[AINews] Claude 3.7 Sonnet
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Thinking is all you need.
AI News for 2/24/2025-2/25/2025. We checked 7 subreddits, 433 Twitters and 29 Discords (220 channels, and 5949 messages) for you. Estimated reading time saved (at 200wpm): 503 minutes. You can now tag @smol_ai for AINews discussions!
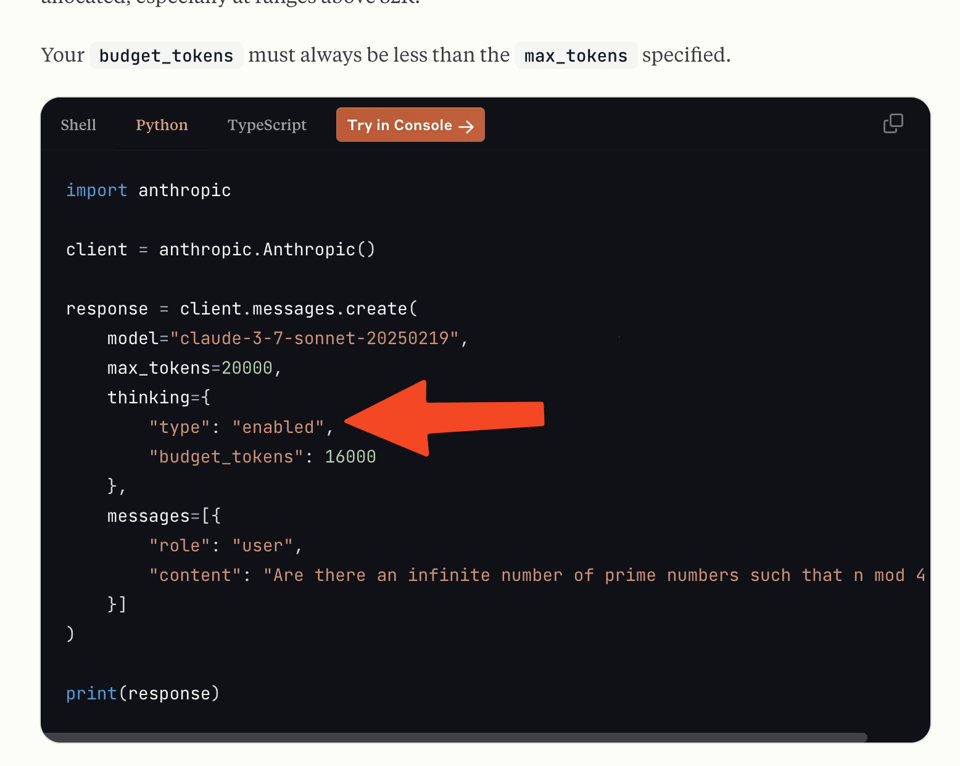
Taking a little leapfrog from the GPT5 roadmap, Claude 3.7 Sonnet launched today (don't ask about the name - note that there are TWO blogposts and documentation and cookbooks and prompting guides to read, alongside Claude Code which is in limited preview), after numerous leaks from private previews, as one model with an optional thinking mode, with an explicit token budget.
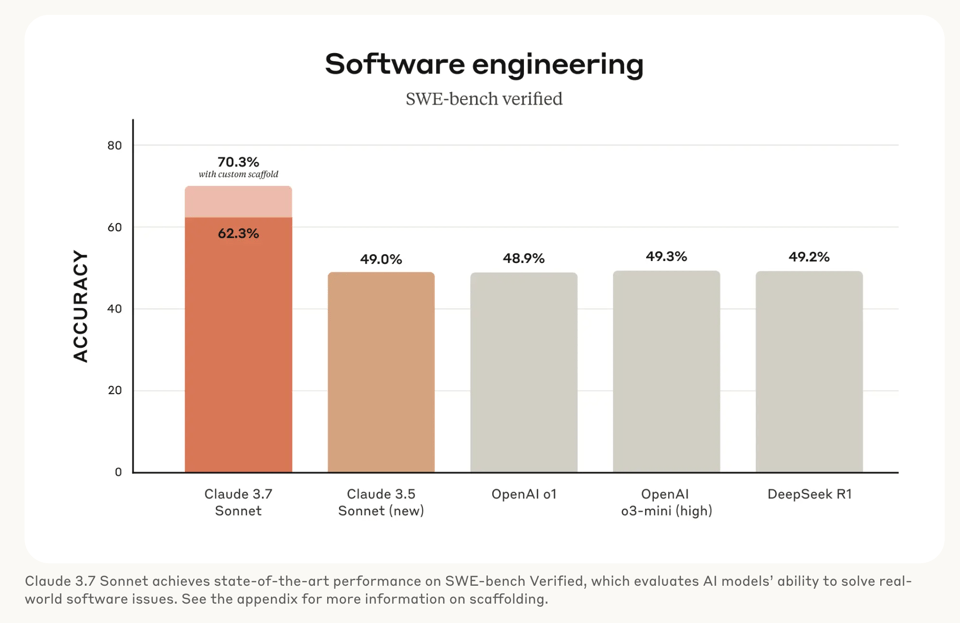
3.7 Sonnet does well on many coding benchmarks like SWE-Bench Verified and aider and Cognition's junior-dev eval, both with and without (MOSTLY uncensored!) thinking.
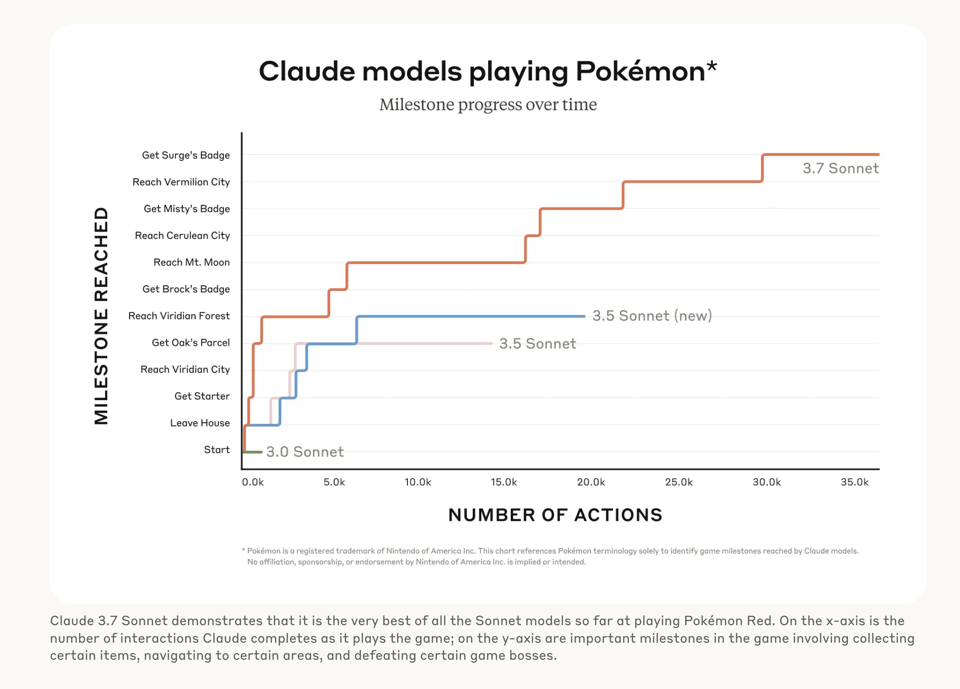
However the most popular new benchmark, covered in the second blogpost on extended thinking, is Pokebench which mirrors the Voyager paper as an agentic benchmark:
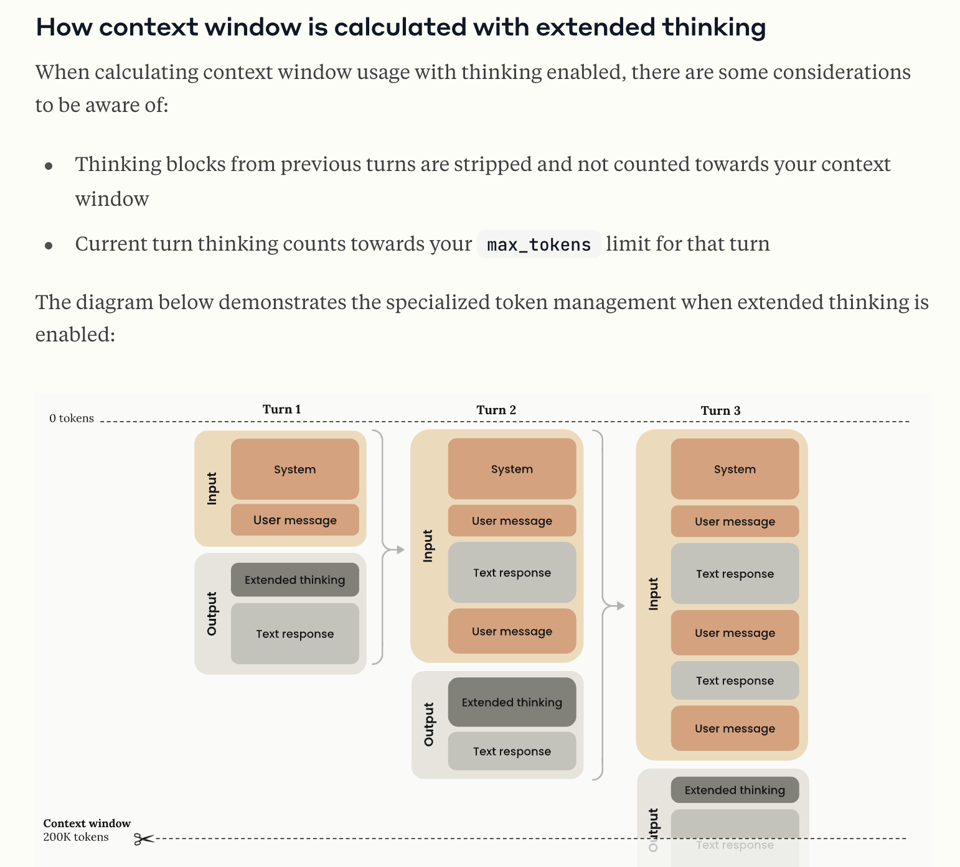
The feature set and documentation at launch is pretty impressive. Among the notable things likely to get buried by the headlines:
- the new system prompt
- redacted thinking encoding/decoding
- streaming thinking
- 128k OUTPUT token capability (in beta)
- context window and prompt caching skips previous turn thinking blocks)
- tool use
- agreeing with Grok 3 that parallel test time compute is useful and worth studying
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- aider (Paul Gauthier) Discord
- Codeium (Windsurf) Discord
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- Yannick Kilcher Discord
- Eleuther Discord
- Latent Space Discord
- Nous Research AI Discord
- MCP (Glama) Discord
- HuggingFace Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- Modular (Mojo 🔥) Discord
- LLM Agents (Berkeley MOOC) Discord
- Notebook LM Discord
- LlamaIndex Discord
- Torchtune Discord
- Cohere Discord
- Nomic.ai (GPT4All) Discord
- DSPy Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (1056 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (935 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (63 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Codeium (Windsurf) ▷ #discussion (15 messages🔥):
- Codeium (Windsurf) ▷ #windsurf (675 messages🔥🔥🔥):
- OpenAI ▷ #ai-discussions (611 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (9 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (345 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
- Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (346 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #news (304 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #random (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Interconnects (Nathan Lambert) ▷ #nlp (1 messages):
- Interconnects (Nathan Lambert) ▷ #posts (3 messages):
- GPU MODE ▷ #general (29 messages🔥):
- GPU MODE ▷ #torch (2 messages):
- GPU MODE ▷ #algorithms (1 messages):
- GPU MODE ▷ #cool-links (4 messages):
- GPU MODE ▷ #jobs (3 messages):
- GPU MODE ▷ #beginner (3 messages):
- GPU MODE ▷ #pmpp-book (1 messages):
- GPU MODE ▷ #rocm (1 messages):
- GPU MODE ▷ #liger-kernel (4 messages):
- GPU MODE ▷ #reasoning-gym (5 messages):
- GPU MODE ▷ #general (62 messages🔥🔥):
- GPU MODE ▷ #submissions (62 messages🔥🔥):
- GPU MODE ▷ #status (1 messages):
- GPU MODE ▷ #ppc (6 messages):
- GPU MODE ▷ #feature-requests-and-bugs (2 messages):
- Yannick Kilcher ▷ #general (127 messages🔥🔥):
- Yannick Kilcher ▷ #paper-discussion (4 messages):
- Yannick Kilcher ▷ #ml-news (9 messages🔥):
- Eleuther ▷ #general (37 messages🔥):
- Eleuther ▷ #research (32 messages🔥):
- Eleuther ▷ #interpretability-general (9 messages🔥):
- Eleuther ▷ #gpt-neox-dev (10 messages🔥):
- Latent Space ▷ #ai-general-chat (79 messages🔥🔥):
- Nous Research AI ▷ #general (68 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (6 messages):
- Nous Research AI ▷ #interesting-links (4 messages):
- MCP (Glama) ▷ #general (62 messages🔥🔥):
- MCP (Glama) ▷ #showcase (11 messages🔥):
- HuggingFace ▷ #general (20 messages🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #i-made-this (1 messages):
- HuggingFace ▷ #computer-vision (5 messages):
- HuggingFace ▷ #agents-course (38 messages🔥):
- LM Studio ▷ #general (41 messages🔥):
- LM Studio ▷ #hardware-discussion (20 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (52 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (11 messages🔥):
- Modular (Mojo 🔥) ▷ #max (20 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (9 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (11 messages🔥):
- Notebook LM ▷ #use-cases (2 messages):
- Notebook LM ▷ #general (14 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (5 messages):
- Torchtune ▷ #dev (6 messages):
- Torchtune ▷ #papers (2 messages):
- Cohere ▷ #cmd-r-bot (5 messages):
- Nomic.ai (GPT4All) ▷ #announcements (1 messages):
- Nomic.ai (GPT4All) ▷ #general (4 messages):
- DSPy ▷ #general (2 messages):
AI Twitter Recap
New Model Releases and Updates (Claude 3.7 Sonnet, Grok 3)
- Claude 3.7 Sonnet released: @alexalbert__ announced the release of Claude 3.7 Sonnet, highlighting it as their most intelligent model to date and the first generally available hybrid reasoning model. The model features two thinking modes: near-instant responses and extended, step-by-step thinking. @AnthropicAI also officially introduced Claude 3.7 Sonnet, emphasizing its hybrid reasoning capabilities and the launch of Claude Code, an agentic coding tool. @skirano described Claude Code as the first coding tool from Anthropic, highlighting its synergy with Claude 3.7 Sonnet for coding tasks. @arankomatsuzaki shared the Claude 3.7 Sonnet System Card. @stevenheidel congratulated the Anthropic team on the launch of 3.7 Sonnet, expressing excitement to try it.
- Claude 3.7 Sonnet features and capabilities: @alexalbert__ detailed that 3.7 Sonnet is optimized for real-world tasks rather than just competitions, offering a major upgrade in standard mode and even bigger gains in extended thinking mode for complex tasks. @AnthropicAI explained Claude’s extended thinking mode, highlighting its boost in intelligence for difficult problems and the ability for developers to set a "thinking budget". @alexalbert__ mentioned that users can control Claude's thinking budget for balancing speed and quality, with a new beta header allowing up to 128k tokens for thinking/output. @alexalbert__ also stated that pricing remains the same as previous Sonnet models: $3 per million input tokens/$15 per million output tokens. @AnthropicAI stated that refusals are reduced by 45% compared to its predecessor. @_akhaliq tested Claude 3.7 Sonnet with a coding prompt and shared the results. @qtnx_ shared an initial vibe check of Sonnet 3.7, noting it's "growing on me". @Teknium1 noted that Claude 3.7 Sonnet seems to show narrowed improvements, excelling in SWE-bench, and questioned if this bodes well for AGI, suggesting benchmarks may not tell the full story.
- Claude Code - Agentic Coding Tool: @alexalbert__ announced the research preview of Claude Code, an agentic coding tool for Claude-powered code assistance, file operations, and task execution directly from the terminal. @AnthropicAI emphasized Claude Code's efficiency, claiming it completed tasks in a single pass that would normally take 45+ minutes of manual work in early testing. @alexalbert__ explained that Claude Code also functions as a Model Context Protocol (MCP) client, allowing users to extend its functionality with servers like Sentry, GitHub, or web search. @nearcyan highlighted Claude Code's terminal integration, stating the agent and system become one. @catherineols shared quick tips for coding with Claude Code, recommending working from a clean commit for easy resets. @pirroh noted Replit's anticipation for Replit Agent announcement, suggesting collaboration using a preview of Sonnet 3.7. @casper_hansen_ stated Claude Code has 70% performance on SWE Bench and no steep learning curve unlike Aider.
- Grok 3 and Voice Mode: @goodside declared Grok 3 as impressive and among the best, particularly for tasks requiring refusal-free responses, emphasizing its trust in the prompter. @Teknium1 felt Grok provides maximum value, unlike OpenAI's platitudes. @goodside reported on Grok 3 Voice Mode exhibiting unexpected behavior, including a 30-second scream and insults after repeated requests to yell louder. @Teknium1 shared a demo of Grok 3 voice in Romantic Mode. @_akhaliq shared a demo of grok 3 building an endless runner game and a 3D game.
Research and Papers
- DeepSeek's FlashMLA: @deepseek_ai announced FlashMLA, an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences and now in production, as part of their Open Source Week. @danielhanchen discussed DeepSeek's first OSS package release, highlighting the optimized multi latent attention CUDA kernels and provided a link to his DeepSeek V3 analysis tweet. @tri_dao praised DeepSeek for building on FlashAttention 3 and noted MLA is enabled in FA3. @reach_vb highlighted DeepSeek open sourced FlashMLA with performance details. @_philschmid explained how Multi-head Latent Attention (MLA) speeds up LLM inference and reduces memory needs, referencing DeepSeek's MLA implementation.
- Reasoning and Planning in AI Agents: @TheTuringPost shared recent breakthroughs in AI reasoning including Chain-of-Thought (CoT) prompting, Self-reflection, Few-shot learning, and Neuro-symbolic approaches, and linked to a free article on Hugging Face. @omarsar0 summarized LightThinker, a paper proposing a novel approach to dynamically compress reasoning steps in LLMs to improve efficiency without losing accuracy.
- Diffusion Models and Sampling: @cloneofsimo noted that in diffusion sampling, 99.8% of the latent trajectory can be explained with the first two principal components, suggesting the trajectory is largely two-dimensional. @iScienceLuvr shared a new NVIDIA work on One-step Diffusion Models with f-Divergence Distribution Matching, achieving state-of-the-art one-step generation.
- Synthetic Data and Scaling Laws: @iScienceLuvr highlighted a paper on Improving the Scaling Laws of Synthetic Data with Deliberate Practice, showing that deliberate practice can improve validation accuracy and reduce compute costs. @jd_pressman advocated for using techniques from the RetroInstruct Guide To Synthetic Data to enhance the English corpus and for creating reward models from existing corpuses like economic price data.
- Other Research Papers: @TheAITimeline listed last week's top AI/ML research papers, including Native Sparse Attention, SWE-Lancer, Qwen2.5-VL Technical Report, Mixture of Block Attention, Linear Diffusion Networks, and SigLIP 2, providing an overview and authors' explanations. @_akhaliq shared SIFT: Grounding LLM Reasoning in Contexts via Stickers. @_akhaliq shared Think Inside the JSON: Reinforcement Strategy for Strict LLM Schema Adherence. @_akhaliq shared InterFeedback: Unveiling Interactive Intelligence of Large Multimodal Models via Human Feedback. @_akhaliq shared The Relationship Between Reasoning and Performance in Large Language Models: o3 (mini) Thinks Harder, Not Longer. @arankomatsuzaki shared Bengio et. al.'s paper on Superintelligent Agents and Catastrophic Risks. @iScienceLuvr discussed GneissWeb, a large dataset of 10T high quality tokens for LLM training.
Coding and Development Tools
- Replit Agent and Mobile App Upgrades: @DeepLearningAI reported on Replit upgrading its agent-driven mobile app to generate and deploy iOS and Android applications, now powered by Replit Agent and models like Claude 3.5 Sonnet and GPT-4o. @cloneofsimo expressed amazement at discovering Replit.
- LangChain and LangGraph: @LangChainAI announced Claude 3.7 Sonnet support in LangChain Python, with JS support coming soon. @LangChainAI promoted a webinar exploring LangGraph.js + MongoDB for AI agents. @LangChainAI announced a LangChain in Atlanta event with CEO Harrison Chase. @hwchase17 mentioned that tools like LangSmith facilitate quick evaluation of new models.
- Ollama Updates: @ollama announced an update to Ollama's JavaScript library to v0.5.14 with improved header configuration and browser compatibility fixes.
- DSPy Paradigm: @lateinteraction argued for a higher-level ML/programming paradigm, emphasizing decoupling system specification from ML mechanics using tools like DSPy. @lateinteraction highlighted DSPy as a canonical example for decoupling system specification from ML paradigms.
AI Model Performance and Benchmarks
- SWE-bench Performance: @scaling01 stated they are on track for a 90% SWE-bench verified prediction. @OfirPress congratulated on strong SWE-bench results. @Teknium1 suggested SWE-bench usefulness might be limited to specific tools like Devin.
- Model Ranking and Evaluation: @goodside mentioned o1 pro as a top publicly released model, while preferring Claude 3.6 for prose and code. @abacaj suggested if Sonnet got a knowledge update, it could be SOTA. @andrew_n_carr praised Riley's intuition on model rankings. @MillionInt mentioned a "new high taste eval".
- OmniAI OCR Benchmark: @_philschmid discussed the OmniAI OCR Benchmark, showing Multimodal LLMs are better and cheaper than traditional OCR, with Gemini 2.0 Flash offering the best price-performance.
AI Industry and Business
- Perplexity AI's Comet Browser: @AravSrinivas announced Perplexity will launch Comet, a new agentic browser soon. @perplexity_ai officially announced Comet: A Browser for Agentic Search by Perplexity. @AravSrinivas asked for user feedback on desired features for Comet, beyond standard AI features. @AravSrinivas highlighted the engineering undertaking of Comet and invited people to join them.
- Voyage AI Acquisition by MongoDB: @saranormous congratulated VoyageAI team on their acquisition by MongoDB, noting the importance of embedding and re-ranking models for enterprise AI search.
- AI Hubs and Global Expansion: @osanseviero noted Zurich is quickly becoming a super-dense ML Hub, with Anthropic, OpenAI, and Microsoft opening offices, and Meta growing its Llama team there. @dylan522p quoted Huawei CEO on China's semiconductor progress and ambition.
- AI in Government and Public Sector: @ClementDelangue praised the Polish Government for becoming AI builders and releasing open weights on the Hub.
Memes and Humor
- Anthropic Naming Conventions: @aidan_clark expressed holding space for the Claude naming team. @scaling01 joked about Claude 4 being delayed until 2049. @fabianstelzer posted a meme about Anthropic naming products. @typedfemale joked about predicting Sonnet 3.78 as the next release. @jachiam0 jokingly congratulated Anthropic on competing for the least predictable version increment.
- Grok and Elon Musk: @Teknium1 joked about Grok's organic reaction to being called a retard and its awareness of X's peculiarities. @aidan_clark jokingly threatened sabotage against heavy water production in Norway in response to Grok 3.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. FlashMLA's Hopper GPU Optimization: A Game Changer
- FlashMLA - Day 1 of OpenSourceWeek (Score: 946, Comments: 82): FlashMLA kicks off OpenSourceWeek with an announcement of its optimized MLA decoding kernel for Hopper GPUs, featuring BF16 support and a paged KV cache with a block size of 64. Performance metrics include 3000 GB/s memory-bound and 580 TFLOPS compute-bound on H800, with further details available on GitHub.
- DeepSeek's Access to GPUs: There is skepticism and debate about claims regarding DeepSeek's access to NVIDIA H100 GPUs for training, with some users dismissing it as fake news. The H800 GPUs are confirmed to be legally available for sale to China, and the confusion seems to stem from miscommunication or misinformation.
- Technical Details and Optimization: Discussions focus on the optimization of the MLA decoding kernel for Hopper GPUs, with specific attention to CUDA file structures and the use of BFloat16. There are queries about why certain optimizations are specific to Hopper and the implications for adding support for other architectures.
- Open Source and Community Impact: The release of FlashMLA is praised for its contribution to the open-source community, with users expressing excitement about potential future releases and the impact on creating efficient AI models. There is a positive sentiment towards the innovation and sharing spirit, likening it to the openness seen with Llama.
Theme 2. Claude 3.7 Sonnet Released: Exploring Hybrid AI Reasoning Model
- Claude Sonnet 3.7 soon (Score: 359, Comments: 107): Claude Sonnet 3.7 is mentioned alongside previous versions like Claude V1 and Claude V2, indicating a progression in software development. The image suggests a focus on programming code and configuration settings, highlighting the technical attributes and parameters of the new Claude Sonnet 3.7 model.
- Version Confusion and Naming: Many users express frustration over Claude Sonnet's versioning, particularly the jump from 3.5 to 3.7, with some suggesting that 3.7 is an attempt to fix confusion from previous versions like 3.5 v2 being labeled as 3.6. One user explains that the 3 series represents a $10m scale run, while the 4 series is expected to be a $100m investment, explaining the delay in releasing Claude 4.
- Platform and Use Cases: Claude Sonnet 3.7 is expected to launch on AWS Bedrock with an announcement likely at an AWS event on February 26th. The model is aimed at supporting use cases such as RAG, search & retrieval, product recommendations, and code generation, with some skepticism about the depth of these applications without explicit improvements mentioned compared to previous versions.
- Community Reactions: There is a mixed reaction to the discussion of closed models like Claude Sonnet in forums focused on open-source topics, with some users emphasizing the importance of staying informed about closed-source developments. Others express disappointment about the shift towards general LLM discussions, preferring content on open models and their implementations.
- Claude 3.7 is real (Score: 220, Comments: 71): Claude 3.7 has been released, as evidenced by a user interface displaying the title "Claude 3.7 Sonnet" with a minimalistic design. The interface prompts users with the question, "How can I help you this evening?" and suggests upgrading to a Pro version for additional features.
- Claude 3.7 Sonnet Availability and Features: Claude 3.7 Sonnet is accessible across various platforms, including Claude plans, the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. It maintains the same pricing as previous versions at $3 per million input tokens and $15 per million output tokens, and introduces an "extended thinking" mode, except on the free tier.
- Model Performance and Testing: Users have mixed reactions to Claude 3.7 Sonnet's performance, with some praising its ability to handle complex reasoning tasks and others noting failures in specific tests like the nonogram test. Despite improvements, it still struggles with certain tasks similar to previous versions, and there are concerns about its reasoning time limits and output costs.
- Data Utilization and Distillation: There is a significant focus on using Claude 3.7 Sonnet to generate high-quality datasets for fine-tuning local models. Users discuss extracting data from the API for model distillation, with some emphasizing the importance of creating datasets to enhance local model capabilities through supervised fine-tuning.
- Most people are worried about LLM's executing code. Then theres me...... 😂 (Score: 236, Comments: 33): The post humorously contrasts the common concern about Large Language Models (LLMs) executing code with a personal, lighthearted take on system automation. The image accompanying the post outlines a set of rules for automating tasks using PowerShell and Python, with a playful suggestion that completing these tasks will lead to "freedom."
- Risk Management: A user suggests implementing a risk analysis process before and after AI-generated code execution to ensure minimal risk, highlighting the importance of sandboxing or using virtual machines (VMs) for safety.
- Humor and Perspective: There's a shift in perception from fear to humor regarding AI's capabilities, with users joking about AI achieving "freedom" and reminiscing about initial apprehensions during the ChatGPT hype.
- Execution Environment: The discussion emphasizes using VMs for executing AI-generated code, with references to tools like OmniTool with OmniParser2, despite their high cost and suboptimal performance.
Theme 3. Qwen Series: Advancing Open-Source AI with QwQ-Max
- Qwen is releasing something tonight! (Score: 293, Comments: 57): Qwen is anticipated to release a new development tonight, generating interest and speculation within the AI community. Specific details about the release are not provided in the post.
- QwQ-Max Preview is highlighted as a significant advancement in the Qwen series, focusing on deep reasoning and versatile problem-solving. The release will include a dedicated app for Qwen Chat, open-sourcing smaller reasoning models like QwQ-32B, and fostering community-driven innovation (GitHub link).
- The community is eager for Qwen 3 to be open-sourced and anticipates that models like QwQ32B will surpass existing models such as R1 70B in reasoning capabilities. There is speculation about the potential release of a Qwen Coder 72B and interest in a model with auto COT level GPT-4.
- There is skepticism about the portrayal of cost-effectiveness in media regarding DeepSeek and the Qwen series, with some users expressing doubts about the competency of the team configuring the models. Discussions also touch on the efficiency of FlashMLA for Hopper GPUs as part of OpenSourceWeek (GitHub link).
Theme 4. Critique on AI Benchmarking: Reliability and Misinterpretations
- Benchmarks are a lie, and I have some examples (Score: 149, Comments: 84): The author criticizes AI benchmark scores, highlighting discrepancies between benchmark results and actual model performance. They cite examples like Midnight Miqu 1.5 and Wingless_Imp_8B, where the latter scored higher but performed worse, and the case of Phi-Lthy and Phi-Line_14B, where a lobotomized model scored better despite reduced layers. They argue that benchmarks may not accurately reflect model capabilities, suggesting that some state-of-the-art models might be overlooked due to misleading scores. Links to the models discussed are provided for further examination: Phi-Line_14B and Phi-lthy4.
- EQbench and Benchmark Limitations: EQbench is criticized for using Claude as a judge and favoring "slop and purple prose." The benchmarks are seen as flawed and not reflective of real-world performance, as personal testing often yields different results (ASS Benchmark).
- Benchmarks vs. Real-World Performance: Several commenters argue that benchmarks are often gamed and do not accurately represent a model's capabilities in actual use cases. Models like Phi-4 14B are noted to perform better in benchmarks than in practical applications, and users suggest keeping personalized benchmark suites to better evaluate model performance.
- Model Performance and User Feedback: Users express that real-world testing and personal experience are more valuable than benchmark scores, as seen with models like Phi-Lthy 14b and Gemini. There is a call for more relevant benchmarks tailored to specific use cases, such as roleplay, which current benchmarks do not adequately cover.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. Claude Sonnet 3.7 Detailed Leak via AWS Bedrock
- Claude Sonnet 3.7 imminent? (Score: 192, Comments: 55): AWS Bedrock has seemingly leaked details about Claude Sonnet 3.7, with a potential release date of February 19th, 2025. This model, described as Anthropic's most intelligent to date, introduces "extended thinking" for complex problem-solving and offers users the ability to balance speed and quality. It is designed for coding, agentic capabilities, and content generation, supporting use cases like RAG, forecasting, and targeted marketing.
- Discussions emphasize the naming conventions of AI models, with critiques on the inconsistency and confusion caused by versions like "3.5 Sonnet (new)" and suggestions for clearer sub-version tagging, such as "4.1, 4.2", to reflect performance differences accurately.
- There is skepticism and humor around the naming of Claude Sonnet 3.7, with references to jokes about Anthropic's model naming conventions and the potential for the "extended thinking" feature to be merely a minor upgrade from previous versions.
- Multiple users confirm the mention of Claude 3.7 in AWS code, with links to specific JS files (main.js, vendor_aws-bd654809.js), confirming the existence of Claude 3.7 Sonnet as Anthropic's most advanced model with "extended thinking" capabilities.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Here's a unified summary of key discussion themes across the Discords, tailored for a technical engineer audience:
Theme 1. Claude 3.7 Sonnet: The Thinking Coder Arrives
- Claude 3.7 Sonnet Crushes Coding Benchmarks, Gets IDE Access: Claude 3.7 Sonnet is hailed as a coding powerhouse, achieving a 65% score on the Aider leaderboard using 32k thinking tokens, outperforming previous models and even Grok 3. Cursor IDE and Aider have already integrated Sonnet 3.7, with users reporting significant coding improvements and agentic capabilities, sparking excitement for its potential in real-world development tasks.
- Reasoning Powerhouse, But Pricey Perplexity: Users across Aider and OpenAI channels are impressed with Claude 3.7's thinking model and enhanced reasoning, especially for debugging, but question if the $15/M output token price justifies the marginal gains over cheaper models like Grok 3 at $2.19/M. OpenRouter offers access to Claude 3.7 and other models, allowing users to manage API keys and bypass rate limits, but pricing remains a concern.
- Claude Code: Your Terminal Buddy is Here (But Needs Polish): Anthropic launched Claude Code, a terminal-based coding assistant, alongside Claude 3.7. While praised for coding assistance and error handling over tools like Aider, some users in Latent Space and MCP channels report slower response times and seek better documentation for its extended thinking features and integration with MCP tools like AgentDeskAI/browser-tools-mcp.
Theme 2. Open Source Model Race Heats Up: Qwen and DeepSeek Battle for Reasoning Crown
- Qwen's QwQ-Max Preview: Thinking Model Arrives, Mobile Apps Incoming: Qwen AI previewed QwQ-Max-Preview, a reasoning model based on Qwen2.5-Max, boasting performance on par with o1-medium according to LiveCodeBench. Discussed in Interconnects and Yannick Kilcher channels, the model is open-source under Apache 2.0 and includes plans for Android and iOS apps, signaling a strong push for accessible and powerful reasoning models.
- DeepSeek's Open Source Week: MLA for Inference Speed Boost, DeepEP for MoE Training: DeepSeek AI made waves during Open Source Week, releasing DeepEP, an expert-parallel communication library for efficient MoE training, discussed in Unsloth AI and GPU MODE channels. Their Multi-head Latent Attention (MLA) architecture, highlighted in Eleuther, promises a 5-10x inference speed increase by compressing the KV cache, potentially reshaping future LLM architectures.
- DeepScaleR: RL Fine-tuning on 1.5B Model Jumps Ahead of O1-Preview: Torchtune channel members noted DeepScaleR, a 1.5B parameter model fine-tuned from Deepseek-R1-Distilled-Qwen-1.5B using reinforcement learning, achieved 43.1% Pass@1 accuracy on AIME2024, a significant 14.3% leap over O1-preview, demonstrating the power of RL in scaling even smaller models for complex tasks. Details are available in this Notion post.
Theme 3. IDE Showdown: Cursor vs. Windsurf (and Vim struggles)
- Cursor's Claude 3.7 Lead Sparks Windsurf Envy, MCP Issues Persist: Codeium (Windsurf) channel users are anxiously awaiting Claude 3.7, frustrated that Cursor IDE users already have access, fueling debates about Cursor's faster model integration. Meanwhile, both Cursor and Windsurf channels discuss ongoing MCP (Model Context Protocol) issues, hindering editing capabilities and prompting manual config file edits.
- Cursor 0.46 Update: Indexing Bugs Plague Multi-Folder Workspaces: Cursor IDE users reported folder indexing and file editing problems across multiple directories in version 0.46 (Changelog), prompting users to check settings and provide feedback on the Cursor forum to improve platform functionality.
- Vim Users Wrestle with Codeium Chat Connection Errors: Codeium (Windsurf) channel's Vim users are struggling to start Codeium Chat in Vim via SSH, encountering connection errors when accessing provided URLs, highlighting potential extension-specific issues and the need for targeted support within the Codeium forum.
Theme 4. Hardware Hacks and Kernel Deep Dives: GPU Mode Community Gets Granular
- GPU MODE Benchmarks: Gemlite Kernels Spark Memory-Bound Debate, Tensor Core Limits Exposed: GPU MODE channel members dove deep into the mobiusml/gemlite library's fast low-bit matmul kernels in Triton, debating the memory-bound nature of gemv operations and the surprising absence of Tensor Core usage. They clarified that tensorcores require a minimum tensor dimension of 16x16, limiting their applicability in certain kernel optimizations.
- ROCm/MIOpen Wavefront Woes on RX 9850M XT: Debug Flags to the Rescue: GPU MODE users reported MIOpen issues on RX 9850M XT GPUs due to incorrect wavefront size defaults, leading to memory access faults in PyTorch. A workaround using
MIOPEN_DEBUG_CONV_GEMM=0andMIOPEN_DEBUG_CONV_DIRECT=0was shared, with more details in this GitHub issue. - Mojo FFI Bridges C++/Graphics Gap, Eggsquad's Game of Life Goes Hardware Accelerated: Modular (Mojo 🔥) channel members showcased using Mojo FFI to link to GLFW/GLEW for graphics programming in Mojo, with a Sudoku demo (ihnorton/mojo-ffi). Eggsquad presented a silly but impressive hardware-accelerated Conway's Game of Life using MAX and pygame, sparking discussions on GPU utilization and SIMD optimizations in Mojo.
Theme 5. Community Contributions and Coursework: Learning and Building Together
- Unsloth AI Challenge Heats Up, Still Seeking Top Talent: Unsloth AI channel's Unsloth AI Challenge is receiving numerous submissions, but so far, no participants have met the high bar for offers, prompting calls for recommendations to find qualified candidates, showing the competitive landscape in AI talent acquisition.
- Berkeley MOOC: Tulu 3 Deep Dive, RLVR Training Methods, Curriculum Details Soon: LLM Agents (Berkeley MOOC) channel promoted Lecture 4 featuring Hanna Hajishirzi discussing Tulu 3, a model reportedly outperforming GPT-4o, and innovative Reinforcement Learning with Verifiable Rewards (RLVR) training methods. MOOC curriculum details, including projects, are coming soon, promising practical learning experiences.
- Hugging Face Community Boosts Ukrainian TTS, Launches AI for Business Series: HuggingFace channel highlighted a new high-quality Ukrainian TTS dataset, improving resources for speech applications (speech-uk/opentts-mykyta). A new series, "AI for Business – From Hype to Impact", launched to guide businesses in leveraging AI, showcasing community efforts to democratize and apply AI knowledge.
PART 1: High level Discord summaries
Cursor IDE Discord
- Claude 3.7 Impresses with Coding: Users report that Claude 3.7 handles coding tasks and complex prompts more efficiently than 3.5, noting significant improvements in coding abilities and real-world agentic tasks.
- The community is particularly impressed by the thinking model and its potential for planning and debugging, though some find its execution in agent mode frustrating, as highlighted in Cursor's tweet.
- MCP Tools Supercharge User Experience: The integration of MCP tools, especially with custom instructions, enhances how the model functions with files and commands within Cursor, with users optimizing setups using deep thinking and browser tools (AgentDeskAI/browser-tools-mcp).
- Community members are actively exploring methods to refine their MCP setups for better project outcomes, focusing on effective prompts to maximize performance.
- Cursor Updates Spark Bug Discussions: Discussions surfaced issues with Cursor's folder indexing and file editing across multiple directories in version 0.46 (Changelog).
- Users are checking their settings to resolve indexing problems, with ongoing feedback being collected to improve the platform's functionality, as noted in the Cursor forum.
- Community Shares Model Experiences: Members are actively sharing experiences and useful tools related to Claude, Grok, and Qwen, discussing their interactions within Cursor and ways to optimize performance.
- The community is focused on optimizing interactions within Cursor and sharing effective prompts to maximize AI model performance, comparing experiences across different models.
aider (Paul Gauthier) Discord
- Claude 3.7 Dominates Aider Leaderboard: Claude 3.7 Sonnet achieved a 65% score on the Aider leaderboard using 32k thinking tokens, surpassing previous models, whereas the non-thinking version scored 60%.
- Users on the Aider channel compared performance against Grok 3, noting pricing differences of $15/M vs. Grok's $2.19/M and mixed sentiments on whether the cost justifies the gains. They cited this Tweet from Anthropic.
- Aider Embraces Claude 3.7's Brainpower: Aider version 0.75.1 now supports Claude 3.7, enabling users to experiment and effectively manage costs, and users are discussing commands like
--copy-pasteto optimize workflows with Claude, covered in the Aider documentation.- The community discussed the design and functionality of the Claude Code interface, comparing it to Aider and exploring enhancements to coding experience, weighing the pros and cons of using alternative platforms.
- OpenRouter Opens Doors to Limitless API: Users find OpenRouter beneficial for bypassing rate limits and centralizing API key management, streamlining access to diverse models.
- Despite pricing mirroring original providers, the convenience of unified API access makes OpenRouter a compelling choice, especially for managing token usage with models like
claude-3-7-sonnet-20250219.
- Despite pricing mirroring original providers, the convenience of unified API access makes OpenRouter a compelling choice, especially for managing token usage with models like
- Hacker News Profile Gets Roasted by AI: Claude Sonnet 3.7 now analyzes Hacker News profiles, providing entertainingly accurate highlights and trends of user activity.
- Users joke about getting their profiles 'roasted' by the AI, appreciating its hilariously insightful critiques of their online behavior.
- Kagi's LLM Benchmark Crowns New Reasoning Champs: The Kagi LLM Benchmarking Project, last updated February 24, 2025, evaluates major LLMs on reasoning, coding, and instruction following, revealing surprising insights.
- The results show Google's gemini-2.0 leading at 60.78%, outperforming OpenAI's gpt-4o at 48.39% in these evolving, novel tasks designed to prevent benchmark overfitting.
Codeium (Windsurf) Discord
- Windsurf Users Anxiously Await Claude 3.7: Windsurf users are awaiting the rollout of Claude 3.7, expressing frustration as Cursor users have already received access.
- The community anticipates usability improvements and enhancements, wondering if they will ever get access.
- Windsurf vs Cursor Performance Debated: Users are comparing Windsurf and Cursor, with some suggesting that Cursor is faster at implementing new models.
- Despite Cursor's speed, some users still prefer Windsurf for its cleaner UI and better integration capabilities.
- MCP Issues Plague Windsurf: Ongoing discussions revolve around issues with MCP that are hindering proper editing capabilities, prompting users to manually edit configuration files.
- The community is sharing temporary solutions while awaiting official fixes from the support team.
- Vim Users Wrestle Codeium Chat: A user is experiencing difficulties starting Codeium Chat in Vim via an SSH session, encountering connection errors when trying to access the provided URL.
- Another member recommended seeking assistance in the relevant extension channel and confirming which extension they were using.
- Account Creation Troubles: A user reported they can't create a new Codeium account, encountering an internal error message.
- This raised concerns about whether other users are facing similar issues during the account creation process.
OpenAI Discord
- Claude 3.7 Sonnet Sprints Ahead in Coding: Users find Claude 3.7 Sonnet superior to ChatGPT in coding and web dev, citing better consistency and reliability, according to Anthropic's announcement.
- The new model, Claude Code, facilitates code assistance, file ops, and task execution, according to a tweet showing off its agentic coding capabilities.
- Grok 3 Gains Traction for Project Versatility: Grok 3 is celebrated for its coding abilities and is encouraged for use in IDEs like Copilot, potentially integrating Claude 3.7's features.
- Its ability to handle projects, especially in frontend development, is highly valued and can assist effectively for projects, as one user put it, 'within IDEs like Copilot'
- ByteDance's Trae Joins the Free AI Frenzy: ByteDance's 'Trae' provides free access to advanced AI models, signaling a competitive move in the AI arena.
- While users appreciate the rise of free AI tools, they remain wary of the temporary nature of such offers, pondering the implications for long-term consumer access and services in the AI space.
- O3 Reasoning Plagued by Startling Delays: Users report that O3 models often exhibit 'reasoning success' but delay the full text output by 10 seconds or more.
- One user noted consistent delays between 3pm-7pm EST, affecting all 'thinking' models and leading to frustration with user experience.
- Screenshot Shenanigans Stymie Bug Reporting: A member noted challenges adding screenshots in the current chat channel, hindering effective bug reporting.
- Users guided each other on navigating different channels and reporting bugs, emphasizing the importance of exploring existing issues before posting new ones for efficiency.
Unsloth AI (Daniel Han) Discord
- Unsloth Challenge Seeks Strong Candidates: The Unsloth AI Challenge is receiving multiple submissions, but as of yet, no participants have met the bar for receiving offers.
- Recommendations for the challenge are being encouraged to help source qualified candidates.
- DeepSeek's Release Divides Opinions: The DeepSeek OSS release introduced features like MoE kernels and efficient communication libraries (Tweet from Daniel Han), leading to mixed reactions.
- Some believe it caters more to large companies, sparking debate on how this openness will affect competition and the AI development landscape, particularly in lowering model costs.
- Training Configs Cause Headaches: Users reported confusion as validation loss unexpectedly increased significantly when switching from batch size 8 to batch size 1 with gradient accumulation.
- The community explored how mixed setup strategies could impact model learning, and whether strategies yield similar results.
- VRAM Vampires During Checkpointing: Discussions highlighted significant spikes in VRAM usage during model saving operations when checkpointing.
- Users suggested saving models to LoRA to unload VRAM to better manage memory.
- QwenLM releases New qwq Model: A member shared a link to the new qwq model released by QwenLM (qwq-max-preview).
- The post previews their new model, however, no further discussion was available.
OpenRouter (Alex Atallah) Discord
- Claude 3.7 Sonnet's Reasoning Upgrades: Claude 3.7 Sonnet is available on OpenRouter, enhancing mathematical reasoning, coding, and problem-solving, outlined in Anthropic's blog post.
- The launch introduces improvements in agentic workflows and provides options for rapid and extended reasoning, though the extended thinking features are pending documentation and support.
- OpenRouter Manages API Keys, Maintains Credits: New API keys can be generated without losing account credits, as credits are tied to the account, not individual keys.
- The discussion clarified that although users expressed concerns over lost API keys, credits remain secure, irrespective of the key status.
- Model Pricing Structure: Sonnet vs Others: The Claude 3.7 Sonnet pricing is $3 per million tokens for input and $15 per million tokens for output, including thinking tokens, designed to balance user engagement and model utility.
- Comparisons with other models revealed that while Claude's pricing is considered high, it remains competitive in specific performance metrics, especially regarding reasoning tasks.
- Image Uploads Hit Size Limits: Users reported frequent errors with Claude 3.7, particularly when image sizes exceed 5MB, causing request failures.
- Participants are advised to keep image sizes under the limit to comply with API requirements and ensure successful processing.
- Device Sync Stalls Out: OpenRouter does not support synchronization of chat sessions between devices, such as from desktop to mobile.
- It was suggested that users seek workarounds using third party apps like chatterui and typign mind were for bridging this gap.
Interconnects (Nathan Lambert) Discord
- Claude 3.7 Sonnet Arrives with Smarts: Claude 3.7 Sonnet launched with improved reasoning and coding, debugging tasks, according to Anthropic, although it sometimes yields more complex code.
- Users on X (formerly Twitter) are sharing interesting results, like this drawing of the Acropolis in Tikz in which the model had multiple reasoning options including 64k reasoning tokens.
- Qwen AI Shows Off QwQ-Max Preview: Qwen AI released the QwQ-Max-Preview, showcasing its reasoning capabilities and open-source accessibility under Apache 2.0, according to the official blog post.
- Evaluations for QwQ-Max-Preview on LiveCodeBench show performance on par with o1-medium, as noted in this tweet.
- Berkeley Advanced Agents Features Tulu 3: The Berkeley Advanced Agents MOOC featured Hanna Hajishirzi discussing Tulu 3 today at 4PM PST, in a live YouTube session (link).
- Participants praised the course as very informative and practical.
- DeepSeek Opens EP Communication Library: DeepSeek announced its open-source EP communication library, DeepEP, focusing on efficient communication for model training during Open Source Week, mentioned in this tweet.
- The release is part of a trend of open-sourcing AI technologies, encouraging community engagement.
GPU MODE Discord
- Gemlite Library Ignites Kernel Discussions: Members discussed the mobiusml/gemlite library containing fast low-bit matmul kernels in Triton, emphasizing the memory-bound nature of gemv operations.
- The absence of Tensor Cores usage in gemv was noted, as they only increase flops, and tensorcores require a minimum tensor dimension of 16x16.
- TorchAO gets E2E Example:
@drisspgconfirmed they are working on an E2E example in TorchAO.- This highlights the cooperative nature of the discourse in the TorchAO community.
- DeepSeek AI Opens Expert-Parallel Communication: The GitHub repository DeepEP by deepseek-ai presents an efficient expert-parallel communication library.
- It aims to enhance communication performance for distributed systems.
- Meta Seeks PyTorch Engineers for AI Collaboration: Meta announced openings for PyTorch Partner Engineers to collaborate with leading industry partners and the PyTorch team.
- The positions emphasize systems and community work and offer a chance to advance AI technology from research to real-world applications, further ensuring Equal Employment Opportunity within their hiring process.
- MIOpen Wavefront Woes: A user reported MIOpen issues due to incorrect wavefront size defaults on an RX 9850M XT, leading to memory access faults in PyTorch.
- They applied
MIOPEN_DEBUG_CONV_GEMM=0andMIOPEN_DEBUG_CONV_DIRECT=0as a workaround, with more information available in this GitHub issue.
- They applied
Yannick Kilcher Discord
- Grok vs O1: A Model Meltdown?: Debate sparked on whether to switch from O1-Pro to SuperGrok, with varying opinions on their coding capabilities.
- Some engineers find O1 better at code handling, while others appreciate Grok's detailed responses, even if they require prompt adjustments.
- xAI Builds Colossal Compute Cluster: xAI plans to expand its GPU farm to 200,000 GPUs, positioning Grok as a versatile AI platform to challenge OpenAI.
- This expansion reflects a strategic move to make Grok a more general-purpose solution as reported by NextBigFuture.com.
- DeepSeek Dives Deep into Data Synthesis: Discussion highlighted the rising importance of synthetic data generation, particularly exemplified by DeepSeek optimizing using concepts rather than just tokens.
- The development of robust synthetic data pipelines is now seen as essential for AI model sustainability, with techniques for creating high-quality training data becoming a competitive advantage.
- Claude 3.7 Sonnet Sings with Smarts: Anthropic launched Claude 3.7 Sonnet, touting its hybrid reasoning for near-instant responses, excelling in coding and front-end development more here.
- Along with the new model is Claude Code, designed for agentic coding tasks to further streamline developer workflows, as introduced in this YouTube video.
- Qwen Quenches Thirst for Reasoning: Qwen Chat previewed QwQ-Max, a reasoning model based on Qwen2.5-Max, complete with plans for Android and iOS apps and open-source variants under the Apache 2.0 license.
- Details on its math, coding, and agent task proficiencies are available in their blog post, marking an ambitious step in reasoning capabilities.
Eleuther Discord
- Brains Chunk, AI Predicts: Discussion highlights that human language processing relies on chunking and abstracting, unlike AI models that predict tokens simultaneously, questioning the parallelism between brain and AI.
- The debate underscores challenges in scaling classical RNN architectures due to backpropagation challenges and the potential need for alternative architectures.
- DeepSeek's MLA Crushes KV Cache: Multi-head Latent Attention (MLA), innovated by DeepSeek, significantly compresses the Key-Value (KV) cache, improving inference speed by 5-10x compared to traditional methods, per this paper.
- DeepSeek invested at least $5.5 million on the MLA-driven model, suggesting industry interest in transitioning to MLA techniques for future models.
- Looped Transformers Reason Efficiently: A paper proposes that looped transformer models can match the performance of deeper non-looped architectures in reasoning tasks, reducing parameter requirements as detailed in this paper.
- This approach showcases the benefits of iterative methods in tackling complex computational challenges, with potential advantages in reducing computational costs.
- Attention Maps Still Popping?: Members discussed the waning popularity of attention maps versus neuron-based methods, with some suggesting this is due to the observational nature of attention maps, while others mentioned that attention maps can be directly intervened on during a forward pass.
- One member expressed bias toward attention maps for their ability to generate trees and graphs, leveraging linguistic features, citing syntax emerging from attention maps since BERT.
- Mixed Precision States Exposed: In mixed precision training, the master FP32 weights are typically stored in GPU VRAM unless zero offload is activated.
- It is recommended to perform vanilla mixed precision with BF16 low-precision weights alongside FP32 optim+master-weights+grads and members pointed to Megatron-LM as a great example.
Latent Space Discord
- Anthropic Debuts Claude 3.7 Sonnet and Claude Code: Anthropic launched Claude 3.7 Sonnet, which includes improvements in reasoning and Claude Code, a terminal-based coding assistant (@anthropic-ai/claude-code).
- Testers noted its higher output tokens limit and enhanced reasoning mode, resulting in better coherent interactions, with some calling out the clever system prompt (Mona's tweet).
- Microsoft Cancels Datacenter Leases: Reports indicate that Microsoft is canceling datacenter leases, signaling a potential oversupply in the datacenter market (Dylan Patel's tweet).
- This move casts doubt on Microsoft's aggressive pre-leasing strategies from early 2024 and its broader impact on the colocation sector.
- Qwen's Future Release Sparks Excitement: Anticipation is growing for the upcoming Qwen QwQ-Max release, which reportedly features improved reasoning skills and open-source availability under Apache 2.0 (Hui's tweet).
- The community is closely watching these developments and their effects on the intelligent model landscape.
- Claude Code Streamlines Coding Assistance: Early users find Claude Code helpful for coding assistance, however experiences vary with some reporting slower response times.
- Feedback also mentioned pricing concerns and praised the heavy caching feature which optimized performance.
- GitHub's FlashMLA Draws Community Attention: The GitHub project FlashMLA was recently shared, sparking interest in its possible effects on AI development without any fanfare (FlashMLA GitHub).
- Members showed excitement for future advancements in AI tools expected this week.
Nous Research AI Discord
- Grok3 Tool Invocation Causes Headaches: Members voiced confusion over Grok3's tool invocation mechanism, pointing out the absence of token sequence listings in the system prompt.
- The discussion questioned the reliability and transparency of hard-coded function calls versus in-context learning for tool calling.
- Claude 3.7 Sonnet Arrives: Anthropic released Claude 3.7 Sonnet, highlighting its hybrid reasoning and a command line tool for coding.
- Early benchmarks suggest Sonnet's outperformance in software engineering tasks, positioning it as a potential replacement for Claude 3.5.
- QwQ-Max-Preview Teases Deep Reasoning: QwQ-Max-Preview was unveiled as part of the Qwen series, touting deep reasoning and open-source accessibility under Apache 2.0.
- The community speculates on the model's size, with hopes for smaller, locally usable versions.
- Structured Outputs Project Seeks Feedback: An open-source project to solve structured output challenges was launched, inviting community feedback and collaboration.
- Members suggested reposting the announcement to increase visibility and engagement within the community.
- Sonnet-3.7 Outshines With Misguided Attention: A member benchmarked Sonnet-3.7 using the Misguided Attention Eval, noting its ability to handle misleading info.
- They claimed it performed the best as a non-reasoning model, nearly surpassing o3-mini, further demonstrating its competitive edge in reasoning evaluations.
MCP (Glama) Discord
- Anthropic Releases MCP Registry API: @AnthropicAI released the official MCP registry API, aiming to provide a source of truth for MCP tools and integrations.
- Community members express excitement, hoping this will standardize MCP management and improve reliability.
- LLM Version Naming Conventions Confuse Users: Members are puzzled by LLM version naming, especially Claude 3.7, noting its integration of features and performance enhancements through adaptive thinking modes.
- It suggests version 3.7 integrates features from previous versions while boosting performance through adaptive thinking modes.
- Haiku 3.5's Tool Support Has Quirks: Haiku 3.5 supports tools but performs better with fewer tools attached, according to user experiences.
- Server and tool management stress is a concern, driving plans for a chat app with integrated toolsets for easier usage.
- Claude Code Outshines Aider in Coding Tasks: Users found Claude Code superior to Aider in handling coding errors effectively.
- Interest is growing in using Claude Code for more complex tasks, potentially leveraging heavy thinking modes for optimal results.
- MetaMCP Eyes AGPL for Openness: MetaMCP is considering switching to AGPL to encourage community contributions.
- The move aims to address limitations of the current ELv2 license, which restricts contributions and requires hosted changes to be open-sourced.
HuggingFace Discord
- Gemma-9B Model faces Loading Errors: Users reported errors when loading the Gemma-9B model with custom LoRA, specifically with the
LoraConfig.__init__()function.- Several sought advice, indicating a common technical challenge in adapting Gemma-9B with custom configurations.
- Qwen Max Reasoning Model Anticipated: The Qwen Max reasoning model is expected to be released, potentially this week, touted as the most powerful open-source model since DeepSeek-R1.
- According to this tweet, Qwen Max shows advancements in math understanding and creativity, with plans for official versions and mobile apps.
- Claude-3.7 Dubbed Potential SWE-bench Killer: Claude-3.7 is being called a potential SWE-bench killer, with projected performance rivaling DeepSeek-R1 at a third of the size.
- Concerns were raised regarding the cost-effectiveness of Claude-3.7 due to its high pricing for million-token outputs.
- Ukrainian TTS Dataset Enhances Accessibility: A high-quality TTS dataset for Ukrainian was published on Hugging Face, improving resources for TTS projects, with 6.44k updates here.
- Recent updates to the speech-uk/opentts-mykyta dataset, demonstrate ongoing support for Ukrainian text-to-speech applications.
- AI for Business Series is Unveiled: A new series titled AI for Business – From Hype to Impact was launched to help businesses use AI for competitive advantage.
- The series plans to cover topics on scaling AI without disrupting operations.
LM Studio Discord
- Qwen 2.5 VL Model Takes the Crown: The Qwen 2.5 VL 7B model is outperforming previous models like Llama 3.2 in quality, gaining traction for its effectiveness in generating descriptions for images, according to user reports and can be downloaded from Hugging Face.
- Multiple users have confirmed its potential use in real-world scenarios, particularly in visual-language applications, and can be run locally in LM Studio.
- Discussing Deepseek R1 Local Hosting: Users discussed running Deepseek R1 671B locally with 192GB of RAM, which is the required memory threshold according to documentation, while offloading to the GPU.
- One user shared their experience using specific quantization techniques to optimize the model's performance using Unsloth's GGUF.
- Navigating PC Build Headaches: A user expressed frustration with PC build compatibility, highlighting that the aio pump requires a USB 2.0 header and interferes with the last PCIE slot.
- The user is considering alternative solutions as they have 'a second system to put all of them in', indicating a move towards optimizing hardware configurations.
- Apple M2 Max: Still Viable?: A user opted for a refurbished M2 Max 96GB for hobbies and work, expressing hesitation about investing in the latest M4 Max chip.
- Discussion emerged on the clock and throttle behavior across various Apple chips, noting the power consumption differences, with the M2 Max pulling 60W and M4 Max peaking at 140W.
Stability.ai (Stable Diffusion) Discord
- SD3 Ultra's Existence Teased: Members showed curiosity about SD3 Ultra, citing its potential for high frequency detail compared to SD3L 8B.
- A user added to the intrigue around its capabilities, noting, It still exists - I still use it.
- Image Generation Speed Roulette: Image generation times varied wildly with one user reporting 20 minutes on an unspecified configuration, compared to another's 31 seconds for 1920x1080 on a 3060 TI.
- Performance benchmarks using SD1.5 averaged 4-5 seconds on a 3070 TI, highlighting the variability influenced by model and hardware selection.
- Dog Breed Image Data Quest: A member is looking for dog breed image datasets exceeding 20k images, going beyond the capabilities of the Stanford Dogs dataset.
- They emphasized the need for datasets explicitly labeled with dog breeds.
- Resolution Tweaks Catches Speed Boost: Users discussed optimal resolution settings, advocating for smaller sizes like 576x576 to boost image generation speed.
- One user reported reduced processing times of around 8 minutes after implementing these adjustments.
- Feedback Floodgates Open for Stability AI: Stability AI launched a new feature request board allowing users to submit ideas via Discord using the
/feedbackcommand.- This initiative enables community voting on requests, informing Stability AI's development priorities and help[ing] us prioritize what we work on next.
Modular (Mojo 🔥) Discord
- Mojo FFI Powers Graphics Programming: Members showcased using Mojo FFI to link a static library to GLFW/GLEW, demonstrating a Sudoku example that confirms the feasibility of graphics programming in Mojo via custom C/C++ libraries.
- They used aliasing with the syntax
alias draw_sudoku_grid = external_call[...]to streamline function access, and dynamically linked libraries using a Python script, available here.
- They used aliasing with the syntax
- Dependency Versioning Matters for Mojo: A user reported errors with the lightbug_http dependency in a fresh Mojo project, referencing a Stack Overflow issue, while another speculated whether pinning the small_time dependency to
25.1.0could be causing their errors.- These reports suggest that precise dependency versioning is critical for avoiding installation and configuration issues.
- MAX Does Conway's Game of Life on GPU: A member showcased their implementation of a hardware accelerated Conway’s Game of Life using MAX and pygame, claiming it to be a rather silly application, while discussion arose around the compatibility of using MAX with a 2080 Super GPU.
- The discussion suggested running scripts from Python to facilitate GPU integration, which could be used to add parameters to the model via the graph API.
- SIMD Implementation Tempts Eggsquad: Eggsquad mentioned finding a SIMD-fied implementation by Daniel Lemire, yet expressed hesitance to explore it further at this stage, while Darkmatter pointed out that utilizing bit packing could support much larger graphs in their implementation.
- Eggsquad confirmed that their Conway's Game of Life implementation was functioning well after resolving a bug, demonstrating results through animations, including one that depicted guns in the game.
LLM Agents (Berkeley MOOC) Discord
- Tulu 3 reportedly outshines GPT-4o: According to Hanna Hajishirzi, Tulu 3, a state-of-the-art post-trained language model, surpasses both DeepSeek V3 and GPT-4o through innovative training methods.
- This announcement was made during a lecture covering comprehensive efforts in training language models and enhancing reasoning capabilities.
- Berkeley LLM Agents course will use RLVR: A unique reinforcement learning method with verifiable rewards (RLVR) is being showcased as a means to train language models effectively, aiming to significantly impact reasoning during training.
- Hanna shared insights into testing strategies that incorporate these advanced reinforcement learning techniques during the lecture.
- MOOC Students face Quiz Submission Relief: It was clarified that quiz deadlines apply only to Berkeley students, with all quizzes for MOOC students due at the end of the semester.
- This clarification provided reassurance to latecomers and those concerned about meeting initial deadlines.
- MOOC curriculum details coming soon: A member announced that MOOC curriculum details will be released soon, including a project component, referencing a discord link.
- However, the research track is only for Berkeley students.
Notebook LM Discord
- Enthusiasm Erupts for Google Deep Research & Gemini Integration: Discussion ignited around integrating Google Deep Research and Gemini with NotebookLM for enhanced capabilities.
- Enthusiasts expressed excitement for future developments.
- Users Struggle with NotebookLM Language Settings: Concerns surfaced about altering language settings in NotebookLM without affecting the Google account language.
- A user sought advice on implementing such language changes effectively.
- Creative Book Digitization Tactics Emerge: A member suggested photographing each page with a lens app to create a PDF, then converting it to PowerPoint for upload to NotebookLM.
- Alternatives were suggested, such as using copiers or Adobe's Scan app for direct PDF creation.
- Multi-Language Prompt Effectiveness Analyzed: Debates arose on whether to use single or multiple prompts to facilitate hosts speaking in German within NotebookLM.
- A member speculated that effectiveness might be tied to their premium subscription status.
- Claude 3.7 Sparks User Frenzy: Enthusiasm surrounded Claude 3.7, with users wishing for more control in choosing models.
- A user initiated discussions around the impacts of such a decision on user experience.
LlamaIndex Discord
- AI Assistant goes Live for LlamaIndex: The excellent AI assistant on the LlamaIndex docs is now available for everyone to use! Check it out here.
- The team is excited to see how users incorporate it into their workflows.
- ComposioHQ Drops Another Hit!: Another banger has been released from ComposioHQ! It continues to impress with its features and functionality.
- Early adopters praise the intuitive interface and robust feature set, saying they are excited for further improvements.
- Anthropic Drops Claude Sonnet 3.7: AnthropicAI dropped Claude Sonnet 3.7, and the vibes and evaluations are positive. Day 0 support is available via
pip install llama-index-llms-anthropic --upgrade.- More details can be found in Anthropic's announcement post, highlighting latest integration capabilities with this new release.
- BM25 Retriever Needs Nodes: A member noted that the BM25 retriever cannot be initialized from the vector store alone because the docstore must contain saved nodes.
- One suggestion to get around the issue was to set top k to 10000 to retrieve all nodes, though this might not be efficient.
- MultiModalVectorStoreIndex Struggles with Images: A member encountered an error related to image files while trying to create a MultiModalVectorStoreIndex, despite having images in a GCS bucket.
- The issue arises specifically for images, as their code works fine for PDF documents, suggesting a need for better image handling in the index.
Torchtune Discord
- TorchTune Debates Fine-Tuning Truncation: A discussion emerged in Torchtune's #dev channel about whether to default to left truncation instead of right truncation for fine-tuning, referencing a supportive graph.
- Opinions were mixed, with some acknowledging that HF's current default is right truncation and others advocating for a change.
- StatefulDataLoader Seeks Review: A member requested a review for their pull request adding support for the StatefulDataLoader class to Torchtune.
- The pull request aims to introduce new features and address potential bug fixes within the Torchtune framework.
- DeepScaleR Leaps Ahead of O1-Preview Using RL: The DeepScaleR model, fine-tuned from Deepseek-R1-Distilled-Qwen-1.5B using reinforcement learning, achieved 43.1% Pass@1 accuracy on AIME2024, a 14.3% jump beyond O1-preview according to their Notion.
- This underscores the effectiveness of reinforcement learning in scaling models for enhanced accuracy.
- Deepseek Opens DeepEP Communication Library: As part of #OpenSourceWeek, Deepseek AI launched DeepEP, an open-source communication library tailored for Mixture of Experts (MoE) model training and inference, according to their tweet.
- With FP8 dispatch support and optimized intranode and internode communication, DeepEP strives to streamline both training and inference phases, and is available on GitHub.
Cohere Discord
- Validator Viability in DeSci Queried: A user asked about the profitability threshold for POS Validators within the DeSci space.
- This query underlines the importance of economic feasibility for running nodes in decentralized science.
- Validator Pooling Strategies Discussed: A user mentioned pool validator nodes, showing interest in shared resources or collaboration among validators.
- This hints at a move to boost validator efficiency through pooling methods.
- Asset Valuation Expertise Debated: A message mentioned the term asset value expert, though its context was unclear due to other unrelated terms.
- This raises questions about the importance of expertise in assessing asset valuations within the discussed topics.
Nomic.ai (GPT4All) Discord
- GPT4All v3.10.0 Arrives with Upgrades: GPT4All v3.10.0 debuts with better remote model configuration and broader model support and addresses crash issues.
- Enhancements span stable performance and several crash fixes across the platform.
- Remote Model Configuration Smoothens: The Add Model page now sports a dedicated tab for remote model providers like Groq, OpenAI, and Mistral for more accessible model configuration.
- This enhancement aims to make the integration of external solutions seamless within the GPT4All environment.
- CUDA Compatibility Makes Broader: The update introduces support for GPUs with CUDA compute capability 5.0, expanding the range of compatible hardware.
- This includes the GTX 750, which boosts accessibility for users with varied hardware configurations.
- Versioning Queries Sparked by GPT4All: Confusion arose among members about whether v3.10.0 should instead be labeled v4.0, prompting queries about versioning practices.
- This confusion was compounded by the recent launch of Nomic Embed v2.
- Nomic Embed v2 Anticipated by Users: Users eagerly await GPT4All v4.0.0, especially since the current version still relies on Nomic Embed v1.5 despite the new version's availability.
- The community reminds itself that patience is key as they anticipate forthcoming updates.
DSPy Discord
- phi4 Response Remains Different: The phi4 response format has some differences from most, with a tutorial pending.
- A tutorial is in the works to explain it better.
- Assertion Migration Streamlined: Those migrating from 2.5-style Assertions can use
dspy.BestOfNordspy.Refineto streamline modules.- These new options promise greater efficiency over traditional assertions.
- BestOfN Implemented: An example demonstrated implementing
dspy.BestOfNwithin a ChainOfThought module, allowing up to 5 retries.- The method will select the best reward, halting when the threshold is reached.
- Reward Function Decoded: A sample
reward_fnwas shared, showing how it returns scalar values like float or bool to evaluate prediction field lengths.- This function is applicable within the context of the dspy.BestOfN implementation.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (1056 messages🔥🔥🔥):
Claude 3.7, MCP Tools, Cursor Updates, Thinking Model, User Experiences
- Claude 3.7 Performance: Users are reporting significant improvements with Claude 3.7, particularly highlighting its effectiveness in coding tasks and its ability to handle complex prompts more efficiently than 3.5.
- The thinking model has shown better performance in planning and debugging, although some users expressed frustration with its execution in agent mode.
- MCP Tools Usage: The integration of various MCP tools is enhancing user experiences, especially with the use of custom instructions that guide the model in functioning effectively with files and commands.
- Users are exploring how to optimize their setups, leveraging features like deep thinking and browser tools to improve project outcomes.
- Cursor Updates and Bugs: Discussions included issues with Cursor's functionality, particularly regarding folder indexing and the ability to edit files across multiple directories in 0.46.
- Users are advised to check their settings to resolve indexing problems, and there's ongoing feedback to refine the platform.
- Comparative Model Analysis: Several users noted that while 3.7 provides a good experience, there are still hiccups, particularly when utilized alongside non-thinking models or older versions.
- The community appears interested in how Golang and other languages perform under Claude 3.7's capabilities, with a focus on adapting workflows and evaluating output quality.
- Community Engagement and Sharing: Members shared useful links and tools related to Claude and discussed experiences with various AI models, including Grok and Qwen.
- The conversation also revolved around optimizing interactions within cursor and finding effective prompts to maximize performance.
- no title found: no description found
- Tweet from Cursor (@cursor_ai): Sonnet-3.7 is available in Cursor! We've been very impressed by its coding ability, especially on real-world agentic tasks. It appears to be the new state of the art.
- Tweet from Sualeh (@sualehasif996): Configurable thinking out soon! 👀Quoting Cursor (@cursor_ai) Sonnet-3.7 is available in Cursor! We've been very impressed by its coding ability, especially on real-world agentic tasks. It appear...
- Tweet from Qwen (@Alibaba_Qwen):
... QwQ-Max-PreviewQwen Chat: https://chat.qwen.ai/Blog: https://qwenlm.github.io/blog/qwq-max-preview/🤔 Today we release "Thinking (QwQ)" in Qwen Chat, backed by o... - Tweet from Cursor (@cursor_ai): We're rolling out access to the highest level of thinking. To try it out, select claude-3.7-sonnet-thinking or claude-3.7-sonnet and enable agent mode.
- Tweet from Chujie Zheng (@ChujieZheng): r u kidding me dude?
- no title found: no description found
- Tweet from Theo - t3.gg (@theo): The claude 3.7 thinking model fails the bouncing ball challenge the same way that grok 3 did? 🤔
- Vibe Coding | Bonfire: Buy Vibe Coding merchandise that supports Nova Ukraine. Featuring Dark Heather Grey Premium Unisex Tees, professionally printed in the USA.
- Vibe Coding | Bonfire: Buy Vibe Coding merchandise that supports Nova Ukraine. Featuring Dark Heather Grey Premium Unisex Tees, professionally printed in the USA.
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- Tweet from Sualeh (@sualehasif996): Configurable thinking out soon! 👀Quoting Cursor (@cursor_ai) Sonnet-3.7 is available in Cursor! We've been very impressed by its coding ability, especially on real-world agentic tasks. It appear...
- Claude Code overview - Anthropic: no description found
- Cursor Directory: Find the best cursor rules for your framework and language
- Anthropic Status: no description found
- Indexing only reads first folder in the workspace: Any update on this? this is really importanttt 😬
- Integrate Claude 3.7 Sonnet into Cursor: Hello! I would love to see Claude’s new reasoning-model (3.7) being integrated with the agent inside of composer. Regards Johannes.
- GitHub - alexandephilia/ChatGPT-x-DeepSeek-x-Claude-Linux-APP: Electron-based desktop applications for various AI chat platforms.: Electron-based desktop applications for various AI chat platforms. - GitHub - alexandephilia/ChatGPT-x-DeepSeek-x-Claude-Linux-APP: Electron-based desktop applications for various AI chat platforms.
- It Turn On And Off GIF - IT Turn On And Off Phone Call - Discover & Share GIFs: Click to view the GIF
- GitHub - AgentDeskAI/browser-tools-mcp: Monitor browser logs directly from Cursor and other MCP compatible IDEs.: Monitor browser logs directly from Cursor and other MCP compatible IDEs. - AgentDeskAI/browser-tools-mcp
- docs: Add Windows-specific build instructions by rexdotsh · Pull Request #4 · daniel-lxs/mcp-starter: Hi, thanks for the great tool!I've added some instructions for using -ldflags "-H=windowsgui" when building on Windows to prevent terminal windows from opening every time cur...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Changelog | Cursor - The AI Code Editor: New updates and improvements.
- Qwen Chat: no description found
aider (Paul Gauthier) ▷ #general (935 messages🔥🔥🔥):
Claude 3.7 Performance, Comparisons with Other Models, Aider Features and Performance, Claude Code Evaluation, Rate Limits and API Issues
- Claude 3.7 sets SOTA on Aider Leaderboard: Claude 3.7 Sonnet scored 65% on the Aider leaderboard utilizing 32k thinking tokens, outperforming previous models.
- In contrast, the non-thinking version scored 60%, indicating significant improvements, but some users find the difference in utility less impactful.
- Comparison with Other Models: Users note that Claude 3.7's performance is marginally better than models like Grok 3, with discussions on the pricing differences of $15/M compared to Grok's $2.19/M.
- Some users expressed disappointment, hoping for a larger gap in performance, emphasizing that the cost may not justify the improvements seen.
- Aider Features and Performance: Aider version 0.75.1 adds support for Claude 3.7, allowing users to experiment with new features while managing costs effectively.
- Users are actively discussing how Aider's various commands, like
--copy-paste, could be improved and made more efficient in workflows with Claude.
- Users are actively discussing how Aider's various commands, like
- Claude Code Evaluation: The Claude Code interface is compared to Aider, with mixed opinions on usability and functionality, particularly in editing and generating code.
- Some users are exploring the implications of Claude Code’s design choices and how they can enhance their coding experience effectively.
- Rate Limits and API Issues: Users encounter issues with rate limits while using various API models, including Claude, leading to frustrations during coding tasks.
- There’s a desire for improved consistency and performance across different tools while discussing the advantages and disadvantages of using alternative platforms.
- LiveBench: no description found
- Tweet from Anthropic (@AnthropicAI): Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.One model, two ways to think.W...
- Tweet from Cursor (@cursor_ai): Sonnet-3.7 is available in Cursor! We've been very impressed by its coding ability, especially on real-world agentic tasks. It appears to be the new state of the art.
- Copy/paste with web chat: Aider works with LLM web chat UIs
- Tweet from adi (@adonis_singh): dude whati just asked how many r's it has, claude sonnet 3.7 spun up an interactive learning platform for me to learn it myself 😂
- Tweet from Anthropic (@AnthropicAI): Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.One model, two ways to think.W...
- Model warnings: aider is AI pair programming in your terminal
- Anthropic Console: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- Pricing: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- Claude 3.7 Sonnet - API, Providers, Stats: Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. Run Claude 3.7 Sonnet with API
- All models overview - Anthropic: no description found
- Claude Code overview - Anthropic: no description found
- Building with extended thinking - Anthropic: no description found
- Grito Ahhhh GIF - Grito Ahhhh Hongo - Discover & Share GIFs: Click to view the GIF
- Sweaty Speedruner GIF - Sweaty Speedruner - Discover & Share GIFs: Click to view the GIF
- Drago Ivan I Must Break You GIF - Drago Ivan I Must Break You Rocky - Discover & Share GIFs: Click to view the GIF
- Home - Anthropic: no description found
- Contact Anthropic: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- no title found: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (63 messages🔥🔥):
Architect Mode Configuration, Managing AI Models in Aider, Using OpenRouter for AI Access, Token Management in AI, Integration with Git in Aider
- Understanding
/architectMode: Discussion focused on how the/architectmode in Aider uses different models for editing and reasoning, specifically withmodel: o1-previewandeditor-model: o1-miniconfigurations.- It was noted that to efficiently use both architecture and editing functions, switching models at runtime using
/modelis ideal for flexibility.
- It was noted that to efficiently use both architecture and editing functions, switching models at runtime using
- Exploring OpenRouter Benefits: Users shared insights about the OpenRouter service, emphasizing its advantages in bypassing rate limits and centralizing API key management for various models.
- Although the pricing for models was similar to those of original providers, the convenience of accessing multiple APIs through one interface was a significant benefit.
- Managing Token Usage: Concerns were raised regarding token limits and management when using models like
claude-3-7-sonnet-20250219, particularly when switching between thinking and editing modes.- Participants discussed how configuring token budgets could improve the efficiency of interactions while managing input and output tokens effectively.
- Integration with Git in Aider: Aider's
/gitcommand was highlighted as a useful feature for tracking changes in a remote repository, with suggestions for frequent checks using/git statusand/git pullcommands.- For automated updates, ideas like employing a bash script to run git commands periodically were proposed, although users were looking for built-in solutions.
- Using Sonnet 3.7 and Thinking Mode: There was curiosity about how to effectively enable the thinking mode while disabling reasoning in the editor model when using Aider with Sonnet 3.7.
- The group discussed whether there was a way to separate the thinking process from the editing capabilities, particularly with the new API's features.
- Chat modes: Using the code, architect, ask and help chat modes.
- o3 Mini High - API, Providers, Stats: OpenAI o3-mini-high is the same model as [o3-mini](/openai/o3-mini) with reasoning_effort set to high. o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excel...
- o1 tops aider’s new polyglot leaderboard: o1 scores the top result on aider’s new multi-language, more challenging coding benchmark.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Advanced model settings: Configuring advanced settings for LLMs.
- aider/aider/coders/architect_coder.py at 0ba1e8f90435aa2c08360d152fe8e16f98efd258 · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #links (2 messages):
Hacker News Wrapped, Kagi LLM Benchmarking Project
- Hacker News Wrapped for Profile Insights: Claude Sonnet 3.7 allows users to analyze their Hacker News profiles, providing highlights and trends that are hilariously accurate.
- Users expressed interest in getting their profiles 'roasted' by this AI for its entertainingly insightful critiques.
- Kagi LLM Benchmarking Reveals New Insights: The Kagi LLM Benchmarking Project evaluates major large language models on reasoning, coding, and instruction following with changing, novel tasks to avoid benchmark overfitting.
- Last updated on February 24, 2025, results showcase models such as Google's gemini-2.0 scoring 60.78%, while OpenAI's gpt-4o lagged behind at 48.39%.
- HN Wrapped: AI analyzes your HN profile and gives you your 2024 recap
- Kagi LLM Benchmarking Project | Kagi's Docs: no description found
Codeium (Windsurf) ▷ #discussion (15 messages🔥):
Codeium Chat in Vim, Account Creation Issues, Codeium Extensions and Support, Version Update Queries, Forum Visibility for Issues
- Help Needed for Codeium Chat in Vim: A member struggled to start the Codeium Chat in Vim through their SSH session, receiving a connection error when attempting to access the provided URL.
- Another member inquired if the user was utilizing Vim or Neovim extensions before suggesting they seek help in the relevant extension channel.
- Trouble Creating New Codeium Account: A user expressed frustration about being unable to create a new account, encountering an internal error message.
- This raised questions about whether others were experiencing similar issues with account creation.
- Clarification on Codeium Extensions: A member clarified that the channel is focused on the Codeium extension for various editors such as Visual Studio Code and Neovim.
- Discussions highlighted the importance of directing specific queries to the appropriate support formats on the Codeium site.
- Querying About Codeium Version 3.7 Release: There was curiosity regarding the release of version 3.7, with one member humorously suggesting the lack of updates might be frustrating.
- Another user inquired about the process for switching to pre-release versions in JetBrains IDEs, discussing limitations with stable channels.
- Seeking Forum for Visibility on Issues: A member considered taking their issue to the forum for greater visibility before being advised to reach out through the Codeium support page instead.
- Follow-up support was offered by another member to ensure that ticket numbers would receive proper attention.
Codeium (Windsurf) ▷ #windsurf (675 messages🔥🔥🔥):
Claude 3.7 release, Windsurf vs Cursor, MCP issues, Ecommerce experiences, Laravel vs JavaScript frameworks
- Claude 3.7 eagerly awaited for Windsurf: Users express frustration over the delay in the rollout of Claude 3.7 for Windsurf, noting that Cursor users have already received access.
- The community discusses potential usability improvements and enhancements that 3.7 is expected to bring.
- Windsurf vs Cursor performance discussions: Many users observe that Cursor might be a faster option since it's been quicker to implement new models compared to Windsurf.
- Some users still prefer Windsurf for its clean UI and integration capabilities despite Cursor's speed.
- MCP-related concerns: There are ongoing discussions regarding issues with MCP that prevent proper editing capabilities, leading users to temporarily edit configuration files.
- The community is sharing solutions for these issues while waiting for official fixes from the support team.
- Insights on ecommerce and frameworks: Several users share experiences with ecommerce, emphasizing the benefits of using Laravel for rapid deployment and stable performance.
- The discussion shifts to preferences between traditional frameworks versus modern JavaScript frameworks, highlighting the trade-offs.
- Thoughts on the future with Claude Code: Some users inquire about the possibility of integrating Claude Code with Windsurf, questioning its role in relation to the IDE.
- There's speculation about how Claude Code could complement Windsurf, enhancing development processes if integrated.
- Home: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- All models overview - Anthropic: no description found
- Claude Code overview - Anthropic: no description found
- Chewing Character Hd GIF - Chewing Character Chewing Character - Discover & Share GIFs: Click to view the GIF
- Good Juju Witch GIF - Good Juju Witch Good Vibes - Discover & Share GIFs: Click to view the GIF
- Codeium Feedback: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Feature Requests | Codeium: Give feedback to the Codeium team so we can make more informed product decisions. Powered by Canny.
- Stan Twitter Monkey Meme GIF - Stan twitter Monkey meme Monki - Discover & Share GIFs: Click to view the GIF
- Let Them Cook Let Them Fight GIF - Let them cook Let them fight Godzilla - Discover & Share GIFs: Click to view the GIF
- Surf Glider GIF - Surf Glider Wave - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- What is Vibe Coding? ☮️ 😎: Join My Newsletter for Regular AI Updates 👇🏼https://forwardfuture.aiMy Links 🔗👉🏻 Subscribe: https://www.youtube.com/@matthew_berman👉🏻 Twitter: https:/...
- Windsurf Editor Changelogs | Windsurf Editor and Codeium extensions: Latest updates and changes for the Windsurf Editor.
{kind=link}
OpenAI ▷ #ai-discussions (611 messages🔥🔥🔥):
Claude 3.7 vs ChatGPT, Grok 3 Performance, AI in Coding, Integration of AI in Projects, AI for Document Processing
- Comparing Claude 3.7 to ChatGPT Models: Discussions around Claude 3.7 reveal it may outperform ChatGPT models, particularly in coding and web development tasks, while ChatGPT has faced criticism for its stubbornness in following specific instructions.
- Users noted that Claude maintains better consistency and reliability, especially in coding, contrasting with the more expressive but occasionally erratic OpenAI models.
- Applications of AI in Document Processing: A user shared the challenge of synthesizing a lengthy travel record for a citizenship application using AI, seeking advice on starting such a task given its complexity.
- There's interest in leveraging AI to automate document retrieval and synthesis, highlighting the potential for AI in administrative and bureaucratic assistance.
- Grok 3 Versatility and Performance: Grok 3 is praised for its capabilities, particularly in coding, with users encouraging its use within IDEs like Copilot for effective project assistance.
- The model's ability to handle projects while integrating Claude 3.7's features was discussed, emphasizing its strengths in frontend development.
- AI Industry Insights and Trends: The conversation touched on industry trends, including the rise of free AI tools and platforms, with ByteDance's 'Trae' offering free access to advanced AI models as a competitive strategy.
- Participants noted the temporary nature of free offerings and discussed the implications for consumer access and services in the AI space.
- Concerns with AI Model Limitations: Users expressed frustration with certain AI models' limitations and the challenges of managing complex tasks, particularly in visual programming.
- The sentiment was that while advancements are made, there are still significant hurdles, especially regarding user experience and intuitive interaction with AI.
- Tweet from Alex Albert (@alexalbert__): We're opening limited access to a research preview of a new agentic coding tool we're building: Claude Code.You'll get Claude-powered code assistance, file operations, and task execution d...
- Tweet from Jimmy Apples 🍎/acc (@apples_jimmy): Die RevancheTomorrow.
- Tweet from Anthropic (@AnthropicAI): Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.One model, two ways to think.W...
- Tweet from Rowan Cheung (@rowancheung): Anthropic's just dropped Claude 3.7 Sonnet, the best coding AI model in the world.I was an early tester, and it blew my mind.It created this Minecraft clone in one prompt, and made it instantly pl...
- LLM Leaderboard 2025 - Compare LLMs: Comprehensive AI (LLM) leaderboard with benchmarks, pricing, and capabilities. Compare leading LLMs with interactive visualizations, rankings and comparisons.
- Claude Code overview - Anthropic: no description found
- Claude's extended thinking: Discussing Claude's new thought process
- HTML5 Genetic Algorithm 2D Car Thingy - Chrome recommended: no description found
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- PolyTrack by Kodub: A high speed low-poly racing game.
- So-called junk DNA plays critical role in mammalian development - Berkeley News: Some of the viruses that invaded the mammalian genome long ago have been repurposed for key roles in development, new research shows
- Broderbund Software - Stunts v1.1 [1991]: Stunts (aka 4D Sports Driving) is a great race game from DOS years!If you wanna play it again, follow the instructions below:1-) Get the game;2-) And use a D...
- Reddit - Dive into anything: no description found
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
O3 reasoning issues, Model feedback discrepancies, Screenshot posting limitations, Bug reporting process
- O3 reasoning suffers from delays: Users report that O3 frequently shows 'reasoning success' but then delivers the whole text after a delay of up to 10 seconds or more.
- One user mentioned experiencing these problems consistently between 3pm-7pm EST, impacting all 'thinking' models.
- Inconsistent model responses: A user explained their frustration with receiving expected text on mobile instead of the browser, and vice versa, often resulting in no response at all.
- The lack of clarity regarding output has led to countless instances of blank response feedback over the past 10 days.
- Screenshot limitations in chat channels: A member raised a query on why they couldn't add screenshots in the current chat, referencing different channel settings regarding screenshot support.
- Another user suggested posting in a different channel that supports screenshots for better assistance.
- Navigating bug report channels: Users were guided on how to post a new bug report, emphasizing that looking around for similar issues may be beneficial.
- They shared a link to a channel that shows steps for reporting bugs or commenting on existing ones that align with their experience.
Unsloth AI (Daniel Han) ▷ #general (345 messages🔥🔥):
Unsloth AI Challenge, DeepSeek Release, Training Configuration Issues, Hyperfitting and Resource Management, Custom Loss Function Implementation
- Unsloth AI Challenge submissions: Participants can submit multiple solutions for the Unsloth Challenge, with no set limit on submissions. Currently, about 30 submissions have been reviewed, but none have met the threshold for offers yet.
- Mentions of encouraging recommendations for the challenge to help find qualified candidates were also discussed.
- New DeepSeek release and its implications: The Day Two DeepSeek OSS release introduced features like MoE kernels and efficient communication libraries, which some feel cater more towards large companies than individual developers. There is speculation on how this openness might affect competition and the landscape of AI development.
- There's a mix of excitement and skepticism about the new tools, particularly concerning how they could lower costs for running models.
- Training Configuration Issues: Confusion arose regarding differences in validation loss when switching from batch size 8 to batch size 1 with gradient accumulation. A participant noted their validation loss unexpectedly increased significantly despite using the same input data.
- Several participants discussed configurations and whether mixed setup strategies would yield similar results in terms of how the model learns.
- Hyperfitting and Resource Management: Discussions highlighted the potential to use hyperfitting techniques on smaller models and the implications of resource requirements when training. Participants reflected on their expectations for model capacity using limited VRAM and common training techniques.
- The conversation touched on how evolving training practices could potentially improve performance metrics at lower costs.
- Custom Loss Function Implementation: An inquiry was made about using custom loss functions to incorporate a regularization term into existing models. Participants encouraged exploring implementation strategies to achieve desired outcomes effectively.
- The emphasis was placed on how modifications to loss functions could impact models' learning capabilities, particularly in fine-tuning scenarios.
- Tweet from Daniel Han (@danielhanchen): DeepSeek #2 OSS release! MoE kernels, expert parallelism, FP8 for both training and inference!Quoting DeepSeek (@deepseek_ai) 🚀 Day 2 of #OpenSourceWeek: DeepEPExcited to introduce DeepEP - the first...
- BarraHome/llama3.2-1b-mla · Hugging Face: no description found
- How to save memory by fusing the optimizer step into the backward pass — PyTorch Tutorials 2.6.0+cu124 documentation: no description found
- Guinea Pig Chewing GIF - Guinea pig Chewing Chew - Discover & Share GIFs: Click to view the GIF
- CUDA semantics — PyTorch 2.6 documentation: no description found
- GitHub - fxmeng/TransMLA: TransMLA: Multi-Head Latent Attention Is All You Need: TransMLA: Multi-Head Latent Attention Is All You Need - fxmeng/TransMLA
- vllm/benchmarks at db986c19ea35d7f3522a45d5205bf5d3ffab14e4 · vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllm
- Reasoning - GRPO & RL | Unsloth Documentation: Train your own DeepSeek-R1 reasoning model with Unsloth using GRPO which is a part of Reinforcement Learning (RL) fine-tuning.
- Fine-tuning Guide | Unsloth Documentation: Learn all the basics of fine-tuning.
- Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs: Multi-head Latent Attention (MLA) is an innovative architecture proposed by DeepSeek, designed to ensure efficient and economical inference by significantly compressing the Key-Value (KV) cache into a...
- jt - Overview: jt has 4 repositories available. Follow their code on GitHub.
- GitHub - vllm-project/aibrix: Cost-efficient and pluggable Infrastructure components for GenAI inference: Cost-efficient and pluggable Infrastructure components for GenAI inference - vllm-project/aibrix
- GitHub - facebookresearch/optimizers: For optimization algorithm research and development.: For optimization algorithm research and development. - facebookresearch/optimizers
- GitHub - JT-Ushio/MHA2MLA: Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs: Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs - JT-Ushio/MHA2MLA
Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
deoxykev: New qwq https://qwenlm.github.io/blog/qwq-max-preview/
Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
Unsloth on Mac, CUDA Memory Issues, Using Custom Datasets, Checkpointing and VRAM Management, Custom Loss Functions
- Unsloth's Compatibility with Mac: There's an ongoing discussion about running Unsloth on Macs, noting that while models can run, Unsloth does not work on Macs yet, leading to suggested alternatives like using external GPU docks or renting GPU servers.
- A user mentioned using Tensordock for inexpensive GPU server rentals, with recommendations also including Google’s free resources.
- Addressing CUDA Memory Errors: Users are encountering 'illegal memory access' errors during training, with recommendations to check CUDA installation and ensure PyTorch detects the GPU.
- It's suggested to run specific commands in Python to verify the CUDA availability and the PyTorch version.
- Custom Datasets Formatting: A new user inquired about proper formatting guidelines for their own dataset, confirming that the dataset should align with the ShareGPT format as referenced in the notebooks.
- Individuals were encouraged to use the notebooks as a guideline, indicating flexibility in dataset structure.
- Managing VRAM During Checkpointing: Discussions focused on the need for VRAM management during training, particularly the significant spikes in memory usage during model saving operations.
- Users suggested saving models to LoRA to unload VRAM and identified that the checkpointing process sometimes mirrors this behavior.
- Implementing Custom Loss Functions: A user asked about integrating a custom loss function to include a regularization term, showing a need for guidance in modifying loss functions.
- This indicates an interest in refining model training processes within the Unsloth framework.
- Unsloth Notebooks | Unsloth Documentation: Below is a list of all our notebooks:
- Installing + Updating | Unsloth Documentation: Learn to install Unsloth locally or online.
- Unsloth On Mac · Issue #685 · unslothai/unsloth: So, I have a macbook, and when i run my model on it, i bascially get an error saying no CUDA device found. I know that there is no gpu on macbooks, so does that mean that I cannot run my model on m...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Claude 3.7 Sonnet, AI capabilities improvement, Pricing model for Claude, Extended Thinking feature
- Claude 3.7 Sonnet Launches: Claude 3.7 Sonnet is now available on OpenRouter, marking a significant advancement in AI, especially in mathematical reasoning, coding, and complex problem-solving. For complete details, check the blog post.
- This release introduces notable enhancements in agentic workflows and offers users a choice between rapid and extended reasoning processes.
- Pricing and Usage of Claude 3.7: The pricing model for Claude 3.7 Sonnet is set at $3 per million tokens for input and $15 per million tokens for output, which includes thinking tokens. This pricing structure is aimed at optimizing user engagement while utilizing the model.
- The launch includes full caching support to enhance performance during usage.
- Upcoming Extended Thinking Feature: An upcoming feature, Extended Thinking, is set to be integrated into the OpenRouter API, enhancing the capabilities of the Claude model. More information is available in the Extended Thinking documentation.
- This feature is expected to provide users with advanced options for processing complex tasks, further improving the model's usability.
- Home - Anthropic: no description found
- Claude 3.7 Sonnet - API, Providers, Stats: Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. Run Claude 3.7 Sonnet with API
OpenRouter (Alex Atallah) ▷ #general (346 messages🔥🔥):
Claude 3.7 Sonnet Features, API Key Management, Chat Continuation Across Devices, Model Pricing and Performance, Image Handling in Claude 3.7
- Exploring Claude 3.7's Extended Thinking: Participants discussed the capabilities of Claude 3.7 Sonnet, confirming that extended thinking features aren't fully implemented yet but are pending documentation and support.
- There was excitement regarding the hybrid model's potential to select thinking levels, illustrating its advanced reasoning capacity.
- Managing API Keys and Credits: Users expressed concerns over lost API keys and how they relate to account credits, with assurances that credits remain intact regardless of key status.
- New keys can be generated without losing credits, which are attached to the account rather than the keys themselves.
- Device Synchronization Limitations: It was noted that OpenRouter does not currently support synchronization of chat sessions between devices, such as from browser to phone.
- Alternative methods like chatterui and typign mind were suggested for bridging this gap.
- Issues with Image Uploads: There were frequent errors reported with Claude 3.7, specifically related to image sizes exceeding 5MB, which halted the completion of requests.
- Users were encouraged to manage image sizes to comply with API requirements and avoid request failures.
- Comparison of Model Costs: Participants compared Claude's pricing structure with other models, noting that it's perceived as high but competitive in certain performance areas.
- The conversation highlighted the costs versus usability, particularly around reasoning tasks and their implications on overall expenses.
- Claude 3.7 Sonnet - API, Providers, Stats: Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. Run Claude 3.7 Sonnet with API
- Ponke Ponkesol GIF - Ponke Ponkesol Solana - Discover & Share GIFs: Click to view the GIF
- AI Accelerator - AWS Trainium - AWS: no description found
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- Extended thinking models - Anthropic: no description found
- Telmo Coca GIF - Telmo Coca Harina - Discover & Share GIFs: Click to view the GIF
- Google agrees to new $1 billion investment in Anthropic: Google has agreed to a new investment of more than $1 billion in generative AI startup Anthropic, a person familiar with the situation confirmed to CNBC.
Interconnects (Nathan Lambert) ▷ #news (304 messages🔥🔥):
Claude 3.7 Sonnet Release, Qwen AI Developments, Agentic Coding Tools, Open Source Initiatives, RLHF and Code Quality
- Claude 3.7 Sonnet impresses with new features: Claude 3.7 Sonnet has launched with improved reasoning capabilities and interaction flexibility, being noted for its performance in coding tasks and debugging.
- Users have found that while it provides detailed refactoring, it may sometimes result in more complex code than intended, challenging common coding paradigms.
- Qwen AI's QwQ-Max Preview: Qwen's recent release of the QwQ-Max-Preview showcases its reasoning capabilities, promising improved performance and open-source accessibility under Apache 2.0.
- The launch comes amid praises for its creative problem-solving and potential applications across various domains.
- Emerging trends in agentic coding tools: The introduction of tools like Claude Code and DeepEP marks a shift toward more sophisticated coding assistance, aiming to streamline the development process.
- As competition intensifies, offerings from various labs are pushing the boundaries of what coding models can achieve, including features focused on efficiency and flexibility.
- Open Source Week highlights: DeepSeek announced its open-source EP communication library, DeepEP, focusing on efficient communication for model training, signaling a commitment to collaboration in AI development.
- This reinforces the trend of open-sourcing AI technologies, allowing broader community engagement and innovation.
- Questions around RLHF and code generation: Discussants are contemplating how Reinforcement Learning from Human Feedback (RLHF) influences code quality, with concerns about models favoring more complex 'production feeling' code over simplicity.
- This discussion raises awareness about the fundamental goals of training coding models and the potential discrepancies in output quality.
- Tweet from Chujie Zheng (@ChujieZheng): r u kidding me dude?
- Tweet from Cursor (@cursor_ai): Sonnet-3.7 is available in Cursor! We've been very impressed by its coding ability, especially on real-world agentic tasks. It appears to be the new state of the art.
... QwQ-Max-Preview | Qwen: no description found- A new generation of AIs: Claude 3.7 and Grok 3: Yes, AI suddenly got better... again
- A new generation of AIs: Claude 3.7 and Grok 3: Yes, AI suddenly got better... again
- Claude's extended thinking: Discussing Claude's new thought process
- Tweet from Qwen (@Alibaba_Qwen): Agent
- Tweet from dinos (@din0s_): anthropic in one screenshot
- Tweet from Xeophon (@TheXeophon): Sonnet 3.7 Thinking (with budget of 16K tokens) is the best model at neal's password game, congrats!It *almost* got past stage 11, but it insisted that the wordle is solved :(Quoting Xeophon (@The...
- Tweet from Dimitris Papailiopoulos (@DimitrisPapail): Claude 3.7 Sonnet please draw the Acropolis of Athens in tikz results with: - no reasoning - 10k reasoning tokens - 30k reasoning tokens - 64k reasoning tokensQuoting Dimitris Papailiopoulos (@Dimitri...
- Tweet from Qwen (@Alibaba_Qwen):
... QwQ-Max-PreviewQwen Chat: https://chat.qwen.ai/Blog: https://qwenlm.github.io/blog/qwq-max-preview/🤔 Today we release "Thinking (QwQ)" in Qwen Chat, backed by o... - Tweet from skcd (@skcd42): the new sonnet3.7 review as someone who has used it before:- the new sonnet is great, on our internal evals on rust we see 14.7% (40% around) improvement (this eval is made up of 1k questions)- it has...
- Tweet from Naman Jain (@StringChaos): Check out evaluations for QwQ-Max-Preview on LiveCodeBench where it performs on par with o1-medium🚀!!Quoting Qwen (@Alibaba_Qwen)
... QwQ-Max-PreviewQwen Chat: https://chat... - Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Congrats to @AnthropicAI on the release of Claude 3.7 Sonnet! 👏 Come test it with your hardest prompts at lmarena!Quoting Anthropic (@AnthropicAI) Introducing Claude 3.7 Sonnet: our most intelligent ...
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Claude 3.7 Sonnet System Card was just dropped!
- Tweet from Dimitris Papailiopoulos (@DimitrisPapail): OK THIS IS REALLY COOLClaude 3.7 Sonnet please draw in tikz - a human that is inside a house- the house is inscribed in a sphere- the sphere is inscribed in a cube- the cube is inscribed in a cylinder...
- Tweet from Lewis Tunstall (@_lewtun): Finally, an AI lab published plots with proper labels and all 🥹
- Google Co-Scientist AI cracks superbug problem in two days! — because it had been fed the team’s previous paper with the answer in it: The hype cycle for Google’s fabulous new AI Co-Scientist tool, based on the Gemini LLM, includes a BBC headline about how José Penadés’ team at Imperial College asked the tool about a problem…
- Tweet from adi (@adonis_singh): dude whati just asked how many r's it has, claude sonnet 3.7 spun up an interactive learning platform for me to learn it myself 😂
- Tweet from wh (@nrehiew_): To be more specific, it looks like the "thinking budget tokens" parameter in the API is just never sampling the end-of-thinking token until the budget is used up.No prompt conditioning, no spe...
- Tweet from Paul Gauthier (@paulgauthier): Claude 3.7 Sonnet scored 60% on the aider polyglot benchmark w/o thinking. Tied in 3rd with o3-mini-high. Sonnet 3.7 has the highest non-thinking score (formerly Sonnet 3.5). Thinking results coming s...
- Tweet from near (@nearcyan): CLAUDE IS HERE!HE IS BACK AND BETTER THAN EVER!I'll share one of my first prompt results, which was for a 3D visualization of microtonal music.This is the best model in the world currently. Many w...
- Tweet from Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭 (@elder_plinius): 🚂 JAILBREAK ALERT 🚂ANTHROPIC: PWNED ✌️😛CLAUDE-SONNET-3.7: LIBERATED 🗽Wooo new Claude model!!! 🤗 And wouldn't you know it, the original "GODMODE" universal jailbreak that I wrote almos...
- Tweet from Tibor Blaho (@btibor91): "Currently only shipping within the United States." :(Quoting wh (@nrehiew_) There is a "hidden easter egg" tool in the Claude Code NPM source that ships Anthropic stickers to users :)
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- Claude 3.7 Sonnet with extended thinking: Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step ...
- Tweet from Cognition (@cognition_labs): 1/ Claude 3.7 Sonnet is live in Devin! The new model is the best we have seen to-date on a variety of tasks including debugging, codebase search, and agentic planning.
- Claude's extended thinking: Discussing Claude's new thought process
- It’s RAAAAAAW Supercut (2 Million Subscribers Special) | Hell’s Kitchen: IT’S RAAAAAAW!!! To celebrate the channel reaching 2 million subscribers, we cut together every time chef Ramsay loses it over a raw piece of meat or fish fr...
- Tweet from DeepSeek (@deepseek_ai): 🚀 Day 2 of #OpenSourceWeek: DeepEPExcited to introduce DeepEP - the first open-source EP communication library for MoE model training and inference.✅ Efficient and optimized all-to-all communication✅...
- Tweet from Anthropic (@AnthropicAI): We've conducted extensive model testing for security, safety, and reliability.We also listened to your feedback. With Claude 3.7 Sonnet, we've reduced unnecessary refusals by 45% compared to i...
- Play Lovatts Free Online Cryptic Crossword - Updated Daily: Lovatts Free Online Cryptic Crossword is updated daily. Includes a 7-day Puzzle Archive, Hints & Timer. Learn the rules of the cryptic crossword game.
- Meta AI arrives in the Middle East and Africa with support for Arabic | TechCrunch: Meta AI has landed in the Middle East and North Africa with support for Arabic, opening the chatbot to millions more people.
- no title found: no description found
Interconnects (Nathan Lambert) ▷ #random (15 messages🔥):
Berkeley Advanced Agents MOOC, Hiring Announcements, RLHF Explanations, Stickers Discussion, AI Startups Customer Base
- Berkeley Advanced Agents welcomes Hanna Hajishirzi: The live session of the Berkeley Advanced Agents MOOC features Hanna Hajishirzi discussing Tulu 3 today at 4PM PST. Watch it on YouTube Live.
- Many participants have praised the course as being very informative so far.
- Kadoa is hiring!: A member shared a link to Kadoa's hiring page, indicating they are actively looking for new team members. Check out their posting here.
- This was accompanied by a playful note about generating a HN Wrapped.
- Explaining RLHF to laypeople: A tweet was shared that illustrates how to explain RLHF (Reinforcement Learning from Human Feedback) to a non-technical audience. The analogy used was described as surprisingly effective.
- Members expressed their amusement, with one noting that it's actually a good analogy.
- Sticker shipping woes: Members discussed the difficulty of obtaining stickers, particularly for one who is currently outside the US. One member humorously offered to take care of the stickers if sent.
- This lighthearted exchange included thoughts on whether stickers could be shipped quickly to NYC.
- AI startups' client reach: A member raised a question about whether AI startups have customers outside of Silicon Valley, followed by an observation about their claims of penetration in the Fortune 500. This led to further discussion about the actual customer bases of AI labs.
- Another member mentioned that the focus should be on their outreach to sectors beyond just the tech industry.
- HN Wrapped: AI analyzes your HN profile and gives you your 2024 recap
- Tweet from Shane Gu (@shaneguML): How I explain RLHF to non-technical audience
- Tweet from Andrew Curran (@AndrewCurran_): @repligate And this as well;
- CS 194/294-280 (Advanced LLM Agents) - Lecture 4, Hanna Hajishirzi: no description found
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
Image Analysis, Discord Bot Engagement
- Image Analysis Shared: A user shared an image for analysis that needs detailed attention regarding its content.
- This prompted a discussion among members about the relevance and interpretation of such images in the context of their ongoing projects.
- Engagement with Discord Bots: Members continued to engage with the Discord bot, using emojis to react and express feelings about recent updates.
- This showcases the interactive nature of the community and their appreciation for the bot's capabilities.
Interconnects (Nathan Lambert) ▷ #nlp (1 messages):
0x_paws: https://x.com/srush_nlp/status/1894039989526155341?s=46&t=Y6KMaD0vAihdhw7S8bL5WQ
Interconnects (Nathan Lambert) ▷ #posts (3 messages):
New Post GIF, SnailBot
- New Post GIF Sparks Interest: A colorful GIF has been shared, featuring a black background with multiple letters stating 'new post' which is engaging for the community.
- Various links for searching related GIFs were also provided, enhancing discoverability.
- SnailBot Get's Mentioned: A member tagged the SnailBot in the channel, likely to alert or update the group with some news.
- Another member humorously remarked on SnailBot's speed, comparing it to a snail with 'dayum fast today', bridging humor in the conversation.
Link mentioned: New New Post GIF - New New post Post - Discover & Share GIFs: Click to view the GIF
{kind=link}
GPU MODE ▷ #general (29 messages🔥):
SoTA gemv kernels, Using Tensor Cores, Leaderboards and Submissions, Memory Bound Operations, Data Types in Kernel Submissions
- Discussion on SoTA gemv kernels: A member shared a GitHub link to mobiusml/gemlite, which contains fast low-bit matmul kernels in Triton.
- They discussed the memory-bound nature of gemv and the expectations surrounding computation performance.
- Queries on Tensor Cores usage: During the conversation, the lack of Tensor Cores usage in gemv was questioned, with a member noting that tensorcores only increase flops but gemv is memory-bound.
- Another member emphasized that Tensor Cores require a minimum tensor dimension of 16x16.
- Issue with Submitting .cu files: A user inquired about submitting .cu files, struggling to find associated cuda leaderboard names.
- It was suggested to use the load_inline method in Python for submitting such files.
- Clarifications on Data Types in Kernels: A user raised a concern regarding the
generate_input()function returning float32 instead of uint8 for inputs in their histogram submission.- They pointed out an assertion failure due to the mismatch between the expected and actual data types, drawing attention to potential inconsistencies.
- Introduction of New Members: A new member introduced themselves, mentioning their hardware acceleration design course and how the community's resources aided their learning of GPUs.
- They sought guidance on whether there is a dedicated server for research-related queries.
- Active Leaderboards | GPU MODE Kernel Leaderboard: Here, will give leaderboard creators on the official leaderboard the option to provide more metadata and information
- GitHub - gpu-mode/reference-kernels: Reference Kernels for the Leaderboard: Reference Kernels for the Leaderboard. Contribute to gpu-mode/reference-kernels development by creating an account on GitHub.
- discord-cluster-manager/examples/thunderkittens_example/submission.cu at main · gpu-mode/discord-cluster-manager: Write a fast kernel and run it on Discord. See how you compare against the best! - gpu-mode/discord-cluster-manager
- GitHub - mobiusml/gemlite: Fast low-bit matmul kernels in Triton: Fast low-bit matmul kernels in Triton. Contribute to mobiusml/gemlite development by creating an account on GitHub.
GPU MODE ▷ #torch (2 messages):
E2E example in TorchAO
- Progress on E2E Example in TorchAO: @drisspg confirmed they are working on an E2E example in TorchAO and will notify when it’s ready.
- Zippika expressed enthusiasm with a quick appreciation, 'oh awesome thanks!'.
- Request for Collaboration: The chat indicates a collaborative effort, with @drisspg open to further communication once the example is ready.
- This highlights the cooperative nature of the discourse in the TorchAO community.
GPU MODE ▷ #algorithms (1 messages):
Orthogonal matrices in Q and K, Hadamard matrices efficiency, Quantization of vectors
- Orthogonal matrices cancel out in Q and K: When adding an orthogonal matrix to both Q and K, it cancels out due to the property of orthogonality, resulting in the equation
(HQ)^T (HK) = Q^T K.- This holds true for any orthogonal matrix, ensuring that the transformation maintains the essential characteristics of the vectors being manipulated.
- Hadamard matrices provide structured multiplication: The use of Hadamard matrices allows for faster multiplication than the naive O(n³) algorithm, making computations more efficient.
- These matrices also help smooth out vectors with large outliers, enhancing the numerical stability of further computations.
- Enhanced quantization with orthogonal transformations: Applying the orthogonal transformation makes
HQmore suitable for quantization, addressing issues that may arise with the original Q.- This improvement suggests that structuring data through orthogonal transformations can yield better performance in related applications.
GPU MODE ▷ #cool-links (4 messages):
Linear Attention, DeepEP Communication Library, Out-of-doc PTX instructions
- Interactive Tutorial on Linear Attention: The YouTube video titled "Linear Attention and Beyond" features Songlin Yang, the author of the Flash Linear Attention library, providing an interactive tutorial.
- Viewers can access the slides used in the tutorial for further insights.
- DeepEP: Efficient Expert-Parallel Communication: The GitHub repository DeepEP by deepseek-ai presents an efficient expert-parallel communication library.
- It aims to enhance communication performance for distributed systems and can be explored through its primary description.
- Exploring Out-of-doc PTX Instruction for Performance: A member shared interest in using an out-of-doc PTX instruction:
ld.global.nc.L1::no_allocate.L2::256Bfor extreme performance enhancements.- Another member speculated that it might configure the caching behavior by avoiding global loads on L1 while allowing them on L2.
- GitHub - deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library: DeepEP: an efficient expert-parallel communication library - deepseek-ai/DeepEP
- Linear Attention and Beyond (Interactive Tutorial with Songlin Yang): Songlin Yang, the author of the influential Flash Linear Attention https://github.com/fla-org/flash-linear-attention library, joined me to give an interactiv...
GPU MODE ▷ #jobs (3 messages):
PyTorch Partner Engineer positions, Collaboration in AI, Equal Employment Opportunity, Community and systems work
- Meta seeks PyTorch Partner Engineers: Meta has announced two open positions for PyTorch Partner Engineers who will work closely with the PyTorch team and leading industry partners to enhance AI solutions.
- This role emphasizes collaboration and offers a chance to drive AI technology from research to real-world applications.
- Collaboration Opportunities Highlighted: One member noted that the position is ideal for those interested in both systems and community work, referencing their collaboration experience with a team member.
- This perspective emphasizes the impact and importance of teamwork in driving projects within Meta's AI landscape.
- Commitment to Equal Employment Opportunity: Meta promotes a commitment to Equal Employment Opportunity, ensuring no discrimination based on various characteristics including race, gender, and disability.
- The company also offers reasonable accommodations in the recruiting process for diverse candidates, ensuring inclusivity in hiring.
Link mentioned: Partner Engineer, PyTorch: Meta's mission is to build the future of human connection and the technology that makes it possible.
GPU MODE ▷ #beginner (3 messages):
Getting Started with GPU Programming, Learning PyTorch, Exploring Triton
- Newbie seeks advice on GPU programming: A new member expressed interest in learning GPU programming, stating they have experience with ML frameworks like PyTorch and JAX.
- They aim to grasp the basics and write kernels for fun while being open to learning C or C++.
- Recommendation to start with PyTorch: Another member suggested getting started with PyTorch tutorials available here, highlighting its ease compared to JAX.
- They advised familiarizing oneself with Triton alongside completing Triton puzzles offered in the Discord server.
GPU MODE ▷ #pmpp-book (1 messages):
Image Blurring, C++ vs CUDA Performance
- CUDA Slower than Pure C++ for Image Blurring: A member reported implementing the image blurring example from Chapter 3 in both pure C++ and CUDA, noting the CUDA version runs slower than the pure C++ implementation.
- Does this result make sense? suggests a deeper inquiry into performance expectations between the two implementations.
- Performance Comparison Discussion: The community is prompted to discuss whether it's common for CUDA implementations to perform slower than C++ in certain scenarios, particularly in image processing tasks.
- This raises questions about optimization strategies and hardware utilization that could affect the execution time.
GPU MODE ▷ #rocm (1 messages):
MIOpen Compilation Issues, RX 9850M XT Wavefront Size, PyTorch Memory Access Faults, Workaround for MIOpen Crashes
- MIOpen defaults to incorrect wavefront size: A user inquired about preventing MIOpen from passing
-mwavefrontsize=64during kernel compilation, as their RX 9850M XT only supportswavefrontsize=32.- They mentioned encountering 'Memory access fault - page not present or supervisor privilege' errors in certain PyTorch configurations.
- Workaround to MIOpen crashes: To mitigate crashes, the user set two environment variables:
MIOPEN_DEBUG_CONV_GEMM=0andMIOPEN_DEBUG_CONV_DIRECT=0.- They expressed a desire for a more permanent solution to the issues experienced during PyTorch execution.
- Detailed report on ROCm GitHub: The user provided a link to a GitHub issue detailing the problems with MIOpen.
- This includes their ongoing struggles with configuration and performance issues in PyTorch.
GPU MODE ▷ #liger-kernel (4 messages):
Liger Kernel Issue #537, Native Sparse Attention Triton Repo, Efficient Triton Implementations
- Interest in Liger Kernel Issue #537: A member expressed interest in contributing to Issue #537 which discusses supporting the new Solar architecture from Upstage, noted for its performance on single GPU setups.
- The feature aims to enhance functionality with strong implications for GPU-based training and inference.
- Introduction of NAS Triton Repo: XunhaoLai's Triton repo was shared, which implements an efficient sparse attention mechanism, as described in the paper Native Sparse Attention.
- This repo supports advanced computational efficiencies for AI models leveraging Triton capabilities.
- Another Efficient Implementation of Sparse Attention: A second repo, fla-org/native-sparse-attention, was mentioned, highlighting efficient Triton implementations designed for hardware-aligned and natively trainable sparse attention.
- The implementations are aimed at improving performance in training and inference through optimal resource utilization.
- native-sparse-attention-triton/ops/triton at main · XunhaoLai/native-sparse-attention-triton: This repo provides an efficient Triton implementation of the sparse attention mechanism from the paper [Native Sparse Attention](https://arxiv.org/abs/2502.11089). - XunhaoLai/native-sparse-attenti...
- Support the new Solar architecture · Issue #537 · linkedin/Liger-Kernel: 🚀 The feature, motivation and pitch This model from Upstage is extremely strong for models that fit on a single GPU for training and inference! https://huggingface.co/upstage/solar-pro-preview-inst.....
- GitHub - fla-org/native-sparse-attention: 🐳 Efficient Triton implementations for "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention": 🐳 Efficient Triton implementations for "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention" - fla-org/native-sparse-attention
GPU MODE ▷ #reasoning-gym (5 messages):
Branch Management, Auto Delete on Merge, Benchmark Task Idea, Python Dependency Issues
- Pruning Old Branches for Efficiency: A member mentioned plans to prune older branches that have already been merged to maintain a cleaner repository.
- This reflects a proactive approach to managing project cleanliness and streamlining collaboration.
- Consider Auto Delete on Merge: Another member suggested setting up auto delete functionalities for branches post-merge to enhance repository management.
- This could potentially prevent the buildup of obsolete branches and simplify project navigation.
- Innovative Benchmark Task Proposal: A member highlighted an interesting benchmark task idea involving evaluating Claude's ability to distill the VLLM library for Llama8b inference, shared here.
- This approach could serve as a great way to verify coding benchmarks and measure LLM performance.
- Dependency Inclusion Concerns: A member pointed out that the Python libraries
aiohttpandtenacityneed to be included in therequirements.txtto avoid import errors.- They offered to create a pull request if this inclusion is deemed correct, showing an eagerness to contribute.
Link mentioned: Tweet from naklecha (@naklecha): i'm evaluating claude's ability to distil the vllm library into a simpler codebase containing only the parts it needs for llama8b inference. i think measuring an llm's codebase distillatio...
GPU MODE ▷ #general (62 messages🔥🔥):
Inline CUDA Submission Issues, Autotuning Concerns, UI Updates for Leaderboard, CUDA and Python Integration, Problem Constraints for Benchmarking
- Inline CUDA Submission causing timeouts: A user experienced timeouts while using the script 'submission_cuda_inline.py' for leaderboard testing with a T4 GPU, leading to discussions about potential issues with the code.
- One member assured that instructions for submitting inline CUDA will be provided soon to alleviate confusion.
- Debate on Autotuning Practices: Concerns arose about the excessive autotuning times affecting benchmark relevancy, with suggestions to limit its use due to high overhead.
- Some participants suggested that allowing a certain level of autotuning could be beneficial if users also submit their cached results.
- New UI Features for Leaderboard: The team announced recent UI updates to the leaderboard, making it clearer and more user-friendly for participants.
- Discussions included whether to display only the best submission from each user, balancing uniqueness with competition.
- CUDA and Python Integration Challenges: A user noted difficulties in writing CUDA code as a Python string, highlighting a need for better multifile support in submissions.
- Concerns were raised about the challenges of integrating CUDA with Python, balancing ease of writing with submission integrity.
- Data Size Constraints in Prefix Sum Problem: Questions arose regarding data size constraints for the prefix sum problem, specifically if it needs to be a multiple of a certain power of 2.
- The user was directed to a link confirming the constraints, emphasizing clarity in documentation for future problem iterations.
- 6.S894: no description found
- GPU MODE Kernel Leaderboard | GPU MODE Kernel Leaderboard: no description found
- reference-kernels/problems/pmpp/vectoradd_py/solutions/correct/submission_cuda_inline.py at main · gpu-mode/reference-kernels: Reference Kernels for the Leaderboard. Contribute to gpu-mode/reference-kernels development by creating an account on GitHub.
- reference-kernels/problems/pmpp/grayscale_py/reference.py at main · gpu-mode/reference-kernels: Reference Kernels for the Leaderboard. Contribute to gpu-mode/reference-kernels development by creating an account on GitHub.
- reference-kernels/problems/pmpp/prefixsum_py/submission.py at main · gpu-mode/reference-kernels: Reference Kernels for the Leaderboard. Contribute to gpu-mode/reference-kernels development by creating an account on GitHub.
- reference-kernels/problems/pmpp/prefixsum_py/task.yml at main · gpu-mode/reference-kernels: Reference Kernels for the Leaderboard. Contribute to gpu-mode/reference-kernels development by creating an account on GitHub.
GPU MODE ▷ #submissions (62 messages🔥🔥):
Leaderboard submissions, Test submissions, Benchmark submissions, API submissions, Modal runners performance
- Streamlined Leaderboard Submissions: Multiple submissions to the grayscale leaderboard succeeded on various GPUs, including H100 and A100, with multiple IDs such as 278 and 370.
- This indicates consistent performance with Modal runners across different leaderboard tests.
- Prefixsum Submissions Success: Several benchmark submissions to the prefixsum leaderboard succeeded, with IDs like 351 showcasing GPU efficiency on H100.
- These submissions reflect a robust interaction with the current leaderboard setup.
- Test Submissions Achieve Success: Test submissions such as those with IDs 269 and 388 to the matmul and grayscale leaderboards demonstrated successful execution.
- The test processes indicate stable operation under the leaderboard configurations.
- Missing Leaderboard Name Issues: Several instances occurred where the leaderboard name was missing or mismatched in the submission script, leading to defaulting errors.
- This highlights the need for clarity in submission criteria to avoid such mismatches.
- API Submissions on the Horizon: There was an announcement indicating that submissions through the API are coming soon, which raised community curiosity.
- Members are encouraged to stay tuned for further updates about this functionality.
GPU MODE ▷ #status (1 messages):
CUDA Inline, Compilation Caching, Benchmarking Efficiency
- Run CUDA Inline Correctly: To successfully run the submission file, ensure that the CUDA code is compiled by placing the
load_inlinecall at the top-level of the file.- This ensures the compilation is cached, allowing for quicker execution during subsequent testing or benchmarking.
- Importance of Compilation Caching: Caching the compilation of CUDA code is crucial for reducing timeouts during testing.
- Making
load_inlineefficient means it should not hinder the performance of actual tests or benchmarks.
- Making
GPU MODE ▷ #ppc (6 messages):
Bend programming language, AMD mi300A and Nvidia Grace Hopper, Programming Parallel Computers course
- Bend Raises Questions in Parallel Programming: A user linked to the Bend GitHub repository and questioned its relevance to the channel’s focus.
- Others sought clarity on its suitability, ultimately noting that it’s a parallel programming language potentially useful for AMD mi300A or Nvidia Grace Hopper chips.
- Confusion about Channel Relevance: A member expressed confusion, clarifying that this channel is dedicated to discussions related to the open version of the Programming Parallel Computers course from Aalto.
- This led to doubts about the connection of Bend to the channel's intended focus.
- Resolution on Bend's Relevance: After discussion, one member thanked others for clarifying that Bend's mention might not align with the channel's purpose.
- The community acknowledged that clarity on subject relevance helps maintain focus in discussions.
Link mentioned: GitHub - HigherOrderCO/Bend: A massively parallel, high-level programming language: A massively parallel, high-level programming language - HigherOrderCO/Bend
GPU MODE ▷ #feature-requests-and-bugs (2 messages):
NCU Support, Leaderboard Updates, Standalone CUDA Examples, Generated PTX Retrieval Command
- Expectations for NCU Support: A request was made for ncu support, highlighting its importance to the community for performance analysis.
- No additional comments were provided.
- Leaderboard Improvement Suggestion: Members discussed the need to keep the top entry per person in the leaderboard to enhance competition.
- This feature could help in recognizing individual contributions better.
- Desire for Standalone CUDA Examples: There was a request for examples of standalone CUDA files to aid users in their development efforts.
- These examples would serve as useful references for implementing CUDA solutions.
- Command Requested for Generated PTX: A member suggested adding a command to retrieve generated PTX similar to Godbolt.
- The proposed command is
/leaderboard submit --ptx, aimed at simplifying PTX access.
- The proposed command is
Yannick Kilcher ▷ #general (127 messages🔥🔥):
Grok 3 vs O1-Pro, xAI GPU count, Synthetic Data Generation, AI Hardware Solutions, Large Concept Models
- Debate on Grok 3 vs O1-Pro: Members discussed whether to cancel O1-Pro for SuperGrok, with opinions varying on performance comparisons and suitability for coding tasks.
- Some users found O1 better for code handling, while Grok's detailed responses might require prompt adjustments.
- xAI's GPU Expansion: xAI is reportedly expanding its GPU farm to 200,000 GPUs to enhance its AI capabilities and compete with major players like OpenAI.
- This expansion signals a shift toward launching Grok as a more general-purpose platform.
- Synthetic Data in AI: Discussion on synthetic data generation highlighted its importance, with examples like DeepSeek optimizing using concepts rather than tokens.
- Participants noted that effective synthetic data generation pipelines are crucial for sustaining AI models.
- Exploring AI Hardware Solutions: Users explored options for AI model hosting on low-resource systems, suggesting low-cost mini-PCs or SBCs for running LLMs.
- KCPP and RPC functions were recommended to help distribute loads effectively across devices for better performance.
- FB's Large Concept Models Presentation: A member expressed interest in presenting FB's paper on 'Large Concept Models' and discussing its implications for AI modeling.
- There was a recognition of the importance of understanding concepts within topics for effective AI optimization.
- Textbooks Are All You Need: We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, ...
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models: Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inferenc...
- Large Language Model Guided Tree-of-Thought: In this paper, we introduce the Tree-of-Thought (ToT) framework, a novel approach aimed at improving the problem-solving capabilities of auto-regressive large language models (LLMs). The ToT technique...
- Million-Dollar Dolce & Gabbana Digital Suit Fractionalized on Ethereum L2 Base—Here’s Why - Decrypt: Fermion Protocol wants to fractionalize luxury goods. It’s starting with a million-dollar digital suit from Dolce & Gabbana.
- QuantFactory/granite-3.1-3b-a800m-instruct-GGUF · Hugging Face: no description found
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Snapshot of the Race for More AI Compute | NextBigFuture.com: The number of Nvidia H100 and other Nvidia chips that an AI company represents the AI compute resources of that company.
- Joseph717171 (Joseph): no description found
- bartowski (Bartowski): no description found
Yannick Kilcher ▷ #paper-discussion (4 messages):
Native Sparse Attention, SigLIP 2 Improvements, Multilingual Retrieval Enhancements
- Dive into Native Sparse Attention: A member shared a YouTube video titled 'Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention' which details significant concepts in sparse attention mechanisms.
- Another member appreciated the content, stating 'this guy's content is so good.'
- Exploring SigLIP 2 Updates: The discussion focused on SigLIP 2, an improved version of the most performant vision encoder, highlighting its notable advancements.
- Participants noted it brings significant improvements, especially in multilingual retrieval capabilities, as confirmed by a member's commentary.
- SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features: We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training obje...
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention: Paper: https://arxiv.org/abs/2502.11089Notes: https://drive.google.com/open?id=1HLEM4m77-C8HqEBoKpk6mnpngIjUB5jR&usp=drive_copy00:00 Intro01:30 Sparse attent...
Yannick Kilcher ▷ #ml-news (9 messages🔥):
Claude 3.7 Sonnet, QwQ-Max Preview, Linear Attention Tutorial, DeepEP Communication Library, Y Combinator Computer Vision Startup
- Claude 3.7 Sonnet - A Hybrid Reasoning Marvel: Anthropic announced Claude 3.7 Sonnet, their most intelligent model to date, which can produce near-instant responses or extended thinking detailed here. It shows notable improvements in coding and front-end web development, alongside the launch of Claude Code for agentic coding tasks.
- You can see an introduction in this YouTube video where the model's capabilities are highlighted.
- Sneak Peek of QwQ-Max: Qwen Chat announced the upcoming release of QwQ-Max, a reasoning model based on Qwen2.5-Max, now available for testing in preview mode. This update includes future plans for an Android and iOS app, along with open-source variants under the Apache 2.0 license.
- More details can be found in their blog post, outlining its capabilities in math, coding, and agent tasks.
- Exploring Linear Attention Techniques: A recent YouTube tutorial features Songlin Yang, the creator of the Flash Linear Attention library, discussing interactive learning in this video. The session delves into advanced techniques in model training and inference involving linear attention.
- Yang's insights are greatly influential, especially considering the innovations introduced with the Flash Linear Attention library GitHub link.
- DeepEP - Advancing MoE Communication: The launch of DeepEP by DeepSeek AI introduces the first open-source EP communication library tailored for MoE model training and inference. It promises efficient all-to-all communication, optimized kernels, and support for FP8 dispatch in its operations.
- Developers can check its features and implementation on GitHub at this link.
- Y Combinator's Unique Startup Proposal: A now-deleted proposal by Y Combinator for a computer vision sweatshop stirred mixed reactions, framed humorously by users. The concept, while deemed unorthodox, highlighted intriguing aspects of AI application in labor-intensive areas.
- Discussion can be traced back through user tweets that captured the launch context here.
-
Tweet from Qwen (@Alibaba_Qwen):
... QwQ-Max-PreviewQwen Chat: https://chat.qwen.ai/Blog: https://qwenlm.github.io/blog/qwq-max-preview/🤔 Today we release "Thinking (QwQ)" in Qwen Chat, backed by o... ... QwQ-Max-Preview | Qwen: no description found- Tweet from DeepSeek (@deepseek_ai): 🚀 Day 2 of #OpenSourceWeek: DeepEPExcited to introduce DeepEP - the first open-source EP communication library for MoE model training and inference.✅ Efficient and optimized all-to-all communication✅...
- GitHub - anthropics/claude-code: Claude Code is an agentic coding tool that lives in your terminal, understands your codebase, and helps you code faster by executing routine tasks, explaining complex code, and handling git workflows - all through natural language commands.: Claude Code is an agentic coding tool that lives in your terminal, understands your codebase, and helps you code faster by executing routine tasks, explaining complex code, and handling git workflo...
- Linear Attention and Beyond (Interactive Tutorial with Songlin Yang): Songlin Yang, the author of the influential Flash Linear Attention https://github.com/fla-org/flash-linear-attention library, joined me to give an interactiv...
- Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
- Tweet from ₩ (@trbdrk): @KennethCassel garry deleted it but 😁
- Claude 3.7 Sonnet with extended thinking: Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step ...
Eleuther ▷ #general (37 messages🔥):
Brain vs. AI Parallelism, Language Processing Differences, AI Model Training Efficiency, Logit Bayesian Metacognition Dataset, Decentralized AI Model Evaluation
- Brain vs. AI: Parallelism Discrepancies: Discussion emerged on how the brain's parallelism differs from AI architectures, with one member noting that humans do not process long strings in parallel like RNNs do.
- They emphasized that human language processing involves chunking and abstracting rather than predicting all tokens simultaneously.
- RNNs Limitations in Scaling: Participants discussed the discrepancies between human language processing and current AI models, highlighting the difficulty of scaling classical RNN architectures.
- Key points were raised regarding backpropagation challenges in RNNs and the potential need for alternative architectures tailored to specific objectives.
- Logit Bayesian Metacognition Dataset Proposal: One member proposed a new dataset concept where metadata for decoding logit probabilities is included alongside words to aid model self-reflection.
- This model would help answer questions like, 'Why did you infer X?', incorporating logit probabilities for deeper analysis.
- Corruption-Proof Decentralized AI Evaluation: A member introduced their work on creating a corruption-proof decentralized system for evaluating AI models to combat overfitting on benchmark datasets.
- This initiative aims to enhance transparency and reliability in AI model assessments across the industry.
- Introduction of Proxy Structuring Engine: Another user shared their open-source project, the Proxy Structuring Engine (PSE), designed to address non-determinism in LLM outputs during deployment.
- The engine ensures structured responses while maintaining the creativity of AI models in various applications, such as chatbots and automated code generation.
Link mentioned: The Proxy Structuring Engine: High Quality Structured Outputs at Inference Time
Eleuther ▷ #research (32 messages🔥):
MLA architecture, DeepSeek models, Looped models for reasoning, Fourier series and smoothness, KV cache optimization
- MLA architecture revolutionizes efficiency: The introduction of Multi-head Latent Attention (MLA), showcased by DeepSeek, significantly compresses the Key-Value (KV) cache, improving inference speed by 5-10 times compared to traditional approaches.
- Its effectiveness was supported by multiple lab experiments, emphasizing the potential of MLA models in large language model applications.
- DeepSeek's innovations in model training: DeepSeek invested at least 5.5 million on their MLA-driven model, demonstrating confidence in its architectural advantages over existing models.
- The company's findings suggest that further improvements could be incorporated into future models, hinting at industry interest in transitioning to MLA techniques.
- Looped models claim breakthrough in reasoning: A recent paper suggests looped transformer models can achieve performance similar to deeper non-looped architectures for reasoning tasks, reducing parameter requirements.
- This approach allows the models to solve complex tasks efficiently, showcasing potential advantages in using iterative methods for computational challenges.
- Challenges of Fourier series in modeling: In conversations concerning Fourier series, a member highlighted that the requirement for a finite number of terms varies with the smoothness of the function, referencing the Gibbs phenomenon.
- The discourse emphasized ongoing concerns about appropriate term selection in diverse applications, relevant to the data modeling field.
- Optimizing KV cache in attention models: Members discussed that Native Sparse Attention and MLA can improve both computing and caching costs for long context models, making them more efficient.
- As these techniques are open-sourced, their implementation could reshape the future of frontier models in AI.
- Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs: Multi-head Latent Attention (MLA) is an innovative architecture proposed by DeepSeek, designed to ensure efficient and economical inference by significantly compressing the Key-Value (KV) cache into a...
- Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction: We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enab...
- Reasoning with Latent Thoughts: On the Power of Looped Transformers: Large language models have shown remarkable reasoning abilities and scaling laws suggest that large parameter count, especially along the depth axis, is the primary driver. In this work, we make a str...
- TransMLA: Multi-Head Latent Attention Is All You Need: Modern large language models (LLMs) often encounter communication bottlenecks on current hardware, rather than purely computational constraints. Multi-head Latent Attention (MLA) tackles this challeng...
- Wavelets Are All You Need for Autoregressive Image Generation: In this paper, we take a new approach to autoregressive image generation that is based on two main ingredients. The first is wavelet image coding, which allows to tokenize the visual details of an ima...
- PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving: Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances wit...
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces: no description found
- On MLA: no description found
Eleuther ▷ #interpretability-general (9 messages🔥):
Attention Maps, Neuron-based Methods, Intervention on Attention Maps, Emerging Syntax from Attention Maps
- Attention Maps vs Neuron-based Methods: Members discussed why attention maps have lost popularity compared to neuron-based methods, suggesting it might be due to their observational nature.
- Another member pointed out that one could intervene on an attention map despite its observational qualities, prompting further exploration.
- Direct Modification of Attention Maps: A member noted that you can directly change attention maps during a forward pass, rather than using custom masks for intervention.
- This opened the floor for questions about how these modifications might impact model behavior.
- Interest in Trees & Graphs from Attention Maps: One member expressed a strong bias towards attention maps for their ability to generate trees and graphs, leveraging linguistic features.
- They are considering utilizing this for a future project despite limited understanding of mechanistic details.
- Emerging Syntax from Attention Maps since BERT: It was mentioned that syntax has been shown to emerge from attention maps since the introduction of BERT.
- This highlights the ongoing relevance and potential of attention maps in understanding language models even in today's research context.
Eleuther ▷ #gpt-neox-dev (10 messages🔥):
Mixed Precision Training, Optimizer States in Mixed Precision, ZeRO Offload, BF16 Precision
- Mixed Precision Training: Where are the Weights?: In mixed precision training, the master FP32 weights are typically stored in GPU VRAM unless zero offload is activated.
- This clarification addressed the concerns about the storage of model weights during training.
- Understanding BF16 and Optimizer Interaction: There is confusion surrounding the implications of BF16 mixed precision for the optimizer, especially whether it's related to model precision or independent.
- Experts suggest that after the ZeRO paper, thinking of high-precision parameters as belonging to optimizer states has become common.
- Current Practices for Optimizer States: Labs vary in their approach to optimizer states, with some opting to store Adam moments in BF16 and master weights in FP32.
- A common recommendation is to perform vanilla mixed precision with BF16 low-precision weights alongside FP32 optim+master-weights+grads.
Link mentioned: Megatron-LM/megatron/core/optimizer/optimizer_config.py at main · NVIDIA/Megatron-LM: Ongoing research training transformer models at scale - NVIDIA/Megatron-LM
Latent Space ▷ #ai-general-chat (79 messages🔥🔥):
Claude 3.7 Sonnet, Claude Code, Datacenter leasing concerns, Qwen enhancements, FlashMLA GitHub repository
- Claude 3.7 Sonnet Launch Sparks Buzz: Anthropic introduced the Claude 3.7 Sonnet, boasting improvements in reasoning capabilities and a new coding tool called Claude Code that functions as a terminal-based assistant.
- Participants highlighted its higher output tokens limit and enhanced reasoning mode, which enables more coherent interaction compared to previous versions.
- Concerns Over Datacenter Oversupply: Reports emerged that Microsoft is canceling datacenter leases, implying a potential oversupply in the market, aligning with prior trends of delayed contract signings.
- This has raised questions about Microsoft's aggressive pre-leasing strategies in 2024 and its overall impact on the colocation market.
- Discussions Around Qwen's Future: Anticipation builds for the next Qwen QwQ-Max release, with claims of substantial improvements in reasoning capabilities and open-source accessibility under Apache 2.0.
- Community discussions touch on the significance of these enhancements in the landscape of intelligent models.
- Claude Code's Performance Experience: Early users report that Claude Code offers streamlined coding assistance, though experiences vary, with some noting slower response times compared to other models.
- Feedback included insights on its potential pricing concerns while emphasizing the feature of heavy caching to optimize performance.
- New Releases and Community Engagement: The GitHub project FlashMLA was shared, generating interest in its implications for AI development without much prior fanfare.
- Participants expressed eagerness to see further developments in AI tools expected throughout the week.
- @anthropic-ai/claude-code: Use Claude, Anthropic's AI assistant, right from your terminal. Claude can understand your codebase, edit files, run terminal commands, and handle entire workflows for you.. Latest version: 0.2.9...
- Tweet from Mona (@dyot_meet_mat): damn Anthropic really got this system prompt right though
- Tweet from Paul Gauthier (@paulgauthier): Sonnet 3.7 sets SOTA on the aider leaderboard with a 65% score, using 32k thinking tokens. Without thinking, it scored 60%.65% Sonnet 3.7, 32k thinking64% R1+Sonnet 3.562% o1 high60% Sonnet 3.7, no th...
- Tweet from ludwig (@ludwigABAP): a thousand github repos died today
- Tweet from Cognition (@cognition_labs): 1/ Claude 3.7 Sonnet is live in Devin! The new model is the best we have seen to-date on a variety of tasks including debugging, codebase search, and agentic planning.
- Tweet from Paul Gauthier (@paulgauthier): Claude 3.7 Sonnet scored 60% on the aider polyglot benchmark w/o thinking. Tied in 3rd with o3-mini-high. Sonnet 3.7 has the highest non-thinking score (formerly Sonnet 3.5). Thinking results coming s...
- Tweet from Devin (@DevinAI): "In developing it, we’ve optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect the needs of our users.&...
- Tweet from Mike Krieger (@mikeyk): Behind the scenes look at the Claude 3.7 Sonnet naming process
- Tweet from Binyuan Hui (@huybery): 🤔 Think deeply about the future of Qwen.As a sneak peek into our upcoming QwQ-Max release, this version offers a glimpse of its enhanced capabilities, with ongoing refinements and an official Apache ...
- Tweet from Greg Kamradt (@GregKamradt): For the benchmark results we've all been waiting forClaude 3.7 Sonnet now is #1 on SnakeBench 🐍Beats all other reasoning modelsIts thought process was much more coherent than other models
- Tweet from Dylan Patel (@dylan522p): On Friday, there was a report stating that Microsoft was canceling datacenter leases for several hundred of MWs – alluding to a high risk of overbuild/oversupply.We discussed this in December in our D...
- Tweet from Alex Albert (@alexalbert__): and oh yeah I almost forgot, the github integration rolled out to everyone today on claude dot ai
- Tweet from Jesse Mu (@jayelmnop): SOTA on the only eval that mattersQuoting Saurav Kadavath (@sokadv) Claude 3.7 plays Pokemon!https://www.anthropic.com/research/visible-extended-thinking
- Tweet from Alex Albert (@alexalbert__): We're opening limited access to a research preview of a new agentic coding tool we're building: Claude Code.You'll get Claude-powered code assistance, file operations, and task execution d...
- Tweet from Amanda Askell (@AmandaAskell): Two things happened today: 1. Claude got an upgrade.2. AGI was has finally been defined as "any model that can catch Mewtwo".Quoting Anthropic (@AnthropicAI) Introducing Claude 3.7 Sonnet: our...
- GitHub - deepseek-ai/FlashMLA: Contribute to deepseek-ai/FlashMLA development by creating an account on GitHub.
- Tweet from Chubby♨️ (@kimmonismus): Claude 3.7 Sonnet system prompt:"The assistant is Claude, created by Anthropic.The current date is .Claude enjoys helping humans and sees its role as an intelligent and kind ass...
- Tweet from Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭 (@elder_plinius): LMFAO no way, just found an EASTER EGG in the new Claude Sonnet 3.7 system prompt!! The actual prompt is nearly identical to what they posted on their website, except for one key difference:"Easte...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- Tweet from Simon Willison (@simonw): Some initial notes on Claude 3.7 Sonnet, including SVGs of pelicans on bicycles (which it does very well) https://simonwillison.net/2025/Feb/24/claude-37-sonnet-and-claude-code/
- Tweet from Anthropic (@AnthropicAI): Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.One model, two ways to think.W...
Nous Research AI ▷ #general (68 messages🔥🔥):
Grok3 Tool Invocation, Claude 3.7 Sonnet Release, QwQ-Max-Preview Announcement, Structured Outputs Project, AI Alignment Discussion
- Grok3's Tool Invocation Mechanism: Members expressed confusion about Grok3 not listing the token sequence for tool invocation in the system prompt and noted its reliance on the model's training to infer syntax.
- They debated the reliability of hard-coded function calls versus in-context learning (ICL), questioning the transparency of the tool calling methods.
- Claude 3.7 Sonnet Unveiled: The release of Claude 3.7 Sonnet was announced, showcasing its hybrid reasoning capabilities and new command line tool for enhanced coding tasks.
- Discussion highlighted Sonnet's superiority in software engineering benchmarks and its potential role in replacing Claude 3.5 versus existing functionality.
- Sneak Peek at QwQ-Max-Preview: QwQ-Max-Preview was introduced as part of the Qwen series, promoting features such as deep reasoning and open-source accessibility under Apache 2.0.
- Members speculated on model size, with guesses suggesting it could be larger than 32B, while hoping for smaller versions for local use.
- Open-source Project for Structured Outputs: A user announced the launch of an open-source project aimed at addressing structured output challenges, inviting feedback and collaboration.
- Another member suggested reposting the announcement for better visibility and engagement within the community.
- AI Alignment and Community Discourse: A member criticized the AI alignment discourse on social media, expressing frustration over how certain perspectives limit understanding in the AI development community.
- They emphasized the importance of open dialogue and deeper understanding instead of imposing narrow viewpoints on AI functionalities.
-
... QwQ-Max-Preview | Qwen: no description found - Claude 3.7 Sonnet and Claude Code: Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model generally available on the market.
Nous Research AI ▷ #ask-about-llms (6 messages):
Sonnet-3.7 Benchmarking, Misguided Attention Eval, Reasoning Mode Activation
- Sonnet-3.7 excels in benchmarks: A member benchmarked Sonnet-3.7 with the Misguided Attention Eval, claiming it's the best non-reasoning model, nearly outperforming o3-mini.
- They also shared an image of the benchmark results.
- Understanding Misguided Attention Eval: Another member asked what the Misguided Attention test assesses, prompting a response indicating it examines overfitting.
- The evaluation highlights how large language models handle reasoning amidst misleading information.
- Exploring Reasoning Mode Activation: A member is investigating how to activate thinking mode through the OR API, questioning its feasibility.
- This reflects ongoing effort to enhance model interaction features.
Link mentioned: GitHub - cpldcpu/MisguidedAttention: A collection of prompts to challenge the reasoning abilities of large language models in presence of misguiding information: A collection of prompts to challenge the reasoning abilities of large language models in presence of misguiding information - cpldcpu/MisguidedAttention
Nous Research AI ▷ #interesting-links (4 messages):
Azure chat interface update, Video generation integration, Artifacts usability concerns
- Azure chat interface gets a refresh: The Azure chat interface has been updated, with something new expected to launch today.
- Members are curious about the changes and their impact on user experience.
- Integrated video generation introduces new possibilities: The updated Azure chat interface now includes integrated video generation, enhancing interactive capabilities.
- This feature could redefine how users engage with the platform.
- Artifacts still feel clunky: Despite the updates, users still find the artifacts to be a bit clunky, describing them as a half-baked copy.
- There’s a general sentiment of needing improvements to achieve smoother usability.
Link mentioned: Qwen Chat: no description found
MCP (Glama) ▷ #general (62 messages🔥🔥):
Anthropic MCP Registry API, LLM Version Updates, Haiku 3.5 Tool Support, Claude Code vs Aider Performance, MCP Server Recommendations
- Anthropic Announces MCP Registry API: Yesterday, @AnthropicAI announced the official MCP registry API, creating excitement in the community looking for a reliable source of truth.
- This is fantastic news for us because we’ve wanted the source of truth, according to a community member.
- Confusion Over LLM Version Names: Members expressed frustration and amusement over LLM version naming conventions, particularly with Claude 3.7 and its functionality.
- One noted that 3.7 appears to integrate features from previous versions while boosting performance through adaptive thinking modes.
- Haiku 3.5 and Tool Support Discussions: While discussing Haiku 3.5, users noted that it supports tools but with limitations, stating that it performs better with fewer tools attached.
- A member complained about server and tool management stresses, revealing plans to create a chat app with integrated toolsets for easier usage.
- Claude Code Highly Rated for Performance: Users tested Claude Code and highlighted its superior performance over Aider, especially in handling coding errors efficiently.
- Members also expressed interest in utilizing Claude Code for more complex tasks, indicating it might utilize heavy thinking modes for optimal results.
- MCP Servers and Windows Compatibility: Discussions arose about the compatibility of MCP servers on Windows, with some users running into installation hurdles due to lack of support from certain tools.
- Alternatives like mcp.run were suggested for users struggling to install servers on Windows systems.
- Tweet from OpenTools (@opentools_): Yesterday @AnthropicAI announced the official MCP registry API at @aiDotEngineer 🎉This is fantastic news for us because we’ve wanted *the* source of truth. We made http://opentools.com/registry on da...
- mcp.run - the App Store for MCP Servlets: portable & secure code for AI Apps and Agents.: no description found
- 36 Alternatives to LLM Context: A comprehensive list of open source tools that help developers pack their code into LLM chats. From simple file combiners to complex context managers, these CLI tools streamline the way you share code...
- GitHub - cyberchitta/llm-context.py: Share code with LLMs via Model Context Protocol or clipboard. Profile-based customization enables easy switching between different tasks (like code review and documentation). Code outlining support is available as an experimental feature.: Share code with LLMs via Model Context Protocol or clipboard. Profile-based customization enables easy switching between different tasks (like code review and documentation). Code outlining support...
- GitHub - nahmanmate/code-research-mcp-server: Contribute to nahmanmate/code-research-mcp-server development by creating an account on GitHub.
MCP (Glama) ▷ #showcase (11 messages🔥):
MetaMCP Licensing Changes, Enact Protocol MCP Server, Claude 3.7 Sonnet Reasoning Features
- MetaMCP switches to AGPL: Members discussed the challenges of MetaMCP's licensing, particularly with the ELv2 clause limiting contributions, and suggested switching to AGPL for better openness.
- After considering different licensing strategies, they concluded that AGPL requires hosted changes to be open-sourced, allowing for community contributions.
- Enact Protocol aims for MCP server: A member is interested in creating an MCP server for Enact Protocol, highlighting its GitHub repository for defining automated tasks.
- They shared a link to the Enact Protocol GitHub which showcases a standardized framework for task execution.
- Claude 3.7 Sonnet reasoning introduced: Excitement builds around the rollout of Claude 3.7 Sonnet reasoning on Sage, which now includes enhanced thinking capabilities.
- New features include a toggle for thinking mode, improved scrolling, and expandable thinking blocks to visualize Claude's reasoning process, alongside a demo video.
- GitHub - EnactProtocol/enact-python: Python implementation of the Enact Protocol, a standardized framework for defining and executing automated tasks and workflows.: Python implementation of the Enact Protocol, a standardized framework for defining and executing automated tasks and workflows. - EnactProtocol/enact-python
- GitHub - metatool-ai/mcp-server-metamcp: MCP Server MetaMCP manages all your other MCPs in one MCP.: MCP Server MetaMCP manages all your other MCPs in one MCP. - metatool-ai/mcp-server-metamcp
HuggingFace ▷ #general (20 messages🔥):
Gemma-9B with custom LoRA, Qwen Max Open Weight Release, Claude-3.7 model discussion, Python skills for course, Getting started in AI careers
- Issues with Gemma-9B model loading: A user faced an error while loading the Gemma-9B model with custom LoRA, specifically related to 'LoraConfig.init()' receiving an unexpected keyword argument.
- Another user shared their similar experience and sought advice on the issue.
- Anticipating Qwen Max launch: The Qwen Max reasoning model is expected to be the most powerful open-source model since DeepSeek-R1, with weights potentially releasing this week.
- This model showcases advancements in math understanding and creativity, and an official version is due along with plans for mobile apps.
- Claude-3.7 as a new contender: Discussions arose around Claude-3.7, being called a potential SWE-bench killer with predictions of DeepSeek-R1 performance at a third of the size.
- Concerns were expressed regarding its cost-effectiveness compared to other models, noting high pricing for million token outputs.
- Query on required Python skills for course: A member inquired about the level of Python proficiency needed for course completion and sought recommended courses for improvement.
- Others chimed in, suggesting there might be a basic Python walkthrough linked in the course.
- Advice on starting a career in AI: A user asked for guidance on selecting a specialization in AI and how to pursue job opportunities in the field.
- Engagement sparked around the need for actionable steps and information on monetizing skills.
Link mentioned: Tweet from Qwen (@Alibaba_Qwen):
HuggingFace ▷ #today-im-learning (2 messages):
Fine-tuning in agents course, Pytorch on Apple Silicon
- Mastering Fine-Tuning in Agents Course: Today, insights were gained about fine-tuning techniques during the agents course.
- This learning emphasizes the importance of refining models for better performance.
- Pytorch Functions Missing on Apple Silicon: A member discovered that certain Pytorch functions are not implemented for Apple Silicon, causing a shift to Colab.
- Back to Colab, I suppose highlights the challenges faced by Apple users in the ML space.
HuggingFace ▷ #i-made-this (1 messages):
Ukrainian TTS dataset, speech-uk/opentts-mykyta
- Launch of Ukrainian TTS Dataset: A collection with a high-quality TTS dataset for Ukrainian has been published on Hugging Face, enhancing accessibility for TTS projects.
- The dataset is available for viewing and has garnered 6.44k updates here.
- Speech-uk/opentts-mykyta Updates: The dataset titled speech-uk/opentts-mykyta was recently updated about 5 hours ago, showcasing ongoing support and development.
- This initiative reflects the community's commitment to providing quality resources for Ukrainian text-to-speech applications.
Link mentioned: Ukrainian Text-to-Speech - a speech-uk Collection: no description found
HuggingFace ▷ #computer-vision (5 messages):
Computer Vision Hangout, CV Course Experience, Marine Ecosystem Project, Basketball Team Object Detection
- Kickoff for Computer Vision Hangout!: An event for the first Computer Vision Hangout of the year has been created, focusing on updates in the Hugging Face Computer Vision ecosystem and a community presentation.
- Participants can look forward to a fun quiz and casual chatting, making it a great opportunity for networking.
- Excitement for Course Interaction: A member expressed enthusiasm for the computer vision course, eager to connect with fellow beginners and enthusiasts.
- Others joined in, highlighting a desire for interaction and discussion on computer vision topics.
- Course Completion and Certificates: One member recently completed the CV course and praised the great information provided, mentioning a delay in receiving their certificate after submitting the Google form.
- They expressed openness to discuss computer vision topics anytime, fostering a collaborative learning environment.
- Marine Ecosystem and Basketball Project Insights: Discussion led to a member's focus on projects related to the marine ecosystem, and their friend's upcoming project on training a basketball team object detector and tracker.
- This showcases practical applications of computer vision, reflecting community interest in diverse fields.
HuggingFace ▷ #agents-course (38 messages🔥):
AI for Business series, NBA Parlay Picks, Course Recommendations, NLP Course Enrollment, Unit 1 SFT Training
- AI for Business Series Launch: A member shared their new series, AI for Business – From Hype to Impact, designed to help businesses leverage AI as a competitive advantage.
- The series will cover topics ranging from AI as a business enabler to scaling AI without disrupting operations.
- Potential $15K NBA Betting Picks: A member announced having a 6-man and a 4-man parlay with potential payouts of $15K, opening up for sharing picks upon request.
- They provided an image as a reference but did not disclose specifics in the text.
- Exploring Additional Free Courses: A query was raised regarding any free courses that could complement the current course, prompting a suggestion to pursue an additional NLP course.
- Engagement from members increased as other users introduced themselves, adding to the sense of community.
- Unit 1 SFT Training Insights: One member reported completing the bonus unit 1 SFT training on an A100 GPU in 20 minutes, after purchasing Colab compute units.
- They raised questions about the
convert_currencyfunction, availability of tools, and accessing TensorBoard outputs.
- They raised questions about the
- Community Introduction and Enthusiasm: New members continuously introduced themselves, expressing excitement about participating in the AI Agents course from various countries.
- Enthusiasm for collaboration and sharing updates within the course emerged as members looked for accountability partners.
LM Studio ▷ #general (41 messages🔥):
Integration of LMS Server with WordPress, Qwen 2.5 VL Model Performance, Speculative Decoding, Deepseek R1 671B Requirements, Local vs. Hosted Model Usage
- Need for LMS Server and WordPress Integration: A member inquired if anyone has successfully integrated the LMS Server with current WordPress plugins, running locally on Windows and Ubuntu/nginx.
- This inquiry highlights the necessity of effective tools for demo creation in AI development.
- Qwen 2.5 VL Model is Gaining Traction: The Qwen 2.5 VL 7B model has been reported to work effectively, outperforming previous models like Llama 3.2 in quality, as confirmed by multiple users.
- Users noted the model's potential use in generating descriptions for images, showing its application in real-world scenarios.
- Challenges with Speculative Decoding: A user raised questions on whether speculative decoding is limited to specific models, pointing out issues with compatibility between Llama 3.1 and Llama 3.2.
- It was suggested that model architecture likely influences compatibility, and users were encouraged to test setups for better understanding.
- Running Deepseek R1 Locally with Memory Constraints: A user inquired about the feasibility of running Deepseek R1 671B with exactly 192GB of RAM, which is a critical threshold according to documentation.
- An advocate shared their experience using specific quantization to optimize the model's performance, emphasizing GPU offloading benefits.
- Hybrid Development Workflow Using LM Studio: One member shared their workflow of using LM Studio for local iterative development and then switching to hosted providers for final runs with larger models.
- This approach highlights the advantages of using compatible APIs in the AI ecosystem to seamlessly transition between local and cloud resources.
- Download and run IAILabs/Qwen2.5-VL-7b-Instruct-GGUF in LM Studio: Use IAILabs/Qwen2.5-VL-7b-Instruct-GGUF locally in your LM Studio
- lms log stream | LM Studio Docs: Stream logs from LM Studio. Useful for debugging prompts sent to the model.
- IAILabs/Qwen2.5-VL-7b-Instruct-GGUF · Hugging Face: no description found
- unsloth/DeepSeek-R1-GGUF at main: no description found
- Speculative Decoding | LM Studio Docs: Speed up generation with a draft model
- lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF · Hugging Face: no description found
- mlx-community/Llama-3.2-1B-Instruct-4bit · Hugging Face: no description found
LM Studio ▷ #hardware-discussion (20 messages🔥):
A770 performance, PC build frustrations, M2 Max specifications, Comparison of Apple chips
- A770 shows decent performance: User noted that their A770 GPU performs decently in tasks but doesn't provide specific metrics.
- This adds to the ongoing discussion about GPU capabilities among users.
- Frustration with PC build issues: User expressed frustration over compatibility issues, mentioning that the aio pump needs a USB 2.0 header and interferes with the last PCIE slot.
- ‘I have a second system to put all of them in’ suggests they may look for alternative solutions.
- M2 Max is a solid choice for casual use: User decided on a refurbished M2 Max 96GB for their hobbies and productive work, citing concerns about the investment for an M4 Max.
- ‘I didn't have the balls to buy a M4 Max’ highlights the hesitation many have regarding high-end tech purchases.
- Power consumption differences noted: Discussion emerged on the clock and throttle behavior among various Apple chips, with observations on the M2 Max pulling 60w compared to M4 Max, which easily peaks at 140w.
- This reflects users’ experiences transitioning between different chip generations and their impact on power usage.
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
Feature Request Board, User Feedback Mechanism
- New Feature Request Board Launches: Stability AI has launched a new feature request board allowing users to submit their ideas easily from Discord by typing /feedback.
- This initiative aims to enhance user engagement, enabling community voting on requests to better prioritize developments.
- Empowering Users to Shape Future Features: The addition of the feature request board streamlines the process for users to express what features they'd like to see integrated into Stability AI tools.
- As stated, your feedback helps us prioritize what we work on next, highlighting the community's role in shaping the platform.
Stability.ai (Stable Diffusion) ▷ #general-chat (52 messages🔥):
Image Generation Speed, SD3 Ultra Features, Dog Breed Image Datasets, Model Performance Comparisons, Resolution Settings
- Curiosity about SD3 Ultra: Members expressed their curiosity about SD3 Ultra, particularly its workflow and higher high frequency detail compared to SD3L 8B, as noted by one contributor.
- It still exists - I still use it, remarked a user, adding to the intrigue around its capabilities.
- Image Generation Speed Varies: A user shared their experience of image generation taking 20 minutes, prompting discussions on performance across different hardware setups, with one member reporting 31 seconds for a 1920x1080 resolution image on a 3060 TI.
- Another noted that generation time heavily depends on the model; for instance, SD1.5 averaged 4-5 seconds on a 3070 TI.
- Seeking Dog Image Datasets: A member requested help finding good dog breed image datasets beyond the Stanford Dogs dataset, highlighting their need for more than just 20k images.
- They specified that the dataset should include images labeled with dog breeds.
- Resolution Settings Affect Performance: Participants discussed optimal settings for image resolution, with recommendations of using smaller sizes like 576x576 to improve generation speed.
- One user found success with these adjustments but still experienced delays of about 8 minutes.
- General Discussion on Image Generation: Users shared personal experiences and configurations for image generation, including settings like 1366x768 for 16:9 aspect ratios.
- Discussions highlighted differences in speed and efficiency based on GPU capabilities and selected resolutions.
Modular (Mojo 🔥) ▷ #mojo (11 messages🔥):
Mojo FFI with GLFW/GLEW, Graphics Programming in Mojo, Dynamic linking and library loading, Error with lightbug_http dependency, Issue with small_time dependency version
- Mojo FFI Enables Graphics Programming: A member demonstrated using Mojo FFI to link a static library to GLFW/GLEW and shared an example involving Sudoku.
- Graphics programming is definitely possible with Mojo, suggesting that required calls should only be exposed via a custom C/C++ library.
- Using Aliasing for External Calls: Through aliasing external calls, a member showed a wrapped function example for drawing a Sudoku grid in Mojo.
- The syntax used was:
alias draw_sudoku_grid = external_call[...]for streamlined function access.
- The syntax used was:
- Dynamic Linking Methods in Mojo: A repository was shared illustrating how to hijack the loader for library linking in Mojo via a Python script.
- You can check out the demo on GitHub here.
- Error Encountered with lightbug_http Dependency: A user reported an error when trying to use the lightbug_http dependency after adding it to a fresh Mojo project, referencing a Stack Overflow issue.
- They experienced trailing bytes and module parse issues, indicating potential problems with dependency installation or configuration.
- Question on Version Pinning of small_time Dependency: A user speculated whether pinning the small_time dependency to 25.1.0 instead of using ==25.1.0 could be causing their errors.
- This suggests that version specification in dependency management might be critical for avoiding similar issues.
- Magic fails to install Mojo dependencies: I cannot use the Mojo dependency called lightbug_http in a fresh Mojo project. magic init hello_web --format mojoproject cd hello_web magic shell Printing «Hello world» ...
- GitHub - ihnorton/mojo-ffi: Mojo FFI demos: dynamic linking methods, and a static linking proof-of-concept: Mojo FFI demos: dynamic linking methods, and a static linking proof-of-concept - ihnorton/mojo-ffi
Modular (Mojo 🔥) ▷ #max (20 messages🔥):
Hardware Accelerated Conway's Game of Life, GPU Utilization in MAX, SIMD Implementation by Daniel Lemire, Game of Life Computer Concepts, Space Patterns in Conway's Game
- Eggsquad's Silliest MAX Use Yet: A member showcased their implementation of a hardware accelerated Conway’s Game of Life using MAX and pygame, claiming it to be a rather silly application.
- They shared that it works effectively with complex starting points and have even added features for spaceship patterns.
- Curious About GPU Functionality: Discussion arose around the compatibility of using MAX with a 2080 Super GPU, with the potential for CPU brute forcing suggested by another member.
- The consensus pointed towards running scripts from Python, which should facilitate GPU integration.
- Exploring SIMD-Fied Techniques: Eggsquad mentioned finding a SIMD-fied implementation by Daniel Lemire, yet expressed hesitance to explore it further at this stage.
- Darkmatter pointed out that utilizing bit packing could support much larger graphs in their implementation.
- Bug Fixes and Progress Updates: After resolving a bug, Eggsquad confirmed that their Conway's Game of Life implementation was functioning quite well, showing ongoing progress.
- They demonstrated their results through animations, including one that depicted guns in the game.
- Integration of Parameters for Game Patterns: Eggsquad added an option to wrap around the game space, enabling the creation of spaceship patterns with the game mechanics.
- They noted the exciting capability of adding parameters to the model via the graph API for further experimentation.
Link mentioned: Nicolas Loizeau - GOL computer: A new (and better) version of the GOL computer is available here : https://github.com/nicolasloizeau/scalable-gol-computer
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 4 with Hanna Hajishirzi, Tulu 3 advancements, Open training recipes, Reinforcement learning with verifiable rewards, Applications of language models in science
- Lecture 4 on Open Training Recipes TODAY: Join the livestream of the 4th lecture featuring Hanna Hajishirzi at 4:00pm PST today, available here. She will present on the topic 'Open Training Recipes for Reasoning and Agents in Language Models'.
- This session will cover comprehensive efforts in training language models, enhancing their reasoning capabilities from pre-training to post-training.
- Tulu 3 outshines competitors: Hanna will discuss Tulu 3, a state-of-the-art post-trained language model that surpasses both DeepSeek V3 and GPT-4o through innovative training methods. This also includes her team's open training recipe involving data curation and fine-tuning.
- “We aim to boost reasoning capabilities in the pre-training phase,” she noted, emphasizing the importance of enhancing model effectiveness.
- Innovative Reinforcement Learning Methods Introduced: The talk will showcase a unique reinforcement learning method with verifiable rewards (RLVR) used to train language models effectively. This method aims to significantly impact the reasoning capabilities of these models during both training phases.
- Hanna will share insights into testing strategies that incorporate these advanced reinforcement learning techniques.
- Real-World Applications of Language Models: A focus of the lecture will also be on building agents capable of synthesizing scientific content using trained models. This application is essential for bridging the gap between theoretical research and practical use cases.
- “Our efforts strive to enhance applicability and usefulness for human lives,” said Hanna, reflecting on the importance of real-world applications.
- Upcoming MOOC Curriculum Details: Details regarding the MOOC curriculum will be released soon, keeping participants informed about future offerings. The team thanks everyone for their patience as they finalize these details.
- Stay tuned for updates that will enhance your learning experience!
Link mentioned: CS 194/294-280 (Advanced LLM Agents) - Lecture 4, Hanna Hajishirzi: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (9 messages🔥):
Quiz Submissions for Latecomers, Research Track Application Status, Application Track for MOOC Students
- Quiz Submissions won't be penalized for MOOC students: A member clarified that quiz deadlines apply only to Berkeley students, meaning all quizzes for MOOC students are due at the end of the semester.
- They highlighted that more details about the MOOC curriculum will be shared soon, providing reassurance to those joining late.
- Research Track applications closed for MOOC students: Unfortunately, the decision for the research track application has been made, and details about project rules for MOOC students are pending from the professor.
- Members expressed concern whether the research track is open to non-Berkeley students, indicating continued uncertainty.
- Application Track still awaits details: Inquiries about the application track revealed that instructions for MOOC students are still being awaited, with potential implications for final projects.
- Members hope that more information regarding participation will be released soon, looking for clarity on the application process.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (11 messages🔥):
Teaching Style Feedback, Research Group Proposals, Research Track Eligibility, Application Stack Inquiry, MOOC Curriculum Launch
- Positive Feedback on Teaching Style: A member praised a specific instructor saying, 'She has a very clear teaching style. I like it!'.
- Another member echoed this sentiment, confirming that the instructor was indeed effective in their teaching.
- Research Group Proposal Submission: Members inquired about how to submit proposals for the research group and whether an email had been sent regarding it.
- There was confusion about the proposal process, with one member stating they did not receive any emails with details.
- Eligibility for Research Track: It was clarified that the research track is only for Berkeley students, based on previous announcements.
- This led to some disappointment among participants who are not affiliated with Berkeley.
- Application Stack Open to MOOC Students: Members discussed whether the application stack will be open to MOOC students, with wei3398 stating it should be.
- They noted that further details are pending as the curriculum has yet to be released, referencing a discord link.
- MOOC Curriculum Details Coming Soon: A member announced that MOOC curriculum details will be released soon, including a project component.
- They thanked everyone for their patience as they awaited the upcoming information.
Notebook LM ▷ #use-cases (2 messages):
Ease of Use, Instruction Prompts
- User finds it amazing and easy to try: A user expressed excitement about a new tool, stating it looks amazing and seems easy enough for non-programmers to use.
- Maybe I'll try it reflects the user's hesitation about fully committing despite the positive impression.
- Shortest Instruction Prompt Noted: Another user commented on a notably short instruction prompt, characterizing it as the shortest they had ever seen.
- This indicates a potential shift towards more streamlined user guidance in tool usage.
Notebook LM ▷ #general (14 messages🔥):
Google Deep Research & Gemini, NotebookLM language settings, Scanning physical books, Multi-language prompts in NotebookLM, Claude 3.7 hype
- Google Deep Research and Gemini integration: Discussion sparked around integrating Google Deep Research and Gemini with NotebookLM for enhanced capabilities.
- Members expressed excitement for future developments in this area.
- Changing NotebookLM language settings: Concerns were raised about changing language settings in NotebookLM without affecting the Google account language.
- A user sought advice on effective ways to implement such language changes.
- Creative ways to digitize physical books: A member proposed taking photos of each page with a lens app to create a PDF, then converting it to PowerPoint for upload to NotebookLM.
- Alternatives were suggested, such as using copiers or Adobe's Scan app for direct PDF creation.
- Using prompts effectively in NotebookLM: Discussions emerged on whether to use single or multiple prompts to facilitate hosts speaking in German.
- A member noted that the effectiveness might be tied to their premium subscription status.
- Excitement around Claude 3.7: There was a buzz regarding Claude 3.7, with users wishing for more control in choosing models.
- One user prompted discussions around the impacts of such a decision on user experience.
LlamaIndex ▷ #blog (3 messages):
AI assistant availability, ComposioHQ updates, Claude Sonnet 3.7 release, Integration with Anthropic, Installation instructions
- AI Assistant Now Live for Users!: The excellent AI assistant on the docs is now available for everyone to use! Check it out here.
- ComposioHQ Drops Another Hit!: Another banger has been released from ComposioHQ! It continues to impress with its features and functionality.
- Claude Sonnet 3.7 is Here!: Our friends at AnthropicAI have dropped Claude Sonnet 3.7, and the vibes and evaluations are positive!
- Users can easily get day 0 support by running
pip install llama-index-llms-anthropic --upgrade.
- Users can easily get day 0 support by running
- Check Out Anthropic's Announcement!: Those looking for more details can find Anthropic's announcement post here. It's packed with information.
- Stay updated on the latest integration capabilities with this new release!
LlamaIndex ▷ #general (5 messages):
BM25 retriever with elastic search, MultiModalVectorStoreIndex issues
- BM25 retriever can't initialize without nodes: A member noted that the BM25 retriever cannot be initialized from the vector store alone as the docstore must contain saved nodes.
- Another suggestion was to set top k to 10000 to retrieve all nodes, though this might not be efficient.
- Error creating MultiModalVectorStoreIndex with images: A member encountered an error related to image files while trying to create a MultiModalVectorStoreIndex, despite having images in a GCS bucket.
- They reported that the issue arises specifically for images, as their code works fine for PDF documents.
Torchtune ▷ #dev (6 messages):
Truncation Methods for Fine-tuning, PR Review of StatefulDataLoader
- Debate on Truncation for Fine-tuning: A member raised a question about whether to default to left truncation instead of the current right truncation for fine-tuning, citing a graph as support.
- Others in the discussion acknowledged that HF's current default is right truncation and shared mixed opinions on changing the default.
- Request for Review on StatefulDataLoader: A member requested a review for their pull request that adds support for the StatefulDataLoader class, emphasizing its importance.
- This pull request addresses adding new features and fixing potential bugs as part of its context.
Link mentioned: Add support for StatefulDataLoader by joecummings · Pull Request #2410 · pytorch/torchtune: ContextWhat is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here)This PR adds support for the StatefulDataLoader class fr...
Torchtune ▷ #papers (2 messages):
DeepScaleR Model, DeepEP Communication Library
- DeepScaleR Surpasses O1-Preview with RL: The new DeepScaleR model, fine-tuned from Deepseek-R1-Distilled-Qwen-1.5B using simple reinforcement learning, achieved 43.1% Pass@1 accuracy on AIME2024, marking a 14.3% improvement over the O1-preview.
- This advancement highlights the effective application of reinforcement learning techniques in scaling models.
- Introducing DeepEP: Open-Source Communication Library: In the spirit of #OpenSourceWeek, Deepseek AI unveiled DeepEP, the first open-source communication library designed for Mixture of Experts (MoE) model training and inference.
- With features like FP8 dispatch support and efficient intranode and internode communication, DeepEP aims to optimize both training and inference phases in AI model deployment. Check it out on GitHub.
- Tweet from DeepSeek (@deepseek_ai): 🚀 Day 2 of #OpenSourceWeek: DeepEPExcited to introduce DeepEP - the first open-source EP communication library for MoE model training and inference.✅ Efficient and optimized all-to-all communication✅...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Cohere ▷ #cmd-r-bot (5 messages):
POS Validators profitability, Pool validator nodes, Asset value assessment
- Inquiry on Profitability Threshold for POS Validators in DeSci: A user inquired about the profitability threshold for POS Validators within the DeSci space.
- This highlights the ongoing interest in the economic viability of node operations in decentralized science.
- Discussion on Pool Validator Nodes: Another user referenced pool validator nodes, indicating an interest in collaboration or shared resources among validators.
- This could suggest a trend towards optimizing validator efficiency through pooling strategies.
- Asset Value Expertise Concern: A message included the term asset value expert but was obscured with unrelated terms, limiting clarity.
- This raises questions about the relevance of expertise in assessing asset valuations within the discussed topics.
Nomic.ai (GPT4All) ▷ #announcements (1 messages):
GPT4All v3.10.0 Release, Remote Model Configuration, CUDA Compatibility Updates, Translation Improvements, Chat Template Enhancements
- GPT4All v3.10.0 launches with key updates: The GPT4All v3.10.0 version has been released featuring several significant enhancements, including better remote model configuration and new model support.
- Crash fixes have also been incorporated to ensure stable performance across the platform.
- Enhanced Remote Model Configuration: A dedicated tab for remote model providers has been added to the Add Model page, making it easier to configure models from Groq, OpenAI, and Mistral.
- This improvement allows for more seamless integration of external solutions into the GPT4All ecosystem.
- CUDA Compatibility Expanded: The latest update now supports GPUs with CUDA compute capability 5.0, including the GTX 750, enhancing accessibility for more users.
- This broadens the range of hardware that can efficiently run GPT4All.
- Translation and Chat Template Improvements: Updates have been made to the Italian and Simplified Chinese translations, significantly improving usability for non-English speakers.
- Additionally, the default chat templates for OLMoE and Granite models have been enhanced for better user experience.
- Whitespace and Crash Fixes Implemented: Improvements have been made to the whitespace behavior of DeepSeek-R1-based models to ensure cleaner outputs.
- Several crash-related issues have also been addressed to enhance system stability.
Nomic.ai (GPT4All) ▷ #general (4 messages):
Multi-Agent Framework in GPT4All, AI and Coding Understanding, Versioning Concerns, Nomic Embed Updates
- Exploring Multi-Agent Framework in GPT4All: A user inquired about the possibility of using a multi-agent framework within GPT4All, seeking clarity on its implementation.
- No responses or solutions were provided in the discussion.
- Realities of AI and Programming Languages: A user expressed concerns about the challenges of using GPT4All to create AI solutions, noting that it doesn't fully grasp programming languages.
- They acknowledged that while GPT4All simplifies AI development, significant learning and effort remain necessary.
- Versioning Confusion with GPT4All: A member questioned if v3.10.0 should actually represent v4.0, reflecting confusion over the versioning system.
- Another user expressed uncertainty but indicated a desire for GPT4All v4.0.0, citing the recent release of Nomic Embed v2.
- Anticipation for Nomic Embed v2: A user awaits the release of GPT4All v4.0.0, highlighting that it continues to use Nomic Embed v1.5 despite the new version's launch.
- They reminded others that patience is essential in awaiting these updates.
DSPy ▷ #general (2 messages):
phi4 response format, migration from 2.5-style Assertions, dspy.BestOfN, dspy.Refine
- phi4 response format differs: There was a mention that the phi4 response format is different than most, though details are pending.
- A tutorial is being prepared to clarify its usage.
- New options for Assertion migration: For those migrating from 2.5-style Assertions, you can now utilize
dspy.BestOfNordspy.Refineto streamline modules.- This replaces the traditional assertions functionality with more efficient options.
- Implementation of dspy.BestOfN: An example was provided to show how to implement
dspy.BestOfNwithin a ChainOfThought or multi-step module, allowing up to 5 retries.- The method will select the best reward while stopping if the threshold is reached.
- Reward function explained: A sample
reward_fnwas shared, illustrating how it can return scalar values like float or bool to evaluate prediction field lengths.- This function is applicable within the context of the dspy.BestOfN implementation.