[AINews] Contextual Document Embeddings: `cde-small-v1`
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Contextual Batching is all you need.
AI News for 10/3/2024-10/4/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (226 channels, and 1896 messages) for you. Estimated reading time saved (at 200wpm): 210 minutes. You can now tag @smol_ai for AINews discussions!
We often give the top story on AINews to movements of the big model labs, and today Meta's new text to video model, Movie Gen, is sweeping the news, with a paper that notably claims that they were able to adapt Llama 3 to video generation much better than OpenAI Sora's Diffusion Transformers. However, there is no actual release, just cherrypicked marketing videos, and we try to focus on news you can use here.
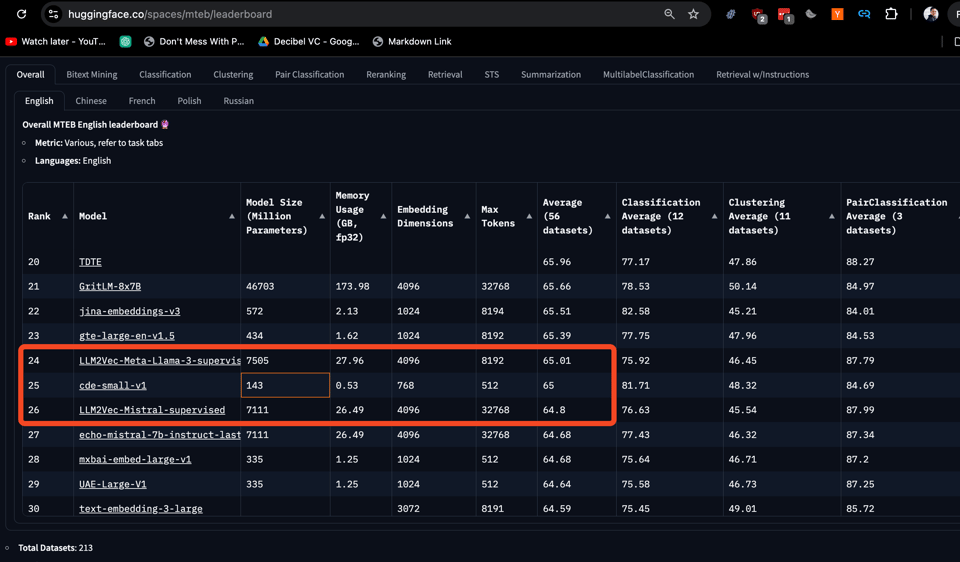
So we are happy to highlight Jack Morris and Sasha Rush's new paper and cde-small-v1 model on Contextual Document Embeddings, "the best BERT-sized text embedding model in the world".

Jack puts it best:
"Typical text embedding models have two main problems:
- training them is complicated and requires many tricks: giant batches, distillation, hard negatives...
- the embeddings don't "know" what corpus they will be used in; consequently, all text spans are encoded the same way"
To fix (1) we develop a new training technique: contextual batching. all batches share a lot of context – one batch might be about horse races in Kentucky, the next batch about differential equations, etc.
And for (2), we propose a new contextual embedding architecture. this requires changes to both the training and evaluation pipeline to incorporate contextual tokens – essentially, model sees extra text from the surrounding context, and can update the embedding accordingly
This seems to make sense - priming the embeddings model to adapt to context tokens first before doing proper embeddings.
While most leaderboard-topping embeddings models are >7B in size (scoring ~72 on MTEB), the 143M parameter cde-small-v1 scores a respectable 65 while sitting comfortably between models 50x larger. A nice efficiency win.
While you're exploring new embeddings models, you might want to explore other advanced RAG techniques from today's sponsor!
Brought to you by RAG++: Query refinement for RAG is like giving your system X-ray vision; with it, the system can “see“ user intentions more clearly - leading to more accurate chunk retrieval and more relevant LLM responses.
Learn about improving your RAG query refinement in this YouTube excerpt from Weights & Biases’ new course RAG++ : From POC to Production and sign up for free LLM api credits to get you started!

The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model and Company Updates
- OpenAI Developments: OpenAI introduced Canvas, a new interface for collaborating with ChatGPT on writing and coding projects. @karinanguyen_ highlighted key features including in-line feedback, targeted editing, and a menu of shortcuts. The canvas model was trained using novel synthetic data generation techniques, allowing for rapid iteration without relying on human data collection.
- Google AI News: @_tim_brooks announced joining Google DeepMind to work on video generation and world simulators. @demishassabis welcomed him, expressing excitement about making the long-standing dream of a world simulator a reality.
- Model Releases and Updates: Google released Gemini 1.5 Flash-8B, offering 50% lower prices and 2x higher rate limits compared to the previous version. @arohan mentioned that Flash 8B incorporates algorithmic efficiency improvements to pack as much as possible into a small form factor. @bfl_ml launched FLUX1.1 [pro], a new state-of-the-art diffusion model that delivers images 3x faster than its predecessor with improved quality.
AI Research and Techniques
- Scaling Laws and Model Training: @soumithchintala discussed how modern transformers follow well-behaved scaling laws, allowing researchers to find hyperparameters at a smaller scale and then scale up parameters and data according to power laws. This approach increases confidence in larger training runs.
- Inference Optimization: @rohanpaul_ai shared a summary of transformer inference optimization techniques, including KV Cache, MQA/GQA, Sliding Window Attention, Linear Attention, FlashAttention, Ring Attention, and PagedAttention.
- AI Safety and Alignment: @RichardMCNgo expressed frustration with the focus on AI safety at the expense of potentially breakthrough research in neural networks, deep learning, and agent foundations.
Industry Trends and Applications
- Voice AI and Call Centers: @rohanpaul_ai highlighted the potential impact of OpenAI's Real-time API on the call center industry, with AI-powered calls costing significantly less than human agents.
- AI in Healthcare: @BorisMPower noted that in a narrow test of professional doctors, AI performed better than human + AI, drawing parallels to observations in chess and Go.
- Developer Tools and Interfaces: Several tweets discussed the importance of novel interfaces for AI, with @finbarrtimbers noting that better interfaces will make LLMs much easier to use, citing Cursor vs Copilot as an example.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Whisper Turbo: Significant Speed Improvements in Speech Recognition
- Open AI's new Whisper Turbo model runs 5.4 times faster LOCALLY than Whisper V3 Large on M1 Pro (Score: 80, Comments: 15): OpenAI's new Whisper Turbo model demonstrates 5.4x faster local transcription compared to Whisper V3 Large on an M1 Pro MacBook Pro, processing a 66-second audio file in 24 seconds versus 130 seconds. The post provides instructions for testing locally using the nexa-sdk python package and includes links to both the Whisper-V3-Large-Turbo and Whisper-V3-Large models on nexaai.com.
- Faster-Whisper outperforms Whisper-Turbo on an RTX3090 Linux system, transcribing a 24:55 audio file in 14 seconds vs 23 seconds. The chunked algorithm is recommended for prioritizing transcription speed and long audio files.
- Users report Whisper Turbo runs faster than real-time on MacBooks, opening possibilities for local real-time assistant solutions. The model supports multiple languages, not just English.
- Discussions on streaming input/output for ASR models like Whisper highlight challenges due to its 30-second chunk architecture. A working prototype exists but is less reliable compared to non-async architectures.
- Finally, a User-Friendly Whisper Transcription App: SoftWhisper (Score: 62, Comments: 19): SoftWhisper, a new desktop app for Whisper AI transcription, offers an intuitive interface with features including a built-in media player, speaker diarization (using Hugging Face API), SRT subtitle creation, and the ability to handle long files. Developed using Python and Tkinter, the app aims to make transcription accessible, with the developer seeking feedback and potential collaborators for future improvements such as GPU optimization.
- Users discussed running the application, with the developer providing a tutorial and dependency_installer.bat script for easier setup. The project now includes a requirements.txt file and instructions for Python installation.
- A user shared a GitHub repository for offline diarization using Pyannote, which the developer expressed interest in exploring. The offline usage of Pyannote was confirmed as permissible.
- Suggestions for future improvements included real-time capture capability for meetings and support for multiple audio stream videos. The developer confirmed that SoftWhisper can transcribe video formats by extracting audio, though format support may be limited.
Theme 2. Qwen 2.5: Controversy Over Chinese AI Models in Conservative Industries
- Gemma 2 2b-it is an underrated SLM GOAT (Score: 92, Comments: 21): Gemma 2 2b-it is praised as an exceptional Small Language Model (SLM), outperforming many larger models in various benchmarks. The model demonstrates impressive capabilities, including zero-shot reasoning, few-shot learning, and strong performance in coding tasks, despite its relatively small size of 2 billion parameters. Its efficiency and performance make it a strong contender in the SLM space, challenging larger models like Mistral 7B and Llama 2 13B.
- A separate leaderboard for Small Language Models (SLMs) was suggested, with potential for locally-run AGI on smartphones. However, debate arose over the term "SLM", with some arguing that model size doesn't define whether it's a large or small language model.
- The Qwen2.5-3B-Instruct model shows impressive performance compared to other small models like Gemma2-2B-IT and Phi3.5-mini-Instruct. A detailed performance comparison table was shared, highlighting Qwen's strengths in tasks like MATH (65.9%) and GSM8K (86.7%).
- Gemma 2 2b-it is praised for its capabilities, with users noting its performance against older, larger models like Claude 2 and Gemini 1 Pro. The model's efficiency and low cost for fine-tuning were also highlighted.
- Qwen 2.5 = China = Bad (Score: 300, Comments: 232): The post discusses concerns about using the Chinese AI model Qwen 2.5 in a conservative industry, where superiors have rejected its use due to fears of it being a trojan from Alibaba. The author argues that these concerns are unfounded, especially given plans to use the model on-premise without internet connection and to finetune it, potentially making it unrecognizable from its original form.
- Users discussed potential security risks of LLMs, including sleeper agents that can persist through safety training and models trained to insert exploitable code under specific conditions. Some argued air-gapping and using safetensors format could mitigate risks.
- Several commenters pointed out that while technical risks may be low, perceived risks can have real consequences for businesses, including impacts on risk assessments, insurance premiums, and investor relations. Some suggested using alternative models to avoid these issues.
- There was debate about whether concerns over Chinese models like Qwen are justified. Some argued it's no riskier than other tech products made in China, while others cited examples of Chinese espionage and suggested caution when dealing with sensitive data or applications.
Theme 3. XTC Sampler: New Technique to Reduce GPTisms in LLM Outputs
- Say goodbye to GPTisms and slop! XTC sampler for llama.cpp (Score: 144, Comments: 45): The post introduces an XTC sampler implementation for llama.cpp, designed to reduce GPTisms and slop in language model outputs. This sampling method aims to improve the quality and coherence of generated text by addressing common issues associated with traditional sampling techniques used in large language models.
- The XTC sampler implementation for llama.cpp aims to reduce GPTisms and improve creativity by ignoring top tokens during sampling. Users can find examples and usage instructions in the GitHub repository.
- Discussions arose about the effectiveness of XTC, with some users praising its ability to enhance creative writing, while others questioned its impact on general performance. The recommended parameter values are threshold = 0.1 and probability = 0.5, with viable ranges of 0.05-0.2 for threshold and 0.3-1.0 for probability.
- Debate ensued over whether removing top token candidates is the best approach for improving language model outputs. Some argued it could lead to decreased performance in non-creative tasks, while others emphasized its potential for reducing repetitive phrases and enhancing diversity in generated text.
- Quantization testing to see if Aphrodite Engine's custom FPx quantization is any good (Score: 64, Comments: 32): Aphrodite Engine's custom FPx quantization was tested against standard FP16 and INT8 quantization methods. Results showed that FPx outperformed INT8 and matched or slightly exceeded FP16 performance, while offering potential memory savings. The testing utilized MMLU and HumanEval benchmarks, with plans for further evaluation using TinyStories and Alpaca datasets.
- Aphrodite's custom FP quantization showed impressive results, with FP6 recommended for <8-bit fast inferencing. FP5 unexpectedly achieved the highest score (40.61%), potentially due to unintentional Chain of Thought reasoning.
- Benchmark results revealed GGUF Q4_K_M performed surprisingly well, outperforming GPTQ and FP4 quantizations. Aphrodite's FP quants demonstrated high speed, scaling faster at lower quantization levels, while GGUF models were notably slower.
- The study concluded that >4-bit quantization using Aphrodite's custom FP quants is optimal for speed. For 4-bit or lower quantization, GGUF performs better. 8-bit quantization showed similar performance to full BF16 models across methods.
Theme 4. Tool Calling in Open-Source LLMs: Building Agentic AI Systems
- Tool Calling in LLMs: An Introductory Guide (Score: 73, Comments: 3): The post introduces tool calling in LLMs, defining tools as functions with names, parameters, and descriptions made available to language models. It explains that LLMs don't directly execute tools but generate a structured schema (usually a JSON object) containing the tool's name and parameter values when a relevant tool is identified for a given query. The post outlines a 4-step workflow for tool calling, from defining a tool to generating a complete answer using tool outputs, and provides a link to an in-depth guide on using tool calling with agents in open-source Llama 3.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Techniques
- Google DeepMind advances multimodal learning: A new paper demonstrates how data curation via joint example selection can accelerate multimodal learning.
- Microsoft's MInference speeds up long-context inference: MInference enables inference of up to millions of tokens for long-context tasks while maintaining accuracy.
- Scaling synthetic data creation: A paper on scaling synthetic data creation leverages 1 billion web-curated personas to generate diverse training data.
- Exact volume rendering for NeRFs: A new paper achieves exact volume rendering at 30FPS@720p, producing highly detailed 3D-consistent NeRFs.
AI Model Releases and Improvements
- Salesforce releases xLAM-1b: This 1 billion parameter model achieves 70% accuracy in function calling, surpassing GPT 3.5.
- Phi-3 Mini updated with function calling: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
- iPhone photo style LoRA for Flux: A new LoRA fine-tuning improves the realism of Stable Diffusion Flux outputs to match iPhone photo aesthetics.
AI Industry Developments
- High demand for Nvidia's Blackwell AI chip: Nvidia CEO Jensen Huang reports "insane" demand from major tech companies for their next-generation AI chip.
- OpenAI discourages investors from backing competitors: OpenAI is asking investors not to fund certain AI competitors, raising concerns about monopolistic practices.
- Sora lead joins Google: Tim Brooks, a lead researcher on OpenAI's Sora video generation model, has joined Google.
AI Ethics and Societal Impact
- Debate over AI alignment and corporate control: Discussions around OpenAI's shift towards profit-seeking and concerns about corporate control of AGI development.
- EU AI regulation concerns: French President Macron warns that over-regulation and under-investment in AI could harm the EU's competitiveness.
- Unions and AI adoption: A Swedish union leader's perspective on embracing new technology while protecting workers highlights the need for retraining and adaptation.
AI Capabilities and Milestones
- Claims of human-level reasoning: OpenAI CEO Sam Altman suggests they've reached human-level reasoning capabilities, though the exact meaning and implications are debated.
- Improvements in image generation: Demonstrations of highly realistic photo generation using Stable Diffusion Flux, though some claims are disputed.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: Meta Unveils Movie Gen, Revolutionizes Video Generation
- Meta Premieres Movie Gen, Redefines Multimedia Creation: Meta's Movie Gen introduces advanced models that generate high-quality images, videos, and synchronized audio from text prompts. Capabilities include precise video editing and personalized content generation.
- AI Community Buzzes Over Movie Gen's Potential: The Movie Gen research paper showcases groundbreaking techniques in video content creation. Meta is collaborating with creatives to refine the tool before wider release.
- Movie Gen Sparks Excitement Across AI Forums: Discussions highlight Movie Gen's promise to push the boundaries of AI-generated video, with enthusiasts eager to explore its applications in multimedia projects.
Theme 2: New AI Models and Benchmarks Lead the Charge
- Nvidia Drops a Bombshell with GPT-4 Rival: Nvidia's new AI model is open, massive, and set to challenge GPT-4, as reported by VentureBeat. The AI community is eager to see how it stacks up.
- Finance LLM Leaderboard Crowns Top Performers: A new LLM leaderboard for finance ranks OpenAI's GPT-4, Meta's Llama 3.1, and Alibaba's Qwen as leaders across 40 tasks. This offers fresh metrics for evaluating models in financial applications.
- Gemini 1.5 Flash-8B Delivers Budget-Friendly AI Power: Now available on OpenRouter at $0.0375 per million tokens, Gemini 1.5 Flash-8B provides a cost-effective option without sacrificing performance.
Theme 3: Advances in Model Optimization and Training Techniques
- TorchAO Lights Up PyTorch with Model Optimization: The new torchao library introduces quantization and low-bit datatypes, boosting model performance and slashing memory usage. It's a significant leap forward for PyTorch users.
- SageAttention Speeds Past Competitors: SageAttention achieves 2.1x speedups over FlashAttention2 and 2.7x over xformers, all without losing accuracy. This quantization method turbocharges attention mechanisms.
- VinePPO Unlocks RL Potential in LLMs: The VinePPO algorithm addresses credit assignment issues in LLM reasoning tasks, outperforming PPO with up to 9x fewer steps and 3x less time, while using half the memory.
Theme 4: OpenAI's Canvas Tool and Models Stir Mixed Reactions
- OpenAI's Canvas Tool Sparks Joy and Frustration: The new Canvas tool streamlines coding by integrating features and reducing scrolling. However, users lament missing essentials like a continue button and face editing hiccups.
- Advanced Voice Mode Could Elevate Coding: Discussions suggest that combining Advanced Voice Mode with Canvas could enhance programming workflows. Community-shared setup guides aim to smooth integration.
- OpenAI's o1 Models Impress Developers: The introduction of o1-preview and o1-mini models enhances chatbot capabilities. Users note o1-mini's surprising prowess in tackling complex tasks.
Theme 5: Recurrent Neural Networks Make a Comeback
- RNNs Strike Back with 175x Faster Training: The paper “Were RNNs All We Needed?” reveals that minLSTMs and minGRUs without hidden state dependencies train dramatically faster, reigniting interest in RNN architectures.
- Minimalist RNNs Enable Efficient Parallel Training: By eliminating backpropagation through time, these simplified RNNs allow for parallel computation, challenging Transformers in sequence modeling efficiency.
- Community Explores RNNs' Modern Potential: Enthusiasts discuss how streamlining RNNs can lead to scalable training methods suitable for today's AI demands, potentially reshaping the landscape of neural network architectures.
PART 1: High level Discord summaries
Nous Research AI Discord
- torchao Library Introduces Model Optimization: The torchao library from PyTorch features quantization and low-bit datatype techniques, boosting model performance and memory use.
- It promises automatic quantization alongside existing tools, marking a significant advancement in PyTorch.
- OpenAI's Canvas Tool Streamlines Coding: OpenAI's Canvas tool has garnered excitement for its integrated features, reducing unnecessary scrolling during coding.
- Users noted that its editing capabilities are a significant advancement over previous tools like Claude.
- Meta's Movie Gen Models Show Great Potential: Meta has launched its Movie Gen models that generate high-quality multimedia from text prompts.
- These models feature precise video editing and personalized generation, highlighting their creative applications.
- Cultural Biases Limit AI Training Understanding: Current discussions point out that LLM training lacks human biases and relies heavily on large datasets, affecting concepts like love and morality.
- Members question how AI might 'learn' these complex emotions without true inherent understanding.
- VinePPO Addresses LLM Credit Assignment: The paper on VinePPO critiques Proximal Policy Optimization (PPO) for its inconsistency in reasoning tasks and introduces a refinement to tackle credit assignment.
- It shows that existing value networks in PPO yield high-variance updates, merely outperforming random baselines.
aider (Paul Gauthier) Discord
- Aider's Telemetry Needs Urged: Members highlighted the importance of telemetry in Aider, suggesting opt-in features for user privacy while improving insight on performance.
- System call tracing was proposed to diagnose performance issues, emphasizing the need for transparency about the data collected.
- OpenRouter Free Models put to the Test: OpenRouter's free models present strict account-wide limits of 200 messages per day, impacting flexibility for users wanting more access.
- Participants raised concerns about lacking paid options for certain models, questioning the overall usability.
- Benchmarking Models Raises Questions: Participants shared experiences from benchmarking various models, noting mixed performance on processing error rates.
- Aider’s ability to manage editing tasks was a focal point, with users reporting issues linked to token limits alongside specific errors.
- Ollama Model Performance with Aider: Users reported slow response times while using Aider with Ollama's local 8B model, questioning the benefit of paid API keys.
- Discussions revealed local models may struggle with editing tasks, indicating a preference for models with stronger editing capabilities.
- Exploring File Addition Complexity: Testing the /read-only command in Aider illustrated it now only completes tasks by folder, complicating file access.
- Another user confirmed that correct usage should still add all files, revealing nuances in command functionality.
HuggingFace Discord
- Salamandra on-device demo shines: Salamandra demo showcased impressive capabilities, engaging users while highlighting its features.
- The excitement around Salamandra's spotlight in the community reflects the growing interest in on-device AI applications.
- Nvidia launches a game-changing AI model: Nvidia's new AI model is open, massive, and prepared to rival GPT-4 according to a report from VentureBeat. The community is eager to see how this model will compete and what unique capabilities it possesses.
- This announcement has stirred excitement within the AI community.
- OpenAI introduces new models: Two new OpenAI models, o1-preview and o1-mini, were integrated into the open-source chatbot, enhancing its functionality. Members celebrated these additions as a significant leap towards more robust chatbot experiences.
- MusicGen iOS app shows progress: Updates on the iOS app for MusicGen reveal features including a noise cancel for input audio and a 'tame the gary' toggle, focusing on drums. One member remarked that it aims for refined audio input-output integration, targeting enhanced user experience.
- AI Sentience Prediction raises questions: An article titled 'The Sentience Prediction Equation' discusses potential future AI sentience and its implications, questioning if AI will ponder its purpose. It humorously notes AI might ask, 'Why do humans insist on putting pineapple on pizza?' introducing the Prediction Equation as an estimation tool.
OpenAI Discord
- Canvas Model Enhancements Spark Excitement: The new Canvas model is generating buzz, with members discussing its potential functionality and integration with GPT-4o. However, frustration arose due to missing features like a continue button and editing issues.
- Users are hopeful that improvements will enhance the UX for programming tasks while addressing current limitations.
- Advanced Voice Mode Could Boost Integration: Conversations about the Advanced Voice Mode highlighted its potential synergy with the Canvas tool for smoother user experiences in coding. Community members circulated setup guides on GitHub to aid seamless integration.
- They proposed features like real-time API integration to boost coding efficiency as an exciting next step.
- Custom GPTs Experience Mixed Results: Users reported challenges with integrating Google API/OAuth within Custom GPTs during its initial rollout, causing some concern about its reliability. They have yet to check in on recent improvements regarding stability.
- This lack of consistency has left some users wary about re-engaging with the integration.
- ChatGPT's Evaluation Inconsistencies Take Center Stage: Frustrations emerged over inconsistent evaluations from ChatGPT when tasked with scoring answers on a scale at temperature 0.7, prompting suggestions for stricter grading scales. A user recommended using a grading rubric to enhance clarity and consistency.
- Another proposed the Chain-of-Thought reasoning framework to improve scoring accuracy and evaluative clarity.
- Efficient JSON Processing Tips Shared: A developer sought advice on parsing 10,000 snippets into JSON with GPT-4o and inquired about the necessity of resending protocol parameters for each snippet. Suggestions encouraged optimization by only sending new snippets during processing.
- This conversation illustrates the ongoing need for cost efficiency in model interactions and JSON handling.
Unsloth AI (Daniel Han) Discord
- Unsloth AI Projects streamline fine-tuning: Members discussed using Unsloth AI for continual pretraining of LLMs, achieving up to 2x faster training while using 50% less VRAM compared to traditional methods.
- Essential tools like the continued pretraining notebook were emphasized for expanding model training capabilities.
- ZLUDA's funding brings new hopes: ZLUDA's development has secured backing from a new commercial entity, targeting enhanced functionality for LLMs.
- Concerns linger about possible legal disputes with NVIDIA, echoing issues experienced in previous equity backing scenarios.
- Generational Preferences: A humorous take: Members playfully debated their generational identities, one claiming to feel as a boomer at just 24, touching on cultural perceptions.
- The lighthearted conversation noted that Legos and modded Minecraft define generational boundaries, hinting at shifting cultural practices.
- Local inference script woes: A member faced challenges with their local inference script for gguf models using llama-cpp, reporting sluggish performance despite a capable GPU.
- Suggestions like using llama-cli emerged, indicating a potential for enhanced script efficiency.
- Revival of Recurrent Neural Networks: A recent paper suggests minimal LSTMs and GRUs trained 175x faster by eliminating hidden state dependencies, sparking renewed interest in RNNs.
- This finding points towards new possibilities in scalable training methods relevant to modern architectures.
Eleuther Discord
- IREE faces unpredictable adoption timelines: Members discussed whether large labs might adopt IREE for serving models at scale, amid indications that many use custom inference runtimes.
- Some noted that it's typical for new technologies like IREE to have unpredictable adoption timelines.
- RWKV introduces efficient parallelization: RWKV employs partial parallelization by structuring networks into smaller layers, enabling computations while waiting for token inputs.
- This approach aims to streamline performance while managing model interdependencies effectively.
- Exploring Linear Attention models: Dialogue focused on linear attention and gated linear attention's capacity to function as RNNs, enabling parallel computations across sequences.
- Interest grew around Songlin Yang's research uncovering complex RNN classes improving parallelization.
- VinePPO struggles with credit assignment: The VinePPO paper outlines how value networks face credit assignment challenges in complex reasoning tasks, underperforming against random baselines.
- This emphasizes the necessity for improved models or techniques to optimize credit assignment in Proximal Policy Optimization (PPO).
- lm-evaluation-harness seeks contributors: The lm-evaluation-harness is inviting contributions for integrating new LLM evaluations and addressing bugs, with many issues available to tackle.
- Potential contributors can find more detailed information in the GitHub repository.
OpenRouter (Alex Atallah) Discord
- SambaNova AI Impresses with Throughput: SambaNova AI launched their endpoints for Llama 3.1 and 3.2 on OpenRouter, claiming the fastest throughput measurements recorded.
- They noted, ‘These are the fastest we’ve seen’, indicating a significant edge in their throughput metrics compared to competitors.
- Gemini 1.5 Flash-8B Officially Launches: The Gemini 1.5 Flash-8B model is now available, priced at $0.0375 per million tokens, making it a noteworthy budget option compared to peers.
- For access, check the link here; discussions have also centered on its performance scaling potential.
- o1 Mini Surprises with Task Performance: o1 Mini has shown improved capability in resolving complex tasks, exceeding community expectations for its performance.
- A member mentioned plans to utilize o1 Mini for a bot handling image descriptions, showcasing its practical applications.
- Anthropic Rides Funding Wave: Discussions revealed that Anthropic's rapid model development, particularly for Claude, stems from a team of ex-OpenAI engineers and backing from Amazon.
- Speculations arose regarding how Anthropic competes effectively in performance with less financial support compared to giants in the sector.
- OpenRouter Infrastructure Expansions on the Horizon: Anticipation builds around expansions in OpenRouter to accommodate diverse model functionalities, including image and audio processing.
- Development leads are confirmed to be actively working on upgrades to handle increased traffic and new model releases.
LM Studio Discord
- Langflow Integration Boosts LM Studio: LM Studio is now integrating support for Langflow, as highlighted in a recent GitHub pull request, enhancing functionalities for building LLM applications.
- This integration is set to streamline user experience and broaden the capabilities of LM Studio.
- Memory Leak Drama with v0.3.2.6: Users reported significant memory leak issues with LM Studio version v0.3.2.6, which resulted in models generating nonsensical output.
- Recommendations suggest checking if the problem persists in version v0.3.3 for resolution.
- Model Downloading Troubles Trigger Errors: A persistent issue with model downloads from Hugging Face surfaced, where errors occurred while selecting models in LM Studio.
- Members suggested sideloading models directly into the models directory to bypass these errors.
- Chat Cache Location Not Customizable: Questions arose regarding the ability to customize the chat cache location in LM Studio, which is currently hardcoded.
- LM Studio saves conversation data in JSON format, but there are no options for changing the cache location at this time.
- AI Model Recommendations Spark Discussions: Discussions highlighted Llama-3-8B as not meeting expectations for some users when used as a chatbot assistant.
- Users were encouraged to explore various options on the LM Studio Model Catalog for potentially better fits.
Latent Space Discord
- LangChain launches Voice ReAct Agent: LangChain introduced a Voice ReAct Agent leveraging the Realtime API for custom voice experiences, demonstrated with an agent using a calculator and a Tavily web search tool.
- This innovative agent showcases new possibilities for voice interaction in interactive applications.
- GPT-4o Bots chat up a storm: A demo highlighted two GPT-4o Voice AI bots conversing using the Realtime API, underlining the advancements in voice AI technology.
- The bots exhibited impressive turn-taking latency, revealing notable improvements in interaction fluidity.
- Meta Movie Gen strides into video generation: Meta showcased its latest project, Meta Movie Gen, aimed at pioneering video generation but without a set release date. More details can be explored on their AI research page and its associated paper.
- The project promises to push the boundaries of video content creation, driven by state-of-the-art models.
- New LLM leaderboard introduces finance leaders: The latest LLM leaderboard for finance positions OpenAI's GPT-4, Meta's Llama 3.1, and Alibaba's Qwen as top performers across 40 relevant tasks, as explained in a Hugging Face blog post.
- This evaluation method offers a fresh approach to measuring model performance in financial applications.
- Luma AI sparks interest in 3D modeling: Enthusiastic discussions about Luma AI emphasized its potential in creating lifelike 3D models for platforms like Unity and Unreal, with members sharing various functional showcases.
- Luma AI's capabilities were highlighted in its applications for film editing and detailed 3D models, indicating its promise in creative tech.
GPU MODE Discord
- Performance Benchmarks Inquiry: Members are seeking performance benchmarks for tools and methodologies, especially comparing these metrics to raw performance from fio tools.
- There's a drive to analyze the data access methods to understand their effectiveness against traditional performance metrics.
- OpenAI's Financial Success: OpenAI is reportedly setting financial records thanks to recent innovations, with speculations on hardware development to leverage this growth.
- Conversations growing around new product development point to possibilities of a mobile device focusing on user data applications, reminiscent of Apple's privacy concerns.
- Event Planning Strategies: The event planning timeline suggests it might occur around September, aligning with the school season to encourage attendance.
- Colocation with the Triton and PyTorch conferences has been proposed for better group travel, showcasing effective planning strategies.
- Triton Kernel Challenges: Users are troubleshooting Triton kernels, especially facing issues with non-contiguous inputs, indicating a possible need for reshape.
- There are also persistent problems with OptimState8bit dispatch errors, spotlighting limitations of 8-bit optimizer implementations.
- Need for a Hyperparameter Scaling Guide: A member called for a hyperparameter scaling guide, indicating confusion due to the lack of clear heuristics for larger model training.
- Concerns about training methodologies suggest a gap in accessible resources that could support community members in this technical area.
Perplexity AI Discord
- Perplexity AI Updates Collections UI: Perplexity AI is enhancing its Collections feature with a new UI to support custom instructions and files uploads, slated for future deployment.
- The upcoming Files search feature aims to improve information organization and user experience.
- Boeing 777-300ER Specs Released: A detailed outline of the Boeing 777-300ER specifications has been shared, covering dimensions, performance, and capacity.
- Key highlights include a maximum range of 7,370 nautical miles and the potential to seat up to 550 passengers.
- TradingView Premium Cracked Version Disclosed: A free cracked version of TradingView Premium (Version 2.9) was circulated, offering advanced trading tools without fees.
- This disclosure has generated interest among traders seeking improved charting capabilities.
- Llama 3.2 Release Anticipated: Users are buzzing about the expected features and release date of Llama 3.2, showing keen interest in its advancements.
- The community is excited about potential innovations that this new iteration could bring.
- Claude 3.5 Outshines Competitors: Discussion emerged comparing Claude 3.5 Sonnet to other models, with many asserting its reliability in information retrieval.
- Members highlighted the synergy of Perplexity Pro and Claude for improved data extraction from resources.
Cohere Discord
- Command R 08-2024 Fine-tuning Highlights: The updated Command R 08-2024 introduces support for newer options designed to provide users with more control and visibility. This update features a seamless integration with Weights & Biases for enhanced performance tracking.
- Members expressed enthusiasm for the Command R update, with comments like 'Awesome' capturing the excitement and anticipation from the community.
- Metrics are missing in the platform: A user reported that they are unable to see the metrics boxes for their models across various tabs like Overview and API, which previously displayed essential information. They highlighted that it's taken 2 days without resolution.
- This has raised concerns about the consistency of the platform, questioning the status of model creation.
- Pricing Page Confusion: The pricing page indicates $3 per 1M tokens for training, but the finetune UI shows a price of $8. This discrepancy raises questions about the accuracy of the pricing information across different platforms.
- This has caused confusion that could impact users budgeting for training and fine-tuning projects.
Stability.ai (Stable Diffusion) Discord
- Finding OpenPose Alternatives: Users expressed frustrations with OpenPose when generating sitting poses, prompting discussion of alternatives like DWPose and exploring custom model training options.
- Training one’s own model could also be a viable solution with sufficient reference images available.
- Improving ComfyUI's Image Quality: A member raised questions on achieving ComfyUI outputs comparable to Auto1111, as recent images appear cartoony in quality.
- Specific nodes in ComfyUI were recommended as potential methods for better quality outputs.
- Clarity on SDXL Model Varieties: Multiple versions of SDXL were under discussion, particularly
SDXL 1.0, covering aspects like starting resolutions at 1024x1024.- Participants confirmed that all variations relate back to the SDXL 1.0 model framework.
- Reference Images Yielding Poses: It was confirmed that generating poses with a single reference image is feasible in Stable Diffusion, though accuracy may suffer.
- The img2img feature was highlighted as the correct approach, suggesting that multiple reference images would improve fidelity.
- Query for AI Object Placement Tools: Discussions uncovered interest in OpenPose techniques to assist with object placement, specifically regarding a LoRA model for items like swords.
- While various training styles in Stable Diffusion exist, users noted a gap in dedicated posing methods.
LAION Discord
- MinGRU Architecture Takes Recurrent Networks Down a Notch: The introduction of minGRUs proposes a simpler form of GRUs that eliminates hidden state dependencies, boosting training speed by 175x.
- This paper highlights that all it takes are two linear layers to achieve parallel hidden state computations, sparking conversations about simplifying NLP architectures.
- Hunting for Resources to Build a BARK Model: A newcomer is eager to train a BARK-like model from scratch within 2-3 months but struggles to find relevant literature.
- They noted connections between BARK and models like Audio LM and VALL-E, seeking community suggestions for papers to steer their training efforts.
- Navigating Language Challenges in Tech: A member raised concerns about the predominance of English in technical discourse, stating that many complex terms, like embeddings and transformers, often lack straightforward translations.
- Frustration with language preferences complicates technical discussions, as effective communication hinges on shared terminology.
- Community Scam Alerts Keep Members Cautious: Numerous warnings surfaced about potential scams targeting members with false promises of earning $50k in 72 hours for a 10% share of profits.
- Individuals were advised to approach such schemes with skepticism, especially those involving unsolicited Telegram outreach.
LLM Agents (Berkeley MOOC) Discord
- Inquiry on Article Scores Sparks Interest: A member asked how to view scores for three articles they submitted, including a draft and LinkedIn links, which underscores ongoing concerns about submission feedback.
- Submission feedback remains a hot topic among members seeking clarity on their contributions.
- Real-time Streaming Stalled by Garbage Collection: One member expressed a desire to stream chat_manager responses directly into the frontend in real-time, noting current responses stream only post garbage collection.
- Another confirmed a Streamlit UI had been created around 8 months ago, resolving this challenge.
- Chainlit Shows Promise for Chat Management: A member indicated a solution using Chainlit exists, with a potential recipe in the AutoGen project on GitHub to facilitate real-time chat features.
- This implementation could effectively address the needs for improved chat management highlighted in ongoing discussions.
- GitHub Pull Request Chat Processing Insights: A member shared a relevant GitHub pull request that focuses on processing messages before sending them, enhancing customization.
- This development aligns with previous inquiries about real-time streaming, showing community momentum towards improved features.
- Campus Course Location Clarified: A member inquired about the specific room on Berkeley Campus for a certain course, highlighting logistical concerns among participants.
- Coordinating activities seems crucial as community members navigate their educational requirements.
LlamaIndex Discord
- Build AI Agents with LlamaCloud: Learn how to build AI agents using LlamaCloud and Qdrant Engine, focusing on implementing semantic caching for better speed and efficiency.
- The demo includes advanced techniques like query routing and query decomposition to optimize agent interactions.
- Enhance Security in RAG Deployments: A discussion emerged about utilizing Box's enterprise-grade security combined with LlamaIndex for secure RAG implementations.
- Members stressed the significance of a permission-aware RAG experience to ensure robust data handling.
- Voice Interaction with OpenAI's APIs: Marcus showcased a new function using OpenAI's real-time audio APIs that enables voice commands for document chat.
- This feature revolutionizes document interaction, allowing users to engage via spoken language.
- Combat Hallucination in RAG: CleanlabAI's solution tackles hallucination issues in RAG by implementing a trustworthiness scoring system for LLM outputs.
- This methodology boosts data quality by pinpointing and removing unreliable responses.
- Exciting Hackathon Opportunity Announced: The upcoming hackathon, featuring over $12,000 in cash prizes, kicks off on October 11th at 500 Global VC's headquarters in Palo Alto.
- Participants will have a chance to create innovative projects while competing for substantial cash rewards throughout the weekend.
DSPy Discord
- Live Demos of dslmodel Scheduled: Interactive coding sessions for dslmodel live demos occur at 4:30 PST, inviting participation in the coding lounge.
- These demos aim to showcase real-time applications and user engagement with the dslmodel functionalities.
- Sentiment Analysis Results Impress: The SentimentModel accurately classified the phrase ‘This is a wonderful experience!’ with sentiment='positive' and a confidence level of 1.0.
- This highlights its effectiveness in sentiment classification tasks, providing users reliable outcomes.
- Summarization Model Effectively Captures Themes: Using the SummarizationModel, the document's key message was distilled to: 'Motivational speech on success and perseverance.'
- The model effectively pinpointed themes of control, success, and resilience, illustrating its capability in summarization tasks.
- DSPy Decodes Its Acronym: Members clarified that DSPy stands for Declarative Self-improving Language Programs, also cheekily dubbed Declarative Self-Improving Python.
- The conversation showcased community engagement and humor while navigating the interpretations of the DSPy acronym.
- DSPy Signatures Explained: A user shared details on DSPy signatures, emphasizing their role as declarative specifications for module input/output behaviors.
- These signatures provide a structured way to define and manage module interactions, diverging from standard function signatures.
OpenInterpreter Discord
- Event Participation Limit Rolls Back to 25: Members noted that participation for the event was capped at 25 people, despite a proposed change to 99 by MikeBirdTech.
- One user confirmed repeated attempts to join but still encountered a full status.
- Join the Human Devices Event: MikeBirdTech shared the link for the upcoming Human Devices event: Join Here.
- Participants are encouraged to request or share anything related to the event in the designated channel.
- Obelisk: A Handy GitHub Tool: A member highlighted the Obelisk project from GitHub, a tool for saving web pages as a single HTML file.
- They suggested it could be quite useful in many contexts, providing a link to explore: GitHub - go-shiori/obelisk.
- Meta Movie Gen Launches: Today, Meta premiered Movie Gen, a suite of advanced media foundation models designed to enhance video and audio creation.
- The models generate high-quality images, videos, and synchronized audio with impressive alignment and quality.
- Mozilla's Open Source Vision: In a discussion about Meta Movie Gen's openness, a member clarified that while Mozilla promotes open source, this initiative is more about showcasing their vision.
- The distinction between Mozilla's principles and the nature of Movie Gen highlights its alignment with broader goals.
LangChain AI Discord
- FAANG Companies Demand SDLC Certification: A user inquired about recognized courses for Software Development Lifecycle (SDLC) certifications acknowledged by FAANG companies, aside from PMP.
- This poses a significant concern for applicants transitioning from various industries into tech roles.
- LangChain API Calls Changing: A member noticed changes in the API chain for LangChain and seeks the latest methods for API calls.
- This highlights the continuous updates and developments within the LangChain framework.
- LangChain Takes on GPT Real-time API: A user asked when LangChain would support the recently announced GPT real-time API, referencing upcoming integration.
- Further clarification was provided via a YouTube video addressing these inquiries.
- Evaluating RAG Pipeline Retrievers: Advice was sought on evaluating and comparing performance among three different retrievers in a RAG pipeline.
- One member suggested using query_similarity_score to identify the top-performing retriever and offered to share code snippets through LinkedIn.
- User Interest in LangChain Chatbots: A user requested guidance on creating their own chatbot using LangChain.
- This indicates a rising interest in utilizing LangChain for chatbot development.
Interconnects (Nathan Lambert) Discord
- NeurIPS 2024 adjusts dates for Taylor Swift fans: The start date for the NeurIPS 2024 conference has been moved to Tuesday, December 10, humorously noted due to Taylor Swift's Eras Tour influence.
- This change allows delegates to arrive a day earlier, aligning better with travel plans, as highlighted in a tweet.
- Elon Musk hosts a security-heavy xAI recruiting bash: Elon Musk's xAI recruiting event featured live music generated via code amid ID checks and metal detectors, generating excitement in AI recruitment.
- This event coincided with OpenAI's Dev Day, stirring discussion as Musk aims to attract top talent amid funding rumors.
- OpenAI CEO speaks at a packed Dev Day: Sam Altman, CEO of OpenAI, addressed a full house of developers during their annual Dev Day, promoting recent advancements and upcoming projects.
- Rumors about OpenAI closing in on a record-breaking funding round circulated during the event.
- Meta Movie Gen Launches Advanced Features: Meta premiered Movie Gen, a suite of media foundation models capable of generating high-quality images, videos, and audio from text prompts, boasting impressive capabilities like personalized video creation.
- They reported working closely with creative professionals to enhance the tool's features before a broader release.
- Reinforcement Learning Enhances LLMs for Code: A new paper proposes an end-to-end reinforcement learning method for LLMs in competitive coding tasks, achieving state-of-the-art results while improving efficiency.
- This method shows how execution feedback can drastically reduce sample requirements while enhancing catalyst performance.
tinygrad (George Hotz) Discord
- Tensors: Permuting vs Reshaping Dilemma: A member inquired whether to use
.permuteor.reshapeto transform a target tensor from sizes (1024,1,14,1) to (14,1024,1), highlighting the complexities of tensor operations in deep learning.- Dumb q. reflects some frustration, indicating a need for clarity on tensor manipulation best practices.
- Efficient Stable Diffusion Training: An inquiry was raised regarding the feasibility of training a Stable Diffusion model on an M3 MacBook Air within 48 hours, signaling interest in efficient model training methods.
- This suggests a demand for streamlined resources that make high-performance training more accessible to users.
- Need for Enhanced bfloat16 Tests: George emphasized the importance of increasing bfloat16 tests in tinygrad, pointing out the current limitations in
test_dtype.py.- A member questioned what additional tests would actually enhance the robustness of the testing framework.
- Check Out These Triton Talks: A member shared a YouTube link to a Triton talk that covers various developments within Triton technology, providing insights for developers.
- You can watch it here to gain a deeper understanding of Triton's capabilities.
- Analyzing Tinygrad CI Warnings and Failures: A call went out for insights into recent CI warnings during Tinygrad's test runs, aiming to improve the framework's reliability.
- Reviewing the node cleanup and test speeds boosts understanding of recent changes and stability efforts.
Torchtune Discord
- Torchtune's KTO Training Query: A user asked if Torchtune supports KTO training, indicating interest in its capabilities for efficiency.
- No further details or responses were shared in this thread.
- VinePPO transforms RL for LLM Reasoning: A member showcased VinePPO, a modification to PPO, achieving up to 9x fewer steps and 3x less time for RL-based methods.
- These results suggest a potential shift in RL post-training approaches, with significant memory savings as well.
- Flex Attention boosts runtime efficiency: Flex Attention preserves runtime performance by leveraging block sparsity in attention masks, showing equal performance for bsz=1 and bsz=2 setups.
- Testing has confirmed that processing 1000 tokens retains time and memory efficiency similar to batching.
- Streamlining Batch Size in Packed Runs: A proposal was made to eliminate the batch size option in packed runs, focusing on tokens_per_pack for a stable bs=1.
- This could enhance efficiency and simplify performance metrics considerations.
- DDP Implementation Discussion: Members speculated on the integration of Distributed Data Parallel (DDP), with each sampler set to bsz=1, optimizing single device resource usage.
- This could potentially improve performance allocation across devices.
Modular (Mojo 🔥) Discord
- AI boosts network speeds while software lags: Recent discussions noted that AI advancements have made 100 Gbps technology more affordable, with labs achieving 1.6 Tbps.
- Darkmatter highlighted that software hasn't kept up with the 80x bandwidth increase, resulting in challenges even at 10 Gbps.
- Urgency to enhance network capabilities: Luanon404 expressed a strong desire for improvements in networking, declaring, 'it's time to speed up the network.'
- This underscores a growing concern regarding optimal throughput and latency in current networking frameworks.
OpenAccess AI Collective (axolotl) Discord
- Exploring Alternatives to pip for axolotl: A member found dependency management in axolotl frustrating and suggested using non-pip packagers like uv for installing and updating.
- They showed eagerness to contribute to ongoing efforts aimed at enhancing the axolotl experience.
- Community Engagement in axolotl Development: The same member expressed their willingness to improve the axolotl library by investigating diverse packaging options.
- Their goal is to prompt other developers to get involved and address shared frustrations with dependency management.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!