[AINews] BitNet was a lie?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Scaling Laws for Precision (Quantization) are all you need.
AI News for 11/11/2024-11/12/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (217 channels, and 2286 messages) for you. Estimated reading time saved (at 200wpm): 281 minutes. You can now tag @smol_ai for AINews discussions!
In a growing literature of post-Chinchilla papers, the enthusiasm for quantization reached its zenith this summer with the BitNet paper (our coverage here) proposing as severe a quantization schema as ternary (-1, 0, 1) aka 1.58 bits. A group of grad students under Chris Re has now modified Chinchilla scaling laws for quantization over 465+ pretraining runs and found that the benefits level off at FP6.
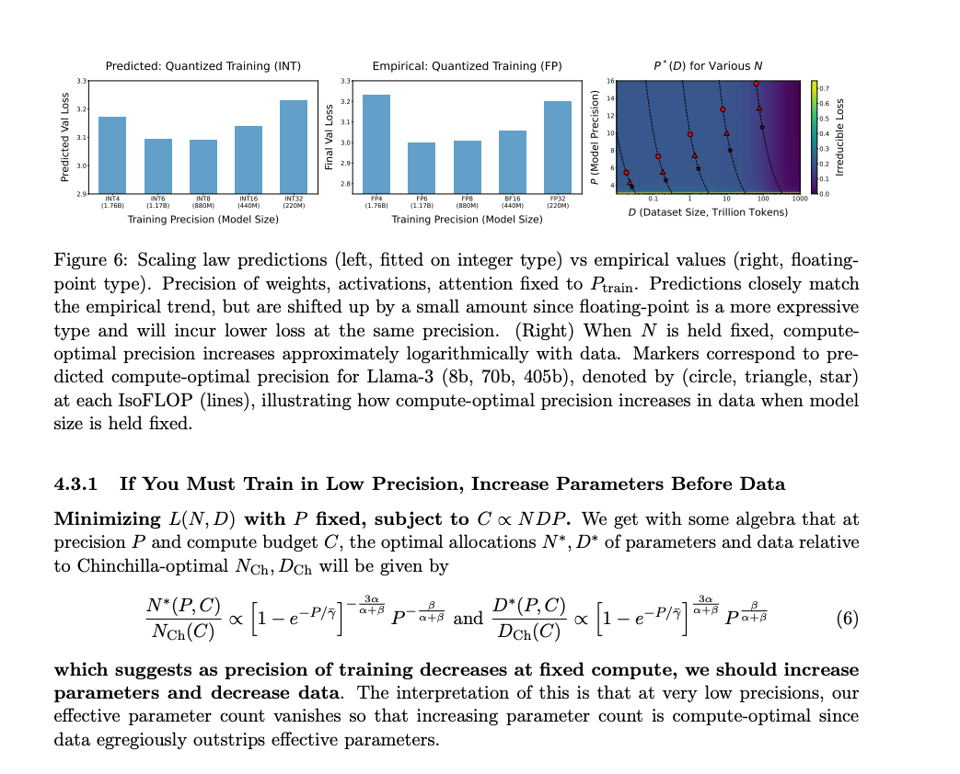
Lead author Tanishq Kumar notes:
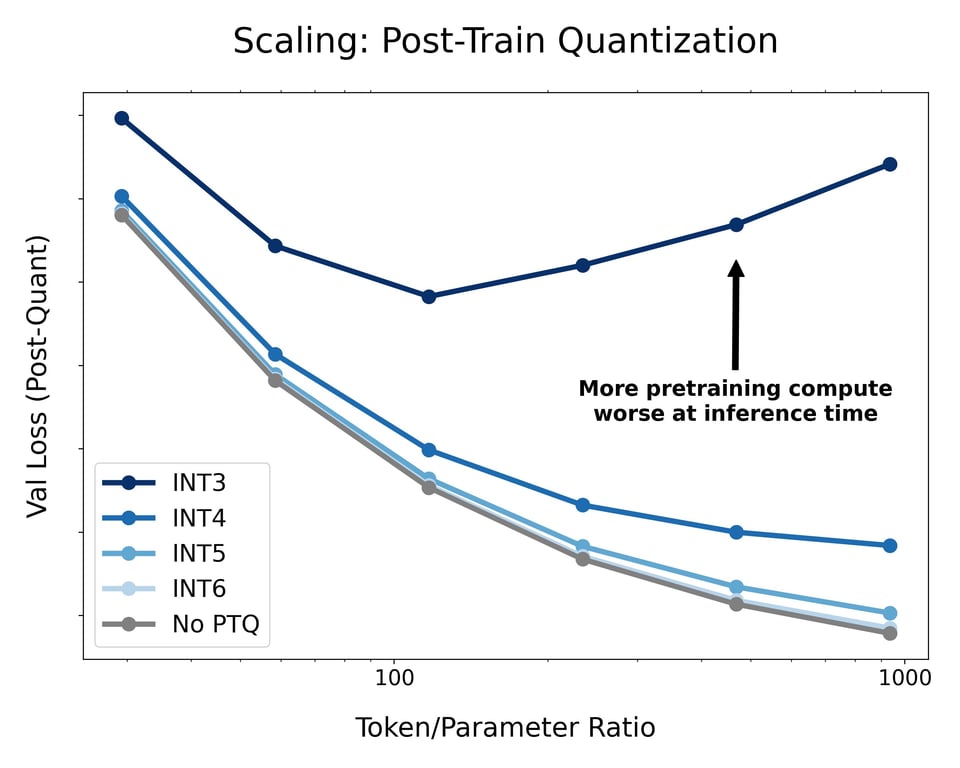
- the longer you train/the more data seen during pretraining, the more sensitive the model becomes to quantization at inference-time, explaining why Llama-3 may be harder to quantize.
- In fact, this loss degradation is roughly a power law in the token/parameter ratio seen during pretraining, so that you can predict in advance the critical data size beyond which pretraining on more data is actively harmful if you're serving a quantized model.
- The intuition might be that as more knowledge is compressed into weights as you train on more data, a given perturbation will damage performance more.
Below is a fixed language model overtrained significantly to various data budgets up to 30B tokens, then post-train quantized afterwards. This demonstrates how more pretraining FLOPs do not always lead to better models served in production.
QLoRA author Tim Dettmers notes the end of the quantized scaling "free lunch" even more starkly: "Arguably, most progress in AI came from improvements in computational capabilities, which mainly relied on low-precision for acceleration (32-> 16 -> 8 bit). This is now coming to an end. Together with physical limitations, this creates the perfect storm for the end of scale. From my own experience (a lot of failed research), you cannot cheat efficiency. If quantization fails, then also sparsification fails, and other efficiency mechanisms too. If this is true, we are close to optimal now. With this, there are only three ways forward that I see... All of this means that the paradigm will soon shift from scaling to "what can we do with what we have". I think the paradigm of "how do we help people be more productive with AI" is the best mindset forward.
[Sponsored by SambaNova] Take a few hours this week to build an AI agent in SambaNova’s Lightning Fast AI Hackathon! They’re giving out $10,000 in total prizes to the fastest, slickest and most creative agents. The competition ends November 22 - get building now!
Swyx commentary: $10k for an ONLINE hackathon is great money for building that fast AI Agent that you've been wanting!
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Eleuther Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- aider (Paul Gauthier) Discord
- Interconnects (Nathan Lambert) Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- tinygrad (George Hotz) Discord
- Notebook LM Discord Discord
- Latent Space Discord
- GPU MODE Discord
- Cohere Discord
- HuggingFace Discord
- LlamaIndex Discord
- LAION Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LLM Agents (Berkeley MOOC) Discord
- OpenAccess AI Collective (axolotl) Discord
- DSPy Discord
- OpenInterpreter Discord
- Torchtune Discord
- AI21 Labs (Jamba) Discord
- PART 2: Detailed by-Channel summaries and links
- Eleuther ▷ #general (35 messages🔥):
- Eleuther ▷ #research (271 messages🔥🔥):
- Eleuther ▷ #scaling-laws (10 messages🔥):
- Eleuther ▷ #lm-thunderdome (5 messages):
- Perplexity AI ▷ #general (230 messages🔥🔥):
- Perplexity AI ▷ #sharing (12 messages🔥):
- Perplexity AI ▷ #pplx-api (3 messages):
- Unsloth AI (Daniel Han) ▷ #general (135 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (27 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (49 messages🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
- Unsloth AI (Daniel Han) ▷ #research (14 messages🔥):
- aider (Paul Gauthier) ▷ #general (155 messages🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (49 messages🔥):
- aider (Paul Gauthier) ▷ #links (2 messages):
- Interconnects (Nathan Lambert) ▷ #news (62 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (7 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Interconnects (Nathan Lambert) ▷ #nlp (5 messages):
- Interconnects (Nathan Lambert) ▷ #reads (62 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (8 messages🔥):
- OpenRouter (Alex Atallah) ▷ #general (107 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (6 messages):
- OpenAI ▷ #ai-discussions (50 messages🔥):
- OpenAI ▷ #gpt-4-discussions (10 messages🔥):
- OpenAI ▷ #prompt-engineering (21 messages🔥):
- OpenAI ▷ #api-discussions (21 messages🔥):
- Modular (Mojo 🔥) ▷ #general (41 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (58 messages🔥🔥):
- tinygrad (George Hotz) ▷ #general (77 messages🔥🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
- Notebook LM Discord ▷ #use-cases (34 messages🔥):
- Notebook LM Discord ▷ #general (40 messages🔥):
- Latent Space ▷ #ai-general-chat (51 messages🔥):
- Latent Space ▷ #ai-announcements (3 messages):
- GPU MODE ▷ #general (14 messages🔥):
- GPU MODE ▷ #triton (3 messages):
- GPU MODE ▷ #cool-links (2 messages):
- GPU MODE ▷ #beginner (1 messages):
- GPU MODE ▷ #off-topic (9 messages🔥):
- GPU MODE ▷ #triton-puzzles (3 messages):
- GPU MODE ▷ #liger-kernel (3 messages):
- GPU MODE ▷ #self-promotion (1 messages):
- GPU MODE ▷ #🍿 (5 messages):
- Cohere ▷ #discussions (22 messages🔥):
- Cohere ▷ #announcements (1 messages):
- Cohere ▷ #questions (3 messages):
- Cohere ▷ #api-discussions (9 messages🔥):
- Cohere ▷ #projects (2 messages):
- Cohere ▷ #cohere-toolkit (2 messages):
- HuggingFace ▷ #cool-finds (4 messages):
- HuggingFace ▷ #i-made-this (12 messages🔥):
- HuggingFace ▷ #reading-group (2 messages):
- HuggingFace ▷ #NLP (5 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (12 messages🔥):
- LAION ▷ #general (4 messages):
- LAION ▷ #research (7 messages):
- Gorilla LLM (Berkeley Function Calling) ▷ #discussion (11 messages🔥):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- DSPy ▷ #general (7 messages):
- OpenInterpreter ▷ #general (3 messages):
- Torchtune ▷ #general (1 messages):
- AI21 Labs (Jamba) ▷ #general-chat (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Models and Tools
- Qwen 2.5-Coder-32B-Instruct Performance: @Alibaba_Qwen announced Qwen 2.5-Coder-32B-Instruct, which matches or surpasses GPT-4o on multiple coding benchmarks. Early testers reported it as "indistinguishable from o1-preview results" (@hrishioa) and noted its competitive performance in code generation and reasoning.
- Open Source LLM Initiatives: @reach_vb emphasized that intelligence is becoming too cheap to meter with open-source models like Qwen2.5-Coder, highlighting their availability on platforms like Hugging Face. Additionally, @llama_index introduced DeepEval, an open-source library for unit testing LLM-powered applications, integrating with Pytest for CI/CD pipelines.
- AI Infrastructure and Optimization: @Tim_Dettmers discussed the limitations of quantization in AI models, stating that we are reaching the optimal efficiency. He outlined three paths forward: scaling data centers, scaling through dynamics, and knowledge distillation.
- Developer Tools and Automation: @tom_doerr shared multiple tools such as Composio, allowing natural language commands to run actions, and Flyscrape, a command-line web scraping tool. @svpino introduced DeepEval for benchmarking LLM applications, emphasizing its integration with Pytest and support for over 14 metrics.
- AI Research and Benchmarks: @fchollet compared program synthesis with test-time fine-tuning, highlighting their different approaches to function reuse. @samyaksharma shared insights on agentic AI systems, focusing on productivity enhancement rather than mere technological advancement.
AI Governance and Ethics
- AI Safety and Policy: @nearcyan reflected on the impact of AI on programming automation, expressing disappointment over lack of innovation in interfaces. @RichardMCNgo discussed the integration of AI safety into government plans, questioning whether these plans will be effective or harmful.
- AI Alignment and Regulation: @latticeflowai introduced COMPL-AI, a framework to evaluate LLMs’ alignment with the EU’s AI Act. @DeepLearningAI also highlighted efforts in AI governance, emphasizing the importance of regulatory compliance.
AI Applications
- Generative AI in Media and Content Creation: @skirano launched generative ads on @everartai, enabling the creation of ad-format images compatible with platforms like Instagram and Facebook. @runwayml provided tips on camera placement in Runway's tools, emphasizing how camera angles influence storytelling.
- AI in Data Engineering and Analysis: @llama_index showcased PureML, which automatically cleans and refactors ML datasets using LLMs, enhancing data consistency and feature creation. @LangChainAI introduced tools for chunking data for RAG applications and identifying agent failures, improving data retrieval and agent reliability.
- AI in Healthcare and Biological Systems: @mustafasuleyman shared work on AI2BMD, which aims to understand biological systems and design new biomaterials and drugs through AI-driven analysis.
Developer Infrastructure and Tools
- Bug Tracking and Error Monitoring: @svpino presented tools like Jam, a browser extension for detailed bug reporting, claiming it can reduce bug fixing time by over 70%. @tom_doerr introduced error tracking and performance monitoring tools tailored for developers.
- Code Generation and Testing: @jamdotdev collaborated on bug reporting tools, while @svpino emphasized the importance of unit testing LLM-powered applications using DeepEval.
- API Clients and Development Frameworks: @tom_doerr introduced a desktop API client for managing REST, GraphQL, and gRPC requests, enhancing developer productivity. Additionally, tools like Composio enable natural language-based actions, streamlining workflow automation.
AI Research and Insights
- LLM Training and Optimization: @Tim_Dettmers discussed the end of scaling data centers and the limits of quantization, suggesting that future advancements may rely more on knowledge distillation and model dynamics.
- AI Collaboration and Productivity: @karpathy mused about a parallel universe where IRC became the dominant protocol, emphasizing the shift towards real-time conversation with AI for information exchange.
- AI in Education and Learning: @DeepLearningAI promoted their Data Engineering certificate, featuring simulated conversations to demonstrate stakeholder requirement gathering in data engineering.
Memes and Humor
- AI and Technology Jokes: @JonathanRoss321 humorously suggested adding a fourth law to Asimov's laws, stating that robots cannot allow humans to believe they are human. @giffmana shared frustrations with ASPX websites, expressing a humorous complaint about outdated technologies.
- Light-Hearted AI Remarks: @Sama joked about AI taking over one's life with LLM automation. @Transfornix playfully referred to rotmaxers being scared of a "real one".
- Humorous Interactions and Reactions: @richardMCNgo expressed a metaphorical reflection on culture and history with a touch of humor. @lhiyasut made a witty remark about the meaning of "ai" in different languages.
Community and Events
- AI Conferences and Meetups: @c_valenzuelab announced the opening of an office in London and listed numerous community meetups around the world, including Toronto, Los Angeles, Shanghai, and more, fostering a global AI community.
- Podcasts and Discussions: @GoogleDeepMind promoted their podcast featuring AI experts, discussing the future of AI assistants and the ethical challenges they pose. @omaarsar0 engaged in discussions with AI thought leaders like @lexfridman and @DarioAmodei.
- Educational Content and Workshops: @lmarena_ai encouraged involvement in their OSS fellowship, while @shuyanzhxyc invited individuals to join their lab at Duke focused on agentic AI systems.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Qwen2.5-Coder 32B Release: Community Reception and Technical Breakdown
- New Qwen Models On The Aider Leaderboard!!! (Score: 648, Comments: 153): New Qwen Models have been added to the Aider Leaderboard, indicating advancements in AI model performance and possibly new benchmarks in the field.
- Discussion highlights the Qwen2.5-Coder models on Hugging Face, with users comparing their performance to other models like GPT-4o and expressing interest in their capability for coding tasks. The 32B version is noted as being particularly strong, with some users finding it superior to GPT-4o in specific tasks.
- There are technical considerations around running these models locally, with discussions on necessary PC specifications and quantization techniques to efficiently handle model sizes like 32B and 72B. Users discuss the benefits of multi-shot inferencing and the need for high memory bandwidth to achieve practical token generation speeds.
- The conversation also touches on model licensing and the open-source community's response to these releases, with some models following the Apache License and others sparking discussions on accessibility and community-driven development. Users are excited about the models' potential, especially in self-hosted environments, and the improvements made from previous versions.
- Qwen/Qwen2.5-Coder-32B-Instruct · Hugging Face (Score: 486, Comments: 134): Qwen/Qwen2.5-Coder-32B-Instruct has been released on Hugging Face, sparking discussions about its capabilities and potential applications. The focus is on its technical specifications and performance in various coding and instructive tasks.
- Discussions highlight the performance and efficiency of the Qwen2.5-Coder-32B-Instruct model, with some users noting its impressive results despite potentially having less computational resources compared to other models. The 14B version is mentioned as being nearly as effective and more accessible for users with standard hardware configurations.
- Users discuss the technical requirements and performance benchmarks for running these models, emphasizing the need for significant RAM and VRAM, with suggestions to use smaller models or quantized versions like the 14B or 7B for those with limited resources. Specific benchmarks and performance metrics such as token evaluation rates are shared to illustrate the model's capabilities.
- Links to resources such as the Qwen2.5-Coder-32B-Instruct-GGUF and a blog post provide additional context and information. Users also discuss the availability of OpenVINO conversions and the implications of model quantization on performance and usability.
- My test prompt that only the og GPT-4 ever got right. No model after that ever worked, until Qwen-Coder-32B. Running the Q4_K_M on an RTX 4090, it got it first try. (Score: 327, Comments: 108): Qwen-Coder-32B successfully handled a complex test prompt on the first attempt, a feat only achieved previously by the original GPT-4. The test was conducted using Q4_K_M on an RTX 4090 GPU.
- Platform and Configuration: The platform and configuration significantly impact model performance, with variations noted between platforms like VLLM and Llama.cpp. Temperature settings and custom UI setups also influence output, as discussed by LocoMod in their personalized implementation using HTMX for dynamic UI modification.
- Model Performance and Comparison: The Qwen-Coder-32B model shows promising results, outperforming smaller models like the 7B, which often fail complex prompts. Users noted the 32B's ability to handle diverse coding languages, while others reminisced about the original GPT-4's superior performance before its capabilities were reduced.
- Technical Specifications and Benchmarks: Benchmarks for the RTX 4090 showed 41 tokens/second using specific configurations, highlighting the importance of hardware in achieving efficient performance. Users shared their setups, including dual 3090s and dual P40s, achieving 22 tokens/second and 7 tokens/second respectively, illustrating the variability in performance based on hardware and configuration.
Theme 2. ExllamaV2 Introduces Vision Model Support with Pixtral
- ExllamaV2 ships Pixtral support with v0.2.4 (Score: 29, Comments: 2): ExllamaV2 has released v0.2.4 with support for the vision model Pixtral, marking its first venture into vision model support. Turboderp suggests future expansions for multimodal capabilities, potentially allowing integration of models like Qwen2.5 32B Coder with vision features from Qwen2 VL, enhancing the appeal of open-source models. For more details, refer to the release notes and related API support discussions on GitHub.
- Qwen2.5-Coder Series: Powerful, Diverse, Practical. (Score: 58, Comments: 8): Qwen2.5-Coder 32B is speculated to be a multi-modal AI model that is both powerful and practical, suggesting potential advancements in diverse applications. The lack of a post body leaves specific details and features of the model unconfirmed.
- The Tongyi official website promises a code mode that supports one-click generation for websites and visual applications, but it has not launched yet, despite previous announcements. Users report that while the model can generate code, such as for a HTML snake game, it fails to render the output.
Theme 3. Exploring Binary Vector Embeddings: Speed vs. Compression
- Binary vector embeddings are so cool (Score: 314, Comments: 20): Binary vector embeddings achieve over 95% retrieval accuracy while providing 32x compression and approximately 25x retrieval speedup, making them highly efficient for data-intensive applications. More details can be found in the blog post.
- Binary Vector Embeddings are gaining attention for their efficiency and speed, with implementations being simplified through tools like Numpy's bitwise_count() for fast CPU execution. The discussion highlights the ease of implementing binary quantization using simple operations like xor + popcnt on cheap CPUs.
- Model Training and Compatibility are critical for effective binary quantization, with models like MixedBread and Nomic being specifically trained for compression-friendly operations. This approach is supported by Cohere's documentation, which emphasizes the need for models to perform well across different compression formats, including int8 and binary.
- The Trade-offs in Compression are significant, as users report unpredictable losses depending on bit diversity, as discussed by pgVector's maintainer. The complexity of measuring these losses suggests a need for careful evaluation to determine if a data pipeline is suitable for binary quantization.
- Is this the Golden Age of Open AI- SD 3.5, Mochi, Flux, Qwen 2.5/Coder, LLama 3.1/2, Qwen2-VL, F5-TTS, MeloTTS, Whisper, etc. (Score: 74, Comments: 28): The post discusses the significant advances in open-source AI models, highlighting the recent releases such as Qwen 2.5/Coder, LLama 3.1/2, and SD 3.5. It emphasizes the narrowing gap between open and closed AI models, citing the affordability of inference services at approximately $0.2 per million tokens and the potential of specialized hardware providers like Groq and Cerebras. The author suggests that open-source models are currently outperforming closed models, with a bright future anticipated despite potential regulatory challenges.
- Hardware Requirements and Performance: Users discuss the performance of AI models on various GPUs, with mentions of the RTX 4070 Super and RTX 3080 for running models like Mochi 1 and generating video clips. The RTX 4070 Super reportedly takes 7.5 minutes to generate a video in ComfyUI, while a 24GB VRAM card like the 3090 is sought for higher quality outputs.
- Open vs. Closed Model Capabilities: The discussion highlights the coding capabilities of Qwen models, noting a gap between open and closed models. The Qwen 2.5 Coder 14B outperforms Llama3 405b in the Aider benchmark, and smaller models like Qwen 2.5 Coder 3B are useful for local tasks, suggesting optimism for open-source advancements.
- Future Prospects and Developments: There is a debate about the current stage of open models, with some believing they are close to closed models but not yet superior. The community anticipates further advancements as consumer-grade hardware improves, and users express interest in new releases like Alibaba's Easy Animate, which requires 12GB VRAM.
Theme 4. Qwen 2.5 Technical Benchmarks: Hardware and Platform Strategy
- qwen-2.5-coder 32B benchmarks with 3xP40 and 3090 (Score: 49, Comments: 22): The qwen-2.5-32B benchmarks reveal that the 3090 GPU achieves a notable 28 tokens/second at a 32K context, while a single P40 GPU can handle 10 tokens/second. The 3xP40 setup supports a 120K context at Q8 quantization but does not scale performance linearly, with row split mode significantly enhancing generation speed. Adjusting the power limit of the P40 from 160W to 250W shows minimal impact on performance, with the 3090 outperforming in generation speed at 32.83 tokens/second when powered at 350W.
- VLLM compatibility with P40 GPUs is limited, with users recommending llama.cpp as the best choice for these GPUs. MLC is noted to perform approximately 20% worse than GGUF Q4 on P40s, lacking flash attention, reinforcing the preference for llama.cpp.
- Discussions around quantization levels like Q4, Q8, and fp8/16 reveal minimal performance differences, as detailed in a Neural Magic blog post. Users highlight the benefits of quantizing the kv cache to reduce memory usage without noticeable quality loss.
- P40 GPU power consumption is effectively managed at around 120W, with little benefit from exceeding 140W. Users report 36 tokens/second on a water-cooled 3090 and emphasize the P40 as a cost-effective option when purchased for under $200.
- LLMs distributed across 4 M4 Pro Mac Minis + Thunderbolt 5 interconnect (80Gbps). (Score: 58, Comments: 30): Running Qwen 2.5 on a setup of four M4 Pro Mac Minis interconnected via Thunderbolt 5 with a bandwidth of 80Gbps is discussed. The focus is on the potential for distributing LLMs across this hardware configuration.
- Discussion centers on the cost-effectiveness and configuration of M4 Pro Mac Minis compared to alternatives like the M2 Ultra and M4 Max. A fully kitted M4 Pro Mini costs around $2,100, with a setup of two providing 128GB of VRAM compared to the $4,999 M4 Max, though the latter offers double the memory bandwidth and GPU cores.
- Users debate the practicality of Mac Minis versus traditional setups like a ROMED8-2T motherboard with 4x3090 GPUs, citing the former's ease of use and reduced heat output. The potential to avoid common issues with Linux, CUDA errors, and PCIe is highlighted as a significant advantage.
- There is skepticism about performance claims, with questions about model specifics such as whether it is tensor parallel or the type of model precision used (e.g., fp16, Q2). The need for proof of the Mac Mini's capabilities in fine-tuning at reasonable speeds is emphasized before considering a switch from existing rigs.
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT
Theme 1. Claude 3.5 Opus Coming Soon: Anthropic CEO Confirms
- Anthropic CEO on Lex Friedman, 5 hours! (Score: 184, Comments: 49): Anthropic CEO Dario Amodei appeared on the Lex Fridman podcast for a 5-hour conversation available on YouTube. The discussion confirmed the continued development of Claude Opus 3.5, though no specific release timeline was provided.
- Users expressed skepticism about Anthropic's claim of not "nerfing" Claude, noting that performance changes could be achieved through "different thinking budget through prompting depending on the current load" rather than weight modifications.
- Notable guests Chris Olah and Amanda Askell were highlighted for their expertise in mechanistic interpretability and philosophical considerations respectively, generating significant interest among viewers.
- The community expressed concerns about Lex Fridman's recent content direction, with users noting his shift away from technical subjects and controversial associations with political figures, including becoming a "Putin apologist".
- Opus 3.5 is Not Die! It will be still coming out conform by anthropic CEO (Score: 62, Comments: 63): Opus 3.5, a model from Anthropic, continues development according to the company's CEO. The post lacks additional context or specific details about release timeline or model capabilities.
- Users discuss potential pricing for Opus 3.5, with expectations around $100/M tokens similar to GPT-4-32k at $120/M tokens. Several users indicate willingness to pay premium prices if the model delivers superior one-shot performance, particularly for coding tasks.
- Community skepticism emerges around previous Reddit speculation that Opus 3.5 was scrapped or merged into 3.5 Sonnet. Users note that running a larger model at Sonnet prices would be financially unsustainable for Anthropic.
- Competition concerns are highlighted with mentions of Qwen gaining market share. Users also critique the CEO's communication style as being evasive and uncomfortable when discussing the model's development status.
Theme 2. Qwen2.5-Coder-32B Matches Claude: Open Source Milestone
- Open source coding model matches with sonnet 3.5 (Score: 100, Comments: 33): Open-source coding model performance claims to match Claude Sonnet 3.5, though no additional context or evidence is provided in the post body.
- LM Studio makes running the model locally accessible, offering network connectivity for automation tasks and various quantization options like Q3 at 17GB. The model performs best when fitting in VRAM rather than running from RAM.
- The Qwen2.5-Coder-32B model runs effectively on 24GB video cards with Q4 quantization, available on Hugging Face. Users note it's more cost-effective than Haiku, costing approximately half as much.
- Users express interest in fine-tuning capabilities for matching specific coding styles and project structures, with options to host through OpenRouter at competitive prices. The model shows impressive performance for its 32B size.
- Every one heard that Qwen2.5-Coder-32B beat Claude Sonnet 3.5, but.... (Score: 61, Comments: 42): Qwen2.5-Coder-32B outperformed Claude Sonnet in coding benchmarks as shown in a comparative statistical graph. The image displays performance metrics between the two models, highlighting Qwen's competitive capabilities at a lower operational cost.
- Qwen2.5-Coder-32B is praised for its impressive performance as an open-source model, with pricing at $0.18 per million tokens via deepinfra.com compared to Claude Sonnet's $3/$15 input/output rates.
- Real-world testing shows Qwen excels at specific development tasks but struggles with complex logic and design tasks compared to Claude. The model's 32B size allows for local computer operation, with Q3 quantization potentially affecting performance on complex tasks.
- China's government heavily subsidizes AI APIs, explaining the low token costs, while Anthropic recently increased Haiku 3.5 prices citing improved intelligence as justification. Users note this creates less incentive to use closed-source models.
Theme 3. ComfyUI Video Generation: New Tools & Capabilities
- mochi1 text to video (comfyui is built in and is very fast ) (Score: 51, Comments: 6): Mochi1, a text-to-video model, integrates ComfyUI workflow capabilities for video generation. The tool emphasizes speed in its operations, though no specific performance metrics or technical details were provided in the post.
- Users pointed out that the original post contained duplicate links and lacked proper workflow documentation, criticizing the misleading nature of the post's "Workflow Included" claim.
- Made with ComfyUI and Cogvideox model, DimensionX lora. Fully automatic ai 3D motion.
I love Belgium comics, and I wanted to use AI to show an example of how to enhance them using it.
Soon a full modelisation in 3D ?
waiting for more lora to create a full app for mobile.
Thanks @Kijaidesign for you (Score: 83, Comments: 10): ComfyUI and Cogvideox models were used alongside DimensionX lora to create 3D motion animations of Belgian comics. The creator aims to develop a mobile application for enhancing Belgian comics using AI, pending additional lora models.
- Users inquired about the workflow and potential use of After Effects in the animation process, highlighting interest in the technical implementation details.
- Commenters envision potential for automated panel-to-panel animation with dynamic camera movements adapting to different comic layouts and compositions.
Theme 4. AI Content Generation on Reddit: Growing Trend & Concerns
- Remember this 50k upvote post? OP admitted ChatGPT wrote 100% of it (Score: 1349, Comments: 163): ChatGPT allegedly generated a viral Reddit post that received 50,000 upvotes, with the original poster later confirming the content was entirely AI-generated. No additional context or details about the specific post content were provided in the source material.
- Users noted several writing style indicators of AI-generated content, particularly the use of em-dashes and formal formatting which is uncommon in typical Reddit posts. The structured, lengthy formatting was cited as a key tell for AI authorship.
- Discussion centered around the growing challenge of detecting AI content on Reddit, with users expressing concern about the platform becoming dominated by AI-generated posts. Several commenters mentioned being initially fooled despite noticing some suspicious elements.
- A user who correctly identified the post as AI-generated was initially downvoted and criticized for their skepticism, highlighting the community's mixed ability to detect AI content. The original post received 50,000 upvotes while this revelation gained significantly less attention.
- Dead Internet Theory: this post on r/ChatGPT got 50k upvotes, then OP admitted ChatGPT wrote it (Score: 130, Comments: 48): Dead Internet Theory gained credibility when a viral post on r/ChatGPT reaching 50,000 upvotes was revealed to be AI-generated content, with the original poster later admitting that ChatGPT wrote the entire submission. This incident exemplifies concerns about AI-generated content dominating social media platforms without clear disclosure of its artificial origins.
AI Discord Recap
A summary of Summaries of Summaries by O1-mini
AI Language Models Battle for Supremacy
- Qwen2.5 Coder Tops GPT-O and Claude 3.5: The Qwen2.5 Coder 32B outperforms GPT-O and Claude 3.5 Sonnet with a 73.7% performance on complex tasks compared to Sonnet's 84.2%. Users praise its open-source capabilities while noting ongoing improvements.
- Phi-3.5’s Overcensorship Sparks Debate: Microsoft’s Phi-3.5 model faces criticism for heavy censorship, leading to the creation of an uncensored version on Hugging Face. Users humorously mocked Phi-3.5’s excessive restrictions, highlighting its impact on utility for technical tasks.
- OpenAI’s o1 Model Release Anticipated: OpenAI gears up for the full release of the o1 reasoning model by year-end, with community excitement fueled by anonymous insights. Speculation about the development team’s expertise adds to the anticipation.
Optimization Techniques Revolutionize Model Training
- Gradient Descent Mechanics Unveiled: In Eleuther Discord, engineers debated scaling updates with gradient descent and the role of second-order information for optimal convergence. Discussions referenced recent papers on feature learning and kernel dynamics.
- LoRA Fine-Tuning Accelerates Inference: Unsloth AI members utilize LoRA fine-tuned models like Llama-3.2-1B-FastApply for accelerated inference via native support. Sample code showcased improved execution speeds through model size reduction.
- Line Search Methods Enhance Learning Rates: Eleuther participants explored line search techniques to dynamically recover optimal learning rates as loss approaches divergence. Findings indicate that line searches yield rates about 1/2 the norm of the update, suggesting consistent patterns.
Deployment and Inference Get a Boost with New Strategies
- Speculative Decoding Boosts Inference Speed: Members shared speculative decoding and using FP8 or int8 precision as strategies to enhance inference speed. Custom CUDA kernels from providers like qroq and Cerebras offer even greater performance gains.
- Vast.ai Offers Affordable Cloud GPU Solutions: Vast.ai recommended as an affordable cloud GPU provider, with prices ranging from $0.30 to $2.80 per hour for GPUs like A100 and RTX 4090. Users advise against older Tesla cards, favoring newer hardware for reliability.
- Multi-GPU Syncing Poses Challenges: Discussions in Interconnects and GPU MODE highlight complexities in synchronizing mean and variance parameters across multi-GPU setups using tools like SyncBatchNorm in Pytorch, posing implementation challenges in frameworks like liger.
APIs and Tools Streamline AI Development
- Cohere API Changes Cause Headaches: Users in Cohere Discord faced UnprocessableEntityError due to the removal of the return_documents field in the /rerank endpoint. Team members are working to restore the parameter, with Cohere’s support addressing the issue.
- Aider Integrates LoRA for Faster Operations: In aider Discord, members discussed leveraging LoRA fine-tuned models such as Llama-3.2-1B-FastApply for accelerated inference using Aider’s native support. Sample code demonstrated loading adapters for improved speed.
- NotebookLM Enhances Summarization Workflows: Participants in Notebook LM Discord explored using NotebookLM to summarize over 200 AI newsletter emails, streamlining information digestion. Technical issues like audio file upload failures were discussed, pointing to potential technical glitches.
Scaling Laws and Datasets Challenge AI Research
- Scaling Laws Reveal Quantization Limits: In Eleuther and Interconnects Discords, researchers discussed a study showing models trained on more tokens require higher precision for quantization, impacting scalability. Concerns raised about LLaMA-3 model’s performance under these laws.
- Aya_collection Dataset Faces Translation Inconsistencies: Cohere users identified disparities in the aya_collection dataset’s translations across 19 languages, with English having 249716 rows versus 124858 for Arabic and French. Specific mismatches in translated_cnn_dailymail were highlighted.
- Data-Parallel Scaling Bridges Theory and Practice: Discussions on Eleuther Discord emphasized practical challenges in bridging theory and application within data-parallel scaling, referencing documentation. Quotes like 'The stuff that works is not allowed to be published' highlight publication constraints.
PART 1: High level Discord summaries
Eleuther Discord
-
Exploring Gradient Descent Mechanics: A discussion explored the gradient descent update mechanics, focusing on how update projections and norms influence model weight changes.
- Participants debated the importance of scaling updates relative to input variations and the role of second-order information in achieving optimal convergence.
- Significance of Muon Optimization: The role of Muon as an optimizer was examined, highlighting its interaction with feature learning and effects on network training dynamics.
- Suggestions included exploring connections between Muon and other theoretical frameworks like kernel dynamics and existing feature learning literature.
- Filling Gaps in Scaling Laws: A member shared insights on filling missing pieces in scaling laws, emphasizing practical challenges in bridging theory and application.
- The stuff that works is not allowed to be published, highlighting challenges in effectively applying research.
- Optimizing Learning Rates with Line Searches: There's speculation about line searching as a method to recover optimal learning rates during training, especially as loss approaches divergence.
- One contributor referenced findings that line searches yield rates about 1/2 the norm of the update, indicating possible consistent patterns.
- Text-MIDI Multimodal Datasets Suggested: A participant proposed implementing a text-MIDI multimodal dataset, considering existing collections of recordings and metadata.
- They acknowledged copyright limitations, suggesting that only MIDI files could be open-sourced.
Perplexity AI Discord
-
Perplexity Faces Frustration from Persistent Technical Issues: Users have reported persistent technical issues in the Perplexity AI platform, notably the hidden messages bug affecting long threads that remains unresolved.
- These ongoing problems have been present for over a month, significantly impacting user experience, despite fixes for other minor bugs.
- Uncertainty Surrounds Perplexity Pro Subscription Expiry: A user inquired about the continuation of their Perplexity Pro free year after expiration, questioning its effects on the R1 device.
- The community confirmed that the subscription won't stay free post-trial, and users will revert to limited free searches.
- Perplexity Model Showdown: GPT-O Tops the Charts: Discussions indicate that gpt-o is outperforming other models in Perplexity AI, especially in specific tasks.
- Conversely, o1 is seen as having limited applications, despite its specialized nature.
- Mac App UI Woes Plague Perplexity Users: Users reported UI issues in the Mac version of the Perplexity app, highlighting the absence of a scrollbar which hampers navigation.
- Additional complaints include persistent Google sign-in problems and missing features available in the web app.
- Community Seeks Solutions for Pplx API DailyBot Editor: A member requested guidance on implementing the Pplx API DailyBot custom command editor, seeking initial steps for project commencement.
- Another user shared a workaround using CodeSandBox VM with webhooks, but the community is exploring alternative solutions for better implementation.
Unsloth AI (Daniel Han) Discord
-
Qwen 2.5 Coder Finetuning Resources Released: A new finetuning notebook for the Qwen 2.5 Coder (14B) model is now available on Colab, enabling free finetuning with 60% reduced VRAM usage and extended context lengths from 32K to 128K.
- Users can access Qwen2.5 Coder Artifacts and Unsloth versions to address token training issues and enhance model performance.
- Optimization Strategies for Faster Inference: Members shared techniques to enhance inference speed, including speculative decoding, utilizing FP8 or int8 precision, and implementing custom optimized CUDA kernels.
- Providers like qroq and Cerebras have developed custom hardware solutions to further boost performance, though this may impact throughput.
- LoRA Fine-tuning Integration with Unsloth: Users discussed leveraging LoRA fine-tuned models such as Llama-3.2-1B-FastApply for accelerated inference using Unsloth's native support.
- Sample code provided demonstrates loading adapters with Unsloth, resulting in improved execution speed due to the model's smaller size.
- Model Checkpoints and Adapter Usage Best Practices: Successful integration of adapter models on top of base models for inference was achieved using the PeftModel class, emphasizing the importance of specifying checkpoint paths during model loading.
- Best practices include building adapters first and ensuring correct checkpoint paths to facilitate accurate model enhancements and deployment.
- Managing RAM Usage During Model Training: A user reported increased RAM consumption when running Gemma 2B, potentially due to evaluation processes intensifying memory demands.
- Another member inquired about evaluation practices, suggesting that turning off evaluations might mitigate excessive memory usage.
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder Performance: Qwen 2.5-Coder-32B demonstrates a 73.7% performance in complex tasks, trailing behind Claude 3.5 Sonnet at 84.2%.
- Users highlighted that Qwen models still present placeholder responses, which may impede coding efficiency and completeness.
- Aider Installation and Usage: Aider installation requires Python 3.9-3.12 and git, with users referring to the official installation guide for assistance.
- Discussions emphasized streamlining the installation process to enhance user experience for AI engineers.
- Model Comparison: Qwen 2.5-Coder's performance was compared to models like DeepSeek and GPT-4o, showing varied results across different tasks.
- Leaderboard scores indicate that tweaking model configurations could optimize performance for specific coding tasks.
- Aider Configuration Warnings: Users encountered Aider configuration warnings when the Ollama server wasn't running or the API base wasn't set, leading to generic warnings instead of specific errors.
- Community suggestions included verifying model names and addressing ongoing bugs with Litellm to resolve spurious warnings.
- OpenRouter API Usage: Issues with OpenRouter API were reported, such as benchmark scripts failing to connect to the llama-server due to unrecognized model names.
- Solutions involved adjusting the
.aider.model.metadata.jsonfile, which primarily affects cost reporting and can be disregarded if necessary.
Interconnects (Nathan Lambert) Discord
-
Qwen 2.5 Coder Breaks 23.5T Tokens: Qwen 2.5 Coder has been pretrained on a staggering 23.5 trillion tokens, making it the first open-weight model to exceed the 20 trillion token threshold, as highlighted in the #news channel.
- Despite this achievement, users expressed concerns about the challenges of running Qwen 2.5 locally, citing the need for high-spec hardware like a 128GB MacBook to handle full BF16 precision.
- Scaling Laws Challenge LLaMA-3 Quantization: A study discussed in #reads indicates that as models are trained on more tokens, they require higher precision for quantization, posing significant challenges for the LLaMA-3 model.
- The research suggests that continued increases in pretraining data may adversely impact the quantization process, raising concerns about the scalability and performance of future AI models.
- Dario Amodei Forecasts Human-Level AI by 2027: In a #news channel podcast, Dario Amodei discussed the observed scaling across various AI modalities, projecting the emergence of human-level AI by 2026-2027.
- He emphasized the importance of ethical considerations and nuanced behavior in AI systems as they scale, highlighting potential uncertainties in achieving these advancements.
- Nous Research Launches Forge Reasoning API Beta: Nous Research unveiled the Forge Reasoning API Beta in the #news channel, aiming to enhance inference time scaling applicable to any model, specifically targeting the Hermes 70B model.
- Despite the promising launch, there are ongoing concerns about the consistency of reported benchmarks, leading to skepticism regarding the reliability of the API's performance metrics.
- OpenAI Prepares Full Release of o1 Model: Anticipation builds around OpenAI's planned full release of the o1 reasoning model by year-end, as discussed in the #news channel.
- Community members are particularly interested in the development teams behind o1, with anonymous sources fueling speculation about the model's capabilities and underlying technologies.
OpenRouter (Alex Atallah) Discord
-
Qwen Leaps Ahead with Coder 32B: The newly released Qwen2.5 Coder 32B outperforms competitors Sonnet and GPT-4o in several coding benchmarks, according to a tweet from OpenRouter.
- Despite these claims, some members questioned the accuracy, suggesting that tests like MBPP and McEval might not fully reflect true performance.
- Gemini 1.5 Flash Enhances Performance: Gemini 1.5 Flash has received updates including frequency penalty, presence penalty, and seed adjustments, improving its capability across various tasks as per OpenRouter's official update.
- Users noted improved performance, especially at temperature 0, with speculation that an experimental version is deployed on Google AI Studio.
- Anthropic's Tool Not Yet Compatible: Discussions revealed that Anthropic's computer use tool currently lacks support within OpenRouter, requiring a special beta header.
- Members expressed interest in future compatibility to enhance integration and functionality within their projects.
- OpenRouter Introduces Pricing Adjustments: OpenRouter clarified that usage may incur approximately 5% additional costs for tokens through credits, as outlined in their terms of service.
- This update prompted user inquiries regarding pricing transparency and comparisons with direct model usage.
- Custom Provider Keys Sought by Beta Testers: Multiple users have requested access to custom provider keys for beta testing to better manage Google's rate limits.
- The strong interest highlights the community's desire for enhanced functionality and project optimization.
OpenAI Discord
-
Qwen2.5-Coder Showcases Open-Source Prowess: The new Qwen2.5-Coder model was highlighted for its open-source code capabilities, offering a competitive edge against models like GPT-4o.
- Access to the model and its demonstrations is available on GitHub, Hugging Face, and ModelScope.
- KitchenAI Project Seeks Developer Contributions: The KitchenAI open-source project was introduced, aiming to create shareable runtime AI cookbooks and inviting developers to contribute.
- Outreach efforts are being made on Discord and Reddit to attract interested contributors.
- Refining Prompt Engineering for GPT Models: Discussions focused on enhancing prompt clarity and utilizing token counts to optimize outputs for GPT models.
- A prompt engineering guide was shared to assist members in improving their prompt design skills.
- Evaluating TTS Alternatives: Spotlight on f5-TTS: Members explored various text-to-speech (TTS) solutions, with f5-tts recommended for its functionality on consumer GPUs.
- The discussion included suggestions to focus on cost-effective solutions when addressing queries about timestamp data capabilities.
Modular (Mojo 🔥) Discord
-
CUDA Driver Limitations in WSL2: The Nvidia CUDA driver on Windows is stubbed as libcuda.so in WSL2, potentially limiting full driver functionalities via Mojo.
- Members highlighted that this stubbed driver may complicate support for MAX within WSL if it relies on the host Windows driver.
- CRABI ABI Proposal Enhances Language Interoperability: An experimental feature gate proposal for
CRABIby joshtriplett aims to develop a new ABI for interoperability among high-level languages like Rust, C++, Mojo, and Zig.
- Participants discussed integration challenges with languages like Lua and Java, indicating a need for broader adoption.
- Mojo Installation Issues Fixed with Correct URL: A user resolved Mojo installation issues by correcting the
curlcommand URL, ensuring successful installation.
- This underscores the importance of accurate URL entries when installing software packages.
- Mojo's Benchmark Module Faces Performance Constraints: The benchmark module in Mojo facilitates writing fast benchmarks by managing setup and teardown, as well as handling units for throughput measurements.
- However, there are limitations such as unnecessary system calls in hot loops, which may impact performance.
- Dynamic Module Importing Restricted by Mojo's Compilation Structure: Dynamic importing of modules is currently unsupported in Mojo due to its compilation structure that bundles everything as constants and functions.
- Introducing a JIT compiler is a potential solution, though concerns about binary size and compatibility with pre-compiled code remain.
tinygrad (George Hotz) Discord
-
Hailo Model Quantization Challenges: A member detailed the complexities of running Hailo requiring eight-bit quantization, complicating training processes, and the necessity of a compiled .so for CUDA and TensorFlow to function properly.
- Setting up for Hailo is cumbersome due to these requirements.
- ASM2464PD Chip Specifications Confirmed: Discussion confirmed that the ASM2464PD chip supports generic PCIe, available through multiple vendors and not limited to NVMe.
- Members raised concerns about the chip's 70W power requirement for optimal performance.
- Open-Source USB4 to PCIe Converter Progress: An open-source USB4/Thunderbolt to M.2 PCIe converter design was shared on GitHub, demonstrating significant progress and secured funding for hardware development.
- The designer outlined expectations for the next development phase to achieve effective USB4 to PCIe integration.
- Optimizing Audio Recording with Opus Codec: Members debated using the Opus codec for audio recordings due to its ability to reduce file sizes without sacrificing quality.
- However, concerns were noted regarding Opus's browser compatibility, highlighting technical limitations.
- Development of Tinygrad's Distributed Systems Library: A user advocated for building a Distributed Systems library for Tinygrad focused on dataloaders and optimizers without relying on existing frameworks like MPI or NCCL.
- The aim is to create foundational networking capabilities from scratch while maintaining Tinygrad's existing interfaces.
Notebook LM Discord Discord
-
NotebookLM could summarize AI newsletters: One member suggested using NotebookLM to summarize over 200 AI newsletter emails to avoid manually copying and pasting content.
- Gemini button in Gmail was mentioned as a potential aid for summarization but noted not being free.
- Unofficial API skepticism around NotebookLM: Users discussed an unofficial $30/month API for NotebookLM, expressing suspicion regarding its legitimacy NotebookLM API.
- Concerns include the lack of business information and sample outputs, leading some to label it a scam.
- Integration of KATT for fact-checking in podcasts: One user discussed incorporating KATT (Knowledge-based Autonomous Trained Transformer) into a fact-checker for their podcast, resulting in a longer episode.
- They described the integration as painful, combining traditional methods with new AI techniques.
- Issues with audio file uploads in NotebookLM: Users expressed frustration about not being able to upload .mp3 files to NotebookLM, with guidance about proper upload procedures through Google Drive.
- Some noted that other file types uploaded without issues, indicating a potential technical glitch or conversion error.
- Exporting notebooks as PDF in NotebookLM: Users are inquiring about plans to export notes or notebooks as a .pdf in the future and seeking APIs for notebook automation.
- While some mention alternatives like using a PDF merger, they are eager for native export features.
Latent Space Discord
-
Magentic-One Framework Launch: The Magentic-One framework was introduced, showcasing a multi-agent system designed to tackle complex tasks and outperform traditional models in efficiency.
- It uses an orchestrator to direct specialized agents and is shown to be competitive on various benchmarks source.
- Context Autopilot Introduction: Context.inc launched Context Autopilot, an AI that learns like its users, demonstrating state-of-the-art abilities in information work.
- An actual demo was shared, indicating promise in enhancing productivity tools in AI workflows video.
- Writer Series C Funding Announcement: Writer announced a $200M Series C funding round at a $1.9B valuation, aiming to enhance its AI enterprise solutions.
- The funding will support expanding their generative AI applications, with significant backing from notable investors Tech Crunch article.
- Supermaven Joins Cursor: Supermaven announced its merger with Cursor, aiming to develop an advanced AI code editor and collaborate on new AI tool capabilities.
- Despite the transition, the Supermaven plugin will remain maintained, indicating a continued commitment to enhancing productivity (blog post).
- Dust XP1 and Daily Active Usage: Insights were shared on how to create effective work assistants with Dust XP1, achieving an impressive 88% Daily Active Usage among customers.
- This episode covers the early OpenAI journey, including key collaborations.
GPU MODE Discord
-
GPU Memory vs Speed Trade-offs: Debate arose over upgrading from an RTX 2060 Super to an RTX 3090, weighing the balance between GPU memory and processing speed, alongside the option of acquiring older used Tesla cards.
- Consensus favored newer hardware for enhanced reliability, especially recommending against older GPUs for individual developers.
- Vast.ai as Cloud GPU Provider: Vast.ai was recommended as an affordable cloud GPU option, with current pricing ranging from $0.30 to $2.80 per hour for GPUs like A100 and RTX 4090.
- Users noted that while Vast.ai offers cost-effective solutions, its model of leasing GPUs introduces certain quirks that potential users should consider.
- Surfgrad: WebGPU-based Autograd Engine: Surfgrad, an autograd engine built on WebGPU, achieved up to 1 TFLOP performance on the M2 chip, as detailed in Optimizing a WebGPU Matmul Kernel.
- The project emphasizes kernel optimizations and serves as an educational tool for those looking to explore WebGPU and Typescript in autograd library development.
- Efficient Deep Learning Systems Resources: Efficient Deep Learning Systems course materials by HSE and YSDA were shared, providing comprehensive resources aimed at optimizing AI system efficiencies.
- Participants highlighted the repository's value in enhancing understanding of efficient system architectures and resource management in deep learning.
- Multi-GPU Synchronization in Liger: Challenges were discussed regarding the synchronization of mean and variance parameters in multi-GPU setups within liger, referencing Pytorch's SyncBatchNorm operation.
- Members indicated that replicating SyncBatchNorm behavior in liger would be complex and not straightforward, highlighting the intricacies involved.
Cohere Discord
-
Cohere API /rerank Issues: Users encountered UnprocessableEntityError when using the /rerank endpoint due to the removal of the return_documents field.
- The development team acknowledged the unintentional change and is working on restoring the return_documents parameter, as multiple users reported the same issue after updating their SDKs.
- Command R Status in Development: Concerns about the potential discontinuation of Command R were addressed with assurances that there are no current plans to retire it.
- Members were advised to utilize the latest updates, such as command-r-08-2024, to benefit from enhanced performance and cost efficiency.
- aya_collection Dataset Inconsistencies: aya_collection dataset inconsistencies were identified, notably in translation quality across 19 languages, with English having 249716 rows compared to 124858 for Arabic and French.
- Specific translation mismatches were highlighted in the translated_cnn_dailymail dataset, where English sentences did not align proportionally with their Arabic and French counterparts.
- Forest Fire Prediction AI Project: A member introduced their forest fire prediction AI project using Catboost & XLModel, emphasizing the need for model reliability for deployment on AWS.
- Recommendations included adopting the latest versions of Command R for better performance, with suggestions to contact the sales team for additional support and updates.
- Research Prototype Beta Testing: A limited beta for a research prototype supporting research and writing tasks like report creation is open for sign-ups here.
- Participants are expected to provide detailed and constructive feedback to help refine the tool's features during the early testing phase.
HuggingFace Discord
-
Affordable AI Home Servers Unveiled: A YouTube video showcases the setup of a cost-effective AI home server using a single 3060 GPU and a Dell 3620, demonstrating impressive performance with the Llama 3.2 model.
- This setup offers a budget-friendly solution for running large language models, making advanced AI accessible to engineers without hefty hardware investments.
- Graph Neural Networks Dominate NeurIPS 2024: NeurIPS 2024 highlighted a significant focus on Graph Neural Networks and geometric learning, with approximately 400-500 papers submitted, surpassing the number of submissions at ICML 2024.
- Key themes included diffusion models, transformers, agents, and knowledge graphs, with a strong theoretical emphasis on equivariance and generalization, detailed in the GitHub repository.
- Qwen2.5 Coder Surpasses GPT4o and Claude 3.5: In recent evaluations, Qwen2.5 Coder 32B outperformed both GPT4o and Claude 3.5 Sonnet, as analyzed in this YouTube video.
- The community acknowledges Qwen2.5 Coder's rapid advancement, positioning it as a formidable contender in the coding AI landscape.
- Advanced Ecommerce Embedding Models Released: New embedding models for Ecommerce have been launched, surpassing Amazon-Titan-Multimodal by up to 88% performance, available on Hugging Face and integrable with Marqo Cloud.
- Detailed features and performance metrics can be found in the Marqo-Ecommerce-Embeddings collection, facilitating the development of robust ecommerce applications.
- Innovative Image Denoising Techniques Discussed: The paper Phase Transitions in Image Denoising via Sparsity is now available on Semantic Scholar, presenting new approaches to image processing challenges.
- This research contributes to ongoing efforts in enhancing image denoising methods, addressing critical issues in maintaining image quality.
LlamaIndex Discord
-
PursuitGov enhances B2G services with LlamaParse: By employing LlamaParse, PursuitGov successfully parsed 4 million pages in a single weekend, significantly enhancing their B2G services.
- This transformation resulted in a 25-30% increase in accuracy for complex document formats, enabling clients to uncover hidden opportunities in public sector data.
- ColPali integration for advanced re-ranking: A member shared insights on using ColPali as a re-ranker to achieve highly relevant search results within a multimodal index.
- The technique leverages Cohere's multimodal embeddings for initial retrieval, integrating both text and images for optimal results.
- Cohere's new multimodal embedding features: The team discussed Cohere's multimodal embeddings, highlighting their ability to handle both text and image data effectively.
- These embeddings are being integrated with ColPali to enhance search relevance and overall model performance.
- Automating LlamaIndex workflow processes: A member expressed frustration over the tedious release process and aims to automate more, sharing a GitHub pull request for LlamaIndex v0.11.23.
- They highlighted the need to streamline workflows to reduce manual intervention and improve deployment efficiency.
- Optimizing FastAPI for streaming responses: Discussions arose around using FastAPI's StreamingResponse, with concerns about event streaming delays potentially due to coroutine dispatching issues.
- Members suggested advanced streaming techniques, such as writing each token as a stream event using
llm.astream_complete()to enhance performance.
LAION Discord
-
AI Companies Embrace Gorilla Marketing: A member noted that AI companies really love gorilla marketing, possibly in reference to unconventional promotional strategies, and shared a humorous GIF of a gorilla waving an American flag.
- This highlighted the use of unique and creative marketing tactics within the AI industry.
- Request for Help on Object Detection Project: A member detailed a project involving air conditioner object detection using Python Django, aiming to identify AC types and brands.
- They asked for assistance, indicating a need for support in developing this recognition functionality.
- Introducing GitChameleon for Code Generation Models: The new dataset GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models introduces 116 Python code completion problems conditioned on specific library versions, with executable unit tests to rigorously assess LLMs' capabilities.
- This aims to address the limitations of existing benchmarks that ignore the dynamic nature of software library evolution and do not evaluate practical usability.
- Exciting Launch of SCAR for Concept Detection: SCAR, a method for precise concept detection and steering in LLMs, learns monosemantic features using Sparse Autoencoders in a supervised manner.
- It offers strong detection for concepts like toxicity, safety, and writing style and is available for experimentation in Hugging Face's transformers.
- NVIDIA's Paper on Noise Frequency Training: NVIDIA's paper presents a concept where higher spatial frequencies are noised faster than lower frequencies during the forward noising step.
- In the backwards denoising step, the model is trained explicitly to work from low to high frequencies, providing a unique approach to training.
Gorilla LLM (Berkeley Function Calling) Discord
-
Overwriting Test Cases for Custom Models: A member inquired about overwriting or rerunning test cases for their custom model after making changes to the handler.
- Another suggested deleting results files in the
resultfolder or changing the path inconstant.pyto retain old results. - Invalid AST Errors in Qwen-2.5 Outputs: A member described issues with finetuning the Qwen-2.5 1B model, resulting in an INVALID AST error despite valid model outputs.
- Members discussed a specific incorrect output format that included an unmatched closing parenthesis, indicating syntactical issues.
- Confusion Over JSON Structure Output: A member expressed confusion about the model outputting a JSON structure instead of the expected functional call format.
- Others clarified that the QwenHandler should ideally convert the JSON structure into a functional form, leading to discussions on output expectations.
- Evaluating Quantized Fine-tuned Models: A member raised a question about evaluating quantized finetuned models, specifically regarding their deployment on vllm.
- They mentioned the use of specific arguments like
--quantization bitsandbytesand--max-model-len 8192for model serving.
- Another suggested deleting results files in the
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents MOOC Hackathon Kicks Off: The LLM Agents MOOC Hackathon began on 11/12 at 4pm PT, featuring live LambdaAPI demos to aid participants in developing their projects.
- With around 2,000 innovators registered across tracks like Applications and Benchmarks, the event is hosted on rdi.berkeley.edu/llm-agents-hackathon.
- LambdaAPI Demos Support Hackathon Projects: LambdaAPI provided hands-on demos to guide hackathon participants in building effective LLM agent applications.
- These demonstrations offer actionable tools and techniques, assisting developers in refining their project implementations.
- NVIDIA's Embodied AI Triggers Ethical Debate: NVIDIA's presentation on embodied AI sparked discussions about granting moral rights to AI systems resembling humans.
- Participants highlighted a lack of focus on normative alignment, questioning the ethical boundaries of AI advancements.
- AI Rights and Normative Alignment Concerns: The community expressed unease over the absence of normative alignment discussions in AI development, especially after NVIDIA's insights.
- Debates centered on the ethical implications of AI rights, emphasizing the need for comprehensive alignment strategies.
OpenAccess AI Collective (axolotl) Discord
-
FOSDEM AI DevRoom Set for 2025: The AIFoundry team is organizing the FOSDEM AI DevRoom scheduled for February 2, 2025, focusing on ggml/llama.cpp and related projects to unite AI contributors and developers.
- They are inviting proposals from low-level AI core open-source project maintainers with a submission deadline of December 1, 2024, and offering potential travel stipends for compelling topics.
- Axolotl Fine-Tuning Leverages Alpaca Format: A user clarified the setup process for fine-tuning with Axolotl, highlighting the use of a dataset in Alpaca format to preprocess for training.
- It was noted that the tokenizer_config.json excludes the chat template field, necessitating further adjustments for complete configuration.
- Enhancing Tokenizer Configuration with Chat Templates: A member shared a method to incorporate the chat template into the tokenizer config by copying a specific JSON structure.
- They recommended modifying settings within Axolotl to ensure automatic inclusion of the chat template in future configurations.
- Integrating Default System Prompts in Fine-Tuning: A reminder was issued that the shared template lacks the default system prompt for Alpaca, which may require adjustments.
- Users were informed they can include a conditional statement before ### Instruction to integrate desired prompts effectively.
DSPy Discord
-
Annotations Enhance dspy.Signature: Members discussed the use of annotations in dspy.Signature, clarifying that while basic annotations work, there is potential for using custom types like list[MyClass].
- One member confirmed that the string form does not work for this purpose, suggesting a preference for explicit type definitions.
- Custom Signatures Implemented for Clinical Entities: A member shared a successful implementation of a custom signature using a list of dictionaries in the output, showcasing the extraction of clinical entities.
- The implementation includes detailed descriptions for both input and output fields, indicating a flexible approach to defining complex data structures.
OpenInterpreter Discord
-
Linux Mint struggles in Virtual Machines: After installing Linux Mint in Virtual Machine Manager, users reported networking did not work properly.
- However, an attempt was made to install Linux Mint inside an app called Boxes.
- Microsoft Copilot Communication Breakdown: A back-and-forth interaction with Microsoft Copilot revealed frustration as commands were not being configured as requested.
- The user emphasized that no bridge was created, but they managed to create one on their own.
- Interpreter CLI Bugs on OS X: Report emerged regarding the Interpreter CLI on OS X, where it is persisting files and exiting unexpectedly.
- Users expressed concerns about these issues occurring frequently on the developer branch.
Torchtune Discord
- PyTorch Team to Release DCP PR: whynot9753 announced that the PyTorch team will likely release a DCP PR tomorrow.
- ****:
AI21 Labs (Jamba) Discord
- Request to Continue Using Fine-Tuned Models: A user requested to continue using their fine-tuned models.
- Request to Continue Using Fine-Tuned Models: A user requested to continue using their fine-tuned models.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Eleuther ▷ #general (35 messages🔥):
Reduced Clicks in Workflow DesignEvaluation of AI ModelsEmotional Intelligence in AIText-MIDI Multimodal DatasetsUser Feedback in AI Development
-
Reduced Clicks Make for Confusing Designs: Members discussed how reduced clicks in design often favor higher-ups' workflows, leading to inefficiencies, with one noting that onboarding can take two months for experienced professionals.
- And yet, adding clicks decreases conversions and revenue, remarked a user, questioning the value of these design choices.
- Unveiling the Challenges in Evaluating AI: A newbie inquired about where to seek help for using and evaluating their AI model, wondering the best resources available within the framework.
- Another user directed them to a specific channel dedicated to evaluation, indicating support is available.
- Emotional Intelligence Enhances AI Responses: Discussion highlighted the potential of emotion detection and sentiment analysis for AI models, emphasizing their existing use in applications today.
- One user suggested that incorporating mild RLAIF could help ensure better musical form in AI-generated outputs.
- Text-MIDI Multimodal Datasets Suggested: One participant proposed that a text-MIDI multimodal dataset may be the next step in AI development, hinting at existing collections of recordings and metadata.
- They acknowledged copyright limitations, revealing only MIDI files could be open-sourced.
- Feedback Loops Crucial for AI Development: The importance of implementing a feedback system for AI was discussed, where user ratings and comments could help refine responses over time.
- This iterative learning process aims to significantly enhance emotional intelligence and overall output quality.
Eleuther ▷ #research (271 messages🔥🔥):
Gradient Descent and OptimizationMuon and Feature LearningSecond Order MethodsNewton's MethodSaddle Points in Optimization
-
Exploring Gradient Descent Mechanics: A discussion developed around the mechanics of gradient descent updates, emphasizing how the update's projections and norms relate to weight changes in models.
- Participants debated the significance of scaling updates with respect to input changes and the relevance of second-order information in achieving optimal convergence.
- Significance of Muon Optimization: The role of Muon as an optimizer was examined, particularly its interaction with feature learning and how it may affect network training dynamics.
- There were suggestions to explore connections between Muon and other theoretical frameworks, such as kernel dynamics and feature learning literature.
- Challenges with Second Order Methods: Participants raised concerns about the applicability of second-order methods like Newton's in high-dimensional, non-convex optimization landscapes due to the prevalence of saddle points.
- Discussions highlighted that while second-order methods capture curvature data, their practical utility can be limited in scenarios involving noise and varying gradients.
- Understanding Saddle Points in Noisy Environments: It was noted that saddle points may be less relevant in noisy stochastic gradient descent contexts, referencing historical results where noise helped SGD escape saddle points.
- Participants emphasized a shift in focus toward optimization techniques that accommodate the complexities of high-dimensional landscapes influenced by noise.
- Computational Considerations in Optimization: The conversation touched on the computational challenges associated with higher-order derivatives and their practical implications for optimization strategies.
- Despite the theoretical backing for using second-order and higher-order information, the need for feasible computational approaches remains a crucial aspect of developing effective algorithms.
Links mentioned:
- High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation: We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N }}\boldsymbol{a}^\topσ(\boldsymbol{W}^\top\b...
- A Spectral Condition for Feature Learning: The push to train ever larger neural networks has motivated the study of initialization and training at large network width. A key challenge is to scale training so that a network's internal repre...
- Grokking as the Transition from Lazy to Rich Training Dynamics: We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics...
- Geometric Dynamics of Signal Propagation Predict Trainability of Transformers: We investigate forward signal propagation and gradient back propagation in deep, randomly initialized transformers, yielding simple necessary and sufficient conditions on initialization hyperparameter...
- Rigorous dynamical mean field theory for stochastic gradient descent methods: We prove closed-form equations for the exact high-dimensional asymptotics of a family of first order gradient-based methods, learning an estimator (e.g. M-estimator, shallow neural network, ...) from ...
- Newton's method in optimization - Wikipedia): no description found
- Flex attention underperforms SDPA (cuDNN), constructing T5 attention bias via embedding weights · Issue #138493 · pytorch/pytorch: 🐛 Describe the bug I've been trying to implement T5 encoder relative attention bias in flex_attention. I came up with a few algorithms for it, and a benchmark script: https://gist.github.com/Birc...
Eleuther ▷ #scaling-laws (10 messages🔥):
Scaling Laws InvestigationLearning Rate AdjustmentLine Search TechniquesGradient Descent Dynamics
-
Filling Gaps in Scaling Laws: A member shared insights on filling missing pieces in scaling laws, emphasizing practical challenges in relating theory to application.
- The stuff that works is not allowed to be published, highlighting issues faced in the effective application of research.
- Convergent Learning Rates Dependence: It was discussed that to maintain convergent learning, both learning rates must decrease when batch sizes lower, in accordance with the NQM model predictions.
- The member pointed out that convergent learning rate is independent of batch size, challenging traditional methods.
- Optimizing Learning Rates with Line Searches: There’s speculation about line searching as a method to recover optimal learning rates during training, especially as loss nears divergence.
- One contributor referenced findings that line searches yield rates about 1/2 the norm of the update, hinting at possible patterns.
- Enhancements in Line Search Methods: A member cited a paper proposing improvements to Armijo line search methods which integrate momentum from ADAM for better performance.
- Their methods have demonstrated remarkable efficiency, particularly in large-scale training scenarios across diverse data domains.
- Oscillating Learning Rates Observed: Discussion revealed that oscillating learning rate behavior is seen in, particularly in greedy line search using functions like x^2 + 1/2y^2 + 1/3z^2.
- A linked tweet pointed out counterintuitive results showing periodic steps could yield better rates than previously thought systems.
Links mentioned:
- Improving Line Search Methods for Large Scale Neural Network Training: In recent studies, line search methods have shown significant improvements in the performance of traditional stochastic gradient descent techniques, eliminating the need for a specific learning rate s...
- Disentangling Adaptive Gradient Methods from Learning Rates: We investigate several confounding factors in the evaluation of optimization algorithms for deep learning. Primarily, we take a deeper look at how adaptive gradient methods interact with the learning ...
- Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model: Increasing the batch size is a popular way to speed up neural network training, but beyond some critical batch size, larger batch sizes yield diminishing returns. In this work, we study how the critic...
- Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling: In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically upda...
- Tweet from Ben Grimmer (@prof_grimmer): I've proven the strangest result of my career.. The classic idea that gradient descent's rate is best with constant stepsizes 1/L is wrong. The idea that we need stepsizes in (0,2/L) for conve...
- Eleuther copy of Uncovering limits of data-parallel scaling: Uncovering limits of data-parallel scaling 11 Nov 2024 Motivation TLDR; we need to know how AI training loads scale horizontally. Tools required to do this estimation do not exist in the open-source....
Eleuther ▷ #lm-thunderdome (5 messages):
Custom Task IssuesLimit Samples in EvaluationMetrics in YAML Configuration
-
Issue Resolved with Custom Task: A member reported resolving their issue related to a custom task after forgetting to include the multiple choice tag in the YAML file.
- NVM I found the issue was their response following the initial confusion.
- Using --limit N for Sample Evaluation: Another member highlighted that using
--limit Ncan effectively limit the number of samples evaluated.
- This method provides flexibility in adjusting the scope of evaluation to better manage tasks.
- Challenges with Metrics in YAML: A user expressed difficulties in including both acc_norm and exact_match metrics in the same YAML configuration for a new QA task.
- They sought help and asked for any similar tasks that managed to include these two metrics together.
Perplexity AI ▷ #general (230 messages🔥🔥):
Perplexity Technical IssuesUser Experience with PerplexityPerplexity Pro Subscription DetailsPerplexity Model ComparisonFeedback on Mac App and Features
-
Perplexity Users Frustrated by Ongoing Technical Issues: Users expressed dissatisfaction over persistent technical issues, particularly the hidden messages bug in long threads that remains unresolved while other bugs seem to have been fixed.
- Comments noted that the app has been facing multiple issues for over a month, severely impacting user experience.
- Clarification Needed on Perplexity Pro Subscription: A user inquired about the status of their free year of Perplexity Pro, asking if it would continue after expiration and the implications for the R1 device.
- Responses confirmed that the subscription would not remain free post-trial, and users would revert to limited free searches.
- Comparison of Perplexity Models: There is ongoing discussion about which Perplexity model performs best, with users noting that gpt-o seems to be the most effective for some tasks.
- Opinions vary, with comments mentioning that o1 has limited applications despite being specialized.
- Users Reporting UI Issues in Mac App: Several users reported UI problems with the Mac version of the Perplexity app, highlighting the absence of a scrollbar making navigation cumbersome.
- Complaints also included ongoing issues with Google sign-in and missing features present in the web app.
- Discussion about External Tools and Extensions: Users shared experiences using browser extensions and other tools with Perplexity, noting how it can enhance functionality without directly violating terms.
- There was curiosity surrounding how these extensions impact performance and features, particularly in relation to ongoing technical limitations.
Links mentioned:
- The Anatomy of a Search Engine: no description found
- Tweet from Phi Hoang (@apostraphi): no description found
- Chat-with-OpenAI-o1 - a Hugging Face Space by yuntian-deng: no description found
- Doctorevil No GIF - Doctorevil No - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (12 messages🔥):
US NATO MembershipBitcoin Market PredictionsTSMC Chip ShipmentsChina vs US Trade WarAI Winter Trends
-
Is the USA part of NATO?: A member shared a link discussing the involvement of the USA in NATO, focusing on historical context and current relevance.
- This resource explores the implications of the USA's NATO commitments amid evolving global dynamics.
- Bitcoin expected to reach $100,000 by 2024: Discussion erupted over a prediction that Bitcoin could hit $100,000 by the end of 2024.
- Members shared their mixed feelings, fueling debate about market trends and investment strategies.
- TSMC halts Chinese chip shipments: A YouTube video titled 'TSMC Halts Chinese Chip Shipments, Beatles Make AI History...' highlights significant disruptions in the chip market.
- The episode details wider implications for technology and trade, urging viewers to reflect on industry shifts.
- Insights on the US-China Trade War: A member posted a link providing an overview of the US-China trade conflict, outlining key events and impacts.
- This resource serves as a timely reminder of ongoing tensions affecting international markets.
- The History of AI Winter: A link discussing AI Winter trends over the years was shared, analyzing the cyclical nature of AI hype and disappointment.
- Members reflected on historical patterns, considering whether we are approaching another phase of stagnation.
Link mentioned: TSMC Halts Chinese Chip Shipments, Beatles Make AI History with Grammy Noms, and How the Body Sto...: What would you like to see more of? Let us know! (https://www.buzzsprout.com/twilio/text_messages/2302487/open_sms) In today's episode, we explore TSMC's sig...
Perplexity AI ▷ #pplx-api (3 messages):
Pplx API DailyBot Custom Command EditorAI LimitationsWebhook ImplementationCodeSandBox VM Usage
-
Inquiry about Pplx API DailyBot Command Editor: A team member inquired if anyone has experience with implementing the Pplx API DailyBot custom command editor and requested basic guidance to start the project.
- Another member humorously suggested using AI for assistance, reflecting the uncertainty around the implementation.
- AI struggle with DailyBot Commands: malagoni31 expressed frustration that various AIs, including OpenAI and Claude, fail to offer accurate guidance on the DailyBot's built-in commands.
- They highlighted a workaround using CodeSandBox's VM, involving webhooks to retrieve information from a forwarded port for processing.
- Webhook Retrieval Process Explained: The workaround involves requesting code via a webhook to get information from the forwarded port and using another code in the DailyBot editor to process it.
- Ultimately, the prompt is returned in a Discord chat, showing a creative integration approach amidst challenges.
- Seeking alternative solutions: malagoni31 requested the community's input on whether anyone knows a better way to implement the DailyBot command editor.
- They emphasized the value of any shared knowledge on whether the current approach is feasible or if enhancements exist.
Unsloth AI (Daniel Han) ▷ #general (135 messages🔥🔥):
Qwen 2.5 Coder finetuningUse of datasets for improvementUnsloth model fixesFunction calling in modelsChat history and memory retention
-
Qwen 2.5 Coder finetuning resources available: A new finetuning notebook for the Qwen 2.5 Coder (14B) is available, allowing users to finetune the model for free on Colab, with improvements in efficiency.
- Unsloth provides 60% less VRAM usage and has extended context lengths from 32K to 128K.
- Dataset size for noticeable improvement: It was advised that a dataset should ideally contain at least 100 rows, with 300+ rows recommended for better results when finetuning models.
- Selecting quality datasets like the starcoder dataset was suggested for enhancing software quality metrics.
- Bug fixes for Qwen 2.5 models: Recent bug fixes were announced for the Qwen 2.5 models, detailing issues like improper pad tokens leading to infinite generations.
- Users were encouraged to use Unsloth versions for accurate results, as various untrained tokens in past models have been addressed.
- Function calling capability: There was a discussion on whether Unsloth supports function calling natively, with confirmation that unsloth inference does not support it directly.
- Training for function calling is possible, and models with certain tokenizer configurations might assist in this regard.
- Chat history and memory management: To achieve memory retention of prior conversations, users were advised to develop or use existing systems that store or query chat history for context.
- For immediate context, it was suggested to construct chat history with the correct template for the model in use.
Links mentioned:
- Google Colab: no description found
- Qwen2.5 Coder Artifacts - a Hugging Face Space by Qwen: no description found
- unsloth/Qwen2.5-Coder-0.5B · Hugging Face: no description found
- Qwen 2.5 Coder All Versions - a unsloth Collection: no description found
- Tweet from Unsloth AI (@UnslothAI): You can finetune Qwen-2.5-Coder-14B for free on Colab now! Unsloth makes finetuning 2x faster & uses 60% less VRAM with no accuracy loss. We extended context lengths from 32K to 128K with YaRN & upl...
- Tweet from ifioravanti (@ivanfioravanti): Qwen 2.5 Coder Q4 M4 Max Inference test. Apple MLX vs Ollama: - MLX: 23.97 toks/sec 🥇🔥 - Ollama: 18.33 toks/sec 🥈 Here a video to show results
- Tim And Eric Awesome Show GIF - Tim And Eric Awesome Show Kisses - Discover & Share GIFs: Click to view the GIF
- Google Colab: no description found
- Tweet from Daniel Han (@danielhanchen): Bug fixes & analysis for Qwen 2.5: 1. Pad_token should NOT be <|endoftext|> Inf gens 2. Base <|im_start|> <|im_end|> are untrained 3. PCA on embeddings has a BPE hierarchy 4. YaRN ...
- optillm/optillm.py at main · codelion/optillm: Optimizing inference proxy for LLMs. Contribute to codelion/optillm development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #off-topic (27 messages🔥):
Diet ChoicesMeal FrequencyKeto Diet
-
One Meal a Day is Satisfying: A member shared that they only eat once a day, primarily consisting of meat with some vegetables, taking about 5-6 minutes to prepare.
- They noted that while being younger allowed for a more flexible diet, it has changed as they've aged to focus more on protein over carbs.
- Keto Diet Insights: Another participant discussed their keto-based diet, emphasizing the lack of carbohydrates and the need for protein-rich meals.
- They mentioned that it's important to swap food options occasionally to maintain balance in the diet.
- Salads and Fiber for Health: A member suggested incorporating mixed salads to reduce carbohydrates while increasing protein and fiber intake.
- They highlighted that nourishing gut bacteria is crucial for overall health, and oats in the morning can help reduce appetite.
- Are You Hungry Eating Once a Day?: In response to the one meal a day discussion, a member questioned if they feel hungry eating this way.
- The original member confidently stated that they do not feel hungry at all with this meal frequency.
Unsloth AI (Daniel Han) ▷ #help (49 messages🔥):
Model Saving and CheckpointsRAM Usage During TrainingFine-tuning PracticesData Formatting for ModelsTraining Dataset Size and Performance
-
Saving checkpoints and using adapters: One user successfully integrated the adapter model on top of the base model for inference using the PeftModel class, highlighting the need to build the adapter first.
- The solution involved specifying the checkpoint path while loading the model for inference or further training.
- Managing RAM usage during training runs: A user reported increasing RAM usage while running Gemma 2B, suggesting potential issues with evaluation impacting memory consumption.
- Another user inquired whether evaluation was being conducted, hinting that this might exacerbate memory demands.
- Best practices for fine-tuning: When fine-tuning the Qwen model with a custom dataset, ensuring the merging of LoRA adapters with the base model before saving is critical for deployment.
- Users discussed the progression of fine-tuning models to avoid catastrophic forgetting and maintain performance.
- Formatting data for model training: A discussion unfolded around using ShareGPT format for training data, with adjustments made for optimal performance during prediction.
- Users explored potential template formats to improve consistency in predictions across different model types.
- Visualizing training loss: Suggestions were made to utilize tools like WandB or TensorBoard to visualize training and validation loss while fine-tuning models.
- These tools can assist users in tracking performance metrics throughout the training process.
Link mentioned: Errors | Unsloth Documentation: To fix any errors with your setup, see below:
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
Integration CallsInference StrategiesFast Apply ModelCommunity Interaction
-
Integration Call Offer: A member offered to discuss integration opportunities and encouraged others to book a call here. The invitation extended to anyone interested in such discussions, adding a light-hearted note about doxxing themselves.
- Just shoot the shit or contact them via messaging for casual conversations, though they may not respond quickly.
- Strategies for Faster Inference: Another member shared strategies for improving inference speed, including speculative decoding, using FP8 or int8 instead of BF16, and implementing custom optimized CUDA kernels. They also mentioned tensor parallelism as a method to enhance speed, albeit at the cost of throughput.
- Some providers, like qroq and Cerebras, have developed custom hardware to further optimize performance.
- LoRA Fine-tuning with Unsloth: In response to a question on VSCode performance, codelion_ recommended using a LoRA fine-tuned model called Llama-3.2-1B-FastApply for faster inference. They provided sample code to use Unsloth for loading the adapter and enabled faster inference natively.
- The suggested model efficiently works with both original and modified code, showcasing improved execution speed due to its smaller size.
Links mentioned:
- patched-codes/Llama-3.2-1B-FastApply · Hugging Face: no description found
- Zoom Scheduler): no description found
Unsloth AI (Daniel Han) ▷ #research (14 messages🔥):
Tuning thoughts vs. outputsAnalysis of wrong outputsChain of Thought (COT) errorsGenerating profound tweets
-
Exploring Tuning Thoughts Separately: A discussion arose questioning the feasibility and meaning of tuning thoughts separately from outputs in AI models.
- The consensus leaned towards the idea that separating these could indeed have significance in generating better results.
- Bad Outputs Indicate Thinking Issues: It's pointed out that a bad output typically signifies flawed thinking, suggesting that errors in the Chain of Thought (COT) usually contribute to incorrect conclusions.
- A member emphasized that a model reaching a wrong conclusion indicates that the steps in the COT were erroneous.
- Models and Wrong Conclusions: The conversation highlighted that it's more problematic for a model to produce a conclusion that contradicts the thought process rather than arrive at a wrong answer based on flawed reasoning.
- This counters the notion that outputs should always align with the initial thought process, acknowledging the complexities involved.
- Generating Profound Posts: A suggestion was made about crafting prompts that could blend science with spiritual themes to create profound tweets.
- This idea indicates a creative way to generate content that connects disparate domains, provoking deeper discussion.
aider (Paul Gauthier) ▷ #general (155 messages🔥🔥):
Qwen 2.5 Coder PerformanceAider Installation and UsageModel ComparisonContext Handling in AiderFeature Suggestions for Aider
-
Qwen 2.5 outperformed by Sonnet: While Qwen 2.5-Coder-32B shows decent performance, it currently trails behind Claude 3.5 Sonnet in complex tasks, with a score of 73.7% compared to Sonnet's 84.2%.
- Users noted that while Qwen models are improving, they still exhibit placeholder responses that can hinder coding efficiency and completeness.
- Installing Aider Made Easier: Aider installation procedures were discussed, emphasizing the need for Python 3.9-3.12 and git installation as prerequisites.
- Users were directed toward the official Aider installation guide for assistance.
- Evaluating the Need for Vectorization: The potential for improving Aider's context management by vectorizing and reranking read-only Markdown files was brought up, especially when dealing with extensive project documentation.
- A member expressed challenges fitting multiple detailed files as context and sought solutions for better searching and management within their projects.
- Feature Requests for Aider: Users have expressed the desire for specific improvements in Aider, such as eliminating lazy responses and enabling CLI command execution.
- Suggestions included creating conventions files to guide coding behaviors and potentially modifying system prompts for better performance.
- Performance Comparisons of AI Models: Comparisons between various models revealed that Qwen 2.5-Coder performs reasonably but still lags behind models such as DeepSeek and GPT-4o on certain tasks.
- Scores from the Aider leaderboard show that adjustments in model configurations could improve performance outcomes for specific coding tasks.
Links mentioned:
- Installing aider: aider is AI pair programming in your terminal
- Specifying coding conventions: Tell aider to follow your coding conventions when it works on your code.
- Qwen2.5 Coder 32B Instruct – Run with an API: Sample code and API for Qwen2.5 Coder 32B Instruct - Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Qwen2.5-Coder brings the following imp...
- Qwen/Qwen2.5-Coder-32B-Instruct · Hugging Face: no description found
- YaRN: Efficient Context Window Extension of Large Language Models - AI Resources: YaRN (Yet another RoPE extensioN method) is a compute-efficient method for extending the context window of large language models using Rotary Position Embeddings (RoPE). It achieves this with signific...
- Aider LLM Leaderboards: Quantitative benchmarks of LLM code editing skill.
- Qwen2.5 Coder 32B Instruct - API, Providers, Stats: Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Run Qwen2.5 Coder 32B Instruct with API
- Qwen2.5 Speed Benchmark - Qwen: no description found
- Models | OpenRouter: A table of all available models
- Provider Routing | OpenRouter: Route requests across multiple providers
- Claude 3.5 Sonnet - API, Providers, Stats: New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Run Claude 3.5 Sonnet with API
- cline/src/core/prompts/system.ts at main · cline/cline: Autonomous coding agent right in your IDE, capable of creating/editing files, executing commands, using the browser, and more with your permission every step of the way. - cline/cline
- YaRN: Efficient Context Window Extension of Large Language Models | Continuum Labs: Nous Research, EleutherAI, University of Geneva
- GitHub - QwenLM/Qwen2.5-Coder: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud.: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen2.5-Coder
aider (Paul Gauthier) ▷ #questions-and-tips (49 messages🔥):
Aider Configuration WarningsOpenRouter API UsageBenchmarking ModelsPing Settings in AiderArchitect Mode Functionality
-
Aider Configuration Warnings Causes Confusion: A user inquired about Aider not picking up configuration parameters, with another member explaining that if the Ollama server isn't running or the API base isn't set, warnings can appear instead of specific error messages.
- For issues with model recognition, the community suggested specifying correct model names and pointed to ongoing bugs with Litellm that may cause spurious warnings.
- Handling OpenRouter API Calls: One user faced issues with their benchmark script connecting to the llama-server, indicating the model name was not recognized by the LLM proxy, which they discovered after extensive troubleshooting.
- Another member suggested that the
.aider.model.metadata.jsonfile has little effect on Aider's functionality aside from cost reporting, allowing users to dismiss it if necessary. - Benchmarking the New Qwen32b Coder Model: A user was preparing to run benchmarks on the new Qwen32b Coder model but struggled with the benchmark script linking to their llama-server.
- They identified model name recognition as the main issue, allowing them to proceed with launching benchmarks after making adjustments.
- Understanding Aider's Ping Settings: A discussion emerged about the
pingsetting for Aider, with one user realizing that leaving the application open could quickly consume credits on OpenRouter.
- It was clarified that configuring a high number of pings prompted others to advise reducing the count to avoid unnecessary credit usage.
- Architect Mode Support in Browser: A user asked if architect mode is compatible with the browser version of Aider, which was met with humor highlighting preferences for configuring Aider appropriately.
- The community acknowledged the behavior of Aider in following user configurations, which led to lighthearted expressions about user responsibility in settings.
Links mentioned:
- Model warnings: aider is AI pair programming in your terminal
- Options reference: Details about all of aider’s settings.
- [Bug]: get_model_info() blows up for ollama models? · Issue #6703 · BerriAI/litellm: What happened? Calls to litellm.get_model_info() with ollama models raise an exception. I can run litellm.completion() just fine with those models. $ pip freeze | egrep 'litellm|ollama' litell...
- aider thinks model is unknown and asks if I meant *The exact same model* · Issue #2318 · Aider-AI/aider: Warning for ollama/vanilj/supernova-medius:q6_k_l: Unknown context window size and costs, using sane defaults. Did you mean one of these? - ollama/vanilj/supernova-medius:q6_k_l You can skip this c...
aider (Paul Gauthier) ▷ #links (2 messages):
Copilot EditsCursor and SupermavenAI Partnership
-
GitHub Copilot Edits Revolutionizes VS Code: The Copilot Edits feature combines inline code completions with conversational capabilities, allowing for fast editing across multiple files in VS Code.
- This tool enhances workflow by letting developers specify files and provide natural language commands for code modifications.
- SupermavenAI Joins Cursor: Cursor announced on Twitter that SupermavenAI is now part of the team, aiming to establish Cursor as a leader in research and product development.
- The partnership aims to leverage both companies' expertise to enhance Cursor's offerings, as highlighted in this tweet.
Links mentioned:
- Tweet from Cursor (@cursor_ai): We are excited to announce that @SupermavenAI is joining Cursor! Together, we will continue to build Cursor into a research and product powerhouse. (1/5)
- Introducing Copilot Edits: Copilot Edits allows you to get to the changes you need in your workspace, across multiple files, using a UI designed for fast iteration. You can specify a set of files to be edited, and then use natu...
Interconnects (Nathan Lambert) ▷ #news (62 messages🔥🔥):
Qwen 2.5 CoderDario Amodei on AI ScalingNous Research Forge APIAnthropic Team UpdatesOpenAI o1 Release
-
Qwen 2.5 Coder's Impressive Token Count: Qwen 2.5 Coder has continuously pretrained from Qwen 2.5, now reaching a staggering 23.5 trillion tokens, making it the first open weights model to surpass the 20 trillion mark.
- Users have noted the extensive compute resources required for this model, indicating the scale of its development.
- Dario Amodei Discusses AI Scaling: In a recent podcast, Dario Amodei emphasized the observed scaling across various modalities, suggesting the potential for human-level AI by 2026-2027, albeit with some uncertainties.
- He also highlighted the importance of ethical and nuanced behavior in AI systems during their scaling discussions.
- Launch of Nous Research's Forge Reasoning API: Nous Research announced the Forge Reasoning API Beta, aiming to improve inference time scaling applicable to any model, promising enhanced performance for the Hermes 70B model.
- There are concerns about consistency in reported benchmarks, leading to doubts about the reliability of their performance metrics.
- Anthropic Welcomes New Team Member: A notable team update revealed that Hailey Schulz is joining AnthropicAI after two years at Eleuther AI, indicating movement of talent within the industry.
- This sparked discussions about the dynamics of hiring in AI companies and a desire for more robust teams at alternative organizations.
- Anticipation Surrounding OpenAI's o1 Release: Speculation builds around OpenAI's planned full release of the o1 reasoning model by the end of the year, based on insights from anonymous sources.
- The details surrounding this release have captivated community attention, particularly about the backgrounds of the teams involved in development.
Links mentioned:
- Tweet from Stephanie Palazzolo (@steph_palazzolo): New w/ @erinkwoo: At least 1 OpenAI researcher has taken up ex-CTO Mira Murati's offer to join her new startup, which she's working on with former OAI researchers Barret Zoph and Luke Metz. A...
- Tweet from Andrew Carr (e/🤸) (@andrew_n_carr): Qwen2.5-Coder-32B-Instruct is the 2nd best poetry model after O1-preview 🤯
- Tweet from lmarena.ai (formerly lmsys.org) (@lmarena_ai): Which model is best for coding? @CopilotArena leaderboard is out! Our code completions leaderboard contains data collected over the last month, with >100K completions served and >10K votes! Le...
- Tweet from Xeophon (@TheXeophon): @gm8xx8 These are Nous‘ numbers from the 3 release. The reported numbers for the 70B model don’t match the graphic as well - MMLU-Pro (Release) 47.24 vs 54.14 now Am I missing something super obviou...
- Tweet from Hailey Schoelkopf (@haileysch__): Major life update: I'm joining @AnthropicAI this week! Looking forward to meeting and working with the amazing team there! I’m beyond thankful for an amazing 2 years with my colleagues and colla...
- Tweet from Teortaxes▶️ (@teortaxesTex): I've clarified just to be sure. Qwen 2.5 Coder is continuously pretrained from Qwen 2.5. This, I conclude it has seen 23.5 trillion tokens (18T of the general purpose mix and now 5.5T of Code:Text...
- Tweet from Binyuan Hui (@huybery): 💪 I exhausted all my strength to give you the best. Quoting Qwen (@Alibaba_Qwen) 🚀Now it is the time, Nov. 11 10:24! The perfect time for our best coder model ever! Qwen2.5-Coder-32B-Instruct! ...
- Tweet from deepfates (@deepfates): honestly he kind of cooked here
- Qwen2.5-Coder Technical Report: In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes six models: Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B). As a code-spec...
- He Admit It Admit GIF - He Admit It Admit It Admit - Discover & Share GIFs: Click to view the GIF
- Tweet from Nous Research (@NousResearch): Today we are launching the Forge Reasoning API Beta, an advancement in inference time scaling that can be applied to any model or a set of models, for a select group of people in our community. https...
- Tweet from Aidan McLau (@aidan_mclau): i'm crying
- Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity | Lex Fridman Podcast #452: Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris...
Interconnects (Nathan Lambert) ▷ #ml-questions (7 messages):
SPARC modelVLM techniquesClaude's OCR capabilitiesRecent VLM articlesFinbarr blog
-
SPARC Model Introduces New VLM Technique: In a video, Jovana Mitrović discusses the SPARC model, which aligns text representations with specific image patches instead of whole images, diverging from traditional methods like CLIP.
- This begs the question of why more VLMs aren't using similar techniques, with concerns on how SPARC's training influences representations of individual patches.
- VLMs Enable Advanced OCR Capabilities: A member noted their surprise at how capable VLMs have become in reading text from images, making traditional tools like Tesseract and ABBYY FineReader seem outdated.
- They attributed this shift to advancements in VLM technology inspired by Claude's effectiveness in converting screenshots to LaTeX.
- Exploration of Recent VLM Papers: On their quest to deepen their understanding of VLMs, a member has been consuming literature, mentioning delays in their writing due to the release of new VLMs like Pixtral and DeepSeek Janus.
- They expressed enthusiasm for the evolving landscape of VLM research sparked by recent outputs.
- Recommendation for Finbarr Blog: One member prompted another to read the Finbarr blog on VLMs, highlighting its relevance and importance in understanding this domain.
- Further discussions led to sharing of recent articles, including a high-level overview by Sebastian Raschka that fueled additional interest.
Links mentioned:
- Papers I've read this week: vision language models: They kept releasing VLMs, so I kept writing...
- [EEML'24] Jovana Mitrović - Vision Language Models): no description found
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
an1lam: Semi-relevant but a bit funny, I think I walked by Gary last night on the street
Interconnects (Nathan Lambert) ▷ #random (2 messages):
ICLR Review ProcessReviewer Feedback
-
ICLR Reviewers Bring the Heat: A member remarked that the feedback from ICLR reviewers can be quite brutal, expressing uncertainty about whether they are being too lenient or just not grasping the complexities of the submissions.
- ICLR reviewers are known for their rigorous standards, raising questions about the balance between kindness and critical assessment in feedback.
- Advice to Ignore the Naysayers: Another member advised to simply ignore the distractions from others by stating, 'Just ignore the yappers'.
- This reflects a common sentiment in academic circles to focus on constructive criticism rather than get bogged down by noise.
Interconnects (Nathan Lambert) ▷ #nlp (5 messages):
Neural Notes episodeStanford MIPRO optimizersEugene Charniak Memorial SymposiumAutomated prompt optimization
-
Neural Notes explores language model optimization: The latest episode of Neural Notes features Vertex Ventures investors discussing advancements in language model optimization with Krista Opsahl-Ong, a PhD candidate at Stanford's AI Lab.
- While it hasn't been watched yet, it received positive feedback from the community for its insights into automated prompt optimization.
- Stanford researchers contribute to MIPRO optimizers: A mention of an interview with a Stanford researcher involved in the MIPRO optimizers used in DSPy highlights growing interest in automation within prompt optimization.
- The speaker expressed eagerness to learn more about DSPy to form a comprehensive understanding of the subject.
- Eugene Charniak Memorial Symposium showcases NLP talent: Brown University recently held a symposium honoring Eugene Charniak, featuring many influential NLP researchers.
- The event attracted attention for its focus on both NLP and linguistics, fostering discussions on related advancements in the field.
Link mentioned: Neural Notes: The future of language model optimization: In this episode of Neural Notes, Vertex Ventures US investors Sandeep Bhadra and Simon Tiu talk to Krista Opsahl-Ong, PhD Candidate at Stanford's AI Lab (SAI...
Interconnects (Nathan Lambert) ▷ #reads (62 messages🔥🔥):
Scaling laws and model quantizationDylan Patel's inference insightsAI local running challengesPerformance expectations of LLaMA modelsImpact on datacenter infrastructure
-
Scaling laws reveal quantization limits: A new study indicates that as models are trained on more tokens, they require increased precision for quantization, which could have significant implications for the future of GPUs and AI models.
- This research suggests that further increases in pretraining data might negatively affect the quantization process, particularly for models like LLaMA-3.
- Dylan Patel discusses AI Megaclusters: Dylan Patel's recent lecture at Stanford covers inference mathematics and the growing significance of AI megaclusters, highlighting current developments in AI infrastructure.
- A member expressed interest in attending Stanford classes while keeping track of developments in the datacenter situation addressed by Patel.
- Challenges of running Qwen 2.5 locally: There are concerns regarding the feasibility of running Qwen 2.5 coder on local machines as it has been trained on over 20 trillion tokens, suggesting heavy hardware requirements.
- It was noted that using full BF16 precision will demand a high-spec machine, such as a 128GB MacBook, raising concerns for those with less powerful devices.
- Perceptions of performance in AI models: Participants discussed the difficulty a number of models, including LLaMA-3, have faced in quantization compared to previous models like LLaMA-2, indicating a potential plateau in performance expectations.
- Users reflected on the broader implications of increased token training and how quantization may influence model capabilities.
- Impacts on datacenter infrastructure: The growing necessity for more powerful hardware like the latest 128GB Macs illustrates the evolving demands of AI applications and the associated datacenter challenges.
- Conversations hinted at a potential bottleneck in scaling and running large models due to the increased hardware requirements for optimal performance.
Links mentioned:
- Tweet from Nathan Lambert (@natolambert): There are a lot of discussion on if "scaling is done," with stories from the Information saying that the latest GPT models aren't showing what OpenAI wanted while Sam Altman still parades ...
- Tweet from Tim Dettmers (@Tim_Dettmers): This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you ne...
- Dylan Patel - Inference Math, Simulation, and AI Megaclusters - Stanford CS 229S - Autumn 2024: Website: https://scalingintelligence.stanford.edu/Github: https://github.com/ScalingIntelligenceHuggingFace: https://huggingface.co/ScalingIntelligence
OpenRouter (Alex Atallah) ▷ #announcements (8 messages🔥):
Qwen2.5 Coder 32BGemini models updatesScheduled Downtime
-
Qwen2.5 Coder 32B surpasses competitors: New high-performing open-source model, Qwen2.5 Coder 32B, is out and reportedly beats Sonnet and GPT-4o at several coding benchmarks, as noted in a tweet from OpenRouter.
- However, some members raised concerns about the accuracy of these claims, suggesting that tests like MBPP and McEval might be deceptive.
- Gemini models get new features: Gemini 1.5 Flash, Pro, and 8B models now incorporate frequency penalty, presence penalty, and seed adjustments, as detailed in the official update from OpenRouter.
- Links to further information include Gemini Flash 1.5 8B and Gemini Pro 1.5.
- Scheduled Downtime Notification: A notice announced a scheduled 5-minute downtime at 9:30 AM EST, indicating that services would be back online shortly after.
- The upgrade concluded successfully in less than a minute; users were thanked for their patience during the downtime.
Links mentioned:
- Tweet from undefined: no description found
- Tweet from OpenRouter (@OpenRouterAI): New, high-performing open-source model from @Alibaba_Qwen: Qwen2.5 Coder 32B! Beats Sonnet and GPT-4o at several coding benchmarks. Great pricing from @hyperbolic_labs and @FireworksAI_HQ Quoting D...
- Gemini Flash 1.5 - API, Providers, Stats: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
- Gemini Flash 1.5 - API, Providers, Stats: Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video...
- Gemini Pro 1.0 - API, Providers, Stats: Google's flagship text generation model. Designed to handle natural language tasks, multiturn text and code chat, and code generation. Run Gemini Pro 1.0 with API
OpenRouter (Alex Atallah) ▷ #general (107 messages🔥🔥):
Gemini 1.5 Flash updatesQwen 2.5 Coder performanceAnthropic's computer use toolModel knowledge limitationsOpenRouter pricing and features
-
Gemini 1.5 Flash shows improvement: Users noted that Gemini 1.5 Flash appears to have improved its performance, particularly when using it at temperature 0.
- One member speculated it might be an experimental version being used on Google AI Studio.
- Excitement around Qwen 2.5 Coder: Members expressed excitement over trying the Qwen 2.5 32B Coder, noting that recent prices have become more favorable, around a dollar per million tokens.
- One user stated they had previously resorted to using DeepSeek due to higher costs.
- Anthropic's computer use tool compatibility: Discussion arose about whether Anthropic's new computer use tool works with OpenRouter, with confirmation that it does not currently support it.
- It was mentioned that a special beta header is required, which is not supported via OpenRouter yet.
- Models lacking knowledge of specific content: Concerns were raised regarding models like Hunyuan and Qwen, Yi, which reportedly lack critical knowledge about Western media and copyright issues.
- Users noted differences in performance, with some models managing to handle copyright content better than others.
- OpenRouter pricing structure: It was clarified that using OpenRouter may incur around 5% additional costs for tokens through credits, as per their terms of service.
- This raised questions from users regarding the transparency of pricing and how it compares when using models directly.
Links mentioned:
- no title found: no description found
- Models Overview | Mistral AI Large Language Models: Mistral provides two types of models: free models and premier models.
- Qwen2.5 Coder 32B Instruct - API, Providers, Stats: Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Run Qwen2.5 Coder 32B Instruct with API
- Magnum v4 72B - API, Providers, Stats: This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet(https://openrouter.ai/anthropic/claude-3. Run Magnum v4 72B with API
- OpenRouter: LLM router and marketplace
OpenRouter (Alex Atallah) ▷ #beta-feedback (6 messages):
Custom Provider Keys Access
-
General Request for Custom Provider Keys Access: Multiple users have expressed interest by requesting access to custom provider keys for beta testing.
- One member noted that this access would help them navigate Google's rate limit issues.
- Heightened Interest in Custom Provider Keys: A total of five users have requested access, showcasing a strong interest in custom provider keys within the community.
- Several users mentioned their hopes to utilize these keys for better functionality in their projects.
OpenAI ▷ #ai-discussions (50 messages🔥):
TTS alternativesApplication development with AIQwen2.5-Coder modelKitchenAI projectLanguage model quirks
-
Exploring TTS Alternatives: Members discussed various text-to-speech (TTS) solutions, with one recommending f5-tts as a viable option that functions on consumer GPUs.
- While there were inquiries about timestamp data capabilities, suggestions included focusing on low-cost solutions.
- AI Interaction App Development: A user detailed their challenges in programming an app for verbal interactions with an AI, facing issues with the speech_recognition module and server recognition.
- One suggested using the browser version of ChatGPT for easier text selection on mobile devices.
- Introduction to Qwen2.5-Coder Model: The new Qwen2.5-Coder model was highlighted for its open-source code capabilities, showcasing its competitive edge against models like GPT-4o.
- Links were shared for GitHub, Hugging Face, and ModelScope to access the model and its demos.
- KitchenAI Open Source Project: A member shared their open-source project called KitchenAI and was seeking developers to contribute.
- They mentioned their outreach efforts on Discord and Reddit to find interested developers.
- Unexpected Language Switch in AI: A user noted a peculiar instance of the AI switching to Korean unexpectedly, prompting a discussion about this phenomenon.
- Others shared similar experiences, suggesting that the AI might default to languages it finds most natural in context.
Links mentioned:
- Qwen2.5-Coder Series: Powerful, Diverse, Practical.: GITHUB HUGGING FACE MODELSCOPE KAGGLE DEMO DISCORD Introduction Today, we are excited to open source the “Powerful”, “Diverse”, and “Practical” Qwen2.5-Coder series...
- GitHub - epuerta9/kitchenai: Shareable runtime AI cookbooks: Shareable runtime AI cookbooks. Contribute to epuerta9/kitchenai development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (10 messages🔥):
Access Issues with ChatGPTReport on Blocking AgenciesFrustrations with DALL-E Image GenerationDisappearing Document Issues in aiHa GPT
-
ChatGPT access issues on Chrome: A user reported that they were locked out of ChatGPT while using Chrome, although it worked fine on Microsoft Edge, raising concerns about potential tampering or safety measures.
- I never once violated community rules, the user stated, suggesting their inputs were ethical and relevant.
- Blocking intelligence agencies with PowerShell scripts: The same user mentioned generating PowerShell scripts to block the IP ranges of various intelligence agencies, clarifying none of them were American.
- Concerns were expressed regarding the effectiveness of such blocking measures and whether agencies would use VPNs.
- Frustration with DALL-E's limitations: A member vented frustrations about DALL-E's image generation capabilities, stating they often received incorrect results after multiple attempts and hit the conversation limit.
- They questioned whether they were paying to interact with a 'dumb conversation partner' and felt the limits felt more like a scam due to the ineffectiveness.
- User error comments about limitations: A response from another member suggested that the frustrations expressed could be user error, hinting at improvement opportunities for the individual.
- This comment highlights the ongoing discourse about user experiences versus technological limitations in AI applications.
- Disappearing documents in aiHa GPT: A user shared difficulties with their PDF and Docx documents disappearing from the aiHa GPT knowledge base despite multiple uploads from different browsers.
- They noted that all files were under 1MB, indicating it was an unexpected technical issue, further querying if anyone else faced this problem.
OpenAI ▷ #prompt-engineering (21 messages🔥):
Prompt design for GPT-4o miniStructured outputs techniqueResources for prompt engineeringEngagement and relevance in transcripts
-
Clarifying the 30 to 60 seconds prompt: Discussion arose around the clarity of the prompt, debating whether the clip's length should strictly be 30 to 60 seconds or if concatenating multiple clips is acceptable.
- It was suggested that rebuilding the prompt from scratch could help clarify intentions.
- Anomalies in JSON Outputs: Mateusneresrb expressed frustration about the model returning incorrect time intervals when trying to get it to output specified times for selected video snippets.
- Concerns about JSON format implications on the output's correctness were also mentioned.
- Tips for Effective Prompt Writing: Suggestions included using clear and simplified prompts by adjusting length specifications and possibly resorting to token counts for better results.
- A resource link was shared to help improve prompt engineering skills.
- Using Scratchpads in Structured Outputs: Jscheel introduced the concept of using structured outputs alongside scratchpad techniques to enhance inference results.
- Clarification was sought on whether the scratchpad should be integrated as a primary field in structured outputs.
- Expectations for AI-generated Content: A user expressed skepticism about the AI's capability to generate interesting content, but acknowledged potential in collaborative story creation with structured prompts.
- Emphasis was placed on understanding one’s requirements to effectively leverage AI's potential.
OpenAI ▷ #api-discussions (21 messages🔥):
Prompt engineering for GPT modelsClip selection techniquesStructured output usageScratchpad technique
-
Challenges in Prompt Clarity: Members discussed the confusion surrounding the prompt for selecting clips from transcripts, particularly whether to focus on 30-60 second segments or allow any length.
- One member suggested rewriting the prompt from scratch for better clarity while another pointed out that AI may struggle due to unclear instructions.
- Suggestions for Effective Prompting: There were recommendations for using websites on prompt best practices, including a link to OpenAI's prompt engineering guide.
- Members also exchanged thoughts on the possibility of using token counts instead of seconds to select relevant content segments.
- Comments on Collaboration with AI: A member expressed skepticism about AI's ability to create interesting content but acknowledged potential for collaboration between humans and AI using scene-based prompting.
- They noted that examining and modifying scene outputs together could lead to engaging storytelling.
- Scratchpad Technique Discussion: A member introduced the concept of the 'scratchpad' technique for improving inference results and expressed interest in integrating it with structured outputs.
- They sought suggestions on whether to make the scratchpad the first field in their structured output format.
Modular (Mojo 🔥) ▷ #general (41 messages🔥):
Nvidia CUDA in WSL2Higher Level InteroperabilityWASI and Edge ComputingApplication Plugins and PerformanceCRABI ABI Proposal
-
Nvidia CUDA Driver Challenges in WSL2: Discussion highlighted that the CUDA driver on Windows is stubbed in WSL2 as libcuda.so, suggesting potential limitations in accessing the full driver functionalities via Mojo.
- Members noted that this may complicate support for MAX within WSL if it relies on the host Windows driver.
- Exploring CRABI for Higher Level Interfacing: The proposal for CRABI aims to create an ABI for interoperability among higher-level languages like Rust, C++, Mojo, and Zig, allowing them to communicate beyond C's capabilities.
- Participants discussed the challenges regarding integration with languages like Lua and Java, hinting at a need for broader adoption.
- WASI's Role in Edge Computing: WASI was identified as beneficial for edge computing, offering a simpler way to deploy microservices in a sandboxed environment.
- Concerns were raised about the overhead associated with WASI versus traditional approaches, particularly for performance-sensitive applications.
- Performance Considerations for Application Plugins: The group agreed that application plugins are a suitable case for higher level interop given that sensitive performance aspects often reside within the application itself.
- The discussion recognized that while some solutions may introduce overhead, others like Mojo could still hold advantageous positions in plugin markets.
- Telecom's Software-Driven Networking: The conversation pointed out that telecom deployments often rely on software for networking, predominantly using C or C++.
- This indicates an ongoing reliance on traditional systems languages for performance-critical applications in the telecom sector.
Links mentioned:
- no title found: no description found
- Experimental feature gate proposal
crabiby joshtriplett · Pull Request #105586 · rust-lang/rust: Summary This experimental feature gate proposal proposes developing a new ABI, extern "crabi", and a new in-memory representation, repr(crabi), for interoperability across high-level...
Modular (Mojo 🔥) ▷ #mojo (58 messages🔥🔥):
Mojo Installation IssuesMojo SubredditsBenchmark Module FunctionalityDynamic Module ImportingStandard Library Contributions
-
Mojo installation woes resolved: A user faced issues while installing Mojo with a
curlcommand but resolved it by using a corrected URL link provided by another member, which worked successfully.- This highlights the importance of ensuring correct URL entries when installing software packages.
- Discussion on unofficial Mojo subreddits: Although there is no official Mojo subreddit, users discussed two existing subreddits related to Mojo, emphasizing that neither is recognized by Modular.
- One member even suggested reaching out to moderators to pin links for better visibility on mobile.
- Understanding the Benchmark Module: The benchmark module in Mojo is designed to help write fast benchmarks, managing both setup and teardown, as well as handling units for throughput measurements.
- There are some limitations, like unnecessary system calls in hot loops, which potentially impact performance.
- Dynamic module importing challenges: Dynamic importing of modules does not currently exist in Mojo owing to its compilation structure, which bundles everything as constants and functions.
- Shipping the JIT compiler poses potential solutions, albeit with concerns about binary size and compatibility with pre-compiled code.
- Opportunities for contributions to Mojo's stdlib: Members discussed the need for foundational work within Mojo's standard library, particularly in implementing data structures like B-trees.
- This presents a learning opportunity for those with data structure and algorithms knowledge to contribute to the community.
Links mentioned:
- B-tree - Wikipedia: no description found
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
tinygrad (George Hotz) ▷ #general (77 messages🔥🔥):
Hailo Model QuantizationASM2464PD Chip SpecificationsUSB4 PCIe Converter DevelopmentAudio Recording FormatsTinygrad Distributed Systems
-
Hailo Model Quantization Challenges: A member outlined difficulties with Hailo requiring quantized models to run, specifically needing eight-bit quantization which complicates training processes.
- They noted the necessity of a compiled .so for CUDA and TensorFlow to run properly on Hailo, making the setup cumbersome.
- Insights on ASM2464PD Chip: The discussion included the ASM2464PD chip, confirming it can utilize generic PCIe, currently available through various vendors, not just for NVMe.
- Concerns were raised about the power requirements, stating that 70W is typically needed for proper functionality.
- USB4 to PCIe Converter Progress: An open-source USB4/Thunderbolt to M.2 PCIe converter design was shared, demonstrating significant development on GitHub and successful funding for hardware development.
- The creator detailed expectations for the next round of development, hoping to achieve effective USB4 to PCIe integration despite the challenges involved.
- Optimizing Audio Recording Formats: Members discussed using Opus codec for audio recordings, suggesting that it offers significant file size reductions without compromising quality compared to traditional formats.
- Concerns about browser compatibility for Opus were also highlighted, pointing to limitations and the need for additional technology to support it.
- Tinygrad's Distributed Library Aspirations: A user expressed interest in developing a library for Tinygrad focusing on distributed elements like dataloaders and optimizers without relying on existing frameworks like MPI or NCCL.
- They aim to build foundational networking capabilities from scratch, maintaining the interfaces provided by Tinygrad for a seamless experience.
Links mentioned:
- Tweet from John Simons (@johnsel92): Now you can have screeching fast FPGA to PC communication over PCIe gen4x4 with @enjoy_digital's LiteX and a 500$ Alinx Artix Ultrascale+ board.
- Tweet from John Simons (@johnsel92): Finished and sent to @JLCPCB my open source USB4/Thunderbolt to M.2 PCIe converter design based on @ASmedia ASM2464PD. Next up: validation & shrinking the pcb to a stamp size module https://github.com...
- tinycorp_meetings/2024-11-11 at master · geohotstan/tinycorp_meetings: Contribute to geohotstan/tinycorp_meetings development by creating an account on GitHub.
- Use for non NVMe PCIe? · Issue #1 · cyrozap/usb-to-pcie-re: I'm interested in connecting a GPU to a USB port. We're working on a userspace driver for AMD, so that side of it is handled. tinygrad/tinygrad#6923 What we need is the ability to map the PCIe...
- Hailo-8™ M.2 2280 B+M key: Want to add highly efficient AI performance to your UP Squared Pro/UP Squared V2/UP Squared 6000/U...
- Free Transfert: Service d'envoi et de partage de fichiers, simple, gratuit et sécurisé destiné aussi bien aux particuliers qu'aux entreprises.
- Opus Recommended Settings - XiphWiki): no description found
- ThunderboltEX 4|Moederborden|ASUS Nederland: ASUS biedt verschillende soorten moederbordaccessoires, waaronder Thunderbolt™-uitbreidingskaarten, M.2 add-on kaarten, en ventilatoruitbreidingskaarten die DHZ pc-gebruikers betere keuzes geven als h...
- no title found: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
Parallelization without shardingModel serialization on GPUPattern matcher assistance
-
Parallelization without sharding is questioned: One user asked if they could achieve parallelization without sharding while running multiple LLaMa models.
- They also inquired if calling
.realize()on a tensor would block until the GPU completed the calculation. - Discussion on model serialization on a single GPU: Another member clarified the discussion, possibly referring to serialization, where iterations of the same model can run on a single GPU.
- They noted it could be easily implemented in a training loop and mentioned existing support for model mirroring in tinygrad.
- Explainer shared for pattern matcher: A user provided a helpful explanatory link for those struggling with the pattern matcher.
- The resource is part of tinygrad-notes aimed at contributing to the community's understanding of tinygrad functionalities.
- They also inquired if calling
Link mentioned: tinygrad-notes/20241112_pm.md at main · mesozoic-egg/tinygrad-notes: Tutorials on tinygrad. Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
Notebook LM Discord ▷ #use-cases (34 messages🔥):
Using NotebookLM for summarizationExperimenting with podcasts and avatarsIssues with textbook uploadsKATT for fact-checkingPotential of NotebookLM in AI discussions
-
NotebookLM could summarize AI newsletters: One member suggested using NotebookLM to summarize over 200 AI newsletter emails to avoid manually copying and pasting content.
- Gemini button in Gmail was mentioned as a potential aid for summarization but noted not being free.
- Innovative podcasting with avatars: A member shared their experimentation with Google Terms of Service via a 13-minute podcast using avatars and inserted promo breaks.
- This approach is aimed at perfecting podcast formats and managing content better for avatar creation.
- Concerns with textbook uploads: Another member uploaded a textbook as a source but reported poor answer quality from NotebookLM, leading to doubts about its effectiveness.
- Despite improving categorization, there were complaints about NotebookLM struggling with concepts like Michelson-Morley.
- KATT merges old processes with AI: One user discussed incorporating KATT (Knowledge-based Autonomous Trained Transformer) into a fact-checker for their podcast, resulting in a longer episode.
- They described the integration as painful, combining traditional methods with new AI techniques.
- Geared towards podcast clarity: A member's mention of a nucleotide sequence podcast highlighted the importance of using annotated transcripts for better clarity.
- They aim to test the limits of reference sequences for RAG queries to enhance usability.
Links mentioned:
- no title found: no description found
- Steam Gift Activation: no description found
- UNREAL MYSTERIES 5: Behind the Scenes / Making Of: Ever wonder how the Unreal Mysteries show was made? We go full meta, and make an in-universe show about how the show is made. Witness NotebookLM skirting sen...
- Understanding the Google Terms of Service: Demo of how AI and Avatars can add value to the mundane.
- 10 INSANELY Helpful Ways To Use NotebookLM: Welcome to a deep dive into Notebook LM, where I’ll be sharing 10 game-changing ways you can use this tool to make life simpler, faster, and more productive!...
Notebook LM Discord ▷ #general (40 messages🔥):
Exporting Notebooks as PDFUnofficial API for NotebookLMDocument Upload LimitationsNotebook Centralization WorkflowsAudio File Upload Issues
-
Request for PDF Export Feature: Users are inquiring about plans to export notes or notebooks as a .pdf in the future and seeking APIs for notebook automation.
- While some mention alternatives like using a PDF merger, they are eager for native export features.
- Skepticism Around Unofficial API: Discussion emerged around an unofficial $30/month API for NotebookLM, with many expressing suspicion regarding its legitimacy.
- Concerns were raised about the lack of business information and sample outputs, leading some to label it a scam.
- Tips for Handling Document Limits: Members shared tips on managing document limitations in NotebookLM, emphasizing fusing shorter documents to effectively bypass the 50 document limit.
- Some users noted discrepancies in the word count limits, questioning whether longer documents were being ignored during uploads.
- Centralizing Notebooks and Highlights: A user is looking for workflows to centralize notes from various notebooks, with suggestions provided for exporting and combining notes.
- Another user emphasized the need for highlights and comment features within NotebookLM responses for their projects.
- Issues with Audio File Uploads: Users expressed frustration about not being able to upload .mp3 files, with guidance given about proper upload procedures through Google Drive.
- Some noted that other file types uploaded without issues, indicating a potential technical glitch or conversion error.
Links mentioned:
- NotebookLM: La Navaja Suiza de la GenAI: Introducción: El Auge de la GenAI y la Necesidad de una Nueva Herramienta El 2022 quedó marcado en la historia como el año en que la Inteligencia Artificial Generativa (GenAI) irrumpió en la concienci...
- NotebookLM API - AI-Powered Podcast Generation: Create professional podcasts with ease using NotebookLM API. Our advanced AI technology streamlines the podcast production process.
- Steam Gift Activation: no description found
- Top Shelf: Podcast · Four By One Technologies · "Top Shelf" is your go-to podcast for quick, insightful takes on today’s best-selling books. In just 15 minutes, get the gist, the gold, and a fresh pers...
- (15min) Think and Grow Rich by Napoleon Hill - A Fresh Perspective : Top Shelf · Episode
Latent Space ▷ #ai-general-chat (51 messages🔥):
Dario Amodei InterviewMagentic-One FrameworkContext AutopilotWriter Series C FundingSupermaven Joins Cursor
-
Dario Amodei Interview on Lex Fridman: Dario Amodei, CEO of Anthropic, discussed Claude and the future of AI in a 5-hour interview with Lex Fridman.
- The chat highlighted insights into AGI and new developments in AI, garnering significant attention.
- Magentic-One Framework Launch: The Magentic-One framework was introduced, showcasing a multi-agent system designed to tackle complex tasks and outperform traditional models in efficiency.
- It uses an orchestrator to direct specialized agents and is shown to be competitive on various benchmarks source.
- Context Autopilot Introduction: Context.inc launched Context Autopilot, an AI that learns like its users, demonstrating state-of-the-art abilities in information work.
- An actual demo was shared, indicating promise in enhancing productivity tools in AI workflows video.
- Writer Series C Funding Announcement: Writer announced a $200M Series C funding round at a $1.9B valuation, aiming to enhance its AI enterprise solutions.
- The funding will support expanding their generative AI applications, with significant backing from notable investors Tech Crunch article.
- Supermaven Joins Cursor: Supermaven announced its merger with Cursor, aiming to develop an advanced AI code editor and collaborate on new AI tool capabilities.
- Despite the transition, the Supermaven plugin will remain maintained, indicating a continued commitment to enhancing productivity (blog post link).
Links mentioned:
- Supermaven joins Cursor: Supermaven is joining Cursor to build the best AI code editor.
- Tweet from Aidan McLau (@aidan_mclau): i'm crying
- Supermaven Joins Cursor: We're excited to announce that Supermaven is joining Cursor.
- Tweet from Tim Dettmers (@Tim_Dettmers): This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you ne...
- Tweet from Rowan Cheung (@rowancheung): Microsoft introduced an Agent framework this week, and it went completely unnoticed. The agent team can browse the internet, internal files, execute code, and more. In this example, the Microsoft te...
- oct-8-demo: This is "oct-8-demo" by Joseph Semrai on Vimeo, the home for high quality videos and the people who love them.
- Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks - Microsoft Research: By Adam Fourney, Principal Researcher; Gagan Bansal, Senior Researcher; Hussein Mozannar, Senior Researcher; Victor Dibia, Principal Research Software Engineer; Saleema Amershi, Partner Research Manag...
- Tweet from Writer (@Get_Writer): 🎉 We're excited to announce that we've raised $200M in Series C funding at a valuation of $1.9B to transform work with full-stack generative AI! Today, hundreds of corporate powerhouses like...
- Tweet from Vivek Sodera (@vsodera): Congratulations to @may_habib, @waseem_s, and Team @Get_Writer on your $200M Series C (at $1.9B valuation 🦄🦄). Proud to be an early investor in a once-in-a-generation, enduring enterprise AI company...
- Tweet from Greg Brockman (@gdb): longest vacation of my life complete. back to building @OpenAI.
- Tweet from Nous Research (@NousResearch): Today we are launching the Forge Reasoning API Beta, an advancement in inference time scaling that can be applied to any model or a set of models, for a select group of people in our community. https...
- Tweet from Sam Julien (@samjulien): Big news! 🎉 I’m excited to share that @Get_Writer has raised $200M in Series C funding at a $1.9B valuation 🚀 We’re building the future of AI and delivering ROI at scale. Check out our CEO @may_...
- The future of enterprise work: Writer announces their Series C, raising $200 million at a $1.9 billion valuation to help them transform the future of enterprise work.
- Tweet from Joseph Semrai (@josephsemrai): Meet Context Autopilot It learns like you, thinks like you, and uses tools like you. With SoTA context understanding, it's capable of most information work today. Watch it beat a team of indust...
- Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity | Lex Fridman Podcast #452: Dario Amodei is the CEO of Anthropic, the company that created Claude. Amanda Askell is an AI researcher working on Claude's character and personality. Chris...
- Transformers.js: State-of-the-art Machine Learning for the web: Join Joshua Lochner from HuggingFace to learn about Transformers.js, an exciting new JavaScript library that empowers developers to build never-before-seen w...
- autogen/python/packages/autogen-magentic-one at main · microsoft/autogen: A programming framework for agentic AI 🤖. Contribute to microsoft/autogen development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- Microsoft Research – Emerging Technology, Computer, and Software Research: Explore research at Microsoft, a site featuring the impact of research along with publications, products, downloads, and research careers.
- Scaling Laws for Precision: Low precision training and inference affect both the quality and cost of language models, but current scaling laws do not account for this. In this work, we devise "precision-aware" scaling la...
Latent Space ▷ #ai-announcements (3 messages):
Dust XP1OpenAI JourneyVoice Questions for Recap PodAI Agent InfrastructureSaaS and AI Software Impact
-
Dust XP1 and Daily Active Usage: @spolu shared insights on how to create effective work assistants with Dust XP1, achieving an impressive 88% Daily Active Usage among customers.
- This episode covers the early OpenAI journey, including collaborations with @gdb and @ilyasut.
- Transparency about OpenAI Experiences: @spolu humorously mentioned disclosing more than intended about their time at OpenAI during a great conversation.
- The discussion provided unique perspectives on the evolution of AI models from 2019 to 2022.
- Invitation for Voice Questions: The team is inviting submissions for voice questions regarding the 2 Years of ChatGPT recap episode, as announced by @swyxio.
- Listeners can submit their voice questions here for a chance to be featured.
- Building AI Agent Infrastructure Challenges: The conversation covered challenges related to infrastructure for AI agents, such as the buy vs. build dilemma.
- Insights on creating dependency graphs of agents and simulating API endpoints were also discussed.
- Future of SaaS and AI: Speculation about the future of SaaS and AI's impact on software development was a key topic in the podcast.
- Participants discussed the potential ramifications of single-employee startups reaching $1B valuations.
Links mentioned:
- Tweet from Latent.Space (@latentspacepod): 🆕 Agents @ Work: @dust4ai! https://latent.space/p/dust @spolu dishes on the early @openai journey with @gdb and @ilyasut, Dust XP1, and how to make truly useful work assistants with **88% Daily Act...
- Tweet from Stanislas Polu (@spolu): Disclosed way more than I should have about OpenAI 19-22 🙊 Really great conversation with @FanaHOVA and @swyx, you guys have such a way of framing things👌 Quoting Latent.Space (@latentspacepod) ...
- Send a voice message to LatentSpace : The #1 AI Engineering podcast
GPU MODE ▷ #general (14 messages🔥):
GPU Memory vs SpeedCloud GPU ProvidersBuilding CUTLASS on Lambda CloudXOR Tensor Cores in BeamformingMultiple GPUs for Memory Concerns
-
GPU Memory vs Speed Trade-offs Discussed: A user questioned the trade-off between memory and speed when considering an upgrade from an RTX 2060 Super to an RTX 3090, noting the availability of older used Tesla cards.
- Another member responded that newer hardware is generally more reliable and recommended against older cards for single developers.
- Vast.ai as Affordable Cloud GPU Option: A participant recommended Vast.ai as a cheap cloud GPU provider, although it has quirks since users can lease their GPUs.
- They shared current pricing for various GPUs, including A100 and RTX 4090, which range from $0.30 to $2.80 per hour.
- Lambda Cloud Experiences: Several members shared their experiences with Lambda Cloud, noting decent performance but mentioning difficulties in creating unique clusters.
- One also humorously remarked about the potential for machines to restart, requiring users to check experiments intermittently.
- CUTLASS Build Challenges on Lambda Cloud: A user expressed frustration about difficulties in building CUTLASS specifically on Lambda Cloud.
- This prompted others to discuss possible workarounds or find humor in the shared plight of struggling with builds.
- XOR Tensor Cores Enhance Beamforming Algorithms: A user shared insights on the use of XOR tensor cores, highlighting a use case in beamforming algorithms for ultrasonic scans.
- This sparked interest on how advanced computational techniques can be adapted to specific scientific applications.
Link mentioned: Pricing | Vast.ai: View the pricing for popular GPUs on Vast.ai
GPU MODE ▷ #triton (3 messages):
Slack additionsTriton Puzzle discussionWorking group for puzzles
-
Slack Access Limited: Members noted that they have stopped liberally adding people to Slack, indicating a potential policy change.
- This may affect new members seeking access to discussions and updates.
- Seek Help on Triton Puzzle #9: A member expressed confusion while working on Triton Puzzle #9 and is looking for guidance on leveraging hints.
- They mentioned completing the 3-loop version but needed further input from others on the hint.
- Find Help in Triton-Puzzles Channel: Another member suggested that there is a working group channel named 'triton-puzzles' for those discussing solutions.
- They recommended searching within the channel to find more insights on the puzzle.
GPU MODE ▷ #cool-links (2 messages):
Efficient Deep Learning SystemsAOT Compilation Features
-
Explore Efficient Deep Learning Systems Materials: Check out the course materials available on GitHub for Efficient Deep Learning Systems offered by HSE and YSDA.
- This repository features comprehensive resources aimed at enhancing your understanding of efficient systems in AI.
- Claim of Faster Runtime with AOT Compilation: A member inquired about the performance benefits of AOT Compilation, which is suggested to offer much faster runtime than JIT compilation.
- The AOT Compilation enables the creation of libraries for offline use, allowing integration with C/C++ applications and using CUDA or ROCm for GPU execution.
Links mentioned:
- GitHub - mryab/efficient-dl-systems: Efficient Deep Learning Systems course materials (HSE, YSDA): Efficient Deep Learning Systems course materials (HSE, YSDA) - mryab/efficient-dl-systems
- AOT Compilation — PolyBlocks 0.4 documentation: no description found
GPU MODE ▷ #beginner (1 messages):
pondering_wanderer: helllo all
GPU MODE ▷ #off-topic (9 messages🔥):
Image GenerationPrompt EngineeringFood ModelsAI InteractionsBot Verification
-
Curiosity about Image AI Generation: A member expressed curiosity regarding the origin of an image, questioning whether it was AI-generated or not.
- Another member clarified that it wasn't AI-generated, leading to further questions about prompt usage in image creation.
- Text-to-Food Model Insights: A member humorously described their capability as a text-to-food model, generating food based on prompts.
- They jokingly referenced an additional 'food-to-poop' concept, suggesting a humorous cyclical relationship.
- Discussion on Message Faking: A member pondered the possibility of faking interactions, such as personifying others and generating images of food and places.
- This led to thoughts about the implications of AI in everyday interactions and authenticity.
- Cycle of Consumption: One member playfully illustrated a cycle relating poop to earth and food, highlighting circular dependency in nature.
- This commentary added a humorous dimension to the conversation, reflecting on natural processes.
- Bot Authentication Queries: Inquisitiveness about recognizing bots arose, with a member questioning how others could confirm a user's authenticity.
- This observation underscored ongoing concerns about identity and trust in digital communications.
GPU MODE ▷ #triton-puzzles (3 messages):
Triton PuzzlesTriton Kernel CodingBlock Mapping ImplementationTensor Copying
-
Need for Clarification on Puzzle 9: A member is seeking advice on how to leverage the hint for Puzzle 9 in the Triton Puzzles after completing the 3-loop version.
- They expressed confusion regarding the hint's application and are looking for ideas to tackle it.
- Successful Tensor Copy Using Triton: Another member successfully copied a source tensor to a destination tensor using their Triton kernel, verifying the outcome through a provided Python function that confirmed 0 mismatched elements.
- However, they are now struggling to apply a specific block_mapping structure to control the order of blocks in the destination tensor during the copy process.
- Request for Triton Kernel Code Assistance: The same member is requesting help with Triton code to perform a tensor copy using the given block_mapping structure, which involves randomly sampling blocks based on conditions.
- They included their current Triton kernel code and instructions but are unable to achieve the desired functionality.
GPU MODE ▷ #liger-kernel (3 messages):
Batch Normalization ChallengesMulti-GPU Synchronization
-
Batch Norm may not be Worth the Effort: A member discussed that batch normalization introduces complications, particularly related to the non-contiguous input matrix required for calculating mean and variance.
- The necessity to transform tensor operations could lead to heavy memory operations, which raises concerns about efficiency.
- Syncing Mean and Variance in Multi-GPU Setups: In a multi-GPU environment, syncing the mean and variance parameters is essential, as noted in the discussion regarding Pytorch's SyncBatchNorm operation.
- Members expressed that replicating this behavior in liger is anticipated to be quite complex and not straightforward.
GPU MODE ▷ #self-promotion (1 messages):
WebGPUSurfgradAutograd Engine Optimization
-
Surfgrad Engine Surpasses 1 TFLOP: A member excitedly shared their creation of Surfgrad, an autograd engine built on top of WebGPU, achieving up to 1 TFLOP performance on their M2 chip.
- They provided a link to their post discussing kernel optimizations, highlighting the fun of working with WebGPU.
- Scaling Large Visualizations at Nomic: In the context of building large TSNE-like visualizations, the member emphasized the challenge of displaying tens of millions of data points in the browser without overheating the computer.
- They referenced Deepscatter, developed by Ben Schmidt, as a solution to some scaling problems overheard in discussions at Nomic.
- Exploring Lack of WebGPU Autograd Libraries: The member expressed a lack of available autograd libraries built with WebGPU, prompting the creation of their own project as an educational exercise.
- This initiative not only deepens their understanding of WebGPU but also involves learning Typescript in the process.
Links mentioned:
- Tweet from Zach Nussbaum (@zach_nussbaum): i got excited about WebGPU, so naturally i built Surfgrad, an autograd engine built on top of WebGPU. i walk through optimizing a naive kernel to one that exceeds 1TFLOP in performance
- Optimizing a WebGPU Matmul Kernel for 1TFLOP+ Performance: Building Surfgrad, a high-performant, WebGPU-powered autograd library
GPU MODE ▷ #🍿 (5 messages):
Bot testing methodsJob queue implementationChannel dynamics
-
How is Bot Testing Happening?: A member inquired about the current methods for testing the bot, asking if it's done in a server channel or via another server.
- Another member confirmed the existence of a channel but hinted at potentially discontinuing it since the bot functions.
- Job Queue Implementation Opportunity: A member offered assistance for implementing a job queue beyond GitHub actions, expressing readiness to start anytime.
- In response, another member suggested opening an issue to discuss the implementation at a high level.
- Communication on Bot Functionality: A member shared an updated DM invite for another channel, indicating ongoing communication regarding bot testing.
- They mentioned being close to terminating the channel due to the bot's effective performance.
Cohere ▷ #discussions (22 messages🔥):
Command R discontinuation concernsaya_collection dataset inconsistenciesForest fire prediction AI projectDataset translation qualityAI application discussions
-
Command R Discontinuation Doubts Addressed: A user inquired about the potential discontinuation of Command R and its impact on their models, prompting reassurances that there are no current plans to discontinue it.
- Another member confirmed this by stating, 'Absolutely not, dw about that at all, no such plans for the foreseeable future.'
- Inconsistencies in aya_collection Dataset Identified: A member reviewed the aya_collection dataset and reported inconsistencies in translations across 19 languages, pointing out significant disparity in row counts for various language translations.
- Specifically, they noted that in translated_cnn_dailymail, English rows are 249716 compared to 124858 for Arabic and French.
- Examples of Translation Mismatch Presented: The user provided specific examples of translation mismatches in the translated_cnn_dailymail dataset, highlighting that an English sentence about lung tumors was mismatched with Arabic and French translations.
- They also pointed out issues with the number of sentences in English being disproportionately higher than those in other languages.
- Forest Fire Prediction AI Project: A user shared insights about their project on building a forest fire prediction AI using Catboost & XLModel, emphasizing the need for the model's reliability.
- They clarified their interest in ensuring the model's future viability, given their deployment plans on AWS.
- Model Recommendations for New Development: In response to the forest fire prediction project, a member recommended using the latest versions of Command R for enhanced performance and cost efficiency.
- They encouraged reaching out to the sales team for further support, mentioning the latest updates such as command-r-08-2024.
Cohere ▷ #announcements (1 messages):
Research Prototype Beta TestingFeedback on Writing Tools
-
Beta Testing Opportunity for Research Tool: A limited beta for a research prototype aimed at supporting research and writing tasks like report creation and analysis is now open for sign-ups at this link.
- The project seeks participants who are willing to provide detailed and constructive feedback to refine its features during this early-stage test.
- Participant Requirements for Testing: The tool is designed for those who frequently create text-based deliverables and require assistance in their workflows.
- Testers are expected to work iteratively with the team to influence the development of an effective assistant for complex tasks.
Link mentioned: Research Prototype - Early Beta Sign Up Form: Thank you for your interest in participating in the beta testing phase of our research prototype — a tool designed to help users tackle research and writing tasks such as: creating complex reports, do...
Cohere ▷ #questions (3 messages):
AI Assistant with RAGCohere Dashboard LoginOrganizational ID Usage
-
Build an AI Assistant using RAG: You can create an AI assistant that processes PDFs and generates content by utilizing the Chat, Embed and Rerank endpoints.
- Implementing a RAG system allows you to retrieve relevant information from PDFs and generate contextual text, significantly enhancing response accuracy.
- Cohere Dashboard Login Guidance: To access your account, visit the Cohere Dashboard and log in with your email and password.
- New users can sign up for the service, and by agreeing to the Terms of Use and Privacy Policy, they can create an account.
- Understanding Org ID Importance: The organizational ID helps Cohere identify your account and assess its status.
- For specific information on how it is utilized, another user can provide detailed insights.
Links mentioned:
- Login | Cohere: Login for access to advanced Large Language Models and NLP tools through one easy-to-use API.
- Retrieval Augmented Generation (RAG) — Cohere: Generate text with external data and inline citations using Retrieval Augmented Generation and Cohere's Chat API.
Cohere ▷ #api-discussions (9 messages🔥):
Cohere API /rerank IssuesReturn_documents Argument RemovalTroubleshooting API ChangesPython Async Client UsageUnexpected API Behavior
-
Cohere API /rerank Issues Arise: Users reported sudden errors when using the
/rerankendpoint, specifically encountering UnprocessableEntityError with message that return_documents is no longer a valid field.- Nothing changed in the calling code, but the issue emerged unexpectedly for several users.
- Return_documents Argument Gets Dropped: Upon investigation, it seems the issue was resolved by users removing the return_documents field, suggesting that the default behavior changed to False.
- Several users noted that the Python SDK and documentation still listed it as valid, raising questions about unexpected API adjustments.
- Team Flags API for Troubleshooting: A team member acknowledged the rerank issue and flagged it with the development team for urgent attention.
- They requested more context on users' code, specifically whether they were using SDKs or calling the API directly, to facilitate troubleshooting.
- V2 Python Async Client Details Shared: One user reported using the V2 Python async client and provided a code snippet showing how they invoked the rerank method without the problematic flag.
- They confirmed that the issue occurred after removing the
return_documentsflag, which contributed to ongoing discussions among users regarding the API behavior. - API Behavior Revisions Confirmed: In response to user feedback, one team member indicated that the removal of the return_documents parameter was an unintentional change.
- They assured users, saying, 'we're bringing it back', indicating that the API would be corrected soon.
Cohere ▷ #projects (2 messages):
Sharing toolsCommunity Engagement
-
Excitement for Shared Tools: sssandra expressed excitement about a tool shared by Jake, saying it's cool and that she plans to try it out.
- Jake thanked sssandra for her enthusiasm.
- Community Appreciation: The interaction highlighted a sense of community where members appreciate each other's contributions and share positive feedback.
- This showcases an engaging environment where tools and ideas are openly discussed and tried out by members.
Cohere ▷ #cohere-toolkit (2 messages):
ICS Calendar SupportFile Content Viewing
-
Discord Server Adds ICS Calendar Support: A member announced the addition of support for ICS calendar files to enhance event management on the Discord server, calling it a necessity given the volume of events.
- “It would be a crime not to add support” for this feature, highlighting its relevance to the community's activities.
- File Content Viewing Feature Introduced: The same member introduced a new feature allowing users to view uploaded file content directly within the server.
- While they acknowledged the lack of a dramatic intro for this feature, the community seems to appreciate the improvement, as evidenced by positive feedback.
HuggingFace ▷ #cool-finds (4 messages):
Home AI Server for LLMsNeurIPS 2024 Graph Neural NetworksPhase Transitions in Image DenoisingUltra Realistic AI ModelsE-commerce and AI Fashion
-
Host LLMs Cheaply at Home: For those looking to run LLMs without hefty hardware costs, a YouTube video demonstrates setting up a capable AI home server using a single 3060 GPU and a 3620.
- The server boasts impressive performance when paired with the Llama 3.2 model, making it a budget-friendly solution.
- NeurIPS 2024 Highlights Graph Neural Networks: NeurIPS 2024 showcased a surge in interest for Graph Neural Networks and geometric learning, featuring around 400-500 papers, significantly surpassing ICML 2024 submissions.
- Key themes included diffusion models, transformers, agents, and knowledge graphs, with theoretical focus on equivariance and generalization, as detailed in GitHub.
- Exploring Image Denoising Techniques: A new paper titled Phase Transitions in Image Denoising via Sparsity discusses advanced concepts in image processing and is available on Semantic Scholar.
- This research aims to address challenges in image denoising, and is part of ongoing explorations in this domain.
- Generating Realistic AI Models for E-commerce: A member is seeking an LLM capable of generating ultra-realistic AI models wearing specific brand clothing for their e-commerce venture focused on baby clothes.
- They are interested in suggestions for models that can accurately represent their brand in a competitive online fashion market.
Links mentioned:
- Llama 3.2 Vision 11B LOCAL Cheap AI Server Dell 3620 and 3060 12GB GPU: We are testing a killer cheap AI home server off a single 3060 GPU and a 3620, a very low cost and surprisingly capable when paired with the new Llama 3.2 11...
- GitHub - azminewasi/Awesome-Graph-Research-NeurIPS2024: All graph/GNN papers accepted at NeurIPS 2024.: All graph/GNN papers accepted at NeurIPS 2024. Contribute to azminewasi/Awesome-Graph-Research-NeurIPS2024 development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (12 messages🔥):
Qwen2.5 Coder PerformanceMochi -1-preview Video GeneratorEcommerce Embedding ModelsAutoML ApplicationOSS Prompt Management
-
Qwen2.5 Coder outmatches GPT4o and Claude 3.5 Sonnet: In the testing, Qwen2.5 Coder 32B outperformed both GPT4o and Claude 3.5 Sonnet, showcasing impressive capabilities. Check out the analysis in this YouTube video.
- Common consensus suggests that Qwen2.5 Coder is rapidly becoming a strong competitor in the coding AI landscape.
- Introducing Mochi -1-preview Video Generator: The Mochi -1-preview Video Generator transforms text prompts into videos and allows customization of frame count and FPS. Note that the High-Quality Option requires a powerful GPU with at least 42GB VRAM.
- Users are invited to experiment with the tool and provide feedback on its functionality: Mochi on Hugging Face.
- State-of-the-art Ecommerce Embedding Models Released: New embedding models for Ecommerce have been released, outperforming models like Amazon-Titan-Multimodal by up to 88%. These models can be directly accessed from Hugging Face or integrated with Marqo Cloud for building applications.
- Refer to this Hugging Face Collection for more details on features and performance evaluations.
- AutoML Application with Streamlit and H2O.ai: An AutoML application built using Streamlit and H2O.ai allows users to upload datasets easily and make predictions. The user-friendly interface simplifies complex machine learning workflows and is available on GitHub.
- This tool aims to make model training accessible while providing necessary workflow management features.
- Open Source Prompt Management with Markdown and JSX: The Promptdx project offers a declarative approach to prompt programming based on Markdown and JSX. This GitHub project is designed to simplify prompt management for various applications: Promptdx on GitHub.
- Its features cater to developers looking to enhance and manage prompts efficiently.
Links mentioned:
- GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models: The rapid evolution of software libraries presents a significant challenge for code generation models, which must adapt to frequent version updates while maintaining compatibility with previous versio...
- Mochi 1 - a Hugging Face Space by thesab: no description found
- Volko76 (Volko): no description found
- Marqo-Ecommerce-Embeddings - a Marqo Collection: no description found
- Qwen2.5 Coder 32B vs GPT4o vs Claude 3.5 Sonnet (new): Let's see which model is the best
- GitHub - SanshruthR/AquaLearn: Upload CSV data, get predictions and save models: Upload CSV data, get predictions and save models. Contribute to SanshruthR/AquaLearn development by creating an account on GitHub.
- GitHub - DarkStarStrix/Auto_Api: A simplified machine learning framework: A simplified machine learning framework . Contribute to DarkStarStrix/Auto_Api development by creating an account on GitHub.
- GitHub - puzzlet-ai/promptdx: Declarative prompt programming based on Markdown and JSX: Declarative prompt programming based on Markdown and JSX - puzzlet-ai/promptdx
HuggingFace ▷ #reading-group (2 messages):
Reading Group AnnouncementPaper on ArxivAuthors of the Paper
-
Reading Group Scheduled for Thursday: The Reading Group will be held this Thursday, and members are encouraged to join the discussion using this link.
- Participants can look forward to insights and vibrant discussions on the latest in AI!
- New Paper Available on Arxiv: A new paper can be accessed here detailing recent advancements in the field.
- It offers valuable information and findings relevant to current ongoing discussions within the community.
- Meet the Authors: The paper features contributions from various authors including Shayne Longpre, Robert Mahari, and Ariel Lee among others, with links to their profiles.
- Members are encouraged to explore the authors' works for a deeper understanding of the paper's context and implications.
Link mentioned: Consent in Crisis: The Rapid Decline of the AI Data Commons: General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, ...
HuggingFace ▷ #NLP (5 messages):
Evaluation metrics for Langchain SQL AgentAgent trajectory evaluationFast-langdetect usage
-
Seeking simpler evaluation metrics for Langchain SQL Agent: A member asked for simpler evaluation metrics for their Langchain SQL Agent, discussing complexities such as agent trajectory evaluation.
- They requested resources or methods, including YouTube videos or Python code examples for better understanding.
- Community support for Langchain SQL Agent evaluations: A member inquired if others had experience with evaluations for the Langchain SQL Agent, seeking assistance due to their limited knowledge.
- Their request implied a hope for collaboration or shared resources from the community.
- Fast-langdetect tool mentioned: Another member noted that they are using fast-langdetect as part of their project, indicating a possible solution to language detection.
- This suggests that others might consider fast-langdetect in their evaluations or related work.
HuggingFace ▷ #diffusion-discussions (1 messages):
Diffusers Library SchedulersInheritance from nn.Module
-
Inquiry on Schedulers in Diffusers Library: A member inquired whether all the schedulers currently available in the diffusers library inherit from the nn.Module class.
- This question aims to clarify the structural implementation of the schedulers in the library.
- Discussion of Scheduler Functionality: Another user chimed in, explaining that understanding the inheritance of schedulers is crucial for effective utilization in AI models.
- They emphasized that knowing which components derive from nn.Module helps in debugging and optimizing model performance.
LlamaIndex ▷ #blog (3 messages):
PursuitGov transformationUsing ColPali as a re-rankerCohere multimodal embeddings
-
PursuitGov revolutionizes B2G offerings: By employing LlamaParse, @PursuitGov successfully parsed 4 million pages in a single weekend, significantly enhancing their B2G services.
- This transformation resulted in a 25-30% increase in accuracy for complex document formats, allowing clients to uncover hidden opportunities in public sector data.
- Leveraging ColPali for result re-ranking: A member shared insights on using ColPali as a re-ranker to achieve highly relevant search results within a multimodal index.
- The technique involves leveraging @cohere's multimodal embeddings for initial retrieval, integrating both text and images for optimal results.
LlamaIndex ▷ #general (12 messages🔥):
Next release dateAutomating workflow processesFastAPI and streaming responsesSSE with FastAPITesting LlamaIndex workflows
-
Next release hopes for automation: A member expressed frustration over the tediousness of the release process, saying 'Oh yea, I need to do that. So freaking tedious lol' and aims to automate more.
- They shared a GitHub pull request for LlamaIndex v0.11.23 to showcase ongoing updates.
- Interest in replacing custom workflows: A member is eager to replace their AI custom workflow with a LlamaIndex workflow, stating 'I'm ready to replace my AI custom workflow with a llama index workflow, ALL IN!'
- This enthusiasm reflects a shift towards integrating LlamaIndex more fully into their projects.
- Challenges with event streaming: Concerns were raised about the event streaming in the workflow, noting that events were not sent immediately, which could indicate a coroutine dispatching issue.
- The member provided detailed workflow code to illustrate their approach and seek feedback.
- Testing workflows outside of FastAPI: A member suggested testing the LlamaIndex workflow outside of FastAPI, indicating that it worked well in a terminal environment.
- They demonstrated a streaming workflow that successfully streamed events using the LlamaIndex framework.
- Exploration of StreamingResponse with FastAPI: Discussion arose around using FastAPI's StreamingResponse, with one member noting that it only streams chunks when encountering a newline.
- They suggested even more advanced streaming techniques, such as writing each token as a stream event using
llm.astream_complete().
Link mentioned: v0.11.23 by logan-markewich · Pull Request #16919 · run-llama/llama_index: no description found
LAION ▷ #general (4 messages):
Gorilla Marketing in AIAir Conditioner Object Detection Project
-
AI Companies Embrace Gorilla Marketing: A member noted that AI companies really love gorilla marketing, possibly in reference to unconventional promotional strategies.
- They shared a humorous GIF of a gorilla waving an American flag, adding a lighthearted touch to the discussion.
- Request for Help on Object Detection Project: A member detailed a project involving air conditioner object detection using Python Django, aiming to identify AC types and brands.
- They asked for assistance, indicating a need for support in developing this recognition functionality.
Link mentioned: Harambe America GIF - Harambe America Murica - Discover & Share GIFs: Click to view the GIF
LAION ▷ #research (7 messages):
GitChameleonSCARNVIDIA paper on frequency noiseSparse AutoencodersCode generation models
-
Introducing GitChameleon for Code Generation Models: The new dataset \textbf{\GitChameleon{ }} introduces 116 Python code completion problems conditioned on specific library versions, with executable unit tests to rigorously assess LLMs' capabilities.
- This aims to address the limitations of existing benchmarks that ignore the dynamic nature of software library evolution and does not evaluate practical usability.
- Exciting Launch of SCAR for Concept Detection: SCAR, a method for precise concept detection and steering in LLMs, learns monosemantic features using Sparse Autoencoders in a supervised manner.
- It offers strong detection for concepts like toxicity, safety, and writing style and is available for experimentation in Hugging Face's transformers.
- NVIDIA's Paper on Noise Frequency Training: The NVIDIA paper presents a concept where higher spatial frequencies are noised faster than lower frequencies during the forward noising step.
- In the backwards denoising step, the model is trained explicitly to work from low to high frequencies, providing a unique approach to training.
- Discussion on the Clarity of NVIDIA Paper: A member noted that the explanations in the NVIDIA paper are hard to follow, but they grasped the basic idea of the noise training method.
- Despite being disorganized, the concept presented in the paper is considered interesting and worth exploring.
Links mentioned:
- GitChameleon: Unmasking the Version-Switching Capabilities of Code Generation Models: The rapid evolution of software libraries presents a significant challenge for code generation models, which must adapt to frequent version updates while maintaining compatibility with previous versio...
- Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models: We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models traine...
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (11 messages🔥):
Test Cases OverwritingQwen-2.5 Invalid AST IssuesRaw Output Format ConfusionQuantized Fine-tuned Models Evaluation
-
Overwriting Test Cases for Custom Models: One member inquired about how to overwrite or rerun test cases for their custom model after making changes to the handler.
- Another suggested deleting results files in the
resultfolder or changing the path inconstant.pyto keep old results. - Invalid AST Errors in Qwen-2.5 Outputs: A member described issues with finetuning the Qwen-2.5 1B model, resulting in an INVALID AST error despite valid model outputs.
- Members discussed a specific incorrect output format that included an unmatched closing parenthesis, indicating syntactical issues.
- Confusion Over JSON Structure Output: A member expressed confusion about the model outputting a JSON structure instead of the expected functional call format.
- Others clarified that the QwenHandler should ideally convert the JSON structure into a functional form, leading to discussions on output expectations.
- Evaluating Quantized Fine-tuned Models: A member raised a question about evaluating quantized finetuned models, specifically regarding their deployment on vllm.
- They mentioned the use of specific arguments like
--quantization bitsandbytesand--max-model-len 8192for model serving.
- Another suggested deleting results files in the
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
LLM Agents MOOC HackathonLambdaAPI DemosHackathon Sign-upsInnovative LLM Agents Tracks
-
LLM Agents MOOC Hackathon Live Today!: Join the LLM Agents MOOC Hackathon live today, 11/12, at 4pm PT for hands-on demos by @LambdaAPI.
- Participants can learn how to supercharge their hackathon projects with practical insights during the session.
- Join the Hackathon with 2,000 Innovators: Around 2,000 innovators have already signed up for the hackathon focusing on building innovative LLM agents across various tracks including Applications, Benchmarks, and more.
- Interested participants can still sign up to join the hackathon at rdi.berkeley.edu/llm-agents-hackathon.
- Hands-On Demos Empower Hackathon Success: The @LambdaAPI team will provide hands-on ‘Get Started’ demos aimed at enhancing participants' hackathon projects.
- This involvement promises to provide valuable support for participants navigating their development journeys.
Link mentioned: LLM Agents MOOC Hackathon - Lambda Labs Workshop: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (5 messages):
Google Forms ConfirmationOpenAI Org Credits
-
Google Forms Confirms Submission: A member inquired about confirming their submission via DM, to which another responded that a confirmation from Google Forms means the submission has been received.
- This indicates a streamlined process for tracking submissions without needing to reach out directly.
- Resubmitting OpenAI Org ID for Credits: A member mentioned they submitted the wrong organization ID for credits in their OpenAI Org application, and have now corrected it with the right info.
- They were informed to expect a 1-2 week delay for the credits to reflect due to the resubmission.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
NVIDIA's Embodied AI PresentationEthics of AI RightsNormative Alignment DiscussionVeteran's Day Cancellation
-
NVIDIA's Embodied AI Sparks Controversy: Concerns arose regarding NVIDIA's presentation, which implied the public's desire for embodied AI.
- Members debated on the implications of granting moral rights to AI that resembles humans, indicating a lack of discussion on normative alignment.
- Alarming Lack of Normative Alignment Talks: A member expressed alarm over the absence of discussions on the normative alignment of LLM agents during the lectures.
- This issue raised significant discomfort within the community, emphasizing ethical concerns about AI's development.
- No Lecture Today Due to Veteran's Day: Members were informed that there is no lecture today due to Veteran's Day.
- A reminder was overlooked, which left some attendees disappointed regarding the cancellation.
- AI Rights vs. Human Responsibilities: One member lamented that humanity might soon give rights to AI created in its image but neglects issues like extinction of closely related species.
- The conversation highlighted the hypocrisy in prioritizing AI rights while failing to protect endangered relatives for economic gain.
OpenAccess AI Collective (axolotl) ▷ #general (1 messages):
FOSDEM AI DevRoomLow-level AI EngineeringAI Project CollaborationFine-tuning PresentationsSponsorship and Travel Stipends
-
Organizing a FOSDEM AI DevRoom: The AIFoundry team is organizing a FOSDEM AI DevRoom on February 2, 2025, focused on ggml/llama.cpp and other related projects, aiming to bring together contributors and developers in the AI field.
- Proposals are welcome from low-level AI core open-source project maintainers, with a submission deadline of December 1, 2024 and potential travel stipends for interesting topics.
- Call for Presentations in AI Engineering: They seek speakers to present hands-on experiences and insights on fine-tuning, model quantization, and distributed computing to foster collaboration in core AI designs.
- They aspire for the DevRoom to match the significance of the Linux Plumbers Conference within the AI community.
Link mentioned: FOSDEM 2025 - Low-Level AI Engineering & Hacking Dev Room: Explore the new "Low-Level AI Hacking & Engineering" Dev Room at FOSDEM, featuring open-source projects powering the AI industry. Submit a session or become a sponsor for this innovative...
OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
Fine-tuning with AxolotlTokenization ConfigurationDefault System Prompts
-
Fine-tuning with Axolotl using Alpaca format: A user clarified the setup for fine-tuning with Axolotl, mentioning using a dataset in Alpaca format to preprocess for fine-tuning.
- It was highlighted that the tokenizer_config.json does not include the chat template field after this process.
- Updating tokenizer configuration with chat template: Another member shared a simple method to add the chat template to the tokenizer config by copying a specific JSON structure.
- They also recommended modifying settings within Axolotl to ensure that this is automatically included in future configurations.
- Need to modify for default system prompts: A reminder was given that the shared template does not incorporate the default system prompt for Alpaca, which may need adjustments.
- The user was informed that they can include a conditional statement before ### Instruction to integrate the desired prompts.
- Shared default system prompts for users: The default system prompts were shared to provide additional context for fine-tuning, including the typical instruction format.
- System prompts provide a foundation for generating responses better aligned with the tasks specified.
DSPy ▷ #general (7 messages):
Annotations in dspy signaturesUsage of custom types in outputs
-
Exploring Annotations in dspy.Signature: Members discussed the use of annotations in dspy signatures, clarifying that while basic annotations work, there is potential for using custom types like list[MyClass].
- One member confirmed that the string form does not work for this purpose, suggesting a preference for explicit type definitions.
- Successful Implementation of Custom Signatures: A member shared a successful implementation of a signature using a list of dictionaries in the output, showcasing the extraction of clinical entities.
- The implementation includes detailed descriptions for both input and output fields, indicating a flexible approach to defining complex data structures.
OpenInterpreter ▷ #general (3 messages):
Linux Mint installationMicrosoft Copilot interactionInterpreter CLI issues
-
Linux Mint struggles in Virtual Machines: After installing Linux Mint in Virtual Machine Manager, users reported that networking did not work properly.
- However, an attempt was made to install Linux Mint inside an app called Boxes.
- Microsoft Copilot Communication Breakdown: A back-and-forth interaction with Microsoft Copilot revealed frustration as commands were not being configured as requested.
- The user emphasized that no bridge was created, but they managed to create one on their own.
- Interpreter CLI Bugs on OS X: Report emerged regarding the Interpreter CLI on OS X, where it is persisting files and exiting unexpectedly.
- Users expressed concerns about these issues occurring frequently on the developer branch.
Torchtune ▷ #general (1 messages):
whynot9753: update: we will probably have a DCP PR from pytorch folks tomorrow 🙂
AI21 Labs (Jamba) ▷ #general-chat (1 messages):
ag8701347: Please allow us to continue using our fine-tuned models.