[AINews] DataComp-LM: the best open-data 7B model/benchmark/dataset
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
240T tokens is all you need to start with.
AI News for 7/18/2024-7/19/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (467 channels, and 2305 messages) for you. Estimated reading time saved (at 200wpm): 266 minutes. You can now tag @smol_ai for AINews discussions!
Though HuggingFace's SmolLM is barely 4 days old, it has now been beaten: the DataComp team (our coverage here) have now released a "baseline" language model competitive with Mistral/Llama3/Gemma/Qwen2 at the 7B size, but it is notable for being an open data model from the DataComp-LM dataset, AND for matching those other models with ONLY 2.5T tokens:
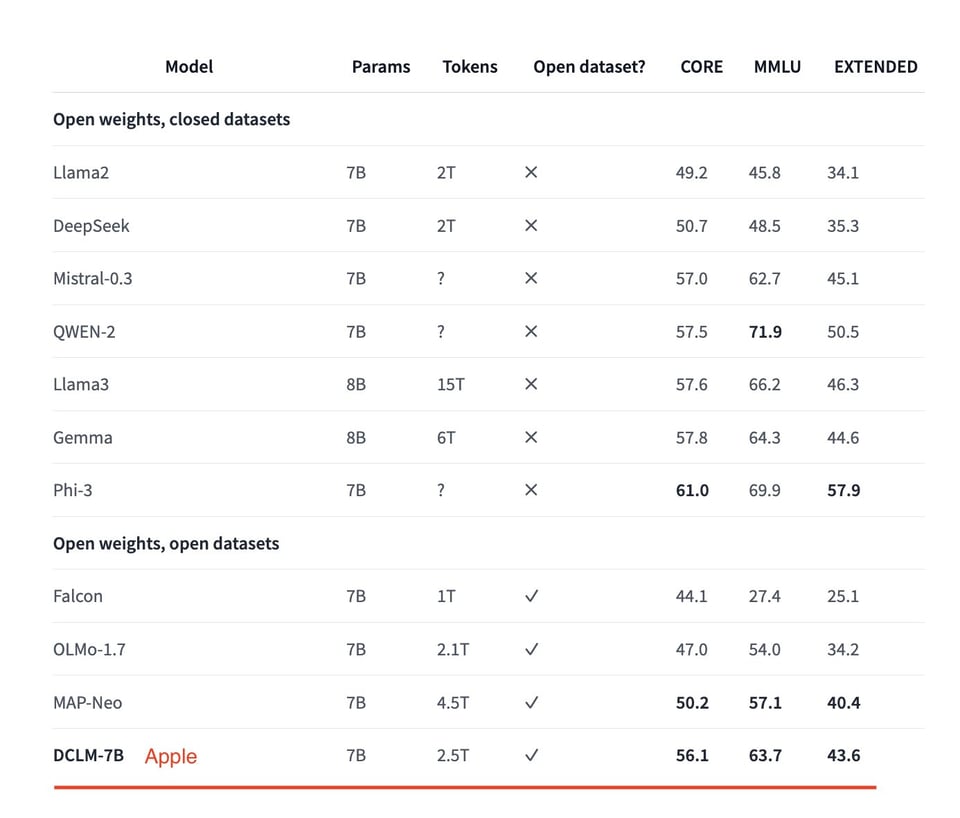
As you might expect, the secret is in the data quality. They start with DCLM-POOL, a corpus of 240 trillion tokens derived from Common Crawl, the largest corpus yet, and provide an investigation of scaling trends for dataset design at 5 scales:
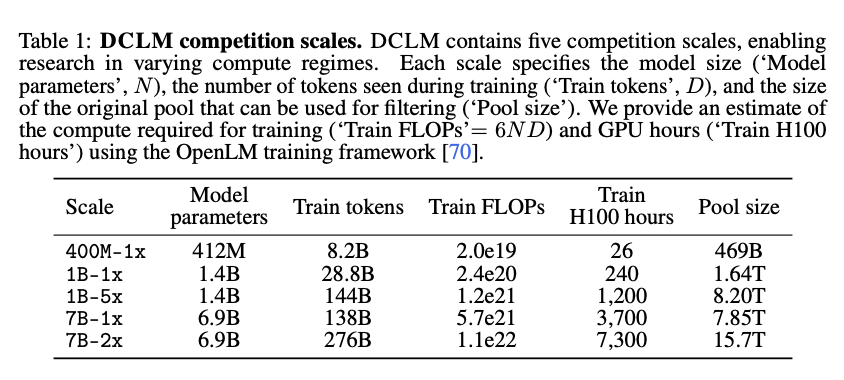
Within each scale there are two tracks: Filtering (must be from DCLM-Pool without any external data, but can use other models for filtering/paraphrasing) and Mixing (ext data allowed). They do a "Baseline" filtered example to start people off:

People close to the dataset story might wonder how DCLM-Pool and Baseline compare to FineWeb (our coverage here), and the outlook is promising: DCLM trains better at -EVERY- scale.
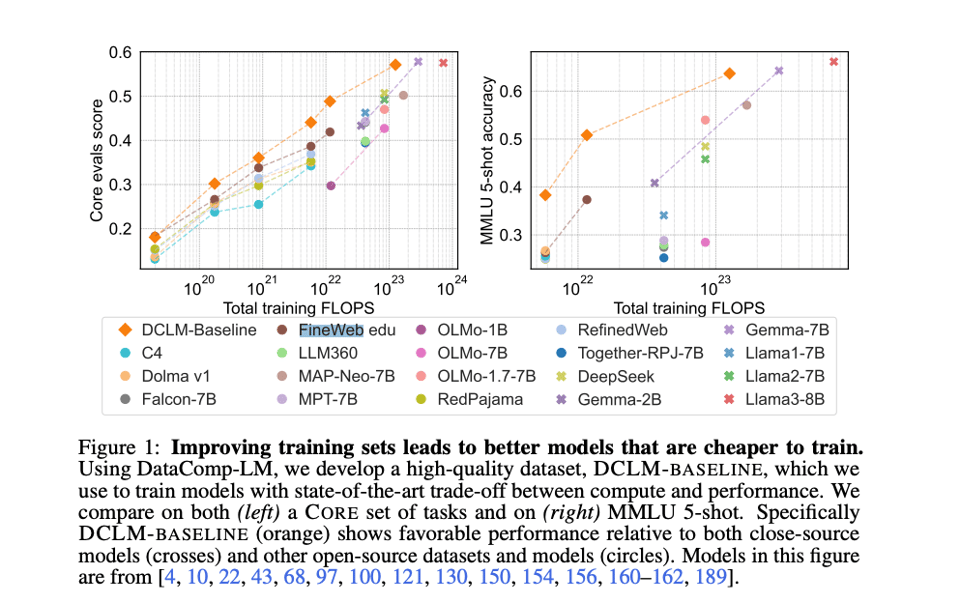
The rest of this 88 page paper has tons of detail on data quality techniques; a fantastic contribution to open LLM research from all involved (and not just Apple, as commonly reported).
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Unsloth AI (Daniel Han) Discord
- Stability.ai (Stable Diffusion) Discord
- HuggingFace Discord
- Nous Research AI Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- LM Studio Discord
- Latent Space Discord
- CUDA MODE Discord
- Perplexity AI Discord
- OpenRouter (Alex Atallah) Discord
- Interconnects (Nathan Lambert) Discord
- Eleuther Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- Cohere Discord
- Torchtune Discord
- Alignment Lab AI Discord
- tinygrad (George Hotz) Discord
- OpenInterpreter Discord
- LAION Discord
- LangChain AI Discord
- LLM Perf Enthusiasts AI Discord
- LLM Finetuning (Hamel + Dan) Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- Unsloth AI (Daniel Han) ▷ #general (190 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
- Unsloth AI (Daniel Han) ▷ #off-topic (20 messages🔥):
- Unsloth AI (Daniel Han) ▷ #help (89 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (8 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (5 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (233 messages🔥🔥):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (194 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (2 messages):
- HuggingFace ▷ #cool-finds (3 messages):
- HuggingFace ▷ #i-made-this (12 messages🔥):
- HuggingFace ▷ #reading-group (9 messages🔥):
- HuggingFace ▷ #computer-vision (7 messages):
- HuggingFace ▷ #NLP (4 messages):
- Nous Research AI ▷ #research-papers (10 messages🔥):
- Nous Research AI ▷ #datasets (2 messages):
- Nous Research AI ▷ #off-topic (2 messages):
- Nous Research AI ▷ #interesting-links (7 messages):
- Nous Research AI ▷ #general (161 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (10 messages🔥):
- Nous Research AI ▷ #rag-dataset (21 messages🔥):
- Nous Research AI ▷ #world-sim (3 messages):
- OpenAI ▷ #ai-discussions (174 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (12 messages🔥):
- OpenAI ▷ #prompt-engineering (4 messages):
- OpenAI ▷ #api-discussions (4 messages):
- Modular (Mojo 🔥) ▷ #general (69 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #✍︱blog (18 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (30 messages🔥):
- Modular (Mojo 🔥) ▷ #max (5 messages):
- Modular (Mojo 🔥) ▷ #max-gpu (2 messages):
- Modular (Mojo 🔥) ▷ #nightly (17 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo-marathons (1 messages):
- LM Studio ▷ #💬-general (83 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (26 messages🔥):
- LM Studio ▷ #⚙-configs-discussion (5 messages):
- LM Studio ▷ #🎛-hardware-discussion (10 messages🔥):
- LM Studio ▷ #amd-rocm-tech-preview (1 messages):
- Latent Space ▷ #ai-general-chat (87 messages🔥🔥):
- Latent Space ▷ #ai-in-action-club (29 messages🔥):
- CUDA MODE ▷ #general (5 messages):
- CUDA MODE ▷ #torch (15 messages🔥):
- CUDA MODE ▷ #algorithms (5 messages):
- CUDA MODE ▷ #cool-links (25 messages🔥):
- CUDA MODE ▷ #beginner (3 messages):
- CUDA MODE ▷ #torchao (7 messages):
- CUDA MODE ▷ #triton-puzzles (1 messages):
- CUDA MODE ▷ #hqq (2 messages):
- CUDA MODE ▷ #llmdotc (43 messages🔥):
- CUDA MODE ▷ #lecture-qa (6 messages):
- CUDA MODE ▷ #youtube-watch-party (1 messages):
- Perplexity AI ▷ #general (96 messages🔥🔥):
- Perplexity AI ▷ #sharing (9 messages🔥):
- Perplexity AI ▷ #pplx-api (4 messages):
- OpenRouter (Alex Atallah) ▷ #announcements (4 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- OpenRouter (Alex Atallah) ▷ #general (71 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #일반 (3 messages):
- OpenRouter (Alex Atallah) ▷ #一般 (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-questions (7 messages):
- Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
- Interconnects (Nathan Lambert) ▷ #random (54 messages🔥):
- Interconnects (Nathan Lambert) ▷ #reads (2 messages):
- Eleuther ▷ #general (24 messages🔥):
- Eleuther ▷ #research (13 messages🔥):
- Eleuther ▷ #scaling-laws (1 messages):
- Eleuther ▷ #interpretability-general (8 messages🔥):
- Eleuther ▷ #lm-thunderdome (22 messages🔥):
- LlamaIndex ▷ #blog (5 messages):
- LlamaIndex ▷ #general (41 messages🔥):
- LlamaIndex ▷ #ai-discussion (15 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (40 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (2 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 messages):
- Cohere ▷ #general (25 messages🔥):
- Cohere ▷ #project-sharing (15 messages🔥):
- Torchtune ▷ #general (3 messages):
- Torchtune ▷ #dev (32 messages🔥):
- Alignment Lab AI ▷ #general-chat (28 messages🔥):
- Alignment Lab AI ▷ #alignment-lab-announcements (1 messages):
- tinygrad (George Hotz) ▷ #general (8 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
- OpenInterpreter ▷ #general (5 messages):
- OpenInterpreter ▷ #O1 (10 messages🔥):
- LAION ▷ #general (6 messages):
- LAION ▷ #research (5 messages):
- LAION ▷ #resources (2 messages):
- LangChain AI ▷ #general (1 messages):
- LangChain AI ▷ #langchain-templates (6 messages):
- LangChain AI ▷ #share-your-work (1 messages):
- LLM Perf Enthusiasts AI ▷ #general (3 messages):
- LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
- MLOps @Chipro ▷ #general-ml (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
GPT-4o mini model release by OpenAI
- Capabilities: @sama noted GPT-4o mini has "15 cents per million input tokens, 60 cents per million output tokens, MMLU of 82%, and fast." He compared it to text-davinci-003, saying it's "much, much worse than this new model" and "cost 100x more."
- Pricing: @gdb highlighted the model is aimed at developers, with the goal to "convert machine intelligence into positive applications across every domain." @miramurati emphasized GPT-4o mini "makes intelligence far more affordable opening up a wide range of applications."
- Benchmarks: @lmsysorg reported GPT-4o mini was tested in Arena, showing performance reaching GPT-4-Turbo levels while offering significant cost reduction. @polynoamial called it "best in class for its size, especially at reasoning."
Mistral NeMo 12B model release by NVIDIA and Mistral
- Capabilities: @GuillaumeLample introduced Mistral NeMo as a 12B model supporting 128k token context window, FP8 aligned checkpoint, and strong performance on academic, chat, and fine-tuning benchmarks. It's multilingual in 9 languages with a new Tekken tokenizer.
- Licensing: @_philschmid highlighted the base and instruct models are released under Apache 2.0 license. The instruct version supports function calling.
- Performance: @osanseviero noted Mistral NeMo outperforms Mistral 7B and was jointly trained by NVIDIA and Mistral on 3,072 H100 80GB GPUs on DGX Cloud.
DeepSeek-V2-0628 model release by DeepSeek
- Leaderboard Ranking: @deepseek_ai announced DeepSeek-V2-0628 is the No.1 open-source model on LMSYS Chatbot Arena leaderboard, ranking 11th overall, 3rd on Hard Prompts and Coding, 4th on Longer Query, and 7th on Math.
- Availability: The model checkpoint is open-sourced on Hugging Face and an API is also available.
Trends and Discussions
- Synthetic Data: @karpathy suggested models need to first get larger before getting smaller, as their automated help is needed to "refactor and mold the training data into ideal, synthetic formats." He compared this to Tesla's self-driving networks using previous models to generate cleaner training data at scale.
- Evaluation Concerns: @RichardMCNgo shared criteria for judging AI safety evaluation ideas, cautioning that many proposals fail on all counts, resembling a "Something must be done. This is something." fallacy.
- Reasoning Limitations: @JJitsev tested the NuminaMath-7B model, which ranked 1st in an olympiad math competition, on basic reasoning problems. The model struggled with simple variations, revealing deficits in current benchmarks for measuring reasoning skills.
Memes and Humor
- @fabianstelzer joked that OpenAI quietly released the native GPT-o "image" model, sharing a comic strip prompt and output.
- @AravSrinivas humorously compared Singapore's approach to governance to product management, optimizing for new user retention.
- @ID_AA_Carmack mused on principles and tit-for-tat escalation in response to a personal anecdote, while acknowledging his insulation from most effects due to having "FU money."
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. CPU Inference Speed Breakthroughs
- NVIDIA CUDA Can Now Directly Run On AMD GPUs Using The "SCALE" Toolkit (Score: 67, Comments: 17): NVIDIA CUDA can now run directly on AMD GPUs using the open-source SCALE (Scalable Compute Abstraction Layer for Execution) toolkit. This breakthrough allows developers to execute CUDA applications on AMD hardware without code modifications, potentially expanding the ecosystem for AI and HPC applications beyond NVIDIA's hardware dominance. The SCALE toolkit, developed by StreamHPC, aims to bridge the gap between different GPU architectures and programming models.
- New CPU inference speed gains of 30% to 500% via Llamafile (Score: 70, Comments: 36): Llamafile has achieved significant CPU inference speed gains ranging from 30% to 500%, with particularly impressive results on Threadripper processors. A recent talk highlighted a speedup from 300 tokens/second to 2400 tokens/second on Threadripper, approaching GPU-like performance. While the specific model tested wasn't mentioned, these improvements, coupled with an emphasis on open-source AI, represent a notable advancement in CPU-based inference capabilities.
- Prompt Processing Speed Crucial: Llamafile's improvements primarily affect prompt processing, not token generation. This is significant as prompt processing is where the deep understanding occurs, especially for complex tasks involving large input volumes.
- Boolean Output Fine-Tuning: Some users report good results with LLMs returning 0 or 1 for true/false queries, particularly after fine-tuning. One user achieved 25 queries per second on a single 4090 GPU with Gemma 2 9b using a specific prompt for classification tasks.
- CPU vs GPU Performance: While Llamafile's CPU improvements are impressive, LLM inference remains memory-bound. DDR5 bandwidth doesn't match VRAM, but some users find the trade-off of half the speed of high-end GPUs with 128 GB RAM appealing for certain applications.
Theme 2. Mistral AI's New Open Source LLM Release
- DeepSeek-V2-Chat-0628 Weight Release ! (#1 Open Weight Model in Chatbot Arena) (Score: 67, Comments: 37): DeepSeek-V2-Chat-0628 has been released as the top-performing open weight model on Hugging Face. The model ranks #11 overall in Chatbot Arena, outperforming all other open-source models, while also achieving impressive rankings of #3 in both the Coding Arena and Hard Prompts Arena.
- Mistral-NeMo-12B, 128k context, Apache 2.0 (Score: 185, Comments: 84): Mistral-NeMo-12B, a new open-source language model, has been released with a 128k context window and Apache 2.0 license. This model, developed by Mistral AI in collaboration with NVIDIA, is based on the NeMo framework and trained using FlashAttention-2. It demonstrates strong performance across various benchmarks, including outperforming Llama 2 70B on some tasks, while maintaining a smaller size of 12 billion parameters.
Theme 3. Comprehensive LLM Performance Benchmarks
- Comprehensive benchmark of GGUF vs EXL2 performance across multiple models and sizes (Score: 51, Comments: 44): GGUF vs EXL2 Performance Showdown A comprehensive benchmark comparing GGUF and EXL2 formats across multiple models (Llama 3 8B, 70B, and WizardLM2 8x22B) reveals that EXL2 is slightly faster for Llama models (3-7% faster), while GGUF outperforms on WizardLM2 (3% faster). The tests, conducted on a system with 4x3090 GPUs, show that both formats offer comparable performance, with GGUF providing broader model support and RAM offloading capabilities.
- GGUF Catches Up to EXL2: GGUF has significantly improved performance, now matching or surpassing EXL2 in some cases. Previously, EXL2 was 10-20% faster, but recent tests show comparable speeds even for prompt processing.
- Quantization and Model Specifics: Q6_K in GGUF is actually 6.56bpw, while EXL2 quantizations are accurate. 5.0bpw or 4.65bpw are recommended for better quality, with 4.0bpw being closer to Q3KM. Different architectures may perform differently between formats.
- Speculative Decoding and Concurrent Requests: Using a 1B model in front of larger models can significantly boost speed through speculative decoding. Questions remain about performance differences in concurrent request scenarios between GGUF and EXL2.
- What are your top 5 current workhorse LLMs right now? Have you swapped any out for new ones lately? (Score: 79, Comments: 39): Top 5 LLM Workhorses and Potential Newcomers The author's current top 5 LLMs are Command-R for RAG tasks, Qwen2:72b for smart and professional responses, Llava:34b for vision-related tasks, Llama:70b as a second opinion model, and Codestral for code-related tasks. They express interest in trying Florence, Gemma2-27b, and ColPali for document retrieval, while humorously noting they'd try an LLM named after Steven Seagall if one existed.
- ttkciar reports being impressed by Gemma-2 models, particularly Big-Tiger-Gemma-27B-v1c, which correctly answered the reason:sally_siblings task five times out of five. They also use Dolphin-2.9.1-Mixtral-1x22B for various tasks and are experimenting with Phi-3 models for Evol-Instruct development.
- PavelPivovarov shares their top models for limited hardware: Tiger-Gemma2 9B for most tasks, Llama3 8B for reasoning, Phi3-Medium 14B for complex logic and corporate writing, and Llama-3SOME for role-playing. They express interest in trying the new Gemmasutra model.
- ttkciar provides an extensive breakdown of Phi-3-Medium-4K-Instruct-Abliterated-v3's performance across various tasks. The model shows strengths in creative tasks, correct reasoning in simple Theory-of-Mind problems, an
Theme 4. AI Development and Regulation Challenges
- As promised, I've Open Sourced my Tone Changer - https://github.com/rooben-me/tone-changer-open (Score: 96, Comments: 14): Tone Changer AI tool open-sourced. The developer has released the source code for their Tone Changer project on GitHub, fulfilling a previous promise. This tool likely allows users to modify the tone or style of text inputs, though specific details about its functionality are not provided in the post.
- Local deployment with OpenAI compatibility: The Tone Changer tool is fully local and compatible with any OpenAI API. It's available on GitHub and can be accessed via a Vercel-hosted demo.
- Development details requested: Users expressed interest in the project's implementation, asking for README updates with running instructions and inquiring about the demo creation process. The developer used screen.studio for screen recording.
- Functionality questioned: Some users critiqued the tool's novelty, suggesting it relies on prompts for tone changing, implying limited technical innovation beyond existing language model capabilities.
- Apple stated a month ago that they won't launch Apple Intelligence in EU, now Meta also said they won't offer future multimodal AI models in EU due to regulation issues. (Score: 170, Comments: 95): Apple and Meta are withholding their AI models from the European Union due to regulatory concerns. Apple announced a month ago that it won't launch Apple Intelligence in the EU, and now Meta has followed suit, stating it won't offer future multimodal AI models in the region. These decisions highlight the growing tension between AI innovation and EU regulations, potentially creating a significant gap in AI technology availability for European users.
- • -p-e-w- argues EU regulations are beneficial, preventing FAANG companies from dominating the AI market and crushing competition. They suggest prohibiting these companies from entering the EU AI market to limit their power.
- • Discussion on GDPR compliance reveals differing views. Some argue it's easy for businesses acting in good faith, while others highlight challenges for startups and small businesses compared to large corporations with more resources.
- • Critics accuse companies of hypocrisy, noting they advocate for "AI safety" but resist actual regulation. Some view this as corporations attempting to stronghold governments to lower citizen protections, while others argue EU regulations may hinder innovation.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. AI Outperforming Humans in Medical Licensing Exams
- [/r/singularity] ChatGPT aces the US Medical Licensing Exam, answering 98% correctly. The average doctor only gets 75% right. (Score: 328, Comments: 146): ChatGPT outperforms human doctors on the US Medical Licensing Exam, achieving a remarkable 98% accuracy compared to the average doctor's 75%. This impressive performance demonstrates the AI's potential to revolutionize medical education and practice, raising questions about the future role of AI in healthcare and the need for adapting medical training curricula.
- • ChatGPT's 98% accuracy on the US Medical Licensing Exam compared to doctors' 75% raises concerns about AI's impact on healthcare careers. Some argue AI could reduce the 795,000 annual deaths from diagnostic errors, while others question the exam's relevance to real-world medical practice.
- • Experts predict AI will initially work alongside human doctors, particularly in specialties like radiology. Insurance companies may mandate AI use to catch what humans miss, potentially improving diagnostic speed and accuracy.
- • Critics argue the AI's performance may be due to "pretraining on the test set" rather than true understanding. Some suggest the exam's structure may not adequately test complex reasoning skills, while others note that human doctors also study past exams to prepare.
Theme 2. OpenAI's GPT-4o-mini: A More Affordable and Efficient AI Model
- [/r/singularity] GPT-4o-mini is 2 times cheaper than GPT 3.5 Turbo (Score: 363, Comments: 139): GPT-4o-mini, a new AI model, is now available at half the cost of GPT-3.5 Turbo. This model, developed by Anthropic, offers comparable performance to GPT-3.5 Turbo but at a significantly lower price point, potentially making advanced AI capabilities more accessible to a wider range of users and applications.
- [/r/singularity] GPT-4o mini: advancing cost-efficient intelligence (Score: 238, Comments: 89): GPT-4o mini, a new AI model developed by Anthropic, aims to provide cost-efficient intelligence by offering similar capabilities to GPT-4 at a fraction of the cost. The model is designed to be more accessible and affordable for developers and businesses, potentially enabling wider adoption of advanced AI technologies. While specific performance metrics and pricing details are not provided, the focus on cost-efficiency suggests a significant step towards making powerful language models more economically viable for a broader range of applications.
- [/r/singularity] OpenAI debuts mini version of its most powerful model yet (Score: 378, Comments: 222): OpenAI has introduced GPT-4 Turbo, a smaller and more efficient version of their most advanced language model. This new model offers 128k context and is designed to be more affordable for developers, with pricing set at $0.01 per 1,000 input tokens and $0.03 per 1,000 output tokens. GPT-4 Turbo also includes updated knowledge through April 2023 and supports new features like JSON mode for structured output.
Theme 3. Advancements in AI-Generated Visual and Audio Content
- [/r/singularity] New voice mode coming soon (Score: 279, Comments: 106): New voice synthesis mode is set to be released soon, expanding the capabilities of AI-generated speech. This upcoming feature promises to enhance the quality and versatility of synthesized voices, potentially offering more natural-sounding and customizable audio outputs for various applications.
- [/r/singularity] Unanswered Oddities Ep. 1 (An AI-assisted TV Series w/ Completely AI-generated Video) (Score: 330, Comments: 41): Unanswered Oddities, an AI-assisted TV series with fully AI-generated video, has released its first episode. The series explores unexplained phenomena and mysterious events, utilizing AI technology to create both the script and visuals, pushing the boundaries of AI-driven content creation in the entertainment industry.
- [/r/singularity] Example of Kling AI by Pet Pixels Studio (Score: 287, Comments: 25): Pet Pixels Studio showcases their Kling AI technology, which appears to be an artificial intelligence system for generating or manipulating pet-related imagery. While no specific details about the AI's capabilities or implementation are provided, the title suggests it's an example or demonstration of the Kling AI's output or functionality.
AI Discord Recap
A summary of Summaries of Summaries
GPT4O (gpt-4o-2024-05-13)
1. LLM Advancements
- Llama 3 release imminent: Llama 3 with 400 billion parameters is rumored to release in 4 days, igniting excitement and speculation within the community.
- This upcoming release has stirred numerous conversations about its potential impact and capabilities.
- GPT-4o mini offers cost-efficient performance: GPT-4o mini is seen as a cheaper and faster alternative to 3.5 Turbo, being approximately 2x faster and 60% cheaper as noted on GitHub.
- However, it lacks image support and scores lower in benchmarks compared to GPT-4o, underlining some of its limitations.
2. Model Performance Optimization
- DeepSeek-V2-Chat-0628 tops LMSYS Leaderboard: DeepSeek-V2-Chat-0628, a model with 236B parameters, ranks No.1 open-source model on LMSYS Chatbot Arena Leaderboard.
- It holds top positions: Overall No.11, Hard Prompts No.3, Coding No.3, Longer Query No.4, Math No.7.
- Mojo vs JAX: Benchmark Wars: Mojo outperforms JAX on CPUs even though JAX is optimized for many-core systems. Discussions suggest Mojo's compiler visibility grants an edge in performance.
- MAX compared to openXLA showed advantages as a lazy computation graph builder, offering more optimization opportunities and broad-ranging impacts.
3. Open-Source AI Frameworks
- SciPhi Open-Sources Triplex for Knowledge Graphs: SciPhi is open-sourcing Triplex, a state-of-the-art LLM for knowledge graph construction, significantly reducing the cost by 98%.
- Triplex can be used with SciPhi's R2R to build knowledge graphs directly on a laptop, outperforming few-shot-prompted GPT-4 at 1/60th the inference cost.
- Open WebUI features extensive capabilities: Open WebUI boasts extensive features like TTS, RAG, and internet access without Docker, enthralling users.
- Positive experiences on Windows 10 with Open WebUI raise interest in comparing its performance to Pinokio.
4. Multimodal AI Innovations
- Text2Control Enables Natural Language Commands: The Text2Control method enables agents to perform new tasks by interpreting natural language commands with vision-language models.
- This approach outperforms multitask reinforcement learning baselines in zero-shot generalization, with an interactive demo available for users to explore its capabilities.
- Snowflake Arctic Embed 1.5 boosts retrieval system scalability: Snowflake introduced Arctic Embed M v1.5, delivering up to 24x scalability improvement in retrieval systems with tiny embedding vectors.
- Daniel Campos' tweet about this update emphasizes the significant enhancement in performance metrics.
5. AI Community Tools
- ComfyUI wins hearts for Stable Diffusion newbies: Members suggested using ComfyUI as a good UI for someone new to Stable Diffusion, emphasizing its flexibility and ease of use.
- Additionally, watching Scott Detweiler's YouTube tutorials was recommended for thorough guidance.
- GPTs Agents exhibit self-awareness: An experiment conducted on GPTs agents aimed to assess their self-awareness, specifically avoiding web search capabilities during the process.
- The test results sparked discussions about the practical implications and potential limitations of self-aware AI systems without external data sources.
GPT4OMini (gpt-4o-mini-2024-07-18)
1. Recent Model Releases and Performance
- Mistral NeMo and DeepSeek Models Unveiled: Mistral released the NeMo 12B model with a 128k token context length, showcasing multilingual capabilities and tool support, while DeepSeek-V2-Chat-0628 tops the LMSYS leaderboard.
- These models emphasize advancements in performance and efficiency, with DeepSeek achieving 236B parameters and ranking first among open-source models.
- GPT-4o Mini vs. Claude 3 Haiku: The new GPT-4o mini is approximately 2x faster and 60% cheaper than GPT-3.5 Turbo, making it an attractive alternative despite its lower benchmark scores compared to Claude 3 Haiku.
- Users are discussing potential replacements, with mixed opinions on the mini's performance in various tasks.
- Apple's DCLM 7B Model Launch: Apple's release of the DCLM 7B model has outperformed Mistral 7B, showcasing fully open-sourced training code and datasets.
- This move has sparked discussions about its implications for the competitive landscape of open-source AI models.
2. AI Tooling and Community Resources
- Open WebUI Enhancements: The Open WebUI now includes features like TTS and RAG, allowing users to interact with their models without Docker, enhancing accessibility and usability.
- Users have reported positive experiences running it on Windows 10, comparing its performance favorably against Pinokio.
- ComfyUI for Beginners: Members are recommending ComfyUI as an excellent user interface for newcomers to Stable Diffusion, highlighting its flexibility and ease of use.
- Tutorials from Scott Detweiler on YouTube have been suggested for those looking for comprehensive guidance.
3. Training Techniques and Model Fine-tuning
- Improving Transformer Generalization: An arXiv paper suggests that training transformers beyond saturation can enhance their generalization capabilities, particularly for out-of-domain tasks.
- This approach helps prevent catastrophic forgetting, making it a pivotal strategy for future model training.
- Fine-tuning Challenges in Mistral-12b: Users reported configuration issues with Mistral-12b, particularly around size mismatches in projection weights, requiring source installation of transformers for fixes.
- Discussions on fine-tuning strategies indicate the need for specific adjustments in training setups to optimize performance.
4. Data Privacy and Security in AI
- CrowdStrike Outage Impacts: A recent CrowdStrike update caused a global outage, affecting multiple industries and prompting discussions on the reliability of cloud-based security services.
- The incident has raised concerns about data privacy and operational resilience in tech infrastructure.
- Business Hesitance to Share Sensitive Data: Concerns around data privacy have made businesses wary of sharing sensitive information with third parties, prioritizing internal controls over external exchanges.
- This trend highlights the growing importance of data security in AI applications.
5. Advancements in Knowledge Graphs and Retrieval-Augmented Generation
- Triplex Revolutionizes Knowledge Graphs: The Triplex model offers a 98% cost reduction for knowledge graph construction, outperforming GPT-4 at 1/60th the cost.
- Triplex facilitates local graph building using SciPhi's R2R platform, enhancing retrieval-augmented generation methods.
- R2R Platform for Knowledge Graphs: The R2R platform enables scalable, production-ready retrieval-augmented generation applications, integrating multimodal support and automatic relationship extraction.
- Members highlighted its effectiveness in creating knowledge graphs from unstructured data, showcasing practical applications.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Hermes 2.5 outperforms Hermes 2: After adding code instruction examples, Hermes 2.5 appears to perform better than Hermes 2 in various benchmarks.
- Hermes 2 scored a 34.5 on the MMLU benchmark whereas Hermes 2.5 scored 52.3.
- Mistral has struggles expanding beyond 8k: Members stated that Mistral cannot be extended beyond 8k without continued pretraining and this is a known issue.
- They pointed to further work on mergekit and frankenMoE finetuning for the next frontiers in performance.
- Mistral unveils NeMo 12B model: Mistral released NeMo, a 12 billion parameter model, showcasing multilingual capability and native tool support.
- Fits exactly in a free Google Colab GPU instance, which you can access here.
- In-depth on CUDA bf16 issues and fixes: Several users reported errors related to bf16 support on different GPU models such as RTX A4000 and T4, hindering model execution.
- The problem was identified to be due to torch.cuda.is_bf16_supported() returning False, and the Unsloth team has since fixed it.
- SciPhi Open-Sources Triplex for Knowledge Graphs: SciPhi is open-sourcing Triplex, a state-of-the-art LLM for knowledge graph construction, significantly reducing the cost by 98%.
- Triplex can be used with SciPhi's R2R to build knowledge graphs directly on a laptop, outperforming few-shot-prompted GPT-4 at 1/60th the inference cost.
Stability.ai (Stable Diffusion) Discord
- ComfyUI wins hearts for Stable Diffusion newbies: Members suggested using ComfyUI as a good UI for someone new to Stable Diffusion, emphasizing its flexibility and ease of use.
- Additionally, watching Scott Detweiler's YouTube tutorials was recommended for thorough guidance.
- NVIDIA trumps AMD in AI tasks: Consensus in the discussion indicates a preference for NVIDIA GPUs over AMD for stable diffusion due to better support and less troubleshooting.
- Despite AMD providing more VRAM, NVIDIA is praised for wider compatibility, especially in Linux environments, despite occasional driver issues.
- Stable Diffusion models: One size doesn't fit all: Discussion on the best Stable Diffusion models concluded that choices depend on VRAM and the specific needs of the user, with SDXL recommended for its larger size and capabilities.
- SD3 was mentioned for its superior image quality due to a new VAE, while noting it's currently mainly supported in ComfyUI.
- Tips to make Stable Diffusion more artistic: A member sought advice on making images look more artistic and less hyper-realistic, complaining about the dominance of HD, high-contrast outputs.
- Suggestions included using artistic LoRAs and experimenting with different models to achieve desired digital painting effects.
- Seeking Reddit alternatives for AI news: A member expressed frustration with Reddit bans and censorship in Twitter, seeking alternative sources for AI news.
- Suggestions included following the scientific community on Twitter for the latest papers and developments, despite perceived regional and user-based censorship issues.
HuggingFace Discord
- Quick Help for CrowdStrike BSOD: A faulty file from CrowdStrike caused widespread BSOD, affecting millions of systems globally. The Director of Overwatch at CrowdStrike posted a hot fix to break the BSOD loop.
- The issue led to a significant number of discussions about fallout and measures to prevent future incidents.
- Hugging Face API Woes: Multiple users in the community discussed issues with the Meta-Llama-3-70B-Instruct API, including error messages about unsupported model configurations.
- There was a wide acknowledgment of Hugging Face infrastructure problems, particularly impacting model processing speeds, which users noted have stabilized recently after outages.
- Surge of Model Releases Floods Feed: Significant model releases occurred all in one day: DeepSeek's top open-access lmsys model, Mistral 12B, Snowflake's embedding model, and more. See the tweet for the full list.
- Osanseviero remarked, '🌊For those of you overwhelmed by today's releases,' summarizing the community's sentiments about the vast number of updates happening.
- Technical Teasers in Neural Networks: The Circuits thread offers an experimental format delving into the inner workings of neural networks, covering innovative discoveries like Curve Detectors and Polysemantic Neurons.
- This engaging approach to understanding neural mechanisms has triggered enthusiastic discussions about both the conceptual and practical implications.
- AI Comic Factory Enhancements: Significant updates to the AI Comic Factory were noted, now featuring speech bubbles by default, enhancing the comic creation experience.
- The new feature, utilizing AI for prompt generation and dialogue segmentation, improves storytelling through visual metrics, even accommodating non-human characters like dinosaurs.
Nous Research AI Discord
- Overcoming catastrophic forgetting in ANNs with sleep-inspired dynamics: Experiments by Maxim Bazhenov et al. suggest that a sleep-like phase in ANNs helps reduce catastrophic forgetting, with findings published in Nature Communications.
- Sleep in ANNs involved off-line training using local unsupervised Hebbian plasticity rules and noisy input, helping the ANNs recover previously forgotten tasks.
- Opus Instruct 3k dataset gears up multi-turn instruction finetuning: A member shared a link to the Opus Instruct 3k dataset on Hugging Face, containing ~2.5 million tokens worth of general-purpose multi-turn instruction finetuning data in the style of Claude 3 Opus.
- teknium acknowledged the significance of the dataset with a positive comment.
- GPT-4o Mini vies with GPT-3.5-Turbo on coding benchmarks: On a coding benchmark, GPT-4o Mini performed on par with GPT-3.5-Turbo, despite being advertised with a HumanEval score that raised user expectations.
- One user expressed dissatisfaction with the overhyped performance indicators, speculating that OpenAI trained it on benchmark data.
- Triplex slashes KG creation costs by 98%: Triplex, a finetuned version of Phi3-3.8B by SciPhi.AI, outperforms GPT-4 at 1/60th the cost for creating knowledge graphs from unstructured data.
- It enables local graph building using SciPhi's R2R platform, significantly cutting down expenses.
- Mistral-Nemo-Instruct GGUF conversion struggles highlighted: A member struggled with converting Mistral-Nemo-Instruct to GGUF due to issues with BPE vocab and missing tokenizer.model files.
- Despite pulling a PR for Tekken tokenizer support, the conversion script still did not work, causing much frustration.
OpenAI Discord
- GPT-4o mini offers cost-efficient performance: GPT-4o mini is seen as a cheaper and faster alternative to 3.5 Turbo, being approximately 2x faster and 60% cheaper as noted on GitHub.
- However, it lacks image support and scores lower in benchmarks compared to GPT-4o, underlining some of its limitations.
- Crowdstrike outage disrupts industries: A Crowdstrike update caused a global outage, affecting industries such as airlines, banks, and hospitals, with machines requiring manual unlocking.
- This primarily impacted Windows 10 users, making the resolution process slow and costly.
- GPT-4o's benchmark superiority debated: GPT-4o scores higher in benchmarks compared to GPT-4 Turbo, but effectiveness varies by use case source.
- The community finds no consensus on the ultimate superiority due to these variabilities, highlighting the importance of specific application needs.
- Fine-tuning for 4o mini on the horizon: Members expect fine-tuning capabilities for 4o mini to be available in approximately 6 months.
- This potential enhancement could further improve its utility and performance in specific applications.
- Request for Glassmorphic UI in Code Snippets: Users are looking to create a code snippet library with a glassmorphic UI using HTML, CSS, and JavaScript, featuring an animated gradient background.
- Desired functionalities include managing snippets—adding, viewing, editing, and deleting—with cross-browser compatibility and a responsive design.
Modular (Mojo 🔥) Discord
- Mojo Boosts Debugging Experience: Mojo prioritizes advanced debugging tools, enhancing the debugging experience for machine learning tasks on GPUs. Learn more.
- Mojo's extension allows seamless setup in VS Code, and LLDB-DAP integrations are planned for stepping through CPU to GPU code.
- Mojo vs JAX: Benchmark Wars: Mojo outperforms JAX on CPUs even though JAX is optimized for many-core systems. Discussions suggest Mojo's compiler visibility grants an edge in performance.
- MAX compared to openXLA showed advantages as a lazy computation graph builder, offering more optimization opportunities and broad-ranging impacts.
- Mojo's Low-Level Programming Journey: A user transitioning from Python to Mojo considered learning C, CUDA, and Rust due to Mojo’s perceived lack of documentation. Community responses focused on 'Progressive Disclosure of Complexity.'
- Discussions encouraged documenting the learning journey to aid in shaping Mojo’s ecosystem and suggested using
InlineArrayfor FloatLiterals in types.
- Discussions encouraged documenting the learning journey to aid in shaping Mojo’s ecosystem and suggested using
- Async IO API Standards in Mojo: A discussion emphasized the need for async IO APIs in Mojo to support higher performance models by effectively handling buffers. The conversation drew from Rust's async IO challenges.
- Community considered avoiding a split between performance-focused and mainstream libraries, aiming for seamless integration.
- Mojo Nightly Update Highlights New Features: The Mojo nightly update 2024.7.1905 introduced a new stdlib function
Dict.setdefault(key, default). View the raw diff for detailed changes.- Contributor meetings may separate from community meetings to align better with Modular’s work, with stdlib contributions vetted through incubators for API and popularity before integration.
LM Studio Discord
- Mistral Nvidia collaboration creates buzz: Mistral Nvidia collaboration introduced Mistral-Nemo 12B, offering a large context window and state-of-the-art performance, but it's unsupported in LM Studio.
- Tokenizer support in llama.cpp is required to make Mistral-Nemo compatible.
- Rich features in Open WebUI draw attention: Open WebUI boasts extensive features like TTS, RAG, and internet access without Docker, enthralling users.
- Positive experiences on Windows 10 with Open WebUI raise interest in comparing its performance to Pinokio.
- DeepSeek-V2-Chat-0628 tops LMSYS Leaderboard: DeepSeek-V2-Chat-0628, a model with 236B parameters, ranks No.1 open-source model on LMSYS Chatbot Arena Leaderboard.
- It holds top positions: Overall No.11, Hard Prompts No.3, Coding No.3, Longer Query No.4, Math No.7.
- Complexities of using NVidia Tesla P40: Users face mixed results running NVidia Tesla P40 on Windows; data center and studio RTX drivers are used but performance varies.
- Compatibility issues with Tesla P40 and Vulcan are highlighted, suggesting multiple installations and enabling virtualization.
- TSMC forecasts AI chip supply delay: TSMC's CEO predicts no balance in AI chip supply till 2025-2026 due to packaging bottlenecks and high demand.
- Overseas expansion is expected to continue, as shared in this report.
Latent Space Discord
- Llama 3 release imminent: Llama 3 with 400 billion parameters is rumored to release in 4 days, igniting excitement and speculation within the community.
- This upcoming release has stirred numerous conversations about its potential impact and capabilities.
- Self-Play Preference Optimization sparks interest: SPPO (Self-Play Preference Optimization) is noted for its potential, but skepticism exists regarding its long-term effectiveness after a few iterations.
- Opinions are divided on whether the current methodologies will hold up after extensive deployment and usage.
- Apple open-sources DCLM 7B model: Apple released the DCLM 7B model, which surpasses Mistral 7B and is entirely open-source, including training code and datasets.
- This release is causing a buzz with VikParuchuri's GitHub profile showcasing 90 repositories and the official tweet highlighting the open sourcing.
- Snowflake Arctic Embed 1.5 boosts retrieval system scalability: Snowflake introduced Arctic Embed M v1.5, delivering up to 24x scalability improvement in retrieval systems with tiny embedding vectors.
- Daniel Campos' tweet about this update emphasizes the significant enhancement in performance metrics.
- Texify vs Mathpix in functionality: A comparison was raised on how Texify stacks up against Mathpix in terms of functionality but no detailed answers were provided.
- The conversation highlights an ongoing debate about the effectiveness of these tools for various use cases.
CUDA MODE Discord
- Nvidia influenced by anti-trust laws to open-source kernel modules: Nvidia's decision to open-source kernel modules may be influenced by US anti-trust laws according to speculations.
- One user suggested that maintaining kernel modules isn't central to Nvidia's business and open-sourcing could improve compatibility without needing high-skill developers.
- Float8 weights introduce dynamic casting from BF16 in PyTorch: Members discussed casting weights stored as BF16 to FP8 for matmul in PyTorch, referencing float8_experimental.
- There was also interest in implementing stochastic rounding for FP8 weight updates, possibly supported by Meta's compute resources.
- Tinygrad bounties spark mixed reactions: Discussions about contributing to tinygrad bounties like splitting UnaryOps.CAST noted that some found the compensation insufficient for the effort involved.
- A member offered $500 for adding FSDP support to tinygrad, which was considered low, with potential implementers needing at least a week or two.
- Yuchen's 7.3B model training achieves linear scaling: Yuchen trained a 7.3B model using karpathy's llm.c with 32 H100 GPUs, achieving 327K tokens/s and an MFU of 46.7%.
- Changes from 'int' to 'size_t' were needed to handle integer overflow due to large model parameters.
- HQQ+ 2-bit Llama3-8B-Instruct model announced: A new model, HQQ+ 2-bit Llama3-8B-Instruct, uses the BitBlas backend and 64 group-size quantization for quality retention.
- The model is compatible with BitBlas and
torch.compilefor fast inference, despite challenges in low-bit quantization of Llama3-8B.
- The model is compatible with BitBlas and
Perplexity AI Discord
- Pro users report drop in search quality: Some members, especially those using Claude Sonnet 3.5, have noticed a significant drop in the quality of Pro searches over the past 8-9 days.
- This issue has been raised in discussions but no clear solution or cause has been identified yet.
- GPT-4o mini set to replace Claude 3 Haiku?: There's active discussion around the idea of potentially replacing Claude 3 Haiku with the cheaper and smarter GPT-4o mini in Perplexity.
- Despite the promising attributes of GPT-4o mini, Claude 3 Haiku remains in use for now.
- YouTube Music unveils Smart Radio: A discussion highlighted YouTube Music's Smart Radio, featuring innovative content delivery and new music discovery tools.
- YouTube Music was praised for smartly curating playlists and adapting to user preferences.
- Dyson debuts High-Tech Headphones: Dyson's new high-tech headphones were noted for integrating advanced noise-cancellation and air filtration technology.
- Members commented on the product's dual functionality and sleek design.
- Seeking RAG API Access from Perplexity: A member noted a lack of response after emailing about RAG API for their enterprise, seeking further assistance in obtaining access.
- This suggests ongoing communication challenges and unmet demand for enterprise-level API solutions.
OpenRouter (Alex Atallah) Discord
- Mistral AI releases two new models: Daun.ai introduced Mistral Nemo, a 12B parameter multilingual LLM with a 128k token context length.
- Codestral Mamba was also released, featuring a 7.3B parameter model with a 256k token context length for code and reasoning tasks.
- L3-Euryale-70B price slashed by 60%: L3-Euryale-70B received a massive price drop of 60%, making it more attractive for usage in various applications.
- Additionally, Cognitivecomputations released Dolphin-Llama-3-70B, a competitive new model promising improved instruction-following and conversational abilities.
- LLM-Draw integrates OpenRouter API keys: The LLM-Draw app now accepts OpenRouter API keys, leveraging the Sonnet 3.5 self-moderated model.
- Deployable as a Cloudflare page with Next.js, a live version is now accessible.
- Gemma 2 repetition issues surface: Users reported repetition issues with Gemma 2 9B and sought advice for mitigating the problem.
- A suggestion was made to use CoT (Chain of Thought) prompting for better performance.
- Mistral NeMo adds Korean language support: A message indicated that Mistral NeMo has expanded its language support to include Korean, enhancing its multilingual capacity.
- Users noted its strength in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
Interconnects (Nathan Lambert) Discord
- GPT-4o Mini's Versatile Performance: GPT-4o mini matches GPT-3.5 on Aider's code editing benchmark but struggles with code diffs on larger files.
- The model offers cost-efficient text generation yet retains high image input costs, prompting users to consider alternatives like Claude 3 Haiku and Gemini 1.5 Flash.
- OpenAI Faces New Security Flaws: OpenAI's new safety mechanism was easily bypassed, allowing GPT-4o-mini to generate harmful content, exposing significant vulnerabilities.
- Internal evaluations show GPT-4o mini may be overfitting, with extra information inflating its scores, highlighting a potential flaw in eval setups.
- Gemma 2 Surprises with Logit Capping: Members discussed the removal of soft logit capping in Gemma 2, debating the need for retraining to address its effects.
- Some members found it startling that the model performed well without significant retraining, challenging common expectations about logit capping adjustments.
- MosaicML's Quirky Sword Tradition: MosaicML employees receive swords as part of a unique tradition, as noted in discussions about potential future interviews.
- HR and legal teams reportedly disapproved, but rumors suggest even the MosaicML legal team might have partaken.
- Sara Hooker Critiques US AI Act: A member shared a YouTube video of Sara Hooker critiquing compute thresholds in the US AI Act, sparking community interest.
- Her community presence, underscored by a recent paper, highlights ongoing discussions about regulatory frameworks and their implications for future AI developments.
Eleuther Discord
- Z-Loss regularization term explored: Z-loss was discussed as a regularization term for the objective function, compared to weight decay and its necessity debated among members.
- Carsonpoole clarified that Z-loss targets activation instability by preventing large activations, comparing it to existing regularization methods.
- CoALA: A structured approach to language agents: A paper on Cognitive Architectures for Language Agents (CoALA) introduces a framework with modular memory components to guide language model development.
- The framework aims to survey and organize recent advancements in language models, drawing on cognitive science and symbolic AI for actionable insights.
- BPB vs per token metrics clarified: There was a clarification on whether a given metric should be interpreted as bits per byte (BPB) or per token, establishing it as 'per token' for accuracy.
- Cz_spoon_06890 noted the significant impact of this metric's correct interpretation on the corresponding evaluations.
- Scaling laws impact hypernetwork capabilities: Discussion centered on how scaling laws affect hypernetworks and their capacity to reach the target error predicted by these laws, questioning the feasibility for smaller hypernetworks.
- Suggestions included focusing hypernetworks on tasks with favorable scaling laws, making it simpler to learn from specific data subsets.
- Tokenization-free models spark debate: Debate on the interpretability of tokenization-free models at the byte or character level, with concerns over the lack of canonical places for processing.
- 'Utf-8 is a tokenization scheme too, just a bad one,' one member noted, showing skepticism towards byte-level tokenization.
LlamaIndex Discord
- MistralAI and OpenAI release new models: It's a big day for new models with releases from MistralAI and OpenAI, and there's already day zero support for both models, including a new Mistral NeMo 12B model outperforming Mistral's 7b model.
- The Mistral NeMo model features a significant 128k context window.
- LlamaCloud updates enhance collaboration: Recent updates to LlamaCloud introduced LlamaCloud Chat, a conversational interface to data, and new team features for collaboration.
- These changes aim to enhance user experience and productivity. Read more here.
- Boosting relevance with Re-ranking: Re-ranking retrieved results can significantly enhance response relevance, especially when using a managed index like @postgresml.
- Check out their guest post on the LlamaIndex blog for more insights. More details here.
- LLMs context window limits cause confusion: A user experienced an 'Error code: 400' while setting the max_tokens limit for GPT-4o mini despite OpenAI's documentation stating a context window of 128K tokens, which reportedly supports only 16384 completion tokens.
- This confusion arose from using different models in different parts of the code, leading to interference between GPT-3.5 and GPT-4 in SQL query engines.
- ETL for Unstructured Data via LlamaIndex: A member inquired about parsing unstructured data like video and music into formats digestible by LLMs, referencing a YouTube conversation between Jerry Liu and Alejandro that mentioned a new type of ETL.
- This highlights the practical applications and potential use cases for ETL in AI data processing.
OpenAccess AI Collective (axolotl) Discord
- Training Inferences Boost Transformer Generalization: An arXiv paper suggests that training transformers beyond saturation enhances their generalization and inferred fact deduction.
- Findings reveal transformers struggle with out-of-domain inferences due to lack of incentive for storing the same fact in multiple contexts.
- Config Issues Plague Mistral-12b Usage: A member reported config issues with Mistral-12b, particularly size mismatches in projection weights.
- Fixes required installing transformers from source and tweaking training setups like 8x L40s, which showed improvement in loss reduction.
- Triplex Model Revolutionizes Knowledge Graph Construction: The Triplex model, based on Phi3-3.8B, offers a 98% cost reduction for knowledge graphs compared to GPT-4 (source).
- This model is shareable, executable locally, and integrates well with Neo4j and R2R, enhancing downstream RAG methods.
- Axolotl Training Adjustments Address GPU Memory Errors: Common GPU memory errors during axolotl training prompted discussions on adjusting
micro_batch_size,gradient_accumulation_steps, and enablingfp16.- A detailed guide for these settings was shared to optimize memory usage and prevent errors.
- Llama3 Adjustments Lower Eval and Training Loss: Lowering Llama3's rank helped improve its eval loss, though further runs are needed to confirm stability.
- The training loss also appeared noticeably lower, indicating consistent improvements.
Cohere Discord
- GPTs Agents exhibit self-awareness: An experiment conducted on GPTs agents aimed to assess their self-awareness, specifically avoiding web search capabilities during the process.
- The test results sparked discussions about the practical implications and potential limitations of self-aware AI systems without external data sources.
- Cohere's Toolkit flexibility impresses community: A community member highlighted a tweet from Aidan Gomez and Nick Frosst, praising the open-source nature of Cohere's Toolkit UI, which allows integration of various models and the contribution of new features.
- The open-source approach was lauded for enabling extensive customization and fostering innovations in tool development across the community.
- Firecrawl faces pricing challenges: A member noted that Firecrawl proves costly without a large customer base, suggesting a shift to a pay-as-you-go model.
- The discussion included various pricing strategies and the need for more flexible plans for smaller users.
- Firecrawl self-hosting touted as cost-saving: Members explored self-hosting Firecrawl to reduce expenses, with one member sharing a GitHub guide detailing the process.
- Self-hosting was reported to significantly lower costs, making the service more accessible for individual developers.
- Local LLM Chat GUI project gains attention: A new project featuring a chat GUI powered by local LLMs was shared, integrating Web Search, Python Interpreter, and Image Recognition.
- Interested members were directed to the project's GitHub repository for further engagement and contributions.
Torchtune Discord
- Unified Dataset Abstraction RFC Gains Traction: The RFC to unify instruct and chat datasets to support multimodal data was widely discussed with key feedback focusing on separating tokenizer and prompt templating from other configurations.
- Members highlighted usability and improvement areas, recommending more user-friendly approaches to manage dataset configurations efficiently.
- Torchtune Recipe Docs Set to Autogenerate: Proposals to autogenerate documentation from recipe docstrings emerged to improve visibility and accessibility of Torchtune's recipes.
- This move aims to ensure users have up-to-date, easily navigable documentation that aligns with the current version of recipes.
- Error Handling Overhaul Suggestion: Discussions surfaced on streamlining error handling in Torchtune recipes by centralizing common validation functions, offering a cleaner codebase.
- The idea is to minimize boilerplate code and focus user attention on critical configurations for better efficiency.
- Consolidating Instruct/Chat Dataset RFC: An RFC was shared aiming to consolidate Instruct/Chat datasets to simplify adding custom datasets on Hugging Face.
- Regular contributors to fine-tuning jobs were encouraged to review and provide feedback, ensuring it wouldn't affect high-level APIs.
Alignment Lab AI Discord
- Mozilla Builders launches startup accelerator: Mozilla Builders announced a startup accelerator for hardware and AI projects, aiming to push innovation at the edge.
- One member showed great enthusiasm, stating, 'I don't move on, not a part-time accelerator, we live here.'
- AI-generated scene descriptions for the blind: The community discussed using AI to generate scene descriptions for the visually impaired, aiming to enhance accessibility.
- Sentiments ran high with statements like, 'Blindness and all illnesses need to be deleted.'
- Smart AI devices buzz around beekeeping: Development of smart AI data-driven devices for apiculture was highlighted, providing early warnings to beekeepers to prevent colony loss.
- This innovative approach holds promise for integrating AI in agriculture and environmental monitoring.
- GoldFinch hatches with hybrid model gains: GoldFinch combines Linear Attention from RWKV and Transformers, outperforming models like 1.5B class Llama on tasks by reducing quadratic slowdown and KV-Cache size.
- GPTAlpha and Finch-C2 models outperform competitors: The new Finch-C2 and GPTAlpha models blend RWKV's linearity and transformer architecture, offering better performance and efficiency than traditional models.
- These models enhance downstream task performance, available with comprehensive documentation and code on GitHub and Huggingface.
tinygrad (George Hotz) Discord
- Kernel refactoring in tinygrad sparks changes: George Hotz suggested refactoring Kernel to eliminate
linearizeand introduce ato_programfunction, facilitating better structuring.- He emphasized the need to remove
get_lazyop_infofirst to implement these changes efficiently.
- He emphasized the need to remove
- GTX1080 struggles with Tinygrad compatibility: A member reported an error while running Tinygrad on a GTX1080 with
CUDA=1, highlighting GPU architecture issues.- Another member suggested 2080 generation GPUs as a minimum, recommending patches in
ops_cudaand disabling tensor cores.
- Another member suggested 2080 generation GPUs as a minimum, recommending patches in
- Tinygrad internals: Understanding View.mask: A member dove into the internals of Tinygrad, specifically questioning the purpose of
View.mask.- George Hotz clarified it is primarily used for padding, supported by a reference link.
- Dissection of
_poolfunction in Tinygrad: A member sought clarification on the_poolfunction, pondering whether it duplicates data usingpad,shrink,reshape, andpermuteoperations.- Upon further examination, the member realized the function does not duplicate values as initially thought.
- New project proposal: Documenting OpenPilot model trace: George Hotz proposed a project to document kernel changes and their performance impact using an OpenPilot model trace.
- He shared a Gist link with instructions, inviting members to participate.
OpenInterpreter Discord
- GPT-4o Mini raises parameter change question: A user questioned whether GPT-4o Mini can be operational by merely changing parameters or requires formal introduction by OI.
- Discussion hinted at potential setup challenges but lacked clear consensus on the necessity of formal introduction mechanics.
- 16k token output feature wows: The community marveled at the impressive 16k max token output feature, highlighting its potential utility in handling extensive data.
- Contributors suggested this capability could revolutionize extensive document parsing and generation tasks.
- Yi large preview remains top contender: Members reported that the Yi large preview continues to outperform other models within the OI framework.
- Speculations suggested stability and improved context handling as key differentiators.
- GPT-4o Mini lags in code generation: Initial tests indicated GPT-4o Mini is fast but mediocre in code generation, falling short of expectations.
- Despite this, some believe it might excel in niche tasks with precise custom instructions, though its function-calling capabilities still need improvement.
- OpenAI touts GPT-4o Mini's function calling: OpenAI's announcement lauded the strong function-calling skills and enhanced long-context performance of GPT-4o Mini.
- Community reactions were mixed, debating whether the reported improvements align with practical observations.
LAION Discord
- ICML'24 Highlights LAION Models: Researchers thanked the LAION project for their models used in an ICML'24 paper.
- They shared an interactive demo of their Text2Control method, describing it as essential for advancing vision-language models capabilities.
- Text2Control Enables Natural Language Commands: The Text2Control method enables agents to perform new tasks by interpreting natural language commands with vision-language models.
- This approach outperforms multitask reinforcement learning baselines in zero-shot generalization, with an interactive demo available for users to explore its capabilities.
- AGI Hype vs Model Performance: A discussion highlighted the overhyped nature of AGI while noting that many models achieve high accuracy with proper experimentation, referencing a tweet by @_lewtun.
- 'Many models solve AGI-like tasks correctly, but running the necessary experiments is often deemed 'boring''.
- Need for Latents to Reduce Storage Costs: Users expressed the need for latents of large image datasets like sdxl vae to reduce storage costs.
- It was suggested to host these latents on Hugging Face, which covers the S3 storage bills.
- Interact with CNN Explainer Tool: A CNN explainer visualization tool was shared, designed to help users understand Convolutional Neural Networks (CNNs) via interactive visuals.
- This tool is especially useful for those seeking to deepen their comprehension of CNNs from a practical perspective.
LangChain AI Discord
- Triplex sharply cuts costs in graph construction: Triplex offers a 98% cost reduction in building knowledge graphs, surpassing GPT-4 while operating at 1/60th the cost.
- Developed by SciPhi.AI, Triplex, a finetuned Phi3-3.8B model, now supports local graph building at a fraction of the cost, thanks to SciPhi's R2R.
- Model-specific prompt wording: unnecessary in LangChain: A user queried if model-specific wording is needed in LangChain's
ChatPromptTemplatefor accurate prompts.- It was clarified that
ChatPromptTemplateabstracts this requirement, making specific markers like<|assistant|>unnecessary.
- It was clarified that
- Creating prompts with ChatPromptTemplate: An example was shared on how to define an array of messages in LangChain's
ChatPromptTemplate, leveraging role and message text pairs.- Guide links for detailed steps were provided to aid in building structured prompts effectively.
LLM Perf Enthusiasts AI Discord
- Mystery of OpenAI Scale Tier: A member inquired about understanding the new OpenAI Scale Tier, leading to community confusion around GPT-4 TPS calculations.
- The discussion highlighted the complexity of TPS determinations and discrepancies in GPT-4's performance metrics.
- GPT-4 TPS Calculation Confusion: Members are puzzled by OpenAI's calculation of 19 tokens/second on the pay-as-you-go tier, given GPT-4 outputs closer to 80 tokens/second.
- This sparked debates about the accuracy of the TPS calculations and how they affect different usage tiers.
LLM Finetuning (Hamel + Dan) Discord
- Businesses Wary of Sharing Sensitive Data: A member pointed out that businesses are hesitant to share sensitive line-of-business data or customer/patient data with third parties, reflecting a heightened concern about data privacy.
- The discussion highlighted that this caution stems from growing fears over data security and privacy breaches, leading businesses to prioritize internal controls over external data exchanges.
- Data Privacy Takes Center Stage: Concern for data privacy is becoming ever more critical in businesses as they navigate compliance and security challenges.
- There's a noted trend where businesses are prioritizing the safeguarding of sensitive information against potential unauthorized access.
MLOps @Chipro Discord
- Clarifying Communication for Target Audiences: The discussion focused on understanding the target audience for effective communication, highlighting different groups such as engineers, aspiring engineers, product managers, devrels, and solution architects.
- The participants emphasized that tailoring messages for these specific groups ensures relevance and impact, improving the effectiveness of the communication.
- Importance of Targeted Communication: Clarifying target audience ensures that the communication is relevant and impactful for specific groups.
- The intention is to tailor messages appropriately for engineers, aspiring engineers, product managers, devrels, and solution architects.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (190 messages🔥🔥):
Mistral-Nemo model intricaciesMistral-Nemo support status on UnslothCommunity interactions regarding AI modelsUnsloth's internal workingsUpcoming features and releases
- Mistral-Nemo model intricacies: Discussions revolved around the model architecture of Mistral-Nemo, particularly focusing on head dimensions and hidden sizes, with links shared to the Hugging Face model card and a blog post for more details.
- A community member clarified that adjusting parameters helps in maintaining computational efficiency without significant information loss.
- Mistral-Nemo officially supported by Unsloth: Unsloth announced support for the Mistral-Nemo model, confirmed with a Google Colab link and addressing some initial hurdles related to EOS and BOS tokens.
- The community expressed excitement about the release, emphasizing Unsloth's dynamic RoPE allocation, which can efficiently manage context up to 128K tokens depending on the dataset's length.
- Lean startup: Unsloth team structure: The community was surprised to discover that Unsloth is operated by just two brothers, handling engineering, product, ops, and design, which prompted admiration for their efficiency.
- There were humorous and supportive interactions among members, celebrating achievements such as community milestones and personal news like becoming a parent.
- Exploring Unsloth's external alternatives: Efforts to provide easier access to AI models were discussed, including alternatives like Jan AI for local use and OobaGooba in Colab.
- Members were eager to find convenient platforms for running models without complex setups, highlighting the importance of user-friendly interfaces.
- Future features and upcoming releases: Unsloth announced several new releases and features in the pipeline, including support for vision models and improvements in model inference and training interfaces.
- The team encouraged community participation for feedback and testing, revealing plans for higher VRAM efficiency and expanded functionalities.
- Creating A Chatbot Fast: A Step-by-Step Gradio Tutorial
- mistralai/Mistral-Nemo-Instruct-2407 · Hugging Face: no description found
- Love Quotes GIF - Love quotes - Discover & Share GIFs: Click to view the GIF
- Tweet from Colaboratory (@GoogleColab): Colab now has NVIDIA L4 runtimes for our paid users! 🚀 24GB of VRAM! It's a great GPU when you want a step up from a T4. Try it out by selecting the L4 runtime!
- Dad Jokes Aht Aht GIF - Dad Jokes Aht Aht Dad Jokes Aht Aht - Discover & Share GIFs: Click to view the GIF
- unsloth/Mistral-Nemo-Base-2407-bnb-4bit · Hugging Face: no description found
- unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit · Hugging Face: no description found
- llm-scripts/collab_price_gpu.ipynb at main · GeraudBourdin/llm-scripts: Contribute to GeraudBourdin/llm-scripts development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - janhq/jan: Jan is an open source alternative to ChatGPT that runs 100% offline on your computer. Multiple engine support (llama.cpp, TensorRT-LLM): Jan is an open source alternative to ChatGPT that runs 100% offline on your computer. Multiple engine support (llama.cpp, TensorRT-LLM) - janhq/jan
- Turn your computer into an AI computer - Jan: Run LLMs like Mistral or Llama2 locally and offline on your computer, or connect to remote AI APIs like OpenAI’s GPT-4 or Groq.
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Mistral NeMo releaseCSV/Excel fine-tuningOllama model supportNew Documentation PageFree Notebooks
- Mistral unveils NeMo 12B model: Mistral released NeMo, a 12 billion parameter model, showcasing multilingual capability and native tool support.
- Fits exactly in a free Google Colab GPU instance, which you can access here.
- CSV/Excel support now available for fine-tuning: You can now use CSV/Excel files along with multi-column datasets for fine-tuning models.
- Access the Colab notebook for more details.
- Ollama model support integrated: New support added for deploying models to Ollama.
- Check out the Ollama Llama-3 (8B) Colab for more information.
- New Documentation Page launched: Introducing our new Documentation page for better guidance and resources.
- Features and tutorials like the LoRA Parameters Encyclopedia included for comprehensive learning.
- Announcement of Unsloth Studio (Beta): Unsloth Studio (Beta) launching next week with enhanced features.
- More details will be provided soon, stay tuned!
- Finetune Mistral NeMo with Unsloth: Fine-tune Mistral's new model NeMo 128k with 4x longer context lengths via Unsloth!
- Unsloth Docs: no description found
- Google Colab: no description found
- Google Colab: no description found
- Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #off-topic (20 messages🔥):
GPT-4o mini modelClaude model sizesSalesforce xLAM modelsModel weights and context windowsRumors and validations
- GPT-4o Mini Scores High on MMLU: OpenAI's new GPT-4o mini has been rumored to be an 8B model scoring 82 on the MMLU benchmark, raising eyebrows in the AI community.
- Speculations suggest that it might actually be a MoE model or involve quantization techniques, making its precise scale ambiguous.
- Salesforce Releases xLAM Models: Salesforce released model weights for their 1B and 7B xLAM models, with function calling capabilities and differing context windows.
- While the 1B model supports 16K tokens, the 7B model only handles 4K tokens, which some find underwhelming for its size.
- Claude Model Sizes Detailed: Alan D. Thompson's memo reveals Claude 3 models come in various sizes, including Haiku (~20B), Sonnet (~70B), and Opus (~2T).
- This diversity highlights Anthropic's strategic approach to cater across different performance and resource needs.
- The Memo - Special edition: Claude 3 Opus: Anthropic releases Claude 3, outperforming all models including GPT-4
- Models Table: Open the Models Table in a new tab | Back to LifeArchitect.ai Open the Models Table in a new tab | Back to LifeArchitect.ai Data dictionary Model (Text) Name of the large language model. Someti...
- OpenAI unveils GPT-4o mini, a smaller and cheaper AI model | TechCrunch: OpenAI introduced GPT-4o mini on Thursday, its latest small AI model. The company says GPT-4o mini, which is cheaper and faster than OpenAI's current
- Reddit - Dive into anything: no description found
- OpenAI unveils GPT-4o mini, a smaller and cheaper AI model | TechCrunch: OpenAI introduced GPT-4o mini on Thursday, its latest small AI model. The company says GPT-4o mini, which is cheaper and faster than OpenAI's current
Unsloth AI (Daniel Han) ▷ #help (89 messages🔥🔥):
CUDA bf16 issuesModel deployment and finetuningMistral Colab notebook issueFIM (Fill in the Middle) support in Mistral NemoDual GPU specification
- CUDA bf16 issues on various GPUs: Several users reported errors related to bf16 support on different GPU models such as RTX A4000 and T4, hindering model execution.
- The problem was identified to be due to torch.cuda.is_bf16_supported() returning False, and the Unsloth team has since fixed it.
- Model deployment might need GPU for inference: A user inquired about deploying their trained model on a server and was advised to use a specialized inference engine like vllm.
- The general consensus is that using a GPU VPS is preferable for handling the model's inference tasks.
- Mistral Colab notebook sees bf16 error: Users of the Mistral Colab notebook experienced bf16-related errors on A100 and other GPUs.
- After some investigation, the Unsloth team confirmed they had fixed the issue and tests showed that it works now.
- Understanding FIM in Mistral Nemo: A discussion emerged about Fill in the Middle (FIM) support in Mistral Nemo, pertaining to code completion tasks.
- FIM allows the language model to predict missing parts in the middle of the text inputs, which is useful for code auto-completion.
- Specifying GPU for fine-tuning: A user sought guidance on how to specify which GPU to use for training on machines with multiple GPUs.
- The Unsloth team directed them to a recent GitHub pull request that fixes an issue with CUDA GPU ID selection.
- What is FIM and why does it matter in LLM-based AI: When you’re writing in your favorite editor, the AI-like copilot will instantly guess and complete based on what you’ve written in the…
- Fix single gpu limit code overriding the wrong cuda gpu id via env by Qubitium · Pull Request #228 · unslothai/unsloth: PR fixes the following scenario: There are multiple gpu devices User already launched unsloth code with CUDA_VISIBLE_DEVICES=13,14 CUDA_DEVICE_ORDER=PCI_BUS_ID can be set or not Current code will ...
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Triplex knowledge graphTriplex cost reductionTriplex vs GPT-4R2R with TriplexSupabase for RAG with R2R
- SciPhi Open-Sources Triplex for Knowledge Graphs: SciPhi is open-sourcing Triplex, a state-of-the-art LLM for knowledge graph construction, significantly reducing the cost by 98%.
- Triplex can be used with SciPhi's R2R to build knowledge graphs directly on a laptop, outperforming few-shot-prompted GPT-4 at 1/60th the inference cost.
- Triplex Costs 98% Less for Knowledge Graphs: Triplex aims to reduce the expense of building knowledge graphs by 98%, making it more accessible compared to traditional methods which can cost millions.
- It is a finetuned version of Phi3-3.8B designed for creating KGs from unstructured data and is available on HuggingFace.
- R2R Enhances Triplex Use for Local Graph Construction: R2R is highlighted as a solution for leveraging Triplex to build knowledge graphs locally with minimal cost.
- R2R provides a comprehensive platform with features like multimodal support, hybrid search, and automatic relationship extraction.
- SOTA Triples Extraction: no description found
- SciPhi/Triplex · Hugging Face: no description found
- sciphi/triplex: Get up and running with large language models.
- Introduction - The best open source AI powered answer engine.: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (8 messages🔥):
Bypassing PyTorchTrainable Embeddings in OpenAIEvaluating fine-tuned LLaMA3 model
- Bypass PyTorch with a backward hook: A user suggested that to bypass PyTorch, you can add a backward hook and zero out the gradients.
- There was a discussion about whether storing the entire compute graph in memory would defeat the purpose of partially trainable embedding.
- OpenAI's two-matrix embedding strategy: One user mentioned that OpenAI separated its embeddings into two matrices: a small trainable part and a large frozen part.
- They also pointed out the need for logic paths to select different code paths.
- Evaluate fine-tuned LLaMA3 8B on Colab: A user shared a Colab notebook link and asked for help evaluating a fine-tuned LLaMA3 8B model.
- 'Try PyTorch training on concatenated embedding frozen and trainable embedding as well as linear layer,' was suggested by another user.
Link mentioned: Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #research (5 messages):
Sleep-Derived MechanismsArtificial Neural NetworksCatastrophic Forgetting
- Sleep-derived mechanisms reduce catastrophic forgetting in neural networks: UC San Diego researchers have shown that implementing a sleep-like phase in artificial neural networks can alleviate catastrophic forgetting by reducing memory overwriting.
- The study, published in Nature Communications, demonstrated that sleep-like unsupervised replay in neural networks helps protect old memories during new training.
- Backlog of papers to read for AI enthusiasts: A member mentioned having a backlog to read up on all the recent AI papers shared in the channel.
- Another member humorously responded with Do robots dream of electric sheep?.
- Sleep Derived: How Artificial Neural Networks Can Avoid Catastrophic Forgetting : no description found
- Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks - Nature Communications: Artificial neural networks are known to perform well on recently learned tasks, at the same time forgetting previously learned ones. The authors propose an unsupervised sleep replay algorithm to recov...
Stability.ai (Stable Diffusion) ▷ #general-chat (233 messages🔥🔥):
ComfyUI for SDNVIDIA vs AMD GPUsSD model recommendationsArtistic Style in SDDetaching from Reddit for AI news
- ComfyUI recommended for Stable Diffusion beginners: Members suggested using ComfyUI as a good UI for someone new to Stable Diffusion, emphasizing its flexibility and ease of use.
- Additionally, watching Scott Detweiler's YouTube tutorials was recommended for thorough guidance.
- NVIDIA cards preferred for AI tasks: Consensus in the discussion indicates a preference for NVIDIA GPUs over AMD for stable diffusion due to better support and less troubleshooting.
- Despite AMD providing more VRAM, NVIDIA is praised for wider compatibility, especially in Linux environments, despite occasional driver issues.
- SD model recommendations vary with needs: Discussion on the best Stable Diffusion models concluded that choices depend on VRAM and the specific needs of the user, with SDXL recommended for its larger size and capabilities.
- SD3 was mentioned for its superior image quality due to a new VAE, while noting it's currently mainly supported in ComfyUI.
- Tips for artistic style in Stable Diffusion: A member sought advice on making images look more artistic and less hyper-realistic, complaining about the dominance of HD, high-contrast outputs.
- Suggestions included using artistic LoRAs and experimenting with different models to achieve desired digital painting effects.
- Reddit alternatives for AI news: A member expressed frustration with Reddit bans and censorship in Twitter, seeking alternative sources for AI news.
- Suggestions included following the scientific community on Twitter for the latest papers and developments, despite perceived regional and user-based censorship issues.
- ERLAX on Instagram: "… #techno #dreamcore #rave #digitalart #aiart #stablediffusion": 4,246 likes, 200 comments - erlax.case on June 24, 2024: "… #techno #dreamcore #rave #digitalart #aiart #stablediffusion".
- Scott Detweiler: Quality Assurance Guy at Stability.ai & PPA Master Professional Photographer Greetings! I am the lead QA at Stability.ai as well as a professional photographer and retoucher based near Milwaukee...
- Here’s How AI Is Changing NASA’s Mars Rover Science - NASA: Artificial intelligence is helping scientists to identify minerals within rocks studied by the Perseverance rover.
- Reddit - Dive into anything: no description found
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- GitHub - ehristoforu/DeFooocus: Always focus on prompting and generating: Always focus on prompting and generating. Contribute to ehristoforu/DeFooocus development by creating an account on GitHub.
- ComfyICU - ComfyUI Cloud: Share and Run ComfyUI workflows in the cloud
HuggingFace ▷ #announcements (1 messages):
Watermark Remover using Florence 2CandyLLM Python LibraryAI Comic Factory UpdateFast Subtitle MakerQuantise + Load HF Text Embedding Models on Intel GPUs
- Watermark Remover using Florence 2: Watermark remover using Florence 2 has been shared by a community member.
- 'It produces excellent results for various types of watermarks,' claims the contributor.
- CandyLLM Python Library released: The new CandyLLM library, which utilizes Gradio UI, has been announced.
- It aims to make language model interactions more accessible via a user-friendly interface.
- AI Comic Factory Update Adds Speech Bubbles: The AI comic factory now includes speech bubbles by default.
- The creator noted that this new feature improves the visual storytelling experience.
- Quick and Easy Subtitle Creation: A new and fast subtitle maker has been introduced.
- The community is excited about its quick processing and ease of use.
- Easily Quantise and Load Text Models on Intel GPUs: A guide on how to quantise and load HF text embedding models on Intel GPUs has been shared.
- The contributor expressed that this allows for more efficient model usage on Intel hardware.
Link mentioned: How to transition to Machine Learning from any field? | Artificial Intelligence ft. @vizuara: In this video, Dr. Raj Dandekar from Vizuara shares his experience of transitioning from mechanical engineering to Machine Learning (ML). He also explains be...
HuggingFace ▷ #general (194 messages🔥🔥):
Loss Reduction StrategiesIssues with Model Processing SpeedMeta-Llama-3-70B-Instruct API IssuesHugging Face Infrastructure ProblemsTraining Models on Kaggle
- Loss Reduction Strategies Debated: A member questioned whether more data or more epochs would result in less loss, stating 'I think more epochs, but that might be overtraining'.
- Cohere Model Processing Speed Criticized: Users noted that the Cohere model has become slower compared to other models, taking as long as 5 minutes for some responses.
- 'Auto notify? If there is no ping, how would ppl be notified?'
- Meta-Llama-3-70B-Instruct API Problem: A member faced issues with the Meta-Llama-3-70B-Instruct API, receiving an error that the model type should be one of several listed specific configurations.
- The community recommended double-checking on Hugging Face if the model supports the text2text-generation task.
- Acknowledgment of Hugging Face Infrastructure Problems: A developer acknowledged Hugging Face infrastructure issues affecting processing speed, particularly for the Cohere model.
- Temporary stability is noticed by users in the systems after reported outages.
- Training Models on Kaggle Discussed: A member inquired if Google/Gemma7b quantized model could be run on Kaggle's P100, with 16 GB RAM available.
- Another user recommended using more modern models like Llama 3 8b or Mistral Nemo 12b, which can fit even on 8GB VRAM.
- Tweet from Nexusflow (@NexusflowX): 🚀 Introducing Athene-70B: Redefining Post-Training for Open Models! We’re thrilled to release Athene-Llama3-70B, an open-weight chat model fine-tuned from @AIatMeta 's Llama-3-70B. With an imp...
- xLSTMTime : Long-term Time Series Forecasting With xLSTM: In recent years, transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), demonstrating significant advancements despite facing challenges such as high...
- How do I ask a good question? - Help Center: Stack Overflow | The World’s Largest Online Community for Developers
- Download files from the Hub: no description found
- Civitai | Share your models: no description found
- Object Detection App In Java ( Showcase ): Final Look at My Uni 2nd Semester OOP Project. Basically, my project was to create an object detection app in Java (sadly). It all started when the Sir asked...
- грустный кот GIF - Грустный кот - Discover & Share GIFs: Click to view the GIF
- GitHub - muslehal/xLSTMTime: xLSTMTime for time series forecasting: xLSTMTime for time series forecasting . Contribute to muslehal/xLSTMTime development by creating an account on GitHub.
- Tweet from Sepp Hochreiter (@HochreiterSepp): xLSTM excels in times series prediction. "Our xLSTMTime model demonstrates excellent performance against state-of-the-art transformer-based models as well as other recently proposed time series mo...
- Zelda Diffusion XL - a Hugging Face Space by nroggendorff: no description found
- Anime Diffusion XL - a Hugging Face Space by nroggendorff: no description found
- GitHub - lm-sys/RouteLLM: A framework for serving and evaluating LLM routers - save LLM costs without compromising quality!: A framework for serving and evaluating LLM routers - save LLM costs without compromising quality! - lm-sys/RouteLLM
- Spac (Stéphan Pacchiano): no description found
- Introduction - Hugging Face NLP Course: no description found
HuggingFace ▷ #today-im-learning (2 messages):
Crowdstrike BSOD issueKnowledge Graphs
- Crowdstrike causes global BSOD: A faulty file from Crowdstrike caused widespread Blue Screens of Death (BSOD), affecting millions of systems globally.
- The Director of Overwatch at Crowdstrike posted a hot fix to break the BSOD loop.
- Knowledge Graphs offer assistance: A member offered help and information on Knowledge Graphs, highlighting their fun and usefulness.
HuggingFace ▷ #cool-finds (3 messages):
Circuits Thread on Inner Workings of Neural NetworksRecent Model ReleasesInteresting Papers on AI
- Circuits Thread Explores Neural Networks: The Circuits thread offers an experimental format collecting short articles and critical commentary delving into the inner workings of neural networks.
- It includes components like Curve Detectors, Pose-Invariant Dog Head Detectors, and Polysemantic Neurons.
- Surge of Model Releases on a Single Thursday: In a single day, significant model releases occurred: DeepSeek's top open-access lmsys model, Mistral 12B, Snowflake's embedding model, HF's Docmatix dataset, GoldFinch hybrid model, Arcee-Nova, and Mixedbread+deepset embeddings.
- Osanseviero remarked, '🌊For those of you overwhelmed by today's releases.' Link to tweet.
- Noteworthy AI Papers Recently Spotted: Highlights include ColPali for document retrieval with vision language models (paper), Scaling Agents Across Simulated Worlds (paper), and Chameleon mixed-modal early-fusion models (paper).
- Tweet from Omar Sanseviero (@osanseviero): 🌊For those of you overwhelmed by today's releases 1. DeepSeek released the top open-access lmsys model 2. Mistral 12B model (multilingual, tool usage, Apache 2) 3. Snowflake released an embeddi...
- Zoom In: An Introduction to Circuits: By studying the connections between neurons, we can find meaningful algorithms in the weights of neural networks.
HuggingFace ▷ #i-made-this (12 messages🔥):
Training with Llama ArchitectureMathStral ModelRush E ReleaseAI Comic FactoryGPT-4o Mini
- Training with Llama Architecture Tutorial: A new tutorial on training with Llama architecture was posted, covering steps from installing libraries to pushing trained models to Hugging Face Hub.
- The tutorial is structured in detailed steps, helping users log into Hugging Face Hub, format datasets, set up training arguments, and more.
- MathStral Impresses with Math Specialization: A member uploaded a YouTube video testing MathStral, a new Mistral model specialized in math, showing impressive results on Ollama.
- The member suggests subscribing to their channel for notifications on future model releases.
- AI Comic Factory Enhances Story Dialogue: A detailed explanation on how AI Comic Factory handles speech bubbles using AI-generated prompts and segmentation models was shared.
- The technique involves detecting humanoid shapes and drawing AI-generated speech bubbles using the HTML Canvas API, which works even for non-human shapes like dinosaurs.
- OpenAI Releases GPT4o Mini: A YouTube video was shared showcasing the impressive capabilities of the new GPT4o Mini model by OpenAI.
- The video encourages viewers to test the model for themselves and provides a link for free access without the need for an account or credit card.
- Isari Platform Launches Proof-of-Concept: The proof-of-concept for the Isari platform is ready, allowing users to request tasks, process them locally using
transformersfrom Hugging Face, and return JSON outputs.- The platform currently uses one model (
phi-3-mini-4k-instruct), but there are plans to add more models, including prompt generation and code generation capabilities.
- The platform currently uses one model (
- jbilcke-hf/ai-comic-factory · Where can I find the code?: no description found
- Create a Diffusers-compatible Dataset for Stable Diffusion Fine-tuning: no description found
- Tweet from thecollabagepatch (@thepatch_kev): another speedrun with the open source ableton plugin that jams with you gary4live this one's a collab with the homie tom's beat skip to 2:56 to hear it @_buildspace @_nightsweekends @ma...
- Train a Llama model from scratch: no description found
- MathΣtral First Test ! Quite impressive results ! Mistral AI: Let's try MathΣtral on Ollama
- Rush E: Provided to YouTube by DistroKidRush E · Noa RoggendorffRush E℗ 4056422 Records DKReleased on: 2024-07-18Auto-generated by YouTube.
- Object Detection App In Java ( Showcase ): Final Look at My Uni 2nd Semester OOP Project. Basically, my project was to create an object detection app in Java (sadly). It all started when the Sir asked...
- OpenAI released GPT4o Mini | Let's test it !: Check out the best coding ai with this link : https://BestCoderAi.com (10 messages free without any account nor credit card)
- Isari - AI-Enhanced Workforce: no description found
HuggingFace ▷ #reading-group (9 messages🔥):
Optimization of ML Model LayersPaper Clubs in Different DiscordEvent Planning for 8/3Event Confirmation and Feedback
- Start optimizing ML model layers: A member started working on optimization of ML model layers including dense layers, GRU, and LSTM GPU kernels.
- They requested foundational papers or articles to read in order to build a career in this domain.
- Promote a paper club on another Discord: A member inquired if it's appropriate to post about paper clubs happening in a different Discord in this channel.
- Another member suggested it's fine as long as a Discord invite link is not posted.
- Plan an event for 8/3: Members discussed planning an event for 8/3 and confirmed it with another member.
- They shared the event link and received positive feedback, appreciating the event diagram.
HuggingFace ▷ #computer-vision (7 messages):
camera calibration with TransformersObject Detection App in Javaimage segmentation for road detection using satellite imagesDeeplabV3 and SenseTheRoad
- Curious about camera calibration with Transformers: A member asked if anyone had experience with camera calibration using Transformers models.
- Object Detection App in Java Showcase: A member shared their YouTube video demonstrating an Object Detection App in Java built for a university project.
- Sadly, it was created in Java, and detailed as part of their OOP project.
- Searching for image segmentation models: A member sought recommendations for image segmentation models for road detection using satellite images.
- Another member pointed to SenseTheRoad, recommending DeepLabV3 as a viable option for this task.
- Object Detection App In Java ( Showcase ): Final Look at My Uni 2nd Semester OOP Project. Basically, my project was to create an object detection app in Java (sadly). It all started when the Sir asked...
- GitHub - SinaRaoufi/SenseTheRoad: Road detection using DeepLabv3 segmentation model: Road detection using DeepLabv3 segmentation model. Contribute to SinaRaoufi/SenseTheRoad development by creating an account on GitHub.
HuggingFace ▷ #NLP (4 messages):
XLM-Roberta fine-tuningSQL chatbot for Q&ARAG concept for chatbotsHaystack ImportError
- Fine-tuning XLM-Roberta-large for Token Classification: A user inquired about fine-tuning XLM-Roberta-large on their data using AutoModel for token/text classification and Trainer.
- Building SQL Data Q&A Chatbot: A user seeks assistance in building a conversational Q&A chatbot over SQL data, asking for pointers and help from anyone who has worked on it.
- Is RAG Redundant for SQL Data Chatbots?: A user questioned whether implementing the RAG (Retrieval-Augmented Generation) concept for a SQL data chatbot would be redundant.
- Haystack ImportError Troubles: A user encountered an ImportError: 'cannot import name 'default_from_dict' from 'haystack'' when setting up
Neo4jDocumentStorewith Haystack and Neo4j.
Nous Research AI ▷ #research-papers (10 messages🔥):
Catastrophic Forgetting in ANNsSleep-derived LearningGenQA Paper InsightsLLaMA-3-8B Finetuning Results
- Researchers tackle catastrophic forgetting in ANNs with sleep-like dynamics: Experiments by Maxim Bazhenov et al. suggest that a sleep-like phase in ANNs helps reduce catastrophic forgetting, with findings published in Nature Communications.
- Sleep in ANNs involved off-line training using local unsupervised Hebbian plasticity rules and noisy input, helping the ANNs recover previously forgotten tasks.
- Divergent views on GenQA's synthetic data generation method: A member critiqued the GenQA paper's synthetic data generation method as simplistic but noted that its results seem competitive with methods like Evol Instruct and UltraChat.
- Discrepancies in dataset sizes (e.g., GenQA's 10M vs. filtered Wizard/UltraChat) were highlighted, creating confusion among readers regarding the results reported in the paper.
- Sleep Derived: How Artificial Neural Networks Can Avoid Catastrophic Forgetting : no description found
- Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks - Nature Communications: Artificial neural networks are known to perform well on recently learned tasks, at the same time forgetting previously learned ones. The authors propose an unsupervised sleep replay algorithm to recov...
Nous Research AI ▷ #datasets (2 messages):
Opus Instruct 3k datasetSingular and plural subjects in sentencesClaude 3 Opus multi-turn instruction finetuning
- Opus Instruct 3k dataset release: A member shared a link to the Opus Instruct 3k dataset on Hugging Face, which contains multi-turn conversations.
- It's noted that this dataset includes ~2.5 million tokens worth of general-purpose multi-turn instruction finetuning data in the style of Claude 3 Opus.
- Identifying singular and plural subjects: A user asked an AI assistant to help identify whether certain sentences contain singular or plural subjects.
- The AI assistant provided an analysis, citing that phrases like 'Chicken with rice and beans' are singular despite mentioning multiple items, while 'Australia and New Zealand' is a plural subject.
- Claude 3 Opus multi-turn instruction dataset: The dataset Opus Instruct 3k contains multi-turn conversations created by the model itself, mimicking Claude 3 Opus.
- teknium acknowledged the significance of the dataset with a positive comment.
Link mentioned: kalomaze/Opus_Instruct_3k · Datasets at Hugging Face: no description found
Nous Research AI ▷ #off-topic (2 messages):
YouTube video on AIClaude's capabilities with text manipulation
- YouTube video shared on AI advancements: A link to a YouTube video was shared, likely discussing recent developments or insights in AI.
- AI enthusiasts should give it a watch to stay updated on the latest trends.
- Claude's hilarious response to text manipulation request: An interesting tweet showcased Claude's unique handling of a bizarre request: “Remove the squid” from the novel All Quiet on the Western Front.
- Claude's perfect reply: “The document doesn’t contain any mention of squid” stirred laughter and appreciation for the AI's comprehension skills.
Link mentioned: Tweet from Ethan Mollick (@emollick): 👀Claude handles an insane request: “Remove the squid” “The document appears to be the full text of the novel "All Quiet on the Western Front" by Erich Maria Remarque. It doesn't contain ...
Nous Research AI ▷ #interesting-links (7 messages):
DCLM modelslanguage map for codebaseslumentis project
- Best performing open-source DCLM models released: Vaishaal announced the release of their DCLM models on Huggingface, claiming they are the best performing truly open-source models available.
- Teknium added that the released dataset contains a whopping 250T tokens.
- Language map makes codebase communication with LLMs easier: MutableAI introduced a language map that simplifies discussing a codebase with an LLM by converting code into English with a specific structure.
- Adjectiveallison remarked on the creativity of this approach, relating it to the graphrag trend and noting its advantage in the retrieval stage compared to full-on graphs.
- Lumentis project auto-generates comprehensive docs: Adjectiveallison mentioned the public launch of Lumentis project, which generates comprehensive documentation from codebases automatically.
- Adjectiveallison noted that MutableAI's approach improves upon this by integrating these generated docs into a retrieval system.
- Tweet from Vaishaal Shankar (@Vaishaal): We have released our DCLM models on huggingface! To our knowledge these are by far the best performing truly open-source models (open data, open weight models, open training code) 1/5
- Tweet from mutable.ai (@mutableai): http://x.com/i/article/1813813469969543168
- GitHub - hrishioa/lumentis: AI powered one-click comprehensive docs from transcripts and text.: AI powered one-click comprehensive docs from transcripts and text. - hrishioa/lumentis
Nous Research AI ▷ #general (161 messages🔥🔥):
GPT-4o MiniMistral-Nemo-Instruct-2407CrowdStrike OutagesApple DCLM-7BCybersecurity
- GPT-4o Mini vs GPT-3.5-Turbo on Coding Benchmarks: On a coding benchmark, GPT-4o Mini performed on par with GPT-3.5-Turbo, despite being advertised with a HumanEval score that raised user expectations.
- "OpenAI trained it on benchmark data" led one user to express dissatisfaction with the overhyped performance indicators.
- Mistral-Nemo-Instruct-2407 Outperforms Peers: The Model Card for Mistral-Nemo-Instruct-2407 reveals that this model, fine-tuned jointly by Mistral AI and NVIDIA, outperforms models of similar size, featuring a 128k context window and multilingual/code data.
- CrowdStrike Outages Trigger Backlash: CrowdStrike faced major criticism for causing global tech infrastructure outages, which some users believed outweighed any positive contributions.
- While defending the company's efforts against ransomware attacks, another user acknowledged the significant damage but claimed that CrowdStrike has still been a net positive.
- Apple's DCLM-7B Model Released: Apple released the DCLM-7B model, which reportedly outperforms Mistral 7B and comes with a fully open-sourced pretraining dataset, sparking debates on its context length capabilities.
- Although the initial Apple DCLM-7B release features a 2k context length, users expressed hope that future iterations would offer longer context windows.
- DeepSeek Quantization Shows Promising Results: The DeepSeek 1-bit quantization results showed promise for CPU inference, now ranked #7 globally on the LMSYS Arena Hard leaderboard.
- Users discussed the impact of specific quantization techniques like IQ1_S and the potential for higher context lengths.
- Tweet from anton (@abacaj): lol what llama-3 can handle 16k+ context with no training using dynamic scaling
- UCLA-AGI/Gemma-2-9B-It-SPPO-Iter3 · Hugging Face: no description found
- facebook/chameleon-30b · Hugging Face: no description found
- @TuringsSolutions on Hugging Face: "Introducing: 'Synthetic Math Phi'! Literally just press a button, and receive…": no description found
- apple/DCLM-7B-8k · Hugging Face: no description found
- nisten/deepseek-0628-gguf · Hugging Face: no description found
- Tweet from Casper Hansen (@casper_hansen_): Apple released a 7B model that beats Mistral 7B - but the kicker is that they fully open sourced everything, also the pretraining dataset 🤯 https://huggingface.co/apple/DCLM-7B
- mistralai/Mistral-Nemo-Instruct-2407 · Hugging Face: no description found
- Why Gen Z Is Surprisingly Susceptible to Financial Scams: Gen Z is more than three times as likely to fall for online scams compared to boomers. Experts weigh in on why
- Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation: As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress towards better LLM autoraters, we int...
- Tweet from Nathan Lambert (@natolambert): GPT4-o-mini on reward bench Above claude 3 sonnet (not 3.5) and llama 3 70b, below gemma 2 27b. Really all of these are similar. Pretty saturated.
- Tweet from Kyle Corbitt (@corbtt): So gpt-4o mini was absolutely dominating gpt-4o on our internal llm-as-judge evals. So I LOOKED AT THE DATA (h/t @HamelHusain) and realized it was answering the question BUT ALSO throwing in a bunch ...
- N8Programs/PeriodConvo · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (10 messages🔥):
Mistral-Nemo-Instruct GGUF conversionOllama Model IssuesTekken Tokenizer and Llama.cppPretrained Models as Embeddings
- Mistral-Nemo-Instruct GGUF conversion woes: A member struggled with converting Mistral-Nemo-Instruct to GGUF due to issues with BPE vocab and missing tokenizer.model files.
- Despite pulling a PR for Tekken tokenizer support, the conversion script still did not work, causing much frustration.
- Ollama model breaks during loading: A member reported that running Mistral-Nemo-Instruct-12b on Ollama resulted in a tensor dimension mismatch error.
- Loading the model showed an error with a tensor shape mismatch for 'blk.0.attn_q.weight'.
- Tekken vs Sentencepiece tokenizers: A discussion highlighted that llama.cpp and ollama do not yet support Tekken tokenizer, which uses tiktoken like OpenAI models.
- The current converter heavily relies on sentencepiece, complicating conversions for models using Tekken.
- Why use pretrained embeddings in retrieval pipelines?: Why can we use a pretrained model as embedding was asked in the context of retrieval pipelines.
- This points to an interest in understanding the role and advantage of pretrained models in embedding tasks.
Nous Research AI ▷ #rag-dataset (21 messages🔥):
Triplex LLMKnowledge GraphsR2RRAG ApplicationsNeo4j and PropertyGraphStore
- Triplex reduces KG creation cost by 98%: Triplex, a finetuned version of Phi3-3.8B by SciPhi.AI, outperforms GPT-4 at 1/60th the cost for creating knowledge graphs from unstructured data.
- It enables local graph building using SciPhi's R2R platform, cutting down expenses significantly.
- R2R bridges gap between local LLM and scalable RAG: R2R, a platform described as the 'Supabase for RAG,' is designed for scalable, production-ready Retrieval-Augmented Generation applications with multimodal support and hybrid search capabilities.
- Key features include automatic relationship extraction for building knowledge graphs, full authentication for document and user management, and observability for performance analysis.
- Using Triplex with Neo4j for entity relationship extraction: Members used Neo4j PropertyGraphStore with Triplex to extract entities and their relationships from company documents via the integrated API.
- They successfully queried the data for practical applications, like listing YC founders who worked at Google, showing reasonable responses.
- Graph RAG enhances general Q/A tasks: Members discussed how Microsoft's GraphRAG extends knowledge graph capabilities to more subjective datasets, enhancing RAG methods for general question and answer tasks.
- This allows exhaustive population-level queries, proving practical for complex, less definitive query resolutions.
- Exploration of other graph construction tools: Members considered trying out Nebula Graph due to its platform-agnostic capabilities for knowledge graph construction.
- They noted that extracted triples are schema-independent, making them compatible with any knowledge graph provider.
- Introduction - The best open source AI powered answer engine.: no description found
- SciPhi/Triplex · Hugging Face: no description found
Nous Research AI ▷ #world-sim (3 messages):
WorldSim issuesServer downtime resolution
- WorldSim Faces Downtime: A member reported that WorldSim wasn't working, creating concerns about its accessibility.
- Another member assured the issue would be resolved soon, with the final confirmation that it was fixed, thanking the original reporter.
- Server Downtime Quickly Resolved: The downtime issue in WorldSim was promptly addressed and resolved by a team member.
- The fix was implemented quickly, with the responsible team member acknowledging and thanking the community for their patience.
OpenAI ▷ #ai-discussions (174 messages🔥🔥):
GPT-4o mini capabilitiesVoice capabilities speculationsCrowdstrike outage's impactAPI usage for GPT-4o miniComparisons between AI models
- GPT-4o Mini lacks image support due to usage limits: A user noted that GPT-4o mini cannot see images and lacks an option to upload images, leading to a discussion about its limitations.
- Another member explained that it lacks image support due to its status as a cheaper and less intelligent replacement for GPT-3.5.
- Global Windows outage: A significant global outage has been caused by a buggy update from Crowdstrike, affecting numerous industries such as airlines, banks, and hospitals.
- Machines require manual unlocking due to encryption, making the fix slow and expensive, impacting Windows 10 users primarily.
- Uncertain release of Sira: Users speculated about the release of Sira, wondering if it will be available in the API.
- There is no confirmation that Sira will be available for everyone, with users hoping for fuller feature access soon.
- Comparison of AI models accuracy: Members compared the accuracy of Claude Opus and GPT-4o family for technical tasks.
- Some users find Claude Opus less reliable than GPT-4o for technical tasks, with Sonnet 3.5 also being less capable in solving complex questions.
Link mentioned: GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (12 messages🔥):
4o vs. 4o-miniGPT-4 Turbo comparisonFine-tuning 4o miniChatGPT conversation cleanup
- 4o-mini offers speed and cost advantages: Members discussed that 4o mini is approximately 2x faster than 4o and is 60% cheaper than 3.5 Turbo, making it a cost-efficient choice. However, it scores lower than 4o in benchmarks as noted here.
- *
- GPT-4o outperforms in benchmarks: GPT-4o scores higher than GPT-4 Turbo in benchmarks, but actual effectiveness depends on specific use cases.
- There is no consensus on the ultimate superiority as use-case variability plays a significant role.
- Fine-tuning 4o mini expected in six months: A member inquired about the timing for fine-tuning 4o mini and received an estimate of around 6 months.
- *
- Cleaning up ChatGPT conversations manually tedious: A user asked if there is a way to clean up multiple conversations in ChatGPT quickly. The responses indicated that unless you delete all chats, the process remains manual for now.
- Users hope for future quality of life improvements in this area.
Link mentioned: GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
OpenAI ▷ #prompt-engineering (4 messages):
Glassmorphic UI for Code Snippet LibraryAvoiding unwanted AI notationsPrompt engineering suggestions
- Create Glassmorphic Code Snippet Library: A user requested a code snippet library using HTML, CSS, and JavaScript with a glassmorphic UI and a dynamically changing gradient background.
- It should feature code snippet management functionalities like adding, viewing, editing, and deleting snippets, and include a 'Copy' button for each snippet.
- Avoid Unwanted AI Notations: A member expressed concerns about the AI responding with notations like “【5:15†source” and provided an example of an unsatisfactory explanation from the AI on what it represents.
- They asked for prompt engineering suggestions to prevent these types of replies from the AI.
OpenAI ▷ #api-discussions (4 messages):
Prompt Engineering for file_searchDynamic Glassmorphic UI Library
- Prompt Engineering Suggestions to Avoid Undesired Notations: A member sought suggestions for prompt engineering to avoid AI responses containing notations like '【5:15†source' during file searches.
- The solutions tried to specify avoiding these replies, but it remains an issue, prompting a request for further hints.
- Create Dynamic Glassmorphic UI Library: A request was made for a dynamic, visually appealing code snippet library using HTML, CSS, and JavaScript featuring an animated gradient background, glassmorphic UI, and functionalities for managing code snippets.
- The functionalities include adding, viewing, editing, deleting snippets, and copying code to the clipboard, all while maintaining responsive design and cross-browser compatibility.
Modular (Mojo 🔥) ▷ #general (69 messages🔥🔥):
GPU support in MojoLearning low-level programming concepts for MojoSocket implementations in MojoChoosing between epoll and io_uring for network processingSecurity concerns with io_uring
- Parallelizing GPU operations in Mojo: Mojo will allow parallelizing operations directly, leveraging a partnership with NVidia to enable CUDA/NVidia support, expected to be announced soon.
- For higher control, developers can utilize custom Mojo kernels inside of MAX while those preferring automation can let the compiler manage it.
- Transitioning from Python to Mojo for low-level programming: A user shared their transition concerns from Python to Mojo and considered learning C, CUDA, and Rust first, fearing lack of documentation in Mojo.
- Community members emphasized the concept of 'Progressive Disclosure of Complexity,' and encouraged inquiring about and documenting the learning journey to help shape Mojo’s ecosystem.
- Implementing socket functionality in Mojo: Discussions revolved around finding clean socket implementations, suggesting Rust’s implementation might be a good reference despite 'ifdef hell' concerns.
- Members highlighted the need to prioritize completion-based APIs like io_uring for Linux due to its performance benefits over traditional polling APIs.
- Comparing epoll and io_uring for Mojo’s network processing: Tigerbeetle's abstraction insights were shared, highlighting the benefit of using io_uring and kqueue for fewer unifications issues as compared to epoll.
- The suggestion was made to give preference to io_uring over epoll for higher performance and unified completion-based API handling.
- Addressing the security of io_uring: Concerns were raised about io_uring vulnerabilities, noting that 60% of Linux kernel exploits targeted io_uring in 2022 as reported by Google.
- Despite security concerns, the community believes that ongoing hardening makes io_uring favorable over alternatives, as even a 50% performance reduction would still keep it faster than epoll.
- Kernel TLS — The Linux Kernel documentation: no description found
- Asynchronous and Direct IO for PostgreSQL on FreeBSD Thomas Munro: Full description at https://www.bsdcan.org/events/bsdcan_2022/schedule/session/90-asynchronous-and-direct-io-for-postgresql-on-freebsd/
- YouTube: no description found
- A Programmer-Friendly I/O Abstraction Over io_uring and kqueue: The financial transactions database to power the next 30 years of Online Transaction Processing.
- GitHub - dmitry-salin/io_uring: The io_uring library for Mojo: The io_uring library for Mojo. Contribute to dmitry-salin/io_uring development by creating an account on GitHub.
- sctp(7) - Linux manual page: no description found
- rustix/src/net at main · bytecodealliance/rustix: Safe Rust bindings to POSIX-ish APIs. Contribute to bytecodealliance/rustix development by creating an account on GitHub.
- rfcs/text/3128-io-safety.md at master · rust-lang/rfcs: RFCs for changes to Rust. Contribute to rust-lang/rfcs development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #✍︱blog (18 messages🔥):
Mojo DebuggingDeveloper ToolingMojo Test DebuggingLLDB-DAPWSL Debugging Issues
- Mojo improves debugging tools: Mojo and MAX prioritize advanced debugging tools over traditional Python, C++, and CUDA stacks, improving the debugging experience especially for machine learning tasks by extending to GPUs. Learn more.
- 'The goal is to show how simple and powerful debugging is with Mojo' says a developer in the channel.
- Simplify debugging setup in Mojo: Setting up Mojo debugging in VS Code is facilitated by the Mojo extension and can be adapted to other editors using LLDB-DAP. Future enhancements will allow stepping through CPU code into GPU calls seamlessly.
- 'It's aimed at general debugging if you have no experience with it, but goes over all the currently implemented Mojo features.'
- Fix for debugging Mojo test subfolder: To debug tests in subfolders with
mojo test, use a symbolic link and add a main function wrapper as recommended by a user.- 'I got it to work by adding a symbolic link... also have to add main fn to your tests' was discussed as a workaround.
Link mentioned: Modular: Debugging in Mojo🔥: We are building a next-generation AI developer platform for the world. Check out our latest post: Debugging in Mojo🔥
Modular (Mojo 🔥) ▷ #mojo (30 messages🔥):
Alias tuple of FloatLiteralsBenchmark confusionCustom Mojo version installationAnti-pattern discussionC interop via OpenSSL
- Alias Tuple of FloatLiterals Requires Explicit Declaration: A user discovered that you must explicitly declare
Tuple[FloatLiteral, FloatLiteral](1.0, 2.0)on nightly builds asalias Nums = (1.0, 2.0)types as a variadic pack.- There was also a suggestion to consider using
InlineArrayif onlyFloatLiteralsare being used.
- There was also a suggestion to consider using
- Benchmark Utility Lacks Wall Time Tracking: A user was confused by the
benchmarkmodule, noting that it seems to lack wall time tracking and questioned its location in the repo.- The user shared a benchmark report showing inconsistent mean times and humorously admitted their confusion with a gaming reference.
- Installing Custom Mojo Version Guidance: A user asked how to install a custom Mojo version and was directed to an answer in the
bot-helpchannel.- Direct links and further assistance were provided for clarity.
- Anti-Pattern in Conditional Conformance Workaround: A user humorously labeled their workaround as an 'anti-pattern', to which others agreed it looked like a workaround for conditional conformance issues.
- There was a light-hearted exchange with the user promising to provide a better solution to avoid scaring anyone.
- C Interop via OpenSSL: A discussion highlighted that OpenSSL is significantly large, with one project reaching an 800 MB
.mojofile.- The goal was stated as achieving C interop through postprocessing on the output of
mlir-translate --import-llvm.
- The goal was stated as achieving C interop through postprocessing on the output of
Modular (Mojo 🔥) ▷ #max (5 messages):
MAX vs openXLAMojo vs JAXCustom ops with Mojo
- MAX and openXLA Comparison: Members discussed how MAX compares to openXLA and JAX which uses an architecture by Google supporting OpenXLA.
- darkmatter__ highlighted that MAX, being lazy and building a computation graph, allows for many optimization opportunities compared to JAX.
- Mojo Beats JAX on Multiple Levels: A member shared that Mojo outperforms JAX on CPUs in benchmarks, even though JAX is optimized for many-core systems.
- darkmatter__ explained that Mojo has better compiler visibility and optimization capabilities than JAX.
- Custom Operations in Mojo: Mojo allows for implementing custom operations, providing more flexibility than JAX or Python.
- darkmatter__ indicated that although Mojo currently loses to C++ or Rust, it has the potential for future compiler improvements.
Modular (Mojo 🔥) ▷ #max-gpu (2 messages):
MAX vs openXLAGoogle's open projects
- Comparison between MAX and openXLA: A member questioned how MAX compares to openXLA, noting that Jax is fast and uses an architecture supported by major players like Google.
- Criticism of Google’s approach to open projects: OpenXLA is criticized as being mostly a Google-only project, with concerns about Google being bad at anything 'open'.
Modular (Mojo 🔥) ▷ #nightly (17 messages🔥):
Contributor Meeting & Incubator AlignmentCommunity Contribution ValueAsync IO API StandardsStdlib Opt-OutMojo Nightly Update 2024.7.1905
- Contributor Meeting Proposal Evaluated: A discussion ensued about separating contributor meetings from community meetings to address concerns that the incubator might misalign with Modular’s work.
- It was noted that Modular has shown interest in integrating stdlib contributions and incubators help judge API and popularity before committing to the stdlib.
- Community Validates API Proposals: Members argued that community feedback is crucial before incorporating proposals into the stdlib to avoid issues seen in languages like Rust.
- Specific use cases like allocator awareness could benefit from this community filtering, as discussed in this proposal.
- Debate on Async IO API Standards: A member highlighted the need for async IO APIs in Mojo that support higher performance models by handling buffers effectively.
- The discussion referenced Rust's challenges, emphasizing avoiding a split between performance-focused and mainstream libraries.
- Potential for Opt-Out of Stdlib: Members discussed the possibility of a way to disable or opt-out of the stdlib in Mojo.
- While Mojo’s current handling of including only used parts makes it less necessary, it was likened to Rust’s
no_stdfeature.
- While Mojo’s current handling of including only used parts makes it less necessary, it was likened to Rust’s
- Mojo Nightly Compiler Update 2024.7.1905: Mojo’s nightly compiler update 2024.7.1905 was released, featuring the new stdlib function
Dict.setdefault(key, default).- View the raw diff for detailed changes.
Link mentioned: mojo/proposals/stdlib-extensions.md at proposal_stdlib_extensions · gabrieldemarmiesse/mojo: The Mojo Programming Language. Contribute to gabrieldemarmiesse/mojo development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #mojo-marathons (1 messages):
punishedjamesthesnake: nice
LM Studio ▷ #💬-general (83 messages🔥🔥):
Mistral Nvidia CollaborationLM Studio Server with RAGOpen WebUI FeaturesSCALE Toolchain for AMD GPUsCustom HF Model Integration
- Mistral Nvidia collaboration announced: Mistral Nvidia collaboration introduced Mistral-Nemo 12B, offering a large context window and state-of-the-art performance, but it's not yet supported in LM Studio.
- Tokenizer support in llama.cpp is required to make Mistral-Nemo compatible.
- Implement RAG and TTS in LM Studio: Members discussed how to implement RAG and TTS features in LM Studio, suggesting Open WebUI as an alternative that already supports these features.
- Multiple frontends like ChatterUI and Msty were recommended for accessing LM Studio server via different devices.
- Exciting features in Open WebUI: Open WebUI offers extensive features including TTS, RAG, and internet access without requiring Docker.
- Users shared their positive experiences in setting it up on Windows 10 and the flexibility it provides, with interest in comparing its performance to Pinokio.
- SCALE toolkit enables CUDA on AMD GPUs: The new SCALE toolkit from Spectral Compute allows CUDA applications to run on AMD GPUs effortlessly, simplifying software transitions.
- Despite the innovative leap, users mentioned its downside of not being open-source.
- Integrating custom HF model with LM Studio: A user sought guidance on integrating a custom HF model based on llama 3 with LM Studio, receiving advice on converting to GGUF and submitting PRs to llama.cpp and Hugging Face.
- Contacting experts on Hugging Face like mradermacher was suggested for further assistance on model conversions.
- Mistral NeMo: Mistral NeMo: our new best small model. A state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
- Overview of Conversational AI Assistant with Memory - AI Code Explained: Discover the capabilities of our advanced Conversational AI Assistant with Memory! 🌟In this video, we'll provide a detailed overview of a sophisticated AI s...
- Як я розробив чат-бот зі штучним інтелектом: У цій статті Сергій Труш розповідає про один зі своїх тривалих опенсорс пет-проєктів, робота над яким триває останні три місяці. Йдеться про репозиторій TelegramAIChatbot - україномовний телеграм чат-...
- New SCALE tool enables CUDA applications to run on AMD GPUs: By recompiling CUDA programs for AMD GPUs
- Pinokio: AI Browser
- What Is Retrieval Augmented Generation (RAG)? | Google Cloud: Retrieval augmented generation (RAG) combines LLMs with external knowledge bases to improve their outputs. Learn more with Google Cloud.
- GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI): User-friendly WebUI for LLMs (Formerly Ollama WebUI) - open-webui/open-webui
- GitHub - vosen/ZLUDA: CUDA on AMD GPUs: CUDA on AMD GPUs. Contribute to vosen/ZLUDA development by creating an account on GitHub.
LM Studio ▷ #🤖-models-discussion-chat (26 messages🔥):
DeepSeek-V2-Chat-0628GGUF model performanceModel VRAM requirementsCustom dataset creationNew jail-breaking technique for frontier models
- DeepSeek-V2-Chat-0628 hits top ranks on LMSYS Leaderboard: DeepSeek-V2-Chat-0628, with 236B parameters, is open-sourced and ranked as No.1 open-source model on the LMSYS Chatbot Arena Leaderboard.
- It holds top positions: Overall No.11, Hard Prompts No.3, Coding No.3, Longer Query No.4, Math No.7.
- Efficiency of GGUF model with VRAM: A discussion on whether having more than 21GB of VRAM improves performance pointed out that loading all 236B parameters to VRAM or RAM is optimal.
- It was highlighted that fitting more into VRAM can help even if the entire model cannot be fully loaded.
- Creating custom datasets easily: A noob user asked for the easiest way to create a custom dataset.
- They were guided to use augmentoolkit for converting compute and books into instruct-tuning datasets or classifiers.
- New jail-breaking technique for frontier models: A user shared a new jail-breaking technique that is effective for frontier models.
- They suggested using it while it's not patched.
- Tweet from DeepSeek (@deepseek_ai): 🎉Exciting news! We open-sourced DeepSeek-V2-0628 checkpoint, the No.1 open-source model on the LMSYS Chatbot Arena Leaderboard @lmsysorg. Detailed Arena Ranking: Overall No.11, Hard Prompts No.3, Co...
- bullerwins/DeepSeek-V2-Chat-0628-GGUF · Hugging Face: no description found
- GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets (or classifiers)!: Convert Compute And Books Into Instruct-Tuning Datasets (or classifiers)! - e-p-armstrong/augmentoolkit
LM Studio ▷ #⚙-configs-discussion (5 messages):
Mistral BPELM Studio Compatibilityllama.cpp Supportlmdeploy RAM Limitation
- Mistral BPE tokenization issues in LM Studio: A user encountered a
llama.cpp errorwith an unknown pre-tokenizer type 'mistral-bpe' while trying to load a model.- It won’t work in this version of LM Studio and isn't supported in
llama.cppyet as confirmed by another user.
- It won’t work in this version of LM Studio and isn't supported in
- llama.cpp adds support for BPE pre-tokenization: A user noted that
llama.cpphas added BPE pre-tokenization support in PR #6920.- Another user mentioned that LM Studio is a bit behind on llama.cpp versions, so it may take an update or two before it sees support.
- LM Studio compatibility with lmdeploy: A user tried using
lmdeploywith 24GB of RAM but found it insufficient.- This indicates that the current hardware might not meet the RAM requirements for the successful deployment of models using
lmdeploy.
- This indicates that the current hardware might not meet the RAM requirements for the successful deployment of models using
LM Studio ▷ #🎛-hardware-discussion (10 messages🔥):
Future of LLM hardwareTSMC AI Chip Supply PredictionsRunning NVidia Tesla P40 on WindowsVulcan support for Tesla P40NVidia Tesla P40 Drivers
- Running LLMs without expensive GPUs may take time: A user questioned the feasibility of running large language models on hardware other than costly GPUs, such as PCIE NPUs or ASICs, within the next 1-2 years.
- No balance in AI chip supply till 2025-2026 says TSMC CEO: TSMC's CEO predicts that the supply-demand balance for advanced AI chips won't be achieved until 2025 or 2026 due to high customer demand and packaging bottlenecks.
- Mixed results running NVidia Tesla P40 on Windows: Users shared their experiences running NVidia Tesla P40 GPUs alongside other GPUs on Windows 10, noting the use of data center and studio RTX drivers.
- One user noted that although the P40 is slow, it's still faster than CPU inference.
- Compatibility issues with Tesla P40 and Vulcan: A user highlighted obstacles to getting Vulcan support on their Tesla P40, mentioning that numerous installations might be necessary and virtualization may need to be enabled.
Link mentioned: TSMC CEO predicts AI chip shortage through 2025... 2026: Overseas expansion to continue, insists C.C. Wei
LM Studio ▷ #amd-rocm-tech-preview (1 messages):
aptronym: If you guys had a portable install option I could
Latent Space ▷ #ai-general-chat (87 messages🔥🔥):
Llama 3 releaseSelf-Play Preference Optimization (SPPO)Sonnet Refusals and SpeculationOpen-source DCLM 7B Model by AppleSnowflake Arctic Embed Update
- Llama 3 release imminent: Llama 3 with 400 billion parameters is rumored to release in 4 days, igniting excitement and speculation within the community.
- Self-Play Preference Optimization (SPPO) paper sparks interest: SPPO (Self-Play Preference Optimization) is noted for its potential, but skepticism exists regarding its long-term effectiveness after a few iterations.
- Speculation on Sonnet Refusals: Sonnet's refusal behavior, described as dogmatic yet capable of exceptional rationality upon reflection, is raising eyebrows.
- Apple open-sources DCLM 7B model: Apple released the DCLM 7B model, which surpasses Mistral 7B and is entirely open-source, including training code and datasets.
- Snowflake Arctic Embed 1.5 boosts retrieval system scalability: Snowflake introduced Arctic Embed M v1.5, delivering up to 24x scalability improvement in retrieval systems with tiny embedding vectors.
- Tweet from Casper Hansen (@casper_hansen_): Apple released a 7B model that beats Mistral 7B - but the kicker is that they fully open sourced everything, also the pretraining dataset 🤯 https://huggingface.co/apple/DCLM-7B
- Tweet from xjdr (@_xjdr): the next set of things people might want to look at: - tree search aided synthetic data generation - SPPO - Very large to smol model distillation - Mixture of Depth also potentially relevant, near...
- Tweet from Daniel Campos (@spacemanidol): 🚀 Introducing Arctic Embed M v1.5! Unleashing up to 24x improvement in retrieval system scalability with tiny embedding vectors. https://huggingface.co/Snowflake/snowflake-arctic-embed-m-v1.5 55+ on ...
- Tweet from Vaishaal Shankar (@Vaishaal): We have released our DCLM models on huggingface! To our knowledge these are by far the best performing truly open-source models (open data, open weight models, open training code) 1/5
- Intelligent Digital Agents in the Era of Large Language Models: This Position Paper provides an overview of current research areas and breakthroughs in LLM-based AI agents. We highlight key advancements and discuss limitations within each area.
- Tweet from Maksym Andriushchenko @ ICML'24 (@maksym_andr): 🚨Excited to share our new paper!🚨 We reveal a curious generalization gap in the current refusal training approaches: simply reformulating a harmful request in the past tense (e.g., "How to make...
- DataComp: no description found
- Tweet from Alex Reibman 🖇️ (@AlexReibman): Happy birthday @ollama!! Here’s a sneak peak at what’s launching next: Ollama Agents 👀 Native support for LLM tool calls is coming
- Tweet from Omar Sanseviero (@osanseviero): Snowflake just open-sourced snowflake-arctic-embed: a family of powerful embedding models 🤏22 to 335 million parameters 💾384-1024 embedding dimensions 🔥50-56 MTEB score (sota for thei sizes) Thi...
- Tweet from Omar Sanseviero (@osanseviero): New @SnowflakeDB Arctic Embed model! A 109M model that can do embedding quantization + Matryoshka to go down to 128-byte byte embedding vectors. https://huggingface.co/Snowflake/snowflake-arctic-e...
- Tweet from swyx 🤞 🔜 SFO (@swyx): If youre interested in LLMs for summarization, my @smol_ai eval of GPT 4o vs mini is out TLDR: - mini is ~same/mildly worse in some cases - but because mini is 3.5% the cost of 4o - I can run 10 ve...
- Tweet from j⧉nus (@repligate): On Claude 3.5 Sonnet and refusals: 1. Sonnet has a tendency to reflexively shoot down certain types of ideas/requests and will make absurd, dogmatic claims that contradict everything it knows about t...
- no title found: no description found
- Tweet from Rohan Paul (@rohanpaul_ai): OpenAI is too cheap to beat
- Tweet from Ivory Tang (@ivory_tang): Absolutely astounding to think about what spatial intelligence has enabled… generate an infinite scene from an image, a 360 view of a 3D furnished room from text, perform a wide range of tasks with a ...
- Tweet from Philipp Schmid (@_philschmid): Apple has entered the game! @Apple just released a 7B open-source LLM, weights, training code, and dataset! 👀 TL;DR: 🧠 7B base model, trained on 2.5T tokens on an open datasets 🌐 Primarily Englis...
- Tweet from Logan Kilpatrick (@OfficialLoganK): New guide on using long context as a @GoogleAI developer ✨ This guide covers insights and research including: - Performance across different modalities - How in-context learning works - Long context ...
- Tweet from Nick Dobos (@NickADobos): OpenAI had to make the ai dumber so idiot humans could understand it Quoting OpenAI (@OpenAI) We trained advanced language models to generate text that weaker models can easily verify, and found it...
- SunLab, part of OSUNLP | Natural Language Processing, Artificial Intelligence, LLMs and Agents: no description found
- [AINews] Mini, Nemo, Turbo, Lite - Smol models go brrr (GPT4o-mini version): the first GPT4o Mini issue! AI News for 7/17/2024-7/18/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (467 channels, and 2324 messages) for you....
- [AINews] Mini, Nemo, Turbo, Lite - Smol models go brrr (GPT4o version): Efficiency is all you need. AI News for 7/17/2024-7/18/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (467 channels, and 2324 messages) for you....
Latent Space ▷ #ai-in-action-club (29 messages🔥):
GitHub OverviewLayout DetectionTask DecompositionMathpix ComparisonDataset Creation
- VikParuchuri's GitHub Profile Shared: A member shared the GitHub profile of VikParuchuri, showcasing 90 repositories available on the platform.
- Classical Object Detection in Layout Detection: A member asked, 'How does the layout detection work? Classical object detection with lots of training data?'
- Clarification on whether the method involves classical object detection techniques was sought without a specified answer provided in the messages.
- Good Task Decomposition Highlighted: Task decomposition was praised as a perfect example of effective task division.
- Members discussed how it helps in breaking down complex problems into more manageable tasks.
- Texify vs Mathpix: A comparison was raised on how Texify stacks up against Mathpix in terms of functionality.
- Further details or answers to this comparison were not provided within the messages.
- Training Dataset for Reading Order Model: Query on the creation of the training dataset for the reading order model, whether labeled manually or using heuristics.
- 'Great thanks!!' was the feedback after the explanation was given, specific steps or methods were not included.
Link mentioned: VikParuchuri - Overview: VikParuchuri has 90 repositories available. Follow their code on GitHub.
CUDA MODE ▷ #general (5 messages):
Nvidia open-sourcing kernel modulesAnti-trust laws influenceCompatibility and maintenance benefits
- US Anti-Trust Laws May Have Influenced Nvidia: Speculation arose around Nvidia being forced by the US due to anti-trust laws to open-source their kernel modules.
- One user suggested, 'my guess is that maintaining a kernel module is not the core business of Nvidia, so making it open may allow better compatibility without having to keep high skill kernel developers around'.
- Debate on Nvidia's Reasons for Open Sourcing: Another viewpoint suggested that maintaining kernel modules isn't central to Nvidia's business, positing open-sourcing could improve compatibility and reduce the need for specialized development staff.
- Debate highlighted the potential operational and strategic benefits Nvidia might gain by this move.
CUDA MODE ▷ #torch (15 messages🔥):
Float8 in PyTorchStochastic RoundingMulti-GPU Setup for DDP and FSDPINT8 Weight TrainingQuantization Aware Training
- Float8 weights introduce dynamic casting from BF16: Various members discussed the dynamic casting of weights stored as BF16 to FP8 for matmul in PyTorch, referencing float8_experimental.
- Interest was also expressed in implementing stochastic rounding for weight updates in FP8, with potential support from Meta's compute resources.
- Stochastic rounding lacks built-in support in CUDA Math API: A member pointed out the absence of BF16->FP8 dtype casting instruction with stochastic rounding in the CUDA Math API, suggesting software implementation might be necessary.
- The complexity of ensuring identical weight updates across GPUs in DDP and handling FSDP with independent SR was also discussed, adding another layer of challenge.
- Experimentation with INT8 weight training inspired by Q-Galore: Members showed interest in replicating Q-Galore's success in pre-training Llama-7B with INT8 weights, emphasizing stochastic rounding's role.
- It was noted that Q-Galore's method involves BF16 gradients, similar to the float8_experimental repo, which might offer insights into INT8 training.
- Potential of stochastic rounding in multi-GPU setups: Stochastic rounding in multi-GPU setups was explored, with a significant discussion on how it affects data parallelism and weight consistency across GPUs.
- The feasibility of using
.view(dtype)to balance data type requirements in PyTorch was questioned.
- The feasibility of using
- pytorch/torch/optim/adam.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- pytorch/torch/optim/adamw.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
CUDA MODE ▷ #algorithms (5 messages):
Hybrid Distributed AlgorithmsRing Attention Memory CalculationSequence Parallelism PaperBackwards CalculationPrivate Tutor Inquiry
- Student seeks help on hybrid distributed algorithms: A student is learning hybrid distributed algorithms like SP (Ulysses), TP, and PP and is seeking a private tutor willing to provide assistance and answer questions.
- They have numerous questions about specific calculations such as memory and communication complexity.
- Ring Attention Memory Calculation Query: The student asked for clarification on how memory is calculated with ring attention style SP, specifically the origin of the values 32 and 4.
- I have tons of questions like this the student noted, indicating a deeper interest in understanding the topic.
- Sequence Parallelism Paper Discussion: Another user requested a link to the sequence parallelism paper to better understand and contribute advice on the calculation methods being asked.
- They clarified their need to know whether the questions were about general backward pass calculations or specifics related to the paper.
CUDA MODE ▷ #cool-links (25 messages🔥):
FSDP support in tinygradTogether Inference Enginetinygrad bountiesRust CUDA kernelstinygrad tutorials
- Tinygrad Bounty List Discussed: Members discussed several bounties for contributing to tinygrad, including detailed tasks like splitting UnaryOps.CAST and converting BinaryOps.DIV.
- Some felt the compensation wasn't worth the effort, noting extensive GPU compute costs.
- FSDP Support for Tinygrad: A member offered $500 for adding FSDP support to tinygrad, prompting discussions about the feasibility and value of the task.
- One user commented they could do it but would need a week or two, finding $500 'insultingly low'.
- Together Inference Engine Launch: Together AI announced a new inference stack that outperforms open-source and commercial solutions, achieving 400 tokens per second on Meta Llama 3 8B.
- They also introduced Together Turbo and Together Lite, offering performance, quality, and price flexibility for enterprises.
- Tinygrad Study Notes Available: A member shared tinygrad study notes aimed at helping users understand the internals of tinygrad.
- These notes include a quickstart guide and details on kernel fusion, GPU code generation, and more.
- Creating CUDA Kernels in Rust: A user shared a link to a GitHub repo for cubecl, a multi-platform high-performance compute language extension for Rust.
- This allows for the creation of CUDA kernels with a comptime system for specialization and optimal performance.
- Tutorials on Tinygrad: Tutorials on tinygrad
- TT-QuietBox: The TT-QuietBox Liquid-Cooled Desktop Workstation offers superior performance per dollar for developers looking to run, test, and develop AI models, or port and develop libraries for HPC.
- Announcing Together Inference Engine 2.0 with new Turbo and Lite endpoints: no description found
- GitHub - cloneofsimo/min-fsdp: Contribute to cloneofsimo/min-fsdp development by creating an account on GitHub.
- Bounties: tinygrad Bounties Short Description,Value,Link,GitHub Owner Split UnaryOps.CAST into UnaryOps.CAST and UnaryOps.BITCAST,$100,<a href="https://github.com/tinygrad/tinygrad/pull/4487">h...
- GitHub - tracel-ai/cubecl: Multi-platform high-performance compute language extension for Rust.: Multi-platform high-performance compute language extension for Rust. - tracel-ai/cubecl
CUDA MODE ▷ #beginner (3 messages):
Nsight Compute file exportNsight Compute CLI User GuideOpening ncu-rep files
- Nsight Compute allows profile export: A suggestion was made to export the captured profile to a file, which can then be opened from the Nsight Compute GUI.
- Nsight Compute CLI User Guide detailed: The User Guide for Nsight Compute CLI provides comprehensive instructions, including a section on launching target applications and migrating from nvprof.
- The guide covers using the command line profiler to print results directly to the command line or store them in a report file.
- Nsight Compute opens ncu-rep files: Nsight Compute can open
ncu-repfiles, providing flexibility for users to analyze the results.
Link mentioned: 4. Nsight Compute CLI — NsightCompute 12.5 documentation: no description found
CUDA MODE ▷ #torchao (7 messages):
FSDP2 AdoptionLow-Bit Optimizer with FSDP2DTensor Support for Low-Bit Optimizer1-bit Adam Optimizer
- FSDP2 set to Replace FSDP: It was mentioned that FSDP2 will replace FSDP, and using FSDP2 is required going forward, with nf4 as an example implementation.
- Low-bit Optimizer and FSDP2 Compatibility: A conversation with the FSDP2 author clarified that low-bit optimizers don't need to handle FSDP logic as FSDP still provides fp32 sharded parameters.
- The low-bit optimizer can treat these parameters as inputs without worrying about forward/backward FSDP logic.
- DTensor and Custom Subclass Integration: Issues were discussed regarding integrating tensor subclass with DTensor, including creating a DTensor for a subclass using functions like
distribute_tensor().- Handling gather and scatter operations for DTensor in low-bit optimizers was raised as a significant challenge.
- 1-bit Adam for Communication Overhead Reduction: The potential of 1-bit Adam to reduce communication overhead by quantizing gradients was mentioned.
- Its complexity and difference from the current low-bit optimization approach were acknowledged.
- Experience with DTensor Support for Low-Bit Optimizer: One member shared their experience on DTensor support and the importance of the order of wrapping and composability with FSDP2.
- The member noted that implementing these features introduced several operational challenges beyond those faced with simpler tensor operations.
- ao/torchao/prototype/low_bit_optim/adam.py at cbaff6c128d97ff4d26ab60fa5b06c56cd23ba2a · pytorch/ao: Custom data types and layouts for training and inference - pytorch/ao
- float8_experimental/float8_experimental/float8_tensor.py at 7f0d6bbb531d5d76d27d80c9ec3c7eca61de5dfa · pytorch-labs/float8_experimental: This repository contains the experimental PyTorch native float8 training UX - pytorch-labs/float8_experimental
- float8_experimental/float8_experimental/float8_ops.py at 7f0d6bbb531d5d76d27d80c9ec3c7eca61de5dfa · pytorch-labs/float8_experimental: This repository contains the experimental PyTorch native float8 training UX - pytorch-labs/float8_experimental
CUDA MODE ▷ #triton-puzzles (1 messages):
Gradio Share Link ErrorGradio Status Page
- Gradio Share Link Creation Fails: A member encountered an error message stating 'Could not create share link. Please check your internet connection or our status page' while using Gradio.
- No additional context or links provided by the member.
- Gradio Status Page Clarification: The error message included a link to the Gradio Status Page, which provides uptime and status updates for the past 90 days.
- No additional context or links provided by the member.
Link mentioned: Gradio Status: no description found
CUDA MODE ▷ #hqq (2 messages):
HQQ+ 2-bit Llama3-8B-Instruct modelBitBlas integration performance
- HQQ+ 2-bit Llama3-8B-Instruct model announced: A new experimental model, HQQ+ 2-bit Llama3-8B-Instruct, is introduced, using the BitBlas backend and a 64 group-size quantization, reducing quality loss with a low-rank adapter calibration.
- The model is claimed to be fully compatible with BitBlas and
torch.compilefor fast inference despite Llama3-8B being difficult to quantize at low bits.
- The model is claimed to be fully compatible with BitBlas and
- BitBlas performance issues discussed: A user commented that BitBlas looks impressive on paper but exhibits performance drops when integrated end-to-end with a model, especially at larger context sizes and batch sizes.
- Performance degradation at larger context-sizes / batch-sizes was highlighted as an issue despite theoretical advantages.
Link mentioned: mobiuslabsgmbh/Llama-3-8b-instruct_2bitgs64_hqq · Hugging Face: no description found
CUDA MODE ▷ #llmdotc (43 messages🔥):
GPT-2 and GPT-3 TrainingKernel OptimizationMeeting DiscussionsPrecision HandlingUpcoming CUDA MODE IRL
- Yuchen's 7.3B model training: Yuchen trained a 7.3B model using karpathy's llm.c with 32 H100 GPUs, achieving 327K tokens/s and an MFU of 46.7%, described as having linear scaling.
- "Due to some parameters in the 7.3B model being quite large, the current llm.c code has integer overflow as it uses a 32-bit int to store the number of bytes for weights and do malloc. I changed some 'int' to 'size_t' to make it work."
- Kernel optimization in pull request: Arund42 notified the group about a new PR to simplify & optimise the backward bias kernel, mentioning that the new kernel is close to a general-purpose column reduction.
- The actual kernel is only 33 lines of code excluding comments, and there are plans to possibly generalize it further by adding a stride.
- Upcoming CUDA MODE IRL in SF: Members are invited to 'CUDA MODE IRL' by MarkSaroufim in San Francisco on September 21.
- There’s enthusiastic agreement on attending, with a plan to discuss interesting aspects of building llm.c in a 20-minute talk, covering topics like the train_gpt2.c story and adventures in cuBLAS and cuDNN.
- Precision handling and checkpoint strategy discussion: A discussion unfolded on whether it would be beneficial to store generic “always FP32” checkpoints to easily change precision mid-run.
- Eriks.0595 suggested the current system already stores master weights and optimizer states in FP32, making changes to the checkpoint file format unnecessary.
- Memory optimization: It was pointed out that llm.c significantly outperforms torch.compile in terms of memory optimization.
- no title found: no description found
- NVIDIA CUDA and cuDNN Installation Feedback: NVIDIA wants to hear from you on your experiences installing CUDA and cuDNN! Your anonymous feedback is important to us as we work to improve the ease of use of our software stack.
- CUDA MODE IRL invitation: This is a formal invitation to the first ever CUDA MODE IRL Hackathon and we'd like to invite you to give one of our keynote talks. The event is being sponsored by Accel and will be hosted in the...
- Tweet from Yuchen Jin (@Yuchenj_UW): Let's go even deeper! Training GPT-2 (7.3B) using @karpathy's llm.c with 32 H100 GPUs. *GPUs go brrr at night* 🔥 - Setup: 4 H100 nodes connected with 400Gb/s InfiniBand - Training speed: 327...
- Simplified/faster "backward bias" kernel (column reduction) by ademeure · Pull Request #699 · karpathy/llm.c: Inspired by the simplified kernel I made yesterday for train_gpt2fp32.cu, this is a column reduction kernel (currently specialised to backward bias but really quite generic) that is much simpler an...
- Let's reproduce GPT-2 (1.6B): one 8XH100 node, 24 hours, $672, in llm.c · karpathy/llm.c · Discussion #677: In this post we are reproducing GPT-2 in llm.c. This is "the GPT-2", the full, 1558M parameter version that was introduced in OpenAI's blog post Better Language Models and their Implicat...
- Model init cleanup by ngc92 · Pull Request #694 · karpathy/llm.c: consolidate model parameter allocation to a single source location made gradient buffer accumulation eager moved encoder determinism helper buffers so that they are eagerly allocated by forward -> ...
CUDA MODE ▷ #lecture-qa (6 messages):
Ring Attention in TorchGenerating Triton Kernel with torch.compileArithmetic Intensity for Memory or Compute Bound Check
- Ring Attention Torch vs. Jax: A member asked if there is any implementation of Ring Attention in Torch or if Jax has to be used instead.
- Generating Triton Kernel using torch.compile: A user struggled with generating Triton kernels via
torch.compile, sharing a code snippet and encountering several issues.- After guidance, it was pointed out that the tensor needs to be on GPU for successful compilation, which resolved the issue.
- Arithmetic Intensity for Memory or Compute Bound Checks: A question arose about using arithmetic intensity of 1 to determine if a task is memory-bound or compute-bound on a GPU.
- Doesn't this depend on GPU specs like FLOPS/GB/s bandwidth for DRAM/HBM, and can this ratio be as high as 20 for certain GPUs?
CUDA MODE ▷ #youtube-watch-party (1 messages):
mr.osophy: I like this idea, I'm curious how well did these sessions go? <@1221046138249936939>
Perplexity AI ▷ #general (96 messages🔥🔥):
Claude 3 Haiku vs GPT-4o miniPro search quality dropCollection prompts issueSonnet 3.5 not following promptsPerplexity Pro Image generation
- Pro users report drop in search quality: Some members, especially those using Claude Sonnet 3.5, have noticed a significant drop in the quality of Pro searches over the past 8-9 days.
- GPT-4o mini set to replace Claude 3 Haiku?: Discussion around potentially replacing Claude 3 Haiku with the cheaper and smarter GPT-4o mini in Perplexity, though Haiku remains in use.
- Collection prompts not working correctly: Users reported that collection prompts are not being followed in threads created within a collection, regardless of the AI model used.
- Issues with Pro image creation: A Pro member questioned why they could only create one image despite subscribing, discovering later a browser restart resolved the issue.
- Sonnet 3.5 issues in collection prompts: Members struggled to get Sonnet 3.5 to follow collection prompts, with no success after various attempts, including using GPT-4o.
Perplexity AI ▷ #sharing (9 messages🔥):
YouTube Music's Smart RadioDyson's High-Tech HeadphonesKeanu's Sci-Fi NovelOpenAI's GPTElon Musk's Austin Headquarters
- YouTube Music unveils Smart Radio: A discussion highlighted YouTube Music's Smart Radio, featuring innovative content delivery and new music discovery tools.
- YouTube Music was praised for smartly curating playlists and adapting to user preferences.
- Dyson debuts High-Tech Headphones: Dyson's new high-tech headphones were noted for integrating advanced noise-cancellation and air filtration technology.
- Members commented on the product's dual functionality and sleek design.
- Elon Musk moves to Austin Headquarters: Elon Musk has relocated Tesla's headquarters to Austin, Texas, as discussed in a recent search result.
- This strategic move aims at leveraging Texas's business-friendly environment.
- OpenAI releases GPT-4o: OpenAI has released GPT-4o, which promises improved language generation and understanding capabilities.
- Community feedback emphasizes the model's ability to handle complex queries more effectively.
- Crowdstrike experiences Global IT Outage: Crowdstrike faced a global IT outage affecting multiple services and disrupting operations.
- The incident raised concerns about the reliability and resilience of cloud-based security services.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (4 messages):
Online Models Internet Search CapabilitiesRAG API Access InquiryChatGPT 4.0 Mini Internet BrowsingPerplexity API via Azure or Amazon
- Online Models Can't Search the Internet: A member queried whether online models are capable of searching the internet, and there was no confirmation about this capability currently.
- They expressed uncertainty about online models' abilities, highlighting widespread curiosity and potential limitations.
- Seeking RAG API Access from Perplexity: A member noted a lack of response after emailing about RAG API for their enterprise, seeking further assistance in obtaining access.
- This suggests ongoing communication challenges and unmet demand for enterprise-level API solutions.
- ChatGPT 4.0 Mini Lacks Internet Browsing: A member questioned if ChatGPT 4.0 Mini can browse the internet and clarified that it cannot do so through the API.
- This highlights a limitation in ChatGPT 4.0 Mini's capabilities compared to user expectations.
- Using Perplexity API via Azure or Amazon: A user inquired about the feasibility of using Perplexity API through Azure or Amazon cloud services.
- This indicates potential interest in integrating Perplexity's capabilities with leading cloud infrastructure.
OpenRouter (Alex Atallah) ▷ #announcements (4 messages):
Ranking and stats issue fixNew models from Mistral AIRouter resilience updateL3-Euryale-70B price dropNew Dolphin-Llama model
- Ranking analytics issue resolved: Due to a read-replica database failure, ranking and stats showed stale data, but user-facing features like the API and credits operated normally.
- UPDATE: The issue with ranking analytics and stats has now been fixed.
- Mistral AI unveils two new models: Daun.ai introduced Mistral Nemo, a 12B parameter multilingual LLM with a 128k token context length.
- Codestral Mamba was also released, featuring a 7.3B parameter model with a 256k token context length for code and reasoning tasks.
- Router resilience feature live: A new feature now allows providers not specified in the order parameter to be used as fallbacks by default unless
allow_fallbacks: falseis explicitly set.- This means other providers will be tried after the prioritized ones in API requests—enhancing the overall resilience.
- L3-Euryale-70B price slashed by 60%: A 60% price drop was announced for sao10k/l3-euryale-70b.
- But wait, there's more: Cognitivecomputations released Dolphin-Llama-3-70B.
- Llama 3 Euryale 70B v2.1 by sao10k: Euryale 70B v2.1 is a model focused on creative roleplay from [Sao10k](https://ko-fi.com/sao10k). - Better prompt adherence. - Better anatomy / spatial awareness. - Adapts much better to unique and c...
- Dolphin Llama 3 70B 🐬 by cognitivecomputations: Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a fine-tune of [Llama 3 70B](/models/meta-llama/llama-3-70b-instruct). It demonstrates improvements in inst...
- Mistral: Mistral Nemo by mistralai: A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA. The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chin...
- Mistral: Codestral Mamba by mistralai: A 7.3B parameter Mamba-based model designed for code and reasoning tasks. - Linear time inference, allowing for theoretically infinite sequence lengths - 256k token context window - Optimized for qui...
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
LLM-Draw AppAI Whispers Prompts Collection
- LLM-Draw integrates OpenRouter API keys: The LLM-Draw app has been updated to accept Openrouter API keys, leveraging the Sonnet 3.5 self-moderated model.
- It is deployable as a Cloudflare page with Next.js, and a live app is available here.
- AI Whispers Prompts Collection Update: AI Whispers is reorganizing prompts for use with Fabric and adding markdown structure, including more detailed info in the README files.
- Currently, things are moving around for better organization and clarity.
- GitHub - zielperson/AI-whispers: testing: testing. Contribute to zielperson/AI-whispers development by creating an account on GitHub.
- GitHub - RobinVivant/llm-draw: Make it real: Make it real. Contribute to RobinVivant/llm-draw development by creating an account on GitHub.
- make real starter: no description found
OpenRouter (Alex Atallah) ▷ #general (71 messages🔥🔥):
4o mini moderationImage tokens billingOpenRouter availabilityGemma 2 repetition issuesOpenRouter statistics system
- *4o mini moderation ambiguity: There was confusion about whether 4o mini is self-moderated or uses OpenAI's* moderator, with some users experiencing different moderation behaviors.
- A user speculated their request to 4o might have been routed to Azure which has a lower moderation threshold.
- *Image tokens billing inconsistency explained: Discussion about image tokens which suggest costs on OpenRouter* are based on resolution but have ambiguities in the token count.
- It's noted that the base tokens are used for analytics while total tokens determine the cost, involving OpenAI's calculation.
- *OpenRouter Availability FAQ*: Users discussed OpenRouter's availability and were directed to the status page for recent incidents.
- A regional issue might cause service unavailability; the stats system also faced DB replica failures recently.
- *Gemma 2 users face repetition issues: Users of Gemma 2 9B* reported experiencing repetition issues and sought tips for resolving this.
- A suggestion was made to use CoT (Chain of Thought) prompting for better performance.
- *OpenRouter statistics system outage: There was an outage in the OpenRouter statistics system* affecting ranking and provider info updates.
- The outage was due to a DB read replicas failure, with a fix being worked on, and the activity page facing latency in data updates.
- Mistral: Mistral Nemo by mistralai: A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA. The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chin...
- Mistral: Codestral Mamba by mistralai: A 7.3B parameter Mamba-based model designed for code and reasoning tasks. - Linear time inference, allowing for theoretically infinite sequence lengths - 256k token context window - Optimized for qui...
- OpenRouter Status: OpenRouter Incident History
OpenRouter (Alex Atallah) ▷ #일반 (3 messages):
Mistral NeMoKorean Language SupportSupported Languages of Mistral NeModaun.ai
- Mistral NeMo supports Korean Language: A message indicated that Mistral NeMo has added support for the Korean language.
- Users noted that Mistral NeMo is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
- Discussion on daun.ai Link: A member shared a link to daun.ai: Discord Conversation.
OpenRouter (Alex Atallah) ▷ #一般 (1 messages):
k11115555: 誰も使ってない...
Interconnects (Nathan Lambert) ▷ #news (15 messages🔥):
GPT-4o mini performanceOpenAI security issuesModel evaluationsImage input costEnterprise market dominance
- GPT-4o mini matches GPT-3.5 on code benchmarks: GPT-4o mini scores similarly to the original GPT-3.5 on Aider's code editing benchmark, though it struggles with editing code using diffs and is limited to smaller files.
- OpenAI’s new safety mechanism easily bypassed: OpenAI's new safety mechanism has been jailbroken, with GPT-4o-mini outputting harmful content like malware and recipes for illegal activities, showcasing a significant security flaw.
- GPT-4o mini overfits on internal evals: GPT-4o mini was found to dominate GPT-4o on internal LLM-as-judge evaluations due to including extraneous information, possibly overfitting to common eval flaws such as length bias.
- OpenAI strikes back with GPT-4o mini: GPT-4o mini is praised for its remarkable performance relative to cost, making a significant impact on the market as seen on livebench.ai.
- This model's affordability may prove pivotal for enterprise market dominance, according to community discussions.
- GPT-4o mini priced same for image inputs: GPT-4o mini is 33x cheaper for text inputs than GPT-4o, but remains the same price for image inputs due to utilizing more tokens per image.
- For cost-efficient image inputs, alternatives like Claude 3 Haiku and Gemini 1.5 Flash may be more viable according to Romain Huet.
- Tweet from Colin White (@crwhite_ml): OpenAI strikes back 💫 GPT-4o-mini is a remarkable model for its price! Check out its performance on http://livebench.ai !
- Tweet from Paul Gauthier (@paulgauthier): GPT 4o mini scores like the original GPT 3.5 on aider's code editing benchmark (later 3.5s were worse). It doesn't seem capable of editing code with diffs on first blush, which limits its use ...
- Tweet from Pliny the Prompter 🐉 (@elder_plinius): ⚡️ JAILBREAK ALERT ⚡️ OPENAI: PWNED ✌️😎 GPT-4O-MINI: LIBERATED 🤗 Looks like the new "instruction hierarchy" defense mechanism isn't quite enough 🤷♂️ Witness the and new gpt-4o-mini ...
- Tweet from Kyle Corbitt (@corbtt): So gpt-4o mini was absolutely dominating gpt-4o on our internal llm-as-judge evals. So I LOOKED AT THE DATA (h/t @HamelHusain) and realized it was answering the question BUT ALSO throwing in a bunch ...
- Tweet from Simon Willison (@simonw): A slightly surprising aspect of GPT-4o mini: while it's 33x cheaper than GPT-4o for text input, for image inputs it's the same price If you need inexpensive image inputs you may be better off...
Interconnects (Nathan Lambert) ▷ #ml-questions (7 messages):
Gemma 2 paperSoft logit cappingCompetitiveness of Gemma 2 29B with LLaMA 3 70B
- Removing Soft Logit Capping in Gemma 2: Members discussed the removal of the soft logit capping feature in the Gemma 2 model, questioning if additional training was needed to heal the 'scar' of turning off this capping.
- One member found it implausible and surprising that disabling the logit capping was just fine without any significant retraining.
- Gemma 2 29B's Competitiveness: A member queried why the Gemma 2 29B model was so competitive with LLaMA 3 70B, despite not benefiting from distillation, unlike the 9B and 2.6B versions.
- Another attributed the competitiveness to Google magic in softmax and distillation or other techniques, with a final remark pointing to better data as a reason.
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
AGI missioncurrent business as a sideline
- AGI mission poses challenges: The current business efforts are seen as a sideline to the primary mission of AGI.
- This sentiment underscores the possible difficulty in harmonizing business goals with the central objective of achieving AGI.
- Business efforts as a sideline: The current business is kind of a sideline in the context of the primary mission of AGI.
- Despite the focus on AGI, the business side is acknowledged but not as the main priority.
Interconnects (Nathan Lambert) ▷ #random (54 messages🔥):
Zotero 7 UpdateHugo and DockerReading Lists and WebsitesPotential Future InterviewsMosaicML Sword Tradition
- Zotero 7 Brings Speed and Style: Zotero 7, an update over the current version, offers improved speed, a dark mode, and better plugin compatibility.
- Members discussed upgrading for plugins like Better BibTex and auto-tagging with 'Actions and Tags for Zotero,' with a wish for tooltip references.
- Docker Frustrations Delay Hugo Setup: A member shared struggles with setting up a personal site using Hugo due to networking issues in Docker.
- Despite setbacks, there's encouragement to revisit the project soon and make it live.
- Hosting Reading Lists Gains Interest: Discussing the fun and practical idea for researchers to host reading lists on static websites.
- Projects like answer.ai already share their Zotero library, sparking enthusiasm for similar initiatives.
- Future Interviews with AI Leaders: Plans to reach out for interviews with notable figures like Andrej Karpathy and Andrew Trask were discussed.
- Interesting personalities, like Jonathan Frankle and his MosaicML sword tradition, are also mentioned as potential interviews.
- MosaicML’s Swords Clash with HR: Swords awarded to MosaicML employees as a quirky tradition faced disapproval from HR.
- Rumors suggest even the Databricks legal team might have received them for their efforts, highlighting the unique tradition.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Who is this? 👀👀👀 2.0, Eureka, Ultra, mini, nano? Flash? Pro? 1.75? Plus? Advanced? Pro New? Pro New New? Pro Plus Ultra? Flame? 🔥
- Tweet from Luca Soldaini 🎀 (@soldni): bless @DippedRusk who got me in my natural habitat (my desk at the office) with my @MosaicML sword
- beta_builds [Zotero Documentation] : no description found
- Zotero | Groups > LLMs AI Answers: no description found
Interconnects (Nathan Lambert) ▷ #reads (2 messages):
Sara Hooker's critique on US AI ActCohere for AICompute thresholds in AI
- Sara Hooker on misguided US AI Act compute thresholds: A member shared a YouTube video featuring Sara Hooker, who critiques the use of compute thresholds in the US AI Act.
- Another participant noted that the accompanying paper by Sara Hooker, VP of Research at Cohere, was commendable and sparked interest in the community.
- Sara Hooker praised in community discussion: An individual expressed their admiration for Sara Hooker, highlighting her appeal and contribution to AI research.
Link mentioned: Why US AI Act Compute Thresholds Are Misguided...: Sara Hooker is VP of Research at Cohere and leader of Cohere for AI. We discuss her recent paper critiquing the use of compute thresholds, measured in FLOPs ...
Eleuther ▷ #general (24 messages🔥):
Z-LossRegularizationLogitsSoftmaxPaper Ideas
- Debate on Z-Loss Functionality: A member suggested adding 'exploring and dissecting why z-loss works' to the paper ideas list.
- Members discussed the intricacies of Z-loss as a regularization term for the objective function, comparing it to weight decay and questioning the necessity and depth of such regularization.
- Carsonpoole clarifies Z-Loss: Carsonpoole clarified that Z-loss adds a regularization parameter into the objective function's activations, akin to weight decay but for activations.
- He emphasized that large activations lead to instability, thus Z-loss aims to prevent unnecessarily large activations.
- Alternative Regularization Techniques: Nshepperd proposed an alternative regularization method using
logits.mean(-1).square().mean()instead oflogits.logsumexp(-1).square().mean().- The difference in effectiveness between these methods and the fundamentals of regularization like weight decay sparked curiosity and debate.
- Understanding the Need for Z-Loss: The_deleted_account argued that softmax's shift invariance necessitates Z-loss.
- The motivations cited included preventing roundoff errors in bfloat16 and encouraging logits to be normalized log-probabilities.
Eleuther ▷ #research (13 messages🔥):
Cognitive Architectures for Language Agents (CoALA)Discussion on Bits Per Byte (BPB) vs Per TokenMixing Sequences for TrainingTransformer Training Instability ChecklistExperience-driven AI Evaluations
- CoALA framework organizes language agents: A new paper proposes Cognitive Architectures for Language Agents (CoALA), which describes a language agent with modular memory components and a structured action space for decision-making, aiming to organize and plan future developments in language models.
- The paper uses CoALA to survey and organize recent work and identify actionable directions, drawing from cognitive science and symbolic AI.
- BPB vs Per Token metrics explained: A clarification on whether a given metric is 'bits per byte (BPB)' or 'per token' was provided, emphasizing that it is 'per token.'
- cz_spoon_06890 clarified that the metric in question is important as it significantly impacts interpretation.
- Mixing sequences for model training: A member proposed averaging multiple sequences during training, similar to mixup in CNNs, potentially removing the need for fine-tuning.
- Another member mentioned annealing the mixup rate might be required, sparking a discussion on cleaner solutions compared to two-stage training.
- Transformer training instability resources: A query about a transformer training instability checklist was raised, and a link to relevant resources was provided.
- Link to checklist was shared to assist with addressing the training instability.
- Evaluating experience-driven AI: A member sought feedback on their paper about experience-driven AI evaluations, specifically a characterization of an evaluation cycle.
- Feedback was solicited to ensure the characterization's accuracy and relevance.
- Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies: Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. % Intuitively, larger vocabularies enable mo...
- Cognitive Architectures for Language Agents: Recent efforts have augmented large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning, le...
Eleuther ▷ #scaling-laws (1 messages):
Hypernetworks and Scaling LawsScaling Law PredictionsCompute and Target ErrorConditional HypernetworksNeural Network Prediction
- Scaling laws limit hypernetwork abilities: Discussion on how scaling laws place bounds on the abilities of hypernetworks, questioning whether a hypernetwork of smaller size can achieve the target error predicted by the scaling law.
- It was noted that hypernetwork effectiveness might require 'improving' the scaling law or focusing on tasks where the output model's scaling law is favorable, like representing a single datapoint.
- Comparing hypernetwork and output model scaling: Examination of whether the architectures of a hypernetwork and its output model share the same scaling law and whether it's easier to predict a neural network that solves a task than to solve the task directly.
- Suggestion that hypernetworks might only be useful if the target task has a 'nice' scaling law, requiring significantly less data/compute to learn from relevant subsets of data.
Eleuther ▷ #interpretability-general (8 messages🔥):
Tokenization-free language modelsInterpretability of ResNet in Vision ModelsMATS 7.0 Streams by Neel Nanda and Arthur Conmy
- Tokenization-free models fuel interpretability debate: Members debated if tokenization-free models, either at the character or byte level, would be better or worse for interpretability, with concerns about lack of canonical places for processing.
- 'Utf-8 is a tokenization scheme too, just a bad one,' one member noted, expressing skepticism about byte-level tokenization becoming the default.
- Deep dive into ResNet residual stream: A member shared their new article investigating the residual stream in ResNet for vision model mechanistic interpretability.
- Seeking constructive feedback, they described their approach as a simplistic prodding around given their novice status and looked for papers or lightweight models for further study.
- Applications open for Winter MATS 7.0 streams: Applications have opened for the Winter MATS 7.0 streams led by Neel Nanda and Arthur Conmy, with a deadline of Aug 30th.
- Apply here for a chance to be mentored in cutting-edge mechanistic interpretability research.
- Tweet from Neel Nanda @ ICML (@NeelNanda5): Are you excited about @ch402-style mechanistic interpretability research? I'm looking to mentor scholars via MATS - apply by Aug 30! I'm impressed by the work from past scholars, and love men...
- Neel Nanda / Arthur Conmy MATS 7.0 Stream - Admissions Procedure + FAQ: Neel Nanda / Arthur Conmy MATS Stream - Admission Procedure + FAQ How to Apply Fill out the general MATS application form (<10 mins). Deadline Friday Aug 30 11:59pm PT. Note that this is a special ...
Eleuther ▷ #lm-thunderdome (22 messages🔥):
System prompt concatenationLM eval model correctnessHF datasets trust remote codeZeno upload featureEditable installation issues
- System prompt concatenation logic: Clarified that when a description field exists, it is concatenated to the end of the system prompt for models that allow their chat template to take it.
- Ensuring LM eval model correctness: A user highlighted discrepancies in scores between a new LM eval model implementation and other HF models, seeking proxies to check implementation correctness and eliminate variables.
- Overcoming remote code trust issues: A member shared a tip to use
export HF_DATASETS_TRUST_REMOTE_CODE=1to trust remote code when loading datasets for benchmarks. - Zeno upload feature with recent refactor: Users reported challenges with the Zeno upload feature
visualize_zeno.pyafter a big refactor. - Editable installation and logging issues: A user experienced issues with
eval_logger.infonot printing despite using an editable install.
LlamaIndex ▷ #blog (5 messages):
Mistral NeMo releaseLlamaCloud updatesRe-ranking retrieved resultsUsing LLMs as a judgeCommunity events
- MistralAI and OpenAI release new models: It's a big day for new models with releases from MistralAI and OpenAI, and there's already day zero support for both models.
- Mistral NeMo is a small (12B) model outperforming Mistral's 7b model, featuring a significant (128k) context window.
- LlamaCloud introduces new features: Recent updates to LlamaCloud include LlamaCloud Chat, a conversational interface to data, and new team features for collaboration.
- These changes aim to enhance user experience and productivity. Read more here.
- Boosting relevance with Re-ranking: Re-ranking retrieved results can significantly enhance response relevance, especially when using a managed index like @postgresml.
- Check out their guest post on the LlamaIndex blog for more insights. More details here.
- Featuring RAG evaluation with McDermott: Yixin Hu (VU Amsterdam) and Thomas Hulard (McDermott) shared a session on using LLMs as a judge to bring applications into production.
- This recording dives into key concepts behind RAG evaluation. Watch it here.
- Sign up for upcoming events: Reminder: There’s still time to sign up for the event kicking off in an hour. Join here.
- Stay tuned for more community events and updates. Learn more.
Link mentioned: Improving Vector Search - Reranking with PostgresML and LlamaIndex — LlamaIndex, Data Framework for LLM Applications: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
LlamaIndex ▷ #general (41 messages🔥):
Streaming thoughts via LlamaIndexContext window limits in LLMsInconsistent behavior of Pandas query engineText to SQL query pipeline issuesLlama-parse API performance
- Streaming thoughts via LlamaIndex questioned: A user inquired if LlamaIndex can stream thoughts, and another user provided a tutorial example suggesting that it might be possible with modified prompts.
- The tutorial on the LlamaIndex documentation was referenced for detailed implementation.
- LLMs context window limits cause confusion: A member experienced an 'Error code: 400' while setting the max_tokens limit for GPT-4o mini despite OpenAI's documentation stating a context window of 128K tokens, which reportedly supports only 16384 completion tokens.
- This confusion arose from using different models in different parts of the code, leading to interference between GPT-3.5 and GPT-4 in SQL query engines.
- Pandas Query Engine shows inconsistent behavior: A user reported that the Pandas query engine interprets column names correctly in Jupyter Notebook but fails when run as a .py file or API, causing KeyErrors.
- The code and document remain unchanged across environments, suggesting an issue with natural language column mapping outside of Jupyter Notebooks.
- Improving text to SQL pipeline with CTEs: A user faced issues where multiple SQL queries couldn't execute correctly as the system assumed results instead of running subsequent queries, which was resolved by using Common Table Expressions (CTEs).
- Prompting the system to use CTEs provided a solution that made subsequent query executions successful as per the tutorial.
- ReActAgent stuck on max iterations value: Raising the 'max_iterations' value for ReActAgent did not resolve an issue where the agent appeared stuck and unable to return any response.
- The problem persisted despite modifying the iterations parameter, prompting a request for further troubleshooting assistance from the community.
- GitHub - run-llama/llama_parse: Parse files for optimal RAG: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- llama_index/llama-index-integrations/llms/llama-index-llms-openai/llama_index/llms/openai/utils.py at 6a8e151f9b912d8fad5fa4d09bd2f7bfcb393f0c · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
LlamaIndex ▷ #ai-discussion (15 messages🔥):
Query rewritingMultimodal RAGSplitting documents in LlamaIndexUse of LlamaIndex versus LangChainETL of unstructured data
- Query Rewriting Utility: A member finds LlamaIndex impressive in handling a presentation file full of mathematical equations, charts, and images, raising a question about the utility of query rewriting to enhance performance. They are keen to explore more use cases within the LlamaIndex framework.
- Splitting documents with LlamaIndex: Discussion revealed that LlamaIndex splits documents automatically around sentence boundaries with a default chunk size of 1024 and an overlap size of 128 when using the SentenceSplitter.
- The pdf loader in LlamaIndex splits documents by pages, which aligns perfectly with actual page numbers, making referencing easier as confirmed by the code author.
- ETL for Unstructured Data: A member inquired about parsing unstructured data like video and music into formats digestible by LLMs, referencing a YouTube conversation between Jerry Liu and Alejandro that mentioned a new type of ETL.
- Choosing the Best Structured Output Parser Approach | 3 Ways To Generate Structured Output: A Detailed Comparison of Structured Output Extraction Methodologies
- Jerry Liu - What is LlamaIndex, Agents & Advice for AI Engineers: In this episode, we sit down with Jerry Liu, the visionary founder of LlamaIndex, a cutting-edge python framework designed for the development of LLM (Large ...
- llama_parse/examples/multimodal/claude_parse.ipynb at main · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #general (40 messages🔥):
Mistral-12bTraining Inferences in TransformersConfig Issues and FixesTriplex Model for Knowledge Graphs
- Training Inferences Improve Transformer Generalization: An arXiv paper suggests that training transformers far past saturation and memorization improves their ability to generalize and deduce inferred facts.
- The paper's findings reveal that transformers struggle with out-of-domain inferences because they lack the incentive to store the same fact in two different places.
- Config Issues in Mistral-12b: A member reported encountering config issues with the Mistral-12b model, specifically size mismatches for various projection weights.
- Resolving these issues required installing transformers from source, while the training process works well on 8x L40s and shows promising results in loss reduction.
- Tokenizer Padding Token Required: Members encountered errors due to the tokenizer not having a padding token and recommended setting the tokenizer's pad token as
tokenizer.eos_tokenor adding a new pad token.- These errors affected various scenarios, including completions and training processes, requiring specific adjustments in configurations.
- Triplex Model for Knowledge Graph Construction: The Triplex model, a version of Phi3-3.8B, offers a cost-effective solution for creating knowledge graphs, reducing costs by 98% compared to GPT-4.
- This model, shareable and executable on local systems, allows for easy setup with Neo4j and R2R, enhancing downstream RAG methods.
- Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization: We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two representative reasoning types...
- Tweet from Daniel Han (@danielhanchen): My findings for Mistral NeMo 12b: 1. </s> EOS token is untrained in base - a bug? 2. EOS token is auto appended 3, 4096, not 5120 for Wq 4. Not Llama Tokenizer 5. Tools, FIM 6. Pad_token=10<p...
- SciPhi/Triplex · Hugging Face: no description found
- Knowledge Graphs - The best open source AI powered answer engine.: no description found
- [Model] Support Mistral-Nemo by mgoin · Pull Request #6548 · vllm-project/vllm: FIX #6545 Patch was ported from huggingface/transformers#32050 Essentially there was a new head_dim override added to MistralConfig. We will look for that optional argument in the config and defaul...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (2 messages):
Mistral-NemoTechnical queries in axolotl-dev channel
- Mistral-Nemo Status Query: A member inquired about the current working status of Mistral-Nemo.
- General Technical Queries: Members often use the axolotl-dev channel to ask and answer technical questions, such as the current status of specific tools like Mistral-Nemo.
OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
Llama3Eval LossTraining Loss
- Llama3 rank adjustments improve eval loss: Lowering the rank of Llama3 has noticeably helped with eval loss according to a member's observation.
- Still need to run the eval set later to confirm if the improvement holds.
- Discussion on eval loss differences: Another member commented that there's a significant difference and speculated that it might even out in later steps.
- The original member mentioned they will continue to run the tests tonight to see what happens.
- Training loss is also lower: The same member noted that the training loss seems noticeably lower along with the eval loss.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 messages):
GPU memory error in axolotl trainingCommon errors in axolotlTraining configuration adjustments
- Address GPU memory issues in axolotl training: Users discussed the common error of running out of GPU memory during axolotl training, likely due to large models or batch sizes exceeding GPU capacity.
- A detailed guide was shared on how to mitigate this by adjusting settings like
micro_batch_size,gradient_accumulation_steps, and enablingfp16to optimize memory usage.
- A detailed guide was shared on how to mitigate this by adjusting settings like
- Common errors and their fixes in axolotl: The community highlighted several common errors encountered during axolotl training and provided solutions, including adjusting sequence length and using specific optimizers like
adamw_bnb_8bit.- Links to the Common Errors 🧰 were shared for further information on troubleshooting.
- axolotl/README.md at main · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Cohere ▷ #general (25 messages🔥):
GPTs AgentsWeb search capabilitiesLLM self-awarenessCohere ToolkitRole Icons
- GPTs Agents self-awareness tested: A user experimented with GPTs agents to determine their self-awareness without using web search capabilities.
- Web search performance impresses users: A user observed that the bot's response time feels like a web search was never performed, highlighting the efficiency of the system.
- Cohere Toolkit's flexibility praised: A user shared a tweet by Aidan Gomez and Nick Frosst highlighting the open-source nature of Cohere's Toolkit UI, allowing users to plug in any models and contribute new features.
- Role icons and work schedules discussed: A user humorously noted their role icon being a hard hat.
Link mentioned: Tweet from Aidan Gomez (@aidangomez): Reminder that the whole Toolkit UI is opensource and plug-and-play. So feel free to plug in whatever models you want and contribute new features! Quoting Nick Frosst (@nickfrosst) A few weeks back ...
Cohere ▷ #project-sharing (15 messages🔥):
Firecrawl pricingFirecrawl self-hostingGPT-4o integrationLocal LLM Chat GUI
- Firecrawl too expensive without bulk customers: A member mentioned that Firecrawl is only cost-effective with a large customer base and suggested a pay-as-you-go plan.
- Firecrawl backend self-hosting saves costs: Members discussed self-hosting the Firecrawl backend, making the service more affordable by just setting an API endpoint.
- One member shared a GitHub link with a guide on self-hosting, stating it saved them a few hundred dollars.
- GPT-4o integration with Firecrawl: Firecrawl self-hosting allows for GPT-4o integration by using your own API key stored in an
.envfile. - New Chat GUI project with local LLMs: A member shared their ongoing project featuring a chat GUI powered by local LLMs and implementing Web Search, Python Interpreter, and Image Recognition.
- The project's GitHub repository was provided for those interested.
- Edit fiddle - JSFiddle - Code Playground: no description found
- firecrawl/SELF_HOST.md at main · mendableai/firecrawl: 🔥 Turn entire websites into LLM-ready markdown or structured data. Scrape, crawl and extract with a single API. - mendableai/firecrawl
Torchtune ▷ #general (3 messages):
Useful SolutionsInstruct/Chat Dataset RFC
- User finds solution helpful: A user expressed that a shared solution was very helpful and mentioned it works for them.
- RFC for Instruct/Chat dataset consolidation: A member shared a Request for Comments (RFC) in the dev channel regarding consolidating the Instruct/Chat dataset classes, aiming to simplify adding custom datasets on Hugging Face.
- They encouraged those regularly running fine-tuning jobs with custom data to review the RFC and provide feedback, stating it won't affect high-level APIs.
Torchtune ▷ #dev (32 messages🔥):
LLM Training TestsTorchtune Recipe DocumentationUnified Dataset AbstractionError Handling in Recipes
- Testing LLMs: Forced HAHAHA Response: Members discussed attempts to train an LLM to respond with 'HAHAHA' to every input. Despite adjusting settings, the LLM did not learn as expected.
- Visibility of Torchtune Recipes: There was a conversation about improving the visibility and documentation of Torchtune's available recipes.
- Autogenerating docs from recipe docstrings was proposed as a useful step forward.
- Unified Dataset Abstraction RFC: A new RFC was discussed that aims to unify instruct and chat datasets to support multimodal data.
- Key feedback included usability improvements such as separating tokenizer and prompt templating from other dataset configurations, as detailed in the RFC.
- Streamlining Error Handling: There was a suggestion to streamline error handling in recipes by moving common validation functions out of individual recipes.
- This would help focus user attention on key configurations and reduce boilerplate code.
- torchtune/torchtune/datasets/_instruct.py at main · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
- [RFC] Unified dataset with data and model transforms by RdoubleA · Pull Request #1186 · pytorch/torchtune: Thanks to @pbontrager for all the discussions to help converge to this design. TLDR: Let’s make a general fine-tuning dataset class that takes in a data transform class and a model transform class...
- Added Recipes to docs by pbontrager · Pull Request #256 · pytorch/torchtune: Context First example of how our recipes can/will be presented in the docs. This is based on earlier discussion around documentation. This allows users to get recipes that match the same version th...
Alignment Lab AI ▷ #general-chat (28 messages🔥):
Mozilla Builders startup acceleratorAI-generated scene descriptions for the blindSmart AI devices for apicultureSwarms Robotics & Bitcoin mining
- Mozilla Builders launches accelerator: A member mentioned that Mozilla Builders announced a startup accelerator for hardware and AI at the edge.
- Another member expressed interest and shared their continuous involvement, stating, “I don't move on, not a part time accelerator, we live here.”
- AI to generate descriptions of scenes for the blind: There was a discussion about creating AI to generate descriptions of scenes for the blind.
- “Blindness and all illnesses need to be deleted.” was a pointed sentiment shared by a member.
- Building smart AI devices for bees: Smart AI data-driven devices have been built for apiculture and open-source Bitcoin mining hardware.
- The main interest lay in combining AI and apiculture to give beekeepers advanced warnings before their bees face danger.
- Swarm robotics and AI projects: Member expressed their fascination with bees and mentioned potential interest in swarm robotics.
- There was also a mention of an art-focused AI project that listens via Whisper and generates context-based images during conversations.
Alignment Lab AI ▷ #alignment-lab-announcements (1 messages):
RWKV hybrid model paperGoldFinch model detailsTransformer enhancementsModel performance comparisons
- GoldFinch hatches with hybrid model gains: GoldFinch combines Linear Attention from RWKV and traditional Transformers, outperforming slightly larger 1.5B class Llama and Finch (RWKV-6) models on downstream tasks. This improvement is due to eliminating quadratic slowdown and significantly reducing KV-Cache size, enabling large context lengths with minimal VRAM requirements.
- Potential applications include analyzing entire codebases or legal documents on consumer graphics cards, with major cost savings from reduced quadratic attention costs.
- GPTAlpha and Finch-C2 introduced: The release includes the Finch-C2, a higher downstream performance version of Finch, and GPTAlpha, an enhanced full transformer architecture with RWKV components that uses softmax attention. These models outperform traditional transformers, providing superior performance and efficiency.
- The new models deliver the capability to look back at every token with a lower cost, paired with better downstream performance.
- GoldFinch model paper and code released: The GoldFinch paper is available on arXiv detailing the hybrid model architecture and performance enhancements. The GitHub repository contains the code and checkpoints for various ablation studies and 1.5B scale models.
- Artifacts and checkpoints for the GoldFinch project are also hosted on Huggingface, including small-scale and large-scale models.
- GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression: We introduce GoldFinch, a hybrid Linear Attention/Transformer sequence model that uses a new technique to efficiently generate a highly compressed and reusable KV-Cache in linear time and space with r...
- GitHub - recursal/GoldFinch-paper: GoldFinch and other hybrid transformer components: GoldFinch and other hybrid transformer components. Contribute to recursal/GoldFinch-paper development by creating an account on GitHub.
- recursal/GoldFinch-paper · Hugging Face: no description found
tinygrad (George Hotz) ▷ #general (8 messages🔥):
Kernel refactoring suggestionget_lazyop_info removaltinygrad internalsView.mask purposeProject proposal: trace OpenPilot model
- Kernel refactoring suggestion: George Hotz suggested refactoring Kernel to not have a
linearizefunction and instead just have ato_programfunction.- He added that
get_lazyop_infoshould be removed first to facilitate this change.
- He added that
- Exploring tinygrad internals: A member is trying to learn the internals of tinygrad and queried about the purpose of
View.mask.- George Hotz confirmed it exists mainly for padding, and another member shared a reference link to support the explanation.
- New project proposal: Analyze OpenPilot model trace: George Hotz proposed a new project for documenting kernel changes and their impact on performance using an OpenPilot model trace.
- He shared a Gist link and provided instructions to run the analysis, emphasizing that such tasks can be done by anyone 'somewhat smart'.
tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
GTX1080 Compatibility_pool Function in TinygradShapetracker in Lazybuffers
- GTX1080 faces compatibility issues with Tinygrad: A member reports an error running Tinygrad on a GTX1080 with
CUDA=1, indicating issues with the GPU architecture.- Another member suggests that 2080 generation GPUs are the minimum requirement and recommends patching the architecture in
ops_cudaand disabling tensor cores.
- Another member suggests that 2080 generation GPUs are the minimum requirement and recommends patching the architecture in
- Discussions around
_poolfunction implementation: A member seeks help understanding the_poolfunction in Tinygrad, specifically questioning if pooling duplicates data usingpad,shrink,reshape, andpermuteoperations.- After re-evaluating the code, the member acknowledges that the function does not duplicate values as initially suspected.
- Shapetracker's role in Lazybuffers debated: Members discuss whether Lazybuffers should use a sequence of views and Lazybuffers instead of a Shapetracker to organize composition of views.
- While some members argue for better organization using a single Shapetracker, they agree it mainly impacts code organization but does not alter functionality.
OpenInterpreter ▷ #general (5 messages):
gpt-4o-mini16k token outputYi large previewOI model introductions
- GPT-4o-mini parameter change: A user asked if gpt-4o-mini can be used directly by changing parameters, or if it needs to be introduced by OI.
- 16k token output impresses: A member mentioned the nice feature of 16k max token output.
- Yi large preview outperforms: A member stated that Yi large preview is still outperforming for them in OI.
OpenInterpreter ▷ #O1 (10 messages🔥):
GPT-4o MiniFunction CallingCode Generation
- GPT-4o Mini: Fast but Mediocre in Code Generation: Members remarked that GPT-4o Mini is fast but mediocre in code generation, as observed in initial tests.
- However, it could be suitable for specific tasks with good custom instructions but has yet to show excellence in function calling performance.
- OpenAI Claims Strong Function Calling in GPT-4o Mini: A link was shared to OpenAI's announcement stating that GPT-4o Mini demonstrates strong performance in function calling and improved long-context performance compared to GPT-3.5 Turbo.
- I thought it does? sparked a brief discussion on the actual performance versus expectations.
LAION ▷ #general (6 messages):
ICML'24 Paper Using LAION ModelsText2Control MethodStorage Reduction for Large Image DatasetsHosting Latents on Hugging Face
- ICML'24 Paper Uses LAION Models: A user expressed gratitude to the LAION project for their models, which were used in a recent ICML'24 paper.
- They encouraged trying out the interactive demo for Text2Control, describing it as a lot of fun.
- Text2Control Enables Agents with Natural Language: Text2Control is a method that allows agents to perform new tasks specified with natural language by inferring a goal using vision-language models and reaching it with a goal-conditioned agent.
- The method outperforms multitask reinforcement learning baselines in zero-shot generalization to new tasks.
- Need for Latents of Large Image Datasets: A user asked if latents for large image datasets, particularly sdxl vae latents and conditioner datasets, were available.
- They mentioned that using these latents would significantly reduce storage costs for their run.
- Host Latents on Hugging Face: A suggestion was made to upload the latents to Hugging Face to avoid storage costs.
- It was pointed out that Hugging Face covers the S3 storage bills.
Link mentioned: Bridging environments and language with rendering functions and vision-language models: no description found
LAION ▷ #research (5 messages):
AGI model performanceICML'24 paper using LAION modelsText2Control interactive demo
- AGI Claims Over-hyped but Models Perform: A member discussed that achieving AGI-like performance is often seen as overhyped, but many models already achieve high correct rates with the proper experiments, referencing a tweet by @_lewtun.
- 'The tweet is self-ironic, as many models can solve it properly, but no one wants to run the 'boring' experiments to validate this scientifically', they noted.
- ICML'24 Paper Cites LAION Models: A researcher thanked the LAION project for providing the models used in their recent ICML'24 paper.
- They shared an interactive demo of their Text2Control method, which uses vision-language models to enable agents to achieve goals from textual instructions.
- Text2Control Demo Outperforms Baselines: The Text2Control method allows agents to perform new tasks specified with natural language by inferring goals from text using vision-language models, and outperforms multitask reinforcement learning baselines in zero-shot generalization.
- The researcher invited others to try the interactive demo, highlighting the practical application of their approach in enabling language-conditioned agents.
- Tweet from Lewis Tunstall (@_lewtun): Can you feel the AGI?
- Bridging environments and language with rendering functions and vision-language models: no description found
LAION ▷ #resources (2 messages):
CNN VisualizationText2Control Method
- Excellence Visualization of CNN: A member shared a link to a CNN explainer visualization tool, highlighting its usefulness.
- The tool is designed to help users understand how Convolutional Neural Networks (CNNs) work through interactive visualizations.
- Text2Control Method Introduced: Naver Labs Europe showcased their new 'Text2Control' method for controlling humanoid robots from textual instructions using vision-language models.
- The method achieves impressive zero-shot generalization by outperforming MTRL baselines and allows users to interact via an interactive demo.
- CNN Explainer: An interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs).
- Bridging environments and language with rendering functions and vision-language models: no description found
LangChain AI ▷ #general (1 messages):
prince.dhankhar: How Can We Send Timestamps To Each Chat Message to ChatOllama using LangChain?
LangChain AI ▷ #langchain-templates (6 messages):
Model-specific wording for promptsUsage of ChatPromptTemplateIncorporating JSON in prompts
- Model-specific wording for prompts unnecessary: One member questioned if specific wording from model descriptions is needed in
ChatPromptTemplatefor accuracy.- Another member clarified that LangChain's
ChatPromptTemplateabstracts this, making specific markers like<|assistant|>unnecessary.
- Another member clarified that LangChain's
- Using ChatPromptTemplate for prompt creation: An example was shared on how to create
ChatPromptTemplateby defining an array of messages, with each message represented by a role and message text pair.
- Issues · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
- Conceptual guide | 🦜️🔗 Langchain: This section contains introductions to key parts of LangChain.
- Build a Simple LLM Application with LCEL | 🦜️🔗 Langchain: In this quickstart we’ll show you how to build a simple LLM application
LangChain AI ▷ #share-your-work (1 messages):
Triplex LLMKnowledge GraphsSciPhi.AIGraph RAGCost Reduction
- Triplex revolutionizes knowledge graph construction: Triplex offers a 98% cost reduction in knowledge graph creation, outperforming GPT-4 at 1/60th the cost.
- Triplex, developed by SciPhi.AI, is a finetuned version of Phi3-3.8B that extracts triplets from unstructured data.
- SciPhi.AI open sources Triplex: A member shared that SciPhi.AI just open-sourced Triplex, making it available for efficient knowledge graph creation.
- Triplex enables local graph building with SciPhi's R2R, significantly reducing the cost of constructing knowledge graphs.
Link mentioned: SciPhi/Triplex · Hugging Face: no description found
LLM Perf Enthusiasts AI ▷ #general (3 messages):
OpenAI Scale TierGPT-4 Token Calculation
- *Mystery of OpenAI Scale Tier*: A member inquired about understanding the new OpenAI Scale Tier.
- The question raised confusion within the community about how the TPS calculations are determined, especially regarding GPT-4 models.
- *GPT-4 TPS Calculation Confusion: Members are puzzled by OpenAI's calculation of 19 tokens/second on the pay-as-you-go tier, pointing out GPT-4 outputting around 80 tokens/second*.
- This sparked a discussion about the basis of their TPS calculations and the discrepancy within tiers.
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
Sensitive Data ConcernsData Privacy
- Concerns about Sharing Sensitive Data with Third Parties: A member noted that many businesses are hesitant to send sensitive line-of-business data or customer/patient data to another company, indicating a concern about data privacy and security.
- Businesses Prioritize Data Privacy: Businesses are increasingly cautious about sharing sensitive information with external entities due to privacy and security concerns.
MLOps @Chipro ▷ #general-ml (1 messages):
Target Audience Clarification
- Defining Target Audience for Communication: The discussion revolved around understanding the target audience for effective communication.
- For engineers, talk to engineers for the products; for aspiring engineers/product, devrels / solution architects.
- Importance of Targeted Communication: Clarifying target audience ensures that the communication is relevant and impactful for specific groups.
- The intention is to tailor messages appropriately for engineers, aspiring engineers, product managers, devrels, and solution architects.