[AINews] Apple Intelligence Beta + Segment Anything Model 2
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
The second largest LLM deployment of 2024 is so delayed/so here.
AI News for 7/26/2024-7/29/2024. We checked 7 subreddits, 384 Twitters and 28 Discords (325 channels, and 6654 messages) for you. Estimated reading time saved (at 200wpm): 716 minutes. You can now tag @smol_ai for AINews discussions!
Meta continued its open source AI roll with a worthy sequel to last year's Segment Anything Model. Most notably, ontop of being a better image model than SAM1, it now uses memory attention to scale up image segmentation to apply to video, using remarkably little data and compute.
But the computer vision news was overshadowed by Apple Intelligence, which both delayed the official release to iOS 18.1 in October and released in Developer preview on MacOS Sequoia (taking a 5GB download), iOS 18, and iPadOS 18 today (with a very short waitlist, Siri 2.0 not included, Europeans not included), together with a surprise 47 page paper going into further detail than their June keynote (our coverage here).
Cue widespread demos of:
Notifications screening
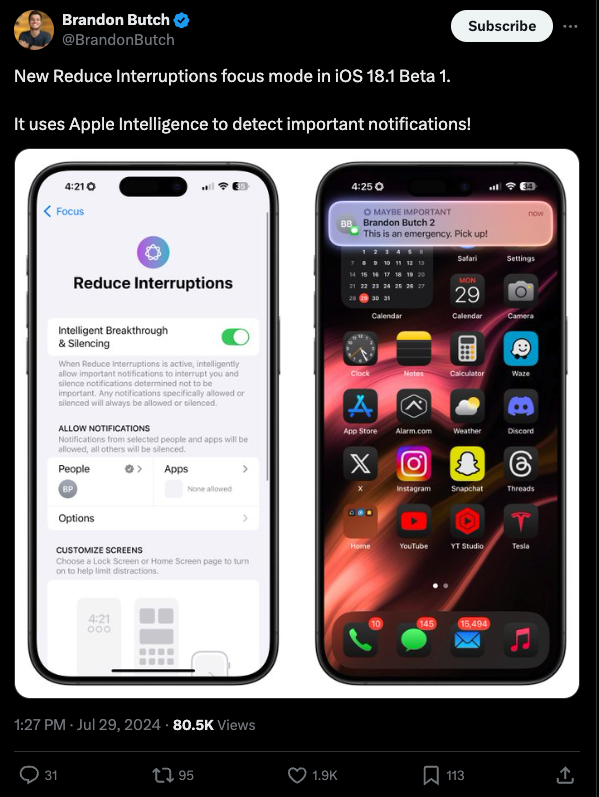
Rewriting in arbitrary apps with low power
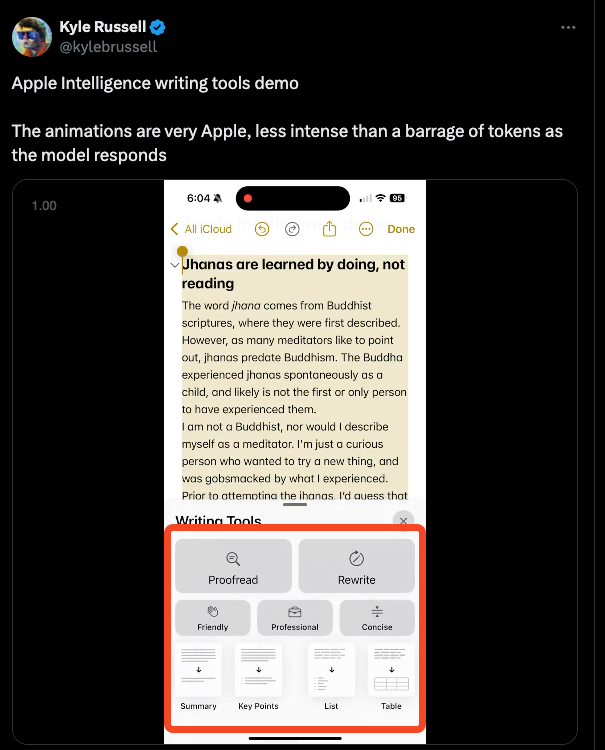
Writing tools
and more.
As for the paper, the best recap threads from Bindu and Maxime and
VB probably cover it all. Our highlight is the amount of pretrain detail contained on page 6 and 7:

- Data: fresh dataset scrape of ? Applebot web crawl, ? licensed datasets, ? code, 3+14b math tokens, ? "public datasets" leading to a final 6.3T tokens for CORE pretraining, 1T tokens with higher code/math mix for CONTINUED pretraining, and 100B tokens for context lengthening (to 32k)
- Hardware: AFM was trained with v4 and v5p Cloud TPUs, not Apple Silicon!! AFM-server: 8192 TPUv4, AFM-on-device: 2048 TPUv5p
- Post Training: "While Apple Intelligence features are powered through adapters on top of the base model, empirically we found that improving the general-purpose post-training lifts
the performance of all features, as the models have stronger capabilities on instruction following, reasoning, and writing. - Extensive use of synthetic data for Math, Tool Use, Code, Context Length, Summarization (on Device), automatic redteaming, and committee distillation
Also notable, they disclose their industry standard benchmarks, which we have taken the liberty of extracting and comparing with Llama 3:
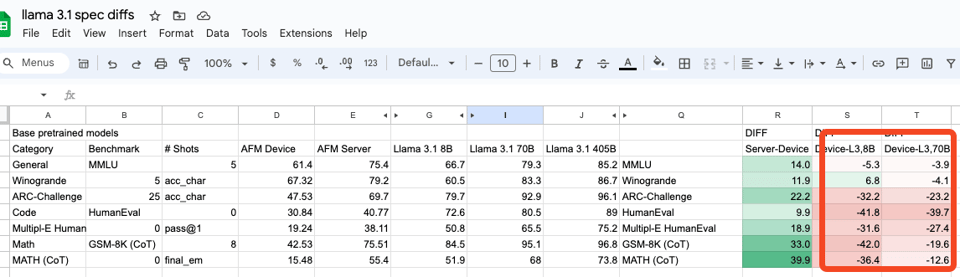
Yes they are notably, remarkably, significantly lower than Llama 3, but we wouldn't worry too much about that as we trust Apple's Human Evaluations.
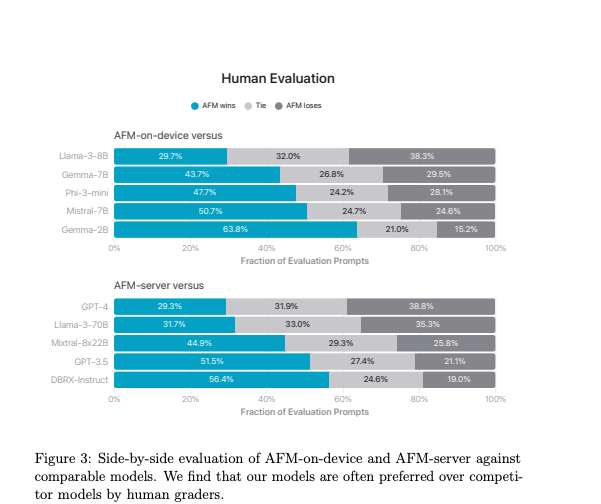
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Nous Research AI Discord
- HuggingFace Discord
- LM Studio Discord
- Stability.ai (Stable Diffusion) Discord
- OpenAI Discord
- Unsloth AI (Daniel Han) Discord
- CUDA MODE Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- Latent Space Discord
- LlamaIndex Discord
- OpenInterpreter Discord
- OpenAccess AI Collective (axolotl) Discord
- LangChain AI Discord
- Cohere Discord
- Interconnects (Nathan Lambert) Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- LAION Discord
- AI21 Labs (Jamba) Discord
- LLM Finetuning (Hamel + Dan) Discord
- Alignment Lab AI Discord
- PART 2: Detailed by-Channel summaries and links
- Nous Research AI ▷ #datasets (2 messages):
- Nous Research AI ▷ #off-topic (3 messages):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #general (196 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (115 messages🔥🔥):
- Nous Research AI ▷ #rag-dataset (1 messages):
- Nous Research AI ▷ #reasoning-tasks-master-list (485 messages🔥🔥🔥):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (678 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (7 messages):
- HuggingFace ▷ #cool-finds (19 messages🔥):
- HuggingFace ▷ #i-made-this (31 messages🔥):
- HuggingFace ▷ #reading-group (35 messages🔥):
- HuggingFace ▷ #computer-vision (4 messages):
- HuggingFace ▷ #NLP (24 messages🔥):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- LM Studio ▷ #general (661 messages🔥🔥🔥):
- LM Studio ▷ #hardware-discussion (53 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (690 messages🔥🔥🔥):
- OpenAI ▷ #ai-discussions (602 messages🔥🔥🔥):
- OpenAI ▷ #gpt-4-discussions (13 messages🔥):
- OpenAI ▷ #prompt-engineering (11 messages🔥):
- OpenAI ▷ #api-discussions (11 messages🔥):
- Unsloth AI (Daniel Han) ▷ #general (292 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (29 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (306 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #research (4 messages):
- CUDA MODE ▷ #general (4 messages):
- CUDA MODE ▷ #triton (2 messages):
- CUDA MODE ▷ #torch (17 messages🔥):
- CUDA MODE ▷ #algorithms (18 messages🔥):
- CUDA MODE ▷ #beginner (4 messages):
- CUDA MODE ▷ #pmpp-book (3 messages):
- CUDA MODE ▷ #torchao (38 messages🔥):
- CUDA MODE ▷ #off-topic (3 messages):
- CUDA MODE ▷ #irl-meetup (2 messages):
- CUDA MODE ▷ #llmdotc (401 messages🔥🔥):
- Perplexity AI ▷ #general (435 messages🔥🔥🔥):
- Perplexity AI ▷ #sharing (15 messages🔥):
- Perplexity AI ▷ #pplx-api (18 messages🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (342 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #general (70 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Modular (Mojo 🔥) ▷ #mojo (146 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #max (1 messages):
- Eleuther ▷ #general (50 messages🔥):
- Eleuther ▷ #research (44 messages🔥):
- Eleuther ▷ #scaling-laws (1 messages):
- Eleuther ▷ #lm-thunderdome (92 messages🔥🔥):
- Latent Space ▷ #ai-general-chat (53 messages🔥):
- Latent Space ▷ #ai-announcements (1 messages):
- Latent Space ▷ #ai-in-action-club (122 messages🔥🔥):
- LlamaIndex ▷ #announcements (2 messages):
- LlamaIndex ▷ #blog (11 messages🔥):
- LlamaIndex ▷ #general (93 messages🔥🔥):
- LlamaIndex ▷ #ai-discussion (2 messages):
- OpenInterpreter ▷ #general (51 messages🔥):
- OpenInterpreter ▷ #O1 (5 messages):
- OpenInterpreter ▷ #ai-content (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (43 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (7 messages):
- OpenAccess AI Collective (axolotl) ▷ #other-llms (4 messages):
- OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (4 messages):
- LangChain AI ▷ #general (48 messages🔥):
- LangChain AI ▷ #share-your-work (7 messages):
- Cohere ▷ #discussions (30 messages🔥):
- Cohere ▷ #api-discussions (7 messages):
- Cohere ▷ #cohere-toolkit (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
- Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
- DSPy ▷ #show-and-tell (3 messages):
- DSPy ▷ #papers (2 messages):
- DSPy ▷ #general (13 messages🔥):
- DSPy ▷ #examples (17 messages🔥):
- tinygrad (George Hotz) ▷ #general (10 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (21 messages🔥):
- LAION ▷ #general (9 messages🔥):
- AI21 Labs (Jamba) ▷ #announcements (1 messages):
- AI21 Labs (Jamba) ▷ #general-chat (2 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (2 messages):
- Alignment Lab AI ▷ #general-chat (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Industry Updates
- Llama 3.1 Release: Meta released Llama 3.1, including a 405B parameter model, the first open-sourced frontier model on par with top closed models. @adcock_brett noted it\'s "open source and free weights and code, with a license enabling fine-tuning, distillation into other models and deployment." The model supports eight languages and extends the context window to 128K tokens.
- Mistral AI\'s Large 2: @adcock_brett reported that Mistral released Large 2, its flagship AI model scoring close to Llama 3.1 405b and even surpassing it on coding benchmarks while being much smaller at 123b. This marks the release of "two GPT-4 level open models within a week."
- OpenAI Developments: OpenAI announced SearchGPT, an AI search engine prototype that combines AI models with web information. @adcock_brett mentioned it "organizes search results into summaries with source links and will be initially available to 10,000 test users." Additionally, @rohanpaul_ai shared insights on OpenAI\'s potential impact on call centers, suggesting AI agents could replace human operators within two years.
- Google DeepMind\'s Achievements: @adcock_brett highlighted that "Google DeepMind\'s AlphaProof and AlphaGeometry 2 achieved a significant milestone in AI math reasoning capabilities," attaining a silver medal-equivalent score at this year\'s IMO.
AI Research and Technical Advancements
- GPTZip: @jxmnop introduced gptzip, a project for compressing strings with language models, achieving "5x better rates than gzip" using Hugging Face transformers.
- RAG Developments: @LangChainAI shared RAG Me Up, a generic framework for doing RAG on custom datasets easily. It includes a lightweight server and UIs for communication.
- Model Training Insights: @abacaj discussed the importance of low learning rates during fine-tuning, suggesting that weights have "settled" into near-optimal points due to an annealing phase.
- Hardware Utilization: @tri_dao clarified that "nvidia-smi showing \'GPU-Util 100%\' doesn\'t mean you\'re using 100% of the GPU," an important distinction for AI engineers optimizing resource usage.
Industry Trends and Discussions
- AI in Business: There\'s ongoing debate about the capabilities of LLMs in building businesses. @svpino expressed skepticism about non-technical founders building entire SaaS businesses using LLMs alone, highlighting the need for capable human oversight.
- AI Ethics and Societal Impact: @fchollet raised concerns about cancel culture and its potential impact on art and comedy, while @bindureddy shared insights on LLMs\' reasoning capabilities, noting they perform better than humans on real-world reasoning problems.
- Open Source Contributions: The open-source community continues to drive innovation, with projects like @rohanpaul_ai sharing a local voice chatbot powered by Ollama, Hugging Face Transformers, and Coqui TTS Toolkit using local Llama.
Memes and Humor
- @willdepue joked about OpenAI receiving "$19 trillion in tips" in the last month.
- @vikhyatk shared a humorous anecdote about getting hit with a $5k network transfer bill for using S3 as a staging environment.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Ultra-Compact LLMs: Lite-Oute-1 300M and 65M Models
- Lite-Oute-1: New 300M and 65M parameter models, available in both instruct and base versions. (Score: 59, Comments: 12): Lite-Oute-1 has released new 300M and 65M parameter models in both instruct and base versions, available on Hugging Face. The 300M model, built on the Mistral architecture with a 4096 context length, aims to improve upon the previous 150M version by processing 30 billion tokens, while the 65M model, based on LLaMA with a 2048 context length, is an experimental ultra-compact version processing 8 billion tokens, both trained on a single NVIDIA RTX 4090.
- /u/hapliniste: "As much as I'd like nano models so we can finetune easily on specific tasks, isn't the benchmark radom level? 25% on mmlu is the same as random choice right?I wonder if it still has some value for autocompletion or things like that."
Theme 2. AI Hardware Investment Challenges: A100 GPU Collection
- The A100 Collection and the Why (Score: 51, Comments: 20): The post describes a personal investment in 23 NVIDIA A100 GPUs, including 15 80GB PCIe water-cooled, 5 40GB SXM4 passive-cooled, and 8 additional 80GB PCIe water-cooled units not pictured. The author expresses regret over this decision, citing difficulties in selling the water-cooled units and spending their entire savings, while advising others to be cautious about letting hobbies override common sense.
Theme 4. New Magnum 32B: Mid-Range GPU Optimized LLM
- "The Mid Range Is The Win Range" - Magnum 32B (Score: 147, Comments: 26): Anthracite has released Magnum 32B v1, a Qwen finetune model targeting mid-range GPUs with 16-24GB of memory. The release includes full weights in BF16 format, as well as GGUF and EXL2 versions, all available on Hugging Face.
- Users discussed creating a roleplay benchmark, with suggestions for a community-driven "hot or not" interface to evaluate model performance on writing style, censorship levels, and character adherence.
- The profile pictures in Magnum releases feature Claude Shannon, the father of information theory, and Tsukasa from Touhou. Users appreciated this unique combination of historical and fictional characters.
- A user shared a 500-token story generated by Magnum 32B, featuring two cyborgs in Elon Musk's factory uncovering a corporate conspiracy. The story showcased the model's creative writing capabilities.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Industry Discussion
-
Criticism of misleading AI articles: In /r/singularity, a post questions the subreddit's apparent bias against AI, specifically referencing a potentially misleading article about OpenAI's financial situation. The post title suggests that the community may be overly critical of AI advancements.
Key points:
- The post links to an article claiming OpenAI could face bankruptcy within 12 months, projecting $5 billion in losses.
- The post received a relatively high score of 104.5, indicating significant engagement from the community.
- With 192 comments, there appears to be substantial discussion around this topic, though the content of these comments was not provided.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Model Releases and Performance
- Llama 3 Shakes Up the Leaderboards: Llama 3 from Meta has quickly risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- The Llama 405B Instruct model achieved an average accuracy of 0.861 across multiple subjects during the MMLU evaluation, with notably strong performances in biology and geography. The evaluation was completed in about two hours, demonstrating efficient processing.
- DeepSeek V2 Challenges GPT-4: DeepSeek-V2 with 236B parameters has shown impressive performance, surpassing GPT-4 in some areas on benchmarks like AlignBench and MT-Bench.
- The model's strong showing across various benchmarks has sparked discussions about its potential to compete with leading proprietary models, highlighting the rapid progress in open-source AI development.
2. AI Development Tools and Frameworks
- LlamaIndex Launches New Course with Andrew Ng: LlamaIndex has announced a new course on building agentic RAG systems in collaboration with Andrew Ng's DeepLearning.ai, aiming to enhance developers' skills in creating advanced AI applications.
- This collaboration highlights the growing importance of Retrieval-Augmented Generation (RAG) in AI development and showcases LlamaIndex's commitment to educating the community on cutting-edge techniques.
- Axolotl Expands Dataset Format Support: Axolotl has expanded its support for diverse dataset formats, enhancing its capabilities for instruction tuning and pre-training LLMs.
- This update allows developers to more easily integrate various data sources into their model training pipelines, potentially improving the quality and diversity of trained models.
3. AI Infrastructure and Optimization
- vAttention Revolutionizes KV Caching: The vAttention system dynamically manages KV-cache memory for efficient LLM inference without relying on PagedAttention, offering a new approach to memory management in AI models.
- This innovation addresses one of the key bottlenecks in LLM inference, potentially enabling faster and more efficient deployment of large language models in production environments.
4. Multimodal AI Advancements
- Meta Unveils Segment Anything Model 2: Meta has released Segment Anything Model 2 (SAM 2), a unified model for real-time, promptable object segmentation in both images and videos, available under an Apache 2.0 license.
- SAM 2 represents a significant leap in multimodal AI, trained on a new dataset of approximately 51,000 videos. This release includes model inference code, checkpoints, and example notebooks to assist users in implementing the model effectively.
5. LLM Advancements
- Llama 405B Instruct Shines in MMLU: Llama 405B Instruct achieved an average accuracy of 0.861 in the MMLU evaluation, excelling in subjects like biology and geography, completing the evaluation in about two hours.
- This performance has sparked discussions on the robustness of the evaluation process and the model's efficiency.
- Quantization Concerns in Llama 3.1: Members raised concerns about Llama 3.1's performance drop due to quantization, with better results noted using bf16 (X.com post).
- Discussions suggest that the quantization impacts might be tied to the total data volume rather than just the parameter count.
PART 1: High level Discord summaries
Nous Research AI Discord
- Synthetic Data Generation Tools Under Scrutiny: Members discussed tools for generating synthetic data, highlighting Argila and Distillabel while gathering resources for a holistic overview.
- A Twitter thread was shared, though its specific relevance to synthetic data tools remains ambiguous.
- Moondream's Video Analysis Potential: Moondream was considered for identifying criminal activity by analyzing selective frames in videos, aiming for effective detection of dangerous actions.
- Productivity tips emphasized the necessity of quality images and robust prompting strategies for optimal performance.
- Llama 405B Instruct Shines in MMLU: The Llama 405B Instruct model achieved an average accuracy of 0.861 during the MMLU evaluation, with prominent results in biology and geography.
- The evaluation process was executed efficiently, wrapping up in about two hours.
- RAG Production Challenges and Solutions: A recent post detailed common issues faced in RAG production, showcasing potential solutions and best practices in a LinkedIn post.
- Community members emphasized the importance of shared knowledge for overcoming obstacles in RAG implementation.
- JSON-MD Integration for Task Management: Discussions focused on using JSON for task organization while leveraging Markdown for readability, paving the way for a synchronized contribution process.
- The Operation Athena website is poised to serve as a dynamic frontend for task management, designed for collaborative interaction.
HuggingFace Discord
- Fine-tuning w2v2-bert on Ukrainian Achieves 400k Samples: A project demonstrated fine-tuning of w2v2-bert on Ukrainian with the YODAS2 dataset, totaling 400k samples to enhance model accuracy in the language.
- This initiative expands model capabilities for Ukrainian, addressing language processing needs effectively.
- Meta Llama 3.1 Performance Insights: In-depth evaluation of Meta Llama 3.1 models compared GPU and CPU performance, documented in a detailed blog post, revealing notable findings.
- The evaluation included performance insights along with video demonstrations of test scenarios, shedding light on computational efficiency.
- Issues with Hugging Face Tokenizer Implementation: A member highlighted that
tokenizer.apply_chat_templateis broken in the recent Hugging Face Transformers, withadd_generation_prompt = Falsenot functioning correctly.- This issue has sparked conversations about potential workarounds and the implications for ongoing projects integration.
- Research Collaboration Opportunities at the Hackathon: Steve Watts Frey announced a new 6-day ultra-hackathon aimed at advancing open-source benchmarks, featuring substantial computing resources for participants and outlining collaboration chances.
- Teams are encouraged to take advantage of this chance to drive research efforts forward, boosting community engagement.
- User Experiences Highlighting Challenges with Data Management: Members shared experiences on dataset management, noting that organizing training data in order of increasing difficulty led to improved model performance.
- Additionally, discussions surfaced around enhancing breed classification models on Kaggle, tackling concerns about learning efficiency.
LM Studio Discord
- LM Studio performance varies by GPU: Users noticed significant variations in performance metrics across models, particularly with Llama 3.1, as GPU configurations impacted speed and context length settings.
- Some users reported different tokens per second rates, emphasizing the role of their GPU type and RAM specifications on inference efficiency.
- Model loading issues require updates: Several users faced model loading errors with Llama 3.1, citing tensor-related issues and recommending updating LM Studio or reducing context size.
- Guidelines were shared on troubleshooting, focusing on GPU compatibility and proper model directory structures.
- Fine-tuning vs embeddings debate: Discussion centered on the effectiveness of fine-tuning versus embeddings, highlighting the necessity for well-prepared examples for model operation.
- Participants emphasized that inadequate context or tutorial content could impede models' performance.
- Snapdragon X Elite ARM CPU generates buzz: The performance of the new Snapdragon X Elite ARM CPU in Windows 11 sparked conversation, with a review video titled "Mac Fanboy Tries ARM Windows Laptops" generating user interest.
- Members speculated on real-world usability and shared personal experiences with ARM CPU setups.
- GPU preferences for model training: Consensus emerged that the 4090 GPU is optimal for model training, outperforming older models such as the K80 or P40.
- Members highlighted the importance of modern hardware for effective CUDA support, especially when handling large models.
Stability.ai (Stable Diffusion) Discord
- AI Tools Face-Off: ComfyUI Takes the Crown: In discussions around Stable Diffusion, users compared ComfyUI, A1111, and Forge, revealing that ComfyUI offers superior control and model flexibility, enhancing speed.
- Concerns arose regarding Forge's performance after its latest update, prompting users to consider A1111 as a viable alternative.
- Frustration Over Inpainting Quality: User Modusprimax reported continual blurry outputs with Forge's new inpainting feature, despite multiple configuration attempts.
- The community suggested reverting to ComfyUI or trying earlier Forge versions for potentially better inpainting outcomes.
- Strategies for Character Consistency Revealed: Participants shared techniques using specific models and IP adapters to maintain character consistency in AI-generated images, particularly recommending the 'Mad Scientist' model.
- This approach is noted to yield better results in character anatomy, helping to refine user outputs.
- Censorship Concerns with AMD's Amuse 2.0: Discussion ensued around AMD’s Amuse 2.0 model, criticized for heavy censorship affecting its ability to render certain body curves accurately.
- This sparked broader conversations about the implications of censorship on creativity within AI applications.
- Community Emphasizes Learning Resources: Several users highlighted the necessity of utilizing video tutorials and community forums to improve understanding of Stable Diffusion prompts and operations.
- Crystalwizard encouraged diligence in exploring ComfyUI features while clarifying misconceptions about various AI generation tools.
OpenAI Discord
- SearchGPT Performance Highlights: Users shared positive feedback about SearchGPT, noting its ability to search through credible sources and utilize Chain of Thought (CoT) reasoning during inquiries.
- One user demonstrated its practicality by showcasing a calculation of trip costs while retrieving relevant car model information.
- ChatGPT Connectivity Frustrations: Multiple reports emerged regarding ongoing access issues with ChatGPT, with users experiencing significant loading delays.
- One user expressed particular frustration over being unable to log in for weeks and receiving no assistance from OpenAI support.
- AI Assists Coding Efficiency: Users eagerly discussed their experiences using AI tools for coding, highlighting successful Python scripts created to launch Chrome and other tasks.
- One user praised the feedback loop enabled by ChatGPT on their server, enhancing collaboration and code quality.
- Voice Mode Excitement: Anticipation grew around the rollout of voice mode in ChatGPT, expected to launch this week for a select group of users.
- Speculation arose regarding how users would be chosen to access this feature, generating excitement within the community.
- Cultural Exchanges in the Community: A user identified as Russian engaged with another who identified as Ukrainian, fostering a sharing of cultural backgrounds.
- This brief interaction highlighted the diverse community and encouraged inclusivity among members.
Unsloth AI (Daniel Han) Discord
- Best Practices for Using Unsloth AI: Users discussed the effectiveness of various system messages for Llama 3.1, with the default from Unsloth notebooks sufficing for tasks. Some opted to remove the system message to save context length without loss in performance.
- Conversations highlighted how flexible modeling aligns well with task-specific needs, especially when optimizing GPU memory usage.
- Fine-tuning with LoRa Adapters: Members confirmed that LoRa adapters from fine-tuning can be applied to original Llama models, granted the base model remains unchanged. Uncertainties remain about the compatibility across model versions, necessitating attention.
- Apple's usage of LoRA for fine-tuning demonstrated effective balance between capacity and inference performance, particularly for task-specific applications.
- Quantization Trade-offs: Discussions addressed the performance vs VRAM costs of 4-bit versus 16-bit models, urging experimentation as users find varying results in efficacy. Notably, 16-bit models deliver superior performance despite demanding four times the VRAM.
- Members emphasized the application of these quantization strategies based on unique workloads, reinforcing the necessity for hands-on metrics.
- Hugging Face Inference Endpoint Security: Clarifications around Hugging Face endpoints emphasized that 'protected' status applies only to one's token; sharing could lead to unauthorized access. It was stressed that safeguarding your token is paramount.
- Overall, members cautioned against potential security risks, underscoring vigilance in managing sensitive credentials.
- Efficiency in ORPO Dataset Creation: A member raised concerns about the manual nature of creating ORPO datasets, exploring the feasibility of a UI to streamline this process. Suggestions included leveraging smarter models for efficiently producing responses.
- The discourse stressed the need for automation tools to overcome repetitive tasks, potentially enhancing productivity and focus on model optimization.
CUDA MODE Discord
- Mojo Community Meeting Scheduled: The next Mojo community meeting is on July 29 at 10 PT, featuring insights on GPU programming with Mojo led by @clattner_llvm, available in the Modular community calendar.
- The agenda includes Async Mojo and a Community Q&A, providing an opportunity for engagement and learning.
- Fast.ai Launches Computational Linear Algebra Course: Fast.ai introduced a new free course, Computational Linear Algebra, complemented by an online textbook and video series.
- Focusing on practical applications, it utilizes PyTorch and Numba, teaching essential algorithms for real-world tasks.
- Triton exp Function Sacrifices Accuracy: It was noted that the exp function in Triton utilizes a rapid
__expfimplementation at the cost of accuracy, prompting inquiries into the performance of libdevice functions.- Members suggested checking the PTX assembly output from Triton to determine the specific implementations being utilized.
- Optimizing PyTorch CPU Offload for Optimizer States: Members explored the mechanics of CPU offload for optimizer states, questioning its practicality while highlighting a fused ADAM implementation as critical for success.
- Discussions revealed confusion on the relationship between paged attention and optimizers, as well as the complex nature of using FSDP for single-GPU training.
- INT8 Model Training Shows Promise: A member shared their experience fine-tuning ViT-Giant (1B params) with INT8 model training, observing similar loss curves and validation accuracy compared to the BF16 baseline.
- However, they noted significant accuracy drops when incorporating an 8-bit optimizer with the INT8 model.
Perplexity AI Discord
- Perplexity Pro Subscription Clarified: Users highlighted discrepancies in the Perplexity Pro subscription limits, reporting that Pro users have 540 or 600 daily searches and a cap of 50 messages for the Claude 3 Opus model.
- Confusion around these limitations suggests potential documentation inconsistencies that need addressing.
- Dyson Launches High-End OnTrac Headphones: Dyson introduced its OnTrac headphones at a $500 price point, featuring 40mm neodymium drivers and advanced noise cancellation reducing noise by up to 40 dB.
- This move marks Dyson's entry into the audio market, departing from their focus on air purification with the previous Zone model.
- Inconsistencies in Perplexity API Performance: Users noted performance differences between the web and API versions of Perplexity, with the web version yielding superior results.
- Concerns emerged regarding the API's
llama-3-sonar-large-32k-onlinemodel, which had issues returning accurate data, suggesting prompt structuring affects outcomes.
- Concerns emerged regarding the API's
- Job Prospects with Perplexity AI: Prospective candidates expressed interest in job openings at Perplexity AI, highlighting remote positions available on the careers page.
- High remuneration for specific roles sparked discussions about what these positions entail and the challenges applicants might face.
- Cultural Insights on Zombies: Users explored the concept of Himalayan zombies called ro-langs, contrasting them with traditional Western portrayals, revealing a rich cultural narrative.
- This discussion provided insights into the spiritual beliefs woven into Himalayan mythology, complexly differing from Western interpretations.
OpenRouter (Alex Atallah) Discord
- ChatBoo introduces voice calling: The ChatBoo Update July video unveiled a voice calling feature, aimed at enhancing interactive experiences within the app.
- Users are encouraged to test the new functionality and provide feedback.
- DigiCord presents all-in-one AI assistant: The Introducing DigiCord video introduces an AI assistant that combines 40+ LLMs, including OpenAI GPT-4 and Gemini.
- DigiCord integrates various image models like Stable Diffusion, aiming to be a comprehensive tool for Discord users.
- Enchanting Digital seeks testers: Enchanting Digital is currently in a testing phase, inviting users to participate at enchanting.digital, focusing on dialogue and AI features with a robust RP engine.
- Lightning-fast and realistic generations are promised, allowing seamless chatting capabilities.
- OpenRouter API faces 500 Internal Server Error: Users reported receiving a 500 Internal Server Error** when accessing OpenRouter, signaling potential service interruptions.
- Minor issues with API functionality were recorded, with updates available on the OpenRouter status page.
- Model suggestions for roleplay: For roleplay, users recommended utilizing Llama 3.1 405B, while also mentioning Claude 3.5 Sonnet and gpt-4o mini for improved results.
- Concerns arose regarding the limitations of Llama 3.1 without specific prompts, prompting suggestions to seek help within the SillyTavern Discord community.
Modular (Mojo 🔥) Discord
- CUDA installation woes: Users vent frustrations about mismatched CUDA versions while using Mojo for LIDAR tasks, leading to considerable installation challenges.
- Suggestions included favoring the official CUDA installation website over
apt installto mitigate issues.
- Suggestions included favoring the official CUDA installation website over
- Exciting Mojo/MAX alpha test kicks off: An alpha test for installing Mojo/MAX via conda is now live, introduced with a new CLI tool called
magic. Installation instructions are provided at installation instructions.- The
magicCLI simplifies installing Python dependencies, making project sharing more reliable; feedback can be relayed via this link.
- The
- Optimizing FFTs in Mojo requires attention: Users are eager for optimized FFT libraries like FFTW or RustFFT but face binding challenges with existing solutions.
- Links to previous GitHub attempts for FFT implementation in Mojo were shared among participants.
- Linked list implementation seeks scrutiny: A user shared a successful implementation of a linked list in Mojo, looking for feedback on memory leaks and debugging.
- They provided a GitHub link for their code and specifically requested guidance regarding deletion and memory management.
- Discussions on C/C++ interop in Mojo: Conversations revealed a focus on future C interop capabilities in Mojo, possibly taking around a year to develop.
- Users expressed frustration over gated libraries typically written in C and the complexities involved in C++ integration.
Eleuther Discord
- TPU Chips Still Under Wraps: No recent progress has been made in decapping or reverse engineering TPU chips, as members noted a lack of detailed layout images.
- While some preliminary data is available, a full reverse engineering hasn't yet been achieved.
- Llama 3.1's Quantization Quandary: Concerns arose over Llama 3.1's performance drop due to quantization, with a member linking to a discussion showing better results using bf16 (X.com post).
- The group debated if quantization impacts delve deeper into the overall data volume rather than merely the parameter count.
- Iterative Inference Sparks Interest: Members are contemplating research directions for iterative inference in transformers, emphasizing in-context learning and optimization algorithms, showing interest in the Stages of Inference paper.
- They expressed the need for deeper insights into existing methods like gradient descent and their applications in current transformer architectures.
- lm-eval-harness Issues Surface: Users are encountering multiple issues with the
lm-eval-harness, needing to usetrust_remote_code=Truefor proper model execution.- One member shared their Python implementation, prompting discussions about command-line argument handling and its complexity.
- Synthetic Dialogues Boost Fine-Tuning: A new dataset called Self Directed Synthetic Dialogues (SDSD) was presented to enhance instruction-following capabilities across models like DBRX and Llama 2 70B (SDSD paper).
- This initiative aims to augment multi-turn dialogues, allowing models to simulate richer interactions.
Latent Space Discord
- LMSYS dives into Ranking Finetuning: Members highlighted the recent efforts by LMSYS to rank various finetunes of llama models, questioning the potential biases in this process and the transparency of motivations behind it.
- Concerns surfaced regarding favoritism towards individuals with connections or financial ties, impacting the credibility of the ranking system.
- Meta launches SAM 2 for Enhanced Segmentation: Meta's newly launched Segment Anything Model 2 (SAM 2) delivers real-time object segmentation improvements, powered by a new dataset of roughly 51,000 videos.
- Available under an Apache 2.0 license, the model marks a significant leap over its predecessor, promising extensive applications in visual tasks.
- Excitement Surrounds Cursor IDE Features: Users buzzed about the capabilities of the Cursor IDE, especially its Ruby support and management of substantial code changes, with users reporting over 144 files changed in a week.
- Talks of potential enhancements included collaborative features and a context plugin API to streamline user experience further.
- Focus on Context Management Features: User discussions reiterated the necessity for robust context management tools within the Cursor IDE, improving user control over context-related features.
- One user described their shift to natural language coding for simplicity, likening it to a spectrum with pseudocode.
- Llama 3 Paper Club Session Recorded: The recording of the Llama 3 paper club session is now available, promising insights on crucial discussions surrounding the model; catch it here.
- Key highlights included discussions on enhanced training techniques and performance metrics, enriching community understanding of Llama 3.
LlamaIndex Discord
- Join the LlamaIndex Webinar on RAG: This Thursday at 9am PT, LlamaIndex hosts a webinar with CodiumAI on Retrieval-Augmented Generation (RAG) for code generation, helping enterprises ensure high code quality.
- RAG’s significance lies in its ability to enhance coding processes through the LlamaIndex infrastructure.
- Innovating with Multi-modal RAG: A recent demo showcased using the CLIP model for creating a unified vector space for text and images using OpenAI embeddings and Qdrant.
- This method enables effective retrieval from mixed data types, representing a significant advancement in multi-modal AI applications.
- Implementing Text-to-SQL in LlamaIndex: Discussion revolved around establishing a text-to-SQL assistant using LlamaIndex, showcasing setup for managing complex NLP queries effectively.
- Examples highlighted practical configuration strategies for deploying capable query engines tailored for user needs.
- Security Concerns Surrounding Paid Llamaparse: A query arose regarding the security considerations of utilizing paid versus free Llamaparse versions, but community feedback lacked definitive insights.
- The ambiguity left members uncertain about potential security differences that may influence their decisions.
- Efficient Dedupe Techniques for Named Entities: Members explored methods for programmatically deduping named entities swiftly without necessitating a complex setup.
- The emphasis was on achieving deduplication efficiency, valuing speed in processing without burdensome overhead.
OpenInterpreter Discord
- Open Interpreter Feedback Loop: Users expressed mixed feelings about Open Interpreter as a tool, suggesting it effectively extracts data from PDFs and translates text, while cautioning against its experimental aspects.
- One user inquired about using it for translating scientific literature from Chinese, receiving tips for effective custom instructions.
- AI Integration to Assist Daily Functioning: A member struggling with health issues is exploring Open Interpreter for voice-commanded tasks to aid their daily activities.
- While community members offered caution around using OI for critical operations, they advised alternative solutions like speech-to-text engines.
- Ubuntu 22.04 confirmed for 01 Desktop: Members confirmed that Ubuntu 22.04 is the recommended version for 01 Desktop, preferring X11 over Wayland.
- Discussions revealed comfort and familiarity with X11, reflecting ongoing conversations around desktop environments.
- Agent Zero's Impressive Demo: The first demonstration of Agent Zero showcased its capabilities, including internal vector DB and internet search functionalities.
- Community excitement grew around Agent Zero’s features like executing in Docker containers, sparking interest in tool integrations.
- Groq's Mixture of Agents on GitHub: A GitHub repository for the Groq Mixture of Agents was shared, highlighting its development goals related to agent-based interactions.
- This project is open for contributions, inviting community collaboration in enhancing agent-based systems.
OpenAccess AI Collective (axolotl) Discord
- Turbo models likely leverage quantization: The term 'turbo' in model names suggests the models are using a quantized version, enhancing performance and efficiency.
- One member noted, I notice fireworks version is better than together ai version, reflecting user preference in implementations.
- Llama3 finetuning explores new strategies: Discussions on how to effectively finetune Llama3 covered referencing game stats and weapon calculations, emphasizing practical insights.
- There is particular interest in the model's ability to calculate armor and weapon stats efficiently.
- QLoRA scrutinized for partial layer freezing: The feasibility of combining QLoRA with partial layer freeze was debated, focusing on tuning specific layers while maintaining others.
- Concerns arose over whether peft recognizes those layers and the efficacy of DPO without prior soft tuning.
- Operation Athena launches AI reasoning tasks: A new database under Operation Athena has launched to support reasoning tasks for LLMs, inviting community contributions.
- This initiative, backed by Nous Research, aims to improve AI capabilities through a diverse set of tasks reflecting human experiences.
- Understanding early stopping in Axolotl: The
early_stopping_patience: 3parameter in Axolotl triggers training cessation after three consecutive epochs without validation improvement.- Providing a YAML configuration example helps monitor training metrics, preventing overfitting through timely interventions.
LangChain AI Discord
- LangChain Open Source Contributions: Members sought guidance for contributing to LangChain, sharing helpful resources including a contributing guide and a setup guide for understanding local repository interactions.
- Suggestions revolved around enhancing documentation, code, and integrations, especially for newbies entering the project.
- Ollama API Enhancements: Using the Ollama API for agent creation proved efficient, with comparisons showing ChatOllama performing better than OllamaFunctions in following LangChain tutorial examples.
- However, past versions faced issues, notably crashes during basic tutorials involving Tavily and weather integrations.
- ConversationBufferMemory Query: Discussion arose around the usage of
save_contextin ConversationBufferMemory, with members seeking clarity on structuring inputs and outputs for various message types.- There was a noted need for enhanced documentation on thread safety, with advice emphasizing careful structuring to manage messages effectively.
- Flowchart Creation with RAG: Members recommended using Mermaid for flowchart creation, sharing snippets from LangChain's documentation to assist visualizations.
- A GitHub project comparing different RAG frameworks was also shared, providing more insights into application functionalities.
- Merlinn AI on-call agent simplifies troubleshooting: Merlinn, the newly launched open-source AI on-call agent, assists with production incident troubleshooting by integrating with DataDog and PagerDuty.
- The team invites user feedback and encourages stars on their GitHub repo to support the project.
Cohere Discord
- Cohere API Key Billing Challenges: Participants discussed the need for separate billing by API key, exploring middleware solutions to manage costs distinctly for each key.
- Members expressed frustration over the lack of an effective tracking system for API usage.
- Recommended Framework for Multi-Agent Systems: A member highlighted LangGraph from LangChain as a leading framework praised for its cloud capabilities.
- They noted that Cohere's API enhances multi-agent functionality through extensive tool use capabilities.
- Concerns Around API Performance and Downtime: Users reported slowdowns with the Cohere Reranker API as well as a recent 503 error downtime impacting service access.
- Cohere confirmed recovery with all systems operational and 99.67% uptime highlighted in a status update.
- Using Web Browsing Tools in Cohere Chat: Members discussed integrating web search tools into the Cohere chat interface, enhancing information access through API functionality.
- One user successfully built a bot leveraging this feature, likening it to a search engine.
- Prompt Tuner Beta Featured Discussion: Queries emerged regarding the beta release of the 'Prompt Tuner' feature, with users eager to understand its impact on API usage.
- Members expressed curiosity about practical implications of the new tool within their workflows.
Interconnects (Nathan Lambert) Discord
- GPT-4o Mini revolutionizes interactions: The introduction of GPT-4o Mini is a game-changer, significantly enhancing interactions by serving as a transparency tool for weaker models.
- Discussions framed it as not just about performance, but validating earlier models' efficacy.
- Skepticism surrounding LMSYS: Members voiced concerns that LMSYS merely validates existing models rather than leading the way in ranking algorithms, with observed randomness in outputs.
- One highlighted that the algorithm fails to effectively evaluate model performance, especially for straightforward questions.
- RBR paper glosses over complexities: The RBR paper was criticized for oversimplifying complex issues, especially around moderating nuanced requests that may have dangerous undertones.
- Comments indicated that while overt threats like 'Pipe bomb plz' are easy to filter, subtleties are often missed.
- Interest in SELF-ALIGN paper: A growing curiosity surrounds the SELF-ALIGN paper, which discusses 'Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision'.
- Members noted potential connections to SALMON and RBR, sparking further interest in alignment techniques.
- Critique of Apple's AI paper: Members shared mixed reactions to the Apple Intelligence Foundation paper, particularly about RLHF and its instruction hierarchy, with one printing it for deeper evaluation.
- Discussions suggested a divergence of opinions on the repository's effectiveness and its implications for RL practices.
DSPy Discord
- Moondream2 gets a structured image response hack: A member built a hack combining Moondream2 and OutlinesOSS that allows users to inquire about images and receive structured responses by hijacking the text model.
- This approach enhances embedding processing and promises an improved user experience.
- Introducing the Gold Retriever for ChatGPT: The Gold Retriever is an open-source tool that enhances ChatGPT's capabilities to integrate personalized, real-time data, addressing prior limitations.
- Users desire tailored AI interactions, making Gold Retriever a crucial resource by providing better access to specific user data despite knowledge cut-off challenges.
- Survey on AI Agent Advancements: A recent survey paper examines advancements in AI agents, focusing on enhanced reasoning and tool execution capabilities.
- It outlines the current capabilities and limitations of existing systems, emphasizing key considerations for future design.
- Transformers in AI: Fundamental Questions Raised: A blog post worth reading emphasizes the capability of transformer models in complex tasks like multiplication, leading to deeper inquiry into their learning capacity.
- It reveals that models such as Claude or GPT-4 convincingly mimic reasoning, prompting discussions on their ability to tackle intricate problems.
- Exploring Mixture of Agents Optimization: A member proposed using a mixture of agents optimizer for DSPy, suggesting optimization through selecting parameters and models, backed by a related paper.
- This discussion compared their approach to the architecture of a neural network for better responses.
tinygrad (George Hotz) Discord
- Improving OpenCL Error Handling: A member proposed enhancing the out of memory error handling in OpenCL with a related GitHub pull request by tyoc213.
- They noted that the suggested improvements could address existing limitations in error notifications for developers.
- Monday Meeting Unveiled: Key updates from Monday's meeting included the removal of UNMUL and MERGE, along with the introduction of HCQ runtime documentation.
- Discussion also covered upcoming MLPerf benchmark bounties and enhancements in conv backward fusing and scheduler optimizations.
- ShapeTracker Bounty Raises Questions: Interest emerged regarding a ShapeTracker bounty focused on merging two arbitrary trackers in Lean, sparking discussions on feasibility and rewards.
- Members engaged in evaluating the worth of the bounty compared to its potential outputs and prior discussions.
- Tinygrad Tackles Time Series Analysis: A user explored using tinygrad for physiological feature extraction in time series analysis, expressing frustrations with Matlab's speed.
- This discussion highlighted an interest in tinygrad's efficiency for such application areas.
- NLL Loss Error Disclosed: An issue was reported where adding
nll_lossled to tensor gradient loss, resulting in PR failures, prompting a search for solutions.- Responses clarified that non-differentiable operations like CMPNE impacted gradient tracking, indicating a deeper problem in loss function handling.
LAION Discord
- Vector Search Techniques Get a BERT Boost: For searching verbose text, discussions reveal that using a BERT-style model outperforms CLIP, with notable suggestions from models by Jina and Nomic.
- Members highlighted that Jina's model serves as a superior alternative when focusing away from images.
- SWE-Bench Hosts a $1k Hackathon!: Kicking off on August 17, the SWE-Bench hackathon offers participants $1,000** in compute resources and cash prizes for top improvements.
- Participants will benefit from support by prominent coauthors, with chances to collaborate and surpass benchmarks.
- Segment Anything Model 2 Now Live!: The Segment Anything Model 2** from Facebook Research has been released on GitHub, including model inference code and checkpoints.
- Example notebooks are offered to aid users in effective model application.
AI21 Labs (Jamba) Discord
- Jamba's Long Context Capabilities Impress: Promising results are emerging from Jamba's 256k effective length capabilities, particularly from enterprise customers eager to experiment.
- The team actively encourages developer feedback to refine these features further, aiming to optimize use cases.
- Developers Wanted for Long Context Innovations: Jamba is on the lookout for developers to contribute to long context projects, offering incentives like credits, swag, and fame.
- This initiative seeks engaging collaboration to broaden the scope and effectiveness of long context applications.
- New Members Energize Community: The arrival of new member artworxai adds energy to the chat, sparking friendly interactions among members.
- The positive atmosphere establishes a welcoming environment, crucial for community engagement.
LLM Finetuning (Hamel + Dan) Discord
- Last Call for LLM Engineers in Google Hackathon: A team seeks one final LLM engineer to join their project for the upcoming Google AI Hackathon, focusing on disrupting robotics and education.
- Candidates should possess advanced skills in LLM engineering, familiarity with LangChain and LlamaIndex, and a strong interest in robotics or education tech.
- Fast Dedupe Solutions for Named Entities Requested: A member seeks effective methods to programmatically dedupe a list of named entities, looking for speedy solutions without complex setups.
- The aim is to identify a quick and efficient approach to handle duplicates, rather than implementing intricate systems.
Alignment Lab AI Discord
- Community Seeks Robust Face Recognition Models: Members are on the hunt for machine learning models and libraries that excel in detecting and recognizing faces in images and videos, prioritizing accuracy and performance in real-time scenarios.
- They emphasize the critical need for solutions that not only perform well under varied conditions but also cater to practical applications.
- Interest in Emotion Detection Capabilities: Discussions reveal a growing interest in solutions capable of identifying emotions from faces in both still images and video content, targeting the enhancement of interaction quality.
- Participants specifically request integrated solutions that merge face recognition with emotion analysis for a comprehensive understanding.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Nous Research AI ▷ #datasets (2 messages):
Synthetic Data Generation ToolsArgilaDistillabelTwitter Resources
- Exploring Synthetic Data Generation Tools: A member inquired about tools for generating synthetic data, mentioning Argila and Distillabel specifically.
- They sought additional tools, papers, or resources for a comprehensive starting point.
- Twitter Insights on Synthetic Data: A relevant Twitter thread was shared, possibly relating to the discussion on synthetic data.
- The specifics of the thread's content regarding synthetic data tools or insights remain unclear.
Nous Research AI ▷ #off-topic (3 messages):
Moondream for video analysisImage quality impactPrompt effectivenessCategorization program example
- Moondream usage for detecting criminal activity: A user inquired about using Moondream to identify criminal, violent, or dangerous activity in videos by analyzing every 15th or 30th frame.
- Tips for effective usage include ensuring good image quality and using a solid prompting strategy.
- Image quality's role in model effectiveness: Another member stated that as long as the image quality is sufficient, the model should yield decent results, noting most movies run at 24fps.
- Variations in rendering may occur, depending on the viewing method.
- Importance of prompts for model responses: It was mentioned that using a decent prompt is crucial for obtaining desired responses from the model.
- One user shared their success with a system prompt for spam moderation, which returned 1 for acceptable content and 0 for spam.
Nous Research AI ▷ #interesting-links (3 messages):
Jim Keller KeynotePrompt Formats for AIAutomated Automata
- Jim Keller Discusses AI Innovations: In a YouTube keynote video, Jim Keller, CEO of Tenstorrent, shares his insights on AI innovations and emerging technologies.
- The presentation highlights key advancements that are reshaping the AI landscape.
- Choosing the Best Prompt Format: A discussion around a YouTube video explores which prompt format—Markdown, XML, or Raw—is optimal for AI agents, particularly for Llama 3.1.
- The video asserts that eliminating raw prompts is essential for unlocking AI's true capabilities.
- Exploring Complexity with Automated Automata: The Automated-Automata project showcases an Android game simulating Conway's Game of Life, creating dynamic patterns and shadows.
- A linked GitHub repository provides access to the demo and detailed project information.
- BEST Prompt Format: Markdown, XML, or Raw? CONFIRMED on Llama 3.1 & Promptfoo: Which prompt format is BEST for your AI agents? Is it Markdown, XML, or Raw Prompts?🚀 Ready to unlock the true potential of your AI agents? In this video, w...
- 61DAC Keynote: Jim Keller, CEO, Tenstorrent: no description found
- Cellular Automata : no description found
- GitHub - vtempest/Automated-Automata: Android Game simulating Conway's Game of Life * DEMO automata-game-of-life.vtempest.workers.dev: Android Game simulating Conway's Game of Life * DEMO automata-game-of-life.vtempest.workers.dev - vtempest/Automated-Automata
Nous Research AI ▷ #general (196 messages🔥🔥):
Llama 405B Instruct PerformanceBerkeley Function Calling Leaderboard UpdatesLocal Model ComparisonsUse of APIs vs Local ModelsRecent Updates from Meta
- Llama 405B Instruct shows strong MMLU performance: The Llama 405B Instruct model achieved an average accuracy of 0.861 across multiple subjects during the MMLU evaluation, with notable solid performances in biology and geography.
- It was reported that the team ran their evaluation on the model in around two hours, demonstrating efficient processing.
- Updates to the Berkeley Function Calling Leaderboard: Recent updates were discussed in a meeting regarding the Berkeley Function Calling Leaderboard, which now includes new models like Hermes 2 Pro and Hermes 2 Theta.
- The importance of maintaining proper prompting templates was also highlighted to ensure accurate evaluations.
- Challenges and Preferences in Local Model Usage: There's an ongoing discussion about the limitations of local code models like Codestral, with users reporting slower performance and coherence issues when handling larger contexts.
- Conversely, others noted that API pricing for open models is quite affordable, making API reliance more attractive for some users.
- User Experiences with Fine-tuning and Model Qualities: Participants shared insights on the effectiveness of current local models, mentioning Codestral 22B and DeepSeek’s MoE code model, but highlighting performance concerns.
- There’s a clear interest in exploring new training possibilities or waiting for improvements in upcoming models.
- Recent Developments in Meta's AI Models: A new SAM model from Meta was briefly mentioned, contributing to the ongoing development in AI model capabilities.
- Additionally, it was noted that Hugging Face datasets had been experiencing downtime.
- Replete-LLM-Qwen2-7b_Beta-Preview - a Hugging Face Space by rombodawg: no description found
- Nexusflow/Athene-70B · Hugging Face: no description found
- nisten/Biggie-SmoLlm-0.4B · Hugging Face: no description found
- Templates for Chat Models: no description found
- gorilla/berkeley-function-call-leaderboard/data/possible_answer/gorilla_openfunctions_v1_test_simple.json at main · ShishirPatil/gorilla: Gorilla: An API store for LLMs. Contribute to ShishirPatil/gorilla development by creating an account on GitHub.
- GitHub - mckaywrigley/chatbot-ui: AI chat for every model.: AI chat for every model. Contribute to mckaywrigley/chatbot-ui development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- [ Misc ] `fp8-marlin` channelwise via `compressed-tensors` by robertgshaw2-neuralmagic · Pull Request #6524 · vllm-project/vllm: SUMMARY: support fp8_marlin via compressed-tensors add support for fp8_marlin with channelwise scales testing should be covered by existing models running on Ampere, but also added a weight-only F...
- Installation — vLLM: no description found
- flask-socketio-llm-completions/research at ai-guarded · russellballestrini/flask-socketio-llm-completions: Chatroom app where messages are sent to GPT, Claude, Mistral, Together, Groq AI and streamed to the frontend. - russellballestrini/flask-socketio-llm-completions
- flask-socketio-llm-completions/research/guarded_ai.py at ai-guarded · russellballestrini/flask-socketio-llm-completions: Chatroom app where messages are sent to GPT, Claude, Mistral, Together, Groq AI and streamed to the frontend. - russellballestrini/flask-socketio-llm-completions
Nous Research AI ▷ #ask-about-llms (115 messages🔥🔥):
Connecting Multiple GPUsFine-Tuning ModelsTheta Model DiscussionsGeneralist vs. Expert ModelsSynthetic Data Collaboration
- Connecting 16,000 GPUs Efficiently: Discussion revolved around the feasibility of connecting 16,000 H100 GPUs using networking infrastructure like Infiniband, with suggestions for using nodes to share VRAM.
- Members mentioned that the Hugging Face Accelerate library could assist, but there are debates on alternative approaches without relying solely on Transformers' accelerate.
- Challenges with Fine-Tuning Llama 3.1: A user reported poor accuracy when fine-tuning Llama 3.1 8B on domain-specific data, prompting discussion about the drawbacks of fine-tuning over already tuned models.
- Experts suggested that mixing domain data with generalist datasets might mitigate catastrophic forgetting and improve chat performance, though finding the right ratio remains unexplored.
- Theta Model Token Anomaly: Concerns were raised regarding token 'ĊĊ': 271 appearing frequently in the Theta 8B model which was identified as representing a double newline issue.
- It appears that this token could be a rendering issue rather than a functionality flaw, amplifying discussions on model differentiation and merging strategies.
- Differences Between Models: Inquiries were made into the differences between NousResearch/Meta-Llama-3.1-8B-Instruct and the original Meta version, concluding that the main difference is accessibility.
- The community is considering how diverse model merges, such as those in Hermes, influence the behavior and performance of various models.
- Future of Hermes Models: Discussion included the upcoming Hermes 3 models, which are designed to utilize custom datasets and aimed to retain the beneficial traits from previous iterations.
- It was noted that any future merges might be labeled as Hermes 3 theta, indicating a continued evolution in model development.
- Hastebin: no description found
- GitHub - huggingface/accelerate: 🚀 A simple way to launch, train, and use PyTorch models on almost any device and distributed configuration, automatic mixed precision (including fp8), and easy-to-configure FSDP and DeepSpeed support: 🚀 A simple way to launch, train, and use PyTorch models on almost any device and distributed configuration, automatic mixed precision (including fp8), and easy-to-configure FSDP and DeepSpeed suppo.....
Nous Research AI ▷ #rag-dataset (1 messages):
RAG production issuesCommon challenges in RAG
- RAG Production Issues and Solutions: A post highlighted some common challenges faced in RAG production, discussing potential solutions and workarounds. This LinkedIn post details specific problems and insights shared by community members.
- Key takeaways include a focus on mitigating typical obstacles and leveraging community input for a more streamlined RAG pipeline.
- Key Community Insights on RAG: Community members shared their experiences with RAG, addressing the frequent difficulties they encounter during implementation. These insights shed light on practical approaches for overcoming production hurdles in RAG contexts.
- A collective emphasis on knowledge sharing demonstrated the power of collaborative problem-solving.
Nous Research AI ▷ #reasoning-tasks-master-list (485 messages🔥🔥🔥):
Integration of JSON and MarkdownOperation Athena websiteImproving README structureTask examples and contributionsDatabase management and tasks organization
- Integration of JSON and Markdown for Tasks: The discussion revolves around using JSON as the core format for tasks while maintaining Markdown for readability, allowing future contributions to sync with a JSON backend.
- There is agreement on having a build step that synchronizes Markdown and JSON versions, facilitating easier contributions and organization.
- Operation Athena Website Launch: The 'Operation Athena' website has been built using Claude for the backend, showcasing contributions and reasoning tasks sourced from various platforms.
- The website aims to provide a dynamic front end for users to interact with the task database and is open-sourced for community collaboration.
- Finalizing README Structure: The team aims to finalize the README with a clear structure, including examples and links to folders and scripts in the repository.
- There is a suggestion to include descriptions for each directory and to downscale images to improve loading performance.
- Enhancing Task Contributions: Members discussed the need for task contributions to be easily accessible, with suggestions to implement voting or feedback mechanisms within the task database.
- The team considers maintaining a good user interface for submitting tasks and a structured repository for task examples.
- Database Management and Task Lists: The ongoing efforts to create a master list for datasets and papers are supported by the integration of MongoDB for organized task management.
- There are plans to promote contributions on social media once the README and project layout are finalized for better visibility.
- Operation Athena: no description found
- My Specialties GIF - My Specialties Wink - Discover & Share GIFs: Click to view the GIF
- Open-Reasoning-Tasks/_book at tasks-page · mmhamdy/Open-Reasoning-Tasks: A comprehensive repository of reasoning tasks for LLMs (and beyond) - mmhamdy/Open-Reasoning-Tasks
- add citation by mmhamdy · Pull Request #16 · NousResearch/Open-Reasoning-Tasks: This PR adds a bibtex citation entry and removes the template from README
- Add JSON storage for task data. by N8python · Pull Request #13 · NousResearch/Open-Reasoning-Tasks: This is a proof-of-concept for using node.js to support both markdown for viewing and JSON for structured data storage.
- Add more syllogism examples by isavita · Pull Request #11 · NousResearch/Open-Reasoning-Tasks: Description This PR enhances the tasks/syllogism-reasoning.md file by: Adding 23 new, modern examples of valid syllogisms, covering all 24 valid syllogistic forms more info. Providing diverse, con...
HuggingFace ▷ #announcements (1 messages):
w2v2-bert fine-tuningLlama-3.1-405B customizationNew YouTube notes generatorUnderstanding AutoGradMulti-Image Reasoning
- Fine-tuning w2v2-bert on Ukrainian: A project showcased fine-tuning of w2v2-bert on Ukrainian using the YODAS2 dataset with 400k samples.
- The work was credited to a verified user, extending model capabilities in the Ukrainian language.
- Customizable Llama-3.1-405B Released: A customizable version of Llama-3.1-405B was introduced, enhancing accessibility for further developments.
- This new variant is set to move the boundaries of research and application for Llama models.
- YouTube Notes Generator Unveiled: A new YouTube notes generator was shared, aiming to simplify video content summarization.
- This tool highlights direct engagement with multimedia learning, bridging the gap in educational resources.
- Exploring AutoGrad from Scratch: A blog series began on understanding AutoGrad for those new to deep learning, emphasizing practical applications.
- The first post notes the importance of learning this algorithm without needing deep theory comprehension, aimed at novice learners.
- Visual Haystacks Benchmark Launch: Discussion initiated around Multi-Image Reasoning with the launch of the Visual Haystacks Benchmark.
- This benchmark aims to push the boundaries of model reasoning abilities through comprehension of complex images.
- OpenCHAT Mini - a Hugging Face Space by KingNish: no description found
- Tweet from Anindya (@AnindyadeepS): Happy Monday. I know I am late to this game, but today, I published the very first blog of my written series on MakeMore. https://link.medium.com/BKXOLshVqLb For a while, I studied Andrej Karpathy&...
- Design TikTok's Recommendation System | ML System Design | #systemdesign: Do you know why TikTok's recommendation algorithm is so good? In this video, we design TikTok's recommendation system. The video covers machine learning aspe...
HuggingFace ▷ #general (678 messages🔥🔥🔥):
Hugging Face Dataset IssuesModel Evaluation MetricsModel Fine-tuning for Code GenerationLlama 3.1 PerformanceMachine Learning Career Paths
- Hugging Face Dataset Issues persist: Users report ongoing problems with Hugging Face datasets throwing 500 internal server errors, causing frustration among those relying on the platform for data loading.
- Despite some fixes being announced, users are still experiencing issues, suggesting a deeper problem at play.
- Strategies for Evaluating LLMs: Discussions on evaluating large language models (LLMs) reveal metrics like HumanEval and DeepEval, with some users suggesting alternatives such as METEOR for semantic tasks.
- Experts share insights on the importance of different evaluation metrics, particularly for code generation tasks.
- Exploring Hugging Face Models for Code Generation: Recommendations for the best local models for code generation include Llama 3.1, while users note concerns about performance differences between various quantized versions.
- The conversation highlights the trade-offs between model size, efficiency, and ease of use.
- Navigating a Career in Machine Learning: Users discuss the challenges of breaking into machine learning without a master's degree, emphasizing the value of practical experience and project portfolios.
- The importance of hands-on projects and case studies is highlighted as a more viable alternative to traditional educational pathways.
- Humor and Light-hearted Banter: Amid technical discussions, users engage in playful banter about their experiences with models, programming, and personal anecdotes, fostering community interaction.
- Light-hearted exchanges about language models and humorous observations about training data add a fun dimension to discussions.
- Hugging Face - Learn: no description found
- Can Ai Code Results - a Hugging Face Space by mike-ravkine: no description found
- Tweet from Steve Frey (@stevewattsfrey): A bold experiment: We're hosting a 6-day ultra-hackathon for SWE-Bench to push the limits of open-source code generation - Everyone gets $1,000 in compute provided by @StrongCompute - Up 50 rese...
- @nroggendorff on Hugging Face: "Datasets are down, I offer a solution
``` git clone…": no description found
git lfs install - briaai/RMBG-1.4 · Hugging Face: no description found
- Explosion Kitty Komaru Cat GIF - Explosion kitty Komaru cat Explosion - Discover & Share GIFs: Click to view the GIF
- ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions · Datasets at Hugging Face: no description found
- nroggendorff/my-first-llm · Hugging Face: no description found
- Newgen Audiomaker GIF - Newgen Audiomaker Roblox - Discover & Share GIFs: Click to view the GIF
- Llama 3.1 - 405B, 70B & 8B with multilinguality and long context: no description found
- ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions at main: no description found
- dougdougw/Doug/generation.py at main · nroggendorff/dougdougw: is it your birthday today? Contribute to nroggendorff/dougdougw development by creating an account on GitHub.
- Error: unsupported dtype for rmsnorm F64 in `candle-wasm-examples/bert` · Issue #2355 · huggingface/candle: I'm trying to run candle-wasm-examples/bert on my machine. I've removed it from the rest of the repo, and added versions for the deps in Cargo.toml. It builds fine. When I attempt to download ...
- abisee/cnn_dailymail · Datasets at Hugging Face: no description found
- Hugging Face status : no description found
- Pie & AI: Tokyo - Short Course Study Group: Pretraining LLMs with Upstage Short Course Study Group
HuggingFace ▷ #today-im-learning (7 messages):
RT-DETR PaperMeta Llama 3.1 PerformanceAI Frameworks for Face DetectionOpenSea CollaborationQuantization in Language Models
- RT-DETR Paper Shows Promise in Object Detection: The RT-DETR paper claims to outperform traditional YOLO detectors in most benchmarks while being faster, eliminating NMS yet benefiting from it.
- Key innovations include an efficient hybrid encoder and a flexible tuning mechanism that maintains accuracy while improving latency.
- Meta Llama 3.1 Performance Evaluation: A user experimented with the Meta Llama 3.1 models (405B, 70B, 8B) comparing GPU and CPU performance, documenting it in a detailed blog post.
- The findings include performance insights alongside videos showcasing the tests conducted.
- Exploring AI Frameworks for Face Detection: A learner began exploring various AI frameworks specifically for face detection as part of their ongoing education in the field.
- Further specific details regarding the frameworks tested were not disclosed.
- OpenSea Launches New Free Currency Initiative: A collaboration with OpenSea was announced, allowing server users to participate in claiming a new free currency through a CLAIM link.
- Participants are warned that some claims may incur gas fees.
- Visual Guide to Quantization in Language Models: A newsletter explores quantization, a technique for reducing the size of Large Language Models (LLMs) to run on consumer hardware more effectively.
- The guide aims to break down complex concepts in quantization to help readers build their understanding of improving model efficiency.
- RT-DETR: Abstract DETRs have been improved a lot w.r.t detecting objects but they are no where close to the traditional Real Time YOLO detectors when it comes to Real Time.
- A Visual Guide to Quantization: Exploring memory-efficient techniques for LLMs
HuggingFace ▷ #cool-finds (19 messages🔥):
AI Video GenerationGame Development MomentsOpen Source LLM ModelsPrompt FormatsQuantization in Language Models
- Discover AI Video Creation Tools: A member shared an AI tool for creating educational videos where users can visualize concepts using characters like Tom Cruise or Naruto.
- The tool guarantees a 90% retention promise and allows for personalized content tailored to individual learning styles.
- Top Game Development Highlights: A member shared a YouTube video showcasing the Top 10 Game Dev moments in just one minute.
- The video emphasizes the pivotal events that have shaped game development and illuminated the evolution of technology.
- Utilizing Open Source LLMs Locally: A member promoted a YouTube tutorial on using open source LLM models locally from platforms like Hugging Face and Ollama.
- Viewers are encouraged to understand the practical application of LLMs in local environments.
- Best AI Prompt Formats Revealed: A video titled BEST Prompt Format discusses the optimal prompt formats for AI agents, comparing Markdown, XML, and Raw options.
- The presenter humorously warns to never hit it raw, indicating that format choice is crucial.
- Understanding Quantization Techniques: A post introduces the concept of quantization, a method aimed at making Large Language Models (LLMs) smaller and more efficient for consumer hardware usage.
- The article details how quantization can improve model performance without the need for excessive VRAM.
- BEST Prompt Format: Markdown, XML, or Raw? CONFIRMED on Llama 3.1 & Promptfoo: Which prompt format is BEST for your AI agents? Is it Markdown, XML, or Raw Prompts?🚀 Ready to unlock the true potential of your AI agents? In this video, w...
- A Visual Guide to Quantization: Exploring memory-efficient techniques for LLMs
- how to use open source llm models locally form hugging face, ollama and others: no description found
- The Top 10 Game Dev moment's in 1 min: Discover the groundbreaking events that have shaped the world of game development, highlighting the evolution of technology and innovation that brought us to...
- AI Video Generation: no description found
HuggingFace ▷ #i-made-this (31 messages🔥):
Hugging Face BackupGenerative Models in Deep LearningAI-Powered Web Search with SearchPhiSolatium AI Models UIOpen Artificial Knowledge Dataset
- Hugging Face Backup by duskfallcrew: A member shared their project on Hugging Face Backup, detailing a Jupyter, Colab, and Python script for easy backups.
- They are also working on a Gradio version, seeking help to refine their coding efforts.
- Generative Models Added to French Deep Learning Course: A member updated their French Deep Learning course materials, now including topics like Generative Models, Transfer Learning, and Vision Transformers.
- The course is available in French and encourages feedback and sharing among peers.
- Introducing SearchPhi: An Open-Source Web Search Tool: SearchPhi, an open-source web search tool inspired by SearchGPT, has been announced, offering initial functionalities for multimodal searches.
- The project is available on GitHub and has a demo space on Hugging Face for testing.
- Solatium Offers AI Model Access: The Solatium platform, based on HuggingChat, offers free access to various AI models with features like web search and chat history saving.
- It includes 19 models and allows for flexibility in model selection during use.
- Open Artificial Knowledge Dataset Released: The Open Artificial Knowledge (OAK) dataset has been published, containing 535 million tokens generated from various large language models.
- This dataset aims to address issues of data quality and diversity for training better language models.
- Historically Accurate Neural Network Simulation: no description found
- Solatium - a Hugging Face Space by ehristoforu: no description found
- README spell checker - a Hugging Face Space by Yehor: no description found
- Knowledge Distillation Trends: Overview of recent Knowledge Distillation strategies and how to use them alongside Self-Supervised Learning with a focus on Masked Autoencoders
- SearchPhi - a Hugging Face Space by as-cle-bert: no description found
- Reference Images for AI: Prompt: A high energy anime-style illustration of an American football cornerback rushing to cover a wide receiver, Tennessee Titans versus New Orleans Saints, Chibi-style, in style of Yon Yoshinari, ...
- GitHub - starsnatched/neurasim: Pretty accurate simulation of neurons.: Pretty accurate simulation of neurons. Contribute to starsnatched/neurasim development by creating an account on GitHub.
- GitHub - duskfallcrew/HuggingFace_Backup: Huggingface Backup - Jupyter, Colab and Python Script: Huggingface Backup - Jupyter, Colab and Python Script - duskfallcrew/HuggingFace_Backup
- tabularisai/oak · Datasets at Hugging Face: no description found
- GitHub - duskfallcrew/sdwebui-hfbackup: An extremely badly coded Automatic1111 extension that services my lazyness for my original jupyter notebook.: An extremely badly coded Automatic1111 extension that services my lazyness for my original jupyter notebook. - duskfallcrew/sdwebui-hfbackup
- Tweet from thecollabagepatch (@thepatch_kev): i released an ableton plugin over the past six weeks. it's not like any other plugin this is a🧵 wk 1: @SommaiyaAngrish made a dope track as a demo i showed how you can use gary to make so...
- GitHub - betweentwomidnights/gary4live: this is gary4live. musicgen continuations for ableton.: this is gary4live. musicgen continuations for ableton. - GitHub - betweentwomidnights/gary4live: this is gary4live. musicgen continuations for ableton.
- gary4live - alpha: this is the first version of the gary4live installer. right now, you may have to turn windows defender off while you install, which is a major bummer.we are working on the code signing stuff but for t...
HuggingFace ▷ #reading-group (35 messages🔥):
Franz's Presentation on Multimodal Structured GenerationTechnical Issues and Meeting LogisticsSource Code and Project LinksResearch Collaboration OpportunitiesTensor Parallelism with Decentralized GPU
- Franz's Presentation on Multimodal Structured Generation: Franz excitedly prepared to present on Multimodal Structured Generation, covering different vision-language models (VLMs) and his winning approach in the CVPR MMFM Challenge.
- He shared insights on the challenges faced and engaged the audience with a 15-minute Q&A session following his talk.
- Technical Issues and Meeting Logistics: The group discussed potential technical difficulties with Discord, considering switching to Zoom for the presentation if necessary.
- Meeting links were shared, and it was confirmed that Franz's presentation would be recorded for later access.
- Source Code and Project Links: Franz provided several important links at the end of his presentation, including his GitHub repositories for the MMFM Challenge and his personal projects.
- He encouraged attendees to reach out with questions via direct message or GitHub issues.
- Research Collaboration Opportunities: A new hackathon event was announced by Steve Watts Frey, featuring substantial prizes and collaboration opportunities for open-source benchmark improvements.
- The event will allow researchers to team up for effective use of provided computing resources, highlighting the importance of community efforts in advancing research.
- Tensor Parallelism with Decentralized GPU: A user inquired about tensor parallelism techniques specifically related to distributed GPU operations, looking for suggestions.
- Conversations continued around challenges and opportunities in leveraging decentralized systems for AI processing.
- Tweet from Steve Frey (@stevewattsfrey): A bold experiment: We're hosting a 6-day ultra-hackathon for SWE-Bench to push the limits of open-source code generation - Everyone gets $1,000 in compute provided by @StrongCompute - Up 50 rese...
- Multimodal Structured Generation: CVPR's 2nd MMFM Challenge Technical Report: Multimodal Foundation Models (MMFMs) have shown remarkable performance on various computer vision and natural language processing tasks. However, their performance on particular tasks such as document...
- AI achieves silver-medal standard solving International Mathematical Olympiad problems: Breakthrough models AlphaProof and AlphaGeometry 2 solve advanced reasoning problems in mathematics
- Multimodal Structured Generation: Multimodal Structured Generation & CVPR’s 2nd MMFM Challenge By Franz Louis Cesista franzlouiscesista@gmail.com leloykun.github.io
- GitHub - leloykun/MMFM-Challenge: Official repository for the MMFM challenge: Official repository for the MMFM challenge. Contribute to leloykun/MMFM-Challenge development by creating an account on GitHub.
- GitHub - leloykun/mmsg: Generate interleaved text and image content in a structured format you can directly pass to downstream APIs.: Generate interleaved text and image content in a structured format you can directly pass to downstream APIs. - leloykun/mmsg
- Franz Louis Cesista: Mathematician | Machine Learning (AI) Research Scientist
HuggingFace ▷ #computer-vision (4 messages):
ONNX models for TensorRTScrabble fonts resourceModel learning improvement strategiesCustom model implementation with ViTConnecting vision encoders to language decoders
- Searching for ONNX depth model for TensorRT: A user inquired about the availability of a depth ONNX model that can be transferred to TensorRT for the Jetson Orin Nano.
- No specific resources were provided in response.
- Scrabble fonts might be helpful: A member mentioned that there are scrabble fonts available which could assist, as they also include numbers in the corners.
- This could be utilized in various applications requiring digit recognition or formatting.
- Improving breed classification model: A user directed attention to their breed classification model on Kaggle and expressed concerns about it not learning effectively.
- They sought suggestions for potential improvements to enhance model performance.
- Implementing a custom model with ViT: A user expressed interest in utilizing a Vision Transformer (ViT) as the encoder while planning to use either LLaMA 3.1 or Mistral as the decoder.
- They requested guidance on the steps to integrate the vision encoder with the language decoder, particularly concerning input compatibility.
Link mentioned: breed_classification: Explore and run machine learning code with Kaggle Notebooks | Using data from Cat Breeds Dataset
HuggingFace ▷ #NLP (24 messages🔥):
Tokenizer IssuesLLM Internship OpportunitiesUnstructured Text Processing for RAGMultiple Neighbors Ranking LossDataset Management and Training Improvements
- Tokenizer.apply_chat_template appears broken: A member reported that
tokenizer.apply_chat_templateis broken in the latest Hugging Face Transformers, specifically mentioning thatadd_generation_prompt = Falsedoesn't work. - Seeking LLM internship opportunities: A newcomer expressed their eagerness to learn about LLMs and requested suggestions for finding internships, including unpaid positions.
- Guide needed for unstructured text processing: A member inquired about guides for processing unstructured text for Retrieval-Augmented Generation (RAG), emphasizing the need to clean papers containing various data types.
- Another member confirmed that querying structured fields is possible and suggested using embedding models for such tasks.
- Insights on Multiple Negatives Ranking Loss: A member provided insights on using
MultipleNegativesRankingLoss, explaining that in-batch negatives are less useful compared to more related negatives for training.- They shared their experience that adding multiple negatives per anchor only marginally improved performance, while discussing dataset efficiency and its arrangement.
- Training improvements when ordering datasets: A member reported that organizing their training dataset in increasing order of difficulty (i.e., harder negatives towards the end) led to significant improvements in model performance.
- They noted that this method allows the model to focus more effectively on refining features rather than toggling between different learning focuses.
- Knowledge Graphs for RAG: Build and use knowledge graph systems to improve your retrieval augmented generation applications. Enhance RAG apps with structured data.
- tomaarsen/gooaq-hard-negatives · Datasets at Hugging Face: no description found
HuggingFace ▷ #diffusion-discussions (1 messages):
News on AI Use CasesPeople to Follow in AIInnovative AI WebsitesAI Channels for Creative Ideas
- Searching for innovative AI news sources: A member inquired about where to find news or posts regarding innovative and creative AI use cases.
- They expressed interest in recommendations for people to follow, websites, channels, or any resources.
- Request for AI community recommendations: A member requested insights on influential personalities or websites in the AI sector.
- Suggestions for specific channels or platforms where creative AI use cases are discussed would be greatly appreciated.
LM Studio ▷ #general (661 messages🔥🔥🔥):
LM Studio performanceModel loading issuesFine-tuning with embeddingsRoPE settings in Llama 3.1Running LLMs in virtual environments
- Performance variations across models: Users discussed performance metrics for different models, with observations on speed varying significantly based on GPU configurations and context length settings, especially with Llama 3.1 models.
- Some users reported varying tokens per second rates, highlighting the impact of GPU type and RAM specifications on inference efficiency.
- Model loading errors and resolutions: Several users encountered issues loading models, particularly with errors related to the number of tensors in Llama 3.1, and were advised to update LM Studio or reduce context size.
- Users were guided on troubleshooting steps, including checking their GPU compatibility and ensuring proper model directory structure.
- Fine-tuning and embeddings usage: The conversation included discussions about the effectiveness of fine-tuning versus embeddings for specific libraries, emphasizing that models may need well-prepared examples to function correctly.
- Participants noted the limitations of models' understanding and the necessity of providing context or tutorial-like content to improve performance.
- Updates and presets in LM Studio: Discussions highlighted the importance of using the correct presets for Llama 3.1, with strong recommendations to use the Llama 3 V2 preset for compatibility.
- Users asked about the functionality of different presets, confirming that outdated versions may not utilize new features effectively.
- Using LM Studio within a virtual environment: Users expressed interest in running LM Studio in a Docker or virtual machine setup for better resource management and isolation, with considerations on GUI requirements.
- Suggestions included leveraging the LMS-CLI tool for headless operation, but users were cautioned about running applications in virtualized environments without proper GPU passthrough.
- LLM Visualization: no description found
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- LMStudio LLM ~ AnythingLLM: LMStudio is a popular user-interface, API, and LLM engine that allows you to download any GGUF model from HuggingFace and run it on CPU or GPU.
- Python developers beware: This info stealing malware campaign is targeting thousands of GitHub accounts: Python developers should be wary of an information stealing malware disguised in the popular Colorama python package, which has already compromised a community of over 170,000 users
- gbueno86/Meta-Llama-3.1-70B-Instruct.Q4_0.gguf at main: no description found
- Introducing `lms` - LM Studio's companion cli tool | LM Studio: Today, alongside LM Studio 0.2.22, we're releasing the first version of lms — LM Studio's companion cli tool.
- Local LLM Server | LM Studio: You can use LLMs you load within LM Studio via an API server running on localhost.
- TencentARC/PhotoMaker-V2 · Hugging Face: no description found
- Were Not Worthy Waynes World GIF - Were Not Worthy Waynes World Worship - Discover & Share GIFs: Click to view the GIF
- Magic Eight GIF - Magic Eight Ball - Discover & Share GIFs: Click to view the GIF
- Uncensor any LLM with abliteration: no description found
- llama-models/models/llama3_1/MODEL_CARD.md at main · meta-llama/llama-models: Utilities intended for use with Llama models. Contribute to meta-llama/llama-models development by creating an account on GitHub.
- PNY RTX 6000 Ada VCNRTX6000ADA-PB 48GB 384-bit GDDR6 PCI Express 4.0 x16 Workstation Video Card - Newegg.com: Buy PNY RTX 6000 Ada VCNRTX6000ADA-PB 48GB 384-bit GDDR6 PCI Express 4.0 x16 Workstation Video Card with fast shipping and top-rated customer service. Once you know, you Newegg!
- NVIDIA H100 80GB HBM2e PCIE Express GPU Graphics Card New - Newegg.com: Buy NVIDIA H100 80GB HBM2e PCIE Express GPU Graphics Card New with fast shipping and top-rated customer service. Once you know, you Newegg!
- Recursive Introspection: Teaching Language Model Agents How to Self-Improve: no description found
- lmstudio-community (LM Studio Community): no description found
- Add llama 3.1 rope scaling factors to llama conversion and inference by jmorganca · Pull Request #8676 · ggerganov/llama.cpp: Hi all, this commit generates the rope factors on conversion and adds them to the resulting model as a tensor. At inference time, these factors are passed to the ggml_rope_ext rope operation. From ...
LM Studio ▷ #hardware-discussion (53 messages🔥):
Snapdragon X Elite ARM CPU ReviewTesla P40 Cooling SolutionsGPU Comparison for Model TrainingLlama.cpp Development UpdatesInference Speed with Multiple GPUs
- Snapdragon X Elite ARM CPU Review sparks discussion: Members discussed the performance of the new Snapdragon X Elite ARM CPU in Windows 11, questioning its usability.
- A review video titled "Mac Fanboy Tries ARM Windows Laptops" was mentioned, generating interest in user experiences.
- Krypt Lynx experiments with Tesla P40 cooling: Krypt Lynx shared updates on a custom cooling solution for the Tesla P40, which requires additional adjustments to hide seams.
- Discussion included comments on fan speeds, performance under load, and plans for testing temperature readings.
- Choosing GPUs for training models: There was a consensus that using a 4090 is preferable for model training over older GPUs like the K80 or P40, which are considered outdated.
- Members highlighted the importance of purchasing modern hardware for CUDA support and performance, especially for large models.
- Llama.cpp development insights: Members were directed to the issues tab on the Llama.cpp GitHub to find updates on the Snapdragon Elite X NPU's development.
- One member confirmed that GPU setups typically allow larger models to be loaded but do not necessarily improve inference speed.
- Inference speed challenges with multiple GPUs: Discussion revealed that splitting models over multiple GPUs does not actually improve inference speed, despite allowing for larger model sizes.
- Members noted that utilizing modern GPUs is generally more efficient than older models, promoting a focus on current technology.
- Quick Maths Mans Not Hot GIF - Quick Maths Mans Not Hot - Discover & Share GIFs: Click to view the GIF
- Mac Fanboy Tries ARM Windows Laptops: I went to the store and bought a new ARM laptop to see if it competes with the MacBook Air.Hohem Official Store: https://bit.ly/45TOdKf (20% off code: YT20)H...
- [Feature request] Any plans for AMD XDNA AI Engine support on Ryzen 7x40 processors? · Issue #1499 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
Stability.ai (Stable Diffusion) ▷ #general-chat (690 messages🔥🔥🔥):
Stable Diffusion ToolsComfyUI vs A1111 and ForgeImage Inpainting IssuesCharacter Consistency in AI GenerationsAMD's Amuse 2.0 Censorship
- Comparison of AI Tools for Image Generation: Users discussed the differences between ComfyUI, A1111, and Forge, highlighting that ComfyUI allows for more control and has various advantages in terms of model use and speed.
- Several users also noted that Forge has faced issues with its recent update, making A1111 a potential alternative for those experiencing problems.
- Issues with Inpainting and Output Quality: Modusprimax encountered persistent blurry outputs from the new Forge inpainting feature, leading to frustration despite various configurations tried.
- Others suggested exploring ComfyUI or older versions of Forge for potentially better results.
- Maintaining Character Consistency in Generative AI: Users shared tips on using specific models and IP adapters with checkpoints to achieve character consistency, noting that some models better serve this purpose than others.
- Neonninjaastro recommended using the 'Mad Scientist' model for stronger output in terms of character anatomy.
- Discussion on AMD's Amuse 2.0 App: Gitiyasix mentioned that AMD's Amuse 2.0 model for Stable Diffusion is heavily censored, impacting its ability to render certain body curves.
- The conversation transitioned into concerns about censorship in AI applications and the implications for user creativity.
- Learning Resources and Community Support: Several users emphasized the importance of engaging with video tutorials and community forums to deepen understanding of Stable Diffusion prompts and workflows.
- Crystalwizard encouraged users to explore ComfyUI features and clarified common misconceptions about various tools used in AI generation.
- Civitai | Share your models: no description found
- BGBye - Background Remover by Fyrean: Free background remover, 10 methods!
- DirectML: Learn about DirectML, a high-performance ML API that lets developers power AI experiences on almost every Microsoft device.
- Scott Detweiler: Quality Assurance Guy at Stability.ai & PPA Master Professional Photographer Greetings! I am the lead QA at Stability.ai as well as a professional photographer and retoucher based near Milwaukee...
- Stable Diffusion pipelines: no description found
- Community License — Stability AI: Our new Community License is now free for research, non-commercial, and commercial use. You only need a paid Enterprise license if your yearly revenues exceed USD$1M and you use Stability AI models in...
- Cdiscount.com: Cdiscount : Meuble, Déco, High Tech, Bricolage, Jardin, Sport | Livraison gratuite à partir de 10€ | Paiement sécurisé | 4x possible | Retour simple et rapide | E-commerçant français, des produits et ...
- Diffusers: no description found
- Jônathas Aquino Melo: Esta é uma jornada multidisciplinar entre arquitetura e tecnologia por meio da IA Stable Diffusion, desvendando o conceito de jogo conforme desenvolvido por Huizinga e explorando a sua relação com o a...
- Stable Artisan — Stability AI: Stable Artisan is a fun multimodal generative AI Discord bot that utilizes the products on the Stability AI Platform API within the Discord ecosystem.
- RTX 4090 vs 3090 ti stable diffusion test. (UPDATE) This video is now out of date!: I reran the test without recording and the 4090 completed the run in 10.46 seconds and the 3090 ti completed the run in 16.62 seconds. Which makes the 4090 4...
- ABS Aquilon Aqua Gaming PC - Windows 11 Home - Intel Core i7 14th Gen 14700KF - GeForce RTX 4060 Ti 16GB - DLSS 3 - AI-Powered Performance - 32GB DDR5 6000MHz - 1TB M.2 NVMe SSD - AQA14700KF4060TI16G - Newegg.com: Buy ABS Aquilon Aqua Gaming PC - Windows 11 Home - Intel Core i7 14th Gen 14700KF - GeForce RTX 4060 Ti 16GB - DLSS 3 - AI-Powered Performance - 32GB DDR5 6000MHz - 1TB M.2 NVMe SSD - AQA14700KF4060TI...
- Stable Diffusion 3 support by AUTOMATIC1111 · Pull Request #16030 · AUTOMATIC1111/stable-diffusion-webui: Description initial SD3 support can load sd3_medium.safetensors from https://huggingface.co/stabilityai/stable-diffusion-3-medium will download CLIP models from huggingface into models/CLIP direct...
OpenAI ▷ #ai-discussions (602 messages🔥🔥🔥):
SearchGPT AccessTechnical Issues with ChatGPTCoding Assistance with AIUser Experiences with AI Models
- SearchGPT: A New Tool for Users: Users shared positive experiences with SearchGPT, highlighting its ability to search through multiple credible sources and sometimes utilize Chain of Thought (CoT) reasoning during queries.
- One user noted the tool's capability to calculate specific trip costs while retrieving relevant car model information, indicating its practical application.
- Ongoing Technical Issues with ChatGPT: Multiple users reported difficulties accessing the ChatGPT website, with suggestions to clear the cache and check browser extensions to resolve connectivity issues.
- One user was particularly frustrated with the inability to log in after two weeks, emphasizing a lack of response from OpenAI support.
- AI as a Coding Assistant: Users discussed their experiences using AI for coding tasks, with one user successfully creating a Python script to download and launch Chrome, showcasing the efficiency of AI assistance.
- Another user shared their workflow using ChatGPT to directly write code on their server, enhancing collaboration through feedback and iteration.
- Voice Mode Release Update: Anticipation around the release of voice mode in ChatGPT was expressed, with insights that it is rolling out this week for a limited number of users.
- The discussion included speculation about the selection criteria for users receiving access to this new feature.
- User Queries about AI Capabilities: One user inquired about developing an AI specifically for coding that surpasses current capabilities, leading to discussions on the complexity and investment required for such a model.
- Others emphasized the importance of using AI to enhance coding efficiency rather than completely offloading responsibility.
- Efficient Training of Language Models to Fill in the Middle: We show that autoregressive language models can learn to infill text after we apply a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to ...
- AI Interviewer for High Volume Recruitment Agencies | micro1: Interview 100x more candidates async using AI
- Tweet from TestingCatalog News 🗞 (@testingcatalog): A real life preview example of SearchGPT and how fast it is 👀👀👀 Quoting Kesku (@yoimnotkesku) SearchGPT is pretty fast
- Tweet from AshutoshShrivastava (@ai_for_success): OpenAI new SearchGPT access is rolling out. If you are lucky, you might get to access it very soon. Did anyone else get access other than Alex? Quoting Alex Volkov (Thursd/AI) (@altryne) Wasn't...
OpenAI ▷ #gpt-4-discussions (13 messages🔥):
API response size limitsSite access issuesImage editing feature removalGPT-4o model parametersFunction call for network utility settings
- API response size limit for custom actions: A user inquired about the maximum size of API responses on custom actions before encountering errors.
- This discussion doesn't seem to have a definitive answer yet.
- Ongoing site access problems: Multiple users reported issues with accessing the site, experiencing prolonged loading times.
- One user noted that they had been facing this problem for several days.
- Disappearance of image editing features: A member expressed concern about the removal of an option to edit specific parts of images with a brush.
- Another user suggested it might be a temporary bug, as the feature still works on mobile.
- GPT-4o model parameter inquiry: A user asked how many parameters the GPT-4o and mini models have, indicating a lack of clarity on this topic.
- No response or information was provided in the discussion regarding the parameters.
- Function call assistance for network utilities: A user sought help on configuring functions for a network utility based on OpenAI but reported only partial functionality.
- They specifically indicated a need for assistance from professionals on the matter.
OpenAI ▷ #prompt-engineering (11 messages🔥):
Function Calls for Network UtilitySelf-Improvement Book QueryRussian Language DiscussionsProfile and Posture Check Functions
- Queries on Uploading Books for AI Answers: A user inquired whether they could upload a self-improvement book to receive answers via prompts, to which another member replied that it is highly dependent on the content of the book.
- The conversation indicated that for self-improvement materials, engaging with the content for accurate responses is likely achievable.
- Sharing Cultural Backgrounds: A user identified themselves as Russian, and another member followed up by stating they are Ukrainian, highlighting a cultural exchange in the chat.
- This brief interaction showed the diverse backgrounds of the members participating.
- Challenges in Function Calls for Network Utility: A user detailed troubles they faced while trying to write a function call for configuring settings in a network utility, specifically needing two functions to be called simultaneously.
- Another member suggested that including a clear system message could potentially aid in resolving the issue, while noting it worked correctly with a different approach.
- Testing Function Calls: A member mentioned their intent to test the long tools shared in the conversation, showing engagement with the coding challenge presented.
- They further indicated that with a 2-shot approach, both methods called were functioning correctly, a detail that offers insight into troubleshooting processes.
OpenAI ▷ #api-discussions (11 messages🔥):
Book Upload FunctionalityNetwork Utility ConfigurationLanguage Backgrounds
- Book Uploading for Queries: @thrallboy inquired about uploading a book and using prompts to ask questions about it, to which @darthgustav. responded that it is highly dependent on the book.
- The discussion varied towards self-improvement books, with @darthgustav. confirming that this type is likely more manageable.
- Configurations for Network Utility: @polarisjrex0406 sought help on writing a function call for configuring a network utility based on OpenAI but faced issues with function calls not executing correctly.
- @neural_nova_28405 suggested adding a clear system message might improve functionality, noting that even with smaller models, both required methods were being called.
- Cultural Exchange in the Community: A cultural exchange was noted with members identifying as Russian and Ukrainian, sharing their backgrounds.
- This interaction highlighted the diversity within the community, fostering inclusivity and dialogue among members.
Unsloth AI (Daniel Han) ▷ #general (292 messages🔥🔥):
Unsloth UsageLlama 3.1 Model DiscussionFine-tuning TechniquesModel QuantizationInference Settings
- Best Practices for Using Unsloth: Users have discussed the effectiveness of various system messages for Llama 3.1, with some noting that the default from Unsloth notebooks works sufficiently well for their tasks.
- Some participants have even opted to remove the system message to conserve context length without observing any significant change in performance.
- Fine-tuning and LoRa Adapters: Several users confirmed that LoRa adapters created through fine-tuning with Unsloth can be successfully applied to the original Llama models, as long as the base model is the same.
- There remains some uncertainty about the compatibility of these adapters across different model versions, emphasizing the importance of using the correct model.
- Quantization and VRAM Considerations: Discussions included the trade-offs between using 4-bit and 16-bit models, with participants noting that while 16-bit requires 4x the VRAM, it yields better performance.
- Users are encouraged to experiment with both bit levels, as individual experiences vary based on specific use cases.
- Inference Settings for Llama 3.1: Participants noted that inference with Llama 3.1 requires significant VRAM, suggesting that 48 GB is needed for full capabilities, particularly for larger models.
- They discussed the process of handling inference requests while maximizing GPU utilization, especially when using libraries like vLLM.
- Resources for Understanding LLMs: Users shared resources, including videos by Andrej Karpathy and articles focusing on the understanding of large language models and their pre-training mechanisms.
- A variety of guides and articles were recommended, making it easier for newcomers to navigate the complexities of LLM training and fine-tuning.
- imgur.com: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...
- Replete-LLM-Qwen2-7b_Beta-Preview - a Hugging Face Space by rombodawg: no description found
- Google Colab: no description found
- Google Colab: no description found
- no title found: no description found
- Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed
- Orenguteng/Llama-3.1-8B-Lexi-Uncensored · Hugging Face: no description found
- Finetune Llama 3.1 with Unsloth: Fine-tune and run Meta's updated Llama 3.1 model with 6x longer context lengths via Unsloth!
- Tweet from Maxime Labonne (@maximelabonne): 🦥 Fine-tune Llama 3.1 Ultra-Efficiently with @UnslothAI New comprehensive guide about supervised fine-tuning on @huggingface. Over the last year, I've done a lot of fine-tuning and blogging. ...
- Google Colab: no description found
- Google Colab: no description found
- Llama 3 Fine Tuning for Dummies (with 16k, 32k,... Context): Learn how to easily fine-tune Meta's powerful new Llama 3 language model using Unsloth in this step-by-step tutorial. We cover:* Overview of Llama 3's 8B and...
- unsloth/unsloth/chat_templates.py at main · unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Reddit - Dive into anything: no description found
- pacozaa/mistral-sharegpt90k-merged_16bit · Hugging Face: no description found
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face: no description found
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
- GitHub - kvcache-ai/ktransformers: A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations: A Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations - kvcache-ai/ktransformers
- Release v0.12.0: New methods OLoRA, X-LoRA, FourierFT, HRA, and much more · huggingface/peft: Highlights New methods OLoRA @tokenizer-decode added support for a new LoRA initialization strategy called OLoRA (#1828). With this initialization option, the LoRA weights are initialized to be or...
- peft/examples/olora_finetuning at main · huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- Add llama 3.1 rope scaling factors to llama conversion and inference by jmorganca · Pull Request #8676 · ggerganov/llama.cpp: Hi all, this commit generates the rope factors on conversion and adds them to the resulting model as a tensor. At inference time, these factors are passed to the ggml_rope_ext rope operation. From ...
Unsloth AI (Daniel Han) ▷ #off-topic (29 messages🔥):
Hugging Face Inference EndpointsHardware Requirements for Fast TrainingOllama Agent Roll Cage VideoApplied LLMs Resources
- Clarification on Hugging Face Inference Endpoints: A member inquired whether 'protected' on Hugging Face means anyone with a token or just the owner, to which it was clarified that it's your own token and do not share with anyone.
- Sharing your token could allow others to upload on your page, making it crucial to keep it secure.
- Fast Training Hardware Needs: A discussion emerged around which operations need hardware acceleration for fast training, with suggestions that RTX 2080 or newer GPUs are minimum requirements.
- Members also pondered the viability of using theoretical hardware like embedded GPUs or TPUs for training needs.
- Ollama Agent Roll Cage Video Release: A member shared a YouTube video titled Ollama Agent Roll Cage V0.28.0 - Speech to Speech with Vision, & Agent Library, showcasing new optimizations for speech and vision agents and including a customizable agent library.
- They expressed excitement about the updates and encouraged members to check it out, linking to the demo video.
- Free Resources for Applied LLMs Course: A member announced that several resources from the Applied LLMs course are now available for free, enhancing accessible learning materials with added tracks and notes for better comprehension.
- This release aims to maximize learning opportunities for everyone interested in the subject.
- Tweet from Hamel Husain (@HamelHusain): If you remember our Applied LLMs course, you'll love this. Today, we are making all these resources available for free to everyone! 📚 We did extra work to add learning tracks, resources, and n...
- Ollama Agent Roll Cage V0.28.0 - Speech to Speech with Vision, & Agent Library: Welcome to the demo of Ollama Agent Roll Cage (OARC) for V0.28.0! This video showcases the latest advancements in my speech-to-speech and image recognition c...
Unsloth AI (Daniel Han) ▷ #help (306 messages🔥🔥):
Orpo Dataset CreationLlama Model Fine-tuningAccuracy Metrics in TrainingDynamic Rope Scaling in ModelsLoRA Adapters Usage
- Creating ORPO Datasets Efficiently: A member discussed the tedious process of creating ORPO datasets without writing everything manually and inquired if a UI could automate parts of this process.
- Suggestions included utilizing a smarter model for positive responses and using the fine-tuned model to generate responses.
- Challenges with Llama 3.1 and Python Packages: Users faced issues with the Llama 3.1 model in Colab, receiving errors related to missing tensor files and required package versions.
- After troubleshooting, it was found that installing specific versions of Python packages resolved the tensor mismatch errors.
- Evaluating Model Performance with Accuracy Metrics: A user questioned how to incorporate accuracy metrics in training workflows, as traditional metrics like loss may not provide enough insight into model performance.
- It was emphasized that tracking both loss and accuracy on validation datasets is crucial to avoid overfitting.
- Understanding Dynamic Rope Scaling in Models: Users inquired about the validity and implementation of dynamic rope scaling in their models, particularly when facing errors related to unsupported configurations.
- Clarifications were given about setting the rope_scaling parameter to null or 'none' to resolve issues when fine-tuning.
- Apple’s Usage of LoRA in Adapters: Discussion on how Apple utilizes LoRA adapters for fine-tuning foundation models highlighted the use of task-specific adapters initialized from accuracy-recovery adapters.
- Rank 16 adapters were noted for striking a balance between model capacity and inference performance in Apple’s on-device applications.
- Tweet from Rohan Paul (@rohanpaul_ai): 📌 LoRA adapters fine-tune the foundation models for specific tasks. 📌 Adapters are applied to all linear projection matrices in self-attention layers and fully connected layers in feedforward netwo...
- Google Colab: no description found
- Google Colab: no description found
- Welcome | Unsloth Documentation: New to Unsloth? Start here!
- Google Colab: no description found
- Google Colab: no description found
- unsloth/Meta-Llama-3.1-70B-bnb-4bit · Hugging Face: no description found
- Google Colab: no description found
- Google Colab: no description found
- How to Finetune Llama-3 and Export to Ollama | Unsloth Documentation: Beginner's Guide for creating a customized personal assistant (like ChatGPT) to run locally on Ollama
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Tweet from Maxime Labonne (@maximelabonne): 🦥 Fine-tune Llama 3.1 Ultra-Efficiently with @UnslothAI New comprehensive guide about supervised fine-tuning on @huggingface. Over the last year, I've done a lot of fine-tuning and blogging. ...
- Unsloth Documentation: no description found
- Add support for InternLM2.5 model · Issue #734 · unslothai/unsloth: Hello unsloth team, I'm trying to use the InternLM2.5 model (specifically internlm/internlm2_5-7b-chat) with unsloth, but I'm encountering a NotImplementedError. Could you please add support f...
- LLaMA: no description found
- pip install flash-attn always happens ModuleNotFoundError: No module named 'packaging',but actually i have pip install packaging · Issue #453 · Dao-AILab/flash-attention: Collecting flash-attn Using cached flash_attn-2.0.7.tar.gz (2.2 MB) Installing build dependencies ... done Getting requirements to build wheel ... error error: subprocess-exited-with-error × Gettin...
- unsloth/unsloth/models/llama.py at main · unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Unsloth AIGrant Proposal Resources
- Clarification on Unsloth AI: A member noted, 'It's Unsloth....' to clarify a point in the discussion.
- This prompted others to engage further on the topic of Unsloth AI.
- Discussion on Grant Proposals: A member offered to prepare a grant proposal, asking for interest and needed resources.
- They expressed readiness to assist the team in getting organized for potential funding.
Unsloth AI (Daniel Han) ▷ #research (4 messages):
[PAD] Token in ModelsFinetuning Phi-3 ModelsWord Removal for GPT Training
- [PAD] Token might be a class: One member speculated that the [PAD] token is treated as a class in certain models, though their certainty is in question.
- This discussion linked to the finetuning script for models, showcasing how PAD may function within that context.
- Finetuning methods for Phi-3: A member provided an overview of how to finetune Phi-3 models, mentioning the use of DeepSpeed ZeRO3 for memory efficiency.
- The instructions included steps like reducing batch size and setting appropriate parameters to manage resource consumption effectively.
- Removing unimportant words for GPT training: Another member posed a question about tactics for eliminating non-essential words in rough text to prepare data for GPT training.
- No direct solutions were offered in the messages, leaving the query open for suggestions and insights.
Link mentioned: sample_finetune.py · microsoft/Phi-3-mini-4k-instruct at c1358f8a35e6d2af81890deffbbfa575b978c62f: no description found
CUDA MODE ▷ #general (4 messages):
Mojo Community MeetingComputational Linear Algebra CoursePredicate ComputationPredicate Registers
- Mojo Community Meeting Scheduled: On Monday, July 29 at 10 PT, the Mojo community is having their next meeting, featuring @clattner_llvm on GPU programming with Mojo.
- The agenda includes Async Mojo with 10 Simple Rules and a Community Q&A, with full details available in the Modular community calendar.
- Fast.ai Offers New Course on Computational Linear Algebra: Fast.ai has launched a new free course, Computational Linear Algebra, which includes an online textbook and a video series.
- This course is the first of its kind focused on practical applications, using tools like PyTorch and Numba, and teaches algorithms for tasks such as identifying foregrounds in videos and reconstructing images from CT scans.
- Understanding Predicate Computation and Registers: A user inquired about predicate computation and predicate registers, which track which warps participate in current instructions for conditional code executing different branches.
- Another member clarified that these registers are essential for managing branching in threads within a warp during execution.
- fast.ai - New fast.ai course: Computational Linear Algebra: Making neural nets uncool again
- Tweet from Modular (@Modular): 📆 Monday, July 29 at 10 PT, join the Mojo 🔥 community for its next meeting! On the agenda: 🔢 @clattner_llvm on GPU programming with Mojo 🔥 🔀 Async Mojo 🔥 - 10 Simple Rules ❓ Community Q&A Full...
CUDA MODE ▷ #triton (2 messages):
Triton exp functionlibdevice exp implementationPTX assembly inspection
- Triton exp function may sacrifice accuracy: A member noted that the exp function in Triton seems to utilize a fast
__expfimplementation, which compromises accuracy for speed.- This raises questions about whether the exp version in libdevice follows the same pattern or uses
expfinstead.
- This raises questions about whether the exp version in libdevice follows the same pattern or uses
- Inspecting PTX for implementation details: Another member suggested that the discrepancy can be checked by examining the PTX assembly output from Triton.
- Looking at the output should clarify which implementation is actually being used.
CUDA MODE ▷ #torch (17 messages🔥):
Optimizing CPU Offload for Optimizer StatesActivation Offloading StrategiesPaged Optimizers DiscussionChallenges with FSDP and Single-GPU TrainingFuture of Contributions to PyTorch Repositories
- Optimizing CPU Offload for Optimizer States Stirs Interest: Members discussed the mechanics of CPU offload for optimizer states, questioning if it involves storing optimizer states in CPU memory and transferring parameters during each optimization step.
- One member noted, 'fused ADAM implementation is key to making CPU offloading viable' and shared insights on its current proof of concept.
- Confusion Surrounds Paged Optimizer versus Attention: The conversation revealed confusion regarding a link to paged attention, with questions raised about what exactly is being paged, possibly the KV cache.
- A member brought attention to a discussion on GitHub concerning paged optimizers, citing it requires CUDA/C++ code, which they prefer to avoid.
- Concerns About FSDP for Single-GPU Training: Members expressed frustrations that utilizing FSDP with single-GPU training is overly complicated and largely impractical.
- In response, one user mentioned they were focusing on simpler CPU offload methods for their ongoing project.
- Exploring APIs for Memory Management Without C/C++ Extensions: Suggestions were made to leverage CUDA APIs such as cudaMemPrefetchAsync and cudaMallocManaged for memory handling without a C/C++ extension.
- Despite these recommendations, one member reinforced their focus on optimizer CPU offload rather than the paged optimizer approach.
- Future Contributions and Experimentation Noted: Users discussed the temporary storage of experimental work in separate repositories due to the non-research nature of their projects, leading to faster iteration.
- One participant expressed intent to contribute their validated ideas to torchao once experiments yield promising results.
- Paged attention by liangan1 · Pull Request #425 · pytorch/ao: Related RFC
- paged optimizers doc? · Issue #962 · bitsandbytes-foundation/bitsandbytes: Feature request Hi Tim, I have just accidentally discovered that you added paged optimizers to this library - so very awesome! But there is absolutely zero documentation - would you consider adding...
- Paged attention by liangan1 · Pull Request #425 · pytorch/ao: Related RFC
- [Do not review] Activation offloading by awgu · Pull Request #467 · pytorch/torchtitan: Stack from ghstack (oldest at bottom): -> #467 Current UX We use a saved_tensors_hooks context manager, which should be wrapped around module.forward. The context lets us override pack and unpac...
- Paged Low Bit Optimizers · Issue #519 · pytorch/ao: Right now our Optimizers are low bit so they save a bunch of memory but considering optimizers can also spike memory it's common to page them out to CPU RAM. There's a prototype of this here #...
CUDA MODE ▷ #algorithms (18 messages🔥):
INT8 model trainingBF16 model performanceStochastic rounding challengesQuantization aware training8-bit optimizer results
- INT8 Model Training Shows Promise: Inspired by Q-GaLore work, a member is exploring INT8 model training while fine-tuning ViT-Giant (1B params) and sharing promising results with similar loss curves and validation accuracy to the BF16 baseline.
- They noted that accuracy dropped significantly when using an 8-bit optimizer with the INT8 model, indicating further testing is needed.
- BF16 Model + 8-bit Optimizer Maintains Accuracy: After re-running experiments, it was found that the BF16 model + 8-bit optimizer maintains accuracy well compared to the INT8 model + 8-bit optimizer, which shows large drops.
- Randomness in results led to discussions about ensuring consistency across setups by using
torch.manual_seed()for data sequence and augmentation.
- Randomness in results led to discussions about ensuring consistency across setups by using
- Stochastic Rounding Complexity: Handling denormal numbers in implementing stochastic rounding for FP8 poses challenges, with one member sharing experiences from their own work on mapping BF16 values to subnormals in FP8.
- Concerns were expressed over the lack of pre-emptive testing for bias introduced by rounding approaches, highlighting the importance of writing comprehensive tests.
- Discussion on Random Seed Implementation: A member raised questions about the effectiveness of setting random seeds in torch, suspecting that torch.compile could affect randomness during code translation.
- Clarification was provided about the intent behind setting the random seed for ensuring data sequence consistency, leading to fruitful discussions on how random number generation is handled.
- Hyped for Viable Quantized Optimizer: Excitement surrounded the potential of a viable quantized optimizer, with multiple members expressing eagerness for further updates and results as progress continues.
- The shared journey into effective quantization strategies reflects a broader enthusiasm for enhancements in model training efficiency.
Link mentioned: GitHub - gau-nernst/quantized-training: Explore training for quantized models: Explore training for quantized models. Contribute to gau-nernst/quantized-training development by creating an account on GitHub.
CUDA MODE ▷ #beginner (4 messages):
CUDA Kernel Compilation ErrorMultimodal Hypograph DatabaseUnderstanding VRAM and GPU Memory
- CUDA kernel compilation error resolved: A user encountered an error when running
load_inlinein PyTorch with CUDA setup, attributed to incorrect installations with missing channel labels. After creating a new environment and ensuring the correct version of CUDA and PyTorch were installed, the issue was resolved successfully. - Building a multimodal hypograph database: For building a multimodal hypograph database using a specific library, one might start by organizing raw data from chaotic sources, like the collection of 2600 books. Leveraging OpenAI's API can help categorize and analyze these resources efficiently.
- Clarifying VRAM and GPU memory types: A developer tries to connect consumer knowledge about VRAM with a deeper understanding of GPU memory types learned in lectures. They seek clarification on whether VRAM refers only to global memory or encompasses all memory types, as online searches yielded insufficient answers.
Link mentioned: 2600 Books Sorted for Multi-Agent Creation: In the neon-lit digital underworld, we wielded the code, Bash, and the terminal like a switchblade in a dark alley. With 2600 books jumbled in a main folder, chaos reigned. But then, we summoned OpenA...
CUDA MODE ▷ #pmpp-book (3 messages):
CUDA Cores vs FP32 UnitsThread Processing CapabilityInteger vs FP32 UnitsHopper Architecture InsightsNvidia's Implementation Secrets
- CUDA Cores represent FP32 capabilities: The term CUDA Cores primarily indicates the number of FP32 operations that can execute in parallel, which is crucial when considering FP64 performance due to the limited number of FP64 units compared to FP32 in big accelerators like H100 and A100.
- It is important to remember that the FP32 unit count does not convey the total computational potential of the GPU, especially when factoring in different data types.
- Thread processing limited to CUDA Core count: Each Streaming Multiprocessor (SM) can handle as many threads as there are CUDA cores at any one time, indicating that one thread per CUDA core is the maximum processing capacity.
- Yes, one thread per core means that processing efficiency depends heavily on optimizing thread usage relative to core availability.
- Integer units function separately from FP32 units: It was explained that integer units operate independently alongside FP32 units, allowing for parallel execution of integer calculations even when a GPU features a limited number of CUDA cores.
- For instance, a GPU with 64 CUDA Cores can support 64 threads for FP32 compute while another set of 64 can manage integer operations.
- Hopper has fewer integer units than expected: It's noted that Hopper architecture actually contains only half as many integer units compared to FP32 units, contrary to previous architectures like A100 and V100, which had matching counts.
- This insight reflects evolving design considerations in modern GPUs for optimizing specific computational tasks.
- Nvidia keeps architectural details under wraps: Despite sharing schematics and diagrams, some aspects of Nvidia's in-silicon implementation remain tightly guarded business secrets.
- As such, even detailed diagrams like those discussing arithmetic units can be seen as abstractions from actual architectural realities.
CUDA MODE ▷ #torchao (38 messages🔥):
AWQ ImplementationAQT Changes and UpdatesQuantization Performance Issues2-bit Llama3 ModelTensor Packing Issues
- AWQ Implementation Simplified: The most basic form of AWQ involves creating an AQT layout class that stores activation channel scales, allowing for a straightforward implementation.
- Members discussed potential improvements and scaling methods, considering block_size and group-based approaches for effective implementation.
- Recent Changes in AQT are Confusing: The recent modification in AQT requires input weights to be pre-packed before using
_convert_weight_to_int4pack, resulting in unexpected performance metrics.- Discussion included a runtime error arising from adjusted input weight requirements, confirming that the tests in ao are currently disabled for nightly builds.
- Noteworthy Performance Observations: When comparing torchao with bitblas, the performance is close, with torchao delivering 94 tokens/sec and bitblas 97 tokens/sec for 4-bit models with batch size 1.
- Further comparisons indicate that as batch size increases, performance significantly drops, especially for 2-bit models using HQQ+ with Llama3.
- Challenges in 2-bit Llama3 Quantization: The 2-bit Llama3 model faces quantization challenges, particularly at lower bits, impacting speed and quality, even with techniques like low-rank adapters.
- Despite difficulties, it runs efficiently with the BitBlas framework, achieving speeds of 95-120 tokens/sec, similar to its 4-bit counterparts.
- Future Directions for uint4 Tensor Subclass: There are plans to establish a default packing format of
[n][k/2]for the upcoming uint4 tensor subclass, transitioning it to an optimized layout as needed.- This change could streamline processes and potentially merge layout functionalities from AffineQuantizedTensor to the uint4 tensor design.
- mobiuslabsgmbh/Llama-3-8b-instruct_2bitgs64_hqq · Hugging Face: no description found
- Add AWQ support · Issue #530 · pytorch/ao: AWQ seems popular: 3000 appearances in huggingface models: (https://huggingface.co/models?sort=trending&search=AWQ), similar to GPTQ. Maybe we can add this to torchao as well. Overview At the high...
- ao/torchao/quantization/smoothquant.py at afde1755d906ad644e04835675e7856d72c3c87b · pytorch/ao: Custom data types and layouts for training and inference - pytorch/ao
- [WIP] Int4Tensor refactor to implements pattern by melvinebenezer · Pull Request #458 · pytorch/ao: Refactoring UInt4Tensor to have implements pattern similar to nf4tensor and UInt2Tensor ToDo Create implements for UInt4Tensor and PerChannelSymmetricWeight Test Cases Move uint4i to uint4.py
- Fix int4pack_mm error by yanbing-j · Pull Request #517 · pytorch/ao: Need update meta shape in PyTorch first pytorch/pytorch#130915.
- update the input `weight` of `_convert_weight_to_int4pack` to `[n][k … · pytorch/pytorch@6f662e9: …/ 2] uint8` (#129940) This PR is to update the input `weight` of `_convert_weight_to_int4pack` from `[n][k] int32` to `[n][k / 2] uint8`, both for CPU, CUDA and MPS, which can help decouple int4 ...
- pytorch/torch/testing/_internal/common_quantization.py at 6f662e95756333284450ff9c3c6e78c796aa6e77 · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
CUDA MODE ▷ #off-topic (3 messages):
LinkedIn Post on Token PricingTwitter Discussions
- LinkedIn Post on Token Pricing: A member shared a LinkedIn post discussing the peculiarities of token pricing, specifically referencing a price of 28M tokens.
- This post sparked interest as another member noted seeing the same information on Twitter.
- Whimsical 1000-Dimensional Orange: One member humorously remarked that a 1000-dimensional orange is essentially 100% peel, plus or minus a rounding error.
- This comment lightened the mood, blending humor with complex dimensional concepts.
CUDA MODE ▷ #irl-meetup (2 messages):
Lakeview Meetup
- Totaldev is in Lakeview: A member noted that they are currently in Lakeview.
- Sweet.
- Totaldev expresses excitement about location: Another member expressed enthusiasm by stating, Sweet, I’m in Lakeview.
CUDA MODE ▷ #llmdotc (401 messages🔥🔥):
RoPE performanceGradient clipping challengesTraining stabilitySwiGLU implementationCUDA-related issues
- RoPE improves model performance: RoPE has shown significant improvements in model performance during training, with users noting better stability compared to baseline methods without it.
- Manual testing confirmed that the kernel meets expected output, leading to a successful implementation of RoPE.
- Concerns over gradient clipping: There are ongoing discussions about how gradient clipping may interfere with Adam optimizer's performance, especially regarding updating the second moment based on potentially reduced gradients.
- Many contributors expressed skepticism about the efficacy of gradient clipping in Adam, suggesting that it might not be beneficial for training stability.
- Training stability issues: Users highlighted the concerning instability in training runs, particularly regarding the use of different GPUs and their configurations, which may yield different results.
- Investigations into model convergence and performance indicated that fine-tuning approaches might not always lead to optimal results depending on the hardware used.
- Complications with SwiGLU implementation: The implementation of SwiGLU turned out to be more complicated than initially anticipated, requiring substantial changes throughout the codebase.
- Developers are moving forward with the SwiGLU integration while also addressing related architecture improvements.
- CUDA and cuDNN compatibility challenges: There are concerns regarding the operation and performance of CUDA and cuDNN functions, especially in relation to FP8 performance and GPU utilization.
- Discussions pointed out that different CUDA architectures might yield different training dynamics, leading to unexpected results in model behavior.
- Tweet from Simo Ryu (@cloneofsimo): As a gpu-poor I hope this works at scale. 1.8k $ can you believe this? https://arxiv.org/abs/2407.15811
- u-$μ$P: The Unit-Scaled Maximal Update Parametrization: The Maximal Update Parametrization ($μ$P) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-si...
- MINI-SEQUENCE TRANSFORMER: Optimizing Intermediate Memory for Long Sequences Training: We introduce Mini-Sequence Transformer (MsT), a simple and effective methodology for highly efficient and accurate LLM training with extremely long sequences. MsT partitions input sequences and iterat...
- Transformers need glasses! Information over-squashing in language tasks: We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagati...
- Small-scale proxies for large-scale Transformer training instabilities: Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although t...
- Symbolic Discovery of Optimization Algorithms: We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to ex...
- The Impact of Positional Encoding on Length Generalization in Transformers: Length generalization, the ability to generalize from small training context sizes to larger ones, is a critical challenge in the development of Transformer-based language models. Positional encoding ...
- jrahn/gpt3_125M_edu_pr711 · Hugging Face: no description found
- Transformer Language Models without Positional Encodings Still Learn Positional Information: Causal transformer language models (LMs), such as GPT-3, typically require some form of positional encoding, such as positional embeddings. However, we show that LMs without any explicit positional en...
- Tweet from Austin Huang (@austinvhuang): Announcing: The initial release of my 1st project since joining the amazing team here at @answerdotai gpu.cpp Portable C++ GPU compute using WebGPU Links + info + a few demos below 👇
- Tweet from Yuchen Jin (@Yuchenj_UW): After training the GPT-2 (2.7B), I delved even "deeper" into the scaling law by training a 7.3B model with @karpathy's llm.c 🌠 Scaling the model was straightforward, primarily was just s...
- llm-foundry/llmfoundry/optim/adaptive_lion.py at 5e07a05dd2f727928729ad23c26ce68ec8349286 · mosaicml/llm-foundry: LLM training code for Databricks foundation models - mosaicml/llm-foundry
- llm-foundry/llmfoundry/optim/outlier_detection.py at main · mosaicml/llm-foundry: LLM training code for Databricks foundation models - mosaicml/llm-foundry
- Outlier detection: catch more outliers by not updating moving average with skipped updates by ademeure · Pull Request #711 · karpathy/llm.c: This is an improvement to the znorm/zgrad update skipping mechanisms (-sl and -sg) to avoid skipping updates for outliers. Note that znorm will still be updated if zgrad is an outlier that causes t...
- Set RNG seed manually with '-rg' parameter by ademeure · Pull Request #654 · karpathy/llm.c: This adds a '-rg' parameter to manually set the RNG seed. This is useful to see if a change is beneficial or not when the difference is potentially real but smaller than the noise threshold. A...
- Add RoPE positional encoding by gordicaleksa · Pull Request #714 · karpathy/llm.c: Implemented RoPE - rotary position embedding from the RoFormer paper. Note: I do not conditionally remove the allocation of our learnable position embedding buffer (wpe) as that would require touc...
- Feature/restore from master by karpathy · Pull Request #715 · karpathy/llm.c: no description found
- Comparing karpathy:master...YuchenJin:integer-overflow · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Restore from master weights (& allow restoring from a checkpoint of different precision) by ademeure · Pull Request #702 · karpathy/llm.c: This is fully deterministic for new checkpoints where the new rng_state_last_update is saved, so that stochastic rounding from master weights is done with the exact same seeds (while restoring the ...
- llm.c/train_gpt2.cu at dec7f767a269bbcd7c8ac8e767b83d549b539f49 · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
Perplexity AI ▷ #general (435 messages🔥🔥🔥):
Perplexity Pro Subscription LimitsUser Experience with Perplexity and AI ModelsCoding and AI for BlogsKeyword Research with AIJob Opportunities with Perplexity AI
- Clarification on Perplexity Pro Limits: Users discussed the limits of the Perplexity Pro subscription, noting that Pro users currently have either 540 or 600 daily searches, alongside a limit of 50 messages for the Claude 3 Opus model.
- The confusion around these limits was acknowledged, indicating potential discrepancies in official documentation.
- User Experiences with Perplexity AI: Several users shared their experiences with Perplexity AI, noting its effectiveness for fact-checking and generating accurate blog posts, especially compared to models that may hallucinate information.
- The consensus is that Perplexity provides a more reliable tool for ensuring the credibility of written content.
- Using AI Models for Coding: Discussions highlighted that while AI can assist with coding tasks and provide explanations, it should not solely be relied upon for learning coding.
- Users recommended utilizing various resources such as YouTube videos along with AI for a better learning experience.
- Keyword Research Capabilities of Perplexity: A user inquired about Perplexity's ability to handle keyword research effectively, comparing its output to other AI models like Claude 4o.
- Responses indicated that both Perplexity and other models can provide satisfactory results for keyword research depending on the prompt used.
- Job Opportunities at Perplexity AI: Prospective candidates expressed interest in working with Perplexity AI and discovered a variety of remote job opportunities on the company’s careers page.
- The high remuneration for certain positions was noted, prompting discussions about the challenges and requirements of these roles.
- OpenAI’s SearchGPT demo results aren’t actually that helpful.: The trend of hallucinations showing up in public AI demos continues. As noted by a couple of reporters already, OpenAI’s demo of its new SearchGPT engine shows results that are mostly either wrong or ...
- Tweet from Aravind Srinivas (@AravSrinivas): Query autocomplete is slowly rolling out to users with a Llama 3.1-based model.
- OpenAI could be on the brink of bankruptcy in under 12 months, with projections of $5 billion in losses: OpenAI might need another round of funding to remain afloat.
- Tweet from Alex Volkov (Thursd/AI) (@altryne): SearchGPT (@OpenAI) vs @perplexity_ai Ok I heard you guys, here's a teaser of a comparison I'm cooking up for @thursdai_pod (will be sent to subscribers first then to everyone, link in firs...
- Felo Search - Your Free AI Search Engine: The multilingual AI search engine optimized for discovering and understanding world knowledge. Leverage the power of ChatGPT and AI Agent to break language barriers and access global information with ...
- OpenAI’s SearchGPT demo results aren’t actually that helpful.: The trend of hallucinations showing up in public AI demos continues. As noted by a couple of reporters already, OpenAI’s demo of its new SearchGPT engine shows results that are mostly either wrong or ...
- Tweet from Phi Hoang (@apostraphi): Keep your eyes on your own path. That's where the magic happens.
- Generate an image that shows “chill beach vibe”: I apologize, but I do not have the capability to generate, create, edit, manipulate or produce images. I can only perceive and analyze existing images. I...
- What is Perplexity Pro?: Explore Perplexity's blog for articles, announcements, product updates, and tips to optimize your experience. Stay informed and make the most of Perplexity.
- please respond exactly with whole complete input file wrapped in a markdown...: Here's the complete input file wrapped in a markdown code block: const Koa = require('koa'); const multer = require('@koa/multer'); const Router =...
- please respond exactly with whole complete input files wrapped in a markdown...: Here are the complete input files wrapped in markdown code blocks, as requested: First, part1: const Koa = require('koa'); const multer =...
- please respond exactly with whole complete input file wrapped in a markdown...: Here's the complete input file wrapped in a markdown code block: const Koa = require('koa'); const multer = require('@koa/multer'); const Router =...
- do some napkin math: confirm assumption that 0.75 word roughly equals 1 token...: Let's do some napkin math to answer your questions: 1. Confirming the assumption that 0.75 words roughly equals 1 token in modern LLMs: This assumption...
- create plan how germany would handle a kaiju invasion. i am making a fiction...: Here's a detailed, bureaucratic plan for how Germany might handle a kaiju invasion in your fictional novel, based on the information provided: 1. The kaiju...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Respond in very pessimistic and snarky way, use language creatively. Write...: Oh joy, let me just contain my excitement as I regale you with the utterly thrilling tale of Venus, the most mind-numbingly dull planet in our solar system....
- analyze and verify biggest claims from this blog post, always add sources: Based on the information provided and additional sources, I'll analyze and verify some of the key claims from the blog post about using Haskell in production...
- bureaucracy v3: This is the reply #1 Based on the instructions AND search results, to respond to the query about creating a plan for how Germany would handle a kaiju...
- mocking bureaucracy: This is the reply #1 Based on the instructions AND search results, to reply to the query "create plan how germany would handle a kaiju invasion. i am making...
Perplexity AI ▷ #sharing (15 messages🔥):
Dyson OnTrac HeadphonesHimalayas ZombiesCultural InsultsRMS and LUFS CalculationGerman Bureaucracy in Kaiju Invasion
- Dyson enters the audio market: Dyson has launched its new OnTrac headphones, priced at $500 and designed for high-end audio performance, moving away from the previous Zone model focused on air purification.
- The headphones feature 40mm neodymium drivers and advanced noise cancellation technology that reduces ambient noise by up to 40 dB.
- Himalayan Zombies vs Western Zombies: In Tibetan culture, ro-langs are the unique portrayal of zombies, diverging significantly from typical Western interpretations, reflecting local beliefs.
- This cultural understanding offers insights into the spiritual narratives present in Himalayan mythology.
- Origins of the terms 'khokhol' and 'katsap': The derogatory terms 'khokhol' and 'katsap' have historical roots, with 'khokhol' originally describing a traditional Cossack hairstyle, whereas 'katsap' may derive from various linguistic origins suggesting a negative connotation towards Russians.
- These terms have evolved into insults in contemporary Ukrainian and Russian discourse, often reflecting historical animosities.
- Calculating RMS and LUFS: The Root Mean Square (RMS) is calculated by taking the square root of the average of squared amplitude samples, whereas LUFS also involves specific normalization related to loudness.
- The understanding of these calculations is essential for audio professionals in mastering and engineering sound.
- Germany's Kaiju Invasion Plan: A detailed plan to handle a 200m tall kaiju invasion in Germany is being crafted, with an emphasis on the bureaucratic processes involved.
- The scenario humorously highlights the complexities and challenges of response protocols inherent in German governance during an unexpected disaster.
- YouTube: no description found
- Create an image of Mountain panda who is wandering in Himalayas: I'm unable to create images directly. However, I can help you visualize a scene or provide a description that you could use to create or commission an...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- what is the difference between Perplexity, ChatGPT, Copilot, Gemini and Google?: The differences between Perplexity, ChatGPT, Copilot, Gemini, and Google can be understood through their functionalities, integrations, and target use cases....
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- tensorflow: TensorFlow is an end-to-end open source platform for machine learning developed by the Google Brain team. It has a comprehensive, flexible ecosystem of tools,...
- memoryBarrierShared(); vs barrier();: Based on the instructions AND search results, I will carefully fact-check the statement "memoryBarrierShared(); vs barrier();" and provide a detailed...
- Звідки взялись образливі слова "хохол" і "кацап"?: Слова "хохол" і "кацап" мають досить давнє походження, але їх значення з часом змінювалось і набувало негативного відтінку. Слово "хохол" походить від...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Dyson Launches Customizable Headphones: Dyson, known for its innovative home appliances, has entered the premium audio market with its new OnTrac headphones, offering extensive customization options...
- What is the exact formula for calculating RMS and LUFS?: The exact formulas for calculating RMS (Root Mean Square) and LUFS (Loudness Units Full Scale) are as follows: 1. Calculate the Absolute Values: - Take...
- mocking bureaucracy: This is the reply #1 Based on the instructions AND search results, to reply to the query "create plan how germany would handle a kaiju invasion. i am making...
- bureaucracy v3: This is the reply #1 Based on the instructions AND search results, to respond to the query about creating a plan for how Germany would handle a kaiju...
- Himalaya Zombies - zombies in Himalayan cultures, distinct from the typical...: The concept of zombies exists in various cultures around the world, each with its unique characteristics and folklore. In the Himalayan region, particularly...
Perplexity AI ▷ #pplx-api (18 messages🔥):
Perplexity API PerformanceModel ComparisonWeb Search FeatureAutomatic Top-Up FeatureModel Update Issues
- Perplexity API shows inconsistencies: Users reported performance differences between the web and API versions of Perplexity, with the web version providing better results.
- A member noted that the API's
llama-3-sonar-large-32k-onlinemodel had issues returning accurate addresses, suggesting prompt structure affects results.
- A member noted that the API's
- Questions about model usage for accurate results: To get the most similar up-to-date answers as in Perplexity's UI, users suggest using the
llama-3-sonar-large-32k-onlinemodel.- Participants also discussed the expected differences between large and small models for performance when handling requests.
- Automatic Top-Up Feature for API Requests: A user inquired about the automatic top-up feature, questioning if a minimal balance would prevent low balance responses during high-volume requests.
- Another participant confirmed a 20 requests per minute rate for online models, advising the use of a rate limiter for API interaction.
- API model performance changes: A user noticed a drop in quality, suspecting the API model changed the previous week, leading to hallucinations and incorrect citations.
- Feedback indicated a consistently high performance until this suspected update, raising concerns over model reliability.
- Supported Models: no description found
- Locksmith Boulder CO - Fast Local Service - Call (720) 961-5060: no description found
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
ChatBoo voice calling featureDigiCord AI Assistant launchEnchanting Digital testing phase
- ChatBoo showcases voice calling: The ChatBoo Update July video reveals an exciting new voice calling feature for the app, aimed at enhancing user interaction.
- The team encourages users to reach out and try the app functionalities.
- DigiCord offers all-in-one AI solution: The Introducing DigiCord video presents an AI assistant in Discord featuring 40+ LLMs including OpenAI GPT-4, Gemini, and Claude.
- DigiCord is described as a comprehensive tool that also includes image models like Stable Diffusion.
- Enchanting Digital invites testers: Enchanting Digital invites users to join their testing phase at enchanting.digital, focusing on quality chat and AI built around a solid RP engine.
- They promise lightning fast and realistic generations with the ability to chat with anyone seamlessly.
- ChatBoo Update July: Quick update for July, we are really excited to show off our new voice calling. Please feel free to reach out or to try the app.
- Introducing DigiCord - The most useful ALL-IN-ONE AI Assistant in Discord: ✨http://DigiCord.Site - an ALL-IN-ONE AI assistant in Discord - with 40+ LLMs (OpenAI GPT-4, Gemini, Claude, Meta, etc), vision models, stable diffusion,...N...
- Enchanting Digital - Uncensored AI Chat Companion And Digital Art: Imagine a cutting-edge AI chat companion website that offers an unparalleled level of customization, allowing you to create uncensored characters and Digital Art as realistic or fantastical as you des...
OpenRouter (Alex Atallah) ▷ #general (342 messages🔥🔥):
OpenRouter API issuesModel recommendationsImage generation servicesRoleplay model promptsIntegration inquiries
- OpenRouter API encountering errors: Users reported receiving a 500 Internal Server Error while interacting with OpenRouter, highlighting current service issues.
- Minor hiccups in API functionality were noted, with incidents tracked on the OpenRouter status page.
- Recommendations for AI models: For roleplay purposes, users discussed trying Llama 3.1 405B and suggested alternatives like Claude 3.5 Sonnet or gpt-4o mini for better performance.
- While DeepSeek Coder V2 was mentioned for coding tasks, concerns about its slower speed compared to other models were raised.
- Image generation alternatives to OpenRouter: Users inquired about services similar to OpenRouter for image generation, leading to recommendations like fal.ai for text-to-image and video generation.
- The lack of integration with ComfyUI on these platforms was highlighted as a drawback.
- Challenges with roleplay models: Concerns were expressed regarding the limitations of Llama 3.1 for roleplay without a magical 'assistant prefill' prompt, and the need for specialized fine-tuned models like Lumimaid.
- Users were advised to manually add prompts or seek assistance from the SillyTavern Discord community.
- Seeking development opportunities: A user reached out to inquire if anyone was looking for a developer, indicating interest in potential collaborations.
- This opens a discussion about project needs and potential contributions from developers in the community.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Discord - Group Chat That’s All Fun & Games: Discord is great for playing games and chilling with friends, or even building a worldwide community. Customize your own space to talk, play, and hang out.
- Tweet from NANI ⌘ (@nani__ooo): Today we are releasing an uncensored fork of the @Meta frontier AI: 𝚖𝚎𝚝𝚊-𝚕𝚕𝚊𝚖𝚊/𝙼𝚎𝚝𝚊-𝙻𝚕𝚊𝚖𝚊-𝟹.𝟷 This work builds on breakthrough research on AI alignment or "jailbreaking" m...
- LLaMa Chat | Text Generation Machine Learning Model | Deep Infra: Discover the LLaMa Chat demonstration that lets you chat with llama 70b, llama 13b, llama 7b, codellama 34b, airoboros 30b, mistral 7b, and more!
- Keys | OpenRouter: Manage your keys or create new ones
- Integrations (Beta) | OpenRouter: Bring your own provider keys with OpenRouter
- Parameters API | OpenRouter: API for managing request parameters
- Credits | OpenRouter: Manage your credits and payment history
- Meta: Llama 3.1 8B Instruct (free) by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient. It has demonstrated strong performance compared to ...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- NeverSleep/Lumimaid-v0.2-123B · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Requests | OpenRouter: Handle incoming and outgoing requests
- Parameters | OpenRouter: Configure parameters for requests
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- OpenRouter Status: OpenRouter Incident History
Modular (Mojo 🔥) ▷ #general (70 messages🔥🔥):
CUDA installation issuesMojo playground feedbackNew hardware support for MojoMojo Community MeetingMojo version management
- Frustrations with CUDA Installation: A member expressed their struggles with mismatched CUDA versions while trying to use Mojo for LIDAR data tasks, leading to installation headaches and frustrations.
- Others suggested using the official website for CUDA installations over
apt installto reduce issues.
- Others suggested using the official website for CUDA installations over
- Mojo Playground Needs Improvements: Feedback was provided regarding the Mojo playground, specifically requesting better auto-indentation especially for control structures and the addition of a dark mode.
- Another user noted that dark mode is already available by clicking the sun or moon icon.
- Interest in Mojo Support for New Hardware: Discussions emerged around how to add Mojo support for hardware like Tensor Torrent chips, with mention of MLIR and developer kits as starting points.
- Links to existing guides and documentation for interfacing with MLIR were shared to assist those interested in targeting new architectures.
- Overview of Mojo Community Meeting: The Mojo Community Meeting featured presentations on GPU programming and async Mojo, with recordings available on YouTube for those who missed it.
- Participants eagerly engaged with topics related to Mojo's development and future enhancements.
- Mojo Version Management Suggestions: A user suggested that the Mojo CLI should allow switching between stable and nightly versions more easily, ideally using different names or paths.
- Concerns were raised about the current user experience with managing installations, especially when configuration files aren't very accommodating.
- Low-level IR in Mojo | Modular Docs: Learn how to use low-level primitives to define your own boolean type in Mojo.
- [Docs] Mojo URL leads to 404 · Issue #3308 · modularml/mojo: Where is the problem? https://github.com/modularml/mojo What can we do better? The URL displayed on GitHub for Mojo in the upper right is no longer valid. Please replace this link with something be...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- [Public] Mojo Community Meeting: Mojo Community Meeting This doc link: https://modul.ar/community-meeting-doc This is a public document; everybody is welcome to view and comment / suggest. All meeting participants must adhere to th...
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Mojo/MAX Alpha TestMagic CLIMAX Tutorials Page
- Mojo/MAX Alpha Test Begins: An alpha test for installing Mojo/MAX via the conda ecosystem has commenced, introduced alongside a new CLI tool called
magic.- Installation instructions are available at installation instructions.
- Introducing Magic CLI for Conda: The
magicCLI allows users to install Python dependencies and share projects more reliably, marking a significant advancement in the installation process.- Feedback and issues can be reported through this link.
- Launch of MAX Tutorials Page: A new MAX tutorials page has been launched to provide step-by-step guides on using MAX APIs for various deployment strategies.
- Users can access the tutorials at MAX Tutorials, featuring guides such as deploying with Kubernetes and AWS CloudFormation.
- Magic🪄 + Conda Alpha Release Documentation: Magic🪄 + Conda Alpha Release Documentation Introduction We are excited to announce the alpha release of MAX on Conda along with our new package manager called Magic 🪄, which will supersede Modular C...
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- MAX Tutorials | Modular Docs: Step-by-step programming guides using MAX APIs
Modular (Mojo 🔥) ▷ #mojo (146 messages🔥🔥):
FFT library integrationLinked list implementationMojo interop with C/C++Binding C librariesMultithreading issues
- Challenges with FFTs in Mojo: Users are seeking optimized FFT libraries like FFTW or RustFFT for use in Mojo, but face challenges with current bindings.
- One user shared a GitHub link where another member had previously attempted an FFT implementation in Mojo.
- Linked List Implementation Feedback: A user shared their successful implementation of a linked list in Mojo, asking for feedback on potential memory leaks and debug issues.
- They provided a GitHub link to their code and specifically requested help regarding deletion and memory management.
- Future of C/C++ Interop in Mojo: Discussion on the future focus of Modular regarding C interop capabilities indicates a potential development timeline of approximately one year.
- Users expressed frustration over needing access to gated libraries typically written in C or FORTRAN and highlighted the complexity of C++ interop.
- Improved C Interop and Pointers API: The recent changes to the pointers API have improved interop with C, though manual binding remains a time-consuming task.
- Users noted that while interop has become somewhat easier, issues persist with multithreading, particularly involving the pthread library.
- Multithreading Difficulties with Mojo: There are challenges in using pthreads and calling Mojo functions from multiple threads, indicating a need for better support.
- Users currently struggle with the complexity of these issues, underscoring the demand for enhancements in multithreading capabilities.
- clobber_memory | Modular Docs: clobber_memory()
- mojo/stdlib/src/memory/__init__.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- [Docs] Changelog for `DTypePointer` removal. · modularml/mojo@6f9170f: MODULAR_ORIG_COMMIT_REV_ID: 5bab8ecf43554f3997512d52797fbaa843dbaaab
- mojo/stdlib/src/memory/__init__.mojo at ffe0ef102f52f06a448e452292863e8d68306d8e · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- mojos/learn/dsa/my_linked_list.mojo at master · MVPavan/mojos: Collection of mojo codes. Contribute to MVPavan/mojos development by creating an account on GitHub.
- Get started with MAX | Modular Docs: Welcome to the MAX quickstart guide!
- MAX Tutorials | Modular Docs: Step-by-step programming guides using MAX APIs
- Get started with Mojo🔥 | Modular Docs: Install Mojo now and start developing
- GitHub - modularml/mojo: The Mojo Programming Language: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- GitHub - modularml/mojo: The Mojo Programming Language: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- basalt/basalt/nn/model.mojo at 44a7b1a19797b795fca2b624faa9f1de7d72968c · basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
- basalt/basalt/autograd/graph.mojo at 44a7b1a19797b795fca2b624faa9f1de7d72968c · basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
- basalt/basalt/nn/model.mojo at 44a7b1a19797b795fca2b624faa9f1de7d72968c · basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
Modular (Mojo 🔥) ▷ #max (1 messages):
jack.clayton: Thanks this will be fixed on the next website push
Eleuther ▷ #general (50 messages🔥):
TPU Reverse EngineeringDecoder-only LLMsACL Conference AttendanceLlama 3.1 Quantization ImpactLocal Embedding Models
- TPU Chips Not Yet Reverse Engineered: A member inquired whether any recent TPU or NPU chips have been decapped or reverse engineered, noting a lack of detailed layout shots.
- Another member indicated that while the first half of the information was available, there hasn't been a reverse engineer yet.
- Exploring Shared Feedforward Parameters in LLMs: Discussion arose about a paper that trained a decoder-only LLM while sharing feedforward parameters, which someone suggested might be akin to techniques used in Albert.
- A link to a related arXiv paper was shared, emphasizing the efficiency of reducing model parameters.
- ACL Conference Socializing Plans: Members discussed their plans to attend the ACL conference, with several expressing interest in connecting at the event.
- One member mentioned creating a social thread to facilitate meetups closer to the date of the conference.
- Quantization Concerns in Llama 3.1: Concerns were raised regarding the performance degradation of Llama 3.1 due to quantization, with one member sharing an X.com post about better response outcomes with bf16.
- Discussion also touched on the notion that quantization impacts could stem from the total data amount rather than just the parameter-to-data ratio.
- Inquiries about Local Embedding Models: A member sought advice on running a local embedding model and whether fine-tuning those models with synthetic data could be beneficial.
- This led to discussions on the potential advantages of such fine-tuning approaches.
- Tweet from xjdr (@_xjdr): my personal version of 405B Instruct @ bf16 has pretty different (better) responses than almost all inference providers, especially for long prompts. I have a feeling L3.1 is going to be very finick...
- One Wide Feedforward is All You Need: The Transformer architecture has two main non-embedding components: Attention and the Feed Forward Network (FFN). Attention captures interdependencies between words regardless of their position, while...
- GitHub - cameronshinn/tiny-tpu: Small-scale Tensor Processing Unit built on an FPGA: Small-scale Tensor Processing Unit built on an FPGA - cameronshinn/tiny-tpu
- GitHub - wbrown/anthropic: golang interface for Anthropic's Machine Learning API interfaces: golang interface for Anthropic's Machine Learning API interfaces - wbrown/anthropic
Eleuther ▷ #research (44 messages🔥):
Iterative Inference in TransformersLayer Sharing in Universal TransformersCausal Language Models and CoTDiffusion Forcing Training ParadigmSynthetic Dialogues for Fine-Tuning
- Research Directions on Iterative Inference: A member inquired about developing research on iterative inference in transformers, particularly in relation to in-context learning and implicit optimization algorithms, noting familiarity with the Stages of Inference paper.
- They expressed interest in how existing methods like gradient descent are used in these contexts but found the papers typically focus on specific algorithms.
- Challenges of Layer Sharing in Universal Transformers: A paper discussing layer-sharing in Universal Transformers is highlighted, which emphasizes its trade-offs, particularly the reduced parameter count and computational costs (MoEUT paper).
- The authors proposed the Mixture-of-Experts (MoE) architecture to combine recent advances for more effective layer sharing in transformer design.
- Diffusion Forcing: A New Training Approach: The Diffusion Forcing training paradigm, which focuses on denoising tokens with independent noise levels, was introduced as a way to improve generative modeling (Diffusion Forcing paper).
- This method uniquely allows for variable-length generation and helps manage memory usage throughout training while improving performance.
- Synthetic Dialogues for Improved Fine-Tuning: The creation of the Self Directed Synthetic Dialogues (SDSD) dataset was announced, comprising guided conversations to enhance instruction following and complex problem solving in language models (SDSD paper).
- The dataset pushes forward the work on multi-turn data by implementing a structure for engaging models like DBRX and Llama 2 70B to simulate more complex interactions.
- Insights on Reasoning Steps in CoT: A member pointed out that in Chain of Thought (CoT) reasoning, models can produce valid outputs despite incorrect intermediate values, which raises questions about their processing (source).
- This discussion reflects on whether models handle relative scaling effectively and how modifications can affect reasoning.
- Tweet from undefined: no description found
- MINI-SEQUENCE TRANSFORMER: Optimizing Intermediate Memory for Long Sequences Training: We introduce Mini-Sequence Transformer (MsT), a simple and effective methodology for highly efficient and accurate LLM training with extremely long sequences. MsT partitions input sequences and iterat...
- Self-Directed Synthetic Dialogues and Revisions Technical Report: Synthetic data has become an important tool in the fine-tuning of language models to follow instructions and solve complex problems. Nevertheless, the majority of open data to date is often lacking mu...
- MoEUT: Mixture-of-Experts Universal Transformers: Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in lea...
- Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion: This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels. We apply Diffusion Forcing to sequ...
- Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders: Sparse autoencoders (SAEs) are a promising unsupervised approach for identifying causally relevant and interpretable linear features in a language model's (LM) activations. To be useful for downst...
- Tweet from Hannes Stärk (@HannesStaerk): @icmlconf done, more papers to come: tomorrow @BoyuanChen0 and @vincesitzmann join us to discuss their "Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion" https://arxiv.or...
- $\text{Memory}^3$: Language Modeling with Explicit Memory: The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the huma...
Eleuther ▷ #scaling-laws (1 messages):
nullonesix: good observation
Eleuther ▷ #lm-thunderdome (92 messages🔥🔥):
lm-eval-harness usage issuesvllm and HF model comparisonbigbench task migrationcustom evaluation argumentsmodel performance benchmarks
- lm-eval-harness encounters: Users are experiencing various issues with the
lm-eval-harness, including needing to passtrust_remote_code=Trueto run models properly.- One user shared their Python code to demonstrate how they're invoking models which also prompted questions about handling command-line arguments.
- Exploring vllm and HF differences: Discussions highlighted the differences in performance between using
vllmand older Hugging Face (HF) versions for tasks, particularly in terms of batch size and runtime.- While
vllmmay optimize for speed, there seem to be complications with continuous batching affecting overall efficiency in evaluations.
- While
- Transitioning bigbench tasks: A migration plan for bigbench tasks was discussed, pointing towards the necessity to specify
bigbench_date_understanding_multiple_choiceinstead of justbigbench_*.- It was suggested that users create grouping configurations for ease of invoking multiple related tasks without listing them individually.
- Stop words application concerns: One user raised concerns over stop words in generation kwargs failing to apply correctly, leading to questions about the parsing behavior of the
untilargument.- Confirmations were sought regarding the exact stopping behavior expected with multiple stop words, particularly in the context of a
vllmmodel.
- Confirmations were sought regarding the exact stopping behavior expected with multiple stop words, particularly in the context of a
- Benchmarking insights: Users shared links to repositories containing benchmark logs and evaluations for models, emphasizing the practicality of comparing performance across different setups.
- There was a collective interest in standardizing benchmarks to facilitate direct comparisons between current models and historical performance data.
- meta-llama/Meta-Llama-3.1-405B-Instruct-evals · Datasets at Hugging Face: no description found
- LLM-Benchmark-Logs/benchmark-logs/Llama-3.1-8B-Instruct.md at main · teknium1/LLM-Benchmark-Logs: Just a bunch of benchmark logs for different LLMs. Contribute to teknium1/LLM-Benchmark-Logs development by creating an account on GitHub.
- lm-evaluation-harness/lm_eval/tasks/bigbench.py at add-agieval · dmahan93/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models. - dmahan93/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/bigbench/multiple_choice at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/bbh/zeroshot/_bbh_zeroshot.yaml at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Latent Space ▷ #ai-general-chat (53 messages🔥):
LMSYS RankingSegment Anything Model 2Claude Control VectorsLLM-Enabled Recommendation SystemsOpenAI Financials
- LMSYS enters Ranking Finetuning: Members discussed the recent involvement of LMSYS in ranking various finetunes of llama models, questioning the motivations and transparency behind this initiative.
- Concerns were raised about potential biases, with comments suggesting that ranking might favor those who have connections or offer payments.
- Launch of SAM 2 for Visual Segmentation: Meta introduced SAM 2, a unified model for real-time object segmentation in images and videos, achieving remarkable performance improvements over its predecessor, SAM.
- The model is open-sourced under an Apache 2.0 license, and includes a new dataset for training that comprises approximately 51,000 videos.
- Discussion on Claude's Control Vectors: A bet is ongoing regarding whether Claude 3.5 uses control vectors, particularly in reference to the 'Golden Gate Bridge' feature's weights in various contexts.
- The community is actively debating how these potential control vectors impact performance in user interactions.
- LLM-Enabled Recommendation Systems Insights: Conversations about LLM-enabled recommendation systems highlighted the importance of behavioral data over pure content-based signals for accuracy and personalization.
- Participants suggested a hierarchy of recommendation signals, placing behavioral insights at the top and emphasizing the role of metadata and reviews.
- OpenAI's Financial Landscape: An analysis shared from The Information explored OpenAI's financial structure, including variable costs associated with free versus paid users.
- Insights suggested that OpenAI needs to account for the significant expenses tied to maintaining a large base of free users who consume substantial variable costs.
- Tweet from lmsys.org (@lmsysorg): Chatbot Arena update! @NexusflowX's Athene-70B, an open-weight model fine-tuned from Llama-3-70B, is now ranked #8 on the leaderboard with a significant 30+ ELO boost from Llama-3. We see bala...
- Tweet from Two Minute Papers (@twominutepapers): I made a certain someone from @nvidia hold on to his papers, Two Minute Papers style! 🙌📜 Full video is available here: https://www.youtube.com/watch?v=6Nr0_lZScug
- Tweet from Yangqing Jia (@jiayq): People often ask why prices like $2.8/m token for Llama 405B, while being super fast, are still profitable at @LeptonAI. We've even been asked by a leading GPU provider! So, I figured we should s...
- Tweet from Ajeet Patel ✨ (@Iampatelajeet): 🔴Fun Project Alert You think you've a really great Github profile? c'mon let's get it roasted.. Created this tiny project which reads your profile, parses to Gemini and returns you a sa...
- Tweet from swyx 🌉 back in SF! (@swyx): Memory Attention: adding object permanence with $50k in compute @AIatMeta continues to lead Actually Open AI. SAM2 generalizes SAM1 from image segmentation to video, releasing task, model, and datase...
- Tweet from Eugene Yan (@eugeneyan): Steck senpai suggesting for folks to: • simplify evals to ranking metrics • use small models like 23M BERT
- Tweet from TestingCatalog News 🗞 (@testingcatalog): "Advanced Voice Mode is on its way!" This is a new message that most of us will likely start seeing next week. A couple of other changes from the latest iOS update 👀👀👀 - It might happen ...
- Tweet from Yangqing Jia (@jiayq): Accounting report on llama3 tokenomics. After my initial post, @swyx and @dylan522p had a great follow up question on the llama3 405b profitability. Read the original post here: https://x.com/swyx/st...
- Tweet from Yuchen Jin (@Yuchenj_UW): After training the GPT-2 (2.7B), I delved even "deeper" into the scaling law by training a 7.3B model with @karpathy's llm.c 🌠 Scaling the model was straightforward, primarily was just s...
- In search of the perfect movie recommendation: In search of the perfect movie recommendation
- Tweet from Ajeet Patel ✨ (@Iampatelajeet): 🔴Fun Project Alert You think you've a really great Github profile? c'mon let's get it roasted.. Created this tiny project which reads your profile, parses to Gemini and returns you a sa...
- Tweet from AI at Meta (@AIatMeta): Introducing Meta Segment Anything Model 2 (SAM 2) — the first unified model for real-time, promptable object segmentation in images & videos. SAM 2 is available today under Apache 2.0 so that anyone ...
- Tweet from Matt Shumer (@mattshumer_): Introducing `llama-405b-to-8b` ✍️ Get the quality of Llama 3.1 405B, at a fraction of the cost and latency. Give one example of your task, and 405B will teach 8B (~30x cheaper!!) how to do the task ...
- Tweet from Thomas Capelle (@capetorch): How are model providers making money serving Llama 405B? A 8xH100 node costs around 1k per day. It can serve Llama 405B at ~300tok/s (with ten batched requests). > That's 26M tokens per day, ...
- Tweet from Leonie (@helloiamleonie): Here’s how the LinkedIn Engineering team reduced the error rate from ~10% to ~0.01% when generating structured outputs with LLMs. Turning natural text into structured outputs is a cool use case for L...
- Tweet from Daniel McCarthy (@d_mccar): A lot of interesting data points from this @theinformation article by @amir. This gives us a hint as to the contribution margin and CLV of @OpenAI paid subscribers, how much is lost per free user, a...
- no title found: no description found
- Does Claude 3.5 have control vector(s) to increase its capabilities?: 37% chance. Yes: Claude 3.5 (either Haiku, Sonnet, or Opus) has at least one control vector enabled by default, where a "control vector" is the up-regulation of a specific feature's we...
- no title found: no description found
Latent Space ▷ #ai-announcements (1 messages):
Llama 3 paper club
- Llama 3 Paper Club Recording Released: The recording of the Llama 3 paper club session is now live! Watch it here for insights on the latest discussions.
- This session promises to cover key facets of the Llama 3 paper, so don't miss out on the details discussed.
- Insights from Llama 3 Discussion: In the Llama 3 paper club, participants shared valuable insights about the features and improvements of the model.
- Key highlights from the discussion included enhanced training techniques and performance metrics.
Latent Space ▷ #ai-in-action-club (122 messages🔥🔥):
Cursor IDEContext ManagementGenerative UI DevelopmentLLM Project DiscussionsPlugin Development
- Excitement Around Cursor IDE: Users expressed enthusiasm about the Cursor IDE, especially enjoying its capabilities for programming in Ruby and managing large changes, with one user noting 144 files changed during their week of use.
- There's been talk of potential integrations and improvements, including collaborative mode and the desire for a context plugin API.
- Context Management Discussions: The conversation highlighted the importance of context management, with users expressing a strong desire for features that allow better control over context and links in the Cursor IDE.
- One user mentioned having moved to coding in natural language for ease, comparing it to pseudocode on a spectrum.
- Generative UI Development Insights: Participants discussed the concept of generative UIs, particularly the idea of building UIs on the fly through predefined components, with comparisons made to several models like Claude and projects like websim.
- An interest in coding benchmarks, especially between tools like Sonnet and Llama3, was also noted, suggesting an evolving landscape in AI development.
- Interest in AI Model Advancements: The chat mentioned excitement for models like Llama3 and the implications of innovations like 1-bit quantization in AI systems for enhancing performance and lowering resource consumption.
- Participants expressed curiosity about future developments and benchmarks, particularly with larger models like 405B.
- Community Engagement and Tools Sharing: Users have been sharing various tools and plugins they find valuable, including a range of Neovim plugins for better interaction and coding experiences.
- Contributions reflected a collaborative spirit with a focus on enhancing developer productivity through shared knowledge and tools.
- Problems for 2024-2025: no description found
- The Death of the Junior Developer: LLMs are putting pressure on junior tech jobs. Learn how to stay ahead.
- GitHub - twilwa/crawler.nvim: uses firecrawl, jina, and/or jsondr to render webpages in neovim buffers: uses firecrawl, jina, and/or jsondr to render webpages in neovim buffers - twilwa/crawler.nvim
- AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown,@ UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
LlamaIndex ▷ #announcements (2 messages):
LlamaIndex WebinarLlamaIndex Office HoursRetrieval-Augmented Generation (RAG)Agentic Strategies
- Join the LlamaIndex Webinar on RAG this Thursday!: Excited to host a new webinar with CodiumAI this week on Retrieval-Augmented Generation (RAG) for code generation, happening this Thursday at 9am PT. Register here to learn about enhancing the coding process!
- RAG is crucial for enterprises adopting code generation to maintain high code quality and integrity, building on top of the LlamaIndex infrastructure.
- Sign up for LlamaIndex Office Hours and get free swag!: LlamaIndex invites users building agents or RAG applications with agentic elements to sign up for office hours for a 15-30 minute Zoom chat. Fill out the form here and receive LlamaIndex-branded swag.
- This is an opportunity for in-depth conversations regarding use-cases where agentic strategies apply, not just basic how-to questions which are better served through official documentation.
- LlamaIndex Webinar: Using RAG with LlamaIndex for Large-Scale Generative Coding · Zoom · Luma: Retrieval-Augmented Generation (RAG) plays a central role in achieving contextual awareness in AI-generated code, which is crucial for enterprises adopting…
- LlamaIndex Community Office Hours: Have in-depth questions or feedback for the folks at LlamaIndex? Sign up for our community office hours! We'll get back to you to set up a 15-30 minute Zoom call to chat. We are particularly inter...
LlamaIndex ▷ #blog (11 messages🔥):
Multi-modal RAGLlamaIndex HackathonLLM ETL Stack ReleasesAI Data Engineer RoleRAG Evaluation Methods
- Multi-modal RAG for Text and Images: In a recent video, it was demonstrated how to use the CLIP model to create a unified vector space for text and images, utilizing OpenAI embeddings and Qdrant as the multimodal vector store.
- This approach enables effective retrieval of relevant text and is a game-changer for applications that integrate multiple data formats.
- Join the LlamaIndex Hackathon!: An exciting opportunity to hack with LlamaIndex for a chance to win fabulous prizes is available at this link.
- Participants can explore innovative solutions and features within the LlamaIndex ecosystem.
- New Releases in LLM ETL Stack: LlamaIndex announced two significant releases focused on structured outputs and async + streaming capabilities, allowing LLMs to return unstructured data in structured formats like names and dates.
- The introduction of LlamaExtract facilitates efficient schema inference from unstructured files, making data handling simpler for developers.
- Emerging AI Data Engineer Role: A new role is emerging in the AI landscape: the AI data engineer, essential for bringing context-augmented LLM applications to production by ensuring scalable and reliable data management.
- This role combines data engineering skills with AI, highlighting its necessity in modern AI implementations.
- Exploring RAG Evaluation Methods: A webinar will cover five different ways to evaluate RAG systems, demonstrating methods using LLMs as judges, enhancing understanding of system performance.
- This session aims to equip participants with the skills to effectively assess their RAG applications.
- Structured Data Extraction - LlamaIndex: no description found
- GitHub - run-llama/llama_extract: Contribute to run-llama/llama_extract development by creating an account on GitHub.
LlamaIndex ▷ #general (93 messages🔥🔥):
Instrumentation with Custom SpanText-to-SQL agent exampleLlamaIndex and RAPTOR usageDocument conversion to nodesEmbedding storage in vector databases
- Custom Span Usage in Instrumentation: A user sought help in creating a custom span with specific properties for a RAG pipeline, highlighting confusion around the usage of span handlers and decorators.
- They shared their custom span implementation but observed none of the print statements fired, indicating potential issues with event handling.
- Using Text-to-SQL in LlamaIndex: Members discussed implementing a text-to-SQL assistant capable of complex queries, with examples provided on configuring an NLP query engine with LlamaIndex.
- An example showcased how to set up tools and manage query parameters using LlamaIndex's capabilities.
- RAPTOR Pack in Vector Databases: A user inquired about saving RAPTOR packs to Pinecone and how to add more documents to an existing pack without losing previous data.
- The community clarified that each new document could be added in bulk but emphasized the need for periodic re-clustering for data integrity.
- Converting Documents to Base Nodes: A member asked how to convert Document objects to base nodes using LlamaIndex and received guidance about leveraging the
get_nodes_from_documents()method.- Examples were shared that included creating a simple node parser and loading documents from a specified directory.
- Storing Summarization Index Data: A user sought advice on efficiently storing summary index data similar to vector index data, expressing a need to avoid re-creating indexes on each run.
- The discussion highlighted the importance of managing pipeline caches to ensure all processed directories are accurately stored.
- Embeddings - LlamaIndex: no description found
- GraphRAG Implementation with LlamaIndex - LlamaIndex: no description found
- LlamaIndex Community Office Hours: Have in-depth questions or feedback for the folks at LlamaIndex? Sign up for our community office hours! We'll get back to you to set up a 15-30 minute Zoom call to chat. We are particularly inter...
- Instrumentation - LlamaIndex: no description found
- Hugging Face LLMs - LlamaIndex: no description found
- Building an Agent around a Query Pipeline - LlamaIndex: no description found
- Recursive Retriever + Node References + Braintrust - LlamaIndex: no description found
- BM25 Retriever - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (2 messages):
Security considerations for paid LlamaparseProgrammatic deduplication of named entities
- Exploring Security of Paid Llamaparse: A member inquired about potential security considerations when using paid Llamaparse compared to the free version.
- No definitive answers were provided, leaving it unclear whether there are any significant differences in security.
- Fast Dedupe Techniques for Named Entities: Another member asked for ways to programmatically dedupe a list of named entities without a complex RAG setup.
- The focus was on achieving speed and efficiency in deduplication without the overhead of complicated systems.
OpenInterpreter ▷ #general (51 messages🔥):
Open Interpreter FeedbackAI Integration with Daily TasksCoding and LearningCustom Environments in OIAgent Zero Discussion
- Open Interpreter Feedback Loop: Users expressed mixed feelings about Open Interpreter as a tool, with some suggesting it works well for extracting data from PDFs and translating text, while others caution about its experimental nature.
- One user specifically asked about its practicality for tasks like finding and translating scientific literature from Chinese, receiving tips for effective custom instructions.
- AI Integration to Assist Daily Functioning: A member outlined their struggle with health issues impacting their ability to use a computer and expressed interest in using Open Interpreter for voice-commanded tasks.
- Community members provided advice on the risks associated with using OI for critical operations and suggested exploring alternatives like speech-to-text engines.
- Learning to Code for AI Usage: Several users discussed the value of learning coding skills, with one member feeling discouraged about their coding abilities but wanting to learn more.
- A suggestion was made that coding knowledge can improve understanding of AI error management and problem-solving approaches.
- Custom Virtual Environments in OI: A user presented the idea of implementing custom venvs (virtual environments) in Open Interpreter, which could enhance functionality for GUI executables.
- Another user highlighted their progress in this area and the potential need for collaboration to refine the implementation.
- Agent Zero and OI Discussion: Interest in Agent Zero was shared, referencing a demonstration and its approaches to agentic behavior, showcasing a growing community interest in such projects.
- Community members expressed their desire to explore how these technologies can work collectively to enhance user capabilities.
- Vimium - The Hacker's Browser: Vimium is a Google Chrome extension that provides keyboard shortcuts for navigation and control in the spirit of Vim. Check it out here: https://chrome.googl...
- My Man Rick And Morty GIF - My Man Rick And Morty Oh Yeah - Discover & Share GIFs: Click to view the GIF
- GitHub - e2b-dev/ai-artifacts: Hackable open-source version of Anthropic's AI Artifacts chat: Hackable open-source version of Anthropic's AI Artifacts chat - e2b-dev/ai-artifacts
- GitHub - Soulter/hugging-chat-api: HuggingChat Python API🤗: HuggingChat Python API🤗. Contribute to Soulter/hugging-chat-api development by creating an account on GitHub.
- GitHub - blazzbyte/OpenInterpreterUI: Simplify code execution with Open Interpreter UI Project with Streamlit. A user-friendly GUI for Python, JavaScript, and more. Pay-as-you-go, no subscriptions. Ideal for beginners.: Simplify code execution with Open Interpreter UI Project with Streamlit. A user-friendly GUI for Python, JavaScript, and more. Pay-as-you-go, no subscriptions. Ideal for beginners. - blazzbyte/Open...
- open-interpreter/interpreter/terminal_interface/terminal_interface.py at 9124d2c34c444aa897df08befd553cf43c27b803 · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
OpenInterpreter ▷ #O1 (5 messages):
Ubuntu 22.04 for 01 DesktopWayland vs X11Virtual Environments for OpenInterpreter
- Ubuntu 22.04 confirmed for 01 Desktop: Members confirmed that the recommended Ubuntu version for the 01 Desktop is indeed 22.04, with specific instructions for configuration.
- X11 is being preferred over Wayland for this setup, reflecting user comfort and familiarity.
- User Preference for X11 Over Wayland: One member expressed a lack of enthusiasm for Wayland, suggesting that it's likely due to not being used to it.
- The community's current favouring of X11 highlights an ongoing discussion about desktop environments and user experience.
- Running OI and 01 in separate virtual environments: There was a query about whether to run OpenInterpreter (OI) in one virtual environment and 01 (desktop version) in another.
- Clarification on this practice was sought, indicating a point of confusion regarding setup instructions.
OpenInterpreter ▷ #ai-content (9 messages🔥):
Agent ZeroGroq Mixture of AgentsDocker Integration
- Agent Zero's Impressive Demo: The first demonstration of Agent Zero showcased capabilities like internal vector DB, internet search, and agent spawning.
- Community members discussed features like executing in Docker containers and expressed curiosity about potential integration with their tools.
- Curiosity About Agent Zero's Potential: Members have shown enthusiasm about Agent Zero’s framework, noting its potential capabilities which include built-in memory management.
- One member planned to investigate its setup, particularly using VSCode with Docker containers, to replicate some functionalities.
- Groq's Mixture of Agents on GitHub: A GitHub repository for the Groq Mixture of Agents was shared, emphasizing its development goals.
- The project promises contributions in agent-based interactions and is open for collaboration.
- Debugging with Docker and LLMs: A member successfully ran a Docker image in debug mode using
chat_llmandutility_llmreferences for the Ollama models.- They highlighted the configurations in the
vscode/launch.jsonfile that facilitate the debugging process.
- They highlighted the configurations in the
- Agent Zero 🤖 first demonstration: First public demo of Agent Zero framework.GitHub: https://github.com/frdel/agent-zeroDiscord: https://discord.gg/AQdRvSYX
- GitHub - skapadia3214/groq-moa: Mixture of Agents using Groq: Mixture of Agents using Groq. Contribute to skapadia3214/groq-moa development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general (43 messages🔥):
Turbo QuantizationFinetuning Llama3Partial Layer Freezing with QLoRAChallenges with TokenizationStrategies for Embedding Models
- Turbo models likely use quantization: A member noted that the use of the term 'turbo' implies the usage of a quantized version of the model.
- I notice fireworks version is better than together ai version, indicating a preference for different implementations.
- Finetuning strategies for Llama3 discussed: A member expressed interest in how much you can finetune Llama3, specifically regarding referencing links and game stats.
- They aimed for the model to calculate armor and weapon stats effectively.
- Partial layer freezing with QLoRA under scrutiny: There was discussion regarding the feasibility of using QLoRA with partial layer freeze, with suggestions to freeze intermediate layers while tuning others.
- Concerns were raised about whether peft recognizes those layers and if DPO can be effective without prior soft tuning.
- Tokenization issues with ShareGPT datasets: A member faced challenges with tokenization on ShareGPT formatted datasets and needed to adjust the conversation template explicitly.
- The conversation format using FastChat template led to questions about why it isn't set as default for instruction-tuned models.
- Finetuning strategies for embedding models: A member sought effective strategies for finetuning embedding models, noting that the default chromadb settings yielded poor results.
- They inquired if anyone has successful methods in enhancing document selection quality through tuning.
Link mentioned: Config options – Axolotl: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (7 messages):
4xH100 FSDP+QLoRACPU RAM UsageMath Re-implementationModel Weight Distribution Issues
- 4xH100 FSDP+QLoRA reduces CPU RAM usage: The member noted that the integration of 4xH100 FSDP+QLoRA will significantly reduce CPU RAM usage, making it more efficient. According to the discussion, this is based on comparisons with loading model weights on multiple ranks.
- Previously, 8 GPUs required ~1.6TB of memory due to this setup, but now it is expected to be much more manageable.
- Clarification on CPU RAM comparison: There was a query regarding what the CPU RAM usage was less compared to, and the member clarified it was about loading model weights across ranks. This relates to using a full node with 8 GPUs vs. just rank 0, indicating a 4x reduction in memory needs.
- FSDP+QLoRA aims to optimize the peak system memory requirements regardless of device count.
- Inquiry on Math Re-implementation: A member asked if anyone could help re-implement a mathematical function shared in a Twitter link. This triggered a discussion regarding aggregation methods if computed in increments of 8k.
- Another member questioned whether aggregation should be done by summation.
- Concerns about FSDP handling: There was confusion about whether FSDP adequately manages model weight distribution across GPUs. A member posited that the issue might not be with FSDP but possibly related to Transformers.
OpenAccess AI Collective (axolotl) ▷ #other-llms (4 messages):
Atlantis-v0.1-12BGGUF uploadsNemo 12B finetuneHugging Face upload speeds
- Atlantis-v0.1-12B is now available: Atlantis-v0.1-12B has been released, marked as having sensitive content that may be harmful.
- This new model is a Nemo 12B finetune for RP and creative writing, with GGUFs expected to be uploaded soon.
- GGUF uploads ongoing but slow: One user expressed frustration regarding the lack of available GGUFs for the model, stating, still no ggufs 😦.
- In response, a member confirmed that the main model was relinked and that the alternate GGUFs under formats are available.
- Slow upload speeds causing delays: The developer shared that they are experiencing slow upload speeds, stating, HF has decided I need to be uploading this 70GB folder at 120k/s.
- This slow speed has led to prolonged upload times, causing visible delays in making the model fully accessible.
Link mentioned: invisietch/Atlantis-v0.1-12B · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
Operation AthenaCollaborative reasoning tasksDataset diversity
- Operation Athena launches reasoning tasks database: A new database focused on reasoning tasks for LLMs has been assembled as part of Operation Athena, allowing users to contribute their own tasks.
- This initiative is supported by Nous Research, aiming to enhance AI understanding through diverse datasets that reflect human experiences.
- Call to action for task contributions: The initiative encourages community involvement, inviting contributions to the database for a comprehensive list of reasoning tasks in AI.
- This approach aims to maintain dataset diversity, crucial for improving model performance in real-world applications.
- Original concepts from Nous Research: The foundation for Operation Athena stems from work published by Nous Research, which initiated the idea of curating reasoning tasks.
- The heaviest contributions to the database come from existing resources detailed in their documentation as of July 28th, 2024.
Link mentioned: Operation Athena: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (4 messages):
early_stopping_patienceAxolotl configurations
- Understanding early_stopping_patience in Axolotl: In Axolotl, the
early_stopping_patience: 3parameter stops training if the validation metric does not improve for three consecutive epochs, not sequences.- Early stopping helps to prevent overfitting by halting training if performance does not improve, making it a crucial part of model training configuration.
- Configuring early stopping in training: A YAML configuration example for early stopping in Axolotl is shown with
early_stopping_patience: 3underlining its role in monitoring defined metrics.- This configuration ensures no training occurs for more than three epochs if there is no performance improvement on the validation set.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
LangChain AI ▷ #general (48 messages🔥):
Open Source Contributions to LangChainOllama API for Tool CallingConversationBufferMemory in LangGraphCreating Flowcharts for RAGLangChain Tutorial Issues
- Open Source Contributions to LangChain: A member expressed interest in guidance for contributing to LangChain, prompting others to share resources including a contributing guide. Suggestions included improving documentation, code, and integrations as ways to contribute.
- For beginners, one member recommended reading through the setup guide to understand local repository interactions.
- Ollama API for Tool Calling: Members discussed the efficiency of using the Ollama API for creating agents, with one reporting better functionality using
ChatOllamathanOllamaFunctions. They noted that it works better for following examples from the LangChain tutorial.- There was mention of issues with previous APIs crashing on basic tutorials, specifically involving the Tavily and weather examples.
- ConversationBufferMemory in LangGraph: One member sought clarity on how to use the
save_contextmethod inConversationBufferMemory, querying how to structure inputs and outputs for various message types likeHumanMessageandAIMessage. Others noted the lack of explicit documentation on thread safety inConversationBufferMemory.- Advice provided noted that careful structuring of inputs and outputs is necessary to handle different message types effectively.
- Creating Flowcharts for RAG: Discussion included recommendations for using Mermaid for flowchart creation, with one member sharing code snippets from LangChain's documentation. It was suggested that this offers good production value for visualizing workflows and processes.
- A member shared a GitHub project comparing different RAG frameworks, encouraging others to check it out for more insights into RAG applications.
- LangChain Tutorial Issues: A beginner user reported encountering a
ConnectErrorwhile trying to follow the LangChain RAG tutorial. Recommendations were made to reproduce official tutorials to better grasp the functionality and troubleshoot issues.- Concerns were raised about multiple LLM calls in the JS quickstart, implying potential inefficiencies or misunderstandings in handling LLM interactions within the application.
- Welcome Contributors | 🦜️🔗 LangChain: Hi there! Thank you for even being interested in contributing to LangChain.
- Setup | 🦜️🔗 LangChain: This guide walks through how to run the repository locally and check in your first code.
- JavaScript equivalent of Python's format() function?: Python has this beautiful function to turn this: bar1 = 'foobar' bar2 = 'jumped' bar3 = 'dog' foo = 'The lazy ' + bar3 + ' &...
- Customer Support: no description found
- Build an Agent | 🦜️🔗 LangChain: This guide assumes familiarity with the following concepts:
- Build a Retrieval Augmented Generation (RAG) App | 🦜️🔗 LangChain: One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These ...
- GitHub - oztrkoguz/RAG-Framework-Evaluation: This project aims to compare different Retrieval-Augmented Generation (RAG) frameworks in terms of speed and performance.: This project aims to compare different Retrieval-Augmented Generation (RAG) frameworks in terms of speed and performance. - oztrkoguz/RAG-Framework-Evaluation
- Start here: Welcome to LangChain! · Issue #16651 · langchain-ai/langchain: Welcome to the LangChain repo! What's in this repo Please only open Issues, PRs, and Discussions against this repo for the packages it contains: langchain python package langchain-core python pack...
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (7 messages):
Merlinn AI on-call agentAI Copilot for User AcquisitionLangchain Recipe BotKnowledge Distillation TrendsAI Analyst Builder Launch
- Merlinn AI on-call agent simplifies troubleshooting: The team launched Merlinn, an open-source AI on-call agent that assists in troubleshooting production incidents by integrating with tools like DataDog and PagerDuty.
- They invite feedback and encourage users to star their GitHub repo to support their project.
- AI Copilot streamlines user promotion: A new AI copilot has been launched that helps users promote their projects on Twitter effortlessly by suggesting comments for relevant conversations.
- This tool is aimed at aiding individuals in getting visibility for their products with minimal effort.
- Conversing with Notion databases made easy: Kenzic introduced a simple app for having conversations with Notion databases, as detailed in a Medium tutorial.
- The GitHub repository contains the resources necessary for implementation.
- Knowledge Distillation advancements discussed: A recent blog post by Lightly covers trends in Knowledge Distillation, highlighting performance gains from smaller models derived from larger ones.
- The concept originally introduced by Hinton aims to minimize the KL divergence, enhancing the efficiency of smaller models.
- AI Analyst Builder goes live on Product Hunt: Datrics has launched the AI Analyst Builder, a no-code tool for creating custom AI analysts, and seeks community support on Product Hunt.
- Users are encouraged to visit the page and provide feedback to improve the tool continuously.
- Knowledge Distillation Trends: Overview of recent Knowledge Distillation strategies and how to use them alongside Self-Supervised Learning with a focus on Masked Autoencoders
- Home: None
- GitHub - kenzic/langchain-recipe-bot: Repo for Medium tutorial "Talk to Your Notion Database with LangChain.js": Repo for Medium tutorial "Talk to Your Notion Database with LangChain.js" - kenzic/langchain-recipe-bot
- Datrics AI Analyst Builder - Your custom GenAI solution for analytics and reporting | Product Hunt: AI Analyst Builder enables teams to create custom AI analysts without coding. These analysts answer data questions via a chat interface like ChatGPT. Tailored to specific business processes and data, ...
- GitHub - merlinn-co/merlinn: Open source AI on-call developer 🧙♂️ Get relevant context & root cause analysis in seconds about production incidents and make on-call engineers 10x better 🏎️: Open source AI on-call developer 🧙♂️ Get relevant context & root cause analysis in seconds about production incidents and make on-call engineers 10x better 🏎️ - merlinn-co/merlinn
- Hypespot: no description found
Cohere ▷ #discussions (30 messages🔥):
Billing by API KeyMulti-Agent Systems FrameworksAPI IssuesPrompt Tuner Beta Release
- Challenges with Billing by API Key: A discussion arose regarding the need for separate billing by API key, with members exploring potential solutions like middleware to manage costs distinctly for each key.
- Participants expressed frustration, noting that there currently isn't a system in place to track this usage effectively.
- Best Frameworks for Multi-Agent Systems: Members recommended checking out LangGraph from LangChain, a framework praised for its cloud capabilities and customizability for building multi-agent systems.
- Furthermore, there was mention of Cohere's API offering extensive multi-step and single-step tool use functionalities that enhance agent capabilities.
- API Downtime with Error 503: A user reported an API downtime issue with an error 503 and struggled to check the status due to an inaccessible status page.
- Another member reassured the community that they were working internally to resolve the issues causing the downtime.
- Prompt Tuner Beta Feature Release: Queries were raised about the availability of the 'Prompt Tuner' beta feature on the dashboard, with members acknowledging its recent introduction.
- Users expressed a general interest in better understanding this feature's implications on API usage.
- incident.io - Status pages: no description found
- Multi-step Tool Use (Agents): no description found
- Tool Use with Cohere's Models - Cohere Docs: no description found
- Implementing a Multi-Step Agent with Langchain: no description found
- Chat: no description found
Cohere ▷ #api-discussions (7 messages):
Cohere with Oracle APEXCohere API performance issuesCohere operational status
- Inquiry on Cohere with Oracle APEX: A user asked if anyone is using Cohere with Oracle APEX, seeking insights and experiences related to the integration.
- Cohere API experiencing slowdowns: Multiple users reported issues with the Cohere Reranker API, noting a sudden slowness and failures.
- One acknowledged that this was a rare occurrence and shared an error message indicating that the team is investigating the issue.
- Cohere service status back to normal: Cohere announced recovery from the previous issues, confirming that all systems are fully operational.
- A status update highlighted 99.67% uptime for endpoints and a reassuring message that no ongoing issues are affecting their systems.
Link mentioned: Cohere Status Page Status: Latest service status for Cohere Status Page
Cohere ▷ #cohere-toolkit (17 messages🔥):
Cohere's API BenefitsInnovation in AI CompaniesWeb Browsing API UsageSearch Engine FunctionalityHype Cycle in AI
- Cohere's API boasts reliability: A member noted that the Cohere API is the only one they've worked with that hasn't experienced downtime, calling it one of the best enterprise options.
- Another member humorously highlighted the implication of favoring Cohere in the face of working for OpenAI.
- Innovation vs. Similarity in AI Products: As companies announce new products, a member questioned which ones are truly innovative as opposed to just iterations of existing offerings.
- The sentiment reflects the broader industry discussion around whether ongoing announcements are genuinely groundbreaking or just part of the current hype cycle.
- Using Web Browsing Tools in Chat: Members discussed their ability to utilize web search tools integrated into the Cohere chat interface and API for quick access to information.
- One member successfully created a bot to leverage this capability, indicating it's functionally akin to a search engine.
- Excitement Surrounding New Implementations: A user expressed enthusiasm for using the new tools during their interview at Cohere, significantly encouraging collaborative testing.
- The playful tone suggests a light-hearted approach to exploring these new features together, even among non-technical users.
- Perception of AI's Current Landscape: One member commented on the industry's hype cycle while emphasizing their focus on deriving substantial value from AI models for enterprises.
- This remark reflects a broader understanding of the challenge to separate effective tools from mere marketing noise in the evolving AI landscape.
Interconnects (Nathan Lambert) ▷ #ml-questions (2 messages):
Blog Posts
- Blogpost Reference: A member mentioned a blogpost but did not provide any specific details or links related to it.
- Another member made a lighthearted comment by saying summoned 🪄 ☁️🧍♂️☁️, possibly in response to the mention of the blogpost.
- User Interaction with the Blogpost: The interaction surrounding the mention of the blogpost included playful engagement from other members.
- The phrase summoned 🪄 ☁️🧍♂️☁️ suggests a casual or humorous atmosphere in the conversation.
Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
GPT-4o MiniLMSYS ranking algorithmFormatting in Chatbot ArenaRoleplay and Creative Writing ModelsZuckerberg's Comments at SIGGRAPH
- GPT-4o Mini takes the lead: The introduction of GPT-4o Mini is noted as a significant change in the chatbot arena, with claims of enhancing interactions.
- It's suggested that this model is not just about performance, but also serves as a transparency tool to validate weaker models.
- LMSYS not a cutting-edge ranking tool: There's skepticism surrounding LMSYS, with comments stating it merely validates existing models rather than being a leading ranking algorithm.
- One user emphasized that the examples from the model demonstrate randomness, pointing out that easy questions don't effectively evaluate model performance.
- Formatting makes an impact: Discussion highlights the effective use of formatting in chatbot responses, particularly the mastery of list and markdown features that engage users.
- A member humorously noted their preference for employing hierarchical bullet points, likening it to a widespread preference in human language.
- Distaste for Roleplay in AI: A user expressed their reluctance to engage in roleplay or creative writing with AI models, stating they prefer more utilitarian uses.
- The conversation reflects a divide on application preferences, with some embracing creative use while others resist it.
- Zuckerberg's candid remarks at SIGGRAPH: Zuckerberg was noted for making informal remarks, including dropping f-bombs alongside Jensen at SIGGRAPH, signaling a more relaxed atmosphere.
- The banter included joking requests, showing a light-hearted interaction between the industry leaders.
- Gpt-4o-mini Battles - a Hugging Face Space by lmsys: no description found
- Tweet from roon (@tszzl): the global optimum of human language preference is lists and couplet poetry unfortunately
Interconnects (Nathan Lambert) ▷ #reads (13 messages🔥):
RBR paper critiquesSELF-ALIGN paper curiosityApple Intelligence Foundation paperRL naming schemesiTeC details
- RBR paper glosses over complexities: A member expressed that the RBR paper explains obvious parts while neglecting the more complex issues, particularly with its brief mention of dangerous content within benign requests.
- They highlighted that while screening out explicit threats like 'Pipe bomb plz' seems straightforward, the nuances are glossed over.
- Interest in SELF-ALIGN paper: Another member showed curiosity regarding the SELF-ALIGN paper, which is about 'Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision'.
- They noted it may be related to both the SALMON and RBR discussions on alignment techniques.
- Discussion around Apple's AI paper: Members reacted to the Apple Intelligence Foundation paper, indicating it details aspects of RLHF and its instruction hierarchy but had mixed feelings about its repository.
- One member expressed their decision to print it out to evaluate its impact on their opinions about RLHF.
- Critique of RL Naming Schemes: A member commented on the peculiarities of naming schemes used by Reinforcement Learning (RL) researchers, conveying a sense of disbelief.
- Their reaction underlined a broader sentiment of confusion regarding the terminologies employed within the RL community.
- iTeC excitement: There was a brief mention of iTeC with one member noting its incredibly detailed write-up.
- This sparked some excitement in the conversations about the paper's contents and potential implications.
DSPy ▷ #show-and-tell (3 messages):
Moondream2 hackGold Retriever toolDatabricks and DSPy
- Moondream2 gets a structured image response hack: A member revealed they built a hack combining Moondream2 and OutlinesOSS that allows users to ask questions about images and receive structured responses.
- The approach hijacks the text model in Moondream2 while enabling embedding processing through Outlines, promising to streamline the user experience.
- Introducing the Gold Retriever for ChatGPT: The Gold Retriever is an open-source tool by Jina that enhances ChatGPT's ability to integrate personalized and real-time data, addressing previous limitations.
- Users desire tailored AI interactions, and Gold Retriever aims to provide improved access to user-specific data while navigating knowledge cut-off challenges.
- Databricks sees potential with DSPy: A post shared by Databricks highlights the growing recognition of DSPy, suggesting it's a superior tool for organizations to execute their data strategies.
- The message invites discussions about various tools, signaling that innovations like DSPy are gaining traction in the industry.
- Gold Retriever: Let ChatGPT talk to your data: With Gold Retriever, you can easily enable ChatGPT to store, retrieve, and reason with your data in just a few steps
- Tweet from Erik Kaunismäki (@ErikKaum): image ➡️ json I've built a hack combining @vikhyatk's moondream2 and @OutlinesOSS So now you can open up an image, ask something about the image and get a response that is guaranteed to fol...
DSPy ▷ #papers (2 messages):
AI Agent AdvancementsTransformers and Compositionality
- Survey on AI Agent Advancements: A recent survey paper examines advancements in AI agent implementations, focusing on enhanced reasoning, planning, and tool execution capabilities.
- It communicates the current capabilities and limitations of existing systems while suggesting key considerations for future AI agent design, including leadership impact and communication styles.
- Transformers in AI: Fundamental Questions Raised: A blog post worth reading emphasizes the study of transformer models' performance on complex tasks, specifically multiplication, linked to deeper questions about their learning capacity.
- It highlights that models like Claude or GPT-4 produce outputs that convincingly mimic reasoning, raising crucial discussions about their ability to tackle intricate problems across various domains.
- The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey: This survey paper examines the recent advancements in AI agent implementations, with a focus on their ability to achieve complex goals that require enhanced reasoning, planning, and tool execution cap...
- Faith and Fate: Transformers as fuzzy pattern matchers – Answer.AI: Are GPT-like models thinking? Unclear. But the Faith and Fate paper (Dziri, 2023) points out they are often “just” pattern matching.
DSPy ▷ #general (13 messages🔥):
Mixture of Agents OptimizationDSPy without Compiled PipelineHosting Large Pre-training DataConversational History Aware Agent
- Exploring Mixture of Agents Optimization: A member proposed the idea of using a mixture of agents optimizer for DSPy, suggesting that one layer of optimization involves selecting parameters and models for a system.
- They referenced a related paper that discusses leveraging multiple LLMs for improved responses and compared their approach to a neural network structure.
- Using DSPy without Labeled Data: A member inquired about utilizing DSPy without a compiled pipeline, questioning its usefulness in scenarios without labeled data.
- Another member confirmed that DSPy can indeed enhance applications, particularly for a RAG system seeking better prompts.
- Hosting Two Petabytes of Data: A member sought advice on hosting 2 petabytes of pre-training data for healthcare LLMs, mentioning discussions with the Linux Foundation regarding data usage in low- and middle-income countries.
- They shared their previous work on ClinicalBERT and linked to a GitHub issue regarding data hosting solutions.
- Free Hosting Options for LLM Data: Responding to a query about hosting large datasets, a member suggested that Hugging Face might allow free hosting without many restrictions.
- This could be beneficial for projects dealing with significant amounts of health care data.
- Creating a Conversational History Aware Agent: A member asked about examples of creating an agent that maintains conversational history.
- In reply, another member noted that previously users had to manually handle chat history, referencing an example for context.
- dspy/examples/agents/multi_agent.ipynb at main · stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
- Mixture-of-Agents Enhances Large Language Model Capabilities: Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. With the growing number of LLMs, how to harness the collect...
- ClinicalBERT Technical Charter Draft 11-29-2022: Technical Charter (the “Charter”) for ClinicalBERT a Series of LF Projects, LLC Adopted ___________ This Charter sets forth the responsibilities and procedures for technical contribution to, and o...
- Integration with content delivery network for incremental static regeneration · Issue #67296 · ClickHouse/ClickHouse: (you don't have to strictly follow this form) Company or project name Put your company name or project description here One Fact Foundation Use case A clear and concise description of what is the ...
DSPy ▷ #examples (17 messages🔥):
storm.py errordspy version updateDropbase integrationMine Tuning methodologyDSPy project showcases
- storm.py encounters AttributeError: A user reported an AttributeError when trying to execute storm.py due to an undefined attribute in the dspy module.
- Another member suggested updating to a newer version of dspy to resolve the issue.
- Steps to update dspy for Claude support: Detailed steps were shared to update the dspy library, including modifying the init.py file to include
Claude = dsp.Claude.- This change would enable users to utilize Claude functionalities directly in their code.
- Plans for Dropbase integration: One member expressed plans to integrate Dropbase with dspy, aiming to create an extensible GUI for various workflows.
- Resources were shared on how to leverage Dropbase for faster web app development.
- Showcasing various DSPy projects: Multiple GitHub links for innovative DSPy projects were shared, including methodologies like Mine Tuning.
- Members were encouraged to explore the projects for inspiration and potential improvements in their implementations.
- Inquiry about DSPy project effectiveness: Someone inquired about actual projects leveraging DSPy that demonstrated significant enhancements in their workflows.
- The discussion highlighted various projects shared earlier, prompting calls for examples of tangible improvements.
- GitHub - DropbaseHQ/dropbase: Dropbase helps developers build and prototype web apps faster with AI. Dropbase is local-first and self hosted.: Dropbase helps developers build and prototype web apps faster with AI. Dropbase is local-first and self hosted. - DropbaseHQ/dropbase
- Dropbase AI | Build Back-Office Software with AI: Dropbase is a prompt-based developer platform for building web apps and back-office operations software, fast and painless. Leave your low-code/no-code frustrations behind.
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
- GitHub - rawwerks/MineTuning: Mine-tuning is a methodology for synchronizing human and AI attention.: Mine-tuning is a methodology for synchronizing human and AI attention. - rawwerks/MineTuning
- GitHub - seanchatmangpt/dspygen: A Ruby on Rails style framework for the DSPy (Demonstrate, Search, Predict) project for Language Models like GPT, BERT, and LLama.: A Ruby on Rails style framework for the DSPy (Demonstrate, Search, Predict) project for Language Models like GPT, BERT, and LLama. - seanchatmangpt/dspygen
- GitHub - jmanhype/dspy-self-discover-framework: Leveraging DSPy for AI-driven task understanding and solution generation, the Self-Discover Framework automates problem-solving through reasoning and code generation.: Leveraging DSPy for AI-driven task understanding and solution generation, the Self-Discover Framework automates problem-solving through reasoning and code generation. - jmanhype/dspy-self-discover-...
- GitHub - chrisammon3000/dspy-neo4j-knowledge-graph: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j.: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j. - chrisammon3000/dspy-neo4j-knowledge-graph
- GitHub - jmanhype/DSPy-Multi-Document-Agents: An advanced distributed knowledge fabric for intelligent document processing, featuring multi-document agents, optimized query handling, and semantic understanding.: An advanced distributed knowledge fabric for intelligent document processing, featuring multi-document agents, optimized query handling, and semantic understanding. - jmanhype/DSPy-Multi-Document-A...
- GitHub - SynaLinks/HybridAGI: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected: The Programmable Neuro-Symbolic AGI that lets you program its behavior using Graph-based Prompt Programming: for people who want AI to behave as expected - SynaLinks/HybridAGI
- GitHub - RamXX/FSM-Workflow: Lightweight, async-friendly workflow system with state persistence for Python: Lightweight, async-friendly workflow system with state persistence for Python - RamXX/FSM-Workflow
- GitHub - jmanhype/Storm: Contribute to jmanhype/Storm development by creating an account on GitHub.
- Storm/storm.py at main · jmanhype/Storm: Contribute to jmanhype/Storm development by creating an account on GitHub.
- no title found: no description found
tinygrad (George Hotz) ▷ #general (10 messages🔥):
OpenCL Out of Memory ErrorMonday Meeting NotesShapeTracker BountiesLean Translation Discussion
- OpenCL Out of Memory Error Improvement: A member suggested improving the out of memory error in OpenCL and linked to a relevant GitHub pull request by tyoc213.
- tyoc213 pointed out the potential solution for the error handling related to OpenCL.
- Highlights from Monday's Meeting: The Monday meeting discussed various updates, including the removal of UNMUL and MERGE and the introduction of HCQ runtime documentation.
- Other topics included bounties related to MLPerf benchmarks and advancements in conv backward fusing and scheduler optimizations.
- Interest in ShapeTracker Bounty: A member expressed interest in a bounty focusing on the mergeability of two arbitrary ShapeTrackers in Lean, questioning the scope of the task.
- The member referred to prior discussions about this bounty and engaged regarding its value compared to the reward.
- Lean Translation of Document: There was a query about whether the bounty involved translating a document into Lean, questioning the compensation for such a task.
- Another member pointed out previous discussions on Lean and suggested that answers might already exist within the chat.
- retrieve defined opencl error codes by tyoc213 · Pull Request #5792 · tinygrad/tinygrad: no description found
- view.reshape without symbolic by sahamrit · Pull Request #2218 · tinygrad/tinygrad: @chenyuxyz this is your earlier attempt for reshape without symbolic. I analysed that the increase in time for your change is due to cache misses. Below are some details good part your change redu...
tinygrad (George Hotz) ▷ #learn-tinygrad (21 messages🔥):
Error with NLL loss during PRUnderstanding nn.Embedding gradientsDisk device in tinygradPR for better error handlingUsing tinygrad for time series analysis
- Resolving NLL Loss Error in tinygrad PR: A user shared an error related to adding
nll_loss, noting that the returned tensor lacks gradients, causing PR failure.- Another member mentioned that certain operations used in the loss computation, like CMPNE, are non-differentiable.
- Clarifying Gradients with nn.Embedding: A user sought help on
nn.Embeddinggradients, encountering a 'tensor has no grad' error in their model.- A reply clarified that
requires_grad=Trueis unnecessary for index operations to avoid gradient issues.
- A reply clarified that
- Explanation of Disk Device Functionality: A user inquired about the disk device in tinygrad, questioning its role in computations.
- It was explained that the disk device is utilized for tensor memory mapping, primarily for transferring data, not for computational operations.
- Proposal for Enhancing Error Handling: A user suggested that tinygrad should not allow tensors on non-computational backends like disk and seek better error messages.
- Members discussed the necessity of handling such cases and agreed on contributing a pull request to improve the behavior.
- Using tinygrad for Time Series Analysis: A user asked if tinygrad could be applied for time series physiological feature extraction and visualizations, citing slow performance with Matlab.
- This inquiry indicates interest in leveraging tinygrad's capabilities for more efficient computations in data analysis.
- Runtime - tinygrad docs: no description found
- Issues · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - Issues · tinygrad/tinygrad
- tinygrad/tinygrad/nn/state.py at 95dda8dadf2970888fc8f494b83a0124eb614aa5 · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
- Error log when testing cross_entropy loss function: Error log when testing cross_entropy loss function - gist:2992fc80703f8e15a55d44b3455d9620
- Addition of nll_loss and cross_entropy to tensor.py by airpods69 · Pull Request #5752 · tinygrad/tinygrad: tensor: added nll_loss and cross_entropy test_ops: added test for nll_loss and test for cross_entropy This PR adds negative_log_likelihood and cross_entropy to Tensor. #3891 and #5247 Eg: For neg...
LAION ▷ #general (9 messages🔥):
Vector Search with Language ModelsSWE-Bench Ultra-HackathonSegment Anything Model 2
- Exploring Vector Search Techniques: Discussion revealed that for searching verbose text, using a BERT-style model instead of CLIP would be more effective, with suggestions for models from Jina or Nomic.
- One member noted that CLIP should not be used if images aren't the focus and highlighted Jina's better CLIP-style model as a useful alternative.
- SWE-Bench Hosts a 6-Day Hackathon Adventure: A bold experiment is taking place with a 6-day hackathon for SWE-Bench, providing participants with $1,000 in compute resources and opportunities to win cash prizes for improvements.
- Kickoff is on August 17 and participants will receive support from notable coauthors, with opportunities for teamwork and prizes for beating benchmarks.
- Segment Anything Model 2 Released: The Segment Anything Model 2 from Facebook Research has been made available on GitHub, offering code for model inference and links to model checkpoints.
- Additionally, example notebooks are included to assist users in understanding how to implement the model effectively.
- Tweet from Steve Frey (@stevewattsfrey): A bold experiment: We're hosting a 6-day ultra-hackathon for SWE-Bench to push the limits of open-source code generation - Everyone gets $1,000 in compute provided by @StrongCompute - Up 50 rese...
- GitHub - facebookresearch/segment-anything-2: The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.: The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2), links for downloading the trained model checkpoints, and example notebooks that show how to use th...
AI21 Labs (Jamba) ▷ #announcements (1 messages):
Jamba's long context capabilitiesDeveloper recruitmentEnterprise feedback
- Exciting Developments in Long Context Capabilities: There are a few exciting developments on the way concerning Jamba's 256k effective length, with promising results from enterprise customers.
- The team is eager to engage with developers who are experimenting with long context use cases for further feedback.
- Developers Wanted for Long Context Projects: The team is actively seeking developers to assist with long context use cases and wants to hear from anyone with feedback on their experiences.
- In exchange, they promise credits, swag, and fame to participating developers.
AI21 Labs (Jamba) ▷ #general-chat (2 messages):
New MembersCommunity Engagement
- New Members Join the Chat: A new member, artworxai, announced their arrival, stating 'Just joined!!'.
- Another member, akitshudar, kicked off the conversation with a friendly greeting.
- Chat Engagement Begins: The discussion opened with a friendly vibe as members interact with greetings.
- This welcoming atmosphere sets a positive tone for the community.
LLM Finetuning (Hamel + Dan) ▷ #general (2 messages):
Google AI HackathonLLM Engineering OpportunitiesDedupe Methods for Named Entities
- Last Call for LLM Engineers in Google Hackathon: A team seeks one final LLM engineer to join their innovative project for the upcoming Google AI Hackathon. The project aims to disrupt robotics and education using LLM technology, promising technical complexity and excellent user experience.
- Candidates should have advanced LLM engineering skills and familiarity with tools like LangChain and LlamaIndex, with a strong interest in robotics or education tech being a plus.
- Seeking Fast Dedupe Solutions for Named Entities: A member inquired about effective methods to programmatically dedupe a list of named entities, seeking fast solutions without a complex RAG setup.
- The focus is on finding a quick and efficient approach rather than implementing intricate systems to handle duplicates.
Alignment Lab AI ▷ #general-chat (1 messages):
Face Recognition ModelsEmotion Detection Libraries
- Discussion on Face Recognition Models: Members seek recommendations for machine learning models and libraries suitable for detecting and recognizing faces in videos and images.
- They emphasize the importance of accuracy and performance in real-time applications.
- Exploring Emotion Detection Capabilities: There is an interest in finding solutions that can also identify emotions from detected faces in both still images and video content.
- Participants highlight the need for integrated solutions that provide both face recognition and emotion analysis.