "word salad" issues with longer GPT-4 outputs. Members also touched upon the customizability and potential memory enhancements for GPT models.
- Coding Assistance and API Best Practices: AI engineers compared coding assistance tools like GPT-4o, Mistral’s codestral, and Copilot, emphasizing speed and accuracy. They also shared knowledge on protecting API keys with proxy backend servers and the importance of considering API stability for extended sessions over browser-based interactions.
- Bias and Troubleshooting in AI Tools: Engineers humorously acknowledged personal bias when evaluating their own AI tools and also exchanged tips for troubleshooting issues, suggesting splitting requests for versions lower than 4 to maintain compatibility.
HuggingFace Discord
- PDFs Befriend AI with Everything-AI Integration: The Everything-AI project now boasts integration with
llama.cppandQdrant, allowing for interactive exchanges with PDFs, as community contributions enhance HuggingFace's repository of tools and models.
- The Competitive Edge of Yuan 2.0-M32: The freshly minted Yuan2.0-M32 model, with its 40 billion parameters and innovative architecture, overshadows Llama 3 70B in Math/ARC tasks, revealed on Twitter and showcased on HuggingFace, with a link to the supporting research paper.
- Visualization Becomes Accessible with Nvidia Embed V1: A user shared their Nvidia Embed V1 Space for showcasing Nvidia's embedding model, and invites enhancements through PRs for refined functionalities or exciting new examples.
- Hugging Face and DuckDB Unite for Smoother Dataset Handling: The fusion of DuckDB and Hugging Face datasets, facilitated by an
hf://path, simplifies data integration processes, as detailed in the tutorial blog post, marking a stride in data manipulation convenience.
- AI Community Geared Up for NeurIPS Model Merging Contest: A competition announced for NeurIPS focused on model merging piques interest within the AI community, promising an $8000 reward and the chance to push the boundaries of model selection techniques, as cited in an official tweet.
- Whisper Model Gets Fine-Tuned with Timestamps: A discussion around extracting word-level timestamps with the Whisper model highlights the method's documentation and credits the work to research like “Robust Speech Recognition via Large-Scale Weak Supervision”, indicating enhancements in audio processing and its applications.
- Open-Source Models Usher in K2's Potential: Two new fully open-source models, including K2, are celebrated for their prowess, with K2 especially noted for its stellar performance compared to Llama 2 70B model with a 35% compute reduction, spotlighting the strides made in efficient AI model engineering.
LM Studio Discord
Codestral Joins the Coding Model Fray: Mistral introduced Codestral-22B-v0.1, capable of dealing with over 80 programming languages, demonstrating impressive performance in tasks like code instruction and Fill in the Middle (FIM). For those interested in testing the model, download and explore Codestral-22B here.
The Never-Ending Context Length Challenge: Engineers highlighted the limitations of models like the llama series, capped at 4096 tokens, and noted RoPE extension allowing a maximum of 16k tokens, with spirited banter about the importance of context size.
Hardware Discussions Heat Up: The RTX 5090 stirred speculation with its purported 448-bit bus and 28 GB GDDR7 memory. Meanwhile, pragmatic comparisons of CPU inference and the pros and cons of GPU setups, such as using multiple 3090 cards, dominated the discussion.
Whisper & Amuse in Spotlight: A technical hiccup was observed with the Whisper models not being compatible with llama.cpp, as well as a broken GitHub link for Amuse. Solutions included utilizing whisper.cpp and accessing Amuse through an available Hugging Face link.
Practical Tips in Adding Inference GPUs: One discussion clarified the reality of adding additional GPUs for inference in LM Studio, stressing the need for appropriate space, power, and correct settings management, proving that juggling hardware is as much art as it is science.
Unsloth AI (Daniel Han) Discord
- Llama3 Trumps Phi3 in AI Showdown: Engineers concurred that Llama3 is superior to Phi3 in testing, with comments praising its performance and criticizing Phi3 for being "extremely synthetic." Users advised against using Phi3 models, highlighting the effectiveness of the base Llama3 instead.
- Refining Role-Playing AI: It was suggested to start with training Llama3 base models, followed by finetuning for instruction following to create bespoke role-playing characters. However, simply prompting Llama3 with instructions to "Pretend you are [X]" may yield better results than a standard fine-tuning process.
- Anti-Prompts for Controlled Conversations: The utility of anti-prompts was debated, revealing a strategy to guide chat models' conversation flow by halting generation at predefined words. This technique enables users to interject before letting the model resume its output.
- Model Training and Fine-tuning Pitfalls: Discussion pointed out that fine-tuning on top of instruction models is generally discouraged due to potential value loss. Using Direct Preference Optimization (DPO) over base models can tailor outputs for specific character roles more effectively.
- Emerging Models and Tech Wrinkles: Enthusiasm was shared for new models like Yuan, with a cautionary note on the importance of practical application over benchmark results. One user faced an issue with an Apple M3 Pro GPU being incompatible with CUDA, which led to advice on utilizing services like Google Colab for model training and fine-tuning.
Stability.ai (Stable Diffusion) Discord
- Economizing AI Training: Members highlighted ways to train Stable Diffusion models cost-effectively, with tools like Google Colab and services such as RunDiffusion being discussed for their budget-friendly solutions.
- Optimizing Image Accuracy: Techniques to enhance image generation were discussed, with a particular focus on using ControlNet and advanced samplers. For dynamic LoRA control, the community shared the sd-webui-loractl GitHub repository.
- Ruby Joins the AI API Fray: A new open-source Ruby SDK for Stability AI's API was introduced, aimed at streamlining image generation tasks with core and SD3 models. The SDK can be found and contributed to on GitHub.
- Anticipation and Anxieties Over SD3: The community exchanged thoughts about Stable Diffusion 3's potential release, voicing concerns over licensing issues and comparing financial support with that of competitors like Midjourney.
- Kid-Friendly AI: A discussion was initiated on how to safely introduce Stable Diffusion to children, with the focus on utilizing ControlNet to responsibly transform children's sketches into polished images.
Eleuther Discord
- AI and the Future of Learning: A burgeoning discussion centered on GPT-4-OMNI's utility as an educational assistant, with the community excited about its multi-modal capabilities signaling a step-change in personalized learning experiences.
- Contamination Alert in Model Updates: Alarm bells in the form of a 29% spike in contamination were rung for the Luxia 21.4b model between versions v1.0 to v1.2, as evidenced by results on the GSM8k tests on HuggingFace, though this issue didn’t plague other testing benchmarks.
- Position Encoding Gets Contextual: Introducing Contextual Position Encoding (CoPE), a fresh take on traditional positional encoding, was part of an active dialogue, underscoring improvements in language modeling and coding tasks, as highlighted by a tweet from Jason Weston.
- The Heavyweights: MLPs vs. Transformers: The community gave airtime to a critical take on MLP-Mixer's constraints regarding causality and sequence lengths, provoking a deeper look into MLPs as static versus transformers' ability for dynamic context-dependent weights.
- Decoding Model Performance: Contributions involved sharing an Arxiv paper on learning rates and weight averaging, debating gradient diversity’s role in mini-batch SGD performance, and announcing a NeurIPS competition with up to $8,000 in rewards focused on model merging, as tweeted by Leshem Choshen and hosted on the official competition page.
CUDA MODE Discord
- CUDA Conundrum Solved: Engineers discovered a bug in Triton code causing int32 multiplication overflow, revealing how production-scale data can expose limitations not evident in unit tests, such as 16-bit grid dimension limits in CUDA.
- Performance Tuning Revealed: It's been suggested that templating block sizes like
blockDim.xcould notably boost performance in CUDA kernels, and discussions include propositions to merge branches for layernorm recomputations in favor of optimizing functional improvements before re-tweaking to minimize redundancies.
- Whisper Model Just Got a Super Update: A member successfully optimized the Whisper model by leveraging static cache, HQQ quantization, torchao 4-bit kernel, and torch.compile with fullgraph, achieving a 6.3x speed up, promising a detailed blog post.
- Intricacies of Low-Precision Multipliers Illustrated: Queries ranged from specifying precise operations of fp4 multiplication to exploring mixed precision layers in activations and gradients. There was mention of a CUDA kernel for FP6-LLM demonstrating a mixed-input multiply for fp16 activations with MX fp6_e3m2 weights, where calculations are performed using tensor cores.
- Resourceful Workarounds with Cloudflare R2 and Internal S3: Engineers discussed using Cloudflare R2 to reduce egress fees and Python dependencies, while considering internal S3 storage with pre-uploaded resources to share large datasets without incurring additional costs. This aligns with the discussion on installation errors and compatibility, including tips for handling builds requiring CUDA capability enhancements and avoiding isolated environment issues.
These targeted discussions reflect the community's focus on achieving performance improvements, optimizing cost efficiency, and tackling practical issues faced in implementing machine learning models at scale.
LlamaIndex Discord
- Codestral Emerges with Multi-Language Support: Mistral AI has introduced Codestral, a new local code-generating model supporting over 80 programming languages, with day 0 integration via LlamaIndex including a tutorial notebook. It's also compatible with Ollama, boosting local execution with direct support.
- Crafting Knowledge Graphs Locally: Engineers discussed local construction of knowledge graphs combining models like Ollama with Neo4j databases, backed by a comprehensive guide and additional how-to details.
- NLP Meetup Set for Financial Insight: London will host an NLP meetup featuring LlamaIndex, Weaviate_io, and Weights & Biases with a focus on using LLMs in financial services, with discussions on vector database management and a sign-up.
- LlamaParse Expands Format Abilities: LlamaParse has improved its functionality to process spreadsheets such as Excel and Numbers, facilitating their usage within RAG pipelines; learn more in the provided notebook and through a demo.
- Navigating the Landscape of API Frameworks and Data Stores: The community exchanged insights on selecting API frameworks, with a nod to FastAPI for asynchronous capabilities, and discussed transitioning data stores from SimpleStore to RedisStore with strategies including the
IngestionPipeline. Links to relevant documentations and examples were shared, including a Google Colab and several LlamaIndex resources.
LAION Discord
- Le Tigre Roars into Multimodal Space: Engineers have been discussing "Le Tigre," a multimodal project based on the Mistral 7B model, influenced by GPT-4-V's architecture, showcased on Devpost and GitHub. Anticipation is brewing for the LAION 5B dataset but its release remains uncertain.
- Sonic Speaks Volumes: Cartesia AI unveiled Sonic, a state-of-the-art generative voice model lauded for its lifelike quality and remarkable 135ms latency; details can be explored through their blog and Twitter announcement.
- The Merger of Models: The NeurIPS Model Merging Competition ignited discussion with an $8,000 prize pool, aiming to advance techniques in model merging, whilst issues on FFT replacing self-attention in transformers sparked intellectual curiosity, inspired by a paper suggesting the method could achieve near-BERT levels of accuracy with lower computational demands - paper.
- Cartoons Get Crafty with ToonCrafter: Skepticism met curiosity over ToonCrafter, a project designed for sketch-guided animation, with engineers noting its potential to disrupt traditional anime production costs which could shift from hundreds of thousands down to lower figures.
- GPT-4-Omni Open Call: LAION's call for contributions to an open GPT-4-Omni project was a notable announcement, aiming to foster collaborative development of large-scale multi-modal capabilities, as detailed in their blog post.
Nous Research AI Discord
- Teaching AI with Timely Prompts: Discussions highlighted the boost in model performance by including context-specific prompts and responses, with a focus on in-context learning tactics using windows of 100k context or less; this can streamline efficient data processing, where state-saving models like RWKV may offer time-saving advantages.
- Beyond Backpropagation and Merging Models: Novel training approaches that forgo traditional backpropagation attracted attention, hinting at potential complexity and transformative implications for model efficiency. A NeurIPS model merging competition has been announced, dangling an $8K prize pool; further details are accessible via a specific tweet.
- Scaling Down to Outperform Giants: The recently unveiled Yuan2-M32 model, boasting 40B parameters with only 3.7B active during generation, rivaled Llama 3 70B in benchmarks with lower resource use, fueling a community call to fine-tune and harness its capabilities.
- Navigating the Age of Specialized AI Tools: The growing trend involves groups preferring Large Language Models (LLMs) with generalized capabilities over niche ones; community members excitedly shared innovations like a rust library for LLM applications and MoRA, a tool for high-rank updating during fine-tuning, available on GitHub.
- Unlocking Access to RAG Datasets: A new RAG dataset is up for grabs on Hugging Face, subject to users agreeing to share their contact details, amidst discussions on measurement metrics for relevance, like MRR and NDCG, critiqued based on insights from Hamel et al.
Modular (Mojo 🔥) Discord
- Swift Embraces ABI Stability: In discussions about ABI stability, it was noted that Swift maintains ABI stability for Apple's operating systems, while Rust deliberately avoids it. Maintaining ABI stability can restrict the potential for performance improvements in some programming languages.
- Skepticism Over Mojo's Potential: The idea of Mojo becoming a widely adopted low-level protocol was met with skepticism, citing deficiencies such as the absence of certain key types and the difficulty of displacing established languages like C.
- Mojo Eyes Better C++ Interoperability: The Modular community highlighted the importance of C++ interoperability for Mojo's success, with possible future support for generating C++ headers from Mojo code being discussed.
- Package Management and Windows Support for Mojo: There is ongoing development for a Mojo package manager, as evidenced by GitHub discussions and proposal threads. However, frustration was voiced over Mojo's unavailability on Windows.
- Evening Out the Nightlies: A significant Mojo nightly build
2024.5.3005has been released with substantial changes, such as the removal of theStringableconstructor and severalmathfunctions fromString. Furthermore, approximately 25% of Mojo installs come from nightly builds to maintain a simple experience for newcomers. Trouble caused by these changes were addressed, such as correctingStringconversion tostrand fixes in CI PR #2883.
OpenRouter (Alex Atallah) Discord
- MixMyAI: The New Kid on the Block: The launch of mixmyai.com, a platform presenting itself as a comprehensive AI toolbox with attractive features like no monthly fees and privacy-centric operations, caught the attention of the community.
- The Secret to Free Tiers Left Uncovered: Discussions around accessing a free tier for an unspecified service piqued interest, yet the method to obtain such an elusive perk remains a topic of mystery with no clear resolution in sight.
- Talent for Hire: A senior developer with skills spanning full stack, blockchain, and AI announced their availability for new opportunities, indicating the community is a hotbed for potential recruitment and collaboration.
- Model Behavior: Moderated vs. Self-Moderated: Clarification on models emerged, drawing a line between models that self-moderate and those using an external moderator; specifically pointing out the unique setups for models like Claude on OpenRouter.
- Programming Packaged: The creation and announcement of integration packages for OpenRouter with Laravel and Ruby—including laravel-openrouter and open_router—demonstrates active community contributions and cross-language support.
Cohere Discord
- Domain-Specific Web Search Through API: A user described how to set a web search connector for a specific domain using the API options object; follow-up discussions on multi-domain restrictions are ongoing.
- AI for Academic Ingenuity: An individual is developing a Retrieval-Augmented Generation (RAG) model to enhance their college's search capabilities, detailing an intent to include both .edu domains and external review sites like RateMyProfessors.
- Type-Switching Embedding Tactics: Conversion of uint8 embeddings to float for mathematical operations was brought up, with the user being redirected to a more specialized technical channel for in-depth assistance.
- Startup Seeks User Retention Insight: A startup offered a $10 incentive for feedback on their no-code AI workflow builder to analyze user drop-off post-registration, with a note that the discussion should continue in a more relevant channel.
- Cohere's Market Strategy: A Cohere employee emphasized that the company is not pursuing Artificial General Intelligence (AGI), but is instead committed to developing scalable models for production environments.
LangChain AI Discord
Memory Lane with ChatMessageHistory: Kapa.ai illustrated the use of LangChain's ChatMessageHistory class for persisting chat conversations, providing a clear example of maintaining context across sessions, with a nod to the LangChain documentation.
Navigating LLM Conversation Complexity: Discussion centered around the difficulties of designing non-linear conversation flows with Large Language Models (LLMs), citing extraction and JSON handling concerns. An experimental approach on GitHub was linked to demonstrate these challenges in action.
Crafting an Analytical Copilot: Engineering dialogue included strategies for pairing LangChain with a PostgreSQL database, offering insight into handling ambiguous SQL query results via few-shot learning.
Hybrid Agents for Enhanced Interactivity: Integration of create_react_agent and create_sql_agent within LangChain was unraveled, detailing steps to avoid common initialization pitfalls and the importance of naming tools correctly for successful operation.
Evolving AI Assistants & Knowledge Graphs: Wave of new releases like Everything-ai v3.0.0 included advancements like integrating llama.cpp and Qdrant-backed vector databases, while a tutorial video shared across channels provided learners with a practical guide to creating bots using Pinecone, LangChain, and OpenAI.
Interconnects (Nathan Lambert) Discord
- Price Hikes Spark Cost-effectiveness Debate: Community members discussed a sharp pricing change for an unnamed service, challenging its previously acclaimed cost-effectiveness; suspicions arise if praise was based on the post-hiked rates.
- GPT-5 Speculation Intensifies: An unconfirmed table from X discussing GPT-5 led to speculation that OpenAI might make GPT-4o free in preparation for the new model; pointers to AI expert Alan D. Thompson's insights were noted About Alan.
- OpenAI Pricing Called Out for Typos: A typo in OpenAI's initial pricing announcement created confusion, later addressed and corrected within 24 hours; corrected pricing now reflects the company's intentions Official post by LoganK.
- OpenAI's Commercial Shift Stirring Discontent: Internal tensions at OpenAI surfaced in discussions referencing Microsoft's alleged pressure on the company to prioritize commercialization over research, leading to division among staff Financial Times article.
- OpenAI and Apple Collaboration Causes a Stir: The community reflected on the strategic implications and potential conflicts within the Azure-Apple partnership given Microsoft's investment in OpenAI; the blend of commercial dynamics and data policy considerations is under scrutiny.
OpenInterpreter Discord
- OpenInterpreter Rocks the Docs: The OpenInterpreter documentation received positive spotlight, featuring a list of language models with the notable LiteLLM supporting 100+ models. Attention was also drawn to the development of an Android/iOS client specifically tailored for the RayNeo X2 and Brilliant Labs frames, with the community eager to test the app shared via GitHub.
- LLaMA Heats Up Discussion: Engineers engaged in a heated debate over the use of LLaMA locally, particularly with NVLinked 3090 setups that run hot. Alternatives were suggested, including taking advantage of Groq for free model access, steering the conversation towards more sustainable and efficient hardware solutions.
- TTS Enthusiasm Voices Concern: The query for personalizing TTS with individual voices sparked curiosity with no direct solutions linked. Meanwhile, a member queried about the shipment of an order placed on April 30, 2024, only to be directed towards specific pinned manufacturing updates, hinting at an operational focus on communication from product developers.
- M5 Cardputer Rallying Anticipation: An update about the M5 cardputer stirred some fuss, balancing users’ excitement with skepticism, and the assurance was found in a pinned message outlining the latest manufacturing details. Additionally, a cautionary reminder circulated about using the ChatTTS model on Hugging Face strictly for educational purposes, emphasizing adhering to academic integrity.
- Model Curiosity Peaks with Codestral: Inquiry into the new Codestral model prompted member interest, suggesting potential for testing and reviews. The community appears willing to explore new modeling wonders, highlighting a proactive engagement with the latest in model development.
Latent Space Discord
- ChatGPT Free Tier Just Got Beefier: OpenAI has enhanced the ChatGPT Free tier with new abilities: browse, vision, data analysis, and file uploads. Users are considering "rate limits" as a potential constraint, with the official announcement available here.
- Conversational Voice AI, A16Z Bets Big: Skepticism and interest mingle as members discuss a16z's investment in voice AI, theorizing how AI might revolutionize phone calls beyond the investor excitement.
- Cartesia Breaks Sound Barriers with Sonic: Cartesia's launch of Sonic, their new low-latency generative voice model, is stirring conversations about its application in real-time multimodal contexts. For more insight, take a look at their blog post.
- YC's Leadership Shuffle Decoded: Paul Graham clarifies on Twitter the speculation regarding Sam's departure from Y Combinator, dismissing rumors of a firing in his tweet.
- Retrieval-Enhancing Embedding Adapters: The engineering crowd paid close attention to TryChroma's technical report on embedding adapters, focusing on improving retrieval performance, a concept closely related to Vespa's use of frozen embeddings.
- Podcast Unpacks Million Context LLMs: A new podcast episode featuring @markatgradient discusses the challenges of training a million context LLM, referencing historical methods and variants like RoPE, ALiBi, and Ring Attention. The episode can be streamed here.
Mozilla AI Discord
LLM360 Launches Community AMA: Mozilla AI's LLM360 kicks off community engagement with an AMA on their new 65B model and open-source initiatives, fostering knowledge sharing and Q&A with AI enthusiasts.
Bay Area Engineers, Mark Your Calendars: An IRL Open Source Hack Lab event has been scheduled in the Bay Area, inviting local members to collaborate and share their expertise.
Embeddings Insight Session: A community session on utilizing llamafiles for generating embeddings promises a practical learning experience for engineers seeking to apply embeddings in their machine learning projects.
Developer Support Enhanced at Mozilla AI: In the "Amplifying Devs" event, moderator-led discussions will focus on better supporting the development community within Mozilla AI, an essential platform for developer growth and collaboration.
Tackling LlamaFile Puzzles: Engineers report challenges with granile-34b-code-instruct.Q5_0.llamafile when running on M2 Studio and using VectorStoreIndex in Python, with solutions involving correct IP binding and addressing WSL localhost quirks. Interest in LlamaFiles with vision/image capabilities is growing, highlighted by Mozilla's llava-v1.5-7b-llamafile available on Hugging Face, potentially offering image support for creative AI applications.
OpenAccess AI Collective (axolotl) Discord
Fine-Tuning LLMs for Multimedia Tasks: Members are exploring ideal strategies to fine-tune large language models (LLMs), such as Llava, for tasks involving image and video understanding. The benefits and practicality of using Direct Preference Optimization (DPO) as opposed to Supervised Fine-Tuning (SFT) have precipitated a lively debate, particularly regarding the volume of data required for effective DPO.
DPO's Diminished VRAM Appetite: An unexpected reduction in VRAM usage during DPO has piqued the interest of one engineer, sparking speculation on recent updates that might have led to such efficiency gains.
Protobuf Heavyweight Champion Wanted: There’s an open call within the community for experts with a strong background in Google's Protobuf, especially those who can boast reverse engineering, malware analysis, or bug bounty hunting skills.
SDXL Custom Ads Campaign Hits a Snag: Someone's request for expertise in refining SDXL models is still hanging in the ether, as they aim to optimize their models for producing customized product advertisements and have not yet obtained the desired results with LoRA training or ControlNet.
Small Data for Grand Conversations: Curiosity abounds as to whether a small dataset of merely hundreds of samples could possibly suffice for successful DPO, particularly for domains as nuanced as general chitchat. It has been suggested that manually compiling such a dataset could be a practical approach.
AI Stack Devs (Yoko Li) Discord
AI-Powered Literature to Gameplay Transition: Rosebud AI is hosting a Game Jam: "Book to Game" where participants will use Phaser JS to turn books into games on the AI Game Maker platform, competing for a $500 prize with submissions due by July 1st. News of the jam was shared via Rosebud AI's tweet and interested devs can join their Discord community.
Android Access Annoyance: A newcomer to the Discord community described the Android experience as "a bit hard to navigate... Glitchy and buggy" but confirmed they are still able to engage with content. They also inquired about changing their username, expressing a feeling of being an "alien".
tinygrad (George Hotz) Discord
- GPU Future Speculations Spark Curiosity: Discussion on the evolution of GPUs in the next 2 to 5 years hinted at the use of larger 64x64 matrix multiplication arrays (MMA), poking fun at the idea with a suggestion to "make a bigger systolic array 😌."
- Tinygrad Outshines Torch with Integer Gradients: Tinygrad has been highlighted for its ability to compute gradients for integers, a task that causes a
RuntimeErrorin Torch. Tinygrad handles this by treating integers as floats during backpropagation before casting back to integers.
- Debating Framework Dominance in AI: A member asserted the superiority of Tinygrad over TensorFlow and PyTorch, igniting a conversation about why TensorFlow might be preferred over PyTorch in the AI community despite individual preferences for Tinygrad.
Datasette - LLM (@SimonW) Discord
- Language-Specific Codestral Proposed: A member sparked a conversation about the potential for a smaller Codestral by splitting it into individual programming languages, postulating that not all languages may contribute equally to the overall model.
- Curiosity about Language Weights: There's curiosity about the weight distribution in the 45GB Codestral model, with speculation that most weights are assigned to English but each programming language might still significantly impact the model's overall capabilities.
MLOps @Chipro Discord
Unfortunately, as there is only one message provided and this message lacks sufficient technical content or details relevant to AI Engineers, it is not possible to create a summary as per the given guidelines. If more messages with the appropriate detail are provided, a summary can be generated.
DiscoResearch Discord
- Join the Open GPT-4-Omni Initiative: LAION calls for community contributions to develop an open version of GPT-4-Omni, providing datasets, tutorials, and a guiding blog post. They also broadcasted their message through a Twitter post encouraging wider involvement.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!