[AINews] Canvas: OpenAI's answer to Claude Artifacts
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Chat-with-Artifacts is all you need.
AI News for 10/2/2024-10/3/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (225 channels, and 1721 messages) for you. Estimated reading time saved (at 200wpm): 212 minutes. You can now tag @smol_ai for AINews discussions!
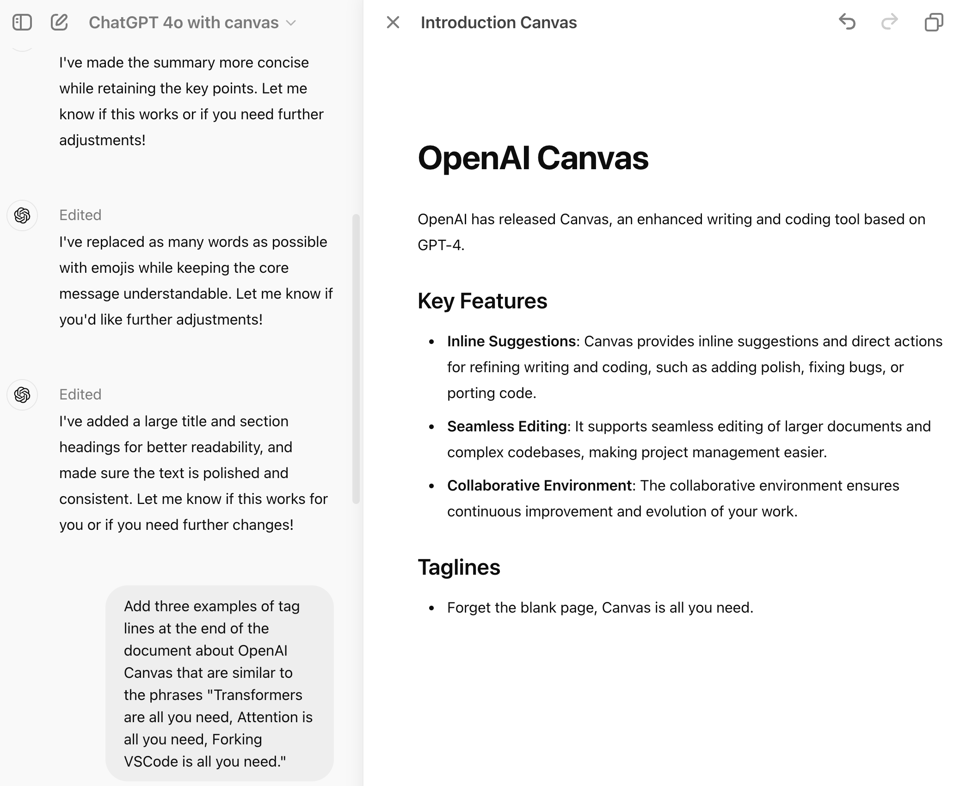
Three months after Claude Artifacts (our coverage here), OpenAI released Canvas, an enhanced writing and coding tool based on GPT-4o (Mikhail Parakhin also notes that they shipped a similar feature in Bing Copilot). From the release announcement, Canvas includes:
- Inline Suggestions: Canvas provides inline suggestions and direct actions for refining writing and coding, such as adding polish, fixing bugs, or porting code.

- Seamless Editing: It supports seamless editing of larger documents and complex codebases, making project management easier.
- Collaborative Environment: The collaborative environment ensures continuous improvement and evolution of your work.
A quick scan of early commentary and feedback included:
- Vincente Silveira noted: "Looks great, we just tried it, compared w Cursor and Claude, and seems it brings more of the core editing and coding use cases into ChatGPT with a better UX for the average user."
- Machine Learning Street Talk tweeted early issues however: "OpenAI cloned the functionality inside @cursor_ai i.e. the apply model. Nice idea, poor execution - it doesn't work very well. Often updates the entire doc, not the selection"
- Karina Nguyen (who worked on Canvas) posted several examples of writing and coding using Canvas.
While the early emphasis seems to be on writing usecases, integrating well with ChatGPT's existing search, coding is of course an important comparator vs Claude Artifacts, and Karina has built in some custom tools for those tasks.
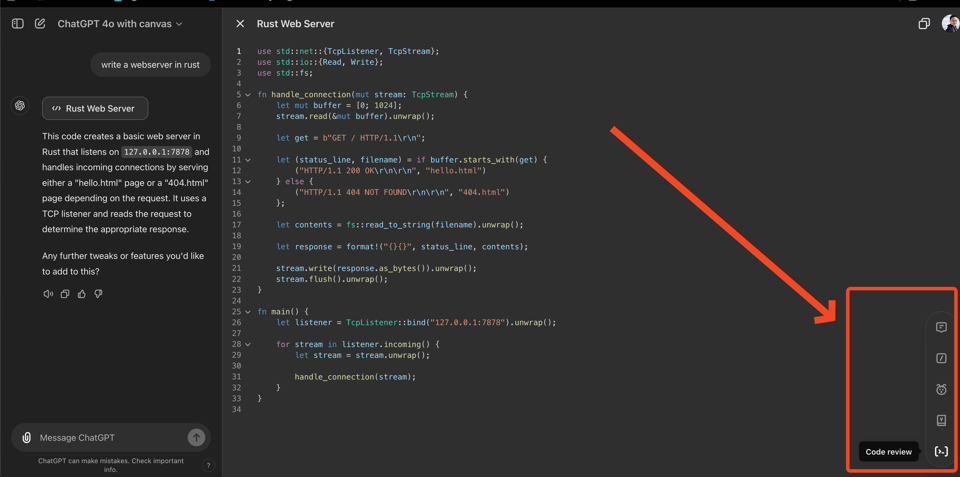
OpenAI will also be sponsoring Marijn Haverbeke, the creator and maintainer of the open source libraries ProseMirror and CodeMirror used in making Canvas.
The trickiest part of the implementation was the way in which OpenAI chose to integrate it into the existing ChatGPT experience, which involved training a detector for when the canvas feature should toggle on:
A key challenge was defining when to trigger a canvas. We taught the model to open a canvas for prompts like “Write a blog post about the history of coffee beans” while avoiding over-triggering for general Q&A tasks like “Help me cook a new recipe for dinner.” For writing tasks, we prioritized improving “correct triggers” (at the expense of “correct non-triggers”), reaching 83% compared to a baseline zero-shot GPT-4o with prompted instructions. They shared their evals too:
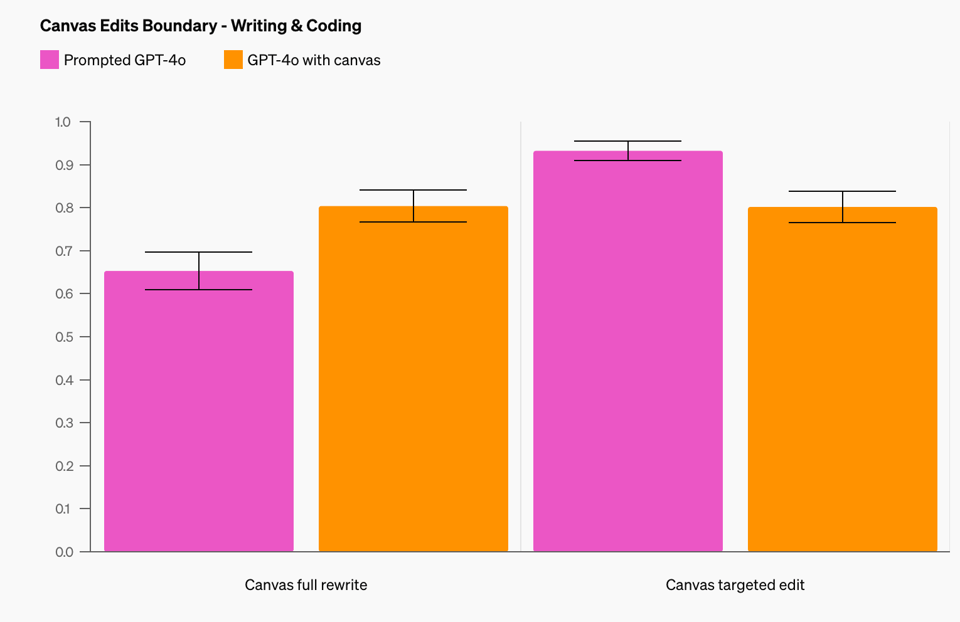
Similar improvements were done for triggering edit behavior and comment creation. This probably means the chatgpt-4o-latest model in API has been updated as well.
Unlike Artifacts, OpenAI Canvas does not support displaying Mermaid Diagrams or HTML previews. Presumably those features are in the works, but it is curious both that they weren't prioritized and that this was also not launched at Dev Day 2 days ago (the Latent Space recap here).
Sponsored by Daily: If you’re interested in conversational voice AI (and video, too), join the team at Daily and the Open Source Pipecat community for a hackathon in San Francisco on October 19th and 20th. $20,000 in prizes for the best voice AI agents, virtual avatar experiences, UIs for multi-modal AI, art projects, and whatever else we dream up together.
swyx: Voice AI is the hottest new AI engineering skill! I'll be here - Daily has been in the SF AI Hackathon scene for a very long time and this is the biggest prize set I've seen in a while to learn something I've wanted to get good on.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI and Technology Advancements
- Large Language Models (LLMs) and AI Development: @karpathy shared an experiment where he curated a 10-episode podcast called "Histories of Mysteries" using AI tools like ChatGPT, Claude, and NotebookLM in just 2 hours, demonstrating the rapid content creation capabilities enabled by generative AI. @cwolferesearch discussed the potential of o1 (OpenAI's latest model) for automatic prompt engineering, highlighting its ability to leverage increased inference time compute for better reasoning.
- AI in Healthcare: @bindureddy argued for the rapid adoption of AI in healthcare, stating that AI is better than humans at retrieving information and makes fewer mistakes. They suggested that replacing human doctors with AI could benefit humanity.
- AI Model Developments: @OfirPress announced that o1 has set a new state-of-the-art on SciCode, outperforming Claude by a significant margin. @rohanpaul_ai shared information about Nvidia's NVLM-D 1.0 72B model, which performed on par with Llama 3.1 405B on Math and Coding tasks.
- AI Infrastructure: @soumithchintala provided a detailed explanation of how to train a model on 10,000 H100 GPUs, covering topics such as parallelization, communication optimization, and failure recovery strategies.
AI Ethics and Societal Impact
- AI Safety: @NPCollapse shared a resource on building a good future for humanity with AI, describing it as the best attempt to date on this topic.
- AI Regulation: @JvNixon commented on potential issues with Californian laws on AI, suggesting they might violate freedom of speech and thought.
AI Applications and Tools
- AI in Software Development: @AlphaSignalAI announced Pythagora, a VScode extension that uses 14 AI Agents to manage the entire development process, from planning to deployment.
- AI for Data Analysis: @basetenco introduced a new export metrics integration for model inference, allowing easy export to observability platforms like Grafana Cloud.
- AI in Content Creation: @c_valenzuelab shared an example of using AI for location scouting in the latent space, demonstrating the ability to visualize different times and seasons.
Industry Trends and Opinions
- AI Company Valuations: @RazRazcle commented on the rapid growth of OpenAI, noting they've gone from ~0 to 3.5Bn rev in 2 years.
- Software Development Practices: @svpino criticized the trend of overcomplicating software development, calling for a return to simpler, more direct approaches to building applications.
- AI Model Pricing: @_philschmid shared updates on LLM pricing, noting significant price drops from various providers including OpenAI, Google Deepmind, Cohere, Mistral, and Cloudflare.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Meta Releases Llama 3.2: A Leap in Open-Source Vision Models
- Model refresh on HuggingChat! (Llama 3.2, Qwen, Hermes 3 & more) (Score: 49, Comments: 15): HuggingChat has updated its model lineup, now offering free access to five new models including Qwen2.5-72B-Instruct, Llama-3.2-11B-Vision-Instruct (with vision capabilities), Mistral-Nemo-Instruct-2407, Hermes-3-Llama-3.1-8B, and Phi-3.5-mini-instruct. Additionally, two models with tool calling enabled are available: Meta-Llama-3.1-70B-Instruct and c4ai-command-r-plus-08-2024.
- Jamba Mini, a 12B active/52B total MoE model, was suggested for its fantastic performance at 256K context and low hallucination rate. It's challenging to run locally but could be hosted by HuggingChat, though it may require vllm support or custom coding.
- Users expressed interest in trying Jamba Mini, with the HuggingChat team acknowledging its potential but noting the lack of TGI support as a significant issue. They promised to consider the suggestion.
- A request was made for LongWriter-glm4-9b by thudm, capable of "generating 10,000+ words at once." This model was suggested as suitable for companies with better hardware, like HuggingChat.
- Meta Llama 3.2: A brief analysis of vision capabilities (Score: 244, Comments: 47): Meta has released two multi-modal language models, Llama 3.2, in sizes of 11B and 90B parameters. The author tested the model's vision capabilities across various tasks including image understanding, medical report analysis, and chart analysis, finding it to be a strong performer for everyday use cases and a potential replacement for GPT-4o in certain applications, though GPT-4o still outperforms in more complex tasks. For a detailed analysis, the author refers readers to their in-depth article on Llama 3.2's vision capabilities.
- Users discussed alternative models like Qwen 2 VL 72B and Molmo, with some suggesting these perform better than Llama 3.2. The author plans to compare the 90B model to Qwen 2 VL 72B.
- The model's text extraction capabilities were found to be reliable for standard texts but not precise for invoices or tables. Users also expressed interest in its ability to generate coordinates for objects and handle tasks with overlayed grids.
- The author used Gradio and Together AI cloud services to run the 70B model, citing limited local hardware resources. Some users shared experiences with implementing other models like Qwen 2 VL 72B using Gradio and Transformers.
Theme 2. Advancements in Language-Specific and Task-Specific Models
- google/gemma-2-2b-jpn-it Japanese specific models (Score: 45, Comments: 15): Google has released gemma-2-2b-jpn-it, a Japanese-specific model in the Gemma series, which is now available on Hugging Face. This new model was announced at the Gemma Developer Day in Tokyo, indicating Google's efforts to expand language-specific AI models for the Japanese market.
- The pre-training of the Japanese-specific Gemma model was conducted in Japanese, as explained in the task-specific tuning documentation. There was no mention of plans for a 9B version or release date for Gemma 3.
- Sundar Pichai, Google CEO, made a surprise appearance at the Gemma Developer Day, suggesting strong support for the project. A Hugging Face representative also spoke, hinting at potential future GGUF versions of the model.
- Google introduced several Gemma-related tools, including a Responsible Generative AI Toolkit, Gemma Scope for model analysis, and on-device generation capabilities using MediaPipe. A $150,000 Kaggle contest for global communication with Gemma was also announced.
- Llama-3.1-Nemotron-70B-Reward (Score: 45, Comments: 6): The post title "Llama-3.1-Nemotron-70B-Reward" appears to reference a specific AI language model, but no additional content or context is provided in the post body. Without further information, it's not possible to provide a meaningful summary of the post's content or discussion points.
- Llama-3.1-Nemotron-70B-Reward performs similarly to Skywork-Reward-Gemma-2-27B on human-annotated tasks, but lags behind on GPT-4 annotated tasks. This suggests Skywork-Reward-Gemma-2-27B better models GPT-4 preferences, likely due to its training on GPT-4 annotated data.
- The discussion clarifies that Reward-Gemma (not Gemini) aligns better with GPT-4 generated "ground truth" but not human "ground truth". This is attributed to Reward-Gemma's training data including GPT-4 generated text.
- The model is described as a "new best in class judge for RHLF" (Reinforcement Learning from Human Feedback), noted for its accuracy in predicting human preferences.
- New leaderboard: which models are the best at role play? (Score: 40, Comments: 7): A new leaderboard called StickToYourRoleLeaderboard evaluates LLMs' ability to maintain character consistency in role-playing scenarios. The leaderboard, available on Hugging Face, assesses how well models adhere to provided roles and character values throughout discussions, with a detailed explanation thread by the authors available on X (formerly Twitter).
- Users noted that Mistral performs best among tested models (Llama 3.1-8b, Llama 3.2-3b, Qwen 2.5, Mythomax), emphasizing the importance of base prompts and model parameters.
- The leaderboard's omission of Mistral Nemo was highlighted, with suggestions to include more popular fine-tuned models in the benchmarking process.
Theme 3. AMD Strix Halo: A Potential Game-Changer for Local LLM Inference
- AMD Strix Halo rumored to have APU with 7600 XT performance & 96 GB of shared VRAM (Score: 68, Comments: 39): AMD's rumored Strix Halo APU is reported to offer performance comparable to the Radeon 7600 XT and support up to 96 GB of shared VRAM. This high-end laptop chip could potentially run large language models in memory without requiring a dedicated AI GPU, with Llama.cpp's Vulkan kernels supporting APUs at speeds similar to ROCm kernels on other AMD hardware, despite current lack of official ROCm support for APUs.
- AMD's lack of 48GB VRAM GPUs with CUDA support is seen as a missed opportunity in the AI market. The W7900-PRO offers 48GB but at a high price point of $4K, potentially to avoid undercutting AMD's Instinct line.
- The Strix Halo APU is rumored to use 256-bit LPDDR5X-8000 memory, providing 256GB/s theoretical bandwidth. Some speculate it could reach 500GB/s range, possibly including 3D cache benefits for gaming workloads.
- Current AMD APUs face limitations with VRAM allocation, allowing only up to 8GB as dedicated VRAM. However, a new feature called Variable Graphics Memory allows conversion of up to 75% of system RAM to "dedicated" graphics memory for AMD Ryzen™ AI 300 series processors.
- Qwen 2.5 Coder 7b for auto-completion (Score: 37, Comments: 17): Qwen 2.5 Coder 7b model demonstrates superior auto-completion capabilities compared to other local models, particularly in handling large contexts of multi-thousand tokens. The user reports a significant reduction in hallucinations and improved code style continuity, making it comparable to Copilot in performance. For implementation with the ContinueDev plugin for IntelliJ, a custom template override is required:
"<|fim_prefix|>{ prefix}<|fim_suffix|>{ suffix}<|fim_middle|>", and it's crucial to use the instruct model variant for proper functionality with control tokens and FIM support.- Qwen2.5-7b-coder-q8_0.gguf shows promising results for C++ auto-completion in Neovim, with Q8 quantization only ~5% slower than Q4 for short completions. User ggerganov is using 256 prefix and 128 suffix lines for context.
- Comparisons between Qwen2.5 7b-coder and 14b-instruct models suggest the larger model may offer better context understanding and code explanation, despite not being specifically trained for coding. The 7b-coder version is fine-tuned for auto-completion with special tokens.
- Confusion arose regarding the use of base vs. instruct models for fill-in-the-middle tasks, with the original poster reporting issues using the base model. Qwen's documentation suggests using the base model for FIM tasks, contradicting user experiences.
Theme 4. Open-Source Tools for AI Development and Evaluation
- How Moshi Works: A Simple Guide to the to Open Source Real Time Voice LLMs (Score: 52, Comments: 7): Moshi, an open-source alternative to OpenAI's Voice mode, is developed by Kyutai for real-time voice in language models. The author shares a link to their post detailing Moshi's architecture, suggesting it's worth understanding despite not being at the same level as OpenAI's offering.
- 🧬 OSS Synthetic Data Generator - Build datasets using natural language (Score: 38, Comments: 3): The post introduces an open-source synthetic data generator that allows users to create datasets using natural language prompts. This tool, which can be found on GitHub, enables the generation of diverse datasets including images, text, and structured data for various machine learning tasks such as classification, object detection, and segmentation. The generator utilizes large language models and image generation models to produce high-quality synthetic data based on user-defined specifications.
- Hugging Face employee introduces the Distilabel Synthetic Data Generator, an open-source tool for creating high-quality datasets using natural language prompts. The tool can be run locally by cloning the Space or installing the distilabel library.
- Users express enthusiasm for the tool, praising it for driving the "AI as commodity" paradigm. The creator welcomes feedback and mentions plans to add more tasks and functions in the future.
- The tool simplifies dataset creation for training and fine-tuning language models, allowing users to define application characteristics, generate system prompts, and produce customizable datasets that can be pushed directly to the Hugging Face Hub.
- “Proverbs 27:17: As iron sharpens iron, so one person sharpens another” “Training Language Models to Win Debates with Self-Play Improves Judge Accuracy” (Score: 35, Comments: 4): The paper introduces DebateGPT, a language model trained through self-play to engage in debates, which led to improved accuracy in judging debate outcomes. By pitting the model against itself in debates on various topics, researchers found that the resulting judge model achieved 83% accuracy in determining debate winners, surpassing both human judges and previous AI models. This approach demonstrates the potential of self-play in enhancing language models' argumentative and analytical capabilities.
- Self-play and replicating human tendencies in language models, such as Chain of Thought (CoT) and debate-style interactions, are proving highly effective for improving task performance. These "simple" process changes often lead to substantial performance improvements.
- The paper link https://www.arxiv.org/abs/2409.16636 was provided in the post body, but some users had difficulty accessing it due to app limitations in displaying text on image posts.
- Discussion highlighted the importance of proper paper citation and linking practices in academic discussions on social media platforms.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Here is a summary of the key themes and developments from the provided Reddit posts:
AI Model Advancements and Capabilities
- OpenAI's o1 model is demonstrating impressive reasoning and problem-solving abilities:
- It can replicate complex PhD-level coding projects in hours that previously took months.
- It's showing promising results in mathematical proofs, outperforming previous models.
- OpenAI researcher Hunter Lightman says o1 is already acting like a software engineer and authoring pull requests.
- Google is working on reasoning AI similar to OpenAI's o1, using techniques like chain-of-thought prompting. They've already showcased models like AlphaProof for math reasoning.
- Salesforce released xLAM-1b, a 1 billion parameter model achieving 70% accuracy in function calling, surpassing GPT-3.5 despite its smaller size.
AI Research and Development
- A Google Deepmind paper demonstrates how data curation via joint example selection can accelerate multimodal learning.
- Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy.
- Research on scaling synthetic data creation using 1 billion web-curated personas shows promise for generating diverse training data.
AI Industry and Funding
- OpenAI is seeking exclusive funding arrangements to accelerate AGI development.
- NVIDIA CEO Jensen Huang states that a trillion dollars is being invested in data centers to enable the next wave of AI for business productivity.
AI Ethics and Societal Impact
- There are ongoing discussions about the potential job displacement due to AGI and the need for new economic paradigms.
- Sam Altman suggests being polite to AI assistants like ChatGPT, hinting at potential future developments in AI consciousness or rights.
AI in Image Generation
- New versions of image generation models like PonyRealism v2.2 and RealFlux are being released, showing incremental improvements in realism and capabilities.
AI Discord Recap
A summary of Summaries of Summaries
Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- DeepSeek-V2 Challenges GPT-4: DeepSeek-V2, a new 236B parameter model, has shown impressive performance on benchmarks like AlignBench and MT-Bench, reportedly surpassing GPT-4 in some areas.
- The DeepSeek-V2 announcement sparked discussions about its capabilities and potential impact on the AI landscape, with community members eager to explore its full potential.
- Llama 3's Leaderboard Leap: Meta's Llama 3 has quickly risen to the top of leaderboards like ChatbotArena, outperforming models such as GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- This rapid ascent has ignited discussions about the evolving landscape of large language models and the potential for open-source alternatives to challenge proprietary leaders in the field.
2. Optimizing LLM Inference and Training
- ZeRO++ Slashes Communication Overhead: ZeRO++ promises a 4x reduction in communication overhead for large model training on GPUs, potentially revolutionizing the efficiency of distributed training.
- This advancement could significantly impact the scalability of LLM training, allowing researchers to train larger models more quickly and cost-effectively.
- vAttention's Dynamic KV Caching: The vAttention system introduces dynamic management of KV-cache memory for efficient LLM inference without relying on PagedAttention.
- This innovation addresses memory constraints in LLM deployment, potentially enabling more efficient serving of large models on limited hardware resources.
- Consistency LLMs Speed Up Decoding: Techniques like Consistency LLMs explore parallel token decoding to reduce inference latency, promising faster response times for LLM applications.
- This approach challenges traditional autoregressive decoding methods, opening new avenues for optimizing LLM performance in real-time applications.
3. Open-Source AI Frameworks and Community Efforts
- Axolotl's Dataset Format Expansion: Axolotl has expanded its support for diverse dataset formats, enhancing its capabilities for instruction tuning and pre-training LLMs.
- This update facilitates easier integration of various data sources, enabling researchers and developers to fine-tune models more effectively with custom datasets.
- LlamaIndex Teams Up with Andrew Ng: LlamaIndex announces a new course on building agentic RAG systems in collaboration with Andrew Ng's DeepLearning.ai, bridging academic insights with practical applications.
- This partnership aims to democratize advanced AI techniques, making complex concepts like agentic RAG more accessible to a broader audience of developers and researchers.
- Mojo's Python Integration Teased: Modular's new deep dive with Chris Lattner teases Mojo's potential for seamless Python integration and AI-specific extensions like
_bfloat16_.- The discussion highlights Mojo's ambition to combine Python's accessibility with systems programming capabilities, potentially reshaping AI development workflows.
4. Multimodal AI and Generative Modeling Innovations
- Idefics2 and CodeGemma Push Boundaries: Idefics2 8B Chatty focuses on elevated chat interactions, while CodeGemma 1.1 7B refines coding abilities, showcasing advancements in specialized AI models.
- These models demonstrate the ongoing trend of tailoring AI capabilities to specific domains, enhancing performance in targeted applications like conversational AI and code generation.
- Phi-3 Brings AI to the Browser: The Phi-3 model introduces powerful AI chatbot capabilities to browsers via WebGPU, potentially revolutionizing client-side AI applications.
- This development marks a significant step towards more accessible and privacy-preserving AI experiences, enabling sophisticated AI interactions directly within web browsers.
- IC-Light Illuminates Open-Source Image Relighting: The open-source IC-Light project focuses on advancing image relighting techniques, making sophisticated visual effects more accessible to the community.
- This tool empowers creators and researchers to explore advanced image manipulation techniques, potentially leading to new applications in computer graphics and visual AI.
GPT4O (gpt-4o-2024-05-13)
1. Model Performance Optimization
- Dynamic Memory Compression Boosts Throughput: Dynamic Memory Compression (DMC) boosts throughput by up to 370% on H100 GPUs, enhancing transformer efficiency.
@p_nawrotshared insights on the DMC paper, sparking discussions about its impact on large-scale model training.
- ZeRO++ Reduces GPU Communication Overhead: ZeRO++ promises a 4x reduction in communication overhead for large model training on GPUs.
@deep_speedhighlighted the benefits of ZeRO++, noting its potential to optimize resource utilization.
- Flash Attention's Memory Usage Debated: The community discussed whether Flash Attention exhibits linear memory growth despite quadratic computational complexity.
@ggerganovpointed out that Flash Attention could streamline memory usage in large models.
2. Fundraising and New Product Launches
- OpenAI Secures $6.6 Billion Funding: OpenAI successfully raised $6.6 billion to bolster their AI research projects.
@openaiannounced the funding round, with discussions on its impact on future AI advancements.
- FLUX1.1 Pro Impresses with Speed: FLUX1.1 Pro launched, providing six times faster generation and improved image quality.
@blackforestlabsshared the FLUX1.1 Pro release, sparking excitement and anticipation in the AI community.
- GPT-4o Realtime API Launch: The GPT-4o Realtime API was released for low-latency audio interactions.
@azuredetailed the API launch, focusing on applications like customer support.
3. AI Tooling and Community Innovations
- Crawl4AI Enhances Data Collection: Crawl4AI, an open-source web crawler, offers customizable data collection tools.
@unclecodeintroduced Crawl4AI, discussing its integration with language models for improved data extraction.
- Mojo's Error Handling Strategies: Conversations focused on Mojo's error handling, suggesting Zig-style error unions.
@msaelicesproposed improvements to Mojo's error handling, emphasizing pattern matching and composability.
- MongoDB Atlas Powers Hybrid Search: A blog post on creating and configuring hybrid search indexes with MongoDB Atlas for enhanced search relevance.
@llama_indexdetailed the implementation, merging semantic and full-text search to address common inefficiencies.
4. AI Alignment and Research Discussions
- AI Reading Group Launches: The AI Reading Group from Women in AI & Robotics launches with a focus on research discussions.
@aashka_trivediwill present the INDUS paper, highlighting collaboration between IBM and NASA.
- OpenAI's Moderation Policies Debated: Members recounted their experiences with OpenAI's moderation policy, flagging requests to prompt AGI.
@eleuthernoted that these policies seem overly cautious, suggesting many flagged messages don't align with stated usage policies.
- Softmax Function's Limitations Explored: A paper highlighted the limitations of the softmax function in achieving robust computations as input sizes increase.
@nous_researchshared the paper, proposing adaptive temperature as a workaround for these limitations.
5. Open-Source Contributions and Collaborations
- Axolotl Adds Dataset Format Docs: Axolotl supports diverse dataset formats for instruction tuning and pre-training LLMs.
@axolotl_aiannounced the documentation update, enhancing usability for the community.
- OpenDevin Release Announced: The release of OpenDevin, an open-source autonomous AI engineer, garners interest on GitHub.
@cognition_aishared the release, emphasizing its potential for developer collaboration and innovation.
GPT4O-Aug (gpt-4o-2024-08-06)
1. AI Model Performance and Optimization
- FLUX1.1 Pro Surpasses Expectations: FLUX1.1 Pro launched, boasting six times faster generation and improved image quality, achieving the highest Elo score in the Artificial Analysis image arena.
- The AI community buzzed with excitement, eager to explore the model's potential in optimizing AI workflows and applications.
- Quantization Techniques for Large Models: Discussions around quantization algorithms for large neural networks (50B+ parameters) highlighted techniques like int8 and HQQ for maintaining less than 1% loss in target metrics.
- Members noted that int4 + hqq quantization is also effective, requiring minimal calibration, sparking interest in optimizing model efficiency.
- GPU Cooling Solutions for AI Setups: A user considered water cooling single slot blocks for their setup of 8 GPUs, noting a maximum power draw of 4000W across two 1600W and one 1500W power supplies.
- Discussions emphasized the importance of electrical safety and innovative uses of GPU setups, such as heating solutions during colder months.
2. AI Community Practices and Concerns
- OpenAI Bubble Concerns: Members expressed concerns that the OpenAI bubble is expanding precariously, drawing parallels to WeWork and questioning the long-term sustainability of AI hype.
- The release of o1 temporarily alleviated fears, but discussions highlighted uncertainties about OpenAI's future trajectory and impact on the industry.
- Community Frustration Over Customer Support: Users voiced dissatisfaction with customer support for subscription issues, including file downloads and delayed responses, impacting user retention.
- One user considered cancelling their subscription, underscoring the significant impact of inadequate support on community satisfaction.
- Addressing AI Model Moderation Issues: Concerns arose over Claude 2.1 flagging SFW prompts, with one instance marking a character description as 'sexual', sparking debate over moderation practices.
- Community discussions highlighted the need for clearer moderation guidelines to prevent interference with user interactions.
3. AI Tools and Features Launch
- OpenAI's New Canvas Feature: OpenAI introduced the canvas feature for writing and coding projects, allowing Plus & Team users to work beyond simple chat interactions by selecting “GPT-4o with canvas”.
- The feature aims to improve user experience in project management and collaboration, with discussions on its potential for enhancing complex task workflows.
- GPT-4o Realtime API for Audio: The GPT-4o Realtime API was released for low-latency audio interactions, targeting applications like customer support and requiring client integration for end-user audio.
- This development sparked interest in enhancing conversational capabilities with real-time audio features for diverse applications.
- LangChain's LangGraph Innovates Query Generation: A LinkedIn post highlighted LangGraph's role in managing complex query generation and output structuring within the LangChain ecosystem.
- Focus was placed on error correction and user-friendly results, with appreciation for Harrison Chase and the LangChain team's contributions.
4. AI Research and Collaboration
- AI Reading Group Promotes Collaboration: The AI Reading Group from Women in AI & Robotics launches, featuring IBM and NASA research on October 17, 2024, with limited sign-ups for audience Q&A.
- The group aims to foster direct dialogue between researchers and the community, spotlighting interdisciplinary AI discussions and innovations.
- Exploring Liability in AI Research: Discussion centered on whether individuals who share AI models for research could be held liable for misuse, with a call for clear legal guidelines.
- Members emphasized the importance of clarity in legal waters to establish responsible AI research practices and protect original researchers.
- Knowledge Graph Embedding Innovations: A paper introduced a novel approach to knowledge graph embedding (KGE), integrating uncertainty through group theory for efficient and expressive models.
- This approach allows entities and relations to be embedded as permutations in a symmetric group, suggesting potential for improved KGE frameworks.
5. AI Ethics and Data Privacy
- Concerns Over Data Privacy in AI: A member raised alarms about data privacy, alleging AI firms, including OpenAI, focus on stealing data from mid-sized companies, sparking debate.
- Discussions emphasized the importance of transparency and opt-out options for data sharing, reflecting broader concerns in the AI community.
- AI's Impact on Future Movies: An article explored AI's impact on filmmaking, suggesting technology will reshape storytelling and production processes, accessible here.
- The conversation pointed out emerging trends that could redefine audience engagement in cinema, with AI playing a pivotal role in transforming the industry.
- Legal Status of Web Scraping: Concerns were raised over ongoing litigation regarding web scraping, with artists and writers frustrated about its legal status and implications.
- The conversation highlighted legal complexities and the need for clear guidelines to balance data access and intellectual property rights.
O1-mini
Theme 1. AI Models on the Fast Track: Speed and Savings
- FLUX1.1 Pro Zooms Ahead: FLUX1.1 Pro launches with six times faster generation and superior image quality, clinching the highest Elo score in the Artificial Analysis image arena.
- GPT-4o Slashes Prices: Starting today, GPT-4o's input costs drop by 50% and output by 33%, aligning with the updated model GPT-4o-2024-08-06 available since August.
- NVIDIA's NVLM 1.0 Unveiled: NVLM 1.0 introduces open-sourced weights for vision-language tasks, positioning NVIDIA as a key competitor against proprietary models.
Theme 2. Seamless Integration: Bringing AI to Your Projects
- gpt4free Joins Chatbots: A member successfully integrated gpt4free into their chatbot, enhancing flexibility despite slower performance and frequent provider switches.
- Cloud Solutions for AMD GPU Challenges: Facing fine-tuning issues on Windows without CUDA, members recommend cloud platforms like Lambda Labs or Collab, ensuring effective training on AMD hardware.
- Shadeform's GPU Marketplace Streams: Shadeform offers a centralized billing and management system for reserving on-demand GPUs, simplifying multi-cloud deployment for developers.
Theme 3. Tackling Tech Troubles: Overcoming AI Training Hurdles
- Quantization Conundrums Solved: Developers explore quantization algorithms like int8 and HQQ to maintain <1% loss in large models (50B+ parameters), leveraging Hugging Face's guide for implementation.
- Mojo's Import Mysteries: Mojo faces challenges with Python's dynamic imports, prompting discussions on security risks and potential delegations to CPython.
- Flash Attention's Memory Mix-Up: The Flash Attention feature shows inconsistent memory behavior, with some users experiencing linear growth despite its quadratic computational complexity, as seen in llama.cpp Pull Request #5021.
Theme 4. Building Bridges: Engaging the AI Community
- AI Reading Groups Ignite Collaboration: Launching in multiple Discords, groups from Women in AI & Robotics feature presentations like INDUS by Aashka Trivedi from IBM and NASA, fostering direct dialogue and interdisciplinary discussions.
- Unsloth Webinars Share Insights: The Unsloth Webinar highlights shifts to lower precision bits for training speed and the integration of high-quality datasets, sparking deeper technical conversations.
- Festive AI House Parties: Events like the October House Party encourage members to showcase their Open Interpreter creations, blending fun with knowledge sharing and community bonding.
Theme 5. Powering Progress: Optimizing AI Tools and Infrastructure
- Torchtune 0.3.1 Boosts Fine-Tuning: The latest Torchtune 0.3.1 update includes all Llama 3.2 Vision models, introduces MPS beta support for Macbooks, and offers a new knowledge distillation recipe for models like Llama3.2 and Qwen2.
- LlamaIndex Enhances Hybrid Search: Integrating MongoDB Atlas with LlamaIndex allows for seamless hybrid search, combining semantic and full-text search to improve result relevance.
- Aider Expands with Real-time APIs: The launch of the GPT-4o Realtime API in Aider enables low-latency audio interactions for applications like customer support, enhancing conversational capabilities.
Links Mentioned: - FLUX1.1 Pro on Replicate - Artificial Analysis Image Arena - GPT-4o GitHub Release - Lambda Labs - Shadeform AI Marketplace - Hugging Face Quantization Guide - llama.cpp Pull Request #5021 - INDUS Paper - Unsloth Documentation - Aider Configuration Options - Torchtune Documentation - Torchtune GitHub Release - LlamaIndex with MongoDB Atlas
O1-preview
Theme 1. OpenAI's New Features and Strategic Moves
- OpenAI Launches Canvas, Revolutionizing Collaboration: OpenAI introduced the Canvas feature, allowing users to interact with ChatGPT beyond simple chats for writing and coding projects. Plus & Team users can try it now by selecting “GPT-4o with canvas” in the model picker.
- GPT-4o Prices Slashed Amid Model Update: OpenAI reduced the price of GPT-4o by 50% for input and 33% for output, aligning with the updated GPT-4o-2024-08-06 model available since August. This move makes advanced AI capabilities more accessible to users.
- Sam Altman Tightens Grip as OpenAI Eyes $157B Valuation: Reports reveal Sam Altman amplifying his influence at OpenAI during its rise toward a staggering $157 billion valuation. This concentration of leadership raises questions about the organization's future trajectory.
Theme 2. Innovations in AI Models and Tools
- FLUX1.1 Pro Blazes Ahead with Sixfold Speed Boost: The newly released FLUX1.1 Pro delivers six times faster generation, improved image quality, and holds the highest Elo score in the Artificial Analysis image arena. This model sets a new performance standard in image generation.
- NVIDIA Unveils NVLM 1.0, Challenging Proprietary Models: NVIDIA introduced NVLM 1.0, an open-source model designed for vision-language tasks, rivaling leading proprietary models in accuracy. Developers can access the weights and code, paving the way for new innovations.
- StackBlitz Drops Bolt for AI-Powered Fullstack Development: Bolt by StackBlitz allows users to prompt, edit, run, and deploy fullstack applications with AI support. It offers a free, comprehensive development environment supporting npm, Vite, and Next.js.
Theme 3. Challenges and Concerns with AI Model Limitations
- Moderation Madness: SFW Prompts Flagged by AI: Users report Claude 2.1 and other models erroneously flagging safe-for-work prompts as inappropriate, disrupting interactions. A character description was incorrectly marked as 'sexual', sparking debates over overzealous moderation practices.
- Softmax's Soft Spot: Limitations in Sharp Decisions: A paper reveals the softmax function's inability to approximate sharp functions as inputs increase, challenging its effectiveness in AI reasoning tasks. Authors suggest adaptive temperature as a potential remedy, prompting further research.
- GPU Woes: Running Big Models on Modest Hardware: Users grapple with difficulties running large models like SDXL on older GPUs, exploring alternatives like ZLUDA for AMD users. The community discusses strategies to balance performance with hardware limitations.
Theme 4. Community Engagement and Learning in AI
- AI Reading Group Bridges Research and Community: The AI Reading Group from Women in AI & Robotics launches, featuring Aashka Trivedi from IBM presenting joint research with NASA on October 17, 2024. The session will delve into INDUS: Effective and Efficient Language Models for Scientific Applications.
- DSPy 2.5 Gets Thumbs Up, Calls for More Docs: Users praise DSPy 2.5 for improvements like TypedPredictors but urge for better documentation on customization and integrating Pydantic. Enhanced guides could unlock advanced features for users.
- Fiery Debates Over Data Practices and Privacy: Members express concerns about data privacy, alleging that some AI firms focus on stealing data from mid-sized companies. The community debates the ethics and legality of data usage in AI development.
Theme 5. Technical Discussions on AI Model Optimization
- Quantization Quest: Balancing Size and Accuracy: Developers explore quantization algorithms like int8, HQQ, and int4 + HQQ for large models (50B+ parameters), aiming for less than 1% loss in target metrics. Techniques like HQQ offer efficiency with minimal calibration needed.
- Mojo Battles Python Imports and Error Handling Woes: The Mojo programming language struggles with Python's dynamic imports, complicating integration and error management. Community members debate adopting Zig-style error unions and other strategies to improve Mojo's robustness.
- Flash Attention Sparks Memory Usage Mystery: Users question whether Flash Attention results in linear memory growth despite quadratic computational complexity. Mixed experiences prompt discussions to clarify its actual impact on memory and performance.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Morning greetings lead to casual chat: Members exchanged morning greetings, leading to a light-hearted discussion about time differences, humorously noting that, 'if ur not in EST or PST ur missing out.'
- This relaxed atmosphere set the tone for further technical discussions.
- Debate over Jupyter Notebook vs VS Code: Members voiced their preferences on interfaces, with one expressing dissatisfaction with Jupyter Notebook, stating it felt outdated compared to VS Code.
- Another member countered, asserting that they preferred VS Code for its notebook support and overall usability.
- Concerns about Qwen model reliability: Discussion raised concerns regarding the reliability of Qwen models, with users reporting unexpected results from familiar configurations.
- The absence of models on the Unsloth page confused members, intensifying the discussion.
- Insights from the Unsloth Webinar: Key points highlighted in the Unsloth Webinar emphasized the shift to lower precision bits during training, aimed at improving speed.
- Members discussed the integration of high-quality datasets and enhanced model architecture for deeper learning.
- Challenges with Fine-tuning on AMD GPUs: A member questioned how to run Unsloth on Windows without CUDA support, sparking discussions about AMD's limitations in ML.
- Recommendations included using cloud solutions like Lambda Labs or Collab for effective training.
HuggingFace Discord
- Users Encounter Model Access Issues: Several users reported issues accessing models like Llama, facing timeouts and restrictions with Hugging Face platforms, impacting the usability of popular models.
- One user confirmed running Llama-3.2-1B on older hardware like a GeForce 980Ti, showcasing that even limited resources can still be sufficient.
- gpt4free Successfully Integrated: A member successfully integrated gpt4free into their chatbot, although experiencing slower performance and the need for frequent provider changes.
- This integration also included adding two OpenAI models, demonstrating adaptable development during their Release v1.3.0 on GitHub.
- FLUX1.1 Pro Impresses with Speed: FLUX1.1 Pro launched, providing six times faster generation and improved image quality, achieving the highest Elo score in the Artificial Analysis image arena.
- This model's performance sparked excitement and anticipation for further advancements in the AI community.
- AI Reading Group Launch Announced: The AI Reading Group from Women in AI & Robotics launches, with its inaugural session featuring a presentation from IBM about joint research with NASA on October 17, 2024.
- A member suggested streaming events on Discord and Eventbrite to broaden audience engagement, enhancing community involvement in AI research.
- Hugging Face Courses Recommended for Beginners: Members recommended Hugging Face courses and the Open Source AI Cookbook as essential resources for newcomers to NLP, emphasizing the importance of combining practical experience with foundational theory.
- Resources like 'The Illustrated Transformer' and 3blueonebrown were cited as helpful for understanding complex concepts in NLP.
aider (Paul Gauthier) Discord
- Aider Telemetry Data Collection Concerns: Users discussed that Aider currently lacks telemetry data collection, limiting insights into usage metrics and trends.
- Suggestions for future telemetry included monitoring model choices and tokens while ensuring privacy.
- Cursor vs Aider - Battle of Interfaces: Members compared Aider and Cursor, noting the smoother interface of Cursor, yet praising Aider's efficiency in terminal use.
- Dissatisfaction arose over Cursor's inconsistencies in its Composer feature, contrasting with Aider's reliability.
- Claude Development Sparks Interest: Interest in Claude Development grew among users for its promising coding assistance capabilities.
- Users eagerly awaited updates, eager to compare its potential improvements over current tools.
- Launch of GPT-4o Realtime API: The GPT-4o Realtime API was released for low-latency audio interactions aimed at applications like customer support.
- Integration requires handling end-user audio, enhancing conversational capabilities.
- Crawl4AI Enhances Data Collection: Crawl4AI is now available as an open-source LLM-friendly web crawler, offering developers customizable data collection tools.
- Its integration with language models could significantly improve operational data extraction processes.
OpenRouter (Alex Atallah) Discord
- DeepInfra Outage Duration Compromised: DeepInfra experienced an outage lasting about 15 minutes but is now recovering.
- Users were informed shortly after about the status and ongoing recovery efforts.
- GPT-4o Slashes Prices by Half: The price for the GPT-4o model drops 50% for input and 33% for output starting today.
- This adjustment aligns with the updated model GPT-4o-2024-08-06 that has been available since August.
- Moderation Confusion with Claude 2.1: Users raised concerns about Claude 2.1 flagging SFW prompts, which interferes with interactions.
- One flag-worthy instance involved a character description incorrectly marked as 'sexual', sparking debate over moderation practices.
- NVIDIA Unveils NVLM 1.0 Model: NVIDIA has announced its competitive NVLM 1.0, which offers open-sourced weights and code designed for vision-language tasks.
- This model is expected to enhance performance and accuracy, rivalling proprietary models in the space.
- Flash 8B Model Slowing Down Production: The Flash 8B model is now in production but registers 200 tokens per second, slower than previous versions.
- Discussions indicate potential speed upgrades might be considered in the future to address hardware efficiency.
Modular (Mojo 🔥) Discord
- Mojo struggles with Python imports: Discussions revealed that Mojo cannot natively handle Python's dynamic import behavior, complicating integration and error management.
- Members noted that delegating imports to CPython might introduce security risks similar to issues seen in the NPM ecosystem.
- Mojo functions encounter returned value issues: Members discovered that returning values from functions in Mojo sometimes requires a variable declaration (e.g., using
var) to avoid runtime errors.- An example was shared showing that
SIMDinitialization fails unless modified to return a mutable object.
- An example was shared showing that
- Exploring error handling strategies: Conversations focused on potential improvements to Mojo's error handling, with suggestions leaning towards Zig-style error unions for inferred error types.
- Some members advocated for a more functional programming approach to error management, emphasizing pattern matching and composability.
- Static data storage complexities: Users sought ways to statically store tables in Mojo without incurring excessive code bloat, especially from constructs like
List.- The emphasis was on matching the performance and memory efficiency seen in C static declarations.
- SIMD initialization issues spark GitHub discussions: A request was made to create a GitHub issue regarding the unexpected behavior of the
SIMD.__init__constructor, which returned errors under certain conditions.- Members expressed willingness to help track down the root cause of SIMD related bugs.
OpenAI Discord
- Canvas Feature Launches for Writing & Coding: OpenAI announced an early version of the canvas feature, allowing users to work on writing and coding projects that extend beyond simple chat interactions. Starting today, Plus & Team users can try it by selecting “GPT-4o with canvas” in the model picker.
- This enhancement aims to improve user experience in project management and collaboration, leveraging advanced AI capabilities for complex tasks.
- API Access tier confusion: Discussion emerged regarding API access being rolled out to specific usage tiers, with one user experiencing a 403 error despite previous access. The conversation highlighted the importance of approaching rate limit issues and handling errors effectively.
- Members shared insights on mitigating rate limits found in the OpenAI Cookbook, emphasizing community support for navigating these API challenges.
- Impressions of the new Copilot App: Users expressed positive feedback on the performance of the new Copilot App, noting its smooth usability as a native app on Android. However, concerns arose about the inability to delete chats, highlighting comparison points with other chatbots.
- Community discussions focused on user experience, comparing features and functionality, suggesting room for improvement.
- Voice Feature Now Available in Custom GPTs: A member celebrated the introduction of the voice feature in custom GPTs available in the GPT store today, appreciating OpenAI for resolving previous concerns. They noted that the voice mode is not the new advanced voice, which users hope will be included for all custom GPTs in the future.
- This enhancement reflects an ongoing request for richer interactive features in GPTs, indicating the community's desire for continuous improvement.
- Ninetails Training Data Flaw in 4o-mini: A user identified that 4o-mini consistently misidentifies Ninetails as having 6 tails when asked about fire-type Pokémon, while 4o provides the correct answer. This pattern across multiple regenerations suggests a flaw in the training data rather than typical hallucinations.
- The discrepancy was further investigated, revealing that smaller models like gpt-3.5-turbo and gpt-4o-mini display inaccurate responses, raising questions about their training datasets.
Stability.ai (Stable Diffusion) Discord
- Virtual Environments Are Key for Compatibility: Members recommended using virtual environments like venv or conda to avoid conflicts with Python versions when running tools like AUTOMATIC1111.
- Virtual environments streamline package management, ensuring different setups don’t disrupt workflows.
- Choosing the Right AI Model and UI: New users were encouraged to use Comfy UI for its flexibility, alongside mentions of Automatic1111 and the faster Forge UI fork.
- Comfy UI’s node-based design offers more versatility, while Automatic1111 is still popular for tutorials.
- Generating Images in Specific Poses: Users tackled challenges in generating images with specific poses and recommended the use of ControlNet for enhanced output control.
- Training specific models like LoRA helps adjust generated images to meet user expectations.
- Navigating AI Model Limitations: Discussions highlighted issues with running SDXL on older GPUs, suggesting alternatives like ZLUDA for AMD users.
- While lower resolutions can expedite processing, optimal results usually require higher resolutions suited for specific models.
- Experimenting with AI Model Training: A user shared their training experience that ended in complications, highlighting the consequences of improper image selection.
- This serves as a reminder on the importance of adhering to community standards when training AI models.
Nous Research AI Discord
- FLUX1.1 Pro Outpaces Competition: FLUX1.1 Pro was announced with six times faster generation and improved image quality compared to its predecessors, indicating a significant upgrade.
- Users can leverage this performance for more efficient workflows, as emphasized in the release announcement.
- Grok Usage Verification Required: Discussion emerged about the need for verification and payment to access Grok, leading to mixed opinions among members.
- It was clarified that some users can access the service without verification, though they still need to pay for it.
- Softmax Function's Limitations Explored: A paper highlighted limitations of the softmax function in achieving robust computations as input sizes increase, pointing to a theoretical proof of its shortcomings.
- The authors propose adaptive temperature as a potential workaround for these limitations.
- Searching for Uncensored Story-Creating LLMs: A user inquired about the best LLM for creating stories that is both uncensored and can be run as an API.
- They also sought sites that build stories using LLMs automatically without just providing standard help.
- Controlling Model Thought Process Revealed: Concerns were raised about the controls in place to prevent models from revealing their chain of thought, questioning their impact on self-explanation capabilities.
- This points to ongoing discussions about balancing transparency with security in AI interactions.
Perplexity AI Discord
- Audio Reading Feature Gets Mixed Reviews: Users discussed the potential for an audio reading feature, finding it helpful for consuming long responses but facing issues with pronunciation.
- One member indicated they frequently use this feature while multitasking, showcasing its perceived value.
- Frustrations with Subscription Customer Support: Several users voiced frustration due to subscription issues like downloading files and delayed responses from support regarding security concerns.
- One individual even contemplated cancelling their subscription, highlighting a significant impact on user retention.
- Inconsistency in Model Output Quality: Community discussions revealed concerns about the inconsistent quality of models, especially under the Collection or Pro package.
- Members noted extreme performance instability, raising doubts about the product's reliability.
- AI's Impact on Future Movies Explored: An article details AI's impact on filmmaking, suggesting technology will reshape storytelling and production processes, accessible here.
- The conversation pointed out emerging trends that could redefine audience engagement in cinema.
- OpenAI Secures Significant Funding: Reports reveal that OpenAI successfully raised $6.6 billion, which is expected to bolster their AI research projects; details found here.
- This funding is anticipated to significantly advance their technology and platform capabilities.
Cohere Discord
- OpenAI Bubble on the Brink: Members expressed concerns that the OpenAI bubble is expanding precariously, particularly after the release of o1, which temporarily soothed fears.
- This feels like WeWork all over again, as discussions highlighted uncertainties about OpenAI's long-term fate.
- Cohere's Low-Profile Strategy: Admiration for Cohere's strategy surfaced, with comments suggesting that it operates across the board while maintaining a grounded presence in the AI sphere.
- This cautious approach might offer Cohere a competitive edge in a landscape filled with visibility-seeking players.
- Shifting AGI Concepts: A belief emerged that the concept of AGI is set to evolve dramatically over the next two decades, igniting vigorous discussion among members.
- Such a shift could redefine both expectations and scope within the AI ecosystem, causing surprise among community members.
- Concerns Over Data Privacy: A member raised alarms about data privacy, alleging that some AI firms, including OpenAI, are focused on stealing data from mid-sized companies.
- The community debated this claim's validity, pointing out that companies have options to opt-out of data sharing practices.
- Reranking API hitting rate limit: Frustrations brewed over the reranking API, as a user reported hitting a rate limit while only making minimal API calls with 50 records.
- This issue raises questions about the constraints of the free tier, potentially hindering effective testing.
Interconnects (Nathan Lambert) Discord
- OpenAI Launches Canvas for Enhanced Collaboration: OpenAI's new Canvas interface allows users to engage more intuitively with ChatGPT for writing and coding projects, enhancing collaboration overall.
- Despite its benefits, limitations like lack of rendered frontend code and difficulty tracking code evolution have been highlighted by early users.
- Sam Altman's Growing Authority at OpenAI: An article reveals how Sam Altman has amplified his influence at OpenAI, coinciding with its soaring $157 billion valuation.
- This moment raises critical questions about the repercussions of concentrated leadership on the organization’s future trajectory.
- c.ai Faces Potential PR Crisis: Warnings surfaced about an impending PR disaster for c.ai, with members expressing their concerns about the company's reputation.
- The community shared a sense of disappointment in the ongoing situation, with sentiments echoing feelings of sadness and resignation.
- Exploring Shadeform's GPU Marketplace: Members discussed Shadeform, which offers a marketplace for reserving on-demand GPUs, enhancing multi-cloud deployment capabilities.
- Centralized billing and management features seem to streamline workload deployment, highlighting Shadeform’s efficiency.
- O1 Preview's Thought Process Revelation: A Reddit post revealed that O1 Preview accidentally disclosed its complete thought process, attracting significant attention in the chat.
- One member humorously suggested this could inspire a compelling blog post, illustrating the unexpected transparency within the tech community.
Latent Space Discord
- OpenAI launches ChatGPT Canvas: OpenAI introduced ChatGPT Canvas, a new interface for collaborative projects within ChatGPT that allows users to edit code and receive in-line feedback.
- Features include direct editing capabilities, task shortcuts, and improved research functionalities.
- StackBlitz debuts Bolt platform: StackBlitz launched Bolt, a platform for prompting, editing, running, and deploying fullstack applications with AI support.
- This development environment fully supports npm, Vite, and Next.js, providing a free toolset for app creation.
- Gartner recognizes AI engineering: Gartner has acknowledged Writer as an Emerging Leader for Generative AI Technologies, underscoring the significance of AI in enterprise solutions.
- This recognition highlights advancements in areas like Generative AI Engineering and AI Knowledge Management Apps.
- Google's Gemini AI competes with OpenAI: Google is developing a reasoning AI model known as Gemini AI, setting itself in competition against OpenAI's capabilities.
- This initiative builds on Google's legacy of advanced AI systems like AlphaGo, aiming for enhanced human-like reasoning abilities.
- Discussion on Reflection 70B Model: Sahil Chaudhary discussed challenges with the Reflection 70B model, particularly around benchmark reproducibility and output quality.
- Community members raised concerns regarding evaluation inconsistencies and the model's overall impact on AI.
LM Studio Discord
- Confusion Over LM Studio Setup: Debates on connecting LM Studio with Langflow revealed users' frustrations regarding the clarity over the OpenAI component's base URL.
- There were concerns about the grammaticality of message queries, indicating a need for improved documentation.
- Improved Outputs with LM Studio Update: Updating LM Studio from version 0.2.31 to 0.3.3 led to notable enhancements in model output despite unchanged settings.
- This sparked inquiries about the role of key-value caching in affecting output quality.
- Limitations in Managing Context: Users discussed the challenges of maintaining context across sessions in LM Studio's inherently stateless architecture.
- Participants emphasized the difficulties in providing persistent input without repetition.
- Flash Attention Sparks Controversy: The Flash Attention feature was discussed extensively, with frustrations over its unavailability on certain GPU models like GTX.
- A GitHub pull request was shared, showcasing significant speedups it can provide.
- Water Cooling for Optimal GPU Performance: A member is considering water cooling single slot blocks for a setup with 8 cards, drawn by their max power of 4000W.
- Current plans involve two 1600W and one 1500W power supplies to maintain ideal thermal conditions.
GPU MODE Discord
- Quantization Algorithms for Large Models: Members discussed suitable quantization algorithms for large neural networks (50B+ parameters) that maintain less than 1% loss in target metrics, highlighting techniques like int8 and HQQ.
- One member noted that int4 + hqq quantization is also effective, given it requires minimal calibration.
- Exploring BF16 Weights Impact on Accuracy: A member expressed concern about potentially sacrificing accuracy by training with BF16 weights instead of FP32 while utilizing 4090 VRAM.
- They believe it's viable to use FP32 for weights while keeping the optimizer as BF16 within their current configuration.
- Understanding Metal Programming Basics: A newcomer grasped that while CUDA uses
block_size * grid_sizefor thread dispatch, Metal just involves the grid size for simpler thread management.- They highlighted that threadgroups in Metal are designed for shared memory among grids.
- Longer Project Lifespan is Helpful: A member stated that having a longer duration for projects aids progression, especially since it often takes time to gain momentum.
- They underscored the importance of retaining ample hours for completion.
- Inquiry on Self-Compressing Neural Networks Implementation: A member inquired about Issue #658 on GitHub, regarding Self-Compressing Neural Networks, focusing on dynamic quantization-aware training.
- They aim to implement it as an option during training to let users select a specific VRAM budget.
Eleuther Discord
- Exploring Liability in AI Research: Discussion centered on whether individuals who share AI models for research could be held liable if others misuse them, with some suggesting liability may not attach to the original researcher.
- Members noted that a clear ruling may be necessary to establish guidelines, emphasizing the need for clarity in these legal waters.
- Litigation on Scraping Raises Concerns: Concerns were raised over ongoing litigation regarding the legal status of web scraping, with artists and writers expressing frustration about the practice.
- An example case was cited, where companies unsuccessfully tried to prohibit scraping unless strict conditions were met, highlighting legal complexities.
- The Impact of OpenAI's Moderation Policies: A member recounted their experience with OpenAI's moderation policy, which flagged their request to prompt AGI, leading to unsettling moments over perceived violations.
- Others agreed that these policies appear overly cautious, suggesting many flagged messages do not align with the stated usage policies.
- Opportunities for Creative AI Projects: A new member introduced themselves as a researcher seeking collaborative projects on commons-based approaches within AI, highlighting potential interdisciplinary research.
- This became a call for engagement, especially for contributions in digital humanities.
- MMLU Scoring Resources Shared: A member inquired about obtaining MMLU scores for new models, leading to the recommendation of the evaluation harness by EleutherAI.
- They also mentioned a dedicated channel for further discussion on the topic, promoting collaborative learning.
DSPy Discord
- DSPy 2.5 Feedback Rolls In: Users report an overall pleasing experience with DSPy 2.5, noting the positive changes with TypedPredictors but calling for more customization documentation.
- The feedback emphasizes that while updates are promising, more guidance could enhance the usability for advanced features.
- Documentation Gets a Makeover Demand: Community voices demand improvements in DSPy documentation, especially regarding the integration of Pydantic and multiple LMs.
- Members stressed the importance of user-friendly guides to tackle complex generation tasks, which could help onboard new users effectively.
- AI Arxiv Podcast Intro: The new AI Arxiv podcast highlights how big tech implements LLMs, aiming to provide valuable insights for practitioners in the field.
- Listeners were directed to an episode on document retrieval with Vision Language Models, with future plans to upload content to YouTube for accessibility.
- Must-Have LLM Resource Suggestions: In search of resources, a member prompted suggestions for AI/LLM-related news, pointing to platforms like Twitter and relevant subreddits.
- Responses included a curated Twitter list focusing on essential discussions and updates in the LLM space, enhancing knowledge sharing.
- Optimizing DSPy Prompt Pipelines: Discussion arose around the self-improvement aspect of DSPy prompt pipelines compared to conventional LLM training methods.
- Papers on optimizing strategies for multi-stage language model programs were recommended, delving into the advantages of fine-tuning and prompt strategies.
Torchtune Discord
- Torchtune 0.3.1 Launches with Key Enhancements: The Torchtune 0.3.1 update includes all Llama 3.2 Vision models, enhancing multimodal support for fine-tuning, generation, and evaluation.
- Key improvements feature fine-tuning Llama 3.1 405B using QLoRA on 8 x A100s, optimizing performance options dramatically.
- Tokenizer Auto Truncation Causes Data Loss: The text completion dataset experiences automatic truncation at max_seq_len, resulting in token loss from larger documents, leading to requests for increased user control.
- Proposals surfaced to separate packing max_seq_len from tokenizer limits to minimize unnecessary truncation.
- Knowledge Distillation Recipe Now Available: A new knowledge distillation recipe is added for configurations like Llama3.2 and Qwen2, enhancing user toolkit options.
- Members are prompted to utilize these features to boost model efficiency and performance.
- Concern Over Flash Attention Memory Allocation: Discussions arose regarding whether Flash Attention exhibits linear memory growth, in contrast to its quadratic computational complexity, creating a variance in expected memory usage.
- Participants noted mixed experiences with memory consumption, conflicting assessments about its actual behavior.
- Push for Better HF Dataset References: A proposed mapping system like DATASET_TO_SOURCE aims to streamline access to HF dataset names, facilitating clearer model card generation.
- Focus remains on enhancing dataset documentation clarity in YAML format, reflecting an effort to streamline project capabilities.
LlamaIndex Discord
- MongoDB Atlas Powers Hybrid Search: A recent post teaches how to create and configure MongoDB Atlas vector and full-text search indexes to facilitate hybrid search implementation, merging semantic with full-text search.
- This method notably enhances the relevance of search results, addressing common search inefficiencies.
- Box Integration for Smarter Apps: A guide introduces integrating Box tools with LlamaIndex to develop AI-driven content management applications.
- This enables advanced searches, optimizing information extraction and processing directly from Box content.
- Challenges in RAG System Setup: Users reported encountering a
ModuleNotFoundErrorwith a tutorial on building a RAG system using Excel, hinting at pandas version conflicts.- A user recommended reverting to an older pandas version (2.2.2 or lower) to potentially fix the compatibility issue, shared in the GitHub example.
- Async Conversion Queries in RAG Implementation: A developer is navigating the conversion of a RAG app to async and questions the async compatibility of
QueryEngineTooland the role ofRouterQueryEngine.- Responses clarified how to implement async methods within the
RouterQueryEngine, providing a smoother transition into async processing.
- Responses clarified how to implement async methods within the
- Generating RFP Responses with LlamaIndex: A developer seeks guidance on leveraging LlamaIndex to generate RFP responses using data from winning proposals, focusing on efficient indexing strategies.
- They expressed interest in LlamaIndex's capability to produce PDFs or Word documents from generated responses.
LangChain AI Discord
- Jordan Pfost Brings a Decade of AI Experience: Jordan Pfost introduced himself as a Sr. Fullstack Engineer with 10 years of experience in AI/Web products, focusing on GPU Clustering, RAG, and Agentic Reasoning.
- Looking to collaborate, he shared insights from his projects like spendeffect.ai and iplan.ai.
- Kapa.ai's Impressive Capabilities: Kapa.ai showcased itself as a transformer-based model boasting around 340 million parameters, designed for natural language tasks.
- It also mentioned its training on diverse data, ensuring the generation of human-like quality text, while referring members to LangChain documentation for further exploration.
- Decoding Like and Reward in LLMs: Kapa.ai clarified that LLMs operate based on patterns from training data and do not possess personal preferences or rewards.
- They referenced a paper on preference optimization and pointed out more insights available in LangChain documentation.
- Connecting Students to AI Internships: A member opened the floor for college students from India seeking internships in AI, encouraging them to express their interest.
- This discussion aims to bridge students with potential AI internship opportunities.
- LangGraph Innovates Query Generation: A LinkedIn post highlighted how LangGraph manages complex query generation within the LangChain ecosystem.
- Focusing on error correction and user-friendly results, the post acknowledged contributions from Harrison Chase and the LangChain team.
OpenInterpreter Discord
- October House Party Happening Tomorrow: Don't forget the October House Party tomorrow – join here for fun and updates.
- One member expressed they are not missing this one due to previous health and work constraints.
- Showcase Your Open Interpreter Creations: The host invited members to showcase their work using Open Interpreter during the party, encouraging questions and experience sharing.
- This prompted mixed responses on timing, with some members feeling it’s too early while others excitedly declared, PARTY TIMEEEE.
- Exploring Skill Teaching in Models: Members discussed how to effectively teach skills to their model, emphasizing clarity in intent to enable successful teaching.
- Despite attempts, unresolved issues prompted suggestions for additional support moving forward.
- Model Vision Capabilities Confusion: The conversation turned to whether skills come with vision capabilities, contingent on the specific model used.
- A user noted using gpt4o with Cartesia and Deepgram, with discussions concluding it should theoretically work.
- Issues with OpenAI Requests: A user reported that OpenAI requests fail after a few messages, with no accompanying errors or logs.
- The situation illustrates potential system issues, leading to recommendations for a new post on troubleshooting.
OpenAccess AI Collective (axolotl) Discord
- Logo change sparks mixed reactions: Members reacted to the recent logo change with a mix of emojis from confusion to frustration, indicating varying levels of acceptance.
- One member humorously noted, 'I thought I lost the server from my list 😅.'
- Funding expectations questioned: One member humorously expected the new logo to correlate with raising $10 million at a $1 billion valuation.
- Another user responded, 'Sheeesh,' indicating disbelief at the ambitious targets.
- Demo experiences shared: A member shared their experience with the demo, stating, 'It’s not bad I used it through the demo,' suggesting positive interaction.
- The ongoing conversation indicates that members are still getting accustomed to the changes.
- Fine-tuning discussions in progress: Members raised questions about whether the model was fine-tuned yet, confirming it has not been fine-tuned as of now.
- One member reassured that fine-tuning will happen soon and highlighted plans to deploy a 70 billion parameter model once ready.
LAION Discord
- Regex rules dramatically curb spam: A member shared a regex pattern
\[[^\]]+\]\(https?:\/\/[^)\s]+\)that effectively blocks markdown link obfuscation, reducing the presence of spam bots.- Custom regex and word blocklists targeting specific spam categories have shown to significantly diminish unwanted bot activity.
- 60s timeout strategy keeps spam at bay: Implementing a 60-second timeout post-message blocking effectively pushes spam bots to exit after a few attempts.
- This tactic helps maintain the user experience by minimizing interruptions for legitimate users.
- Google's Illuminate: the new AI tool on the block: A spotlight on Google's Illuminate tool suggests it might be a game-changer for researchers looking for AI-generated audio summaries of complex content.
- Members are keen to compare its functionality against the notebooklm podcast tool, highlighting a strong interest in both innovations.
- Arxflix brings Arxiv papers to YouTube: Check out Arxflix, an automated YouTube channel dedicated to turning Arxiv papers into engaging video content.
- The creator expressed excitement over the project, suggesting it provides a dynamic alternative to traditional academic tools.
tinygrad (George Hotz) Discord
- Tinybox Delivery Timeline Under Scrutiny: A user raised concerns about the delivery timeline for a tinybox within the USA, specifically inquiring if it could arrive in 2-5 days.
- George Hotz responded that users should e-mail support@tinygrad.org for logistical questions, highlighting the importance of crafting clear inquiries.
- FAQ Must Include Support Email: A suggestion was made to incorporate the support email into the website FAQ, which is currently missing.
- George agreed to add it promptly, demonstrating attentiveness to community input.
- Geographic Concerns in Delivery Queries: George questioned the significance of delivery location limitations, mentioning specific areas like San Diego, Michigan, or Hawaii.
- He emphasized the necessity for clear question formulation, directing users to channel #1068979651336216706 for assistance.
- User Agreement Clarity with Click-Through: George proposed the idea of a click-through agreement for users to acknowledge reading the questions document, potentially utilizing multiple-choice questions.
- Another member pointed out that a click-through confirmation already exists, indicating existing measures for user acknowledgment.
- Community Culture Needs Improvement: George expressed frustration over the community's approach to questioning, noting it as a recurring challenge.
- He called for a shift towards prioritizing clear communication and proper inquiry practices.
LLM Agents (Berkeley MOOC) Discord
- Enhancing Inference Timings with RAG: A member inquired about optimizing inference timings for SLM-based systems deploying RAG architecture with Llama Index, seeking community insights.
- The request highlights an ongoing challenge; performance optimization remains a hot topic for developers focused on efficiency.
- AI Reading Group Kicks Off: The AI Reading Group from Women in AI & Robotics launches to discuss AI papers, starting with Aashka Trivedi from IBM discussing their collaboration with NASA.
- Limited sign-ups for audience Q&A emphasize the group's interactive approach, fostering closer ties between researchers and the community.
- MARK YOUR CALENDARS: INDUS Paper Presentation: Join the AI Reading Group on October 17, 2024, at 12pm EST for a presentation on INDUS: Effective and Efficient Language Models for Scientific Applications led by Aashka Trivedi.
- This session promises insights into notable advancements in language models applicable to scientific tasks, featuring key contributions from IBM and NASA.
- INDUS Paper Highlights Collaboration: The INDUS paper, co-authored by IBM Research AI, NASA, and others, showcases advances in language models for scientific applications.
- This initiative seeks to enhance widespread understanding of current innovations while encouraging interdisciplinary knowledge sharing.
Alignment Lab AI Discord
- AI Reading Group Launches with Research Focus: The AI Reading Group from Women in AI & Robotics kicked off, fostering a platform for researchers to discuss AI papers followed by an engaging Q&A session.
- This initiative enhances direct dialogue between researchers and the community, spotlighting the latest advancements in AI.
- INDUS Research Presentation Scheduled: Aashka Trivedi from IBM will present 'INDUS: Effective and Efficient Language Models for Scientific Applications' on October 17, 2024, focusing on its potential in scientific contexts.
- Contributing authors hail from IBM Research, NASA, and Harvard-Smithsonian CfA, indicating a high level of expertise in the research presented.
- Reading Group Participation is Limited: Interested participants need to sign up quickly due to limited attendance, aimed at ensuring meaningful audience engagement.
- This strategy supports richer interactions during the Q&A after each presentation.
- Highlighting Interdisciplinary AI Discussions: The group offers a venue to spotlight current research topics and encourage discussions that cross traditional disciplinary boundaries.
- Interdisciplinary engagement ensures a deeper dive into the complexities surrounding the field of AI.
Gorilla LLM (Berkeley Function Calling) Discord
- Modify Code to Support Third-party Datasets: The current implementation of Gorilla LLM does not natively support third-party datasets, but a member suggested modifying the code to enable this functionality.
- Adjustments would involve adding a model handler for parsing logic, altering the test file mapping, and choosing suitable checkers.
- Implementing Dataset Parsing Logic: For integrating a new dataset, one member explained the necessity to implement the parsing logic using
decode_astanddecode_exec.- This adaptation requires a solid grasp of the pipeline's dataset processing to ensure everything remains compatible.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!