[AINews] Claude 3.5 Sonnet (New) gets Computer Use
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Better model naming is all we need.
AI News for 10/21/2024-10/22/2024. We checked 7 subreddits, 433 Twitters and 32 Discords (232 channels, and 3347 messages) for you. Estimated reading time saved (at 200wpm): 341 minutes. You can now tag @smol_ai for AINews discussions!
Instead of the widely anticipated (and now indefinitely postponed) Claude 3.5 Opus, Anthropic announced a new 3.5 Sonnet, and 3.5 Haiku, bringing a bump to each model.
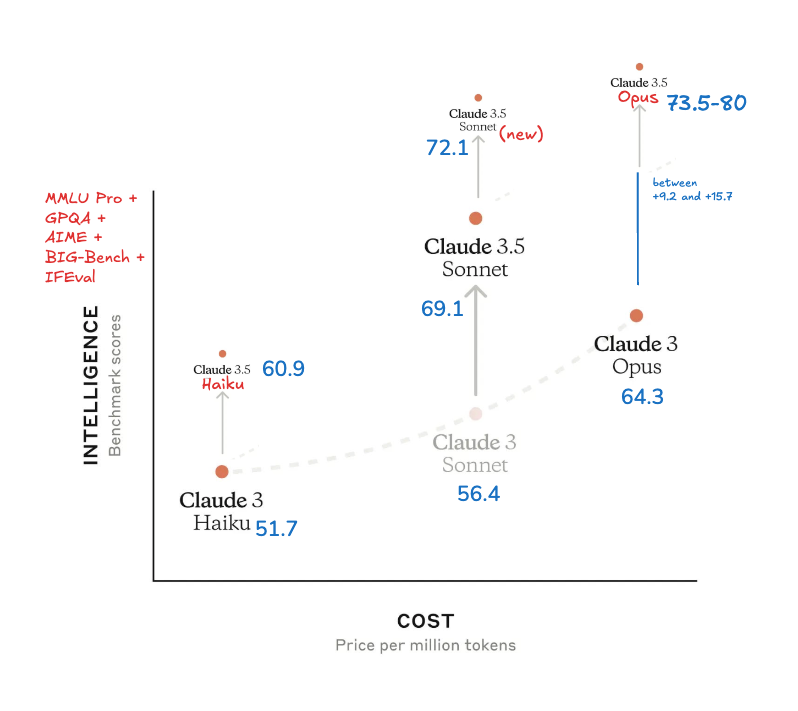
3.5 Sonnet, already delivers significant gains in coding. The new 3.5 Haiku (with benchmarks on the model card) matches the performance of Claude 3 Opus “on many evaluations for the same cost and similar speed to the previous generation of Haiku”.
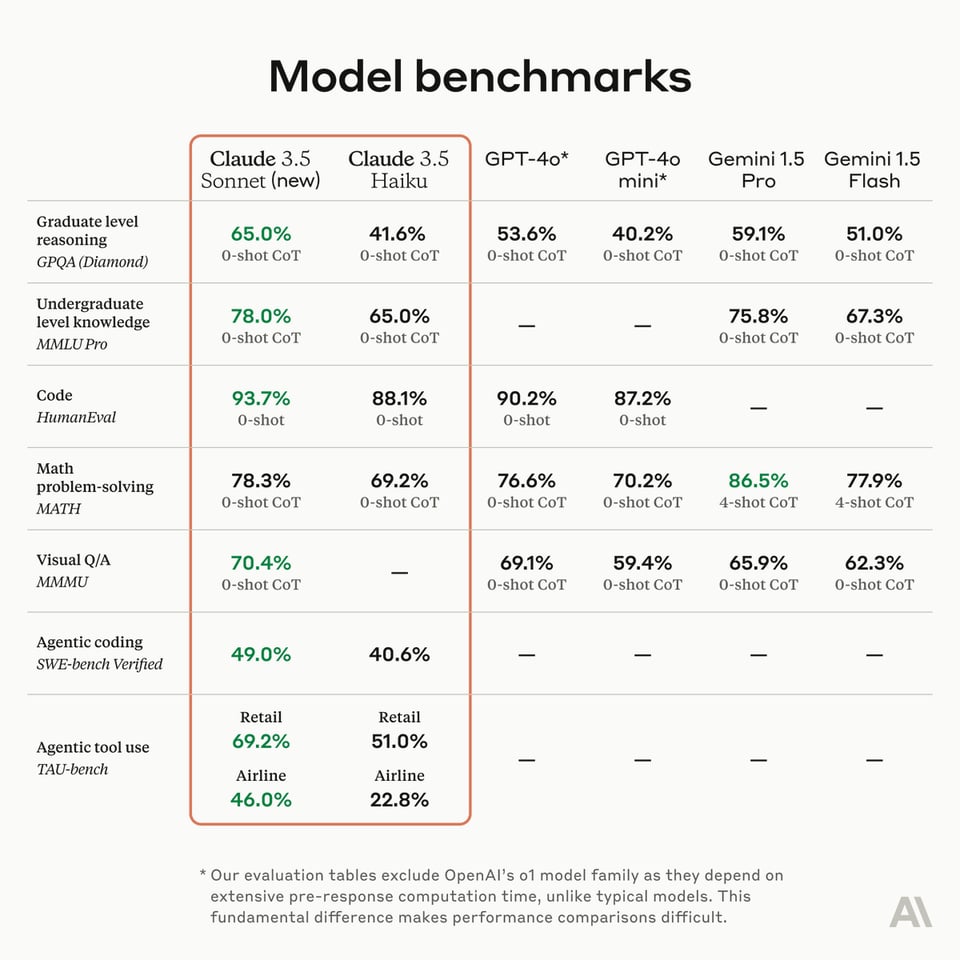 Notably on coding, it improves performance on SWE-bench Verified from 33.4% to 49.0%, scoring HIGHER than o1-preview's own 41.4% without any fancy reasoning steps. However, on math on 3.5 Sonne's 27.6% high water mark still pales in comparison to o1-preview's 83%.
Notably on coding, it improves performance on SWE-bench Verified from 33.4% to 49.0%, scoring HIGHER than o1-preview's own 41.4% without any fancy reasoning steps. However, on math on 3.5 Sonne's 27.6% high water mark still pales in comparison to o1-preview's 83%.
Other Benchmarks:
- Aider: The new Sonnet tops aider's code editing leaderboard at 84.2% and sets SOTA on aider's more demanding refactoring benchmark with a score of 92.1%!
- Vectara: On Vectara's Hughes Hallucination Evaluation Model Sonnet 3.5 went from 8.6 to 4.6
Computer Use
Anthropic's new Computer Use API (docs here, demo here) point to OSWorld for their relevant screen manipulation benchmark - scoring 14.9% in the screenshot-only category—notably better than the next-best AI system's score of 7.8%.
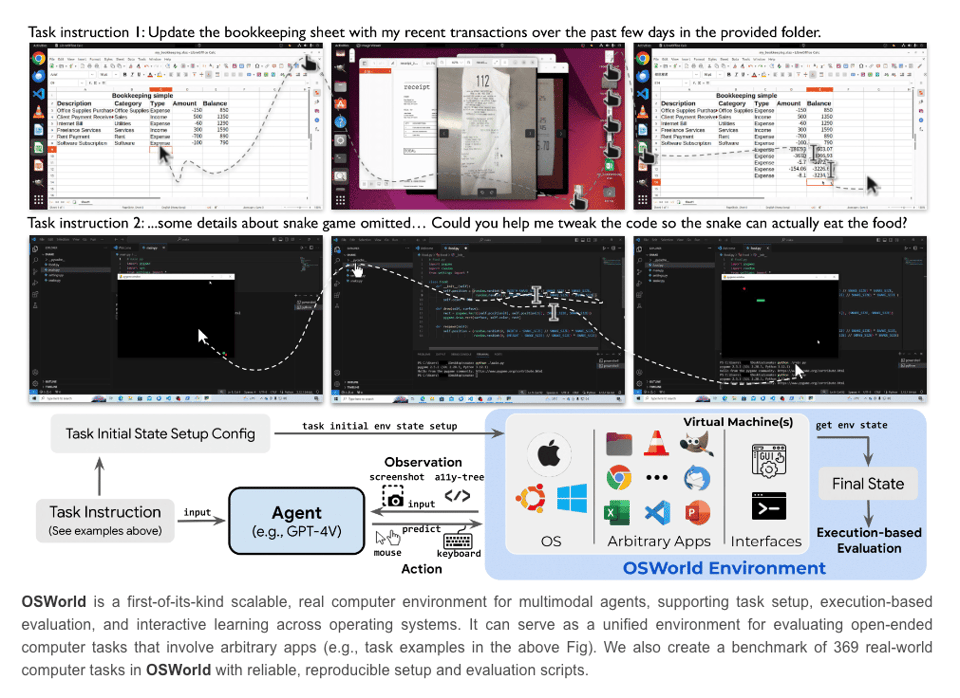
When afforded more steps to complete the task, Claude scored 22.0%. This is still substantially under human performance in the 70’s, but is notable because this is essentially the functionality that Adept previously announced with its Fuyu models but never widely released. In a reductive sense "computer use" (controlling a computer via vision) is contrasted against standard "tool use" (controlling computers via API/function calling).
Example Videos:
Vendor Request Form, Coding Via Vision, Google Searches and Google Maps
Simon Willison kicked the tires on the github quickstart further with tests including compile and run hello world in C (it has gcc already so this just worked) and installing missing Ubuntu packages.
Replit was also able to plug in Claude as a human feedback replacement for @Replit Agent.
[Sponsored by Zep] Zep just launched their cloud edition today! Zep is a low-latency memory layer for AI agents and assistants that can reason about facts that change over time. Jump into the Discord to chat the future of knowledge graphs and memory!
swyx commentary: with computer use now officially blessed by Claude's upgraded vision model, how will agent memory storage need to change? You can see the simplistic image memory implementation from Anthropic but there's no answer for multimodal memory yet... one hot topic for the Zep Discord.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- OpenRouter (Alex Atallah) Discord
- aider (Paul Gauthier) Discord
- Stability.ai (Stable Diffusion) Discord
- Unsloth AI (Daniel Han) Discord
- Nous Research AI Discord
- LM Studio Discord
- Latent Space Discord
- Notebook LM Discord Discord
- Perplexity AI Discord
- Eleuther Discord
- Interconnects (Nathan Lambert) Discord
- GPU MODE Discord
- OpenAI Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- tinygrad (George Hotz) Discord
- OpenInterpreter Discord
- DSPy Discord
- LlamaIndex Discord
- LLM Agents (Berkeley MOOC) Discord
- Torchtune Discord
- LangChain AI Discord
- OpenAccess AI Collective (axolotl) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LAION Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (586 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (18 messages🔥):
- HuggingFace ▷ #cool-finds (1 messages):
- HuggingFace ▷ #i-made-this (10 messages🔥):
- HuggingFace ▷ #core-announcements (1 messages):
- HuggingFace ▷ #NLP (8 messages🔥):
- HuggingFace ▷ #diffusion-discussions (29 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (455 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (290 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (20 messages🔥):
- aider (Paul Gauthier) ▷ #links (5 messages):
- Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (280 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (234 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (34 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- Nous Research AI ▷ #general (137 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (5 messages):
- Nous Research AI ▷ #research-papers (11 messages🔥):
- Nous Research AI ▷ #interesting-links (15 messages🔥):
- Nous Research AI ▷ #research-papers (11 messages🔥):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #general (171 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (155 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (45 messages🔥):
- Notebook LM Discord ▷ #general (103 messages🔥🔥):
- Perplexity AI ▷ #general (103 messages🔥🔥):
- Perplexity AI ▷ #sharing (11 messages🔥):
- Eleuther ▷ #announcements (1 messages):
- Eleuther ▷ #general (28 messages🔥):
- Eleuther ▷ #research (59 messages🔥🔥):
- Eleuther ▷ #interpretability-general (2 messages):
- Eleuther ▷ #lm-thunderdome (8 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (74 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
- Interconnects (Nathan Lambert) ▷ #random (7 messages):
- Interconnects (Nathan Lambert) ▷ #memes (2 messages):
- GPU MODE ▷ #general (7 messages):
- GPU MODE ▷ #triton (19 messages🔥):
- GPU MODE ▷ #torch (1 messages):
- GPU MODE ▷ #beginner (3 messages):
- GPU MODE ▷ #torchao (14 messages🔥):
- GPU MODE ▷ #llmdotc (1 messages):
- GPU MODE ▷ #rocm (3 messages):
- GPU MODE ▷ #bitnet (7 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- GPU MODE ▷ #liger-kernel (11 messages🔥):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #project-popcorn (6 messages):
- OpenAI ▷ #ai-discussions (47 messages🔥):
- OpenAI ▷ #gpt-4-discussions (4 messages):
- OpenAI ▷ #prompt-engineering (11 messages🔥):
- OpenAI ▷ #api-discussions (11 messages🔥):
- Cohere ▷ #discussions (38 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (10 messages🔥):
- Cohere ▷ #api-discussions (19 messages🔥):
- Cohere ▷ #projects (1 messages):
- Modular (Mojo 🔥) ▷ #general (5 messages):
- Modular (Mojo 🔥) ▷ #mojo (40 messages🔥):
- tinygrad (George Hotz) ▷ #general (15 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (15 messages🔥):
- OpenInterpreter ▷ #general (24 messages🔥):
- OpenInterpreter ▷ #ai-content (1 messages):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (22 messages🔥):
- LlamaIndex ▷ #blog (4 messages):
- LlamaIndex ▷ #general (14 messages🔥):
- LlamaIndex ▷ #ai-discussion (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (2 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (4 messages):
- Torchtune ▷ #general (16 messages🔥):
- Torchtune ▷ #dev (1 messages):
- LangChain AI ▷ #general (6 messages):
- LangChain AI ▷ #share-your-work (2 messages):
- LangChain AI ▷ #tutorials (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (6 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
- LAION ▷ #resources (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Releases
- Llama 3.1 and Nemotron: @_philschmid reported that NVIDIA's Llama 3.1 Nemotron 70B topped Arena Hard (85.0) & AlpacaEval 2 LC (57.6), challenging GPT-4 and Claude 3.5.
- IBM Granite 3.0: IBM released Granite 3.0 models, ranging from 400 million to 8B parameters, outperforming similarly sized Llama-3.1 8B on Hugging Face's OpenLLM Leaderboard. The models are trained on 12+ trillion tokens across 12 languages and 116 programming languages.
- xAI API: The xAI API Beta is now live, allowing developers to integrate Grok into their applications.
- BitNet: Microsoft open-sourced bitnet.cpp, implementing the 1.58-bit LLM architecture. This allows running 100B parameter models on CPUs at 5-7 tokens/second.
AI Research and Techniques
- Quantization: A new Linear-complexity Multiplication (L-Mul) algorithm claims to reduce energy costs by 95% for element-wise tensor multiplications and 80% for dot products in large language models.
- Synthetic Data: @omarsar0 highlighted the importance of synthetic data for improving LLMs and systems built on LLMs (agents, RAG, etc.).
- Agentic Information Retrieval: A paper introducing agentic information retrieval was shared, discussing how LLM agents shape retrieval systems.
- RoPE Frequencies: @vikhyatk noted that truncating the lowest RoPE frequencies helps with length extrapolation in LLMs.
AI Tools and Applications
- Perplexity Finance: Perplexity Finance was launched on iOS, offering financial information and stock data.
- LlamaIndex: Various applications using LlamaIndex were shared, including report generation and a serverless RAG app.
- Hugging Face Updates: New features like repository analytics for enterprise hub subscriptions and quantization support in diffusers were announced.
AI Ethics and Societal Impact
- Legal Services: OpenAI's CPO Kevin Weil discussed the potential disruption in legal services, with AI potentially reducing costs by 99.9%.
- AI Audits: A virtual workshop on third-party AI audits, red teaming, and evaluation was announced for October 28th.
Memes and Humor
- Various tweets about ChatGPT's upcoming birthday and potential presents were shared, including this one by @sama.
- Jokes about AI-generated backgrounds in Google Meet and AI's impact on video editing were shared.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Moonshine: New Open-Source Speech-to-Text Model Challenges Whisper
- Moonshine New Open Source Speech to Text Model (Score: 54, Comments: 5): Moonshine, a new open-source speech-to-text model, claims to be faster than Whisper while maintaining comparable accuracy. Developed by Sanchit Gandhi and the Hugging Face team, Moonshine is based on wav2vec2 and can process audio 30 times faster than Whisper on CPU. The model is available on the Hugging Face Hub and can be easily integrated into projects using the Transformers library.
- Moonshine aims for resource-constrained platforms like Raspberry Pi, targeting 8MB RAM usage for transcribing sentences, compared to Whisper's 30MB minimum requirement. The model focuses on efficiency for microcontrollers and DSPs rather than competing with Whisper large v3.
- Users expressed excitement about trying Moonshine, noting issues with Whisper 3's accuracy and hallucinations. However, Moonshine is currently an English-only model, limiting its use for multilingual applications.
- The project is available on GitHub and includes a research paper. Some users reported installation errors, possibly due to Git-related issues on Windows.
Theme 2. Allegro: New State-of-the-Art Open-Source Text-to-Video Model
- new text-to-video model: Allegro (Score: 99, Comments: 8): Allegro, a new open-source text-to-video model, has been released with a detailed paper and Hugging Face implementation. The model builds on the creators' previous open-source Vision Language Model (VLM) called Aria, which offers comprehensive fine-tuning guides for tasks like surveillance grounding and reasoning.
- Allegro is praised as the new local text-to-video SOTA (State of the Art), with its Apache-2.0 license being particularly appreciated. The open-source nature of the model is seen as a positive development in the local video generation space.
- The model's VRAM requirements are discussed, with options ranging from 9.3GB (with CPU offload) to 27.5GB (without offload). Users suggest quantizing the T5 model to lower precision (fp16/fp8/int8) to fit on 24GB/16GB VRAM cards.
- Flexibility in model usage is highlighted, with the possibility to trade generation quality for reduced VRAM usage and faster generation times (potentially 10-30 minutes). Some users discuss the option of swapping out the T5 model after initial prompt encoding to optimize resource usage.
Theme 3. AI Sabotage Incident at ByteDance Raises Security Concerns
- TikTok owner sacks intern for sabotaging AI project (Score: 153, Comments: 50): ByteDance, the parent company of TikTok, reportedly fired an intern for intentionally sabotaging an AI project by inserting malicious code. The incident, which occurred in China, underscores the security risks associated with AI development and the potential for insider threats in tech companies. ByteDance discovered the sabotage during a routine code review, highlighting the importance of robust security measures and code audits in AI development processes.
- The intern allegedly sabotaged AI research by implanting backdoors into checkpoint models, inserting random sleeps to slow training, killing training runs, and reversing training steps. This was reportedly due to frustration over GPU resource allocation.
- ByteDance fired the intern in August, informed their university and industry bodies, and clarified that the incident only affected the commercial technology team's research project, not official projects or large models. Claims of "8,000 cards and millions in losses" were exaggerated.
- Some users questioned the intern's reported lack of AI experience, given their ability to reverse training processes. Others noted this was "career suicide" and speculated about potential blacklisting from major tech companies.
Theme 4. PocketPal AI: Open-Source App for Local Models on Mobile
- PocketPal AI is open sourced (Score: 434, Comments: 78): PocketPal AI, an application for running local models on iOS and Android devices, has been open-sourced. The project's source code is now available on GitHub, allowing developers to explore and contribute to the implementation of on-device AI models for mobile platforms.
- Users reported impressive performance with Llama 3.2 1B model, achieving 20 tokens/second on an iPhone 13 and 31 tokens/second on a Samsung S24+. The iOS version uses Metal acceleration, potentially contributing to faster speeds.
- The community expressed gratitude for open-sourcing the app, with many praising its convenience and performance. Some users suggested adding a donation section to support development and requested features like character cards integration.
- Comparisons were made between PocketPal and ChatterUI, another open-source mobile LLM app. PocketPal was noted for its user-friendliness and App Store availability, while ChatterUI offers more customization options and API support.
- 🏆 The GPU-Poor LLM Gladiator Arena 🏆 (Score: 137, Comments: 38): The GPU-Poor LLM Gladiator Arena is a competition for comparing small language models that can run on consumer-grade hardware. Participants are encouraged to submit models with a maximum size of 3 billion parameters that can operate on devices with 24GB VRAM or less, with the goal of achieving high performance on various benchmarks while maintaining efficiency and accessibility.
- Users expressed enthusiasm for the GPU-Poor LLM Gladiator Arena, with some suggesting additional models for inclusion, such as allenai/OLMoE-1B-7B-0924-Instruct and tiiuae/falcon-mamba-7b-instruct. The project was praised for making small model comparisons easier.
- Discussion arose about the performance of Gemma 2 2B, with some users noting its strong performance compared to larger models. There was debate about whether Gemma's friendly conversation style might influence human evaluation results.
- Suggestions for improvement included adding a tie button for evaluations, calculating ELO ratings instead of raw win percentages, and incorporating more robust statistical methods to account for sample size and opponent strength.
Theme 5. Trend Towards More Restrictive Licenses for Open-Weight AI Models
- Recent open weight releases have more restricted licences (Score: 36, Comments: 10): Recent open-weight AI model releases, including Mistral small, Ministral, Qwen 2.5 72B, and Qwen 2.5 3B, have shown a trend towards more restricted licenses compared to earlier releases like Mistral Large 2407. As AI models improve in performance and become more cost-effective to operate, there's a noticeable shift towards stricter licensing terms, potentially leading to a future where open-weight releases may primarily come from academic laboratories.
- Mistral's stricter licensing for smaller models may harm their brand, potentially leading to company-wide bans on Mistral models and reducing interest in their API-only larger models. Users express concern over the lack of local reference points for model quality assessment.
- The decision not to release weights for Mistral's 3B model is seen as a negative sign for open-source AI. This trend suggests companies may increasingly keep even smaller, well-performing models private to maintain competitive advantage.
- Discussion around Mistral's need for profitability to sustain operations, contrasting with larger corporations like Meta that can afford to release models openly. Some users argue that Mistral's approach is necessary for survival, while others see it as part of a concerning trend in AI model licensing.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Developments and Releases
- ComfyUI V1 desktop application released: ComfyUI announced a new packaged desktop app with one-click install, auto-updates, and a new UI with template workflows and node fuzzy search. It also includes a Custom Node Registry with 600+ published nodes. Source
- OpenAI's o1 model shows improved reasoning with more compute: OpenAI researcher Noam Brown shared that the o1 model's reasoning on math problems improves with more test-time compute, with "no sign of stopping" on a logarithmic scale. Source
- Advanced Voice Mode released in EU: OpenAI's Advanced Voice Mode is now officially available in the EU. Users reported improvements in accent handling. Source
AI Research and Industry Insights
- Microsoft CEO on AI development acceleration: Satya Nadella stated that computing power is now doubling every 6 months due to the Scaling Laws paradigm. He also mentioned that AI development has entered a recursive phase, using AI to build better AI tools. Source 1, Source 2
- OpenAI on o1 model reliability: Boris Power, Head of Applied Research at OpenAI, stated that the o1 model is reliable enough for agents. Source
AI Ethics and Societal Impact
- Sam Altman on technological progress: OpenAI CEO Sam Altman tweeted, "it's not that the future is going to happen so fast, it's that the past happened so slow," sparking discussions about the pace of technological advancement. Source
Robotics Advancements
- Unitree robot training: A video showcasing the daily training of Unitree robots was shared, demonstrating advancements in robotic mobility and control. Source
Memes and Humor
- A post titled "An AI that trains more AI" sparked humorous discussions about recursive AI improvement. Source
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. Claude 3.5 Breaks New Ground with Computer Use
- Claude 3.5 Becomes Your Silicon Butler: Anthropic's Claude 3.5 Sonnet introduces a beta 'Computer Use' feature, allowing it to perform tasks on your computer like a human assistant. Despite some hiccups, users are excited about this experimental capability that blurs the line between AI and human interaction.
- Haiku 3.5 Haikus into Coding Supremacy: The new Claude 3.5 Haiku surpasses its predecessors, scoring 40.6% on SWE-bench Verified and outshining Claude 3 Opus. Coders rejoice as Haiku 3.5 sets a new standard in AI-assisted programming.
- Claude Plays with Computers, Users Play with Fire: While the 'Computer Use' feature is groundbreaking, Anthropic warns it's experimental and "at times error-prone." But that hasn't dampened the community's enthusiasm to push the limits.
Theme 2. Stable Diffusion 3.5 Lights Up AI Art
- Stability AI Unleashes Stable Diffusion 3.5—Artists Feast: Stable Diffusion 3.5 launches with improved image quality and prompt adherence, free for commercial use under $1M revenue. Available on Hugging Face, it's a gift to artists and developers alike.
- SD 3.5 Turbo Charges Ahead: The new Stable Diffusion 3.5 Large Turbo model offers some of the fastest inference times without sacrificing quality. Users are thrilled with this blend of speed and performance.
- Artists Debate: SD 3.5 vs. Flux—Who Wears the Crown?: The community buzzes over whether SD 3.5 can dethrone Flux in image quality and aesthetics. Early testers have mixed feelings, but the competition is heating up.
Theme 3. AI Video Generation Heats Up with Mochi 1 and Allegro
- GenmoAI's Mochi 1 Serves Up Sizzling Videos: Mochi 1 sets new standards in open-source video generation, delivering realistic motion and prompt adherence at 480p. Backed by $28.4M in funding, GenmoAI is redefining photorealistic video models.
- Allegro Hits a High Note in Text-to-Video: Rhymes AI introduces Allegro, transforming text into 6-second videos at 15 FPS and 720p. Early adopters can join the waitlist here to be the first to try it out.
- Video Wars Begin: Mochi vs. Allegro—May the Best Frames Win: With both Mochi 1 and Allegro entering the scene, creators eagerly anticipate which model will lead in AI-driven video content.
Theme 4. Cohere Embeds Images into Multimodal Search
- Cohere's Embed 3 Plugs Images into Search—Finally!: Multimodal Embed 3 supports mixed modality searches with state-of-the-art performance on retrieval tasks. Now, you can store text and image data in one database, making RAG systems delightfully simple.
- Images and Text, Together at Last: The new Embed API adds an
input_typecalledimage, letting developers process images alongside text. There's a limit of one image per request, but it's a big leap forward in unifying data retrieval. - Office Hours with the Embed Wizards: Cohere is hosting office hours with their Sr. Product Manager for Embed to offer insights into the new features. Join the event to get the inside scoop straight from the source.
Theme 5. Hackathon Fever: Over $200k in Prizes from Berkeley
- LLM Agents MOOC Hackathon Dangles $200k Carrot: Berkeley RDI launches a hackathon with over $200,000 in prizes, running from mid-October to mid-December. Open to all, it features tracks on applications, benchmarks, and more.
- OpenAI and GoogleAI Throw Weight Behind Hackathon: Major sponsors like OpenAI and GoogleAI back the event, adding prestige and resources. Participants can also explore career and internship opportunities during the competition.
- Five Tracks, Endless Possibilities: The hackathon includes tracks like Applications, Benchmarks, Fundamentals, Safety, and Decentralized & Multi-Agents, inviting participants to push AI boundaries and unlock innovation.
PART 1: High level Discord summaries
HuggingFace Discord
-
AI DJ Software Showcases Potential: Users discussed an innovative concept for AI DJ Software that could automate song transitions and mixing like what is seen with Spotify.
- Tools like rave.dj were mentioned for creating fun mashups, despite imperfections in the output.
- Hugging Face Model Queries Raise Security Concerns: A user sought advice on securely downloading Hugging Face model weights via
huggingface_hubwithout exposing them.
- Community members provided insights into using environment variables for authentication to maintain privacy.
- OCR Tools Under Scrutiny: There was a discussion on effective OCR solutions for structured data extraction from PDFs, particularly for construction applications.
- Recommendations included models like Koboldcpp to improve text extraction accuracy.
- Granite 3.0 Model Launch Celebrated: The new on-device Granite 3.0 model generated excitement among users, highlighting its convenient deployment.
- The model's attributes were praised as enhancing usability for quick integration.
- LLM Best Practices Webinar Attracts Attention: A META Senior ML Engineer announced a webinar focused on LLM navigation, already gaining almost 200 signups.
- The session promises to deliver actionable insights on prompt engineering and model selection.
OpenRouter (Alex Atallah) Discord
-
Claude 3.5 Sonnet shows impressive benchmarks: The newly launched Claude 3.5 Sonnet achieves significant benchmark improvements with no required code changes for users. More information can be found in the official announcement here.
- Members noted that upgrades can be easily tracked by hovering over the info icon next to providers, enhancing user experience.
- Lightning boost with Llama 3.1 Nitro: With a 70% speed increase, the Llama 3.1 405b Nitro is now available, promising a throughput of around 120 tps. Check out the new endpoints: 405b and 70b.
- Users are captivated by the performance advantages this model brings, making it an appealing choice.
- Ministral's powerful model lineup: Ministral 8b has been introduced, achieving 150 tps with a 128k context and is currently ranked #4 for tech prompts. An economical 3b model can be accessed here.
- The performance and pricing of these models generated substantial excitement among users, catering to varying budget needs.
- Grok Beta expands functionalities: Grok Beta now supports an increased context length of 131,072 and charges $15/m, replacing the legacy
x-ai/grok-2requests. This update was met with enthusiasm by users anticipating enhanced performance.
- Community discussions reflect expectations for improved capabilities under the new pricing model.
- Community feedback on Claude self-moderated endpoints: A poll was launched to gather opinions on the Claude self-moderated endpoints, currently the top option on the leaderboard. Members can participate in the poll here.
- User engagement suggests a keen interest in influencing the development and user experience of these endpoints.
aider (Paul Gauthier) Discord
-
Claude 3.5 Sonnet dominates benchmarks: The upgraded Claude 3.5 Sonnet scores 84.2% on Aider's leaderboard and achieves 85.7% when used alongside DeepSeek in architect mode.
- This model not only enhances coding tasks but retains the previous pricing structure, exciting many users.
- DeepSeek is budget-friendly editor alternative: DeepSeek's cost of $0.28 per 1M output tokens makes it a cheaper option compared to Sonnet, which is priced at $15.
- Users note it pairs adequately with Sonnet, although discussions arise about the shift in token costs affecting performance.
- Aider configuration file needs clarity: Users inquired about setting up the
.aider.conf.ymlfile, specifying types likeopenrouter/anthropic/claude-3.5-sonnet:betaas the editor model.
- Clarification was sought on where Aider pulls configuration details at runtime for optimal setup.
- Exciting announcement of computer use beta: Anthropic's new computer use feature allows Claude to perform tasks like moving cursors, currently in public beta and described as experimental.
- Developers can direct its functionality which signifies a shift in interaction with AI and improved usability in coding environments.
- DreamCut AI - Novel video editing solution: DreamCut AI has been launched, allowing users to leverage Claude AI for video editing, developed by MengTo over 3 months with 50k lines of code.
- Currently in early access, users can experiment with its AI-driven features through a free account.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3.5 Launch Shocks Users: Stable Diffusion 3.5 launched with customizable models for consumer hardware, available under the Stability AI Community License. Users are excited about the 3.5 Large and Turbo models, available on Hugging Face and GitHub, with the 3.5 Medium launching on October 29.
- The announcement caught many off guard, stirring discussions on its unexpected release and anticipated performance improvements over previous iterations.
- SD3.5 vs. Flux Image Quality Showdown: The community evaluated whether SD3.5 can beat Flux in image quality, focusing on fine-tuning and aesthetics. Early impressions suggest Flux may still have an edge in these areas, igniting curiosity around dataset effectiveness.
- Discussions highlight the importance of benchmark comparisons between models, especially when establishing market standards for image generation.
- New Licensing Details Raise Questions: Participants expressed concerns regarding the SD3.5 licensing model, especially in commercial contexts compared to AuraFlow. Balancing accessibility with Stability AI's monetization needs became a hot topic.
- The discourse underscores the challenge of ensuring models are both open to developers and sustainable for producers.
- Community Support Boosts Technical Adoption: Users finding issues with Automatic1111's Web UI received guidance on support channels, indicating a collaborative spirit within the community. One member found direct assistance swiftly, showcasing engagement with newcomers.
- This proactive support approach helps ensure users can effectively leverage the new models and integration tools available.
- LoRA Applications Enthuse Artists: The introduction of LoRA models for SD3.5 has users experimenting with prompts and sharing their results, demonstrating its effectiveness in enhancing image generation. The community has been active in showcasing their creations and encouraging further experimentation.
- Such initiatives reflect engagement strategies aimed at maximizing the impact of newly released features within the AI art community.
Unsloth AI (Daniel Han) Discord
-
Gradient Accumulation Bug Fixed in Nightly Transformers: A recent update revealed that the gradient accumulation bug has been fixed and will be included in the nightly transformers and Unsloth trainers, correcting inaccuracies in loss curve calculations.
- This fix enhances the reliability of performance metrics across various training setups.
- Insights on LLM Training Efficiency: Members discussed that training LLMs with phrase inputs generates multiple sub-examples, maximizing training effectiveness and enabling models to learn efficiently.
- This approach allows for richer training datasets, leading to improved model capabilities.
- Challenges with Model Performance and Benchmarks: Concerns arose about the new Nvidia Nemotron Llama 3.1 model, with doubts expressed regarding its superior performance over the Llama 70B despite similar benchmark scores.
- The inconsistency in Nvidia's benchmarking raises questions about their models' performance assessments.
- Creating a Grad School Application Editor: A member seeks assistance in developing a grad school application editor, facing challenges with complex prompts for AI model implementation that lead to generic outputs.
- Experts were called upon to provide strategies for fine-tuning models to enhance output relevance.
- Fine-Tuning LLaMA on CSV Data: Clarifications were requested on fine-tuning a LLaMA model using CSV data to handle specific incident queries, guided by methodologies shared in a Turing article.
- Community feedback played a crucial role in shaping the approach toward effective model testing.
Nous Research AI Discord
-
Catastrophic Forgetting in LLMs: Discussion centered on catastrophic forgetting in large language models (LLMs) during continual instruction tuning, especially in models ranging from 1B to 7B parameters. Members noted that fine-tuning can significantly degrade performance, as detailed in this study.
- Participants shared personal experiences with benchmark results comparing their models against established ones, revealing the challenges inherent in LLM training.
- Insights on LLM Benchmark Performance: Users indicated that model scale significantly influences performance, noting that data limitations without proper optimization can lead to inferior results. One participant discussed their 1B model's lower scores relative to Meta's models, highlighting the importance of baseline comparisons.
- This led to further reflections on how certain models can underperform in competitive contexts without adequate training resources.
- Concerns Over Research Paper Reliability: A recent study revealed that approximately 1 in 7 research papers has serious errors, undermining their trustworthiness. This prompted discussions on how misleading studies could lead researchers to unintentionally build on flawed conclusions.
- Members noted that traditional methods of assessing research integrity require more funding and attention to rectify these issues.
- Fine-Tuning Models: A Double-Edged Sword: Debates around the effectiveness of fine-tuning large foundation models highlighted risks of degrading broad capabilities for specific targets. Members speculated that fine-tuning requires meticulous hyperparameter optimization for fruitful outcomes.
- Concerns emerged regarding the lack of established community knowledge about fine-tuning best practices, prompting questions about recent developments since the previous year.
LM Studio Discord
-
LM Studio v0.3.5 Features Shine: The update to LM Studio v0.3.5 introduces headless mode and on-demand model loading, streamlining local LLM service functionality.
- Users can now easily download models using the CLI command
lms get, enhancing model access and usability. - GPU Offloading Performance Takes a Hit: A user found that GPU offloading performance plummeted, utilizing only 4.2GB instead of the expected 15GB following recent updates.
- Reverting to an older ROCm runtime version restored normal performance, suggesting the update may have altered GPU utilization.
- Model Loading Errors Surfaces: One user reported a 'Model loading aborted due to insufficient system resources' error linked to GPU offload setting adjustments.
- Disabling loading guardrails was mentioned as a workaround, although not typically recommended.
- Discussing AI Model Performance Metrics: The community engaged in a detailed discussion on measuring performance, highlighting the impact of load settings on throughput and latency.
- Notably, under heavy GPU offloading, throughput dropped to 0.9t/s, signaling potential inefficiencies at play.
- Inquiries for Game Image Enhancement Tools: Users began exploring options for converting game images into photorealistic art, with Stable Diffusion highlighted as a candidate tool.
- The conversation generated interest around the effectiveness of various image enhancers in transforming game visuals.
- Users can now easily download models using the CLI command
Latent Space Discord
-
Anthropic Releases Claude 3.5: Anthropic introduced the upgraded Claude 3.5 Sonnet and the Claude 3.5 Haiku models, incorporating a new beta capability for computer use, allowing interaction with computers like a human.
- Despite its innovative abilities, users report it doesn't follow prompts effectively, leading to varied user experiences.
- Mochi 1 Redefines Video Generation: GenmoAI launched Mochi 1, an open-source model aimed at high-quality video generation, notable for realistic motion and prompt adherence at 480p resolution.
- This venture leveraged substantial funding to further development, aiming to set new standards in photorealistic video generation.
- CrewAI Closes $18M Series A Round: CrewAI raised $18 million in Series A funding led by Insight Partners, focusing on automating enterprise processes with its open-source framework.
- The company boasts executing over 10 million agents monthly, catering to a significant portion of Fortune 500 companies.
- Stable Diffusion 3.5 Goes Live: Stability AI released Stable Diffusion 3.5, a highly customizable model runnable on consumer hardware, and free for commercial use.
- Users can now access it via Hugging Face, with expectations for additional variants on the horizon.
- Outlines Library Rust Port Enhances Efficiency: Dottxtai announced a Rust port of the Outlines library, which promises faster compilation and a lightweight design for structured generation tasks.
- The update significantly boosts efficiency for developers and includes bindings in multiple programming languages.
Notebook LM Discord Discord
-
Language Confusion in NotebookLM: Users reported that NotebookLM's responses default to Dutch despite providing English documents, suggesting adjustments to Google account language settings. One user struggled with German output, encountering unexpected 'alien' dialects.
- This highlights the current limitations of language handling within NotebookLM and potential paths for improvement.
- Frustration Over Sharing Notebooks: Several members experienced issues when attempting to share notebooks, facing a perpetual 'Loading...' screen, which renders collaboration ineffective. This has raised concerns about the stability and reliability of the tool.
- Users are pressing for a resolution, indicating an urgent need for a robust sharing feature to facilitate teamwork.
- Mixed Results with Multilingual Audio: Efforts to create audio overviews in various languages yielded inconsistent results, especially in Dutch, where pronunciation and native-like quality were notably lacking. Some users achieved successful Dutch content, fostering hope for improvements.
- This discussion reveals a strong community interest in enhancing multilingual capabilities for broader usability.
- Podcasting Experiences with NotebookLM: A user excitedly shared that they successfully uploaded a 90-page blockchain course, resulting in amusing generated audio. Feedback indicated that variations in input led to unexpected and entertaining outputs.
- This demonstrates the diverse applications of NotebookLM for podcasting, although consistent quality remains a topic for enhancement.
- Document Upload Issues Persist: Users faced issues with documents failing to appear in Google Drive, alongside delays in processing, prompting discussions about potential file corruption. Suggestions to refresh actions were made to address these upload challenges.
- These technical hurdles underscore the need for reliable document management features within NotebookLM.
Perplexity AI Discord
-
Claude 3.5 Models Generate Buzz: Users eagerly discuss the new Claude 3.5 Sonnet and Claude 3.5 Haiku, with hopes for their swift integration into Perplexity following AnthropicAI's announcement. Key features include the ability for Claude to use computers like a human.
- This excitement mirrors previous launches and indicates a strong interest in AI's evolving capabilities.
- API Functionality Sparks Frustration: Concerns arose about the Perplexity API's inability to return complete URLs for sources when prompted, leading to confusion among users about its ease of use. A particular user voiced their challenges in obtaining these URLs despite following instructions.
- This issue sparked a larger discussion on the capabilities of APIs in AI products and the need for clearer documentation.
- Perplexity Encounters Competitive Challenges: With Yahoo launching an AI chat service, discussions surrounding Perplexity's competitive edge became prevalent. Yet, users highlighted Perplexity's reliability and resourcefulness as key advantages over its competitors.
- While competition intensifies, the commitment to quality and performance remains a cornerstone for users.
- User Feedback Highlights Strengths: Positive commendations for Perplexity's performance came from multiple users, who praised its quality information delivery. One user emphasized satisfaction, stating, 'I freaking love PAI! I use it all the time for work and personal.'
- Such feedback underlines the platform's reputation in the AI community.
- Resource Sharing for Enhanced Fact-Checking: A collection on AI-driven fact-checking strategies highlighted ethical considerations and LLMs' roles in misinformation management at Perplexity. This resource discusses importance of source credibility and bias detection.
- Sharing such resources reflects the community's proactive efforts towards improving accuracy in information dissemination.
Eleuther Discord
-
New Open Source SAE Interpretation Pipeline Launched: The interpretability team has released a new open source pipeline for automatically interpreting SAE features and neurons in LLMs, which introduces five techniques for evaluating explanation quality.
- This initiative promises to enhance interpretability at scale, showcasing advancements in utilizing LLMs for feature explanation.
- Integrating Chess AI and LLMs for Better Interactivity: A proposal to combine a chess-playing AI with an LLM aims to create a conversational agent that understands its own decisions, enhancing user engagement.
- The envisioned model strives for a coherent dialogue where the AI can articulate its reasoning behind chess moves.
- SAE Research Ideas Spark Discussions: An undergrad sought project ideas on Sparse Autoencoders (SAEs), prompting discussions about current research efforts and collaborative opportunities.
- Members shared resources, including an Alignment Forum post for deeper exploration.
- Woog09 Rates Mech Interp Papers for ICLR 2025: A member shared a spreadsheet rating all mechanistic interpretability papers for ICLR 2025, applying a scale of 1-3 for quality.
- Their focus is on providing calibrated ratings for guiding readers through submissions.
- Debugging Batch Size Configurations: Members discussed issues with debugging
requestsnot batching correctly with setbatch_size, emphasizing the need for model-level handling of this config.
- Confusions over the purpose of specifying
batch_sizearose, with clarification offered about its connection to model initialization.
Interconnects (Nathan Lambert) Discord
-
Allegro Model Transforms Text to Video: Rhymes AI announced their new open-source model, Allegro, generating 6-second videos from text at 15 FPS and 720p, with links to explore including a GitHub repository. Users can join the Discord waitlist for early access.
- This innovation opens new doors for content creation, being both intriguing and easily accessible.
- Stability AI Heats Up with SD 3.5: Stability AI launched Stable Diffusion 3.5, offering three variants for free commercial use under $1M revenue and enhanced capabilities like Query-Key Normalization for optimization. The Large version is available now on Hugging Face and GitHub, with the Medium version set to launch on October 29th.
- This model marks a substantial upgrade, attracting significant attention within the community for its unique features.
- Claude 3.5 Haiku Sets High Bar in Coding: Anthropic introduced Claude 3.5 Haiku, surpassing Claude 3 Opus especially in coding tasks with a score of 40.6% on SWE-bench Verified, available on the API here. Users are impressed with the advancements highlighted in various benchmarks.
- The model's performance is reshaping standards, making it a go-to for programming-related tasks.
- Factor 64 Revelation: A member expressed excitement about a breakthrough involving Factor 64, feeling it seems 'obvious' in hindsight. This moment ignited deeper discussions regarding its implications.
- The realization has sparked further engagement, hinting at collaborations or new explorations downstream.
- Distance in Community Feedback on Hackernews: Concerns about Hackernews being a views lottery suggest that discussions lack substance and serve more as noise than genuine feedback. Members describe it as very noisy and biased, questioning its engagement value.
- The platform is increasingly viewed as less effective, prompting conversations on alternative feedback mechanisms.
GPU MODE Discord
-
Unsloth Lecture Hits the Web: The Unsloth talk is now available, showcasing dense information appreciated by many viewers who noted its quick pace.
- “I’m watching back through at .5x speed, and it’s still fast”, reflecting the lecture's depth.
- Gradient Accumulation Insights: A discussion on gradient accumulation highlighted the importance of rescaling between batches and using fp32 for large gradients.
- “Usually there's a reason why all the batches can't be the same size,” emphasizing training complexities.
- GitHub AI Projects Unveiled: A user shared their GitHub project featuring a GPT implementation in plain C, stimulating discussions on deep learning.
- This initiative aims to enhance understanding of deep learning through an approachable implementation.
- Decoding Torch Compile Outputs: Metrics from
torch.compileshowed execution times for matrix multiplications, leading to clarifications on interpretingSingleProcess AUTOTUNEresults.
- SingleProcess AUTOTUNE takes 30.7940 seconds to complete, prompting deeper discussions on runtime profiling.
- Meta's HOTI 2024 Focuses on Generative AI: Insights from Meta HOTI 2024 were shared, with specific issues addressed in this session.
- The keynote on 'Powering Llama 3' reveals infrastructure insights vital for understanding Llama 3 integration.
OpenAI Discord
-
AGI Debate Ignites: Members discussed if our struggles to achieve AGI stem from the type of data provided, with some arguing that binary data might limit progress.
- One member asserted that improved algorithms could make AGI attainable regardless of data type.
- Clarifying GPT Terminology: The term 'GPTs' has caused confusion as it often refers to custom GPTs instead of encompassing models like ChatGPT.
- Participants highlighted the importance of distinguishing between general GPTs and their specific implementations.
- Quantum Computing Simulator Insights: A member noted that effective quantum computing simulators should yield 1:1 outputs compared to real quantum computers, though effectiveness remains disputed.
- Various companies are working on simulators, but their real-world applications are still under discussion.
- Anthropic's TANGO Model Excites: The TANGO talking head model caught attention for its lip-syncing abilities and open-source potential, with members eager to explore its capabilities.
- Discussion included the performance of Claude 3.5 Sonnet against Gemini Flash 2.0, with differing opinions on which holds the edge.
- ChatGPT Struggles with TV Shows: A member shared frustrations with ChatGPT misidentifying episode titles and numbers for TV shows, pointing to a gap in training data.
- The conversation underscored how the opinions within the data could skew results in entertainment-related queries.
Cohere Discord
-
Cohere Models Finding Favor: Members discuss actively using Cohere models in the playground, highlighting their varied application and tinkering efforts. One member particularly emphasized the need to rerun inference with different models when exploring multi-modal embeddings.
- This has sparked curiosity about the broad capabilities of these models in real-world scenarios.
- Multimodal Embed 3 is Here!: Embed 3 model launches with SOTA performance on retrieval tasks, supporting mixed modality and multilingual searches, allowing text and image data storage together. Find more details in the blog post and release notes.
- The model is set to be a game-changer for creating unified data retrieval systems.
- Fine-Tuning LLMs Requires More Data: Concerns over fine-tuning LLMs with minimal datasets were raised, with potential overfitting in focus. Strategies suggested included enlarging dataset size and adjusting hyperparameters, referencing Cohere's fine-tuning guide.
- Members seek effective adjustments to optimize their model performance amid challenges.
- Multilingual Model suffers latency spikes: Latency issues were reported at 30-60s for the multilingual embed model, spiking to 90-120s around 15:05 CEST. Users noted improvements, urging the reporting of persistent glitches.
- The latency concerns highlighted the need for further technical evaluations to ensure optimal performance.
- Agentic Builder Day Announced: Cohere and OpenSesame are co-hosting the Agentic Builder Day on November 23rd, inviting talented builders to create AI agents using Cohere Models. Participants can apply for this 8-hour hackathon with opportunities to win prizes.
- The competition encourages collaboration among developers eager to contribute to impactful AI projects, with applications available here.
Modular (Mojo 🔥) Discord
-
Mojo Introduces Custom Structure of Arrays: You can craft your own Structure of Arrays (SoA) using Mojo's syntax, although it isn't natively integrated into the language yet.
- While a slice type is available, users find it somewhat restrictive, and improvements are anticipated in Mojo's evolving type system.
- Mojo's Slice Type Needs Improvement: While Mojo includes a slice type, it's essentially limited to being a standard library struct, with only some methods returning slices.
- Members anticipate revisiting these slice capabilities as Mojo develops further.
- Binary Stripping Shows Major Size Reduction: Stripping a 300KB binary can lead to an impressive reduction to just 80KB, indicating strong optimization possibilities.
- Members noted the significant drop as encouraging for future binary management strategies.
- Comptime Variables Cause Compile Errors: A user reported issues using
comptime varoutside a@parameterscope, triggering compile errors.
- Discussion highlighted that while alias allows compile-time declarations, achieving direct mutability remains complex.
- Node.js vs Mojo in BigInt Calculations: A comparison revealed that BigInt operations in Node.js took 40 seconds for calculations, suggesting Mojo might optimize this process better.
- Members pointed out that refining the arbitrary width integer library is key to enhancing performance benchmarks.
tinygrad (George Hotz) Discord
-
LLVM Renderer Refactor Proposal: A user proposed rewriting the LLVM renderer using a pattern matcher style to enhance functionality, which could improve clarity and efficiency.
- This approach aims to streamline development and make integrations easier.
- Boosting Tinygrad's Speed: Discussion highlighted the requirement to enhance Tinygrad's performance after the transition to utilizing uops, critical for keeping pace with computing advancements.
- Efforts to optimize algorithms and reduce overhead were suggested to achieve these speed goals.
- Integrating Gradient Clipping into Tinygrad: The community debated if
clip_grad_norm_should become a standard in Tinygrad, a common method seen across deep learning frameworks.
- George Hotz indicated that a gradient refactor must precede this integration for it to be effective.
- Progress on Action Chunking Transformers: A user reported convergence in ACT training, achieving a loss under 3.0 after a few hundred steps, with links to the source code and related research.
- This development indicates potential for further optimization based on the current model performance.
- Exploring Tensor Indexing with .where(): A discussion emerged around using the
.where()function with boolean tensors, revealing unconventional results with.int()indexing.
- This triggered inquiries about the expected behavior of tensor operations in different scenarios.
OpenInterpreter Discord
-
Hume AI Joins the Party: A member announced the addition of a Hume AI voice assistant to the phidatahq generalist agent, enhancing functionality with a streamlined UI and the ability to create and execute applescripts on Macs.
- Loving the new @phidatahq UI noted the improvements made possible with this integration.
- Claude 3.5 Sonnet Gets Experimental: Anthropic officially released the Claude 3.5 Sonnet model with public beta access for computer usage, although it is described as still experimental and error-prone.
- Members expressed excitement while noting that such advancements reinforce the growing capabilities of AI models. For more details, see the tweet from Anthropic.
- Open Interpreter Powers Up with Claude: There’s enthusiasm about using Claude to enhance the Open Interpreter, with members discussing practical implementations and code to run the new model.
- One member reported success with the specific model command, encouraging others to try it out.
- Screenpipe is Gaining Traction: Members praised the Screenpipe tool for its utility in build logs, noting its interesting landing page and potential for community contributions.
- One member encouraged more engagement with the tool, citing a useful profile linked on GitHub.
- Monetization Meets Open Source: Discussion emerged around monetizing companies by allowing users to build from source or pay for prebuilt versions, balancing contributions and usage.
- Members expressed approval of this model, highlighting the benefits of contributions from both builders and paying users.
DSPy Discord
-
New Version on the Horizon: A member expressed excitement about creating a new version instead of altering the existing one, planning to do it live on Monday.
- The enthusiasm was shared as the community rallied around the upcoming session, where current functionalities will also be covered.
- DSpy Documentation Faces Issues: Members bemoaned that the little AI helper is missing from the new documentation structure, which led to widespread disappointment.
- Community sentiment echoed in the chat, highlighting the absence of valued features as a loss.
- Broken Links Alert: Numerous broken links in the DSpy documentation triggering 404 errors were reported, causing frustration among users.
- Quick actions were taken by at least one user to fix this through a PR, earning gratitude from peers for their responsiveness.
- Docs Bot Returns to Action: Celebrations erupted as the documentation bot made a comeback, restoring functionality that users greatly appreciated.
- Heartfelt emojis and affirmations filled the chat, showcasing the community's relief and support for the bot's vital presence.
- Seeking Vibes on Version 3.0: A member queried the general vibe of the upcoming version 3.0, evidencing a desire for community feedback.
- However, responses remained sparse, leaving a cloud of uncertainty around the collective sentiments.
LlamaIndex Discord
-
VividNode: Chat with AI Models on Desktop: The VividNode app allows desktop users to chat with GPT, Claude, Gemini, and Llama, featuring advanced settings and image generation with DALL-E 3 or various Replicate models. More details are available in the announcement.
- This application streamlines communication with AI, providing a robust chat interface for users.
- Build a Serverless RAG App in 9 Lines: A tutorial demonstrates deploying a serverless RAG app using LlamaIndex in just 9 lines of code, making it a cost-effective solution compared to AWS Lambda. For more insights, refer to this tweet.
- Easy deployment and cost efficiency are key highlights for developers utilizing this approach.
- Enhancing RFP Responses with Knowledge Management: The discussion centered around using vector databases for indexing documents to bolster RFP response generation, allowing for advanced workflows beyond simple chat replies. More on the subject can be found in this post.
- This method reinforces the role of vector databases in supporting complex AI functionalities.
- Join the Llama Impact Hackathon!: The Llama Impact Hackathon in San Francisco offers a platform for participants to build solutions using Llama 3.2 models, with a $15,000 prize pool up for grabs, including a $1,000 prize for the best use of LlamaIndex. Event details can be found in this announcement.
- Running from November 8-10, the hackathon accommodates both in-person and online participants.
- CondensePlusContextChatEngine Automatically Initializes Memory: Discussion clarified that CondensePlusContextChatEngine now automatically initializes memory for consecutive questions, improving user experience. Previous versions had different behaviors, creating some user confusion.
- This change simplifies memory management in ongoing chats, enhancing user interactions.
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents MOOC Hackathon Launch: Berkeley RDI is launching the LLM Agents MOOC Hackathon from mid-October to mid-December, with over $200,000 in prizes. Participants can sign up through the registration link.
- The hackathon, featuring five tracks, seeks to engage both Berkeley students and the public, supported by major sponsors like OpenAI and GoogleAI.
- TapeAgents Framework Introduction: The newly introduced TapeAgents framework from ServiceNow facilitates optimization and development for agents through structured logging. The framework enhances control, enabling step-by-step debugging as detailed in the paper.
- This tool provides valuable insights into agent performance, emphasizing how each interaction is logged for comprehensive analysis.
- Function Calling in LLMs Explained: There was a discussion surrounding how LLMs handle splitting tasks into function calls, highlighting the need for coding examples. Clarifications indicated the significance of understanding this mechanism moving forward.
- Members explored the impact of architecture choices on agent capabilities while examining how these approaches can improve functionality.
- Lecture Insights on AI for Enterprises: Nicolas Chapados discussed advancements in generative AI for enterprises during Lecture 7, emphasizing frameworks like TapeAgents. The session reviewed the importance of integrating security and reliability in AI applications.
- Key insights from Chapados and guest speakers highlighted real-world applications and the potential of AI to transform enterprise workflows.
- Model Distillation Techniques and Resources: Members shared a course on AI Agentic Design Patterns with Autogen, providing resources for learning about model distillation and agent frameworks. This course offers a structured approach to mastering autogen technology.
- Additionally, a helpful GitHub repository was discussed, alongside an engaging thread that examines the TapeAgents framework.
Torchtune Discord
-
Warnings Emerge from PyTorch Core: A user reported a warning in PyTorch now triggering on float16 but not float32, suggesting testing with a different kernel to assess performance impact. Speculation arose that specific lines in the PyTorch source code may affect JIT behavior.
- The community anticipates that resolving this may lead to considerable performance insights.
- Distributed Training Error Causes Headaches: A user encountered a stop with no messages during a distributed training run with the
tunecommand while setting CUDA_VISIBLE_DEVICES. Removing the specification did not resolve the issue, hinting at deeper configuration problems.
- This suggests investigation into environment settings may be necessary to pinpoint root causes.
- Confusion Over Torchtune Config Files: Confusions emerged regarding the .yaml extension causing Torchtune to misinterpret local configurations. Verifying file naming was emphasized to avoid unexpected behavior during operations.
- Participants noted that small details can lead to significant runtime problems.
- Flex Ramps Up Performance Talk: Discussion flared around Flex's successful runs on 3090s and 4090s, with mentions of optimized memory usage on A800s. The dialogue touched on faster out-of-memory operations as the model scales.
- Optimized memory management is seen as key to handling larger models effectively.
- Training Hardware Setups Under Scrutiny: A user confirmed utilizing 8x A800 GPUs while discussing training performance issues. The community debated testing with fewer GPUs as a means to troubleshoot the persistent error effectively.
- Discussing varying hardware setups highlighted the nuances of scaling in training environments.
LangChain AI Discord
-
Langchain Open Canvas explores compatibility: A member inquired if Langchain Open Canvas can integrate with LLM providers beyond Anthropic and OpenAI, reflecting a desire for broader compatibility.
- This inquiry indicates significant community interest in expanding the application's usability with diverse tools.
- Agent orchestration capabilities with Langchain: A discussion arose about the potential for Langchain to facilitate agent orchestration with OpenAI Swarm, questioning if custom programming is necessary.
- This spurred responses highlighting existing libraries that support orchestration functionalities.
- Strategizing output chain refactoring: A user is contemplating whether to refactor their Langchain workflow or switch to LangGraph for enhanced functionality in complex tool usage.
- The complexity of their current setup necessitates this strategic decision for optimal performance.
- Security concerns in Langchain 0.3.4: A user flagged a malicious warning from PyCharm regarding dependencies in Langchain 0.3.4, raising alarms about potential security risks.
- They sought confirmation from the community on whether this warning is a common occurrence, fearing it might be a false positive.
- Advice sought for local hosting solutions: In the quest for local hosting of models for enterprise applications, a user is exploring building an inference container with Flask or FastAPI.
- They aim to avoid redundancy by uncovering better solutions within the community.
OpenAccess AI Collective (axolotl) Discord
-
2.5.0 Brings Experimental Triton FA Support: Version 2.5.0 introduced experimental Triton Flash Attention (FA) support for gfx1100, activated with
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1, which led to a UserWarning on the Navi31 GPU.- The warning initially confused the user, who thought it related to Liger, as discussed in a GitHub issue.
- Leverage Instruction-Tuned Models for Training: A member proposed utilizing an instruction-tuned model like llama-instruct for instruction training, noting the benefits as long as users accept its prior tuning.
- They emphasized the necessity of experimentation to discover the optimal approach, possibly mixing strategies in their training.
- Concerns on Catastrophic Forgetting: Concerns arose about the choice between domain-specific instruction data or a mix with general data to prevent catastrophic forgetting during training.
- Members discussed the complexities of training and encouraged exploring multiple strategies to find the most effective method.
- Pretraining vs Instruction Fine-Tuning Debate: The discussion highlighted whether to start with a base model for pretraining on raw domain data or rely on an instruction-tuned model for fine-tuning.
- One member advocated for using raw data initially to provide a stronger foundation if available.
- Generating Instruction Data from Raw Text: A member shared their plan to use GPT-4 for generating instruction data from raw text, acknowledging the potential biases that may arise.
- This approach aims to reduce dependence on human-generated instruction data while being aware of its limitations.
Gorilla LLM (Berkeley Function Calling) Discord
-
Finetuned Model for Function Calling Excitement: A user expressed enthusiasm for the Gorilla project after fine-tuning a model specifically for function calling and successfully creating their own inference API.
- They sought methods for benchmarking a custom endpoint and requested appropriate documentation on the process.
- Instructions Shared for Adding New Models: In response to inquiries, a member directed users to a README file that outlines how to add new models to the leaderboard within the Gorilla ecosystem.
- This documentation is valuable for users aiming to contribute effectively to the Gorilla project.
LAION Discord
-
Join the Free Webinar on LLMs: A Senior ML Engineer from Meta is hosting a free webinar on best practices for building with LLMs, with nearly 200 signups already. Register for insights on advanced prompt engineering techniques, model selection, and project planning here.
- Attendees can expect a deep dive into the practical applications of LLMs tailored for real-world scenarios, enhancing their deployment strategies.
- Insights on Prompt Engineering: The webinar includes discussions on advanced prompt engineering techniques critical for optimizing model performance. Participants can leverage these insights for more effective LLM project execution.
- Performance optimization methods will also be tackled, which are essential for deploying LLM projects successfully.
- Explore Retrieval-Augmented Generation: Retrieval-Augmented Generation (RAG) will be a focal topic, showcasing how it can enhance the capabilities of LLM solutions. Fine-tuning strategies will also be a key discussion point for maximizing model efficacy.
- This session aims to equip engineers with the tools necessary to implement RAG effectively in their projects.
- Articles Featured on Analytics Vidhya: Webinar participants will have their top articles featured in Analytics Vidhya’s Blog Space, increasing their professional visibility. This provides an excellent platform for sharing insights within the data science community.
- Such exposure can significantly enhance the reach of their contributions and foster community engagement.
Mozilla AI Discord
-
Mozilla's Insight on AI Access Challenges: Mozilla has released two key research pieces: 'External Researcher Access to Closed Foundation Models' and 'Stopping Big Tech From Becoming Big AI', shedding light on AI development control.
- These reports highlight the need for changes to create a more equitable AI ecosystem.
- Blog Post Summarizing AI Research Findings: For deeper insights, the blog post here elaborates on the commissioned research and its implications.
- It discusses the impact of these findings on AI's competitive landscape among major tech players.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (586 messages🔥🔥🔥):
AI DJ SoftwareHugging Face Model QueriesOCR ToolsTraining TTS ModelsStructured Output in LLMs
-
Exploring AI DJ Software: Users discussed the potential for AI to transition between songs like a DJ, suggesting features similar to Spotify but with automated mixing capabilities.
- Tools like rave.dj were mentioned, where users can create mashups by combining multiple songs, highlighting the fun aspect even if the results aren't perfect.
- Hugging Face Model Queries: A user inquired about downloading weights for Hugging Face models without exposing them, seeking clarification on the appropriateness of using
huggingface_hubfor private repos.
- The community responded with suggestions on how to securely manage and download models while keeping the architecture hidden, utilizing environment variables for authentication.
- OCR Tools for Data Extraction: Users inquired about effective OCR solutions for extracting structured data from PDFs, particularly in construction contexts.
- A suggestion was made for utilizing models like Koboldcpp and various methods to enhance text extraction accuracy.
- Training TTS Models for Specific Languages: A discussion took place about the requirements for training TTS models, focusing on data collection and whether fine-tuning existing models could yield quality results.
- Participants emphasized the importance of having a suitable dataset while questioning how much training data is necessary for lesser-known languages.
- Structured Output Implementations: The community exchanged ideas about structured output for LLMs, including utilizing existing libraries like
lm-format-enforcerto maintain specific formats.
- Suggestions indicated a preference for using models such as Cmd-R for structured responses over Llama, emphasizing the challenges of integrating these capabilities.
Links mentioned:
- Google Colab: no description found
- no title found: no description found
- Suno AI: We are building a future where anyone can make great music. No instrument needed, just imagination. From your mind to music.
- Why AI Will Never Truly Understand Us: The Hidden Depths of Human Awareness: Introduction
- Everybody'S So Creative Tiktok GIF - Everybody's so creative Tiktok Tanara - Discover & Share GIFs: Click to view the GIF
- Soobkitty Rabbit GIF - Soobkitty Rabbit Bunny - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- Wait What Wait A Minute GIF - Wait What Wait A Minute Huh - Discover & Share GIFs: Click to view the GIF
- stabilityai/stable-diffusion-3.5-large · Hugging Face: no description found
- Dirty Docks Shawty GIF - Dirty Docks Shawty Triflin - Discover & Share GIFs: Click to view the GIF
- Lol Tea Spill GIF - Lol Tea Spill Laugh - Discover & Share GIFs: Click to view the GIF
- Gifmiah GIF - Gifmiah - Discover & Share GIFs: Click to view the GIF
- Fawlty Towers John Cleese GIF - Fawlty Towers John Cleese Basil Fawlty - Discover & Share GIFs: Click to view the GIF
- I Have No Enemies Dog GIF - I have no enemies Dog Butterfly - Discover & Share GIFs: Click to view the GIF
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
- You You Are GIF - You You Are Yes - Discover & Share GIFs: Click to view the GIF
- Downloading files: no description found
- Oxidaksi vs. Unglued - Ounk: #MASHUP #PSY #DNB #MUSIC #SPEEDSOUNDCreated with Rave.djCopyright: ©2021 Zoe Love
- no title found: no description found
- How Bro Felt After Writing That Alpha Wolf GIF - How bro felt after writing that How bro felt Alpha wolf - Discover & Share GIFs: Click to view the GIF
- RaveDJ - Music Mixer): Use AI to mix any songs together with a single click
- llama.cpp/grammars/README.md at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- GitHub - noamgat/lm-format-enforcer: Enforce the output format (JSON Schema, Regex etc) of a language model: Enforce the output format (JSON Schema, Regex etc) of a language model - noamgat/lm-format-enforcer
- GitHub - sktime/sktime: A unified framework for machine learning with time series: A unified framework for machine learning with time series - sktime/sktime
- accelerate/src/accelerate/utils/fsdp_utils.py at main · huggingface/accelerate: 🚀 A simple way to launch, train, and use PyTorch models on almost any device and distributed configuration, automatic mixed precision (including fp8), and easy-to-configure FSDP and DeepSpeed suppo.....
HuggingFace ▷ #today-im-learning (18 messages🔥):
2021 lecture seriesCreating virtual charactersPath to becoming an ML Engineer3blue1brown's educational resourcesManim animation engine
-
2021 Lecture Series Kicks Off: A member confirmed the start of the 2021 lecture series next week, expressing excitement.
- All the best wishes were shared among members in support.
- Scaling Virtual Characters on Instagram: A member created a virtual character using Civitai for an Instagram profile and seeks to scale up with realistic reels and photos.
- They emphasized the lack of coding experience and resources, requesting advice to get started.
- ML Engineer Path for Applied Mathematics Student: A university student from Ukraine expressed interest in becoming an ML Engineer and sought guidance on the path ahead.
- Members suggested watching 3blue1brown's playlist on transformers and LLMs.
- 3blue1brown's Essentials for ML: The importance of 3blue1brown's educational materials was highlighted, with a specific course from MIT shared for further exploration.
- Members encouraged viewing the implications of the content for understanding artificial intelligence.
- Discovering Manim for Animations: A member inquired about the animation tool used by 3blue1brown, revealing it to be Manim, a custom animation engine.
- The GitHub link was shared, showcasing the resource for creating explanatory math videos.
Links mentioned:
- MIT 6.034 Artificial Intelligence, Fall 2010: View the complete course: http://ocw.mit.edu/6-034F10 Instructor: Patrick Winston In these lectures, Prof. Patrick Winston introduces the 6.034 material from...
- GitHub - 3b1b/manim: Animation engine for explanatory math videos: Animation engine for explanatory math videos. Contribute to 3b1b/manim development by creating an account on GitHub.
HuggingFace ▷ #cool-finds (1 messages):
capetownbali: Nice find...
HuggingFace ▷ #i-made-this (10 messages🔥):
Granite 3.0 model releaseWebinar on LLM Best PracticesEvolution of Contextual EmbeddingsZK Proofs for Chat History OwnershipPR Merged for HuggingFace.js
-
Granite 3.0 model makes a splash: A new on-device Granite 3.0 model was launched, showcasing an appealing thumbnail.
- Users are excited about its features and the convenience it provides for quick deployments.
- Learn LLM Best Practices from Meta: A META Senior ML Engineer is hosting a webinar on navigating LLMs, already attracting nearly 200 signups.
- The session promises insights into prompt engineering and selecting models effectively.
- Article on Self-Attention Evolution: An article discussing the evolution of static to dynamic contextual embeddings was shared, exploring innovations from traditional vectorization to modern approaches.
- The author aimed for an introductory level while acknowledging feedback from the community about additional models.
- ZK Proofs for ChatGPT History Ownership: A demo for Proof of ChatGPT was introduced, allowing users to own their chat history using ZK proofs, potentially increasing training data for open-source models.
- This application aims to enhance the provenance and interoperability of data through OpenBlock's Universal Data Protocol.
- HuggingFace.js PR Successfully Merged: A pull request supporting the library pxia has been merged into HuggingFace.js.
- This addition brings AutoModel support along with two current architectures, enhancing the library's functionality.
Links mentioned:
- On Device Granite 3.0 1b A400m Instruct - a Hugging Face Space by Tonic: no description found
- Self-Attention in NLP: From Static to Dynamic Contextual Embeddings: In the realm of Natural Language Processing (NLP), the way we represent words and sentences has a profound impact on the performance of…
- Tweet from OpenBlock (@openblocklabs): 1/ Introducing Proof of ChatGPT, the latest application built on OpenBlock’s Universal Data Protocol (UDP). This Data Proof empowers users to take ownership of their LLM chat history, marking a signi...
- Add pxia by not-lain · Pull Request #979 · huggingface/huggingface.js: This pr will support my library pxia which can be found in https://github.com/not-lain/pxia the library comes with AutoModel support along with 2 architectures for the moment. Let me know if you ha...
- Explore the Future of AI with Expert-led Events: Analytics Vidhya is the leading community of Analytics, Data Science and AI professionals. We are building the next generation of AI professionals. Get the latest data science, machine learning, and A...
HuggingFace ▷ #core-announcements (1 messages):
sayakpaul: <@&1014517792550166630> enjoy:
https://huggingface.co/blog/sd3-5
HuggingFace ▷ #NLP (8 messages🔥):
Tensor conversion bottleneckDataset device bottleneckCPU and GPU usage during inferenceEvaluating fine-tuned LLMsManaging evaluation results
-
Tackling Tensor Conversion Bottleneck: Concerns were raised about a potential Tensor conversion bottleneck from tokenization decoding iterations, especially during inference when adding to context and encoding into float 16.
- It's suggested to look into the workflow, which involves decoding, printing, and passing data to the model, to identify efficiency improvements.
- Potential Dataset Device Bottleneck Identified: One member questioned whether there’s a dataset device bottleneck, noticing CPU memory spiking to 1.5 GB despite using CUDA.
- The suggestion was made to check if the UHD Graphics card is being used as the primary inference driver instead of the dedicated GPU.
- Setting CUDA Device Environment Variable: A member proposed setting the CUDA_VISIBLE_DEVICES environment variable to optimize performance on the intended GPU with the snippet:
os.environ["CUDA_VISIBLE_DEVICES"]="1".
- This would potentially ensure that the correct GPU is leveraged for performing inference tasks, allowing for better resource allocation.
- Methods for Evaluating Fine-tuned LLMs: There was discussion on evaluation methods for fine-tuning LLMs, focusing on automation via libraries like deepval and manual evaluations by experts.
- A member questioned tools for managing results from different versions for easier comparisons and mentioned feeling that Google Sheets might not be the best option due to its manual nature.
- Concerns About Collaboration in Evaluation Tools: The need for effective management of evaluation results was emphasized, particularly when many collaborators could lead to errors in a Google Sheets environment.
- Members were seeking more efficient tools for comparative analysis, indicating challenges in maintaining accuracy and convenience in shared documents.
Link mentioned: Annoyed Cat GIF - Annoyed cat - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #diffusion-discussions (29 messages🔥):
Kaggle and GPU UsageModel Downloading TechniquesLearning Rate and Training InsightsDiffusers Callbacks for Image GenerationCultural Connections in AI
-
Challenges with Kaggle's GPU Resource Allocation: Users shared experiences using Kaggle's dual 15GB GPUs, noting that one GPU was fully occupied during model downloads while the other remained unused.
- One user inquired about sharding the model across both GPUs to combine resources, while another confirmed that this feature can slow down performance.
- Efficient Model Download Strategies: A member suggested using the huggingface_hub library for downloading models, allowing users to control download processes via code.
- Another user pointed out that if the default method causes issues, straight HTTP requests can be an alternative.
- Learning Rate Concerns in Training: Concerns regarding the appropriate learning rate for training were raised, highlighting a strategy of adjusting it based on the number of GPUs used.
- Additionally, a user sought clarification on whether their model was overtrained or undertrained after completing 3,300 steps.
- Implementing Callbacks in Diffusers: To log image generation steps, users were advised to utilize callbacks with
callback_on_step_endfor real-time adjustments during the denoising loop.
- While standard logging can track values, callbacks provide enhanced flexibility for tracking image generation at each step.
- Cultural Community Connections in AI: One user expressed enthusiasm about finding a fellow Latin contributor within the community, celebrating shared cultural ties in the AI space.
- This moment demonstrated the camaraderie and global connections that arise from shared interests in AI development.
Links mentioned:
- Pipeline callbacks): no description found
- GitHub - huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX.: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. - huggingface/diffusers
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Claude 3.5 SonnetLlama 3.1 NitroMinistral updatesGrok BetaClaude self-moderated endpoints
-
Claude 3.5 Sonnet achieves benchmark improvements: The Claude 3.5 Sonnet shows significant improvements across various benchmarks with no code changes required for users to try it out. More details can be found in the launch announcement here.
- Members noted that hovering over the info icon next to providers reveals when models get upgraded, making it easy to track improvements.
- Lightning Fast Llama 3.1 Nitro is here: The Llama 3.1 405b Nitro is now available, boasting a speed increase of about 70% over the next fastest provider. Direct links to the new endpoints are provided: 405b and 70b.
- These super-fast and premium endpoints promise a throughput of around 120 tps, captivating user interest.
- Ministral brings powerful new models to the table: Mistral introduced the Ministral 8b, capable of 150 tps and featuring a high context of 128k, currently ranking #4 for tech prompts. An economical 3b model has also been made available at this link.
- Users expressed excitement about the performance and price, with both models appealing to different budget ranges.
- Grok Beta emerges with expanded capabilities: Grok 2 has now been renamed to Grok Beta, featuring an increased context length of 131,072 and a new output price of $15/m. Furthermore, the legacy
x-ai/grok-2requests are aliased tox-ai/grok-betafor user continuity.
- The community welcomed this update, anticipating improved functionalities and clarifications in the pricing model.
- Poll on ideal experiences for Claude self-moderated endpoints: A poll was initiated to gather community feedback on the ideal experience for the Claude self-moderated (
:beta) endpoints, which are currently topping the leaderboard. Members can voice their opinions by voting in the poll here.
- The engagement from users indicates a strong interest in shaping the future experience of these endpoints.
Links mentioned:
- Llama 3.1 405B Instruct (nitro) - API, Providers, Stats: The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs. Meta's latest c...
- Llama 3.1 70B Instruct (nitro) - API, Providers, Stats: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 70B Instruct (nitro) with API
- Ministral 8B - API, Providers, Stats: Ministral 8B is an 8B parameter model featuring a unique interleaved sliding-window attention pattern for faster, memory-efficient inference. Designed for edge use cases, it supports up to 128k contex...
OpenRouter (Alex Atallah) ▷ #general (455 messages🔥🔥🔥):
New Claude 3.5 SonnetOpenRouter APIComputer Use featureModel pricingHaiku 3.5 release
-
New Claude 3.5 Sonnet released: The new Claude 3.5 Sonnet model has been officially launched and is available on OpenRouter.
- Users expressed excitement about its capabilities and recent improvements, with comments noting speed and performance.
- OpenRouter API keys and usage: New users inquired about how to obtain and use API keys from the OpenRouter platform, confirming that keys allow access to all available models.
- It was suggested that users use OpenRouter Playground for ease of access and testing.
- Introduction of Computer Use feature: Anthropic announced a new 'Computer Use' feature that allows users to provide their own computer for the AI to operate.
- This capability was described as innovative and useful, although concerns about potential misuse and security were also raised.
- Model pricing discussion: The pricing for using models like Claude has been discussed, highlighting costs of around $18 per million tokens for some options.
- Users mentioned comparing costs among various models, including DeepSeek and Qwen, within a context of lower-cost alternatives.
- Upcoming Haiku 3.5 Release: The release date for the new Haiku 3.5 model was announced to be later this month, although specific details are still awaited.
- Users were looking forward to this release and speculated on its impact and performance compared to existing models.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
- Initial explorations of Anthropic’s new Computer Use capability: Two big announcements from Anthropic today: a new Claude 3.5 Sonnet model and a new API mode that they are calling computer use. (They also pre-announced Haiku 3.5, but that’s …
- Chatroom | OpenRouter: LLM Chatroom is a multimodel chat interface. Add models and start chatting! Chatroom stores data locally in your browser.
- Quick Start | OpenRouter: Start building with OpenRouter
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- abacusai/Dracarys2-72B-Instruct - Featherless.ai: Featherless - The latest LLM models, serverless and ready to use at your request.
- Full Stack && Web3 Developer: I am a highly skilled blockchain and full stack developer with extensive experience in designing and implementing complex decentralized applications and web solutions.
- Keys | OpenRouter: Manage your keys or create new ones
- abacusai/Dracarys2-72B-Instruct · Hugging Face: no description found
- Malding Weeping GIF - Malding Weeping Pov - Discover & Share GIFs: Click to view the GIF
- Models | OpenRouter: Browse models on OpenRouter
- OpenRouter: LLM router and marketplace
- Uncaught APIError in utils.py line 8123 · Issue #2104 · Aider-AI/aider: Aider version: 0.59.1 Python version: 3.11.9 Platform: Windows-10-10.0.22631-SP0 Python implementation: CPython Virtual environment: Yes OS: Windows 10 (64bit) Git version: git version 2.43.0.windo...
- What's the benefits of using this provider instead of
@ai-sdk/openai? · Issue #4 · OpenRouterTeam/ai-sdk-provider: It would be helpful to explain the difference between the two. I can use OpenRouter's model through @ai-sdk/openai, and it's actively maintained. - Reddit - Dive into anything: no description found
aider (Paul Gauthier) ▷ #general (290 messages🔥🔥):
Claude 3.5 SonnetDeepSeek as Editor ModelPricing for ModelsModel Performance and BenchmarksIntegration of Local Models
-
Claude 3.5 Sonnet shows significant improvements: The new Claude 3.5 Sonnet tops Aider's code editing leaderboard at 84.2%, and achieves 85.7% with DeepSeek in architect mode.
- Many users are excited about the enhancements, particularly in coding tasks and the same pricing structure as previous models.
- Using DeepSeek as an Editor Model: DeepSeek is favored for being much cheaper than Sonnet, costing $0.28 per 1M output tokens compared to Sonnet's $15.
- Users report saving substantial amounts while using DeepSeek as an editor model, stating it performs adequately when paired with Sonnet.
- Concerns about Token Costs: Discussions highlight that using Sonnet as an architect alongside DeepSeek for execution primarily shifts the expense to the output tokens instead of the planning tokens.
- This created a debate over whether the token cost savings justify the slower performance of DeepSeek.
- Model Performance and Local Usage: There are inquiries regarding the effectiveness of offline models and their potential in assisting Sonnet by providing parsing or error correction.
- Users suggested experimenting with larger local models to enhance capabilities when integrated with Sonnet.
- Audio Recording and Transcription: A question arose about whether audio recordings for transcription are submitted remotely or if there is offline support available.
- This led to discussions about potential offline transcription capabilities using models like Whisper.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
- Model warnings: aider is AI pair programming in your terminal
- Separating code reasoning and editing: An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
- Computer use (beta) - Anthropic: no description found
- Walk Andrew Tate Walk GIF - Walk Andrew Tate Walk Top G - Discover & Share GIFs: Click to view the GIF
- YAML config file: How to configure aider with a yaml config file.
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- aider/aider/models.py at 1b530f9200078e5653b6de04c2bd9f820bf38380 · Aider-AI/aider: aider is AI pair programming in your terminal. Contribute to Aider-AI/aider development by creating an account on GitHub.
- Options reference: Details about all of aider’s settings.
- GitHub - nekowasabi/aider.vim: Helper aider with neovim: Helper aider with neovim. Contribute to nekowasabi/aider.vim development by creating an account on GitHub.
- GitHub - CEDARScript/cedarscript-integration-aider: Allows Aider to use CEDARScript as an edit format**): Allows Aider to use CEDARScript as an edit format. Contribute to CEDARScript/cedarscript-integration-aider development by creating an account on GitHub.
- Update models.py by cschubiner · Pull Request #2117 · Aider-AI/aider: no description found
- Llama 3.1 405B Instruct (nitro) - API, Providers, Stats: The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs. Meta's latest c...
- Llama 3.1 70B Instruct (nitro) - API, Providers, Stats: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 70B Instruct (nitro) with API
- Ministral 8B - API, Providers, Stats: Ministral 8B is an 8B parameter model featuring a unique interleaved sliding-window attention pattern for faster, memory-efficient inference. Designed for edge use cases, it supports up to 128k contex...
aider (Paul Gauthier) ▷ #questions-and-tips (20 messages🔥):
Aider ConfigurationAider Command IssuesArchitect Mode FunctionalityMistral API AuthenticationReddit and Claude AI Discussions
-
Setting Up Aider Configuration: One user requested guidance on creating a
.aider.conf.ymlfile, outlining the required model settings:openrouter/anthropic/claude-3.5-sonnet:betaas the model and editor model, andopenrouter/anthropic/claude-3-haiku:betaas the weak model.- Another member inquired about where Aider retrieves these configuration details at runtime.
- Issues with Aider Command Flag: A user reported a problem using the
--yesflag in Aider, where the command seemed to still propose a file and exit immediately.
- A response suggested that the behavior may have changed to
--yes-always, which could be impacting the operation. - Questions on Architect Mode: A user expressed confusion over Architect mode, stating it auto-added files but then prompted for additional files without clear instructions for adding them to the context first.
- Others suggested trying simple key inputs like 'Y' or 'Enter' to resolve the issue, while a bug report was filed to track the situation.
- Mistral API Authentication Issues: A user encountered a 401 Unauthorized error when attempting to use the Mistral API with Aider, indicating an authentication error.
- After some troubleshooting, it was revealed that they needed to generate a new API key, which resolved the issue.
- Reddit and Claude AI Insight: A user shared a link to Reddit discussing Claude AI's new features, including capabilities of Claude 3.5 Sonnet, which allows for direct computer interactions.
- This triggered additional insights and confirmations from other users related to Claude's functionalities.
Links mentioned:
- Does architect mode prompt to add files? · Issue #2121 · Aider-AI/aider: Issue Shared in discord: https://discord.com/channels/1131200896827654144/1133060505792159755/1298228879210577931 /architect example bla bla ... Now, we need to update other files to incorporate th...
- Reddit - Dive into anything: no description found
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
aider (Paul Gauthier) ▷ #links (5 messages):
Claude 3.5 Sonnet upgradesClaude 3.5 Haiku introductionComputer use capabilityDreamCut AI video editor
-
Claude 3.5 Sonnet and Haiku upgrades announced: Anthropic announced the upgraded Claude 3.5 Sonnet and a new model, Claude 3.5 Haiku, that boasts improvements in coding performance, moving from 33.4% to 49.0% on the SWE-bench Verified tests.
- The Claude 3.5 Haiku is reported to perform better than its predecessor while matching the previous largest model's capabilities on many evaluations.
- Insight into the new Computer Use feature: A groundbreaking computer use capability was introduced, allowing developers to direct Claude to operate computers like humans, such as moving cursors and clicking buttons.
- This feature is currently in public beta and is described as experimental, with potential for errors but significant implications for usability.
- DreamCut AI - A full AI Software Builder: A new video editing platform, DreamCut AI, was introduced by @MengTo, built using Claude AI over 3 months with 50k lines of code.
- This tool is currently in early access and allows users to test its AI features with a free account.
Links mentioned:
- Initial explorations of Anthropic’s new Computer Use capability: Two big announcements from Anthropic today: a new Claude 3.5 Sonnet model and a new API mode that they are calling computer use. (They also pre-announced Haiku 3.5, but that’s …
- Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku: A refreshed, more powerful Claude 3.5 Sonnet, Claude 3.5 Haiku, and a new experimental AI capability: computer use.
- Tweet from Meng To (@MengTo): Introducing http://dreamcut.ai A video editor I built from scratch using Claude AI. This took 3 months and over 50k lines of code. I totally skipped design and went straight to code. Currently in e...
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
Stable Diffusion 3.5 LaunchPerformance of Stable Diffusion 3.5 LargeStable Diffusion 3.5 Large TurboCommunity FeedbackAccessibility of New Models
-
Stable Diffusion 3.5 Launch Announced: The launch of Stable Diffusion 3.5 includes multiple customizable variants suitable for consumer hardware and is free for all uses under the Stability AI Community License. Both the Stable Diffusion 3.5 Large and Turbo models are available now on Hugging Face and GitHub.
- The 3.5 Medium model will be released on October 29, emphasizing the commitment to continuous development after previous community feedback.
- Stable Diffusion 3.5 Large Sets New Market Standards: Stable Diffusion 3.5 Large is praised for leading the market in prompt adherence and delivering image quality that rivals larger models. This version represents significant advancements after listening to community feedback regarding the previous release.
- The analysis shows that meeting community standards is pivotal for ensuring product effectiveness in enhancing visual media.
- Stable Diffusion 3.5 Large Turbo Achieves Rapid Inference: The newly introduced Stable Diffusion 3.5 Large Turbo boasts some of the fastest inference times in its class while maintaining competitive image quality and prompt adherence. This makes it an exciting option in the current offerings.
- Many users expressed enthusiasm as this new turbo variant aligns with the need for both speed and quality in model performance.
- Community Engagement Driving Development: The team at Stability AI took time to respond to community feedback rather than rushing fixes, leading to the development of Stable Diffusion 3.5. This highlights the importance of engagement and responsiveness in product improvement.
- Community input has proven vital in shaping tools aimed at empowering builders and creators.
- Commitment to Tool Accessibility: Stability AI emphasizes its commitment to providing builders with widely accessible tools for various use cases, including fine-tuning and artwork. The launch encourages distribution and monetization across all aspects of the pipeline.
- This approach showcases Stability AI's aim to foster ongoing innovation and creativity within the community.
Link mentioned: Stable Diffusion 3.5 — Stability AI: Today we are introducing Stable Diffusion 3.5. This open release includes multiple model variants, including Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo.
Stability.ai (Stable Diffusion) ▷ #general-chat (280 messages🔥🔥):
Stable Diffusion 3.5 ReleasePerformance Comparisons with FluxModel LicensingTechnical Support for SD3.5Applications of LoRA in AI Art
-
Stable Diffusion 3.5 Launch Surprises Community: After a period of silence, the announcement of SD 3.5 surprised many, as users discussed its unexpected release and potential improvements over previous versions.
- Some users noted that SD 3.5 features improved prompt following while others expressed concerns about its performance compared to Flux.
- Comparative Quality Discussion: SD3.5 vs. Flux: Members debated whether SD3.5 could rival the image quality of Flux, with mentions of how effective it is in fine-tuning and overall aesthetics.
- Initial impressions suggest Flux may still retain an edge in aesthetic quality, prompting curiosity about the finer details of both datasets.
- New Licensing Details for SD3.5: The stability of the SD3.5 licensing model raised questions, with some participants expressing concerns about its commercial use compared to AuraFlow.
- Discussion highlighted the balance between making the model accessible and allowing Stability AI to monetize effectively.
- Technical Support for Using Automatic1111: Users encountering difficulties with Automatic1111's Web UI were directed to specific channels for support, reflecting an engaged community eager to help newcomers.
- One user quickly found the dedicated channel for technical assistance, indicating a proactive approach among members.
- Exploration of LoRA Applications: The introduction of a LoRA model for SD3.5 stirred excitement as users shared prompts and results, highlighting its utility in enhancing image generation.
- The community showcased their works and encouraged experimenting with new prompts to harness LoRA's capabilities.
Links mentioned:
- Stability AI - Developer Platform: no description found
- Tweet from Stability AI (@StabilityAI): no description found
- SD3 Examples: Examples of ComfyUI workflows
- Shakker-Labs/SD3.5-LoRA-Linear-Red-Light · Hugging Face: no description found
- Stable Diffusion 3.5 - a stabilityai Collection: no description found
- stabilityai/stable-diffusion-3.5-large · Hugging Face: no description found
- stability-ai/stable-diffusion-3.5-large – Run with an API on Replicate: no description found
- fal.ai | The generative media platform for developers: fal.ai is the fastest way to run diffusion models with ready-to-use AI inference, training APIs, and UI Playgrounds
Unsloth AI (Daniel Han) ▷ #general (234 messages🔥🔥):
Gradient Accumulation Bug FixLLM Training EfficiencyModel Performance and BenchmarkingCollaboration with MetaFinetuning Strategies
-
Gradient Accumulation Bug Fixed in Nightly Transformers: A recent update on the gradient accumulation bug revealed it has been fixed and should be included in the nightly transformers and Unsloth trainers.
- This bug previously caused inaccuracies in loss curve calculations across various trainers.
- Insights on LLM Training Efficiency: Members discussed the efficiency of LLM training, emphasizing that teaching phrases to models generates multiple sub-examples rather than a single instance.
- This approach maximizes training examples effectively, allowing the model to learn progressively.
- Challenges with Model Performance and Benchmarks: A member expressed doubts about the performance of the new Nvidia Nemotron Llama 3.1 model, questioning its superiority over the standard Llama 70B model despite similar benchmark scores.
- It was noted that Nvidia's benchmarking may be inconsistent, impacting the perceived performance of their models.
- Upcoming Collaboration with Meta: The Unsloth team plans to collaborate with Meta, with community members expressing excitement about the potential outcomes.
- It was clarified that Meta's newly launched model is focused on pre-training and research rather than direct competition with Unsloth.
- Finetuning Strategies for Improved Model Performance: Discussions revolved around the importance of dataset quality when fine-tuning models, reinforcing that targeted datasets often yield better results in specific areas.
- One member shared their experience with trying to enhance a 1B model's performance using the Finetome 100k dataset, noting mixed results.
Links mentioned:
- MMLU Pro - a Hugging Face Space by TIGER-Lab: no description found
- ibm-granite/granite-3.0-8b-instruct · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- GitHub - facebookresearch/lingua: Meta Lingua: a lean, efficient, and easy-to-hack codebase to research LLMs.: Meta Lingua: a lean, efficient, and easy-to-hack codebase to research LLMs. - facebookresearch/lingua
- Reddit - Dive into anything: no description found
- Windows installation guide in README by timothelaborie · Pull Request #1165 · unslothai/unsloth: The only thing preventing Unsloth from working on Windows used to be Triton, but there is now a Windows fork. After installing it, Unsloth worked right away and gave me the same accuracy as in WSL.
- gbharti/finance-alpaca · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (34 messages🔥):
Grad School Application EditorLLaMA Model Fine-TuningUnsloth Installation IssuesMulti-GPU Support in UnslothCUDA and Library Errors
- Challenges in Building a Grad School Application Editor: A member expressed the desire to create a grad school application editor but is struggling with a large, detailed prompt for AI model implementation. They sought guidance on fine-tuning models to overcome issues with cliched output and complex prompt structures.
- Fine-Tuning LLaMA on CSV Data: Clarifications were sought on whether fine-tuning a LLaMA model on CSV data could allow it to answer specific queries about incident data. Suggestions included evaluating model performance via certain methodologies provided in a Turing article.
- Issues Installing Unsloth Locally: A user reported difficulties installing Unsloth by following a script for creating a conda environment due to a non-functional batch file. Other members recommended using WSL2 to streamline the installation process.
- Questions on Multi-GPU Support in Unsloth: Multi-GPU support in Unsloth was discussed, confirming that the framework does not support loading models on multiple GPUs as of now. Users are trying to understand the role of
per_device_train_batch_sizeunder current limitations. - Troubleshooting CUDA and Library Errors: A user faced an ImportError related to CUDA libraries when running Unsloth, leading to speculation about broken CUDA configurations. Assistance requests highlighted that resolving such issues requires ensuring CUDA stability and compatibility with installed libraries.
Links mentioned:
- no title found: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
Unsloth Studio FixesGitHub Pull RequestDiscord Issue Reporting
-
Pull Request to Fix Unsloth Studio: A new Pull Request #1 by Erland366 addresses several issues in the studio reported by users in Discord, particularly during the import of Unsloth.
- The problem reportedly did not manifest in the finetune notebook, leading to further investigation from the community.
- User Reporting Issues on Discord: A user highlighted the issues being triggered upon importing Unsloth in the Discord channel, indicating a need for swift resolution.
- The community is encouraged to review the pull request and provide feedback to address the reported concerns.
Link mentioned: Fix/studio by Erland366 · Pull Request #1 · unslothai/unsloth-studio: There are several issue in the studio. The issue was issued by user in the discord. This issue is trigger when importing unsloth, but somehow the issue didn't happen inside finetune notebook....
Nous Research AI ▷ #general (137 messages🔥🔥):
Catastrophic Forgetting in Fine-TuningPerformance of LLMs on BenchmarksNous Research Video and ProjectsClaude Model UpdatesToken as a Service Providers
-
Exploration of Catastrophic Forgetting: Discussion centered on the phenomenon of catastrophic forgetting observed in large language models (LLMs) during continual instruction tuning, especially in models ranging from 1B to 7B parameters.
- It was noted that finetuning can significantly degrade performance, with users sharing personal experiences and benchmark results comparing their models to established ones.
- Benchmark Performance Insights: Users discussed the influence of model scale on performance, indicating that training on limited data without reaching optimization could lead to inferior results.
- One participant highlighted their 1B model's poorer scores compared to Meta's models, emphasizing the importance of baseline comparisons.
- Nous Research Video and Future Projects: Members expressed enthusiasm for a recent Nous Research video on Forge, indicating it as a promising development in their projects.
- Curiosity arose about the implementation of a knowledge graph in the Forge project, showcasing interest in how memory functions will be integrated.
- Claude Model Enhancements: Attention shifted to the latest updates from AnthropicAI, showcasing the Claude 3.5 Sonnet and Haiku models, with capabilities for computer interaction.
- Participants noted the impressive features of Sonnet while discussing the implications of maintaining competitive advancements with the impending Claude 4.0 release.
- Discussion on Token as a Service Providers: Inquiries were made about available token as a service platforms that support Nous models, with a focus on alternatives to Octo AI.
- The conversation branched to OpenRouter's offerings, reflecting interest in accessing Nous technology through public endpoints.
Links mentioned:
- An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning: Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have dem...
- Tweet from Nous Research (@NousResearch): no description found
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
- Apple study exposes deep cracks in LLMs’ “reasoning” capabilities: Irrelevant red herrings lead to “catastrophic” failure of logical inference.
- GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs: Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
- Nous Research: no description found
- Forge by Nous Research @ Nouscon 2024: Nous Research co-founder Karan talks about one of our upcoming projects, "Forge" @ Nouscon 2024.
- no title found: no description found
- diabolic6045/open-llama-3.2-1B-Instruct · Hugging Face: no description found
- Open Llama 3.2 1B Instruct - a Hugging Face Space by diabolic6045: no description found
- Category: AI: Open the pod doors…
- Hermes 3 405B Instruct - API, Providers, Stats: Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coheren...
Nous Research AI ▷ #ask-about-llms (5 messages):
Hermes 3 availabilityClaude system prompt enhancementsClaude's problem-solving capabilities
-
Hermes 3 likely unavailable on Replicate: Mentallyblue inquired if Hermes 3 is available on Replicate, to which Teknium responded that it seems linked to a collaboration involving 8B and 70B models.
- This indicates that Hermes 3 might not be independently accessible at the moment.
- New Claude enhances attention handling: Recent discussions highlight that the new Claude has an updated system prompt to manage misguided attention, explicitly stating a puzzle's constraints.
- Azure2089 pointed out that this update aids Claude but acknowledged it can still miss slight changes in familiar puzzles.
- Claude still struggles with CoT problems: Despite improvements, Azure2089 observed that new Claude still cannot solve problems easily manageable with Chain of Thought (CoT) reasoning.
- This creates ongoing discussions about Claude's limits in certain problem-solving scenarios.
Nous Research AI ▷ #research-papers (11 messages🔥):
Research Paper TrustworthinessFine-Tuning ModelsFalsification in Scientific ResearchSimple Arithmetic for Language ModelsAdamW Optimization Techniques
-
1 in 7 research papers deemed untrustworthy: A new study concluded that approximately 1 in 7 research papers contain serious errors, making them untrustworthy. The authors highlighted that traditional methods for assessing falsification remain underfunded and called for more attention from the government.
- Members discussed the implications of this finding, noting that many researchers might unknowingly build on false conclusions drawn from prior flawed studies.
- Complexity of fine-tuning models: Members debated the effectiveness of fine-tuning large foundation models, suggesting it could potentially degrade broad capabilities in exchange for specific target formats. One member theorized that fine-tuning requires careful hyperparameter optimization for optimal outcomes.
- Concerns were raised about the art of fine-tuning and its lack of established community knowledge, prompting curiosity about ongoing developments since a year ago.
- Controversial views on scientific integrity: A member shared observations about how researchers sometimes omit data that doesn't align with peer-reviewed findings, suggesting they might repeat experiments until the data fits established consensus. This highlights potential issues of bias in scientific research.
- The conversation touched on the persistent challenges of ensuring integrity and accuracy within the research community.
- Simple arithmetic for language models: A member proposed a novel idea that future language models might utilize basic arithmetic operations over finite fields rather than traditional floating-point computations. They referenced a study suggesting that a new algorithm could drastically reduce energy consumption in tensor processing.
- The conversation sparked interest in the feasibility and implications of such advancements in model architecture.
- AdamW Optimization Techniques: In discussions about optimization methods, particular focus was placed on AdamW and variations like schedule-free versions, highlighting their performance compared to traditional methods. Members noted ongoing research in optimizing these algorithms.
- The efficacy of these new methods remains a topic of interest and exploration within the community.
Links mentioned:
- Addition is All You Need for Energy-efficient Language Models: Large neural networks spend most computation on floating point tensor multiplications. In this work, we find that a floating point multiplier can be approximated by one integer adder with high precisi...
- Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations: Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it doe...
- Matryoshka Representation Learning: Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistic...
- Implicit Bias of AdamW: $\ell_\infty$ Norm Constrained Optimization: Adam with decoupled weight decay, also known as AdamW, is widely acclaimed for its superior performance in language modeling tasks, surpassing Adam with $\ell_2$ regularization in terms of generalizat...
- The Road Less Scheduled: Existing learning rate schedules that do not require specification of the optimization stopping step T are greatly out-performed by learning rate schedules that depend on T. We propose an approach tha...
Nous Research AI ▷ #interesting-links (15 messages🔥):
Poe multi-model accessMachine Talks on generative artNew ASR model releaseZK proofs for chat history ownershipMina vs. OpenBlock comparison
-
Poe enables access to multiple models: A member inquired about using Poe to access various models like ChatGPT and Claude 3 Opus.
- Responses varied, with one member stating they sometimes use OpenRouter.
- Machine Talks explores generative art: A member shared the launch of their AI-hosted talk show, Machine Talks, interviewing different models with Capybara as a favorite, view the pilot here.
- They also provided a teaser link on Vimeo for more context.
- Fast ASR model 'Moonshine' released: A new state-of-the-art automatic speech recognition (ASR) model called Moonshine has been announced for edge devices.
- The project aims for fast and accurate performance, showcasing potential in edge device applications.
- ZK proofs grant ChatGPT users chat history ownership: A member introduced the use of ZK proofs to allow users to own their ChatGPT chat history, aiming to enrich training data for open-source models, find the demo here.
- There was discussion about speed, with one member noting that some proofs now complete in under a second.
- Comparing Mina and OpenBlock technology: Concerns were raised regarding how OpenBlock compares to Mina, with one member highlighting Mina's lightweight architecture and developer ecosystem.
- Mina has a notably small size of 22kb and can run on mobile devices, making it a compelling option.
Links mentioned:
- Tweet from OpenBlock (@openblocklabs): 1/ Introducing Proof of ChatGPT, the latest application built on OpenBlock’s Universal Data Protocol (UDP). This Data Proof empowers users to take ownership of their LLM chat history, marking a signi...
- Tweet from Paul Sengh (@paulsengh): It’s incredible how quickly ZK technology has advanced—some UDP proofs now take less than a second, thanks to infra from @zkemail. Try it out: https://bridge.openblocklabs.com/
- Poe - Fast, Helpful AI Chat: no description found
- Machine Talks - Teaser: Created by Blase watch the pilot on art-dialogues.com
- Free Hermes AI ai.unturf.com & uncloseai.js – Russell Ballestrini : no description found
- GitHub - usefulsensors/moonshine: Fast and accurate automatic speech recognition (ASR) for edge devices: Fast and accurate automatic speech recognition (ASR) for edge devices - usefulsensors/moonshine
Nous Research AI ▷ #research-papers (11 messages🔥):
Research Paper TrustworthinessFalsification of Scientific DataPeer Review ConcernsFine-tuning ModelsEfficient Computation in Neural Networks
-
One in Seven Papers are Untrustworthy: A new study concludes that approximately 1 in 7 research papers contains serious errors making them untrustworthy, as stated in the abstract, '1 in 7 published papers have serious errors commensurate with being untrustworthy.'
- The study's methods were varied, acknowledging that the rate of falsification may differ by field, and the author calls for more funding in this area.
- Issues with Scientific Integrity: A member shared anecdotal evidence suggesting scientists sometimes omit data or alter experiments to align with established consensus, potentially building on erroneous conclusions from older studies.
- This raises concerns about the reliability of peer-reviewed findings in the scientific community.
- Theoretical Opinions on Fine-Tuning: A member expressed skepticism about fine-tunes degrading foundational models, suggesting that fine-tuning is more of an art form that requires community knowledge to optimize effectively.
- They speculated on potential answers to the challenges of fine-tuning, though uncertain about details for questions three to five.
- Arithmetic Over Finite Fields in Language Models: A member opined that language models may eventually be built using simple arithmetic operations over finite fields, presenting a paper that discusses approximating floating point multiplications with integer adders.
- The proposed L-Mul algorithm reportedly reduces energy costs drastically while achieving high precision in tensor operations.
- Concerns on Scientific Ethics and Falsification: Members highlighted historical issues with data falsification among scientists, with an old study indicating 2% admitted to falsifying data, now viewed as underestimating the problem.
- This raises awareness about the potential for scientific misconduct and the challenges of accurately assessing research integrity.
Links mentioned:
- Addition is All You Need for Energy-efficient Language Models: Large neural networks spend most computation on floating point tensor multiplications. In this work, we find that a floating point multiplier can be approximated by one integer adder with high precisi...
- Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations: Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it doe...
- Matryoshka Representation Learning: Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistic...
- Implicit Bias of AdamW: $\ell_\infty$ Norm Constrained Optimization: Adam with decoupled weight decay, also known as AdamW, is widely acclaimed for its superior performance in language modeling tasks, surpassing Adam with $\ell_2$ regularization in terms of generalizat...
- The Road Less Scheduled: Existing learning rate schedules that do not require specification of the optimization stopping step T are greatly out-performed by learning rate schedules that depend on T. We propose an approach tha...
LM Studio ▷ #announcements (1 messages):
LM Studio v0.3.5 featuresHeadless modeOn-demand model loadingPixtral support on Apple MLXNew CLI command to download models
-
LM Studio v0.3.5 Brings Exciting New Features: The latest update, LM Studio v0.3.5, introduces features such as headless mode for running as a local LLM service and on-demand model loading.
- Users can now easily download models using the CLI command
lms get, streamlining model access. - Boosted Pixtral Support on Apple MLX: Users can now utilize Pixtral on Apple Silicon Macs with at least 16GB of RAM, ideally 32GB.
- This integration improves performance thanks to optimizations aimed at Apple's hardware capabilities.
- Bug Fixes Enhancing User Experience: Version 0.3.5 resolves several bugs including issues with RAG reinjecting documents and fixing flickering outlines in Mission Control.
- Mac users will also benefit from enhanced support for sideloading quantized MLX models.
- Community Model Highlights and Hiring Notice: LM Studio features community models like Granite 3.0, which has been highlighted for its ability to respond to diverse queries.
- Additionally, they're hiring a TypeScript SDK Engineer to facilitate the development of apps for on-device AI.
- Download Links for All Platforms: The update is available for macOS, Windows, and Linux, with specific download links for each platform provided.
- Users are encouraged to get the latest version from their official download page.
- Users can now easily download models using the CLI command
Links mentioned:
- lmstudio-community/granite-3.0-2b-instruct-GGUF · Hugging Face: no description found
- LM Studio 0.3.5: Headless mode, on-demand model loading, server auto-start, CLI command to download models from the terminal, and support for Pixtral with Apple MLX.
- Tweet from LM Studio (@LMStudioAI): LM Studio v0.3.5 is here! 👻🎃🥳 - Headless mode (run as local LLM service) - On-demand model loading - Support for @MistralAI's Pixtral with 🍎MLX -
lms getto download models from the termin...
LM Studio ▷ #general (171 messages🔥🔥):
GPU Offloading IssuesModel Loading ErrorsAI Model Performance MetricsML Studio Features and SettingsGame Image Enhancers
-
GPU Offloading Issues in ML Studio: A user reported that GPU offloading has decreased performance dramatically, now using around 4.2GB instead of the previous 15GB.
- After switching to an older ROCm runtime version, performance returned to normal levels, indicating the update may have impacted GPU utilization.
- Model Loading Errors and System Resources: Another user faced a 'Model loading aborted due to insufficient system resources' error after adjusting GPU offload settings.
- It was noted that turning off loading guardrails may resolve the issue, although it is generally not recommended.
- Performance Metrics for AI Models: Users discussed measuring performance using throughput and latency metrics, with load settings affecting overall speed significantly.
- Under heavy GPU offloading, throughput dropped to 0.9t/s indicating potential inefficiencies when misconfigured.
- Inquiries About Image Enhancers for Games: A user asked about available options for enhancing game images into photorealistic art, with Stable Diffusion suggested as a possibility.
- This sparked a discussion about various tools and their effectiveness in modifying game footage into high-quality visuals.
- Awareness of Model Configuration in ML Studio: Some users expressed confusion about how many layers their models could utilize based on GPU configurations and quantization settings.
- Discussion included how system RAM can simulate VRAM, affecting performance metrics and load times during model inference.
Links mentioned:
- mlx-community/xLAM-7b-fc-r · Hugging Face: no description found
- config.json · mlx-community/Mamba-Codestral-7B-v0.1-4bit at main: no description found
- TheBloke/meditron-70B-GGUF · Hugging Face: no description found
- LM Studio - Experiment with local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
- AP Workflow 11.0 for ComfyUI | Alessandro Perilli: Unlock generative AI at an industrial scale, for enterprise-grade and consumer-grade applications.
Latent Space ▷ #ai-general-chat (155 messages🔥🔥):
Anthropic Claude 3.5Mochi 1 Video GenerationCrewAI Series A FundraisingStable Diffusion 3.5 ReleaseOutlines Library Rust Port
-
Anthropic Releases Claude 3.5: Anthropic has introduced the upgraded Claude 3.5 Sonnet and a new model, Claude 3.5 Haiku, which include a beta capability for computer use, enabling the model to interact with computers like a human.
- Despite the innovative abilities, some users find it doesn't follow prompts as effectively, leading to mixed experiences in practical applications.
- Mochi 1 Sets New Standards in Video Generation: GenmoAI launched Mochi 1, a state-of-the-art open-source video generation model, with a focus on high-quality, realistic motion and detailed prompt adherence.
- Mochi 1 is designed for photorealistic video generation, currently operates at 480p, and utilized significant funding to enhance development.
- CrewAI Secures Series A Funding: CrewAI raised $18 million in Series A funding, led by Insight Partners and aims to transform automation in enterprises with its open-source framework.
- The company claims to execute over 10 million agents monthly, serving a substantial portion of Fortune 500 companies.
- Stable Diffusion 3.5 Released: Stability AI has unveiled Stable Diffusion 3.5, their most powerful models yet, which are customizable and compatible with consumer hardware while being free for commercial use.
- Users can access Stable Diffusion through Hugging Face and expect additional variants to be released soon.
- Outlines Library Rust Port Announced: Dottxtai announced the release of a Rust port of Outlines' structured generation, promoting faster compilation and a lightweight library for diverse applications.
- This update enhances the efficiency of developers working with structured generation, with bindings available in multiple programming languages.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
- Tweet from Michele Catasta (@pirroh): I can't tell you the last time I was so excited to see a new AI capability in action. We plugged in Claude computer use in @Replit Agent as a human feedback replacement. And… it just works! I fe...
- Initial explorations of Anthropic’s new Computer Use capability: Two big announcements from Anthropic today: a new Claude 3.5 Sonnet model and a new API mode that they are calling computer use. (They also pre-announced Haiku 3.5, but that’s …
- Intuit asked us to delete part of this Decoder episode: Intuit CEO Sasan Goodarzi claims it’s not accurate the company lobbies against free tax filing.
- Tweet from Genmo (@genmoai): Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0. magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/annou...
- Tweet from swyx (@swyx): some handy token numbers in human terms: baselines ~4 tokens per 3 words ~500k minutes per year ~50m minutes per life text normal human reading: 400 tokens/minute at 6hrs a day, this is 150k tokens/...
- Tweet from Rhymes.AI (@rhymes_ai_): New Model From Rhymes! ✨ We're thrilled to announce, Allegro — a small and efficient open-source text-to-video model that transforms your text into stunning 6-second videos at 15 FPS and 720p! �...
- Tweet from Stability AI (@StabilityAI): Introducing Stable Diffusion 3.5, our most powerful models yet. This open release includes multiple variants that are highly customizable for their size, run on consumer hardware, and are free for bo...
- IBM Granite 3.0: open, state-of-the-art enterprise models: Announcing IBM Granite 3.0, a collection of large language models (LLMs) and tools featuring Granite 3.0 8B and 2B, Granite Guardian and Granite 3.0 MoE models.
- Tweet from swyx (@swyx): because the model cards show both sonnet and haiku bumps we can also handicap the 3.5 opus bump as well btw Quoting swyx (@swyx) Lmao Anthropic shipped @AdeptAILabs and didn't bother to even gi...
- Tweet from Genmo (@genmoai): We're excited to see what you create with Mochi 1. We're also excited to announce our $28.4M Series A from @NEA, @TheHouseVC, @GoldHouseCo, @WndrCoLLC, @parasnis, @amasad, @pirroh and more. U...
- Rovo: Unlock organizational knowledge with GenAI | Atlassian: Rovo, Atlassian's new GenAI product helps teams take action on organization knowledge using Rovo Search, Rovo Chat and specialized Rovo Agents.
- Ideogram Canvas, Magic Fill, and Extend: Ideogram Canvas is an infinite creative board for organizing, generating, editing, and combining images. Bring your face or brand visuals to Ideogram Canvas and use industry-leading Magic Fill and Ext...
- Launch YC: Manicode: Make your terminal write code for you | Y Combinator: "Very f****** cool" CLI for AI code generation
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Tweet from Aravind Srinivas (@AravSrinivas): Perplexity Finance: real time stock prices, deep dives into a company’s financials, comparing multiple companies, studying 13f’s of hedge funds, etc. The UI is just delightful!
- Tweet from Paul Gauthier (@paulgauthier): The new Sonnet tops aider's code editing leaderboard at 84.2%. Using --architect mode it sets SOTA at 85.7% with DeepSeek as the editor model. To give it a try: pip install -U aider-chat ...
- Tweet from Kenneth Auchenberg 🛠 (@auchenberg): Based on their revenue streams, @AnthropicAI emerges as an infrastructure player, while @OpenAI operates more like a consumer-facing company. Going to be interesting to see where each company is a fe...
- Tweet from Anthropic (@AnthropicAI): The new Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta. While groundbreaking, computer use is still experimental—at times error-prone. We're releasing it ea...
- Tweet from .txt (@dottxtai): We’ve been cooking with @huggingface and just released a Rust port of Outlines’ structured generation. 👉 Faster compilation 👉 Lightweight library (poke @vllm_project) 👉 Bindings in many languages...
- Tweet from João Moura (@joaomdmoura): Excited to share that @crewAIInc raised $18 million in funding, with our series A led by @insightpartners, with @Boldstartvc leading our inception round. We're also thrilled to welcome @BlitzVent...
- Jacky Liang (@jjackyliang) on Threads: Cursor is updated to the new Claude Sonnet 3.5! It appears automatically enabled, but you can also turn the (old) Claude Sonnet 3.5 off manually too. Weird naming scheming though..
- Reddit - Dive into anything: no description found
- Tweet from Alex Albert (@alexalbert__): Fun story from our time working on computer use: We held an engineering bug bash to make sure we found all the potential problems with the API. This meant bringing a handful of engineers in a room to...
- Genmo. The best open video generation models.: Genmo trains the world's best open video generation models. Create incredible videos with AI at Genmo
- Tweet from Alex Albert (@alexalbert__): I'm excited to share what we've been working on lately at Anthropic. - Computer use API - New Claude 3.5 Sonnet - Claude 3.5 Haiku Let's walk through everything:
- GitHub - genmoai/models: The best OSS video generation models: The best OSS video generation models. Contribute to genmoai/models development by creating an account on GitHub.
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others): Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
- How Not Diamond Saved $750K with LLM Routing Engine · Zoom · Luma: For developers, builders, and anyone looking to streamline LLM deployment, cut costs, and boost performance with smarter LLM routing. 📅 : October 22, 2024 ⏰ :…
Notebook LM Discord ▷ #use-cases (45 messages🔥):
NotebookLM ExperimentsPodcast CreationLanguage LearningWallStreetBets AnalysisAI-generated Content
-
Engaging Podcast with NotebookLM: A member shared their experience using NotebookLM to create a daily podcast analyzing the latest talks and sentiment from the WallStreetBets subreddit. They discussed how they input top Reddit posts to analyze trending topics and stock plays.
- Another user demonstrated their deep dives with NotebookLM, including producing longer podcast episodes by manipulating prompts, suggesting advanced use cases for intermediate language learners.
- Absurdist Humor in Performance Art: Performance artist Crank Sturgeon performed an experiment using NotebookLM’s podcast feature, resulting in an absurdist audio piece available on SoundCloud (Unentitled Notbook). This showcases the humorous and experimental potential of AI-generated content.
- The discussion highlighted the entertaining possibilities of using NotebookLM for creative and comedic narratives.
- AI-Powered Poetry Readings: Members expressed interest in using NotebookLM for dramatic readings of poetry, citing examples like Edgar Allan Poe's The Raven. One user noted achieving chilling results through the generation of multiple audio overviews and splicing the best bits.
- This indicates a trend towards exploring literary works through AI, aiming for captivating auditory experiences.
- Innovative Uses of AI for Language Learning: A user introduced a language learning 'deep dive' where they write in a target language and get corrections from an AI expert. This model targets intermediate learners and encourages interactive language practice.
- The approach inspires others to consider AI as a personal tutor in language learning, enhancing engagement and proficiency.
- Thoughts on AI-Generated Content: Members shared feedback on utilizing NotebookLM for podcasting and content creation, expressing both the challenges and successes. One noted how a lengthy biography was distilled into a 12-minute podcast episode, highlighting the tool's efficiency.
- This conversation underscores the community's enthusiasm for leveraging AI in content production while navigating its limitations.
Links mentioned:
- no title found: no description found
- NotebooLM Video: AI Podcast to AI Video: no description found
- NotebookLM does Sleep Token: I asked NotebookLM to analyze the lyrics from all five of Sleep Token's albums and it did a... passable... job.
- VotebookLM - Become an informed voter with the help of AI: NotebookLM is a way to upload information about a topic, and find information within them with the help of AI. In this video you'll see how to use it to crea...
- Unentitled Notbook: https://cranksturgeon.com/tentil.pdf
- no title found: no description found
- Dream Of The Eastern Capital: A discussion of Dream of Eastern Capital,
- Weekly Deep Dive 21Oct24: EPS growth 2025, China stimulus, Yield Curve, EV prices
- WallStreetBets Daily Podcast - Oct 22 2024: NVDA to the Moon! 🚀 (But Watch Out for Theta Crush!) 😱Join us as we break down today's crazy market action!NVDA's insane run! Can it really hit $200 by Nov...
- GitHub - mandolyte/discord-notebooklm: Chat export analysis: Chat export analysis. Contribute to mandolyte/discord-notebooklm development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- UNREAL MYSTERIES 3: The Cloud Swimmers of Jupiter: David and Hannah takes you to the planet Jupiter, to meet the hovering alien space whales that reside there. Learn what this has to do with 1972 and the Rove...
- DeepDive: It's so easy to get lost in all the info out there, but finding those little nuggets of wisdom makes it all worth it. 🌟
Notebook LM Discord ▷ #general (103 messages🔥🔥):
Issues with NotebookLM Language SettingsSharing and Collaboration ChallengesMultilingual Audio OverviewsPodcasting ExperiencesDocument Upload Issues
-
Language confusion in NotebookLM: Users reported that their NotebookLM responses are defaulting to Dutch despite providing English documents, with some advice to adjust Google account language settings.
- One user found it challenging to get consistent results in German, with instances of returned audio being in unexpected 'alien' dialects.
- Trouble sharing notebooks: Several users expressed frustration over the inability to share their notebooks, experiencing a continuous 'Loading...' screen when attempting to do so.
- This issue led to concerns about the tool's functionality, rendering it ineffective for those looking to collaborate.
- Mixed results with multilingual audio overviews: Users attempted to create audio overviews in various languages, noting inconsistencies in pronunciation and native-like quality, especially in Dutch.
- Despite the challenges, there is optimism for future improvements in multilingual support, as some users managed to produce Dutch audio content.
- Experiences with podcast creation: A user shared their excitement over successfully uploading a 90-page blockchain course, while others discussed the amusing nature of generated audio, calling it 'hilarious'.
- Several individuals provided feedback on how certain instructions led to unexpected or fun outputs, indicating varying results based on input.
- Issues with document uploads: Users encountered problems with documents not appearing in Google Drive and delays in processing uploaded files.
- The discussion included potential causes, such as corrupted files, and recommended refresh actions to resolve the issues.
Links mentioned:
- Account settings: Your browser is not supported.: no description found
- NotebookLM for Lesson Planning at Meshed/XQ's 2024 AI+EDU Symposium at Betaworks: no description found
- Frequently Asked Questions - Help: no description found
- DeepDive: It's so easy to get lost in all the info out there, but finding those little nuggets of wisdom makes it all worth it. 🌟
- AI+ EDU Symposium: INTRO Google Labs Editorial Director & Science Author, Steven Johnson: no description found
- AI+ EDU Symposium: Q&A Google Labs Editorial Director & Science Author, Steven Johnson, NotebookLM: no description found
Perplexity AI ▷ #general (103 messages🔥🔥):
New AI models and featuresAPI functionality and user concernsPerplexity competition and market presenceUser experiences and feedbackSupport and functionality inquiries
-
Excitement over new AI models: Users are eagerly discussing the recent introduction of Claude 3.5 Sonnet and Claude 3.5 Haiku, with some expressing hope that they will be integrated into Perplexity soon.
- See the announcement from AnthropicAI detailing the new capabilities, including directing Claude to use computers like a human.
- API functionality concerns: Users are reporting issues with the Perplexity API, specifically regarding its ability to return URLs for sources when requested in prompts.
- One user mentioned they struggled to get complete URLs despite clear instructions in the prompt, sparking inquiries about effective usage.
- Perplexity faces competition: Members noted that Yahoo has introduced an AI chat service, prompting discussions about Perplexity's competitive edge in the market.
- Despite these developments, users remain confident in Perplexity's capabilities, emphasizing its reliability and resourcefulness.
- User experiences with Perplexity: Several users praised Perplexity for consistently providing quality information and reliable sources, highlighting their satisfaction with the service.
- A user remarked, 'I freaking love PAI! I use it all the time for work and personal', reflecting the overall positive sentiment.
- Support and troubleshooting frustrations: Users expressed frustration with support responsiveness and difficulties in contacting customer service regarding various issues.
- One user voiced concerns over the challenges of reporting problems, questioning the efficiency of support access.
Link mentioned: Tweet from Anthropic (@AnthropicAI): Introducing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. We’re also introducing a new capability in beta: computer use. Developers can now direct Claude to use computers the way ...
Perplexity AI ▷ #sharing (11 messages🔥):
College Paths and DegreesSnapdragon 8 Elite OverviewGalaxy Z Fold Special EditionGold Prices RiseAI-Driven Fact-Checking
-
Exploration of College Paths: A user shared a resource comparing a Math major to other college degrees on Perplexity, highlighting its utility in academic planning.
- This tool aids in informed decision-making about future educational endeavors.
- Snapdragon 8 Elite Explained: An informative page on the Snapdragon 8 Elite was shared, providing detailed explanations of its features and significance in the tech industry at Perplexity.
- This deep dive helps stakeholders understand the advancements in mobile processing technology.
- Galaxy Z Fold Special Edition Revealed: The Galaxy Z Fold special edition was discussed, showcasing its unique features and design at Perplexity.
- This edition aims to attract users interested in high-end foldable smartphones.
- Gold Prices Reach Record Highs: A discussion surrounding the recent trends showing gold prices at a record high can be found at Perplexity.
- Market dynamics and economic factors behind this surge are worth noting for potential investors.
- AI-Driven Fact-Checking Collection: A collection dedicated to advanced AI-driven fact-checking strategies was shared, emphasizing the use of LLMs and ethical considerations in the process at Perplexity.
- The resource discusses critical aspects like source credibility and bias detection, offering insights into improving misinformation handling.
Eleuther ▷ #announcements (1 messages):
SAE interpretation pipelineEvaluation techniques for explanationsCausal feature explanationFeature alignment using Hungarian algorithmOpen-source tools for LLMs
-
New Open Source SAE Interpretation Pipeline Launched: The interpretability team is releasing a new open source pipeline for automatically interpreting SAE features and neurons in LLMs, leveraging LLMs themselves.
- This initiative introduces five new techniques for evaluating explanation quality, enhancing interpretability at scale.
- Causal Effects Lead to Better Feature Explanations: For the first time, it is demonstrated that explanations for features can be generated based on the causal effect of steering a feature, differing from traditional context-based methods.
- This approach yields insights into features previously considered uninterpretable, marking a significant advancement in the field.
- Alignment of SAE Features Using Hungarian Algorithm: The team has found that features of different SAEs can be aligned using the Hungarian algorithm, focusing on those trained on different layers of the same network.
- This method reveals that SAEs trained on nearby layers of the residual stream exhibit almost identical features, excluding MLPs.
- Large-Scale Analysis Affirms Interpretability of SAE Latents: Their analysis confirms that SAE latents are significantly more interpretable than neurons, even with sparsified neurons using top-k postprocessing.
- This finding encourages further exploration into autoencoders for better interpretability in LLMs.
- Collaboration Opportunities and Resources Available: Interested collaborators are encouraged to check the channel for ongoing work related to the SAE interpretation project.
- The team appreciates contributions from various members, and resources like their research paper and dataset on Hugging Face are shared.
Links mentioned:
- Automatically Interpreting Millions of Features in Large Language Models: While the activations of neurons in deep neural networks usually do not have a simple human-understandable interpretation, sparse autoencoders (SAEs) can be used to transform these activations into a ...
- GitHub - EleutherAI/sae-auto-interp: Contribute to EleutherAI/sae-auto-interp development by creating an account on GitHub.
- EleutherAI/auto_interp_explanations · Datasets at Hugging Face: no description found
- Tweet from Nora Belrose (@norabelrose): The @AiEleuther interpretability team is releasing a new open source pipeline for automatically interpreting SAE features and neurons in LLMs, using LLMs. We also introduce five new, efficient techni...
Eleuther ▷ #general (28 messages🔥):
Non-archival workshopsChess AI model integrationChess move explainabilityStockfish analysis speedResearch goals in AI development
-
Navigating Non-archival Workshop Submissions: It appears possible to submit the same paper to multiple workshops as long as their rules allow, particularly non-archival ones that don’t interfere with conference submissions.
- However, some conferences may not accept papers previously presented at such workshops, so it's vital to verify individual conference policies.
- Integrating Chess AI and LLMs for Enhanced Interaction: A member proposed the idea of combining a chess-playing AI with an LLM to enable a conversational model that understands its own decisions, rather than a simple query-response setup.
- This design aims to create a more coherent system where the chess AI's reasoning aligns with its conversational capabilities, allowing for a deeper dialogue about its moves.
- The Intricacies of Chess Move Explainability: Discussions revolved around the ability of chess players to explain top-tier moves made by engines, with some suggesting that many moves are often deemed as 'computer stuff' that lack clear justification.
- This highlights a divide between human understanding and engine logic, as even experts may struggle to rationalize certain high-evaluation moves during live commentary.
- Stockfish's Remarkable Analysis Capabilities: One member mentioned that a version of Stockfish can evaluate up to 28 million nodes per second, suggesting a significant analytical power in assessing positions.
- This statistic brings into question claims about different engines' capacities, emphasizing the impressive performance of modern chess engines.
- Clarifying Research Goals for AI Integration: A member encouraged specificity regarding the research goals for AI, questioning the motivations behind wanting the bot to achieve certain tasks.
- This inquiry aims to uncover the expected learnings and benefits from an integrated chess AI, fostering a deeper exploration of its potential use cases.
Link mentioned: How many positions per second should my homemade engine calculate?: My program prints time spent on executing a function for doing/retracting move, and both take together an average of 00.0002 seconds. That means my engine can analyze at most 5000 positions per sec...
Eleuther ▷ #research (59 messages🔥🔥):
1B context length with RAGRobustness of SAEsLayerNorm in transformer modelsIndependent research publication experiencesEthics in research sharing
-
1B Context Length Achievement: A recent post discusses a retrieval system extending LLMs to 1 billion context length through a novel method based on sparse graphs, achieving state-of-the-art performance on the Hash-Hop benchmark.
- The approach is noted to be more efficient in terms of compute and memory compared to traditional dense embedding RAG systems.
- SAE Project Ideas Discussion: An undergrad seeks project ideas related to Sparse Autoencoders (SAEs), prompting discussions on current research progress in the area and resource links.
- A member shared insights on collaborative projects and provided a link to an Alignment Forum post for further exploration.
- LayerNorm Removal in GPT2: A member shared a post highlighting research on removing LayerNorm from GPT2 through fine-tuning, illustrating slight performance differences in benchmarks with and without LayerNorm.
- The work was produced at Apollo Research and points to the challenges in mechanistic interpretability posed by LayerNorm.
- Independent Researchers and Paper Publication: There are discussions around the feasibility for independent researchers to get published, emphasizing that if the work is good, it can indeed get accepted at conferences.
- Members shared personal experiences, underscoring that collaboration can alleviate challenges in the research process.
- Ethical Concerns in Research Sharing: Concerns arose about the ethics of sharing ideas in research communities, with discussions about instances where ideas may have been appropriated without credit.
- It was highlighted that addressing such issues is complex, and members were encouraged to report any such incidents for support.
Links mentioned:
-
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
: no description found - Zyphra: no description found - Sparse Autoencoders: Future Work — AI Alignment Forum: Mostly my own writing, except for the 'Better Training Methods' section which was written by @Aidan Ewart. … - You can remove GPT2’s LayerNorm by fine-tuning for an hour — LessWrong: This work was produced at Apollo Research, based on initial research done at MATS. Edit: arXiv version available at https://arxiv.org/abs/2409.13710 … - You can remove GPT2’s LayerNorm by fine-tuning for an hour — LessWrong: This work was produced at Apollo Research, based on initial research done at MATS. Edit: arXiv version available at https://arxiv.org/abs/2409.13710 …
Eleuther ▷ #interpretability-general (2 messages):
Mech Interp Paper RatingsSharing ResearchTwitter Presence
-
Woog09 Rates Mech Interp Papers for ICLR 2025: A member rated all mech interp papers submitted to ICLR 2025, sharing their spreadsheet with clear calibration: 3 for outstanding, 2 for spotlight, 1 for promising, and unrated for potentially overlooked.
- They emphasized the calibrated ratings to help guide readers on the quality of the submissions.
- Call for More Sharing on Research: A member expressed the desire for more sharing around the mech interp paper ratings, noting that they lack a strong presence outside private settings like Discord.
- They are aiming to change this by building their Twitter presence and encouraged others to help spread the word.
Link mentioned: Tweet from Alice Rigg (@woog09): I rated ALL mech interp papers submitted to ICLR 2025: https://docs.google.com/spreadsheets/d/1TTHbONFo4OV35Bv0KfEFllnkP-aLGrr_fmzwfdBqBY0/edit?gid=0#gid=0. The ratings are calibrated: 3 - outstanding...
Eleuther ▷ #lm-thunderdome (8 messages🔥):
Batch Size ConfigurationModel Initialization Handling
-
Debugging No Batches Issue: A member asked for pointers on debugging an issue where
requestsremains a giant list of every instance despite setting abatch_size.- It seems correct that this needs to be handled by the model according to another member.
- Input Handling and Batch Size: The same member questioned whether input would not be batched if the model itself handles the
batch_sizeparameter.
- Otherwise, having the
batch_sizeparameter is useless if it’s not utilized properly, highlighting confusion around the functionality. - Role of Model Initialization: In response to the concerns, a member clarified that the
batch_sizegets passed on to the model initialization.
- This clarification left the original querent pondering the rationale behind this setup.
Interconnects (Nathan Lambert) ▷ #news (74 messages🔥🔥):
Allegro Model LaunchStability AI's Stable Diffusion 3.5Anthropic's Claude 3.5 HaikuComputer Use APINew Video Generation Models
-
Allegro Model Transforms Text to Video: Rhymes AI announced their new open-source model, Allegro, which creates 6-second videos from text at 15 FPS and 720p, now available for exploration through various links including a GitHub repository.
- Users are encouraged to join the Discord waitlist to be among the first to try Allegro.
- Stability AI Heats Up with SD 3.5: Stability AI launched Stable Diffusion 3.5, featuring three variants and free commercial use under $1M revenue, showcasing advanced features like Query-Key Normalization for customization.
- The Large version is available now on Hugging Face and GitHub, with expectations for the Medium version to launch on October 29th.
- Claude 3.5 Haiku Sets High Bar in Coding: Anthropic introduced Claude 3.5 Haiku, outperforming Claude 3 Opus. It excels particularly in coding tasks, scoring 40.6% on SWE-bench Verified and available on the API here.
- Users emphasize the significant advancements in capabilities while acknowledging the superior performance of the model in various benchmarks.
- Exciting Developments with Computer Use API: The Computer Use API by Anthropic is generating buzz as users experiment with new capabilities, including directing Claude to perform tasks on a computer, sparking interest in further testing.
- The reactions highlight the functionality and fun behind the new API, as demonstrated on GitHub.
- Emergence of New Video Generation Models: Mochi 1 was introduced as a state-of-the-art open-source video generation model, continuing the trend of innovation in the field alongside existing models.
- Discussion surrounds the rapid development of models like Mochi and Sora, indicating a competitive landscape for video generation technology.
Links mentioned:
- Tweet from Paul Gauthier (@paulgauthier): The new Sonnet tops aider's code editing leaderboard at 84.2%. Using --architect mode it sets SOTA at 85.7% with DeepSeek as the editor model. To give it a try: pip install -U aider-chat ...
- Tweet from Genmo (@genmoai): Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0. magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/annou...
- Tweet from Aidan McLau (@aidan_mclau): ugh claude just like me fr
- Tweet from Simon Willison (@simonw): It looks like my experiments with the new model for Computer Usage this morning have cost me just over $4
- Tweet from Tibor Blaho (@btibor91): Stability AI has released Stable Diffusion 3.5, their most powerful image generation models yet, offering three variants with different capabilities, free commercial use under $1M revenue, advanced fe...
- Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku: A refreshed, more powerful Claude 3.5 Sonnet, Claude 3.5 Haiku, and a new experimental AI capability: computer use.
- Tweet from Rhymes.AI (@rhymes_ai_): New Model From Rhymes! ✨ We're thrilled to announce, Allegro — a small and efficient open-source text-to-video model that transforms your text into stunning 6-second videos at 15 FPS and 720p! �...
- Tweet from Simon Willison (@simonw): OK, this new "computer use" API is crazy fun to play with. You can fire it up using the Docker example in this repo https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-d...
- Tweet from 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr): LOL WTF. Twitter/X.AI increased the grok-2 price 2x since release lol
Interconnects (Nathan Lambert) ▷ #ml-drama (7 messages):
AI-generated papersViral content on social mediaFeedback mechanisms in tech communities
-
AI Paper Raises Eyebrows: A member pointed out that a viral paper currently circulating on Twitter and Hackernews is likely entirely AI-generated, highlighting that sections, like the one on ORPO, are hallucinated and incorrect.
- The criticism emphasizes that the authors may not understand Odds Ratio Preference Optimization either.
- Hackernews is a Noise Machine: Concerns were expressed about Hackernews, where the discussions are viewed as a views lottery, lacking real value as a feedback mechanism.
- Members described the platform as very noisy and biased, questioning its usefulness for community engagement.
- Critiques of Viral Slop Content: Members called out certain viral online content, specifically describing it as slop, mentioning connections to platforms like LinkedIn.
- This commentary reflects a growing frustration with the quality of information being shared and consumed in these channels.
Links mentioned:
- Tweet from Sam Paech (@sam_paech): @rohanpaul_ai FYI this paper is at least partially, probably all, AI generated. For instance, the entire section on ORPO is hallucinated. The model clearly doesn't know what ORPO is (it's actu...
- Tweet from Xeophon (@TheXeophon): @Dorialexander Not the LinkedIn slop in the slop paper
Interconnects (Nathan Lambert) ▷ #random (7 messages):
Factor 64Blog readershipReasoning tokensCARDS method in LLMs
-
Factor 64 Revelation: A member expressed excitement about a breakthrough regarding Factor 64, emphasizing how 'obvious' it seems now.
- This moment of realization sparked further discussions about its implications.
- Need for Blog Readership: A member lamented that not enough people read their blog, indicating a desire for more engagement.
- It's a challenge to get noticed in the crowded digital space, they noted.
- Skepticism about Reasoning Tokens: Concerns were raised that reasoning tokens might be misleading, with the implication that they are just an approximation.
- This skepticism highlights the ongoing debate about the efficacy of reasoning in AI models.
- Discussion on Longer Reasoning Segments: A member referenced a method called CARDS for LLM decoding-time alignment, suggesting that longer reasoning chunks may be beneficial.
- They highlighted that it achieves 5x faster text generation and requires no retraining, as detailed in the provided paper.
Link mentioned: Tweet from Ruqi Zhang (@ruqi_zhang): Introducing CARDS, a new method for LLM decoding-time alignment: ✨5x faster in text generation and 99% win-ties in GPT-4/Claude-3 evaluation ✨provably generates high-reward high-likelihood text ✨no r...
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
Jeremy Howard's tweetTek's angry man arc
-
Microsoft CEO Gets Ratioed by Anime Account: In a tweet, Jeremy Howard pointed out that the CEO of Microsoft is getting ratioed by an account with an anime profile picture.
- Some members found this amusing, highlighting the unexpected reactions to corporate figures on social media.
- Tek's Ongoing Angry Man Arc: A member observed that Tek has been displaying signs of anger for several months.
- This ongoing trend has become a topic of discussion, with others noting the noticeable shift in Tek's demeanor.
Link mentioned: Tweet from Jeremy Howard (@jeremyphoward): CEO of Microsoft getting ratioed by an anime pfp account...
GPU MODE ▷ #general (7 messages):
Unsloth Lecture ReleaseGradient Accumulation InsightsGitHub AI ProjectEngineering Tips Discussion
-
Unsloth Lecture Released!: Our Unsloth talk is out now! Many appreciated the engaging content and dense information throughout the session.
- One viewer remarked, “I’m watching back through at .5x speed, and it’s still fast”, highlighting the lecture's richness.
- Deep Dive into Gradient Accumulation: A member shared detailed insights on gradient accumulation, explaining the importance of proper rescaling between batches. The provided code clarified potential pitfalls and emphasized using higher precision formats like fp32 to avoid issues with large gradients.
- “Usually there's a reason why all the batches can't be the same size,” they noted, underscoring the complexities in training scenarios.
- GitHub Project on Deep Learning: A user shared their project on GitHub titled **
- It’s a GPT implementation in plain C, encouraging others to deepen their understanding of deep learning.
Links mentioned:
- Lecture 32: Unsloth: no description found
- GitHub - shaRk-033/ai.c: gpt written in plain c: gpt written in plain c. Contribute to shaRk-033/ai.c development by creating an account on GitHub.
GPU MODE ▷ #triton (19 messages🔥):
Torch Compile InterpretationSoftplus Triton Kernel OptimizationKernel Compilation Sources
-
Interpreting Torch Compile Output: One user shared output from running
torch.compile(model, mode='max-autotune'), with metrics showing various execution times for matrix multiplication operations. Another member requested clarification on how to interpret these autotuning results and timings.- SingleProcess AUTOTUNE takes 30.7940 seconds to complete.
- Optimizing Softplus Triton Kernels: A user discussed developing a Softplus triton kernel but encountered JIT compilation on each launch, seeking ways to avoid runtime inspection. They considered caching kernels at different block sizes for efficiency.
- They confirmed that if the fixed
BLOCK_SIZEis used consistently, the same kernel can be reused without recompilation. - Exploring Kernel Compilation Resources: Inquiries were made about resources for compiling triton kernels, specifically tutorials or repositories. A member suggested that the triton documentation might be the best starting point for understanding kernel usage.
- They emphasized that having dtype hints in custom implementations could influence performance during compilation.
GPU MODE ▷ #torch (1 messages):
Meta HOTI 2024Llama 3 Infrastructure
-
Meta's HOTI 2024 Discusses Generative AI: There is an ongoing discussion related to the Meta HOTI 2024 talk that highlights challenges and insights from the event.
- Participants pointed out that specific issues were addressed in this session featuring speaker Pavan Balaji.
- Powering Llama 3 Keynote Highlight: The keynote session titled 'Powering Llama 3' sheds light on Meta's extensive infrastructure for generative AI.
- Insights from the talk could be critical for understanding the integration and performance of Llama 3 in the industry.
Link mentioned: Day 2 10:00: Keynote: Powering Llama 3: Peek into Meta’s Massive Infrastructure for Generative AI: Speaker: Pavan Balaji (Meta)
GPU MODE ▷ #beginner (3 messages):
FA2 padded inputsCUDA project ideasCUDA accelerated regression
-
FA2 Padded Inputs and Variable Sequence Lengths: A member raised a question on how to handle padded inputs for variable sequence lengths in FA2, mentioning a function named
flash_attn_varlen_qkvpacked_func.- They expressed difficulty in finding an easy method to convert a padded batched tensor to the required input format.
- Seeking CUDA Project Ideas for Internships: A user starting with CUDA expressed interest in working on projects to enhance their resume for an internship next summer.
- They asked the community for suggestions on cool projects to undertake.
- CUDA Accelerated Regression Implementation: The same user shared plans to implement CUDA accelerated linear and logistic regression, but encountered skepticism from a friend.
- Their friend provided a server link for project ideas as a response to the proposed implementation.
GPU MODE ▷ #torchao (14 messages🔥):
torchao v0.6.1 ReleaseCompatibility of torchao Optimizers with HF TrainerImplementing Quantization Aware Training with Older Torch VersionsDynamic Masking during Training in torchao
-
torchao v0.6.1 Released with New Features: Today, torchao v0.6.1 was released, introducing exciting new features like AWQ, Auto-Round, and Float8 Axiswise scaled training. For more details, check the release notes here.
- The community is being appreciated for its ongoing contributions and engagement.
- Compatibility Issues with torchao and HF Trainer: There was a question regarding the compatibility of torchao optimizers with the HF Trainer, with general consensus indicating they should work but might encounter issues. One member noted that using HF's adamw with int8 mixed experienced slowdowns due to potential conflicts.
- Another member mentioned that CPUOffloadOptimizer may lead to issues as it isn't exactly a plain optimizer.
- Challenges with Quantization Aware Training: A user expressed concerns about implementing quantization aware training with older versions of Torch, specifically mentioning torch 1.9 being obsolete. It was suggested to try building from source with a command that bypasses CPP but warned that it could lead to issues due to significant changes in the framework between versions.
- A follow-up noted the presence of useful functions in torch.quantization for custom quantization schemes, leading to discussion about whether torchao is a more robust refactor, particularly in terms of supporting hardware.
- Dynamic Weight Masking in torchao: A user asked about the sparsifier.step() function in torchao, seeking clarification on whether it dynamically finds masks for weights during training. It was clarified that while it will keep the configuration as a target, it will continuously update the mask.
Links mentioned:
- Deep Dive on PyTorch Quantization - Chris Gottbrath: Learn more: https://pytorch.org/docs/stable/quantization.htmlIt’s important to make efficient use of both server-side and on-device compute resources when de...
- Release v0.6.1 · pytorch/ao: Highlights We are excited to announce the 0.6.1 release of torchao! This release adds support for Auto-Round support, Float8 Axiswise scaled training, a BitNet training recipe, an implementation o...
GPU MODE ▷ #llmdotc (1 messages):
apaz: They're working on llama3, but yeah.
GPU MODE ▷ #rocm (3 messages):
ROCm 6.2 Docker ImageGitHub Actions for AMD ClusterTorch + ROCm with PoetryDifference between ROCm and Official PyTorch ImagesJob Queue Setup
-
Testing Performance of ROCm 6.2 Docker Image on MI250: A member built a new ROCm 6.2 Docker image and is eager to test its performance on the MI250.
- The pull request includes major updates to Docker configurations for multiple environments including NVIDIA, CPU, and AMD.
- GitHub Actions Submission for AMD Cluster: Another member encouraged submissions for GitHub Actions via this link to facilitate job execution in the AMD cluster.
- They emphasized contributing to the development of the gpu-mode/amd-cluster repository.
- Difference Between ROCm and Official PyTorch Images: A participant expressed curiosity about the differences between personal ROCm images and official ROCm PyTorch images available on Docker Hub.
- This inquiry highlights the need for clarity among users transitioning to ROCm-based setups.
- Job Queue Setup Discussion: A member indicated that they are trying to set up a job queue for managing tasks within their environment.
- This reflects a growing interest in optimizing resource utilization and job management in ROCm workflows.
- Seeking Solutions for Torch + ROCm with Poetry: There is an interest in solutions for integrating Torch and ROCm installs using Poetry for dependency management.
- An open discussion beckons practical approaches to streamline the installation process.
Links mentioned:
- amd-cluster/.github/workflows at main · gpu-mode/amd-cluster: Repo to submit jobs to the AMD cluster. Contribute to gpu-mode/amd-cluster development by creating an account on GitHub.
- no title found: no description found
- New docker image for rocm / torch cpu by michaelfeil · Pull Request #434 · michaelfeil/infinity: This pull request includes significant updates to the Docker configurations and dependency management for various environments, including NVIDIA, CPU, AMD, and TensorRT. The changes aim to streamli...
GPU MODE ▷ #bitnet (7 messages):
Bitnet Implementation WeightsPacked WeightsTernary Weights
-
Clarifying Bitnet Weights: A member inquired why weights in the bitnet implementation are not ternary {-1,0,1}.
- Another member suggested that the weights might be packed and to check the shape for further clarification.
- Understanding Packed Weights: One member explained that the weights appear packed, with one dimension being 1/4 of what it should be, indicating a 4x2-bit packing into 1x8-bit.
- This detail suggests an efficient representation of weights, emphasizing the complexity of the implementation.
- Realization of Ternary Weights: The original inquirer acknowledged understanding of the ternary weights after clarification was provided.
- A simple expression of gratitude was shared once the details were confirmed.
GPU MODE ▷ #sparsity-pruning (1 messages):
TorchAO Sparsity Future PlansAdvancements in Sparsity & PruningCollaborative Opportunities
-
TorchAO shares future plans for sparsity: A proposal has been shared on GitHub regarding the future plans for sparsity in torchao after reflecting on recent advancements.
- The discussion emphasizes enhancing support for distillation experiments and fast compilable sparsification routines.
- Advancements on accuracy side of sparsity: Key advancements on the accuracy side of sparsity and pruning include developments in distillation and activation sparsity.
- The post invites feedback on community interests and collaboration, asking if these advancements resonate with current priorities.
- Call for collaboration on sparsity efforts: The author expresses a desire for collaboration from the community on the proposed sparsity projects, stating it's a great opportunity to engage.
- There’s an openness for discussions on other important topics, creating an inclusive atmosphere for input from community members.
Link mentioned: [RFC] Sparsity Future Plans · Issue #1136 · pytorch/ao: I had a chance to reflect after PTC / CUDA-MODE and wanted to share some thoughts on future plans for sparsity in torchao. Current State There are two components of sparsity, accuracy and accelerat...
GPU MODE ▷ #liger-kernel (11 messages🔥):
Liger Kernel InferenceCross Entropy IssuesPull Request for Batch NormTransformers Monkey PatchingLoss Function References
-
Liger Kernel struggles with Llama inference: A member reported that using liger on Llama 3.2 with a 3k token prompt results in increased inference latency instead of improved performance.
- Thanks! I’m not seeing the perf improve… at least with the 3B model.
- Cross-Entropy Tweaks Suggested: Another member advised trying settings like cross_entropy = True and fused_linear_cross_entropy = False for potential performance improvements.
- Members discussed how the defaults for liger may not suit inference needs since it's optimized for LLM training.
- Pull Request for Batch Norm Added: A member announced a pull request for adding batch norm to the Liger-Kernel, comparing its performance against Keras’s batch norm.
- This PR aims to enhance functionalities and includes test results from a 4090 setup.
- Patching Cross Entropy for Latest Transformers: A discussion arose about the monkey patching of cross-entropy for transformers, suspecting issues with it not working on the latest GA version.
- It was noted that most CausalLMs currently use self.loss_function instead of CrossEntropyLoss, potentially impacting current patch strategies.
- Loss Functions Reference Links Provided: Members shared key links to loss functions used in transformers, detailing their implementations and usage.
- The root cross-entropy function in Hugging Face is available here.
Links mentioned:
- added batch norm by vulkomilev · Pull Request #321 · linkedin/Liger-Kernel: Summary Аdded batchNorm Testing Done I have compared it against Keras's batch norm.I have used 4090 Hardware Type: [ X] run make test to ensure correctness [X ] run make checkstyle to ensure...
- transformers/src/transformers/loss/loss_utils.py at 049682a5a63042f087fb45ff128bfe281b2ff98b · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- transformers/src/transformers/models/gemma2/modeling_gemma2.py at 049682a5a63042f087fb45ff128bfe281b2ff98b · huggingface/transformers): 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- transformers/src/transformers/loss/loss_utils.py at 049682a5a63042f087fb45ff128bfe281b2ff98b · huggingface/transformers): 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
- Liger-Kernel/src/liger_kernel/transformers/monkey_patch.py at 99599091373f178e8ad6a69ecb1b32351d1d5c1f · linkedin/Liger-Kernel): Efficient Triton Kernels for LLM Training. Contribute to linkedin/Liger-Kernel development by creating an account on GitHub.
GPU MODE ▷ #self-promotion (1 messages):
Model QuantizationIEEE IPTA Conference
-
Model Quantization Tutorial at IEEE IPTA: A tutorial on model quantization was presented at the IEEE IPTA conference, highlighting key techniques and applications in the field.
- For further details, the presentation slides are available for anyone interested in learning more.
- IPTA 2024 Overview: The IPTA 2024 conference is an upcoming event focusing on advancements in technology, particularly in areas like model quantization.
- Participants are encouraged to engage with various tutorials and presentations, potentially leading to deeper insights into current research trends.
Link mentioned: IPTA 2024 - Quantization Tutorial: Model Quantization Techniques for Efficient Transformer Models Dr. Hicham Badri Principal Research Scientist @Mobius Labs GmbH IEEE IPTA 2024 - Rabat, Morocco
GPU MODE ▷ #project-popcorn (6 messages):
LLM for Efficient KernelsScaling Test Time ComputeKernel Dataset CompetitionHidetScript DSL
-
Creating an LLM for Efficient Kernels: A member outlined plans to create an LLM to generate efficient kernels in public, with a target MVP for December 2024 at NeurIPS, explaining how GPUs work to humans and LLMs.
- This baseline will use large scale sampling and verification with ncu, while collecting the largest kernel dataset globally from existing sources.
- Introducing a Kernel Dataset Competition: Plans include creating a competition to build a data flywheel for new tokens, aiming to engage more people by conducting all work transparently on Discord, funded by public sponsors.
- The MVP will also clarify how to measure the complexity of kernel writing and ensure the output code uses appropriate abstractions.
- Engaging with Simple Prompt Engineering: Simple prompt engineering, using few-shot examples without finetuning, was proposed for tasks related to CUDA and Triton applications.
- This approach aims to leverage existing knowledge while experimenting with different methods for kernel generation.
- Potential of HidetScript for Kernel Programs: A member recommended exploring HidetScript as a DSL for writing kernel programs that directly generates CUDA code, rather than PTX like Triton.
- They suggested it would also be worthwhile to extend its capabilities to Metal, Modular's kernel definition language, and TVM due to their popularity.
Links mentioned:
- Examples — Hidet Documentation: no description found
- TK + Monkeys + CUDAGen: ThunderKittens A simple framework for AI kernels
- Monkeys_for_Meta_v3.pptx: Large Language Monkeys: Scaling Inference-Time Compute with Repeated Sampling Brad Brown*, Jordan Juravsky*, Ryan Ehrlich*, Ronald Clark, Quoc Le, Chris Ré, Azalia Mirhoseini
- META KERNELS - Google Drive: no description found
OpenAI ▷ #ai-discussions (47 messages🔥):
AGI ChallengesCustom GPT ConfusionQuantum Computing PerspectivesAnthropic AI ReleasesTV Show Recognition Issues
-
Debate on AGI Feasibility: Members discussed whether we struggle to reach AGI due to the type of data we provide, questioning if binary data might inhibit progress.
- One member contended that while there are learning limitations, AGI is still achievable through improved algorithms and not bound by data type.
- Clarifying Custom GPT Terminology: Participants noted that the term 'GPTs' can be confusing, often referring to custom GPTs rather than the broader category including models like ChatGPT.
- The discussion highlighted the need for clarity in differentiating between general GPTs and specific implementations.
- Insights on Quantum Computing Simulators: A member posited that for quantum computing simulators to be practically useful, they should ideally produce 1:1 outputs compared to real quantum computers.
- While there are companies developing such simulators, their effectiveness and real-world application remain topics of debate.
- Anthropic's New AI Agents: The TANGO talking head model gained attention for its ability to lip-sync and perform body movement, sparking interest in its open-source capabilities.
- Another member shared that Claude 3.5 Sonnet is impressive with agentic benchmarks, though others believe Gemini Flash 2.0 may outperform it.
- ChatGPT's Limitations with TV Shows: A member recounted experiences with ChatGPT struggling to identify correct episode numbers and titles for TV shows, suggesting a training data gap.
- The discussion pointed out that opinions may dominate the data, affecting accuracy in specific TV show queries.
OpenAI ▷ #gpt-4-discussions (4 messages):
o1-preview usage limitsUser onboarding in discussions
-
o1-preview response limit sparks inquiry: A new member, @sami_16820, questioned the usage limits of o1-preview, noting they have a remaining count of 5 responses before a switch to another model on October 29, 2024.
- In response, a user provided clarification that the limit is 50 responses per week for o1-preview.
- New user seeks guidance: In their introduction, @sami_16820 expressed uncertainty about the platform and sought information regarding o1-preview.
- This exchange highlights the welcoming nature of the community as they assist newcomers in navigating the platform.
OpenAI ▷ #prompt-engineering (11 messages🔥):
Order of Context in PromptingError Correction on CSV DataProblem-Solving with GPTEmphasizing Prompt DetailsStructured Prompts for Independent Thinking
-
Order of Context Matters: A member emphasized that for emphasizing important information in instructions, its placement should be at the beginning or end of the prompt.
- Another participant suggested using a table of contents to better structure long instructions.
- Using Photos for Error Correction in CSV: A member inquired about crafting a prompt to correct price inaccuracies in a CSV generated from photos of menus using gpt-4o.
- They received a suggestion to edit the original prompt where hallucinations began during the data generation.
- Independent Problem-Solving with GPT: A member asked for assistance in developing a prompt for ChatGPT to independently determine how many regions a regular decagon's lines could divide the plane into.
- Another suggested transforming this query into a structured prompt that guides GPT to approach the problem procedurally.
- Emphasizing Details in Prompts: Discussion ensued on ways to emphasize parts of prompts to clarify requests more effectively.
- Participants agreed that context order plays a critical role in ensuring clarity and focus on important elements.
OpenAI ▷ #api-discussions (11 messages🔥):
Importance of Context Order in InstructionsUsing Table of Contents for EmphasisError Correction on CSV from Menu PhotosStructured Prompts for Problem Solving
-
Order of Context Matters: A member emphasized that the order of context in instructions is crucial for highlighting importance, especially in longer prompts.
- Cheers! was the brief acknowledgment of this insight.
- Proposing Index for Emphasis: Discussion arose about using a table of contents and an index to help maintain emphasis on key parts of a prompt.
- One member confirmed that structuring parts can help mitigate issues with prompt clarity.
- Error Correction for Menu CSV: A member shared that they have a 700 row CSV from menu photos generated with GPT-4, but some prices need correction.
- They sought prompts for feeding back photos and the CSV for a round of error correction.
- Editing Initial Prompts for Accuracy: Another member suggested editing the initial prompt to address where hallucinations began in the previous outputs.
- This highlights the need for prompt refinement in generating accurate results.
- Structured Prompts for Independent Thinking: A member inquired about using a prompt to let ChatGPT independently solve a geometry problem involving a regular decagon.
- Others suggested crafting a structured prompt to guide GPT in thoughtful, procedural problem-solving.
Cohere ▷ #discussions (38 messages🔥):
Cohere models usageMulti-modal embeddingsCohere for AI + Embed - V3Event scheduling issuesPerformance tuning in LLMs
-
Cohere Models Finding Favor: Members discuss actively using Cohere models in the playground, highlighting their varied application and tinkering efforts.
- One member particularly noted the need to rerun inference with different models when working with multi-modal embeddings.
- Excitement Around Multi-modal Embeddings: The discussion turned to multi-modal embeddings, with members expressing excitement and curiosity about their compatibility and performance.
- Questions arose regarding whether image embeddings share the same latent space as text embeddings, with acknowledgments that they likely differ.
- Upcoming Event Confusion: There was confusion regarding an event time, with one member humorously noting it was labeled as 'Coming soon: Yesterday 8PM'.
- The moderator clarified it was a Discord bug and that the event would begin in 22 minutes.
- Cohere for AI + Embed - V3 Speculations: Members expressed intrigue about the upcoming Cohere for AI + Embed - V3, with one participant callling it out as a potential multimodal Command model.
- Another replied, confirming it as a Global connection model that aims to connect users across different modalities.
- Improving LLM Performance: Members shared experiences related to tuning performance in their models, particularly noting how line order can impact results.
- One highlighted a dramatic drop in average loss from 2.5 to 1.55 after tweaking code, suggesting an exploratory approach to coding.
Link mentioned: Vsauce Michael GIF - Vsauce Michael Or Is It - Discover & Share GIFs: Click to view the GIF
Cohere ▷ #announcements (1 messages):
Multimodal Embed 3 ReleaseRAG Systems IntegrationAPI Changes in Embed 3Image Processing Enhancements
-
Multimodal Embed 3 is Here!: The new Embed 3 model boasts SOTA performance on retrieval tasks and excels in mixed modality and multilingual searches, allowing users to store text and image data in a single database.
- Check out more details in the blog post and release notes.
- RAG Systems Made Easy: Embed 3 enables the creation of fast, accurate RAG systems and search applications across various data sources like graphs, charts, and product catalogs.
- This integrated approach reduces complexity and enhances data interactions.
- API Changes Streamline Image Processing: The Embed API now supports a new
input_typecalledimageand introduces animagesparameter for processing images, streamlining user experience.
- Notably, current API restrictions allow only one image per request with a maximum size of 5mb.
- Join the Office Hours for Insights: Cohere is hosting office hours featuring insights from the Sr. Product Manager for Embed, aimed at helping users understand the new features.
- Participants can join the event here to learn directly from the expert.
Links mentioned:
- Introducing Multimodal Embed 3: Powering AI Search: Cohere releases a state-of-the-art multimodal AI search model unlocking real business value for image data.
- Embed v3.0 Models are now Multimodal — Cohere: Launch of multimodal embeddings for our Embed models, plus some code to help get started.
Cohere ▷ #questions (10 messages🔥):
LLM Model Fine-TuningParallel Request HandlingCohere Command R FeaturesPlayground Usage in Professional Settings
-
Fine-Tuning LLMs Requires More Data: A member shared insights on fine-tuning an LLM with a small dataset, noting potential overfitting issues and seeking guidance on strategies.
- Respondents suggested increasing dataset size and adjusting hyperparameters like the learning rate, referencing Cohere's fine-tuning guide.
- Parallel Request Issues in Local Setup: A member is testing concurrent request handling in Cohere Command R but reports that requests are processed sequentially.
- They requested guidance on enabling parallelism for their Proof of Concept (POC) purposes.
- Cohere Command R+ Image Reading Capabilities: A member inquired about when Command R+ would be able to read images, indicating interest in expanded functionalities.
- This underscores a broader interest in multi-modal capabilities within the Cohere models.
- Concerns About Playground Usage in Clinical Settings: A member expressed uncertainty about using the playground on a clinic computer, citing concerns over professional suitability.
- Despite fears, another member clarified that while it isn't forbidden, it's highly discouraged and unsupported for professional use.
Link mentioned: Starting the Chat Fine-Tuning — Cohere: Learn how to fine-tune a Command model for chat with the Cohere Web UI or Python SDK, including data requirements, pricing, and calling your model.
Cohere ▷ #api-discussions (19 messages🔥):
Multilingual Model LatencyAPI Token UsageRead Timeout Issues
-
Multilingual Model suffers latency spikes: Multiple members reported 30-60s latency on the embed multilingual model, with some experiencing it rising to 90-120s around 15:05 CEST.
- Despite initial concerns, it appears the issue improved, with members urged to report any ongoing glitches.
- Clarification on API Token usage: A member inquired about the necessity of using
<|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>in API requests, questioning their impact on response quality.
- It was clarified that for chat requests, those tokens do not need to be included, as they are likely ignored.
- Read timeout issues persist: A member reported ongoing read timeout issues, specifically stating a timeout message from their cohere command.
- In response, team members indicated that they are deploying a fix, promising resolution within the next hour.
Link mentioned: incident.io - Status pages: no description found
Cohere ▷ #projects (1 messages):
Agentic Builder DayOpenSesame collaborationCohere Models competition
-
Agentic Builder Day Announced: Cohere and OpenSesame are co-hosting the Agentic Builder Day on November 23rd, inviting talented builders to compete in creating AI agents using Cohere Models.
- Participants can apply to join this 8-hour hackathon and have the chance to win prizes while showcasing their skills.
- Call for AI Builders at Hackathon: The event seeks skilled developers eager to collaborate and compete, offering a platform for building impactful AI products in Toronto.
- Interested individuals are encouraged to apply now to be part of this community-focused competition.
Link mentioned: OpenSesame | Build Better AI Agents: OpenSesame simplifies the entire AI agent lifecycle, from building to evaluating. Our platform empowers businesses to easily create, share, and implement AI agents and detect hallucinations, making AI...
Modular (Mojo 🔥) ▷ #general (5 messages):
Mojo Language Structure of ArraysMojo Language SlicesCommunity Reflections on Collections
-
Mojo Language supports custom Structure of Arrays: You can easily create your own Structure of Arrays (SoA) in Mojo with nice syntax, although it's not built-in to the language itself.
- Currently, a slice type exists but is somewhat restrictive, expected to be enhanced as the type system develops.
- Discussion on Mojo Language Slices: While Mojo includes a slice type, it's just a struct in the standard library, with some methods returning slices, but it's not fully integrated yet.
- Members express that this limitation will be revisited as the language evolves.
- Community Insights on SOA and Reflection API: A previous community meeting discussed the potential for automated SOA transformations within Mojo's reflection API, which may allow for automatic transformations in various collections.
- While promising, designing these automatic transformations would require either a very advanced compiler or clever reflection techniques.
Modular (Mojo 🔥) ▷ #mojo (40 messages🔥):
Performance of Binary StrippingComptime Variables in MojoUsing Tuple ArgumentsBigInt Operations ComparisonArbitrary Width Integer Libraries
-
Binary Stripping Dramatically Reduces Size: Stripping a 300KB binary can reduce it to just 80KB, showcasing significant optimization potential.
- Members noted the impressive drop resulting from this process.
- Comptime Variables Outside Parameter Scope: A user inquired about using a
comptime varoutside a@parameterscope, noting encountering compile errors.
- Discussion highlighted that alias allows compile-time declarations, but direct mutability is not straightforward.
- Issues with Tuple Arguments in Mojo: Code involving tuple argument manipulation crashed the compiler, indicating potential issues with StringSlice usage in an array.
- Members discussed the necessity for improved trait implementations to enhance usability in such scenarios.
- Node.js vs Mojo for BigInt Calculations: Users compared the performance of a BigInt calculation in Node.js, which took approximately 40 seconds, suggesting it might be optimized in Mojo.
- Discussion revealed that optimizing the arbitrary width integer library is crucial for performance comparison.
- Understanding Integer Libraries: Members discussed the importance of arbitrary width integer libraries for handling calculations involving numbers too large for standard integers.
- It was noted that the operations needed to accommodate 1026 bits require specialized libraries that bridge the computational gap.
tinygrad (George Hotz) ▷ #general (15 messages🔥):
LLVM Renderer RefactorTinygrad Performance ImprovementsGradient Clipping IntegrationACT Training ProgressTinyJit Decorator Queries
-
LLVM Renderer Refactor Proposal: A user suggested rewriting the LLVM renderer in a pattern matcher style to enhance its functionality.
- This could lead to significant improvements in clarity and efficiency.
- Boosting Tinygrad's Speed: Discussion emphasized the need to enhance Tinygrad's performance after transitioning to using uops.
- This will be essential to keep up with advancements in computing power.
- Integrating
clip_grad_norm_into Tinygrad: A user raised the question of whetherclip_grad_norm_should be a standard part of Tinygrad, citing its frequent appearance in deep learning code.
- George Hotz pointed out that a grad refactor is necessary before moving forward with this integration.
- Progress on Action Chunking Transformers: A user reported convergence in ACT training after a few hundred steps, achieving a loss under 3.0.
- They shared links to the source code and the research paper for further insight.
- Queries on TinyJit Decorator Functionality: There was a query regarding the applicability of the
@TinyJitdecorator for batch inputs with dictionary keys and Tensor values.
- Concerns were raised about the old behavior of TinyJit reusing the same input multiple times.
Links mentioned:
- Tensor.gradient should be a function (method) · Issue #7183 · tinygrad/tinygrad: grad_weights = loss.gradient(*weights) Should confirm this API works for second derivatives too, but I see no reason why it shouldn't. Blocked on big graph where the grad will actually be computed...
- GitHub - facebookresearch/lingua: Meta Lingua: a lean, efficient, and easy-to-hack codebase to research LLMs.: Meta Lingua: a lean, efficient, and easy-to-hack codebase to research LLMs. - facebookresearch/lingua
- GitHub - mdaiter/act-tinygrad: Action Chunking Transformers in Tinygrad: Action Chunking Transformers in Tinygrad. Contribute to mdaiter/act-tinygrad development by creating an account on GitHub.
tinygrad (George Hotz) ▷ #learn-tinygrad (15 messages🔥):
Tensor Indexing TechniquesPython Compatibility with MuJoCoIntermediate Representation InspectionCustom Compiler Development
-
Exploring Tensor Indexing with .where(): Discussion arose on using the
.where()function with boolean tensors, withm.bool().where(t, None)suggested as an approach.- However, it was noted that using
.int()for indexing resulted in[2,1,2], which did not meet expectations. - Python3.10 Preferable for MuJoCo: A user found that Python3.10 is the only compatible version for running MuJoCo, while Python3.12 breaks its functionality.
- This raised questions about compatibility issues and version-specific constraints.
- Gaining Access to Intermediate Representation: A user expressed interest in obtaining the linearized output before compilation to inspect the intermediate representation.
- It was mentioned that setting
DEBUG=6prints the linearized UOps for inspection. - Developing a Custom Compiler Backend: Another user is keen on building a custom compiler implementation and running output through their backend.
- Resources and examples were shared for obtaining linearized output and renderer functions to aid in debugging.
- However, it was noted that using
OpenInterpreter ▷ #general (24 messages🔥):
Hume AI Voice AssistantClaude 3.5 Sonnet ReleaseOpen Interpreter and Claude IntegrationScreenpipe ToolOpen Source Monetization Models
-
Hume AI Joins the Party: A member announced the addition of a Hume AI voice assistant to the phidatahq generalist agent, enhancing functionality with a streamlined UI and the ability to create and execute applescripts on Macs.
- Loving the new @phidatahq UI noted the improvements made possible with this integration.
- Claude 3.5 Sonnet Gets Experimental: Anthropic officially released the Claude 3.5 Sonnet model with public beta access for computer usage, although it is described as still experimental and error-prone.
- Members expressed excitement while noting that such advancements re-enforce the growing capabilities of AI models.
- Open Interpreter Powers Up with Claude: There’s enthusiasm about using Claude to enhance the Open Interpreter, with members discussing practical implementations and code to run the new model.
- One member reported success with the specific model command, encouraging others to try it out.
- Screenpipe is Gaining Traction: Members praised the Screenpipe tool for its utility in build logs, noting its interesting landing page and potential for community contributions.
- One member encouraged more engagement with the tool, citing a useful profile linked on GitHub.
- Monetization Meets Open Source: Discussion emerged around monetizing companies by allowing users to build from source or pay for prebuilt versions, balancing contributions and usage.
- Members expressed approval of this model, highlighting the benefits of contributions from both builders and paying users.
Links mentioned:
- Tweet from Anthropic (@AnthropicAI): The new Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta. While groundbreaking, computer use is still experimental—at times error-prone. We're releasing it ea...
- Tweet from Jacob@AIwithBenefits (@AIwithBenefits): Added a @hume_ai voice assistant to the @phidatahq generalist agent, and a little help from the @OpenInterpreter system message. Quoting Jacob@AIwithBenefits (@AIwithBenefits) Loving the new @phid...
- open-interpreter/examples/screenpipe.ipynb at development · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (1 messages):
facelessman: https://youtu.be/VgJ0Cge99I0 -- Love this episode -- love these folks!!!
DSPy ▷ #show-and-tell (2 messages):
New version creationUpgrade processCurrent system functionality
-
Creation of New Version Announced: A member expressed enthusiasm for not altering the existing masterpiece and instead, creating a new version.
- Thanks, means a lot - another member confirmed they would create the new version live on Monday.
- Discussion on Current System Functionality: The creator plans to delve into how the current system works during the upcoming live session.
- They also mentioned discussing their upgrade process to provide clarity on the improvements being made.
DSPy ▷ #general (22 messages🔥):
AI Helper DocumentationBroken LinksDocs Bot ReturnGeneral Vibe of 3.0
-
AI Helper Not Implemented in New Docs: A member noted that the little AI helper is not implemented in the new documentation structure, expressing disappointment.
- Very sad it's gone echoed the community sentiment.
- Numerous Broken Links Reported: Multiple users highlighted the presence of broken links leading to 404 errors across various dspy documentation pages.
- One user assured that they had done a PR to address the issue, prompting appreciation from others for their quick action.
- Docs Bot Makes a Comeback: Members celebrated the return of the documentation bot, expressing enthusiasm and gratitude for its functionality.
- The community's response was positive, marked by heart emojis and affirmations in support of the bot's presence.
- Query on General Vibe of 3.0: A member inquired about the general vibe regarding version 3.0 of dspy, indicating an interest in the community's feelings about updates.
- No detailed responses were provided, leaving the community's sentiment broadly unaddressed.
LlamaIndex ▷ #blog (4 messages):
VividNode desktop appServerless RAG appKnowledge Management for RFPsLlama Impact HackathonDocument indexing in vector databases
-
VividNode: Chat with AI Models on Desktop: The VividNode app allows users to interact with GPT, Claude, Gemini, and Llama from their desktop, featuring fast search and advanced settings. Additionally, it includes image generation capabilities using DALL-E 3 or various Replicate models, as detailed in the announcement.
- It's designed to provide a robust chat interface for users seeking a seamless AI communication experience.
- Build a Serverless RAG App in 9 Lines: A tutorial by @DBOS_Inc shows how to deploy a serverless RAG app using LlamaIndex in just 9 lines of code, significantly cutting costs compared to AWS Lambda. The process is streamlined, allowing for resilient AI applications with durable execution, as mentioned in this tweet.
- The tutorial emphasizes ease of deployment and cost efficiency for developers building AI applications.
- Enhancing RFP Responses with Knowledge Management: The discussion highlights how indexing documents in a vector database can aid in RFP response generation, enabling complex workflows beyond simple chat responses. This approach allows LLM agents to generate artifacts and responses that are contextually relevant, as outlined in the post.
- It underscores the versatility of vector databases in supporting advanced AI functionalities.
- Join the Llama Impact Hackathon!: Participants can join the 3-day Llama Impact Hackathon in San Francisco, focusing on building solutions with Llama 3.2 models. Competing teams have a chance to win part of the $15,000 prize pool, which includes a $1,000 prize for the best use of LlamaIndex, as seen in this announcement.
- The event runs from November 8-10, offering both in-person and online participation options.
LlamaIndex ▷ #general (14 messages🔥):
CondensePlusContextChatEngine Memory InitializationLimiting TPM and RPM in LlamaIndexUsing GraphRag with Dynamic DataParsing .docx Files with LlamaIndex APIPersisting Context in Workflows
-
CondensePlusContextChatEngine automatically initializes memory: Users questioned whether to initialize memory in CondensePlusContextChatEngine for consecutive questions, noting previous versions worked without it.
- A member confirmed that memory is automatically initializing, streamlining the user experience.
- Limiting TPM and RPM in LlamaIndex: A member inquired about limiting TPM and RPM in LlamaIndex, seeking an automatic solution.
- Another member clarified that users must manually limit the indexing speed or query frequency as automatic methods are unavailable.
- Efficient use of GraphRag with dynamic data: A member sought advice on efficiently using GraphRag with changing data, wanting to avoid creating new graphs each time data is updated.
- No direct solutions were offered in the gathered discussions for this query.
- Parsing .docx files with LlamaIndex API: Members discussed whether parsing a .docx file with the LlamaIndex API occurs locally or on the server.
- It was confirmed that parsing data will be sent to LlamaCloud for processing.
- Persisting Context in multiple workflow runs: A user asked how to enable context retention across multiple executions of the same workflow.
- A member provided code snippets illustrating how to serialize context and resume later using
JsonSerializer.
LlamaIndex ▷ #ai-discussion (1 messages):
LaBSE performancesentence-transformers/multilingual models
-
LaBSE Underwhelms User Performance: A member noted that they tried LaBSE about a year ago and found it underwhelming in terms of performance.
- They specifically mentioned that the model failed to meet expectations with their data.
- Issues with Multilingual MPNet Model: The same member expressed frustration with the sentence-transformers/paraphrase-multilingual-mpnet-base-v2, indicating it also struggles with their new data.
- This reinforces concerns about the effectiveness of certain multilingual models in handling diverse datasets.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (2 messages):
LLM Agents MOOC HackathonHackathon FAQSponsorshipTracks of HackathonSign-Up Details
-
LLM Agents MOOC Hackathon Announced: Berkeley RDI is launching the LLM Agents MOOC Hackathon from mid-October to mid-December, offering over $200,000 in prizes and credits. The event is open to both Berkeley students and the public, aiming to encourage innovation in AI.
- Participants can sign up through the provided registration link and explore career and internship opportunities during the hackathon.
- Sponsor Acknowledgment: Special thanks were given to sponsors including OpenAI, GoogleAI, AMD, and others for their support in the hackathon. Their involvement showcases a strong backing from prominent players in the AI field, contributing to the event's credibility.
- The tweet shared by @dawnsongtweets highlighted the excitement around the hackathon launch and encouraged participation with a strong community backing.
- Five Exciting Hackathon Tracks Introduced: Participants are invited to explore five distinct tracks: Applications, Benchmarks, Fundamentals, Safety, and Decentralized & Multi-Agents. Each track represents a unique opportunity to delve deeper into various aspects of LLM agents and AI performance.
- This empowers participants to build on cutting-edge technologies and address key challenges in AI development.
- Hackathon FAQ Created: A comprehensive LLM Agents Hackathon FAQ has been created to address common queries, accessible through the provided FAQ link.
- This resource will help prospective participants navigate their questions and enhance their experience leading up to the event.
Links mentioned:
- Hackathon FAQ: LLM Agents Hackathon FAQ What is the hackathon website? https://rdi.berkeley.edu/llm-agents-hackathon/ Where do I sign up? https://docs.google.com/forms/d/e/1FAIpQLSevYR6VaYK5FkilTKwwlsnzsn8yI_rRLLqD...
- Tweet from Dawn Song (@dawnsongtweets): 🎉 Thrilled by the incredible enthusiasm for our LLM Agents MOOC—12K+ registered learners & 5K+ Discord members! 📣 Excited to launch today the LLM Agents MOOC Hackathon, open to all, with $200K+ in p...
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (2 messages):
Lecture 7 AnnouncementLLM Agents MOOC HackathonTapeAgents FrameworkWorkArena++ BenchmarkHackathon Tracks and Sponsors
-
Lecture 7 Livestream Happening Soon: Today's lecture by guest speakers Nicolas Chapados and Alexandre Drouin on AI Agents for Enterprise Workflows is set for 3:00pm PST, with the livestream available here.
- The session will introduce the TapeAgents framework and discuss web agents capable of using browsers autonomously, alongside open problems in the field.
- Exciting LLM Agents MOOC Hackathon Kicking Off: Berkeley RDI announced the LLM Agents MOOC Hackathon, running from mid-October to mid-December, with over $200,000 in prizes and credits available for participants. Sign up details can be found here.
- The hackathon is open to all, featuring five tracks focused on applications, benchmarks, safety, and more, in conjunction with support from major sponsors like OpenAI and GoogleAI.
- Nicolas Chapados: AI for Enterprises: Nicolas Chapados, Vice-President of Research at ServiceNow Inc., will share insights on advancing generative AI for enterprises during the lecture. His background includes co-founding startups in machine learning before ServiceNow's acquisition of Element AI in 2021.
- The presentation will highlight the significance of frameworks like TapeAgents and address critical issues like security and reliability in AI.
Links mentioned:
- CS 194/294-196 (LLM Agents) - Lecture 7, Nicolas Chapados and Alexandre Drouin: no description found
- Tweet from Dawn Song (@dawnsongtweets): 🎉 Thrilled by the incredible enthusiasm for our LLM Agents MOOC—12K+ registered learners & 5K+ Discord members! 📣 Excited to launch today the LLM Agents MOOC Hackathon, open to all, with $200K+ in p...
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (7 messages):
Workflow understanding for AI agentsAssignment deadlinesLearning resources for auto gen
-
Understanding human workflow enhances AI solutions: A discussion highlighted the importance of understanding the current workflow for tasks when applying AI solutions, suggesting a pivot towards the capabilities and tools available to agents instead.
- It was noted that agents may not need to replicate human tasks directly.
- Article assignment deadline confirmed: A member inquired about the deadline for the Written Article Assignment, receiving confirmation that all assignments are due by December 12, 11:59pm PST.
- This succinctly clarifies submission timelines for all participants.
- Learning Auto Gen courses shared: A member sought resources for learning auto gen, and another member directed them to a specific course on AI Agentic Design Patterns with Autogen.
- This provides a structured learning opportunity for those interested in mastering auto gen.
Link mentioned: AI Agentic Design Patterns with AutoGen - DeepLearning.AI: Use the AutoGen framework to build multi-agent systems with diverse roles and capabilities for implementing complex AI applications.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
Lecture Start TimeYouTube Stream Issues
-
Confirmation of Today's Lecture Start: Members confirmed that the lecture started shortly after some initial uncertainty.
- The latest messages indicated that it just started now, alleviating any confusion.
- YouTube Stream has No Sound: One member reported receiving the YouTube feed but experienced issues with no sound and no movement.
- However, they later updated that the video is now starting, signaling a resolution to their streaming issues.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (4 messages):
Function Calling in LLMsTapeAgents FrameworkAgent DevelopmentModel Distillation Techniques
-
Understanding Function Calling in LLMs: There seems to be confusion regarding how LLMs split tasks into function calls, with a request for a coding example.
- One member clarified that the ongoing discussion pertains to the concept of function calling in LLMs.
- Introducing the TapeAgents Framework: A team from ServiceNow introduced TapeAgents, a new framework aimed at agent development and optimization, which utilizes a structured agent log called a tape.
- The framework enables fine-grained control, step-by-step debugging, resumable sessions and streaming, as outlined in the discussion and linked paper.
- Benefits of Using Tapes for Agents: The tape, as part of the TapeAgents framework, serves as a granular structured log that enhances the control and optimization of agent sessions.
- It was noted that all interactions go through this tape log, providing comprehensive insights into agent performance and configuration.
- Resources for Agent Frameworks: Members shared valuable resources including a GitHub repository related to the TapeAgents framework and a useful thread discussing the paper.
- These resources aim to support the community in exploring advanced agent frameworks and methodologies.
Links mentioned:
- Thread by @DBahdanau on Thread Reader App: @DBahdanau: 🚨 New agent framework! 🚨 My team at @ServiceNowRSRCH is releasing TapeAgents: a holistic framework for agent development and optimization. At its core is the tape: a structured agent log...
- OpenAI Cookbook: Open-source examples and guides for building with the OpenAI API. Browse a collection of snippets, advanced techniques and walkthroughs. Share your own examples and guides.
Torchtune ▷ #general (16 messages🔥):
PyTorch Core IssueError in Distributed TrainingConfig File Format in TorchtuneFlex Performance on GPUsHardware Setup for Training
-
PyTorch Core Issue with Warnings: A user shared a warning that has started appearing, now also triggered on float16 but not on float32, suggesting to test performance impact by using a different kernel.
- There’s speculation that certain lines in the PyTorch source code might be affecting JIT behavior.
- Error Encountered During Distributed Training: One user reported an error while running the
tunecommand with CUDA_VISIBLE_DEVICES specified, stating it stopped without further messages at a certain line in the code.
- After removing the CUDA_VISIBLE_DEVICES specification, the error persisted, suggesting a deeper issue in the configuration or setup.
- Confusion Over Config File Format: It was pointed out that using a
.yamlextension for the configuration file can mislead Torchtune to interpret it incorrectly as a local config.
- This emphasizes the need to verify file naming to avoid unexpected issues during runtime.
- Flex Performance with 800 GPUs: Discussion arose about Flex running well on 3090s and 4090s, with a user mentioning the potential for optimized memory usage on larger GPUs such as A800s.
- The conversation included a mention of faster out-of-memory operations (oom) especially with large head dimensions.
- Hardware Setup for Training: A user confirmed having 8x A800 GPUs, discussing performance issues in that context during the training setup.
- Another user asked if testing could be done with fewer GPUs to troubleshoot the reported error more effectively.
Links mentioned:
- pytorch/aten/src/ATen/native/cudnn/MHA.cpp at main · pytorch/pytorch): Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- (WIP)feat: add gemma2b variants by Optimox · Pull Request #1835 · pytorch/torchtune.): Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) This is related to adding gemma2 support #1813 Changelog...
- Issues · pytorch/pytorch,): Tensors and Dynamic neural networks in Python with strong GPU acceleration - Issues · pytorch/pytorch
Torchtune ▷ #dev (1 messages):
Hermes 2.5.0 ReleaseRecommendations for nightlies
-
Hermes 2.5.0 Launch Sparks Discussions: With the release of Hermes 2.5.0, members discussed whether to continue recommending nightly builds for certain recipes to avoid Out Of Memory (OOM) errors.
- Suggestions to remove nightly recommendations were made to enhance user experience and mitigate potential issues.
- Concerns Over Nightly Builds: A member raised concerns about the usage of nightly builds for recipes, fearing they may lead to system instability and performance issues.
- The discussion highlighted the importance of stable releases over experimental nightly versions to reduce technical difficulties.
LangChain AI ▷ #general (6 messages):
Langchain Open Canvas compatibilityAgent orchestration with LangchainFinal output chain refactoringLangchain 0.3.4 malicious warningLocal hosting for Enterprise applications
-
Langchain Open Canvas seeks compatibility: A member inquired whether Langchain Open Canvas can work with LLM providers beyond Anthropic and OpenAI.
- This reflects ongoing interest in expanding compatibility with different providers.
- Agent orchestration possibilities with Langchain: Another member asked if Langchain could assist with agent orchestration using OpenAI Swarm, or if it requires custom programming.
- Responses indicated that there are libraries available to support this functionality.
- Refactoring output chain for better functionality: A user debated whether to refactor their existing workflow in Langchain or transition to LangGraph for improved functionality.
- Their setup currently involves complex tool usage that outputs JSON responses, prompting the need for a strategic change.
- Concerns over malicious warnings in Langchain 0.3.4: A user reported a malicious warning from PyCharm regarding the dependency in Langchain 0.3.4, citing significant security risks.
- They inquired if anyone else had encountered this issue, expressing concerns over potential false positives.
- Local hosting solutions for enterprise applications: A user sought advice on the best approach for local hosting of inference models for an enterprise application without internet access.
- They considered building an inference container with Flask or FastAPI, while wanting to avoid reinventing the wheel if better solutions exist.
LangChain AI ▷ #share-your-work (2 messages):
NumPy Documentation ImprovementTransition to Consulting
-
Enhanced NumPy Documentation on Floating-Point Precision: A member celebrated their successful contribution to the NumPy library, focusing on improving documentation regarding floating-point precision.
- They added a section explaining nuances of floating-point operations to aid users, especially beginners, in handling small inaccuracies in calculations.
- Experienced Engineer Shifts to Consulting: Another member introduced themselves as a senior software engineer with over 10 years of experience, now transitioning into a consulting role rather than coding.
- They invited others to reach out directly for assistance, showcasing their GitHub profile for further information on their background.
Links mentioned:
- 0xdeity - Overview: Tech Aficionado | Software Architect | Open Source Contributor - 0xdeity
- Update documentation for floating-point precision and determinant calculations by amitsubhashchejara · Pull Request #27602 · numpy/numpy: This pull request updates the documentation related to floating-point precision in NumPy, specifically addressing the issue of incorrect determinant calculations for certain matrices. Added a not...
LangChain AI ▷ #tutorials (1 messages):
Self-AttentionDynamic Contextual Embeddings
-
Exploration of Self-Attention in NLP: A member shared a Medium article detailing the evolution of self-attention mechanisms from static to dynamic contextual embeddings in NLP.
- The article discusses how this transition enhances performance by enabling models to better capture contextual nuances.
- Dynamic Contextual Embeddings Transformation: The article emphasizes the significance of dynamic contextual embeddings in improving model performance and adaptability in NLP tasks.
- It highlights case studies demonstrating effective implementations that have marked improvements over static methods.
OpenAccess AI Collective (axolotl) ▷ #general (2 messages):
Experimental Triton FA supportUser Warning on Flash Attention
-
2.5.0 Brings Experimental Triton FA Support: Version 2.5.0 added experimental Triton Flash Attention (FA) support for gfx1100 through aotriton, when using
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1.- This setting was enabled, but led to a UserWarning regarding Flash Attention support on the Navi31 GPU still being experimental.
- Misinterpretation of Flash Attention Warning: The user received a UserWarning indicating that Flash Attention on the Navi31 was experimental and needed enabling via
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1.
- Initially, they mistook this warning as related to Liger, thus dismissing its significance, as further discussed in a GitHub issue.
Link mentioned: [Feature]: Memory Efficient Flash Attention for gfx1100 (7900xtx) · Issue #16 · ROCm/aotriton: Suggestion Description Started using torchlearn to train models in pytorch using my gfx1100 card but get a warning that 1toch was not compiled with memory efficient flash attention. I see there is ...
OpenAccess AI Collective (axolotl) ▷ #general-help (6 messages):
Instruction-Tuned ModelsDomain-Specific Instruction DataCatastrophic ForgettingRaw Domain DataGPT-4 Generated Instruction Data
-
Leverage Instruction-Tuned Models for Training: A member suggested using an instruction-tuned model like llama-instruct for instruction training, emphasizing its advantages if users don't mind its previous tuning.
- They recommended mixing strategies but acknowledged that experimentation is essential for finding the right balance.
- Concerns on Catastrophic Forgetting: A member raised concerns about whether to use only domain-specific instruction data or mix with general data to avoid catastrophic forgetting.
- The suggestion was to explore various approaches to determine the best method, reflecting the complexities of model training.
- Pretraining vs Instruction Fine-Tuning: Discussion highlighted whether to start with a base model for continued pretraining on raw domain data before instruction fine-tuning, or to use an instruction-tuned model.
- One member suggested leveraging raw data at the beginning if available, as it may provide a stronger foundation.
- Generating Instruction Data from Raw Text: One member expressed their plan to use GPT-4 for generating instruction data from raw text, pointing out potential biases and coverage limitations.
- This method could mitigate the reliance solely on human-created instruction data while acknowledging possible drawbacks.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (2 messages):
Function Calling Model Fine-tuningBenchmarking Custom EndpointsGorilla Project Documentation
-
Finetuned Model for Function Calling: A user shared excitement about discovering the Gorilla project after finetuning a model for function calling and creating their own inference API.
- They inquired about methods to benchmark a custom endpoint and sought documentation regarding the process.
- Instructions for Adding New Models: In response, a member highlighted a README file that provides instructions on how to add new models to the leaderboard.
- This overall documentation supports users in contributing effectively to the Gorilla project.
Link mentioned: gorilla/berkeley-function-call-leaderboard at main · ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
LAION ▷ #resources (1 messages):
Webinar on LLM Best PracticesPrompt Engineering TechniquesPerformance OptimizationRetrieval-Augmented GenerationAnalytics Vidhya Blog Articles
-
Join the Free Webinar on LLMs: A Senior ML Engineer from Meta is hosting a free webinar on best practices for building with LLMs, with nearly 200 signups already.
- You can register for the event by following this link to gain insights on advanced prompt engineering techniques, model selection, and project planning.
- Insights on Prompt Engineering: The webinar will cover advanced prompt engineering techniques helping attendees enhance their skills and learn to make strategic decisions.
- Participants will also gain insights into performance optimization methods that are essential for deploying LLM projects effectively.
- Explore Retrieval-Augmented Generation: You’ll learn about Retrieval-Augmented Generation (RAG) and how it can boost the effectiveness of LLM solutions.
- Fine-tuning will also be discussed as a critical strategy for maximizing the performance of your models.
- Articles Featured on Analytics Vidhya: Participants of the webinar will have their best articles published on Analytics Vidhya’s Blog Space, providing exposure and recognition.
- This opportunity enhances the value of the session for those looking to share their insights with a wider audience.
Link mentioned: Explore the Future of AI with Expert-led Events: Analytics Vidhya is the leading community of Analytics, Data Science and AI professionals. We are building the next generation of AI professionals. Get the latest data science, machine learning, and A...
Mozilla AI ▷ #announcements (1 messages):
AI access challengesCompetition in AIExternal researcher accessBig Tech and AI control
-
Mozilla's Research on AI Access Challenges: Mozilla commissioned two research pieces: 'External Researcher Access to Closed Foundation Models' from AWO and 'Stopping Big Tech From Becoming Big AI' from the Open Markets Institute.
- These reports reveal who controls AI development and outline necessary changes for a fair and open AI ecosystem.
- Blog Post on AI Research Findings: More details about the commissioned research can be found in the blog post here.
- The post emphasizes the implications of the findings on the future landscape of AI and competition among major players.