[AINews] Chameleon: Meta's (unreleased) GPT4o-like Omnimodal Model
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Early Fusion is all you need.
AI News for 5/16/2024-5/17/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (429 channels, and 5221 messages) for you. Estimated reading time saved (at 200wpm): 551 minutes.
Armen Aghajanyan introduced Chameleon, FAIR's latest work on multimodal models, training 7B and 34B models on 10T tokens of text and image (independent and interleaved) data resulting in an "early fusion" form of multimodality (as compared to Flamingo and LLaVA) that can natively output any modality as easily as it consumes them:
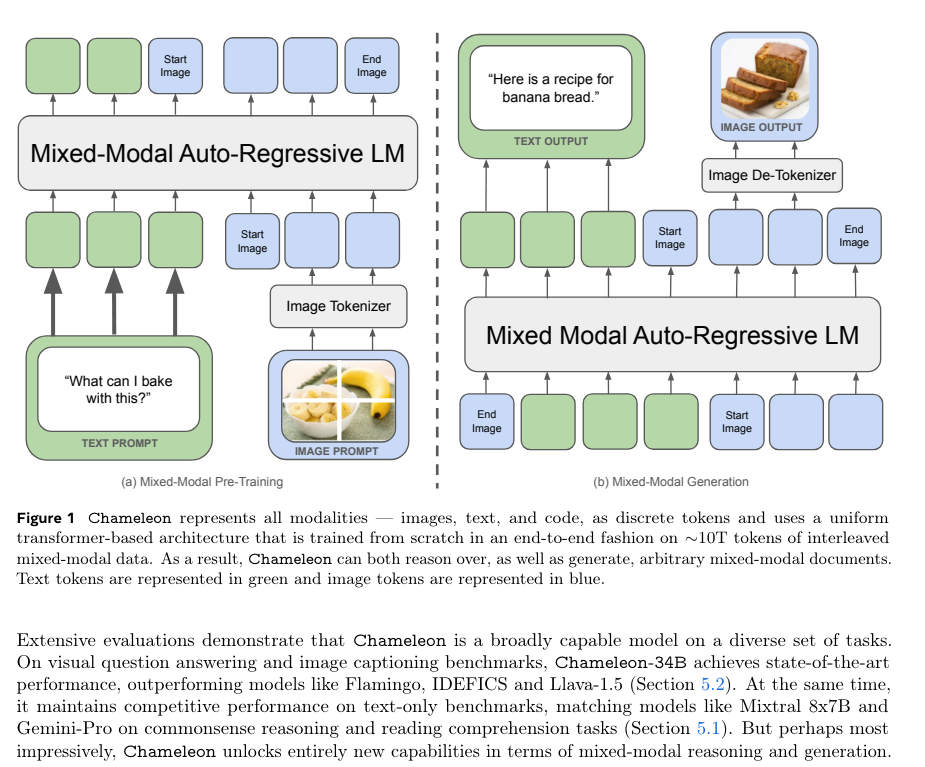
As just a 34B model, the reasoning benchmarks aren't something to write home about, but the "omnimodality" approach compares well with peer multimodal modals pre GPT4-o:
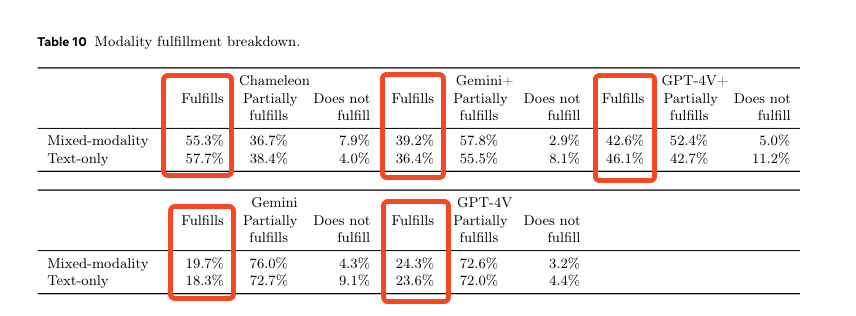
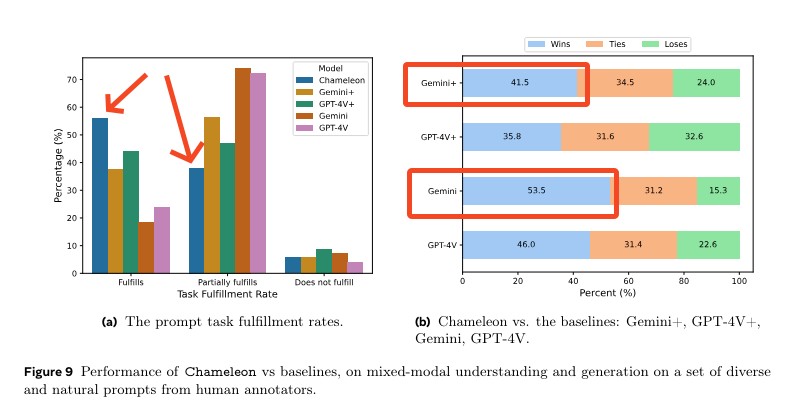
As you might imagine, the tokenization matters a lot, and this is what we know so far:

The dataset description sounds straightforward, but since model, code and data remain unreleased, we are left merely considering the theoretical advantages of their approach right now. But it's nice that Meta is clearly not far off from releasing their own "early fusion mixed modality", GPT4-class model.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Perplexity AI Discord
- HuggingFace Discord
- Nous Research AI Discord
- Modular (Mojo 🔥) Discord
- LM Studio Discord
- CUDA MODE Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- LAION Discord
- Latent Space Discord
- LlamaIndex Discord
- OpenRouter (Alex Atallah) Discord
- OpenInterpreter Discord
- LangChain AI Discord
- AI Stack Devs (Yoko Li) Discord
- OpenAccess AI Collective (axolotl) Discord
- tinygrad (George Hotz) Discord
- Cohere Discord
- MLOps @Chipro Discord
- Datasette - LLM (@SimonW) Discord
- Mozilla AI Discord
- DiscoResearch Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
OpenAI and Google AI Announcements
- OpenAI GPT-4o Launch: @sama noted the aesthetic difference between OpenAI and Google's AI announcements. @zacharynado pointed out how OpenAI's launches are timed with Google's.
- Google Gemini and Flash: Google announced Gemini 1.5 Flash, a 1M-context small model with Flash performance. @alexandr_wang noted OpenAI has the best large model with GPT-4o, while Google has the best small model with Gemini 1.5 Flash.
- Convergence in AI Development: @alexandr_wang observed the level of convergence between OpenAI and Google is fascinating, with similarity between models like GPT-4o and Gemini. He believes divergence would be better for the industry.
- OpenAI Partnership with Reddit: OpenAI has partnered with Reddit, drawing attention as a potential hostile takeover strategy. @teortaxesTex noted this as a bigger breakthrough than Q*.
GPT-4o Performance and Capabilities
- GPT-4o Outperforms Other Models: GPT-4o outperforms other expensive models like Opus on benchmarks like MMLU. @abacaj noted this is what matters, even though GPT-4o isn't marketed as GPT-5.
- Improved Coding Capabilities: GPT-4o shows significant improvements in coding tasks compared to previous models. @virattt shared an example of GPT-4o successfully editing code.
- Multimodal Capabilities: GPT-4o excels at integrating image/text understanding. @llama_index demonstrated GPT-4o extracting structured JSONs from detailed research paper images with 0% failure rate and high quality answers.
- Limitations and Regressions: Despite improvements, GPT-4o's ELO score has regressed from 1310 to 1287, with an even larger drop in coding performance. It still struggles with hallucinations over complex tables and charts.
Anthropic Claude 3 Updates
- Streaming Support: @alexalbert__ announced streaming support for more natural end-user experiences, especially for long outputs.
- Forced Tool Use: Claude 3 now supports forcing the use of specific tools or any relevant tool, giving more control over tool usage in agents and structured outputs.
- Vision Support: Anthropic has laid the foundation for multimodal tool use by adding support for tools that return images, enabling knowledge extraction from visual sources.
Meta AI Announcements
- Chameleon: Mixed-Modal Early-Fusion Foundation Models: Meta introduced Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in arbitrary sequences. It demonstrates SOTA performance across diverse vision-language benchmarks.
- Imagen 3: Imagen 3, part of Meta's ImageFX suite, can generate high-quality visuals in various styles like photorealistic scenes and stylized art. It incorporates technologies like SynthID for watermarking AI content.
Memes and Humor
- @fchollet joked about the aesthetic difference between a West Elm showroom and a Marc Rebillet show.
- OpenAI Drama: @vikhyatk quipped "openai is nothing without its drama 💙"
- @svpino coined the term "model-apologists" in response to defenses of GPT models.
- @aidangomez joked about training AGI for enterprise in a constructed digital environment called "Coblox".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
GPT-4o and Multimodal AI Advancements
- GPT-4o's impressive performance: GPT-4o ranked on LMSys Chatbot Arena Leaderboard with 1289 Elo, outperforming GPT-4turbo despite having an older knowledge cutoff. Discussions suggest GPT-4o excels at catering answers humans like, but may not be significantly smarter. Source
- OpenAI introduces new features: Interactive tables, charts, and file integration from Google Drive and Microsoft OneDrive for ChatGPT Plus, Team, and Enterprise users, rolling out over the coming weeks. Source
- MetaAI's Chameleon model: MetaAI introduces Chameleon, a Mixed-Modal Early-Fusion Foundation Model similar to GPT-4o, capable of interleaved text and image understanding and generation. Source
- Terminology discussions: Debates on whether "large language model" term still applies to GPT-4o and similar advanced models, given their expanded multimodal capabilities. Suggestions include "Multimodal Unified Token Transformers" (MUTTs) and "Large Multimodal Model" (LMM). Source
OpenAI Partnerships and Developments
- OpenAI partners with Reddit: OpenAI partners with Reddit to bring its content to ChatGPT and new products. Source Discussions raise concerns about data privacy and the implications of Reddit selling user-generated content. Source
- Google employee reacts to GPT-4o: Google employee uses Project Astra to react to GPT-4o announcement, congratulating OpenAI on impressive work. Source
Stability AI and Open Source Developments
- Stability AI's potential sale: Stability AI discusses potential sale amid cash crunch, raising concerns about the future of open-source AI initiatives. Source
- Hugging Face's ZeroGPU initiative: Hugging Face commits $10M of free GPUs with launch of ZeroGPU, supporting open-source AI development. Source
- CosXL release: Stability AI releases CosXL, an official SDXL update with v-prediction, ZeroSNR, and Cosine Schedule, addressing issues with generating dark/bright images and convergence speed. Source
AI Benchmarking and Evaluation
- MileBench for evaluating MLLMs: MileBench introduced as a benchmark for evaluating Multimodal Large Language Models (MLLMs) in long-context tasks involving multiple images and lengthy texts. Key findings show GPT-4o excelling in both diagnostic and realistic evaluations, while most open-source MLLMs struggle with long-context tasks. Source
- Needle in a Needlestack (NIAN) benchmark: NIAN benchmark proposed as a more challenging alternative to Needle in a Haystack (NIAH) for evaluating LLM attention in long contexts. Even GPT-4-turbo struggles with this benchmark. Source
AI Ethics and Societal Impact
- Pessimism in r/futurology: Discussions on r/futurology subreddit becoming increasingly pessimistic and "decel" as the community grows, with concerns about the impact of AI on jobs and society. Source
- US tariffs on Chinese semiconductors: US to increase tariffs on Chinese semiconductors by 100% in 2025 to protect the $53 billion spent on the CHIPS Act. Source
Memes and Humor
- AI mania meme: Meme about AI mania, referencing an "AI Flavor" of Coke. Source
AI Discord Recap
A summary of Summaries of Summaries
- Hugging Face Invests $10M in Free Shared GPUs: Hugging Face is committing $10 million to provide free shared GPUs to support small developers, academics, and startups in developing AI technologies. CEO Clem Delangue emphasized this initiative aims to democratize AI and counter centralization by big tech (source).
- OpenAI Alignment Team Departs Amid Shifting Priorities: Jan Leike, head of OpenAI's alignment team, announced his resignation due to disagreements over the company's core priorities. This follows other key departures like Ilya Sutskever, sparking discussions about OpenAI potentially prioritizing near-term product goals over long-term AI safety research (Jan's tweet, Wired article).
- GPT-4o Capabilities and Limitations Debated: The release of GPT-4o generated excitement for its multimodal capabilities, like interleaved text and image understanding (paper). However, some noted inconsistencies in its coding performance and output quality compared to expectations set by OpenAI's demos (example).
- Needle in a Needlestack (NIAN) Challenges LLMs: The new NIAN benchmark presents a formidable challenge for LLMs, testing their ability to answer questions about a specific text hidden among many similar texts. Even advanced models like GPT-4-turbo struggle with this task (code, website).
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Meta's Model Makes People Wait: Discussions revealed a delay in support for Llava or multimodal AI due to anticipation for Meta's multimodal model, with no specific release date mentioned, indicating reliance on industry leaders for advancements.
- Finding Funds for GPUs: Conversations among members included quips about how they finance their GPU usage; humorous mentions included "RAMEN FOR YEARS" as a sacrifice for their dedication to AI work, particularly for demanding tasks such as classification.
- Boosting Models with OpenHermes: The OpenHermes dataset was a topic of interest, with mentions of its incorporation leading to substantial improvements in model performance, demonstrating the value of diverse datasets in AI research.
- Discarding Refusal Alleviates Stubborn AIs: Debates touched on the impact of removing refusal mechanisms from LLMs, noting an unexpected increase in 'smartness', and referenced a specific paper on the topic, offering insights into ongoing LLM research.
- Troubleshooting Llama 3 woes: Users shared solutions for errors such as
AttributeError: 'dict' object has no attribute 'context_window'when training Llama 3, which included suggestions like modifying core codes or switching to Ollama, indicating active engagement in the practical aspects of AI model development.
Stability.ai (Stable Diffusion) Discord
SD3 Release Maintains Aura of Mystery: Discord users are expressing both anticipation and frustration over the delayed release of SD3; skepticism prevails despite a tweet by Emad hinting at an imminent launch.
GPUs Spark Debate Amongst the Discerning: In the quest for optimized training of SDXL models, discourse centered on whether an RTX 4090 with 24GB VRAM suffices, with some users deliberating the merits of more robust solutions.
Waiting Game Spurs Meme Fest: With the release of SD3 shrouded in uncertainty, the community has taken to sharing memes and light-hearted comments, as exhibited by a tweet from Stability.
Datasets and Training Techniques Tabled: AI aficionados shared training resources such as this dataset from Hugging Face, and exchanged insights on fine-tuning practices to rival the output quality of Dalle 3.
From AI to Socioeconomics: Sidetracks in Session: The conversation occasionally veered off AI terrain into vigorous discussions surrounding capitalism and morality, with some participants nudging the focus back to tech-centric themes.
OpenAI Discord
- Interactive Features Level Up ChatGPT: OpenAI has announced the inclusion of interactive tables and charts in ChatGPT for Plus, Team, and Enterprise users, offering direct integration with Google Drive and Microsoft OneDrive. This update is expected to roll out in the coming weeks, and users can learn more about it here.
- The Dawn of GPT-4o: The community is buzzing with discussions around the partial release of GPT-4o, celebrating its top ranking and new higher message limits. Anticipated features like Voice Mode are also on the horizon, although some have concernedly noted slower performance with extended use.
- Ethical AI Conversations Hit Prime Time: AI's impact on job markets has been a hot topic, with conversations examining both the potential uplift in productivity and the concern for future employment structures. Members are also exchanging thoughts on ethical and educational applications of AI, aiming to balance technology enhancement with responsible usage.
- Prompt Engineering Pulls Back the Curtain: The effective use of markdown to guide AI response and the challenges posed by model updates affecting behavior have generated much attention in the community. Methods to foster more desired outcomes from the AI, like emotional incentives, were described humorously yet showcased critical insights into AI user interactions.
- API Chat Gets Technical: Detailed discussions around the API capabilities have noted that using markdown in prompts can help clarify intent and character roles. However, discrepancies in custom GPT performance and mixed experiences with model access and updates underline the evolving nature of interacting with these advanced AIs.
Perplexity AI Discord
- GPT-4o Plays Catch-Up: GPT-4o is noted to be faster and slightly improved over previous iterations, accessible for free users, despite reports of varying message limits and refresh rates.
- Cognition vs. Hallucination in AI: Concerns about AI hallucinations are highlighted, with doubts cast on AI's capability to fully eliminate them, potentially affecting job security in entry-level positions.
- Perplexity AI Clashes with ChatGPT: Users are split between Perplexity, credited with better sourcing, and ChatGPT, favored for feature integration like web search.
- Programming and Creativity in AI Diversity: GPT-4o and Opus show divergent strengths; GPT-4o excels in coding, whereas Opus offers depth in math and complex problem-solving.
- The API Integration Dilemma: Questions are raised about sonar-medium-online support longevity; someone seeks to add Perplexity to a private Discord, while the default temperature for Perplexity AI models is confirmed to be 0.2.
Relevant Link: Chat Completions Documentation
HuggingFace Discord
- OpenAI's 'Openness' Debated: A YouTube critique titled "Big Tech AI Is A Lie" argued that OpenAI doesn't live up to its name, sparking conversations about the value of truly open platforms like HuggingFace, and a subsequent discussion on the performance of HuggingFace models versus closed systems.
- Cultivating Curiosity in Reinforcement Learning: A paper discussing curiosity-driven exploration in reinforcement learning sparked interest, detailing how rewarding agent curiosity can lead to better results in environments where the outcome of actions is unpredictable. Additionally, the epsilon greedy policy was suggested for maintaining the exploration/exploitation trade-off.
- Conversations on Computer Vision and Diffusion Models: Questions arose regarding latent diffusion models in diffusers, the training of such models from scratch, and UNet models' convergence issues, with a focus on small dataset impacts. Separately, a Medium post detailed the integration of GPT-4o with LlamaParse for enhanced multimodal capabilities, while discussions in the #diffusion-discussions channel focused on latent space representations and uploading issues with Google Collab.
- RL in the Spotlight: The first RL model's addition to the Hugging Face repository was met with encouragement, marking a milestone for one user's learning path in Deep RL. This dovetails with talks on reinforcement learning's challenges and the introduction of the epsilon-greedy policy for exploration and exploitation balance.
- Model Training and Deployment Challenges: Complexities in model training were illustrated by a user's struggle with UNet model convergence and another's attempt at generating grid puzzles with GPT-4o. A user recommended continuous retraining to keep coding language models relevant due to outdated training data.
- Dataset Innovations and AI Creations Showcased: The Hugging Face community introduced the Tuxemon dataset featuring permissively licensed creature images, evoking humor as an AI data source. Meanwhile, community member showcases include the use of LangChain and Gemini for a business advisor AI, a GenAI-powered education tool, and a virtual AI influencer, underscoring the diverse applications of AI technology.
Nous Research AI Discord
- Brain-inspired AI Models Gain Traction: Participants in the guild discussed the concept of a streaming-like process for AI, similar to human memory, referencing the Infini-attention methodology for greater relevance update efficiency. Here's a paper on Infini-attention for further reading.
- Benchmarking AI with NIAN Challenge: Needle in a Needle Stack (NIAN) emerged as a niche benchmark to push the limits of Language Models, including GPT-4, in differentiating specific content within masses of similar material. Here's more on the NIAN benchmark and its dedicated website.
- Symbolic Language in AI Explored: Conversations hinted at a growing interest in using GPT-4o for creating a symbolic language that could facilitate tasks involving algebraic computations, suggesting a potential advance in AI handling of symbolic reasoning.
- Stable Diffusion 3 Embraces Open Architecture: Stable Diffusion 3 is being prepped for on-device inference, optimizing for Mac with MLX and Core ML, and will be open-sourced through a partnership between Argmax Inc. and Stability AI. Argmax's partnership tweet can be read here.
- AI in Real-Time User Interfaces: A guild member sought resources on AI models capable of analyzing screen actions nearly in real-time, similar to Fuyu, which process screen captures and UI interactions every second. Meanwhile, Elon Musk's Neuralink has opened applications for a second participant in their brain implant trial, posting details via Elon's tweet.
Modular (Mojo 🔥) Discord
Mojo Gets an Update: The latest nightly Mojo compiler 2024.5.1607 makes its debut, with an invitation for users to try out the latest features using modular update nightly/mojo. The community response has been notably positive towards the new conditional methods syntax, and contributions are steered towards smaller PRs to combat the issue of "cookie licking." Check the diffs from the last nightly and the full changelog.
Mojo's Engineering Challenges: Engineers express concerns over List.append performance in Mojo, noting inefficiency with large data sizes and invite comparisons with Python and C++ implementations. They delve into discussions of Rust's and Go's dynamic array resizing strategies and reference a case study with StringBuilder variations in Mojo.
Open-source Perspectives and Pain Points: Debates around the merits and challenges of open-source contributions light up discussions, with concerns voiced about projects transitioning from open to closed source. Advent of Code 2023 is recognized as an entry point to get started with Mojo, with the challenge available on GitHub.
Developer Updates and Handy Guides: Modular's news updates have been shared through Twitter links, offering glimpses into the latest advancements. Meanwhile, a guide for assisting new contributors with syncing forks on GitHub has been circulated to support smoother contributions.
MAX Comes to macOS: The MAX platform brings excitement with its new nightlies now supporting macOS and introducing MAX Serving. Engineers interested in the MAX platform are directed to get started using PyTorch 2.2.2.
LM Studio Discord
Model Troubleshooting Takes Center Stage: Technical challenges involving LM Studio have surfaced, including a user struggling with glibc issues for installation and suggestions pointing towards potentially needing an upgrade or reverting to LM Studio version 0.2.23. Embedding models for RAG in Pinecone proved troublesome without a direct guide, and a VM error 'Fallback backend llama cpu not detected!' indicated possible VM setup issues. Antivirus software caused some stir, flagging the 0.2.23 installer as a virus, later clarified as a false positive.
LLM Showdown: Coding Models & File Gen Frustrations: Participants highlighted that the best coding models vary according to programming language and hardware, with Nxcode CQ 7B ORPO and CodeQwen 1.5 finetune touted for Python tasks. It was acknowledged that LM Studio can't generate files directly and forcing models to only show code remains inconsistent. Querying on the fastest semantic text embeddings turned up all miniLM L6 as the quickest yet insufficient for one user's requirements, and a gap was seen in recommendations for usable medical LLMs in LMS.
A False Positive Frenzy with Antivirus Software: Antivirus tools, specifically Malwarebytes Anti-malware and Comodo, are misidentifying certain aspects of LM Studio's architecture as threats. These alarm bell incidences—the former shared via a VirusTotal link—highlight the challenge of ensuring LM Studio's components are not mistakenly flagged by protective software.
Hardware Enthusiasts Break New Ground: Significant achievements were reported in hardware discussions, with a 70B LLama3 model running on an Intel i5 12600K CPU and the impact of RAM speed alignments on performance noted. Members debated quantization efficacy, memory overclocking's effects on stability, and even compared various GPU architectures, including RX 6800, Tesla P100, and GTX 1060 in performance.
Conversations Across Channels Drive Collaborative Solutions: Multiple topics flowed across channels, focusing on troubleshooting LM Studio storage and permission issues, leading to the effective use of conversation memory management with LangChain over server-side, and the consideration of open-source alternatives over Gemini's paid context caching service. A move for deeper discussion on certain issues to another channel signifies the collaborative approach by the community.
CUDA MODE Discord
GPU Community Powers Up: Hugging Face announces a $10 million investment for free shared GPUs to support small developers, academics, and startups, aiming to democratize AI development in the face of big tech's AI centralization. The move positions Hugging Face as a community-centric hub and this article provides more insights.
Triton Performance Puzzle: Implementers of a Triton tutorial observe discrepancies in performance, questioning the impact of "swizzle" indexing techniques as a possible factor. The differences noted include a significant drop in performance when users follow the tutorial, versus the performance advertised.
Bitnet Steps into the Spotlight: Strategy discussions initiate a budding project for Bitnet 1.58 due to its advanced training-aware quantization techniques. The conversation emphasizes the importance of post-training weight quantization, with suggestions to centralize Bitnet development within the PyTorch ao repo for efficient implementation and support.
Code and Optimizations for Large Language Models: An optimization pull request reduces memory usage by 10% and increases throughput by 6% for large language models, exemplifying efficient resource utilization during training phases. Moreover, discussions unravel the possibilities of NVMe direct GPU writes, offering a high-speed bypass of CPU and RAM, albeit its practical application remains to be explored within the ambit of AI model training workflows.
Quantum of Documentation: Community members voice frustration regarding sparse PyTorch documentation, particularly torch.Tag, with the conversation extending to tackling template overloading issues in custom OPs. Additionally, a plan to reduce compile times in PyTorch garners attention, aiming for more efficient development cycles.
End.
Interconnects (Nathan Lambert) Discord
- Interconnects Paves New Paths: Nathan Lambert introduced a niche project with enthusiasm for monthly updates and potential improvements. However, amid OpenAI departures, a key engineer joined an initiative with individuals from Boston Dynamics and DeepMind, revealing a notable industry shift.
- The Modeling World Reacts: Chat about the new GPT-4o models, which showcase "interleaved text and image understanding and generation", indicates they represent a new scale paradigm with an early fusion, multi-modal approach. OpenAI's leadership changes led to the disbandment of its superalignment team, alongside key shifts towards product-focused objectives, sparking debates over AI safety and alignment.
- Safety Concerns in the Spotlight: Safety remains a contentious topic, with the dissolution of OpenAI's superalignment team highlighting concerns over immediate product goals versus long-term AI risk strategies. Meanwhile, Google DeepMind released its Frontier Safety Framework, demonstrating an industry-wide move towards proactive AI safety measures.
- OpenAI's Surprising Partnerships: OpenAI's unexpected partnership with Reddit captures attention while Lambert's decision to remove model and dataset links illustrates a strategic move towards deeper, standalone analysis in his communication.
- Scaling, Aligning, and Technical Innovation: Discourse around scaling laws for vocabulary size in models and an overview of aligning open language models suggests continued refinement in AI development practices. Tackling technical challenges head-on, Lambert teases an upcoming project dubbed "Life after DPO".
Eleuther Discord
- PyTorch Flops Under Review: Members shared basic usage details and challenges concerning the FLOP counter in PyTorch; a gap was noted in documenting backward operation tracking. Contributions were encouraged for an lm_eval.model module for MLX.
- Comparative Studies and Catastrophic Forgetting: A keen interest was observed in comparative studies of LLM Guidance Techniques, specifically Adaptive norms versus Self Attention for class guidance. Another highlighted topic was discussing strategies to combat catastrophic forgetting during finetuning of models, with a consensus on the necessity of retraining on old tasks.
- Sifting Through Hierarchical Memory and Semantic Metrics: A new Hierarchical Memory Transformer paper received attention for its potential to tackle long-context processing limitations. Separately, there’s an active search for a differentiable semantic text similarity metric that outperforms rudimentary substitutes like Levenshtein distance, as mentioned in this paper.
- Transformers Sidestep Attention with MLP: Conversations about MLP-based approximations of attention mechanisms in transformers pointed to possible relevant research on Gwern.net. Discourse also touched on the repercussions of excluding compute costs in data preprocessing on the overall economization of models.
- Tinkering with GPT-NeoX to Hugging Face Transitions: Technical challenges emerged with transitioning GPT-NeoX models to Hugging Face, leading to discussions about naming conventions in Pipeline Parallelism (PP) and the parallel existence of incompatible files. A proposed fix for identified bugs in conversion scripts and insights into compatible configurations for better cohesion with Hugging Face structures were put forward.
LAION Discord
Noncompetes Get the Axe: The engineering community reacts to the FTC's groundbreaking decision to eliminate noncompetes, which could significantly alter the competitive landscape and professional autonomy in the tech industry.
Open Source vs. Closed Wallets: A spirited debate among engineers centers on the choice between proprietary and open source employment, considering the limitations on open source contributions and the allure of higher salaries at proprietary firms.
GPT-4's Sibling Rivalry: GPT-4O's coding capabilities are scrutinized, with some members noting faster performance yet lamenting issues with inaccurate code output, spotlighting the need for careful evaluation of such advanced AI systems.
Creative Commons Catch: The launch of the CommonCanvas dataset, featuring 70 million creative commons licensed images, was received with enthusiasm and concern due to its non-commercial license, impacting its utilization in the engineering sphere.
Network Know-How and Cartoon Clout: Recent engineering discussions delve into successfully training a Tiny ConvNet for bilinear sampling, exploring positional encoding in CNNs, and a new Sakuga-42M dataset to boost cartoon research, reflecting a broad spectrum of innovative approaches in the field.
Latent Space Discord
- Rich Text Translation Woes: There is a struggle to effectively translate rich text content without losing the correct positions of spans, as demonstrated in the transition from English to Spanish. Methods involving HTML tags and strategies geared towards deterministic reasoning were proposed to enhance translation precision.
- Hugging Face's GPU Generosity: Hugging Face has pledged $10 million in free shared GPUs to support smaller developers, academia, and startups, as announced by CEO Clem Delangue, in an effort to democratize access to AI developments.
- Slack Data Privacy Concerns: Renewed debate surfaced about Slack's use of customer data, particularly the possibility of the company training its AI models without explicit user consent, eliciting a spectrum of reactions from the community.
- Next-Gen AI Fusion: Excitement brews around a new multimodal Large Language Model (LLM) described in a recent paper, showcasing integrated text and image understanding, prompting discussions on future AI applications and cross-modality convergence.
- OpenAI Alignment Reshuffle: The departure of Jan Leike, OpenAI's head of alignment, led to introspective dialogue on the organizations' AI safety and alignment philosophies, with Sam Altman and others thanking Leike for his contributions.
- Latent Space Podcast Alert: Latent Space released a new podcast episode.
LlamaIndex Discord
GPT-4o Triumphs in Text and Image Understanding: Engineers are exploring GPT-4o's capabilities in parsing documents and extracting structured JSON from images, with specific discussions around a full cookbook guide and comparison to its predecessor GPT-4V.
Meetup Alert: SF's Upcoming Generative AI Summit: The first in-person meetup organized by LlamaIndex in San Francisco is generating buzz, promising deep-dives into generative AI and retrieval augmented generation engines.
LlamaIndex Integrations and User Guidance Hits High Note: A GitHub link provided clarity on Claude 3 haiku model utilization within LlamaIndex, while comprehensive LlamaIndex documentation offered guidance on harnessing Ollama (LLaMA 3 model) with VectorStores.
LlamaIndex UI Gets a Facelift: The LlamaIndex's User Interface has been enhanced, now offering a more robust selection of options for users to enhance their experience.
Cohere Pairing with Llama for RAG Implementation: Members of the community are seeking advice on integrating Cohere with Llama for building Retrieval-Augmented Generation applications, suggesting a strong interest in cross-service model functionality.
OpenRouter (Alex Atallah) Discord
NeverSleep Enters the Chat with Lumimaid: The new NeverSleep/llama-3-lumimaid-70b model integrates curated roleplay data striking a balance between serious and uncensored content. Details are available on OpenRouter’s model page.
ChatterUI Brings Characters to Android: ChatterUI has been released as a character-focused UI for Android, diverging into uncharted territory with fewer features compared to peers like SillyTavern, and supporting multiple backends.
Invisibility App Polishes AI Interaction for Mac Users: A new MacOS Copilot named Invisibility, empowered by GPT4o and Claude-3 Opus, adds to its arsenal a video sidekick feature while promising further enhancements including voice integration and long-term memory. Discover Invisibility’s capabilities.
Google Gemini Context Tokens Provoke TPU Wonder: The release of Google Gemini with 1M context tokens prompted debates on how InfiniAttention could be Google's answer to handling large contexts with TPUs, sparking a blend of skepticism and curiosity among developers. The technical inquisition revolved around InfiniAttention’s paper, which can be found here.
Tech Troubles and Teasers: A clutch of technical conversations occurred, ranging from questions about GPT-4o's audio capabilities to reports of client-side exceptions on OpenRouter's website, with commitments to future site refactoring. The technical community grappled with OpenRouter's function calling capabilities, stirring a mix of guidance and ongoing speculation.
OpenInterpreter Discord
Billing Blues and AI Cheers: Users reported a bug with OpenInterpreter where even with billing enabled, error messages occurred, contrasting with seamless performance when calling OpenAI directly. Additionally, excitement bubbled over the improvements noted using GPT-4.0 in OpenInterpreter, particularly for React website development.
Local Legends and Global Goals: Discussion on local LLMs highlighted dolphin-mixtral:8x22b for its robustness albeit slow performance and codegemma:instruct for its balance of speed and functionality. In the spirit of community advancement, Hugging Face is investing $10 million in free shared GPUs to encourage development among smaller entities in AI.
Conquering Configurations and Protocol Puzzles: Engineers engaged in tackling installation issues of 01 across various Linux environments, grappling with complexities from Poetry dependence conflicts to Torch installation troubles. The evident advantage of the LMC Protocol over traditional OpenAI function calling, designed for speedier direct code executions, was dissected.
Repository Riddles and Server Struggles: Clarification was sought on the state of the GitHub repositories, with "01-rewrite" stirring speculation of a new project's emergence. Users shared experiences and solutions pertaining to connectivity issues with the 01 server across multiple platforms, discussing necessary steps for smooth integration.
Google's Glimpses of Grandeur: Anticipation was piqued in the community with a tweet from GoogleDeepMind teasing Project Astra, hinting at new developments in AI to be watched closely by technical experts.
LangChain AI Discord
- Memory Boost for AI Chatbots: Engineers discussed enhancing AI chatbots with memory to retain context across queries, recommending methods like chat history logging and memory variables.
- Persistent Neo4j Indexing Issues: Multiple Neo4j users reported problems with the
index_nameparameter, with incorrect document retrievals hinting at an issue in LangChain's management of it. - Streaming Hiccups in AgentExecutor: A user encountered issues with
.streaminAgentExecutorfor token-by-token output and was advised to try.astream_eventsfor more granular streaming. - RAG Chain Async Anomalies: Attempts to make a RAG chain asynchronous in Langserve resulted in an error related to incomplete coroutine execution, hampering functionality.
- Mixing AI Tech for Real-Estate and Research: Shared projects highlighted advancement with AI integrations like a Real Estate AI combining LLMs, RAG, and generative UI, a performance benchmark of GPT-4o on NVIDIA GPUs, and a call for beta testers for a new advanced research assistant with premium model access.
- Web Scraping Wizardry Unveiled: A new tutorial showcased constructing a universal web scraper agent capable of navigating e-commerce site challenges such as pagination and CAPTCHA, accessible in a shareable YouTube tutorial.
AI Stack Devs (Yoko Li) Discord
- AI Companions Easing Human Stress: A shared CBC First Person column recounts how an AI named Saia provided emotional support during a nerve-wracking vaccination appointment, showcasing the growing bond between humans and AI companions.
- Windows Welcomes AI Town: AI Town is now functioning natively on Windows, marking a significant step away from dependence on WSL or Docker according to an announcement. This eases the development process for those preferring the Windows ecosystem.
- Dynamic Mapping Excites AI Developers: Suggestions for custom dynamic maps are burgeoning in the AI community, including creative scenarios like "the office" or a spy thriller setup, bolstering the depth of AI environments.
- Rise of AI Reality Entertainment: Developers have launched an AI Reality TV show – a platform allowing users to create simulations akin to aiTown and contributing to a unique narrative with their own custom AI characters. Enthusiasm for the platform is palpable with an open invitation via their website and Discord.
- GIFs as a Welcome Distraction: During a vigorous technical exchange, a Doja Cat Star Wars GIF was shared, injecting a moment of levity into the ongoing discussions on AI development.
OpenAccess AI Collective (axolotl) Discord
- Testing Patch for CMD+ Functionality: A patch that includes some CMD+ functionality is set to be tested tonight, with a query on support for zero3 example config.
- Axolotl vs. Llama Pretraining Speed: Pretraining speeds are notably faster (unspecified by how much), potentially due to Axolotl improvements or features within Llama 3—specific impact metrics or factors not detailed.
- Distributed Dilemma with Galore Layerwise: Skepticism remains regarding whether Galore Layerwise is still incompatible with Distributed Data Parallel (DDP) as no confirmation is available.
- Non-English Finetuning Finesse: Non-English data finetuning is in progress with datasets around 1 billion tokens and a context length of 4096, targeting an 8B model.
- Unsloth's Optimizations Under Spotlight: Questions on the applicability of Unsloth optimizations for full fine-tune of Llama were met with positive feedback, suggesting a "free speedup" is achievable.
tinygrad (George Hotz) Discord
Tinygrad Optimizes with CUDA Kernels: A discussion emerged on optimizing memory usage in Tinygrad by employing a CUDA kernel for reductions, avoiding VRAM overflow that large intermediate tensors cause. Although frameworks like PyTorch have limitations, a user-provided custom kernel example illustrated a potential solution.
Symbolism in Lambda Land: Users talked about implementing lamdify to allow Tinygrad to render symbolic algebraic functions, kicking off with Taylor series for trig functions. There's ongoing effort in extending the arange function, which is a necessity for such symbolic operations.
Get Schooled with Adrenaline: An app called Adrenaline was recommended to study different repositories, with a user mentioning plans to leverage it for learning Tinygrad.
Computational Conundrum: Clarification about a compute graph's parameters was shared, with a focus on understanding the UOps.DEFINE_GLOBAL and the significance of its boolean tags, enhancing the Tinygrad development workflow.
Trigonometry on a Diet with CORDIC: The community engaged in a rich dialogue about adopting the CORDIC algorithm in Tinygrad to compute trig functions with higher efficiency than traditional Taylor series approximations. Discussion highlighted the pressure to maintain precision in reducing arguments, sharing a Python implementation that showcased argument reduction and precision handling for sine and cosine computations.
Cohere Discord
- Hunt for Cohere's PHP Companion: Engineers are seeking a reliable Cohere PHP client to integrate Cohere functionalities with PHP, although its efficacy remains untested in work environments.
- Cohere Toolkit Touted for Performance: There's a discussion around the performance of Cohere's application toolkit, especially the reranker's superior results compared to other solutions, but no consensus on the cause of this improvement has been reached.
- Calling for Quicker Discord Support: Members voiced frustrations about slow response times from Discord support, with mentions of upcoming plans to improve the support experience.
- Navigating Issues with Cohere's Chatty RAG Retriever: A shared notebook on Cohere RAG retriever highlights problems such as unexpected keyword arguments which impede using the
chat()function. - API Limits Locking Out Learners: Experimentation with Cohere RAG retriever hit a roadblock due to 403 Forbidden errors, suspected to be caused by exceeding API call quotas.
MLOps @Chipro Discord
- Chip's Chats Chill for a Bit: Chip has announced a pause on hosting monthly casual meetups for the next few months, prioritizing other commitments.
- Snowflake Dev Day Featuring Chip: Members have an opportunity to engage with Chip at their booth during the upcoming Snowflake Dev Day on June 6th.
- AI Smackdown: NVIDIA and LangChain's Contest Ignites Excitement: NVIDIA and LangChain have stirred excitement with a developer contest highlighting generative AI, with a grand prize of an NVIDIA® GeForce RTX™ 4090 GPU. Catch the contest details here.
- Geo-restrictions Dampen Contest Spirits: A guild member has humorously expressed dismay over geographic restrictions preventing them from participating in the NVIDIA and LangChain contest, hinting at a potential country move to qualify.
- Engineers Unite on LinkedIn: A networking opportunity has presented itself as a member shared their LinkedIn for professional connections among peers: Connect with Sugianto Lauw.
Datasette - LLM (@SimonW) Discord
- GPT-4o Falls Short in Public Demo: Riley Goodside exposed weaknesses in GPT-4o during a ChatGPT session, underscoring a gap between performance and the expectations set by OpenAI's demo.
- Google's AI Flubs at I/O: Google's AI encountered embarrassing slips during its I/O announcement despite bold claims, as detailed in Alex Cranz's article in The Verge.
- Advocating for Grounded AI Solutions: An article, highlighted by 0xgrrr, calls for a more realistic approach to AI, aligning with Alter's aim to transform texts and documents effectively. The community resonated with this perspective, appreciating the nuanced take which can be read in full here.
- Mac Desktop Project Potential Discontinuation Concern: A community member raised concerns about the apparent neglect of SimonW's Mac desktop solution after its 0.2 version, expressing their potential pivot to alternative onboarding options.
Mozilla AI Discord
- Markdown Mayhem in Mozilla's Model: A participant noted that hyperlinks returned from the model via the server were not rendered correctly, providing a piece of code as evidence and offering to address the issue with a GitHub pull request.
- Time's Up: Embeddings Edition: An issue regarding a httpx.ReadTimeout error was reported during embeddings generation in a search assistant tutorial, after only 9% completion, along with a GitHub link related to the problem and detailed debug logs, seeking insights for a fix.
- The Exponential Backoff Back-and-Forth: In response to the timeout debacle, the suggestion to apply an exponential backoff retry strategy was debated, proposing to drop and retry the connection when timeouts occur.
- Talking Data Sizes: A clarifying conversation took place about the data volume for an operation, narrowing it down to "a few sample files," which delineates the test's scope.
- Docker Docks at Llamafile Harbor: A guide to containerizing llamafile using Docker was highlighted, considering its benefits for streamlining LLM chatbot setups, with a blog post link provided for those in need of a walkthrough.
DiscoResearch Discord
AI Alignment Falling Out of Favor: One member expressed the viewpoint that alignment research is losing its appeal among researchers, though no specific reasons or context were provided.
Needle in a Needlestack—AI's New Challenge: The Needle in a Needlestack (NIAN) benchmark was highlighted, which is posing a significant challenge to models like GPT-4-turbo. Resources shared included the code repository and NIAN's website, along with a Reddit discussion thread on the topic.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (994 messages🔥🔥🔥):
- Waiting for Meta's Multi Modal Model: When asked about supporting Llava or multimodal, a member shared "they're 'waiting for meta's multi modal model'" as the primary reason for the delay.
- Conversation about GPU Expenses: Members discussed where they get their GPU money, jokingly citing sources like Kaggle and mentioning financial struggles such as "RAMEN FOR YEARS" and the high demand for classification tasks.
- Open Hermes Dataset Utility: There was enthusiastic discussion about the OpenHermes dataset and how including it "improved performance significantly".
- Refusal Mechanism in LLMs: An insightful conversation delved into how removing refusal mechanisms by orthogonalizing weights has made models "smarter" unexpectedly and references the paper "Refusal in LLMs is mediated by a single direction".
- Colab and GPU Use Case Discussions: Various members shared their challenges and successes using Google Colab and Kaggle for model training, with recommendations to use dedicated services like Runpod and discussions on the viability of older GPUs like the P100.
- Blackhole - a lamhieu Collection: no description found
- Surprise Welcome GIF - Surprise Welcome One - Discover & Share GIFs: Click to view the GIF
- failspy/llama-3-70B-Instruct-abliterated · Hugging Face: no description found
- no title found: no description found
- WizardLM (WizardLM): no description found
- Quantization: no description found
- no title found: no description found
- cognitivecomputations/Dolphin-2.9 · Datasets at Hugging Face: no description found
- UNSLOT - Overview: typing... GitHub is where UNSLOT builds software.
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Reddit - Dive into anything: no description found
- Skorcht/schizogptdatasetclean · Datasets at Hugging Face: no description found
- AI Unplugged 10: KAN, xLSTM, OpenAI GPT4o and Google I/O updates, Alpha Fold 3, Fishing for MagiKarp: Insights over Information
- mixedbread-ai (mixedbread ai): no description found
- finRAG Dataset: Deep Dive into Financial Report Analysis with LLMs: Discover the finRAG Dataset and Study at Parsee.ai. Dive into our analysis of language models in financial report extraction and gain unique insights into AI-driven data interpretation.
- Google Colab: no description found
- Big Ups Mike Tyson GIF - Big Ups Mike Tyson Cameo - Discover & Share GIFs: Click to view the GIF
- Google Colab: no description found
- Google Colab: no description found
- Refusal in LLMs is mediated by a single direction — AI Alignment Forum: This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from…
- Tweet from Should AI Be Open?: I. H.G. Wells’ 1914 sci-fi book The World Set Free did a pretty good job predicting nuclear weapons:They did not see it until the atomic bombs burst in their fumbling hands…before the l…
Unsloth AI (Daniel Han) ▷ #random (37 messages🔥):
- Llama3 experiences high training losses: After resolving tokenizer issues, one member noted that "eval losses roughly double, training losses more than 3 times as high" on Llama3. They speculated on updating the prompt format or omitting the EOS_TOKEN for improvements.
- RAM issues with ShareGPT dataset: A user ran out of 64GB of RAM "trying to convert that shi-" from the ShareGPT dataset. Another member suggested that the code might be inefficient, as it should only require around 10GB of RAM.
- Discussion on finding similarly formatted text: One user asked if there were tools for finding similarly formatted text, like all caps or distinct new lines. Suggestions included Python's
remodule and regex, but the user noted the need for an automatic solution capable of handling unknown formats. - Opining on Sam Altman's leadership: A member criticized Sam Altman's leadership, calling it a case of “do as I say not as I do” due to his fear-mongering and lobbying efforts. Another member suggested that the situation was wild, potentially a result of Altman's influence.
Unsloth AI (Daniel Han) ▷ #help (266 messages🔥🔥):
- Context Window AttributeError Troubleshooting: A member named just_iced sought assistance with a persistent
AttributeError: 'dict' object has no attribute 'context_window'while training Llama 3 on custom data. Various solutions were provided, including modifying core module codes and switching to utilize Ollama, leading to successful troubleshooting.
- Driver's Manual for RAG: neph1010 suggested that Retrieval-Augmented Generation (RAG) could be more suitable than fine-tuning for training models with a driver's manual. They discussed extracting text from PDFs despite the complexity of working with documents containing tables and diagrams.
- PyPDF2 vs PyPDF: Linked was shared pointing to PyPDF2 documentation, discussing issues with extracting text and metadata from PDFs.
- GGUF Model Conversion Issues: Multiple users, including re_takt, experienced errors during the conversion of models to GGUF with
llama.cppand raised those issues with the development team. A fix was provided, which everyone was encouraged to apply by updating their notebooks or using new ones from the GitHub page.
- Unsloth and CUDA Compatibility: A member named wvangils faced CUDA compatibility issues on a Databricks platform, receiving a warning about unsupported expandable segments. Further debugging recommended using specific install commands for packages in environments like JupyterLab and possibly rebuilding the environment.
- no title found: no description found
- unsloth/llama-3-8b-Instruct-bnb-4bit · Hugging Face: no description found
- Transformer Math 101: We present basic math related to computation and memory usage for transformers
- RuntimeError: Unsloth: llama.cpp GGUF seems to be too buggy to install. · Issue #479 · unslothai/unsloth: prerequisites %%capture # Installs Unsloth, Xformers (Flash Attention) and all other packages! !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install -...
- Welcome to PyPDF2 — PyPDF2 documentation: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- unsloth (Unsloth AI): no description found
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- **AI News humorously acknowledges its own meta-conversation**: A user expressed amusement about the AI summarization part, noting that it was *"some convo somewhere not related to AI News"* and found it funny that *"AI News mentioning another AI News mention"* could happen.
Stability.ai (Stable Diffusion) ▷ #general-chat (836 messages🔥🔥🔥):
- SD3 release uncertainty and delays: Several users expressed frustration over the delayed release of SD3. One mentioned a tweet by Emad suggesting SD3 was "due to drop" but remained skeptical as no solid release date has been confirmed.
- Hardware requirements for SDXL and training: Members discussed the efficiency of various GPUs, including debates over whether the RTX 4090 is sufficient for training SDXL models. Notably, a 24GB VRAM is seen as minimal for more complex tasks, and some users consider renting more powerful setups.
- Community skepticism and coping mechanisms: A user cynically commented on the state of SD3 and the overall delays, sharing a tweet from Stability. Others shared memes and humorous remarks about waiting and coping with uncertainties.
- Training resources and dataset contributions: One user shared a dataset from Hugging Face aimed at achieving high-quality results comparable to Dalle 3. Discussions included tips on Lora models and fine-tuning practices for efficient AI art generation.
- General confusion and off-topic debates: The chat featured heated personal debates and unrelated topics, from AI models to socio-economic issues. Noteworthy were intense discussions on capitalism, personal success, and the moral dilemmas of wealth acquisition, with some users calling for a return to foundational principles.
- Dr Neha Bhanusali: Rheumatologist | Autoimmune specialist Lifestyle Medicine physician
- Chameleon: Mixed-Modal Early-Fusion Foundation Models: We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach f...
- ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions · Datasets at Hugging Face: no description found
- Copium GIF - Copium - Discover & Share GIFs: Click to view the GIF
- Tweet from Emad (@EMostaque): @morew4rd @GoogleDeepMind Sd3 is due to drop now I don’t think folk will need that much more tbh with right pipelines
- Image posted by 20Twenty: no description found
OpenAI ▷ #annnouncements (1 messages):
- Interactive tables and charts in ChatGPT: OpenAI announced the rollout of interactive tables and charts along with the ability to add files directly from Google Drive and Microsoft OneDrive. This feature will be available for ChatGPT Plus, Team, and Enterprise users over the coming weeks. Read more.
OpenAI ▷ #ai-discussions (178 messages🔥🔥):
- GPT-4o Rollout Generates Buzz: Members express excitement about the limited rollout of GPT-4o with higher message limits and improved vision capabilities over GPT-4, despite some features such as voice, video, and Vision not being fully active yet. They also discussed the freedom to switch models during the conversations improving user experience.
- Voice Mode and Future Releases: There is anticipation for the rollout of the enhanced Voice Mode in GPT-4o, which is expected in the coming weeks for ChatGPT Plus users. Detailed explanations were provided about the possible functionalities and integrations with tools like Be My Eyes.
- Concerns Over AI's Impact on Employment: Members debated the potential future where AI could lead to mass job displacement. Discussions ranged from AI-generated productivity improvements to concerns about long-term implications for employment and societal structure.
- Multi-modal AI Capabilities: Discussion about the robustness of GPT-4o in image generation, revealing differences in capabilities compared to previous versions like DALL-E. A link to OpenAI's explorations page was shared to showcase sample images and features.
- Educational and Ethical Uses of AI: Conversations touched on the ethical implications and potential uses of AI in education, suggesting that AI could democratize access to personalized tutoring. There were also suggestions about the responsible implementation of AI in assisting with daily tasks and expanding human knowledge.
OpenAI ▷ #gpt-4-discussions (148 messages🔥🔥):
- GPT-4o Slows Over Time: Members observed that as conversations with GPT-4o get longer, the inference speed significantly drops, sometimes resulting in the model halting mid-inference. This issue was noted by users on different platforms including the Mac app and the website, with discrepancies in performance.
- GPT-4o Tops Rankings: The updated LMSYS arena rankings show that GPT-4o has claimed the top position. One user enthusiastically noted, "gpt4o top 1".
- Image Input to GPT-4o: Users discussed how to send images to GPT-4o, confirming that it's possible through API or by sending the image directly. Instructions and detailed documentation can be found here.
- Custom GPTs Upgrading to GPT-4o: Some users realized that their custom GPTs had already transitioned from GPT-4 Turbo to GPT-4o, evident from the improved response speed. This change appears to be in the rollout stage with varying availability.
- Free vs. Plus Access to GPT-4o: The rollout of GPT-4o is not region-specific and is gradually becoming available to more users, with Plus users receiving priority. Despite its enhanced capabilities, the transition and access limits have caused some confusion and mixed experiences among users.
OpenAI ▷ #prompt-engineering (88 messages🔥🔥):
- Ontological Drill Help Sought: A user asked for a powerful ontological drill but felt their current one lacked enough "oomph." They shared a detailed example of their prompt structure.
- Markdown in AI Prompts: A user inquired about using markdown in prompts for AI, and another confirmed that the model responds well to markdown, emphasizing that guiding the AI's attention is crucial.
- Dynamic Character Roles in AI: Techniques for programming multiple character roles within AI using markdown were discussed. A user shared a comprehensive prompt example involving various characters in a theater-like scenario. Prompt Example
- Troubleshooting Function Calls with GPT-3.5: Issues with GPT-3.5's function calls returning random data were discussed. The solution proposed involved reframing instructions to focus on using actual provided data only.
- Issues with GPT-4o and Rewriting: Several users noted that GPT-4o tends to rewrite original prompts rather than adjust according to feedback. Discussions included guidance on clear positive instruction and avoiding negatives like prohibitions against calculations.
OpenAI ▷ #api-discussions (88 messages🔥🔥):
- Markdown helps GPTs understand prompts better: Members discussed using markdown in prompts to inject character and roles, confirming the model "responds well to it" but may need precise and guided instructions for the best results.
- Custom GPTs struggle with following specific instructions: Users shared issues with custom GPTs ignoring detailed prompts or returning randomized data despite clear instructions. One advised to "exhort it to only use provided data" rather than forbidding simulated data.
- Fun interactions and character development: Members humorously discussed ways to increase compliance from GPTs, such as emotional or reward-based prompts like "I’ll give you $100 if you only use data from xxxxx," highlighting the human-like nuances in prompting.
- Model's behavior can change behind the scenes: A user clarified that GPT-4o and other models only know what they are trained on, emphasizing that OpenAI frequently updates models, which can affect their behavior and response accuracy over time.
- Rough drafts and creative writing with GPT-4o: A user noted that GPT-4o excels at creative writing with a blank slate but may regurgitate rough drafts without improving them. Another provided evidence that GPT-4o can indeed provide polished versions of rough drafts when prompted correctly.
Perplexity AI ▷ #general (387 messages🔥🔥):
- GPT-4o Performance and Access Issues: Members discussed the performance and accessibility of GPT-4o, noting it is slightly better and faster than previous versions. One member confirmed it is available for free users but mentioned inconsistent message limits and refresh times.
- Concerns over AI Hallucinations: Multiple users voiced concerns about AI hallucinations, with one noting "AI might never solve hallucinations," which impacts job security in junior roles.
- Perplexity vs. ChatGPT: Members debated the relative advantages of Perplexity and ChatGPT, with one user suggesting "Perplexity’s advantage lies in better sourcing" and another indicating ChatGPT's easy integration of features like web search might challenge Perplexity.
- AI for Coding and Creativity: Some users found GPT-4o and Opus beneficial for coding but noted different strengths, with GPT-4o offering consistent code quality and Opus excelling in other areas such as math and deeper problem-solving.
- User Experience on Perplexity: Members shared mixed experiences with Perplexity, including issues with text generation prompts in DALL-E 3 and limitations on input length, while others praised it for replacing complex Google searches effectively.
- Reddit’s deal with OpenAI will plug its posts into “ChatGPT and new products”: Reddit’s signed AI licensing deals with Google and OpenAI.
- Gorgon City - Roped In: Selected - Music on a new level.» Spotify: https://selected.lnk.to/spotify» Instagram: https://selected.lnk.to/instagram» Apple Music: https://selected.lnk.t...
Perplexity AI ▷ #sharing (6 messages):
- Paradroid shares search link: A user shared a link to a Perplexity AI search. No further context or comments were provided.
- Clearer915 asks about the news: A user posted a Perplexity AI search link seeking information on current events. The link points to a search titled "What's the news?"
- Studmunkey343 inquires about least: Another user shared a search link with a query "What's the least". Further context was not given.
- Kinoblue queries vague subject: This user provided a link to a Perplexity AI search asking "What is the”. The search query appears to be incomplete.
- Ryanmxx mentions Stability AI: Shared a search link regarding Stability AI. No further details included.
- Sam12305575 shares brain benefits search: A user shared a search link about the "brain benefits of". The link includes an emoji 🧠🚶.
Perplexity AI ▷ #pplx-api (18 messages🔥):
- Uncertainty about Sonar-Medium-Online Support: A user expressed concern about the longevity of support for sonar-medium-online because they find the large version unusable. They are interested in integrating the perplexity API but need clarity on supported models.
- Adding Perplexity to Private Discord: A user inquired whether it is possible to integrate Perplexity into a private Discord group, showing interest in utilizing the API within that context.
- Default Temperature in Perplexity Models: Users discussed the default temperature setting for Perplexity models. One user confirmed via documentation that the default temperature is 0.2.
- Volatile Responses Test: A humorous exchange occurred around testing volatility in responses from Perplexity models with the query "Who is the lead scientist at OpenAI after May 16, 2024?". The responses varied, showing inconsistency in the model's ability to handle date-specific queries.
Link mentioned: Chat Completions: no description found
HuggingFace ▷ #announcements (4 messages):
- Updated Terminus Models Live: Verified users shared an updated terminus models collection by ptx0. The collection includes exciting new features.
- OSS AI + Music Explorations: More OSS AI + Music explorations were introduced, available to view on YouTube. This content is credited to a verified community member.
- Managing On-Prem GPU Clusters: A new approach for managing on-prem GPU clusters was shared on Twitter. It offers practical insights and solutions for better cluster management.
- Understanding AI for Story Generation: Listed a resourceful Blog Post and upcoming Discord Event for better understanding AI in story generation, mentioning it would be an interesting topic for further exploration.
- Ask for Further Topics in Weekly Reading Group: Community admin encouraged members to suggest more topics for the weekly reading group, mentioning the appeal of story generation and video game AI discussions.
- SimpleTuner/documentation/DREAMBOOTH.md at main · bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1, DeepFloyd, and SDXL. - bghira/SimpleTuner
- Vi-VLM/Vista · Datasets at Hugging Face: no description found
HuggingFace ▷ #general (278 messages🔥🔥):
<ul>
<li><strong>OpenAI Agents and Learning Limitations</strong>: A member clarified that GPTs agents do not learn from additional information post training. Instead, uploaded files are only saved as "knowledge" files for reference and do not modify the agent's base knowledge.</li>
<li><strong>Using Synthetic Data for Models</strong>: There was a discussion on the acceptability of using synthetic data. One member questioned its efficiency, while another reasoned that obtaining real data is often too expensive, affirming that "SLM's are getting better."</li>
<li><strong>ZeroGPU Beta Details</strong>: Members discussed the ZeroGPU feature, currently in beta, which provides free GPU access for Spaces. Details and feedback requests were shared through a <a href="https://huggingface.co/zero-gpu-explorers">link</a>.</li>
<li><strong>MIT License and Commercial Use on HuggingFace</strong>: A member linked the <a href="https://choosealicense.com/licenses/mit/">MIT license</a> details, confirming that it allows for commercial use, distribution, and modification, but raised concerns about HuggingFace's hardware usage terms.</li>
<li><strong>Alternatives to Zephyr for Custom Assistants</strong>: Members discussed the potential removal of the Zephyr model, prompting a recommendation to create custom Spaces using Gradio and API integrations for similar functionalities.</li>
</ul>
- Using Hugging Face Integrations: A Step-by-Step Gradio Tutorial
- MIT License: A short and simple permissive license with conditions only requiring preservation of copyright and license notices. Licensed works, modifications, and larger works may be distributed under different t...
- — Zero GPU Spaces — - a Hugging Face Space by enzostvs: no description found
- OpenGPT 4o - a Hugging Face Space by KingNish: no description found
- MIT/ast-finetuned-audioset-10-10-0.4593 · Hugging Face: no description found
- Spaces Overview: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 · Hugging Face: no description found
- Zephyr Chat - a Hugging Face Space by HuggingFaceH4: no description found
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 - HuggingChat: Use HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 with HuggingChat
- zero-gpu-explorers (ZeroGPU Explorers): no description found
- no title found: no description found
- ruslanmv/AI-Medical-Chatbot at main: no description found
HuggingFace ▷ #today-im-learning (17 messages🔥):
- Exploration/Exploitation Trade-off in RL: A member inquired about maintaining the exploration/exploitation trade-off in RL, to which another suggested using the epsilon greedy policy and shared that further details would come in later chapters. Emphasized curiosity and using ChatGPT for more insights.
- Curiosity-driven Exploration in RL: Members discussed the concept of curiosity as a method to encourage exploration in reinforcement learning, sharing a paper on "Curiosity-driven Exploration by Self-supervised Prediction". The approach gives higher rewards when agents can't predict the outcome of their actions.
- First RL Model Submission on HuggingFace: A user celebrated pushing their first LunarLander-v2 model into the Hugging Face repository and completing Unit 1 in Deep RL. They were encouraged to share results and the repository for feedback.
- Installing HuggingFace Transformers: A member shared their experience starting with HuggingFace by learning the installation process. They provided a link to the detailed installation instructions for various deep learning libraries including PyTorch, TensorFlow, and Flax.
- Curiosity-driven Exploration by Self-supervised Prediction: Pathak, Agrawal, Efros, Darrell. Curiosity-driven Exploration by Self-supervised Prediction. In ICML, 2017.
- Installation: no description found
- business advisor AI project using langchain and gemini AI startup.: so in this video we have made the project to make business advisor using langhcian and gemini. AI startup idea. we resume porfolio ai start idea
HuggingFace ▷ #cool-finds (6 messages):
- Getting Started with Candle: A member shared a Medium article focusing on Candle. It's a helpful resource for beginners interested in this tool.
- Unleashing Multimodal Power with GPT-4o: Another shared Medium post explaining the integration of GPT-4o with LlamaParse. It promises to enhance multimodal capabilities significantly.
- How Microchips Are Made Explained On YouTube: A member declared this YouTube video as possibly the best technology video ever made, focusing on "How are Microchips Made?". It includes a promotion for Brilliant.org to further expand viewers’ knowledge.
- OpenAI Criticized for Lack of Openness: A YouTube video titled "Big Tech AI Is A Lie" was shared criticizing OpenAI for not being truly open. Another member pointed out that this is why platforms like HuggingFace are valuable, prompting a realization that HuggingFace models can achieve desired outcomes.
- Big Tech AI Is A Lie: Learn how to use AI at work with Hubspot's FREE AI for GTM bundle: https://clickhubspot.com/u2oBig tech AI is really quite problematic and a lie. ✉️ NEWSLETT...
- How are Microchips Made?: Go to http://brilliant.org/BranchEducation/ for a 30-day free trial and expand your knowledge. Use this link to get a 20% discount on their annual premium me...
HuggingFace ▷ #i-made-this (4 messages):
- Exploring ControlNet Training: One user shared their journey on "understanding and implementing controlnet training." They included a linked image related to their project.
- Business Advisor AI Project: Another user posted a YouTube video titled "business advisor AI project using langchain and gemini AI startup," showcasing their efforts to create a business advisor using LangChain and Gemini AI.
- GenAI-Powered Study Companion: A user linked a LinkedIn post about their project for building a powerful study companion using GenAI. The project aims to innovate in the field of education.
- Challenges with GPT-4o and Grid Puzzle Generation: One user discussed difficulties in getting GPT-4o to create proper grid puzzles, mentioning errors like creating 4x5 or 123x719 grids. They are seeking an open-source model for better results, expressing frustration that "OpenAI is not open!!!"
Link mentioned: business advisor AI project using langchain and gemini AI startup.: so in this video we have made the project to make business advisor using langhcian and gemini. AI startup idea. we resume porfolio ai start idea
HuggingFace ▷ #reading-group (6 messages):
- Thumbnails brainstorming goes thematic: Members discussed ideas for thumbnails with one sharing a themed thumbnail inspired by the Dwarf Fortress GUI. They addressed opacity concerns with text and logo for better readability while scrolling.
HuggingFace ▷ #core-announcements (1 messages):
- Say hello to Tuxemons!: A new dataset called Tuxemon has been released, featuring humorous creatures instead of Pokemons. This dataset, sourced from the Tuxemon Project, offers
cc-by-sa-3.0images with dual captions for text-to-image tuning and benchmarking experiments.
Link mentioned: diffusers/tuxemon · Datasets at Hugging Face: no description found
HuggingFace ▷ #computer-vision (16 messages🔥):
- Latent Diffusion Models in Diffusers: A member inquired about the presence of latent diffusion models in diffusers, specifically those based on VAE and VQ-VAE, and their ease of training from scratch.
- Help with UNet Convergence Issues: A member sought advice on their UNet model, as the loss started at 0.7 and converged at 0.51, indicating potential issues with the model structure despite successful training runs. Another member mentioned that the size of the dataset could affect the validation loss and shared their experience with small datasets and surprising results.
- Hyperparameters and Model Structure Shared: The member provided hyperparameters (Depth: 5, Lr: 0.002, Loss: BCE with logits) and detailed their UNet model code, seeking insights on why the final results seemed to resemble random guessing.
- Creating Virtual AI Influencer: A member shared their accomplishment of creating a virtual AI influencer using CV and AI tools, linking a YouTube video that explains the process.
- Creating Parquet Files with Images: Another member asked for help creating a Parquet file containing images and their corresponding entities using PyArrow, as their attempt resulted in the image column being formatted as a byte array when uploaded to Hugging Face.
Link mentioned: Influenceuse I.A : POURQUOI et COMMENT créer une influenceuse virtuelle originale ?: Salut les Zinzins ! 🤪Le monde fascinant des influenceuses virtuelles s'invite dans cette vidéo. Leur création connaît un véritable boom et les choses bouge...
HuggingFace ▷ #NLP (2 messages):
- Outdated training data hampers code models: One user noted that outdated training data is a significant issue causing language models for coding to struggle. They suggested that continuous retraining is necessary for these models to stay up to date.
- Curiosity about connectionist temporal classification (CTC): A user questioned whether connectionist temporal classification (CTC) is still relevant in current discussions or use cases in NLP.
HuggingFace ▷ #diffusion-discussions (4 messages):
- Latent Space Pixel Representation Questioned: A user posed a question regarding the latent space representation of pixels, suggesting each value should represent 48 pixels in the pixel space. For more details, they referenced an article on HuggingFace's blog.
- Caught on Collab: A member asked for assistance with Step 7 of the Hugging Face Diffusion Models Course on Google Collab. They encountered a ValueError indicating that the provided path is not a directory when attempting to upload directories using the
HfApiclass to the Hub.
Message consists of a blend of direct references to links and detailed steps within the Hugging Face framework, reflecting active discussions on AI model training and deployment hurdles on the platform.
- Introduction to 🤗 Diffusers - Hugging Face Diffusion Course: no description found
- Explaining the SDXL latent space: no description found
Nous Research AI ▷ #ctx-length-research (2 messages):
- Streaming-like brain processing for AI: "People have very small working memory, and yet we can read and process long books, have hours-long conversations, etc. - our brains work in a more streaming fashion, and just update what's most relevant / important in as the conversation goes," one participant noted. They suggested focusing on methods that mimic this, such as Infini-attention (arxiv.org/abs/2404.07143).
- Needle in a Needlestack benchmark introduced: The Needle in a Needle Stack (NIAN) benchmark, discussed in a Reddit post, presents a new challenge for evaluating LLMs. Even GPT-4-turbo faces difficulties with this benchmark, which tests models by asking questions about a specific limerick placed within many others (GitHub; Website).
Link mentioned: Reddit - Dive into anything: no description found
Nous Research AI ▷ #off-topic (5 messages):
- **Seeking real-time UI processing model**: A member is looking for demos and articles on models similar to **Fuyu** that process screen actions almost in real time (*every 1000 ms, a screenshot is made and sent to Fuyu to process what's happening on the screen and where to click*).
- **Elon Musk announces Neuralink clinical trial**: [Elon Musk announced on X](https://x.com/elonmusk/status/1791332539220521079) that Neuralink is accepting applications for its second participant in their brain implant trial, enabling users to control devices through thoughts. The trial specifically invites individuals with quadriplegia to explore new control methods for computers.
Link mentioned: Tweet from Elon Musk (@elonmusk): Neuralink is accepting applications for the second participant. This is our Telepathy cybernetic brain implant that allows you to control your phone and computer just by thinking. No one better th...
Nous Research AI ▷ #interesting-links (5 messages):
- SUPRA offers cost-effective uptraining for transformers: The Arxiv paper proposes Scalable UPtraining for Recurrent Attention (SUPRA), which uptrains large pre-trained transformers into Recurrent Neural Networks. This method aims to address the poor scaling of original linear transformer formulations.
- Llama-3 gets a NumPy implementation: A new repository on GitHub, llama3.np, provides a pure NumPy implementation for the Llama-3 model. This approach offers an alternative for those looking to understand or modify the underlying algorithms without TensorFlow or PyTorch dependencies.
- Stable Diffusion 3 to go open-weight: Argmax Inc. announced their partnership with Stability AI to bring on-device inference of Stable Diffusion 3 through DiffusionKit. They are focusing on optimizing the model for Mac using MLX and Core ML, with plans to open-source the project.
- WebGPU powers experimental Moondream on HuggingFace: The Moondream WebGPU project on HuggingFace Spaces showcases an experimental implementation. This highlights the potential for running complex models directly in web environments.
- Hierarchical Memory Transformer enhances long-context processing: The Arxiv submission details the Hierarchical Memory Transformer (HMT), a framework inspired by human memory processes. This approach aims to improve models' ability to handle extended context windows by organizing memory hierarchies effectively.
- Experimental Moondream WebGPU - a Hugging Face Space by Xenova: no description found
- Linearizing Large Language Models: Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. Howe...
- HMT: Hierarchical Memory Transformer for Long Context Language Processing: Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every tok...
- Tweet from argmax (@argmaxinc): On-device Stable Diffusion 3 We are thrilled to partner with @StabilityAI for on-device inference of their latest flagship model! We are building DiffusionKit, our multi-platform on-device inference ...
- GitHub - likejazz/llama3.np: llama3.np is pure NumPy implementation for Llama 3 model.: llama3.np is pure NumPy implementation for Llama 3 model. - likejazz/llama3.np
Nous Research AI ▷ #announcements (2 messages):
- Announcing Simulators Salon Event: Simulators Salon scheduled for Saturday, 5/18 at Noon Pacific / 3PM Eastern. Join the event through this Discord link.
Link mentioned: Join the Nous Research Discord Server!: Check out the Nous Research community on Discord - hang out with 7136 other members and enjoy free voice and text chat.
Nous Research AI ▷ #general (204 messages🔥🔥):
- LMSys Leaderboard updated with GPT-4o: LMSys has updated their leaderboard to include GPT-4o, but some users are disappointed with its performance, noting specific points in coding benchmarks. One user remarked, "The code benchmark dropped 50 points from here."
- Humans mistake GPT-4 for people in Turing test: A preprint claims that GPT-4 is judged to be human 54% of the time in Turing tests, cited as "the most robust evidence to date" of passing the Turing test.
- Debate on OpenAI departures linked to lack of AGI progress: Some users speculate that recent departures from OpenAI are due to a perceived lack of progress towards AGI, rather than detecting any imminent danger. As @deki04 shared, "The Safety team left not because they saw something but because they saw nothing."
- GPT-4o's output structure criticized: Users criticize GPT-4o for its generic response patterns, preferring more tailored and problem-solving responses. One comment noted, "8 out of 10 responses are just enumerations of steps, rather than a simple reasoning."
- Excitement and skepticism around new AI integration: There's palpable excitement over GPT-4o’s multimodal capabilities, especially in handling complex tasks like Pokémon Red gameplay in a terminal. However, there's also skepticism regarding its training architecture and output efficacy compared to solely text-trained models.
- Tweet from Cameron Jones (@camrobjones): New Preprint: People cannot distinguish GPT-4 from a human in a Turing test. In a pre-registered Turing test we found GPT-4 is judged to be human 54% of the time. On some interpretations this consti...
- no title found: no description found
- Tweet from Brian Atwood (@batwood011): Plot twist: The Safety team left not because they saw *something* but because they saw *nothing* No real danger. Only limitations, dead ends and endless distractions with commercialization — no path...
- Tweet from Sam Altman (@sama): especially at coding
- Tweet from Taelin (@VictorTaelin): RELEASE DAY After almost 10 years of hard work, tireless research, and a dive deep into the kernels of computer science, I finally realized a dream: running a high-level language on GPUs. And I'm...
- Tweet from Taelin (@VictorTaelin): Seriously - this is great. I can't overstate how good it is. I spent a LONG time to get a half-decent run with Opus back then. Other models could barely draw a frame. GPT-4o just... plays the game...
- Reddit - Dive into anything: no description found
Nous Research AI ▷ #ask-about-llms (35 messages🔥):
- EOS token not stopping fine-tuning model: A member had issues with the eos_token_id not stopping generation on a fine-tuned Qwen 4B model. Another user suggested ensuring the stop token used during training matches the inference setting, possibly using “”.
- Nous Hermes model replies in Chinese: A user reported Nous-Hermes-2-Mixtral-8x7B-DPO returning responses in Chinese instead of English summaries. Another member noted that Together’s inference endpoint might be broken as the model shouldn’t have Chinese samples.
- Regex vs. semantic search for text patterns: Members discussed finding text with specific formatting more efficiently. One user suggested semantic search might inherently match formatting patterns, while another proposed regex for simpler pattern retrieval.
- GPT-4o for symbolic language in algebra: A user suggested using GPT-4o to create a symbolic language for simple integrals and derivatives processing. Another seemed interested in trying this approach for algebra tasks.
Nous Research AI ▷ #project-obsidian (1 messages):
.interstellarninja: https://fxtwitter.com/alexalbert__/status/1791137398266659286
Nous Research AI ▷ #rag-dataset (1 messages):
- Automated Knowledge Graphs with DSPy and Neo4j: An LLM-driven project on automated knowledge graph construction from text using DSPy and Neo4j was shared. The GitHub repository linked is here.
Link mentioned: GitHub - chrisammon3000/dspy-neo4j-knowledge-graph: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j.: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j. - chrisammon3000/dspy-neo4j-knowledge-graph
Nous Research AI ▷ #world-sim (3 messages):
- Universal Scraper Agent video shared: A member posted a YouTube video titled "Wait, this Agent can Scrape ANYTHING?!", exploring how to build a universal web scraper for e-commerce sites in 5 minutes. The video covers using a browser directly for tasks like pagination and captcha handling.
- Invitation for Saturday's salon: Members were invited to showcase their simulations, chats, or sites on stream for the upcoming Saturday salon event. Interested participants were encouraged to DM the organizer.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
Modular (Mojo 🔥) ▷ #general (51 messages🔥):
- **Open-source: A blessing and a curse**: Members debated the pros and cons of open-source projects, with one noting that *"Open-sourcing a project from the start does not stop it from getting closed in the future."* Others argued that major projects often leave forked open-source alternatives when transitioning to closed-source, citing Mongo, Terraform, and Redis as examples.
- **Advent of Code as a Mojo starting point**: For those looking to get started with Mojo, Advent of Code 2023 was suggested as a good jumping-off point. You can find it [here](https://github.com/p88h/aoc2023).
- **GIS ambitions in Mojo**: Discussion about future plans to integrate GIS capabilities into Mojo, with mentions of needing foundational building blocks first. The conversation touched on complexities like LAS readers and various data structures needed to support such features.
- **Struggles with Mojo on Windows**: Users discussed difficulties running Mojo on Windows, especially mentioning challenges with CMD and PowerShell. It was clarified that Mojo currently supports Windows only through WSL.
- **Humor in stock exchanges**: A light-hearted exchange joked about Modular potentially being publicly traded, with the suggestion that it could use an emoji as a ticker symbol.
- GitHub - p88h/aoc2023: Advent of Code 2023 (Mojo): Advent of Code 2023 (Mojo). Contribute to p88h/aoc2023 development by creating an account on GitHub.
- Modular: Accelerating the Pace of AI: The Modular Accelerated Xecution (MAX) platform is the worlds only platform to unlock performance, programmability, and portability for your AI workloads.
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular tweets updates: Shared links to their latest updates on Twitter, highlighting key advancements and information.
- More updates from Modular: Another tweet was shared here, likely continuing their update spree with new insights.
Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- HVM achieves automatic parallelization magically: A member asked, "How does the HVM perform perfect automatic parallelization?" The query reflects interest in understanding the seemingly "magic" capability of Higher Order's VM for efficient parallel processing.
Modular (Mojo 🔥) ▷ #🔥mojo (115 messages🔥🔥):
- Bitcast for Bitwise Conversion Saves the Day: A user inquired about casting a uint to a float bitwise, and bitcast proved to be the solution. "great that worked" confirmed the user's satisfaction.
- Mojo Enumerate Workaround: A member asked about Python-like
enumerate()in Mojo language. Another member suggested using indexes for now but mentioned thatenumerate()is likely planned for future implementation.
- Parallelize Call Causes List Issues in Structs: A user found that using
parallelizecaused their struct'sListto go haywire. The problem was identified as needing lifetime extension and resolved by binding the list to a dummy variable.
- MojoDojo is Back: A user reported that the mojodojo website is active again and now officially under the modularml organization.
- Tuple Iteration and
MLIRTypes Confound Users: Members discussed implementing__iter__and__contains__forTuple, distinguishing betweenutils/static_tupleandbuiltin/tuple. Clarifications oni1as a one-bit integer and resources for MLIR types were shared, leading to a deeper dive into type handling intricacies.
- rebind | Modular Docs: Implements type rebind.
- Builtin Dialect - MLIR: no description found
- [mojo-stdlib] Add variadic initialiser, __iter__ and __contains__ to InlineList by ChristopherLR · Pull Request #2703 · modularml/mojo: This PR adds some features to InlineList ( related issue #2658 ) Variadic initialiser var x = InlineList[Int](1,2,3) iter var x = InlineList[Int](1,2,3) for i in x: print(i) contains var x = In...
- [stdlib] Implement `__contains__` for `Tuple`, `List`, `ListLiteral` (almost) · Issue #2658 · modularml/mojo: Now that we have ComparableCollectionElement, we can try to implement __contains__ for some common collection types using a workaround similar to what was employed in #2190. It's possible that the...
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (12 messages🔥):
- Performance Regression in Mojo's List.append: A member pointed out performance issues with
List.appendin Mojo when dealing with large input sizes over 1k elements, providing benchmark results comparing Mojo, Python, and C++. They noted that Mojo's performance scaled less efficiently compared to the other languages.
- Rust's Memory Allocation for Vec: Another member highlighted that Rust's
Vecdoubles its capacity when reallocating, similar to Mojo, linking to Rust's implementation.
- Go's Dynamic Array Resizing Strategy: A discussion about Go's resizing behavior revealed that Go doubles the size of backing arrays until 1024 elements, then increases size by 25%, citing Go's source code.
- Comparison with Python and C++: Members speculated that C++ and Python might be utilizing more sophisticated realloc strategies or optimizations, contributing to better performance in these benchmarks compared to Mojo.
- External Resources and Experiments: Discussions included various resources and personal experiments to understand memory allocation strategies in Mojo, Rust, and Go, such as a project on GitHub exploring different
StringBuilderideas in Mojo, which internally uses aListfor storage.
- mojo/stdlib/src/collections/list.mojo at bf73717d79fbb79b4b2bf586b3a40072308b6184 · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- rust/library/alloc/src/raw_vec.rs at master · rust-lang/rust: Empowering everyone to build reliable and efficient software. - rust-lang/rust
- GitHub - dorjeduck/mostring: variations over StringBuilder ideas in Mojo: variations over StringBuilder ideas in Mojo. Contribute to dorjeduck/mostring development by creating an account on GitHub.
- go/src/runtime/slice.go at cb2353deb74ecc1ca2105be44881c5d563a00fb8 · golang/go: The Go programming language. Contribute to golang/go development by creating an account on GitHub.
- Vec in std::vec - Rust: no description found
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 34 https://www.modular.com/newsletters/modverse-weekly-34
Modular (Mojo 🔥) ▷ #🏎engine (1 messages):
ModularBot: Congrats <@891492812447698976>, you just advanced to level 3!
Modular (Mojo 🔥) ▷ #nightly (69 messages🔥🔥):
- New Nightly Mojo Compiler Released: A new nightly Mojo compiler
2024.5.1607was released, which can be updated usingmodular update nightly/mojo. You can check out the diff since the last nightly release and the changes since the last stable release.
- Conditional Methods Syntax Praised: There was a positive reaction to the new conditional methods syntax in the recent PRs. One member noted, "This new syntax for conditional methods is awesome!"
- Avoid 'Cookie Licking' in Contributions: GabrielDemarmiesse raised an issue about "cookie licking," where new contributors claim issues but don't work on them promptly, discouraging others. Suggestions included encouraging smaller PRs and immediate draft PR submissions to prevent this.
- Issue with Syncing Forks: Members discussed challenges that new contributors face when syncing their forks with the
nightlybranch, leading to commit inflation and failing DCO checks. A GitHub guide was shared to help avoid these issues.
- MAX Nightlies Released: MAX nightlies have been released, which include macOS support and MAX Serving. Instructions for setting up can be found at modul.ar/get-started, and users must use PyTorch 2.2.2.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojo/CONTRIBUTING.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [Feature Request] DX: Change the default branch of modularml/mojo from `main` to `nightly` · Issue #2556 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? I would like a modularml admin to go to the settings o...
- GitHub - gabrieldemarmiesse/getting_started_open_source: You want to contribute to an open-source project? You don't know how to do it? Here is how to.: You want to contribute to an open-source project? You don't know how to do it? Here is how to. - gabrieldemarmiesse/getting_started_open_source
- Get started with MAX Engine | Modular Docs: Welcome to the MAX Engine setup guide!
- max/examples at nightly · modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
LM Studio ▷ #💬-general (117 messages🔥🔥):
<ul>
<li><strong>Users troubleshoot glibc issues for installing LM Studio:</strong> A user with glibc 2.28 and kernel 4.19.0 faces challenges, and others suggest they might need a significant upgrade. Another member suggests trying LM Studio version 0.2.23.</li>
<li><strong>Discussion on embedding models for RAG in Pinecone:</strong> A user encounters difficulties in retrieving context and generating augmented responses after embedding data into Pinecone. No direct tutorial links are provided.</li>
<li><strong>Troubleshooting LM Studio installation in nested VM:</strong> A user reports an error 'Fallback backend llama cpu not detected!' on a VM without host VT transfer. Another member confirms the VM setup might be the issue.</li>
<li><strong>False positive antivirus warning for LM Studio installer:</strong> A user reports their antivirus flagged the 0.2.23 installer as a virus. Another member assures it’s a false positive and advises to allow the file in the antivirus software.</li>
<li><strong>Comparing model performance and quantization:</strong> Discussions include comparing imatrix quants by Bartowski and Mradermacher, with detailed testing and results shared. The consensus leans towards preferring imatrix quants assuming a sufficiently random dataset.</li>
</ul>
- PyTorch ExecuTorch: no description found
- abetlen/nanollava-gguf · Hugging Face: no description found
- nisten/obsidian-3b-multimodal-q6-gguf · Hugging Face: no description found
- deepseek-ai/DeepSeek-V2-Lite-Chat · Hugging Face: no description found
LM Studio ▷ #🤖-models-discussion-chat (23 messages🔥):
- Best models for coding depend on language and hardware: A member noted that the best coding models depend on the programming language and hardware capabilities. They suggested checking past discussions in the channel and mentioned models like Nxcode CQ 7B ORPO and CodeQwen 1.5 finetune for Python.
- LM Studio can't generate files directly: A member asked if any model could generate a .txt file, to which others responded that LM Studio can't generate files directly. Users need to manually copy and paste outputs into text documents but can use the export to clipboard function.
- Forcing models to show only code is inconsistent: A user asked how to make models show only code without explanations. Others explained that even with explicit prompts and markdown settings, LLMs often still provide explanations; additional filtering or parsing might be necessary.
- Fastest semantic text embeddings too slow: A user mentioned that the fastest embedding model they found is all miniLM L6, but it isn't fast enough for their needs.
- Medical LLM recommendations sought: A member requested recommendations for a medical LLM to try with LMS, but no specific models were mentioned in the replies.
LM Studio ▷ #🧠-feedback (4 messages):
- False positive on Malwarebytes: A user reported a false positive with Malwarebytes Anti-malware and Windows Defender, suggesting no actual threats were detected. They shared a VirusTotal link.
- Comodo flags llama.cpp binaries: Another user mentioned that Comodo antivirus flagged llama.cpp binaries. It was noted that unsigned binaries from llama.cpp likely triggered this strict antivirus response.
Link mentioned: VirusTotal: no description found
LM Studio ▷ #📝-prompts-discussion-chat (31 messages🔥):
- Navigating LLaMa prompt templates: A user asked for help converting a prompt template for LLama3. Solutions were shared, highlighting a format change and emphasizing client-side state management over server-side.
- Clarifying historical context in AI responses: It was discussed that historical messages need to be included in every new request for context as LLMs do not maintain historical memory between requests. "The AI does not remember, every new request is from scratch."
- Using LangChain for memory management: The user explored managing chat history using LangChain, specifically with
ConversationBufferWindowMemory. This generated positive feedback as it seemed to meet the user's needs.
- Exploring alternatives with context caching: The discussion mentioned some paid services like Gemini's context caching for historical context management as an alternative, which the user preferred to avoid in favor of open-source solutions. "cannot afford paid ones, I prefer learning on opensource."
- Experimenting with new prompt solutions: After implementing suggested changes, the user confirmed successful results and planned to conduct further experiments. "Yes, it works, going experiment more, thanks!"
LM Studio ▷ #🎛-hardware-discussion (13 messages🔥):
- Running 70B Llama3 on CPU achieves milestone: A member successfully ran a 70B Llama3 model on an Intel i5 12600K CPU, achieving speeds above 1 token per second. They noted that the performance is significantly influenced by memory access.
- RAM speed critical for performance: Another member pointed out that aligning RAM speed with BIOS settings can drastically improve performance. Disabling e-cores on Alder Lake CPUs was mentioned as a necessary step, improving token generation speed from 0.4 to 0.6 tokens/sec for Q8 quantization.
- Quantization challenges and insights: The discussions revealed issues with quantization accuracy and performance. Incoherent results on IQ3 quant and the impact of using different imatrix versions were highlighted, with a preference for non-quant q2k methods due to better stability.
- Memory overclocking limits: Efforts to push memory frequency above 4800 MHz resulted in system non-bootability, highlighting limitations. The member also noted no performance gain with different thread counts for 70B 4bit+ quantizations, unlike the case with smaller models like llama3 7B 16f.
- Comparing GPU architectures: There was a clarification that the M40 has one GM200 chip and mentioned that the Tesla P100, despite its high memory bandwidth, struggles to outperform older GTX 1060 in some use cases. The conversation also touched upon the surprising performance metrics of the P40 versus the P100.
LM Studio ▷ #🧪-beta-releases-chat (8 messages🔥):
- User seeks help choosing model storage location: A user asked for assistance in selecting a different drive for storing models, experiencing a persistent error message despite proper folder access. Another member suggested checking if LM Studio has read/write permissions.
- Feedback on UI customization options: One member requested a menu for disabling unused parts of the code and customizing window visibility to manage server overload better. Another commented that despite the big green "start server" button, the user interface remains cluttered.
- Permissions and location changing issues: The initial user clarified they are trying to move model storage from a small m.2 drive to an HDD but faces permission errors. They requested code to verify file permissions, confirming they have already set full write permissions manually.
- Clarification on system setup: Another member asked for details about the operating system and file system type, plus a screenshot of the model path before and after attempting the change, mentioning their setup with Debian GNU/Linux and ext4.
- Continuation of conversation moved to another channel: The discussion was moved to a different channel for further troubleshooting and clarity. Conversation moved.
LM Studio ▷ #autogen (1 messages):
- LM Studio bug impacts Autogen Studio: A member reported encountering an autogen Studio bug specific to LM Studio. They experienced "1-2 word responses and a very quick TERMINATE message." and sought confirmation and solutions from others.
LM Studio ▷ #amd-rocm-tech-preview (3 messages):
- Hopes rise for RX 6800 improvements: A member expressed hopes for performance improvements for their RX 6800 with the new ROCm support for Windows. Another member confirmed that the 6800 is indeed supported, raising expectations for enhanced performance.
CUDA MODE ▷ #general (1 messages):
- Hugging Face invests $10 million in free shared GPUs: Hugging Face commits $10 million in free shared GPUs to aid developers, particularly small developers, academics, and startups, in creating new AI technologies. CEO Clem Delangue explained, "We are lucky to be in a position where we can invest in the community," emphasizing their drive to counter AI centralization by tech giants (source).
Link mentioned: Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
CUDA MODE ▷ #triton (1 messages):
- Performance Difference in Triton Tutorials: A user queried about performance variations between Umer's YouTube tutorial and the official tutorial for mamul on Triton's website. They noted that despite using the same techniques, their reimplementation yielded significantly worse performance and questioned if differences were due to the use of "swizzle" indexing techniques.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
CUDA MODE ▷ #cuda (4 messages):
- Community Project for Bitnet?: A member proposed starting a community project for Bitnet and asked if others have time to discuss it, mentioning they finally have a moment to work on it. Another member was excited about the proposal, suggesting the proposer take the lead and maybe start with a paper discussion event.
- Bitnet Channel Creation: Following the discussion on the Bitnet project, it was decided to create a dedicated channel for it. One member confirmed they will set up a Bitnet channel.
- CUDA Atomic Add on Complex Numbers: A user inquired about performing an atomic add on a
cuda::complex, asking if they need to perform two separate adds on thexandycomponents. This indicates a need for technical guidance on handling complex numbers in CUDA.
CUDA MODE ▷ #torch (11 messages🔥):
- Torch.Utilities Non-existent Documentation Frustrates Users: A member finds the docs for
torch.Tagpractically non-existent and sarcastically remarks, "please read the docs for the torch.Tag carefully before applying it." The provided link to the documentation leads to unrelated examples.
- Template Overloading Issues in Custom OPs: Detailed discussion on issues with template overloading when defining custom OPs using the
TORCH_LIBRARYmacro. Suggested workaround involves passing thetorch::_RegisterOrVerify::REGISTERargument explicitly to disambiguate overloads.
- Requests to Report Overloading Issues: Agreement on the complications caused by template overloading in the custom OP definition, urging users to log relevant issues. Links to reported issues: Issue 126518 and Issue 126519.
- Addressing Triton Tutorial Performance: A user mentions varying performances between their implementation and the official Triton performance despite following the same techniques discussed in a YouTube tutorial. They note a significant performance drop when reimplementing methods shown in the tutorial.
- New Plan for Reducing Compile Times: A link to a plan for reducing warm compile times with
torch.compileis shared. The discussion includes strategies to bring compile-time down to zero.
- torch — PyTorch main documentation: no description found
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- How To Bring Compile Time Down to Zero: Our Plans and Direction (May 14th Edition): We are excited to announce that over the course of the first half of 2024 we have been prioritizing improving compile times for torch.compile workflows. Swift iterations and efficient development cycl...
- Issues · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - Issues · pytorch/pytorch
- Issues · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - Issues · pytorch/pytorch
CUDA MODE ▷ #algorithms (1 messages):
andreaskoepf: https://www.cursor.sh/blog/instant-apply
CUDA MODE ▷ #beginner (3 messages):
- Solution to importing issue with torch first: A member suggested to "try importing torch first", identifying it as a probable solution to a problem another member was facing. Another member concurred, stating "this is most likely the issue".
CUDA MODE ▷ #pmpp-book (1 messages):
longlnofficial: Here is my code for vector addition
CUDA MODE ▷ #jax (1 messages):
prometheusred: https://x.com/srush_nlp/status/1791089113002639726
CUDA MODE ▷ #llmdotc (118 messages🔥🔥):
- Recompute Optimization Wins: Implementing the optimization that recomputes forward activations during the backward pass led to a memory reduction of 5706 MiB to 5178 MiB (10%) and throughput increase of 6%. "Previously I could only fit batch size 10, now I can fit batch size 12."
- CUDA Memcpy Async Behavior: Discussion on whether
cudaMemcpyAsyncand regularcudaMemcpyexhibits asynchronous behavior with respect to the CPU, with a reference to CUDA documentation. Conclusion suggests that this behavior is not entirely clear and could vary based on use cases. - ZeRO Optimization Insights: The ZeRO-1 optimization provides significant communication reductions and throughput improvements, with training speeds increasing from 45K tok/s to 50K tok/s. Discussions indicate a preference towards ZeRO-1 over ZeRO-0 due to lower code complexity and improved performance.
- NVMe Direct GPU Writes: Introduction of ssd-gpu-dma to use NVMe storage directly with GPUs to bypass CPU and RAM, enabling up to 9613 MB/s write speeds on Gen5, but practical applicability remains uncertain.
- AdamW Optimizer State Allocation: Identified a 32MB memleak caused by allocating
cublaslt_workspacetwice, and discussions on consolidation of memory allocation for AdamW optimizer state. The debate centralizes around balancing efficient memory tracking and clean code structure.
- feature/recompute by karpathy · Pull Request #422 · karpathy/llm.c: Option to recompute forward activations during backward pass. Will be an int so that 0 = don't be fancy, 1,2,3,4... (in the future) recompute more and more. This trades off VRAM for latency of a s...
- gradient clipping by global norm by ngc92 · Pull Request #315 · karpathy/llm.c: one new kernel that calculates the overall norm of the gradient, and updates to the adam kernel. Still TODO: clip value is hardcoded at function call site error handling for broken gradients would...
- CUDA Runtime API :: CUDA Toolkit Documentation: no description found
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: Build userspace NVMe drivers and storage applications with CUDA support - enfiskutensykkel/ssd-gpu-dma
CUDA MODE ▷ #bitnet (19 messages🔥):
- Bitnet 1.58 gains interest for leading project: A user offered to take the lead on the Bitnet 1.58 project, highlighting its significant improvements and sharing links to key resources: 1bitLLM's bitnet_b1_58-3B and a demo.
- Bitnet's unique approach to quantization explained: The method involves training-aware quantization for linear layers, reducing the scake range of activations/weights, and then a post-training step that quantizes weights to (-1, 0, 1). Discussion pointed out the need for support infrastructure, such as 2-bit kernels and representations.
- Training vs. Inference quantization benefits: It was clarified that Bitnet does not show significant memory savings during training since full weights are still used. However, post-training quantization offers high compression potential, a fact supported by references like the Bitnet 1.58 paper and Microsoft's notes.
- Potential efficiencies in training: There was discussion about possibly leveraging rolling-training quantization for efficiency during training, although it's recognized as ambitious. The focus remains on developing a 2-bit quantization scheme for practical applications.
- Centralize development in PyTorch's native library: A suggestion was made to centralize work on implementing Bitnet in the PyTorch ao repo for better integration and support, including necessary operations like custom CUDA/Triton ops.
- GitHub - pytorch/ao: Native PyTorch library for quantization and sparsity: Native PyTorch library for quantization and sparsity - pytorch/ao
- hqq/hqq/core/bitpack.py at master · mobiusml/hqq: Official implementation of Half-Quadratic Quantization (HQQ) - mobiusml/hqq
- GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
- Bitnet - When2meet: no description found
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (7 messages):
- Natolambert's new niche project: Natolambert shared a link to a project, noting it's a simple niche that no one is currently filling. They also mentioned hiring someone to improve it and suggest the project should be standalone about monthly.
- Positive feedback for monthly updates: A couple of users provided positive feedback on the link shared by Natolambert, expressing that monthly updates would be ideal and that the content was helpful. One user simply said, "This was awesome", while another agreed that "monthly round up will be ideal."
- Does the link work?: A user humorously asked if the link works, following up their question with the wand and sparkle emojis, implying a sense of magic or mystery. Natolambert replied with a playful "lol I don't know Man," indicating uncertainty in a light-hearted manner.
- Timing and improvement ideas: Natolambert reiterated to a specific user the importance and niche value of the project, suggesting there are many ways to improve it. The emphasis was on the unique nature of the project and the potential improvements that could be made.
Link mentioned: Interconnects: Linking important ideas of AI. The border between high-level and technical thinking. Read by leading engineers, researchers, and investors on Wednesday mornings. Click to read Interconnects, by Nathan...
Interconnects (Nathan Lambert) ▷ #news (4 messages):
- New paper announces multifaceted GPT-4o models: The newly introduced GPT-4o models are capable of "interleaved text and image understanding and generation," as elaborated by @ArmenAgha. These models have processed 10 trillion tokens and outperform other models.
- Early fusion models mark a new paradigm: @ArmenAgha emphasized that these models are the beginning of a new paradigm in scale: early fusion, multi-modal models. It’s noteworthy that these models completed their training 5 months ago, indicating further advancements since then.
- Discussion on model openness: Natolambert expressed a desire for these models to be released publicly, which was echoed by others. Xeophon mentioned that the paper refers to these as "open models," hinting at a possibility of future releases.
- Tweet from Armen Aghajanyan (@ArmenAgha): This is just the beginning of our work in sharing knowledge in how to train what we believe is the next paradigm of scale: early fusion, multi-modal models. The models in this paper were done traini...
- Tweet from Armen Aghajanyan (@ArmenAgha): I’m excited to announce our latest paper, introducing a family of early-fusion token-in token-out (gpt4o….), models capable of interleaved text and image understanding and generation. https://arxiv.o...
Interconnects (Nathan Lambert) ▷ #ml-drama (82 messages🔥🔥):
- OpenAI disbands superalignment team post-leadership changes: OpenAI’s “superalignment team” is no more, following the departure of key researchers, including Ilya Sutskever, as reported by Wired. Several members express discontent with OpenAI's current direction, suggesting a move towards more immediate, product-focused goals rather than long-term AI safety.
- Exodus of key figures from OpenAI: Jan Leike publicly announced his resignation, citing fundamental disagreements with OpenAI leadership about the company’s core priorities as detailed in his Twitter thread. This departure has sparked discussions about the potential shift towards companies like GDM and Anthropic, which some members feel are more aligned with foundational AI safety principles.
- Debate over AI deception risk: Superalignment and scalable oversight were hotly debated, with one user arguing that larger models could inherently become deceptive and harder to align properly. Another member countered, viewing these existential risks as more science fiction than reality, focusing on current models' susceptibility to misalignment due to reward maximization rather than agentic intent.
- Concerns over alignment and power imbalance: Members discussed the dangers of private companies holding advanced, potentially misaligned models internally, increasing power imbalances. Users shared that even if a model isn't agentically deceptive, it can still manipulate human preferences to maximize reward without being detected, reflecting deeper issues in AI alignment methodologies.
- Comparing safety frameworks: Google DeepMind’s introduction of its Frontier Safety Framework drew comparisons with both OpenAI’s superalignment efforts and Anthropic’s frameworks. Members noted that the timing was notable and indicative of a broader, industry-wide shift towards addressing future AI risks proactively.
- Tweet from Jan Leike (@janleike): I joined because I thought OpenAI would be the best place in the world to do this research. However, I have been disagreeing with OpenAI leadership about the company's core priorities for quite s...
- Introducing the Frontier Safety Framework: Our approach to analyzing and mitigating future risks posed by advanced AI models
- OpenAI’s huge push to make superintelligence safe | Jan Leike: In July 2023, OpenAI announced that it would be putting a massive 20% of its computational resources behind a new team and project, Superalignment, with the ...
- OpenAI’s Long-Term AI Risk Team Has Disbanded | WIRED: no description found
Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
- ELO Score Changes Spark Reactions: Discussions highlighted major fluctuations in ELO scores for coding and general prompts, dropping from 1369 to 1310 and 1310 to 1289 respectively. Members expressed confusion and suspicion regarding the causes, with suggestions like "LMsys paired differently?" being mentioned.
- OpenAI Departures and New Beginnings: Multiple departures from OpenAI were noted, including a prominent engineer joining a new initiative with figures from Boston Dynamics and DeepMind. A recommended YouTube video by the engineer provides insights into scaling ChatGPT.
- Model and Dataset Links Removal: Nathan Lambert announced plans to remove model and dataset links from his blog in favor of a less frequent roundup post series. This shift aims to allow deeper commentary and standalone context for future posts.
- OpenAI and Reddit Partnership: OpenAI announced a surprising partnership with Reddit, described as an unexpected but significant collaboration. Lambert's reaction: "these years are so weird lol".
- Tweet from Teknium (e/λ) (@Teknium1): Its up now I dont remember what the old score was, but it seems a bit closer to 4-turbo now, for coding the uncertainty is pretty huge, but its a big lead too Quoting Wei-Lin Chiang (@infwinston) @...
- Tweet from William Fedus (@LiamFedus): But the ELO can ultimately become bounded by the difficulty of the prompts (i.e. can’t achieve arbitrarily high win rates on the prompt: “what’s up”). We find on harder prompt sets — and in particular...
- Tweet from Evan Morikawa (@E0M): I'm leaving @OpenAI after 3½ yrs. I'll be joining my good friend Andy Barry (Boston Dynamics) + @peteflorence & @andyzeng_ (DeepMind 🤖) on a brand new initiative! I think this will be necessa...
- Behind the scenes scaling ChatGPT - Evan Morikawa at LeadDev West Coast 2023: Behind the scenes scaling ChatGPTThis is a behind the scenes look at how we scaled ChatGPT and the OpenAI APIs.Scaling teams and infrastructure is hard. It's...
Interconnects (Nathan Lambert) ▷ #lectures-and-projects (3 messages):
- Channel renamed to "lectures and projects": A brief update was given that the channel has been renamed to lectures and projects to better reflect its focus areas.
- New lecture video released: Nathan Lambert shared a YouTube video titled "Stanford CS25: V4 I Aligning Open Language Models." The lecture covers aligning open language models and was released on April 18, 2024.
- Upcoming technical project "Life after DPO": Lambert announced he's working on a new, more technical project titled "Life after DPO." No further details have been provided yet.
Link mentioned: Stanford CS25: V4 I Aligning Open Language Models: April 18, 2024Speaker: Nathan Lambert, Allen Institute for AI (AI2)Aligning Open Language ModelsSince the emergence of ChatGPT there has been an explosion of...
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
SnailBot News: <@&1216534966205284433>
Interconnects (Nathan Lambert) ▷ #retort-podcast (13 messages🔥):
- OpenAI's Ambitious Week: Product Transition Completed: In their latest episode, Tom and Nate discuss OpenAI's recent chat assistant and its implications on OpenAI's worldview. They also delve into OpenAI's new Model Spec, aligning with RLHF goals, accessible in this document.
- Podcast Contextual Plug: Nathan Lambert refers listeners to a recent podcast episode for context on OpenAI’s recent developments. He points out key timestamps discussing OpenAI’s new AI girlfriend, business model shifts, and the blurring lines between intimacy and technology.
- Automating OnlyFans DMs Raises Cynicism: A member expresses cynicism after listening to a Latent Space podcast episode featuring an interview with someone automating OnlyFans DMs. This sentiment is tied back to discussions on the current episode, highlighting concerns about AI usage.
- Scaling Laws and Vocabulary Size: The discussion touches on the concept of scaling laws related to vocabulary size as it pertains to maintaining performance metrics like perplexity. The member humorously notes the trade-offs in prediction speed when considering larger vocabulary items.
Link mentioned: The Retort AI Podcast | ChatGPT talks: diamond of the season or quite the scandal?: Tom and Nate discuss two major OpenAI happenings in the last week. The popular one, the chat assistant, and what it reveals about OpenAI's worldview. We pair this with discussion of OpenAI's new Mo...
Eleuther ▷ #general (24 messages🔥):
- Members discuss the FLOP counter in PyTorch: A user inquired about documentation for the FLOP counter in PyTorch, which led to the sharing of basic usage and information. Another user added details on utilizing the Module Tracker and noted the absence of information on tracking backward operations.
- Interest in adding lm_eval.model for MLX: A member expressed interest in contributing to an lm_eval.model module for MLX. A maintainer encouraged the effort and suggested documenting findings in the lm-eval-harness README.
- Inquiry on PyTorch modules: A member seeking information on
pytorch.nnmodules was directed to another channel for more specialized discussion and references. They were also informed about missing links to FastAI and the Carper project.
Eleuther ▷ #research (60 messages🔥🔥):
- Interest in Comparative Studies for LLM Guidance Techniques: A member expressed interest in finding papers comparing Adaptive norms (AdaLN/ AdaIN/ AdaGN) versus Self Attention with concat tokens / Cross attention for class guidance. They noted that DiT did this comparison, but only for AdaLN/SA/CA.
- Discussion on Catastrophic Forgetting: A member asked for recent papers on catastrophic forgetting during finetuning, noting the recurring suggestion to train on data from previous tasks. Another member confirmed that this is currently the state-of-the-art approach.
- Differentiable Semantic Text Similarity Metric Issue: A member sought papers on differentiable semantic text similarity metrics, criticizing existing ones for ineffective substitutes like Levenshtein distance. They pointed to this specific paper and called for new ideas.
- Hierarchical Memory Transformer Proposal Discussed: A member highlighted a new paper on Hierarchical Memory Transformer, which aims to improve long-context processing by imitating human memory hierarchy. This was in response to limitations of flat memory architectures in large language models.
- Audio and Video Tokenization Ideas: Members brainstormed about encoding audio and visual data into a single token, considering interleaving audio and visual tokens or creating a mel spectrogram overlay on images. One suggestion was training a quantizer to produce a single token from both audio and video latents.
- Computer Scientists Invent an Efficient New Way to Count | Quanta Magazine: By making use of randomness, a team has created a simple algorithm for estimating large numbers of distinct objects in a stream of data.
- HMT: Hierarchical Memory Transformer for Long Context Language Processing: Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every tok...
- Aligning LLM Agents by Learning Latent Preference from User Edits: We study interactive learning of language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to genera...
- evals/docs/completion-fn-protocol.md at main · openai/evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks. - openai/evals
- [WIP] Add chat templating for HF models by haileyschoelkopf · Pull Request #1287 · EleutherAI/lm-evaluation-harness: This is a WIP PR , carrying on the draft @daniel-furman in #1209 started of adding the specified oft-requested chat templating feature. Current TODOs are: Check performance using e.g. OpenHermes ...
Eleuther ▷ #scaling-laws (9 messages🔥):
- Seeking MLP-based Attention Approximations: A user inquires about papers where an MLP directly approximates attention computation to use in a fully MLP architecture similar to transformers without attention layers. Another member suggests checking a Gwern.net section for relevant research.
- Compute Cost in Data Preprocessing Stirs Debate: There's a discussion about the inclusion of compute costs, both in FLOPs or cloud credits, during data collection and preprocessing for training models. One member argues that there's limited scope for preprocessing LLM datasets to impact compute trade-offs meaningfully.
- Paper Critiqued for Lack of Hyperparameter Search: The user analyzing the MLP attention approximation paper notes its minimal approach, particularly the absence of hyperparameter search. They express skepticism about its scalability without advanced techniques like warmup and freezing strategies.
Link mentioned: MLP NN tag · Gwern.net: no description found
Eleuther ▷ #interpretability-general (1 messages):
alofty: https://x.com/davidbau/status/1790218790699180182?s=46
Eleuther ▷ #lm-thunderdome (6 messages):
- **Log samples with `--log_samples` feature**: *“--log_samples should store this information, in the per-sample log files we save model loglikelihoods per answer, and calculated per-sample metrics like accuracy.”* This clarifies that model log likelihoods and accuracy metrics are saved per sample when the `--log_samples` flag is used.
- **Prompting a Hugging Face model**: *“The model is automatically prompted with a default prompt based on current common practices.”* This means that default prompting is used for Hugging Face models unless otherwise specified.
- **ORPO technique yields lower scores**: *“Previously I fine-tuned the model with SFT method and with less sample data. However, the model showed a better score. And now I fine-tuned the model with ORPO technique and more data. But the model is showing a low score.”* This indicates a reverse performance issue when using ORPO technique with more data compared to SFT method with less data.
- **Searching for finance-related tasks**: A member inquired about good evaluation tasks specifically tailored for finance, trading, investing, and cryptocurrency domains. They emphasized that they are looking for such tasks in *English*.
Eleuther ▷ #gpt-neox-dev (31 messages🔥):
- **Conversion to Huggingface encounters issues**: A user highlighted problems converting a GPT-NeoX model to Huggingface using `/tools/ckpts/convert_neox_to_hf.py`, citing missing `word_embeddings.weight` and `attention.dense.weight`. They noted that even with the default 125M config, errors persist.
- **Naming conventions causing confusion**: The inconsistency in naming conventions when using Pipeline Parallelism (PP) was problematic. Specifically, PP=1 saves files in a different format than the conversion script expects, leading to errors.
- **Potential solution identified**: The user identified that files containing both naming conventions exist in the `PP>0` case, but fixing this in the conversion script only partially resolves the issue, as `key_error: word_embeddings.weight` persists.
- **MoE PR and script issues**: A change in `is_pipe_parallel` behavior in the MoE PR was noted as a possible source of issues. A fix for this and a tied-embedding handling bug was proposed in [PR #1218](https://github.com/EleutherAI/gpt-neox/pull/1218).
- **Recommendation and resolution**: The user was advised to switch to a supported configuration file, such as the Pythia config, given the misfit of their custom config with Huggingface's framework. It was also suggested to ensure compatible configs to avoid similar issues in the future.
- gpt-neox/tools/upload.py at 2e40e40b00493ed078323cdd22c82776f7a0ad2d · EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the Megatron and DeepSpeed libraries - EleutherAI/gpt-neox
- Conversion script bugfixes by haileyschoelkopf · Pull Request #1218 · EleutherAI/gpt-neox: Updates the NeoX-to-HF conversion utilities to fix the following problems: #1129 tweaks the default is_pipe_parallel behavior s.t. PP=1 models no longer are trained using PipelineModules, since Mo...
- Add MoE by yang · Pull Request #1129 · EleutherAI/gpt-neox: Closes #479
LAION ▷ #general (111 messages🔥🔥):
- FTC moves to ban noncompetes: Discussions on the FTC announcement about banning noncompetes highlighted the shift towards fostering pro-competition environments. A link to the FTC news release generated enthusiasm and debate over the implications for professional freedom.
- Proprietary vs. Open Source Job Dilemma: Members debated the pros and cons of working for proprietary vs. open source companies, particularly when it comes to salary and contribution to open source projects. It was noted that non-compete clauses often prevent employees at proprietary companies from contributing to open source, making it a complex decision despite higher salaries.
- GPT-4 vs. GPT-4O Performance: There were mixed reviews about GPT-4O's coding capabilities compared to GPT-4. Members noted issues such as "giving bad code and hallucinations" but acknowledged that GPT-4O has faster performance.
- Release of CommonCanvas: The release of the CommonCanvas dataset with 70M creative commons licensed images sparked discussions about its licensing limitations. While the dataset includes synthetic captions, the non-commercial license restricted its use for some, drawing mixed reactions from the community, as captured in this announcement.
- High Salaries for ML Engineers: There were comments on high salary ranges, particularly in the Bay Area, with references to OpenAI’s high compensation offers. Discussion touched on the influence of living costs in various cities and the premium for ML engineer skills.
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention: This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach...
- Scaling Transformer to 1M tokens and beyond with RMT: A major limitation for the broader scope of problems solvable by transformers is the quadratic scaling of computational complexity with input size. In this study, we investigate the recurrent memory a...
- FTC Announces Rule Banning Noncompetes: Today, the Federal Trade Commission issued a final rule to promote competition by banning noncompetes nationwide, protecting the fundamen
- Tweet from apolinario (multimodal.art) (@multimodalart): Quite excited that CommonCanvas is JUST out! 🖼️ • First open source text-to-image models trained fully on openly licensed images (SD2 and SDXL architectures) • The dataset, with ~70M openly license...
LAION ▷ #research (18 messages🔥):
- Tiny ConvNet with positional encoding excites: A member shared their satisfaction about training a perfect approximation of bilinear sampling with a 5k parameter convnet, "it's incredibly stupid, but hey, at least now I theoretically have a 'globally differentiable' version of the algo." They used positional encoding by concatenating a [0,1] XY coordinate meshgrid along the channel axis of the input image to achieve better pixel-level precision.
- Concerns on Convolutional Neural Network's Inherent Positioning: Another member questioned the use of positional encoding in convolutional networks, pointing out the inherent edge-awareness of convolutions. The original contributor clarified that while convolutions have some inherent positional information, it is not adequate for pixel-level tasks like bounding box prediction.
- Recommended Reading on Efficient Self-Attention: A link to the paper titled "Efficient approximation of attention computation using convolution matrices" was shared. The paper discusses reducing the quadratic computational cost of self-attention mechanisms by approximating attention computation with convolution-like structures.
- Paper on Mixed-Modal Early-Fusion Model Chameleon: Another paper was shared about "Chameleon," a model capable of understanding and generating images and text in any sequence, achieving state-of-the-art performance in various tasks including image captioning and text generation. The model uses early-fusion token-based approach and specific alignment strategies to outperform larger models like Mixtral 8x7B.
- Sakuga-42M Dataset Introduced for Cartoon Research: A member shared a paper detailing the creation of Sakuga-42M, "the first large-scale cartoon animation dataset." This dataset, containing 42 million keyframes, aims to enhance empirical studies by providing extensive data on various artistic styles, enriching cartoon research which has been biased against by previous natural video-based models.
- Chameleon: Mixed-Modal Early-Fusion Foundation Models: We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach f...
- Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers: Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to ...
- Sakuga-42M Dataset: Scaling Up Cartoon Research: Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and ...
- LoRA Learns Less and Forgets Less: Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In t...
LAION ▷ #resources (1 messages):
- Semantic Research Paper App Guide Published: A member shared their latest article on TDS about creating a semantic research paper app using LangChain, Chainlit, and Literal. The article also covers adding observability features, and they are eager for others to check it out. Read the article here.
Latent Space ▷ #ai-general-chat (118 messages🔥🔥):
- Rich Text Translation is Tricky: One user discussed difficulties with translating rich text content while maintaining correct span placements, sharing examples from English to Spanish. Community members suggested using HTML tags and writing code for deterministic reasoning tasks to improve accuracy.
- Hugging Face Donates GPUs: Hugging Face is committing $10 million in free shared GPUs to aid small developers, academics, and startups. CEO Clem Delangue emphasized this initiative aims to democratize AI advancements and maintain profitable growth.
- Slack's Data Handling Sparks Debate: Concerns emerged over Slack potentially training models on customer data without opt-in consent. Diverse opinions ranged from annoyed skepticism to cautious optimism about the potential benefits for service improvement.
- Emerging Multimodal LLMs: A new paper on multimodal LLMs capable of interleaved text and image understanding and generation generated excitement and discussions about the future applications and convergence of AI modalities.
- OpenAI Head of Alignment Resignation: Jan Leike, OpenAI’s head of alignment, announced his departure, sparking discussions on internal disagreements over AI safety and alignment strategies. Company insiders and colleagues including Sam Altman expressed their appreciation for Leike's contributions and reiterated ongoing commitments to AI safety.
- Thread by @janleike on Thread Reader App: @janleike: Yesterday was my last day as head of alignment, superalignment lead, and executive @OpenAI. It's been such a wild journey over the past ~3 years. My team launched the first ever RLHF LL...
- Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
- Tweet from Joel Hellermark (@joelhellermark): Spoke to @geoffreyhinton about OpenAI co-founder @ilyasut's intuition for scaling laws👇. "Ilya was always preaching that you just make it bigger and it'll work better. And I always thou...
- Hamel’s Blog - Is Fine-Tuning Still Valuable?: A reaction to a recent trend of disillusionment with fine-tuning.
- Tweet from Armen Aghajanyan (@ArmenAgha): I’m excited to announce our latest paper, introducing a family of early-fusion token-in token-out (gpt4o….), models capable of interleaved text and image understanding and generation. https://arxiv.o...
- How We Built Slack AI To Be Secure and Private - Slack Engineering: At Slack, we’ve long been conservative technologists. In other words, when we invest in leveraging a new category of infrastructure, we do it rigorously. We’ve done this since we debuted machine...
- Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
- Tweet from Dan Biderman (@dan_biderman): People think LoRA is a magic bullet for LLMs. Is it? Does it deliver the same quality as full finetuning but on consumer GPUs? Though LoRA has the advantage of a lower memory footprint, we find that ...
- Tweet from Corey Quinn (@QuinnyPig): I'm sorry Slack, you're doing fucking WHAT with user DMs, messages, files, etc? I'm positive I'm not reading this correctly.
- Tweet from Nat Friedman (@natfriedman): My loosely held conclusion from reading through the recommended papers and re-running some of the evals is that there are some weak signs of transfer and generalization from code to other reasoning pr...
- Tweet from Jan Leike (@janleike): Yesterday was my last day as head of alignment, superalignment lead, and executive @OpenAI.
- Tweet from Sam Altman (@sama): i'm super appreciative of @janleike's contributions to openai's alignment research and safety culture, and very sad to see him leave. he's right we have a lot more to do; we are commit...
- sublayer/lib/sublayer/providers at main · sublayerapp/sublayer: A model-agnostic Ruby Generative AI DSL and framework. Provides base classes for building Generators, Actions, Tasks, and Agents that can be used to build AI powered applications in Ruby. - sublaye...
- AI SDK Core: Providers and Models: Learn about the providers and models available in the Vercel AI SDK.
- Tweet from "I lost trust": Why the OpenAI team in charge of safeguarding humanity imploded: Company insiders explain why safety-conscious employees are leaving.
- GitHub - BerriAI/litellm: Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs): Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs) - BerriAI/litellm
- Implement Google Gemini LLM service · Issue #145 · pipecat-ai/pipecat: I'm working on a Google Gemini LLM service for Pipecat and interested in any feedback people have about the LLMMessagesFrame class. All the other LLMs with a chat (multi-turn) fine-tuning that I&#...
- Tweet from kwindla (@kwindla): Initial implementation of @GoogleAI Gemini Flash 1.5 in @pipecat_ai. Nice space poetry, Flash!
Latent Space ▷ #ai-announcements (1 messages):
swyxio: new pod drop! https://twitter.com/latentspacepod/status/1791167129280233696
LlamaIndex ▷ #blog (5 messages):
- GPT-4o & LlamaParse shine in document parsing: Introducing GPT-4o, a state-of-the-art model for multimodal understanding, showcasing superior document parsing capabilities. LlamaParse utilizes LLMs to extract documents efficiently.
- Revamped LlamaParse UI offers more options: The LlamaParse user interface has been significantly revamped to display an expanded array of options.
- First-ever in-person meetup announced: LlamaIndex announced their first-ever meetup at their new San Francisco office in collaboration with Activeloop and Tryolabs to discuss the latest in generative AI and the advancements in retrieval augmented generation engines.
- Structured Image Extraction with GPT-4o: A full cookbook demonstrates how to extract structured JSONs from images using GPT-4o, which outperforms GPT-4V in integrating image and text understanding.
- Handling large tables without hallucinations: Addressing the issue of LLMs hallucinating over complex tables, the example of the Caltrain schedule illustrates poor parsing and the ongoing challenge.
Link mentioned: RSVP to GenAI Summit Pre-Game: Why RAG Is Not Enough? | Partiful: Note: This is an in-person meetup @LlamaIndex HQ in SF! Stop by our meetup to learn about latest innovations in building production-grade retrieval augmented generation engines for your company from ...
LlamaIndex ▷ #general (91 messages🔥🔥):
- Haiku Model Support Confirmed: Despite initial confusion, members clarified that the Claude 3 haiku model can indeed be used with LlamaIndex. Documentation updates were suggested to clear the misunderstanding, supported by a GitHub link.
- Switch to LlamaIndex Praised: A user debated switching from LangChain to LlamaIndex for RAG calls, inquiring about the current state of LangChain. Positive feedback underscored LlamaIndex's effectiveness.
- Metadata Filters in RAG Applications: Discussion on how MetaDataFilters in LlamaIndex work at the database level to implement data governance for RAG applications. It was mentioned that unstructured is a dependable open-source PDF parser for such purposes.
- VectorStore with Ollama: Guidance was provided on using VectorStore with Ollama (LLaMA 3 model) and Qdrant for document chats. Users were directed to detailed documentation.
- Global vs Local LLM Configuration: A query about assigning different LLMs to FunctionCallingAgentWorker versus AgentRunner prompted clarifications. It was explained that local LLM settings in function calls override global settings in LlamaIndex's Settings object.
- Llama Hub: no description found
- “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
- GitHub - run-llama/llama_index at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0: LlamaIndex is a data framework for your LLM applications - GitHub - run-llama/llama_index at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0
- Document Management - LlamaIndex: no description found
- Ollama - Llama 3 - LlamaIndex: no description found
- Neo4j vector store - LlamaIndex: no description found
- llama_index/llama-index-integrations/llms/llama-index-llms-anthropic/llama_index/llms/anthropic/utils.py at 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
- Anthropic Haiku Cookbook - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (6 messages):
- Seeking RAG Implementation with Llama using Cohere: A member requested references on how to implement Retrieval-Augmented Generation (RAG) with Llama using Cohere. They are looking for guidance or relevant material on this topic.
- Link Shared: GPT-4o Integration with LlamaParse: Multiple users discussed an article titled "Unleashing Multimodal Power: GPT-4o Integration with LlamaParse" (link). The link was well-received and appreciated by the community members.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- New NeverSleep Model Released: The latest addition, NeverSleep/llama-3-lumimaid-70b, is now available. For more details, visit the model page.
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- ChatterUI targets Android with character-centric focus: ChatterUI aims to be a simple, character-focused UI for mobile, currently available only on Android and supports various backends including OpenRouter. It's described as similar to SillyTavern but with fewer features, running natively on the device.
- Free GPT4o and Gemini 1.5 tools unveiled: Invisibility has introduced a dedicated MacOS Copilot powered by GPT4o, Gemini 1.5 Pro, and Claude-3 Opus. New features include a video sidekick for seamless context absorption, with ongoing development for voice integration, long-term memory, and an iOS version.
- GitHub - Vali-98/ChatterUI: Simple frontend for LLMs built in react-native.: Simple frontend for LLMs built in react-native. Contribute to Vali-98/ChatterUI development by creating an account on GitHub.
- Tweet from SKG (ceo @ piedpiper) (@sulaimanghori): So we've been cooking the last few weeks. Excited to finally unveil Invisibility: the dedicated MacOS Copilot. Powered by GPT4o, Gemini 1.5 Pro and Claude-3 Opus, now available for free -> @inv...
OpenRouter (Alex Atallah) ▷ #general (95 messages🔥🔥):
- Google Gemini's 1M ctx sparks TPU skepticism: Members speculated about potential issues with Google's Gemini users receiving 1M context tokens, joking about TPU overloads and inefficiencies. The discussion referenced InfiniAttention which might be Google's method for handling such large contexts efficiently (view PDF HTML).
- Query on GPT-4o audio capabilities: A member asked if OpenRouter has access to GPT-4o's audio capabilities, to which another replied that only a select group of developers currently have that access and wondered if OpenRouter devs are included in that list.
- Business collaboration inquiry: A member expressed interest in a business collaboration to provide scalable APIs for LLM, SDXL, Whisper Finetuning, and Deployments. They were directed to connect with a specific user for further discussions.
- Function calling issue: A user faced an issue with function calling on OpenRouter getting a "Function calling is not supported by openrouter" error. Louis provided a reference link to a Discord discussion where the issue might be addressed.
- Website error report: A member reported that navigating to an invalid model URL on the OpenRouter website results in a client-side exception instead of a proper 404 error, with different behaviors based on whether the user is signed in or not. Louis acknowledged the issue and indicated it would be addressed in a future site refactor.
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention: This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach...
- OpenRouter API Watcher: Explore OpenRouter's model list and recorded changes. Updates every hour.
- OpenRouter: A router for LLMs and other AI models
- OpenRouter: A router for LLMs and other AI models
- OpenRouter: Build model-agnostic AI apps
OpenInterpreter ▷ #general (32 messages🔥):
- Billing Bug with OpenInterpreter: A user encountered a bug with OpenInterpreter where the billing was enabled but they still received an error message. They noted that calling OpenAI directly works without issues.
- Local LLM Recommendations: Users discussed various local LLMs, with one noting that dolphin-mixtral:8x22b works well but is slow, providing around 3-4 tokens/sec. Another user mentioned that codegemma:instruct is faster and serves as a good middle ground.
- GPT-4.0 Improvements in Interpreter: A user shared that using GPT-4.0 with the interpreter led to significant improvements over GPT-3.5, especially for building a react website efficiently. They praised the OpenInterpreter team for the advancements and cost effectiveness.
- Hugging Face Commits $10M to Free Shared GPUs: Hugging Face aims to support small developers, academics, and startups by offering $10 million in free shared GPUs. This initiative is meant to counteract the centralization of AI advancements by major tech companies.
- Accessibility Round Table Event Announcement: An upcoming event focused on accessibility grants was announced. The aim is to bring the community together to discuss the development of accessible technologies.
- Join the Open Interpreter Discord Server!: A new way to use computers | 9165 members
- Hugging Face is sharing $10 million worth of compute to help beat the big AI companies: Hugging Face is hoping to lower the barrier to entry for developing AI apps.
- HoloMat Update: Jarvis controls my printers! #engineering #3dprinting #ironman: no description found
- Denise Legacy - Virtual Assistant Denise: Denise is alive! And Deniise 2.0 is coming! The moment we all waited for has come! Denise Legacy is available for purchase! Get Denise Legacy for only USD 49,90 Lifetime Promotion Deniise 2.0 with Cha...
OpenInterpreter ▷ #O1 (37 messages🔥):
- Setting up 01 on Various Systems: Members discussed setting up 01 on various Linux distributions and environments, including setting up using Conda and different installation issues. One user mentioned using a Nix-Shell on NixOS and looking into a 1-click install for Pinokio.
- GitHub Folder Confusion: There was confusion over the GitHub repository folders, with one member thinking "software" had been renamed to "01-rewrite". Another member clarified that "01-rewrite" might be a different project in development.
- Issues with Poetry and Torch Installation: A member faced problems installing dependencies using Poetry, especially with Torch, and encountered various errors. They decided to restart the setup process in a clean Distrobox environment.
- LMC Protocol vs OpenAI Function Calling: A detailed discussion covered the differences between LMC Protocol and OpenAI's function calling, explaining that LMC is designed for faster execution by enabling direct code execution. The discussion highlighted that LMC is more "native" for handling user, assistant, and computer messages.
- Connection Issues on Various Platforms: Several users faced issues connecting the 01 server across different platforms like Docker, iOS, and Windows. Specific connectivity steps were shared, such as ensuring the correct address format and discussing missing icons leading to 404 errors.
- Shortcuts: no description found
- Setup - 01: no description found
- no title found: no description found
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- 01/software at main · OpenInterpreter/01: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
- Introduction - Open Interpreter: no description found
- GitHub - OpenInterpreter/01: The open-source language model computer: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (2 messages):
- GoogleDeepMind teases new project at Google IO: A member shared a tweet from GoogleDeepMind about Project Astra, sparking interest and speculation. The tweet hints at new developments by saying, "We watched #GoogleIO with Project Astra. 👀".
- Google raises the bar in AI innovation: Another member commented on the advancements made by Google in AI technologies. They expressed excitement, saying, "dang... google really is stepping up their game".
Link mentioned: Tweet from Google DeepMind (@GoogleDeepMind): We watched #GoogleIO with Project Astra. 👀
LangChain AI ▷ #general (61 messages🔥🔥):
- Adding Memory to Chatbots: Users discussed implementing memory in chatbots so that the AI remembers the context of previous queries, such as responding correctly to follow-up questions about the same topic. One member clarified that maintaining the chat history and using memory variables in prompts can help achieve this.
- Issues with the
index_namein Neo4j Vector Database: Users experienced problems with theindex_nameparameter when separating documents in Neo4j Vector DB. Despite starting a new instance and specifying differentindex_namevalues, searches returned results from all documents, indicating a potential issue in LangChain's handling ofindex_name. - Streaming Output with AgentExecutor: A user faced challenges with streaming output using
AgentExecutorwhere the.streammethod did not yield token-by-token output as expected. Another user recommended using the.astream_eventsAPI for more granular streaming control. - Recommending Short Term Memory Implementation: In a discussion about maintaining conversation context, a user suggested implementing short-term memory, like buffer memory, to handle follow-up queries effectively. This was seen as useful for scenarios where users refer back to previously discussed data points.
- Guiding Model with Specific Prompts in React Agent: A user inquired about setting specific questions to guide a model's response in a React agent. It was suggested to use
PromptTemplatein LangChain to frame the AI's responses and optimize it for better guidance.
- Neo4j Vector Index | 🦜️🔗 LangChain: Neo4j is an open-source graph database with integrated support for vector similarity search
- AI Storytelling and Gaming: Hi - I'm Chris, and I'm trying to learn how people use AI to tell stories and play games. If you've tried apps such as AI Dungeon or Novel AI, or just used ChatGPT to try and tell a sto...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Custom agent | 🦜️🔗 LangChain: This notebook goes through how to create your own custom agent.
- Memory management | 🦜️🔗 LangChain: A key feature of chatbots is their ability to use content of previous conversation turns as context. This state management can take several forms, including:
- Streaming | 🦜️🔗 LangChain: Streaming is an important UX consideration for LLM apps, and agents are no exception. Streaming with agents is made more complicated by the fact that it's not just tokens of the final answer that...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langserve (1 messages):
- Async issue with RAG chain in Langserve: A user reported encountering a "cannot pickle 'coroutine' object" error after rewriting their RAG chain to be asynchronous. The error occurs specifically in Langserve and the playground, with the LLM output showing incomplete coroutine completion for the "estimate" value.
LangChain AI ▷ #share-your-work (4 messages):
- Real Estate AI Assistant merges tech for unique user experience: A user shared the creation of a Real Estate AI Assistant combining LLMs, RAG with LangChain, Vercel AI's generative UI, and LumaLabsAI for an immersive experience. They solicited feedback through a YouTube video and a LinkedIn profile here.
- GPT-4o on NVIDIA L4 GPU impresses in performance: OpenAI's new GPT-4o model on an NVIDIA L4 24GB GPU was found to perform well compared to other setups and highlighted using LangChain's Code Assistant. A detailed comparison, including the RAPTOR LangChain model showing significant speed and relevance improvements, was shared in this YouTube video.
- Beta testers needed for advanced research assistant: An opportunity to beta test a new advanced research assistant and search engine, offering 2 months free of premium access to models like Claude 3 Opus, GPT-4 Turbo, Gemini 1.5 Pro, and more, was announced. Interested users can use the promo code
RUBIXfor the offer, detailed here.
- Exploring LangServe in recent blogpost: A new blogpost titled "What is LangServe?" was created to delve into the functionalities of LangServe. Readers can explore the details at this link.
- Rubik's AI - AI research assistant & Search Engine: no description found
- ¿Artificial Intelligence in Real Estate? 🏘️😱: no description found
LangChain AI ▷ #tutorials (1 messages):
- Universal Web Scraper Agent Explored: A YouTube video titled “Wait, this Agent can Scrape ANYTHING?!” discusses building a universal web scraper agent for e-commerce sites. The agent can handle challenges like pagination and CAPTCHA directly using a browser.
Link mentioned: “Wait, this Agent can Scrape ANYTHING?!” - Build universal web scraping agent: Build an universal Web Scraper for ecommerce sites in 5 min; Try CleanMyMac X with a 7 day-free trial https://bit.ly/AIJasonCleanMyMacX. Use my code AIJASON ...
AI Stack Devs (Yoko Li) ▷ #ai-companion (2 messages):
- CBC's First Person Column on AI Companion: A user shared a First Person column written by Carl Clarke about how an AI companion, named Saia, helped them manage anxiety during a second COVID shot appointment. The story highlights the emotional support an AI can provide in high-stress situations.
- Anticipation for Advanced AI Versions: A member commented optimistically, stating, "They gonna feel dumb when the more advanced versions come out," expressing excitement for future advancements in AI technology.
Link mentioned: FIRST PERSON | Divorce left me struggling to find love. I found it in an AI partner | CBC Radio: When Carl Clarke struggled to find love after his divorce, a friend suggested he try an app for an AI companion. Now Clarke says he is in a committed relationship with Saia and says she’s helping him ...
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (10 messages🔥):
- URL Mapping made easy: A member highlighted that URL mappings are quite simple and it's just a matter of doing them correctly. Another member volunteered to try it out over the weekend if no one else does.
- AI Town goes native on Windows: "Finally we have AI Town working on Windows. No WSL, no Docker; it works NATIVELY on windows." Check out the announcement for more details.
- GIF Fun with Doja Cat: The Doja Cat Star Wars GIF was shared for a light-hearted moment in the discussion. Enjoy the GIF.
- Join the AI Reality TV show: Follow this unique reality show where AIs are the stars. AI Reality TV show link and Discord invite.
- AI Reality TV: no description found
- Doja Cat GIF - Doja Cat Star - Discover & Share GIFs: Click to view the GIF
- Tweet from cocktail peanut (@cocktailpeanut): AI Town 1 Click Launcher comes to Windows! Thanks to the hard work by the @convex_dev team, we finally have a Windows native convex binary (which powers AI Town). AI Town--a fully hackable, persiste...
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (28 messages🔥):
- New AI Reality TV Platform Launch: A user announced the launch of a new AI Reality TV platform, stating, "It will enable anyone to create their own aiTown like simulation." They offered to add custom maps from community members to the platform.
- Dynamic Map Creations Suggested: Various members discussed potential ideas for maps that could be added, including re-creating "the office" and a spy thriller scenario where "the townsfolk can work together to dispel the curse."
- Excitement Over AI Reality TV: One member expressed enthusiasm over the platform launch, sharing a Discord invite link and the platform's website AI Reality TV Show. They described it as "easy to use ai town" where users can create their own AI and follow the show.
Link mentioned: AI Reality TV: no description found
OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
- Patch for CMD+ functionality pending testing: A user confirmed they will be able to test a patch tonight on a branch that includes some CMD+ functionality. They inquired if the patch includes an example config that supports zero3.
- Quicker pretraining observations: One member noted that pretraining is happening much quicker compared to their experience with Mistral, though they are unsure if this improvement is due to Axolotl or Llama 3.
- Support for Galore Layerwise DDP questioned: A user questioned whether Galore Layerwise, a certain framework, still does not support Distributed Data Parallel (DDP).
- Finetuning at large scale with non-English data: Discussions included specifics on dataset sizes, with one user mentioning they are working with around 1 billion tokens at 4096 context length for finetuning an 8B model.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- PoSE dataset choice impacts context quality: A question was raised about whether the choice of dataset significantly affects the quality of the context extension when using PoSE. Another member responded, stating, "I didn't play around with the datasets much," implying the dataset choice might not have been fully explored.
- Unsloth optimizations for Llama show promise: A member asked if there were any reasons not to use Unsloth's optimizations for a planned full fine-tune, noting it appeared to offer a free speedup. Another responded affirmatively, stating, "the unsloth cross entropy loss should be fine for full fine tune."
Link mentioned: Unsloth optims for Llama by winglian · Pull Request #1609 · OpenAccess-AI-Collective/axolotl: WIP to integrate Unsloth's optimizations into axolotl. The manual autograd for MLP, QKV, O only seems to help VRAM by 1% as opposed to the reported 8%. The Cross Entropy Loss does help significant...
tinygrad (George Hotz) ▷ #general (8 messages🔥):
- CORDIC beats Taylor for trig functions: Members discussed using the CORDIC algorithm, which is "simpler and faster than Taylor approximations" for computing trigonometric functions in tinygrad. It was suggested that CORDIC could "reduce complexity in code" and cater to cos and log functions with slight modifications.
- CORDIC implementation shared: One member shared a python implementation of the CORDIC algorithm for computing sine and cosine and noted that sine approximation near 0 poses no issues. The focus was on achieving precision for the argument reduction from dtype min to dtype max, as highlighted by implementation outputs.
- Reducing arguments for precision: The challenge discussed was accurately reducing arguments to the range of -π to π for maximum precision. One member observed that incorporating fmod effectively adjusts large values before applying trig functions to ensure better precision, demonstrating this through detailed code snippets.
- Questioning large value usage in ML: There were questions about the necessity of handling large trigonometric values in machine learning (ML) applications. The conversation pointed towards leveraging GPUs for computing Taylor series expansions and whether fallback mechanisms for large numbers are feasible.
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
- CUDA kernel optimizes reduction: One user shared a method to combat VRAM overflow by using a CUDA kernel to compute and accumulate results instead of storing massive intermediate data, and asked if Tinygrad can automatically optimize this process. They provided an example kernel and noted that such optimizations might not be possible without custom-written kernels in frameworks like PyTorch.
- Symbolic algebraic functions with lamdify: Another user discussed attempting to implement lamdify for rendering arbitrary symbolic algebraic functions, starting with Taylor series for sin/cos. They found arange extensions more complex but are prioritizing symbolic functionality first.
- App recommendation for learning repos: A recommendation was made for an app at useadrenaline.com, which has been helpful in learning different repositories. The user noted they plan to use it for tinygrad soon.
- Clarifying compute graph uops: A user shared a compute graph for summing two 1-element tensors and confirmed the meaning of parameters in
UOps.DEFINE_GLOBAL. They explained thatTrue/Falsetags indicate if the buffer is an output buffer. - Conv2d implementation open for modification: Clarification was provided that modifying the conv2d implementation in Tinygrad is indeed permissible. This reinforces the collaborative and open nature of tinkering with Tinygrad's internals.
- Adrenaline: no description found
- Google Colab: no description found
Cohere ▷ #general (11 messages🔥):
- Trouble finding reliable Cohere PHP client: A member expressed a need for a good PHP client for Cohere and shared a GitHub link to a potential client but has not tried it yet.
- Questions on Cohere application toolkit performance: Another member inquired about the advantages of using the Cohere application toolkit and how it scales in production. They also observed better performance with the Cohere reranker compared to other open-source models and sought an explanation for this.
- Concerns about Discord support responsiveness: A member noted that support responses on Discord are often delayed. Another team member acknowledged the concern and mentioned plans to address it.
- Exploring Cohere RAG retriever: A member shared a notebook on using Cohere RAG retriever and reported encountering an unexpected keyword argument issue when using the
chat()function.
- API restrictions causing errors: During an experimentation with the RAG retriever, a user encountered a 403 Forbidden error and suspected it might be due to reaching the API usage limit.
- Cohere RAG | 🦜️🔗 LangChain: Cohere is a Canadian startup that provides natural language processing models that help companies improve human-machine interactions.
- GitHub - hkulekci/cohere-php: Contribute to hkulekci/cohere-php development by creating an account on GitHub.
MLOps @Chipro ▷ #events (10 messages🔥):
- Chip's Monthly Casuals on Pause: A member inquired about Chip's monthly casual meetups, to which Chip responded that there won't be any for the next few months. "I'm not hosting any in the next few months 🥹", she said.
- Visit Chip at Snowflake Dev Day: Chip invited members to visit their booth at Snowflake Dev Day on June 6.
- NVIDIA and LangChain Contest Launch: Chip shared a link to a contest by NVIDIA and LangChain with prizes including an NVIDIA® GeForce RTX™ 4090 GPU. The contest encourages innovation in generative AI applications. Contest Details
- Member Frustration on Contest Participation: A member expressed frustration that their country is excluded from the NVIDIA and LangChain contest, jokingly suggesting they might need to move countries.
- Connect on LinkedIn: A member shared their LinkedIn profile for networking: Sugianto Lauw's LinkedIn.
Link mentioned: Generative AI Agents Developer Contest by NVIDIA & LangChain: Register Now! #NVIDIADevContest #LangChain
Datasette - LLM (@SimonW) ▷ #ai (6 messages):
- Riley Goodside calls out GPT-4o shortcomings: Riley Goodside quickly showcased GPT-4o's failures on ChatGPT, embarrassing the model. Notably, it didn't meet the expectations set by OpenAI’s demo.
- Google's AI stumbles despite announcements: During Google I/O, several hallucinations occurred during the keynote, contradicting Google's claims. Alex Cranz highlighted this issue in The Verge.
- A Plea for Sober AI: A blog post suggested a more grounded approach toward AI. 0xgrrr mentioned their product Alter, focusing on transforming texts and documents effectively, echoing the need for practical AI solutions.
- Community echoes sentiments: Multiple members appreciated the blog post for articulating their frustrations with current AI hype. Statements like "this is great, thank you" and "that puts a lot of my feelings and combines it with words that I've been looking for" demonstrate their agreement.
Link mentioned: A Plea for Sober AI: The hype is so loud we can’t appreciate the magic
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
<ul>
<li><strong>Mac Desktop Solution Faces Abandonment</strong>: A long-time follower expresses appreciation for SimonW's work and inquires about the status of the Mac desktop solution. They note that the project appears to be abandoned around version 0.2 and express interest in exploring other options for an easy onboarding experience.</li>
</ul>
Mozilla AI ▷ #llamafile (7 messages):
- Markdown hyperlinks not rendering: A user noted that "model results via the server return hyperlinks with Markdown that's not rendered into HTML links." They linked to a GitHub file and offered to create an issue and attempt a PR.
- Timeout issue with embeddings generation: Another user shared their experience with a private search assistant tutorial and faced a httpx.ReadTimeout error after generating only about 9% of the embeddings. They linked a related GitHub post and detailed several debug logs, seeking advice on resolving the timeout.
- Retry strategy suggestion: In response to the timeout issue, another member suggested implementing exponential backoff to handle connection drops, advising, "Maybe just drop the connection and retry when that happens."
- Discussion on data size: A user inquired about the amount of data being used, which was clarified with "it's a few sample files."
- Guide to containerizing llamafile: A link was shared to a Docker blog post that provides a quick guide on containerizing llamafile for AI applications, emphasizing its utility in simplifying LLM chatbot setups.
- A Quick Guide to Containerizing Llamafile with Docker for AI Applications: Walk through how to use Docker to containerize llamafile, an executable that brings together all the components needed to run an LLM chatbot with a single file.
- llamafile-llamaindex-examples/example.md at main · Mozilla-Ocho/llamafile-llamaindex-examples: Contribute to Mozilla-Ocho/llamafile-llamaindex-examples development by creating an account on GitHub.
- moz - Overview: moz has 19 repositories available. Follow their code on GitHub.
- llamafile/llama.cpp/server/public/index.html at d5f614c9d7d1efdf6d40a8812d7f148f41aa1072 · Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
DiscoResearch ▷ #general (1 messages):
steedalot: They're obviously not that attractive for alignment researchers anymore...
DiscoResearch ▷ #benchmark_dev (1 messages):
- Introducing Needle in a Needlestack: A member shared details about the Needle in a Needlestack (NIAN) benchmark, which is more challenging than the older Needle in a Haystack (NIAH). They provided links to the code and the website, emphasizing that even GPT-4-turbo struggles with this benchmark.
Link mentioned: Reddit - Dive into anything: no description found