[AINews] CogVideoX: Zhipu's Open Source Sora
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Open Source Videogen is all you need.
AI News for 8/26/2024-8/27/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (215 channels, and 3433 messages) for you. Estimated reading time saved (at 200wpm): 369 minutes. You can now tag @smol_ai for AINews discussions!
Since Sora was announced in Feb (our coverage here) there have been a host of attempts at alternatives, including Kling (not open) and Open-Sora (only ~1b ish). Zhipu AI, effectively Alibaba's AI arm and China's 3rd largest "AI Tiger" lab, released its new open 5B video model, CogVIdeoX. Here we run into a classic limitation of email newsletters, because we can't embed video:
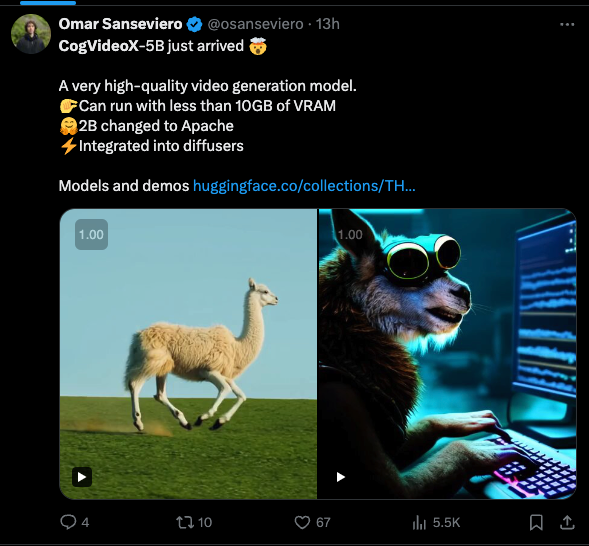
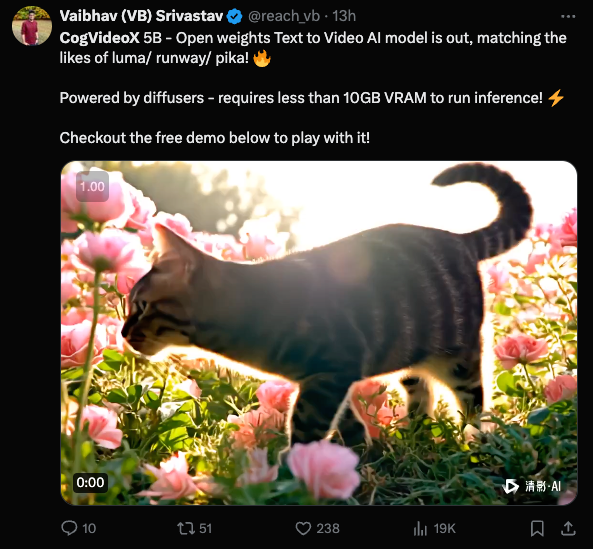
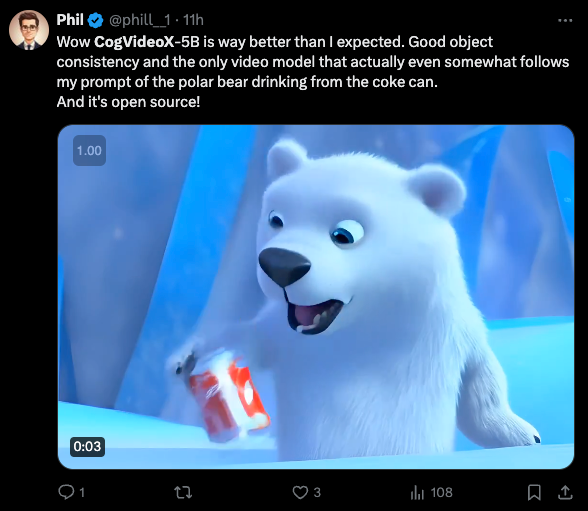
And you don't even need GPUs to run it - you can use Zhipu's live ChatGLM webapp or desktop app (may need a Sinophone friend to help you register your phone number account) - we were able to get it running on first try.

The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Releases
- Llama 3 and Other Model Updates: @AIatMeta announced new trust & safety research and CyberSecEval 3, related to the release of Llama 3.1. @_philschmid reported that Llama 3 405B is now available serverless on Google Cloud Vertex AI & Hugging Face x NVIDIA NIM API.
- Moondream Updates: @vikhyatk released an update to moondream, an open vision language model, with improved performance on DocVQA and TextVQA tasks.
- Phi-3.5 Model: @rohanpaul_ai discussed the Phi-3.5 MoE chat model, a lightweight LLM with 16x3.8B parameters using 6.6B active parameters with 2 experts.
- Together Rerank API: @togethercompute introduced the Together Rerank API, featuring Salesforce's LlamaRank model for improved document and code ranking.
AI Research and Techniques
- Superposition Prompting: @rohanpaul_ai shared insights on superposition prompting, a novel RAG methodology that accelerates and enhances performance without fine-tuning.
- Long-form Content Generation: @rohanpaul_ai discussed the LongWriter paper, which introduced the AgentWrite pipeline for generating coherent outputs exceeding 20,000 words.
- RAG vs. Long Context: @algo_diver summarized a research paper comparing Retrieval Augmented Generation (RAG) to Long Context (LC) approaches, finding that LC consistently outperforms RAG but at higher costs.
AI Tools and Applications
- Not Diamond: @rohanpaul_ai explained Not Diamond, an AI model router that automatically determines the best-suited LLM for a given query.
- AI in Command Line: @JayAlammar highlighted the potential of AI in command line interfaces, enabling operations spanning multiple files.
- Background Removal with WebGPU: @osanseviero shared a fully on-device, open-source background removal tool using WebGPU.
AI Industry and Business
- AI Hiring: @DavidSHolz announced that Midjourney is hiring for their core data team, emphasizing opportunities to learn and make a difference in creative capacity.
- Hyperscaler Capex: @rohanpaul_ai reported on increased hyperscaler capital expenditure for data center spending, with about 50% going to land, leases, and construction.
AI Ethics and Regulation
- California AI Bill SB 1047: @labenz discussed the latest version of California's AI bill SB 1047, which now focuses on requiring frontier companies to develop and publish safety plans and protocols.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. High-Performance Hardware Solutions for AI Development
- Tinybox is finally entering production (Score: 83, Comments: 28): Tinybox, a high-performance GPU cluster solution for AI development, is entering production. The system offers 8x A100 80GB GPUs with NVLink and 400Gbps networking, providing a powerful platform for machine learning tasks at a competitive price point compared to cloud alternatives.
- Tinybox specs are available on tinygrad.org, with a 15k tinybox red6 x 7900 XTX version mentioned. Users discussed potential throughput comparisons between this system and a single A100 running a batched backend.
- Building a similar 6x 4090 setup for $15k instead of the $25k Tinybox price was debated. George Hotz (imgeohot) explained the challenges, including PCIe 4.0 signal integrity, multiple power supplies, and cooling, citing a blog post detailing these issues.
- Some users found the Tinybox build underwhelming, suggesting it could be built for less. Others defended the pricing, noting it funds tinygrad development and offers a ready-built solution for businesses. The system fits in a standard rack (12U), with rails available in the documentation.
Theme 2. Open-source RAG WebUI and Local LLM Deployment Advancements
- Open-source clean & hackable RAG webUI with multi-users support and sane-default RAG pipeline. (Score: 130, Comments: 43): Kotaemon, an open-source RAG WebUI, offers a clean interface with multi-user support and a customizable pipeline for both normal and advanced users. Key features include a minimalistic UI with dark/light mode, multi-user management, a default RAG configuration with hybrid retriever and re-ranking, advanced citations support with in-browser PDF viewing, multi-modal QA support, and complex reasoning methods like question decomposition and agent-based reasoning. The project aims to be extensible, allowing users to integrate custom RAG pipelines and switch between different document and vector store providers.
- The project's GitHub repository is available with setup instructions. Users suggested adding a volume to the default container for persisting configurations, as Gradio apps require frequent point-and-click setups.
- The UI's clean design was praised, with the developer sharing that the theme is available on Hugging Face Hub for use in other projects. The theme can be found here.
- Offline functionality is supported, with users able to use Ollama OpenAI compatible server or LlamaCPP local models directly. The README provides guidelines for this setup, and the app was designed to work offline from the beginning.
Theme 3. Innovations in Distributed AI Training and Infrastructure
- Nous Research publishes a report on DisTrO (Distributed Training Over-the-Internet) (Score: 96, Comments: 7): Nous Research has published a report on DisTrO (Distributed Training Over-the-Internet), a novel approach for training large language models using consumer-grade hardware. The method allows for distributed training across multiple consumer GPUs connected via the internet, potentially enabling more researchers and hobbyists to participate in AI model development. DisTrO aims to address challenges in training large models by leveraging distributed computing techniques and optimizing data transfer between nodes.
- DisTrO is seen as a potentially significant breakthrough, with some users speculating it could be the "holy grail" of distributed optimizers. It may reduce training costs for both local/community models and large firms like Meta.
- Users express skepticism, noting that in machine learning, extraordinary results often come with a catch. Some question the impact on perplexity and overall model performance beyond reduced training time.
- The paper suggests a possible new scaling law where model size increases without increasing communication bandwidth. This could lead to a shift towards designing GPUs with larger VRAM and narrower interconnects, favoring compute-heavy workloads over I/O-heavy operations.
Misc AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Developments and Releases
- FLUX model shows surprising capabilities: A post on r/StableDiffusion discusses unexpected findings about the FLUX model's abilities, with the author noting "every single day, I discover something new with flux that absolutely blows my mind". They suggest we're still far from fully understanding its capabilities.
- Salesforce releases xLAM-1b model: A 1 billion parameter model called xLAM-1b was released by Salesforce, achieving 70% accuracy in function calling and surpassing GPT-3.5 despite its relatively small size.
- Updated Phi-3 Mini model: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
- Joy Caption update: An updated version of Joy Caption was released with batching support for ultrafast NSFW natural language captioning.
AI Research and Techniques
- DisTrO distributed optimizers: Nous Research announced DisTrO, a family of distributed optimizers that reduces inter-GPU communication by 1000x to 10,000x without relying on amortized analysis. This could significantly accelerate AI training.
- AI-powered coding demonstration: A video demonstration of AI-powered coding with Cursor showcased capabilities that would have been unimaginable 5 years ago.
AI Safety and Ethics Concerns
- Exodus of AGI safety researchers from OpenAI: Nearly half of OpenAI's AGI safety staffers have left, according to a former researcher. This has sparked debate about the importance and role of AI safety research.
- Debate on AI safety research: There is significant discussion about whether AI safety research is crucial for progress or potentially holding back innovation. Some argue it's essential for alignment and interpretability, while others see it as unnecessary at this stage.
AI Applications
- TTRPG Maps LoRA: A new version of a TTRPG Maps LoRA was released, demonstrating AI's potential in generating game assets and maps.
- AI-generated "verification" image: An AI-generated animated "verification" image was created using Flux Dev with a "MaryLee" likeness LoRA and Runway ML for animation.
AI Discord Recap
A summary of Summaries of Summaries by Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- DeepSeek V2 Outperforms GPT-4: DeepSeek-V2, with its impressive 236B parameters, has surpassed GPT-4 in benchmarks like AlignBench and MT-Bench, showcasing significant improvements in model performance.
- The DeepSeek-V2 announcement sparked discussions about its capabilities, particularly in areas where it outperforms existing large language models.
- Llama 3.1 Sets New Speed Records: Cerebras Systems announced their inference service delivering a striking 450 tokens/sec for Llama3.1-70B, significantly outpacing traditional GPU setups.
- The service offers an economically appealing rate of just 60 cents per million tokens, attracting developers seeking cost-effective, high-performance solutions for AI applications.
- Google Rolls Out Gemini 1.5 Models: Google introduced three experimental models: Gemini 1.5 Flash-8B, a stronger Gemini 1.5 Pro, and an improved Gemini 1.5 Flash, available for testing on Google AI Studio.
- These new models promise enhancements for coding and complex prompts, with rate limits set at 2 requests per minute and 50 requests per day, sparking interest in their potential capabilities.
2. Open-Source AI Developments
- Intel's Ternary Multimodal LLM Debut: Intel launched LLaVaOLMoBitnet1B, the first Ternary Multimodal LLM capable of processing images and text to produce coherent responses.
- The model is fully open-sourced with training scripts available, encouraging exploration of challenges and opportunities in ternary modeling within the AI community.
- Microsoft's Phi 3.5 Excels in OCR: Microsoft's Phi 3.5 model, released under the MIT license, demonstrates exceptional performance in OCR tasks, particularly excelling in handwriting recognition and tabular data extraction.
- The model's impressive capabilities in text recognition across various vision tasks have generated significant interest within the AI community, highlighting its potential for practical applications.
- LocalAI: Open-Source Alternative to OpenAI: LocalAI, an open-source project by Ettore Di Giacinto, offers a free alternative to OpenAI with a REST API for local inferencing of LLMs, image, and audio generation.
- The platform enables running advanced AI models on consumer-grade hardware without requiring a GPU, democratizing access to powerful AI capabilities.
3. Distributed Training Innovations
- Nous Research's DisTrO Breakthrough: Nous Research released a preliminary report on DisTrO, a distributed training framework that drastically reduces inter-GPU communication by up to 10,000x.
- DisTrO aims to enable resilient training of large language models without reliance on centralized computing resources, potentially democratizing AI research and development.
- Debate Over Nous Research's Optimizer Claims: The AI community expressed skepticism about Nous Research's new optimizer, particularly its claims regarding distributed training capabilities.
- Discussions referenced existing tools like Petals for Bloom and OpenDILo, highlighting the need for more substantial evidence to support Nous's promises in the field of distributed AI training.
4. Multimodal AI Progress
- Cog-5B Video Model Release: The Cog-5B video model was released at CogVideoX-5b, touted as the best open weights for video generation, featuring integration with the Diffusers library.
- This model promises efficient inference with less than 10GB VRAM, showcasing advancements in multimodal AI that combine text, image, and video generation capabilities.
- StoryDiffusion: An Open-Source Sora Alternative: The launch of StoryDiffusion, an open-source alternative to Sora with an MIT license, has generated excitement in the AI community, though the weights have not yet been released.
- This development highlights the growing interest in accessible, high-quality video generation models that can compete with proprietary solutions.
PART 1: High level Discord summaries
Nous Research AI Discord
- DisTrO Algorithm continues to evolve: The DisTrO algorithm is being actively refined with different variants tested to optimize communication bandwidth while ensuring convergence performance.
- Members noted that techniques like SWARM could potentially be better suited for larger models.
- Community is eager for collaborations: Members expressed interest in collaborating on the DisTrO algorithm's implementation, emphasizing open contributions and discussions.
- The team plans to share full code and details in the upcoming weeks.
- Philosophical debates around AI consciousness: The implications of qualia and consciousness in AI are driving serious discussions, calling for more interdisciplinary collaboration.
- Members pointed to a need for deeper cooperation between computer scientists and philosophers.
- DisTrO explores weak device applications: The feasibility of using DisTrO with weak devices such as older phones was discussed, highlighting the need for efficient training methods.
- While DisTrO excels with stronger hardware, exploring its utility in less-capable systems is seen as valuable.
- Tinybox is officially up for grabs: After 18 months, the Tinybox now has a 'buy it now' option thanks to an announcement highlighting 13 units available for purchase.
- The $15k tinybox red is being praised for its performance-to-price ratio in the ML space.
Unsloth AI (Daniel Han) Discord
- Tensor Conversion Struggles: A user faced a
ValueErrorregardingembed_tokens.weightwhile converting a model to GGUF, indicating mismatches between sentence-transformer and causalLM models.- Frustrations arose over the lack of support for pair scoring in current conversion tools.
- Batch Size Optimization Strategies: Discussions revealed a tactic of increasing batch size until reaching out-of-memory errors, prompting users to tweak their training settings.
- One user plans to convert their model to Ollama format after finishing the latest training task.
- Updates on Homoiconic AI Project: The 'Homoiconic AI' project reported improvements in validation loss metrics using hypernets for weight generation and aims for a multimodal integration approach.
- Members discussed how in-context learning helps improve the model's weights, referencing a progress report.
- LigerKernel's Copying Controversy: Concerns arose over LinkedIn's LigerKernel allegedly copying core components from Unsloth, raising questions about claims of major improvements.
- Community members highlighted the lack of original variable naming in the copied code.
- Data Preparation in LLM Finetuning: Discussions highlighted that many wish to finetune LLMs without clear objectives or datasets, raising concerns about understanding the process.
- Members voiced that a solid foundational knowledge is essential before diving into model finetuning.
OpenAI Discord
- Exploring AI's Emotional Depth: The discourse around AI personhood highlights that while AI can simulate emotions, it does not genuinely experience them, prompting ethical concerns when users form attachments.
- Participants are questioning whether treating AI as friends undermines our understanding of emotionality.
- Push for Decentralized AI: Discussions on the decentralization of AI emphasize a shift towards user-owned data, reducing corporate control over AI identities and training data.
- There’s optimism for increased prevalence of open-source models, aiming to disrupt current centralized systems.
- AI Provides Companionship—Sort Of: The discourse reflects skepticism about AI replacing real friendships despite its potential in aiding those feeling isolated.
- Participants shared personal anecdotes about the relief AI could offer, especially in marginalized communities.
- Concerns About GPT-4o's Reasoning: GPT-4o users aired frustrations about its reasoning capabilities, citing factual inaccuracies and inconsistencies compared to earlier models.
- Some users believe GPT-4o has regressed and are discussing what updates could restore its performance.
- Struggles with YouTube Summarization Tools: There are challenges in the efficacy of YouTube summarization tools, mainly due to the platform blocking bot access to transcripts.
- While manual transcript retrieval was suggested, members noted this approach risks violating YouTube's terms of service.
HuggingFace Discord
- Model Deployment Challenges in Hugging Face: Users reported issues deploying the Gemma-7B model due to missing files and runtime errors, considering repository cloning as a workaround.
- The conversation included suggestions about verifying model paths and employing the
.from_pretrainedmethod to resolve configuration issues.
- The conversation included suggestions about verifying model paths and employing the
- PyTorch Lightning's LitServe boosts speeds: LitServe from PyTorch Lightning claims 2x faster model serving than FastAPI, promising enhanced deployment efficiency.
- Users are keen to adopt this update as it accelerates inference times significantly.
- StockLlama Launched for Time Series Forecasting: StockLlama leverages Llama for time series forecasting using custom embeddings, aimed at improving accuracy.
- This introduction sparks interest for developers looking to enhance their forecasting capabilities.
- Gaining Insights on ProteinBERT Structure: Discussions on ProteinBERT clarified its architecture focused on local and global representations for processing protein sequences, with links to the ProteinBERT paper shared for context.
- Users expressed interest in understanding how these representations contribute to effective classification and regression tasks.
- Cog-5B Video Model Released: The Cog-5B video model is now available at CogVideoX-5b, showcasing advanced capabilities in video generation.
- Expectations rise for the forthcoming fine-tuning scripts that will enhance user customization options.
LM Studio Discord
- LM Studio Model Loading Woes: Users reported issues with model loading related to insufficient system resources, encountering an exit error code -1073740791 while attempting to load various models.
- Suggestions to adjust settings to CPU-only and modify guardrails settings emerged as potential fixes.
- AMD vs Nvidia: The GPU Showdown: Discussions pivoted around the performance gap between Nvidia and AMD for LLM tasks, with Nvidia currently leading the charge.
- An Nvidia 3060 12GB was suggested as a balanced option for budget-conscious users aiming for effective model performance.
- CPU Bottlenecks with Ollama: When running LLMs using Ollama, reports surfaced about only one CPU heating up, spotlighting a potential single-CPU performance bottleneck.
- Users highlighted the requirement for dual CPU support to improve inference speeds, though the topic might be contentious.
- Tinygrad: Simplifying Neural Networks: The new Tinygrad framework garnered interest for its simplicity in handling complex networks, featuring operations like ElementwiseOps.
- Despite its limitations, it attracted attention for its potential to streamline workflow in LLM projects.
- Cerebras Takes Inference to New Heights: Cerebras announced their inference service delivering a striking 450 tokens/sec for Llama3.1-70B, outpacing traditional GPU setups.
- The service presents an economically appealing rate of just 60 cents per million tokens, appealing to developers seeking cost-effective solutions.
aider (Paul Gauthier) Discord
- Aider v0.53.0 Introduces Major Enhancements: The latest release of Aider v0.53.0 features improved prompt caching, allowing it to cache prompts effectively during sessions, enhancing coding speed and cost efficiency.
- This version showcases Aider's capability to write 59% of its own code, emphasizing a significant leap in its operational self-sufficiency.
- User Insights on Aider's Functionality: Discussions revealed Aider's challenges in converting large code bases with a single prompt, necessitating refinements for effective results.
- While valuable, users acknowledge that Aider's outputs must be rigorously tested and polished for substantial projects.
- Gemini Model Performance Unveiled: New Gemini 1.5 models have been rolled out, including Gemini 1.5 Pro, which is designed for better performance with complex prompts and coding tasks, available for testing at AI Studio.
- Rate limits for these models are set at 2 requests per minute and 50 requests per day, prompting users to seek creative workarounds for performance benchmarks.
- Anthropic Releases System Prompts for Claude 3: Anthropic has published the system prompts for their Claude 3 models, including Claude 3.5 Sonnet, as of July 12, 2024, promising to keep documentation updated with future changes.
- The prompts are viewed as a notable transparency improvement in LLM documentation, with insights gathered from researcher Amanda Askell on their usage.
- Error Handling Improvements in Aider: Aider v0.53.0 has improved error handling, providing clearer messages when variables are not set, enhancing user troubleshooting experiences.
- Recent bug fixes also address issues with Windows filenames, ensuring smoother operational functionality across different systems.
Stability.ai (Stable Diffusion) Discord
- Anticipation for next-gen AI hardware: Members eagerly discussed upcoming releases of Intel CPUs and NVIDIA GPUs featuring enhanced AI capabilities, sparking interest in new PC builds.
- These innovations are set to significantly improve performance for AI tasks, positioning users for a tech upgrade.
- Impressive capabilities of Flux models: Excitement erupted over the advanced features of Flux, including dynamic angles and depth perspective, which may render older models obsolete.
- Concerns rose about trainability as members speculated on its potential for revolutionizing AI-generated visuals.
- Concerns over ZLUDA development: Participants raised alarms about the future of ZLUDA after emerging reports suggested that AMD had ceased funding its development.
- Members speculated that ongoing legal challenges could further complicate ZLUDA's progress despite GitHub updates.
- Integration of SD Next with ZLUDA: A discussion emerged about why SD.Next performs better with ZLUDA, with thoughts on its backend architecture integrating A1111 and Diffusers.
- This multi-backend framework could enhance compatibility and overall performance across different models.
- Challenges with Streamdiffusion and SDXL Turbo: Members expressed frustration over the difficulties in integrating SDXL Turbo with Streamdiffusion, particularly regarding TensorRT performance.
- Concerns arose about frame rates and resolution compatibility, casting doubt on its practical usability.
Eleuther Discord
- Inquiring About Video Benchmark Examples: A member asked for quality examples of video benchmarks, focusing on tasks like spatial awareness and generative models, leading to suggestions on standard evaluation methods.
- Though action recognition was proposed for discriminative tasks, there’s a notable absence of established benchmarks for generative tasks.
- Discussion on RLHF Libraries: The chat debated whether TRL/TRLX continues to be the top choice for Reinforcement Learning from Human Feedback, with many recommending TRL due to concerns over the outdated TRLX.
- Members expressed a desire for alternatives, but none have emerged in recent discussions.
- Free API Access for Llama 3.1: A member shared a link to a free API for Llama 3.1 405B from SambaNova, highlighting its potential for broader accessibility.
- Details about SambaNova's services were outlined, which could enhance AI projects using their platform.
- Gemini Misrepresentation Claims: The community engaged in a debate over claims by Jamba authors about Gemini, which allegedly caps at 128k without further testing, sparking controversy.
- Defenders argued that the authors' wording does not misrepresent, remarking they couldn’t reproduce results beyond 128k.
- Learning Rate Scaling Insights: Insights were shared on the necessity of sqrt scaling with Adam for learning rate adjustments in relation to batch sizes, with various papers cited.
- The group explored methodological differences in experiments, raising questions regarding validity in their proposed approaches.
CUDA MODE Discord
- Liger Kernel Welcomes New Contributors: New members joined the Liger Kernel community, eager to contribute, with a focus on Triton and its capabilities, including a startup from D.C. interested in training efficiencies.
- Contributing guidelines were shared to promote active collaboration, signaling a growing interest in the project.
- Triton Implementation Comparisons: Developers find Triton implementation tougher than PyTorch but easier than pure CUDA, which presents a unique trade-off.
- Leveraging tools like torch.compile can enhance performance, making the transition worthwhile.
- Encoder-Style Transformers Support Initiatives: The community is exploring support for encoder-only transformers like BERT, creating an issue for tracking feature development.
- There is potential for reusing layers, indicating a collaborative effort to enhance existing models within the Liger Kernel framework.
- Call for Fused Kernel Development: Discussion centered around establishing a 'fused kernel zoo' to streamline the addition of efficient kernels beyond current frameworks.
- Members believe a synergy between PyTorch and Triton can yield optimal results, inviting contributions to kernel requests.
- Insights on Low-Bit Optimization Techniques: Users focus on datasets for fine-tuning a 4-bit optimization model, noting challenges in performance with the Alpaca dataset.
- The Chatbot Arena dataset was recommended as a potential solution, highlighting its comprehensive nature but acknowledging its complexities.
Perplexity AI Discord
- Perplexity app experiences slow performance: Many users reported that the Perplexity app has been experiencing slow response times since this morning, causing frustration among users.
- Complaints included unreliable search results and general dissatisfaction with the platform's recent performance.
- File upload failures across the board: Multiple users attempted image uploads and encountered file upload failed errors, with some expressing disappointment over issues even while on Pro subscriptions.
- While PDFs have been reported to work, users are waiting for a fix as image uploads remain broken.
- Clarifying usage limits for GPT models: The daily message limit for the Claude 3.5 model is reported to be 430 messages, combined across all Pro models, except for Opus, which has a limit of 50.
- Users noted that even with high usage, they rarely hit the limit, with one mentioning their closest was around 250 messages.
- Boeing's Plan to Replace 737: Boeing's plan to replace 737 is highlighted as a strategic move to enhance its fleet's efficiency and sustainability amidst growing demand.
- They aim to address market needs with a new aircraft that improves on existing models' performance and environmental impact.
- Challenges with Perplexity AI implementation in chatbot: A user is trying to implement Perplexity AI into a fact-checking chatbot in Hebrew but is facing issues with shortened responses that lack links and images.
- They noted that responses from the API differ significantly from those on the Perplexity search site, mentioning that links often lead to 404 errors.
OpenRouter (Alex Atallah) Discord
- API Degradation Incident Briefly Affects Services: There was a ~5m period of API degradation that impacted service availability. A patch has been rolled out, and the incident appears to be fully recovered.
- The response team quickly identified the issue during the API degradation period, ensuring minimal disruption. This proactive approach highlights the importance of rapid response in maintaining service integrity.
- Team Efforts Recognized!: A member expressed gratitude towards the team for their contributions, stating, Thank you team! This acknowledgment highlights the collaborative spirit and the hard work put in by individuals involved.
- Furthermore, a tweet was shared that showcases significant developments in AI collaboration. The tweet emphasizes the importance of community efforts in advancing AI technologies.
- OpenRouter Model Pricing and Fees Clarified: A user inquired about whether the price per token displayed in OpenRouter includes the service fee. It was clarified that the price listed is based on OpenRouter credits and does not account for any additional fees incurred when adding credits.
- Concerns were also raised regarding the current display of $0 on the activity page, which could mislead users. Enhanced visibility of model pricing is essential to improve user experience.
- DisTrO Brings New Hope to Distributed Training: A member highlighted the release of a preliminary report on DisTrO (Distributed Training Over-the-Internet) by Nous Research, which improves distributed training efficiency. It promises to drastically reduce inter-GPU communication, enabling more resilient training of large models.
- Community discussions focused on its implications for the future of distributed training strategies. Members expressed eagerness to explore this innovative approach further.
- Exciting Updates for Gemini Models Discussed: The upcoming release of new Gemini 1.5 Flash and Pro models was discussed, sparking excitement about its potential features and performance. Users speculated that these updates might aim to compete with existing models like GPT-4.
- Tweets from official sources outlined the planned release details, generating buzz about the capabilities and enhancements expected in the new models. Community members are closely watching the developments.
tinygrad (George Hotz) Discord
- Tinybox Shipping Challenges in Europe: Discussion arose about the current unavailability of the Tinybox in Europe, especially impacting buyers in the UK. Members recommended contacting support for shipping quotes, while reports of sold out status in France and Italy circulated.
- The community speculated on future shipping solutions, with focus on potential new color editions, though George denied a blue version will be released soon.
- Exploring Tinygrad for BERT Training: A member showed interest in leveraging Tinygrad for pre-training a large BERT model, discussing the necessary support for high-performance setups. There was a debate over using Tinygrad versus Torch, with participants noting Torch's better optimization.
- The conversation highlighted existing hardware needs, mentioning setups with 64 Hopper cards for effective model training.
- Tinybox Sales Update: George shared that about 40 Tinyboxes have been sold, with 60 more in stock. Excitement about increasing sales was tempered by ongoing negotiations for international shipping.
- Members engaged in discussions about the potential for new color editions, expressing curiosity despite George's dismissal of a blue edition.
- Runtime Errors When Using Tinygrad: A user faced
RecursionErrorwhile converting tensors in Tinygrad when processing more than 3500 Wikipedia articles. This problem seemed to resolve for smaller datasets, raising concerns about the function's handling of large inputs.- The community suggested creating a minimal example for debugging; there is interest in collaborative troubleshooting to address these runtime issues.
- Identifying Tinygrad version 0.9.2: A user confirmed they are running Tinygrad version 0.9.2, which may relate to the
RecursionErrorissues encountered during tensor conversion. This version's LazyOp functionality was mentioned as a potential factor in the problems discussed.- Community efforts are directed towards troubleshooting, including possible need for updates or determining if the error is version-specific.
Interconnects (Nathan Lambert) Discord
- Intel launches LLaVaOLMoBitnet1B: Intel has introduced the first Ternary Multimodal LLM, LLaVaOLMoBitnet1B, that processes images and text to produce coherent responses. The model is fully open-sourced, offering training scripts to explore challenges and opportunities in ternary modeling.
- The community is curious about the implications of using this structure for future AI applications, particularly in multimodal interactions.
- OpenAI targets complex reasoning with Orion AI: OpenAI is reportedly developing a new model, Orion, aimed at enhancing complex reasoning skills as it seeks additional investments, as reported by The Information. This initiative aims to strengthen its position in the competitive chatbot space.
- Members are closely watching this development for potential advancements that could reframe AI-assisted problem-solving capabilities.
- Skepticism around Nous Research optimizer: Members expressed doubts regarding the legitimacy of Nous Research's new optimizer, primarily concerning its claims about distributed training capabilities. Discussions referenced existing tools like Petals for Bloom and OpenDILo, further fueling skepticism.
- Calls for more substantial evidence supporting Nous's promises were echoed, highlighting concerns around transparency in AI tool development.
- Cerebras speeds ahead in inference: Cerebras has claimed its inference API achieves speeds of 1,800 tokens/s for 8B models and 450 tokens/s for 70B models, significantly outperforming competitors. This announcement caused a buzz within the community eager for rapid advancements in inference technology.
- Members showed excitement about the implications this speed could have for real-time AI applications and competitiveness in the market.
- Google's Gemini 1.5 models generate interest: Google has rolled out experimental models: Gemini 1.5 Flash-8B and Gemini 1.5 Pro, enhancing coding task capabilities. Access now available through Google's AI Studio, encouraging hands-on exploration from the community.
- Members are keen to test these new models, with discussions indicating a potential shift in project approaches due to their unique features.
OpenAccess AI Collective (axolotl) Discord
- Evaluating lm eval metrics: For multiple choice questions, the metric used is accuracy on target prediction, determining if the model's highest logit aligns with the correct choice.
- Members highlighted nuances in model evaluations, discussing scenarios where answers differ slightly.
- Confusion surrounds Tokenizer v3 specs: Members expressed confusion regarding tokenizer v3, with links to previous discussions on the nemo repo shared.
- There was a consensus on needing proper configuration for supporting multi-role functionalities.
- Deepseek V2 monkey-patch insights: Members discussed using monkey-patching to override the forward method for the Deepseek V2 attention model, sharing relevant code snippets.
- An experience comparison was made about monkey-patching in Java versus Python, showcasing complexities in the implementation.
- FSDP's RAM resource requirements questioned: Concerns regarding whether FSDP (Fully Sharded Data Parallel) requires significant system RAM for effective functioning were raised.
- This led to discussions about optimal system resources necessary for operating FSDP effectively.
- AI Ratings vs Human Ratings Unpacked: A member utilized llm-as-judge for rating and questioned the accuracy of AI judgments compared to human ratings.
- Further inquiries were made about any conducted tests evaluating this accuracy, emphasizing the need for metric validation.
Modular (Mojo 🔥) Discord
- Call for User Feedback on Magic: The team seeks 5 participants for a 30-minute feedback session specifically on magic features, offering exclusive swag as a reward.
- Participants can book a slot here to contribute their insights and receive first dibs on design-phase swag.
- ClassStruct Lets You Play with Variadic Parameters: ClassStruct in Mojo enables dynamic parameterization, allowing variations without creating separate structs, illustrated by a
carexample for engine size.- This efficiency lets developers define struct fields based on compile-time parameters, enhancing flexibility.
- Performance Takes a Hit with Struct Fields: Compiling structs with numerous fields can significantly slow performance, with 100 fields reportedly taking 1.2 seconds to compile.
- This delayed performance hints at resizing issues in underlying data structures that becomes apparent over a certain field threshold.
- Type Inference in Mojo Hits a Wall: Mojo faces challenges with type inference, especially regarding generics, making it less convenient compared to Rust's robust inference system.
- Participants noted that Mojo's generics and typeclasses could limit flexibility, raising concerns about the developer experience.
- Mojo and Luma: A Type System Showdown: Discussions compared Mojo with Luma, noting that while Luma boasts stronger type inference, Mojo provides unique elements like typeclasses but with restrictions.
- The consensus suggests that Mojo is evolving and may align closer to Rust's capabilities, hinting at potential features like effect systems.
LlamaIndex Discord
- Get Ready for RAG-a-thon with Pinecone!: We're hosting our second RAG-a-thon with over $7k in cash prizes from October 11-13 at the 500GlobalVC offices in Palo Alto!
- It's a great opportunity to showcase innovative ideas and gain valuable experience in a collaborative environment.
- Llama 3.1-8b Breaks Speed Records: Need ultra-fast responses? Llama 3.1-8b offers 1800 tokens per second, making it the fastest LLM available, as discussed here.
- Achieving this speed is crucial for applications needing quick responses, especially in complex systems.
- Build Serverless RAG App with LlamaIndex: Learn to create a serverless RAG application using LlamaIndex and Azure OpenAI through this comprehensive guide by Wassim Chegham link to guide.
- It covers RAG architecture and shows how to leverage your own business data for improved AI-powered responses.
- Neo4j Can't Build Relationships: A user reported trouble replicating a property graph tutorial from LlamaIndex with Neo4j Desktop, where relationships weren't being extracted correctly.
- They clarified that they followed the tutorial strictly, suspecting their Neo4j setup might not align with default expectations.
- Enhancing Data Extraction with LlamaParse: A user discussed potential issues with LlamaParse converting tabular data due to scanning problems and sought solutions for integrating image extraction.
- Questions arose about chunking strategies for processing multiple tables combined with images.
Latent Space Discord
- DisTrO Transforms Distributed Training: Nous Research's DisTrO drastically reduces inter-GPU communication by up to 10,000x, facilitating resilient LLM training.
- This framework promotes shared AI research efforts, circumventing reliance on centralized entities to enhance security and competitiveness.
- Phi 3.5 Shines in OCR Tasks: Microsoft's Phi 3.5 excels in OCR, especially handwriting recognition and tabular data extraction, under a permissive MIT license.
- The model's impressive performance in text recognition has generated significant community interest and discussion.
- Cerebras Breaks Inference Speed Records: Cerebras announced an inference service achieving 1,800 tokens/s for 8B models, outperforming NVIDIA and Groq.
- Backed by their WSE-3 chip, Cerebras is also pushing competitive pricing for Llama models, leading to heated discussions about its economic viability.
- Google Launches Gemini 1.5 Models: Google introduced the Gemini 1.5 series, featuring a smaller variant and a powerful Pro model, boasting capabilities in coding and handling complex prompts.
- These launches have sparked comparisons to models like GPT-4o-mini, as developers assess their relative performance and edge.
- Anthropic's Artifacts Raises Eyebrows: Anthropic unveiled Artifacts, intriguing many with their development insights and methodologies.
- Concerns emerged about the reasons behind the timely release, with speculation of potential paid placements in the conversations.
OpenInterpreter Discord
- Streamlit Python Server for Chat: A member introduced an easy Streamlit Python server to create a chat interface in a web browser, fostering quick implementation.
- This sparked interest with another member expressing intention to explore this solution further.
- Configuring Telegram Bot with Open Interpreter: Issues arose when a member shared their setup for a Telegram bot using Open Interpreter, including necessary API key settings.
- They faced image display issues, leading to a valuable discussion for troubleshooting potential fixes.
- Cython for Black-Scholes Model Efficiency: An example using Cython to implement the Black-Scholes model was shared, emphasizing optimized computations for options pricing.
- This highlights how to define efficient functions in Cython, enhancing the overall performance of Jupyter notebooks.
- Daily Podcast Feat. Cloned Voices Takes Off: Mike and Ty humorously toyed with creating a daily podcast using voice cloning technology from ElevenLabs, cultivating laughter within the community.
- Their playful banter showcases innovative ideas on blending voice synthesis technology into engaging content.
- First Meetup Brand Documentation Shared: A member presented a link to accessible brand documentation for the 01 project via Canva.
- This document includes design insights with promises of more comprehensive updates expected in their GitHub repository soon.
Torchtune Discord
- Llama 3.1 Struggles on CPU: A user reported that inference for Llama 3.1 8B on CPU is extremely slow (<0.05 tok/s) even on a high-end AWS server, highlighting a substantial performance gap.
- The conversation acknowledged that CPU setups are inherently slower than GPU configurations, particularly when using Ollama.
- Optimized Frameworks to Consider: Members recommended using Ollama or vLLM for serving models, as these frameworks provide better optimization for inference compared to Torchtune.
- A helpful tutorial on using Ollama with custom checkpoints was shared to assist newcomers.
- Inquiries on LoRA Model Loading: A user asked if
from_pretrained()correctly loads LoRA fine-tuned weights from local checkpoints, revealing common user concerns about model integration.- An informative link to a discussion on loading LoRA adapters into HF was provided for clarity.
- AWS Instance Cost Discussions: The cost of AWS instances was debated, indicating that an AWS c7a.24xlarge might run around $5/hour, leading to discussions on cost-effectiveness.
- Recommendations were made to explore alternatives like Runpod, though regulatory constraints were noted as limiting factors for some users.
- Performance Challenges with CPU Servers: Users expressed a preference for CPU servers due to cost-effectiveness and satisfactory response times for their projects.
- However, it was noted that low CPU performance could drastically affect inference speeds, pushing users to rethink using optimized frameworks.
Cohere Discord
- Concerns About Request Limits: Members expressed apprehension about surpassing the 1k requests threshold, especially in testing scenarios.
- One member doubted how to reach this 1k limit, suggesting it feels unachievable.
- Intermittent Model Not Found Errors: A member reported encountering a 'model not found' error thought to be linked to the model's versioning, as the reranker is now on v3.
- This raises potential stability concerns amid ongoing updates.
- Clarification on Production Key 403: A vague mention of production key 403 led to confusion, prompting requests for context from other members.
- The lack of clarity indicates a need for improved communication about key references.
- 404 Errors with Langchain and Cohere TypeScript: An issue arose where initial calls using Langchain with Cohere TypeScript worked, but subsequent calls resulted in a 404 error.
- This suggests a potential misconfiguration or instability in the integration.
LangChain AI Discord
- Flutter Collaboration Sparks Interest: In a bid to improve Flutter app development, collaboration was proposed following fritzlandry's inquiry, addressing a gap in shared expertise.
- This response could lead to productive partnerships, enhancing Flutter's application in engineering projects.
- vllm's RAG Capabilities Under Review: A discussion emerged regarding the possibility of running Retrieval-Augmented Generation (RAG) with vllm, citing accessible models for embedding and answering tasks.
- This shows growth in multi-model approaches, urging engineers to push the boundaries of vllm applications.
- Quest for LLM Workflow Builders: A call for existing LLM workflow builders highlighted a push for automation amidst user workflows, seeking innovative solutions.
- This reflects a growing demand for tools that integrate LLM capabilities effectively.
- Local Embedding Models Preferred: Frustration towards cloud options like Pinecone spurred inquiries for local embedding model recommendations, as users long for optimized performance.
- Discussions pointed towards maximizing efficiency for models, stressing local setups over cloud reliance.
- Dashboard’s Value in Question: Concerns over the dashboard's effectiveness arose, with frustration noted regarding errors from models like Claude and GPT in handling complex tasks.
- This dialogue underscores a need for accuracy in AI outputs, pushing for improvements in the user experience.
Gorilla LLM (Berkeley Function Calling) Discord
- Models must be accessible for leaderboard: Models listed on the leaderboard must be publicly accessible, whether open-source or through an API for inference.
- The requirement necessitates that even if registration or tokens are used, the endpoint should be open to the public.
- Benchmarking limitations without public access: While models can be benchmarked with BFCL, only publicly accessible models can be displayed on the leaderboard, creating a notable distinction.
- This limitation impacts which models can be showcased and which can merely be evaluated.
- Function Calling Feature Drops Performance: Using a system prompt directly with GPT-4-1106-Preview achieves an accuracy of 85.65, while enabling function calling drops it to 79.65.
- This discrepancy raises questions about the relationship between function calling and overall model performance, prompting further investigation.
- BFCL Optimization Strategies Under Scrutiny: A user expressed concerns over their optimization strategies for a function-calling feature, questioning compliance with BFCL guidelines.
- They queried if optimizations like system prompt updates could be perceived as unfair practices which are not generalizable across all models.
- Seeking benchmarking guidance for Llama 3.1: A user is seeking advice on benchmarking Llama 3.1, specifically using a custom API endpoint hosted by their company.
- They are looking for effective pointers on how to initiate the benchmarking process smoothly.
DSPy Discord
- Community Solves DSPy Output Truncation: A member reported DSPy outputs getting truncated, suspecting token limits; they resolved this by adjusting max_tokens during initialization and using your_lm.inspect_history() to inspect prompts.
- The original poster confirmed the community's advice effectively addressed their issue, showcasing helpful member collaboration.
- Typing Support Error Stumps User: One member hit an error on import,
module is installed, but missing library stubs or py.typed, questioning if DSPy supports typing in Python, signaling a documentation gap.- No follow-up or resolution was offered, indicating lingering uncertainty about typing support within the library.
- Growing Interest in Text Scoring with DSPy: A user inquired about scoring generated texts with DSPy based on metrics like BLEU or ROUGE, reflecting a community push for evaluating text performance.
- Unfortunately, no members replied, leaving their experiences and insights on text scoring in the dark.
LLM Finetuning (Hamel + Dan) Discord
- Hamel's Check-in Needed: A member asked for Hamel's presence in the channel, indicating potential discussions on LLM finetuning were on the horizon.
- No further context provided, but members await insights directly from Hamel regarding relevant projects.
- Discussion on LLM Models: The conversation hinted at the importance of having Hamel present for potential discussions on enhancing LLM performance through finetuning techniques.
- Members are likely interested in strategies for model optimization and learning enhancements.
MLOps @Chipro Discord
- Join the LLM Observability Tools Webinar: This Saturday, August 31st, at 11:30 AM EST, a webinar will cover over 60 LLM observability tools to evaluate their monitoring effectiveness. Register for the session here.
- Participants will gain insights on observability basics, tool selection, and LLM integration strategies for better model management.
- Testing the Hype of ML Monitoring Platforms: The upcoming webinar aims to critically assess if the plethora of ML monitoring tools meet practitioners' real needs in monitoring and debugging models. Expect a hands-on evaluation to sift through marketing claims.
- The focus will be on practicality and user-friendliness, ensuring the tools deliver genuine benefits.
- Cohort on Machine Learning in Production Initiatives: A live cohort for 'Machine Learning in Production' is available to enhance practical skills in deploying ML models effectively. Interested participants can find more details here.
- The course promises to provide essential tools and knowledge for effective ML management in real-world applications.
LAION Discord
- LAION-aesthetic link issues: A member reported that the link to LAION-aesthetic on the LAION website is broken and requested an alternative link from Hugging Face.
- Any updates on a working link would be greatly appreciated, highlighting the ongoing community need for reliable resources.
- Request for functional LAION-aesthetic resource: The discussion emphasized the importance of having a functioning link to LAION-aesthetic, essential for users accessing data models.
- Members expressed frustration over the non-functional website and urged for prompt solutions to improve usability.
Mozilla AI Discord
- Get Ready for LocalAI AMA with Ettore Di Giacinto: Join the LocalAI AMA with Ettore Di Giacinto in two hours to explore its features as an open-source alternative to OpenAI, featuring a REST API for local inferencing.
- LocalAI enables LLMs, image, and audio generation locally on consumer-grade hardware without needing a GPU.
- Participation Link for LocalAI Event: The participation link for the LocalAI event is available now; join here to engage directly.
- Get your questions answered about this project and see how it integrates into your workflow.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!