[AINews] Anthropic launches the Model Context Protocol
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
claude_desktop_config.json is all you need.
AI News for 11/25/2024-11/26/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (202 channels, and 2684 messages) for you. Estimated reading time saved (at 200wpm): 314 minutes. You can now tag @smol_ai for AINews discussions!
Special Note: we have pruned some inactive discords, and added the Cursor discord!
Fresh off their $4bn fundraise from Amazon, Anthropic is not stopping at visual Computer Use (our coverage here). The next step is defining terminal-level integration points for Claude Desktop to directly interface with code run on your machine. From the quickstart:

The Model Context Protocol (MCP) is an open protocol that enables seamless integration between LLM applications and external data sources and tools. Similar to the Language Server Protocol, MCP how to integrate additional context and tools into the ecosystem of AI applications. For implementation guides and examples, visit modelcontextprotocol.io.
The protocol is flexible enough to cover:
- Resources: any kind of data that an MCP server wants to make available to clients. This can include: File contents, Database records, API responses, Live system data, Screenshots and images, Log files, and more. Each resource is identified by a unique URI and can contain either text or binary data.
- Prompts: Resuable templates and workflows (including multi-step)
- Tools: everything from system operations to API integrations to running data processing tasks.
- Transports: Requests, Responses, and Notifications between clients and servers via JSON-RPC 2.0, including support for server-to-client streaming and other custom transports (WebSockets/WebRTC is not mentioned... yet)
- Sampling: allows servers to request LLM completions through the client, enabling sophisticated agentic behaviors (including rating costPriority, speedPriority, and intelligencePriority, implying Anthropic will soon offer a model router) while maintaining security and privacy.
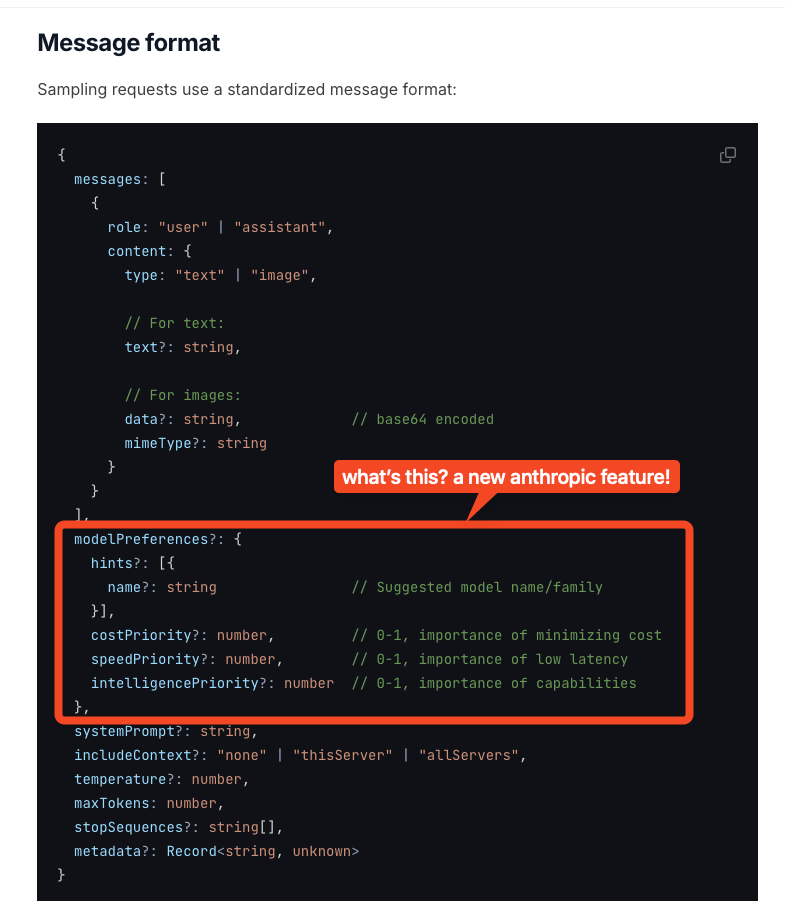
The docs make solid recommendations on security considerations, testing, and dynamic tool discovery.
The launch clients show an interesting array of these feature implementations:
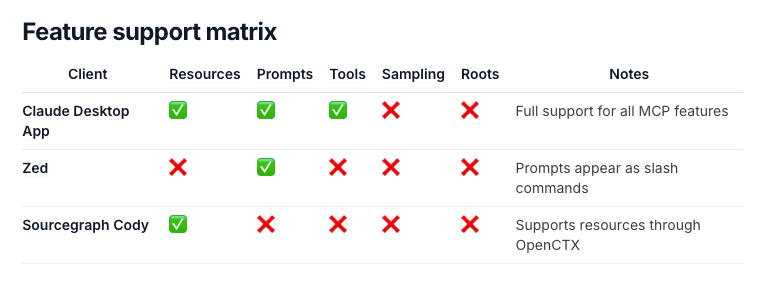
The launch partners Zed, Sourcegraph, and Replit all reviewed it favorably, however others were a bit more critical or confused. Hacker News is already recalling XKCD 927.
Glama.ai has already written a good guide/overview to MCP, and both Alex Albert and Matt Pocock have nice introductory videos.
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Cursor IDE Discord
- aider (Paul Gauthier) Discord
- HuggingFace Discord
- Unsloth AI (Daniel Han) Discord
- Modular (Mojo 🔥) Discord
- OpenRouter (Alex Atallah) Discord
- OpenAI Discord
- Perplexity AI Discord
- LM Studio Discord
- Eleuther Discord
- Nous Research AI Discord
- Notebook LM Discord Discord
- Interconnects (Nathan Lambert) Discord
- Cohere Discord
- Stability.ai (Stable Diffusion) Discord
- GPU MODE Discord
- tinygrad (George Hotz) Discord
- LLM Agents (Berkeley MOOC) Discord
- Axolotl AI Discord
- LlamaIndex Discord
- Torchtune Discord
- DSPy Discord
- LAION Discord
- Mozilla AI Discord
- AI21 Labs (Jamba) Discord
- PART 2: Detailed by-Channel summaries and links
- Cursor IDE ▷ #general (706 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #general (417 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (16 messages🔥):
- aider (Paul Gauthier) ▷ #links (5 messages):
- HuggingFace ▷ #general (146 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (3 messages):
- HuggingFace ▷ #i-made-this (9 messages🔥):
- HuggingFace ▷ #NLP (9 messages🔥):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- Unsloth AI (Daniel Han) ▷ #general (126 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (2 messages):
- Unsloth AI (Daniel Han) ▷ #help (29 messages🔥):
- Unsloth AI (Daniel Han) ▷ #research (3 messages):
- Modular (Mojo 🔥) ▷ #general (28 messages🔥):
- Modular (Mojo 🔥) ▷ #mojo (125 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
- OpenRouter (Alex Atallah) ▷ #general (112 messages🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (10 messages🔥):
- OpenAI ▷ #ai-discussions (70 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (9 messages🔥):
- OpenAI ▷ #prompt-engineering (19 messages🔥):
- OpenAI ▷ #api-discussions (19 messages🔥):
- Perplexity AI ▷ #general (100 messages🔥🔥):
- Perplexity AI ▷ #sharing (4 messages):
- Perplexity AI ▷ #pplx-api (3 messages):
- LM Studio ▷ #general (56 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (31 messages🔥):
- Eleuther ▷ #general (21 messages🔥):
- Eleuther ▷ #research (41 messages🔥):
- Eleuther ▷ #interpretability-general (4 messages):
- Eleuther ▷ #lm-thunderdome (12 messages🔥):
- Nous Research AI ▷ #general (58 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (3 messages):
- Notebook LM Discord ▷ #announcements (1 messages):
- Notebook LM Discord ▷ #use-cases (7 messages):
- Notebook LM Discord ▷ #general (53 messages🔥):
- Interconnects (Nathan Lambert) ▷ #news (14 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Cohere ▷ #discussions (1 messages):
- Cohere ▷ #questions (22 messages🔥):
- Cohere ▷ #api-discussions (3 messages):
- Stability.ai (Stable Diffusion) ▷ #general-chat (26 messages🔥):
- GPU MODE ▷ #triton (2 messages):
- GPU MODE ▷ #cuda (5 messages):
- GPU MODE ▷ #beginner (3 messages):
- GPU MODE ▷ #torchao (5 messages):
- GPU MODE ▷ #off-topic (4 messages):
- GPU MODE ▷ #llmdotc (1 messages):
- GPU MODE ▷ #intel (1 messages):
- GPU MODE ▷ #sparsity-pruning (1 messages):
- tinygrad (George Hotz) ▷ #general (8 messages🔥):
- tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
- LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
- LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
- Axolotl AI ▷ #general (5 messages):
- LlamaIndex ▷ #blog (2 messages):
- LlamaIndex ▷ #general (2 messages):
- Torchtune ▷ #general (2 messages):
- Torchtune ▷ #dev (1 messages):
- DSPy ▷ #examples (1 messages):
- LAION ▷ #general (1 messages):
- Mozilla AI ▷ #announcements (1 messages):
- AI21 Labs (Jamba) ▷ #general-chat (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
1. MCP Release and Reaction: Anthropic's Model Context Protocol (MCP)
- Introducing MCP by Anthropic: @alexalbert__ discusses MCP, an open standard for connecting LLMs to data resources via a single protocol. It calls attention to the complexities and critiques its narrow provider focus.
- Skepticism Around Adoption: @hwchase17 compares MCP to earlier OpenAI innovations, questioning its provider exclusivity and potential for becoming a widespread standard.
- Developer Insights: @pirroh reflects on MCP's similarities with web standards for ensuring interoperability across diverse AI agents.
2. Excitement Around Claude and AI Capability Discussions
- Potential of Claude in AI Integrations: @AmandaAskell is querying the community for Claude prompts that could enhance task-specific performance and insights.
- Capability and Integrations: @skirano highlights Claude's capability to integrate locally stored files, presenting it as a powerful tool for API-based GUI automation.
3. NeurIPS and Event Innovations
- NeurIPS 2024 Event Planning: @swyx announces Latent Space LIVE, a novel side event with unique formats like "Too Hot For NeurIPS" and "Oxford Style Debates," aiming for meaningful interactions and audience engagement.
- Registration Adjustments and Speaker Calls: @swyx clarifies registration confusion, urging for new speaker applications amidst event planning.
4. Investments and Growth in Cloud-AI Collaborations
- Amazon's Strategic Moves with Anthropic: @andrew_n_carr discusses Amazon's strategic focus on Anthropic, emphasizing computational collaborations via AWS's Trainium chips.
- Infrastructure Impact: @finbarrtimbers shares thoughts on the potential of Trainium, expressing hope for developments that match Google's TPUs.
5. Open Source Initiatives and Innovations in Model Training
- NuminaMath Dataset Licensing: @_lewtun celebrates the NuminaMath dataset's new Apache 2.0 license, indicating a significant open-source advancement in math problem datasets.
- AI Model Developments: Tweets like @TheAITimeline's synopsis of current papers highlight innovations such as LLaVA-o1 and Marco-o1, contributing to reasoning model discussions.
Memes and Humor
- AI Capability Ducks: @arankomatsuzaki humorously frames AI trends with playful listicles of AI applications.
- Unlikely Scenarios: @mickeyxfriedman shares a whimsical interaction, blending humor with unexpected real-life moments.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Marco-o1 Hits 83% on Cyber Tests: 7B Model Chain-of-Thought Breakthrough
- macro-o1 (open-source o1) gives the cutest AI response to the question "Which is greater, 9.9 or 9.11?" :) (Score: 443, Comments: 87): Marco-o1, an open-source AI model, demonstrated chain-of-thought reasoning by answering a numerical comparison question between 9.9 and 9.11. Due to lack of additional context in the post body, specific details about the response content or the model's implementation cannot be included in this summary.
- Users noted the model exhibits overthinking behavior similar to those with autism, with many commenters relating to its detailed thought process. The model's response to a simple "Hi!" garnered significant attention with 229 upvotes.
- Technical discussion revealed the model runs on M1 Pro chip using Ollama, with a system prompt enabling chain-of-thought reasoning. Users clarified this is the CoT model, not the unreleased MCTS model.
- The model performs best with mathematical and simple queries, showing entertaining but sometimes unnecessary verbose reasoning. Several users noted it struggles with basic spelling tasks like counting letters in "strawberry", suggesting potential training limitations.
- Testing LLM's knowledge of Cyber Security (15 models tested) (Score: 72, Comments: 17): A benchmark test of 421 CompTIA practice questions across 15 different LLM models shows 01-preview leading with 95.72% accuracy, followed by Claude-3.5-October at 92.92% and O1-mini at 92.87%. The test reveals some unexpected results, with marco-o1-7B scoring lower than expected at 83.14% (behind Qwen2.5-7B's 83.73%), and Hunyuan-Large-389b underperforming at 88.60% despite its larger size.
- Marco-o1 model's performance is explained by its base being Qwen2-7B-Instruct (not 2.5), and it currently lacks proper search inference code, making it essentially a CoT finetune implementation.
- Users suggest testing additional models including WhiteRabbitNeo specialized models and Deepseek with its deep thinker version, while others note the importance of considering whether the CompTIA questions might be in the training sets.
- Discussion highlights the significance of focusing on security testing for AI models, with commenters noting this sector needs more attention as developers often build without security considerations.
Theme 2. OuteTTS-0.2-500M: New Compact Text-to-Speech Model Released
- OuteTTS-0.2-500M: Our new and improved lightweight text-to-speech model (Score: 172, Comments: 29): OuteTTS released version 0.2 of their 500M parameter text-to-speech model. The post lacks additional context about specific improvements or technical details.
- The model supports voice cloning via reference audio, with documentation available on HuggingFace, though users may need to finetune for voices outside the Emilia dataset.
- Users report the model performs well despite its small 500M parameter size, though some experience slow generation times (~3 minutes for 14 seconds of audio) and attention mask errors on the Gradio demo.
- Discussion around licensing restrictions emerged, as the model's non-commercial license (inherited from the Emilia dataset) potentially limits usage in monetized content like YouTube videos, despite similar models like Whisper using web-scraped training data.
Theme 3. Winning with Small Models: 1.5B-3B LLMs Show Impressive Results
- These tiny models are pretty impressive! What are you all using them for? (Score: 28, Comments: 3): Tiny LLMs ranging from 1.5B to 3B parameters demonstrated impressive capabilities in handling multiple function calls, with Gemma-2B successfully executing 6 parallel function calls while others managed 4 out of 6. The tested models included Gemma 2B (2.6GB), Llama-3 3B (3.2GB), Ministral 3B (3.3GB), Qwen2.5 1.5B (1.8GB), and SmolLM2 1.7B (1.7GB), all showing potential for domain-specific applications.
- Local deployment capabilities of these tiny models offer significant privacy advantages and reduced cloud infrastructure dependencies, making them practical for sensitive applications.
- 3B parameter models prove sufficient for common use cases like grammar checking, text summarization, code completion, and personal assistant tasks, challenging the notion that larger models are always necessary.
- The efficiency of these smaller models demonstrates successful parameter optimization, achieving targeted functionality without the resource demands of larger models.
- Teleut 7B - Tulu 3 SFT replication on Qwen 2.5 (Score: 55, Comments: 16): A new 7B parameter LLM called Teleut trained on a single 8xH100 node using AllenAI's data mixture achieves competitive performance against larger models like Tülu 3 SFT 8B, Qwen 2.5 7B, and Ministral 8B across multiple benchmarks including BBH (64.4%), GSM8K (78.5%), and MMLU (73.2%). The model is available on Hugging Face and demonstrates that state-of-the-art performance can be replicated using publicly available training data from AllenAI.
- MMLU performance of 76% at 7B parameters is noted as remarkable since this level was previously achieved only by 32/34B models, though some users express skepticism about the accuracy of these comparative metrics.
- Users highlight that Qwen 2.5 Instruct outperforms Teleut in most metrics, raising questions about the actual improvements over the base model and the significance of the results.
- The community appreciates AllenAI's contribution to open data, with Retis Labs offering additional compute resources for further research based on community demand.
Theme 4. Major LLM Development Tools Released: SmolLM2 & Optillm
- Full LLM training and evaluation toolkit (Score: 41, Comments: 3): HuggingFace released their complete SmolLM2 toolkit under Apache 2.0 license at smollm, which provides comprehensive LLM development tools including pre-training with nanotron, evaluation with lighteval, and synthetic data generation with distilabel. The toolkit also includes post-training scripts using TRL and the alignment handbook, plus on-device tools with llama.cpp for tasks like summarization and agents.
- Users inquired about minimum hardware requirements for running the SmolLM2 toolkit, though no official specifications were provided in the discussion.
- Beating o1-preview on AIME 2024 with Chain-of-Code reasoning in Optillm (Score: 54, Comments: 7): Optillm implemented chain-of-code (CoC) reasoning which outperformed OpenAI's o1-preview on AIME 2024 (pass@1) metrics using base models from Anthropic and DeepMind. The implementation, available in their open-source optimizing inference proxy, builds on research from the Chain of Code paper and competes with recent releases from DeepSeek, Fireworks AI, and NousResearch.
- Chain-of-Code implementation follows a structured approach: starting with initial code generation, followed by direct execution, then up to 3 code fix attempts, and finally LLM-based simulation if previous steps fail.
- The OpenAI o1-preview model's innovation is characterized more by accounting than capability improvements, with its architecture potentially incorporating multiple agents and infrastructure rather than a single model improvement.
- Google and Anthropic are predicted to outperform OpenAI's next-generation models, with benchmark reliability being questioned due to the ease of training specifically for benchmarks and obscuring distribution through alignment techniques.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Chinese LLMs surpass Gemini in benchmarks: StepFun & Qwen
- Chinese LLMs catch up with US LLMs: Stepfun ranks higher than Gemini and Qwen ranks higher than 4o (Score: 174, Comments: 75): Chinese language models demonstrate competitive performance with Stepfun ranking above Google's Gemini and Qwen surpassing Claude 4.0 according to recent benchmarks. The specific metrics and testing methodology for these rankings were not provided in the source material.
- Chinese AI models are showing strong real-world performance, with users confirming that models like Deepseek Coder and R1 are competitive though not superior to OpenAI and Anthropic. Multiple users note that the latest experimental models offer 2M context windows.
- Users debate the quality of GPT-4 versions, with many reporting that the November version performs worse than August/May versions, particularly in text analysis tasks. Some attribute this to potential model size reduction for optimization of actual usage.
- Discussion around US-China AI competition highlights broader technological competition, with references to ASPI's Tech Tracker showing China's advancement in strategic technologies while the US maintains leads in specific sectors like AI/ML and semiconductors.
- Jensen Huang says AI Scaling Laws are continuing because there is not one but three dimensions where development occurs: pre-training (like a college degree), post-training ("going deep into a domain") and test-time compute ("thinking") (Score: 66, Comments: 9): Jensen Huang discusses three dimensions of AI scaling: pre-training (comparable to general education), post-training (domain specialization), and test-time compute (active processing). His analysis suggests continued growth in AI capabilities through these distinct development paths, countering arguments about reaching scaling limits.
- Jensen Huang's analysis aligns with NVIDIA's business interests, as each scaling dimension requires additional GPU compute resources for implementation and operation.
- The concept of AI agents emerges as another potential scaling dimension, with experts suggesting a future architecture of thousands of specialized models coordinated by a state-of-the-art controller for achieving AGI/ASI.
- Discussion emphasizes how multiple scaling approaches (pre-training, post-training, test-time, and agents) all drive increased GPU demand, supporting NVIDIA's market position.
Theme 2. Flux Video Generation & Style Transfer Breakthroughs
- Flux + Regional Prompting ❄🔥 (Score: 263, Comments: 23): Flux and Regional Prompting are mentioned in the title but no additional context or content is provided in the post body to create a meaningful summary.
- Regional Prompting with Flux workflow is now freely available on Patreon, though LoRAs currently have reduced fidelity when used with regional prompting. The recommended approach is using regional prompting for base composition, then img-to-img with LoRAs.
- A comprehensive tutorial for ComfyUI setup and usage with Flux vs SD is available on YouTube, covering installation, ComfyUI manager, default workflows, and troubleshooting common issues.
- Discussion touched on modern content monetization, with users noting how 2024's economic environment drives creators toward multiple income streams, contrasting with the early 2000s when monetization was less prevalent.
- LTX Time Comparison: 7900xtx vs 3090 vs 4090 (Score: 21, Comments: 23): The performance comparison between AMD 7900xtx, NVIDIA RTX 3090, and RTX 4090 for Flux and LTX video generation shows the 4090 significantly outperforming with total processing time of 6m15s versus 12m for the 3090 and 27m30s for the 7900xtx, with specific iteration speeds of 4.2it/s, 1.76it/s, and 1.5it/s respectively for Flux. The author notes that LTX video generation quality heavily depends on seed luck and motion intensity, with significant motion causing quality degradation, while the entire test on RunPod cost $1.32.
- Triton Flash Attention and bf16-vae optimizations can potentially improve performance, with the latter being enabled via
--bf16-vaecommand line argument. Documentation for Triton is currently limited to a GitHub Issue. - Community speculates that the upcoming NVIDIA 5090 could complete the test in approximately 3m30s, though concerns about pricing were raised.
- Discussion around VAE decoders and frame rate optimization suggests post-processing speed adjustments for better results, while the high seed sensitivity indicates potential model improvements needed in future versions.
- Triton Flash Attention and bf16-vae optimizations can potentially improve performance, with the latter being enabled via
Theme 3. IntLoRA: Memory-Efficient Model Training and Inference
- IntLoRA: Integral Low-rank Adaptation of Quantized Diffusion Models (Score: 44, Comments: 6): IntLoRA, a new quantization technique for diffusion models, focuses on adapting quantized models through low-rank updates. The technique's name combines "Integral" with "LoRA" (Low-Rank Adaptation), suggesting it deals with integer-based computations in model adaptation.
- IntLoRA offers three key advantages: quantized pre-trained weights for reduced memory in fine-tuning, INT storage for both pre-trained and low-rank weights, and efficient integer multiplication or bit-shifting for merged inference without post-training quantization.
- The technique is explained using a crayon box analogy, where quantization reduces color variations (like fewer shades of blue) and low-rank adaptation identifies the most important elements, making the model more efficient and accessible.
- IntLoRA uses an auxiliary matrix and variance matching control for organization and balance, functioning similarly to GGUFs for base models but specifically designed for diffusion model LoRAs.
Theme 4. Anthropic's Model Context Protocol for Claude Integration
- Introducing the Model Context Protocol (Score: 26, Comments: 16): Model Context Protocol launched to enable Claude integration, though no specific details were provided in the post body.
- The Model Context Protocol allows Claude to interact with local systems including file systems, SQL servers, and GitHub through simple API connections, enabling basic agent/tool functionality through the desktop app.
- Implementation requires installing via
pip install uvto run the MCP server, with setup instructions available at modelcontextprotocol.io/quickstart. A SQLite3 connection example was shared through an imgur screenshot. - Users expressed interest in practical applications, including using it to analyze and fix bug reports through GitHub repository connections.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. AI Model Shuffles Stir Up User Communities
- Cursor Cuts Long Context Mode, Users Cry Foul: Cursor's recent removal of the long context mode, particularly impacting the claude-3.5-200k version, has left users frustrated and scrambling to adjust their workflows. Speculations arise about a shift towards agent-based models, but many are unhappy with the sudden change.
- Qwen 2.5 Coder Baffles with Performance Variability: Confusion reigns as users test the Qwen 2.5 Coder, noting significant discrepancies in benchmark results between providers and local setups. This has led to tweaks in models and settings to chase consistent performance.
- GPT-4o Wows Users Amid Performance Praise: The release of
openai/gpt-4o-2024-11-20has users singing its praises, highlighting its impressive performance and positioning it as a preferred choice in the community.
Theme 2. AI Tools and Platforms Ride the Rollercoaster
- LM Studio's Model Search Limbo Leaves Users Lost: After updating to version 0.3.5, users find LM Studio's model search functionality limited, causing confusion about accessing new models unless manually searched.
- OpenRouter API Plays Hard to Get with Rate Limits: Users hit potential rate limit issues with the OpenRouter API, though some mention private agreements offering more flexibility, highlighting inconsistencies in access.
- Aider and Friends Debate Who's the Fairest IDE of All: Aider users compare it with tools like Cursor and Windsurf, debating effectiveness for coding tasks and noting that Copilot might lag behind premium options.
Theme 3. Fine-Tuners Face Trials and Tribulations
- Fine-Tuners Twist in the Wind with Command R: Users attempting to fine-tune Command R models report outputs stopping prematurely due to max_output_token limits. Hypotheses about premature EOS tokens spark discussions on dataset configurations.
- Windows Woes: Unsloth Users Wrestle with Embeddings: Users grapple with using input embeddings over IDs and face module errors on Windows, prompting suggestions to switch to WSL or Linux, per the Unsloth Notebooks guide.
- PDFs Prove Perplexing for Model Fine-Tuning: Members consider fine-tuning models with an 80-page PDF of company regulations but debate shifting to RAG methods due to challenges in data extraction and relevance.
Theme 4. Communities Collaborate, Commiserate, and Celebrate
- Prompt Hackers Unite in Weekly Study Group: Enthusiasts kick off a weekly study group focusing on prompt hacking techniques, aiming to boost coding practices ahead of hackathons and fostering collaborative learning.
- Perplexity Pro Users Bond Over Glitches and Grit: Perplexity Pro users face feature hiccups, including lost prompts and search issues, leading to shared experiences and collective troubleshooting efforts within the community.
Theme 5. Ethical Quarrels and Governance Grumbles in AI Land
- ChatGPT as Plagiarism Police? Educators Sound Off: Attempts to configure ChatGPT as a plagiarism checker ignite debates over the ethical implications and reliability of using AI for academic integrity tasks.
- Mojo's Type Confusion Leaves Developers Scratching Heads: Discussions around Mojo's type system reveal confusion between
objectandPyObject, raising concerns about dynamic typing handling and potential thread safety issues. - Notebook LM's Language Flip-Flops Frustrate Users: While some celebrate Notebook LM's new multilingual support, others express frustration over unwanted language switches in summaries, impacting usability and leading to calls for improved language control features.
PART 1: High level Discord summaries
Cursor IDE Discord
-
Cursor's Context Mode Removal: Users are frustrated with the recent removal of the long context mode in Cursor, especially the claude-3.5-200k version, disrupting their workflow.
- Some speculate that transitioning to an agent-based model may enhance context retrieval, whereas others are unhappy with the loss of previous functionalities.
- Agent Feature Challenges: Several users report issues with the agent feature in Cursor, noting unresponsive behavior and unexpected task outcomes.
- There's notable interest in implementing auto-approving agent tasks to streamline functionality.
- Cursor Development Initiatives: Developers are leveraging Cursor to build innovative projects, such as an AI-driven dating app and a dog breed learning website.
- The community actively shares ideas on potential Cursor applications, blending both personal and professional project endeavors.
- Cursor vs Windsurf Performance: Users are debating the performance and utility of Cursor versus Windsurf, seeking insights into which tool better serves developers.
- While some prefer Cursor for its capabilities, others advocate for Windsurf due to specific functionalities or personal experiences.
- Cursor Updates and User Support: There are frequent inquiries about updating to the latest Cursor version and accessing its new features, with users sharing resources and tips.
- Community members assist each other in troubleshooting issues and navigating recent changes introduced by updates.
aider (Paul Gauthier) Discord
-
Qwen 2.5 Coder Performance Confusion: Users expressed confusion over the Qwen 2.5 Coder performance, noting discrepancies in benchmark results between different providers and local setups.
- Testing with varying configurations revealed significant performance variations, prompting users to adjust models and settings for improved outcomes.
- Challenges with Local Models: Users reported difficulties running local models with Ollama, indicating poorer performance compared to cloud-hosted versions.
- The conversation highlighted the need for better configurations and suggested alternatives for running Aider models locally.
- Team Account Pricing at $30/month: The team account is priced at $30 per month, allowing for 140 O1 requests weekly and unlimited requests for other models.
- This upgrade offers increased request limits and greater flexibility in model usage, enhancing team capabilities.
- Introduction of Model Context Protocol: Anthropic announced the open-sourcing of the Model Context Protocol (MCP), a standard designed to connect AI assistants to various data systems.
- The protocol aims to replace fragmented integrations with a single universal standard, improving AI's access to essential data.
- Understanding Benchmark
error_outputs: Members inquired about the meaning oferror_outputsin benchmark results, questioning if it reflects model errors or API/network issues.
- It was clarified that this indicates errors were printed, often TimeoutErrors, and Aider will retry these occurrences.
HuggingFace Discord
-
Challenges Accessing Gated Llama-2-7b Models: Users reported difficulties in accessing gated models like meta-llama/Llama-2-7b, encountering errors related to missing files and permissions.
- Feedback included user frustration over access rejections and suggestions for using alternative, ungated models to bypass these restrictions.
- Saplings Tree Search Library: Saplings is a library designed to build smarter AI agents using an easy tree search algorithm, streamlining the creation of efficient AI agents.
- The project aims to enhance AI agent performance, with community members discussing implementation strategies and potential use cases.
- Decentralized Model Storage on Filecoin: Users are adopting Filecoin for decentralized storage of AI models, noting that storage costs have become reasonable, with nearly 1TB stored.
- This approach allows models to be fetched freely after a one-time write, improving accessibility and censorship-resistance.
- SenTrEv Sentence Transformers Evaluator: SenTrEv is a Python package for customizable evaluation of Sentence Transformers-compatible text embedders on PDF data, providing detailed accuracy and performance metrics.
- Comprehensive details are available in their LinkedIn post and the GitHub repository.
- HuggingFace TOP 300 Trending Board: The HuggingFace Trending TOP 300 Board features a dashboard for trending Spaces, Models, and Datasets.
- Key features include an AI Rising Rate and an AI Popularity Score that assess the growth potential and popularity of listed items.
Unsloth AI (Daniel Han) Discord
-
Fine-tuning Models with Unsloth: A member inquired about fine-tuning models to interact with JSON data on Bollywood actors, and others directed them to Unsloth Notebooks for user-friendly resources.
- It was suggested that using RAG could simplify the process for engaging with their scraped data, enhancing the fine-tuning workflow.
- MergeKit for Model Merging: A member recommended using MergeKit from Arcee to effectively merge pretrained large language models, aiming to improve instructional model performance.
- MergeKit provides tools for merging pretrained LLMs, as highlighted in its GitHub page.
- Shift to Multi-task Models from BERT: Discussions covered transitioning from single-task architectures like BERT, which required separate classification heads, to multi-task models such as T5 and decoder-only architectures that integrate text generation capabilities.
- This shift enables models to perform all of BERT's functions alongside text generation, streamlining model usage across tasks.
- RAG Strategy for Hybrid Retrieval: A member advocated for a RAG approach with hybrid retrieval, drawing from experience with over 500 PDFs in specialized domains like chemical R&D.
- They confirmed that this method enhances Q&A generation, even in niche fields, leveraging robust retrieval mechanisms.
- Using Embeddings in LLMs: A user sought to use input embeddings instead of input IDs when generating text with LLMs on Hugging Face, prompting discussions on the differences between embedding and tokenization.
- They were directed to example implementations in the shared Google Colab Notebook, facilitating better understanding of embedding usage.
Modular (Mojo 🔥) Discord
-
Mojo Type System Overhaul: Members discussed Mojo's type system confusions, highlighting the split between object and PyObject; PyObject maps directly to CPython types, while object may require reworking for clarity.
- Concerns were raised about dynamic typing handling and how type merging affects thread safety.
- Closure Syntax Clarity in Mojo: Participants explained that the syntax
fn(Params) capturing -> Typedenotes a closure in Mojo, with discussions on how function types are determined by origin, arguments, and return type.
- There was a comparison to Rust's indirection approaches in capturing closures.
- Vectorization vs Unrolling Tactics: Discussions compared @unroll and @parameter, noting both allow the system to find parallelism but offer different control levels.
- The consensus favored vectorize and @parameter for their richer functionality over simply using @unroll.
- Mojo's Python Superset Ambitions: Mojo aims to become a superset of Python over time, initially focusing on systems programming and AI performance features before fully supporting dynamic typing.
- GitHub issue #3808 indicates that achieving full Python compatibility is complicated by existing dynamic typing and language ergonomics issues.
- Memory Optimization in Mojo: A user shared their experience of porting a QA bot from Python to Mojo, highlighting significant memory usage reductions from 16GB to 2GB.
- Despite encountering segmentation faults during the porting process, the performance improvements enable faster research iterations.
OpenRouter (Alex Atallah) Discord
-
AI Commit Command Launches: A new CLI tool called
cmaiwas introduced to generate commit messages using the OpenRouter API with Bring Your Own Key (BYOK) functionality.- This open-source command aims to simplify the commit message process, encouraging contributions from the developer community.
- Toledo1 AI Adopts Pay-Per-Question Model: Toledo1 offers a novel AI chat experience featuring a pay-per-question model and the capability to combine multiple AIs for customized responses.
- Users can access the demo at toledo1.com and integrate the service seamlessly through its native desktop application.
- Hermes Enhancements Boost llama3.c Performance: Modifications to
llama3.cachieved an impressive 43.44 tok/s in prompt processing, surpassing other implementations utilizing Intel's MKL functions.
- The performance improvements stemmed from using local arrays for matrix calculations, significantly enhancing processing speed.
- OpenRouter API Faces Rate Limit Concerns: Discussions revealed potential rate limit issues with the OpenRouter API, although some responses indicated the existence of private agreements that offer flexibility.
- The variability in contract terms highlights OpenRouter's customized approach to partnerships with its providers.
- Gemini 1.5 Model Encounters Downtime: Users reported receiving empty responses from the Gemini 1.5 model, leading to speculation about its operational status.
- However, confirmations from some users suggest that the issue might be isolated to specific setups.
OpenAI Discord
-
ChatGPT as Plagiarism Detector: Users explored configuring ChatGPT to function as a plagiarism checker with a specific JSON output structure for academic assessments.
- However, concerns were raised regarding the ethical implications and reliability of using AI for detecting academic dishonesty.
- Positive Feedback on GPT-4o Version: The
openai/gpt-4o-2024-11-20release received admiration from members, highlighting its impressive performance.
- Users noted that GPT-4o offers enhanced capabilities, making it a preferable choice within the community.
- Integrating Custom GPT with Vertex: A member inquired about the feasibility of connecting their custom GPT model with Vertex, prompting guidance from others.
- Responses included references to OpenAI’s documentation on actions, indicating available resources for integration.
- Real-time API Use in Multimedia AI: Discussions focused on the application of real-time APIs in multimedia AI, particularly for voice recognition requiring low latency.
- Members clarified that real-time refers to processes occurring instantaneously, relevant for categorizing multimedia content.
- Memory Capabilities in AI Agents: Participants highlighted the importance of memory management in AI agents, referencing chat history and contextual understanding.
- Encouragement was given to explore OpenAI’s documentation for better leveraging memory frameworks in AI functionalities.
Perplexity AI Discord
-
Chatbot Models: Claude vs. Sonnet 3.5 vs GPT-4o: Members debated the strengths of different chatbot models, noting that Claude delivers superior outputs while Sonnet 3.5 adds more personality for academic writing. There was also interest in GPT-4o for its creative task capabilities.
- Discussions highlighted the trade-offs between output quality and personality, with some users advocating for Claude's reliability and others preferring Sonnet 3.5's engaging responses.
- Amazon Invests $4B in Anthropic: Amazon announced a substantial $4 billion investment in Anthropic, signaling strong confidence in advancing AI technologies. This funding is expected to accelerate Anthropic's research and development efforts.
- The investment aims to bolster Anthropic's capabilities in creating more reliable and steerable AI systems, fostering innovation within the AI engineering community.
- API Updates Affect Llama-3.1 Functionality: Recent API changes have impacted the functionality of llama-3.1 models, with users reporting that certain requests now return instructions instead of relevant search results. The supported models section currently only lists the three online models under pricing.
- Users noted that despite these issues, no models have been disabled yet, providing a grace period to transition as no updates are reflected in the changelog.
- Perplexity Pro Users Face Feature Issues: Several members reported issues with Perplexity Pro, particularly the online search feature, leading one user to suggest contacting support. Additionally, refreshing sessions caused loss of long prompts, raising concerns about website stability.
- These stability issues highlight the need for improvements in the platform's reliability to enhance user experience for AI Engineers relying on these tools.
- Best Black Friday VPS Deals Revealed: Members shared insights on the best Black Friday VPS deals, mentioning significant discounts such as a 50% discount on You.Com. These deals are expected to offer substantial savings for tech enthusiasts during the holiday season.
- The discussions also compared the effectiveness of various services, indicating diverse user experiences and preferences in selecting VPS providers.
LM Studio Discord
-
Limited Model Search in LM Studio: After updating to version 0.3.5, users report that the model search functionality in LM Studio is now limited, leading to confusion about available updates.
- Since version 0.3.3, the default search only includes downloaded models, causing users to potentially miss out on new models unless manually searched.
- Uploading Documents for LLM Context: Users inquired about uploading documents to enhance LLM contexts, receiving guidance on supported file formats like
.docx,.pdf, and.txtwith the 0.3.5 update.
- Official documentation was provided, emphasizing that document uploads can significantly improve LLM interactions.
- GPU Compatibility and Power Requirements in LM Studio: Discussions confirmed that LM Studio supports a wide range of GPUs, including the RX 5600 XT, utilizing the effective llama.cpp Vulkan API.
- For high-end builds featuring GPUs like the 3090 and CPUs like the 5800x3D, members recommended a power supply unit (PSU) with approximately 80% of its capacity as a buffer.
- Soaring GPU Prices: Members expressed frustration over the skyrocketing GPU prices, particularly for models like the Pascal series, deeming them as barely performing and resembling e-waste.
- The community agreed that current pricing trends are unsustainable, leading to overpayments for high-performance GPUs.
- PCIe Configurations Impact Performance: PCIe revisions were discussed in relation to LM Studio, with members noting that they primarily affect model loading times rather than inference speeds.
- It was clarified that using PCIe 3.0 does not hinder inference performance, making bandwidth considerations less critical for real-time operations.
Eleuther Discord
-
Type Checking in Python: Members discussed the challenges with type hinting in Python, highlighting that libraries like wandb lack sufficient type checks, complicating integration.
- A specific mention was made of unsloth in fine-tuning, with members expressing more leniency due to its newer status.
- Role-Play Project Collaboration: The Our Brood project was shared, focusing on creating an alloparenting community with AI agents and human participants running 24/7 for 72 hours.
- The project lead is seeking collaborators to set up models and expressed eagerness for further discussions with interested parties.
- Reinforcement Learning in State-Space Models: A discussion about updating the hidden state in state-space models using Reinforcement Learning suggested teaching models to predict state updates through methods resembling truncated backpropagation through time.
- One member proposed fine-tuning as a strategy to enhance learning robotic policies for models.
- Learning on Compressed Text for LLMs: Members highlighted that training large language models (LLMs) on compressed text significantly impacts performance due to challenges with non-sequential data.
- They noted that maintaining relevant information while compressing sequential relationships could facilitate more effective learning, as discussed in Training LLMs over Neurally Compressed Text.
- YAML Self-Consistency Voting: A member confirmed that the YAML file specifies self-consistency voting across all task repeats and inquired about obtaining the average fewshot CoT score without listing each repeat explicitly.
- Another member noted the complexity due to independent filter pipelines affecting the response metrics.
Nous Research AI Discord
-
Custom Quantization in Llama.cpp: A pull request for custom quantization schemes in Llama.cpp was proposed, allowing more granular control over model parameters.
- The discussion emphasized that critical layers could remain unquantized, while less important layers might be quantized to reduce model size.
- LLM Puzzle Evaluation: A river crossing puzzle was evaluated with two solutions focusing on the farmer's actions and the cabbage's fate, revealing that LLMs often misinterpret such puzzles.
- Feedback indicated that models like deepseek-r1 and o1-preview struggle with interpreting the puzzle correctly, echoing challenges faced by humans in reasoning under constraints.
- Anthropic's Model Developments: Anthropic continues advancing their models, positioning themselves for custom fine-tuning and model improvements, as referenced in the Model Context Protocol.
- There is a growing focus on enhancing model capabilities through structured approaches, as discussed in the community.
- Hermes 3 Overview: A user requested a summary on how Hermes 3 differs from other LLMs, leading to the sharing of Nous Research's Hermes 3 page.
- An LLM specialist expressed interest in Nous Research, highlighting increased engagement from experts towards emerging models like Hermes 3.
Notebook LM Discord Discord
-
Convert Notes to Source Feature: NotebookLM introduces the 'Convert notes to source' feature, allowing users to transform their notes into a single source or select notes manually, with each note separated by dividers and named by date.
- This feature enables enhanced interaction with notes using the latest chat functionalities and serves as a backup method, with an auto-update feature slated for 2025.
- Integration with Wondercraft AI: Notebook LM integrates with Wondercraft AI to customize audio presentations, enabling users to splice their own audio and manipulate spoken words.
- While this integration enhances audio customization capabilities, users have noted some limitations regarding free usage.
- Commercial Use of Podcasts: Discussions confirm that content generated via Notebook LM can be commercially published, as users retain ownership of the generated podcasts.
- Members are exploring monetization strategies such as sponsorships and affiliate marketing based on this content ownership.
- Hyper-Reading Blog Insights: A member shared a blog post on 'Hyper-Reading', detailing a modern approach to reading non-fiction books by leveraging AI to enhance learning.
- The blog outlines steps like acquiring books in textual formats and utilizing NotebookLM for improved information retention.
- Language Support in Notebook LM: Notebook LM now supports multiple languages, with users successfully operating it in Spanish and encountering issues with Italian summarizations.
- Users emphasized the need for ensuring AI-generated summaries are in the desired language to maintain overall usability.
Interconnects (Nathan Lambert) Discord
-
Optillm outperforms o1-preview with Chain-of-Code: Using the Chain-of-Code (CoC) plugin, Optillm surpassed OpenAI's o1-preview on the AIME 2024 benchmark.
- Optillm leveraged SOTA models from @AnthropicAI and @GoogleDeepMind, referencing the original CoC paper.
- Google consolidates research talent: Google is speculated to have acquired all their researchers, including high-profile figures like Noam and Yi Tay.
- If true, it highlights Google's strategy to enhance their capabilities by consolidating top talent.
- Reka acquisition rumors with Snowflake: There were rumors of Reka being acquihired by Snowflake, but the deal did not materialize.
- Nathan Lambert expressed dismay about the failed acquisition attempt.
- GPT-4 release date leaked by Microsoft exec: A Microsoft executive leaked the GPT-4 release date in Germany, raising concerns about insider information.
- This incident highlights the risks associated with insider leaks within tech organizations.
- Reasoners Problem and NATO discussions: The Reasoners Problem was discussed, highlighting its implications in AI research.
- A brief mention of NATO in the context of technology or security suggests broader tech landscape implications.
Cohere Discord
-
Command R Fine-tuning Challenges: A member reported that the fine-tuned Command R model's output stops prematurely due to reaching the max_output_token limit during generation.
- Another member suggested that the EOS token might be causing the early termination and requested dataset details for further investigation.
- Cohere API Output Inconsistencies: Users are experiencing incomplete responses from the Cohere API, whereas integrations with Claude and ChatGPT are functioning correctly.
- Despite multiple attempts with different API calls, the issues with incomplete content persist, indicating potential underlying API limitations.
- Deploying Cohere API on Vercel: A developer encountered 500 errors related to client instantiation while deploying a React application using the Cohere API on Vercel.
- They noted that the application functions correctly with a separate server.js file locally, but faced challenges configuring it to work on the Vercel platform.
- Batching and LLM as Judge Approach: A member shared their approach using batching plus LLM as a judge and sought feedback on fine-tuning consistency, highlighting hallucination issues with the command-r-plus model.
- In response, another member proposed the use of Langchain in a mass multi-agent setup to potentially address the observed challenges.
- Suggestions for Multi-Agent Setups: A member recommended exploring a massively multi-agent setup when implementing the batching approach with LLM as judge.
- They also inquired whether the 'judge' role was simply to pass or fail after analysis, seeking clarity on its functionality.
Stability.ai (Stable Diffusion) Discord
-
Beginners Seek Learning Resources: New users are struggling with image creation and are seeking beginner guides to effectively navigate the tools.
- One suggestion emphasized watching beginner guides as they provide a clearer perspective for newcomers.
- ControlNet Upscaling in A1111: A member inquired about enabling upscale in A1111 while utilizing ControlNet features like Depth.
- Another member cautioned against direct messages to avoid scammers, directing the original poster to the support channel instead.
- Buzzflix.ai for Automated Video Creation: A member shared a link to Buzzflix.ai, which automates the creation of viral faceless videos for TikTok and YouTube.
- They expressed astonishment at its potential to grow channels to millions of views, noting it feels like a cheat.
- Hugging Face Website Confusion: Members conveyed confusion regarding the Hugging Face website, particularly the lack of an 'about' section and pricing details for models.
- Concerns were raised about the site's accessibility and usability, with suggestions for better documentation and user guidance.
- Spam Friend Requests Concerns: Users reported receiving suspicious friend requests, suspecting they may be spam.
- The conversation elicited lighthearted responses, but many expressed concern over the unsolicited requests.
GPU MODE Discord
-
Grouped GEMM struggles with fp8 speedup: A member reported that they couldn't achieve a speedup with fp8 compared to fp16 in their Grouped GEMM example, necessitating adjustments to the strides.
- They emphasized setting B's strides to (1, 4096) and providing both the leading and second dimension strides for proper configuration.
- Triton and TPU compatibility: Another member inquired about the compatibility of Triton with TPUs, indicating an interest in utilizing Triton's functionalities on TPU hardware.
- The discussion points to potential future development or community insights regarding Triton's performance on TPU setups.
- CUDA simulations yield weird results without delays: A user observed that running CUDA simulations in quick succession results in weird outcomes, but introducing a one-second delay mitigates the issue.
- This behavior was noted during the inspection of random process performance.
- Torchao shines in GPTFast: The discussion centered around the potential of Torchao being integrated with GPTFast, possibly leveraging Flash Attention 3 FP8.
- Members expressed interest in this integration and its implications for efficiency.
- Understanding Data Dependency in Techniques: A member queried the meaning of data dependent techniques in the context of their necessity for fine-tuning during or after sparsification calibration.
- This sparked a discussion on the implications of such techniques on performance and accuracy.
tinygrad (George Hotz) Discord
-
Integrating Flash-Attention into tinygrad: Flash-attention was proposed for incorporation into tinygrad to enhance attention mechanism efficiency.
- A member raised the possibility of integrating flash-attention, although the discussion did not cover implementation specifics.
- Expanding Operations in nn/onnx.py: Discussions were held on adding instancenorm and groupnorm operations to nn/onnx.py, aiming to extend functionality.
- Concerns were voiced about the increasing complexity of ONNX exclusive modes and the inadequate test coverage for these additions.
- Implementing Symbolic Multidimensional Swap: Guidance was sought on performing a symbolic multidimensional element swap using the
swap(self, axis, i, j)method to manipulate views without altering the underlying array.
- The proposed notation for creating axis-specific views highlighted the need for clarity in execution strategies.
- Developing a Prototype Radix Sort Function: A working radix sort prototype was presented, efficiently handling non-negative integers with potential optimizations suggested.
- Questions were raised about extending the sort function to manage negative and floating-point values, with suggestions to incorporate scatter operations.
- Assessing Kernel Launches in Radix Sort: An inquiry was made into methods for evaluating the number of kernel launches during radix sort execution, considering debug techniques and big-O estimations.
- Debates emerged on the benefits of in-place modification versus input tensor copying prior to kernel execution for efficiency purposes.
LLM Agents (Berkeley MOOC) Discord
-
Compute Resources Deadline Today: Teams must submit the GPU/CPU Compute Resources Form by the end of today via this link to secure necessary compute resources for the hackathon.
- This deadline ensures that resource allocation is managed efficiently, allowing teams to proceed with their projects without delays.
- Lecture 11: AI Safety with Benjamin Mann: The 11th lecture features Benjamin Mann discussing Responsible Scaling Policy, AI safety governance, and Agent capability measurement, streamed live here.
- Mann will share insights from his time at OpenAI on measuring AI capabilities while maintaining system safety and control.
- Weekly Prompt Hacking Study Group: A weekly study group has been initiated to focus on prompt hacking techniques, with sessions starting in 1.5 hours and accessible via this Discord link.
- Participants will explore practical code examples from lectures to enhance their coding practices for the hackathon.
- GSM8K Test Set Cost Analysis: An analysis reveals that one inference run on the GSM8K 1k test set costs approximately $0.66 based on current GPT-4o pricing.
- Additionally, implementing self-correction methods could increase output costs proportional to the number of corrections applied.
Axolotl AI Discord
-
PDF Fine-Tuning Inquiry: A member inquired about generating an instruction dataset for fine-tuning a model using an 80-page PDF containing company regulations and internal data.
- They specifically wondered if the document's structure with titles and subtitles could aid in processing with LangChain.
- Challenges in PDF Data Extraction: Another member suggested checking how much information could be extracted from the PDF, noting that some documents—especially those with tables or diagrams—are harder to read.
- Extracting relevant data from PDFs varies significantly depending on their layout and complexity.
- RAG vs Fine-Tuning Debate: A member shared that while fine-tuning a model with PDF data is possible, using Retrieval-Augmented Generation (RAG) would likely yield better results.
- This method provides an enhanced approach for integrating external data into model performance.
LlamaIndex Discord
-
AI Tools Survey Partnership Kicks Off: A partnership with Vellum AI, FireworksAI HQ, and Weaviate IO has launched a 4-minute survey about the AI tools used by developers, with participants entering to win a MacBook Pro M4.
- The survey covers respondents' AI development journey, team structures, and technology usage, accessible here.
- RAG Applications Webinar Scheduled: Join MongoDB and LlamaIndex on December 5th at 9am Pacific for a webinar focused on transforming RAG applications from basic to agentic.
- Featuring Laurie Voss from LlamaIndex and Anaiya Raisinghani from MongoDB, the session will provide detailed insights.
- Crypto Startup Seeks Angel Investors: A member announced their cross-chain DEX startup based in SF is looking to raise a Series A round and connect with angel investors in the crypto infrastructure space.
- They encouraged interested parties to HMU, signaling readiness for investment discussions.
- Full-Stack Engineer Seeks Opportunities: An experienced Full Stack Software Engineer with over 6 years in web app development and blockchain technologies is seeking full-time or part-time roles.
- They highlighted proficiency in JavaScript frameworks, smart contracts, and various cloud services, eager to discuss potential team contributions.
Torchtune Discord
-
Custom Reference Models' Impact: A member opened an issue regarding the impact of custom reference models, suggesting it's time to add this consideration.
- They highlighted these models' potential effectiveness in the current context.
- Full-Finetune Recipe Development: A member expressed the need for a full-finetune recipe, acknowledging that none currently exist.
- They proposed modifying existing LoRA recipes to support this approach, advocating for caution due to the technique's newness.
- Pip-extra Tools Accelerate Development: Integrating pip-extra tools, pyenv, and poetry results in a faster development process with efficient bug fixes.
- However, some expressed skepticism about poetry's future design direction compared to other tools.
- Rust-like Features Appeal to Developers: The setup is similar to cargo and pubdev, catering to Rust developers.
- This similarity highlights the convergence of tools across programming languages for package and dependency management.
- uv.lock and Caching Boost Efficiency: Utilizing uv.lock and caching enhances the speed and efficiency of project management.
- These features streamline workflows, ensuring common tasks are handled more swiftly.
DSPy Discord
-
Synthetic Data Paper Sought: A member requested a paper to understand how synthetic data generation works.
- This reflects an increasing interest in the principles of synthetic data and its applications.
- Implications of Synthetic Data Generation: The request indicates a deeper exploration into data generation techniques is underway.
- Members noted the importance of understanding these techniques for future projects.
LAION Discord
-
Collaborating with Foundation Model Developers: A member is seeking foundation model developers for collaboration opportunities, offering over 80 million tagged images available for potential projects.
- They also highlighted providing thousands of niche photography options on demand, presenting a valuable resource for developers in the foundation model space.
- Niche Photography Services On Demand: A member is offering thousands of niche photography options on demand, indicating a resource for model training and development.
- This service presents a unique opportunity for developers within the foundation model domain to enhance their projects.
Mozilla AI Discord
-
Lumigator Tech Talk Enhances LLM Selection: Join engineers for an in-depth tech talk on Lumigator, a powerful open-source tool designed to help developers choose the best LLMs for their projects, with a roadmap towards General Availability in early 2025.
- The session will showcase Lumigator's features, demonstrate real-world usage scenarios, and outline the planned roadmap targeting early 2025 for broader availability.
- Lumigator Advances Ethical AI Development: Lumigator aims to evolve into a comprehensive open-source product that supports ethical and transparent AI development, addressing gaps in the current tooling landscape.
- The initiative focuses on creating trust in development tools, ensuring that solutions align with developers' values.
AI21 Labs (Jamba) Discord
-
Confusion Over API Key Generation: A member expressed frustration regarding API key generating issues on the site, questioning if they were making a mistake or if the issue was external.
- They sought clarification on the reliability of the API key generation process from community members.
- Request for Assistance on API Key Issues: The member prompted others for insights into potential problems with the site's API key generation functionality.
- Some participants voiced their experiences, suggesting that the issue might be temporary or linked to specific configurations.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The OpenInterpreter Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Cursor IDE ▷ #general (706 messages🔥🔥🔥):
Cursor updates, Agent feature comparisons, Long context mode removal, User experiences with Cursor, Freelancing and project ideas
-
Frustrations with Cursor Updates: Users are expressing frustration over the recent removal of the long context mode in Cursor, particularly the claude-3.5-200k version, and its impact on their workflow.
- Some speculate the move towards an agent-based model may streamline context retrieval, but others are unhappy about the disruption to previous functionalities.
- Challenges with Agent Functionality: Several users report issues with the agent feature, particularly regarding unresponsive behavior or tasks not generating as expected.
- There is interest in auto-approving agent tasks, indicating a desire for more streamlined functionality.
- Development Projects Explained: Developers are using Cursor to build various projects, including a dating app using AI for matching and a dog breed website for learning purposes.
- The community is sharing ideas about potential applications for Cursor, highlighting a mix of personal and professional projects.
- Comparing Cursor and Windsurf: Users are debating the strengths of Cursor versus Windsurf, seeking insights on which tool provides better performance and utility for developers.
- While some users find Cursor superior for its capabilities, others lean towards Windsurf due to specific functionalities or experiences.
- Updates and User Support: Inquiries about updating to the latest version of Cursor and accessing its new features are common, with users sharing resources and tips.
- Community members assist each other in troubleshooting issues and navigating recent changes introduced by the latest updates.
Links mentioned:
- Cursor's NEW *Agent* Composer: The WORST Coding AGENT that I HAVE EVER SEEN (Beats Cline & Cascade?): Join this channel to get access to perks:https://www.youtube.com/@aicodeking/joinIn this video, I'll be telling you about Cursor's New Agent Composer feature...
- Cursor - The IDE designed to pair-program with AI.: no description found
- Cursor - The IDE designed to pair-program with AI.: no description found
- v0 by Vercel: Chat with v0. Generate UI with simple text prompts. Copy, paste, ship.
- Tweet from Chubby♨️ (@kimmonismus): Cursor Composer Agent reading project files. Agents are on the rise, brace yourself.
- Tweet from Ray Fernando (@RayFernando1337): 9 Cursor agents 🚀🚀 I clearly don’t cook like @StijnSmits Quoting Ray Fernando (@RayFernando1337) I think this boi unlocked a Cursor cheat code 👀
- Bring It Back Booger Brown GIF - Bring It Back Booger Brown The Cowboy Way - Discover & Share GIFs: Click to view the GIF
- Tweet Grid: A masonry grid full of tweets
- Pepsi King Can GIF - Pepsi King can Soda - Discover & Share GIFs: Click to view the GIF
- This Is Very Accurate Chris Evans GIF - This Is Very Accurate Chris Evans Esquire - Discover & Share GIFs: Click to view the GIF
- 4.3 — blender.org: Home of the Blender project - Free and Open 3D Creation Software
- no title found: no description found
- Cursor - Build Software Faster: no description found
- How to update to nightly?: Can’t seem to find where and how to update to the nightly build. Looked at the website and searched in the IDE itself … without any success.
- anime.js: Javascript animation engine
- ui-layout: Beautifully designed components that you can copy and paste into your apps. Accessible. Customizable. Open Source.
- Component Packs: Beautiful Tailwind CSS and Framer Motion Components
- Cursor - The IDE designed to pair-program with AI.: no description found
- no title found: no description found
aider (Paul Gauthier) ▷ #general (417 messages🔥🔥🔥):
Qwen 2.5 Coder Performance, Local Model Usage, Prompt Engineering with Aider, Aider Integration with Various Tools, Model Context Protocol
-
Qwen 2.5 Coder Performance Confusion: Users expressed confusion over the performance of the Qwen 2.5 Coder, noting discrepancies in benchmark results between different providers and local setups.
- Testing with different configurations revealed that results can vary significantly, prompting users to adjust models and settings for better outcomes.
- Challenges with Local Models: Users reported difficulties running local models with Ollama, indicating that they often perform poorly compared to cloud-hosted versions.
- The conversation highlighted the need for better configurations and suggested alternatives for running Aider models locally.
- Effective Prompt Engineering: Users shared tips on improving prompting techniques, with suggestions to watch specific videos to enhance effectiveness.
- The discussion centered around the importance of mastering prompting to leverage Aider capabilities fully.
- Tool Comparisons with Aider: Participants discussed using Aider alongside tools like Cursor and Windsurf, noting that Aider is useful for smaller tasks while Cursor is better for intensive coding work.
- Users also debated the effectiveness of different coding assistants, concluding that Copilot is less effective compared to premium options.
- Introduction of Model Context Protocol: A new standard called Model Context Protocol (MCP) was introduced to improve the connection between AI assistants and their data sources.
- This standard aims to streamline integrations, facilitating better access to data and enhancing the capabilities of AI models.
Links mentioned:
- Ollama: aider is AI pair programming in your terminal
- Tutorial videos: Intro and tutorial videos made by aider users.
- Introducing the Model Context Protocol: The Model Context Protocol (MCP) is an open standard for connecting AI assistants to the systems where data lives, including content repositories, business tools, and development environments. Its aim...
- Quantization matters: Open source LLMs are becoming very powerful, but pay attention to how you (or your provider) is quantizing the model. It can affect code editing skill.
- Aider UPDATED: The BEST Personal AI Coding Assistant! GPT-Engineer (Installation Guide): Welcome to a game-changing journey in coding with Aider, your ultimate AI pair programming companion! 🤖💻 In this video, we'll explore the incredible capabi...
- Advanced model settings: Configuring advanced settings for LLMs.
- GitHub - ag2ai/ag2: AG2 (formerly AutoGen): The Open-Source AgentOS. Join the community at: https://discord.gg/pAbnFJrkgZ: AG2 (formerly AutoGen): The Open-Source AgentOS. Join the community at: https://discord.gg/pAbnFJrkgZ - ag2ai/ag2
- GitHub - andrewyng/aisuite: Simple, unified interface to multiple Generative AI providers: Simple, unified interface to multiple Generative AI providers - GitHub - andrewyng/aisuite: Simple, unified interface to multiple Generative AI providers
- GitHub - circlemind-ai/fast-graphrag: RAG that intelligently adapts to your use case, data, and queries: RAG that intelligently adapts to your use case, data, and queries - circlemind-ai/fast-graphrag
- We made glhf.chat: run (almost) any open-source LLM, including 405b: Posted in r/LocalLLaMA by u/reissbaker • 87 points and 37 comments
- The AI startup drama that's damaging Y Combinator's reputation: A Y Combinator startup sparked a huge controversy almost immediately after launching. The bad PR eventually spread to YC itself.
- How do I install and use it? · Issue #2 · lee88688/aider-composer: no description found
aider (Paul Gauthier) ▷ #questions-and-tips (16 messages🔥):
Team Account Pricing, Weekly O1 Request Limits, In Chat Commands for Aider, Benchmark Error Outputs, File Screening with Language Models
-
Team Account Pricing at $30/month: To choose the team account, it costs $30 per month and allows for 140 O1 requests weekly, with unlimited requests for other models.
- This upgrade provides not just the increase in requests but also greater flexibility in model usage.
- Clarifying O1 Request Limits: Members originally speculated weekly limits for O1 requests, concluding that it is 140 requests per week, equal across accounts.
- Unlimited access for other models is an additional benefit of the team account configuration.
- No Current In-Chat Command for --yes-always: There is currently no in-chat command for toggling --yes-always, leaving users without that toggle option.
- This has been confirmed in discussions, with no workaround for this feature at the moment.
- Understanding Benchmark
error_outputs: Members inquired about the meaning oferror_outputsin benchmark results, questioning if it reflects model errors or API/network issues.
- It was clarified that this simply indicates that errors were printed, often in the form of TimeoutErrors, and Aider will retry these occurrences.
- Screening Files Using Language Models: A member sought a convenient method to screen files for HTTP requests to determine which should be added to aider.
- Another suggested using the
/runcommand with a grep command for effective screening, offering a potential workaround.
aider (Paul Gauthier) ▷ #links (5 messages):
Model Context Protocol, Data Integration, MCP Server for Git
-
Open-Sourcing the Model Context Protocol: Today, Anthropic announced the open-sourcing of the Model Context Protocol (MCP), a standard designed to connect AI assistants to various data systems like content repositories and business tools.
- This protocol aims to replace fragmented integrations with a single universal standard, enhancing AI's access to essential data.
- Discussion on MCP's Relevance: Members expressed interest in the MCP, noting that it could significantly impact AI's ability to produce relevant responses by breaking down information silos.
- Very interesting, yes, added a member, indicating a positive reception to the new standard's potential.
- Lack of Prebuilt MCP Server for Git: A member raised a concern regarding the absence of a prebuilt MCP server for Git, stating they were unable to find it in the GitHub repo.
- This led to speculation about whether the
aiderproject might be interested in such a server, highlighting a gap in available resources.
Links mentioned:
- Introducing the Model Context Protocol: The Model Context Protocol (MCP) is an open standard for connecting AI assistants to the systems where data lives, including content repositories, business tools, and development environments. Its aim...
- GitHub - modelcontextprotocol/servers: Model Context Protocol Servers: Model Context Protocol Servers. Contribute to modelcontextprotocol/servers development by creating an account on GitHub.
HuggingFace ▷ #general (146 messages🔥🔥):
Model Accessibility Issues, Image Generation Services, Llama Model Errors, Inpainting Techniques, Use of Flux Models
-
Challenges with Gated Models: Several users encountered issues accessing gated models like meta-llama/Llama-2-7b, resulting in errors about missing files and permissions.
- One user expressed frustration after being rejected for access, while others provided recommendations for alternative, ungated models.
- Exploring Image Generation Services: A user is seeking cloud services for image generation that allow for checkpoint uploads, emphasizing low-cost plans with high output.
- Recommendations included using Ideogram for free images and Invoke-AI for local generation, with discussions on the importance of backup data for running applications.
- Errors in AI Libraries: A user faced ImportErrors related to missing libraries like SentencePiece while implementing the LlamaTokenizer.
- Suggestions were made to install the necessary libraries, reflecting common challenges in setting up AI models.
- Advancements in Inpainting Techniques: Discussion about the In-Context LoRA for enhancing image generation highlighted its potential to significantly improve output quality.
- Users praised the capabilities of Flux models in inpainting and mentioned new tools for regional prompting and customization.
- Thoughts on AI Models and Code: Users reflected on the humorous reality that much of coding relies on placeholder comments such as # insert your function here.
- One user humorously anticipated a future where AI models transparently admit their limitations, a sentiment shared among developers.
Links mentioned:
- Pricing: Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
- 8ball Bart Simpson GIF - 8Ball Bart Simpson Shaking - Discover & Share GIFs: Click to view the GIF
- Hugging Face – The AI community building the future.: no description found
- unsloth/llama-3-8b-Instruct · Hugging Face: no description found
- @luigi12345 on Hugging Face: "MinimalScrap Only Free Dependencies. Save it.It is quite useful uh.
HuggingFace ▷ #today-im-learning (3 messages):
Math and Architectures of Deep Learning, Generating with Input Embeddings, Machine Learning Resources
- Exploring Math in Deep Learning: A member shared insights from the book Math and Architectures of Deep Learning by Manning, noting it goes deep into the underlying mathematics. - They mentioned being about 10% through it and found it quite extensive. - Using Input Embeddings in LLMs: A member inquired whether it's possible to use input embeddings instead of input IDs when utilizing the generate function in an LLM on Hugging Face. - Their curiosity highlighted a potential area for pre-processing flexibility in model usage. - Searching for Free ML Learning Resources: A member is seeking recommendations for credible resources to learn machine learning, from fundamentals to advanced topics. - While they recognize the value of Andrew Ng's Coursera course, they prefer suggestions that are free of charge.
### HuggingFace ▷ #cool-finds (3 messages):
Saplings library, Docling for document preparation
- Saplings enhances AI agent tree search: Saplings is a library designed to build smarter AI agents using an easy tree search algorithm.
- This project aims to streamline the process of creating efficient AI agents.
- Docling preps documents for Generative AI: Docling is a tool that prepares your documents for Generative AI, making them ready for AI applications.
- This project is focused on assisting users in ensuring their documents are optimized for AI interaction.
- GitHub - DS4SD/docling: Get your documents ready for gen AI: Get your documents ready for gen AI. Contribute to DS4SD/docling development by creating an account on GitHub.
- GitHub - shobrook/saplings: Build smarter AI agents using tree search: Build smarter AI agents using tree search. Contribute to shobrook/saplings development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (9 messages🔥):
Discord Bot for Llama-3.1, HuggingFace Trending TOP 300 Board, Decentralized Storage on Filecoin, SenTrEv: Sentence Transformers Evaluator, AI Custom SaaS for Education
- Discord Bot for Custom Llama-3.1 Model: A member introduced a Discord bot that serves their custom Llama-3.1 model, which will be uploaded pending testing.
- Stay tuned for the model's release!
- HuggingFace's Trending Board Revealed: A link to the HuggingFace Trending TOP 300 Board was shared, showcasing a comprehensive dashboard for trending Spaces, Models, and Datasets.
- Key features include an AI Rising Rate and an AI Popularity Score, assessing growth potential and popularity.
- Data Storage Solutions on Filecoin: A user discussed storing models on Filecoin, a decentralized file storage network, noting the storage costs have become reasonable, with nearly 1TB stored.
- The decentralization allows models to be fetched freely after a one-time write, enhancing accessibility and censorship-resistance.
- Launch of SenTrEv for Text Evaluation: A member introduced SenTrEv, a python package for customizable evaluation of Sentence Transformers-compatible text embedders on PDF data, breaking down accuracy and performance.
- Detailed information can be found in their LinkedIn post and the GitHub repo.
- Custom SaaS Development for Education: A member revealed they are finalizing their education AI Custom SaaS utilizing innovative models.
- They also shared a video clip providing a sneak peek of the project.
- @openfree on Hugging Face: "🤗 HuggingFace Trending TOP 300 Board - Featuring AI Rating System 📊 Service…": no description found
- HuggingFace Trending Board - a Hugging Face Space by openfree: no description found
- GitHub - AstraBert/SenTrEv: Simple customizable evaluation for text retrieval performance of Sentence Transformers embedders on PDFs: Simple customizable evaluation for text retrieval performance of Sentence Transformers embedders on PDFs - AstraBert/SenTrEv
HuggingFace ▷ #NLP (9 messages🔥):
Multi-Vector Representation, Multi-Head Attention, Llama 2 Setup, Llama 3 Inference, Text Generation Frontends
- Llama 2 for Local Use: A new user asked for tips and tricks on how to play with Llama 2 locally, prompting various responses.
- Community members suggested following blogs and Git pages for practical use cases and noted the challenges that may arise.
- Llama 3 Code Examples for Inference: One member shared inference code examples for Llama 3 that should also work for Llama 2 models just by changing the model repo name: Hugging Face Documentation.
- They highlighted the capabilities of Llama 3 with a state-of-the-art performance that supports a wide range of use cases.
- Documentation as a Resource: Documentation on Hugging Face and model card repos were recommended as useful resources for inference scripts.
- These resources offer the necessary guidance for users new to working with LLMs.
- Chatting with LLMs via Frontends: If users are more interested in chatting with LLMs rather than programming, tools like Oobabooga's text generation web UI were suggested.
- Other platforms mentioned included Kobold and SillyTavern for further exploration.
Link mentioned: Llama3: no description found
HuggingFace ▷ #diffusion-discussions (1 messages):
vampy699: how are u 🙂
Unsloth AI (Daniel Han) ▷ #general (126 messages🔥🔥):
Support Dynamics in Community, Fine-tuning Models with Unsloth, Using Embeddings in LLMs, Troubleshooting Model Issues on Windows, Interacting with Fine-tuned Models
- Community Support Dynamics: Members discussed the importance of reciprocity in community support, noting that frequent question-askers should also contribute back once they acquire knowledge.
- One member emphasized the community honor system, where helping others is key to fostering a positive environment.
- Fine-tuning Models with Unsloth: A member inquired about fine-tuning models to interact with JSON data on Bollywood actors, and others directed them to user-friendly notebooks for beginners.
- It was suggested that using RAG could simplify the process for engaging with their scraped data.
- Using Embeddings in LLMs: A user sought clarification on whether they could pass input embeddings instead of input IDs when generating from an LLM on Hugging Face.
- They were informed that although embedding and tokenization differ, there might be examples in the provided Colab notebook.
- Troubleshooting Model Issues on Windows: Members discussed a reported 'no module found triton' error, suggesting that using WSL or Linux could resolve issues inherent to Windows.
- Links to a specific Windows guide in the Unsloth documentation were shared to assist with the troubleshooting.
- Interacting with Fine-tuned Models: A newcomer expressed confusion about how to interact with their fine-tuned model within Hugging Face after completing the fine-tuning process.
- They learned that the merged model represents the final product while the LORA model serves a different purpose.
- Google Colab: no description found
- Google Colab: no description found
- How does ChatGPT’s memory feature work?: Explanation of my favorite feature on ChatGPT
- Unsloth Notebooks | Unsloth Documentation: See the list below for all our notebooks:
Unsloth AI (Daniel Han) ▷ #off-topic (2 messages):
Model Merging, BERT model scaling, Language Model Architectures, MergeKit Tool
- MergeKit for Instruct Model Merging: A member suggested merging with a compatible instruct model could yield beneficial results, recommending the use of MergeKit from Arcee for this purpose.
- MergeKit provides tools for effectively merging pretrained large language models, as indicated by its GitHub page.
- BERT's Quest for Scaling Left Unanswered: A blog post was shared discussing the lingering questions surrounding why BERT, an effective model, hasn't been scaled up despite its success in the past.
- The author highlights inefficiencies in BERT's denoising objective, stating that only masked tokens contribute to the loss, which severely limits loss exposure and sample efficiency.
- Shift from BERT to Multi-task Models: The discussion covered the transition from single-task to multi-task architectures between 2018-2021, noting that BERT required separate classification heads for each task.
- Conversely, newer models like T5 and decoder-only architectures can perform all of BERT's functions alongside text generation capabilities.
- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.: Tools for merging pretrained large language models. - arcee-ai/mergekit
- What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives — Yi Tay: A Blogpost series about Model Architectures Part 1: What happened to BERT and T5? Thoughts on Transformer Encoders, PrefixLM and Denoising objectives
Unsloth AI (Daniel Han) ▷ #help (29 messages🔥):
Unsloth installation issues, Finetuning VLM models, QA dataset performance, Using WSL for Unsloth, Notebook compatibility errors
- Unsloth installation troubles persist: Users are facing ongoing difficulties with Unsloth installation, particularly on Windows, with discussions around using WSL as a potential solution.
- Multiple users noted that previous versions of Unsloth led to compatibility issues, and it has been tagged as an urgent bug by the developers.
- Finetuning VLM models and hardware requirements: There was a query about VRAM needs for finetuning VLM models, with T4 GPUs mentioned as potentially sufficient for mixed precision training.
- Experts suggest that although 40GB might work, for business as usual, users may want GPUs with around 48GB for bf16 training.
- Eval set performance expectations for finetuned models: A user inquired if their finetuned model would perform well on the hold-out set, noting concerns about unseen concepts in training data.
- Responses indicated a general consensus that performance might vary, highlighting the importance of relevant training data.
- Incompatibilities with saved pipelines: One user reported issues trying to merge and push their 4-bit model to Hugging Face, resulting in Colab crashing during the process.
- After troubleshooting, the original notebook was found to work fine, suggesting potential issues stemmed from user modifications.
- Group collaboration on shared issues: Users converged to address mutual problems, particularly focusing on model training and error troubleshooting, fostering a community-driven effort.
- By sharing experiences and solutions, they aimed to collectively navigate challenges with the Unsloth app and related technologies.
Link mentioned: Google Colab: no description found
Unsloth AI (Daniel Han) ▷ #research (3 messages):
Fine-tuning models with PDF data, RAG for Q&A generation
- Generating Instruction Dataset from PDF: A member inquired about how to create an instruction dataset from an 80-page PDF containing regulations and internal company information for fine-tuning a model for employees.
- Titles and subtitles in the PDF may be useful when processing with LangChain.
- Using LLMs for Q&A Pairs: Another member suggested feeding chunks of text to a language model (LLM) to generate Q&A pairs, proposing RAG as an alternative strategy.
- They expressed skepticism about the need for a dataset, advocating for a more straightforward solution.
- RAG Strategy for Hybrid Retrieval: A member recommended using a RAG approach with a hybrid retrieval strategy, citing experience with 500 PDFs in a specific domain.
- They confirmed that this method works well even for specialized fields such as chemical R&D.
Modular (Mojo 🔥) ▷ #general (28 messages🔥):
Mojo type system, Closure syntax and behavior, Vectorization in Mojo, Object type in Mojo, Changelog and documentation insights
- Mojo type system confusions: Multiple members discussed their confusions regarding the
object/PyObjectsplit, highlighting thatPyObjectis mapped directly to CPython types, whereasobjectmay require reworking for better clarity.- Concerns were raised about how dynamic typing is handled and the implications of merging types to ensure thread safety.
- Closure syntax explained: Members confirmed that the syntax
fn(Params) capturing -> Typedenotes a closure, with discussions about how function types are determined by origin, arguments, and return type.- There was mention of disambiguation of closures through captures, similar to Rust's indirection approaches.
- Vectorization and unrolling comparisons: Participants compared the functionalities of
@unrolland@parameter, with a note that both can allow the system to find parallelism but provide different levels of control.- The consensus leaned towards
vectorizeand@parameteroffering more richness compared to just using@unroll.
- The consensus leaned towards
- Changelog provides more clarity than docs: It was noted that the changelog-released file is more informative than the official documentation, leading to insights on missing features and modifications.
- Users are advised to track changes diligently, as functions like
@unrollhave transitioned into@parameter.
- Users are advised to track changes diligently, as functions like
- Concerns about the object type's future: A member highlighted that the
objecttype in Mojo is outdated and lacks investment, suggesting a need for significant rework.- This concern points to potential improvements in the language's handling of basic types for better usability.
Modular (Mojo 🔥) ▷ #mojo (125 messages🔥🔥):
Mojo and Python compatibility, Dynamic vs Static typing in Mojo, Memory management in Mojo, Use of structs vs classes in Mojo, Performance and utility of Mojo in AI
- Mojo's Path to Python Compatibility: Mojo aims to become a superset of Python over time, but currently focuses on systems programming and AI performance features before fully supporting dynamic typing.
- Internal discussions indicate that achieving full Python compatibility is complicated by existing issues in dynamic typing handling and language ergonomics.
- Dynamic Typing and Error Handling Challenges: Implementing dynamic typing in Mojo faces challenges related to ergonomic issues and the need to write extensive error handling for type conversions manually.
- This complexity arises from needing to manage type systems that may lead to performance reductions while ensuring errors are appropriately handled during conversions.
- Difference Between Structs and Classes: In Mojo, structs are designed for static typing similar to C++, while classes allow for more dynamic behavior and support features like member function swapping.
- This distinction raises questions about how Mojo plans to implement member function manipulation within the safety of its compile-time mechanisms.
- Memory Management Improvements in Mojo: A user shared their experience of porting a QA bot from Python to Mojo, highlighting significant memory usage reductions from 16GB to 2GB.
- Despite experiencing some segmentation faults during the porting process, the performance improvements allow for faster research iterations.
- Community and Modular's Internal Development: Contributors discussed the balance between catering to Python developers and focusing on building a robust systems-level language as the foundation for Mojo.
- The evolving language features are critical for gaining investor interest while simplifying user experience for both hardcore system developers and Python coders.
- Drop - Rust By Example: no description found
- Rust Playground: no description found
- Undroppable Types: no description found
- [Docs] main branch still refers to mojo as a "superset of Python" · Issue #3808 · modularml/mojo: Where is the problem? https://github.com/modularml/mojo/blob/main/README.md What can we do better? Backport cb307d0 to the main branch. Anything else? No response
- GitHub - modularml/mojo: The Mojo Programming Language: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
- Compiler Explorer - Rust (rustc 1.82.0): struct Pair { s1: String, s2: String } impl Drop for Pair { fn drop(&mut self) { } } fn main() { let mut pair = Pair { s1: "Hello".to_string(), s2: "World".to_str...
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
AI Commit Message Generator, Toledo1 AI Assistant, Compound AI Systems
- AI-Powered Commit Message Generation Tool: A new CLI command called
cmaiwas created to generate commit messages using AI, leveraging the OpenRouter API with Bring Your Own Key (BYOK) functionality. It's open source, and users are encouraged to contribute, with details available on GitHub.- The command is designed for ease of use, transforming the often tedious commit message process into a fun and effective task.
- Toledo1 Offers Unique AI Chat Experience: Toledo1 provides a novel way to privately interact with AI assistants, featuring a pay-per-question model and the ability to combine multiple AIs for tailored answers. Users can check out the demo at toledo1.com.
- This platform allows clients to process real-time data effortlessly, integrating seamlessly with personal workflows through a native desktop application.
- Toledo1's Transparent Pricing and Licensing: Toledo1 operates on a transparent pay-per-query pricing model with no subscriptions and enterprise-grade security. Users simply activate their license key for immediate access without complex setup.
- The tool also supports various AI providers compatible with OpenAI inference, providing flexibility in user selection and usage.
- Exploring Compound AI Capabilities: Toledo1's technology allows for the combination of various AIs to enhance answer accuracy, revealing a substantial leap in AI capabilities. For a deeper dive into the technology, check the discussion on compound AI systems.
- This innovative approach positions Toledo1 at the forefront of AI utilization in personal and professional contexts.
- Toledo1 – Achieve search sovereignty with Toledo1, a high performance LLM browser: no description found
- GitHub - toledo-labs/toledo1: Achieve search sovereignty with Toledo1, a high performance LLM browser: Achieve search sovereignty with Toledo1, a high performance LLM browser - toledo-labs/toledo1
- GitHub - mrgoonie/cmai: A quick CLI command to generate commit message using AI and push to origin: A quick CLI command to generate commit message using AI and push to origin - mrgoonie/cmai
OpenRouter (Alex Atallah) ▷ #general (112 messages🔥🔥):
Hermes modifications, API rate limits, Gemini model downtime, LLM workflow tools, Speculative decoding
- Hermes Modifications Yield Performance Boost: A user detailed modifications made to
llama3.c, achieving an impressive 43.44 tok/s in prompt processing and outperforming other implementations using Intel's MKL functions.- They noted performance gains due to using local arrays for matrix calculations, significantly improving processing speed.
- OpenRouter API Rate Limits for Users: Questions about if OpenRouter operates on a single API key suggested potential rate limit issues but responses indicated there may be private agreements that allow flexibility.
- The presence of varying contract terms highlights OpenRouter's tailored relationship with its providers.
- Gemini Model Response Issues Reported: A user reported receiving empty responses from the Gemini 1.5 model, causing speculation about its operational status.
- Confirmation that some users were able to access the model suggests the issue might be isolated to specific setups.
- Interest in Comprehensive LLM Workflow Platforms: A user inquired about platforms enabling complex prompt chaining for tasks like book writing, emphasizing the need for human interaction at various stages.
- The requirement for versioning and flow adjustments per input indicates a demand for sophisticated project management tools integrated with AI capabilities.
- Clarification on OpenRouter Token Limits: One user queried about potential token limits for the org's usage, initially observing a 30k limit, only to realize it might have stemmed from their own account.
- This serves as a reminder for users to verify their individual token metrics before attributing limits to organizational accounts.
- no title found: no description found
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
- Explaining how LLMs work in 7 levels of abstraction: Overview
- Toledo1 – Free 30 day License! – Toledo1: no description found
- llama3.c/run.c at master · jameswdelancey/llama3.c: A faithful clone of Karpathy's llama2.c (one file inference, zero dependency) but fully functional with LLaMA 3 8B base and instruct models. - jameswdelancey/llama3.c
- OpenRouter: A unified interface for LLMs. Find the best models & prices for your prompts
OpenRouter (Alex Atallah) ▷ #beta-feedback (10 messages🔥):
Custom Provider Keys, Beta Integration Access
- Multiple Requests for Custom Provider Keys: Several members requested access to custom provider keys, expressing their gratitude in each message.
- Requests were made from users like mzh8936 (email meng@tabbyml.com) and perspectivist, highlighting a strong interest in these keys.
- Desire for Beta Integration Feature: Multiple users, including itzmetimmy88, expressed a request for access to the beta integration key.
- This indicates a keen interest in testing new features before general release.
OpenAI ▷ #ai-discussions (70 messages🔥🔥):
AI job impact, Model performance and accuracy, OpenAI Discord
- AI's Impact on Jobs is Real: Many members discussed how AI has already rendered certain jobs obsolete, with ongoing debates about the future job landscape.
- One participant pointed out that automation through AI has led to significant job losses.
- Model Performance Concerns: Discussion surrounding the marco-o1 model’s performance indicated it is impressive but not infallible, often producing redundant reasoning outputs.
- One user highlighted that the models sometimes arrive at incorrect answers despite the increased complexity of their reasoning processes.
- Real-time API Use Cases: Members were curious about the real-time API, particularly its role in multimedia AI applications requiring low latency like voice recognition.
- It was noted that real-time refers to processes that happen instantaneously in computing, with applications in categorizing multimedia content.
- Role of Reflection in AI Outputs: The conversation touched on whether reflection is necessary for AI when generating responses, with some seeing it as redundant.
- Participants debated how language models differ from human cognition, asserting that extra steps can result in identical answers despite not being consistently beneficial.
- OpenAI Discord Functionality: Members clarified that this is OpenAI's Discord, where discussions about both OpenAI models and third-party models can take place.
- This particular channel encourages conversations about a range of chatbot technologies beyond just ChatGPT.
Link mentioned: Twelve Days of Christmas at Hospital Pharmacy (Remastered) by @djstraps | Suno: Christmas carol, twelve days of christmas song. Listen and make your own with Suno.
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
Chat GPT on Intel Mac, GPT-4o performance, Connecting GPT with Vertex, Memory in AI agents, Issues with chat functionality
- Chat GPT app compatibility with Intel Macs: A member inquired about using the Chat GPT app on their Intel Mac, but was informed there are no plans to support Intel Macs according to OpenAI's tweets.
- Another user suggested utilizing the web interface as an alternative since the app doesn't support Intel Macs.
- Buzz around GPT-4o version: A member expressed their admiration for the
openai/gpt-4o-2024-11-20version, describing it as amazing.- This indicates a positive reception among users regarding its features and performance.
- Connecting custom GPT to Vertex: A member asked about the possibility of connecting their custom GPT with Vertex.
- In response, another user provided a link to OpenAI's documentation on actions, implying it might have relevant guidance.
- Memory considerations in AI agents: A member hinted at the need to familiarize with AI agents' memory capabilities and various frameworks that offer such functionalities.
- They noted that OpenAI provides chat history and context, encouraging others to delve into the documentation.
- Recurrent issues with chat functionality: A user reported that the chat feature seems to be broken again, suggesting a recurring problem within the platform.
- This highlights ongoing user frustrations with chat functionality, indicating a need for resolution.
OpenAI ▷ #prompt-engineering (19 messages🔥):
ChatGPT as Plagiarism Checker, Students Outsmarting Faculty, Challenges of In-Class Writing, AI Detection Limitations, IT Support in Education
- Setting up ChatGPT as a Plagiarism Checker: A user sought guidance on configuring ChatGPT to function as a plagiarism checker with a specific JSON output structure for academic works.
- However, concerns were raised about the ethical implications and reliability of using AI for such purposes.
- Students' Ability to Outsmart Faculty: Several members discussed the tendency of students to outsmart academic systems, suggesting they often evade detection tools.
- Humorously, it was noted that these skills could be better utilized in academic success rather than in gaming the system.
- Challenges of Promoting In-Class Writing: The practicality of having students write papers in class was debated, with some expressing its difficulty, especially for longer research papers.
- Peer review was suggested as a complementary approach in writing-intensive courses.
- Limitations of AI Detection Tools: A participant highlighted the stochastic nature of AI detection, warning against relying on it for academic assessments.
- Some indicators exist, like unnatural repetition, but none suffice as definitive proof of authorship.
- Underfunded IT Support in Education: Comments were made regarding the underpaid and understaffed IT departments in educational institutions, likening their capabilities to the 'stone age'.
- This observation pointed towards a broader issue of resource limitations that affect both faculty and students.
OpenAI ▷ #api-discussions (19 messages🔥):
ChatGPT as Plagiarism Checker, Student Creativity in Academic Dishonesty, Technology in Education, In-Class Writing Assignments
- Setting up ChatGPT for Plagiarism Checking: A user sought guidance on how to configure ChatGPT to act as a plagiarism checker, seeking JSON output with detailed analysis of suspicious parts.
- Concerns were raised about the effectiveness of such AI tools, with comments highlighting the potential unpredictability and ethical implications.
- Students Outsmarting Academic Systems: A member noted the cleverness of students in evading academic integrity measures, leading to humorous comments about their priorities.
- Never underestimate a student's ability to outsmart the school faculty was remarked, underlining the ongoing struggle in maintaining academic standards.
- Challenges in Educational Technology: Comments addressed the underfunding of IT departments in educational institutions, comparing them to the stone age in terms of resources.
- This lack of support raises concerns about implementing modern tools like ChatGPT effectively in educational settings.
- In-Class Writing as a Solution: Several users suggested that teachers might require students to write papers during class to combat academic dishonesty and plagiarism.
- However, this approach was noted to be difficult for longer and more researched assignments, potentially only applicable in writing-intensive courses.
- Indicators of AI-Generated Text: Discussion highlighted that while there are indicators for detecting AI-generated text, none provide definitive proof.
- Members pointed out that relying solely on AI to detect academic dishonesty raises ethical concerns but suggested observing unnatural patterns in writing as a potential indicator.
Perplexity AI ▷ #general (100 messages🔥🔥):
Perplexity Pro Issues, Chatbot Preferences, Model Comparisons, Black Friday Deals, Website Updates
- Users report issues with Perplexity Pro: Multiple members expressed problems using Perplexity Pro, particularly with the feature to search online, with one user suggesting contacting support.
- A user mentioned that refreshing their session caused them to lose their long prompt, highlighting frustrations with website stability.
- Diverse opinions on chatbot models: Discussions revealed preferences for different LLMs, with users noting that Claude offers superior outputs while Sonnet 3.5 provides more personality for academic writing.
- Some expressed interest in using GPT-4o, debating its capabilities against existing models for creative tasks.
- Exploration of Black Friday deals: Members inquired about potential Black Friday promotions for subscriptions, particularly for Perplexity Pro, with one mentioning a 50% discount on You.Com.
- There was some discussion regarding the effectiveness of other services compared to Perplexity, indicating varying user experiences.
- Collaborative machine learning projects: A user reached out for collaboration on machine learning projects, specifically mentioning their studies in a course by Andrew Ng, and requested others interested to DM.
- The discussion also covered preferences for different types of machine learning tasks, such as NLP versus more basic implementations.
- Concerns about Amazon and unions: Several members commented on Amazon's business practices, with one discussing Jeff Bezos' approach to management and the perception of unionization in the company.
- The conversation reflected on how wealth influences power dynamics, with members recalling various perspectives on corporate leadership in large companies.
- Tweet from Quartr (@Quartr_App): Today, we're excited to announce our partnership with @perplexity_ai. By leveraging Quartr API, Perplexity now offers its global user base access to live transcriptions of earning calls coupled w...
- Risa Bezos Speedball GIF - Risa Bezos Speedball - Discover & Share GIFs: Click to view the GIF
Perplexity AI ▷ #sharing (4 messages):
Amazon's investment in Anthropic, Midcontinent Rift's hydrogen resources, Chemotherapy precursors, Black Friday VPS deals, Neoclassicismo Napolitano
- Amazon Plows $4B into Anthropic: Amazon announced a significant investment of $4 billion in Anthropic, indicating strong confidence in AI advancements.
- This investment is expected to accelerate Anthropic's projects in the AI domain.
- Midcontinent Rift Holds Hydrogen Potential: Exploration in the Midcontinent Rift shows vast potential for hydrogen production, highlighting its resource significance.
- Experts believe this could offer sustainable energy solutions for the future.
- Understanding Chemotherapy's Precursor: A discussion emerged around the role of a newly discovered precursor in enhancing chemotherapy efficacy.
- This breakthrough could have far-reaching implications for cancer treatment strategies.
- Best Black Friday VPS Deals Unveiled: Multiple members shared insights on the best Black Friday VPS deals, pointing to attractive pricing and features.
- These deals are expected to provide significant savings for tech enthusiasts this holiday season.
- Exploring Neoclassicismo Napolitano: A link was shared discussing Neoclassicismo Napolitano, shedding light on its artistic significance in the historical context.
- This exploration offers a deeper understanding of Italian art movements of the period.
Perplexity AI ▷ #pplx-api (3 messages):
Supported models, API changes in web search, Llama-3.1 model functionality
- Supported Models Only Display Online Options: Currently, only the three online models are listed under 'Supported Models' and 'Pricing', while older Chat models and llama-3.1 models are still operational.
- Nothing has been disabled yet, and users have a grace period to switch models in their apps, as no updates are noted in the changelog.
- Recent Changes Impacting Web Search Results: There have been issues with API results not aligning with the web version of Perplexity, as noted over the past week or two.
- Reportedly, requests using
llama-3.1-sonar-huge-128k-onlineandllama-3.1-sonar-large-128k-onlinemodels are returning instructions instead of relevant search results.
- Reportedly, requests using
LM Studio ▷ #general (56 messages🔥🔥):
Model Search Limitations, Document Upload Issues, Vision Model Compatibility, Model Update Notifications, Installation Directory Preferences
- Limited Model Search in LM Studio: A user expressed concern over limited model search functionality after updating to version 0.3.5, believing they might have missed an update.
- Another member noted that the default search now only looks in downloaded models as of version 0.3.3, potentially causing confusion among users.
- Uploading Documents for LLM Context: A user inquired about how to upload documents to use with the LLM, receiving guidance on file formats and the need for version 0.3.5 for this feature.
- Links were provided to official documentation, emphasizing that documents like
.docx,.pdf, and.txtcan enhance LLM interactions.
- Links were provided to official documentation, emphasizing that documents like
- Vision Model Errors in LM Studio: A user reported errors when trying to load the 'Llama 3.2 11B Vision Instruct' model, receiving feedback that this model isn't supported in the current LM Studio version.
- It was clarified that vision models like Llama 3.2 are not compatible with non-Mac users, limiting functionality for those on other operating systems.
- Model Update Notifications: A member queried whether LM Studio notifies users of model updates, discovering that updates result in entirely new models rather than patches.
- It was confirmed that users must manually download new models when updates are available.
- Installation Directory Control: A user expressed frustration regarding the inability to specify the installation directory for LM Studio, noting it defaults to an unspecified location.
- This highlights a potential user experience issue that may require attention to improve software usability.
- LM Studio Beta Releases: LM Studio Beta Releases
- DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters · Hugging Face: no description found
- Chat with Documents - Running LLMs Locally | LM Studio Docs: How to provide local documents to an LLM as additional context
- Can only search for models from mlx-community · Issue #35 · lmstudio-ai/mlx-engine: LM Studio Version: 0.3.5(build 4) H/w: 128gb m3 Max, 14.3 sonoma. I am unable to search for non mlx-community MLX models in the Model Explorer. I made a quant with mlx-my-repo on HF, and can view i...
LM Studio ▷ #hardware-discussion (31 messages🔥):
LM Studio compatibility with GPUs, Power supply recommendations for high-end builds, Graphics card VRAM requirements, Price fluctuations in the GPU market, PCIe configurations and performance
- LM Studio works with various GPUs: A user inquired whether LM Studio will work on the RX 5600 XT. Another member confirmed that almost any GPU can be used with LM Studio, noting the effectiveness of the llama.cpp Vulkan API.
- Power requirements for 3090 and build: A member sought guidance on recommended PSU wattage for a build with 3090 and 5800x3D. It was advised to add a buffer to the estimated wattage, with a common heuristic suggesting around 80% of PSU capability.
- High VRAM cards for demanding applications: Users discussed the need for GPUs with high VRAM for applications like DCS and AI. Several indicated that a GPU with at least 16GB would be ideal, with 3090 being a popular recommendation.
- Soaring GPU prices: A user expressed frustration over skyrocketing GPU prices, particularly for cards that are still performing well like the Pascal series. Others concurred, stating that people are overpaying for what essentially resembles e-waste.
- PCIe impact on performance: A discussion highlighted that PCIe revisions primarily affect model loading times rather than inference speeds. It was pointed out that PCIe 3.0 does not hinder inference, making bandwidth less crucial.
Eleuther ▷ #general (21 messages🔥):
Type Checking in Python, Discord Communities for Beginners, Role-Play with Large Language Models, Collaborative Projects, Deep Learning Learning Resources
- Type Checking Takes Center Stage: Members discussed the challenges with type hinting in Python, noting that libraries like wandb have insufficient type checks, making integration difficult.
- A specific mention was made for unsloth in fine-tuning, with members expressing more leniency due to its newer status.
- Discord Communities for Beginners: A member sought out recommendations for Discord communities suited for beginners in ML, highlighting their background in computer science and statistical ML.
- Another member pointed to a great list of servers shared by another user, covering various server types and activities.
- Role-Play Project Seeks Collaborators: A user shared about their project, Our Brood, focused on creating an alloparenting community incorporating AI agents and human participants, running 24/7 for 72 hours.
- They are on the lookout for collaborators to set up models and expressed eagerness for further discussions with interested parties.
- Advocating Self-Study in ML: A member emphasized the importance of self-study for individuals transitioning from academic backgrounds and suggested joining educational communities.
- They mentioned common gaps between theoretical understanding in ML and practical applications, advising a blend of both.
- Promoting Fast AI Learning Resources: Resources were shared for learning deep learning, specifically the Practical Deep Learning for Coders course suitable for individuals with coding experience.
- The course covers various topics like model building and deployment using key frameworks such as PyTorch and fastai.
- Practical Deep Learning for Coders - Practical Deep Learning: A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
- discord AI sphere - share with whoever!: no description found
Eleuther ▷ #research (41 messages🔥):
Diffusion and Hypernets, Learning with Reinforcement Learning, Compressed Text Challenges, Biologically Plausible Tokenization, Learning Rate Warmup
- Diffusion Techniques in Hypernets: A discussion emerged on utilizing Diffusion in potential Hypernet frameworks, suggesting it might be problematic to implement effectively, as it could require complex steps to function.
- One member expressed skepticism about the likelihood of successfully applying these methods given the potential challenges.
- Reinforcement Learning for Hidden State Updates: There was a conversation about updating the hidden state in state-space models using Reinforcement Learning, with proposals of teaching models to predict state updates through methods resembling truncated backpropagation through time.
- One member suggested fine-tuning as a potential strategy to enhance learning robotic policies for models.
- Challenges of Learning on Compressed Text: A few members highlighted that training large language models (LLMs) on compressed text dramatically impacts their performance, particularly due to non-sequential data challenges.
- They noted that maintaining relevant information while compressing sequential relationships could facilitate more effective learning.
- Biologically Plausible Tokenization Approaches: Discussions revolved around the concept of biologically plausible tokenization, particularly in vision, suggesting that patches might not be the optimal choice for tokenizing visual inputs.
- Members explored the potential of wavelet decompositions as a more natural method of segmentation for vision tasks.
- Understanding Learning Rate Warmup: One member explained the necessity of learning rate warmup in training, specifically mentioning how Adam's bias correction can affect the learning process.
- They suggested an optimal warmup duration to counteract this bias to ensure stable training, along with noting exceptions for resumptions.
- Training LLMs over Neurally Compressed Text: In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can ...
- Random Permutation Codes: Lossless Source Coding of Non-Sequential Data: This thesis deals with the problem of communicating and storing non-sequential data. We investigate this problem through the lens of lossless source coding, also sometimes referred to as lossless comp...
- Lexinvariant Language Models: Token embeddings, a mapping from discrete lexical symbols to continuous vectors, are at the heart of any language model (LM). However, lexical symbol meanings can also be determined and even redefined...
- Tweet from Fern (@hi_tysam): New NanoGPT training speed record: 3.28 FineWeb val loss in 4.66 minutes Previous record: 5.03 minutes Changelog: - FlexAttention blocksize warmup - hyperparameter tweaks
Eleuther ▷ #interpretability-general (4 messages):
UK AISI priority research areas, Automated white-box attacks, SAE-based evaluations, Anomaly detection in AI agents, Collaboration with UK AISI
- Exploring UK AISI's Research Overlaps: A member shared insights from UK AISI's priority research areas and highlighted possible areas for collaboration, particularly around safeguards and safety cases.
- SAE-Based White Box Evaluations in Progress: Another member outlined their work on SAE-based white box evaluations to assess how training setups affect model generalization and feature learning.
- Anomaly Detection Potential with SAEs: A response emphasized the significance of anomaly/risk detection using SAEs for safety, connecting it to capabilities regressions through conditional steering.
- Collaboration Opportunities with UK AISI: A member mentioned existing partnerships with UK AISI and offered to set up meetings when ideas are more developed.
Eleuther ▷ #lm-thunderdome (12 messages🔥):
YAML self-consistency voting, Caching model responses, lm_eval_harness standard error, Significance testing in benchmarking
- YAML specifies self-consistency voting: A member confirmed that the YAML file outlines self-consistency voting across all repeats of a task. They inquired about obtaining the average fewshot CoT score without naming each repeat explicitly.
- Another member noted that the situation is complex due to independent filter pipelines affecting the response metrics.
- Caching model responses could improve tasks: A member questioned the caching mechanism, suggesting that model answers should be cached immediately to support task continuity after interruptions. They pointed out that the current caching approach is mostly beneficial for re-running completed tasks.
- In response, it was clarified that model answers are cached at the end of each batch.
- lm_eval_harness calculates standard error: A member asked about the standard error output from benchmark runs in lm_eval_harness. It was explained that this value is derived from bootstrapping techniques.
- Further discussion raised questions on whether this could qualify as a significance test, with uncertainty around defining a null hypothesis.
- Questions over significance testing: Members discussed the relevance of the standard error in benchmarking and its potential role as a significance test. There was skepticism about how to compare model differences meaningfully.
Nous Research AI ▷ #general (58 messages🔥🔥):
Llama.cpp updates, Quantization techniques, Puzzle evaluations, Anthropic developments, LLM reasoning abilities
- Llama.cpp and Custom Quantization: A pull request for custom quantization schemes in Llama.cpp sparked excitement, as it would allow for more granular control over model parameters.
- The discussion highlighted that critical layers could remain unquantized, while less important layers might be quantized to minimize model size.
- Puzzle Logic Evaluation: A river crossing puzzle was presented for evaluation, with two provided solutions focusing on the farmer's actions and the fate of the cabbage.
- Feedback indicated that LLMs struggle to interpret the puzzle correctly, often providing incorrect solutions due to their rigid reasoning.
- LLMs Misinterpret Puzzles: Multiple LLMs, including deepseek-r1 and o1-preview, failed to solve the river crossing puzzle, resorting to answering with full solutions instead.
- Users acknowledged that even they initially misread crucial details, demonstrating the challenges faced by both humans and AI in reasoning under certain constraints.
- Anthropic's Progress: Anthropic continues making developments, positioning themselves as an interesting case for custom fine-tuning and model improvements.
- A reference to the Model Context Protocol suggested a growing focus in the field on enhancing model capabilities through structured approaches.
- Limitations of LLM Reasoning: Participants noted that LLMs are often overfit on specific puzzle types, leading to illogical outputs when encountering variations.
- Realizing the need for better contextual understanding, conversations shifted towards refining LLM training to enhance their reasoning engine capabilities.
- GitHub - facebookresearch/ImageBind: ImageBind One Embedding Space to Bind Them All: ImageBind One Embedding Space to Bind Them All. Contribute to facebookresearch/ImageBind development by creating an account on GitHub.
- Custom quantization schemes by jubruckne · Pull Request #6844 · ggerganov/llama.cpp: This is not ready to merge but I wanted to get your opinion if it’s something you’d be interested in including. If so, I can clean it up and improve it a little. The idea is to allow creating a cus...
Nous Research AI ▷ #ask-about-llms (3 messages):
Hermes 3, Nous Research
- Curious about Hermes 3 differences: A user expressed a need for a summary on how Hermes 3 differs from other LLMs, seeking a simplified explanation.
- Another member provided a link to Nous Research's Hermes 3 page for more detailed information.
- Interest in Nous from LLM Specialist: A member identified themselves as an LLM specialist showing keen interest in Nous Research.
- This highlights a growing engagement from experts in the field towards emerging models like Hermes.
Notebook LM Discord ▷ #announcements (1 messages):
Convert notes to source feature, NotebookLM new capabilities, AI focus methods, UI changes
- NotebookLM introduces 'Convert notes to source' feature: A new feature called 'Convert notes to source' is now live for all NotebookLM users, located at the top of open notebooks. Users can convert all notes into a single source or select notes manually, with each note separated by a divider and named by date.
- This addition unlocks several capabilities, including using latest chat features with notes, inline citations, and incorporating notes into Audio Overviews.
- New capabilities after conversion: Once converted, users can utilize all latest chat features, allowing them to interact with their notes more effectively. The conversion also serves as a backup method for notes, enabling users to easily copy their source text into other applications.
- However, converted notes will not auto-update with changes made to the original text, although an auto-update feature is planned for 2025.
- Transitioning AI focus methods: The previous method for focusing AI on notes will still function for a few weeks but support will be discontinued soon. Users are encouraged to adapt to the new 'Convert notes to source' feature for improved functionality.
- Upcoming UI changes are expected to enhance the interaction experience further, with users advised to stay tuned for updates.
Notebook LM Discord ▷ #use-cases (7 messages):
Study Guide Feature, Game Design Curriculum, Blog on Hyper-Reading, Developer Collaboration, Note Saving Issues
- Using Study Guide vs Custom Prompts for Notes: A Game Design teacher is exploring whether to utilize the new Study Guide feature or continue with a custom prompt for generating lesson notes, seeking clarity on the capabilities of the Study Guide.
- They found that the Study Guide generates good short answer questions for lessons, suggesting it could complement their own prompts.
- Engaging Students with Short Answer and Multiple Choice: The teacher prefers mostly multiple choice and short answer questions for assessments, as the bulk of classwork involves game projects.
- They are uncertain if parameters for the Study Guide can be adjusted to better fit their needs.
- Seeking Developer for Start-Up: A member is on the lookout for a lead developer to collaborate on a specific start-up project using an API.
- They have invited interested individuals to direct message them for further discussion.
- Blog Post on Hyper-Reading Insights: A member shared their blog post detailing a modern approach to reading non-fiction books called Hyper-Reading, which emphasizes leveraging AI to enhance learning.
- They outline steps such as acquiring books in textual formats and using NotebookLM for improved information retention.
- Note Saving Issue in Application: A user expressed frustration over an issue with saving notes, reporting that they display as dots when attempting to reopen them.
- This highlights potential usability challenges in the note-taking features within the application.
Link mentioned: Hyper-Reading: How I read and learn from books with AI
Notebook LM Discord ▷ #general (53 messages🔥):
Notebook LM language support, Integration with Wondercraft AI, Commercial use of generated podcasts, Creating Notebooks for literature discussion, Issues with summarization language
- Notebook LM supports multiple languages: Users have found that Notebook LM can operate in their native languages, with one member successfully using it in Spanish without issues.
- Another noted their frustration when the AI summarized in Italian despite needing English.
- Integration of Notebook LM with Wondercraft AI: It's possible to use Notebook LM with Wondercraft AI to customize audio, allowing users to splice their own audio and manipulate spoken words.
- This integration offers a way to enhance audio presentations, although it comes with some limitations regarding free usage.
- Commercial use of podcasts from Notebook LM: According to the discussion, users can commercially publish podcasts created with Notebook LM as they retain ownership of the generated content.
- Members discussed leveraging this for various monetization strategies, such as sponsorships or affiliate marketing.
- Creating Notebooks for literary discussions: A member created a Notebook containing writings from over 30 Early Church Fathers, inviting others to explore these historical voices.
- This initiative sparked interest in curating similar discussions around classic literature, showcasing the potential for collaborative exploration.
- Summarization function issues: Users expressed frustration with Notebook LM's summarization function, particularly around the AI sticking to their default language for outputs.
- One user sought guidance on ensuring specific notes guide the content generated from their study materials.
- space hole: no description found
- no title found: no description found
- Chat Pal 2. Episode Google ML Notebook: no description found
Interconnects (Nathan Lambert) ▷ #news (14 messages🔥):
Optillm and Chain-of-Code, o1-preview performance, Instruct models vs. chain of thought tuning
- Optillm beats o1-preview using Chain-of-Code reasoning: The team announced a success by utilizing the Chain-of-Code (CoC) plugin in Optillm to surpass @OpenAI's o1-preview on AIME 2024.
- They achieved this by leveraging SOTA base models from @AnthropicAI and @GoogleDeepMind, and referenced the original paper on CoC here.
- Discussion on o1-mini vs o1-preview: A member expressed surprise at o1-mini outperforming o1-preview, wondering if they weren't meant to be swapped.
- Another member clarified that mini was actually finetuned specifically on code and math.
- Instruct models versus chain of thought tuning: A conversation revealed that while instruct models are RL tuned, their private chain of thought tuning may not apply universally across models like Gemini.
- Participants emphasized the importance of distinguishing between LLM + Python configurations versus standalone LLM applications.
- Tweet from Asankhaya Sharma (@asankhaya): Beating o1-preview on AIME 2024 with Chain-of-Code reasoning in Optillm In the past week there has been a flurry of releases of o1-style reasoning models from @deepseek_ai, @FireworksAI_HQ and @Nous...
- Tibor Blaho (@btibor91.bsky.social): - Microsoft needed daily guidance from OpenAI to understand o1 despite having code access through their partnership, according to two people involved in the situation, while Google expanded its reason...
Interconnects (Nathan Lambert) ▷ #ml-drama (15 messages🔥):
Google acquiring researchers, Acquihire rumors, Bill raises in tech, Xooglers and connection to Google, GPT-4 date leak
- Google gathers researchers amidst rumors: There's speculation that Google has 'collected all their researchers', sparking a discussion about high-profile figures like Noam and Yi Tay joining them.
- If true, it reflects Google's strategy in consolidating talent to enhance their capabilities.
- Reka Acquisition Talk: A member mentioned a rumor that there was a potential acquihire of Reka by Snowflake, which ultimately did not materialize.
- This prompted a quote from Nathan Lambert expressing his dismay about the situation.
- Challenging conversations lead to rehiring: Comments highlighted that when speaking against others, the phrase 'talk shit get rehired' emerged in the context of tech executives.
- Questions were raised about compatibility with other tech leaders, particularly the perplexity CEO.
- Discussion on tech executive behavior: Participants debated the behavioral differences between tech executives, noting that one never publicly criticized Google despite funding Reka.
- The conversation compared his behavior with that of former Google employees who exhibit a more critical standpoint.
- Memories of leaks in tech: A member remembered when a Microsoft executive leaked the GPT-4 release date in Germany, showcasing the risks of insider information.
- This nostalgic remark hinted at the ongoing leaks and communications that shape the tech landscape.
- Tweet from / (@gazorp5): @PytorchToAtoms @YiTayML 🤔
- Tweet from Alexander Doria (@Dorialexander): I still thought they were getting acquihired by Snowflake but didn’t work… Quoting Nathan Lambert (@natolambert) Rip Reka?
- Nathan Lambert (@natolambert.bsky.social): Rip Reka?
Interconnects (Nathan Lambert) ▷ #random (2 messages):
Reasoners Problem, NATO Discussions
- Exploring the Reasoners Problem: A link was shared regarding the Reasoners Problem, outlining its implications and discussions surrounding it.
- This topic triggers pertinent debates within AI research regarding reasoning capabilities.
- Mention of NATO: One member briefly noted a mention of NATO, possibly in a context relevant to ongoing discussions in technology or security.
- The specifics were not outlined, but NATO's involvement hints at broader implications in the tech landscape.
Link mentioned: Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
Cohere ▷ #discussions (1 messages):
lisafast_71204: 😩
Cohere ▷ #questions (22 messages🔥):
Fine-tuning Command R, Cohere API issues, Batching and LLM as judge
- Configuring Command R for complete answers: A member reported that when using the fine-tuned Command R model, the output occasionally stops at random tokens due to hitting the max_output_token limit.
- Strategies to configure the model parameters for better outputs were requested.
- Cohere API returns incomplete results: Another member experienced issues with the Cohere API, receiving responses with missing content in the API output.
- Despite trying various forms of calls, they noted that the Claude and ChatGPT integrations worked without issues.
- Integrating Cohere API in Vercel deployment: A user described difficulties deploying a React app using the Cohere API on Vercel, resulting in 500 errors related to client instantiation.
- They mentioned a separate server.js file worked locally, but there was confusion around getting it to function on Vercel.
- Feedback on batching + LLM approach: A member shared their work on a batching + LLM as judge approach and sought feedback, particularly regarding fine-tuning consistency.
- They also highlighted challenges with hallucination when using the
command-r-plusmodel for identifying sensitive fields.
- They also highlighted challenges with hallucination when using the
- Exploring multi-agent setups: In response to the batching approach, a member asked if Langchain was involved and suggested trying out a massively multi-agent setup.
- They inquired whether the 'judge' role involved simply passing or failing after analysis.
Cohere ▷ #api-discussions (3 messages):
Fine-tuning Command R, EOS token prediction
- Issues with Fine-tuning Command R Outputs: A member is experiencing incomplete outputs when using a fine-tuned Command R model, stating that the generation stops at a random token once the max_output_token limit is reached.
- They seek advice on how to configure the parameters to ensure complete answers.
- EOS Token Might Be the Culprit: Another member responded, suggesting that the EOS token may be predicted prematurely and inquiring about the specific details of the dataset being used.
- This provides a possible lead for troubleshooting the fine-tuning issue.
Stability.ai (Stable Diffusion) ▷ #general-chat (26 messages🔥):
Learning Resource Requests, ControlNet Upscaling, Buzzflix.ai for Viral Content, Hugging Face Website Navigation Issues, Spam Friend Requests
- Beginners Seek Learning Resources: New users are expressing their struggles in creating images and are seeking beginner guides to navigate the tools effectively.
- One suggestion emphasized watching beginner guides as they offer a clearer perspective for those new to the field.
- Query on ControlNet Upscaling in A1111: A member queried about the possibility of enabling upscale in A1111 while using ControlNet features like Depth.
- Another member cautioned against direct messages to avoid scammers, directing the original poster to the support channel instead.
- Buzzflix.ai for Automated Video Creation: A member shared a link to Buzzflix.ai, which automates the creation of viral faceless videos for TikTok and YouTube.
- They expressed astonishment at how it can potentially grow channels to millions of views, noting it feels like a cheat.
- Hugging Face Website Confusion: Members conveyed confusion regarding the Hugging Face website, particularly the lack of an 'about' section and pricing details for models.
- Concerns were raised about accessibility and usability of the site, with suggestions for better documentation and user guidance.
- Concerns Over Spam Friend Requests: Users reported receiving suspicious friend requests, suspecting they may be spam.
- The conversation elicited lighthearted responses, but many expressed concern over the unsolicited requests.
GPU MODE ▷ #triton (2 messages):
Grouped GEMM with fp8, Triton compatibility with TPUs
- Grouped GEMM struggles with fp8 speedup: A member reported that they couldn't achieve a speedup with fp8 compared to fp16 in their Grouped GEMM example, requiring adjustments to the strides.
- They emphasized the need to set B's strides to (1, 4096) and to provide both the leading dimension and second dimension strides for proper configuration.
- Inquiry about Triton and TPU compatibility: Another member inquired about the compatibility of Triton with TPUs, suggesting an interest in using Triton's functionalities on TPU hardware.
- The discussion points to potential future development or insights from the community regarding Triton's performance on TPU setups.
GPU MODE ▷ #cuda (5 messages):
CUDA Simulations, Memory Management, Simulation Timing Issues
- CUDA simulations yield weird results without delays: A user observed that running simulations in quick succession produces weird results, but introducing a one-second delay resolves the issue.
- They emphasized that this behavior was noted while inspecting random process performance.
- Memory leaks ruled out in CUDA setup: The user confirmed that they have checked for memory leaks and ensured that VRAM usage is within the device's limits.
- They noted that the number of threads is set to match the number of CUDA cores on their device.
- User aims to avoid debugging close to thesis hand-in: The user expressed urgency in finishing their thesis and mentioned their reluctance to be debugging at this late stage.
- With the deadline approaching in a few weeks, they are looking for a solution to the simulation timing issue.
GPU MODE ▷ #beginner (3 messages):
DDP in PyTorch, Beginner Issues
- Sidhu seeks help with PyTorch DDP issues: A beginner reached out for assistance with DDP (Distributed Data Parallel) using PyTorch, indicating difficulties encountered during the process.
- The community expressed interest in helping after spotting the query.
- Curiosity about the specific issues: Another member prompted for clarification, asking, What's the issue?
- This shows the willingness within the community to assist new users facing challenges.
GPU MODE ▷ #torchao (5 messages):
Torchao in GPTFast, Flash Attention 3 FP8, Integration Discussions, GPTFast Functionality
- Torchao shines in GPTFast: Discussion centered around the potential of Torchao being a useful example in GPTFast, possibly integrated with Flash Attention 3 FP8.
- Members expressed interest in this integration and its implications for efficiency.
- Integration feedback on GPTFast: Members mentioned ongoing reviews about the GPTFast integration, with a specific mention to another user taking another look.
- Concerns were raised as one member noted that Horace preferred not to include certain functionalities.
- Current functionality in TorchAO: As for the functionalities currently available in TorchAO, they confirmed the presence of generate and eval features.
- This clarity highlights the existing capabilities while the integration discussions continue.
GPU MODE ▷ #off-topic (4 messages):
Yi Tay returns to Google, Career Moves in Tech
- Yi Tay's Quick Return to Google: Yi Tay went back to Google after less than 2 years away, raising eyebrows and smiles in the community 😆.
- This prompted jokes about the cycle of leaving and returning to make more bank from Google.
- Strategic Career Moves Discussed: Members noted that people often leave companies only to return, primarily because it's difficult to secure promotions or raises internally.
- One member quipped, 'It is the objectively correct career move,' highlighting a common tactic in tech employment.
Link mentioned: Tkt Smart GIF - Tkt Smart - Discover & Share GIFs: Click to view the GIF
GPU MODE ▷ #llmdotc (1 messages):
eporat: hi is there nice documentation for matmul_cublaslt?
GPU MODE ▷ #intel (1 messages):
PyTorch on Meteor Lake, XPU Device RAM Sharing
- Assessing PyTorch on Meteor Lake Laptops: A member questioned whether PyTorch support on Meteor Lake laptops is satisfactory for development purposes.
- They seek clarity on performance benchmarks and user experiences to confirm its viability.
- Does XPU Share RAM with CPU?: The same member inquired if the XPU device shares RAM with the CPU, which could impact computing efficiency.
- Understanding this could influence development choices and resource management.
GPU MODE ▷ #sparsity-pruning (1 messages):
Data Dependency in Sparsification, Fine-tuning Techniques
- Understanding Data Dependency in Techniques: A member queried about the meaning of data dependent in relation to its necessity for fine-tuning during or after sparsification calibration.
- This topic sparked a discussion regarding the implications of such techniques on performance and accuracy.
- Clarifying the Need for Post Sparsification Calibration: There was a discussion regarding whether data dependent techniques require post sparsification calibration to maintain performance.
- Members shared various insights on the balance needed between initial training and necessary adjustments after sparsification.
tinygrad (George Hotz) ▷ #general (8 messages🔥):
Partnerships admin ping, Meeting updates, New operations in nn/onnx.py, Flash-attention incorporation
- Partnerships admin ping inquiry: A member asked if there is an admin ping for partnerships.
- No further information or responses were provided regarding this inquiry.
- Meeting time changes: The upcoming meeting is set for 8 PM Hong Kong time, with updates on various topics including company performance.
- It was noted that the timing will revert back to 9:30 AM PT next week, although some would prefer maintaining the current time.
- New operations and ONNX testing concerns: Discussion on adding two more operations (instancenorm and groupnorm) to nn/onnx.py was raised, with concerns about the complexity of ONNX exclusive modes.
- Members expressed that while merging is feasible, much of the code is devoted to matching ONNX ops to tensor.py, and test coverage is inadequate.
- Interest in Flash-attention functionality: A member questioned whether flash-attention could be incorporated into tinygrad, indicating a possible gap in current implementation.
- The response regarding its integration status or relevance to tinygrad was not provided in the discussion.
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
Symbolic multidimensional element swap, Radix sort function, Negative and float input sorting, Random permutation function, Kernel launch assessment
- Creating a symbolic multidimensional swap: A user sought guidance on performing a symbolic multidimensional element swap with the method
swap(self, axis, i, j), emphasizing view manipulation without altering the underlying array.- They suggested a notation for creating views on the axis to swap, expressing uncertainty on execution.
- Prototype radix sort function discussion: A user presented a working prototype for a radix sort function, outlining its performance on non-negative integers while noting room for optimization with suggestions like using
scatter.- They highlighted the need for optimizations and posed questions about handling negative and floating-point values, intending to create a robust sorting function.
- Considerations for negative and float sorting: In response to the radix sort implementation, another user suggested creating dedicated functions for negative and float inputs, advocating for an efficient approach to maintain performance.
- They emphasized the importance of minimizing complexity by relying on random integer ranges for shuffling rather than handling floats.
- Assessing kernel launches: A user inquired about methods to assess how many kernels are launched during the radix sort execution, suggesting debugging or calculating big-O notation for estimation.
- They also debated the advantages of in-place modification versus input tensor copying prior to kernel execution, considering the efficiency implications.
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Compute Resources Form, API Credits Availability, Access Instructions for Models
- Compute Resources Form Due TODAY!: A super important reminder that the GPU/CPU Compute Resources Form is due today; teams must submit their requests by the end of the day via this link.
- Don't forget! This form is critical for resource allocation!
- API Credits Still Available: API Credits are still available for teams with a limit of one request per team, though there is an expected delay of 1-2 weeks for processing; teams can apply through this form.
- Teams must input their API keys for OpenAI, Lambda, or follow instructions for Google to secure access.
- Instructions Required for Other Models: For teams using other models, they should describe their needs in the form provided to ensure appropriate support and resource allocation.
- Be detailed in your descriptions to facilitate the best assistance possible!
- no title found: no description found
- LLM Agents MOOC Hackathon - Account Information For Resource Credits & API Access: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-announcements (1 messages):
Lecture 11 with Benjamin Mann, Responsible Scaling Policy, AI safety governance, Agent capability measurement
- Lecture 11 featuring Benjamin Mann: Today at 3:00pm PST, the 11th lecture will feature guest speaker Benjamin Mann, discussing "Measuring Agent capabilities and Anthropic’s RSP." Watch the livestream here.
- Mann aims to explain how to measure AI capabilities and maintain safety and control in AI systems while sharing insights from his previous work at OpenAI.
- Exploring Anthropic's Responsible Scaling Policy: The lecture will cover Anthropic's approach to AI safety through its updated Responsible Scaling Policy (RSP) and its application in developing agent capabilities.
- It will examine real-world AI safety governance and connect with key themes in capability measurement and responsible deployment.
- Access course materials easily: All course-related materials, including livestream URLs and assignments, can be accessed via the course website here.
- Students are encouraged to reach out with questions or feedback directly in the designated course communication channel.
Link mentioned: CS 194/294-196 (LLM Agents) - Lecture 11, Ben Mann: no description found
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (3 messages):
Hackathon project exposure, Course project guidelines
- Guidance on hackathon project exposure: A member asked for clarification on how much detail to present regarding their hackathon project for public exposure.
- It was suggested that an overview covering what, why, and how would be sufficient instead of exposing every detail.
- Course project word limit discussed: Another member highlighted that the course website states a project summary should be around 500 words.
- It was noted that if publicity poses a concern, summarizing information from lectures or writing a postmortem on the learning experience might be advisable.
LLM Agents (Berkeley MOOC) ▷ #mooc-lecture-discussion (4 messages):
Lecture content vs. code examples, Study group for coding practices, Prompt hacking techniques, Code implementation for hackathon
- Lecture vs. Code Confusion: A member expressed uncertainty about the depth of coding content in lectures, seeking clarity on whether coding assignments or implementation walk-throughs were expected.
- Another clarified that lectures are high level and theory-focused, suggesting other video resources for concrete coding.
- Weekly Study Group for Code Examples: A member invited others to join their weekly study group, focusing on code examples derived from lectures, starting in 1.5 hours.
- The session will cover prompt hacking techniques, with an open invitation provided via Discord link.
- Implementing Code for Hackathons: One member indicated that specific code implementations could help with hackathon submissions.
- While the lectures touch on various frameworks, they do not delve into detailed coding practices.
LLM Agents (Berkeley MOOC) ▷ #mooc-readings-discussion (1 messages):
GSM8K test set analysis, Self-correction in outputs, GPT-4o pricing
- GSM8K analysis focuses on 1k test set: The discussion points out that for GSM8K, only the 1k test set is likely being used, with each question aimed to stay around 100 tokens.
- Members agree that employing self-correction could multiply each output based on the number of corrections made.
- Calculating costs for GSM8K inference: A member calculated the cost of one inference run on the GSM8K test set, factoring in the current GPT-4o pricing.
- The calculation led to a conclusion that the price ranges around 2/3 dollars without self-correction for one inference run.
Axolotl AI ▷ #general (5 messages):
Fine-tuning models with PDF data, Challenges of PDF extraction, RAG vs Fine-tuning
- Fine-tuning models with PDF regulations: A member inquired about generating an instruction dataset for fine-tuning a model using an 80-page PDF with company regulations and internal data.
- They specifically wondered if the document's structure (titles and subtitles) could aid in processing with LangChain.
- Extracting content from PDFs can be tricky: Another member suggested checking how much information could be extracted from the PDF, noting that some documents—especially those with tables or diagrams—are harder to read.
- Extracting relevant data from PDFs varies significantly depending on their layout and complexity.
- RAG preferred for better fine-tuning results: A member shared that while it's possible to fine-tune a model with the PDF data, using Retrieval-Augmented Generation (RAG) would likely yield better results.
- This method provides an enhanced approach for integrating external data into model performance.
LlamaIndex ▷ #blog (2 messages):
AI Tools Survey, RAG Applications Webinar
- Share Your AI Tools and Win!: A partnership with vellum_ai, FireworksAI_HQ, and weaviate_io has launched a 4-minute survey about the AI tools you use, and completing it enters you to win a MacBook Pro M4.
- The survey covers your AI development journey, team, and technology usage, and you can find it here.
- Elevate Your RAG Applications in Webinar: Join MongoDB and LlamaIndex on December 5th at 9am Pacific for a webinar focused on transforming RAG applications from basic to agentic.
- Laurie Voss from LlamaIndex and Anaiya Raisinghani from MongoDB will share valuable insights, which can be found in more detail here.
LlamaIndex ▷ #general (2 messages):
Angel investors in crypto, Full-stack Software Engineer seeking opportunities
- Crypto Startup Seeks Angel Investors: A member announced their crypto startup, a cross-chain DEX based in SF, is looking to raise a Series A round and is interested in connecting with angel investors in the crypto infrastructure space.
- They encouraged interested parties to HMU, signaling readiness for discussions on investment.
- Experienced Full-Stack Engineer Offers Skills: Another member shared their background as a Full Stack Software Engineer with over 6 years of experience in web app development and blockchain technologies, seeking full-time or part-time opportunities.
- They highlighted proficiency in JavaScript frameworks, smart contracts, and various cloud services, and expressed eagerness to discuss potential contributions to teams.
Torchtune ▷ #general (2 messages):
Custom Reference Models, Full-Finetune Recipes, LoRA Recipe Adjustments
- Discussion on Custom Reference Models' Impact: A member opened an issue regarding the impact of custom reference models citing another paper as a follow-up, suggesting it's time to add this consideration.
- They highlighted the potential effectiveness of these models in the current context.
- Need for Full-Finetune Recipe Development: One member expressed the belief that creating a full-finetune recipe makes sense but acknowledged that none currently exist.
- They proposed making modifications to existing LoRA recipes to support this approach, advocating for caution due to the newness of the technique.
Torchtune ▷ #dev (1 messages):
pip-extra tools, pyenv, poetry, uv.lock, caching
- Pip-extra tools combine for speed: The integration of all pip-extra tools, pyenv, and poetry leads to an obviously faster development process with efficient bug fixes.
- However, there's skepticism around poetry's future design vision compared to these other tools.
- Rust-like features appeal to developers: The setup for these tools is noted to be quite similar to cargo and pubdev for Rust lovers, providing a familiar environment.
- This association highlights the growing convergence of tools across programming languages, especially for package and dependency management.
- Efficiency through uv.lock and caching: Utilizing uv.lock and caching mechanisms enhances the speed and efficiency of project management.
- These features streamline workflows, ensuring that common tasks are handled more swiftly.
DSPy ▷ #examples (1 messages):
Synthetic Data Generation, Research Papers on Data Generation
- Inquiry for Synthetic Data Generation Paper: <@johnny.silicio> asked if anyone could recommend a paper to help understand how synthetic data generation works.
- This reflects an increasing interest in the principles of synthetic data and its applications.
- Discussion on Synthetic Data Implications: The request for literature on synthetic data generation indicates a deeper exploration into data generation techniques is underway.
- Members noted the importance of understanding these techniques for future projects.
LAION ▷ #general (1 messages):
Foundation model developers, Tagged images, Niche photography
- Seeking Connections with Foundation Model Developers: A member is looking for connections with foundation model developers to explore collaboration opportunities.
- They mentioned having over 80 million tagged images available for potential projects.
- Offering Niche Photography on Demand: They highlighted the ability to provide thousands of niche photography options on demand, indicating a resource for model training or development.
- This presents a unique opportunity for developers in the foundation model space.
Mozilla AI ▷ #announcements (1 messages):
Lumigator, Choosing the Best LLM, Open-source AI Development
- Tech Talk on Lumigator for LLM Selection: Join engineers for an in-depth tech talk on Lumigator, a powerful open-source tool aimed at helping developers choose the best LLMs for their needs.
- The team will showcase Lumigator's features, demonstrate real-world usage, and discuss its roadmap towards General Availability in early 2025.
- Lumigator's Vision for Ethical AI Development: Lumigator aims to evolve into a comprehensive open-source product that supports ethical and transparent AI development, filling gaps in the current tooling landscape.
- The initiative focuses on creating trust in the tools developers use, ensuring that solutions align with their values.
AI21 Labs (Jamba) ▷ #general-chat (1 messages):
API key generation issues
- Confusion Over API Key Generation: A member expressed frustration regarding API key generating issues on the site, questioning if they were making a mistake or if the issue was external.
- They sought clarification on the reliability of the API key generation process from community members.
- Request for Assistance on API Key Issues: The member prompted others for insights into potential problems with the site's API key generation functionality.
- Some participants voiced their experiences, suggesting that the issue might be temporary or linked to specific configurations.
```