[AINews] ChatGPT Advanced Voice Mode
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Patience is all you need, Jimmy.
AI News for 9/23/2024-9/24/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (222 channels, and 2572 messages) for you. Estimated reading time saved (at 200wpm): 294 minutes. You can now tag @smol_ai for AINews discussions!
Ahead of rumored Llama 3 and Claude 3.5 updates due tomorrow:
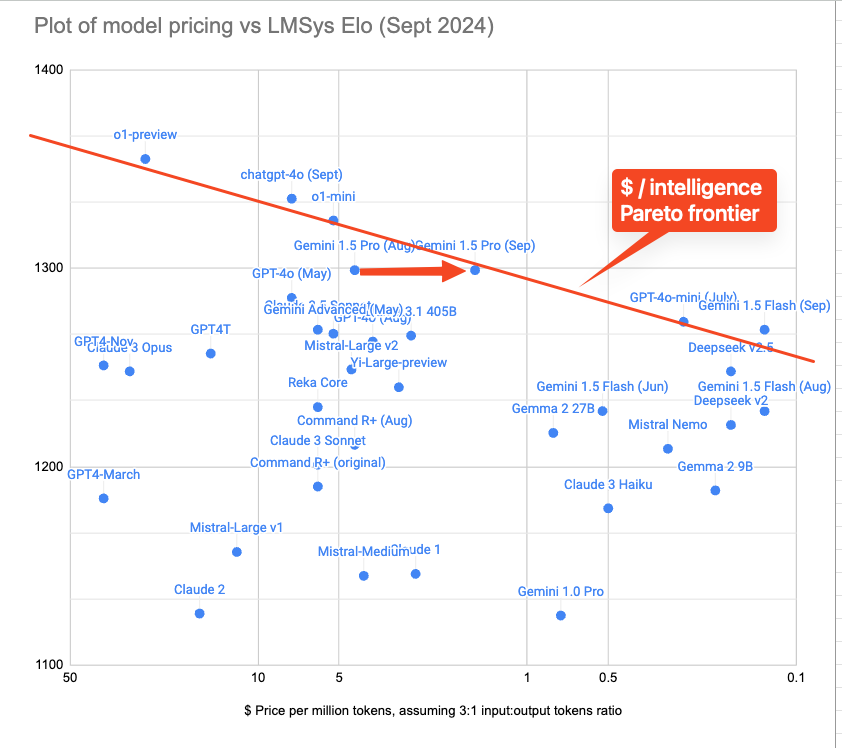
Today we saw a big Gemini Pro price cut, updating Gemini pricing inline with the new $/intelligence frontier we have been charting on this newsletter.
But probably the headline story is ChatGPT Advanced Voice Mode, which company leaders (like Mira!) announced as "rolling out this week" but it seems most people in the US received access by the end of day. There are 5 new voices, and improved accent/language support. and yes, with some effort, it can still sing!

The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Releases
- OpenAI's o1-preview model: @omarsar0 shared insights on o1-preview's performance in planning tasks, noting it shows progress but lacks robustness on longer problems and unsolvable instances. The model achieved 52.8% accuracy on Randomized Mystery Blocksworld, significantly outperforming other LLMs.
- Anthropic's rumored new model: @bindureddy and @rohanpaul_ai mentioned rumors of Anthropic dropping a new model, generating excitement in the AI community.
- Qwen 2.5 release: @_philschmid highlighted the release of Qwen 2.5, with the 7B model matching OpenAI's GPT-4 0613 on various benchmarks. The model is available in sizes 1.5B, 7B, and 32B (coming soon), supporting up to 128K tokens.
AI Research and Benchmarks
- PlanBench evaluation: @omarsar0 discussed a paper evaluating o1-preview on PlanBench, comparing it to LLMs and classical planners. The study revealed o1-preview's strengths in planning tasks but also highlighted its limitations.
- Multilingual MMLU dataset: @_philschmid announced OpenAI's release of a Multilingual Massive Multitask Language Understanding (MMMLU) dataset on Hugging Face, covering 14 languages and 57 categories.
- RAG research standardization: @rohanpaul_ai mentioned RAGLAB, a framework for standardizing Retrieval-Augmented Generation (RAG) research, allowing fair comparisons of 6 RAG algorithms across 10 benchmarks.
AI Applications and Tools
- PDF2Audio: @_akhaliq shared a tool for converting PDFs into audio podcasts, lectures, and summaries.
- Open-source AI starter kit: @svpino introduced a self-hosted AI starter kit with components for low-code development, local model running, vector storage, and PostgreSQL.
- Moshi speech-based AI assistant: @ylecun announced the open-sourcing of Moshi, a speech-based AI assistant from Kyutai.
AI Industry and Business
- Scale AI developments: @alexandr_wang reported Scale AI's growth, hitting nearly $1B ARR earlier than expected and growing 4x year-over-year.
- Together Enterprise Platform: @togethercompute introduced their platform for centralized GenAI process management, offering 2-3x faster inference and up to 50% reduction in operational costs.
AI Ethics and Societal Impact
- Sam Altman's blog post: @rohanpaul_ai shared insights from Sam Altman's blog post "The Intelligence Age," discussing the potential impact of AI on human capabilities and society.
- AI regulation discussions: @togelius expressed concerns about proposed AI regulation bills, arguing they might hinder open-source development and concentrate power in private companies.
Memes and Humor
- @agihippo joked about normalizing YAML configs for ordering sandwiches, highlighting the pervasiveness of tech concepts in everyday life.
- @Teknium1 humorously commented on o1's inability to rewrite code, poking fun at the model's limitations.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Qwen 2.5: A New Benchmark in Local LLM Performance
- Qwen2.5 Bugs & Issues + fixes, Colab finetuning notebook (Score: 85, Comments: 15): The post highlights critical bugs in Qwen 2.5 models, including incorrect EOS tokens and chat template issues that can cause NaN gradients. The author has uploaded fixed models and 4-bit quantized versions to Unsloth's Hugging Face page, and provided Kaggle and Colab notebooks for finetuning Qwen 2.5 models (base and conversational) using Unsloth, which offers 2x faster and 70% less VRAM usage during finetuning.
- Qwen 2.5 72B is now available for free on HuggingChat! (Score: 196, Comments: 36): Qwen 2.5 72B, a large language model, is now accessible for free on HuggingChat. This model, developed by Alibaba Cloud, boasts 72 billion parameters and is part of the Qwen (Tongyi Qianwen) series, offering capabilities in various languages including English, Chinese, and code generation.
- Qwen 2.5 72B is now available on HuggingChat with a 32k context window, improved role-playing abilities, and structured data handling. The developer is seeking feedback and resources on tool use for potential integration with their tools feature.
- Users discussed replacing outdated Mixtral models with alternatives like Mistral Small, which is comparable to Llama 3.1 70B in performance. HuggingChat offers generous usage limits with only per-minute rate limiting and no daily caps.
- Some users noted the model's improved performance over smaller versions, while others pointed out an amusing quirk where it claims to be developed by Anthropic instead of acknowledging its true identity as Qwen.
- How did Qwen do it? (Score: 235, Comments: 127): The Qwen 2.5 models are receiving positive feedback for their impressive performance, with the 32B model performing similarly to 70B models. This raises questions about the efficiency of running larger models when smaller ones can achieve comparable results, potentially making local LLMs more attractive. The post author inquires about the factors behind Qwen's success, speculating on possible reasons such as improved data quality, extended training periods, or other advancements in model development.
- Qwen2.5 models were trained on up to 18 trillion tokens of high-quality data, with the 32B model performing similarly to older 70B models. The Apache 2.0 license applies to most models except the commercially valuable 3B and 72B versions.
- Users report that Qwen2.5 72B outperforms Mistral Large and Cohere Command R+ in most tasks, except story writing. The 32B model has replaced Hermes 3 Llama 3.1 70B for some users, offering similar or better results with faster performance.
- Concerns were raised about Qwen2.5 models lacking cultural knowledge, as discussed in a Hugging Face thread. Some users argue this trade-off is acceptable for specialized tasks, while others believe baseline knowledge is necessary for a well-rounded LLM.
Theme 2. Advancements in LLM Efficiency and Quantization
- New Llama-3.1-Nemotron-51B instruct model from NVIDIA (Score: 205, Comments: 47): NVIDIA has released Llama-3.1-Nemotron-51B-instruct, a 51.5B parameter LLM derived from Llama-3.1-70B-instruct through block-wise distillation and optimization for a single H100-80GB GPU. The model underwent knowledge distillation using 40 billion tokens from FineWeb, Buzz-V1.2, and Dolma datasets, focusing on English single and multi-turn chat use-cases, and is available on Huggingface with a repo size of 103.4GB.
- Users expressed excitement for width-pruned Qwen 2.5 32B and Qwen 70B models. The Qwen 14B model achieves an MMLU score of ~80, comparable to 4th-year university level, as detailed on the Qwen blog.
- NVIDIA also developed a 40B variant of the model, achieving a 3.2x speed increase over the parent model with moderate accuracy loss. The architecture resembles DeciLM, suggesting NVIDIA may have integrated Deci's AutoNAC technology.
- The model's context size is unclear, with conflicting information in the configuration. The
max_position_embeddingsis set to 131,072, but theoriginal_max_position_embeddingsin the RoPE scaling settings is 8,192.
- Running LLMs at Custom Floating-Points (Near-Lossless FP6) (Score: 54, Comments: 20): The post discusses the implementation of custom floating-point formats for runtime quantization of LLMs, allowing loading of FP16 models directly into FP4, FP5, FP6, and FP7 with minimal accuracy loss and throughput penalty. The author explains the technical details of their approach, including bit-level pre-packing and SIMT-efficient GPU runtime with parallel dequantization, which enables competitive performance even with irregular bit-widths. Benchmarks show that FP5 and FP7 achieve similar results to FP8 on GMS8K, while FP6 even exceeds BF16 quantization, leading the author to suggest FP6 as a potential standard for balancing memory and accuracy trade-offs.
- Custom floating-point formats for runtime quantization are discussed, with users noting potential compute efficiency advantages over grouped quantizations like exl2 6bpw and GPTQ. The 5bpw format is highlighted as a meaningful trade-off for certain models and sizes.
- Concerns about the statistical significance of benchmark results on GMS8K were raised, suggesting the need for more comprehensive evaluations. The author acknowledged this, mentioning plans to run MMLU-Pro and possibly perplexity/KL divergence tests.
- Users inquired about model conversion to FP6 format, with instructions provided for using the command line interface. The author noted that exporting models in these formats is not currently possible but may be integrated into llm-compressor if demand increases.
Theme 3. AI for Creative Applications: Gaming and Music
- OpenMusic: Awesome open-source text-to-music generation! (Score: 59, Comments: 6): OpenMusic is an open-source text-to-music generation project available on Hugging Face. The project, which also has a GitHub repository, allows users to generate music from text prompts.
- I'm experimenting with small LLMS for a Skyrim + AI setup. I am astonished by Qwen's inference speed. (Score: 87, Comments: 46): The author is experimenting with small language models for a Skyrim + AI setup and expresses astonishment at the inference speed of Qwen. While no specific performance metrics are provided, the post suggests that Qwen's speed stands out compared to other models tested in this gaming-related AI application.
- Skyrim AI mods like Mantella and AI Follower Framework (AIFF) enable NPC interactions using LLMs. AIFF offers more features but is limited to companions, while Mantella allows conversations with any NPC.
- Users are experimenting with various LLMs for Skyrim, including Qwen 2.5 7B, Llama 3.1 8B, and Gemma 9B. Roleplay-tuned models are recommended for more believable NPC interactions.
- The author is using an MSI GP66 11UH-032 gaming laptop with an RTX 3080 mobile 8GB GPU, aiming to run LLMs on less than 6GB VRAM. Quantized 7b-8b GGUF models have shown excellent performance.
Theme 4. New AI Datasets and Research Papers
- Open Dataset release by OpenAI! (Score: 235, Comments: 51): OpenAI has released the Multilingual Massive Multitask Language Understanding (MMMLU) dataset on Hugging Face. The dataset is now publicly available at https://huggingface.co/datasets/openai/MMMLU, providing researchers and developers with a new resource for multilingual language understanding tasks.
- Users expressed skepticism about OpenAI's motives, with some suggesting the dataset might be "poisoned" or designed to favor their models. The GPTslop epidemic was cited as a reason for caution when using OpenAI's outputs for training.
- The choice to translate MMLU was questioned, as it's known to have problematic questions and invalid answer choices. Some suggested MMLU-Pro would have been a better option, given that many models already score around 90% on MMLU.
- Despite skepticism, users acknowledged the value of open benchmarks for reproducibility and model comparison. The dataset's size (194k test set) was noted as potentially excessive for computing a single score.
- Google has released a new paper: Training Language Models to Self-Correct via Reinforcement Learning (Score: 229, Comments: 30): Google researchers have introduced a novel approach called Self-Correction via Reinforcement Learning (SCRL) to improve language model outputs. The method uses reinforcement learning to train models to self-correct their initial outputs, resulting in improved performance across various tasks including question answering, summarization, and reasoning. SCRL demonstrates significant improvements over standard fine-tuning, with gains of up to 11.8% on certain benchmarks.
- The Self-Correction via Reinforcement Learning (SCRL) method's effectiveness was questioned, with users discussing how to ensure genuine self-correction rather than intentional error generation. The paper's focus on generalizing self-correction ability was highlighted as a key insight.
- Users debated the paper's methodology, noting that the prompt doesn't explicitly state the solution is wrong. Some pointed out that Qwen 72B model could solve all 8 math problems zero-shot, raising questions about data leakage and the need for novel evaluation sets.
- Discussion touched on the paper's theoretical focus versus practical application, emphasizing that research papers often test specific theories rather than producing end products. The concept of generalizing improvement steps was explained using an ELI5 analogy of number addition.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Releases
- OpenAI's GPT-4 Turbo (o1) models: Several posts discuss the impressive capabilities of OpenAI's new o1 models, particularly o1-mini. Users report significant improvements in tasks like complex mathematical problem-solving, with one user describing it as "using actual magic" for certain applications.
- Anthropic's new model release: Anthropic was expected to release a new AI model, generating excitement in the AI community.
- Cost reductions in AI inference: OpenAI's Dane Vahey reported that the cost per million tokens has fallen from $36 to $0.25 in 18 months, representing a significant decrease in AI operational costs.
AI Research and Development
- Multi-agent AI research: Both Google DeepMind and OpenAI are forming teams focused on multi-agent artificial general intelligence research, indicating a growing interest in this area.
- AI in image and video generation: Advancements in AI-powered image and video manipulation were highlighted, including a workflow for CogVideoX-I2V and a demonstration of simultaneous control of multiple subjects in video generation.
Industry and Market Developments
- Anthropic's potential valuation increase: Anthropic is reportedly in talks with investors about raising capital at a valuation of $30-40 billion, potentially doubling its previous valuation.
- Political engagement with AI: U.S. Vice President Kamala Harris pledged to boost AI investments in a fundraiser speech, indicating growing political interest in AI development.
Perspectives on AI Progress
- Rapid advancement of AI capabilities: Several posts reflect on the rapid progress in AI capabilities, with many tasks previously thought to be far from solved now being achievable.
- Future AI predictions: Yann LeCun predicted that AI matching or surpassing human intelligence will arrive soon, along with AI assistants in smart glasses capable of translating hundreds of languages within a year or two.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Models Level Up: New Releases and Major Updates
- Mistral Small Model Unleashes 22 Billion Parameters: The new Mistral Small model is live, boasting 22 billion parameters to advance AI performance across tasks. Users can explore it via the HF Collection.
- OpenAI's o1 Models Spark Interest Despite Unlabeled Graphs: OpenAI released the o1 family of models with scaling law graphs missing x-axis labels, prompting users to reconstruct data using the o1-mini API. Discussions ponder whether the compute involves mere tens of thousands of tokens.
- Gemini Models Get a Boost and a Price Cut: Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002 received updates with over 2x higher rate limits and a 50% price drop. Developers are thrilled about these changes, marking "a good day to be a developer."
Theme 2. Voice Features Roll Out Amidst Controversy
- OpenAI's Advanced Voice Feature Speaks 50+ Languages: Advanced Voice is rolling out to Plus and Team users, adding Custom Instructions, Memory, and five new voices with improved accents. Users can now express phrases in over 50 languages.
- European Users Left Voiceless and Frustrated: Despite the rollout, European users are disappointed as Advanced Voice is not yet available in several European countries. Many express that it "falls short of earlier demos."
- Users Debate Voice Assistant's Censorship and Limitations: Discussions highlight that OpenAI's focus on safety leads to a limited voice assistant. Users complain it lacks the dynamism seen in roleplaying AI products like Character.ai.
Theme 3. Developers Wrestle with AI Integration and Optimization
- OpenRouter Integrates with Cursor and Offers Demo Apps: OpenRouter now works seamlessly in Cursor with all models, including Anthropic's. They've also released demo apps on GitHub to kickstart development.
- Aider Installation Frustrations Spark Uninstalls: Users face challenges installing Aider, leading to multiple reinstall attempts using pipx without resolving the issues. Some resort to reverting to older versions to regain functionality.
- GPU MODE Changes Name but Sparks Mixed Feelings: The community formerly known as CUDA MODE transitions to GPU MODE, aiming for a broader focus. Members have mixed reactions, with humorous suggestions like "Gigachad Processing" and debates over the name change.
Theme 4. AI Reasoning and Reliability Under the Microscope
- LLMs Can't Plan? OpenAI's o1 Evaluated: A new research note critically assesses OpenAI's o1 model's planning capabilities, suggesting it "can't plan" despite being marketed as a Large Reasoning Model.
- Hallucinations Haunt High-Temperature Outputs: Users report that increasing the temperature above 1.25 causes models to hallucinate, questioning the reliability of outputs. Instructing models not to hallucinate helps but doesn't fully solve the problem.
- JSON Formatting Fiasco Frustrates Developers: API users struggle with JSON formatted outputs, often receiving incomplete or incorrect responses like a simple '{'. Better-defined prompt structures are suggested but issues persist.
Theme 5. Collaborative Efforts and Tools Enhance AI Development
- DSPy 2.5.0 Launch Tackles 100 Issues Faster Than You Can Say 'Chain-of-Thought': The release of DSPy 2.5.0 aims to swiftly address 50-100 issues, with users enthusiastic about new features and upcoming intro notebooks.
- GitHub Repositories Blossom with AI Tools: New tools like YouTube-to-Audio offer easy extraction of audio from videos, while frameworks like LitServe simplify serving and scaling LLMs using FastAPI.
- Community Bands Together for Fine-Tuning and Model Training: Members share experiences in fine-tuning models like Vit_B16 and Llama3.1, emphasizing the importance of high-quality data. Collaborations with model developers help resolve issues like bugs in Qwen 2.5.
Note: All links and details are based on the discussions across various Discord channels and reflect the latest updates and community sentiments.
PART 1: High level Discord summaries
OpenRouter (Alex Atallah) Discord
- Cursor integrates with OpenRouter!: OpenRouter now works seamlessly in Cursor with all models, including those from Anthropic. Thank you @cursor_ai for fixing this! 🍾
- This integration enhances user experience by simplifying operations and expanding model accessibility.
- Gemini models upgraded with better performance!: Two updated models, Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002, are now available, featuring reduced pricing and improved performance metrics.
- These models are optimized for efficiency, with faster outputs and higher rate limits, and will auto-update user-facing aliases by October 8, 2024.
- OpenRouter rolls out demo apps for quick start: The OpenRouter team has announced basic demo apps available on GitHub to help developers kickstart their projects.
- These demos include a simple 'tool calling' feature, making it easier for users to create applications from scratch.
- Discussion on Middle-Out Transform implications: Users expressed concerns over disabling the middle-out transform as default, citing negative impacts on workflows and infrastructure.
- The community stressed the need for clearer communication and updates regarding model changes to mitigate disruptions.
- Insights on Token Pricing Structures: A relevant discussion highlighted varying token pricing across models, stating that OpenRouter utilizes native tokens returned from upstream for cost calculations.
- Users noted that discrepancies in tokenizers between models like GPT-4o and Qwen can significantly affect token counts and pricing estimations.
HuggingFace Discord
- Mistral Small Model Launches: The new Mistral Small model is live, featuring 22 billion parameters, aimed at advancing AI performance in various tasks.
- Users can explore this model further via the HF Collection.
- Gradio 5 Sets Performance Standards: Gradio 5 (Beta) is officially released, introducing major usability improvements and server-side rendering for faster app loading.
- Feedback has been encouraged before a public rollout, aiming to refine features based on community insights.
- FinePersonas Adds Richness to Synthetic Data: The latest FinePersonas v0.1 offers 21 million personas, enhancing synthetic data generation for diverse applications.
- This dataset aims to provide realistic query generation tailored to specific persona needs, revolutionizing large-scale data projects.
- Hugging Face Token Issues Afloat: Multiple users reported problems with invalid Hugging Face tokens, prompting discussions on potential rate limit issues and reinstalling the huggingface-hub package.
- Despite troubleshooting efforts, many continued to experience token validation failures.
- OpenAI’s Word Generation Numbers Astonish: OpenAI reportedly generates about 100 billion words daily, with a user questioning if Hugging Face could approach this metric using its own models.
- This discussion highlights the significant text generation capability differences between entities in the AI space.
Eleuther Discord
- RWKV Architecture Offers Unique Insights: The community dissected the RWKV architecture, especially its efficiency over convolutions, emphasizing a need for simpler explanations to foster adoption.
- Familiarity with GLA is essential, as participants advocate for a clearer breakdown of complexities surrounding RWKV.
- Introducing the YouTube-to-Audio Tool: A user unveiled youtube-to-audio, a command-line tool that extracts audio in various formats like MP3 and WAV from YouTube, enhancing user experience.
- This tool also supports playlist downloads and custom file names, positioning itself as an ad-free alternative to existing solutions.
- Dynamic Evaluation Sparks Debate: Dynamic Evaluation in ML proposes fine-tuning models on the test set, raising concerns over its external validity and alignment with classic practices.
- Although valid, members highlighted the critical need for similar distributions between training and testing datasets.
- muP Implementation Clarified: The community works to simplify muP (Maximal Update Parameterization) concepts for neural networks, critical for increasing community engagement.
- The push for clearer implementations alongside theoretical insights aims to boost ease of integration for developers.
- OpenAI's LRM Displaying Planning Limitations: Members evaluated OpenAI's o1 (Strawberry) as a Large Reasoning Model (LRM) and debated its effectiveness, especially under specific test conditions.
- Concern arose over its planning capabilities, with reports indicating inference time compute leapfrogging to over 50%.
aider (Paul Gauthier) Discord
- Gemini Models Get Major Updates: The introduction of Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002 brings a 50% price drop and enhanced rate limits, impressing developers though coding benchmarks remain static.
- As of October 1st, input costs decrease from $3.50 to $1.25/million tokens for inputs under 128,000 tokens.
- RoRF Open-Sourced for Enhanced Performance: The Routing on Random Forest (RoRF) has been launched as open-source, offering 12 pre-trained model routers that significantly improve MMLU performance.
- This release is poised to advance model routing techniques across various applications.
- Anticipation Builds for New Claude Models: Speculations arise about upcoming releases of new Claude models like Haiku 3.5 or Opus, as users express frustration over the wait since the last update.
- This delay has fed hopes for timely announcements in the upcoming weeks.
- Inconveniences with Aider Installation: Users face challenges installing Aider, often needing to reinstall using pipx after functionalities fail, despite efforts to fix their setups.
- Reverting to older versions is among the suggested solutions as users navigate these complications.
- Prompt Caching Features Under Discussion: The configuration of AIDER_CACHE_KEEPALIVE_PINGS for prompt caching with Anthropic API and OpenRouter is a hot topic, as users seek clarity on implementations.
- Links to the Prompt Caching documentation are shared to facilitate understanding.
OpenAI Discord
- Advanced Voice Features Rolled Out: The Advanced Voice feature is now available for Plus and Team users, enhancing interaction within the ChatGPT app with new functionalities like Custom Instructions. This update also introduces five new voices and significantly boosts multilingual capabilities, allowing expressions in over 50 languages.
- However, the rollout has caused confusion and disappointment among European users, with some noting it falls short of earlier demos.
- JSON Formatting Quality Under Fire: Users are facing issues with JSON formatted outputs, often retrieving unsatisfactory responses like simple '{', leading to frustration among API users seeking structured data. Suggestions have been made to improve the quality of these outputs through better-defined structures.
- Despite recommendations for clearer prompts, many still encounter poor performance, limiting their ability to achieve effective API responses.
- Clarifying Prompt Engineering for Better Outputs: Discussion around prompt engineering emphasizes the necessity of clear, detailed requests to maximize model performance and relevance in outputs. Several members underscored that specific examples in prompts greatly enhance the quality of generated responses.
- The challenges highlighted include generating diverse content, particularly in niche applications like Minecraft questioning, which has faced repetitiveness.
- Hallucinations and Response Reliability Concerns: Participants raised alarms about the model's propensity to hallucinate as the temperature setting exceeds 1.25, indicating a lack of reliability in outputs. Insights from members suggest that instructing the model to avoid hallucination may limit irrelevant content but does not entirely solve the issue.
- This concern about hallucination extends to various functions within the ChatGPT, prompting users to seek methods for better performance.
- Generating Engaging Minecraft Questions: A user tested a prompt aimed at generating fun and engaging Minecraft questions in JSON format, facing hurdles in achieving diverse and engaging queries. Feedback from the community aimed to refine this process amid challenges of repetitive output and hallucination.
- This quest for creativity in question formation has sparked discussions on improving prompt strategies and effectively utilizing API capabilities.
GPU MODE Discord
- GPU Mode Transition: The community transitioned from CUDA MODE to GPU MODE, aiming for a broader focus on various GPU programming frameworks beyond just CUDA.
- Members expressed mixed feelings about the name change, suggesting alternatives like Heterogeneous Computing or even humorous names like Gigachad Processing.
- Training Optimizations with Distributed Systems: Discussions highlighted scaling issues during training with 2x 4090 GPUs, noting that DDP offers better performance than FSDP under low bandwidth conditions.
- Participants emphasized the impact of communication bandwidth on scalability and shared experiences in optimizing distributed training workloads.
- WebNN Integration Prospects: Suggestions arose for creating a dedicated channel for WebNN, reflecting on its role in integrating WebGPU and WASM, which may face challenges in standardization.
- Clarifications were made regarding WebNN's ability to interface with NPU APIs, demonstrating its potential for diverse hardware setups.
- Luma Job Openings for Performance Engineers: Luma is actively seeking engineers for their Dream Machine project, offering positions focused on performance optimizations for multimodal foundation models.
- Candidates are expected to have significant experience in distributed training and low-level kernel optimization, with the company highlighted as rapidly growing.
- Data Handling Challenges on GPU: Members noted that effective data transfer on GPUs is heavily dependent on latency and memory bandwidth, with inquiries about comparisons to CPU setups.
- One participant raised concerns about how these factors impact GPU performance and usability in systems-on-a-chip architectures.
Interconnects (Nathan Lambert) Discord
- OpenAI's o1 Models Raise Interest: OpenAI released the o1 family of models along with a graph showing scaling laws for test-time compute, although the x-axis was unlabeled, sparking discussions about reconstructing the data using the o1-mini API.
- Members pointed out that the compute likely involves only tens of thousands of tokens, raising feasibility questions around scaling further without a proper structure.
- Anthropic's Potential $40 Billion Valuation: Reports indicate that Anthropic is in discussions to raise capital, which might boost its valuation to between $30 billion and $40 billion, effectively doubling from earlier this year.
- This reflects a serious competitive drive as AI companies scramble for substantial financial backing in a fast-evolving market.
- James Cameron Joins Stability AI Board: Stability AI welcomed James Cameron to its Board of Directors, aiming to leverage his expertise to explore innovations in visual media.
- This strategic move is seen as crucial for developing a more comprehensive AI pipeline tailored for creators.
- Gemini Model Enhancements Announced: Updates for the Gemini models reveal enhancements including over 2x higher rate limits and a 50% price drop on Gemini 1.5 Pro, along with new features for developers.
- The revisions also introduce opt-in filters for improved safety and reliability, allowing better control over model settings.
- Scale AI's Financial Growth Insights: Scale AI reported nearly quadrupled sales in H1 despite low gross margins, indicating robust growth amidst rising demand for AI services.
- This financial surge puts Scale AI in a compelling position as the landscape continues to shift towards AI-enabled solutions.
Nous Research AI Discord
- O1 Planning Capabilities Evaluation: A recent research note on O1 outlines its planning capabilities, with team members reportedly burning the midnight oil for completion.
- The findings detail a thorough examination, with more insights promised following its public release.
- World Simulator API Offers Low-Cost Access: Discussion centered around World Sim, highlighting an opportunity for users to earn credits upon sign-up, while incurring low costs for API usage.
- Encouragement for account creation to leverage free credits was a common sentiment in the channel.
- Hermes & Monad Showing Stubbornness: Concerns about Hermes and Monad reported becoming less effective in interactions, particularly in tagging abilities.
- One suggestion involved implementing a presence penalty, while others noted differences based on hosting environments.
- Gemini 1.5 Sparks Excitement: Anticipation builds around the Gemini 1.5 upgrade released in September, coupled with a minor rollout for GPT-4o.
- Members expressed eagerness for breakthroughs that may emerge from the upcoming Meta Connect event.
- DisTrO Efficient in Poor Bandwidth: Initial findings indicate DisTrO operates effectively over asymmetric bandwidth and heterogeneous GPU environments, enhancing resource management.
- This positions DisTrO as a viable option for resource allocation in suboptimal network conditions.
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 model issues resolved: Members discussed problems with the Qwen 2.5 model, reporting crashes and bugs, but shared solutions like improved templates and modified training approaches.
- Collaboration with the Qwen team yielded progress in addressing some of these issues, allowing for better model stability.
- Unsloth Trainer's memory usage optimized: A user experienced memory issues initializing the UnslothTrainer and suggested reducing dataset mapping processes to resolve it.
- Their follow-up indicated success with fewer processes, highlighting the significance of balancing for better memory performance.
- Fine-tuning models insights shared: Experience shared on fine-tuning a Vit_B16 model highlighted that high-quality data trumps sheer volume for improved results.
- The user plans to enhance their model further with additional quality images after achieving notable accuracy.
- Memory issues with Llama3.1 addressed: A user faced out of memory errors loading the 4-bit quantized Llama3.1, with 20GB allocations failing when 14.75GB was used by PyTorch.
- Community members suggested adjustments to the model configurations as a troubleshooting step for these OOM issues.
- Exploring improvements with Reinforcement Learning: Discussion on how OpenAI applies RLHF (Reinforcement Learning from Human Feedback) to upgrade their models based on user interactions.
- Participants noted the challenges of utilizing prior conversations for guiding model improvements, emphasizing a lack of structured feedback in training methodologies.
Perplexity AI Discord
- Anticipation Builds for New Anthropic Model Release: A source confirmed that a major AI model upgrade from Anthropic is expected to be released soon, with full details available after the embargo lifts.
- Members are buzzing about the implications this upgrade may have for developers in the AI landscape.
- Perplexity Pro Features Leave Users Curious: Confusion arises as users discuss limitations with Perplexity Pro accounts, particularly regarding daily search limits.
- While some users question the value of Pro accounts, others acknowledge the benefits of a more personalized search experience.
- Merlin Extension Gains Traction: Discussion around the Merlin extension highlights its capability to chat with various LLMs directly, providing unlimited model access.
- Users appreciate the unlimited queries but express concerns over transparency in the model settings compared to HARPA AI.
- Inconsistencies in Citation Outputs Cause Frustration: Members express frustration over inconsistent citation outputs fetched via the API, alternating between HTML and Markdown formats.
- This inconsistency is reportedly hampering automation efforts, complicating reliable output generation.
- AI's Role in Education Scrutinized: An exploration of how AI impacts education reveals both transformative benefits and challenges, with an ongoing discussion on its implications.
- Members analyze different facets of AI integration into educational settings and the potential shifts in learning dynamics.
LM Studio Discord
- LM Studio Installation on Air-Gapped Machines: Members discussed the feasibility of installing LM Studio on air-gapped machines, emphasizing that initial setup and file transfers are necessary even though the installation itself does not require internet.
- Air-gapped installations require careful planning, particularly for downloading installers and models separately.
- Model Performance Hits a Wall: Users reported performance issues with models when approaching their token limits, noting that slowdowns occur due to VRAM constraints as tokens fill up.
- This leads to the recommendation of managing token limits to maintain optimal performance.
- LongWriter Model Sparks Interest: The LongWriter model was praised for its ability to generate extensive texts, with resources shared for interested members to explore its properties further.
- Members were encouraged to review the GitHub page for LongWriter for insights on usage and capabilities.
- Concerns Over Dual GPU Compatibility: A discussion on whether LM Studio supports dual GPU setups raised inquiries about mixing an RTX 4070 Ti with an RTX 3080, along with the potential performance benefits.
- Advice centered on assessing compatibility concerns before attempting such configurations.
- High GPU Prices Frustrate EU Buyers: Members expressed frustration over higher GPU prices in the EU, often reaching around $750, compared to lower pricing in the US.
- Regional pricing issues were attributed to VAT and taxes, alongside a discussion on the advantages of consumer protections available in Europe.
Modular (Mojo 🔥) Discord
- Mojo Tops the Language Tier List: A user ranked Mojo at the top of their personal language tier list, citing it above C# and Rust as a subjective but heartfelt decision.
- There’s a call for a clearer separation in C++ categories, particularly emphasizing the importance of clean C interoperability.
- Rust Faces Slow Compilation Scares: Users lamented Rust's slow compilation times, especially in larger projects like a 40k line game, which can drag on significantly.
- Generics were identified as major contributors to these slowdowns, with suggestions to optimize file system settings on Windows.
- NixOS Sparks Interest Amid Caution: Conversations around migrating to NixOS praised its package management, but concerns arose about the overall complexity of the system.
- Members debated the potential of Ansible as a simpler tool for smaller projects while exploring NixOS's reproducibility benefits.
- MLIR Wins Over LLVM in Discussions: Questions about why MLIR might be better than LLVM centered on improvements in parallel compilation and high-level semantics handling.
- MLIR's ability to retain debug information is seen as a crucial advantage, especially as compilers evolve.
- Celebrating Mojo's Progress and Future: The community celebrated Mojo's two-year anniversary, reflecting on its growth, including key developments like the Mojo SDK release.
- Enthusiasm about the language's future was palpable, with users eagerly discussing how its evolution will shape the years ahead.
DSPy Discord
- DSPy 2.5.0 Launch Spreads Excitement: The launch of DSPy 2.5.0 aims to swiftly tackle 50-100 issues, garnering enthusiasm for new features and upcoming intro notebooks.
- Members suggested establishing public weekly meetings for further feedback on the release.
- Effective GROQ API Key Setup: User guidance on setting the GROQ_API_KEY and executing
lm = dspy.LM('groq/llama3-8b-8192')facilitates Llama 3 integrations.- This instruction streamlines usage of the dspy library with models hosted on GROQ.
- Chain of Thought Evaluated in Recent Paper: A paper highlights a quantitative meta-analysis of over 100 studies on Chain-of-Thought (CoT) prompting, showing its effectiveness enhances tasks with math or logic.
- Key findings indicate that direct answering matches CoT on MMLU for symbolic operations, stressing the need for reasoning when questions involve an equals sign.
- Custom Adapters for LLM Usage Discussed: Members explored the creation of custom adapters to specify additional parameters like
grammarfor structured outputs with dspy.LM.- The conversation focuses on sharing experiences and a need for clearer best practices regarding parameter usage.
- Anticipation Builds for Multimodal Capabilities: Newly expected multimodal features of DSPy are set to roll out next week, with compatibility inquiries regarding audio models like Ultravox.
- Official responses indicate the initial focus will be on Vision Language Models (VLMs).
LLM Agents (Berkeley MOOC) Discord
- Today's Lecture on AI Frameworks and Multimodal Assistants: The 3rd lecture of the Berkeley MOOC, featuring this livestream, will cover Agentic AI Frameworks & AutoGen with Chi Wang and steps to build a multimodal knowledge assistant with Jerry Liu starting at 3:00pm PST.
- Chi will address core design considerations of agentic AI programming while Jerry will discuss elements like structured outputs and event-driven workflows.
- Clarification on Course Attendance Confusion: The attendance form for the livestream is meant for Berkeley students only, causing some confusion among MOOC participants.
- Next time, clearer instructions will accompany the QR code to prevent misunderstandings.
- Exploring Open Embedding Models: Members identified jina-embeddings-v3 from Jina AI as the leading open embedding model offering multilingual capabilities and utilizing Task LoRA.
- This model enhances performance in neural search applications, emphasizing the importance of effective indexing and relevance.
- AutoGen vs. CrewAI on Customization and Speed: In multi-agent collaboration, members noted AutoGen allows for greater customization, while CrewAI shines in quick prototyping, albeit lacking in back-and-forth communication.
- The conversable_agent in AutoGen enables more complex interactions, a feature CrewAI users found limiting.
- Search/Retrieval Techniques for RAG: Discussion suggested focusing on classical NLP techniques to enhance information retrieval, particularly ranking algorithms and semantic understanding.
- Understanding these techniques is critical for improving search within the RAG framework, allowing for better indexing and relevance.
Latent Space Discord
- Letta AI Emerges from Stealth: Excitement surrounds the launch of Letta AI, a company focused on developing stateful LLM agents, by founders Sarah Wooders and Charles Packer. They are actively hiring and building their team in San Francisco.
- Read more about Letta in TechCrunch.
- Gemini Model Enhancements: Gemini models received significant updates, including double the rate limits and over a 50% price reduction on Gemini 1.5 Pro. Filters have switched to opt-in, and an updated Flash 8B experimental model has been released.
- Developers are optimistic about these changes, viewing it as a great time for developers, as explained in the Google Developers Blog.
- Voice Feature Rollout: OpenAI announced that Advanced Voice is rolling out to Plus and Team users within the ChatGPT app, introducing multiple new features and improved accents. Notably, it can express phrases in over 50 different languages.
- However, access is not yet available in several European nations, as highlighted by OpenAI's announcement.
- Customer Service Agent Experimentation: Discussion about challenges in managing multi-turn conversations with agent simulations revealed important insights into maintaining effective user interaction. Suggestions included implementing stage markers and setting clear conversation termination guidelines.
- Users are exploring various approaches to integrate reinforcement learning into conversation management to improve the customer agent experience.
- HuggingChat macOS App Introduction: The newly released HuggingChat app for macOS offers native integration of open-source LLMs with features like markdown support and web browsing. It marks a significant step forward in user-friendly AI tools for direct desktop use.
- This app demonstrates a trend toward enhancing accessibility and functionality in AI-driven applications.
Cohere Discord
- Newcomers drawn to Cohere AI: Members like Nav, a Mechanical Engineering student, showcased interest in learning about Cohere and AI while seeking resources such as blogs or videos, leading to a shared link about the Aya Research initiative to advance multilingual AI.
- This initiative aims to enhance accessibility, enabling a broader understanding of AI applications across languages.
- Job anxiety alleviated in community chat: Milansarapa voiced concerns over job insecurity, prompting community assurance about having a contract in hand, reinforcing the importance of support.
- You have the contract already became a reassuring mantra, highlighting the usefulness of community engagement.
- Cohere Toolkit gets notable features: Recent updates to the Cohere Toolkit have fixed various back-end/UI issues and introduced features such as pinning chats and support for parquet and tsv files, with a YouTube demo available.
- These enhancements significantly improve user experience and demonstrate the team's commitment to community feedback.
- Reranker faces multilingual challenges: Reports surfaced that the multilingual reranker suffers from low relevance scores in languages like Polish, filtering out useful data, which renders it ineffective.
- The relevance score is so low that it gets filtered out indicates a need for better handling of diverse languages within the reranking process.
- Exploring Chain of Thought (COT): Milansarapa queried about the Chain of Thought (COT) mechanism, prompting discussions on how it can enhance performance on certain tasks.
- Ultimately, COT serves as a valuable approach for problem-solving, though its application varies case by case.
Stability.ai (Stable Diffusion) Discord
- James Cameron Joins Stability AI Board: Legendary filmmaker James Cameron has joined the Stability AI Board of Directors, announced by CEO Prem Akkaraju. This addition supports Stability AI's mission to transform visual media with cutting-edge technology.
- Known for The Terminator and Avatar, Cameron aims to revolutionize storytelling through innovative AI solutions for visual media.
- Seeking FNAF Loras Collaborators: A member seeks fellow FNAF fans to assist in creating Loras for the game. They're looking for collaborators to bring this project to life.
- Anyone interested in collaborating on this project?
- Boosting SDXL Performance with 3090 EGPU: A user reported purchasing a 3090 EGPU to enhance their SDXL gameplay experience, overcoming past failures with similar products. They shared frustrations about certain Aurus gaming boxes.
- Quality issues with similar products were noted, leading to this decision.
- Exploring ControlNet's Capabilities: A user inquired about ControlNet, which guides image generation, particularly for poses. Specifications can be challenging to clarify with only language.
- Effective guidance methods are a crucial focus for improved image outputs.
- Troubleshooting OpenPose Editor Installation: A user reported issues with the OpenPose editor in Forge, suggesting it may require a specific installation command. Assistance was provided about running pip install basicsr in the virtual environment.
- Clarifications around installation commands were shared for better integration.
LlamaIndex Discord
- Beware of fraudulent LlamaParse site: A warning has been issued about a fraudulent site pretending to be LlamaIndex's LlamaParse, directing users to avoid it.
- The legitimate LlamaParse can be accessed at cloud.llamaindex.ai to prevent confusion.
- LitServe simplifies serving LLMs: The LitServe framework from LightningAI simplifies serving and scaling LLMs using FastAPI, as showcased in a demo with LlamaIndex.
- This setup can host a straightforward RAG server locally against Llama 3.1, making it efficient for developers.
- Creating an AI Product Manager in 50 Lines!: An AI product manager can be built in just 50 lines of code using LlamaIndex and ComposioHQ, which includes features like email feedback reading.
- If approved, it integrates feedback into a Linear board for edits, showcasing the efficacy of the function calling agent architecture.
- Exploring Human-in-the-Loop Workflows: Members discussed implementing human-in-the-loop (HITL) interactions with nested workflows, aiming to ease user control return post-events.
- An event-driven approach was proposed for managing user responses dynamically during workflow processes.
- Effective Web Crawling Techniques for RAG: A discussion centered on technologies for crawling web pages for embedding, with inquiries on options like Puppeteer versus tools such as Firecrawl or Crawlee.
- Members shared insights into effective methods for integrating web-crawled data into retrieval-augmented generation (RAG) pipelines.
LAION Discord
- User Feedback Sparks Blendtain Improvements: A user shared excitement for Blendtain but noted its tendency to cut off messages, suggesting a feature to adjust message length.
- Another user simply agreed with a thumbs-up, reflecting positive reception of the feedback.
- Playlist Generator Launched by dykyi_vladk: Adify.pro was introduced as a new playlist generator that customizes playlists based on user prompts, created by dykyi_vladk.
- The creator proudly referred to it as his 'coolest thing', indicating personal investment in the project.
- Collaborative Machine Learning Study Proposal: dykyi_vladk invited others to DM him for a collaborative Machine Learning study initiative, promoting community engagement.
- This was presented in a friendly tone, emphasizing teamwork in pursuing knowledge.
- Dominance Shifts in Image Processing Algorithms: A member questioned the current dominance of GANs, CNNs, and ViTs in image processing tasks, seeking confirmation of these trends.
- They expressed interest in a visual timeline to illustrate shifts among these algorithms over time.
- EleutherAI's muTransfer Collaboration: EleutherAI launched a project with Cerebras to enhance the accessibility of muTransfer, aiming to decrease training costs.
- Members speculated that the approach might already be dated, questioning its relevance compared to newer methods.
OpenAccess AI Collective (axolotl) Discord
- Nvidia's 51B Synthetic Data Model Excites: Discussion ignited over Nvidia's 51B synthetic data model, which reportedly exhibits strong MMLU performance and potential for enhanced applications.
- It would be fun to try fine-tuning and inferencing with it, highlighting members' eagerness to explore practical applications.
- Auto Chunking: A Loss of Context?: A debate emerged over the practicality of auto chunking in conversations, with concerns that Imagine your convo split in half midway. The context is lost.
- One member pointed out that systems like ST and Kobold typically manage overflow by retaining initial messages.
- Dynamic Context Management Proposed: There were discussions on how dynamic context management could assist LLMs in handling conversational shifts more effectively.
- Members suggested this strategy as a probable fix for exceeding context limits.
- Qwen 2.5 Supported on Axolotl: Confirmation came in that Qwen 2.5 is supported on Axolotl for normal text processing, though vision features might lack support.
- The acknowledgment reflects limitations potentially affecting applications involving visual data.
- Analysis of Fine-Tuning Spikes: A member reported a significant spike during fine-tuning on a 100K row dataset, seeking correlations through logging.
- The lack of immediate logging help was noted, impacting troubleshooting efforts.
LangChain AI Discord
- LangChain Pydantic Compatibility Broken: Users encounter an error while importing
ChatOpenAIfromlangchain_openai, due to the__modify_schema__method being unsupported in Pydantic v2. They are advised to check their Pydantic version and use__get_pydantic_json_schema__instead, as detailed in the LangChain documentation.- As Pydantic v2 was released in June 2023, developers should ensure they are using compatible methods to avoid integration issues.
- Watch Out for GraphRecursionError!: A
GraphRecursionErrorarises in LangGraph applications when the recursion limit of 25 is hit, hindering execution. Users can increase the recursion limit in their configuration, as suggested in a related GitHub issue.- This adjustment is critical for preventing crashes during complex graph operations in LangGraph.
- Call for LLM Friendly Docs!: A user prompts for more LLM-friendly documentation to boost LangChain productivity. Ongoing discussions indicate a community interest in improving resources available for developers working with LangChain.
- This shows a need for better guidelines tailored to enhancing LLM integrations, indicating the community’s focused efforts.
- Mistral vs Mixtral: The Great Showdown: A comparison is brewing between Mistral and Mixtral regarding self-hosting solutions in the open-source arena. Members are curious about performance metrics and usability when it comes to these models.
- This conversation highlights the community's interest in optimizing and selecting the best open-source models for practical applications.
Torchtune Discord
- Confusions Around CPU Offloading in Optimizers: Discussion arose about why CPU offloading for the optimizer isn't being utilized, referencing this old issue that mentioned slowdowns.
- One member suggested using PagedAdam with CPU offloading to optimize performance while emphasizing the need for a PR to consider single-device fine-tuning.
- Comparative Analysis of Optimizer Methods: It was noted that using torchao's CPUOffloadOptimizer doesn't pair well with the optimizer in backward, raising questions about faster alternatives like Adam.
- Recommendations included trying
offload_gradients=Truefor gradient memory savings while optimizing CPU and GPU processing as detailed in this PR.
- Recommendations included trying
- CUDA MODE Community Invitation: A suggestion was made to join the GPU MODE Discord group for members interested in performance optimization, highlighting more qualified individuals available for help.
- The link shared for joining is here, encouraging broader participation in discussions on optimization.
tinygrad (George Hotz) Discord
- Exploring the Concept of a Planetary Brain: Members playfully compared the potential of tinyboxes connecting for a planetary brain through distributed training, pushing the boundaries of collective intelligence.
- This suggests a fascinating future where advanced distributed training might operate on a global scale.
- Introduction to DisTrO for Distributed Training: Discussion centered on the DisTrO project that facilitates Distributed Training Over-The-Internet, targeting revolutionary collaboration across models.
- This initiative emphasizes the need for cooperative frameworks in model training, enhancing scalability and accessibility.
- AttributeError: 'Tensor' lacking cross_entropy: A user faced an 'AttributeError' due to the Tensor object lacking the
cross_entropyattribute during the training step, highlighting a potential implementation flaw.- Participants speculated on the underlying causes, pointing to a possible gap within the Tensor functionality.
- Tinygrad Version Debate: The conversation sparked over the correct Tinygrad version after a user transitioned from version 0.9.2 to the latest master, exposing functional limitations.
- Recommendations were made to consistently update to incorporate essential features for performance gains.
- Model Architecture and Training Insights: One participant shared their model architecture leveraging multiple convolutional layers followed by a flattening operation and linear layers to enhance training efficacy.
- The dialogue emphasized design strategies aimed at optimizing model performance during training iterations.
OpenInterpreter Discord
- Open Interpreter Gets Refreshing Updates: Open Interpreter is actively receiving updates on GitHub, showcasing continuous development efforts.
- Significant focus surrounds project '01', aimed at integrating a dedicated voice assistant mode, as detailed here.
- LLM Takes On Browser Automation: A member discussed using Open Interpreter for LLM-based browser automation, confirming functionality while noting it's limited by task complexity.
- They recommended employing Playwright for enhancements and shared a prompt example they have been honing.
- Community Pumps Up the Enthusiasm: Despite initial skepticism, community members are eager to automate submissions to directories using shared prompts.
- Engagement remains strong as members respond to questions and exchange experiences with the tool.
- Exciting Community Event on the Way: An upcoming event related to Open Interpreter was announced, with a Discord link for more details shared.
- This news sparked excitement among users, indicating that community interest is alive and well.
- Project Perception Nuances Explored: In response to a query, a member humorously highlighted that some in the community might not be fully aware of the project's progress.
- This points to varying perceptions on Open Interpreter's vitality within discussions.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!