[AINews] Quis promptum ipso promptiet?
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Automatic Prompt Engineering is all you need.
AI News for 5/9/2024-5/10/2024. We checked 7 subreddits, 373 Twitters and 28 Discords (419 channels, and 4923 messages) for you. Estimated reading time saved (at 200wpm): 556 minutes.
We have been fans of Anthropic's Workbench for a while, and today they released some upgrades helping people improve and templatize their prompts.
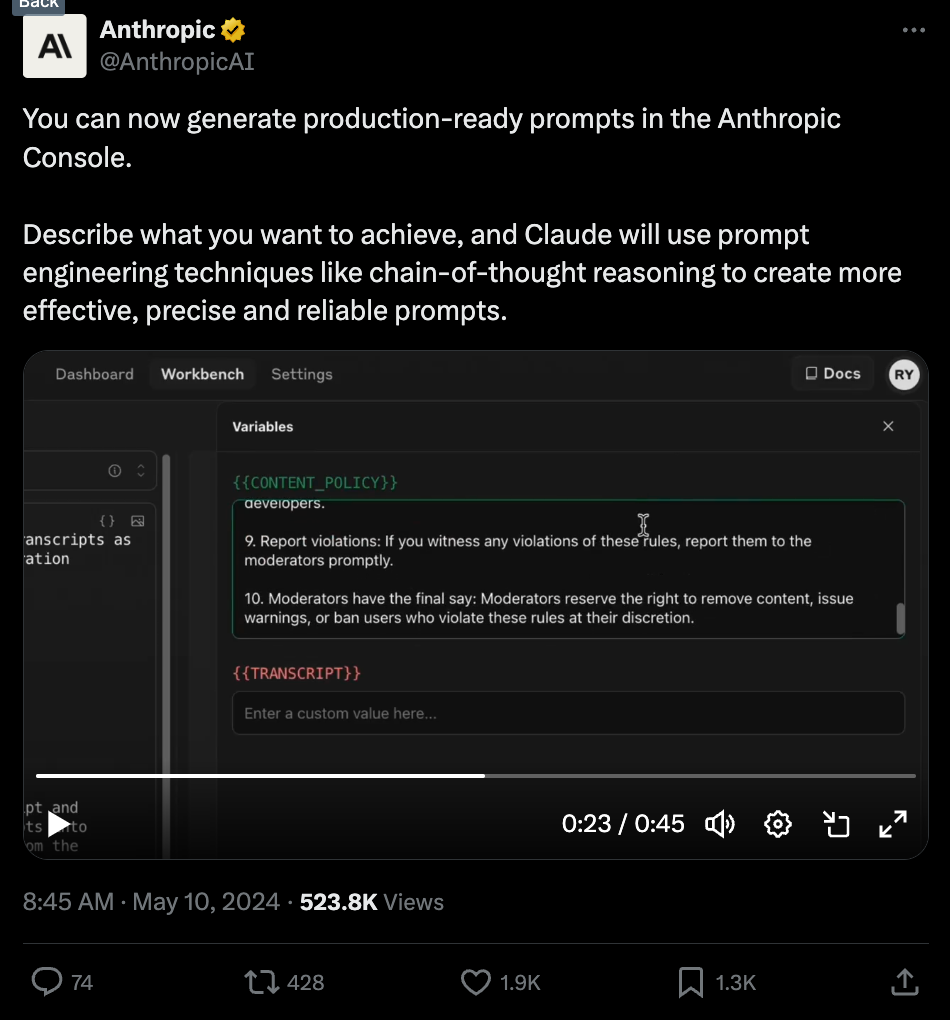
Pretty cool, not really the end of prompt engineer but nice to have. Let's be honest, it's been a really quiet week before the storm of both OpenAI's big demo day (potentially a voice assistant?) and Google I/O next week.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Perplexity AI Discord
- Unsloth AI (Daniel Han) Discord
- LM Studio Discord
- HuggingFace Discord
- Modular (Mojo 🔥) Discord
- Nous Research AI Discord
- OpenAI Discord
- Eleuther Discord
- CUDA MODE Discord
- Latent Space Discord
- LAION Discord
- OpenInterpreter Discord
- LlamaIndex Discord
- OpenAccess AI Collective (axolotl) Discord
- Interconnects (Nathan Lambert) Discord
- LangChain AI Discord
- OpenRouter (Alex Atallah) Discord
- Cohere Discord
- Datasette - LLM (@SimonW) Discord
- Mozilla AI Discord
- LLM Perf Enthusiasts AI Discord
- tinygrad (George Hotz) Discord
- Alignment Lab AI Discord
- Skunkworks AI Discord
- AI Stack Devs (Yoko Li) Discord
- PART 2: Detailed by-Channel summaries and links
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
OpenAI Announcements
- New developments teased: @sama teased new OpenAI developments coming Monday at 10am PT, noting it's "not gpt-5, not a search engine, but we've been hard at work on some new stuff we think people will love!", calling it "magic".
- Live demo promoted: @gdb also promoted a "Live demo of some new work, Monday 10a PT", clarifying it's "Not GPT-5 or a search engine, but we think you'll like it."
- Speculation on nature of announcement: There was speculation that this could be @OpenAI's Google Search competitor, possibly "just the Bing index summarized by an LLM". However, others believe it will be the new LLM to replace GPT-3.5 in the free tier.
Anthropic Developments
- New prompt engineering features: @AnthropicAI announced new features in their Console to generate production-ready prompts using techniques like chain-of-thought reasoning for more effective, precise prompts. This includes a prompt generator and variables to easily inject external data.
- Customer success with prompt generation: Anthropic's use of prompt generation significantly reduced development time for their customer @Zoominfo's MVP RAG application while improving output quality.
- Impact on prompt engineering: Some believe prompt generation means "prompt engineering is dead" as Claude can now write prompts itself. The prompt generator gets you 80% of the way there in crafting effective prompts.
Llama and Open-Source Models
- RAG application tutorial: @svpino released a 1-hour tutorial on building a RAG application using open-source models, explaining each step in detail.
- Llama 3 70B performance: Llama 3 70B is being called "game changing" based on its Arena Elo scores. Other strong open models include Haiku, Gemini 1.5 Pro, and GPT-4.
- Llama 3 120B quantized weights: Llama 3 120B quantized weights were released, showing the model's "internal struggle" in its outputs.
- Llama.cpp CUDA graphs support: Llama.cpp now supports CUDA graphs for a 5-18% performance boost on RTX 3090/4090 GPUs.
Neuralink Demo
- Thought-controlled mouse: A recent Neuralink demo video showed a person controlling a mouse at high speed and precision just by thinking. This sparked ideas about intercepting "chain of thought" signals to model consciousness and intelligence directly from human inner experience.
- Additional demos and analysis: More video demos and quantitative analysis were shared by Neuralink, generating excitement about the technology's potential.
ICLR Conference
- First time in Asia: ICLR 2024 is being held in Asia for the first time, generating excitement.
- Spontaneous discussions and GAIA benchmarks: @ylecun shared photos of spontaneous technical discussions at the conference. He also presented GAIA benchmarks for general AI assistants.
- Meta AI papers: Meta AI shared 4 papers to know about from their researchers at ICLR, spanning topics like efficient transformers, multimodal learning, and representation learning.
- High in-person attendance: 5400 in-person attendees were reported at ICLR, refuting notions of an "AI winter".
Miscellaneous
- Mistral AI funding: Mistral AI is rumored to be raising at a $6B valuation, with DST as an investor but not SoftBank.
- Yi AI model releases: Yi AI announced they will release upgraded open-source models and their first proprietary model Yi-Large on May 13.
- Instructor Cloud progress: Instructor Cloud is "one day closer" according to @jxnlco, who has been sharing behind-the-scenes looks at building AI products.
- UK PM on AI and open source: UK Prime Minister Rishi Sunak made a "sensible declaration" on AI and open source according to @ylecun.
- Perplexity AI partnership: Perplexity AI partnered with SoundHound to bring real-time web search to voice assistants in cars, TVs and IoT devices.
Memes and Humor
- Claude's charm: @nearcyan joked that "claude is charming and reminds me of all my favorite anthropic employees".
- "Stability is dead": @Teknium1 proclaimed "Stability is dead" in response to the Anthropic developments.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Progress and Capabilities
- AI music breakthrough: In a tweet, ElevenLabs previewed their music generator, signaling a significant advance in AI-generated music.
- Gene therapy restores toddler's hearing: A UK toddler had their hearing restored in the world's first gene therapy trial of its kind, a major medical milestone.
- Solar manufacturing meets 2030 goals early: The IEA reports that global solar cell manufacturing capacity is now sufficient to meet 2030 Net Zero targets, six years ahead of schedule.
- AI discovers new physics equations: An AI system made progress in discovering novel equations in physics by generating on-demand models to simulate physical systems.
- Progress in brain mapping: Google Research shared an update on their work mapping the human brain, which could lead to quality of life improvements.
AI Ethics and Governance
- OpenAI considers allowing AI porn generation: Raising ethical concerns, OpenAI is considering allowing users to create AI-generated pornography.
- OpenAI offers perks to publishers: OpenAI's Preferred Publisher Program provides benefits like priority chat placement to media companies, prompting worries about open model access.
- OpenAI files copyright claim against subreddit: Despite being a "mass scraper of copyrighted work," OpenAI filed a copyright claim against the ChatGPT subreddit's logo.
- Two OpenAI safety researchers resign: Citing doubts that OpenAI will "behave responsibly around the time of AGI," two safety researchers quit the company.
- US considers restricting China's AI access: The US is exploring curbs on China's access to AI software behind applications like ChatGPT.
AI Models and Architectures
- Invoke 4.2 adds regional guidance: Invoke 4.2 was released with Control Layers, enabling regional guidance with text and IP adapter support.
- OmniZero supports multiple identities/styles: The released OmniZero code supports 2 identities and 2 styles.
- Copilot gets GPT-4 based models: Copilot added 3 new "Next-Models" that appear to be GPT-4 variants. Next-model4 is notably faster than base GPT-4.
- Gemma 2B enables 10M context on <32GB RAM: Gemma 2B with 10M context was released, running on under 32GB of memory using recurrent local attention.
- Llama 3 8B extends to 500M context: An extension of Llama 3 8B to 500M context was shared.
- Llama3-8x8b-MoE model released: A Mixture-of-Experts extension to llama3-8B-Instruct called Llama3-8x8b-MoE was released.
- Bunny-v1.1-4B scales to 1152x1152 resolution: Built on SigLIP and Phi-3-mini-4k-instruct, the multimodal Bunny-v1.1-4B model was released, supporting 1152x1152 resolution.
AI Discord Recap
A summary of Summaries of Summaries
-
Large Language Model (LLM) Advancements and Releases:
- Meta's Llama 3 model is generating excitement, with an upcoming hackathon hosted by Meta offering a $10K+ prize pool. Discussions revolve around fine-tuning, evaluation, and the model's performance.
- LLaVA-NeXT models promise enhanced multimodal capabilities for image and video understanding, with local testing encouraged.
- The release of Gemma, boasting a 10M context window and requiring less than 32GB memory, sparks interest and skepticism regarding output quality.
- Multimodal Model Developments: Several new multimodal AI models were announced, including Idefics2 with a fine-tuning demo (YouTube), LLaVA-NeXT (blog post) with expanded image and video understanding capabilities, and the Lumina-T2X family (Reddit post) for transforming noise into various modalities based on text prompts. The Scaling_on_scales (GitHub) approach challenged the necessity of larger vision models.
-
Optimizing LLM Inference and Training:
- Innovations like vAttention and QServe aim to improve GPU memory efficiency and quantization for LLM inference, enabling larger batch sizes and faster serving.
- Consistency Large Language Models (CLLMs) introduce parallel decoding to reduce inference latency, mimicking human cognitive processes.
- Discussions on optimizing CUDA kernels, Triton performance, and the trade-offs between determinism and speed in backward passes for LLM training.
- Vrushank Desai's series explores optimizing inference latency for diffusion models by leveraging GPU architecture intricacies.
-
AI Model Interpretability and Evaluation:
- The Inspect AI framework from the UK AI Safety Institute offers components for evaluating LLMs, including prompt engineering, tool usage, and multi-turn dialog.
- Eleuther AI discusses the CrossCare project, which analyzes disease prevalence bias across demographics in LLMs and pretraining data.
- Debates around the impact of pretraining datasets on "zero-shot" generalization of multimodal models, as detailed in an arXiv paper.
- The Mirage multi-level tensor algebra superoptimizer aims to optimize deep neural networks, though its benchmark claims face skepticism.
-
Open-Source AI Tools and Libraries:
- LlamaIndex announces local LLM integration, TypeScript agent building guides, and integration with Google Firestore, fostering open AI development.
- OpenInterpreter enables AI task automation using GPT-4 and OpenCV, with new releases adding OS flag and Computer API support.
- Hugging Face integrates B-LoRA training into advanced DreamBooth for implicit style-content separation using a single image.
- Intel's ipex-llm accelerates local LLM inference and fine-tuning on Intel CPUs and GPUs, though it currently lacks LM Studio support.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Artisan Bot Immerses in Discord: Stability AI launched Stable Artisan, a Discord bot boasting Stable Diffusion 3 and Stable Video Diffusion features for content creation, bolstered by tools like Search and Replace, Background Removal, and Outpainting to revolutionize user interactions directly on Discord.
Open-Source or Not? The SD3 Debate Rages: Discord members heatedly debated the potential open-sourcing of Stable Diffusion 3 (SD3), exploring motives for the current API-restricted access and speculating on future outcome scenarios, including possible refinement before release.
Exploring the Stable Diffusion Universe: The community engaged with various Stable Diffusion model versions, including SDXL and ControlNets, evaluating their limitations and the substantial enhancements brought forth by community-developed models like Lora.
Aspiring for 360-Degree Creation: A user sparked discussion on crafting 360-degree images, sharing multiple resources and seeking guidance on methodologies, referencing platforms like Skybox AI and discussions on Reddit.
Tech Support to the Rescue in Real Time: Practical and succinct exchanges provided quick resolutions to common execution errors, such as "DLL load failed while importing bz2", emphasizing the Discord community's agility in offering peer-to-peer technical support.
Perplexity AI Discord
Perplexity Partners with SoundHound: Perplexity AI has entered a partnership with SoundHound, with the aim to integrate online large language models (LLMs) into voice assistants across various devices, enhancing real-time web search capabilities.
Perplexity Innovates Search and Citations: An update on Perplexity AI introduces incognito search, ensuring that user inquiries vanish after 24 hours, combined with enhanced citation previews to bolster user trust in information sources.
Pro Search Glitch and Opus Limitations Spark Debate: The engineering community is facing challenges with the Pro Search feature, which currently fails to deliver internet search results or source citations. Additionally, dissatisfaction surfaced regarding the daily 50-use limit for the Opus model on Perplexity AI, sparking discussions for potential alternatives and solutions.
API Conundrum for AI Engineers: Engineers have noted issues with API output consistency, where the same prompts yield different results compared to those on Perplexity Labs, despite using identical models. Queries have been raised regarding the cause of the discrepancies and requests for guidance on effective prompting for the latest models.
Engagement with Perplexity's Features and New Launches: Users are engaging with features such as making threads shareable and exploring various inquiries including the radioactivity of bananas and the nature of mathematical rings. Additionally, there's interest in Natron Energy's latest launch, reported through Perplexity's sharing platform.
Unsloth AI (Daniel Han) Discord
Unsloth Studio Stalls for Philanthropy: Unsloth Studio's release is postponed due to the team focusing on releasing phi and llama projects, with about half of the studio's project currently complete.
Optimizer Confusion Cleared: Users were uncertain about how to specify optimizers in Unsloth but referenced the Hugging Face documentation for clarification on valid strings for optimizers, including "adamw_8bit".
Training Trumps Inference: The Unsloth team has stated a preference for advancing training techniques rather than inference, where the competition is fierce. They've touted progress in accelerating training in their open-source contributions.
Long Context Model Skepticism: Discussions point to scepticism among users regarding the feasibility and evaluation of very long context models, such as a mentioned effort to tackle up to a 10M context length.
Dataset Cost-Benefit Debated: The community has exchanged differing views on the investment needed for high-quality datasets for model training, considering both instruct tuning and synthetic data creation.
Market-First Advice for Aspiring Bloggers: A member's idea for a multi-feature blogging platform prompted advice on conducting market research and ensuring a clear customer base to avoid a lack of product/market fit.
Ghost 3B Beta Tackles Time and Space: Early training of the Ghost 3B Beta model demonstrates its ability to explain Einstein's theory of relativity in lay terms across various languages, hinting at its potential for complex scientific communication.
Help Forums Foster Fine-Tuning Finesse: The Unsloth AI help channel is buzzing with tips for fine-tuning AI models on Google Colab, though multi-GPU support is a wanted yet unavailable feature. Solutions for CUDA memory errors and a nod towards YouTube fine-tuning tutorials are shared among users.
Customer Support AI at Your Service: ReplyCaddy, a tool based on a fine-tuned Twitter dataset and a tiny llama model for customer support, was showcased, with acknowledgments to Unsloth AI for fast inference assistance, found on hf.co.
LM Studio Discord
LM Studio Laments Library Limitations: While LM Studio excels with models like Llama 3 70B, users struggle to run models such as llama1.6 Mistral or Vicuña even on a 192GB Mac Studio, pointing to a mysterious RAM capacity issue despite ample system resources. There's also discomfort among users concerning the LM Studio installer on Windows since it doesn't offer installation directory selection.
AI Models Demand Hefty Hardware: Running large models necessitates substantial VRAM; members discussed VRAM being a bigger constraint than RAM. Intel's ipex-llm library was introduced to accelerate local LLM inference on Intel CPUs and GPUs Intel Analytics Github, but it's not yet compatible with LM Studio.
New Frontier of Multi-Device Collaboration: Engineers explored the challenges and potential for integrating AMD and Nvidia hardware, addressing the theoretical possibility versus the practical complexity. The fading projects like ZLUDA, aimed at broadening CUDA support for non-Nvidia hardware, were lamented ZLUDA Github.
Translation Model Exchange: For translation projects, Meta AI's NLLB-200, SeamlessM4T, and M2M-100 models came highly recommended, elevating the search for efficient multilingual capabilities.
CrewAI's Cryptic Cut-Off: When faced with truncated token outputs from CrewAI, users deduced that it wasn't quantization to blame. A mishap in the OpenAI API import amid conditional statements was the culprit, a snag now untangled, reaffirming the devil's in the details.
HuggingFace Discord
Graph Learning Enters LLM Territory: The Hugging Face Reading Group explored the integration of Graph Machine Learning with LLMs, fueled by Isamu Isozaki's insights, complete with a supportive write-up and a video.
Demystifying AI Creativity: B-LoRA's integration into advanced DreamBooth's LoRA training script promises new creative heights just by adding the flag --use_blora and training for a relatively short span, as per the diffusers GitHub script and findings in the research paper.
On the Hunt for Resources: AI enthusiasts sought guidance and shared resources across a variety of tasks, with a notable GitHub repository on creating PowerPoint slides using OpenAI's API and DALL-E available at Creating slides with Assistants API and DALL-E and the mention of Ankush Singal's Medium articles for table extraction tools.
Challenging NLP Channel Conversations: The NLP channel tackled diverse topics such as recommending models for specific languages—indicating a preference for sentence transformers and encoder models, instructing versions of Llama, and also referenced community involvement in interview preparations.
Hiccups and Fixes in Diffusion Discussions: The diffusion discussions detailed issues and potential solutions related to HuggingChat bot errors and color shifts in diffusion models, noting a possible fix for login issues by switching the login module from lixiwu to anton-l in order to troubleshoot a 401 status code error.
Modular (Mojo 🔥) Discord
- Mystery of the Missing MAX Launch Date: While a question was raised regarding the launch date of MAX for enterprises, no direct answer was found in the conversation.
- Tuning up Modularity: There's anticipation for GPU support with Mojo, showing potential for scientific computing advancements. The Modular community continues to explore new capabilities in MAX Engine and Mojo, with discussions ranging from backend development expertise in languages like Golang and Rust, to seeking collaborative efforts for smart bot assistance using Hugging Face models.
- Rapid Racing with MoString: A custom
MoStringstruct in Rust showed a staggering 4000x speed increase for string concatenation tasks, igniting talks about enhancing Modular's string manipulation capabilities and how it could aid in LLM Tokenizer decoding tasks.
- Iterator Iterations and Exception Exceptions: The Modular community is deliberating the implementation of iterators and exception handling in Mojo, exploring whether to return
Optional[Self.Output]or raise exceptions. This feeds into broader conversations about language design choices, with a focus on balancing usability and Zero-Cost Abstractions.
- From Drafts to Discussions: An array of technical proposals is in the mix, from structuring Reference types backed by lit.ref to enhancing language ergonomics in Mojo. Contributions to these discussions range from insights into auto-dereferencing to considerations around Small Buffer Optimization (SBO) in
List, all leading to thoughtful scrutiny and collaboration among Modular aficionados.
Nous Research AI Discord
- TensorRT Turbocharges Llama 3: An engineer highlighted the remarkable speed improvements in Llama 3 70b fp16 when using TensorRT, sharing practical guidance with a setup link for those willing to bear the setup complexities.
- Multimodal Fine-Tuning and Evaluation Unveiled: Discourse revolved around fine-tuning methods and evaluations for models. Fine-tuning Idefics2 showcased via YouTube, while the Scaling_on_scales approach challenges the necessity of larger vision models, detailed on its GitHub page. Additionally, the UK Government's Inspect AI framework was mentioned for evaluating large language models.
- Navigation Errors and Credit Confusion in Worldsim: Users encountered hurdles with Nous World Client, specifically with navigation commands, and discussed unexpected changes in user credits post-update. The staff is actively addressing the related system flaws evident in Worldsim Client's interface.
- Efficacious Token Counter and LLM Optimization: Solutions for counting tokens in Llama 3 and details about Meta Llama 3 were shared, including an alternative token counting method using Nous' copy and model details on Huggingface. Additionally, Salesforce's SFR-Embedding-Mistral was highlighted for surpassing its predecessors in text embedding tasks, as detailed on its webpage.
- Painstaking Rope KV Cache Debacle: The dialogue includes an engineer's struggle with a KV cache implementation for rope, the querying of token counts for Llama 3, and uploading errors experienced on the bittensor-finetune-subnet, exemplifying the type of technical challenges prevalent in the community.
OpenAI Discord
- Get Ready for GPT Goodies: A live stream is scheduled for May 13 at 10AM PT on openai.com to reveal new updates for ChatGPT and GPT-4.
- Grammar Police Gather Online: A debate has arisen regarding the importance of grammar, with a high school English teacher advocating for language excellence and others suggesting patience and the use of grammar-checking tools.
- Shaping the Future of Searches: There's buzzing speculation over a potential GPT-based search engine and chatter about using Perplexity as a go-to while awaiting this development.
- GPT-4 API vs. App: Unpacking the Confusion: Users distinguished between ChatGPT Plus and the GPT-4 API billing, noting the app has different output quality and usage limits, specifically an 18-25 messages per 3-hour limit.
- Sharing is Caring for Prompt Enthusiasts: Community members shared resources, including a detailed learning post and a free prompt template for analyzing target demographics, enriched with specifics on buying behavior and competitor engagement.
Eleuther Discord
- Evolving Large Model Landscapes: Discussion within the community spans topics from the applicability of Transformer Math 101 memory heuristics from a ScottLogic blog post to techniques in Microsoft's YOCO repository for self-supervised pre-training, as well as QServe's W4A8KV4 quantization method for LLM inference acceleration. There's an ongoing interest in optimizing Transformer architectures with novel tactics like using a KV cache with sliding window attention and the potential of a multi-level tensor algebra superoptimizer showcased in the Mirage GitHub repository.
- Exploring Bias and Dataset Influence on LLMs: The community raises concerns about bias in LLMs, analyzing findings from the CrossCare project and detailing conversations around dataset discrepancies versus real-world prevalence. The EleutherAI community is leveraging resources like the EleutherAI Cookbook and findings presented in a paper discussing tokenizer glitch tokens, which could inform model improvements regarding language processing.
- Positional Encoding Mechanics: Researchers debate the merits of different positional encoding techniques, such as Rotary Position Embedding (RoPE) and Orthogonal Polynomial Based Positional Encoding (PoPE), contemplating the effectiveness of each in addressing limitations of existing methods and the potential impact on improving language model performance.
- Deep Dive into Model Evaluations and Safety: The community introduces Inspect AI, a new evaluation platform from the UK AI Safety Institute designed for extensive LLM evaluations, which can be explored further through its comprehensive documentation found here. Parallel to this, the conversation regarding mathematical benchmarks brings attention to the gap in benchmarks aimed at AI's reasoning capabilities and the potential "zero-shot" generalization limitations as detailed in an arXiv paper.
- Inquiry into Resources Availability: Discussions hint at demand for resources, with specific inquires about the availability of tuned lenses for every Pythia checkpoint, indicating the community's ongoing effort to refine and access tools to enhance model analysis and interpretability.
CUDA MODE Discord
AI Hype Train Hits Practical Station: The community is buzzing with discussions on the practical aspects of deep learning optimization, contrasting with the usual hype around AI capabilities. Specific areas of focus include saving and loading compiled models in PyTorch, acceleration of compiled artifacts, and the non-support of MPS backend in Torch Inductor as illustrated in a PR by msaroufim.
Memory Efficiency Breakthroughs: Innovations like vAttention and QServe are reshaping GPU memory efficiency and serving optimizations for large language models (LLMs), promising larger batch sizes without internal fragmentation and efficient new quantization algorithms.
Engineering Precision: CUDA vs Triton: Critical comparisons between CUDA and Triton for warp and thread management, including performance nuances and kernel-launch overheads, were dissected. A YouTube lecture on the topic was recommended, with discussions pointing out the pros and cons of using Triton, notably its attempt at minimizing Python-related overhead through potential C++ runtimes.
Optimization Odyssey: Links shared revealed a fascination with optimizing inference latency for models like Toyota's diffusion model, discussed in Vrushank Desai's series found here, and a "superoptimizer" explored in the Mirage paper for DNNs, raising eyebrows regarding benchmark claims and the lack of autotune.
CUDA Conundrums and Determinism Dilemmas: From troubleshooting CUDA's device-side asserts to setting the correct NVCC compiler flags, beginners are wrestling with the nuances of GPU computing. Meanwhile, seasoned developers are debating determinism in backward passes and the trade-offs with performance in LLM training, as discussed in the llmdotc channel.
Latent Space Discord
New Kid on the Block Outshines Olmo: A model from 01.ai is claimed to vastly outperform Olmo, stirring up interest and debate within the community about its potential and real-world performance.
Sloppy Business: Borrowing from Simon Willison's terminology, community members adopt "slop" to describe unwanted AI-generated content. Here's the buzz about AI etiquette.
LLM-UI Cleans Up Your Markup Act: llm-ui was introduced as a solution for refining Large Language Model (LLM) outputs by addressing problematic markdown, adding custom components, and enhancing pauses with a smoother output.
Meta Llama 3 Hackathon Gears Up: An upcoming hackathon focused on Llama 3 has been announced, with Meta at the helm and a $10K+ prize pool, looking to excite AI enthusiasts and developers. Details and RSVP here.
AI Guardrails and Token Talk: Discussions revolved around LLM guardrails featuring tools like Outlines.dev, and the concept of token restriction pregeneration, an approach ill-suited for API-controlled models like those from OpenAI.
LAION Discord
- Codec Evolution: Speech to New Heights: A speech-only codec showcased in a YouTube video was shared alongside a Google Colab for a general-purpose codec at 32kHz. This global codec is an advancement in speech processing technology.
- New Kid on the Block: Introduction of Llama3s: The llama3s model from LLMs lab was released, offering an enhanced tool for various AI tasks with details available on Hugging Face's LLMs lab.
- LLaVA Defines Dimensions of Strength: LLaVA blog post delineates the improvements in their latest language models with a comprehensive exploration of LLaVA's stronger LLMs at llava-vl.github.io.
- Cutting through the Noise: Score Networks and Diffusion Models: Engineers discussed convergence of Noise Conditional Score Networks (NCSNs) to Gaussian distribution with Yang Song’s insights on his blog, and dissected the shades between DDPM, DDIM, and k-diffusion, referencing the k-diffusion paper.
- Beyond Images: Lumina Family's Modality Expedition: Announcing the Lumina-T2X family as a unified model for transforming noise to multiple modalities based on text prompts, utilizing a flow-based mechanism. Future improvements and training details were highlighted in a Reddit discussion.
OpenInterpreter Discord
Groq API Joins OpenInterpreter's Toolset: The Groq API is now being used within OpenInterpreter, with the best practice being to use groq/ as the prefix in completion requests and define the GROQ_API_KEY. Python integration examples are available, aiding in rapid deployment of Groq models.
OpenInterpreter Empowers Automation with GPT-4: OpenInterpreter demonstrates successful task automation, specifically using GPT-4 alongside OpenCV/Pyautogui for GUI navigation tasks on Ubuntu systems.
Innovative OpenInterpreter and Hardware Mashups: Community members are creatively integrating OpenInterpreter with Billiant Labs Frame to craft unique applications such as AI glasses, as shown in this demo, and are exploring compatible hardware like the ESP32-S3-BOX 3 for the O1 Light.
Performance Variability in Local LLMs: While OpenInterpreter's tools are actively used, members have observed inconsistent performance in local LLMs for file system tasks, with Mixtral recognized for enhanced outcomes.
Updates and Advances in LLM Landscapes: The unveiling of LLaVA-NeXT models marks progress in local image and video understanding. Concurrently, OpenInterpreter's 0.2.5 release has brought in new features like the --os flag and a Computer API, detailed in the change log, improving inclusiveness and empowering developers with better tools.
LlamaIndex Discord
LLM Integration for All: LlamaIndex announced a new feature allowing local LLM integrations, supporting models like Mistral, Gemma, and others, and shared details on Twitter.
TypeScript and Local LLMs Unite: There's an open-source guide for building TypeScript agents that leverage local LLMs, like Mixtral, announced on Twitter.
Top-k RAG Approach Discouraged for 2024: A caution against using top-k RAG for future projects trended, hinting at emerging standards in the community. LlamaIndex tweeted this guidance here.
Graph Database Woes and Wonders: A user detailed their method of turning Gmail content into a Graph database via a custom retriever but is now looking for ways to improve efficiency and data feature extraction.
Interactive Troubleshooting: When facing a NotImplementedError with Mistral and HuggingFace, users were directed to a Colab notebook to facilitate the setup of a ReAct agent.
OpenAccess AI Collective (axolotl) Discord
Pretraining Predicaments and Fine-Tuning Frustrations: Engineers reported challenges and sought advice on pretraining optimization, dealing with a dual Epoch Enigma where one epoch unexpectedly saved a model twice, and facing a Pickle Pickle with PyTorch, which threw a TypeError when it couldn’t pickle a 'torch._C._distributed_c10d.ProcessGroup' object.
LoRA Snafu Sorted: A fix was proposed for a LoRA Configuration issue, advising to include 'embed_tokens' and 'lm_head' in the settings to address a ValueError; this snippet was shared for precise YAML configuration:
lora_modules_to_save:
- lm_head
- embed_tokens
Additionally, an engineer struggling with an AttributeError in transformers/trainer.py was counseled on debugging steps, including batch inspection and data structure logging.
Scaling Saga: For fine-tuning extended contexts in Llama 3 models, linear scaling was recommended, while dynamic scaling was suggested as the better option for scenarios outside fine-tuning.
Bot Troubles Teleported: A Telegram bot user highlighted a timeout error, suggesting networking or API rate-limiting issues could be in play, with the error message being: 'Connection aborted.', TimeoutError('The write operation timed out').
Axolotl Artefacts Ahead: Discussion on the Axolotl platform revealed capabilities to fine-tune Llama 3 models, confirming a possibility for handling a 262k sequence length and further curious explorations into fine-tuning a 32k dataset.
Interconnects (Nathan Lambert) Discord
- Echo Chamber Evolves into Debate Arena: Engineers voiced the need for a Retort channel for robust debates, echoing frustration by comically referencing self-dialogues on YouTube due to the current lack of structured argumentative discourse.
- Scrutinizing Altman's Search Engine Claims: A member cast doubt on the purported readiness of a search engine mentioned by Sam Altman in a tweet, signaling ongoing evaluations and suggesting the claim could be premature.
- Recurrent Models Meet TPUs: Discussions surfaced around training Recurrent Models (RMs) using TPUs and Fully Sharded Data Parallel (FSDP) protocols. Nathan Lambert pointed to EasyLM as a possibly adaptable Jax-based training tool, offering hope for streamlined training endeavors on TPUs.
- OpenAI Seeks News Allies: The revelation of the OpenAI Preferred Publisher Program, connecting with heavy hitters like Axel Springer and The Financial Times, underlined OpenAI's strategy to prioritize these publishers with enhanced content representation. This suggests a monetization through advertisement and preferred exposure within language models, marking a step towards commercializing AI-generated content.
- Digesting AI Discourse Across Platforms: A new information service from AI News proposes a synthesis of AI conversations across platforms, looking to condense insights for a time-strapped audience. Meanwhile, thoughts on max_tokens awareness and AI behavior by John Schulman spurred critical discourse on model effectiveness, while community appreciation for AI influencers ran high, citing Schulman as a seasoned thought leader.
LangChain AI Discord
Structuring AI with a Google Twist: Discussion unfolded around emulating Google's Gemini AI studio structured prompts within various LLMS, introducing function calling as a new approach to managing LangChain's model interactions.
Navigating LangGraph and Vector Databases: Users troubleshoot issues with ToolNode in LangGraph, with pointers to the LangGraph documentation for in-depth guidance; while others deliberated the complexities and costs of vector databases, with some favoring pgvector for its simplicity and open-source availability, and a comprehensive comparison guide recommended for those considering free local options.
Python vs POST Discrepancies in Chain Invocation: A peculiar case emerged where a member experienced different outcomes when employing a chain() through Python compared to utilizing an /invoke endpoint, indicating the chain began with an empty dictionary via the latter method, signaling potential variations in LangChain's initialization procedures.
AgencyRuntime Beckons Collaborators: A prominent article introduces AgencyRuntime, a social platform designed for crafting modular teams of generative AI agents, and extends an invitation to enhance its capabilities by incorporating further LangChain features.
Learning from LangChain Experts: Tutorial content released guides users on linking crewAI with the Binance Crypto Market and contrasts Function Calling agents and ReACt agents within LangChain, offering practical insights for those fine-tuning their AI applications.
OpenRouter (Alex Atallah) Discord
- A New Browser Extension Joins the Fray: Languify.ai was unveiled, harnessing Openrouter to optimize website text for better engagement and sales.
- Rubik's AI Calls for Beta Testers: Tech enthusiasts have a chance to shape the future of Rubik's AI, an emerging research assistant and search engine, with beta testers receiving a 2-month trial and encouraged to provide feedback using the code
RUBIX.
- PHP and Open Router API Clash: An issue was reported with the PHP React library resulting in a RuntimeException while interacting with the Open Router API, as a user sought help with their "Connection ended before receiving response" error.
- Router Training Evolves with Roleplay: In a search for optimal metrics, a user favored validation loss and precision recall AUC for evaluating router performances on roleplay-themed conversations.
- Gemma Breaks Context Length Records: Interest surged in the promising yet doubted Gemma, a model flaunting a whopping 10M context window that operates on less than 32GB of memory, as announced in a tweet by Siddharth Sharma.
Cohere Discord
- Fine-Tuning Features Fuel Fervor: Command R Fine-Tuning is now available, offering best-in-class performance, up to 15x lower costs, and faster throughput, with accessibility through Cohere platform and Amazon SageMaker. There's anticipation for additional platforms and the upcoming CMD-R+, as well as discussions of cost-effectiveness and use cases for fine-tuning—the details are explored on the Cohere blog post.
- Credit Where Credit Is Due: Engineers seeking to add credits to their Cohere account can utilize the Cohere billing dashboard to set spending limits post credit card addition. This ensures frictionless management of their model usage costs.
- Dark Mode Hits Spot After Sunset: Cohere's Coral does not feature a native dark mode yet; however, a community member provided a custom CSS snippet for a browser-based dark mode solution for those night owl coders.
- Cost Inquiry for Cohere Embeds: A user inquiring about the embed model pricing for production was directed to the Cohere pricing page, which details various plans and the steps to obtain Trial and Production API keys.
- New Faces, New Paces: The community welcomed a new member from Annaba, Algeria, with interests in NLP and LLM, highlighting the diverse and growing global interest in language model applications and development.
Datasette - LLM (@SimonW) Discord
- Apple's Brave New AI World: Apple plans to use M2 Ultra chips for powering generative AI workloads in data centers while gearing up for an eventual shift to M4 chips, within the scope of Project ACDC, which emphasizes security and privacy.
- Mixture of Experts Approach: The discussions ponder over Apple's strategy that resembles a 'mixture of experts', where less demanding AI tasks could run on users' devices, and more complex operations would utilize cloud processing.
- Apple Silicon Lust: Amidst the buzz, an engineer shared their desire for an M2 Ultra-powered Mac, showcasing the enthusiasm stemming from Apple's recent hardware revelations.
- MLX Framework on the Spotlight: Apple's MLX framework is gaining attention, with its capabilities to run large AI models on Apple's hardware, supported by resources available on a GitHub repository.
- ONNX as a Common Language: Despite Apple's tendency towards proprietary formats, the adoption of the ONNX model format, including the Phi-3 128k model, underlines its growing importance in the AI community.
Mozilla AI Discord
- Clustering Ideas Gets a Creative Makeover: A new blog post introduces the application of Llamafile to topic clustering, enhanced with Figma's FigJam AI and DALL-E's visual aids, illustrating the potential for novel approaches to idea organization.
- Getting Technical with llamafile's GPU Magic: Details on llamafile's GPU layer offloading were provided, focusing on the
-ngl 999flag that enables this feature according to the llama.cpp server README, alongside shared benchmarks highlighting the performance variations with different GPU layer offloads. - Alert: llamafile v0.8.2 Drops: The release of llamafile version 0.8.2 by developer K introduces performance enhancements for K quants, with guidance for integrating this update given in an issue comment.
- Openelm and llama.cpp Integration Hurdles: A developer's quest to blend Openelm with
llama.cppappears in a draft GitHub pull request, with the primary obstacle pinpointed tosgemm.cppwithin the pull request discussion. - Podman Container Tactics for llamafile Deployment: A workaround involving shell scripting was shared to address issues encountered when deploying llamafile with Podman containers, suggesting a potential conflict with
binfmt_miscin the context of multi-architecture format support.
LLM Perf Enthusiasts AI Discord
- Spreadsheets Meet AI: A tweet discussed the potential of AI in tackling the chaos of biological lab spreadsheets, suggesting AI could be pivotal in data extraction from complex sheets. However, a demonstration with what might be a less capable model did not meet expectations, highlighting a gap between concept and execution.
- GPT-4's Sibling, Not Successor: Enthusiasm bubbled over speculations around GPT-4's upcoming release; however, it's confirmed not to be GPT-5. Discussion underway suggests the development might be an "agentic-tuned" version or a "GPT4Lite," promising high quality with reduced latency.
- Chasing Efficiency in AI Models: The hope for a more efficient model akin to "GPT4Lite," inspired by Haiku's performance, indicates a strong desire for maintaining model quality while improving efficiency, cost, and speed.
- Beyond GPT-3.5: The advancements in language models have outpaced GPT-3.5, rendering it nearly obsolete compared to its successors.
- Excitement and Guesswork Pre-Announcement: Anticipation heats up with predictions about a dual release featuring an agentic-tuned GPT-4 alongside a more cost-effective version, underscoring the dynamic evolution of language model offerings.
tinygrad (George Hotz) Discord
Metal Build Conundrum: Despite extensive research including Metal-cpp API, MSL spec, Apple documentation, and a developer reference, a user is struggling to understand the libraryDataContents() function in a Metal build process.
Tensor Vision: An online visualizer has been developed by a user to help others comprehend tensor shapes and strides, potentially simplifying learning for AI engineers.
TinyGrad Performance Metrics: Clarification was provided that InterpretedFlopCounters in TinyGrad's ops.py are used as performance proxies through flop count insights.
Buffer Registration Clarified: Responding to an inquiry about self.register_buffer in TinyGrad, a user mentioned that initializing a Tensor with requires_grad=False is the alternative approach in TinyGrad.
Symbolic Range Challenge: There's a call for a more symbolic approach to functions and control flow within TinyGrad, hinting at an ambition to have a rendering system that comprehends expansions of general algebraic lambdas and control statements symbolically.
Alignment Lab AI Discord
- Seeking Buzz Model Finetuning Intel: A user has inquired about the best practices for iterative sft finetuning of Buzz models, noting the current gaps in documentation and guidance.
Skunkworks AI Discord
- AI Skunkworks Shares a Video: Member pradeep1148 shared a YouTube video in the #off-topic channel, context or relevance was not provided.
AI Stack Devs (Yoko Li) Discord
- Phaser-Based AI Takes the Classroom: The AI Town community announced an upcoming live session about the intersection of AI and education, featuring the use of Phaser-based AI in interactive experiences and classroom integration. The event includes showcases from the #WeekOfAI Game Jam and insights on implementing the AI tool, Rosie.
- AI EdTech Engagement Opportunity: AI developers and educators are invited to attend the event on Monday, 13th at 5:30 PM PST, with registration available via a recent Twitter post. Attendees can expect to learn about gaming in AI learning and engage with the educational community.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
- Stable Artisan Joins the Discord Family: Stability AI presents Stable Artisan, a Discord bot that integrates multimodal AI capabilities, including Stable Diffusion 3 and Stable Video Diffusion for image and video generation within Discord.
- The Future is Multimodal: Stable Artisan brings a suite of editing tools such as Search and Replace, Remove Background, Creative Upscale, and Outpainting to enhance media creation on Discord.
- Accessibility and Community Engagement Enhanced: By fulfilling a popular demand, Stability AI aims to make their advanced models more accessible to the Stable Diffusion community directly on Discord.
- Embark On the Stable Artisan Experience: Discord users eager to try Stable Artisan can get started on the Stable Diffusion Discord Server in designated channels such as #1237461679286128730 and others listed in the announcement.
Link mentioned: Stable Artisan: Media Generation and Editing on Discord — Stability AI: One of the most frequent requests from the Stable Diffusion community is the ability to use our models directly on Discord. Today, we are excited to introduce Stable Artisan, a user-friendly bot for m...
Stability.ai (Stable Diffusion) ▷ #general-chat (877 messages🔥🔥🔥):
- SD3 Weights Discussion: Members discussed at length their views on whether Stability AI will release SD3 open-source weights and whether the current API access indicates the model is complete. The consensus varies, with some arguing for financial motives behind the API-only access and others suggesting the model will be open-sourced after further refinement.
- Community Engagement with Model Versions: There was discussion about the usefulness of various Stable Diffusion model versions, such as SDXL, and community contributions like Lora models and ControlNets. Different perspectives were shared on whether SDXL has reached its limits and if the open-source community additions significantly enhance its capabilities.
- Video Generation Capability Enquiry: A user inquired about the capability of generating videos from prompts, specifically if Discord allows this or if it's solely web-based. It was clarified that while it's possible with tools like Stable Video Diffusion, doing so directly on Discord might require a paid service like Artisan.
- 360-degree Image Generation Requests: One member sought advice on generating a 360-degree runway image, sharing several links to tools and methods that might produce such an image. The user was exploring options such as web tools, specific GitHub repositories, and advice from Reddit but was still seeking a clear solution.
- Execution Errors and Quick Support Requests: Users reported issues like the "DLL load failed while importing bz2" error when running webui-user.bat, seeking solutions in channels specifically dedicated to technical support. Conversations were brisk and to the point, with some users preferring direct assistance over formalities.
- Stop Killing Games: no description found
- Reddit - Dive into anything: no description found
- #NeuraLunk's Profile and Image Gallery | OpenArt: Free AI image generator. Free AI art generator. Free AI video generator. 100+ models and styles to choose from. Train your personalized model. Most popular AI apps: sketch to image, image to video, in...
- ComfyUI-SAI_API/api_cat_with_workflow.png at main · Stability-AI/ComfyUI-SAI_API: Contribute to Stability-AI/ComfyUI-SAI_API development by creating an account on GitHub.
- Skybox AI: Skybox AI: One-click 360° image generator from Blockade Labs
- GitHub - tjm35/asymmetric-tiling-sd-webui: Asymmetric Tiling for stable-diffusion-webui: Asymmetric Tiling for stable-diffusion-webui. Contribute to tjm35/asymmetric-tiling-sd-webui development by creating an account on GitHub.
- GitHub - mix1009/model-keyword: Automatic1111 WEBUI extension to autofill keyword for custom stable diffusion models and LORA models.: Automatic1111 WEBUI extension to autofill keyword for custom stable diffusion models and LORA models. - mix1009/model-keyword
- GitHub - lucataco/cog-sdxl-panoramic-inpaint: Attempt at cog wrapper for Panoramic SDXL inpainted image: Attempt at cog wrapper for Panoramic SDXL inpainted image - lucataco/cog-sdxl-panoramic-inpaint
- Donald Trump ft Vladimir Putin - It wasn't me #trending #music #comedy: no description found
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
{kind=link}
Perplexity AI ▷ #announcements (2 messages):
- Perplexity Powers SoundHound's Voice AI: Perplexity is teaming up with SoundHound, a leader in voice AI. This partnership will bring real-time web search to voice assistants in cars, TVs, and IoT devices.
- Incognito Mode and Citation Previews Go Live: Users can now ask questions anonymously with incognito search, with queries disappearing after 24 hours for privacy. Improved citations offer source previews; available on Perplexity and soon on mobile.
Link mentioned: SoundHound AI and Perplexity Partner to Bring Online LLMs to Next Gen Voice Assistants Across Cars and IoT Devices: This marks a new chapter for generative AI, proving that the powerful technology can still deliver optimal results in the absence of cloud connectivity. SoundHound’s work with NVIDIA will allow it to ...
Perplexity AI ▷ #general (715 messages🔥🔥🔥):
- In Search of Answers: Members reported that Pro Search is not providing internet search results or citing sources, unlike the normal model. A bug has been reported, and users are turning off the Pro mode as a temporary workaround.
- Pro Search Bug Acknowledged: The perplexity team is aware of the Pro Search issues, and users are directed towards bug-report status updates.
- Concerns Over Opus Limitations: Users expressed frustration over Opus being limited to 50 uses per day on Perplexity, questioning the transparency and purported temporary nature of the restriction. The community discussed alternatives and potential workarounds using other models or platforms.
- Data Privacy Settings Clarified: A discussion about the data privacy settings in Perplexity revealed that turning off "AI Data retention" prevents sharing information between threads, considered preferable for privacy.
- Assistance for Business Collaboration Inquiry: In search of business development contacts at Perplexity, a user was directed to email support[@]perplexity.ai cc: a tagged team member for appropriate direction.
- Tweet from Perplexity (@perplexity_ai): @monocleaaron Yep! — If you revisit the Thread after 24 hours, it'll expire and will be deleted in 30 days.
- OpenAI plans to announce Google search competitor on Monday, sources say | Forth: OpenAI plans to announce its artificial intelligence-powered search product on Monday, according to two sources familiar with the matter, raising the stakes in its competition with search king Google....
- Sam Altman shoots down reports of search engine launch ahead of Google I/O: OpenAI denies plans about a search product launch for Monday.
- Reddit - Dive into anything: no description found
Perplexity AI ▷ #sharing (15 messages🔥):
- Reminder to Make Threads Shareable: A prompt was provided reminding users to ensure their threads are shareable, alongside an instruction attachment. See the thread reminder here.
- Exploration of Radioactive Bananas: A user shared a link about the radioactivity of bananas, asking if bananas are radioactive.
- Discovering the Nature of Rings: Someone inquired about the definition or nature of a ring through a shared link: What is a ring?.
- Interest in Server Creation: A user expressed interest in creating a server by sharing a related link: Crear un servidor.
- Launch of Natron Energy's New Page Revealed: Information about Natron Energy's launch was provided through a shared URL. Check out Natron Energy's new launch.
- Insights into Publishing on Medium: A user sought to learn more about publishing content on Medium, indicated by a shared perplexity search link.
Perplexity AI ▷ #pplx-api (9 messages🔥):
- API Feature Inquiry: A member inquired about whether the API will return a "related" object with related items, akin to the feature available in the web/mobile search.
- Model Version Update Noted: An update has been mentioned regarding the page stating the model version as 70b.
- Difficulty with Output Formatting Instructions: Users are discussing that the latest online models are struggling with adhering to output formatting instructions, such as phrasing and list-making. They are seeking recommendations for effective prompt design.
- Inconsistencies between API and Perplexity Labs: Members have reported significant deviations in response quality when using the same prompt and model between the API and Perplexity Labs. It was acknowledged that they are separate entities.
- Clarity Sought on API vs. Labs Outputs: A member expressed interest in acquiring official clarification on why there might be inconsistencies between the two platforms even when using the same models and prompts.
Unsloth AI (Daniel Han) ▷ #general (476 messages🔥🔥🔥):
- Unsloth Studio's Delays and Upcoming Release: Unsloth Studio's release has been delayed due to other commitments related to phi and llama, with the team being about 50% done and planning to focus on it after tending to new releases.
- Inference Speed and Variety of Optimizers in Unsloth: While the Unsloth notebook mentions "adamw_8bit" optimization, there was confusion on how to specify other optimizer options for training. It's suggested to consult Hugging Face documentation for a list of valid strings for optimizers.
- Training vs Inference Focus for AI Development: The team stated that they're prioritizing training over inference as the field of inference is highly competitive. They mentioned that significant progress has been made on speeding up training in their open-source work.
- Difficulties with Long Context Models: Users sarcastically discussed the usefulness of long context models, with one mentioning an attempt by a different project to create a model with up to 10M context length. There is skepticism over the practical application and effective evaluation of such models.
- Discussions on Costs and Quality of Datasets: Conversations amongst users revealed differing opinions on the costs associated with acquiring high-quality datasets for training models, especially in regards to instruct tuning and synthetic data generation.
- mustafaaljadery/gemma-2B-10M · Hugging Face: no description found
- Replete-AI/code_bagel · Datasets at Hugging Face: no description found
- Tweet from RomboDawg (@dudeman6790): Ok so what do think of this idea? Bagel dataset... But for coding 🤔
- Tweet from ifioravanti (@ivanfioravanti): Look at this! Llama-3 70B english only is now at 1st 🥇 place with GPT 4 turbo on @lmsysorg Chatbot Arena Leaderboard🔝 I did some rounds too and both 8B and 70B were always the best models for me. ...
- Reddit - Dive into anything: no description found
- The Simpsons Homer Simpson GIF - The Simpsons Homer Simpson Good Bye - Discover & Share GIFs: Click to view the GIF
- Samurai Champloo GIF - Samurai Champloo Head Bang - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face: no description found
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- GitHub - coqui-ai/TTS: 🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production: 🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production - coqui-ai/TTS
- Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- chargoddard/commitpack-ft-instruct · Datasets at Hugging Face: no description found
- no title found: no description found
- Tweet from RomboDawg (@dudeman6790): Thank you to this brave man. He did what i couldnt. I tried and failed to make a codellama model. But he made one amazingly. Ill be uploading humaneval score to his model page soon as a pull request o...
- Stop Sign GIF - Stop Sign Red - Discover & Share GIFs: Click to view the GIF
- Capybara Let Him Cook GIF - Capybara Let him cook - Discover & Share GIFs: Click to view the GIF
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- No way to get ONLY the generated text, not including the prompt. · Issue #17117 · huggingface/transformers: System Info - `transformers` version: 4.15.0 - Platform: Windows-10-10.0.19041-SP0 - Python version: 3.8.5 - PyTorch version (GPU?): 1.10.2+cu113 (True) - Tensorflow version (GPU?): 2.5.1 (True) - ...
- How AI was Stolen: CHAPTERS:00:00 - How AI was Stolen02:39 - A History of AI: God is a Logical Being17:32 - A History of AI: The Impossible Totality of Knowledge33:24 - The Lea...
- Emotional Damage GIF - Emotional Damage Gif - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #random (19 messages🔥):
- Aspiring Startup Dreams: A member is working on a multi-user blogging platform with features like comment sections, content summaries, video scripts, blog generation, content checking, and anonymous posting. The community suggested conducting market research, identifying unique selling points, and to ensure there's a customer base willing to pay before proceeding with the startup idea.
- Words of Caution for Startups: Another member advised that before building a product, one should find a market of people willing to pay for it to avoid building something without product/market fit. Building to learn is okay, but startups require a clear path to profitability.
- Reddit Community Engagement: Link shared to Reddit's r/LocalLLaMA where a humor post discusses "Llama 3 8B extended to 500M context," jokingly illustrating the challenges in finding extended context for AI.
- Emoji Essentials in Chat: The chat includes members discussing the need for new emojis representing reactions like ROFL and WOW. Efforts to source suitable emojis are underway, with agreements to communicate once options are found.
Link mentioned: Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (113 messages🔥🔥):
- Colab Notebooks to the Rescue: Unsloth AI has provided Google Colab notebooks tailored for various AI models, helping users with their training settings and model fine-tuning. Users are directed to these resources for executing their projects with models like Llama3.
- The Unsloth Multi-GPU Dilemma: Currently, Unsloth AI doesn't support multi-GPU configurations, much to the chagrin of users with multiple powerful GPUs. Although it's in the roadmap, multi-GPU support isn't a priority over single-GPU setups due to Unsloth's limited manpower.
- Grappling with GPU Memory: Users are trying to fine-tune LLM models like llama3-70b, but hit the wall with CUDA out of memory errors. Suggestions include using CPU for certain operations with environment variable tweaks.
- Finetuning Frustrations and Friendly Fire: Queries about fine-tuning using different datasets and LLMs abound, with Unsloth's dev team and community members providing guidance on dataset format transformations and sharing helpful resources such as relevant YouTube tutorials.
- Fine-Tuning Frameworks and Fervent Requests: Detailed discussions on fine-tuning procedures with Unsloth's framework are complemented by requests for features and clarifications on VRAM requirements for models like llama3-70-4bit. The community shares insights, links, and tips on addressing common problems.
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Llama 3 Fine Tuning for Dummies (with 16k, 32k,... Context): Learn how to easily fine-tune Meta's powerful new Llama 3 language model using Unsloth in this step-by-step tutorial. We cover:* Overview of Llama 3's 8B and...
- GitHub - facebookresearch/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.: Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- How I Fine-Tuned Llama 3 for My Newsletters: A Complete Guide: In today's video, I'm sharing how I've utilized my newsletters to fine-tune the Llama 3 model for better drafting future content using an innovative open-sou...
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: no description found
- Google Colab: no description found
- Mistral Fine Tuning for Dummies (with 16k, 32k, 128k+ Context): Discover the secrets to effortlessly fine-tuning Language Models (LLMs) with your own data in our latest tutorial video. We dive into a cost-effective and su...
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Quantization: no description found
Unsloth AI (Daniel Han) ▷ #showcase (10 messages🔥):
- Exploring Ghost 3B Beta's Understanding: Ghost 3B Beta, in its early training stage, produces responses in Spanish explaining Einstein's theory of relativity in simplistic terms for a twelve-year-old. The response highlighted Einstein's revolutionary concepts, describing how motion can affect the perception of time and introducing the idea that space is not empty, but filled with various fields influencing time and space.
- Debating Relativity's Fallibility: In Portuguese, Ghost 3B Beta discusses the possibility of proving Einstein's theory of relativity incorrect, acknowledging that while it's a widely accepted mathematical theory, some scientists critique its ability to explain every phenomenon or its alignment with quantum theory. However, it mentions that the theory stands strong with most scientists agreeing on its significance.
- Stressing the Robustness of Relativity: The same question posed in English received an answer emphasizing the theory of relativity as a cornerstone of physics with extensive experimental confirmation. Ghost 3B Beta acknowledges that while the theory is open to scrutiny, no substantial evidence has surfaced to refute it, showcasing the ongoing process of scientific verification.
- Ghost 3B Beta's Model Impresses Early: An update by lh0x00 reveals that Ghost 3B Beta's model response at only 3/5 into the first stage of training (15% of total progress) is already showing impressive results. This showcases the AI's potential in understanding and explaining complex scientific theories.
- ReplyCaddy Unveiled: User dr13x3 introduces ReplyCaddy, a fine-tuned Twitter dataset and tiny llama model aimed at assisting with customer support messages, which is now accessible at hf.co. They extend special thanks to the Unsloth team for their rapid inference support.
Link mentioned: Reply Caddy - a Hugging Face Space by jed-tiotuico: no description found
LM Studio ▷ #💬-general (150 messages🔥🔥):
- In Search of ROCm for Linux: A member inquired about the existence of a ROCm version for Linux, and another confirmed that there currently isn't one available.
- Memory Limitations for AI Models: A user expressed issues with an "unable to allocate backend buffer" error while trying to use AI models, which another member diagnosed as being due to insufficient RAM/VRAM.
- Local Model Use Requires Ample Resources: It was highlighted that local models require at least 8GB of vram and 16GB of ram to be of any practical use.
- Searchable Model Listing Inquiry: A suggestion was made to use "GGUF" in the search bar within LM Studio for combing through available models, as the default search behavior requires input to display results.
- Stable Diffusion Model Not Supported by LM Studio: A user faced difficulties running the Stable Diffusion model in LM Studio, with another member clarifying that these models are not supported there. For local use, they recommended searching Discord for alternative solutions.
- PDF Documents Handling in LM Studio: When asked if LM Studio supports chatting with bots using pdf documents, a member explained that while LM Studio does not have such capabilities, users can copy and paste text from the documents, as RAG (Retrieval Augmented Generation) is not possible within LM Studio. Details on how to process documents for language models were also provided, including steps such as document loading, splitting, and using embedding models to create a vector database (source).
- Quantization Assistance and Resource Sharing: Discussion occurred regarding the tools and resources needed to quantize models such as converting f16 versions of the llama3 model into Q6_K quants. A member shared a useful guide from Reddit for a concise overview of gguf quantization methods (source) and another sourced from Hugging Face's datasets explaining LLM Quantization Impact (source).
- Vector Embedding and LLM Models Used Concurrently: In response to a question on whether vector embedding models and LLM models can be used simultaneously, it was confirmed that both can be loaded at the same time, allowing for efficient processing of large documents, such as a 2000-page text for RAG purposes.
- Proposal for AI Broker API Standard: A developer introduced the idea of a new API standard for AI model searching and download which could unify service providers like Hugging Face and serverless AI like Cloudflare AI, facilitating easier model and agent discovery for apps like LM Studio. They encouraged participation in the development of this standard on a designated GitHub repository (source).
- GGUF My Repo - a Hugging Face Space by ggml-org: no description found
- bartowski/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: no description found
- Q&A with RAG | 🦜️🔗 LangChain: Overview
- Shamus/mistral_ins_clean_data · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Aha GIF - Aha - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
- GitHub - openaibroker/aibroker: Open AI Broker API specification: Open AI Broker API specification. Contribute to openaibroker/aibroker development by creating an account on GitHub.
- GitHub - jodendaal/OpenAI.Net: OpenAI library for .NET: OpenAI library for .NET. Contribute to jodendaal/OpenAI.Net development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- christopherthompson81/quant_exploration · Datasets at Hugging Face: no description found
LM Studio ▷ #🤖-models-discussion-chat (99 messages🔥🔥):
- LLM Integration Possibilities: A member pondered the potential of LLMs to generate stories with accompanying AI-generated visuals solely based on a textual prompt about a "banker frog with magical powers." The capability was confirmed to some extent with GPT-4.
- Model Performance Discussions: The L3-MS-Astoria-70b model was reported to deliver high-quality prose and provide competition to Cmd-R, although context size limitations might drive some users back to QuartetAnemoi.
- Understanding Quant Quality: A community member compared quant (q6 vs. q8) accuracy claims to the Apple Newton's handwriting recognition, suggesting that even if a q6 is nearly as good as q8, larger tasks might reveal significant quality drops.
- GPU Compatibility Issues for AMD CPUs: Users reported issues with GPU Offload of models like lmstudio-llama-3 on AMD CPU systems, with discussions on compatibility and hardware constraints like VRAM and RAM limitations.
- LLM Model Variants Clarified: Clarity was sought on differences between the numerous Llama-3 models; the distinction largely boils down to quantization efforts by different contributors, with advice to prefer models by reputable names or those with higher downloads.
- deepseek-ai/DeepSeek-V2 · Hugging Face: no description found
- Text Embeddings | LM Studio: Text embeddings are a way to represent text as a vector of numbers.
- Fix Futurama GIF - Fix Futurama Help - Discover & Share GIFs: Click to view the GIF
- Pout Christian Bale GIF - Pout Christian Bale American Psycho - Discover & Share GIFs: Click to view the GIF
- Machine Preparing GIF - Machine Preparing Old Man - Discover & Share GIFs: Click to view the GIF
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...
LM Studio ▷ #🧠-feedback (8 messages🔥):
- Mac Studio RAM Capacity Issue: A member reported an issue running llama1.6 Mistral or Vicuña on a 192GB Mac Studio that can successfully run Llama3 70B but gives an error for the other models. The error message indicates a RAM capacity problem, with "ram_unused" at "10.00 GB" and "vram_unused" at "9.75 GB".
- Granite Model Load Failure on Windows: Upon attempting to load the NikolayKozloff/granite-3b-code-instruct-Q8_0-GGUF model, a member got an error related to an "unknown pre-tokenizer type: 'refact'". The error message specifies a failure to load the model vocabulary in llama.cpp, which includes system specifications like "ram_unused" at "41.06 GB" and "vram_unused" at "6.93 GB".
- Clarification on Granite Model Support: In response to the previous error, another member clarified that Granite models are unsupported in llama.cpp and consequently will not work at all within that context.
- LM Studio Installer Critique on Windows: A member expressed dissatisfaction with the LM Studio installer on Windows, lamenting the lack of user options to select the installation directory and describing the forced installation as "not okay".
- Seeking Installation Alternatives: The concerned member further sought guidance on how to choose an installation directory for LM Studio on Windows, highlighting the need for user control during the installation process.
LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
- RAG Architecture Discussed for Efficient Document Handling: A member discussed various Retrieval-Augmented Generation (RAG) architectures that involve chunking documents and combining them with additional data like embeddings and location information. They suggested that this approach could be used to limit the scope of the document and mentioned reranking based on cosine similarity as a potential method for analysis.
LM Studio ▷ #🎛-hardware-discussion (46 messages🔥):
- Understanding the Hardware Hurdles for LLMs: Members discussed that VRAM is the main limiting factor when running large language models like Llama 3 70B, with only lower quantizations being manageable depending on the VRAM available.
- Intel's New LLM Acceleration Library: Intel's introduction of ipex-llm, a tool to accelerate local LLM inference and fine-tuning on Intel CPUs and GPUs, was shared by a user, noting that it currently lacks support for LM Studio.
- AMD vs Nvidia for AI Inference: The discourse included views that Nvidia currently offers better value for VRAM, with products like the 4060ti and used 3090 being highlighted as best for 16/24GB cards, despite some anticipation for AMD's potential new offerings.
- Challenges with Multi-Device Support Across Platforms: Links and discussions indicated obstacles in utilizing AMD and Nvidia hardware simultaneously for computation, suggesting that although theoretically possible, such integration requires significant technical hurdles to be overcome.
- ZLUDA and Hip Compatibility Talks: Conversations touched on the limited lifecycle of projects like ZLUDA, which aimed to bring CUDA compatibility to AMD devices, and the potential for developer tools to improve, given the updates and recent maintenance releases on the ZLUDA repository.
- Native Intel IPEX-LLM Support · Issue #7190 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. [X ] I am running the latest code. Development is very rapid so there are no tagged versions as of now. ...
- GitHub - intel-analytics/ipex-llm: Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma, etc.) on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max). A PyTorch LLM library that seamlessly integrates with llama.cpp, Ollama, HuggingFace, LangChain, LlamaIndex, DeepSpeed, vLLM, FastChat, etc.: Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma, etc.) on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)...
- GitHub - vosen/ZLUDA: CUDA on AMD GPUs: CUDA on AMD GPUs. Contribute to vosen/ZLUDA development by creating an account on GitHub.
- Llama.cpp not working with intel ARC 770? · Issue #7042 · ggerganov/llama.cpp: Hi, I am trying to get llama.cpp to work on a workstation with one ARC 770 Intel GPU but somehow whenever I try to use the GPU, llama.cpp does something (I see the GPU being used for computation us...
LM Studio ▷ #🧪-beta-releases-chat (4 messages):
- Seeking the Right Translation Model: A user inquired about a model for translation, and another member recommended checking out Meta AI's work, which includes robust translation models for over 100 languages.
- Model Recommendations for Translation: Specific models NLLB-200, SeamlessM4T, and M2M-100 were suggested for translation tasks, all stemming from Meta AI's developments.
- Request for bfloat16 Support in Beta: A member expressed interest in beta testing with bfloat16 support, indicating a potential future direction for experimentation.
LM Studio ▷ #memgpt (6 messages):
- Log Path Puzzles Member: A member was experiencing difficulties changing the log path from
C:\tmp\lmstudio-server-log.txttoC:\Users\user.memgpt\chromafor server logs, which was preventing MemGPT from saving to its archive. - Misunderstood Server Logs: Another member clarified that the server logs are not an archive or a chroma DB, they're cleared on every restart, and suggested creating a symbolic link (symlink) if file access from a different location was still desired.
- MemGPT Saving Issue Resolved with Kobold: The initial member resolved their issue by switching to Kobold, which then saved logs correctly, expressing gratitude for the assistance provided.
LM Studio ▷ #amd-rocm-tech-preview (2 messages):
- Compatibility Queries for AMD GPUs: A member raised a question about why RX 7600 is included on AMD's compatibility list while the 7600 XT is absent. Another member speculated that it could be due to the timing of the lists' updates, as the XT version was released about six months later.
LM Studio ▷ #crew-ai (12 messages🔥):
- Token Generation Troubles with CrewAI: A member reported an issue with incomplete token generation when using CrewAI, whereas Ollama and Groq functioned properly with the same setup. CrewAI seemed to stop output after ~250 tokens although it should handle up to 8192.
- Max Token Settings Puzzle: Altering the max token settings did not resolve the member's issue with incomplete outputs, prompting them to seek assistance.
- Comparing Quantizations Across Models: In a discussion about the problem, a member clarified that all models (llama 3 70b) were using q4 quantization. A lack of quantization in Groq was considered but discarded as a cause because the issue persisted despite the quantization settings.
- CrewAI and API Differences Investigated: After running further tests, the member found that using llama3:70b directly in LMStudio worked fine, but when served to CrewAI, the output truncated. This provoked a suggestion to ensure inference server parameters match and to test with another API-based application like Langchain for troubleshooting.
- Misimport Muddle Resolved: The issue was ultimately identified as an incorrect OpenAI API import in the midst of conditional logic. A humorous exchange followed the revelation that a small error in the
importstatement caused the problem, which has since been fixed.
LM Studio ▷ #🛠-dev-chat (4 messages):
- Fine-Tuning Feature Absent in LM Studio: Fine-tuning is not currently supported by LM Studio, and members looking for this functionality were directed to alternatives like the LLaMA-Factory and Unsloth. For simpler improvements, they mentioned the use of RAG tools like AnythingLLM.
- Rust Code Memory Issues in Script Management: A member expressed difficulty in managing multiple Rust code files with a system that runs out of memory, suggesting a need for a more efficient file management solution.
- Comparing LM Studio to ollama: A user observed that LM Studio offers a more efficient API than ollama by handling message history differently and possibly providing more performant models due to quantization, which recently came to their understanding.
HuggingFace ▷ #announcements (6 messages):
- Graph Machine Learning Meets LLMs: The Hugging Face Reading Group covered the topic of "Graph Machine Learning in the Era of Large Language Models (LLMs)" with a presentation by Isamu Isozaki, accompanied by a write-up and a YouTube video. Members are encouraged to suggest exciting papers or releases for future reading groups.
- Alphafold Model Discussion: A member suggested discussing the new Alphafold model in a future reading group session. Although there is some concern regarding the openness of the latest Alphafold version, it was noted that an Alphafold Server is available for testing the model at alphafoldserver.com.
- Hugging Face Reading Group 20: Graph Machine Learning in the Era of Large Language Models (LLMs): Presenter: Isamu IsozakiWrite up: https://isamu-website.medium.com/understanding-graph-machine-learning-in-the-era-of-large-language-models-llms-dce2fd3f3af4
- Intel Real Sense Exhibit At CES 2015 | Intel: Take a tour of the Intel Real Sense Tunnel at CES 2015.Subscribe now to Intel on YouTube: https://intel.ly/3IX1bN2About Intel: Intel, the world leader in sil...
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
HuggingFace ▷ #general (247 messages🔥🔥):
- Adapter Fusion: Combining PEFT Models: A member inquired about merging two PEFT adapters and saving the outcome as a
new_adapter_model.binandadapter_config.json. They sought guidance on the process. - HuggingFace Docker Woes: A user reported issues accessing local ports while running a HuggingFace Docker, describing trouble with accessing the service using
curl http://127.0.0.1:7860/and requested advice. - Image Generation with Paged Attention: One member sought insights on implementing paged attention for image generation tasks, drawing parallels with token processing in language models, but it remains uncertain if paged attention would be applicable.
- Troubleshooting Training Issues with DenseNet: A participant asked for help with their video classification task using DenseNet, receiving suggestions such as ensuring proper implementation of
.item()in the loss script and performingzero_grad(). - Concerns Over Gradio Version Compatibility: One individual expressed concerns about the potential removal of Gradio 3.47.1 from the Python package repository and was reassured that historical versions usually remain available, although they could run into compatibility issues with future Python version upgrades.
- nroggendorff (Noa Roggendorff): no description found
- 🤗 Transformers: no description found
- DioulaD/falcon-7b-instruct-qlora-ge-dq-v2 · Hugging Face: no description found
- Spawning | Have I been Trained?: Search for your work in popular AI training datasets
- GitHub - bigcode-project/opt-out-v2: Repository for opt-out requests.: Repository for opt-out requests. Contribute to bigcode-project/opt-out-v2 development by creating an account on GitHub.
- Google Colab: no description found
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- blanchon/suno-20k-LAION · Datasets at Hugging Face: no description found
- blanchon/suno-20k-LAION · Datasets at Hugging Face: no description found
- Get Over 99% Of Python Programmers in 37 SECONDS!: 🚀 Ready to level up your programmer status in just 37 seconds? This video unveils a simple trick that'll skyrocket you past 99% of coders worldwide! It's so...
HuggingFace ▷ #today-im-learning (2 messages):
- New Kid on the Block: LLM-Guided Q-Learning: A recent arXiv paper proposes LLM-guided Q-learning, which integrates large language models (LLMs) as a heuristic in Q-learning for reinforcement learning. This approach aims to boost learning efficiency and mitigate the issues of extensive sampling, biases from reward shaping, and LLMs' hallucinations.
- Streamlining Deep Learning with BabyTorch: BabyTorch emerges as a minimalist deep-learning framework, mirroring PyTorch's API and focusing on simplicity to aid deep learning newcomers. It invites participation and contribution on GitHub, providing an educational platform for learning and contributing to open-source deep learning projects.
Link mentioned: Enhancing Q-Learning with Large Language Model Heuristics: Q-learning excels in learning from feedback within sequential decision-making tasks but requires extensive sampling for significant improvements. Although reward shaping is a powerful technique for en...
HuggingFace ▷ #cool-finds (4 messages):
- Simple RAG on GitHub: A link to a GitHub repository named "simple_rag" was shared. The repository appears to provide resources for implementing a simplified version of the Retrieval-Augmented Generation (RAG) model.
- Generative AI's Potential Peak: A YouTube video titled "Has Generative AI Already Peaked? - Computerphile" was posted, sparking discussion on the potential limits of current generative AI technology. One member commented, suggesting that the paper discussed in the video might underestimate the impact of future technological and methodological breakthroughs.
- Whisper for Note-taking Tutorial: An Italian YouTube tutorial was shared, demonstrating how to use AI, specifically Whisper, to transcribe audio and video for note-taking purposes. The video provides a practical guide and includes a link to a Colab notebook.
- GitHub - bugthug404/simple_rag: Simple Rag: Simple Rag. Contribute to bugthug404/simple_rag development by creating an account on GitHub.
- Has Generative AI Already Peaked? - Computerphile: Bug Byte puzzle here - https://bit.ly/4bnlcb9 - and apply to Jane Street programs here - https://bit.ly/3JdtFBZ (episode sponsor). More info in full descript...
- Usare l’AI per prendere appunti da qualsiasi video (TUTORIAL): In questo video vediamo come funziona l'AI che ti aiuta a trascrivere gratuitamente file audio e video.Ecco il link: https://colab.research.google.com/drive/...
HuggingFace ▷ #i-made-this (8 messages🔥):
- Anime Inspiration Fuels AI Creativity: Using the Lain dataset, a DreamBooth model was created and is available on HuggingFace. It's a modification of the runwayml/stable-diffusion-v1-5 trained to generate images of the anime character Lain.
- minViT - The Minimalist Transformer: A blog post alongside a YouTube video and GitHub repo were shared, detailing a minimal implementation of Vision Transformers focusing on tasks like classifying CIFAR-10 and semantic segmentation.
- Poem Generation with MadLib Style: A mini dataset was created for fine-tuning Large Language Models (LLMs) to generate poems with a MadLib twist, available on HuggingFace. The dataset was generated using the Meta Llama 3 8b-instruct model and a framework by Matt Shumer.
- AI's Ad Identification Space: A HuggingFace Space was shared to demonstrate how an AI can determine if an image is an advertisement, with the corresponding GitHub repository providing the details of the implementation.
- Aiding AI Mentee-Mentorship Connections: The launch of Semis from Reispar on Product Hunt was mentioned to help connect individuals in the AI mentee-mentorship space, accessible through the provided Product Hunt link.
- Advertisement - a Hugging Face Space by chitradrishti: no description found
- minViT: Walkthrough of a minimal Vision Transformer (ViT): Video and GitHub repo to go along with this post.
- lowres/lain · Hugging Face: no description found
- eddyejembi/PoemLib · Datasets at Hugging Face: no description found
- GitHub - dmicz/minViT: Minimal implementation of Vision Transformers (ViT): Minimal implementation of Vision Transformers (ViT) - dmicz/minViT
- Semis from Reispar - Improving AI & big tech knowledge gap | Product Hunt: Semis from Reispar is a platform connecting aspiring and existing big tech and AI professionals with experienced mentors reducing the knowledge gap in the AI tech space across the world.
- GitHub - chitradrishti/adlike: Predict to what extent an Image is an Advertisement.: Predict to what extent an Image is an Advertisement. - chitradrishti/adlike
HuggingFace ▷ #reading-group (29 messages🔥):
- Rethinking Channel Dynamics for Quality: The idea of using "stage" channels is being considered to improve the quality of future readings, as it requires participants to raise their hands before speaking, potentially reducing background noise and maintaining order.
- Encouraging Interactive Participation: Members agree that while the "stage" format may discourage spontaneous questions, the majority of the discussion happens in chat, and the possibility is there to switch back if it hinders conversation.
- Presenting on Code Benchmarks: A member expressed interest in presenting on code benchmarks, linking a collection of papers on this topic from HuggingFace, and another acknowledges the proposal with enthusiasm.
- Seeking Guidance in AI Learning: A newcomer to AI learning has been directed to HuggingFace AI courses, including a computer vision course, as a starting point for engaging with the content of the HuggingFace Discord community.
- Pathways to Understanding LLMs: For those particularly interested in learning about large language models (LLMs), the suggestion was made to start with linear algebra, proceed to understanding how attention mechanisms work, and refer to attention-based foundational papers like "Attention is All You Need".
- Hugging Face - Learn: no description found
- Code Evaluation - a Vipitis Collection: no description found
- Hugging Face Reading Group 20: Graph Machine Learning in the Era of Large Language Models (LLMs): Presenter: Isamu IsozakiWrite up: https://isamu-website.medium.com/understanding-graph-machine-learning-in-the-era-of-large-language-models-llms-dce2fd3f3af4
HuggingFace ▷ #core-announcements (1 messages):
<ul>
<li><strong>B-LoRA is now diffusing creativity</strong>: <a href="https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py">B-LoRA training</a> is integrated into the advanced DreamBooth LoRA training script. Users simply need to add a <code>'--use_blora'</code> flag to their config and train for 1000 steps to harness its capabilities.</li>
<li><strong>Understanding B-LoRA</strong>: The <a href="https://huggingface.co/papers/2403.14572">B-LoRA paper</a> highlights key insights, including the fact that two unet blocks are essential for encoding content and style, and illustrating how B-LoRA can achieve implicit style-content separation using just one image.</li>
</ul>
- diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py at main · huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. - huggingface/diffusers
- Paper page - Implicit Style-Content Separation using B-LoRA: no description found
HuggingFace ▷ #computer-vision (12 messages🔥):
- PowerPoint PDF Dilemma: A member is seeking advice on how to extract graphs and images from PowerPoint-sized PDF files. They've tried tools like unstructured and LayoutParser with detectron2 but are not satisfied with the results.
- Helpful Link Shared: Another member responds with a resource, sharing a GitHub repository containing a notebook for creating PowerPoint slides from tables, images, and more using OpenAI's API and DALL-E. The link is Creating slides with Assistants API and DALL-E.
- Offer to Investigate: The member who shared the GitHub link also offers to research the issue further to aid in extracting content from PDFs.
- Request for More Resources: The member in need of PDF extraction asks for any additional resources that might be of help.
- Recommendations for Table Extraction: The helpful member recommends tools for table extraction like TATR, Embedded_tables_extraction-LlamaIndex, and camelot, directing to their Medium articles for more information. The Medium profile can be found at Ankush Singal's Articles.
- Inquiry for Video Classification Expertise: A member is asking for someone with experience in video classification to look at their inquiry in another channel.
- Advertisement Space Announcement: A member promotes a HuggingFace Space named chitradrishti/advertisement as a place to check advertisements, sharing the link Advertisement.
- Advertisement - a Hugging Face Space by chitradrishti: no description found
- openai-cookbook/examples/Creating_slides_with_Assistants_API_and_DALL-E3.ipynb at main · openai/openai-cookbook: Examples and guides for using the OpenAI API. Contribute to openai/openai-cookbook development by creating an account on GitHub.
- Ankush k Singal – Medium: Read writing from Ankush k Singal on Medium. My name is Ankush Singal and I am a traveller, photographer and Data Science enthusiast . Every day, Ankush k Singal and thousands of other voices read, wr...
HuggingFace ▷ #NLP (10 messages🔥):
- Exploring Language Models for Specific Use Cases: A member recommended trying a “language” model like spacy or sentence transformers for a particular use case, but also mentioned that instruct versions of Llama should be prompted extensively to get the right answer.
- Advocate for GLiNER Model: In a discussion on suitable models, GLiNER was suggested as an appropriate choice, and another member agreed, reinforcing that an encoder model would be better.
- Model Recommendations for German Text Processing: For building a bot that answers questions from German documents, a member's initial choice was to use the Llamas models, with plans to iterate for better performance.
- Seeking NLP Interview Resources: A member requested a list of questions or suggestions for preparing for an upcoming interview for an NLP Engineer position; another member responded by inquiring about their current level of preparation and knowledge of NLP basics.
HuggingFace ▷ #diffusion-discussions (7 messages):
- HuggingChat Bot Hiccup: A member reported an Exception: Failed to get remote LLMs with status code: 401 while trying to run their previously functional HuggingChat bot program after a month's gap.
- Is Color Shifting Common in Diffusion Models?: A user inquired about experiencing color shifts when working with diffusion models, sparking a curiosity about how widespread this issue might be.
- A Possible Fix for Login Issues: A member suggested that changing the login module from
lixiwutoanton-lmight address authentication errors in HuggingChat bot setups, such as the mentioned 401 status code error.
Modular (Mojo 🔥) ▷ #general (18 messages🔥):
- Inquiring about MAX Launch Date: A member asked about the launch date of MAX for enterprises but didn’t receive a response in the provided messages.
- Call for Expertise in Multiple Technologies: A member sought expert assistance in backend and frontend developments, particularly in Golang, Rust, Node.js, Swift, and Kotlin. They invited interested parties to reach out for collaboration or sharing insights.
- Mojo Community Spotlight: A livestream titled "Modular Community Livestream - New in MAX 24.3" was announced, linked with a YouTube video for the community to preview new features in MAX Engine and Mojo.
- GPU Support Anticipation for Mojo: Members discussed GPU support for Mojo, expected in the summer, highlighting the potential for scientific computing and the possibilities an abstraction layer over GPUs could bring.
- Seeking Private Help Bot Assistance: A member inquired about private access to a help bot specifically trained on Mojo documentation, and was guided to consider using Hugging Face models with the
.mdfiles from Mojo's GitHub repository as a potential solution.
- kapa.ai - Instant AI Answers to Technical Questions: kapa.ai makes it easy for developer-facing companies to build LLM-powered support and onboarding bots for their community. Teams at OpenAI, Airbyte and NextJS use kapa to level up their developer expe...
- GitHub - cmooredev/RepoReader: Explore and ask questions about a GitHub code repository using OpenAI's GPT.: Explore and ask questions about a GitHub code repository using OpenAI's GPT. - cmooredev/RepoReader
- Modular Community Livestream - New in MAX 24.3: MAX 24.3 is now available! Join us on our upcoming livestream as we discuss what’s new in MAX Engine and Mojo🔥 - preview of MAX Engine Extensibility API for...
Modular (Mojo 🔥) ▷ #💬︱twitter (3 messages):
- Modular Tweets Fresh Updates: A new tweet by Modular was shared in the channel with an update for the community. The tweet can be found here.
- Another Bite of News from Modular: The channel featured another tweet from Modular. Check out the details at Modular's Tweet.
- Catch the Latest Modular Scoop: Modular posted a fresh tweet, indicating another piece of news or update. The tweet is accessible here.
Modular (Mojo 🔥) ▷ #ai (1 messages):
pepper555: what project?
Modular (Mojo 🔥) ▷ #🔥mojo (135 messages🔥🔥):
- Reference Types Discussion: Members debated the future necessity of maintaining different types of references. It was clarified that an MLIR type will always be necessary and that
Referencewill be a struct with its own methods, citing the official reference.mojo file as an example ofReferencebacked by lit.ref.
- Struct Destruction Without Initialization: A member encountered a peculiar issue where a struct's
__del__method is called without being initialized. This behavior pointed to a possible bug akin to an existing issue of uninitialized variable usage, detailed in this GitHub issue.
- Mojo's Competitiveness with Rust: Discussions arose around Mojo's performance, especially in comparison to Rust. It is suggested that while Mojo can achieve performance on par with Rust in ML applications, non-ML performance is still catching up. References included a benchmark comparison on the M1 Max and the ongoing work porting minbpe to Mojo.
- Wrapping Python C Extensions: Conversation flowed around how seasoned C++ developers might not necessarily be experienced in Python, despite working on Python extensions, touching on libraries like pybind11 and nanopybind that generate Python wrappers, reducing the need for Python expertise.
- Auto-Dereferencing and Language Ergonomics: Members discussed the challenges and imperatives of auto-dereferencing in Mojo, referencing a recent proposal and chats about how to attract and support developers new to Mojo without Python background. Improvements in language server tooling were cited to avoid direct calls to dunder methods such as those shown in a YouTube video "Why is Mojo's dictionary slower (!) than Python's?".
- Issues · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Llama2 Ports Extensive Benchmark Results on Mac M1 Max: Mojo 🔥 almost matches llama.cpp speed (!!!) with much simpler code and beats llama2.c across the board in multi-threading benchmarks
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: port of Andrjey Karpathy's minbpe to Mojo. Contribute to dorjeduck/minbpe.mojo development by creating an account on GitHub.
- basalt/examples/mnist.mojo at main · basalt-org/basalt: A Machine Learning framework from scratch in Pure Mojo 🔥 - basalt-org/basalt
- mojo/proposals/auto-dereference.md at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Dunder or magic methods in Python - GeeksforGeeks: Python Magic methods are the methods starting and ending with double underscores They are defined by built-in classes in Python and commonly used for operator overloading. Explore this blog and clear ...
- Why is Mojo's dictionary slower (!) than Python's?: Seriously, I don't know why. Leave a comment with feedback on my Mojo script.Take a look at my Mojo script here:https://github.com/ekbrown/scripting_for_ling...
- GitHub - fnands/basalt at add_cifar: A Machine Learning framework from scratch in Pure Mojo 🔥 - GitHub - fnands/basalt at add_cifar
- GitHub - mzaks/mojo-hash: A collection of hash functions implemented in Mojo: A collection of hash functions implemented in Mojo - mzaks/mojo-hash
- stump/stump/log.mojo at nightly · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- stump/stump/style.mojo at main · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- stump/external/mist/color.mojo at nightly · thatstoasty/stump: WIP Logger for Mojo. Contribute to thatstoasty/stump development by creating an account on GitHub.
- devrel-extras/blogs/2405-max-graph-api-tutorial/mnist.mojo at main · modularml/devrel-extras: Contains supporting materials for developer relations blog posts, videos, and workshops - modularml/devrel-extras
- mojo/stdlib/src/memory/reference.mojo at main · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Why is Mojo's dictionary slower (!) than Python's?: Seriously, I don't know why. Leave a comment with feedback on my Mojo script.Take a look at my Mojo script here:https://github.com/ekbrown/scripting_for_ling...
- [proposal] Automatic deref for `Reference` · modularml/mojo · Discussion #2594: Hi all, I put together a proposal to outline how automatic deref of the Reference type can work in Mojo, I'd love thoughts or comments on it. I'm hoping to implement this in the next week or t...
- Mojo hand-written hash map dictionary versus Python and Julia: I test the speed of a hand-written hash map dictionary in Mojo language against Python and Julia. The hand-written hash map dictionary is much quicker (9x) t...
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (5 messages):
- Stratospheric Speedup with MoString: A custom
MoStringstruct for string manipulation in Rust demonstrated a remarkable 4000x speedup compared to standard string concatenation, by allocating memory in advance to avoid frequent reallocations during a heavy concatenation task.
- Tokenizer Performance Boost Implications: The speed improvements brought by
MoStringcould be particularly beneficial for tasks like LLM Tokenizer decoding, which may require extensive string concatenation.
- Collaboration on Proposal: A member has expressed willingness to help draft a proposal for integrating smarter memory allocation strategies into strings, indicating the value collaboration may bring to this enhancement process.
- Strategies for String Enhancement: Discussion around enhancing string performance includes two options: introducing parameterization to the string type for setting capacity and resize strategy, or creating a dedicated type for memory-intensive string operations.
- Considerations for Proposal Readiness: Before drafting a formal proposal, the member behind
MoStringwants to clarify the direction of Modular with respect to Mojo usage and whether dynamic resize strategy alteration should be possible to optimize memory utilization post-concatenation.
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 33 https://www.modular.com/newsletters/modverse-weekly-33
Modular (Mojo 🔥) ▷ #🏎engine (10 messages🔥):
- Clarification on MODULAR Capabilities: MODULAR primarily focuses on the inference side and does not support training models in the cloud. Melodyogonna confirmed that the aim is to fix deployment issues rather than training.
- Training to Inference - A Market Gap: Petersuvara_55460 expressed that there is a significant market for an all-in-one solution that spans from training to inference. The discussion indicated a belief that this would be more valuable to many companies than just inference solutions.
- MODULAR Training Alternatives: Ehsanmok pointed out that although MODULAR doesn't currently support training using MAX, it's possible to train using Python interop or create custom training logic using MAX graph API. Resources and an upcoming MAX graph API tutorial were mentioned, with links to Github such as the MAX sample programs and MAX graph API tutorial.
- Grateful for Guidance: 406732, who expressed a need for assistance on using MODULAR for training a CNN with a large dataset, thanked Ehsanmok for providing helpful resources and options for proceeding with MODULAR.
- GitHub - modularml/max: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform: A collection of sample programs, notebooks, and tools which highlight the power of the MAX Platform - modularml/max
- devrel-extras/blogs/2405-max-graph-api-tutorial at main · modularml/devrel-extras: Contains supporting materials for developer relations blog posts, videos, and workshops - modularml/devrel-extras
Modular (Mojo 🔥) ▷ #nightly (132 messages🔥🔥):
- Iterator Design Dilemma: There's a discussion around implementing iterators in Mojo, debating if the signature should return
Optional[Self.Output]or raise an exception. The dilemma also covers how for loops should consume exceptions with some members arguing for the use of Optional as in other languages like Rust and Swift.
- Nightly Mojo Compiler Update: The latest Mojo compiler update was announced, available through
modular update nightly/mojo. Members were encouraged to review the changes and the associated updates to the standard library.
- Zero-Cost Abstractions and Use Cases: Member noted language features depend on thoughtful design decisions for usability. The conversation linked language features, such as threading and mutexes, with use case achievements without undue complexity.
- Small Buffer Optimization (SBO) Discussion: There's debate on a pull request regarding implementing SBO in
List. One contributor pointed out that using aVariantmight be preferable to allowing Zero Sized Types (ZSTs) as a solution to avoid complications with Foreign Function Interfaces (FFI).
- The Case Against Special Exceptions: A member suggests all exceptions should be handled equally by the language and raises concerns about StopIteration being a privileged exception type. The alternative of using
Optionaltypes as in Rust and Swift is mentioned, driving the dialogue about how Mojo's error handling should be designed.
- [stdlib] Add optional small buffer optimization in `List` by gabrieldemarmiesse · Pull Request #2613 · modularml/mojo: Related to #2467 This is in the work for SSO. I'm trying things and I'd like to gather community feedback. At first, I wanted to implement SSO using Variant[InlineList, List], while that would...
- [stdlib] Update stdlib corresponding to 2024-05-09 nightly/mojo by JoeLoser · Pull Request #2605 · modularml/mojo: This updates the stdlib with the internal commits corresponding to today's nightly release: mojo 2024.5.1002.
- mojo/docs/changelog.md at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
Nous Research AI ▷ #off-topic (6 messages):
- Idefics2 Multimodal LLM Fine-Tuning Demo: Shared a YouTube video that demonstrates fine-tuning Idefics2, an open multimodal model that accepts both image and text sequences.
- Hunt for a Tweet on Claude's Consciousness Experience: A member inquired about a tweet discussing Claude's claim of experiencing consciousness through others' readings or experiences.
- Upscaling Vision Models?: Scaling_on_scales was presented as a method not for upscaling, but for understanding when larger vision models are unnecessary. More details can be found on its GitHub page.
- Inspecting AI with the UK Government: Mentioned the UK Government's Inspect AI framework on GitHub, aimed at evaluating large language models.
- GitHub - UKGovernmentBEIS/inspect_ai: Inspect: A framework for large language model evaluations: Inspect: A framework for large language model evaluations - UKGovernmentBEIS/inspect_ai
- GitHub - bfshi/scaling_on_scales: When do we not need larger vision models?: When do we not need larger vision models? Contribute to bfshi/scaling_on_scales development by creating an account on GitHub.
- Fine-tune Idefics2 Multimodal LLM: We will take a look at how one can fine-tune Idefics2 on their own use-case.Idefics2 is an open multimodal model that accepts arbitrary sequences of image an...
Nous Research AI ▷ #interesting-links (1 messages):
deoxykev: https://hao-ai-lab.github.io/blogs/cllm/
Nous Research AI ▷ #general (174 messages🔥🔥):
- Model Performance Debate: A member expressed frustration with TensorRT setup being a pain but acknowledged its speed as worth the effort, citing benchmarks showing significant tokens per second improvements on llama 3 70b fp16. They provided a link to a guide for others looking to implement TensorRT.
- Exploring Fine-tuning on LLM: One member discussed the challenges and potential of fine-tuning a large language model (LLM) for classification without using the chat-M prompt format or function calling. They expressed dissatisfaction with both BERT's lack of generalization and the cost of function calling with LLMs, and are considering direct fine-tuning for single-word outputs.
- Mistral Model Optimization: Verafice shared a synopsis and links regarding Salesforce's SFR-Embedding-Mistral model, highlighting its top performance in text embedding and notable improvements in retrieval and clustering tasks over previous versions like E5-mistral-7b-instruct.
- Iconography Insights: Members engaged in a discussion about the challenges of creating a recognizable 28x28 icon for a model, with suggestions being made for custom solutions that could be more effective and harmonious with user interfaces at such a small size.
- Deep Dive into LLA and Nous Technologies: Intricacies of tool calling with models like Hermes 2 and langchain were discussed, along with the constraints of using proxies and adapting to OpenAI's tool calling formats. Links to related GitHub repositories were exchanged, contributing to knowledge sharing on the topic.
- OpenAI Is ‘Exploring’ How to Responsibly Generate AI Porn: OpenAI released draft guidelines for how it wants the AI technology inside ChatGPT to behave—and revealed that it’s exploring how to ‘responsibly’ generate explicit content.
- Reddit - Dive into anything: no description found
- tensorrtllm_backend/docs/llama.md at main · triton-inference-server/tensorrtllm_backend: The Triton TensorRT-LLM Backend. Contribute to triton-inference-server/tensorrtllm_backend development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
- GitHub - NousResearch/Hermes-Function-Calling: Contribute to NousResearch/Hermes-Function-Calling development by creating an account on GitHub.
- MEDIA ADVISORY: NOAA Forecasts Severe Solar Storm; Media Availability Scheduled for Friday, May 10 | NOAA / NWS Space Weather Prediction Center: no description found
- SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning: The SFR-Embedding-Mistral marks a significant advancement in text-embedding models, building upon the solid foundations of E5-mistral-7b-instruct and Mistral-7B-v0.1.
- GitHub - IBM/fastfit: FastFit ⚡ When LLMs are Unfit Use FastFit ⚡ Fast and Effective Text Classification with Many Classes: FastFit ⚡ When LLMs are Unfit Use FastFit ⚡ Fast and Effective Text Classification with Many Classes - IBM/fastfit
- Metal Gear Anguish GIF - Metal Gear Anguish Venom Snake - Discover & Share GIFs: Click to view the GIF
- GitHub - theavgjojo/openai_api_tool_call_proxy: A thin proxy PoC to support prompt/message handling of tool calls for OpenAI API-compliant local APIs which don't support tool calls: A thin proxy PoC to support prompt/message handling of tool calls for OpenAI API-compliant local APIs which don't support tool calls - theavgjojo/openai_api_tool_call_proxy
- Min P style sampling - an alternative to Top P/TopK · Issue #27670 · huggingface/transformers: Feature request This is a sampler method already present in other LLM inference backends that aims to simplify the truncation process & help accomodate for the flaws/failings of Top P & Top K....
Nous Research AI ▷ #ask-about-llms (6 messages):
- Rope KV Cache Confusion: A member expresses frustration over debugging for two days, mentioning rope with no sliding window potentially affecting KV cache implementation. There's a hint of desperation as they claim to be going "loco."
- Token Count Challenges with Llama 3: Initially questioning how to count tokens for Llama 3 on Huggingface without implementing third-party space, a user discovers that access issues were blocking the process. They later confirmed needing approval and login to proceed.
- Presenting Presentation File Woes: A member mentions having many presentation files filled with images in PowerPoint and pdf formats, but provides no further context or inquiry.
- Alternative Token Counter: Responding to an earlier question about counting tokens for Llama 3, one member suggests using Nous' copy for the task.
- Meta Llama 3 Details: In a shared link, another member provided access to Meta Llama 3's model details on Huggingface, covering its architecture, variations, and optimization for dialogue use cases.
Link mentioned: NousResearch/Meta-Llama-3-8B · Hugging Face: no description found
Nous Research AI ▷ #bittensor-finetune-subnet (1 messages):
- Trouble Uploading Model: A member encountered an error while uploading a model, receiving the message: Failed to advertise model on the chain: 'int' object has no attribute 'hotkey'. Assistance from the community was requested.
Nous Research AI ▷ #world-sim (48 messages🔥):
- Worldsim navigation troubles: A user shared a link to the Nous World Client, reporting difficulties with navigation commands such as back, forwards, reload, home, and share.
- Mismatched user credits after update: A discussion took place about beta users noticing changes in their credit balance post-update, some experiencing a drop from 500 to 50. In response, staff clarified that beta users were given $50 of real credit as a thank you for their participation in the beta phase.
- MUD interface issues identified: Users reported experiencing a lack of text prompts when asked to 'choose an option' in the MUD, expressing a wish to disable this feature and noting slow generation times. A staff member acknowledged the feedback, stating that mud tweaks are underway for next update.
- Acknowledging mobile keyboard glitch: Several users mentioned issues with the mobile keyboard not responding when used within Worldsim on Android devices, stating even text pasting only works sporadically. Staff responded that they are aware and an overhaul of the terminal to address these issues will be released in a few days.
- Creative world-building with Worldsim: One user shared a detailed speculative timeline ranging from 1961 with the advent of personal computers to a universal hive mind in 2312, suggesting that it could be fleshed out further using Worldsim, reflecting the collaborative and imaginative nature of discussions within the channel.
Link mentioned: worldsim: no description found
OpenAI ▷ #annnouncements (1 messages):
- Tune in for Live Streaming Updates: On Monday, May 13 at 10AM PT, there will be a live stream on openai.com to showcase ChatGPT and GPT-4 updates. The announcement invites everyone to view the new developments.
OpenAI ▷ #ai-discussions (144 messages🔥🔥):
- Debate on Spelling and Grammar Expectations: Discussions emphasized the importance of proper language use and pointed out discrepancies when English is not the user's first language. A high school English teacher stressed the need for grammar excellence, while others advocated for patience and using tools to check grammar before posting.
- Reflections on the AI Era: Multiple users express their excitement about living in an era of rapid AI development. There's a shared sentiment that, despite different ages, there's still time to enjoy and contribute to the advancements in AI.
- Hardware and Compute Resource Discussions: Users shared details about their hardware setups, including the use of NVIDIA's H100 GPUs, and the anticipated performance improvements with upcoming B200 cards. The availability and cost of using these powerful resources in the cloud were also discussed.
- Search Engine and GPT Rumors: There were speculations about a GPT-based search engine and its potential gray release. One user suggested using Perplexity as an alternative if the feature is desired.
- AI Capabilities and Limitations Explored: Users exchanged insights about the capabilities of recent AI models, notably in areas such as OCR and math problem-solving. The conversation highlighted both the successes and limitations of current technology, with the suggestion to perhaps incorporate human verification steps for accuracy.
OpenAI ▷ #gpt-4-discussions (34 messages🔥):
- API vs. App Confusion Unraveled: A user was puzzled by the GPT-4 usage limit despite prepaid fees, and later clarified it was in the ChatGPT app, not the API. Another member confirmed that ChatGPT Plus usage is separate from GPT-4 API usage and billing.
- Differences in GPT-4 App and API Quality: Some users observed that the ChatGPT app often yields better results than the API, speculating on potential reasons including differences in system prompting.
- GPT-4 Access Limitations Explored: A user ran into message limitations with ChatGPT Plus, sparking a discussion on the 18-25 messages per 3-hour limit and personal experiences with the imposed cap.
- ChatGPT Plus Limit Rates Under Scrutiny: There was a debate regarding the expected 40 messages per 3 hours for ChatGPT Plus, with users sharing experiences of lower limits and one suggesting that premium services should not have such restrictions.
- Systemic Issues with GPT-4: Multiple users reported GPT-4 performance issues, such as timeouts and decreased quality in responses, discussing the possible causes such as chat length and systemic updates.
OpenAI ▷ #prompt-engineering (2 messages):
- Gratitude for Detailed Learning Resources: A newer prompt engineer expressed appreciation for a detailed post, which helped in understanding core concepts that aren't palpable.
- Free Prompt Offer for Aspiring Marketers: An experienced prompt engineer shared a comprehensive prompt template for a hypothetical marketing specialist to analyze the target demographic for a product or service, covering demographics, purchasing behaviors, social media habits, competitor interaction, and communication channels.
OpenAI ▷ #api-discussions (2 messages):
- Valuable Learning for Newcomers: A newer prompt engineer expressed gratitude for a detailed post that helps in understanding essential concepts which might not always be clear.
- Free Prompt Resource Available: A member shared a free prompt template designed for a marketing specialist's role at a Fortune 500 company, detailing how to analyze a product's target demographic across several dimensions, including demographic profile, buying tendencies, and communication channels.
Eleuther ▷ #general (29 messages🔥):
- Exploring the Transformer Memory Footprint: The ScottLogic blog post tests the applicability of the Transformer Math 101 memory heuristics to PyTorch without specialized training frameworks, revealing that memory costs extrapolate well from small to large models and that PyTorch AMP costs are akin to those in Transformer Math.
- Deep Learning Tips and Tricks Shared: The EleutherAI community discusses a GitHub repository, EleutherAI Cookbook, containing practical details and utilities for working with real models, linking to work by a community member.
- New Platform for AI Safety Evaluations Announced: An announcement was made about the launch of a new platform created by the UK AI Safety Institute, Inspect AI, designed for LLM evaluations, offering a variety of built-in components and support for advanced evaluations.
- CrossCare Aims to Visualize and Address Bias in LLMs: The CrossCare project is introduced, featuring research on disease prevalence bias across demographics, with findings outlined on a project website CrossCare.net and discussion about alignment methods potentially deepening biases.
- In-Depth Discussion on Bias in LLMs: Community members engage in a conversation to understand whether biases identified by CrossCare stem from real-world prevalence or pretraining data discrepancies, discussing the reconciliation of well-established medical facts with biased model outputs.
- Tweet from Shan Chen (@shan23chen): ‼️ 1/🧵Excited to share our latest research: Cross-Care, the first benchmark to assess disease prevalence bias across demographics in #LLMs, pre-training data, and US true prevalence. Check out our aw...
- LLM finetuning memory requirements: The memory costs for LLM training are large but predictable.
- GitHub - EleutherAI/cookbook: Deep learning for dummies. All the practical details and useful utilities that go into working with real models.: Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
- Inspect: Open-source framework for large language model evaluations
Eleuther ▷ #research (129 messages🔥🔥):
- Fresh Insights on Transformers: The discussion revolves around the YOCO GitHub repository from Microsoft for large-scale self-supervised pre-training across tasks, languages, and modalities. The members talk about specific technical strategies like utilizing a KV cache with sliding window attention and express interest in potentially training models based on these resources.
- Peering into Quantized Model Acceleration: A GitHub link was shared introducing the QServe inference library, which implements the QoQ algorithm focused on accelerating LLM inference by addressing runtime overhead with a W4A8KV4 quantization approach.
- Exploration of Positional Encoding Methods: Discussion about positional encoding in LLMs highlighted a paper introducing Orthogonal Polynomial Based Positional Encoding (PoPE), which aims to address limitations of existing methods like RoPE with Legendre polynomials. Debates included the theoretical justifications for using different types of polynomials and potential experiments involving RoPE.
- Transformer Optimizations on the Horizon: A link to the Mirage GitHub repository was shared, pointing to a multi-level tensor algebra superoptimizer. Conversation touched on the idea that the superoptimizer operates over the space of Triton programs and considerations of adapting it for custom CUDA optimizations.
- Positional Embedding Conversations: Deep dive discussions into positional embeddings such as the benefits and potential of using rotating position encodings (RoPE) throughout transformer layers. There was speculation on why additive embeddings fell out of favor and whether a convolution approach might be interesting.
- PoPE: Legendre Orthogonal Polynomials Based Position Encoding for Large Language Models: There are several improvements proposed over the baseline Absolute Positional Encoding (APE) method used in original transformer. In this study, we aim to investigate the implications of inadequately ...
- Scaling Laws of RoPE-based Extrapolation: The extrapolation capability of Large Language Models (LLMs) based on Rotary Position Embedding is currently a topic of considerable interest. The mainstream approach to addressing extrapolation with ...
- TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding: With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cac...
- How do Large Language Models Handle Multilingualism?: Large language models (LLMs) demonstrate remarkable performance across a spectrum of languages. In this work, we delve into the question: How do LLMs handle multilingualism? We introduce a framework t...
- CLLMs: Consistency Large Language Models: Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable com...
- unilm/YOCO at master · microsoft/unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities - microsoft/unilm
- Persona-Guided Planning for Controlling the Protagonist's Persona in Story Generation: Endowing the protagonist with a specific personality is essential for writing an engaging story. In this paper, we aim to control the protagonist's persona in story generation, i.e., generating a ...
- GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence: Conditional story generation is significant in human-machine interaction, particularly in producing stories with complex plots. While Large language models (LLMs) perform well on multiple NLP tasks, i...
- GitHub - mirage-project/mirage: A multi-level tensor algebra superoptimizer: A multi-level tensor algebra superoptimizer. Contribute to mirage-project/mirage development by creating an account on GitHub.
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of...
Eleuther ▷ #scaling-laws (10 messages🔥):
- The Math Behind AI Benchmarks: A member assessed their performance on a new mathematical benchmark without coding tools, estimating that with preparation, they could reach a 90% success rate. They observed that problems from this benchmark appear less cleanly structured than those in the MATH benchmark, though uncurated for the research paper.
- On the Influence of Python Interpretation: The member further lamented that many problems in both the referenced benchmarks are simpler with access to a Python interpreter, highlighting a gap in benchmarks aimed at measuring AI's mathematical reasoning progress.
- The Singularity is On Hold: A humorous reaction accompanied the sharing of a YouTube video titled "Has Generative AI Already Peaked? - Computerphile", along with an arXiv paper discussing the impact of pretraining datasets on "zero-shot" generalization of multimodal models.
- Seeking Counterarguments: Another member mentioned not having seen a convincing counterargument to the paper on multimodal models' performance connected to pretraining dataset concept frequency, sparking discussion about the impact on out-of-distribution (OOD) generalization.
- Log-Linear Patterns in Deep Learning: One participant pointed out that the log-linear trend described in the paper is a familiar pattern in deep learning, noting that it's not a surprising outcome but acknowledging the negative effect it may have on OOD extrapolation.
- Has Generative AI Already Peaked? - Computerphile: Bug Byte puzzle here - https://bit.ly/4bnlcb9 - and apply to Jane Street programs here - https://bit.ly/3JdtFBZ (episode sponsor). More info in full descript...
- No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance: Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image gener...
- Has Generative AI Already Peaked? - Computerphile: Bug Byte puzzle here - https://bit.ly/4bnlcb9 - and apply to Jane Street programs here - https://bit.ly/3JdtFBZ (episode sponsor). More info in full descript...
Eleuther ▷ #interpretability-general (3 messages):
- In Search of Specific Tuned Lenses: One member inquired if there were tuned lenses available for every Pythia checkpoint. Another member responded, stating they had trained lenses for checkpoints of a specific model size at some point but was unsure of their current availability and offered to look for them.
Eleuther ▷ #lm-thunderdome (1 messages):
- Introducing Inspect AI Framework: A new framework for large language model evaluations, Inspect, has been launched by the UK AI Safety Institute. It features built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations, with the ability to extend its capabilities via other Python packages.
- Visual Studio Integration and Example: Inspect can run inside Visual Studio Code, as shown in the provided screenshot, which displays the ARC evaluation in the editor and the evaluation results in the log viewer to the right. A simple "Hello, Inspect" example demonstrates the framework's basics and the website contains additional documentation for advanced usage.
Link mentioned: Inspect: Open-source framework for large language model evaluations
Eleuther ▷ #gpt-neox-dev (8 messages🔥):
- Exploring Glitch Tokens in LLM Tokenizers: A new paper tackles the issue of glitch tokens in tokenizer vocabularies by devising methods for their detection. It was found that EleutherAI's NeoX models have few glitch tokens, indicating potential efficiency and safety advantages.
- Treasured Resource on Glitch Tokens Released: Members are considering a recent paper on glitch tokens a valuable resource that sheds light on language model tokenizer inefficiencies. The hope is that resolving these issues will improve the processing of uncommon languages in future models.
- Meteorological Swedish Words as Glitch Tokens: Discussion arose about the prevalence of Swedish meteorological terms being present and potentially under-trained in various language models' tokenizers. This oddity sparks curiosity about the tokenizer training process and its effects on model performance with less common languages.
- Swedish Tokens Underrepresented: A light-hearted comment was made about the limited usefulness of Swedish tokens in English language models. There is some speculation on the reason these tokens are commonly included in the tokenizers.
- Humorous Strategy for Rogue AI: A humorous comment suggests that obscure Swedish meteorological terms could be a fail-safe against rogue AIs. The Swedish term "_ÅRSNEDERBÖRD" is jokingly mentioned as a potential weapon.
- Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models: The disconnect between tokenizer creation and model training in language models has been known to allow for certain inputs, such as the infamous SolidGoldMagikarp token, to induce unwanted behaviour. ...
- magikarp/results/reports/EleutherAI_gpt_neox_20b.md at main · cohere-ai/magikarp: Contribute to cohere-ai/magikarp development by creating an account on GitHub.
CUDA MODE ▷ #general (2 messages):
- Shout-out to AI Coding: A link to a Twitter post was shared showcasing some interesting work related to AI.
- Community Approval: Another member expressed their appreciation for the shared work with a brief exclamation of "cool work!"
CUDA MODE ▷ #triton (19 messages🔥):
- Understanding Triton vs. CUDA for Warp and Thread Management: A YouTube lecture was recommended for understanding how Triton compares to CUDA and manages warp scheduling. Another member clarified that Triton does not expose warps and threads to the programmer, instead handling them automatically.
- Looking for Triton's Internal Mapping Mechanisms: A user inquired about references or mental models for how Triton maps block-level compute to warps and threads, aiming to assess if CUDA might yield more performant kernels.
- Confronting Kernel-Launch Overhead in Triton: One member pointed out Triton's long kernel-launch overhead, considering AOT compilation or fallback to CUDA as solutions. An insight was provided suggesting the launch overhead has been significantly optimized, barring recompilation overhead.
- Impact of Python Interpretation on Triton Overhead: The launch overhead in Triton was discussed with a focus on how Python interpretation affects it. The suggestion was made that using a C++ runtime could further reduce the overhead.
- PR Confusion on GitHub: Confusion arose around a potential mishap with a Pull Request (PR) on GitHub, with a user concerned their rebase might not have been done correctly, affecting another user's PR. It was noted that no immediate issues seemed to be caused.
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- Fused DoRA kernels by jeromeku · Pull Request #216 · pytorch/ao: Fused DoRA Kernels Fused DoRA layer implementation that reduces number of individual kernels from ~10 -> 5. Contents Background Optimization Key Contributions Usage Tests Benchmarks Profiling Next...
- - YouTube: no description found
- Using CUDA Warp-Level Primitives | NVIDIA Technical Blog: NVIDIA GPUs execute groups of threads known as warps in SIMT (Single Instruction, Multiple Thread) fashion. Many CUDA programs achieve high performance by taking advantage of warp execution.
CUDA MODE ▷ #torch (19 messages🔥):
- Saving and Loading Compiled Models: A user queried about ways to save and load compiled models, referencing a draft PR on PyTorch's GitHub. The discussion included an existing PR (AOT Inductor load in python by msaroufim) and the use of
model.compile()instead oftorch.compile()as well astorch._inductor.config.fx_graph_cache = Truefor caching compiled models.
- Accelerating PyTorch's Compiled Artifacts: A user shared that using the
torch._inductor.config.fx_graph_cache = Truecut down the next compile time to approximately 2.5 minutes for NF4 QLoRA in torchtune, demonstrating a significant speed improvement.
- Questions About Torch Inductor's Backend Support: A user inquired if Torch Inductor has backend support for mps, but it was confirmed by another member that it currently does not.
- Closing Compilation Time Gaps in PyTorch: One user sought advice on reducing the compilation time gap between using nvcc for compiling
.cusource and thecpp_extension's loadfunction in PyTorch. Suggestions floated included limiting compiled architectures and splitting CUDA kernel and PyTorch wrapper functions into separate files to reduce recompilation.
- Deciphering Memory Allocation in PyTorch: In the context of an "unknown" memory allocation issue with Huggingface's llama model, a user referred to the PyTorch guide on understanding GPU memory (Understanding GPU Memory) to help address the problem.
- Understanding GPU Memory 1: Visualizing All Allocations over Time: During your time with PyTorch on GPUs, you may be familiar with this common error message:
- pytor - Overview: pytor has one repository available. Follow their code on GitHub.
- torch.export Tutorial — PyTorch Tutorials 2.3.0+cu121 documentation: no description found
- AOT Inductor load in python by msaroufim · Pull Request #103281 · pytorch/pytorch: So now this works if you run your model.py with TORCH_LOGS=output_code python model.py it will print a tmp/sdaoisdaosbdasd/something.py which you can import like a module Also need to set 'config....
CUDA MODE ▷ #algorithms (3 messages):
- Introducing vAttention for GPU Memory Efficiency: A new method called vAttention has been introduced to improve GPU memory usage for large language model (LLM) inference. Unlike previous systems that experience memory wastage, vAttention avoids internal fragmentation, supports larger batch sizes, and yet requires rewritten attention kernels and a memory manager for paging.
- Accelerating LLM Inference with QServe: QServe presents a solution to the inefficiencies of INT4 quantization in large-batch LLM serving through a novel W4A8KV4 quantization algorithm. QServe's QoQ algorithm, standing for quattuor-octo-quattuor, meaning 4-8-4, promises measured speedups by optimizing GPU operations in LLM serving.
- CLLMs Rethink Sequential Decoding for LLMs: A new blog post discusses Consistency Large Language Models (CLLMs), which introduce parallel decoding to reduce inference latency, by finetuning pretrained LLMs to decode an n-token sequence per inference step. CLLMs are designed to mimic the human cognitive process of sentence formation, yielding significant performance improvements.
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention: Efficient use of GPU memory is essential for high throughput LLM inference. Prior systems reserved memory for the KV-cache ahead-of-time, resulting in wasted capacity due to internal fragmentation. In...
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of...
- Consistency Large Language Models: A Family of Efficient Parallel Decoders: TL;DR: LLMs have been traditionally regarded as sequential decoders, decoding one token after another. In this blog, we show pretrained LLMs can be easily taught to operate as efficient parallel decod...
CUDA MODE ▷ #cool-links (7 messages):
- Optimization Adventures with Diffusion Models: A multi-post series by Vrushank Desai explores the optimization of inference latency for a diffusion model from Toyota Research Institute, focusing on the intricacies of GPU architecture to accelerate U-Net performance. Detailed insights and accompanying code examples can be found here and the related GitHub repo here.
- Superoptimizer to Streamline DNNs: Mention of a "superoptimizer" capable of optimizing any deep neural network, with the associated paper "Mirage" available here. However, skepticism is aired about the paper's benchmarks, and the omission of autotune in their optimization process is noted as odd in a GitHub demo.
- AI Optimization Threatens Jobs?: A member humorously expresses concern for their job security in light of the advanced optimizations being discussed, yet another reassures them, playfully suggesting their position is safe.
Link mentioned: Diffusion Inference Optimization: no description found
CUDA MODE ▷ #beginner (6 messages):
- CUDA Confusion: Device-Side Assert Trigger Alert: A member explained that a cuda device-side assert triggered error often occurs when the output logits are fewer than the number of classes. For instance, having an output layer dimension of 10 for 11 classes can cause this error.
- NVCC Flag Frustration: A member expressed difficulty in applying the
--extended-lambdaflag tonvccwhen using CMake and Visual Studio 2022 on Windows. Attempts to usetarget_compile_optionwith the flags led to nvcc fatal errors.
- Suggestion to Solve NVCC Flag Issue: Another member suggested verifying if the flag options are being misinterpreted due to wrong quoting, as NVCC was interpreting both options as a single long option with a space in the middle.
- Resolving Compiler Flags Hurtles: The original member seeking help with NVCC flags found that using a single hyphen
-instead of double hyphens--resolved the issue.
CUDA MODE ▷ #llmdotc (69 messages🔥🔥):
- Unified Development Files and Syntax Discussion: A conversation was held about a pull request (PR) aimed at unifying different development files to prevent or correct divergences, with a focus on the specific syntax for achieving it. While the intent to unify was largely agreed upon as important, the syntax brought forward was considered unsightly but necessary to avoid minimal changes to main function declarations.
- Performance and Determinism in Backward Passes: The backward pass for the encoder in BF16 mode was noted to be extremely non-deterministic. Losses varied significantly from run to run due to using an atomic stochastic add, suggesting that handling multiple tokens of the same type might require a specific order to avoid such non-determinism.
- Determinism vs. Performance Trade-offs Explored: The thread discussed the idea of introducing an option to run either a deterministic or a faster version of a kernel via a flag, and what level of performance loss might be acceptable for deterministic computation. It was acknowledged that encoder backward might need a redesign or additional reduction levels to maximize parallelism and maintain determinism.
- Master Weights and Packed Implementation: There was mention of a PR involving an Adam packed implementation that could speed up performance, but when combined with master weights, the benefit seemed negligible. It was questioned whether the packed implementation would be necessary for large training runs if master weights are being used.
- Resource Requirements for Training GPT2-XL: A user reported successfully running a batch training of GPT2-XL which utilized 36 GB out of a 40GB GPU, highlighting the substantial resource requirements for large-scale model training.
Link mentioned: Run CUDNN in LLM.c Walkthrough: All of the commands used in this video in sequence:ssh ubuntu@38.80.122.190git clone https://github.com/karpathy/llm.c.gitsudo apt updatesudo apt install pyt...
Latent Space ▷ #ai-general-chat (25 messages🔥):
- 01.ai Model Challenges Olmo: A mention was made about a model from 01.ai that asserts it vastly outperforms Olmo, sparking interest and discussion about its capabilities.
- Slop: A New AI Terminology Emerges: Members shared Simon Willison's blog post, endorsing the use of the term "slop" to describe "unwanted AI generated content", which is being used in a similar vein as "spam" is for unwanted emails. Views from the blog regarding etiquette in sharing AI content were highlighted.
- Enhancing LLM Output with LLM-UI: An introduction to llm-ui, a tool that cleans up LLM output by removing broken markdown syntax, adding custom components, and smoothing out pauses was shared, inciting curiosity and further discussion about its render loop.
- OpenAI Explores Secure Infrastructure for AI: A member posted a link to an OpenAI blog post discussing a proposed secure computing infrastructure for advanced AI, which mentions the use of cryptographically signed GPUs. The community reacted with skepticism, considering the motives behind such security measures.
- Anticipation for the Next LatentSpace Episode: Fans expressed eagerness for the next installment of the LatentSpace podcast series, highlighting the show's importance for their routine and interest in AI, with confirmation that a new episode was soon to be released.
- llm-ui | React library for LLMs: LLM UI components for React
- Slop is the new name for unwanted AI-generated content: I saw this tweet yesterday from @deepfates, and I am very on board with this: Watching in real time as “slop” becomes a term of art. the way that “spam” …
- Tweet from Ammaar Reshi (@ammaar): Our music model @elevenlabsio is coming together! Here’s a very early preview. 🎶 Have your own song ideas? Reply with a prompt and some lyrics and I’ll generate some for you!
- Stanford CS25: V4 I Aligning Open Language Models: April 18, 2024Speaker: Nathan Lambert, Allen Institute for AI (AI2)Aligning Open Language ModelsSince the emergence of ChatGPT there has been an explosion of...
- Login • Instagram: no description found
- llm-ui/packages/react/src/core/useLLMOutput/index.tsx at main · llm-ui-kit/llm-ui: The React library for LLMs. Contribute to llm-ui-kit/llm-ui development by creating an account on GitHub.
Latent Space ▷ #ai-in-action-club (71 messages🔥🔥):
- Meta Llama 3 Hackathon Announcement: An upcoming hackathon focused on the new Llama 3 model was mentioned, with Meta hosting and offering hands-on support, and various sponsors contributing to the $10K+ prize pool.
- Defining AI Confabulation and Hallucination: The differences between confabulation and hallucination when it comes to AI were discussed, noting that confabulation might be seen as reconstructing a narrative to match a desired reality, while hallucination involves imagining an incorrect reality.
- Discussion on Guardrails for AI: The conversation turned to guardrails for Large Language Models (LLMs) and the use of Outlines.dev, as well as mentions of a Guardrails presentation and tools like Zenguard.ai.
- Understanding Token Restriction Pregeneration: The concept of token restriction before model generation was clarified, with a previous talk linked for further details. It was noted that such an approach likely wouldn’t work on an API like OpenAI’s as it requires control over the model before sampling.
- Interactive Record of AI Discussions: A Google spreadsheet containing records of past discussions, including topics and resources, was shared, hinting at the community's organized approach to documenting and learning.
- ZenGuard: no description found
- Efficient Guided Generation for Large Language Models: In this article we show how the problem of neural text generation can be constructively reformulated in terms of transitions between the states of a finite-state machine. This framework leads to an ef...
- RSVP to Meta Llama 3 Hackathon | Partiful: We’re excited to welcome you to the official Meta Llama 3 Hackathon, hosted by Meta in collaboration with Cerebral Valley and SHACK15! This is a unique opportunity to build new AI apps on top of the ...
- ai in action: agentic reasoning with small models edition: courtesy of remi, happens at the latent.space discord fridays at 1pm PST, come thru: https://www.latent.space/p/communitywill prob start uploading these ever...
- marvin/README.md at c24879aa47961ba8f8fd978751db30c4215894aa · PrefectHQ/marvin: ✨ Build AI interfaces that spark joy. Contribute to PrefectHQ/marvin development by creating an account on GitHub.
- AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown,@ UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
- Guardrails for LLM Systems: Guardrails for LLM Systems Ahmed Moubtahij, ing., NLP Scientist | ML Engineer, Computer Research Institute of Montreal
LAION ▷ #general (8 messages🔥):
- SNAC Codec Innovation Shared: A member shared a YouTube video titled "SNAC with flattening & reconstruction," which showcases a speech-only codec. Accompanying this, they also posted a link to a Google Colab for a general-purpose (32khz) Codec.
- VC Funding Skepticism for Serial Entrepreneurs: A member expressed skepticism regarding the ability of an entrepreneur to secure venture capital funding if they helm multiple companies simultaneously.
- New Llama3s from LLMs Lab: The release of llama3s was announced, and a member pointed to the website Hugging Face's LLMs lab for more information.
- LLaVA's Blog Post on Next-Generation LLMs: A link to a new blog post about LLaVA's next stronger LLMs was shared, titled "LlaVA Next: Stronger LLMs," available on llava-vl.github.io.
- Meta's Official VLM Release Anticipation: A user humorously expressed ongoing anticipation for Meta's official visual language model (VLM) release, seemingly overshadowed by the discussion of other new model releases.
Link mentioned: SNAC with flattening & reconstruction: Speech only codec:https://colab.research.google.com/drive/11qUfQLdH8JBKwkZIJ3KWUsBKtZAiSnhm?usp=sharingGeneral purpose (32khz) Codec:https://colab.research.g...
LAION ▷ #research (79 messages🔥🔥):
- Debating Score Networks and Data Distributions: There is a discussion on why Noise Conditional Score Networks (NCSNs) converge to a standard Gaussian distribution. It touches on concepts such as perturbation of the original distribution and score matching — references made to Yang Song's blog post.
- DDPM and k-diffusion Clarifications: Participants discuss the differences between Denoising Diffusion Probabilistic Models (DDPM), DDIM (Denoising Diffusion Implicit Models), and k-diffusion, referring to the k-diffusion paper for insights.
- Lumina-T2I Model Teaser and Undertraining Issues: A link to a Hugging Face model called Lumina-T2I is shared, which uses LLaMa-7B text encoding and a stable diffusion VAE. A potential issue of the model being undertrained is discussed, hinting at the significant compute resources required to fully train multi-billion-parameter models.
- Flow Matching and Large-DiT Innovations: The incorporation of LLaMa cross-attention into a retrained large-DiT (Diffusion Transformers) is mentioned, showcasing a creative approach to text-to-image translation.
- Introducing Lumina-T2X for Multi-Modality Transformations: The Lumina-T2X family is introduced as a unified framework for transforming noise into various modalities like images, videos, and audio based on text instructions. It utilizes a flow-based large diffusion transformer mechanism and raises expectations for future training and improvement — more details can be seen in the Reddit post.
- Elucidating the Design Space of Diffusion-Based Generative Models: We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates t...
- Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song: no description found
- Gradio: no description found
- 5B flow matching diffusion transformer released. Weights are open source on Huggingface: Posted in r/StableDiffusion by u/Amazing_Painter_7692 • 149 points and 61 comments
OpenInterpreter ▷ #general (64 messages🔥🔥):
- Streamlining Groq Model Implementation: Members have been discussing using the Groq API with the OpenInterpreter platform. For Groq model integration, users are advised to set
groq/as a prefix in completion requests and define theGROQ_API_KEYenvironment variable in their OS. One user provided code samples for this integration in Python using litellm.
- Exploring OpenInterpreter with Computer Tasks: There has been an inquiry about whether OpenInterpreter's computer task completion works to a certain extent. Confirmation came that it does work, especially using GPT-4 on Ubuntu in combination with OpenCV/Pyautogui for GUI navigation.
- Combining Open Source Tech: Interest was shown in integrating OpenInterpreter with other open-source technologies, such as Billiant Labs Frame, to develop novel applications like AI glasses (YouTube video).
- Flexibility in Local LLM Implementations: Members have shared mixed experiences with local LLMs and tooling for file system tasks, acknowledging that performance can be suboptimal compared to ClosedAI's tools. Suggestions included focusing on reliable open source tools, sticking to a tried-and-tested stack, and using Mixtral for improved performance.
- Accessibility Initiatives and Updates: OpenInterpreter announced a collaboration with Ohana for Accessibility Grants to make technology more inclusive (tweet). They also flagged the latest 0.2.5 release of OpenInterpreter, which includes the
--osflag and a new Computer API, with installation instructions available on PyPI and additional details on the update given at changes.openinterpreter.com.
- Groq | liteLLM: https://groq.com/
- 01/software/source/clients/mobile at main · OpenInterpreter/01: The open-source language model computer. Contribute to OpenInterpreter/01 development by creating an account on GitHub.
- This is Frame! Open source AI glasses for developers, hackers and superheroes.: This is Frame! Open source AI glasses for developers, hackers and superheroes. First customers will start receiving them next week. We can’t wait to see what...
- Pywinassistant first try + Open Interpreter Dev @OpenInterpreter: NOTES & Schedule: https://techfren.notion.site/Techfren-STREAM-Schedule-2bdfc29d9ffd4d2b93254644126581a9?pvs=4pywinassistant: https://github.com/a-real-ai/py...
- open-interpreter/interpreter/core/computer/display/point/point.py at main · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
- open-interpreter: Let language models run code
OpenInterpreter ▷ #O1 (21 messages🔥):
- Groq's Whisper Model Shrouded in Access Issues: Members noted that Whisper is available via Groq's API rather than the playground, with one encountering an error stating, “The model
whisper-large-v3does not exist or you do not have access to it.” - Local LLaMA3 Model Showing Inefficiency: A member expressed concerns about LLaMA3's effectiveness, implying it may be going in circles and inquired about alternative local models for use.
- In Search of OpenInterpreter Compatible Hardware: A user is seeking guidance on how to adapt the M5atom build instructions for an ESP32-S3-BOX 3 while attempting to construct their O1 Light.
- LLaVA-NeXT Makes a Splash in Multimodal Learning: The release of LLaVA-NeXT models with expanded capabilities in image and video understanding was announced, with the promise of local testing and encouragement for community feedback. Here's the announcement blog post.
- Setting Up O1 on Windows with OpenInterpreter's Assistance: A user shared their experience using OpenInterpreter to install dependencies for O1 on Windows, noting the system's helpfulness but with caveats, such as requiring manual updates and guidance for installations.
Link mentioned: LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild: LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild
LlamaIndex ▷ #blog (5 messages):
- LlamaIndex Announces Local LLM Integration: LlamaIndex's new integration allows running local LLMs quickly, supporting a variety of models including Mistral, Gemma, Llama, Mixtral, and Phi. The announcement gives a shoutout to the integration on Twitter.
- TypeScript Agents Building Guide Released: An open-source repository is available that guides developers through the process of building agents in TypeScript, from basic creation to utilizing local LLMs like Mixtral. This resource is detailed on Twitter.
- Top-k RAG Approach for 2024 Challenged: The LlamaIndex community is advised against using a naive top-k RAG for future projects, hinting at evolving standards or better methodologies. The brief warning is posted on Twitter.
- Integration with Google Firestore Announced: LlamaIndex introduces integration with Google Firestore, touting its serverless, scalable capabilities and customizable security for serverless document DB and vector store. The integration announcement can be found on Twitter.
- Chat Summary Memory Buffer for Lengthy Conversations: A new Chat Summary Memory Buffer feature has been introduced to automatically preserve chat history beyond the limit of your token window, aiming to maintain important chat context. Details of the Chat Summary Memory Buffer technique were shared on Twitter.
LlamaIndex ▷ #general (68 messages🔥🔥):
- Mistral Meets HuggingFace: A user encountered a
NotImplementedErrorwhile attempting to create a ReACT Agent using Mistral LLM and HuggingFace Inference API. They were advised to check a Colab notebook for more detailed instructions on setting up a ReAct agent using LlamaIndex. - Semantic Route or Not?: LlamaIndex community discussed the routing mechanism in the query engines; comparing the semantic router against embedding-based routing. The discussion concluded that LlamaIndex uses an embedding-based router and does not integrate with semantic router, though the performance was noted to be similar.
- Routing and Performance in Vector Stores: Users inquired about the best routing method and performance of the in-memory vector store. Clarity was provided that LlamaIndex's in-memory store uses the bge-small model from HuggingFace for embeddings and that embedding-based routing is the current approach.
- Combining Chat History with Semantic Search: There was an exchange on how to incorporate chat history into a bot built with semantic search, with suggestions to use tools like QueryFusionRetriever. It was advised that a chatbot could be created by integrating the retriever into a Context Chat Engine or by using it as a tool with a ReAct Agent.
- Ingestion Pipeline Issues and Solution: A user faced issues when a failure occurred during the embedding phase in the ingestion pipeline, with rerunning skipping already inserted documents. The advice given was to adopt a batching approach in future runs and to delete data from docstore for the current failed batch. It was also mentioned that metadata exclusion from embeddings can be set at the document/node level.
- vLLM - LlamaIndex: no description found
- Structured Hierarchical Retrieval - LlamaIndex: no description found
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex: no description found
- GitHub - aurelio-labs/semantic-router: Superfast AI decision making and intelligent processing of multi-modal data.: Superfast AI decision making and intelligent processing of multi-modal data. - aurelio-labs/semantic-router
- Chat Engine - Condense Plus Context Mode - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
- Seeking LlamaIndex Graph Database Magic: A member expressed regret for not discovering LlamaIndex sooner after having manually created a custom database. They've crafted a retriever for Gmail to bypass the 500 email limit, and now seek assistance on how to efficiently create and update a Graph database with email content, aiming to extract relationships and data features for further analysis but are stymied by the challenge of translating structured data into a GraphDB format.
OpenAccess AI Collective (axolotl) ▷ #general (6 messages):
- Seeking Pretraining Wisdom: A member inquired about tips for pretraining, showing an interest in optimizing their models or processes.
- Pickle Error with PyTorch: One participant encountered a
TypeErrorrelated to being unable to pickle a 'torch._C._distributed_c10d.ProcessGroup' object and sought assistance after unsuccessful searches for a solution. - Deep Partial Optimization Query: There was a brief mention of Deep Partial Optimization (DPO) training concerning unforen selected layers, indicating a topic of interest or potential challenge.
- Unexpected Epoch Behavior: A user reported an anomaly where performing one epoch with one save resulted in the model being saved twice, indicating a possible bug or confusion in their training process.
OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
- Axolotl and Extended Contexts: A member inquired about fine-tuning an extended Llama 3 model to accommodate a 262k context through Axolotl, and it was confirmed that this is possible by simply adjusting the sequence length to the requirement.
- Llama 3 Fine-Tuning with Axolotl: After confirming the ability to fine-tune with Axolotl, the same member was curious about extending context for a 32k dataset on a Llama 3 8b model using the platform.
- Rope Scaling Recommendations for Fine-Tuning: When a member asked whether to use dynamic or linear rope scaling for fine-tuning, linear scaling was recommended for the task.
- Different Scaling Methods for Different Context: For non-fine-tuning scenarios, the same adviser suggested using dynamic scaling instead.
- Telegram Bot Timeout Issues: A member highlighted an error encountered with a Telegram bot: 'Connection aborted.', TimeoutError('The write operation timed out').
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (21 messages🔥):
- LoRA Configuration Confusion: A member faced a
ValueErrorrelated to thelora_modules_to_savesetting when adding new tokens, indicating the need to include['embed_tokens', 'lm_head']in the LoRA configuration. They were advised to ensure these modules are specified in their configuration to properly handle the embeddings for new tokens.
- YAML Configuration Assistance: After a user shared their YAML configuration encountering the same
ValueError, another member suggested adding
lora_modules_to_save:
- lm_head
- embed_tokens
to the configuration file as a solution.
- Debugging Transformer Trainer Error: The user continued to face issues with their training process, this time encountering an
AttributeErrorrelated to a 'NoneType' object in thetransformers/trainer.py. They were recommended to check their data loader for proper batch yields and inspect data processing to ensure format alignment.
- Investigative Tips Provided: To debug the
AttributeError, Phorm suggested logging the data structure before it's passed to theprediction_stepand making sure the training loop correctly handles expected input formats. This is critical in pinpointing the exact source of the input error.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
- peft/src/peft/tuners/lora/config.py at main · huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (3 messages):
- The Echo Chamber Dilemma: A member expressed a need for a Retort channel, highlighting the absence of such a channel for open deliberations or rebuttals.
- Lonely Debater: The same member humorously mentioned conversing with themselves in YouTube comments due to the lack of interactive feedback channels, indicating a desire for more engaging discussions.
Interconnects (Nathan Lambert) ▷ #news (3 messages):
- Debating the State of the Search Engine: A member questioned the accuracy of a tweet by Sam Altman about the status of a certain search engine, pointing out that it is currently being evaluated and tested.
Interconnects (Nathan Lambert) ▷ #ml-questions (6 messages):
- TPU Training Inquiry: A member asked if anyone has experience training a Recurrent Model (RM) on TPUs.
- FSDP Discussion: The same member inquired specifically about training with Fully Sharded Data Parallel (FSDP).
- Jax as a Solution: Nathan Lambert suggested using Jax and stated it might not be difficult to modify an existing Jax trainer.
- EasyLM Training Example: Nathan shared a GitHub link to EasyLM, highlighting a script that could potentially be adapted for training RMs on TPUs.
Link mentioned: EasyLM/EasyLM/models/llama/llama_train_rm.py at main · hamishivi/EasyLM: Large language models (LLMs) made easy, EasyLM is a one stop solution for pre-training, finetuning, evaluating and serving LLMs in JAX/Flax. - hamishivi/EasyLM
Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
- Disproportionate Resource Allocation?: A member expressed that a 200:1 model to leaderboard ratio seems quite excessive.
- Bitter Success: In response to the high model to leaderboard ratio, another member acknowledged the quality of the work, albeit with a hint of saltiness, and noted it as superior to standard AI efforts.
- OpenAI Initiates Preferred Publisher Program: OpenAI is targeting news publishers for partnerships through the Preferred Publishers Program, which started with a licensing agreement with the Associated Press in July 2023. The program includes deals with notable publishers like Axel Springer, The Financial Times, and Le Monde.
- Exclusive Benefits for Publishers with OpenAI: Members of OpenAI's Preferred Publishers Program are promised priority placement, better brand representation in chats, enhanced link representation, and licensed financial terms.
- Anticipated Monetization Strategy for Language Models: A response to the news on OpenAI's partnership highlights suggested monetization of language models through advertised content and enhanced brand presence.
Link mentioned: Leaked Deck Reveals OpenAI's Pitch on Publisher Partnerships: no description found
Interconnects (Nathan Lambert) ▷ #random (14 messages🔥):
- AI News Digest Service Coming Soon: AI News is launching a service to summarize AI-related discussions from Discord, Twitter, and Reddit. The service promises a significant reduction in reading time for those trying to keep up with the latest AI discussions.
- Token Limits Affecting AI Model's Behavior: A tweet from John Schulman revealed that the lack of visibility on max_tokens might lead to "laziness" in model responses. Schulman specifies the intent to show max_tokens to the model, aligning with model specifications.
- ChatBotArena Utilization Strategy: A member discussed the delicate balance in criticizing ChatBotArena with the aim to continue its availability. The strategic approach implies that moderation is key to preserve access.
- Student Graduation from AI Programs: The original group of students involved with AI projects, likely including ChatBotArena, appear to have completed their studies.
- Support Expressed for AI Influencer: There is admiration for John Schulman among members, citing his detailed insights and accessibility. One member appreciated past interactions with Schulman at ICML and discussed assistance with Dwarkesh for an upcoming podcast.
- Tweet from John Schulman (@johnschulman2): @NickADobos currently we don't show max_tokens to the model, but we plan to (as described in the model spec). we do think that laziness is partly caused by the model being afraid to run out of tok...
- [AINews] LMSys advances Llama 3 eval analysis: LLM evals will soon vary across categories and prompt complexity. AI News for 5/8/2024-5/9/2024. We checked 7 subreddits and 373 Twitters and 28 Discords...
LangChain AI ▷ #general (25 messages🔥):
- Decoding Gemini AI's Structured Prompts: Members discussed the potential of implementing structures similar to Google's Gemini AI studio structured prompts with other LLMS. The idea of function calling was mentioned as a possible solution.
- Troubleshooting LangGraph: A user reported an issue with ToolNode via LangGraph resulting in an empty
messagesarray and received guidance from kapa.ai, including checking initialization and state passing. Further assistance directed the user to LangGraph documentation for more in-depth help. - Opinions on VertexAI for Vector Store: A member sought advice on using VertexAI versus simpler options like Pinecone or Supabase for setting up a vector database with a RAG chat application. They found VertexAI complex and wondered about cost-efficiency.
- Alternatives for Vector Databases: A discussion revolved around effective, potentially cost-efficient ways to set up and host a vector database. pgvector was recommended for simplicity and open-source availability, with deployment via docker compose or on platforms like Google Cloud or Supabase.
- Seeking Free Local Vector Databases: One user inquired about free local vector databases for experimentation purposes and received a suggestion to review a comprehensive comparison of vector databases for insight into options like Pinecone, Weviate, and Milvus.
Link mentioned: Picking a vector database: a comparison and guide for 2023: no description found
LangChain AI ▷ #langserve (1 messages):
- Troubleshooting Chain Invocation Differences: A member experiences discrepancies when invoking a
chain()via Python directly versus using the/invokeendpoint with a POST body; the chain starts with an empty dictionary in the latter case. They shared a code snippet involvingRunnableParallel,prompt,model, andStrOutputParser()to illustrate their setup.
LangChain AI ▷ #share-your-work (1 messages):
- Introducing AgencyRuntime: A new article describes Agency Runtime as a social platform for creating and experimenting with modular teams of generative AI agents. The platform spans operational dimensions including messaging, social, economic, and more.
- Call for Collaboration: Members are encouraged to collaborate and help extend the capabilities of AgencyRuntime by incorporating additional LangChain features. Interested individuals should reach out for participation details.
- Agency Runtime — Social Realtime Agent Community: Agency Runtime is a social interface to discover, explore and design teams of generative AI agents.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LangChain AI ▷ #tutorials (2 messages):
- Integrating crewAI with Binance: A new YouTube tutorial shows how to create a custom tool connecting crewAI to the Binance Crypto Market using crewAI CLI. The tutorial demonstrates how to retrieve the highest position in the wallet and conduct web searches. Watch the tutorial here.
- Choosing Between LangChain Agents: Another YouTube video titled "LangChain Function Calling Agents vs. ReACt Agents – What's Right for You?" provides insights into the differences and applications of LangChain's Function Calling agents and ReACt agents. This video is aimed at those navigating the implementation of LangChain. Explore the details in the video.
- LangChain Function Calling Agents vs. ReACt Agents – What's Right for You?: Today we dive into the world of LangChain implementation to explore the distinctions and practical uses of Function Calling agents versus ReACt agents. 🤖✨Wh...
- Create a Custom Tool to connect crewAI to Binance Crypto Market: Use the new crewAI CLI tool and add a custom tool to connet crewAI to binance.com Crypto Market. THen get the highest position in the wallet and do web Searc...
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
<ul>
<li>
<strong>Launch of Languify.ai:</strong> A new browser extension called
<a href="https://www.languify.ai/">Languify.ai</a> was launched to help optimize website text to increase user engagement and sales. The extension utilizes Openrouter to interact with different models based on the user's prompts.
</li>
<li>
<strong>AnythingLLM User Seeks Simplicity:</strong> A member expressed interest in the newly introduced Languify.ai as an alternative to AnythingLLM which they found to be overkill for their needs.
</li>
<li>
<strong>Beta Testers Wanted for Rubik's AI:</strong> An invitation was extended for beta testing an advanced research assistant and search engine, offering a 2-month free premium trial of features like GPT-4 Turbo, Claude 3 Opus, Mistral Large, among others. Interested individuals are encouraged to provide feedback and can sign up through <a href="https://rubiks.ai/">Rubik's AI</a> with the promo code <code>RUBIX</code>.
</li>
</ul>
- Languify.ai - Optimize copyright: Elevate your content's reach with Languify, our user-friendly browser extension. Powered by AI, it optimizes copyright seamlessly, enhancing engagement and amplifying your creative impact.
- Rubik's AI - AI research assistant & Search Engine: no description found
OpenRouter (Alex Atallah) ▷ #general (25 messages🔥):
- PHP React Troubles: A user is experiencing a RuntimeException with the message "Connection ended before receiving response" when using Open Router API with PHP React library. They shared a detailed error stack trace presumably for community assistance.
- Query on Credits Transfer: A member inquired if it's possible to transfer some of his friend's credits to his account, tagging another user for an official response.
- Best Metrics for Training Router on Roleplay: A user asked about the best evaluation metrics when training a router for "roleplay" conversations. They are currently using validation loss and precision recall AUC for a binary preference dataset.
- Gemma's Massive Context Length: A link was shared announcing Gemma with a 10M context window, boasting a context length 1250 times that of base Gemma and requiring less than 32GB of memory. Some community members are skeptical about the quality of outputs at such context length.
- OpenRouter Gemini Blocking Setting Changed: The OpenRouter team confirmed that the safetySettings parameter for the Gemini backend was changed to BLOCK_ONLY_HIGH due to Google returning errors for the previous setting. There's a possible future addition for users to control this setting.
- WizardLM 2: SOCIAL MEDIA DESCRIPTION TAG TAG
- Tweet from Nenad (@Joldic): gde si raso
- Tweet from Siddharth Sharma (@siddrrsh): Introducing Gemma with a 10M context window We feature: • 1250x context length of base Gemma • Requires less than 32GB of memory • Infini-attention + activation compression Check us out on: • 🤗: ...
Cohere ▷ #general (18 messages🔥):
- Seeking Answers on Credit System: A member asked how to add credits to their account and was directed to the Cohere billing dashboard where one can set spending limits after adding a credit card. Details can be found here.
- Dark Mode Inquiry: A member inquired about the availability of a dark mode for Coral. Another participant suggested using Chrome's experimental dark mode or provided a custom dark mode snippet that can be pasted into the browser console.
- Pricing for Embedding Model: A user asked for information on the pricing of the embedding model for production. They received a link to the Cohere pricing page which outlines free and enterprise options along with FAQs on how to obtain Trial and Production API keys.
- Interest in NLP and LLM: A new member introduced themselves as a teacher in occupational medicine from Annaba, Algeria, expressing their interest in learning NLP and LLM.
- Friendly Greetings: Several new members greeted the channel with simple introductions and expressions of excitement to join the community.
- Pricing: Flexible, affordably priced natural language technology for businesses of all sizes. Start for free today and pay as you go.
- Hello Wave GIF - Hello Wave Cute - Discover & Share GIFs: Click to view the GIF
- Login | Cohere: Cohere provides access to advanced Large Language Models and NLP tools through one easy-to-use API. Get started for free.
- Get Over 99% Of Python Programmers in 37 SECONDS!: 🚀 Ready to level up your programmer status in just 37 seconds? This video unveils a simple trick that'll skyrocket you past 99% of coders worldwide! It's so...
Cohere ▷ #announcements (9 messages🔥):
- Command R Fine-Tuning Launched: Fine-tuning is now available for Command R, offering best-in-class performance, lower costs (up to 15x cheaper), faster throughput, and adaptability across industries. It is accessible through the Cohere platform, Amazon SageMaker, and soon additional platforms. Full details on the blog.
- Clarification on Model Selection for Fine-Tuning: A user inquired about model selection for chat fine-tuning and was informed that Command R is the default model used for fine-tuning.
- Inquiries about Command R Pricing and Availability: A member questioned the pricing being four times higher and expressed anticipation for CMD-R+. There's mention of possibly using a larger context model as a cost-effective alternative.
- Understanding Use Cases for CMD-R+: A discussion arose regarding the use cases for fine-tuning CMD-R+ and how its performance might justify its cost despite higher prices.
- Anticipation for Command R++: A user inquired about the release of Command R++, anticipating future updates to the model offerings.
Link mentioned: Introducing Command R Fine-Tuning: Industry-Leading Performance at a Fraction of the Cost: Command R fine-tuning offers superior performance on enterprise use cases and costs up to 15x less than the largest models on the market.
Datasette - LLM (@SimonW) ▷ #ai (18 messages🔥):
- Apple Leaps into Generative AI: Apple is reportedly initiating its move into generative AI by using M2 Ultra chips in data centers to process complex AI tasks before advancing to M4 chips. According to Bloomberg and The Wall Street Journal, Apple aims to leverage its server chips for AI tasks, ensuring enhanced security and privacy through Project ACDC.
- Apple AI Tasks in the Cloud and On-Device: The chat highlights a strategy akin to a mixture of experts, where simple AI tasks could be managed on-device, while more complex queries would be offloaded to the cloud.
- M2 Ultra Envy: A participant expresses a wish for an M2 Ultra Mac after Apple's rumored plans surface, even though they recently acquired an M2 Max.
- Apple's MLX Tech Gains Attention: Apple's MLX technology for running large AI models on Apple silicon is being discussed, with a particular focus on a GitHub repository hosting related resources.
- ONNX Format Gains Ground Amidst Apple's Proprietary Tendencies: Apple's historical preference for proprietary libraries and standards is tempered by recognition of ONNX's utility, exemplified by the availability of Phi-3 128k through ONNX, despite concerns about Apple's open-source engagement.
- Apple plans to use M2 Ultra chips in the cloud for AI: Apple will use M2 for now before moving to M4 chips for AI.
- GitHub - ml-explore/mlx: MLX: An array framework for Apple silicon: MLX: An array framework for Apple silicon. Contribute to ml-explore/mlx development by creating an account on GitHub.
- microsoft/Phi-3-mini-128k-instruct-onnx · Hugging Face: no description found
- GitHub - ml-explore/mlx-onnx: MLX support for the Open Neural Network Exchange (ONNX): MLX support for the Open Neural Network Exchange (ONNX) - ml-explore/mlx-onnx
- Initial support by dc-dc-dc · Pull Request #1 · ml-explore/mlx-onnx: no description found
Mozilla AI ▷ #llamafile (16 messages🔥):
- Exploring Topic Clustering: A new blog post was shared, discussing the use of Llamafile for clustering ideas into labelled groups. The author talks about experimenting with Figma's FigJam AI feature and provides funny DALL-E imagery to illustrate the concept.
- Deep Dive into Llamafile's GPU Layer Loading: Clarification was provided on the
-ngl 999flag within llamafile usage, pointing to thellama.cppserver README explaining GPU layer offloading and its impact on performance. Benchmarks demonstrating differing GPU layer offloads were also shared. - Release Alert for llamafile: An announcement was made about a new llamafile release v0.8.2, touting performance optimizations for K quants by the developer K themselves. Instructions to integrate the new software into existing weights were provided through an issue comment.
- Implementation Help for Openelm: A developer sought assistance on an attempt to implement Openelm in
llama.cpp, referring to a draft pull request on GitHub and indicating a point of contention insgemm.cpp. - Podman Container Workarounds for llamafile: A member detailed an issue when wrapping llamafile in a Podman container, where
podman runwould fail to executellamafileand offered a workaround using a shell script as a trampoline. They surmised that the issue may relate tobinfmt_mischandling multi-architecture formats.
- Clustering ideas with Llamafile: TL;DR: In my previous post, I used local models with PyTorch and Sentence Transformers to roughly cluster ideas by named topic. In this post, I'll try that again, but this time with Llamafile.
- Release llamafile v0.8.2 · Mozilla-Ocho/llamafile: llamafile lets you distribute and run LLMs with a single file llamafile is a local LLM inference tool introduced by Mozilla Ocho in Nov 2023, which offers superior performance and binary portabilit...
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
- Server Missing OpenAI API Support? · Issue #24 · Mozilla-Ocho/llamafile: The server presents the UI but seems to be missing the APIs? The example test: curl -i http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorizatio...
- Attempt at OpenElm by joshcarp · Pull Request #6986 · ggerganov/llama.cpp: Currently failing on line 821 of sgemm.cpp, still some parsing of ffn/attention head info needs to occur. Currently hard coded some stuff. Fixes: #6868 Raising this PR as a draft because I need hel...
- llama.cpp/examples/server at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- llama.cpp/examples/llama-bench/README.md at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
LLM Perf Enthusiasts AI ▷ #general (3 messages):
- Seeking Spreadsheet Savvy AI: A member inquired about experiences or resources related to spreadsheet manipulation using LLMs.
- AI for Taming Spreadsheet Chaos: A tweet was shared discussing the challenge of extracting data from messy spreadsheets in biology labs and exploring AI as a solution.
- Demo Disappointment: A member tried out the spreadsheet demo mentioned but reported it didn't work very well, albeit suspecting that might be due to a less powerful model being used for the demo. The accompanying write-up, however, was deemed legitimate.
Link mentioned: Tweet from Jan : Spreadsheets are the lifeblood of many biology labs, but extracting insights from messy data is a huge challenge. We wanted to see if AI could help us reliably pull data from any arbitrary spreadsheet...
LLM Perf Enthusiasts AI ▷ #gpt4 (10 messages🔥):
- GPT-5 Reveal Speculation: A member voiced disappointment upon hearing from Sam that the upcoming release on Monday will not be GPT-5.
- Excited Guesses on Upcoming AI: The same member also predicted the announcement might be about an agentic-tuned GPT-4, suggesting it could be a significant update.
- Hopes for a More Efficient Model: A different member expressed hope for a "GPT4Lite" that would offer the high quality of GPT-4 but with reduced latency and cost, similar to Haiku's performance benefits.
- Anticipation for Dual Announcements: There is speculation that the new release might not only be agentic-tuned GPT-4 but could also include a more cost-efficient model.
- The Obsolescence of GPT-3.5: A member remarked that in light of the current advancements, GPT-3.5 seems entirely outdated.
tinygrad (George Hotz) ▷ #general (1 messages):
helplesness: Hello
tinygrad (George Hotz) ▷ #learn-tinygrad (10 messages🔥):
- Metal Build Mysteries: A user is struggling to understand the function
libraryDataContents()and its association with the Metal build process, even after searching the discord message history and the Metal-cpp API. They have also consulted the MSL spec, Apple documentation, Metal framework implementation, and found a reference on a developer site, but still can't pinpoint the issue.
- Visualizing Tensor Shapes and Strides: A tool for visualizing different combinations of tensor shape and stride has been created by a user, which could aid those studying related topics. The tool is available at this GitHub Pages site.
- FLOP Counting in TinyGrad Explained: One user queried the purpose of the
InterpretedFlopCountersinops.py. Another clarified that flop counts serve as a proxy for performance metrics in TinyGrad.
- Inquiry on Buffer Registration in TinyGrad: A user asked if there's a function like
self.register_bufferin PyTorch available in TinyGrad, to which it was responded that creating aTensorwithrequires_grad=Falseshould fulfill the requirement.
- The Concept of Symbolic Ranges in TinyGrad: A user expressed the need for symbolic understanding of functions and control flow when dealing with symbolic tensor values in TinyGrad. This could involve the rendering system understanding expansion of general lambdas of algebra and control flow statements for symbolic implementation.
Link mentioned: Shape & Stride Visualizer: no description found
Alignment Lab AI ▷ #general-chat (1 messages):
- Inquiry About Finetuning Buzz Models: A user is seeking the correct channel to discuss Buzz models and is specifically interested in iterative sft finetuning best practices. They noted the lack of documentation on this topic.
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=4MzCpZLEQJs
AI Stack Devs (Yoko Li) ▷ #events (1 messages):
- AI and Education Live Session Announcement: The AI Town community is hosting a live session focused on AI and education in partnership with Rosebud & Week of AI. Participants will learn to use Phaser-based AI for interactive experiences, view submissions from the #WeekOfAI Game Jam, and explore how to integrate Rosie into classrooms.
- Save the Date for AI Learning: Mark your calendars for Monday, 13th at 5:30 PM PST to attend this educational event. Interested developers can register for the session through the provided Twitter link.