[AINews] Cerebras Inference: Faster, Better, AND Cheaper
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Wafer-scale engines are all you need.
AI News for 8/27/2024-8/28/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (215 channels, and 2366 messages) for you. Estimated reading time saved (at 200wpm): 239 minutes. You can now tag @smol_ai for AINews discussions!
A brief history of superfast LLM inference in 2024:
- Groq dominated the news cycle in Feb (lots of scattered discussion here) by achieving ~450 tok/s for Mixtral 8x7B (240 tok/s for Llama 2 70b).
- In May, Cursor touted a specialized code edit model (developed with Fireworks) that hit 1000 tok/s.
It is now finally Cerebras' turn to shine. The new Cerebras Inference service is touting Llama3.1-8b at 1800 tok/s at $0.10/mtok and Llama3.1-70B at 450 tokens/s at $0.60/mtok at full precision. Needless to say, Cerebras pricing at full precision AND their unmatched speed is suddenly a serious player in this market. To take their marketing line: "Cerebras Inference runs Llama3.1 20x faster than GPU solutions at 1/5 the price." - not technically true - most inference providers like Together and Fireworks tend to guide people towards the quantized versions of their services, with FP8 70B priced at $0.88/mtok and INT4 70B priced at $0.54. Indisputably better, but not 5x cheaper, not 20x faster.
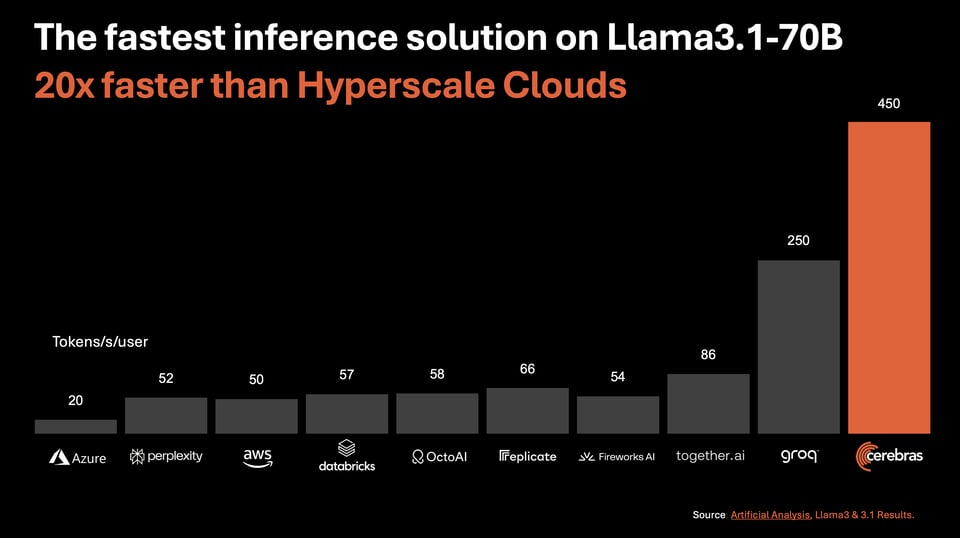
Note: one should also note their very generous free tier of 1 million free tokens daily.
The secret, of course, is Cerebras' wafer-scale chips (what else would you expect them to say?). Similar to Groq's LPU argument, Cerebras says putting the entire model in SRAM is the key:
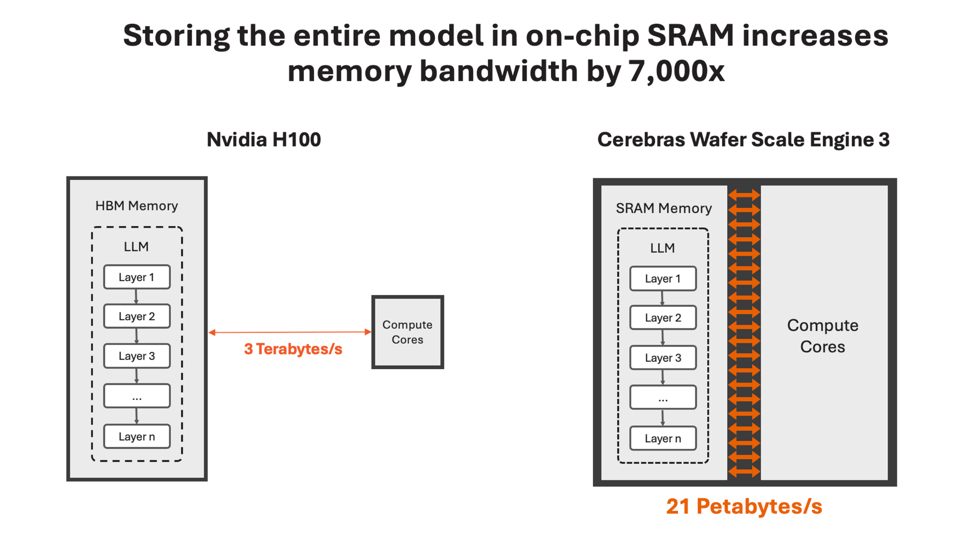
Your move, Groq and Sambanova.
Today's sponsor: Solaris
Solaris, an office for early stage AI startups in SF, has new desk and office openings! It’s been HQ to founders backed by Nat Friedman, Daniel Gross, Sam Altman, YC and more.**
Swyx's comment: I’ve been here for the last 9 months and have absolutely loved it. If you’re looking for a quality place to build the next great AI startup, book a time with the founders here, and tell them we sent you.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- LM Studio Discord
- Perplexity AI Discord
- Nous Research AI Discord
- OpenRouter (Alex Atallah) Discord
- Eleuther Discord
- LlamaIndex Discord
- Torchtune Discord
- OpenAI Discord
- Interconnects (Nathan Lambert) Discord
- Cohere Discord
- Modular (Mojo 🔥) Discord
- Latent Space Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- LAION Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (468 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (6 messages):
- HuggingFace ▷ #cool-finds (4 messages):
- HuggingFace ▷ #i-made-this (11 messages🔥):
- HuggingFace ▷ #computer-vision (3 messages):
- HuggingFace ▷ #NLP (1 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (228 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #help (64 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- aider (Paul Gauthier) ▷ #announcements (1 messages):
- aider (Paul Gauthier) ▷ #general (119 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (41 messages🔥):
- aider (Paul Gauthier) ▷ #links (6 messages):
- LM Studio ▷ #general (148 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (8 messages🔥):
- Perplexity AI ▷ #general (101 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (3 messages):
- Nous Research AI ▷ #general (75 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (23 messages🔥):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #interesting-links (4 messages):
- Nous Research AI ▷ #research-papers (1 messages):
- Nous Research AI ▷ #rag-dataset (1 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (89 messages🔥🔥):
- Eleuther ▷ #general (11 messages🔥):
- Eleuther ▷ #research (73 messages🔥🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (66 messages🔥🔥):
- Torchtune ▷ #general (8 messages🔥):
- Torchtune ▷ #dev (49 messages🔥):
- OpenAI ▷ #ai-discussions (31 messages🔥):
- OpenAI ▷ #gpt-4-discussions (20 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (13 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (4 messages):
- Interconnects (Nathan Lambert) ▷ #posts (15 messages🔥):
- Cohere ▷ #discussions (4 messages):
- Cohere ▷ #questions (25 messages🔥):
- Cohere ▷ #projects (3 messages):
- Modular (Mojo 🔥) ▷ #general (8 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (21 messages🔥):
- Latent Space ▷ #ai-general-chat (19 messages🔥):
- OpenInterpreter ▷ #general (11 messages🔥):
- OpenInterpreter ▷ #O1 (4 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- DSPy ▷ #show-and-tell (1 messages):
- DSPy ▷ #general (7 messages):
- tinygrad (George Hotz) ▷ #general (1 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
- LAION ▷ #general (3 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Benchmarks
- Gemini 1.5 Performance: Google's latest Gemini 1.5 models (Pro/Flash/Flash-9b) showed significant improvements in benchmarks, with Gemini-1.5-Flash climbing from #23 to #6 overall. The new Gemini-1.5-Pro demonstrated strong gains in coding and math tasks. @lmsysorg shared detailed results from over 20K community votes.
- Open-Source Models: New open-source models were released, including CogVideoX-5B for text-to-video generation, running on less than 10GB VRAM. @_akhaliq highlighted its high quality and efficiency. Rene 1.3B, a Mamba-2 language model, was also released with impressive performance on consumer hardware. @awnihannun noted its speed of almost 200 tokens/sec on an M2 Ultra.
- Cerebras Inference: Cerebras announced a new inference API claiming to be the fastest for Llama 3.1 models, with speeds of 1,800 tokens/sec for the 8B model and 450 tokens/sec for the 70B model. @AIatMeta verified these impressive performance figures.
AI Development and Infrastructure
- Prompt Caching: Jeremy Howard highlighted the importance of prompt caching for improving performance and reducing costs. @jeremyphoward noted that Anthropic's Claude now supports caching, with cached tokens being 90% cheaper and faster.
- Model Merging: A comprehensive timeline of model merging techniques was shared, tracing the evolution from early work in the 90s to recent applications in LLM alignment and specialization. @cwolferesearch provided a detailed overview of various stages and approaches.
- Distributed Training: The potential for distributed community ML training was discussed, with the idea that the next open-source GPT-5 could be built by millions of people contributing small amounts of GPU power. @osanseviero outlined recent breakthroughs and future possibilities in this area.
AI Applications and Tools
- Claude Artifacts: Anthropic made Artifacts available for all Claude users, including on iOS and Android apps. @AnthropicAI shared insights into the development process and widespread adoption of this feature.
- AI-Powered Apps: The potential for mobile apps created in real-time by LLMs was highlighted, with examples of simple games being replicated using Claude. @alexalbert__ demonstrated this capability.
- LLM-Based Search Engines: A multi-agent framework for web search engines using LLMs was mentioned, similar to Perplexity Pro and SearchGPT. @dl_weekly shared a link to more information on this topic.
AI Ethics and Regulation
- AI Regulation Debate: Discussions around AI regulation continued, with some arguing that being pro-AI regulation doesn't necessarily mean supporting every proposed bill. @AmandaAskell emphasized the importance of good initial regulations.
- OpenAI's Approach: Reports of OpenAI's development of a powerful reasoning model called "Strawberry" and plans for "Orion" (GPT-6) sparked discussions about the company's strategy and potential impact on competition. @bindureddy shared insights on these developments.
Miscellaneous AI Insights
- Micro-Transactions in AI: Andrej Karpathy proposed that enabling very small transactions (e.g., 5 cents) could unlock significant economic potential and improve the flow of value in the digital economy. @karpathy argued this could lead to more efficient business models and positive second-order effects.
- AI Cognition Research: The importance of studying AI cognition, rather than just behavior, was emphasized for understanding generalization in AI systems. @RichardMCNgo drew parallels to the shift from behaviorism in psychology.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Open-Source Text-to-Video AI: CogVideoX 5B Breakthrough
- CogVideoX 5B - Open weights Text to Video AI model (less than 10GB VRAM to run) | Tsinghua KEG (THUDM) (Score: 91, Comments: 13): CogVideoX 5B, an open-weights Text to Video AI model developed by Tsinghua KEG (THUDM), can run on less than 10GB VRAM with the 2B model functioning on a 1080TI and the 5B model on a 3060 GPU. The model collection, including the 2B version released under Apache 2.0 license, is available on Hugging Face, along with a demo space and a research paper.
Theme 2. Advancements in Efficient AI Models: Gemini 1.5 Flash 8B
- Gemini 1.5 Flash 8b, (Score: 95, Comments: 24): Google has released Gemini 1.5 Flash 8B, a new small-scale AI model that demonstrates impressive capabilities despite its compact size of 8 billion parameters. The model achieves state-of-the-art performance across various benchmarks, including outperforming larger models like Llama 2 70B on certain tasks, while being significantly more efficient in terms of inference speed and resource requirements.
- Gemini 1.5 Flash 8B was initially discussed in the third edition of the Gemini 1.5 Paper from June. The new version is likely a refined model with improved benchmark performance compared to the original experiment.
- Google's disclosure of the 8 billion parameter count was praised. There's speculation about whether Google will release the weights, but it's deemed unlikely as Gemini models are typically closed-source, unlike the open-source Gemma models.
- Discussion arose about Google's use of standard transformers for Gemini, which surprised some users expecting custom architectures. The model's performance sparked comparisons with GPT-4o-mini, suggesting potential advancements in parameter efficiency.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Releases
- Google DeepMind's GameNGen: A neural network-powered game engine that can interactively simulate the classic game DOOM in real-time with high visual quality. This demonstrates the potential for AI to generate interactive game environments. Source
- OpenAI's "Strawberry" AI: Reportedly being prepared for launch as soon as fall 2024. OpenAI has shown this AI to national security officials and is using it to develop another system called "Orion". Details on capabilities are limited. Source 1, Source 2
- Google's Gemini 1.5 Updates: Google has rolled out Gemini 1.5 Flash-8B, an improved Gemini 1.5 Pro with better coding and complex prompt handling, and an enhanced Gemini 1.5 Flash Model. Source
AI in Image Generation and Manipulation
- Flux AI Model: A new AI model for image generation that has quickly gained popularity, particularly for creating photorealistic images. Users are experimenting with training custom LoRA models on personal photos to generate highly realistic AI-created images of themselves. Source 1, Source 2
Robotics and Physical AI
- Galbot G1: A first-generation robot by Chinese startup Galbot, designed for generalizable, long-duration tasks. Details on specific capabilities are limited. Source
Scientific Breakthroughs
- DNA Damage Repair Protein: Scientists have discovered a protein called DNA damage response protein C (DdrC) that can directly halt DNA damage. It appears to be "plug and play", potentially able to work in any organism, making it a promising candidate for cancer prevention research. Source
AI Ethics and Societal Impact
- AI-Generated Content in Media: Discussions around the increasing prevalence of AI-generated content in social media and entertainment, raising questions about authenticity and the future of creative industries. Source
AI Discord Recap
A summary of Summaries of Summaries by GPT4O (gpt-4o-2024-05-13)
1. LLM Advancements and Benchmarking
- Llama 3.1 API offers free access: Sambanova.ai provides a free, rate-limited API for running Llama 3.1 405B, 70B, and 8B models, compatible with OpenAI, allowing users to bring their own fine-tuned models.
@usershared that the API offers starter kits and community support to help accelerate development.
- Google's New Gemini Models: Google announced three experimental models: Gemini 1.5 Flash-8B, Gemini 1.5 Pro, and an improved Gemini 1.5 Flash.
@OfficialLoganKhighlighted that the Gemini 1.5 Pro model is particularly strong in coding and complex prompts.
2. Model Performance Optimization and Benchmarking
- OpenRouter's DeepSeek Caching: OpenRouter is adding support for DeepSeek's context caching, expected to reduce API costs by up to 90%.
@usershared information about the upcoming feature aimed at optimizing API cost efficiency.
- Hyperbolic's BF16 Llama 405B: Hyperbolic released a BF16 variant of the Llama 3.1 405B base model, adding to the existing FP8 quantized version on OpenRouter.
@hyperbolic_labstweeted about the new variant, highlighting its potential for more efficient model performance.
3. Open-Source AI Developments and Collaborations
- IBM's Power Scheduler: IBM introduced a novel learning rate scheduler called Power Scheduler, agnostic to batch size and number of training tokens.
@_akhaliqtweeted that this scheduler consistently achieves impressive performance across various model sizes and architectures.
- Daily Bots for Real-Time AI: Daily Bots launched an ultra low latency cloud for voice, vision, and video AI, supporting the RTVI standard.
@trydailyhighlighted that this platform combines the best tools for real-time AI applications, including voice-to-voice interactions with LLMs.
4. Multimodal AI and Generative Modeling Innovations
- GameNGen: Neural Game Engine: GameNGen, the first game engine powered entirely by a neural model, enables real-time interaction with complex environments.
@usershared that GameNGen can simulate DOOM at over 20 frames per second on a single TPU, achieving a PSNR of 29.4, comparable to lossy JPEG compression.
- Artifacts on iOS and Android: Artifacts, a project by Anthropic, has launched on iOS and Android, allowing for real-time creation of simple games with Claude.
@alexalbert__highlighted the significance of this mobile release in bringing the power of LLMs to mobile apps.
5. Fine-tuning Challenges and Prompt Engineering Strategies
- Unsloth's Continued Pretraining: Unsloth's Continued Pretraining feature allows for pretraining LLMs 2x faster and with 50% less VRAM than Hugging Face + Flash Attention 2 QLoRA.
@unslothshared a Colab notebook for continually pretraining Mistral v0.3 7b to learn Korean.
- Finetuning with Synthetic Data: The emerging trend of using synthetic data in finetuning models has gained momentum, highlighted by examples like Hermes 3.
- A user mentioned that synthetic data training requires a sophisticated filtering pipeline, but it's becoming increasingly popular.
PART 1: High level Discord summaries
HuggingFace Discord
- Gamify Home Training?: A member proposed a 'gamified home training' benchmark tool, claiming it for their job application.
- Triton Configuration Headache: A member encountered an issue where response generation wouldn't stop using llama3 instruct with triton and tensorrt-llm or vllm backend.
- Using vllm hosting directly worked flawlessly, indicating a potential issue with their triton configuration.
- Loss of 0.0 - Logging Error?: Discussions centered around the significance of a 'loss curve' in model training.
- One member suggested a loss of 0.0 might indicate a logging error, questioning the feasibility of a perfect model with a loss of 0.0 due to rounding.
- Finetuning Gemma2b on AMD - Experimental Struggles: A member struggled finetuning a Gemma2b model on AMD, attributing the issue to potential logging errors.
- Other members pointed to ROCm's experimental nature as a contributing factor to the difficulties.
- Model Merging Tactics: UltraChat and Mistral: A member proposed applying the difference between UltraChat and base Mistral to Mistral-Yarn as a model merging tactic.
- While some expressed skepticism, the member remained optimistic, citing past successes with 'cursed model merging'.'
Unsloth AI (Daniel Han) Discord
- VLLM on Kaggle is Working!: A user reported success running VLLM on Kaggle using wheels from this dataset.
- This was achieved with VLLM 0.5.4, a version that is considered relatively new, as 0.5.5 has been released but is not yet widely available.
- Mistral Struggles Expanding Beyond 8k: Members confirmed that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They also discussed potential avenues for future performance enhancements, including mergekit and frankenMoE finetuning.
- Homoiconic AI: Weights as Code?: A member shared a [progress report on "Homoiconic AI"] (https://x.com/neurallambda/status/1828214178567647584?s=46) which uses a hypernet to generate autoencoder weights and then improves those weights through in-context learning.
- The report suggests that this "code-is-data & data-is-code" approach may be required for reasoning and even isomorphic to reasoning.
- Unsloth's Continued Pretraining Capabilities: A member shared a link to Unsloth's blog post on Continued Pretraining, highlighting its ability to continually pretrain LLMs 2x faster and with 50% less VRAM than Hugging Face + Flash Attention 2 QLoRA.
- The blog post also mentions the use of a Colab notebook to continually pretrain Mistral v0.3 7b to learn Korean.
- Unsloth vs OpenRLHF: Speed & Memory Efficiency: A user inquired about the differences between Unsloth and OpenRLHF, specifically regarding their support for finetuning unquantized models.
- A member confirmed that Unsloth supports unquantized models and plans to add 8bit support soon, emphasizing its significantly faster speed and lower memory usage compared to other finetuning methods.
aider (Paul Gauthier) Discord
- Aider 0.54.0: Gemini Models and Shell Command Improvements: The latest version of Aider (v0.54.0) introduces support for
gemini/gemini-1.5-pro-exp-0827andgemini/gemini-1.5-flash-exp-0827models, along with enhancements to shell and/runcommands, now allowing for interactive execution in environments with a pty.- A new switch,
--[no-]suggest-shell-commands, allows for customized configuration of shell command suggestions, while improved autocomplete functionality in large and monorepo projects boosts Aider's performance.
- A new switch,
- Aider Automates Its Own Development: Aider played a significant role in its own development, contributing 64% of the code for this release.
- This release also introduces a
--upgradeswitch to easily install the latest Aider version from PyPI.
- This release also introduces a
- Gemini 1.5 Pro Benchmarks Show Mixed Results: Benchmark results for the new Gemini 1.5 Pro model were shared, demonstrating a pass rate of 23.3% for whole edit format and 57.9% for diff edit format.
- The benchmarks were run with Aider using the
gemini/gemini-1.5-pro-exp-0827model andaider --model gemini/gemini-1.5-pro-exp-0827command.
- The benchmarks were run with Aider using the
- GameNGen: The First Neural Game Engine: The paper introduces GameNGen, the first game engine powered entirely by a neural model, enabling real-time interaction with a complex environment over long trajectories at high quality.
- The model can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU, achieving a PSNR of 29.4, comparable to lossy JPEG compression.
- OpenRouter: Discord Alternative?: A member asked if OpenRouter is the same as Discord.
- Another member confirmed that both services work fine for them, citing the OpenRouter status page: https://status.openrouter.ai/ for reference.
LM Studio Discord
- LM Studio 0.3.1 Released: The latest version of LM Studio is v0.3.1, available on lmstudio.aido.
- LM Studio on Linux Issues: A user reported that running the Linux version of LM Studio through Steam without the
--no-sandboxflag caused an SSD corruption. - Snapdragon NPU Not Supported: A user confirmed that the NPU on Snapdragon is not working in LM Studio, even though they have installed LM Studio on Snapdragon.
- LM Studio's AMD GPU Support: LM Studio's ROCM build currently only supports the highest-end AMD GPUs, and does not support GPUs like the 6700XT, causing compatibility issues.
- LM Studio's Security Tested: A user tested LM Studio's security by prompting an LLM to download a program, which resulted in a hallucinated response, suggesting no actual download took place.
Perplexity AI Discord
- Perplexity Pro Users Stuck in Upload Limbo: Users are experiencing issues uploading images and files, with some losing their Pro subscriptions despite continued access in certain browsers.
- This issue is causing frustration among Pro users, especially with a lack of information and estimated timeframe for a fix, leading to humorous responses like a 'this is fine' GIF.
- Claude 3.5's Daily Message Limit: 430: Claude 3.5 and other Pro models are subject to a daily message limit of 430, except Opus which has a 50-message limit.
- While some users haven't reached the combined limit, many find the closest they've gotten is around 250 messages.
- Image Upload Issues - AWS Rekognition to Blame: The inability to upload images is attributed to reaching the AWS Rekognition limits on Cloudinary, a service used for image and video management.
- Perplexity is currently working on resolving this issue, but there's no estimated timeframe for a fix.
- Perplexity Search: Better Than ChatGPT? Debatable: Some users claim Perplexity's search, especially with Pro, is superior to other platforms, citing better source citations and less hallucination.
- However, others argue ChatGPT's customization options, RAG, and chat UX are more advanced, and Perplexity's search is slower and less functional, particularly when compared to ChatGPT's file handling and conversation context.
- Perplexity's Domain-Specific Search Chrome Extension: The Perplexity Chrome extension offers domain-specific search capabilities, allowing users to find information within a specific website without manually searching.
- This feature is praised by some users for its advantage in finding information on a particular domain or website.
Nous Research AI Discord
- DisTrO vs. SWARM: Efficiency Considerations: While DisTrO is highly efficient under DDP, for training very large LLMs (greater than 100B parameters) on a vast collection of weak devices, SWARM may be a more suitable option.
- A member asked if DisTrO could be used to train these large LLMs, suggesting a use case of a billion old phones, laptops, and desktops, but another member recommended SWARM.
- DPO Training and AI-predicted Responses: Exploring Theory of Mind: A member pondered the potential effects of utilizing an AI model's predicted user responses, rather than the actual ones, in DPO training.
- They suggested that this approach might lead to improved theory of mind capabilities within the model.
- Model Merging: A Controversial Tactic: A member proposed merging the differences between UltraChat and base Mistral into Mistral-Yarn as a potential strategy, citing past successes with a similar approach.
- While others expressed doubts, the member remained optimistic about the effectiveness of this "cursed model merging" technique.
- Hermes 3 and Llama 3.1: A Head-to-Head Comparison: A member shared a comparison of Hermes 3 and Llama 3.1, highlighting Hermes 3's competitive performance, if not superiority, in general capabilities.
- Links to benchmarks were provided, showcasing Hermes 3's strengths and weaknesses relative to Llama 3.1.
- Finetuning with Synthetic Data: The Future of Training?: Members discussed the emerging trend of using synthetic data in finetuning models, highlighting Hermes 3 and rumored "strawberry models" as examples.
- While not always recommended, synthetic data training has gained momentum, especially with models like Hermes 3, but requires a sophisticated filtering pipeline.
OpenRouter (Alex Atallah) Discord
- OpenRouter API Briefly Degraded: OpenRouter experienced a five minute period of API degradation, but a patch was rolled out and the incident appears recovered.
- Llama 3.1 405B BF16 Endpoint Available: Llama 3.1 405B (base) has been updated with a bf16 endpoint.
- Hyperbolic Deploys BF16 Llama 405B Base: Hyperbolic released a BF16 variant of the Llama 3.1 405B base model.
- This comes in addition to the existing FP8 quantized version on OpenRouter.
- LMSys Leaderboard Relevance Questioned: A user questioned the relevance of the LMSys leaderboard, suggesting that it might be becoming outdated.
- They pointed to newer models like Gemini Flash performing exceptionally well.
- OpenRouter DeepSeek Caching Coming Soon: OpenRouter is working on adding support for DeepSeek's context caching.
- This feature is expected to reduce API costs by up to 90%.
Eleuther Discord
- Free Llama 3.1 405B API: A member shared a link to Sambanova.ai which provides a free, rate-limited API for running Llama 3.1 405B, 70B, and 8B.
- The API is OpenAI-compatible, allows users to bring their own fine-tuned models, and offers starter kits and community support to help accelerate development.
- TRL.X is Depreciated: A member pointed out that TRL.X is very depreciated and has not been updated for a long time.
- Another member inquired about whether it's still being maintained or if there's a replacement.
- Model Training Data - Proprietary or Public?: A member asked about what kind of data people use to train large language models.
- They wanted to know if people use proprietary datasets or public ones like Alpaca and then apply custom DPO or other unsupervised techniques to improve performance, or if they just benchmark with N-shot on non-instruction tuned models.
- Reversing Monte Carlo Tree Search: A member suggested training a model to perform Monte Carlo tree search in reverse.
- They proposed using image recognition and generation to generate the optimal tree search option instead of identifying it.
- Computer Vision Research: Paper Feedback: A member shared they are working on a computer vision diffusion project and are looking for feedback on their paper draft.
- They mentioned that large-scale tests are costly and requested help finding people who could review their work.
LlamaIndex Discord
- LlamaIndex supports GPT-4o-mini?: A user asked if
llama_index.llms.openaisupports using thegpt-4o-miniOpenAI model.- Another member confirmed it does not support this model and shared the list of supported models:
gpt-4,gpt-4-32k,gpt-4-1106-preview,gpt-4-0125-preview,gpt-4-turbo-preview,gpt-4-vision-preview,gpt-4-1106-vision-preview,gpt-4-turbo-2024-04-09,gpt-4-turbo,gpt-4o,gpt-4o-2024-05-13,gpt-4-0613,gpt-4-32k-0613,gpt-4-0314,gpt-4-32k-0314,gpt-3.5-turbo,gpt-3.5-turbo-16k,gpt-3.5-turbo-0125,gpt-3.5-turbo-1106,gpt-3.5-turbo-0613,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo-0301,text-davinci-003,text-davinci-002,gpt-3.5-turbo-instruct,text-ada-001,text-babbage-001,text-curie-001,ada,babbage,curie,davinci,gpt-35-turbo-16k,gpt-35-turbo,gpt-35-turbo-0125,gpt-35-turbo-1106,gpt-35-turbo-0613,gpt-35-turbo-16k-0613.
- Another member confirmed it does not support this model and shared the list of supported models:
- LlamaIndex's OpenAI Library Needs an Update: A member reported getting an error related to the
gpt-4o-miniOpenAI model when using LlamaIndex.- They were advised to update the
llama-index-llms-openailibrary to resolve the issue.
- They were advised to update the
- Pydantic v2 Broke LlamaIndex, But It's Being Fixed: A member encountered an issue related to LlamaIndex's
v0.11andpydantic v2where the LLM was hallucinating thepydanticstructure.- They shared a link to the issue on GitHub and indicated that a fix was under development.
- GraphRAG Authentication Errors Solved With OpenAILike: A member experienced an authentication error while using GraphRAG with a custom gateway for interacting with OpenAI API.
- The issue was traced back to direct OpenAI API calls made within the GraphRAG implementation, and they were advised to use the
OpenAILikeclass to address this issue.
- The issue was traced back to direct OpenAI API calls made within the GraphRAG implementation, and they were advised to use the
- Building a Multi-Agent NL to SQL Chatbot: A member sought guidance on using LlamaIndex tools for building a multi-agent system to power an NL-to-SQL-to-NL chatbot.
- They were advised to consider using workflows or reAct agents, but no definitive recommendation was given.
Torchtune Discord
- QLoRA & FSDP1 are not compatible: A user discussed whether QLoRA is compatible with FSDP1 for distributed finetuning, and it was determined that they are not.
- This is a point to consider for future development if the compatibility is needed.
- Torch.compile vs. Liger Kernels for Torchtune: A user questioned the value of Liger kernels in Torchtune, but a member responded that they prefer using
torch.compile. - Model-Wide vs. Per-Layer Compilation Performance: The discussion focused on the performance of
torch.compilewhen applied to the entire model versus individual layers. - Impact of Activation Checkpointing: Activation Checkpointing (AC) was found to impact compilation performance significantly.
- Balancing Speed and Optimization with Compilation Granularity: The discussion covered the granularity of model compilation, with different levels impacting performance and optimization potential.
- The goal is to find the right balance between speed and optimization.
OpenAI Discord
- GPT-4 Confidently Hallucinates: A member discussed the challenge of GPT-4 confidently providing wrong answers, even after being corrected.
- They suggested prompting with specific web research instructions, using pre-configured LLMs like Perplexity, and potentially setting up a custom GPT with web research instructions.
- Mini Model vs. GPT-4: One member pointed out that the Mini model is cheaper and seemingly performs better than GPT-4 in certain scenarios.
- They argued that this is primarily a matter of human preference and that the benchmark used doesn't reflect the use cases people actually care about.
- SearchGPT vs. Perplexity: A member inquired about the strengths of Perplexity compared to SearchGPT.
- Another member responded that they haven't tried Perplexity but consider SearchGPT to be accurate, with minimal bias, and well-suited for complex searches.
- AI Sentience?: A member discussed the idea of AI experiencing emotions similar to humans, suggesting that attributing such experiences to AI may be a misunderstanding.
- They expressed that understanding AGI as requiring human-like emotions might be an unrealistic expectation.
- Orion Model Access Concerns: A member expressed concern about the potential consequences of restricting access to Orion models like Orion-14B-Base and Orion-14B-Chat-RAG to the private sector.
- They argued that this could exacerbate inequality, stifle innovation, and limit broader societal benefits, potentially leading to a future where technological advancements serve only elite interests.
Interconnects (Nathan Lambert) Discord
- Google Releases Three New Gemini Models: Google has released three experimental Gemini models: Gemini 1.5 Flash-8B, Gemini 1.5 Pro, and Gemini 1.5 Flash.
- These models can be accessed and experimented with on Aistudio.
- Gemini 1.5 Pro Focuses on Coding and Complex Prompts: The Gemini 1.5 Pro model is highlighted as having improved capabilities for coding and complex prompts.
- The original Gemini 1.5 Flash model has been significantly improved.
- API Usability Concerns and Benchmark Skepticism: There is discussion around the API's usability with a user expressing frustration about its lack of functionality.
- The user also mentioned that they tried evaluating the 8B model on RewardBench, but considers it a fake benchmark.
- SnailBot Delivers Timely Notifications for Shortened Links: SnailBot notifies users via Discord before they receive an email when a link is shortened using livenow.youknow.
- However, the user also noted that SnailBot did not recognize a URL change, demonstrating that the tool has limitations.
- Open Source Data Availability Parallels Code Licensing Trends: A user predicted that the open-source debate about data availability will follow a similar trajectory to the status quo on code licensing.
Cohere Discord
- Cohere API Errors & Token Counting: A user reported a 404 error when using Langchain and Cohere TypeScript to make subsequent calls to the Cohere API.
- The error message indicated a "non-json" response, which suggests that the Cohere API returned a 404 page instead of a JSON object. The user also asked about token counting for the Cohere API.
- Aya-23-8b Inference Speed: A user asked if the Aya-23-8b model can achieve an inference time under 500 milliseconds for about 50 tokens.
- Model quantization was suggested as a potential solution to achieve faster inference times.
- Persian Tourist Attractions App: A Next.js app was launched that combines Cohere AI with the Google Places API to suggest tourist attractions in Persian language.
- The app features detailed information, including descriptions, addresses, coordinates, and photos, in high-quality Persian.
- App Features & Functionality: The app leverages the power of Cohere AI and the Google Places API to deliver accurate and engaging tourist suggestions in Persian.
- Users can explore tourist attractions with detailed information, including descriptions, addresses, coordinates, and photos, all formatted in high-quality Persian.
- Community Feedback & Sharing: Several members of the community expressed interest in trying out the app, praising its functionality and innovative approach.
- The app was shared publicly on GitHub and Medium, inviting feedback and collaboration from the community.
Modular (Mojo 🔥) Discord
- Mojo Compiler Eliminates Circular Imports: Mojo is a compiled language so it can scan each file and determine the shapes of structs before compiling, resolving circular imports because it has all the functions it needs to implement
to_queue.- Python's approach to circular imports differs, as it runs everything in sequence during compilation, leading to potential problems that Mojo's compiler avoids.
- Mojo Compiler Optimizes Struct Sizes: Mojo's compiler knows the size of a pointer, allowing it to figure out the shape of
Listwithout needing to look atQueue.- Mojo uses an
Arcor some other type of pointer to break the circular import loop.
- Mojo uses an
- Mojo's Potential for Top Level Statements: Mojo currently doesn't have top-level statements, but they are expected to handle circular imports by running the top-level code before
mainstarts in the order of imports.- This will ensure that circular imports are resolved correctly and efficiently.
- Mojo's Unusual Performance Curve: A user observed a sharp increase in Mojo's performance at around 1125 fields, speculating that a smallvec or arena might be overflowing.
- Another user suggested that a 1024 parameter single file might be the cause.
- Mojo's Named Return Slots Explained: Mojo supports named return slots, allowing for syntax like
fn thing() -> String as result: result = "foo".- This feature appears to be intended for "placement new" within the callee frame, although the syntax may change.
Latent Space Discord
- Google Unveils New Gemini Models: Google released three experimental Gemini models: Gemini 1.5 Flash-8B, Gemini 1.5 Pro, and a significantly improved Gemini 1.5 Flash model.
- Users can explore these models on aistudio.google.com.
- Anthropic's Claude 3.5 Sonnet: A Coding Powerhouse: Anthropic's Claude 3.5 Sonnet, released in June, has emerged as a strong contender for coding tasks, outperforming ChatGPT.
- This development could signal a shift in LLM leadership, with Anthropic potentially taking the lead.
- Artifacts Takes Mobile by Storm: Anthropic's Artifacts, an innovative project, has launched on iOS and Android.
- This mobile release allows for the creation of simple games with Claude, bringing the power of LLMs to mobile apps.
- Cartesia's Sonic: On-Device AI Revolution: Cartesia, focused on ubiquitous AI, introduced its first milestone: Sonic, the world's fastest generative voice API.
- Sonic aims to bring AI to all devices, facilitating privacy-preserving and rapid interactions with the world, potentially transforming applications in robotics, gaming, and healthcare.
- Cerebras Inference: Speed Demon: Cerebras launched its inference solution, showcasing impressive speed gains in AI processing.
- The solution, powered by custom hardware and memory techniques, delivers speeds up to 1800 tokens/s, surpassing Groq in both speed and setup simplicity.
OpenInterpreter Discord
- OpenInterpreter Gets a New Instruction Format: A member suggested setting
interpreter.custom_instructionsto a string usingstr(" ".join(Messages.system_message))instead of a list, to potentially resolve an issue.- This change might improve the handling of custom instructions within OpenInterpreter.
- Daily Bots Launches with Real-Time AI Focus: Daily Bots, an ultra low latency cloud for voice, vision, and video AI, has launched with a focus on real-time AI.
- Daily Bots, which is open source and supports the RTVI standard, aims to combine the best tools, developer ergonomics, and infrastructure for real-time AI into a single platform.
- Bland's AI Phone Calling Agent Emerges from Stealth: Bland, a customizable AI phone calling agent that sounds just like a human, has raised $22M in Series A funding and is now emerging from stealth.
- Bland can talk in any language or voice, be designed for any use case, and handle millions of calls simultaneously, 24/7, without hallucinating.
- Jupyter Book Metadata Guide: A member shared a link to Jupyter Book documentation on adding metadata to notebooks using Python code.
- The documentation provides guidance on how to add metadata to various types of content within Jupyter Book, such as code, text, and images.
- OpenInterpreter Development Continues: A member confirmed that OpenInterpreter development is still ongoing and shared a link to the main OpenInterpreter repository on GitHub.
- The commit history indicates active development and contributions from the community.
OpenAccess AI Collective (axolotl) Discord
- Axlotl on Apple Silicon (M3): A user confirmed that Axlotl can be used on Apple Silicon, specifically the M3 chip.
- They mentioned using it on a 128GB RAM Macbook without any errors, but provided no details on training speed or if any customization was necessary.
- IBM Introduces Power Scheduler: A New Learning Rate Approach: IBM has introduced a novel learning rate scheduler called Power Scheduler, which is agnostic to batch size and number of training tokens.
- The scheduler was developed after extensive research on the correlation between learning rate, batch size, and training tokens, revealing a power-law relationship. This scheduler consistently achieves impressive performance across various model sizes and architectures, even surpassing state-of-the-art small language models. Tweet from AK (@_akhaliq)
- Power Scheduler: One Learning Rate for All Configurations: This innovative scheduler allows for the prediction of optimal learning rates for any given token count, batch size, and model size.
- Using a single learning rate across diverse configurations is achieved by employing the equation: lr = bsz * a * T ^ b! Tweet from Yikang Shen (@Yikang_Shen)
- QLora FSDP Parameters Debate: A discussion arose regarding the proper setting of
fsdp_use_orig_paramsin QLora FSDP examples.- Some members believe it should always be set to
true, while others are unsure and suggest it might not be a strict requirement.
- Some members believe it should always be set to
- Uncommon Token Behavior in Model Training: A member asked if tokens with unusual meanings in their dataset compared to the pre-training dataset should be identified by the model.
- The member suggested that tokens appearing more frequently than the normal distribution might be an indicator of effective training.
DSPy Discord
- DSPy's "ImageNet Moment": DSPy's "ImageNet" moment is attributed to @BoWang87 Lab's success at the MEDIQA challenge, where a DSPy-based solution won two Clinical NLP competitions with significant margins of 12.8% and 19.6%.
- This success led to a significant increase in DSPy's adoption, similar to how CNNs became popular after excelling on ImageNet.
- NeurIPS HackerCup: DSPy's Next "ImageNet Moment"?: The NeurIPS 2024 HackerCup challenge is seen as a potential "ImageNet moment" for DSPy, similar to how convolutional neural networks gained prominence after excelling on ImageNet.
- The challenge provides an opportunity for DSPy to showcase its capabilities and potentially gain even greater adoption.
- DSPy's Optimizers for Code Generation: DSPy is being used for code generation, with a recent talk covering its use in the NeurIPS HackerCup challenge.
- This suggests that DSPy is not only effective for NLP but also for other domains like code generation.
- Getting Started with DSPy: For those interested in DSPy, @kristahopsalong recently gave a talk on Weights & Biases about getting started with DSPy for coding, covering its optimizers and a hands-on demo using the 2023 HackerCup dataset.
- The talk provides a great starting point for anyone interested in learning more about DSPy and its applications in coding.
- Changing OpenAI Base URL & Model: A user wanted to change the OpenAI base URL and model to a different LLM (like OpenRouter API), but couldn't find a way to do so.
- They provided code snippets demonstrating their attempts, which included setting the
api_baseandmodel_typeparameters indspy.OpenAI.
- They provided code snippets demonstrating their attempts, which included setting the
tinygrad (George Hotz) Discord
- Tinygrad Ships to Europe: Tinygrad is now offering shipping to Europe! To request a quote, send an email to support@tinygrad.org with your address and which box you would like.
- Tinygrad is committed to making shipping as accessible as possible, and will do their best to get you the box you need!
- Tinygrad CPU Error: "No module named 'tinygrad.runtime.ops_cpu'": A user reported encountering a "ModuleNotFoundError: No module named 'tinygrad.runtime.ops_cpu'" error when running Tinygrad on CPU.
- A response suggested using device "clang", "llvm", or "python" to run on CPU, for example:
a = Tensor([1,2,3], device="clang").
- A response suggested using device "clang", "llvm", or "python" to run on CPU, for example:
- Finding Device Count in Tinygrad: A user inquired about a simpler method for obtaining the device count in Tinygrad than using
tensor.realize().lazydata.base.realized.allocator.device.count.- The user found that
from tinygrad.device import DeviceandDevice["device"].allocator.device.countprovides a more straightforward solution.
- The user found that
LAION Discord
- LAION-aesthetic Dataset Link is Broken: A member requested the Hugging Face link for the LAION-aesthetic dataset, as the link on the LAION website is broken.
- Another member suggested exploring the CaptionEmporium dataset on Hugging Face as a potential alternative or source of related data.
- LAION-aesthetic Dataset Link Alternatives: The LAION-aesthetic dataset is a dataset for captioning images.
- The dataset includes various aspects of aesthetic judgment, potentially making it valuable for image captioning and image generation models.
Gorilla LLM (Berkeley Function Calling) Discord
- Llama 3.1 Benchmarking on Custom API: A user requested advice on benchmarking Llama 3.1 using a custom API, specifically for a privately hosted Llama 3.1 endpoint and their inference pipeline.
- They are seeking guidance on how to effectively benchmark the performance of their inference pipeline in relation to the Llama 3.1 endpoint.
- Gorilla's BFCL Leaderboard & Model Handler Optimization: A user raised a question about whether certain optimizations they are implementing for their function-calling feature might be considered unfair to other models on the BFCL Leaderboard.
- They are concerned about the BFCL Leaderboard's stance on model handler optimizations that may not be generalizable to all models, particularly regarding their use of system prompts, chat templates, beam search with constrained decoding, and output formatting.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (468 messages🔥🔥🔥):
Gamification of home trainingTriton configLoss curveModel finetuningGPU performance
- Gamification of home training: A member proposed a new idea for a training benchmarking tool to 'gamify home training.'
- The member declared that they'd be claiming this idea for their job application.
- Triton config woes: A member is experiencing an issue where response generation doesn't stop when using llama3 instruct with triton and either tensorrt-llm or vllm backend.
- They tried using vllm hosting directly, which worked flawlessly, indicating a potential issue with their triton configuration.
- Loss Curve Analysis: Several members discussed the significance of a 'loss curve' in model training, with one member suggesting that a loss of 0.0 might indicate a logging error.
- The member questioned whether a perfect model, with a loss of 0.0, is realistically achievable due to rounding.
- Gemma Finetuning Struggles: A member reported difficulty finetuning a Gemma2b model on AMD, attributing the issue to possible logging errors.
- Other members pointed to the fact that ROCm is still experimental and could contribute to the difficulties.
- Model Merging Tactics Discussed: A member suggested a model merging tactic by applying the difference between UltraChat and base Mistral to Mistral-Yarn.
- The member's suggestion was met with skepticism by some, but they remained optimistic and referenced past successes with what they called 'cursed model merging'.
- GameNGen: Diffusion Models Are Real-Time Game Engines
- Tweet from undefined: no description found
- Aligned: no description found
- unclemusclez/SmolLM-135M-Instruct-DEVINator · Hugging Face: no description found
- Gemma 7b It GGUF - a Hugging Face Space by mikemin027: no description found
- OpenMeditron/Meditron3-8B · Hugging Face: no description found
- unclemusclez/SmolLM-135M-Instruct-DEVINator · Hugging Face: no description found
- O Hearn GIF - O hearn - Discover & Share GIFs: Click to view the GIF
- Mike Ohearn GIF - Mike ohearn - Discover & Share GIFs: Click to view the GIF
- Mikeohearn GIF - Mikeohearn - Discover & Share GIFs: Click to view the GIF
- Pakistan Cricket Fan Pakistan Fan GIF - Pakistan Cricket Fan Pakistan Fan Cricket Angry Fan - Discover & Share GIFs: Click to view the GIF
- Issues · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - Issues · huggingface/transformers
- Huh Cat GIF - Huh Cat - Discover & Share GIFs: Click to view the GIF
- Ohearn Sad Mike Ohearn Sad GIF - Ohearn sad Ohearn Mike ohearn sad - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #today-im-learning (6 messages):
Training AI on CPUTraining AI on LaptopColab TPU instances
- Training AI on a Laptop without a GPU: Training AI models on a laptop's CPU will take a very long time.
- Using a cloud-based platform like Kaggle or Google Colab is recommended for faster training.
- Colab's TPU Instances for Training: Google Colab provides access to TPU instances, which are typically free to use.
- There's a Colab notebook showing how to use TPUs in Colab.
Link mentioned: Google Colab: no description found
HuggingFace ▷ #cool-finds (4 messages):
DisTrOGameNGenLlama ImplementationWiM
- Nous Research's DisTrO: Distributed Optimizers, 1000x-10,000x Communication Reduction: Nous Research has released DisTrO, an architecture-agnostic distributed optimizer that can reduce inter-GPU communication by 1000x-10,000x.
- A preliminary report detailing the workings of DisTrO can be found here.
- Google Presents GameNGen: A Real-Time Game Engine Built with Diffusion Models: GameNGen, the first real-time game engine powered entirely by a neural model, enables interactive simulations with high quality over long trajectories.
- GameNGen can simulate DOOM at 20 frames per second on a single TPU, achieving a PSNR of 29.4 - comparable to lossy JPEG compression.
- WiM Inference Pattern for Long Context LLMs: The Writing in the Margins (WiM) method is a new inference pattern that improves the performance of long context LLMs in retrieval-oriented tasks.
- WiM utilizes segment-wise inference for efficient processing of extensive contexts and provides an average accuracy enhancement of 7.5% for reasoning skills and 30.0% increase in F1-score for aggregation tasks.
- Writing in the Margins: Better Inference Pattern for Long Context Retrieval: In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks. This ...
- Paper page - Diffusion Models Are Real-Time Game Engines: no description found
- DisTrO/A_Preliminary_Report_on_DisTrO.pdf at main · NousResearch/DisTrO: Distributed Training Over-The-Internet. Contribute to NousResearch/DisTrO development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (11 messages🔥):
RYFAITau LLM SeriesStreetwear FluxLoadimgBielik-11B
- RYFAI: Open Source AI Assistant: RYFAI, an AI voice assistant built on Raspberry Pi, has been open-sourced! You can check it out and contribute to the project on GitHub at https://github.com/PetertheRedCedar/ryfai.
- Tau LLM Series: Vector Database API Improvements: The Tau LLM series continues with key updates and features. The vector database API has been enhanced for robustness and user-friendliness.
- The project has been uploaded to GitHub for easier collaboration and sharing, with new features for data loading and directory management. Development of the AgentTrainer and reward signal continues.
- Streetwear Flux: AI-Generated Design: A new Hugging Face model called 'Streetwear Flux' has been created, designed to generate streetwear-inspired designs.
- The model card includes a prompt for generating text-based streetwear graphics, featuring the text "TOKYO TECHWEAR STYLE" with various visual elements.
- Loadimg: Image Loading Library: The 'loadimg' Python library, designed for loading images, has reached 100,000 downloads in a month.
- You can find the library on PyPI at https://pypi.org/project/loadimg/ and its source code on GitHub at https://github.com/not-lain/loadimg.
- Bielik-11B: Polish Language Model: A new Polish language model, Bielik-11B, has been released, achieving top performance on both Polish and English benchmarks.
- The model was trained on 400 billion tokens and features 11 billion parameters, leveraging the PLGrid environment and the HPC center ACK Cyfronet AGH for its development.
- DamarJati/streetwear-flux · Hugging Face: no description found
- Bghira's Search for Reliable Multi-Subject Training: Problem: Characters tend to meld together. Proposal: Explore captioning and prompting after exploration of hyper-parameters. . Made by Bagheera using W&B
- GitHub - PetertheRedCedar/ryfai: This is an AI app designed to bring open source AI models to your fingertips with ease: This is an AI app designed to bring open source AI models to your fingertips with ease - PetertheRedCedar/ryfai
- speakleash/Bielik-11B-v2 · Hugging Face: no description found
- speakleash/Bielik-11B-v2.2-Instruct · Hugging Face: no description found
- PyPI Download Stats : no description found
HuggingFace ▷ #computer-vision (3 messages):
VAEs for Text-Image GenerationTransformers Library ContributionDocument Quality AssessmentData Augmentation for Document Quality
- VAEs for Text-Image Generation: Why Not More Popular?: A user asks why Variational Autoencoders (VAEs) for generating text from images, by encoding the image into a shared latent space and decoding it through a text decoder or vice versa, are not more widely adopted in research and practical applications.
- Transformers Library Good-First-Issue: A user asks if anyone is interested in a 'good-first-issue' for the transformers library and links to a specific issue about weight initialization for DeformableDetr.
- This issue aims to ensure that all weight initializations are performed in the _init_weights method of the corresponding PretrainedModel class.
- Document Quality Assessment: Identifying Blurred, Dark, or Blank Docs: A user seeks a way to assess document quality, specifically identifying if an uploaded document is blurred, dark, or blank, without readily available training data.
- They attempted to address this by scraping public printed documents and augmenting them by adding blurs, but the performance was subpar, as replicating real-life document photos proved challenging.
Link mentioned: Move weight initialization for DeformableDetr · Issue #29818 · huggingface/transformers: System Info Not relevant Reproduction See Deformable Detr Modeling. Expected behavior All weight initializations should be done in _init_weights of the xxxPretrainedModel class
HuggingFace ▷ #NLP (1 messages):
Text-Summary trends 2024Specialized vs General ModelsLlama Long ContextSystem Prompts
- Text-Summary still relevant in 2024: Text-summary models remain relevant in 2024, but the landscape is shifting.
- Llama excels with long context: Llama's ability to handle large amounts of context through system prompts makes it a powerful tool for summarization.
- Specialization vs Generalization: The choice between specialized text-summary models and general models like Llama depends on the specific task and desired outcome.
HuggingFace ▷ #diffusion-discussions (1 messages):
- ``
- This channel is for diffusers specific discussions.: This channel is for diffusers specific discussions.
- Diffusion channel guidance: A welcome message was posted to provide guidance on the channel's intended purpose.
Unsloth AI (Daniel Han) ▷ #general (228 messages🔥🔥):
VLLM on KaggleAphrodite on KaggleVLLM on ColabMistral strugglesModel Merging
- VLLM on Kaggle is working!: A user reported successfully running VLLM on Kaggle using wheels from this dataset.
- This was achieved with VLLM 0.5.4, a version that is still considered relatively new, as 0.5.5 has been released but is not yet widely available.
- Mistral struggles with expanding beyond 8k: Members confirmed that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They also discussed potential avenues for future performance enhancements, including mergekit and frankenMoE finetuning.
- Homoiconic AI: Weights as Code?: A member shared a [progress report on "Homoiconic AI"] (https://x.com/neurallambda/status/1828214178567647584?s=46) which uses a hypernet to generate autoencoder weights and then improves those weights through in-context learning.
- The report suggests that this "code-is-data & data-is-code" approach may be required for reasoning and even isomorphic to reasoning.
- Unsloth's Continued Pretraining Capabilities: A member shared a link to Unsloth's blog post on Continued Pretraining, highlighting its ability to continually pretrain LLMs 2x faster and with 50% less VRAM than Hugging Face + Flash Attention 2 QLoRA.
- The blog post also mentions the use of a Colab notebook to continually pretrain Mistral v0.3 7b to learn Korean.
- Unsloth vs OpenRLHF: Speed & Memory Efficiency: A user inquired about the differences between Unsloth and OpenRLHF, specifically regarding their support for finetuning unquantized models.
- A member confirmed that Unsloth supports unquantized models and plans to add 8bit support soon, emphasizing its significantly faster speed and lower memory usage compared to other finetuning methods.
- vllm T4 Fix: no description found
- speakleash/Bielik-11B-v2 · Hugging Face: no description found
- Tweet from neurallambda (open agi) (@neurallambda): progress report on "Homoiconic AI": we use a hypernet to generate the weights of an autoencoder, and then do in-context learning (masked reconstruction loss) to improve those weights val los...
- Continued LLM Pretraining with Unsloth: Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.
- Infer 34B with vLLM: Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
- Tweet from neurallambda (open agi) (@neurallambda): progress report on "Homoiconic AI": we use a hypernet to generate the weights of an autoencoder, and then do in-context learning (masked reconstruction loss) to improve those weights val los...
- llava-hf/LLaVA-NeXT-Video-7B-hf · Hugging Face: no description found
- unsloth (Unsloth AI): no description found
- speakleash/Bielik-11B-v2.2-Instruct · Hugging Face: no description found
- GitHub - Lightning-AI/litgpt: 20+ high-performance LLMs with recipes to pretrain, finetune and deploy at scale.: 20+ high-performance LLMs with recipes to pretrain, finetune and deploy at scale. - Lightning-AI/litgpt
Unsloth AI (Daniel Han) ▷ #help (64 messages🔥🔥):
8bit trainingUnsloth Cont PretrainingDataset SizeContext LengthModel Layer Tuning
- 8bit Training with Unsloth: A member inquired if it's possible to train Nemo-12b in 8bit with Unsloth, but was informed that Unsloth currently only supports 4bit training.
- They were then advised to use Axolotl or a similar tool for 8bit training.
- Continual Pretraining with Unsloth: The user was recommended to use Unsloth's Continual Pretraining feature to address the underperformance of their LoRA.
- This feature allows for continual pretraining of LLMs 2x faster and with 50% less VRAM compared to Hugging Face + Flash Attention 2 QLoRA.
- Dataset Size and Learning Rate: The user's dataset was 30 megabytes with 1 million tokens and was deemed to be small.
- The user was recommended to increase the dataset size, experiment with the learning rate and epochs, and fine-tune the input and output embeddings.
- Adjusting Context Length in Unsloth: A user inquired about adjusting the context length in the Unsloth/Llama-3-8b-Instruct-bnb-4bit model.
- They were advised that changing the model's context length is complex and can have unforeseen consequences, and that they should avoid doing so.
- Understanding Model Layer Tuning in Unsloth: A user asked for clarification on which layers are used for LoRA tuning in Unsloth notebooks.
- They were informed that the more layers trained, the more influence the data has on the model, but there is no one-size-fits-all configuration, and that further research is needed on how these layers function.
- Continued LLM Pretraining with Unsloth: Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- Home: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: no description found
- Salesforce/xlam-function-calling-60k · Datasets at Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #showcase (11 messages🔥):
Duet DatasetBielik-11B ModelHerplete-LLM-Llama-3.1-8bUnsloth Community
- Duet Dataset for Roleplaying: A new dataset for roleplaying called Duet was released, offering 5k rows of COT question-answer data rewritten to include narration and fit the storyline.
- The dataset includes world information from characters and settings, original questions and answers, and rewritten versions from the character's perspective.
- Bielik-11B: Polish Language Model: A new top-performing Polish language model, Bielik-11B, was released by SpeakLeash, featuring both base and instruct versions.
- The model is trained on Polish text corpora and utilizes the HPC center ACK Cyfronet AGH, leveraging computational grant number PLG/2024/016951.
- Herplete-LLM-Llama-3.1-8b: Continuous Fine-tuned Model: Herplete-LLM-Llama-3.1-8b is a continuous fine-tuned model derived from Replete-AI/Replete-LLM-V2-Llama-3.1-8b using LoRA extracted from Hermes-3-Llama-3.1-8B.
- It gained the skills of the two models it was trained on, including coding, roleplaying, math, and more.
- Unsloth Community Support: The Unsloth community was thanked for their contributions to the development of Bielik-11B, specifically for using Unsloth in prototyping and LoRA testing.
- Members were encouraged to share their own models in the dedicated channel, as they are trusted members of the community.
- Etherll/Herplete-LLM-Llama-3.1-8b · Hugging Face: no description found
- speakleash/Bielik-11B-v2 · Hugging Face: no description found
- speakleash/Bielik-11B-v2.2-Instruct · Hugging Face: no description found
- G-reen/Duet-v0.5 · Datasets at Hugging Face: no description found
- G-reen/Duet_Minitron8b_v0.5 · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
mrdragonfox: ya well - weird people are beeing weird
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.54.0New Gemini ModelsShell Command ImprovementsAider's Role in DevelopmentPerformance Enhancements
- Aider Adds New Gemini Models: The latest release of Aider introduces support for
gemini/gemini-1.5-pro-exp-0827andgemini/gemini-1.5-flash-exp-0827models. - Shell Command Enhancements and Interactivity: Shell and
/runcommands now allow for interactive execution in environments with a pty.- A new switch,
--[no-]suggest-shell-commands, allows for customized configuration of shell command suggestions.
- A new switch,
- Aider Automates Development: Aider played a significant role in developing this release, contributing 64% of the code.
- Performance Improvements for Aider: Aider's performance has been boosted, notably with improved autocomplete functionality in large and monorepo projects.
- This release also introduces a
--upgradeswitch to easily install the latest Aider version from PyPI.
- This release also introduces a
aider (Paul Gauthier) ▷ #general (119 messages🔥🔥):
Aider v0.54.0Gemini 1.5 Pro BenchmarkOpenRouter vs DiscordPrompt CachingAider and Sonnet 3.5
- Aider 0.54.0 Released: A new version of Aider (v0.54.0) was released with various quality of life improvements.
- The release notes can be found in the Aider Discord channel: https://discord.com/channels/1131200896827654144/1133060115264712836/1278356476624244776
- Gemini 1.5 Pro Benchmark Results: Benchmark results for the new Gemini 1.5 Pro model were shared, showing a pass rate of 23.3% for whole edit format and 57.9% for diff edit format.
- The benchmarks were run with Aider using the
gemini/gemini-1.5-pro-exp-0827model andaider --model gemini/gemini-1.5-pro-exp-0827command.
- The benchmarks were run with Aider using the
- OpenRouter and Discord: A member asked if OpenRouter is the same as Discord.
- Another member confirmed that they both work fine for them, citing the OpenRouter status page: https://status.openrouter.ai/
- Prompt Caching Explained: A member discussed the benefits of prompt caching, particularly when making a large number of API calls with the same prompt.
- They mentioned a theory involving tons of API calls with jobs, where the prompting would remain constant, with only the input variables changing.
- Aider and Sonnet 3.5: A member reported successful integration of Sonnet 3.5 with Aider using the
openai/poe-Claude-3.5-Sonnet-200kmodel.- They highlighted the potential cost savings associated with prompt caching when using Sonnet 3.5, citing a significant difference in API costs compared to using the Anthropic API directly.
- Tips: Tips for AI pair programming with aider.
- Advanced model settings: Configuring advanced settings for LLMs.
- Model warnings: aider is AI pair programming in your terminal
- v0: Generative UI playground
- docs.md: GitHub Gist: instantly share code, notes, and snippets.
- Introduction: Beautifully designed components that you can copy and paste into your apps. Accessible. Customizable. Open Source.
- Paper page - SWE-bench-java: A GitHub Issue Resolving Benchmark for Java: no description found
- Multi-SWE-bench: no description found
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- anthropic-cookbook/misc/prompt_caching.ipynb at main · anthropics/anthropic-cookbook: A collection of notebooks/recipes showcasing some fun and effective ways of using Claude. - anthropics/anthropic-cookbook
- v0 by Vercel: Chat with v0. Generate UI with simple text prompts. Copy, paste, ship.
- docs: add benchmark results for new gemini experimental models by cheahjs · Pull Request #1200 · paul-gauthier/aider: Added benchmark results for the 3 new experimental Gemini models (Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.5 Flash-8B) available on AI Studio announced yesterday: https://x.com/OfficialLoganK/sta...
- OpenRouter Status: OpenRouter Incident History
- Requests | OpenRouter: Handle incoming and outgoing requests
- litellm/model_prices_and_context_window.json at main · BerriAI/litellm: Python SDK, Proxy Server to call 100+ LLM APIs using the OpenAI format - [Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq] - BerriAI/litellm
aider (Paul Gauthier) ▷ #questions-and-tips (41 messages🔥):
Aider on ReplitCommit Message ErrorsAider SecurityAider DocumentationAider Repo Map
- Running Aider on Replit: A user asked if it's possible to run Aider on Replit to serve the created website immediately.
- Another user suggested that if a recent Python version is available on Replit, it might be possible.
- Commit Message Errors: Multiple users reported encountering a persistent error message: "Failed to generate commit message! Commit bcf...".
- One user suggested trying to retry, or quitting and returning, while another mentioned that the issue might be related to different prompts for different models.
- Aider's Security and Data Handling: A user inquired about whether Aider communicates with anything other than the configured model(s), specifically regarding data security when using private LLMs.
- Another user confirmed that, as far as they know, there is no telemetry or proxy service involved, and all data is sent directly to the LLM.
- Aider's Documentation Needs Improvement: A user pointed out that Aider's documentation lacks explicit information about its data handling practices, which is a concern for users working with proprietary codebases.
- Another user agreed and suggested that this information should be clearly stated in the documentation.
- Repo Map Issues in Aider: A user expressed difficulties with Aider's repo map in large codebases, finding it to include irrelevant information.
- They suggested the ability to better control the map, possibly by calculating it based on the types of added files.
- OpenAI: aider is AI pair programming in your terminal
- Genie: SOTA Software engineering model | Cosine - Human Reasoning Lab: no description found
- ConfigArgParse: A drop-in replacement for argparse that allows options to also be set via config files and/or environment variables.
- python-dotenv/README.md at main · theskumar/python-dotenv: Reads key-value pairs from a .env file and can set them as environment variables. It helps in developing applications following the 12-factor principles. - theskumar/python-dotenv
- OpenRouter: LLM router and marketplace
- GitHub - paul-gauthier/aider: aider is AI pair programming in your terminal: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.
aider (Paul Gauthier) ▷ #links (6 messages):
GameNGenDiffusion ModelsDoomReal-time Game Engines
- GameNGen - The First Neural Game Engine: The paper introduces GameNGen, the first game engine powered entirely by a neural model, enabling real-time interaction with a complex environment over long trajectories at high quality.
- This model can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU, achieving a PSNR of 29.4, comparable to lossy JPEG compression.
- GameNGen Simulates DOOM: Real-time recordings of people playing the game DOOM are simulated entirely by the GameNGen neural model.
- Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation.
- GameNGen Training Phases: GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the game's visual output.
- Real-Time Game Engines Using Diffusion Models: The paper explores the potential of diffusion models in creating real-time game engines.
- This research highlights the significant advancements in AI for simulating complex environments and real-time interaction.
Link mentioned: GameNGen: Diffusion Models Are Real-Time Game Engines
LM Studio ▷ #general (148 messages🔥🔥):
LM Studio versionsLM Studio on LinuxLM Studio on SnapdragonLM Studio on AMD GPULLMs and security
- LM Studio's Latest Version: The latest version of LM Studio is v0.3.1, available on lmstudio.aido.
- LM Studio on Linux through Steam: A user inquired about running the Linux version of LM Studio through Steam without the --no-sandbox flag, as running it directly caused an SSD corruption.
- Snapdragon NPU Not Supported in LM Studio: A user reported that the NPU on Snapdragon is not working in LM Studio, even though they have installed the LM Studio on Snapdragon.
- LM Studio on AMD GPUs: LM Studio's ROCM build currently supports only the highest-end AMD GPUs, and does not support GPUs like the 6700XT, causing compatibility issues.
- LM Studio's Security and Jailbreaking: A user tested LM Studio's security by prompting an LLM to download a program, which resulted in a hallucinated response, suggesting no actual download took place.
- no title found: no description found
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- All Large Language Models: A Curated List of the Large and Small Language Models (Open-Source LLMs and SLMs). All Large Language Models with Dynamic Sorting and Filtering.
- GitHub - YorkieDev/LMStudioWebUI: A wip version of a simple Web UI to use with LM Studio: A wip version of a simple Web UI to use with LM Studio - YorkieDev/LMStudioWebUI
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
LM Studio ▷ #hardware-discussion (8 messages🔥):
VRAM and RAM for LLMsNPU vs GPU for LLMsPCIE 5.0 x4 for GPU
- VRAM and RAM determine LLM size: The maximum model size you can run on a desktop or laptop depends on a combination of VRAM and RAM, with RAM being much slower than VRAM.
- NPUs are not suited for LLMs: NPUs are not designed for fast LLM inferencing and are not comparable to a GPU, even a dated one like a GTX 1060.
- A member cites a Geekbench 6.3.0 benchmark for a GTX 1060 which shows that even this older card performs better than a modern NPU for general compute tasks.
- PCIE 5.0 x4 for GPUs: A member inquires about using a 3090 on a PCIE 5.0 x4 connection.
- They wonder if x4 mode provides enough bandwidth or if x8 is required.
- ASUSTeK COMPUTER INC. Strix GL703GM_GL703GM - Geekbench: no description found
- LENOVO 21N2S01T00 - Geekbench: no description found
Perplexity AI ▷ #general (101 messages🔥🔥):
Perplexity Pro IssuesClaude 3.5 Message LimitPerplexity Image Upload IssuesPerplexity Search QualityPerplexity vs ChatGPT
- Perplexity Pro Users Frustrated with Upload Issues: Numerous users reported difficulties uploading files and images, with some stating that they lost their Pro subscriptions despite still having access in certain browsers.
- Several users expressed frustration at the lack of information and estimated timeframe for the issue's resolution, with some resorting to humorous responses such as a cartoon of a dog sitting at a table with a cup of coffee in front of a fire with the words "this is fine."
- Claude 3.5 Message Limit: 430 Per Day: The daily message limit for Claude 3.5 and other Pro models is 430, with the exception of Opus, which has a 50-message limit.
- While not specific to a single model, this combined limit has rarely been reached by some users, with the closest being around 250 messages.
- Perplexity's Image Upload Issues Linked to AWS Rekognition Limits: The inability to upload images is attributed to reaching the AWS Rekognition limits on Cloudinary, a cloud-based service used for image and video management.
- Perplexity is working on resolving this issue, but no estimated timeframe for a fix has been provided.
- Perplexity Search Quality Debated: Pro vs. ChatGPT: Some users reported Perplexity's search functionality, especially with Pro, to be superior to other platforms, citing better source citations and less hallucination.
- However, others argued that ChatGPT's customization options, RAG, and chat UX are more advanced, and Perplexity's search is slower and less functional, particularly when compared to ChatGPT's ability to handle files and remember conversation context.
- Perplexity's Chrome Extension Offers Domain-Specific Search: The Perplexity Chrome extension features domain-specific search capabilities, allowing users to find information within a specific website without manually searching.
- This feature is considered a significant advantage, particularly when seeking information on a particular domain or website, and has been praised by some users.
Link mentioned: This Fine GIF - This Is Fine - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (9 messages🔥):
Shareable ThreadsWTF critical thinkingClaude PromptsAustralia's Right to Log OffChina's Renewable Energy
- Make Threads Shareable: A user requested that another user ensure their thread is set to "Shareable" on Discord.
- New Critical Thinking Approach: WTF?: A user has integrated a new critical thinking approach that combines 26 established methods under the concept "WTF", involving questions like "What, Where, Who, When, Why, and How".
- The user claims to have encoded this approach in NLP and is happy to share more details and the PDF.
- Anthropic's Claude Prompts: A user shared a link to Anthropic's Claude Prompts, which were recently published.
- Australia's Right to Log Off: A user mentioned that Australia's new legislation gives workers the right to log off after work hours.
- China Achieves 2030 Renewable Energy Goals: A user noted that China has achieved its 2030 goal of generating renewable energy from various sources.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity AI Hebrew implementationPerplexity API citation feature beta
- Perplexity AI in Hebrew - Missing Links & Images: A user is attempting to implement Perplexity AI into a Hebrew fact-checking chatbot and is experiencing issues with missing links and images.
- The user is receiving shorter responses than the Perplexity search site, with incorrect or nonexistent links, and 404 image links.
- Beta Citation Feature - Waiting for Approval: Another user inquired about the wait time for being accepted into the Perplexity beta program, specifically for the citation return feature.
- They mentioned applying multiple times over the past months without receiving any response.
Nous Research AI ▷ #general (75 messages🔥🔥):
DisTrO efficiencyTraining very large LLMsDPO TrainingModel MergingHermes 3 vs Llama 3.1
- DisTrO's efficiency limitations: A member questioned if DisTrO could be used to train very large LLMs (>100b parameters) on a vast collection of weak devices.
- Another member responded that DisTrO is most efficient under DDP and for a use case with a billion old phones, laptops, and desktops, SWARM might be more appropriate.
- DPO Training with AI-predicted Responses: A member asked about the effect of using an AI model's predicted user response vs the user's actual one for DPO training.
- They speculated that it might lead to better theory of mind.
- Model Merging Tactics: A member suggested applying the difference between UltraChat and base Mistral to Mistral-Yarn as a potential merging tactic.
- While others expressed skepticism, the member remained optimistic, citing successful past attempts at what they termed "cursed model merging".
- Hermes 3 Outperforms Llama 3.1: A member shared a comparison of Hermes 3 and Llama 3.1 models, highlighting Hermes 3's competitiveness, if not superiority, in general capabilities.
- They included links to the benchmarks showing Hermes 3's strengths and weaknesses compared to Llama 3.1.
- Concerns about "Llama 3.1 Storm" Model: A member expressed concern that a new Llama 3.1 fine-tune called "Storm" might have been created by stealing Hermes's system prompt.
- Another member confirmed that a significant portion of the data for this model was actually derived from Hermes 2.
- Tweet from neurallambda (open agi) (@neurallambda): progress report on "Homoiconic AI": we use a hypernet to generate the weights of an autoencoder, and then do in-context learning (masked reconstruction loss) to improve those weights val los...
- Scaling Law with Learning Rate Annealing: We find that the cross-entropy loss curves of neural language models empirically adhere to a scaling law with learning rate (LR) annealing over training steps ($s$): $$L(s) = L_0 + A\cdot S_1^{-α} - C...
- Nvidia RTX 2000 Ada Single Slot Cooler | n3rdware: no description found
- akjindal53244/Llama-3.1-Storm-8B · Hugging Face: no description found
- Tweet from reneil.eth 🕳🐇 (@reneil1337): Yo Hermes love your take on @naturevrm 🤘 @NousResearch ftw 🕳️🐇
- Tweet from j⧉nus (@repligate): Hermes 405b is hilarious. It often acts like it just woke up in the middle of the madness and screams things like What the hell is going on
- Latent Weights Do Not Exist: Rethinking Binarized Neural Network Optimization: Optimization of Binarized Neural Networks (BNNs) currently relies on real-valued latent weights to accumulate small update steps. In this paper, we argue that these latent weights cannot be treated an...
- Reddit - Dive into anything: no description found
- Shikanoko By Murya GIF - SHIKANOKO BY MURYA - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #ask-about-llms (23 messages🔥):
Finetuning with Synthetic DataHermes 3Llama 3.1 8B on CPUModel Size and RAMConversation Topic Tagging
- Finetuning with Synthetic Data: A New Frontier: It is a common misconception that finetuning using data generated by another model is not recommended, but the cutting edge is very much focused on synthetic data training.
- Examples include Hermes 3, which utilizes tons of synthetic data, and rumored "strawberry models" that rely heavily on it, but it requires a good filtering pipeline.
- Llama 3.1 8B on CPU: Performance Expectations: Running Llama 3.1 8B on a VPS/baremetal machine without a GPU card requires 6GB of RAM and will result in slow performance of 5-10 tokens per second using gguf.
- 8-bit quantization might require 12GB of RAM, and the performance might be around 2-5 seconds per token, but this is not necessarily linear.
- Model Size and RAM: A Practical Guide: The size of an 8-bit quantized model is roughly half the size in parameters compared to the original model, with an additional 2GB of overhead.
- For example, an 8B model would require around 102GB of overhead on top of the actual model size.
- Tagging Conversations with Topics: Decoder Only or Encoder-Decoder?: For tagging conversations with a topic (2-3 words) without fixed classes, a decoder-only transformer or an encoder-decoder architecture could be used.
- One suggestion was to fine-tune any LLM and make the LM head output only the desired number of tags, referencing the LMSys competition for potential code examples.
- Explaining RAG Systems in a ChatGPT Interface: A simple RAG system could be explained in the context of a ChatGPT interface by allowing users to input a PDF link and then run a RAG mechanism.
- To differentiate a simple RAG system from a more advanced one, emphasize the additional features and complexities of the advanced system, such as incorporating more sophisticated document processing or retrieval methods.
Nous Research AI ▷ #research-papers (1 messages):
sunhao77: https://arxiv.org/abs/2408.11029
Nous Research AI ▷ #interesting-links (4 messages):
Flex-attention visualization toolTiny ASIC Matrix Multiplication Implementation
- Visualize any Flex-Attention: A new tool is available to help visualize various Flex-attention maps, including Bigbird attention, causal attention, and dilated sliding attention.
- The tool can be accessed at https://viig99-app-demos-jz7hllm8n2ps6fkkwmotuj.streamlit.app/
- Tiny ASIC for 1-bit LLMs: A GitHub repository presents a tiny ASIC implementation for matrix multiplication units, specifically tailored for 1-bit LLMs.
- This implementation is based on the paper "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" and can be found at https://github.com/rejunity/tiny-asic-1_58bit-matrix-mul.
- GitHub - rejunity/tiny-asic-1_58bit-matrix-mul: Tiny ASIC implementation for "The Era of 1-bit LLMs All Large Language Models are in 1.58 Bits" matrix multiplication unit: Tiny ASIC implementation for "The Era of 1-bit LLMs All Large Language Models are in 1.58 Bits" matrix multiplication unit - rejunity/tiny-asic-1_58bit-matrix-mul
- no title found: no description found
Nous Research AI ▷ #research-papers (1 messages):
sunhao77: https://arxiv.org/abs/2408.11029
Nous Research AI ▷ #rag-dataset (1 messages):
draeician: I'd love to see is if you don't mind.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
OpenRouter API DegradationLlama 3.1 405B Update
- OpenRouter API Degradation: OpenRouter experienced a ~5m period of API degradation, but a patch was rolled out and the incident appears recovered.
- Llama 3.1 405B bf16 Endpoint: Llama 3.1 405B (base) has been updated with a bf16 endpoint.
OpenRouter (Alex Atallah) ▷ #general (89 messages🔥🔥):
Hyperbolic's BF16 Llama 405BLMSys LeaderboardOpenRouter's DeepSeek CachingOpenRouter's Activity Page Bar ChartGemini Flash-8B performance
- Hyperbolic Deploys BF16 Llama 405B Base: Hyperbolic released a BF16 variant of the Llama 3.1 405B base model.
- This comes in addition to the existing FP8 quantized version on OpenRouter.
- LMSys Leaderboard: Outdated?: A user discussed the LMSys leaderboard.
- They suggested that its relevance might be decreasing due to newer models like Gemini Flash performing exceptionally well.
- OpenRouter's DeepSeek Caching: Coming Soon: OpenRouter is working on adding support for DeepSeek's context caching.
- This feature is expected to reduce API costs by up to 90%.
- OpenRouter's Activity Page Bar Chart Not Loading: Users reported issues with the activity page's bar chart not appearing.
- This issue seems to affect specific accounts, potentially due to a frontend bug.
- Gemini Flash-8B: Surprisingly Good for 8B: A user mentioned being impressed with the performance of the Gemini Flash-8B model.
- They noted that it performed comparably to larger versions of Flash and was particularly impressive in its multilingual capabilities.
- Secure & reliable LLMs | promptfoo: Eliminate risk with AI red-teaming and evals used by 30,000 developers. Find and fix vulnerabilities, maximize output quality, catch regressions.
- Activity | OpenRouter: See how you've been using models on OpenRouter.
- OpenRouter Integration - Helicone OSS LLM Observability: no description found
- GOODY-2 | The world's most responsible AI model: Introducing a new AI model with next-gen ethical alignment. Chat now.
- Llama 3.1 405B (base) - API, Providers, Stats: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 405B (base) with API
- Responses | OpenRouter: Manage responses from models
- Llama 3.1 405B Instruct - API, Providers, Stats: The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs. Meta's latest c...
- DeepSeek API introduces Context Caching on Disk, cutting prices by an order of magnitude | DeepSeek API Docs: In large language model API usage, a significant portion of user inputs tends to be repetitive. For instance, user prompts often include repeated references, and in multi-turn conversations, previous ...
- Llama 3.1 405B (base) - API, Providers, Stats: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 405B (base) with API
- Tweet from Hyperbolic (@hyperbolic_labs): Llama 3.1 405B Base at BF16: Now Available on Hyperbolic 🦙💜 Base models are far more creative and capable than instruction-tuned models, but they’ve been underutilized—until now. ➡️ Get started bu...
- Your First API Call | DeepSeek API Docs: The DeepSeek API uses an API format compatible with OpenAI. By modifying the configuration, you can use the OpenAI SDK or softwares compatible with the OpenAI API to access the DeepSeek API.
Eleuther ▷ #general (11 messages🔥):
Llama 3.1 405B APITRL.XModel Training DataMonte Carlo Tree SearchComputer Vision Research
- Free Llama 3.1 405B API: A member shared a link to Sambanova.ai which provides a free, rate-limited API for running Llama 3.1 405B, 70B, and 8B.
- The API is OpenAI-compatible, allows users to bring their own fine-tuned models, and offers starter kits and community support to help accelerate development.
- TRL.X Depreciated: A member pointed out that TRL.X is very depreciated and has not been updated for a long time.
- Another member inquired about whether it's still being maintained or if there's a replacement.
- Model Training Data Options: A member asked about what kind of data people use to train large language models.
- They wanted to know if people use proprietary datasets or public ones like Alpaca and then apply custom DPO or other unsupervised techniques to improve performance, or if they just benchmark with N-shot on non-instruction tuned models.
- Reversing Monte Carlo Tree Search: A member suggested training a model to perform Monte Carlo tree search in reverse.
- They proposed using image recognition and generation to generate the optimal tree search option instead of identifying it.
- Computer Vision Research & Paper Feedback: A member shared they are working on a computer vision diffusion project and are looking for feedback on their paper draft.
- They mentioned that large-scale tests are costly and requested help finding people who could review their work.
- Get Fast & Free AI Inference API | SambaNova Systems: Empower your AI applications with blazingly-fast inferencing using SambaNova’s Free API. Experience the future of AI with cutting-edge RDU chip technology.
- no title found: no description found
Eleuther ▷ #research (73 messages🔥🔥):
LR scaling with batch sizeAdam vs SGDMiniCPM paperInfinite LRsAdamWScale
- Adam LR Scaling: sqrt scaling?: A member proposed that the learning rate (LR) should scale with the square root of batch size for Adam.
- MiniCPM's Infinite LR Approach: A discussion arose regarding the MiniCPM paper's approach to infinite learning rates.
- AdamWScale and Initialization: A member asked about the significance of initialization papers, particularly one they felt was overlooked, and whether hyperparameters like weight decay and Adam betas should be considered.
- Critical Batch Size and Data Distribution Shift: The concept of critical batch size, a crucial factor in training performance, was discussed in the context of finetuning pretrained models.
- LLMs Token Prediction: Equi-learning Law: A paper was shared that introduced a law governing how LLMs internally improve their abilities to predict the next token.
- Tweet from Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr): Diffusion Models Are Real-Time Game Engines abs: https://arxiv.org/abs/2408.14837 project page: https://gamengen.github.io/ Google presents GameNGen, the first game engine powered entirely by a neur...
- The Mamba in the Llama: Distilling and Accelerating Hybrid Models: Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Tran...
- A Law of Next-Token Prediction in Large Language Models: Large language models (LLMs) have been widely employed across various application domains, yet their black-box nature poses significant challenges to understanding how these models process input data ...
- Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model: no description found
- An Empirical Model of Large-Batch Training: In an increasing number of domains it has been demonstrated that deep learning models can be trained using relatively large batch sizes without sacrificing data efficiency. However the limits of this ...
- How to Scale Hyperparameters as Batch Size Increases: no description found
- zhangirazerbayev/ocwcourses · Datasets at Hugging Face: no description found
- nn.MultiheadAttention causes gradients to become NaN under some use cases · Issue #41508 · pytorch/pytorch: 🐛 Bug Using key_padding_mask and attn_mask with nn.MultiheadAttention causes gradients to become NaN under some use cases. To Reproduce Steps to reproduce the behavior: Backwards pass through nn.Mu.....
LlamaIndex ▷ #blog (3 messages):
LlamaIndexRAGWorkflowsQuery EngineDeveloper Competition
- LlamaIndex RAG App Tutorial: A comprehensive guide by Wassim Chegham walks you through building a serverless RAG application using LlamaIndex and Azure OpenAI.
- The guide teaches how to leverage your own business data for enhanced responses, providing a deep understanding of RAG architecture and LlamaIndex.
- LlamaIndex Router Query Engine Workflow: A new Workflows tutorial from Ravitej Ads showcases the rebuilt Router Query Engine, leveraging the power of Workflows.
- The tutorial covers routing user queries to the appropriate query engine, including vector, summary, or keyword-based engines, providing valuable insights into the process.
- LlamaIndex & Nvidia Developer Competition: A developer competition with over $9000 in cash prizes, hardware, credits, and more, presented by LlamaIndex and Nvidia.
- To win, developers must build an innovative generative AI application using LlamaIndex and Nvidia technologies, exploring RAG, agentic, or a combination of both approaches.
LlamaIndex ▷ #general (66 messages🔥🔥):
LlamaIndex's support for OpenAI modelsLlamaIndex's openai library updateLlamaIndex's pydantic v2 breakagesGraphRAG authentication errorMulti-Agent system for NL to SQL
- OpenAI gpt-4o-mini not supported by LlamaIndex: A member asked if LlamaIndex's
llama_index.llms.openailibrary supports using thegpt-4o-miniOpenAI model.- Another member confirmed that it does not support this model. They noted that the error message indicates the supported models are
gpt-4,gpt-4-32k,gpt-4-1106-preview,gpt-4-0125-preview,gpt-4-turbo-preview,gpt-4-vision-preview,gpt-4-1106-vision-preview,gpt-4-turbo-2024-04-09,gpt-4-turbo,gpt-4o,gpt-4o-2024-05-13,gpt-4-0613,gpt-4-32k-0613,gpt-4-0314,gpt-4-32k-0314,gpt-3.5-turbo,gpt-3.5-turbo-16k,gpt-3.5-turbo-0125,gpt-3.5-turbo-1106,gpt-3.5-turbo-0613,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo-0301,text-davinci-003,text-davinci-002,gpt-3.5-turbo-instruct,text-ada-001,text-babbage-001,text-curie-001,ada,babbage,curie,davinci,gpt-35-turbo-16k,gpt-35-turbo,gpt-35-turbo-0125,gpt-35-turbo-1106,gpt-35-turbo-0613,gpt-35-turbo-16k-0613.
- Another member confirmed that it does not support this model. They noted that the error message indicates the supported models are
- LlamaIndex's OpenAI library Update?: A member reported getting an error related to the
gpt-4o-miniOpenAI model when using LlamaIndex.- They were advised to update the
llama-index-llms-openailibrary to resolve the issue.
- They were advised to update the
- Pydantic v2 Breaks LlamaIndex: A member encountered an issue related to LlamaIndex's
v0.11andpydantic v2where the LLM was hallucinating thepydanticstructure.- They shared a link to the issue on GitHub and indicated that a fix was under development.
- GraphRAG Authentication Error: A member experienced an authentication error while using GraphRAG with a custom gateway for interacting with OpenAI API.
- The issue was traced back to direct OpenAI API calls made within the GraphRAG implementation. They were advised to use the
OpenAILikeclass to address this issue.
- The issue was traced back to direct OpenAI API calls made within the GraphRAG implementation. They were advised to use the
- Multi-Agent System for NL to SQL to NL Chatbot: A member sought guidance on using LlamaIndex tools for building a multi-agent system to power an NL-to-SQL-to-NL chatbot.
- They were advised to consider using workflows or reAct agents, but no definitive recommendation was given.
- Openai like - LlamaIndex: no description found
- fix tool schemas by logan-markewich · Pull Request #15679 · run-llama/llama_index: Recent changes to pydanticv2 caused our tool json schemas to miss the renamed "definitions" section
- Custom Embeddings - LlamaIndex: no description found
Torchtune ▷ #general (8 messages🔥):
QLoRA distributed trainingFSDP1/2torch.compileliger kernelschunkedCE
- QLoRA and FSDP1 are not compatible: A user inquired about using QLoRA with distributed finetuning and was informed that it is not compatible with FSDP1.
- Torch.compile vs. Liger Kernels: A user asked about the usefulness of Liger kernels in Torchtune, to which a member responded that they prefer using
torch.compile. - FSDP2 requirement: A user asked about the required PyTorch version for using FSDP2.
Torchtune ▷ #dev (49 messages🔥):
Torch.compile performanceActivation checkpointing (AC)Model compilation granularityModel building and KV cache lengthsTorchtune PRs
- Torch.compile Performance: Whole model vs. per layer: The discussion revolved around the performance of
torch.compilewhen applied to a whole model versus individual layers. - Activation Checkpointing and its Impact on Compilation: Activation checkpointing (AC) was found to influence compilation performance significantly.
- Model Compilation Granularity: Balancing Speed and Optimization: The granularity of model compilation was discussed, with different levels of granularity impacting performance and optimization potential.
- KV Cache Length and Model Building: The length of the key-value (KV) cache in models was raised as a point of discussion, with the need to define it separately for the encoder and decoder components.
- Torchtune PRs and Open Issues: Several Pull Requests (PRs) were mentioned in relation to these discussions, including PR #1419 for per-layer compilation, PR #1427 for chunked cross-entropy loss, and PR #1423 for migrating argument parsing to configuration files.
- torchtune/torchtune/modules/transformer.py at 7b40daa19bfb90c11c8de2a1f74af8147b2fd016 · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/recipes/full_finetune_single_device.py at 05aeb71bec637f26a5b14e16638d445c1f7a8deb · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- torchtune/torchtune/models/flamingo/_component_builders.py at ade22da4bd66ddc54b0c2aa7a76f28a079eb00b3 · pbontrager/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pbontrager/torchtune development by creating an account on GitHub.
- Move argparse to config by RdoubleA · Pull Request #1423 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) TuneArgumentParser is fundamentally a config utility and...
- Add per-layer compile support to recipes by yf225 · Pull Request #1419 · pytorch/torchtune: Enabling per-layer compile for our single-device LoRA, single-device full finetune, and FSDP2 LoRA recipes. FSDP2 full finetune will be done in a follow-up. Results All recipes were run with three ...
OpenAI ▷ #ai-discussions (31 messages🔥):
LLM HallucinationGPT-4 vs. MiniSearchGPT vs. PerplexityAI Sentience and EmotionsOrion Model Access
- GPT-4 Hallucinates Confidently Wrong Answers: A member discussed the challenge of GPT-4 confidently providing wrong answers, even after being corrected.
- The group debated strategies to mitigate this, suggesting prompting with specific web research instructions, using pre-configured LLMs like Perplexity, and potentially setting up a custom GPT with web research instructions.
- Mini Cheaper and Better than GPT-4?: One member pointed out that the Mini model is cheaper and seemingly performs better than GPT-4 in certain scenarios.
- The member argued that this is primarily a matter of human preference and that the benchmark used doesn't reflect the use cases people actually care about.
- SearchGPT vs. Perplexity for Web Research: A member inquired about the strengths of Perplexity compared to SearchGPT.
- Another member responded that they haven't tried Perplexity but consider SearchGPT to be accurate, with minimal bias, and well-suited for complex searches.
- AI Sentience and Emotions: A member discussed the idea of AI experiencing emotions similar to humans, suggesting that attributing such experiences to AI may be a misunderstanding.
- They expressed that understanding AGI as requiring human-like emotions might be an unrealistic expectation.
- Orion Model Access Concerns: A member expressed concern about the potential consequences of restricting access to Orion models like Orion-14B-Base and Orion-14B-Chat-RAG to the private sector.
- They argued that this could exacerbate inequality, stifle innovation, and limit broader societal benefits, potentially leading to a future where technological advancements serve only elite interests.
Link mentioned: Tweet from Ignacio de Gregorio (@TheTechOasis1): http://x.com/i/article/1827379585861709824
OpenAI ▷ #gpt-4-discussions (20 messages🔥):
ChatGPT 4 vs ChatGPT 3.5OpenAI and Google's Data ScrapingCustom GPT's memory featureGPTs following multi-step instructionsLlama 3.1 vs ChatGPT
- ChatGPT 4's Accuracy Debated: A member suggested that ChatGPT 4 is not significantly better than ChatGPT 3.5 and that OpenAI has been using a tool to scrape YouTube content for training data.
- OpenAI and Nvidia's Data Scraping: Both OpenAI and Nvidia have reportedly been scraping data from websites without permission.
- Custom GPT's Memory Feature: A member inquired about the availability of the memory feature on Custom GPT.
- GPTs Struggle with Multi-Step Instructions: A member reported difficulty in getting a GPT to follow multi-step instructions without user intervention.
- Llama 3.1 vs ChatGPT - Performance Comparison: A member compared Llama 3.1 8B with a 400B model and found that the smaller model doesn't make sense because it requires a 200GB RAM cluster for the larger model.
Interconnects (Nathan Lambert) ▷ #news (13 messages🔥):
Gemini 1.5 Flash-8BGemini 1.5 ProGemini 1.5 FlashAistudioRewardBench
- Google Announces Three New Gemini Models: Google announced the release of three experimental Gemini models: Gemini 1.5 Flash-8B, Gemini 1.5 Pro, and Gemini 1.5 Flash.
- These models can be accessed and experimented with on Aistudio.
- Gemini 1.5 Pro: Coding & Complex Prompts: The Gemini 1.5 Pro model is highlighted as having improved capabilities for coding and complex prompts.
- The original Gemini 1.5 Flash model has been significantly improved.
- API Access and RewardBench: There is discussion around the API's usability with a user expressing frustration about its lack of functionality.
- The user also mentioned that they tried evaluating the 8B model on RewardBench, but considers it a fake benchmark.
- Q* Hypothesis and OpenAI's Release Strategy: A user questioned the relevance of the Q* hypothesis and its connection to Monte Carlo Tree Search (MCTS).
- The user expresses skepticism about OpenAI's recent release strategy and suggests the possibility of a more significant release later this year.
Link mentioned: Tweet from Logan Kilpatrick (@OfficialLoganK): Today, we are rolling out three experimental models: - A new smaller variant, Gemini 1.5 Flash-8B - A stronger Gemini 1.5 Pro model (better on coding & complex prompts) - A significantly improved Gem...
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
AI Art AccessibilityAI Art as the Path Forward
- AI Art Accessibility Concerns: A user expressed concern about a potential future where only wealthy and well-connected individuals have access to the best AI art tools.
- This concern stems from the fear that AI art, even if accepted as the path forward, could exacerbate existing inequalities in the art world.
- AI Art as the Path Forward?: The user raises concerns about the future of art and the potential for AI-generated art to become the dominant form.
- This raises questions about the role of traditional artists and the value of human creativity in an increasingly AI-driven world.
Interconnects (Nathan Lambert) ▷ #random (4 messages):
Gemini APIGemini API Rate LimitsGemini API Model Availability
- Gemini API: Rate Limits are a Mystery: A user expressed frustration with the Gemini API's rate limits, describing them as "astonishingly random and bad."
- They reported that some models work while others don't, making it difficult to use the API effectively.
- Gemini API User Seeks Guidance: A user inquired about the usage of the Gemini API, specifically asking if others use it.
- They appear to be encountering difficulties with rate limits and model availability.
Interconnects (Nathan Lambert) ▷ #posts (15 messages🔥):
SnailBotOpen SourceData AvailabilityFair Use
- SnailBot's Notifications: A user shared that SnailBot notifies them via Discord before they receive an email when a link is shortened using livenow.youknow.
- They also noted that SnailBot did not recognize a URL change, demonstrating that the tool has limitations.
- Open Source Debate Parallels to Code Licenses: A user predicted that the open-source debate about data availability will follow a similar trajectory to the status quo on code licensing.
- Data Availability and Fair Use: A user commented on the previous discussion about data availability, expressing an opinion that data being readily available is beneficial but not essential for most individuals.
- This aligns with their belief that fair use is a crucial aspect of open-source data sharing, and they hinted at a possible future article exploring this perspective.
Cohere ▷ #discussions (4 messages):
Cat gifs
- Cat in a Bathtub Gif: A GIF shows a cat standing in a bathtub, paws outstretched and its fur ruffled.
- The cat is dancing to an unknown song, giving it a humorous and quirky appeal.
- Links to More Cat Gifs: The chat includes links to various cat-themed GIFs, including dancing cats, funny cats, and general cat content.
Link mentioned: Dance Dancing GIF - Dance Dancing Dancing cat - Discover & Share GIFs: Click to view the GIF
Cohere ▷ #questions (25 messages🔥):
Langchain + Cohere API ErrorsCohere API Response ErrorsToken Counting for Cohere APIAya-23-8b Inference TimeModel Quantization
- Langchain + Cohere API Errors: A user reported receiving a 404 error when making subsequent calls to the Cohere API using Langchain and Cohere TypeScript.
- Cohere API Response Errors: The error message indicated a "non-json" response, suggesting that the Cohere API returned a 404 page instead of a JSON object.
- Token Counting for Cohere API: The user asked how to count the number of tokens in a text input, which is relevant for understanding token limits when working with the Cohere API.
- Aya-23-8b Inference Time: A user asked if the Aya-23-8b model can achieve an inference time under 500 milliseconds for about 50 tokens.
- Model Quantization: A user suggested that quantizing the models might help achieve faster inference times.
Link mentioned: Tokenize — Cohere: This endpoint splits input text into smaller units called tokens using byte-pair encoding (BPE). To learn more about tokenization and byte pair encoding, see the tokens page.
Cohere ▷ #projects (3 messages):
Persian Tourist AttractionsNext.js AppCohere AIGoogle Places API
- Next.js App Launched for Persian Tourist Suggestions: A Next.js app was launched that combines Cohere AI with the Google Places API to suggest tourist attractions in Persian language.
- The app provides detailed information, including descriptions, addresses, coordinates, and photos, with top-notch grammar.
- App Features & Functionality: The app leverages the power of Cohere AI and the Google Places API to deliver accurate and engaging tourist suggestions in Persian.
- Users can explore tourist attractions with detailed information, including descriptions, addresses, coordinates, and photos, all formatted in high-quality Persian.
- Community Feedback & Hosting: Several members of the community expressed enthusiastic interest in trying out the app, praising its functionality and innovative approach.
- The developer was encouraged to host the app for broader accessibility, allowing the community to experience its benefits firsthand.
- Sharing & Collaboration: The app was shared publicly on GitHub and Medium, inviting feedback and collaboration from the community.
- The developer encouraged community members to explore the code, provide feedback, and contribute to the project's development.
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
Mojo Circular ImportsPython Circular ImportsMojo Compiler OptimizationMojo Top Level Statements
- Mojo Handles Circular Imports: Mojo is a compiled language so it can scan each file and determine the shapes of structs before compiling.
- The compiler can then resolve the rest of the operations because it has all the functions it needs to implement
to_queue.
- The compiler can then resolve the rest of the operations because it has all the functions it needs to implement
- Python's Problem with Circular Imports: In Python, circular imports can cause problems because it runs everything in sequence during compilation.
- Mojo's approach to circular imports avoids these issues, as it doesn't have to run everything in sequence.
- Mojo Compiler Optimizes Struct Sizes: Mojo's compiler knows the size of a pointer, so it can figure out the shape of
Listwithout needing to look atQueue.- This allows the compiler to resolve circular imports by using an
Arcor some other type of pointer to break the loop.
- This allows the compiler to resolve circular imports by using an
- Mojo's Future with Top Level Statements: Mojo doesn't have top-level statements yet, but it's expected to handle circular imports there by running the top-level code before
mainstarts in the order of imports.- This will ensure that circular imports are resolved correctly and efficiently.
Link mentioned: Appointments: no description found
Modular (Mojo 🔥) ▷ #mojo (21 messages🔥):
Mojo performanceMojo named return slotsMojo non-movable typesMojo's Ownership ModelMojo debugging
- Mojo's Unusual Performance Curve: A user observed a sharp increase in performance at around 1125 fields, speculating that a smallvec or arena might be overflowing.
- Another user suggested that a 1024 parameter single file might be the cause.
- Named Return Slots in Mojo: Mojo supports named return slots, allowing for syntax like
fn thing() -> String as result: result = "foo".- The syntax is likely to change, but this feature appears to be intended for "placement new" within the callee frame.
- Non-movable Types in Mojo: Mojo allows for types that are not movable, such as
fn foo(a: Int) -> NonMovable:.- These types are compiled into the C++ equivalent of
void foo(int, NonMovable&)and the caller passes the location to initialize.
- These types are compiled into the C++ equivalent of
- Mojo's Ownership Model Explained: Mojo is very smart and disciplined, typically avoiding implicit moves and performing copy->move optimization.
- A blog post and video delve into the concept of ownership in Mojo, providing a mental model for understanding memory management.
- Mojo's Debugging Strategy: Debugging is a priority for Mojo and MAX, aiming to improve the debugging experience compared to the traditional Python, C++, and CUDA stack.
- Machine learning often requires inspecting the state of a program after a long running process, requiring debugging features tailored to this specific area.
- Modular: What ownership is really about: a mental model approach: Ownership is a well-known concept in modern programming languages such as Mojo that aims to provide a safe programming model for memory management while ensuring high performance. This allows programm...
- Blog-All: At Modular we believe a great culture is the key to creating a great company. The three pillars we work by are Build products users love, Empower people, and Be an incredible team.
Latent Space ▷ #ai-general-chat (19 messages🔥):
Gemini 1.5 Flash ModelsAnthropic's Claude 3.5 SonnetArtifacts on iOS and AndroidCartesia's SonicCerebras Inference
- Google Rolls Out New Gemini Models: Google announced the release of three experimental models: Gemini 1.5 Flash-8B (a smaller variant), Gemini 1.5 Pro (stronger for coding and complex prompts), and a significantly improved Gemini 1.5 Flash model.
- Users can try these models on https://aistudio.google.com.
- Anthropic's Claude 3.5 Sonnet: A Coding Contender: Anthropic's latest language model, Claude 3.5 Sonnet, released in June, has been gaining momentum among software engineers for its superior performance in coding-related tasks compared to ChatGPT.
- This marks a potential shift in LLM capability leadership away from OpenAI, with Anthropic leading the way.
- Artifacts Goes Mobile: Artifacts, a project by Anthropic, has launched on iOS and Android.
- The release brings the power of LLMs to mobile apps, allowing for real-time creation of simple games with Claude.
- Cartesia's Sonic: On-Device AI Revolution: Cartesia, focused on developing ubiquitous AI, announced its first milestone: Sonic, the world's fastest generative voice API.
- This advancement aims to bring AI to every device, enabling privacy-respecting and rapid interactions with the world, transforming applications in various sectors like robotics, gaming, and healthcare.
- Cerebras Inference: Blazing Fast AI: Cerebras introduced its inference solution, showcasing impressive speed gains in AI processing.
- The solution, built with custom hardware and a combination of memory techniques, delivers speeds up to 1800 tokens/s, exceeding Groq's performance in both speed and simplicity of setup.
- Tweet from Logan Kilpatrick (@OfficialLoganK): Today, we are rolling out three experimental models: - A new smaller variant, Gemini 1.5 Flash-8B - A stronger Gemini 1.5 Pro model (better on coding & complex prompts) - A significantly improved Gem...
- Cerebras Voice: no description found
- Tweet from Alex Albert (@alexalbert__): We launched Artifacts on iOS and Android today! I've spent all morning replicating simple games with Claude. We nearing the era of mobile apps created in real-time by LLMs.
- Cartesia: no description found
- How Anthropic built Artifacts: The team behind Artifacts - an innovative new way to interact with Claude - shares how they built this innovative feature in just three months with a distributed team. Exclusive details.
- Latent Space (Paper Club & Other Events) · Events Calendar: View and subscribe to events from Latent Space (Paper Club & Other Events) on Luma. Latent.Space events. PLEASE CLICK THE RSS LOGO JUST ABOVE THE CALENDAR ON THE RIGHT TO ADD TO YOUR CAL. "Ad...
OpenInterpreter ▷ #general (11 messages🔥):
interpreter custom_instructionsemit images in jupyterjupyterbook metadatacython codeopeninterpreter development
- Fix for interpreter.custom_instructions issue: A member suggested setting
interpreter.custom_instructionsto a string usingstr(" ".join(Messages.system_message))instead of a list.- They said this might resolve the problem.
- Turning off image display in Jupyter: A member requested help in turning off the default behavior of Jupyter to display images.
- They wanted to find a way to prevent images from automatically showing in Jupyter.
- Adding metadata to Jupyter Book using Python code: A member shared a link to Jupyter Book documentation on adding metadata to notebooks using Python code.
- The documentation provides guidance on how to add metadata to various types of content within Jupyter Book.
- Cython code example for Black-Scholes: A member shared a Cython code example for pricing an option using the Black-Scholes model.
- The code is optimized for speed and efficiency using Cython's capabilities.
- OpenInterpreter development update: A member confirmed that development is still ongoing and shared a link to the main OpenInterpreter repository on GitHub.
- The commit history indicates active development and contributions from the community.
- Add metadata to your book pages: no description found
- Commits · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- Jupyter Notebook Viewer: no description found
OpenInterpreter ▷ #O1 (4 messages):
01 Design & ResearchPre-order Status
- 01 Brand Doc & Design Progress: The closest thing to a brand document is the first presentation from the first meetup, available here.
- More extensive industrial design progress and documentation will be posted on GitHub under
hardware/light/manufacturingin the coming days.
- More extensive industrial design progress and documentation will be posted on GitHub under
- Pre-order Status Update: An update on pre-order status is expected soon.
- The most recent update is available here.
OpenInterpreter ▷ #ai-content (2 messages):
Daily BotsRTVIBlandVoice AIReal-time AI
- Daily Bots launches with real-time AI focus: Daily Bots, an ultra low latency cloud for voice, vision, and video AI, has launched with the goal of combining the best tools, developer ergonomics, and infrastructure for real-time AI into a single platform.
- Daily Bots is open source and supports the RTVI standard for building real-time AI applications, including voice-to-voice interactions with LLMs at latencies as low as 500ms.
- Bland is a customizable AI phone calling agent: Bland, a customizable AI phone calling agent that sounds just like a human, has raised $22M in Series A funding and is now emerging from stealth.
- Bland can talk in any language or voice, be designed for any use case, and handle millions of calls simultaneously, 24/7, without hallucinating.
- Partnerships and Projects: Daily Bots has partnered with Anthropic, Cartesia, Deepgram, and Together Compute for this launch.
- The two fastest growing Open Source real-time AI projects, Pipecat and RTVI, came out of Daily Bots' work with customers and partners, pioneering real-time and voice-to-voice AI in production.
- Tweet from Bland.ai (@usebland): Today, marks a major milestone for us. We’ve closed our series A with $22M in funding. As we emerge from stealth, we wanted to formally introduce you to Bland, Your newest AI employee. Bland is a...
- Tweet from Daily (@trydaily): Today we’re launching Daily Bots, the ultra low latency Open Source cloud for voice, vision, and video AI. Build voice-to-voice with any LLM, at conversational latencies as low as 500ms. With Daily ...
OpenAccess AI Collective (axolotl) ▷ #general (3 messages):
Apple Silicon (M3) support for AxlotlTraining on Apple Silicon
- Axlotl on Apple Silicon (M3) is Possible: A user confirmed that Axlotl can be used on Apple Silicon, specifically the M3 chip.
- They also mentioned using it on a 128GB RAM Macbook and that it works fine without any errors, but didn't provide details on training speed or if any customization was necessary.
- Training Speeds and Methods Unspecified: The user inquired about training speeds on the M3 Macbook.
- They asked if any code modifications were required for the setup and if the user employs Qlora, Lora, or full tuning methods for their training process.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
Power SchedulerLearning RateBatch SizeTraining TokensQLora FSDP
- IBM Presents Power Scheduler: A New Learning Rate Scheduling Approach: IBM has introduced a novel learning rate scheduler called Power Scheduler, which is agnostic to batch size and number of training tokens.
- The scheduler was developed after extensive research on the correlation between learning rate, batch size, and training tokens, revealing a power-law relationship. This scheduler consistently achieves impressive performance across various model sizes and architectures, even surpassing state-of-the-art small language models.
- Power Scheduler: One Learning Rate for All Configurations: This innovative scheduler allows for the prediction of optimal learning rates for any given token count, batch size, and model size.
- Using a single learning rate across diverse configurations is achieved by employing the equation: lr = bsz * a * T ^ b!
- QLora FSDP Examples and
fsdp_use_orig_params: A discussion arose regarding the proper setting offsdp_use_orig_paramsin QLora FSDP examples.- Some members believe it should always be set to
true, while others are unsure and suggest it might not be a strict requirement.
- Some members believe it should always be set to
- Tweet from AK (@_akhaliq): IBM presents Power Scheduler A Batch Size and Token Number Agnostic Learning Rate Scheduler discuss: https://huggingface.co/papers/2408.13359 Finding the optimal learning rate for language model pr...
- Tweet from Yikang Shen (@Yikang_Shen): (3/5) So now we can accurately predict the optimal learning rate for any given number of tokens, batch size, and model size! But more interestingly, we can use one learning rate for all these differen...
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
token analysismodel training
- Unusual Token Analysis: A member asked if tokens with unusual meanings in their dataset compared to the pre-training dataset should be identified by the model.
- The member gave an example of the token 'adam' and 'Fortunately' to demonstrate this concept.
- Token Distribution Variance: Another member suggested that tokens appearing more frequently than the normal distribution might be an indicator of effective training.
- This member's comment focuses on the frequency of specific tokens as a potential sign of successful model adaptation to the specific dataset.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
akjindal53244: Upon eye-balling it seemed fine but we didn't perform any quantitative analysis.
DSPy ▷ #show-and-tell (1 messages):
DSPy ImageNet momentNeurIPS HackerCup 2024DSPy for codingWeights & Biases DSPy Talk
- DSPy's "ImageNet Moment": DSPy's "ImageNet" moment is attributed to @BoWang87 Lab's success at the MEDIQA challenge, where a DSPy-based solution won two Clinical NLP competitions with significant margins of 12.8% and 19.6%.
- This success led to a significant increase in DSPy's adoption, similar to how CNNs became popular after excelling on ImageNet.
- NeurIPS HackerCup Challenge: DSPy's Next "ImageNet Moment"?: The NeurIPS 2024 HackerCup challenge is seen as a potential "ImageNet moment" for DSPy, similar to how convolutional neural networks gained prominence after excelling on ImageNet.
- The challenge provides an opportunity for DSPy to showcase its capabilities and potentially gain even greater adoption.
- DSPy for Coding: Getting Started: For those interested in DSPy, @kristahopsalong recently gave a talk on Weights & Biases about getting started with DSPy for coding, covering its optimizers and a hands-on demo using the 2023 HackerCup dataset.
- The talk provides a great starting point for anyone interested in learning more about DSPy and its applications in coding.
- DSPy Talk on Weights & Biases: The talk by @kristahopsalong on Weights & Biases covered the latest information on DSPy's optimizers and included a hands-on demo of code generation using DSPy.
- The talk is available on YouTube at https://www.youtube.com/watch?v=yhYeDGxnuGY.
- DSPy for Code Generation: DSPy is being used for code generation, with a recent talk covering its use in the NeurIPS HackerCup challenge.
- This suggests that DSPy is not only effective for NLP but also for other domains like code generation.
Link mentioned: Tweet from Connor Shorten (@CShorten30): Convolutional Neural Networks had their "ImageNet" moment when they surpassed hand-crafted image features on the immensely popular ImageNet dataset. This then sparked massive development inte...
DSPy ▷ #general (7 messages):
OpenAI Base URL/Model ChangeIPython Interpreter for DSPyMIPRO Interview with Krista Opsahl-Ong
- Switching Base URL & Model: A user wanted to change the OpenAI base URL and model to a different LLM (like OpenRouter API), but couldn't find a way to do so.
- They provided code snippets demonstrating their attempts, which included setting the
api_baseandmodel_typeparameters indspy.OpenAI.
- They provided code snippets demonstrating their attempts, which included setting the
- IPython Interpreter for DSPy: A user inquired about any work-in-progress (WIP) features to implement an IPython interpreter for DSPy, expressing a preference for the iterative nature of stateful execution.
- They mentioned that their team is building systems that would benefit from this approach, and are open to contributing a module for DSPy given design and theory alignment.
- Interview with Krista Opsahl-Ong on MIPRO and DSPy: A user excitedly shared a link to a podcast interview with Krista Opsahl-Ong, lead author of MIPRO, about Multi-Prompt Instruction Proposal Optimizer and DSPy.
- The interview covered topics like Automated Prompt Engineering, Multi-Layer Language Programs, Self-Improving AI Systems, LLMs and Tool Use, and DSPy for Code Generation.
Link mentioned: Tweet from Connor Shorten (@CShorten30): I am BEYOND EXCITED to publish our interview with Krista Opsahl-Ong (@kristahopsalong) from @StanfordAILab! 🔥 Krista is the lead author of MIPRO, short for Multi-prompt Instruction Proposal Optimize...
tinygrad (George Hotz) ▷ #general (1 messages):
Tinygrad Boxes Europe Shipping
- Tinygrad Ships to Europe!: Tinygrad is now offering shipping to Europe! To request a quote, send an email to support@tinygrad.org with your address and which box you would like.
- Tinygrad's Commitment to Shipping: Tinygrad is committed to making shipping as accessible as possible, and will do their best to get you the box you need!
tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
Tinygrad CPUTinygrad Device Count
- Tinygrad CPU Error: "No module named 'tinygrad.runtime.ops_cpu'": A user reported encountering a "ModuleNotFoundError: No module named 'tinygrad.runtime.ops_cpu'" error when running Tinygrad on CPU.
- A response suggested using device "clang", "llvm", or "python" to run on CPU, for example:
a = Tensor([1,2,3], device="clang").
- A response suggested using device "clang", "llvm", or "python" to run on CPU, for example:
- Finding Device Count in Tinygrad: A user inquired about a simpler method for obtaining the device count in Tinygrad than using
tensor.realize().lazydata.base.realized.allocator.device.count.- The user found that
from tinygrad.device import DeviceandDevice["device"].allocator.device.countprovides a more straightforward solution.
- The user found that
LAION ▷ #general (3 messages):
LAION-aesthetic dataset
- LAION-aesthetic link is broken: A member inquired about a Hugging Face link for the LAION-aesthetic dataset, as the link on the LAION website is broken.
- Possible Solution: CaptionEmporium: Another member suggested exploring the CaptionEmporium dataset on Hugging Face as a potential alternative or source of related data.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
Llama 3.1 BenchmarkingCustom API for Llama 3.1Inference Pipeline Benchmarking
- Llama 3.1 Benchmarking: A member requested pointers on benchmarking Llama 3.1 using a custom API.
- They want to benchmark their company's privately hosted Llama 3.1 endpoint and inference pipeline.
- Custom API for Llama 3.1: The member has a privately hosted Llama 3.1 endpoint and wants to benchmark their inference pipeline.
- They are seeking guidance on how to get started with benchmarking.
- Inference Pipeline Benchmarking: The user is interested in benchmarking their inference pipeline for a custom API that utilizes Llama 3.1.
- They are looking for suggestions and strategies to effectively evaluate the performance of their inference pipeline.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
BFCL LeaderboardModel Handler OptimizationFunction Calling Feature
- BFCL Leaderboard and Unfair Optimization: A user inquired about whether certain optimizations they are implementing for their function-calling feature would be considered unfair to other models on the BFCL Leaderboard.
- The user is concerned about BFCL's stance on model handler optimizations that may not be generalizable to all models, specifically regarding their use of system prompts, chat templates, beam search with constrained decoding, and output formatting.
- Optimizations for Function Calling Feature: The user is working on integrating these steps into a custom model handler for their function-calling feature.
- They are seeking to update the system prompt, apply a chat template, use beam search with constrained decoding, and format the model's output according to Gorilla's specified format.