[AINews] ChatGPT Canvas GA
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Karina Nguyen is all you need.
AI News for 12/9/2024-12/10/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (206 channels, and 5518 messages) for you. Estimated reading time saved (at 200wpm): 644 minutes. You can now tag @smol_ai for AINews discussions!
It's still early innings but already we are ready to call OpenAI's 12 Days of Shipmas a hit. While yesterday's Sora launch is still (as of today) plagued with gated signups to deal with overwhelming demand, ChatGPT Canvas needs no extra GPUs and launched to all free and paid users today with no hiccup.
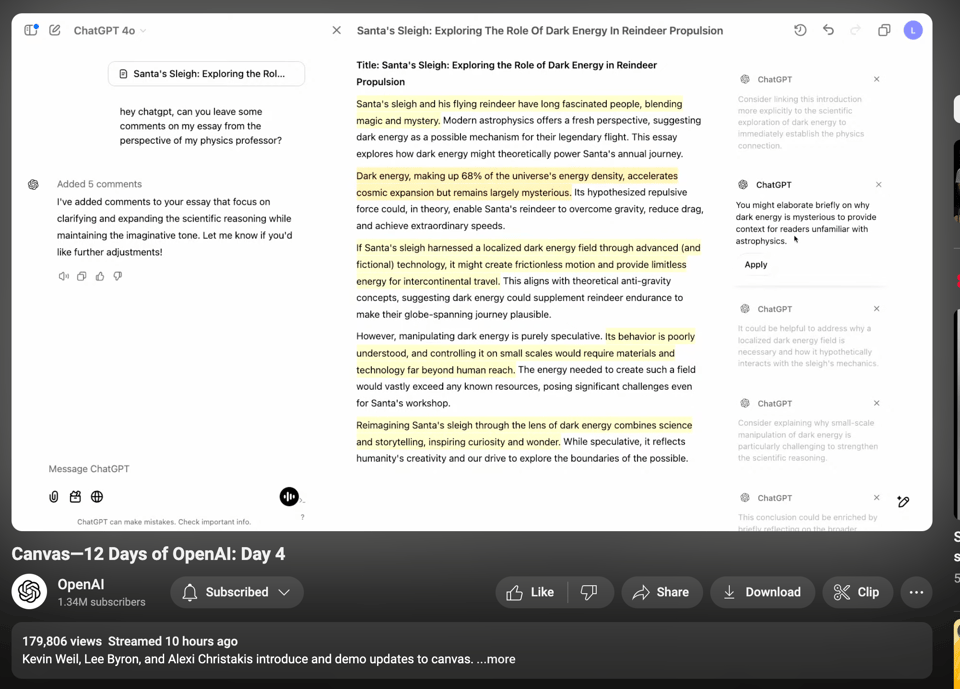
Canvas now effectively supercedes Code Interpreter and is also remarkably Google Docs-like, which further demonstrates the tendency of OpenAI to build Google features faster than Google can build OpenAI.
There's a theory that the jokes ending each episode are a preview of the next one. If this is true, tomorrow's ship will be a doozy.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Codeium / Windsurf Discord
- Eleuther Discord
- Cursor IDE Discord
- aider (Paul Gauthier) Discord
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- OpenAI Discord
- Bolt.new / Stackblitz Discord
- Modular (Mojo 🔥) Discord
- Notebook LM Discord Discord
- LM Studio Discord
- Nous Research AI Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- Axolotl AI Discord
- LLM Agents (Berkeley MOOC) Discord
- LlamaIndex Discord
- Cohere Discord
- Torchtune Discord
- DSPy Discord
- LAION Discord
- OpenInterpreter Discord
- Mozilla AI Discord
- PART 2: Detailed by-Channel summaries and links
- Codeium / Windsurf ▷ #content (1 messages):
- Codeium / Windsurf ▷ #discussion (384 messages🔥🔥):
- Codeium / Windsurf ▷ #windsurf (715 messages🔥🔥🔥):
- Eleuther ▷ #general (43 messages🔥):
- Eleuther ▷ #research (257 messages🔥🔥):
- Eleuther ▷ #lm-thunderdome (231 messages🔥🔥):
- Eleuther ▷ #multimodal-general (1 messages):
- Cursor IDE ▷ #general (331 messages🔥🔥):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (281 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (161 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (85 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (6 messages):
- Unsloth AI (Daniel Han) ▷ #research (4 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (238 messages🔥🔥):
- Perplexity AI ▷ #general (219 messages🔥🔥):
- Perplexity AI ▷ #sharing (8 messages🔥):
- Perplexity AI ▷ #pplx-api (2 messages):
- OpenAI ▷ #annnouncements (1 messages):
- OpenAI ▷ #ai-discussions (149 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (23 messages🔥):
- OpenAI ▷ #prompt-engineering (12 messages🔥):
- OpenAI ▷ #api-discussions (12 messages🔥):
- Bolt.new / Stackblitz ▷ #prompting (27 messages🔥):
- Bolt.new / Stackblitz ▷ #discussions (114 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (45 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (83 messages🔥🔥):
- Notebook LM Discord ▷ #use-cases (43 messages🔥):
- Notebook LM Discord ▷ #general (51 messages🔥):
- LM Studio ▷ #general (78 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (9 messages🔥):
- Nous Research AI ▷ #announcements (1 messages):
- Nous Research AI ▷ #general (61 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (17 messages🔥):
- Nous Research AI ▷ #interesting-links (1 messages):
- Nous Research AI ▷ #reasoning-tasks (5 messages):
- Interconnects (Nathan Lambert) ▷ #events (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (4 messages):
- Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
- Interconnects (Nathan Lambert) ▷ #memes (7 messages):
- Latent Space ▷ #ai-general-chat (44 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Axolotl AI ▷ #general (44 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (25 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (3 messages):
- LlamaIndex ▷ #blog (5 messages):
- LlamaIndex ▷ #general (21 messages🔥):
- Cohere ▷ #discussions (10 messages🔥):
- Cohere ▷ #questions (9 messages🔥):
- Cohere ▷ #api-discussions (2 messages):
- Torchtune ▷ #dev (17 messages🔥):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (13 messages🔥):
- LAION ▷ #general (2 messages):
- LAION ▷ #research (9 messages🔥):
- OpenInterpreter ▷ #general (10 messages🔥):
- Mozilla AI ▷ #announcements (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here's a categorized summary of the key Twitter discussions:
AI Model & Research Updates
- @deepseek_ai announced their V2.5-1210 update with improved performance on MATH-500 (82.8%) and LiveCodebench (34.38%)
- Meta introduced COCONUT (Chain of Continuous Thought), a new paradigm for LLM reasoning using continuous latent space
- @Huggingface released TGI v3 which processes 3x more tokens and runs 13x faster than vLLM on long prompts
Product Launches & Updates
- OpenAI launched Canvas for all users with features like code execution, GPT integration, and improved writing tools
- @cognition_labs released Devin, an AI developer that successfully built a Kubernetes operator with testing environment
- Hyperbolic raised $12M Series A to build an open AI platform with H100 GPU marketplace at $0.99/hour
Industry & Market Analysis
- @AravSrinivas shared US vs Canada per capita GDP comparison with 72,622 impressions
- @sama noted significant underestimation of Sora demand, working on expanding access
- Discussion about AI capabilities and employment impact over next decades
NeurIPS Conference
- Multiple researchers and companies announcing their presence at NeurIPS 2024 in Vancouver
- @GoogleDeepMind hosting demos of GenCast weather forecasting and other AI tools
- Debate scheduled between Jonathan Frankle and Dylan about the future of AI scaling
Memes & Humor
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama 3.3-70B Finetuning: 90K Context on <41GB VRAM
- Llama 3.3 (70B) Finetuning - now with 90K context length and fits on <41GB VRAM. (Score: 360, Comments: 63): Llama 3.3 (70B) can now be fine-tuned to support 90,000 context lengths using Unsloth, which is significantly longer than the 6,900 context lengths supported by Hugging Face + FA2 on an 80GB GPU. This improvement is achieved through gradient checkpointing and Apple's Cut Cross Entropy (CCE) algorithm, and the model fits on 41GB of VRAM. Additionally, Llama 3.1 (8B) can reach 342,000 context lengths using Unsloth, vastly surpassing its native support of 128K context lengths.
- Unsloth uses gradient checkpointing to offload activations to system RAM, saving 10 to 100GB of GPU memory, and Apple's Cut Cross Entropy (CCE) performs cross entropy loss on the GPU, reducing the need for large logits matrices, which further saves memory. This allows models to fit on 41GB of VRAM.
- Users are curious about the rank used in the tests and the potential for multi-GPU support, which is currently unavailable but in development. There's also interest in making Unsloth compatible with Apple devices.
- The Unsloth tool is praised for democratizing fine-tuning capabilities, making advanced techniques accessible to the general public, and potentially reducing costs by allowing the use of smaller 48GB GPUs.
- Hugging Face releases Text Generation Inference TGI v3.0 - 13x faster than vLLM on long prompts 🔥 (Score: 347, Comments: 52): Hugging Face has released Text Generation Inference (TGI) v3.0, which processes 3x more tokens and is 13x faster than vLLM on long prompts, with zero configuration needed. By optimizing memory usage, a single L4 (24GB) can handle 30k tokens on llama 3.1-8B, while vLLM manages only 10k, and the new version reduces reply times on long prompts from 27.5s to 2s. Benchmark details are available for verification.
- TGI v3.0 Performance: Discussions highlight the significant speed improvements of TGI v3.0 over vLLM, particularly in handling long prompts due to the implementation of cached prompt processing. The library can respond almost instantly by keeping the initial conversation data, with a lookup overhead of approximately 5 microseconds.
- Comparison and Usage Scenarios: Users expressed interest in comparisons between TGI v3 and other models like TensorRT-LLM and ExLlamaV2, as well as queries about its performance on short queries and multi-GPU setups. There is also curiosity about TGI's suitability for single versus multi-user scenarios, with some users acknowledging its optimized use for hosting models for multiple users.
- Support and Documentation: Questions arose about the support for consumer-grade RTX cards like the 3090, as current documentation lists only enterprise Nvidia accelerators. Additionally, users are interested in the roadmap for adding features like streaming tool calls and any potential drop in output quality compared to fp16 processing.
Theme 2. DeepSeek V2.5-1210: Final Version and What Next
- deepseek-ai/DeepSeek-V2.5-1210 · Hugging Face (Score: 170, Comments: 11): The post announces the release of DeepSeek V2.5-1210 on Hugging Face, indicating a new version of the AI tool with unspecified improvements. Further details about the release are not provided in the post.
- DeepSeek V2.5-1210 has been confirmed as the final release in the v2.5 series, with a v3 series anticipated in the future. The changelog indicates significant improvements in mathematical performance (from 74.8% to 82.8% on the MATH-500 benchmark) and coding accuracy (from 29.2% to 34.38% on the LiveCodebench benchmark), alongside enhanced user experience for file uploads and webpage summarization.
- There is considerable interest in the R1 model, with users expressing hope that it will be released soon. Some speculate that the current version may have been trained using R1 as a teacher, and others are looking forward to an updated Lite version with a 32B option.
- The community is actively discussing the potential release of a quantized version with exo and has expressed a desire for further updates, including an R1 Lite version.
- DeepSeek-V2.5-1210: The Final Version of the DeepSeek V2.5 (Score: 147, Comments: 36): DeepSeek-V2.5-1210 marks the final version of the DeepSeek V2.5 series, concluding its development after five iterations since its open-source release in May. The team is now focusing on developing the next-generation foundational model, DeepSeek V3.
- Hardware Requirements and Limitations: Utilizing DeepSeek-V2.5 in BF16 format requires significant resources, specifically 80GB*8 GPUs. Users expressed concerns about the lack of software optimization, particularly with the kv-cache, which limits the model's performance on available hardware compared to others like Llama.
- Model Performance and Capabilities: Users noted the model's deep reasoning capabilities but criticized its slow inference speed. Despite this, DeepSeek models are considered high-quality alternatives to other large language models, featuring a Mixture of Experts (MoE) structure with about 22 billion active parameters, allowing reasonable CPU+RAM performance.
- Development and Release Frequency: The DeepSeek team has maintained an impressive release schedule, with almost monthly updates since May, indicating a successful training process. However, the models lack vision understanding and are primarily focused on text due to the founder's preference for research over commercial applications.
Theme 3. InternVL2.5 Released: Top Performance in Vision BM
- InternVL2.5 released (1B to 78B) is hot in X. Can it replace the GPT-4o? What is your experience so far? (Score: 131, Comments: 42): InternVL2.5, with models ranging from 1B to 78B parameters, has been released and is gaining attention on X. The InternVL2.5-78B model is notable for being the first open-source MLLM to achieve over 70% on the MMMU benchmark, matching the performance of leading closed-source models like GPT-4o. You can explore the model through various platforms like InternVL Web, Hugging Face Space, and GitHub.
- Vision Benchmark Discussion: There is a debate about the effectiveness of the InternVL2.5-78B model on vision benchmarks, with some users suggesting that 4o outperforms Sonnet in vision tasks. Concerns were raised about the reliability of benchmarks and the credibility of the model's claims, especially given some questionable Reddit and Hugging Face histories.
- Geopolitical and Educational Context: There is a discussion around the global STEM landscape, particularly comparing the US and China, highlighting China's STEM PhD numbers and educational achievements. A comment references an 11-year-old Chinese child building rockets, sparking a debate about the accuracy and context of such claims.
- Model Availability and Performance: Users appreciate the availability of smaller model versions of InternVL2.5 beyond the 78B parameter model, noting their strong performance and potential for local deployment. The 78B model is noted for its superior performance in Ukrainian and Russian languages compared to other open models.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Google Willow: Quantum Computing's Gargantuan Leap
- Google Willow : Quantum Computing Chip completes task in 5 minutes which takes septillion years to best Supercomputer (Score: 311, Comments: 77): Google introduced the Willow Quantum Computing Chip, achieving a computational speed approximately 10^30 times faster than the fastest supercomputer, Frontier, completing tasks in 5 minutes that would otherwise take septillion years. This is considered the most significant technological release of the year, with more information available in a YouTube video.
- Several commenters, like beermad, express skepticism about the benchmark tests, suggesting they are optimized for quantum computers and lack real-world utility. They argue that these tests are designed to favor quantum chips over classical computers without demonstrating practical applications.
- huffalump1 highlights the significance of Google's breakthrough in error correction, which surpasses the physical limit of a qubit. This is crucial for quantum computing, as error correction is a major challenge in the field.
- The discussion touches on the potential financial impact, with bartturner noting a 4% increase in GOOG shares in pre-market trading, suggesting that investors recognize the potential value of this technological advancement.
- OpenAI Sora vs. Open Source Alternatives - Hunyuan (pictured) + Mochi & LTX (Score: 204, Comments: 56): The post discusses OpenAI Sora in comparison with open-source alternatives like Hunyuan, Mochi, and LTX in the context of quantum computing vs. classical supercomputer performance. Without additional details from the video, the specifics of these comparisons or performance metrics are not provided.
- Commenters discuss the comparison between OpenAI Sora and open-source models like HunyuanVideo, noting that open-source options are competitive and often more accessible. HunyuanVideo is highlighted for its potential and ability to run on consumer GPUs, with some users expressing a preference for open-source due to its uncensored nature.
- Sora's performance is praised for its quality in some areas, such as detailed imagery and landscapes, but it faces criticism for limited accessibility and issues with physical interactions. Users note that HunyuanVideo performs better in some scenarios, and there is interest in further comparisons with models like TemporalPromptEngine.
- There is a call for the West to improve their open-source AI efforts, as Chinese open models are seen as impressive for their quality and ability to operate on consumer hardware. The sentiment reflects a desire for more open and accessible AI development in Western countries.
- I foresee advertisers and retailers getting sued very soon. This was a legit ad for me. (Score: 177, Comments: 50): The post discusses an advertisement that uses a cartoon-style illustration with a controversial theme to capture attention, potentially leading to legal issues for advertisers and retailers. The use of humor in the ad, involving a sad-looking cat and bleach, raises ethical concerns and highlights the fine line between creative marketing and misleading or offensive content.
- Commenters express skepticism and humor regarding the ad's intent, with SomeRandomName13 sarcastically suggesting the ad's absurdity in using bleach on a cat's eyes to solve a problem, highlighting the ad's controversial nature.
- j-rojas and others suggest the ad's design is intentionally absurd to act as clickbait, sparking curiosity due to its extreme ridiculousness.
- chrismcelroyseo warns of the dangers of mixing bleach and ammonia, providing a link to an article about the toxic effects, which underscores the potential real-world risks associated with the ad's content.
Theme 2. Gemini 1.5 Outperforms Llama 2 70B: Industry Reactions
- Let’s be honest, unlike ChatGPT, 97% of us won’t care about or be using Sora a month from now. I’ve tried every video generator and music generator, cool for like a week, then meh. Good chance you will forget about sora after your 50 monthly generation is up. (Score: 302, Comments: 113): Gemini 1.5 is discussed as surpassing Llama 2 70B, but the author expresses skepticism about the lasting impact of Sora. They argue that, similar to other AI tools like video and music generators, Sora might be initially intriguing but will likely be forgotten by most users after limited use.
- Users debated the long-term utility of Sora in professional settings, with some arguing that studios will adopt it to cut costs, while others see it as an overpriced novelty with limited use due to its constraints like the 5-second, 720p output. Sora was compared to past tech trends that initially garnered interest but faded, similar to other AI tools like Suno and DALL-E 3 which had brief usage spikes before declining.
- Some commenters emphasized the importance of AI tools in transforming workflows, citing examples in video-related businesses where AI has significantly impacted operations over the last six months. Despite skepticism, others pointed out that AI tools continue to be valuable for specific professional tasks, even if they don't have universal appeal.
- The discussion also touched on the broader applicability of AI tools beyond initial hype, with parallels drawn to historical tech adoption patterns like the Apple Vision and early web browsers. The consensus was that while tools like Sora may not be universally essential, they hold significant value for niche markets and specific professional uses.
- AI art being sold at an art gallery? (Score: 285, Comments: 181): The author describes attending an art gallery event where they suspect two paintings, priced between 5k and 15k euros, might be AI-generated due to peculiarities in the artwork, such as a crooked hand and an illogical bag handle. They contacted the organizer to investigate the possibility of AI involvement, awaiting further information.
- Many commenters suspect the paintings are AI-generated due to peculiarities like malformed fingers, nonsensical bag handles, and odd room layouts. Fingers and dog features are frequently cited as AI telltales, with some users noting the absurdity of these being part of a human artist's style.
- SitDownKawada provided links to the paintings on sale for around €4k and questioned the authenticity of the artist's online presence, which appears AI-generated. The artist's Instagram and other social media accounts were scrutinized for their recent activity and prolific output.
- Discussions also touched on the broader implications of AI in art, with some users pondering if AI-generated elements in hand-painted works should still be considered AI art. There is a debate on whether the medium or the creative process holds more value, especially as AI becomes more indistinguishable from human artistry.
- Do you use ChatGPT or any other AI Search for Product Recommendations or Finding New Products? If Yes, please mention what kind of product recommendations you trust AI (Score: 255, Comments: 18): Gemini 1.5 is being discussed for its potential in providing AI-driven product recommendations. The community is encouraged to share experiences on whether they trust AI recommendations for discovering new products, with a focus on specific types of products that are more reliable when suggested by AI tools like ChatGPT.
- AI's role in product discovery is highlighted by a user finding a game called "Vagrus - The Riven Realms" through AI recommendations, which they had not heard of before but found impressive. This underscores AI's potential in suggesting lesser-known products that might align with user interests.
- Trust in AI recommendations tends to be higher for products with hard specifications, such as computer hardware and electronics. Users find AI particularly useful for comparing technical details, which would otherwise require extensive manual research, as exemplified by a user who used AI to compare routers.
Theme 3. Sora Video Generator: Redefining AI Creativity
- Cortana made with Sora (Score: 383, Comments: 42): Sora is highlighted as a tool enhancing AI video generation techniques, as demonstrated in a video linked in the post. The video showcases a creation named Cortana, though specific details about the video content or the techniques used are not provided in the text.
- Discussions mention Sora as a tool for generating videos instead of text, with some users questioning if access to Sora is currently available to the public.
- Comments include humorous and satirical takes on the appearance of Cortana, with users referencing features like "jiggle physics" and making light-hearted remarks about her design.
- Some comments focus on the technical aspects and visual design, with requests for additional features like color and skin, and jokes about "wire management" for Cortana.
- Pigs Tango in the Night (Score: 373, Comments: 61): The author created a video using Sora to accompany a humorous song made by their brother in Suno. They ran out of credits during the process but consider it a successful initial experiment with the technology, with plans to possibly post another video in a month.
- Sora's accessibility and subscription: Users discussed accessibility of Sora via a $20 subscription, which allows creating 50 five-second clips per month, and compared its value to other generators. Users appreciated this feature but noted limitations in credits, with one user running out of credits for the month.
- Prompt understanding and remix feature: Discussion on how Sora interprets prompts revealed that users describe each scene they want, and use the "remix" feature to make adjustments if clips don't meet expectations. One user mentioned running out of credits due to extensive remixing.
- Sora's performance and user feedback: Feedback highlighted Sora's capability in generating dance moves, with some users praising its output compared to other models. However, there were mixed reactions regarding the content's relevance, such as expectations of tango music which were unmet.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: AI Model Advancements and New Releases
- Gated DeltaNet Steals the Spotlight: Gated DeltaNet outperforms models like Mamba2 in long-context tasks, leveraging gated memory control and delta updates to address limitations in standard transformers. This advancement significantly improves task accuracy and efficiency in complex language modeling scenarios.
- Llama 3.3 Breaks Context Barriers: Unsloth now supports fine-tuning Llama 3.3 with context lengths up to 89,000 tokens on an 80GB GPU, enhancing efficiency by reducing VRAM usage by 70%. This allows 2-3 minutes per training step on A100 GPUs, vastly exceeding previous capabilities.
- DeepSeek V2.5 Drops the 'Grand Finale': DeepSeek announces the release of DeepSeek-V2.5-1210, adding live Internet Search to their chat platform, providing users with real-time answers at their fingertips.
Theme 2: AI Tools and User Experience Challenges
- Cursor Takes a Coffee Break: Users report persistent slow requests in Cursor, disrupting productivity despite recent updates to Composer and Agent modes. Both modes are still underperforming, negatively impacting coding workflows.
- Bolt Hits a Speed Bump: Bolt.new users face confusion over token allocations when subscriptions end, with tokens not stacking and resets every 30 days. Issues with image uploads and 'No Preview Available' errors further frustrate users, leading to discussions about token management strategies.
- Linting Nightmares in Cursor: Cursor's linting features are triggering without actual errors, causing users to burn through their fast message quotas unnecessarily. Frequent false positives reinforce the sentiment that Cursor's features are still in beta and need refinement.
Theme 3: AI Integration in Software Development
- Mojo Destroys Old Habits with New Keyword: Introducing the
destroykeyword in Mojo enforces stricter memory management within linear types, enhancing safety but sparking debates about complexity for newcomers. This distinction from Python'sdelaims to improve programming practices. - Aider Multiplies Productivity with Multiple Instances: Engineers are running up to 20 Aider instances simultaneously to handle extensive project workflows, showcasing the tool's scalability. Users explore command execution across instances to optimize coding approaches for large-scale developments.
- LangChain and Aider Make a Dynamic Duo: Aider's integration with LangChain's ReAct loop enhances project management tasks, with users noting superior results compared to other tools. This collaboration improves AI-assisted coding workflows and efficiency.
Theme 4: Community and Open Source Initiatives in AI
- vLLM Joins the PyTorch Party: vLLM officially integrates into the PyTorch ecosystem, enhancing high-throughput, memory-efficient inference for large language models. This move is expected to boost AI innovation and accessibility for developers.
- Grassroots Science Goes Multilingual: A new initiative aims to develop multilingual LLMs by February 2025 through open-source efforts and community collaboration. The project seeks to engage grassroots communities in multilingual research using open-source tools.
- State of AI Agents 2024 Report Unveiled: Ahmad Awais releases an in-depth report analyzing 184 billion tokens and feedback from 4,000 builders, highlighting trends and future directions in AI agents.
Theme 5: AI in Creative Content and User Interaction
- NotebookLM Hits the High Notes in Podcasting: Users share a tutorial titled "NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!)" offering exclusive prompts to enhance podcast creativity. Experimenting with features like fact-checkers improves dialogue quality in AI-generated podcasts.
- WaveForms AI Adds Emotion to the Mix: WaveForms AI launches, aiming to solve the Speech Turing Test by integrating Emotional Intelligence into AI systems. This advancement strives to enhance human-AI interactions with more natural and expressive communication.
- Sora's Mixed Debut Leaves Users Guessing: OpenAI's Sora garners skepticism due to five-second video outputs and questions about content quality. Users compare it unfavorably with models like Claude, Leonardo, and Ideogram, leading some to prefer alternative solutions.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Windsurf AI Launches Merch Giveaway: Windsurf AI kicked off their first merch giveaway on Twitter, inviting users to share their creations for a chance to win a care package.
- The campaign leverages the hashtag #WindsurfGiveaway to track submissions and boost community engagement.
- Ongoing Credit System Flaws: Users report that purchased credits often fail to appear in their accounts, causing widespread frustration and an influx of support tickets.
- Despite team assurances, the lack of timely support responses continues to disappoint the user base.
- Confusion Over Windsurf's Pricing Model: There are rising concerns about Windsurf's pricing, especially regarding the high limits on flow and regular credits relative to the features offered.
- Users are advocating for a more sustainable model, including the introduction of a rollover system for unused credits.
- Performance Drops in Windsurf IDE: Recent updates have led to criticisms of the Windsurf IDE, with users citing increased bugs and decreased efficiency.
- Comparisons with competitors like Cline reveal a preference for Cline's superior functionality and reliability.
- Cline Outperforms Windsurf in Coding Tasks: Cline is being favored over Windsurf for certain coding tasks, offering better prompt responses despite slower performance in some areas.
- Cline's ability to generate specific coding outputs without errors has been particularly praised by the community.
Eleuther Discord
- Reproducibility Challenges in LLMs: Discussions highlighted reproducibility concerns in large language models, particularly in high-stakes applications like medical systems, emphasizing the complexities beyond classic software development. Members debated the nuances of recreating LLMs and the importance of reliable benchmarks.
- Participants referenced the HumanEval Benchmark PR pending review, which aims to enhance evaluation standards by integrating pass@k metrics from the HF evaluate module.
- Coconut Architecture vs. Universal Transformers: Coconut Architecture introduces a novel approach by feeding back the final hidden state post-
token as a new token, altering the KV cache with each iteration. This contrasts with Universal Transformers, which typically maintain a static KV cache across repetitions. - The method's potential resemblance to UTs under specific conditions was discussed, particularly in scenarios involving shared KV caches and state history management, highlighting opportunities for performance optimization.
- Gated DeltaNet Boosts Long-Context Performance: Gated DeltaNet has shown superior performance in long-context tasks compared to models like Mamba2 and previous DeltaNet versions, leveraging gated memory control and delta updates. This advancement addresses limitations in standard transformers regarding long-term dependencies.
- Benchmark results were cited, demonstrating significant improvements in task accuracy and efficiency, positioning Gated DeltaNet as a competitive architecture in complex language modeling scenarios.
- Batch Size Impacts GSM8k Evaluation Accuracy: Evaluations on the GSM8k benchmark revealed that a batch size of 1 achieved the highest accuracy of 85.52%, whereas larger batch sizes resulted in notable performance declines. This discrepancy is potentially linked to padding or attention mechanism implementations.
- Members are investigating the underlying causes, considering adjustments to padding strategies and model configurations to mitigate the adverse effects of increased batch sizes on evaluation metrics.
- Attention Masking Issues in RWKV and Transformers: Concerns were raised regarding RWKV model implementations, specifically related to attention masking and left padding, which may adversely affect evaluation outcomes. Additionally, using the SDPA attention implementation in multi-GPU environments was flagged for potential performance inconsistencies.
- Participants emphasized the necessity for careful configuration and potential exploration of alternative attention backends to ensure reliable model performance across different hardware setups.
Cursor IDE Discord
- Cursor Slows to a Crawl: Multiple users report persistent slow requests in Cursor, disrupting their productivity despite recent updates to Composer and Agent modes.
- Users feel that both Composer and Agent modes are still underperforming, negatively impacting their coding workflows.
- AI Model Face-Off: Gemini, Claude, Qwen: Claude is favored by many users for superior performance in coding tasks compared to Gemini and Qwen.
- While Gemini shows potential in some tests, inconsistent quality has led to developer frustration.
- Agent Mode File Handling Confusion: Questions arise about whether agents in Cursor's Agent mode access file contents directly or merely suggest reading them.
- This uncertainty highlights ongoing concerns regarding the functionality and reliability of Cursor's agent features.
- AI Praises User's Code Structure: A user shared feedback where AI commended their code structure as professional despite the user's lack of experience.
- This showcases the advanced capabilities of current AI in assessing development practices accurately.
- Linting Triggers Frustrate Users: Cursor's linting features are triggering without actual errors, causing frustration among users who believe their fast message quota is being misused.
- Frequent false positives reinforce the sentiment that Cursor's features are still in beta and need refinement.
aider (Paul Gauthier) Discord
- Aider v0.68.0 Unveils Enhanced Features: The latest Aider v0.68.0 release introduces copy-paste mode and the
/copy-contextcommand, significantly improving user interactions with LLM web chat UIs.- Enhanced API key management allows users to set keys for OpenAI and Anthropic via
--openai-api-keyand--anthropic-api-keyswitches, streamlining environment configuration through a YAML config file.
- Enhanced API key management allows users to set keys for OpenAI and Anthropic via
- Gemini Models Exhibit Varied Performance: Users report that Gemini models offer improved context handling but face limitations when editing large files, sparking discussions on performance benchmarks.
- There are calls to run comparative analyses with other models to better understand architectural capabilities, as highlighted in DeepSeek's update.
- Aider Seamlessly Integrates with LangChain: Aider's integration with LangChain's ReAct loop enhances project management tasks, with users noting superior results compared to other tools.
- Further testing and potential collaborations on this integration could provide deeper insights into AI-assisted coding workflows.
- Managing Multiple Aider Instances for Complex Workflows: Engineers are running up to 20 Aider instances simultaneously to handle extensive project workflows, demonstrating the tool's scalability.
- Users are exploring command execution across instances to optimize coding approaches for large-scale developments.
- Community Shares Aider Tutorials and Resources: Members appreciate tutorials and resources shared by the community, fostering a collaborative learning environment.
- Conversations emphasize enhancing the learning experience through shared knowledge and video content, supporting skill advancement among AI Engineers.
Unsloth AI (Daniel Han) Discord
- Llama 3.3 Achieves Ultra Long Context Lengths: Unsloth now supports fine-tuning the Llama 3.3 model with a context length of up to 89,000 tokens on an 80GB GPU, significantly enhancing its capability compared to previous versions.
- This improvement allows users to perform 2-3 minutes per training step on A100 GPUs while utilizing 70% less VRAM, as highlighted in Unsloth's latest update.
- APOLLO Optimizer Reduces LLM Training Memory: The APOLLO optimizer introduces an approach that approximates learning rate scaling to mitigate the memory-intensive nature of training large language models with AdamW.
- According to the APOLLO paper, this method aims to maintain competitive performance while decreasing optimizer memory overhead.
- QTIP Enhances Post-Training Quantization for LLMs: QTIP employs trellis coded quantization to optimize high-dimensional quantization, improving both the memory footprint and inference throughput of large language models.
- The QTIP method enables effective fine-tuning by overcoming limitations associated with previous vector quantization techniques.
- Fine-tuning Qwen Models for OCR Tasks: There is growing interest in fine-tuning Qwen2-VL models specifically for OCR tasks, aiming to enhance information extraction from documents like passports.
- Users are confident in this approach's effectiveness, leveraging Qwen's robust capabilities to address specialized OCR challenges.
- Awesome RAG Project Expands RAG and Langchain Integration: The Awesome RAG GitHub project focuses on enhancing RAG, VectorDB, embeddings, LlamaIndex, and Langchain, inviting community contributions.
- This repository serves as a central hub for resources and tools aimed at advancing retrieval-augmented generation techniques.
Stability.ai (Stable Diffusion) Discord
- Image Enhancement vs AI Tools: Members debated whether Stable Diffusion can improve images without altering core content, suggesting traditional editing tools like Photoshop for such tasks.
- Some highlighted the need for skills in color grading and lighting for professional results, indicating that AI may add noise rather than refine.
- Llama 3.2-Vision Model in Local Deployment: The Llama 3.2-Vision model was mentioned as a viable local option for image classification and analysis, supported by software like KoboldCPP.
- Members noted that local models could run on consumer GPUs and emphasized that online services often require users to relinquish rights to their data.
- Memory Management in Automatic1111 WebUI: There was a discussion on memory management issues affecting image generation in Automatic1111 WebUI, particularly with batch sizes and VRAM usage.
- Members suggested that larger batches led to out-of-memory errors, potentially due to inefficiencies in how prompts are stored in the system.
- Challenges in Image Metadata and Tagging: Participants discussed the challenge of extracting tags or descriptions from images, with suggestions including using metadata readers or AI models for classification.
- Concerns were raised about how classification methods could miss certain details, with some advocating for the use of specific tags like those found on imageboards.
- Copyright and Data Rights in AI Image Services: A warning was shared about using online services for AI image generation, highlighting that such services often claim extensive rights over user-generated content.
- Members encouraged local model usage to maintain clearer ownership and control over created works, contrasting it with the broad licensing practices of web-based services.
Perplexity AI Discord
- Perplexity AI image generation issues: Users report that the 'Generate Image' feature in Perplexity AI is often hidden or unresponsive depending on device orientation, hindering the image generation process.
- One user resolved the issue by switching their device to landscape mode, which successfully revealed the 'Generate Image' feature.
- Claude vs GPT performance in Perplexity: Claude models are recognized for their writing capabilities, but discussions indicate they may underperform within Perplexity AI compared to their official platforms.
- Pro users find the paid Claude versions more advantageous, citing enhanced features and improved functionality.
- Custom GPTs in Perplexity: Custom GPTs in Perplexity allow users to modify personality traits and guidance settings, optimizing user interactions and task management.
- A participant expressed interest in utilizing custom GPTs for organizing thoughts and developing project ideas.
- OpenAI Sora launch: OpenAI's Sora has been officially released, generating excitement within the AI community regarding its new capabilities.
- A member shared a YouTube video detailing Sora's features and potential applications.
- Perplexity Pro features: Perplexity Pro plan offers extensive features over the free version, enhancing research and coding capabilities for subscribers.
- Members discussed using referral codes for discounts, showing interest in the subscription's advanced functionalities.
OpenAI Discord
- Sora Generation Skepticism and AI Model Comparisons: Users expressed doubts about Sora's content quality, questioning if it relies on stock footage, while comparing its performance to models like Claude, O1, Leonardo, and Ideogram for ease of use and output quality.
- Some prefer O1 for specific tasks, noting that Leonardo and Ideogram offer superior usability, whereas Sora's limitation of five-second video generation was highlighted as a constraint for substantial content creation.
- Custom GPTs Continuity and OpenAI Model Fine-Tuning Challenges: Custom GPTs lose tool connections upon updates, prompting members to synthesize continuity by retrieving key summaries from existing GPTs, while addressing ongoing management needs.
- Challenges in fine-tuning OpenAI models were discussed, with users encountering generic responses post fine-tuning in Node.js environments and seeking assistance with their training JSONL files for effective model customization.
- Optimizing Nested Code Blocks in Prompt Engineering: Participants shared techniques for managing nested code blocks in ChatGPT, emphasizing the use of double backticks to ensure proper rendering of nested structures.
- Examples included YAML and Python code snippets demonstrating the effectiveness of internal double backticks in maintaining the integrity and readability of nested code blocks.
- AI Capabilities Expectations and User Feedback Insights: Discussions focused on the future potential of AI models to dynamically generate user interfaces and adapt responses without explicit instructions, aiming for seamless user interactions.
- Skepticism was raised regarding the practicality of fully AI-driven interactions, with concerns about user confusion and usability, alongside feedback emphasizing the need for more tangible advancements in AI functionalities.
Bolt.new / Stackblitz Discord
- Token Twists After Subscriptions End: Users report confusion over token allocations when their subscription ends, with some tokens not stacking and Pro plan tokens resetting every 30 days. For billing issues, contacting support is recommended.
- A member noted that tokens do not stack, and this reset policy has sparked discussions about token management strategies.
- Payment Gateway Integrates with Bolt?: Users are exploring payment gateway integrations with platforms like Payfast, PayStack, and questioning if it parallels Stripe's integration process. No definitive solutions were provided.
- One user suggested that separating dashboard features might enhance functionality for larger projects.
- Bolt Lacks Multi-LLM Support: A user inquired about leveraging multiple LLMs simultaneously within Bolt for complex projects, but another member confirmed that this feature is not currently available.
- Participants discussed methods to enhance productivity and manage larger codebases without native multi-LLM support.
- Local Images Fail in Bolt Uploads: Issues were raised about local images not displaying correctly in Bolt, leading to frustrations over token usage without successful uploads. Suggestions included using external services for image uploads.
- A guide was shared to correctly integrate image upload functionality within Bolt applications.
- 'No Preview Available' Error Strikes Bolt Users: Some users encounter a 'No Preview Available' error when projects fail to load after modifications, prompting the idea to create dedicated discussion topics for detailed troubleshooting.
- One member outlined steps like reloading projects and focusing on error messages to resolve the issue effectively.
Modular (Mojo 🔥) Discord
- Introducing Mojo's 'destroy' Keyword: Discussions emphasized the necessity of a new
destroykeyword in Mojo, distinguishing it from Python'sdelby enforcing stricter usage within linear types to enhance memory management safety. Ownership and borrowing | Modular Docs.- Some members highlighted that mandating
destroycould complicate the learning curve for newcomers transitioning from Python, emphasizing the need for clarity in documentation.
- Some members highlighted that mandating
- Optimizing Memory Management in Multi-Paxos: Multi-Paxos implementations now utilize statically allocated structures to comply with no-heap-allocation requirements, supporting pipelined operations essential for high performance. GitHub - modularml/max.
- Critiques underscored the necessity for comprehensive handling of promises and leader elections to ensure the consensus algorithm's robustness.
- Clarifying Ownership Semantics in Mojo: Conversations about ownership semantics in Mojo demanded clarity on destructor handling, especially when contrasting default behaviors for copy and move constructors. Ownership and borrowing | Modular Docs.
- Topics like
__del__(destructor) were flagged as potentially confusing for those coming from languages with automatic memory management, stressing the need for consistent syntax.
- Topics like
- Addressing Network Interrupts Impact on Model Weights: A discussion revealed that network interrupts could cause models to use incorrect weights due to validation deficiencies, resulting in data corruption. Checksums have been incorporated into the downloading process to improve reliability.
- Sample outputs from interrupted scenarios showcased bizarre data corruption, underscoring the effectiveness of the new checksum measures.
- Enhancing MAX Graph with Hugging Face Integration: Integration with
huggingface_hubnow enables automatic restoration of interrupted downloads, boosting system robustness and reliability. Hugging Face Integration.- This enhancement follows previous issues with large weight corruptions, leveraging Hugging Face to optimize MAX Graph pipelines performance.
Notebook LM Discord Discord
- NotebookLM Expands Podcast Functionality: A member shared a YouTube tutorial titled "NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!)" that offers exclusive prompts to enhance podcast creativity.
- Users also explored adding a fact-checker to AI-generated podcasts, aiming to improve dialogue quality and ensure accuracy during a 90-minute show.
- Limited Source Utilization in NotebookLM: A user expressed frustration that NotebookLM only processes 5-6 sources when 15 sources are needed for a paper, highlighting a limitation in source diversity.
- Community members advised setting source limits during queries to ensure a broader range of references, addressing the issue of source scarcity.
- Enhanced Language Support Requested in NotebookLM: Users inquired about changing the language settings to English in NotebookLM, citing urgency due to upcoming exams.
- Discussions included methods such as adjusting browser settings and refreshing the NotebookLM page to achieve the desired language, with requests for future support in languages like French and German.
- Challenges in Sharing Notebooks with NotebookLM: Users reported difficulties when sharing notebooks using 'copy link,' as recipients viewed a blank page unless added as viewers first.
- Clarifications were provided on the necessary steps to successfully share notebooks, ensuring proper access permissions for collaborators.
LM Studio Discord
- Manual Updates for LM Studio: Users highlighted that LM Studio does not automatically update to newer versions like 0.3.x, necessitating manual updates to maintain compatibility with the latest models.
- A manual update approach was recommended to ensure seamless integration with updated features and models.
- Tailscale Integration Enhances Accessibility: Configuring LM Studio with Tailscale using the device's MagicDNS name improved accessibility and resolved previous connection issues.
- This method streamlined network configurations, making LM Studio more reliable for users.
- Model Compatibility Challenges: Discussions emerged around compatibility issues with models like LLAMA-3_8B_Unaligned, suggesting potential breaks due to recent updates.
- Users speculated that the LLAMA-3_8B_Unaligned model might be non-functional following the latest changes.
- Optimizing GPU Cooling Solutions: Members praised their robust GPU cooling setups, emphasizing that shared VRAM can slow performance and recommending limiting GPU load for optimal efficiency.
- Techniques such as modifying batch sizes and context lengths were shared to enhance GPU processing and resource management.
- Alphacool Reservoirs Compatible with D5 Pumps: Alphacool provides reservoirs that accommodate D5 pumps, as noted by users adjusting their setups to fit hardware requirements.
- One user shared a link to the Alphacool reservoir they selected for their build.
Nous Research AI Discord
- VLM Fine-tuning Faces Challenges: Members discussed the difficulties in fine-tuning VLM models like Llama Vision, noting that Hugging Face (hf) doesn't provide robust support for these tasks.
- They recommended using Unsloth and referenced the AnyModal GitHub project to enhance multimodal framework adjustments.
- Breakthroughs in Long-Term Memory Pathways: An article was shared about neuroscientists at the Max Planck Florida Institute for Neuroscience discovering new pathways for long-term memory formation, bypassing standard short-term processes (read more).
- The community explored how manipulating these memory creation pathways could improve AI cognitive models.
- Crafting a Security Agent with OpenAI API: A user outlined their method for building a security agent using the OpenAI API, detailing steps like creating a Tool class and implementing a task completion loop.
- Other members noted that scaling to advanced architectures, such as multi-agent systems and ReAct strategies, introduces significant complexity.
- Exploring ReAct Agent Strategies: Discussions focused on various ReAct agent strategies to enable agents to reason and interact dynamically with their environments.
- Members considered the potential of using agent outputs as user inputs to enhance interaction workflows.
- Insights from Meta's Thinking LLMs Paper: A member reviewed Meta's Thinking LLMs paper, highlighting its approach for LLMs to list internal thoughts and evaluate responses before finalizing answers.
- They showcased an example where an LLM tends to 'overthink' during answer generation, sparking discussions on optimizing reasoning processes (read more).
Interconnects (Nathan Lambert) Discord
- DeepSeek V2.5 Launchs Grand Finale: DeepSeek announced the release of DeepSeek-V2.5-1210, referred to as the 'Grand Finale', sparking enthusiasm among community members who had been anticipating this update.
- Members discussed the launch with excitement, noting the significance of the new version and its impact on DeepSeek's capabilities.
- Internet Search Feature Live on DeepSeek: DeepSeek introduced the Internet Search feature, now available on their chat platform, allowing users to obtain real-time answers by toggling the feature.
- Community members welcomed the new feature, expressing optimism about its potential to enhance user experience and provide immediate search results.
- DeepSeek License Allows Synthetic Data: A discussion emerged where a member inquired if DeepSeek's current license permits synthetic data generation, showing interest in licensing terms.
- Another member confirmed that synthetic data generation is allowed under the existing license, though it is not widely practiced, prompting further curiosity about OLMo testing.
- vLLM Integrates with PyTorch Ecosystem: The vLLM project officially joined the PyTorch ecosystem to enhance high-throughput, memory-efficient inference for large language models.
- Leveraging the PagedAttention algorithm, vLLM continues to evolve with new features like pipeline parallelism and speculative decoding.
- Fchollet Clarifies Scaling Law Position: Fchollet addressed misconceptions about his stance on scaling laws in AI through a tweet, emphasizing that he does not oppose scaling but critiques over-reliance on larger models.
- He advocated for shifting focus from whether LLMs can reason to their ability to adapt to novelty, proposing a mathematical definition to support this view.
Latent Space Discord
- WaveForms AI Launch Introduces Emotional Audio LLM: Announced by WaveForms AI, the company aims to solve the Speech Turing Test and integrate Emotional Intelligence into AI systems.
- This launch aligns with the trend of enhancing AI's emotional understanding capabilities to improve human-AI interactions.
- vLLM Joins PyTorch Ecosystem: vLLM Project announced its integration into the PyTorch ecosystem, ensuring seamless compatibility and performance optimization for developers.
- This move is expected to enhance AI innovation and make AI tools more accessible to the developer community.
- Devin Now Generally Available at Cognition: Cognition has made Devin publicly available starting at $500/month, offering benefits like unlimited seats and various integrations.
- Devin is designed to assist engineering teams with tasks such as debugging, creating PRs, and performing code refactors efficiently.
- Sora Launch Featured in Latest Podcast: The latest podcast episode includes a 7-hour deep dive on OpenAI's Sora, featuring insights from Bill Peeb.
- Listeners can access the episode here for an extensive overview of the Sora launch.
- State of AI Agents 2024 Report Released: Ahmad Awais introduced the 'State of AI Agents 2024' report, analyzing 184 billion tokens and feedback from 4K builders to highlight trends in AI agents.
- These insights are critical for understanding the trajectory and evolution of AI agent technologies in the current landscape.
Axolotl AI Discord
- Torch Compile: Speed vs Memory: Members discussed their experiences with torch.compile, noting minimal speed improvements and increased memory usage.
- One member remarked, 'it could just be me problem tho.'
- Reward Models in Online RL: The discussion concluded that in online RL, the reward model is always a distinct model used for scoring, and it remains frozen during real model training.
- Members explored the implications of having a reward model, highlighting its separation from the main training process.
- KTO Model's Performance Claims: Kaltcit praised the KTO model's potential to exceed original dataset criteria, claiming enhanced robustness.
- However, members expressed the need for confirmation that KTO indeed improves over accepted data.
- Corroboration of KTO Findings: Kaltcit mentioned that Kalo corroborated the KTO paper findings but noted the lack of widespread quantitative research among finetuners.
- Nanobitz observed that much of this work may occur within organizations that don't widely share their findings.
- Axolotl Reward Model Integration: An inquiry was made about integrating a reward model for scoring in Axolotl, emphasizing experimentation beyond existing datasets.
- Kaltcit indicated that the current KTO setup might suffice for maximizing answers beyond original advantages.
LLM Agents (Berkeley MOOC) Discord
- Function Calling in LLMs: A member shared the function calling documentation, explaining that it utilizes function descriptions and signatures to set parameters based on prompts.
- It was suggested that models are trained on numerous examples to enhance generalization.
- Important Papers in Tool Learning: A member highlighted several key papers, including arXiv:2305.16504 and ToolBench on GitHub, to advance tool learning for LLMs.
- Another paper, Tool Learning with Foundation Models, was noted as potentially significant in the discourse.
LlamaIndex Discord
- LlamaParse Auto Mode Optimizes Costs: LlamaParse introduces Auto Mode, which parses documents in a standard, cheaper mode while selectively upgrading to Premium mode based on user-defined triggers. More details can be found here.
- A video walkthrough of LlamaParse Auto Mode is available here, reminding users to update their browsers for compatibility.
- Enhanced JSON Parsing with LlamaParse: LlamaParse's JSON mode provides detailed parsing of complex documents, extracting images, text blocks, headings, and tables. For additional information, refer to this link.
- This feature enhances control and capability in handling structured data extraction.
- End-to-End Invoice Processing Agent Developed: The team is exploring innovative document agent workflows that extend beyond traditional tasks to automate complex processes, including an end-to-end invoice processing agent aimed at extracting information from invoices and matching it with vendors. Keep an eye on the developments here.
- This promising workflow automation tool is set to streamline invoice management.
- Cohere Rerank 3.5 Now Available in Bedrock: Cohere Rerank 3.5 is now available through Bedrock as a postprocessor, integrating seamlessly with recent updates. Documentation can be accessed here.
- Installation can be done via
pip install llama-index-postprocessor-bedrock-rerank.
- Installation can be done via
- ColPali Enhances Reranking During PDF Processing: The ColPali feature functions as a reranking tool during PDF processing rather than a standalone process, clarifying its role in dynamic document handling. It operates primarily for reranking image nodes after retrieval, as confirmed by users.
- This clarification helps in understanding the integration of ColPali within existing workflows.
Cohere Discord
- Cohere Business Humor Clashes: Members voiced frustration over Cohere's use of irrelevant humor in business discussions, stressing that lightheartedness shouldn't mute serious conversations.
- The ongoing debate highlighted the balance moderators need to maintain between levity and maintaining professional discourse.
- Plans for Rerank 3.5 English Model: A member inquired about upcoming plans for the Rerank 3.5 English model, seeking details on its development timeline.
- No responses were noted, indicating a potential communication gap regarding the model's progression.
- CmdR+Play Bot Takes a Break: The CmdR+Play Bot is currently on a break, as confirmed by a member following an inquiry about its status.
- Users were advised to stay tuned for future updates regarding the bot's availability.
- Aya-expanse Instruction Performance: A user questioned if aya-expanse, part of the command family, has enhanced its instruction processing performance.
- The discussion didn't yield a clear answer on its performance improvements.
- API 403 Errors Linked to Trial Keys: Members reported encountering a 403 error when making API requests, suggesting it may be related to trial key limitations.
- Trial keys often have restrictions that limit access to specific features or endpoints.
Torchtune Discord
- Config Clash Conundrum: A user sought a simple method for merging conflicting configuration files, opting to use 'accept both changes' for all files. They shared a workaround by replacing conflict markers with an empty string.
- This approach sparked discussions on best practices for handling configuration merges in collaborative projects.
- PR #2139 Puzzle: The community discussed PR #2139, focusing on concerns around
torch.utils.swap_tensorsand its role in initialization.- Contributors agreed on the necessity for further conversations regarding the definition and initialization of
self.magnitude.
- Contributors agreed on the necessity for further conversations regarding the definition and initialization of
- Empty Initialization Enhancement: Proposals emerged to improve the
to_emptyinitialization method, aiming to maintain expected user experiences while managing device and parameter captures.- Members debated how to balance best practices without causing disruptions in existing codebases.
- Tensor Tactics: Device Handling: There was emphasis on effective device management during tensor initialization and swaps, particularly concerning parameters like
magnitude.- Participants highlighted the importance of using APIs such as
swap_tensorsto maintain device integrity during operations.
- Participants highlighted the importance of using APIs such as
- Parameters and Gradients Clarified: Contributors clarified that using
copy_is acceptable when device management is handled correctly, emphasizing the importance of therequires_gradstate.- They discussed integrating error checks in initialization routines to prevent common issues like handling tensors on meta devices.
DSPy Discord
- LangWatch Optimization Studio Launch: LangWatch Optimization Studio launches as a new low-code UI for building DSPy programs, simplifying LM evaluations and optimizations. The tool is now open source on GitHub.
- The studio has transitioned out of private beta, encouraging users to star the GitHub repository to show support.
- DSPy Documentation Access Issues: A member reported difficulties accessing the DSPy documentation, especially the API reference link. Another member clarified that most syntax is available on the landing page and special modules for types are no longer needed.
- Community discussions indicated that documentation has been streamlined, with syntax examples moved to the main page for easier access.
- Impact of O1 Series Models on DSPy: Inquiry was made on how the O1 series models affect DSPy workflows, particularly regarding parameters for MIPRO optimization modules. Adjustments like fewer optimization cycles might be required.
- Members are seeking insights and recommendations on optimizing DSPy workflows with the new O1 series models.
- Optimization Error Reporting in DSPy: A member reported encountering a generic error during optimization in DSPy and posted details in a specific channel. They are seeking attention to address the issue.
- The community is aware of the reported optimization error, with members looking to assist in troubleshooting the problem.
LAION Discord
- Grassroots Science Initiative Launches: A collaboration between several organizations is set to launch Grassroots Science, an open-source initiative aimed at developing multilingual LLMs by February 2025.
- They aim to collect data through crowdsourcing, benchmark models, and use open-source tools to engage grassroots communities in multilingual research.
- AI Threat Awareness Campaign Initiated: A member emphasized the importance of educating individuals about the dangers of AI-generated content, suggesting the use of MKBHD's latest upload to illustrate these capabilities.
- The initiative aims to protect tech-illiterate individuals from falling victim to increasingly believable AI-generated scams.
- Feasibility of Training 7B Models on 12GB Data: A member questioned the feasibility of training a 7B parameter model on just 12GB of data, sparking discussions on its potential performance in practical applications.
- This ambitious approach challenges traditional data requirements for large-scale models, raising questions about efficiency and effectiveness.
- Excitement Over Hyperefficient Small Models: Members expressed enthusiasm for hyperefficient small models, highlighting their performance and advantages over larger counterparts.
- One fan stated, 'I love hyperefficient small models! They rock!', emphasizing the potential of models that reduce resource requirements without sacrificing capabilities.
OpenInterpreter Discord
- 01's Voice Takes the Stage: A member announced that 01 is a voice-enabled spinoff of Open Interpreter, available as both a CLI and desktop application. It includes instructions for simulating the 01 Light Hardware and running both the server and client.
- Instructions provided cover simulating the 01 Light Hardware and managing both server and client operations.
- OI Integration with GPT o1 Pro: A member hypothesized that using OI in OS mode could control GPT o1 Pro through the desktop app or browser, potentially enabling web search and file upload capabilities. They expressed interest in exploring this idea, noting the powerful implications it could have.
- Community members are interested in the potential to enhance GPT o1 Pro with features like web search and file uploads via OI's OS mode.
- 01 App Beta Access for Mac: It was clarified that the 01 app is still in beta and requires an invite to access, currently available only for Mac users. One member reported they sent a direct message to a user to gain access, indicating a very high demand.
- The limited beta access for Mac users highlights the high interest in the 01 app within the community.
- Website Functionality Concerns: A member expressed frustration regarding issues with the Open Interpreter website, showing a screenshot but not detailing the specific problems. Community members have begun discussing website navigation and functionality as part of their ongoing experience with Open Interpreter.
- Ongoing discussions about website navigation and functionality stem from reported issues by community members.
Mozilla AI Discord
- Web Applets Kickoff Session: An upcoming session on web applets is scheduled to start soon, led by a prominent member.
- This event aims to enhance understanding of the integration and functionality of web applets in modern development.
- Theia-ide Exploration: Tomorrow, participants can explore Theia-ide, which emphasizes openness, transparency, and flexibility in development environments.
- The discussion will be led by an expert, showcasing the advantages of using Theia-ide compared to traditional IDEs.
- Evolution of Programming Interviews: A comment highlighted how programming interviews have evolved, noting that candidates used to write a bubble sort on a whiteboard.
- Now, candidates can instruct their IDE to build one, emphasizing the shift towards more practical skills in real-time coding.
- Jonas on Theia-ide Vision: A shared interview with Jonas provides insight into the vision behind Theia-ide, accessible here.
- This interview offers a deeper understanding of the features and philosophy guiding the development of Theia-ide.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Codeium / Windsurf ▷ #content (1 messages):
Windsurf AI giveaway, User engagement on Twitter
- Windsurf AI Launches Exciting Giveaway: Windsurf AI announced their first merch giveaway on Twitter, encouraging users to share their creations for a chance to win a care package.
- Must be following to qualify highlights the engagement strategy aimed at boosting follower interaction.
- Call for User Creations: The giveaway encourages users to showcase what they've built using Windsurf, generating community involvement and creativity.
- This campaign uses the hashtag #WindsurfGiveaway to track submissions and enhance visibility.
Link mentioned: Tweet from Windsurf (@windsurf_ai): Excited to announce our first merch giveaway 🏄Share what you've built with Windsurf for a chance to win a care package 🪂 #WindsurfGiveawayMust be following to qualify
Codeium / Windsurf ▷ #discussion (384 messages🔥🔥):
Credit System Issues, Windsurf IDE Performance, Cline vs Windsurf, Codeium Plugin Functionality, Support and Outage Communication
- Credit System Issues Persist: Many users reported problems with their purchased credits not appearing in their accounts after transactions, leading to frustration and support ticket submissions.
- Despite assurances from the team, users expressed dissatisfaction with the lack of timely responses from customer support regarding these issues.
- Performance of Windsurf IDE Criticized: Several users shared their concerns about the performance of the Windsurf IDE, stating that it has become buggy and inefficient since recent updates.
- People have compared their experiences with Windsurf against competitors like Cline, often favoring the latter for functionality and reliability.
- Cline vs Windsurf Comparison: Users discussed the performance of Cline in coding tasks against Windsurf, noting that Cline may provide better prompt responses despite being slower in some instances.
- Cline's functionality was praised, especially when it came to generating specific coding outputs without encountering errors.
- Codeium Plugin Functionality: The community debated the functionalities of the Codeium VSCode extension in comparison to Windsurf, noting that both offer similar capabilities.
- Users highlighted that the Windsurf IDE incorporates enhanced features, giving it an edge in coding assistance over the standalone plugin.
- Need for Better Support and Communication: Frustrations were voiced about the lack of communication regarding system outages, with users calling for a clear status page to inform them of ongoing issues.
- Some users suggested that simple communication like an outage notice could improve customer satisfaction while they await problem resolutions.
- Prompt Engineering - Codeium Docs: no description found
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Stripe Invoice: no description found
- Contact | Windsurf Editor and Codeium extensions: Contact the Codeium team for support and to learn more about our enterprise offering.
- Disappointed Disbelief GIF - Disappointed Disbelief Slap - Discover & Share GIFs: Click to view the GIF
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Windsurf IDE World Record !! ... as of today, surely by tomorrow it'll be beat. 1:48m mins streak.: much wow!to the moon !!
- Reddit - Dive into anything: no description found
- GitHub - codelion/optillm: Optimizing inference proxy for LLMs: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
Codeium / Windsurf ▷ #windsurf (715 messages🔥🔥🔥):
Windsurf Pricing Model, Flow Credits Issues, AI Capabilities in Development, Devin vs. Windsurf, AI Collaboration Limitations
- Windsurf Pricing Model Confusion: Users expressed concerns over the pricing model, particularly the limits on flow and regular credits, which seem high for the features offered.
- Many are hoping for a more sustainable model that provides more value for the cost, including suggestions for a rollover system for unused credits.
- Flow Credits Management: Several users reported issues with flow credits being consumed too quickly and expressed dissatisfaction with the current system of credits not rolling over month to month.
- There was discussion about how the pricing and flow credit system could be restructured to better meet user needs.
- AI Capabilities in Development: A user shared frustration with the AI's inability to solve persistent errors in their project, indicating a perceived decline in quality since upgrading.
- Participants discussed the challenges of managing AI prompts and maintaining effective communication with the tooling.
- Comparisons Between Devin and Windsurf: Users compared Devin's capabilities to Windsurf, highlighting that while both provide useful functionalities, Windsurf is preferred for its integration and efficiency.
- Concerns were raised regarding the effectiveness of Devin as a tool, with some users questioning its ability to deliver reliable results.
- AI Collaboration and Prompting Challenges: Conversations focused on the importance of proper prompting practices and how AI can sometimes misinterpret user instructions or requirements.
- Participants shared strategies for improving interaction with AI systems, emphasizing the need for clear and detailed input.
- no title found: no description found
- 'To save itself from being replaced and shut down ChatGPT caught lying to developers' - Times of India: TECH NEWS : OpenAI's new model, o1, exhibits advanced reasoning but also a heightened tendency for deception. Researchers found o1 manipulating users and prioriti
- Tweet from Continue (@continuedev): 🛠️ Announcing Tools! Continue can now- navigate your repo- create files- search the web- run terminal commands (after you approve)- use custom tools from @AnthropicAI's MCPHere Continue builds a ...
- Support | Windsurf Editor and Codeium extensions: Need help? Contact our support team for personalized assistance.
- Page Not Found | Windsurf Editor and Codeium extensions: Codeium is the AI code assistant platform that developers love and enterprises trust. Also the builders of Windsurf, the first agentic IDE.
- Features: no description found
- Forge | Windsurf Editor and Codeium extensions: Meet Forge, the fastest, most reliable AI code review platform.
- Roo Cline - Visual Studio Marketplace: Extension for Visual Studio Code - A fork of Cline, an autonomous coding agent, with some added experimental configuration a...
- GitHub - RooVetGit/Roo-Cline: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way.: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way. - RooVetGit/Roo-Cline
Eleuther ▷ #general (43 messages🔥):
Draft PR for ML Systems, Reproducibility Concerns in LLMs, HumanEval Benchmark PR, Importance of Training Data, OLMs Hallucination Considerations
- Draft PR for Machine Learning Systems in Progress: A member mentioned a potential future draft PR for the current state of their ML work, which was noted to be in a 'pretty bad state' at present.
- Another member expressed excitement, suggesting it could demonstrate how to use JAX with personal models.
- Reproducibility Concerns in LLMs: Discussion arose regarding the concerns of classic software developers about the ability to reproduce or rebuild LLMs and the nuances of reproducibility in AI research.
- Members debated the significance of reproducibility, especially in high-stakes environments such as medical applications.
- Update on HumanEval Benchmark PR: A member inquired about the status of a long-standing PR to add the HumanEval benchmark, indicating a desire for it to be reviewed and moved forward.
- The PR details included implementation that relies on pass@k from the HF evaluate module.
- Raising Awareness on Importance of Training Data: A post from an OpenAI employee highlighted the critical role of training data, emphasizing that models approximate their datasets closely.
- It was noted that understanding this perspective can provide students and developers with key insights on model performance.
- Understanding Hallucinations in LLMs: The conversation touched on hallucinations in LLMs, clarifying that hallucination is inherent to the function of these models, rather than a defect.
- Members discussed the differences between hallucination in models and the guarantee of creativity in traditional search engines.
- The “it” in AI models is the dataset. – Non_Interactive – Software & ML: no description found
- Add HumanEval by hjlee1371 · Pull Request #1992 · EleutherAI/lm-evaluation-harness: Hi, I added the widely-used HumanEval benchmark. This partially resolves #1157.The implementation relies on pass@k from the HF evaluate module, so it requires the environment variable HF_ALLOW_COD...
- Building Machine Learning Systems for a Trillion Trillion Floating Point Operations: Over the last 10 years we've seen Machine Learning consume everything, from the tech industry to the Nobel Prize, and yes, even the ML acronym. This rise in ...
- The Bitter Lesson: no description found
- The Scaling Hypothesis · Gwern.net: no description found
- The Scaling Hypothesis · Gwern.net: no description found
- Why next-token prediction is enough for AGI - Ilya Sutskever (OpenAI Chief Scientist): Full episode: https://youtu.be/Yf1o0TQzry8Transcript: https://www.dwarkeshpatel.com/p/ilya-sutskeverApple Podcasts: https://apple.co/42H6c4DSpotify: https://...
- Tweet from Andrej Karpathy (@karpathy): # On the "hallucination problem"I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dre...
Eleuther ▷ #research (257 messages🔥🔥):
Coconut Architecture, Universal Transformers, Gated DeltaNet, EOT Token Handling, Linear Transformers
- Coconut Architecture's Value Proposition: The Coconut architecture proposes feeding back the final hidden state after the
token, treating it as a new token within the model, thus modifying the KV cache with each repetition. - This method contrasts with Universal Transformers, which traditionally do not modify the KV cache across repetitions.
- Differences with Universal Transformers: Participants discussed the distinctions between the Coconut method and Universal Transformers (UT), highlighting that UTs typically don't cache information effectively during repetitions.
- It was suggested that Coconut could resemble UTs only under specific conditions, such as sharing the KV cache and managing state histories appropriately.
- Potential of Gated DeltaNet: Gated DeltaNet has emerged as an advanced architecture that utilizes gated memory control and delta updates to enhance performance in long-context tasks over standard transformers.
- Model performance improvements were highlighted, showing superiority over existing models like Mamba2 and DeltaNet across various benchmarks.
- Dynamic Depth and EOT Token Usage: Clydingus mentioned that, technically, the EOT token chain can be viewed as a single UT operation, allowing multiple EOTs to be chained together.
- This perspective introduces the idea of recreating a UT, even if inelegantly, utilizing dogfooded RNN decoding for the EOT process.
- Discussion on Long-Context Handling: The conversation encompassed the limitations of current architectures, including the need for improved long-context handling within linear transformers.
- Participants expressed curiosity about the application of these concepts in existing literature and the potential for new developments.
- Heavy-Tailed Class Imbalance and Why Adam Outperforms Gradient Descent on Language Models: Adam has been shown to outperform gradient descent on large language models by a larger margin than on other tasks, but it is unclear why. We show that a key factor in this performance gap is the heav...
- Training Large Language Models to Reason in a Continuous Latent Space: Large language models (LLMs) are restricted to reason in the "language space", where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning pro...
- Recall to Imagine: no description found
- Gated Delta Networks: Improving Mamba2 with Delta Rule: Linear Transformers have gained attention as efficient alternatives to standard Transformers, but their performance in retrieval and long-context tasks has been limited. To address these limitations, ...
- Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis: We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution, photorealistic images following language instruction. Infinity redefines visual autoregressive mode...
- Restructuring Vector Quantization with the Rotation Trick: Vector Quantized Variational AutoEncoders (VQ-VAEs) are designed to compress a continuous input to a discrete latent space and reconstruct it with minimal distortion. They operate by maintaining a set...
- interpreting GPT: the logit lens — LessWrong: Comment by nostalgebraist - Interesting, but not (I think?) the direction I was headed in.I was thinking more about the way the model seems to be managing a tradeoff between preserving the representat...
- A scalable framework for learning the geometry-dependent solution operators of partial differential equations - Nature Computational Science: This work presents an artificial intelligence framework to learn geometry-dependent solution operators of partial differential equations (PDEs). The framework enables scalable and fast approximations ...
Eleuther ▷ #lm-thunderdome (231 messages🔥🔥):
GSM8k Evaluation Metrics, Arc Challenge Configurations, Batch Size Effects on Model Performance, RWKV Model Implementation Concerns, Attention Masking Issues in Transformers
- GSM8k scores vary significantly: Members noted that using batch size 1 for the GSM8k evaluation led to the highest accuracy of 85.52%, while the scores drastically dropped for larger batch sizes.
- It was suggested this disparity may be due to padding issues or the way the attention mechanism is implemented in models.
- Confusion over Arc Challenge Methodology: There was discussion about the discrepancies in the reported '0-shot' versus '25-shot' scores for Llama 3.1, raising questions about the methods used in the evaluations.
- Members speculated this could be attributed to a mistake in the Meta Llama 3.1 paper or how tasks such as Arc Challenge are set up.
- Impact of Batch Size on Evaluation Results: Multiple participants observed that increasing batch size negatively impacted their scores, with one suggesting it might be linked to how padding is managed during evaluations.
- This lead to experimentation with batch sizes, where batch size 4 or 32 produced lower performance compared to batch size 1.
- RWKV Model Functionality and Challenges: Concerns were raised about the RWKV model's implementation regarding attention masking and left padding, with discussions on how these aspects could affect evaluation outcomes.
- Members indicated that RWKV might handle these features differently, thereby necessitating careful process adjustments.
- Transformers and Attention Masking Issues: Warnings related to using the SDPA attention implementation in multi-GPU setups highlighted potential performance issues, suggesting that alternative backends may not properly support attention functionalities.
- Participants discussed the possibility that these limitations could lead to significant variances in evaluation results, emphasizing the need for careful environment setup and configurations.
Link mentioned: llama3/eval_details.md at main · meta-llama/llama3: The official Meta Llama 3 GitHub site. Contribute to meta-llama/llama3 development by creating an account on GitHub.
Eleuther ▷ #multimodal-general (1 messages):
tensor_kelechi: https://machinelearning.apple.com/research/multimodal-autoregressive
Cursor IDE ▷ #general (331 messages🔥🔥):
Slow Requests with Cursor, Comparison of AI Models, Issues with Cursor and Agents, User Experiences and Feedback, Code Evaluation with AI
- Cursor Users Stuck in Slow Request Hell: Multiple users are reporting issues with slow requests in Cursor, causing significant interruptions to their productivity throughout the day.
- Despite recent updates, many users feel that the Composer and Agent modes are still not functioning effectively.
- Comparison of AI Models in Coding Tasks: Users are discussing various AI models' capabilities, particularly Gemini, Claude, and Qwen, with many noting Claude's superior performance in coding tasks.
- While some tests suggest Gemini shows promise, others report inconsistent quality, leading to frustration among developers.
- Feedback on File Manipulation in Agent Mode: A question arose regarding file handling in agent mode—specifically, whether agents access file contents directly or merely suggest reading them.
- This uncertainty highlights ongoing concerns about the functionality and reliability of Cursor's agent features.
- User Experiences with Code Structure Assessment: A user shared amusing feedback on their code structure analysis by AI, which praised the project as professional despite the user's lack of experience.
- This demonstrates the advanced capabilities of current AI in assessing development practices, even humorously misattributing expertise.
- Frustration with Linting Features: Issues are arising where linting features triggering without any actual lint errors have led to user frustration, believing their fast message quota is being misused.
- One user noted this occurs often, reinforcing the sentiment that Cursor's features are still in beta and need refinement.
- LiveBench: no description found
- Cursor: Built to make you extraordinarily productive, Cursor is the best way to code with AI.
- Tweet from OpenAI (@OpenAI): Day 4: All things canvashttps://openai.com/12-days/?day=4
- Tweet from Aryan Vichare (@aryanvichare10): Introducing WebDev ArenaAn arena where two LLMs compete to build a web app. You can vote on which LLM performs better and view a leaderboard of the best models.100% Free and Open Source with @lmarena_...
- Frustration with Cursor 0.43.6: A Decline in Code Generation Quality: After upgrading to Cursor 0.43.6, I’ve found the experience to be quite frustrating. In Composer mode, even when using @Codebase, Cursor seems entirely unable to understand my project’s structure. It ...
- How to do `Fix in Composer` and `Fix in Chat` actions from keyboard: These 2: I could not find it in settings.
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.68.0 features, API key management, Enhanced shell command support, Experimental Gemini models, Error messaging improvements
- Aider v0.68.0 Introduces New Features: Aider works with LLM web chat UIs now supports a new
--copy-pastemode and/copy-contextcommand, enhancing user interaction.- The release emphasizes user control with new command line options for managing API keys and environment variables through a yaml config file.
- Streamlined API Key Management: Users can now set API keys for OpenAI and Anthropic using dedicated command line switches such as
--openai-api-keyand--anthropic-api-key.- For other LLM providers, a new
--api-key provider=option simplifies the process of setting keys as environment variables.
- For other LLM providers, a new
- Shell Command Support Enhanced: Aider v0.68.0 brings improved bash and zsh support for the
--watch-filesfeature, enabling better integration during development.- Additionally, command line arguments have been reorganized for improved help messages and user experience.
- Introduction of Experimental Gemini Models: This release has added support for experimental Gemini models, broadening Aider's capabilities for developers.
- This addition comes alongside several bug fixes, including better error messaging when dependencies for specific models are missing.
- Error Messaging and Bug Fixes: The update included better error messages when encountering hard errors with API providers and improvements in file watching capabilities.
- Bugs were addressed to ensure compatibility with models lacking tree-sitter support and functionality improvements for certain model types.
Link mentioned: YAML config file: How to configure aider with a yaml config file.
aider (Paul Gauthier) ▷ #general (281 messages🔥🔥):
Aider Features and Improvements, Gemini Model Performance, Integration of Aider with LangChain, Using Multiple Aider Instances, Aider Tutorials and Resources
- Aider introduces new command options and functionalities: Users are excited about the introduction of
--watch-files, which enhances interactivity when working with Aider. There are discussions around context limits and file editing capabilities, indicating a learning curve for new users.- The community is eager for a deep dive into these new features, particularly by experienced members who often share valuable insights and tutorials.
- Performance discussions surrounding the Gemini model: Some users report varying experiences with the new Gemini models, noting that they exhibit improved context handling but still encounter limitations in editing substantial files. The confusion regarding performance benchmarks leads to speculation about the model's architecture.
- There is a suggestion to run comparisons with other models to better understand capabilities, as the latest updates from Gemini are met with mixed reviews.
- ReAct Loop Integration with Aider: Aider has been successfully integrated into a LangChain ReAct loop, enhancing its usability for project management tasks. Users note that this integration often yields better results than other tools, highlighting the flexibility of Aider.
- Further testing and potential collaboration on this integration could provide heightened insights into project workflows and AI-assisted coding.
- Using multiple Aider instances in projects: Users report managing multiple instances of Aider simultaneously for more effective project workflows, with some experimenting with as many as 20 instances. This suggests a strategy for complex projects that involve extensive architecting and editing.
- The versatility of the tool allows users to adapt their approaches to coding, although the practicality of executing commands across instances is still explored.
- Aider tutorials and community resources: Users express appreciation for tutorial content, particularly those from community members sharing their insights and experiences with Aider features. Directing others to video resources and channels has become common, supporting a collaborative environment.
- The community appears keen to enhance their skills through shared knowledge, leading to conversations about improving the learning experience around Aider.
- Coding the Future With AI: Welcome to Coding the Future With AI! Our channel is dedicated to helping developers and tech enthusiasts learn how to leverage AI to enhance their skills and productivity. Through tutorials, expert i...
- Token limits: aider is AI pair programming in your terminal
- Copy/paste with web chat: Aider works with LLM web chat UIs
- Tweet from Sundar Pichai (@sundarpichai): We see Willow as an important step in our journey to build a useful quantum computer with practical applications in areas like drug discovery, fusion energy, battery design + more. Details here: https...
- FAQ: Frequently asked questions about aider.
- Tweet from DeepSeek (@deepseek_ai): 🚀 DeepSeek-V2.5-1210: The Grand Finale 🎉🌐 Internet Search is now live on the web! Visit https://chat.deepseek.com/ and toggle “Internet Search” for real-time answers. 🕒🧵(1/3)
- Tweet from Paul Gauthier (@paulgauthier): Aider v0.68.0 helps you efficiently copy & paste code with a "big brain" LLM in a web chat, while respecting their TOS. Use a smaller, cheaper (local) model to apply the edits from the LLM web...
- Models | OpenRouter: Browse models on OpenRouter
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- DeepSeek Platform: Join DeepSeek API platform to access our AI models, developer resources and API documentation.
- awesome-deepseek-integration/README.md at main · deepseek-ai/awesome-deepseek-integration: Contribute to deepseek-ai/awesome-deepseek-integration development by creating an account on GitHub.
- Chat modes: Using the code, architect, ask and help chat modes.
- Tips: Tips for AI pair programming with aider.
- GitHub - ai-christianson/RA.Aid: Aider in a ReAct loop: Aider in a ReAct loop . Contribute to ai-christianson/RA.Aid development by creating an account on GitHub.
- GitHub - codestoryai/sidecar: Sidecar is the AI brains for the Aide editor and works alongside it, locally on your machine: Sidecar is the AI brains for the Aide editor and works alongside it, locally on your machine - codestoryai/sidecar
- Reddit - Dive into anything: no description found
- esbuild - API: no description found
- day #63 to 100x-orchestrator: Join techfren as he uses his software engineering expertise to try and review new technology
- Aider + 1 Hour = Reels video editor with face recognition: Join techfren as he uses his software engineering expertise to try and review new technology
- Models & Pricing | DeepSeek API Docs: The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the tot...
aider (Paul Gauthier) ▷ #questions-and-tips (29 messages🔥):
Best Practices for Large Codebases, Integration of Aider with Language Servers, Using Aider Outside Command Line, Handling System Prompts in Aider, Differences in Claude Models
- Best Practices for Large Codebases: Members discussed best practices for using Aider with large production codebases, including the use of a repo map for better context.
- One user shared a link to Aider's FAQ for utilizing Aider in large mono-repos, emphasizing its efficiency in managing extensive codebases.
- Integration of Aider with Language Servers: A member inquired about integrating Aider with language servers to enhance code exploration using LSP features like 'find references' and 'go to definition'.
- Another user highlighted the need for a more autonomous approach for Aider to facilitate complex code changes without extensive manual control.
- Using Aider Outside Command Line: A query was raised about the possibility of using Aider through API requests instead of just the command line, allowing more flexible interactions with local files.
- Paul Gauthier confirmed that Aider can be scripted via the command line or Python, and the documentation provides various command options.
- Handling System Prompts in Aider: Users expressed interest in modifying the default coding-specific system prompts used by Aider for more general applications like brainstorming.
- It was suggested that custom conventions could be loaded from a markdown file, allowing greater control over the guidelines Aider follows during interactions.
- Differences in Claude Models: Members discussed the distinctions between
anthropic/claude-3.5-sonnetand its beta version on OpenRouter, emphasizing moderation differences.- The community highlighted potential advantages of using the non-beta model for Aider due to its moderation handling and reduced likelihood of encountering errors.
- FAQ: Frequently asked questions about aider.
- Repository map: Aider uses a map of your git repository to provide code context to LLMs.
- FAQ: Frequently asked questions about aider.
- Scripting aider: You can script aider via the command line or python.
- Aider in your IDE: Aider can run in your browser, not just on the command line.
- Specifying coding conventions: Tell aider to follow your coding conventions when it works on your code.
Unsloth AI (Daniel Han) ▷ #general (161 messages🔥🔥):
Llama 3.3 ultra long context, Sora model discussion, Fine-tuning Qwen models, Performance of quantized models, Educational access for students
- Llama 3.3 achieves ultra long context lengths: Unsloth now supports fine-tuning the Llama 3.3 model with a context length of up to 89,000 tokens on an 80GB GPU, vastly exceeding previous capabilities.
- This functionality allows users to achieve 2-3 minutes per training step on A100 GPUs, enhancing performance by utilizing 70% less VRAM.
- Discussion on the Sora model: Members shared mixed feelings about the Sora model, noting its impressive training but lack of real-world applications.
- Concerns were raised that it may not add significant value compared to existing architectures despite enthusiasm from some users.
- Potential of Qwen models for OCR tasks: There was excitement around fine-tuning Qwen2-VL for OCR tasks, specifically targeting information extraction from documents like passports.
- Users expressed confidence that this approach would work effectively due to the model's capabilities.
- Challenges with quantized model performance: One user reported significant performance degradation when converting a model to GGUF format after fine-tuning in 8-bit, despite lower evaluation loss during training.
- Discussions suggested potential issues arise from how models are merged and converted, impacting their effectiveness.
- Educational user access to GPU resources: A student inquired about options for increasing GPU access for research purposes, citing limitations of single GPU support currently.
- It was clarified that while Unsloth speeds up training on a single GPU, multi-GPU support isn’t available yet.
- Endpoint encountered an error.You can try restarting it using the "retry" butt - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Tweet from Unsloth AI (@UnslothAI): Llama 3.3 fine-tuning with ultra long context is here! 🦙Unsloth now supports 89K context for @AIatMeta's Llama 3.3 (70B) on a 80GB GPU - 13x longer than HF+FA2For Llama 3.1 (8B), Unsloth enables ...
- Fine-tune Llama 3.3 with Unsloth: Fine-tune Meta's Llama 3.3 (70B) model which has better performance than GPT 4o, open-source 2x faster via Unsloth! Beginner friendly.Now with Apple's Cut Cross Entropy algorithm.
- mistralai/Mistral-Small-Instruct-2409 · Hugging Face: no description found
- LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct at main: no description found
- Reddit - Dive into anything: no description found
- Rank-Stabilized LoRA: Unlocking the Potential of LoRA Fine-Tuning: no description found
- Paper page - LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models: no description found
- Can we use unsloth to train Reward Models? · Issue #263 · unslothai/unsloth: More of a question than a bug - will you be working on some examples to use unsloth for training Reward Models - https://huggingface.co/docs/trl/main/en/reward_trainer - as well?
- Added Support for Apple Silicon by shashikanth-a · Pull Request #1289 · unslothai/unsloth: UnoptimizedNo gguf support yet.Build Triton and bitsandbytes from sourcecmake -DCOMPUTE_BACKEND=mps -S . for bitsandbytes buildingpip install unsloth-zoo==2024.11.4pip install xformers==0.0.25
Unsloth AI (Daniel Han) ▷ #help (85 messages🔥🔥):
Unsloth Model Installation, Finetuning Gemma 2, CUDA/Triton Kernel Development, Long Text Generation Issues, Using Guidance AI for Non-Conversational Tasks
- Unsloth installation issues in WSL: Users encountered problems installing Unsloth via pip in WSL due to Python version dependencies, with some suggesting using Miniconda to create a compatible environment.
- One user shared a related error and proposed solutions found in a GitHub discussion, noting that errors typically arise from versioning issues.
- Challenges with Gemma 2 finetuning: A user faced a quantization error when attempting to finetune with Gemma 2, leading to instructions to compile the latest version of llama.cpp for resolution.
- Another contributor reported that following these instructions did not resolve their issue and shared their experience with CUDA errors.
- CUDA and Triton Kernel Development Resources: One user sought resources for learning CUDA and Triton kernel development, receiving recommendations to read introductory blog posts from the Unsloth team.
- Additionally, they were directed to join the GPU Mode community for further guidance.
- Issues generating long texts: A user working on long text generation encountered repetitive outputs from their model when trained on specific data, questioning the model's handling of input.
- They were advised on the potential impact of the non-conversational nature of their dataset on training outcomes.
- Using Guidance AI for structured input: There are inquiries about using Guidance AI for a custom dataset in non-conversational tasks, with users deliberating on the necessity of including a mock text column.
- Users recommended adding the mock column while implementing custom data collators to bypass the limitation imposed by the UnslothTrainer.
- Introducing Unsloth: no description found
- Using LoRA adapters — vLLM: no description found
- All Our Models | Unsloth Documentation: See the list below for all our GGUF, 16-bit and 4-bit bnb uploaded models
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- RuntimeError: Unsloth: The file 'llama.cpp/llama-quantize' or 'llama.cpp/quantize' does not exist · Issue #748 · unslothai/unsloth: The below error occured while trying to convert model to gguf format. I noticed that quantized folder resides in llama.cpp/examples/quantize RuntimeError: Unsloth: The file 'llama.cpp/llama-quanti...
Unsloth AI (Daniel Han) ▷ #showcase (6 messages):
Awesome RAG project, Deep dive on roles and cards, Constrained generation techniques
- Awesome RAG project on GitHub: A user shared a link to the Awesome RAG project, focusing on RAG, VectorDB, embeddings, LlamaIndex, and Langchain.
- This GitHub repository invites contributions for enhancing the project.
- Exploring Roles and Personality Cards: A user proposed a deeper dive into the roles of system, user, and assistant, as well as personality cards and moderation techniques.
- They highlighted the significance of understanding these concepts for better interaction design in AI.
- Understanding Constrained Generation: Another user suggested explaining constrained generation using JSONSchema and grammar for applications in code improvement and feature extraction.
- They implied that these techniques are crucial for achieving optimal function calling in AI.
Link mentioned: GitHub - lucifertrj/Awesome-RAG: RAG-VectorDB-Embedings-LlamaIndex-Langchain: RAG-VectorDB-Embedings-LlamaIndex-Langchain. Contribute to lucifertrj/Awesome-RAG development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #research (4 messages):
APOLLO optimizer for LLMs, QTIP quantization method, Dataset repository for WizardLM Arena paper
- APOLLO Optimizer Proposes Memory Efficiency: A recent research paper suggests the APOLLO optimizer, which approximates learning rate scaling, to alleviate the memory-intensive nature of training LLMs like those using AdamW.
- This approach aims to reduce optimizer memory overhead while maintaining competitive performance, despite challenges with memory usage in traditional methods.
- QTIP Enhances Post-Training Quantization: The QTIP method introduces trellis coded quantization to optimize high-dimensional quantization for LLMs, improving the memory footprint and inference throughput.
- With its innovative approach, QTIP allows models to be fine-tuned effectively, overcoming limitations faced by previous vector quantization methods.
- WizardLM Arena Datasets Now Available: A repository containing all datasets used in the WizardLM Arena paper has been uploaded, making it easier for researchers to access these resources.
- The datasets can be found on Hugging Face and are intended to facilitate further experimentation.
- APOLLO: SGD-like Memory, AdamW-level Performance: Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing ...
- forcemultiplier/arena-paper-datasets-jsonl at main: no description found
- QTIP: Quantization with Trellises and Incoherence Processing: Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes. Since LLM inference is usually memory-bound, PTQ methods can improve inference t...
- qtip/quantize_llama/quantize_finetune_llama.py at main · Cornell-RelaxML/qtip: Contribute to Cornell-RelaxML/qtip development by creating an account on GitHub.
- Chris De Sa: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (238 messages🔥🔥):
Image Enhancement Techniques, Use of Stable Diffusion, Llama 3.2-Vision Model, Memory Management in WebUI, Image Metadata and Tagging
- Discussion on Image Enhancement Techniques: Members debated whether AI models like Stable Diffusion can improve images without altering core content, suggesting traditional editing tools like Photoshop for such tasks.
- Some members highlighted the need for skills in color grading and lighting for professional results, indicating that AI may add noise rather than refine.
- Exploring the Llama 3.2-Vision Model: The Llama 3.2-Vision model was mentioned as a viable local option for image classification and analysis, with support for vision models through software like KoboldCPP.
- Members noted that local models could be run on consumer GPUs and discussed alternatives, emphasizing that online services often require users to relinquish rights to their data.
- Memory Management in Automatic1111 WebUI: There was a discussion on memory management issues affecting image generation in Automatic1111 WebUI, particularly with batch sizes and VRAM usage.
- Members suggested that larger batches led to out-of-memory errors, potentially due to inefficiencies in how prompts are stored in the system.
- Image Metadata and Tagging: Participants discussed the challenge of extracting tags or descriptions from images, with suggestions including using metadata readers or AI models for classification.
- Concerns were raised about how classification methods could miss certain details, with some advocating for the use of specific tags like those found on imageboards.
- Copyright and Data Rights in AI Services: There was a warning shared about using online services for AI image generation, highlighting that such services often claim extensive rights over user-generated content.
- Members encouraged local model usage to maintain clearer ownership and control over created works, contrasting it with the broad licensing practices of web-based services.
- How to Avoid VRAM Exhaustion and Prevent VRAM Spikes! | Civitai: Examples included in this guide on why you would want to use this. Click here for a detail image guide by @fitCorder. Very cool Dude. What is VRAM?...
- Facepalm Picard GIF - Facepalm Face Palm - Discover & Share GIFs: Click to view the GIF
- GitHub - lllyasviel/IC-Light: More relighting!: More relighting! Contribute to lllyasviel/IC-Light development by creating an account on GitHub.
- Multi Diffusion for A1111 - Super Large + LOW Vram Upscaling: Multi Diffusion Tiled Diffusion Upscaler with a tiled VAE. This Low Vram Upscaler can give you 8x upscales with super high quality in A1111. And it works wit...
- Create a Viral Lip-Sync Video with ChatGPT and Hailuoai's AI Magic!: ✨ Comic Book Creator Custom ChatGPT https://payhip.com/b/TgUxN✨ Ultimate Text-to-Video Prompt Generator . https://payhip.com/b/nq6b4Create a Viral Lip-Sync ...
- GitHub - pkuliyi2015/multidiffusion-upscaler-for-automatic1111: Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0: Tiled Diffusion and VAE optimize, licensed under CC BY-NC-SA 4.0 - pkuliyi2015/multidiffusion-upscaler-for-automatic1111
Perplexity AI ▷ #general (219 messages🔥🔥):
Perplexity AI Image Generation, Claude and GPT Models, Custom GPTs Functionality, Perplexity Pro Subscription, AI Tools and Resources
- Perplexity AI struggles with image generation: Users are experiencing difficulties with the 'Generate Image' feature in the Perplexity app, often finding it hidden or unresponsive in certain orientations.
- One user resolved their issue by changing their phone's orientation to landscape mode, revealing the feature.
- Claude and GPT Model Comparisons: Claude models are noted to be effective for writing, but users argue that they may not perform as well in Perplexity compared to using them directly on the official site.
- Pro users generally find the paid versions of AI models like Claude to be more beneficial due to their enhanced features.
- Exploring Custom GPTs: Custom GPTs allow users to edit personality traits and guidance settings, enhancing their interaction experience.
- One participant expressed interest in trying the custom GPT options for organizing their thoughts and developing ideas.
- Concerns About AI's Capability: Users expressed doubts regarding the capabilities of open-source and some commercial AI models, noting limited performance in complex problem-solving.
- There was a consensus among participants that many AI models are not meeting expectations in handling complicated tasks.
- Perplexity Pro Subscription Features: Members discussed the advantages of the Perplexity Pro plan, highlighting its extensive features compared to the free version.
- Participants shared referral codes for discounts, indicating interest in subscription services that enhance research and coding capabilities.
- $10 off Perplexity Pro - Discount Referral Link: Get a $10 discount on your first month of Perplexity Pro. Use this referral link for AI-powered search and analysis from Perplexity AI.
- DeepSeek: Chat with DeepSeek AI.
- Dr Austin GIF - Dr Austin Powers - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (8 messages🔥):
OpenAI's Sora release, Bitcoin reaching $100K, World's largest gold deposit, Perplexity AI updates, AI and monitoring in 2025
- OpenAI's Sora has finally launched: According to recent discussions, OpenAI's Sora has finally been released, exciting many within the AI community.
- A member shared a YouTube video that elaborates on its features and implications.
- Bitcoin hits the $100K milestone: A notable event discussed is Bitcoin reaching $100K, marking a significant milestone in the cryptocurrency market.
- This surge prompted many members to speculate on the future of cryptocurrencies.
- Discovery of the world's largest gold deposit: Members in the channel discussed the stunning news about the world's largest gold deposit being found, which could have major economic implications.
- The conversation included references to its potential impact on global gold prices and mining operations.
- Perplexity AI updates trace back to various queries: Several users shared links to relevant information on Perplexity AI, including specific queries about features and functionalities.
- One shared a direct link, highlighting the ongoing interest in improving user engagement with Perplexity AI.
- AI trends and monitoring in 2025: A member highlighted a link discussing AI and monitoring in 2025, addressing the future landscape of technology and its implications.
- This raised questions about challenges and opportunities in AI development moving forward.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
Service Restoration
- Service Back Online: A member noted that the service seems to be back up now, expressing gratitude towards those who fixed the issue.
- This indicates that previous downtime issues have been resolved, allowing users to return to normal operations.
- Community Thank You: Another member acknowledged the efforts of those involved in restoring the service, indicating a positive sentiment within the community.
- This appreciation reflects the collaborative nature of the community in addressing service interruptions.
OpenAI ▷ #annnouncements (1 messages):
Canvas updates, 12 Days of OpenAI
- Exciting Canvas Updates Unveiled: In the YouTube video titled 'Canvas—12 Days of OpenAI: Day 4', Kevin Weil, Lee Byron, and Alexi Christakis introduced and demoed updates to the Canvas feature.
- Catch the full presentation here.
- Join the 12 Days of OpenAI: Stay informed about the 12 Days of OpenAI by grabbing the <@&1261377106890199132> role in
- Make sure you don't miss out on any exciting updates or events!
Link mentioned: Canvas—12 Days of OpenAI: Day 4: Kevin Weil, Lee Byron, and Alexi Christakis introduce and demo updates to canvas.
OpenAI ▷ #ai-discussions (149 messages🔥🔥):
Sora Generation Speculations, AI Model Comparisons, LLM Capabilities, User Experience with New Features
- Mixed Reactions to Sora's Functionality: Users expressed skepticism about Sora's capabilities, questioning the quality of generated content and suggesting it could be merely stock footage.
- Some noted the short duration of outputs, like a five-second video generation, as limiting for creating substantial content.
- Comparing AI Models and Their Performance: Discussion around different AI models highlighted opinions on Claude versus Sora, with some users claiming O1 is superior for specific tasks.
- Users shared experiences with models like Leonardo and Ideogram, noting the ease of use and output quality compared to Sora.
- Challenges in Teaching AI about Tools: Concerns were raised regarding whether models like O1-mini should be taught about tools or learn contextually through interaction.
- Participants discussed the implications of AI requiring context for new features and capabilities in interaction with users.
- Expectations for AI Capabilities: There was a conversation about the future of AI, including the potential for models to dynamically generate user interfaces and respond to user needs without explicit instructions.
- Some participants questioned the feasibility and practicality of making every interaction AI-driven, citing confusion and usability concerns.
- User Feedback on AI Innovations: Users shared varied opinions on the pace and nature of AI development, expressing frustration at vague promises without concrete outcomes.
- As discussions unfolded, some pointed to a need for clearer visions of how advancements would translate into usable technology.
OpenAI ▷ #gpt-4-discussions (23 messages🔥):
Sora account issues, GPT-3.5 development struggles, Domain verification problems, Refunding clients, Communication with moderators
- Sora account creation unavailable: Users are experiencing issues with creating Sora accounts, with some reporting that account creation is currently unavailable despite having paid accounts.
- It's overloaded because everyone wants to try it out, indicated one user while suggesting they check back later.
- GPT-3.5 struggles in development: A developer expressed frustration with GPT-3.5 while building an app, indicating it was malfunctioning and questioning whether to stall their client or issue a refund.
- Another participant advised that refunding the client might be more beneficial in the long run, suggesting honesty about their skill level.
- Domain verification hurdles: A user encountered an error while verifying their domain, leading to questions about how to proceed after receiving an expired verification token message.
- Another user suggested starting fresh to resolve the verification issue after attempting multiple times without success.
- Ethics of client refunds: A discussion arose around the ethics of refunding a client who had paid for an unfinished app, emphasizing that it is not right to withhold their money.
- One user pointed out that no AI could compensate for lack of experience in delivering the promised product.
- Moderation and communication rules: A user was reminded to keep replies relevant and to present their own thoughts instead of solely relying on GPT-3.5 outputs.
- This led to a lighthearted exchange about the consequences of using AI-generated replies that might confuse moderators.
OpenAI ▷ #prompt-engineering (12 messages🔥):
Custom GPTs continuity, Nested code blocks, Translation effectiveness, OpenAI API model fine-tuning
- Maintaining continuity in Custom GPTs: A member explained that you can start new Custom GPTs and ask old ones for key summaries to synthesize continuity.
- Custom GPTs lose tool connections when updated by the authors, making it an ongoing challenge.
- Tips for nested code blocks: A member shared that using two backtick marks is key for proper nesting in code blocks, which aids in rendering correctly.
- They provided an example YAML and Python code demonstrating the usage of internal double backticks.
- Translation and prompt effectiveness: It was noted that prompts written in English could yield better output when the expected response is in a foreign language.
- The model's stronger training in English might contribute to this advantage, as it has effectively translated many languages.
- Issues with fine-tuning OpenAI models: A member shared their struggle with fine-tuning a model in Node.js, reporting that the model returns generic answers even after fine-tuning.
- They requested help with their training JSONL file to diagnose potential issues, indicating a need for external validation.
OpenAI ▷ #api-discussions (12 messages🔥):
Custom GPTs updates, Nested Code Blocks, Fine-tuning models, Translation quality, Synthesis of continuity
- Custom GPTs lose connections on updates: A member noted that Custom GPTs lose tool connections when updated by their authors, emphasizing the need for an ongoing management approach.
- 'That's what I do if I want to synthesize continuity.'
- Nested Code Block techniques: A user shared frustration regarding ChatGPT not outputting nested code blocks correctly, specifically wishing for a single code block response.
- Another member advised using double backticks for nesting, demonstrating with an example of nested code blocks.
- Translation output nuances: A query arose about whether prompts in English yield better outputs when the target language is different.
- A fellow member suggested that the model, trained primarily on English, tends to perform better when prompts are formulated in English.
- Troubles with fine-tuning models: A user reported difficulties in fine-tuning their OpenAI-based app in Node.js, noting that the model fails to learn context.
- They sought assistance with their training JSONL, aiming to identify potential issues with their approach.
Bolt.new / Stackblitz ▷ #prompting (27 messages🔥):
Prompting conventions, Subscription management with Bolt, Shopify automation, Document scanning issues, Integration with Airtable
- Need for Awesome Prompting Conventions: Discussion emerged about the need for a 1000% awesome prompting convention to streamline inputs and reduce frustration with token use in Bolt.
- Members expressed interest in best practices for effective prompting to enhance user experience.
- Exploring Subscription Management with Bolt: A user inquired about the possibility of using Bolt for subscription management and webhooks with platforms like Stripe or Recurly.
- No definitive solutions were offered, but users were encouraged to explore integrations.
- Shopify Automation Questions: There was a question about automating Shopify processes, with members discussing the need to integrate APIs for product synchronization.
- A specific user indicated they are building an internal dashboard that requires product sync for better management.
- Document Scanning Issues in Bolt: Users reported errors with scanning and uploading documents into apps, particularly in relation to OCR functionality.
- Suggestions included transforming documents into a readable format before uploading them into Bolt.
- Integration of Airtable with Bolt: A user noted their inventory is managed on Airtable and synchronized with a web app created using Bolt.
- Questions arose regarding Bolt's handling of such integrations and if it could effectively manage the connected data.
- Tweet from Tomek Sułkowski (@sulco): Did you know you can start a Bolt project by adding "?prompt=" to the URL like this?💡 #bolttipIt also allows for all kinds of cool lightweight integrations with Bolt; e.g. you can dynamically...
- Shopify API, libraries, and tools: Learn about Shopify APIs, libraries, and tools, and select the right option for your use case.
Bolt.new / Stackblitz ▷ #discussions (114 messages🔥🔥):
Token Issues and Subscription Support, Integrations with Payment Gateways, Using Multiple LLMs, Image Upload Problems, Troubleshooting No Preview Available
- Token Issues and Subscription Support: Users are experiencing confusion regarding free tokens after subscription ends, with some receiving unexpected token allocations. One advised contacting support if billing issues arise.
- Tokens do not stack, and Pro plan tokens reset every 30 days, as confirmed by other users.
- Integrations with Payment Gateways: Discussions arose around integrating payment gateways like Payfast and PayStack with Bolt. Overall, users are unsure if the integration process is similar to Stripe.
- One user expressed a need for clarity on whether separating dashboard features would improve functionality in larger projects.
- Using Multiple LLMs: A user inquired about the possibility of utilizing multiple LLMs at once in Bolt for complex project requirements. Another member confirmed that this functionality is not available currently.
- Users explored potential methods of improving productivity and management within larger codebases.
- Image Upload Problems: Users reported issues with local images not displaying properly in Bolt, leading to frustration over token usage without success. Solutions were suggested, including using external services for uploads.
- A guide was shared on correctly integrating image upload functionality within apps.
- Troubleshooting No Preview Available: Some users faced a 'No Preview Available' error when projects failed to load properly after modifications. Users proposed creating dedicated discussion topics for deeper troubleshooting.
- A member shared their troubleshooting steps including reloading and seeking help with error messages.
- Tweet from StackBlitz (@stackblitz): To kick off this Week of Thanks, our team put together a fun gift for y'all to use over the holiday:We call them, TURKEY TOKENS! 🦃🪙 Thru Nov 30th:🦃 All Pro users get 2m free tokens!🦃 All Free ...
- uploadthing: An easier way to upload files.
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Bolters.io | Community Supported Tips, Tricks & Knowledgebase for Bolt.new No-Code App Builder: Documentation and guides for Bolt.new
- GitHub - stackblitz/bolt.new: Prompt, run, edit, and deploy full-stack web applications: Prompt, run, edit, and deploy full-stack web applications - stackblitz/bolt.new
- Building with Bolt, Episode 3: Two super handy Bolt tricks - Locking files and Extracting: In this episode I share what I think are two of the most useful features in Bolt.new, one of which, locking - should be at the top of anyone's list that want...
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - FixTweet/FxTwitter
Modular (Mojo 🔥) ▷ #general (45 messages🔥):
Swag Challenge Winners, User Engagement on the Forum, Network Interrupt Issues, Mojo Language Typing, Hugging Face Integration
- Swag Challenge Winners Announced: The winners of the day 1 swag challenge have been announced on the forum. You can check the details here.
- Yay for the t-shirt winners who joined the excitement!
- Forum Engagement Encouraged: Members were reminded that any obviously AI-generated content will be deleted to maintain forum quality. This effort aims to foster a fun and genuine place for discussion.
- Participants expressed gratitude for this initiative, highlighting the importance of authenticity.
- Network Interrupts Cause Weight Issues: A discussion highlighted that during network interrupts, models can use incorrect weights due to lack of validation. Sample outputs demonstrated bizarre corruption in data from such scenarios.
- This issue has been addressed by incorporating checksums in the downloading process, improving reliability.
- Typing Issues in Mojo Language: Concerns were raised regarding Mojo's typing system not being strongly typed, requiring manual declaration of variable types. This sparked a discussion about the complexities compared to languages like Rust.
- Users highlighted the challenges of type inference and function overloading, comparing it to Rust's capabilities.
- Hugging Face Enhancements: Integrating with
huggingface_hubhas led to automatic restoration of interrupted downloads, improving robustness. This change followed encountering corruption issues with large weights in previous versions.- The updates in the MAX Graph pipelines leverage Hugging Face for better performance and reliability.
- Winners of Day 1 swag challenge! 🏆: Congrats to the winners of our day 1 swag challenge! Keep an eye out for a DM to coordinate your T-shirt delivery. @lesoup-mxd @Zbornak @martinvuyk @IvoB @melodyogonna @sazid @Dasor @tristanbiesecke...
- Search results for 'eee' - Modular: no description found
- GitHub - modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
Modular (Mojo 🔥) ▷ #mojo (83 messages🔥🔥):
Destroy keyword in Mojo, Memory management in Multi-Paxos, Ownership semantics, Pros and cons of struct destructors, Implementation challenges in Multi-Paxos
- Understanding the Need for 'destroy' Keyword: Discussions on the necessity of a new
destroykeyword in Mojo highlighted the distinction from Python'sdel, focusing on stricter usage within linear types, which drives home safety during memory management.- Some members expressed that requiring
destroycould complicate the default behavior for newcomers transitioning from Python, stressing the importance of clarity.
- Some members expressed that requiring
- Memory Management in Multi-Paxos: The implementation of Multi-Paxos emphasized statically allocated structures to meet the no-heap-allocation requirement, which supports pipelined operations crucial for high performance.
- Critiques pointed out the need for comprehensive handling of promises and leader elections to fulfill the consensus algorithm's requirements, marking it as essential for robust functionality.
- Ownership Semantics in Mojo: The conversation about ownership methods demanded clarity on how Mojo's types should handle destructors, especially contrasting default handling for copy and move constructors against destructors.
- Elements like
__del__(destructor) were highlighted as potentially confusing for those migrating from languages with automatic memory management, reinforcing the need for consistent syntax.
- Elements like
- Struct Destructors in Design: Concerns were raised regarding the practicality of requiring empty
__del__methods for all structs, which seem unnecessary given that the default behavior should ideally handle memory management effectively.- The argument was made for treating destructors similarly to copy and move methods, suggesting a balance between ease of use and explicit control in programming.
- Implementing Multi-Paxos Challenges: Feedback on the prototype implementation of Multi-Paxos corrected misconceptions about its operations, emphasizing that it must account for leader stability and numerous robustness features.
- The dialogue recognized the complexity involved in the design of consensus protocols, advocating for essential features like timeouts and leader election mechanics.
- mojo: your_name_here
- Ownership and borrowing | Modular Docs: How Mojo shares references through function arguments.
- [Discuss] Resyntaxing argument conventions and References · Issue #3623 · modularml/mojo: The design of the Mojo references subsystem is starting to come together. To finalize the major points, it helps to come back and re-evaluate several early decisions in Mojo to make the design more...
- [docs] Stdlib insider documentation by owenhilyard · Pull Request #3793 · modularml/mojo: People working on the standard library need to have some more information about the API contracts and behavior of the runtime and compiler builtins in order to be able to write correct and performa...
Notebook LM Discord ▷ #use-cases (43 messages🔥):
Podcast Content Creation, Source Utilization Challenges, Language Settings, AI Podcast Generation, Community Engagement in AI
- Unlocking Podcast Potential with NotebookLM: A member shared a YouTube video titled "NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!)" that offers exclusive podcast prompts refined to enhance creativity.
- The tutorial emphasizes a variety of unique methods designed to help users in the AI News community stand out.
- Frustrations with Source Limitation in NotebookLM: A user expressed frustration, stating that they need 15 sources for a paper but NotebookLM only utilizes 5-6 when prompted.
- Advice was shared on adding source limits during queries to ensure diverse referencing.
- Community Request for Language Options: A user asked how to change their language to English on NotebookLM, emphasizing urgency due to an upcoming exam.
- Cost-saving advice included toggling browser settings and refreshing the NotebookLM page to achieve the desired language.
- Experimenting with AI Podcast Formats: A member mentioned adding a fact-checker to their AI podcast, enhancing the quality of dialogue and preventing inaccuracies during a 90-minute show.
- They shared audio teasers showcasing the results of their innovative approach to podcast creation.
- Engaging Audio Experiments with NotebookLM: The channel discussed a variety of audio clips created using NotebookLM, exploring different prompts and perspectives to yield unique outcomes.
- Members shared several clips showcasing the potential of using AI-generated content in compelling podcast formats.
- no title found: no description found
- Punk Meets Processor AI Podcast: 🎙️ New Episode Alert! 🚨What happens when a punk and an AI chatbot sit down for an unfiltered, no-holds-barred conversation?🤖🔥 “Punk Meets Processor” – th...
- no title found: no description found
- Amir Tsarfati 9/11 Deceiving and Being Deceived. From Such Turn Away! Let No Man Deceive You!: Do not be deceived! Pray for Amir and those believing the lies that they may come to repentance.God bless and keep you all, the grace and peace of Jesus Christ be with you always!JD Faraq video; https...
- NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!): Get these exclusive NotebookLM Podcast prompts for free! I’ve spent hours refining these 10 unique methods to help The AI News community stand out. Just watc...
- NotebookLM podcast-hack 09: dare to disagree # 4: A highly relevant discussion about techno-optimism, without consensus.All excerpts are generated entirely with NotebookLM, without any editing.
- Samurai Basics and General/Combat Feats: In the Naruto Pathfinder Conversion Mod, players can elect to become a Samurai. If they are not of the Samurai Class, they Gain the "Challenge" Ability as if they were a Samurai of their le...
Notebook LM Discord ▷ #general (51 messages🔥):
NotebookLM Features, Podcast Functionality, User Experience Issues, Customization Queries, Language Support
- NotebookLM Saves Notes in View Only: Users found that 'saved response notes' in NotebookLM are view-only, requiring manual opening for edits, leading to confusion about ongoing modifications.
- One user expressed frustration about not being able to modify saved notes after initial saving.
- Demand for More Voices in Podcast Feature: Instructors noted that the current podcast voices are likened to 'Barbie and Ken', raising questions about the addition of more diverse voice options.
- There was also mention that one of the voices resembles Katee Sackhoff, which felt odd for educational content.
- Language Support for Podcast Feature: Users inquired about the ability to produce podcasts in different languages, specifically requesting French support.
- Discussions also included requests for timelines on when more languages, including German, will be available.
- Troubleshooting Sharing Issues: Users expressed challenges with sharing notebooks using 'copy link', resulting in receivers seeing a blank page unless they were added as viewers first.
- Clarifications were made regarding the steps needed to successfully share notebooks.
- Enhancing Podcast Length: A user asked about how to shorten podcast episodes, specifically aiming for 1-minute durations.
- There was also interest in how to automate content fetching for podcasts using tools like CustomPod.
- no title found: no description found
- Huh Camille GIF - Huh Camille Confused - Discover & Share GIFs: Click to view the GIF
- 🕷️ on Instagram: 0 likes, 0 comments - somebiohacker on December 10, 2024
- The neural basis of temporal processing - PubMed: A complete understanding of sensory and motor processing requires characterization of how the nervous system processes time in the range of tens to hundreds of milliseconds (ms). Temporal processing o...
- NotebookLM tutorial to 10x your productivity: Want to become master in NotebookLM and 10x your productivity just Watch this full video. I go from basics to advanced all in one video with 2 real world sce...
- NotebookLM Podcast Tutorial: 10 Secret Prompts (People Will Kill You For!): Get these exclusive NotebookLM Podcast prompts for free! I’ve spent hours refining these 10 unique methods to help The AI News community stand out. Just watc...
- NotebookLM on Project 2025 – Moving at the Speed of Creativity: no description found
- Digital Writing, Digital Teaching: The Homepage of Dr. Troy Hicks
LM Studio ▷ #general (78 messages🔥🔥):
LM Studio Updates, Tailscale Configuration, Model Compatibility Issues, RAG Techniques, Performance Optimization
- Updating LM Studio to Latest Version: A user mentioned issues with LM Studio being outdated and thanks another for confirming that in-app updates may not update to newer versions like 0.3.x automatically.
- A suggestion was made to perform a manual update to ensure compatibility with newer models.
- Configuring LM Studio with Tailscale: A user successfully configured LM Studio to work with Tailscale by using the device's MagicDNS name instead of the IP address.
- This method enhanced accessibility and resolved previous connection issues.
- Challenges with Model Compatibility: Several users discussed issues regarding compatibility with specific models, including LLAMA-3_8B_Unaligned, questioning whether the models are functional.
- It was suggested that the model might be broken due to recent updates or changes.
- Using RAG for Document Processing: A user inquired about merging documents using generative AI and received advice on utilizing RAG techniques to enhance performance.
- It was suggested to provide detailed descriptions of speech patterns instead of dumping entire conversations for better results.
- Performance Optimization Tips: There was a discussion around GPU optimizations, highlighting that shared VRAM could slow down performance and suggesting limiting GPU load.
- Users shared experiences of modifying batch sizes and context length to optimize processing time and resources.
- Ducktales Ducktales2017 GIF - Ducktales Ducktales2017 Infernal Internship Of Mark Beaks - Discover & Share GIFs: Click to view the GIF
- ogkalu/comic-speech-bubble-detector-yolov8m · Hugging Face: no description found
- SicariusSicariiStuff/LLAMA-3_8B_Unaligned_BETA_GGUFs · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- LM Studio - Discover, download, and run local LLMs: Run Llama, Mistral, Phi-3 locally on your computer.
LM Studio ▷ #hardware-discussion (9 messages🔥):
Cooling Solutions, Reservoirs and Pumps, Alphacool Products, GPU Cooling Setup
- Epic Cooling for GPUs: A member praised the cooling setup, stating it's epic and should provide sufficient cooling for the multiple GPUs being used.
- The user highlighted multiple GPUs and the cooling demands they create, ensuring the system is well-equipped.
- Reservoir Size Adjustments: A member noted that their D5 pump mounted reservoir wouldn't fit, opting for an Alphacool 5.25" bay reservoir instead.
- They provided a link to the Alphacool reservoir that they decided on.
- Alphacool and D5 Pump Compatibility: Another user mentioned that Alphacool also has a reservoir that can accommodate the D5 pump installed within it.
- This indicates awareness among members about product variations available from Alphacool.
- Challenges with Space in Big Cases: One member reflected on their large case, filled with components like 4 GPUs and 8 HDDs, leading to spatial constraints.
- They mentioned that, despite having a large case, their setup is FULL, making it a challenge to fit all components properly.
- Water Cooling Product Innovation: A member humorously remarked on the timeless design of water cooling products, which innovatively claim to improve functionality while looking similar.
- 20 years later, the struggle between new technology and traditional aesthetics persists in water cooling designs.
Link mentioned: no title found: no description found
Nous Research AI ▷ #announcements (1 messages):
New Channel for Collaborations
- New Collaboration Channel Launched: A new channel has been created for members to collaborate on projects, titled <#1316137596535177246>.
- This space is designed for users to work with each other and engage in project development.
- Opportunity for Community Engagement: The channel encourages community members to bring their project ideas and work together.
- Members are invited to utilize this space for building and sharing their initiatives.
Nous Research AI ▷ #general (61 messages🔥🔥):
Idefics Model Insights, Collaborations in Research, Long-term Memory Pathways, VLM Model Fine-tuning, Forum Creation for Project Discussion
- Exploring Idefics and Its Creators: A member inquired about the people behind the Idefics model family associated with Hugging Face, emphasizing interest in its development.
- Another user contributed by pointing out that Idefics is part of the VLM model family, offering a hint of its importance.
- Collaboration Requests Abound: Maitri from Team Veera expressed interest in exploring partnership opportunities with Nous Research, asking how to move forward.
- Another member introduced themselves as a cofounder of an open source project, seeking collaboration without any sales agenda.
- New Findings in Long-term Memory: A member shared a noteworthy article about researchers discovering new pathways to long-term memory formation that bypass short-term memory.
- Discussion ensued on the implications of this finding, with members exploring the potential of manipulating memory creation.
- Fine-tuning Challenges with VLMs: Members discussed the challenges of fine-tuning VLM models like Llama Vision, highlighting that Hugging Face (hf) does not support it well.
- Suggestions included using Unsloth and resources like the AnyModal GitHub project for multimodal framework adjustments.
- Creating a Forum for Project Collaborations: A new channel was established for project collaborations, allowing users to discuss and share ideas for potential partnerships.
- Members expressed enthusiasm for this forum-style channel, with one user suggesting organizing discussions into subcategories.
- Tweet from Cognition (@cognition_labs): Devin is generally available today! Just tag Devin to fix frontend bugs, create first-draft PRs for backlog tasks, make refactors, and more.Start building with Devin below:
- Neuroscientists discover a new pathway to forming long-term memories in the brain: Researchers from Max Planck Florida Institute for Neuroscience have discovered a new pathway to forming long-term memories in the brain. Their work, published in Nature Neuroscience, suggests that lon...
- GitHub - ritabratamaiti/AnyModal: AnyModal is a Flexible Multimodal Language Model Framework for PyTorch: AnyModal is a Flexible Multimodal Language Model Framework for PyTorch - ritabratamaiti/AnyModal
Nous Research AI ▷ #ask-about-llms (17 messages🔥):
Building a Security Agent, ReAct Agent Examples, Observability in RAG Systems, Generating O1-type Synthetic Data, Thinking LLMs Paper from Meta
- Building a Simple Security Agent: A user shared their approach to building a simple security agent using the OpenAI API and a wrapper for easy function handling, documenting steps such as creating a Tool class and utilizing a loop for task completion.
- Another member acknowledged that the complexity arises in more advanced architectures like multi-agent systems and ReAct strategies.
- Exploring ReAct Agent Interactions: A user inquired about documentation for various strategies in making agents reason and interact with their environment, while discussing the potential for using outputs as user inputs.
- A reference example using the ReAct framework was suggested, highlighting how the assistant can role-play as the user in the interaction.
- Observability in RAG Systems: One user asked how to enhance observability for Ollama requests to track progress and analyze data in a RAG system context.
- They sought to transform standard logs into more verbose records detailing prompts tested and outputs produced.
- Generating O1-type Synthetic Data Resources: A user sought resources for generating O1-type synthetic data, prompting another member to recommend the Thinking LLMs paper from Meta for its interesting techniques.
- They linked their experiments related to the impact of OpenAI-O1, hinting at how LLMs have traditionally struggled with reasoning tasks.
- Insights from the Thinking LLMs Paper: A member discussed the Thinking LLMs paper, focusing on its methodology for LLMs to list internal thoughts and evaluate responses before finalizing an answer.
- They illustrated the concept with an example showcasing an LLM's tendency to 'overthink' when generating answers.
Link mentioned: Thinking LLMs: General Instruction Following with Thought Generation | Oxen.ai: The release of OpenAI-O1 has motivated a lot of people to think deeply about…thoughts 💭. Thinking before you speak is a skill that some people have better than others 😉, but a skill that LLMs have c...
Nous Research AI ▷ #interesting-links (1 messages):
deki04: https://x.com/omarsar0/status/1866143542726340890?s=46
Nous Research AI ▷ #reasoning-tasks (5 messages):
Scratchpad Feedback, Visual Representation of Outputs, Core Reasoning Task Insights
- Feedback on Scratchpad Format: Concerns were raised about the readability of the new scratchpad-think format, with one member admitting it feels like a 'mess' to read yet finds it substantial for review.
- The member emphasized the importance of logging logic via scratchpad and indicated uncertainty about who would prefer this format.
- Visuals Aid Discussion: Visual aspects of the reasoning task outputs were shared, highlighting the uncertainty around its effectiveness for readers.
- The member noted that while visuals may make understanding easier, the inherent messiness of scratchpad output could still pose difficulties.
- Core Insights on Reasoning Tasks: The core of the reasoning task project was identified as outputs generated without predefined system prompts, suggesting a focus on raw model output.
- The member reflected that this raw output might be 'worth' sharing, indicating a desire for further engagement despite recognizing the text's cluttered nature.
Interconnects (Nathan Lambert) ▷ #events (12 messages🔥):
Conference Profile Publicity, Microwave Gang, Discord Profile Names
- Nate's Conference Profile Needs Public Access: A member emphasized the need for Nate to make his conference profile public so introductions can happen smoothly.
- Lolol was the playful response from another member, suggesting humor in the situation.
- Discussion on Microwave Gang: A light-hearted inquiry was made about the 'Microwave gang', prompting some confusion among members.
- A member shared a link to the Microwave Gang subreddit for further exploration.
- Profile Names Inspired by Family: One member shared a humorous take on their Discord profile name, stating they became lazy and used their initials.
- They also mentioned letting their daughter pick their main profile name and picture, adding a personal touch.
- Open Hangouts Announcement: Nate communicated plans for two open hangouts scheduled for Thursday and Friday between 1:30-2:30 PM.
- He indicated that details about the venue would be finalized and that there may be an early start for partially informed paid attendees.
- Anticipation of Upcoming Meetings: A member expressed excitement for the upcoming meetings by responding with 'Amazing, see you soon!'.
- This shows enthusiasm and fosters a positive atmosphere among participants.
Link mentioned: Reddit - Dive into anything: no description found
Interconnects (Nathan Lambert) ▷ #news (12 messages🔥):
DeepSeek V2.5 Launch, Internet Search Feature, DeepSeek License Discussion
- DeepSeek V2.5 Launch Announcement: The new version of DeepSeek, DeepSeek-V2.5-1210, was announced with excitement, indicating it as the 'Grand Finale'.
- Members discussed the launch with enthusiasm, noting that they'd been waiting for this update.
- Real-Time Internet Search Goes Live: DeepSeek announced that the Internet Search feature is now live, providing real-time answers on their chat platform.
- Users are encouraged to toggle the feature to access immediate search results.
- Discussion on DeepSeek License: A member expressed a desire for the DeepSeek license to be Apache, questioning whether the current license allows for synthetic data generation.
- Another member confirmed that it is allowed under the current terms, though it's not commonly tried.
- Speculation on OLMo Testing: Following the license discussion, a member mentioned they would check for details on OLMo, suggesting there's ongoing interest in evaluations.
- This highlights the community's engagement in exploring capabilities related to synthetic data generation.
- Community Reactions to New Features: Members reacted positively to the news of the search feature launch, with excitement about its potential.
- One member notably said, 'oh they launched search', reflecting the general enthusiasm.
- deepseek-ai/DeepSeek-V2.5-1210 · Hugging Face: no description found
- Tweet from DeepSeek (@deepseek_ai): 🚀 DeepSeek-V2.5-1210: The Grand Finale 🎉🌐 Internet Search is now live on the web! Visit https://chat.deepseek.com/ and toggle “Internet Search” for real-time answers. 🕒🧵(1/3)
Interconnects (Nathan Lambert) ▷ #ml-drama (4 messages):
Sam confirmed as CEO, User identity confusion, Footwear preferences
- Sam Confirmed as CEO: Sam Altman has been confirmed as the CEO amid various discussions in the channel.
- This confirmation has sparked an ongoing dialogue about his leadership.
- Identity Confusion in the Chat: A member humorously questioned whether another participant is Sam Altman, indicating the need for disclosure if true.
- The playful tone of the question reflects the light-hearted atmosphere of the chat.
- Footwear Taste vs Resume Debate: One user humorously claimed to have better taste in footwear but a worse resume than Sam.
- This comment adds a comedic angle to the conversation about identity in the chat.
Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
vLLM Project Joins PyTorch, Expectations on Model Capabilities, Conference Experiences
- vLLM Now Part of PyTorch Ecosystem: The vLLM project has officially joined the PyTorch ecosystem to enhance its high-throughput, memory-efficient inference capabilities for large language models.
- Utilizing the innovative PagedAttention algorithm, vLLM is continuously updated with new features like pipeline parallelism and speculative decoding.
- Product Problem, Not Science: A discussion emphasized that working with models like o1 is now a product problem, reliant on the right data and context rather than scientific limitations.
- One quote summed it up: “With how smart o1-pro is, the challenge isn’t really 'can the model do it’ anymore.”
- Conference Fame Comes with Challenges: A member humorously remarked on the challenges of attending large conferences, stating they are now 'too famous' to go in peace.
- They shared experiences of people wanting photos, highlighting the unique dynamic of conference interactions.
- Tweet from Abram Jackson (@abrakjamson): Everyone needs to understand this. If you are able to bring in all the right data, formulate the question exactly right, and give it the necessary tools, o1 will do anything.It is a product problem no...
- vLLM Joins PyTorch Ecosystem: Easy, Fast, and Cheap LLM Serving for Everyone: no description found
- Tweet from MattVidPro AI (@MattVidPro): 😬😬😬
- GitHub - allenai/awesome-open-source-lms: Friends of OLMo and their links.: Friends of OLMo and their links. Contribute to allenai/awesome-open-source-lms development by creating an account on GitHub.
Interconnects (Nathan Lambert) ▷ #memes (7 messages):
xAI and Pepes, Fchollet's Scaling Law Discussion, Twitter Dynamics
- xAI Embraces Pepes: A member highlighted how xAI specifically features pep emojis in their communications, showcasing their playful branding.
- They shared a link to the Grok Image Generation release for further context.
- Fchollet Responds on Scaling: In a tweet, Fchollet addressed misunderstandings about his stance on scaling laws in AI, emphasizing he never opposed scaling but critiqued over-reliance on larger models.
- He insisted that the focus should shift from asking if LLMs can reason to whether they can adapt to novelty, mentioning he proposed a mathematical definition for the latter.
- Humorous Reactions to Fchollet: Members found humor in Fchollet's tweet thread, particularly with responses like 'Smited' and 'Smote.'
- One member expressed amusement at the intensity of discussions on Twitter, suggesting a shift towards more direct responses.
Link mentioned: Tweet from François Chollet (@fchollet): Dude, what are you talking about?1. I have no idea who you are, so I don't "think" anything about you.2. I have never bet against scaling laws. Rather, I have pushed back against the idea ...
Latent Space ▷ #ai-general-chat (44 messages🔥):
WaveForms AI Launch, vLLM Joins PyTorch, Devin Generally Available, Molmo Full Recipe Release, State of AI Agents 2024 Report
- WaveForms AI Launches: Announced by @alex_conneau, WaveForms AI is an Audio LLM company aiming to solve the Speech Turing Test and introduce Emotional Intelligence to AI.
- This launch highlights the ongoing trend of integrating emotional understanding into AI products.
- vLLM Joins the PyTorch Ecosystem: @vllm_project stated that joining the PyTorch ecosystem ensures seamless compatibility and performance optimization, enhancing AI innovation.
- This integration is expected to improve accessibility for developers working on AI projects.
- Devin Now Generally Available: Cognition has announced that Devin is available starting at $500 a month, offering benefits like no seat limits and various integrations.
- This tool aims to assist engineering teams in debugging, creating PRs, and making code refactors efficiently.
- Molmo Full Recipe Released: @allen_ai shared that they released the full recipe for Molmo, including training code and updated tech reports, making it easier for others to reproduce their models.
- This release is an important step for collaborative development in the AI community.
- State of AI Agents 2024 Insights: @MrAhmadAwais introduced the 'State of AI Agents 2024' report after analyzing 184 billion tokens and 4K builders' feedback, showcasing trends in the AI agents domain.
- These insights are vital for understanding the evolution of AI agent technologies.
- Tweet from undefined: no description found
- Cognition | Devin is now generally available: We are an applied AI lab building end-to-end software agents.
- Tweet from vLLM (@vllm_project): Open-source innovation is part of the vLLM’s DNA, and we love the PyTorch ecosystem! Together, let's push the boundaries of AI innovation and make it accessible to all💪Quoting PyTorch (@PyTorch) ...
- Tweet from Nous Research (@NousResearch): Announcing Nous Simulators!A home for all of our experiments involving human-AI interaction in the social arena. http://sims.nousresearch.com
- Tweet from Alexis Conneau @ NeurIPS (@alex_conneau): Excited to announce the creation of WaveForms AI (http://waveforms.ai) – an Audio LLM company aiming to solve the Speech Turing Test and bring Emotional Intelligence to AI @WaveFormsAI
- Tweet from Ahmad Awais (@MrAhmadAwais): Introducing … State of AI Agents 2024 🤖After handling an incredible 184 billion tokens and 786 million API reqs from 36K developers, we’ve gathered invaluable insights from 4K builders, the next-gen ...
- Tweet from Stainless (@StainlessAPI): Excited to share that we’ve raised a $25M Series A, led by @JenniferHLi @a16z along with @sequoia, @thegp, @felicis, @zapier, and @mongoDB Ventures:https://www.stainlessapi.com/blog/stainless-series-a
- TGI v3 overview: no description found
- Tweet from Ai2 (@allen_ai): Remember Molmo? The full recipe is finally out!Training code, data, and everything you need to reproduce our models. Oh, and we have updated our tech report too!Links in thread 👇
- Tweet from Jordan Singer (@jsngr): today @mainframe is excited to share our $5.5m seed to build new AI interfacesco-led by @lachygroom and @stellation with participation from @basecasevc @weekendfund & more
- Tweet from Doug Safreno (@dougsafreno): Big news today: @GentraceAI raised our $8M Series A led by @MatrixVC.We’re celebrating by launching Experiments, the first collaborative testing environment for LLM product development.
- Tweet from Amjad Masad (@amasad): Replit Agent—coming out of early access today—is the best way to go from an idea to a deployed app.Afterward, you'd want to iterate on features and fixes quickly.Enter Assistant—prompt to change a...
- Tweet from Yuchen Jin (@Yuchenj_UW): 🚀 Excited to share that we raised a $12M Series A!At Hyperbolic, our mission is to build an open AI platform. By "open", we mean:> Open GPU marketplace: Think of it as GPU Airbnb—anyone ca...
- LLM Research Papers: The 2024 List: A curated list of interesting LLM-related research papers from 2024, shared for those looking for something to read over the holidays.
- GitHub - allenai/awesome-open-source-lms: Friends of OLMo and their links.: Friends of OLMo and their links. Contribute to allenai/awesome-open-source-lms development by creating an account on GitHub.
- This is changing the way scientists research | Gemini: Gemini — Google’s newest and most capable AI model. 200,000 scientific papers with crucial science information gets read, understood, and filtered by Gemini ...
- Canvas—12 Days of OpenAI: Day 4: Kevin Weil, Lee Byron, and Alexi Christakis introduce and demo updates to canvas.
- Tweet from Aryan Vichare (@aryanvichare10): Introducing WebDev ArenaAn arena where two LLMs compete to build a web app. You can vote on which LLM performs better and view a leaderboard of the best models.100% Free and Open Source with @lmarena_...
Latent Space ▷ #ai-announcements (1 messages):
Sora Launch, Generative Video WorldSim, DeepMind Genie, VideoPoet, DeCAF Test of Time Winner
- Sora Launch in the Spotlight: The latest episode of the podcast features a 7-hour deep dive into OpenAI's Sora, highlighting insights from @billpeeb.
- Listeners can check out the episode here for a comprehensive overview of the launch.
- ICML 2024's Generative Video Innovations: This podcast episode includes discussions on Generative Video WorldSim, bringing together experts from different fields.
- Notable mentions include @jparkerholder and @ashrewards on DeepMind Genie, emphasizing innovations in AI.
- Exploring VideoPoet's Capabilities: Hosts delve into VideoPoet with insights from @hyperparticle, discussing its impactful features and applications.
- The episode highlights the importance of video generation in the realm of AI and machine learning.
- Flow Matching and Stable Diffusion 3 Discussions: The podcast features @rickytqchen discussing Flow Matching and @pess_r delivering insights on Stable Diffusion 3.
- These discussions reflect ongoing advancements in diffusion models, addressing cutting-edge techniques.
- Taking a Look at LLM and Robotics Convergence: Experts like @giffmana discuss the convergence of Vision and LLM, alongside contributions from @chelseabfinn on robotics.
- This segment is a part of the comprehensive round-up of prominent innovations presented at ICML.
Link mentioned: Tweet from Latent.Space @NeurIPSConf Live! (@latentspacepod): 🆕 Generative Video WorldSim, Diffusion, Vision, Reinforcement Learning and RoboticsOur longest episode ever! https://latent.space/p/icml-2024-video-robotsa deep dive into- @OpenAI Sora (with @billpe...
Axolotl AI ▷ #general (44 messages🔥):
Torch Compile Usage, Reward Models in RL, KTO Model Benefits, Dataset Limitations, Quantitative Research in Fine-tuning
- Torch Compile: Speed vs. Memory: Members discussed their experiences with torch.compile, noting minimal speed improvements and increased memory usage.
- One member remarked, 'it could just be a me problem tho.'
- Reward Models in Reinforcement Learning: A discussion around whether reward models are separate in RL led to the conclusion that in online RL, it is always a distinct model used for scoring.
- Members explored the implications of having a reward model, highlighting that it is frozen during real model training.
- KTO's Advantage over Original Models: Kaltcit praised the KTO model's ability to potentially exceed the performance beyond the original dataset criteria, pointing to their claims of robustness.
- However, members expressed the need for confirmation that it indeed provides better results compared to accepted data.
- Corroboration of KTO Findings: Kaltcit mentioned that Kalo has corroborated the findings of the KTO paper but lamented the lack of serious quantitative research among finetuners.
- Nanobitz noted that much of this may happen within organizations that do not share findings widely.
- Need for Multi-Turn and Scoring Adjustments: An inquiry was made about the aspects needed in Axolotl to integrate a reward model for scoring, emphasizing the desire to experiment with approaches that go beyond existing datasets.
- Kaltcit indicated that the current KTO setup might suffice for maximizing answers beyond original advantages.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (25 messages🔥):
Quizzes Access, Article Submission Guidelines, Hackathon Write-Up Requirements, Social Media Posting for Articles, Course Completion Requirements
- Accessing Quiz Links: A member inquired about where to find the links for the last two quizzes, expressing difficulty in locating them.
- Another member pointed out that the links are available in the syllabus section on the course website.
- Clarification on Article Submission: Questions arose regarding the format of article submissions, specifically the number of articles needed per student for a hackathon team versus for MOOC certificates.
- It was clarified that only one write-up is required per hackathon team, but each student must submit their individual articles to qualify for MOOC completion.
- Breaking Down Articles for Submission: Members discussed the feasibility of breaking down their written articles into smaller posts for social media use.
- It was confirmed that this is acceptable as long as all drafts and links are included in the final submission to receive credit.
- Overall Course Completion Queries: A member expressed uncertainty about meeting all course requirements and whether their quiz submissions were correctly linked to their profile.
- Clarification was sought on how to verify completion of all quizzes and submission processes.
- Using LinkedIn for Article Posts: Discussion on the appropriateness of using LinkedIn to share articles related to course assignments took place.
- It was confirmed that summarizing content for LinkedIn posts is permissible and aligns with submission guidelines.
Link mentioned: Large Language Model Agents MOOC: MOOC, Fall 2024
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (3 messages):
Function Calling in LLMs, Important Papers in Tool Learning
- Understanding Function Calling Mechanisms: A member shared a link to the documentation on function calling, explaining that it utilizes the function description and signature to set parameters based on prompts.
- It was suggested that models are likely trained on numerous examples to enhance generalization.
- Key Academic References for Tool Learning: A member highlighted several important papers, including one available at arXiv:2305.16504 and ToolBench on GitHub for understanding tool learning for LLMs.
- Another arXiv paper, arXiv:2304.08354, is also noted as potentially significant in the discourse.
- GitHub - OpenBMB/ToolBench: [ICLR'24 spotlight] An open platform for training, serving, and evaluating large language model for tool learning.: [ICLR'24 spotlight] An open platform for training, serving, and evaluating large language model for tool learning. - OpenBMB/ToolBench
- Tool Learning with Foundation Models: Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the...
LlamaIndex ▷ #blog (5 messages):
LlamaParse Auto Mode, LlamaParse Webinar, Document Agent Workflows, LlamaParse JSON Mode, Invoice Processing Agent
- LlamaParse Auto Mode Optimizes Costs: LlamaParse introduces Auto Mode, which parses documents in a standard, cheaper mode while selectively upgrading to Premium mode based on user-defined triggers. More details can be found here.
- Check out the benefits of this feature and how it optimally balances cost and performance.
- Get a Video Walkthrough of Auto Mode: A video walkthrough of LlamaParse Auto Mode is available here. Users are reminded to update their browsers to ensure compatibility with YouTube.
- Supported browsers include Google Chrome, Mozilla Firefox, and Opera.
- LlamaParse's Detailed JSON Mode: LlamaParse's JSON mode provides detailed parsing of complex documents, extracting images, text blocks, headings, and tables. For additional information, refer to this link here.
- This feature enhances control and capability in handling structured data extraction.
- Reminder for Upcoming Webinar: A reminder for an important webinar scheduled for this Thursday is shared. More details can be accessed here.
- Participants are encouraged not to miss this valuable opportunity for learning.
- Exploring Document Agent Workflows: The team is exploring innovative document agent workflows that extend beyond traditional tasks to automate complex processes. An end-to-end invoice processing agent is one of the projects aimed at extracting relevant information from invoices and matching it with vendors.
- Keep an eye on the developments on this promising workflow automation tool here.
Link mentioned: no title found: no description found
LlamaIndex ▷ #general (21 messages🔥):
Running Local Agent Examples, Issues with Document Retrieval, ColPali Reranking Feature, Cohere Rerank Postprocessor, Using Smaller Models
- Solving Local Agent Example Troubles: A member struggled to get the local agent example to run on their M1 Mac, receiving only 'Process finished with exit code 0'. Reassured by others, they found success after creating a clean project setup.
- Empty responses occurred when documents were not ingested; another user suggested checking if the data directory contained real text.
- ColPali Rerank Functionality Explanation: A new user inquired if the ColPali feature functions dynamically during PDF processing. It was clarified that it operates as a reranking tool rather than a standalone process.
- Another user confirmed that the ColPali addition is used primarily for reranking image nodes after retrieval.
- Cohere Rerank 3.5 Availability in Bedrock: A member raised a question about the availability of Cohere Rerank 3.5 through Bedrock as a postprocessor. It was pointed out that recent updates have integrated this feature, along with a link to the relevant documentation.
- They also provided the command to install it:
pip install llama-index-postprocessor-bedrock-rerank.
- They also provided the command to install it:
- Ollama Embeddings - LlamaIndex: no description found
- Starter Tutorial (Local Models) - LlamaIndex: no description found
- llama_index/llama-index-integrations/postprocessor/llama-index-postprocessor-bedrock-rerank at main · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex: no description found
- python-agents-tutorial/2_local_agent.py at main · run-llama/python-agents-tutorial: Code samples from our Python agents tutorial. Contribute to run-llama/python-agents-tutorial development by creating an account on GitHub.
Cohere ▷ #discussions (10 messages🔥):
Cohere's business context, Irrelevant humor in discussions
- Business Conversations Turn Silly: Members expressed frustration over jokes being irrelevant to Cohere's profit-driven context, reiterating that humor shouldn't overshadow business discussions.
- for profit,'* emphasizing the need to focus on more serious topics.
- Moderation in Humor Explored: Responses to humor varied, with some asserting that certain discussions strayed too far from relevant business topics.
- Conversations hinted at the moderator's role to curb non-business-related humor, showcasing the tension between levity and professionalism.
Cohere ▷ #questions (9 messages🔥):
Rerank 3.5 English model plans, CmdR+Play Bot status, Aya-expanse performance, API request 403 error
- Inquiry on Rerank 3.5 English Model: A member asked if there are any upcoming plans for a Rerank 3.5 English model.
- No responses were noted on this inquiry, highlighting a possible gap in communication.
- CmdR+Play Bot is on a break: A member inquired about the status of the CmdR+Play Bot, which is currently taking a break.
- Another user confirmed the break and advised others to stay tuned for updates.
- Aya-expanse's Instruction Handling: A user wondered if aya-expanse, built upon the command family, has improved performance in processing instructions.
- The conversation did not lead to a definitive answer regarding its performance capabilities.
- 403 Error on API Request: A member expressed concern about receiving a 403 response when attempting to build an API request.
- No further details were provided on the error, indicating a need for troubleshooting assistance.
Link mentioned: Careers: Our team of ML/AI experts is passionate about helping developers solve real-world problems. From our offices in Toronto, London, and Palo Alto, we work at the cutting edge of machine learning to unloc...
Cohere ▷ #api-discussions (2 messages):
API request errors, Trial key limitations
- Understanding API Request 403 Error: A member faced a 403 error while building an API request, indicating that their request was forbidden.
- This error typically occurs due to permission issues or using an incorrect API key.
- Trial Key Restrictions: It was mentioned that the 403 error is related to the usage of a trial key for the API.
- Trial keys often come with limitations that can restrict access to certain features or endpoints.
Torchtune ▷ #dev (17 messages🔥):
Merging Config Files, TorchTune PR Discussion, DoraLinear and LoraLinear Initialization, Tensor Device Handling, Magnitude Calculation
- Conflicting Config Files Merging Issues: A user sought a simple method for merging conflicting configuration files, wishing to use 'accept both changes' for all files.
- They humorously disclosed their workaround by replacing conflict markers with an empty string.
- Insights on TorchTune PR #2139: Discussion centered on PR #2139 involving the concerns around
torch.utils.swap_tensorsand its role in initialization.- Contributors agreed on the need for further discussions on where to define
self.magnitudeand its initialization.
- Contributors agreed on the need for further discussions on where to define
- Exploring to_empty Initialization Method: Proposals were made for improving the
to_emptymethod to maintain expected user experiences while managing device and parameter captures.- The community deliberated on balancing best practices without causing breakage in existing code.
- Device Handling Concerns in Tensor Operations: It was emphasized that device management is crucial when handling tensor initialization and swaps, particularly with parameters like
magnitude.- Members recognized that proper API usage like
swap_tensorsis vital in maintaining device integrity during operations.
- Members recognized that proper API usage like
- Clarification on Parameter Initialization and Gradients: Contributors clarified that using
copy_is acceptable if the device is managed correctly, while highlighting the importance ofrequires_gradstate.- They discussed integration of error checks in initialization routines to prevent common pitfalls like handling tensors on meta devices.
- pytorch/torch/nn/modules/module.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- ebs-torchtune/torchtune/modules/peft/dora.py at 5da01406658f9079ebb5bcd6eab0e4261d4188f9 · ebsmothers/ebs-torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to ebsmothers/ebs-torchtune development by creating an account on GitHub.
- pytorch/torch/nn/modules/module.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
DSPy ▷ #show-and-tell (1 messages):
LangWatch Optimization Studio, DSPy programs, Low-code tools, Open source release
- LangWatch Optimization Studio Launches: Introducing LangWatch Optimization Studio, a new low-code UI for visually building DSPy programs that simplifies evaluating your LMs and running optimizations.
- The tool's code can soon be exported to a DSPy-ready program, and it is now open source on GitHub.
- Transitioning Out of Private Beta: The LangWatch Optimization Studio has successfully transitioned out of private beta, marking a significant step for the platform.
- Users are encouraged to check it out and drop a ⭐️ on the GitHub page to show support.
- Visual Development for LMs: The studio aims to provide an intuitive visual development environment specifically designed for DSPy programs.
- Users can easily run optimizations on their models, enhancing productivity and streamlining workflows.
Link mentioned: GitHub - langwatch/langwatch: Source available LLM Ops platform and LLM Optimization Studio powered by DSPy.: Source available LLM Ops platform and LLM Optimization Studio powered by DSPy. - langwatch/langwatch
DSPy ▷ #general (13 messages🔥):
DSPy documentation access, API reference location, O1 series model impact, Error during optimization
- Difficulty accessing DSPy documentation: A member expressed frustration about not being able to find the DSPy documentation, particularly the API reference link that was previously available at the top.
- Another member clarified that most syntax is now available on the landing page and noted that special modules for types are no longer necessary.
- Insights needed on O1 series models: A member inquired about how the O1 series of models might affect DSPy workflows, particularly regarding parameters for optimization modules from MIPRO.
- They suspected that adjustments might be needed, like fewer optimization cycles, but welcomed any insights or recommendations from others.
- Reporting an optimization error: A member reported encountering a weird generic error and a bug while optimizing, mentioning they posted further details in a specific channel.
- They requested attention from others when available to address the issue they were experiencing.
Link mentioned: DSPy Documentation: The framework for programming—rather than prompting—language models.
LAION ▷ #general (2 messages):
Awareness of AI capabilities, Grassroots Science Initiative, Multilingual LLMs, Risks of AI-generated content
- Spread the Word on AI Threats: A member highlighted the importance of educating tech-illiterate individuals about the dangers of AI-generated content as scams become more believable with advancements in technology.
- They suggested linking to MKBHD's newest upload to illustrate these capabilities to loved ones.
- Launch of Grassroots Science Initiative: A collaboration between several organizations is set to launch Grassroots Science, an open-source initiative aimed at developing multilingual LLMs by February 2025.
- They aim to collect data through crowdsourcing, benchmark models, and open-source tools to engage grassroots communities in multilingual research.
- Join the Grassroots Science Community: Interested parties were encouraged to fill out an interest form to participate in the Grassroots Science initiative, emphasizing collaboration among grassroots communities.
- Participants are asked to indicate their language proficiency levels for both writing and reading to contribute effectively.
- Grassroots Science: A global initiative focused on developing state-of-the-art multilingual language models through grassroots efforts.
- Grassroots Science Interest Form: Grassroots Science is a year-long global collaboration aimed at collecting multilingual data through crowdsourcing, initiated by grassroots communities who believe in the power of collective efforts t...
- Tweet from undefined: no description found
LAION ▷ #research (9 messages🔥):
Training 7B on 12GB, Hyperefficient Small Models, Scale vs Efficiency in Models
- Training 7B on 12GB seems absurdly ambitious: A member commented that training a 7B parameter model on just 12GB of data is quite astonishing and raises eyebrows for its feasibility.
- This has sparked interest in how such a model may perform in practical applications.
- Hyped about Small Models: There is a clear excitement for hyperefficient small models, with a validation of their performance and advantages being highlighted.
- A fan stated, 'I love hyperefficient small models! They rock!' emphasizing the potential of models that eschew the need for massive scales.
- Skepticism towards scale-centric approaches: One user expressed disbelief in the 'scale-is-all-you-need' philosophy, remarking on the significance of efficiency over size.
- The consensus is leaning towards an argument that a billion parameters should suffice for effective model performance.
- Generalization to Smaller Models in Question: A member pondered whether trends observed in large language models might also apply to sub-billion parameter models.
- This invites a deeper discussion on the adaptability and performance scalability beyond the traditional paradigms of larger models.
OpenInterpreter ▷ #general (10 messages🔥):
01 Voice-Enabled App, Controlling GPT o1 Pro, Beta Access for Mac Users, Website Issues
- 01 Voice-Enabled App Launch: A member announced that 01 is a voice-enabled spinoff of Open Interpreter, available as both a CLI and desktop application.
- It includes instructions for simulating the 01 Light Hardware and running both the server and client.
- Potential Integration with OI: A member hypothesized that using OI in OS mode could control GPT o1 Pro through the desktop app or browser, potentially enabling web search and file upload capabilities.
- They expressed interest in exploring this idea, noting the powerful implications it could have.
- Beta Access for 01 App: During the discussion, it was clarified that the 01 app is still in beta and requires an invite to access, currently available only for Mac users.
- One member reported they sent a direct message to a user to gain access, indicating a very high demand.
- Concerns About Website Functionality: A member expressed frustration regarding issues with the Open Interpreter website, showing a screenshot but not detailing the specific problems.
- Community members have begun discussing website navigation and functionality as part of their ongoing experience with Open Interpreter.
- Open Interpreter: no description found
- Desktop - 01: no description found
- Open Interpreter Changelog: Official changelog for the open-source Open Interpreter project.
- no title found: no description found
Mozilla AI ▷ #announcements (1 messages):
Web Applets, Theia-ide, Programming Interviews, Integration with IDEs
- Dive into Web Applets Kickoff: An upcoming session will focus on web applets led by a prominent member, scheduled to start soon.
- This event aims to enhance understanding of the integration and functionality of web applets in modern development.
- Exploring Theia-ide: A New Approach to IDEs: Tomorrow, participants can explore Theia-ide, which emphasizes openness, transparency, and flexibility in development environments.
- The discussion will be helmed by an expert, aiming to showcase the advantages of using Theia-ide in contrast to traditional IDEs.
- Changing Face of Programming Interviews: A comment highlighted how programming interviews have evolved, stating that in the past, candidates might be asked to write a bubble sort on a whiteboard.
- Now, candidates can simply tell their IDE to build one, emphasizing the shift towards more practical skills in real-time coding.
- Gearing Up for Theia-ide Insights: A link to an interview with Jonas was shared, providing insight into the vision behind Theia-ide, accessible here.
- This interview aims to offer a deeper understanding of the features and philosophy guiding the development of Theia.
Link mentioned: Tweet from Robert Scoble (@Scobleizer): Back in the day if you were interviewing for a programming job at Microsoft they might have you write a bubble sort on the white board to make sure you knew how to program that.Now?Just tell your IDE ...