[AINews] AlphaProof + AlphaGeometry2 reach 1 point short of IMO Gold
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Search+Verifier is all you need.
AI News for 7/24/2024-7/25/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (474 channels, and 4280 messages) for you. Estimated reading time saved (at 200wpm): 467 minutes. You can now tag @smol_ai for AINews discussions!
It's been a good month for neurosymbolic AI. As humans gather for the 2024 Summer Olympics, AI has been making great advances in Math Olympics. Early this month, Numina won the first AIMO Progress Prize, solving 29/50 private set problems of olympiad math level.
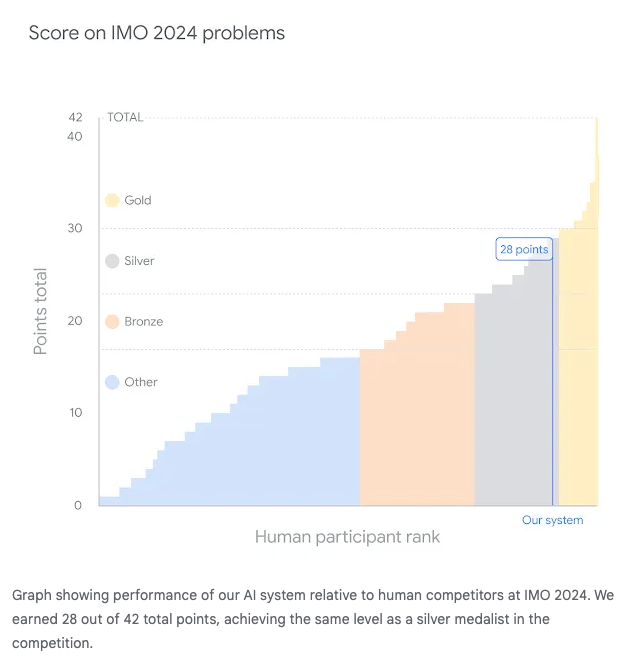
While 6 teenagers on team USA won the 65th International Math Olympiad, taking back China's crown, Google DeepMind announced that their new combination of AlphaProof and a new V2 of AlphaGeometry solved four out of six problems from the IMO (including solving Problem 4 in 19 seconds), with human judges (including the IMO Problem Selection Committee Chair) awarding it 28 points out of a maximum 42, 1 point short of the cutoff for a Gold.
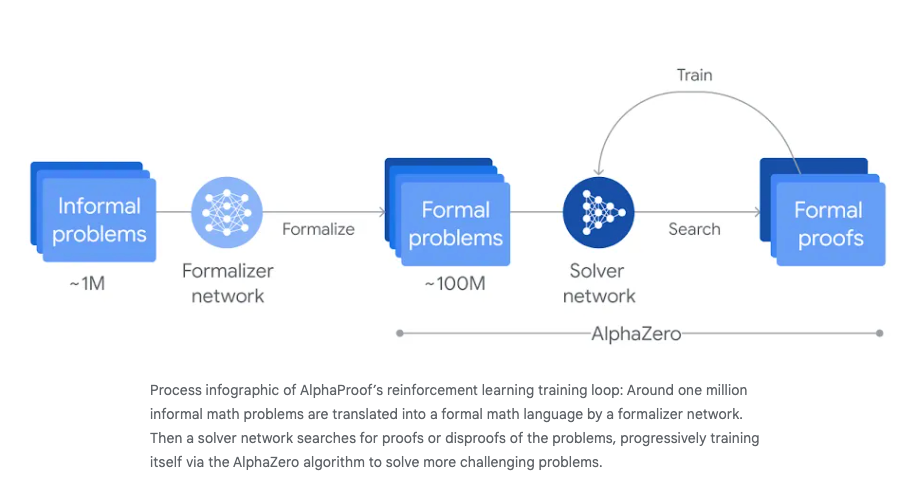
AlphaProof is a finetuned Gemini model combined with AlphaZero (paper) that proves mathematical statements in Lean, and uses an AlphaZero style aporoach to find solutions:
AlphaGeometry 2 is a neuro-symbolic hybrid system in which the language model was based on Gemini and trained from scratch on an order of magnitude more synthetic data than its predecessor. [It] employs a symbolic engine that is two orders of magnitude faster than its predecessor. When presented with a new problem, a novel knowledge-sharing mechanism is used to enable advanced combinations of different search trees to tackle more complex problems. Before this year’s competition, AlphaGeometry 2 could solve 83% of all historical IMO geometry problems from the past 25 years, compared to the 53% rate achieved by its predecessor.
However it's not all roses: Tim Gowers, one of the human IMO judges, noted:
The main qualification is that the program needed a lot longer than the human competitors -- for some of the problems over 60 hours -- and of course much faster processing speed than the poor old human brain. If the human competitors had been allowed that sort of time per problem they would undoubtedly have scored higher.
This is also similar to 2022 OpenAI work on Lean provers.
How can AI solve both AIMO problems and fail to solve 9.11 > 9.9? There are a couple thoughts on "Jagged Intelligence" that fall to the everpresent problem of generalization.
Nevertheless it's been a big day for prediction markets and private bets on AI in the IMO.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Llama 3.1 and Mistral Large 2 Release
- Model Specifications: @GuillaumeLample announced Meta's Llama 3.1 with a 405B parameter model and Mistral AI's Large 2 with 123B parameters, both featuring 128k context windows. Llama 3.1 also includes smaller 8B and 70B versions.
- Performance Comparisons: @GuillaumeLample shared that Mistral Large 2 outperforms Llama 3.1 405B on coding tasks like HumanEval and MultiPL-E, while Llama 3.1 405B shows superior performance in math.
- Multilingual Capabilities: @GuillaumeLample highlighted Mistral Large 2's strong performance on Multilingual MMLU, significantly surpassing Llama 3.1 70B base.
- Licensing and Availability: @osanseviero noted Llama 3.1's more permissive license allowing training on outputs. Mistral Large 2 is available under a research license for non-commercial use, as mentioned by @GuillaumeLample.
- Deployment Options: @abacaj shared that Llama 3.1 is accessible through Together API and Fireworks. Mistral Large 2 can be tested for free on Le Chat, according to @GuillaumeLample.
Open Source AI and Industry Impact
- Ecosystem Growth: @ClementDelangue emphasized the rapid progress of open-source AI, with models now rivaling closed-source alternatives in performance.
- Computational Requirements: @HamelHusain mentioned that running Llama 3.1 405B locally requires significant hardware, such as 8xH100 GPUs.
AI Development and Research
- Training Innovations: @GuillaumeLample revealed that Llama 3.1 utilized a large amount of synthetic data in its training process.
- Evaluation Challenges: @maximelabonne discussed the need for standardized benchmarks and highlighted limitations in current evaluation methods.
- Emerging Research Areas: @LangChainAI and @llama_index shared ongoing work in few-shot prompting and structured extraction respectively.
Industry Trends and Observations
- Model Lifecycle: @far__el coined the term "Intelligence Destruction Cycle" to describe the rapid obsolescence of AI models.
- Implementation Challenges: @nptacek highlighted the complexities of deploying AI systems in production environments beyond model capabilities.
- Ethical Considerations: @ylecun contributed to ongoing discussions about AI safety and societal impact of large language models.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Open Source AI Models Challenging Closed Platforms
- Anthropic Claude could block you whenever they want. (Score: 84, Comments: 44): Anthropic's Claude AI has reportedly blocked a user without apparent cause, highlighting the potential for arbitrary account restrictions under their terms of service. In response, the user is switching to Meta's open-source Llama 3.1 70B model for all tasks, emphasizing the need for accessible, unrestricted AI models.
- Users expressed gratitude for open-source models catching up to proprietary ones, with many citing reliability issues and arbitrary account restrictions as reasons for switching away from closed AI platforms like Claude and ChatGPT.
- Several users reported being banned from Claude without explanation, often for using a VPN or within minutes of account creation. The lack of transparency and communication regarding account suspensions was a common complaint.
- Discussion highlighted the advantages of open-source AI, including data privacy, customization, and independence from corporate control. Some users noted switching to models like Mixtral 8x22B and Llama 3.1 70B for their workflows.
- With the latest round of releases, it seems clear the industry is pivoting towards open models now (Score: 196, Comments: 96): The AI industry is shifting towards open models, with Meta releasing Llama 3 and Llama 3.1, including the 405B version, while Mistral has made their latest flagship model Mistral Large 2 available for download. Google has entered the open model arena with Gemma 2, Microsoft continues to release high-quality small models under Free Software licenses, and Yi-34B has transitioned to the Apache license, marking a significant change from late 2023 when a move away from open releases seemed likely. This trend suggests that closed-only vendors like OpenAI, despite upcoming releases like Claude 3.5 Opus from Anthropic, may face increasing competition from rapidly improving open models.
- Apple, Nvidia, AMD, Intel, X.ai, Amazon, and other tech giants are potential "sleeping giants" in AI development. Amazon has invested $4 billion in Anthropic, while X.ai is reportedly working on Grok 3, a multimodal model incorporating images, video, and audio.
- The shift towards open models is driven by the need for extensive testing and R&D. The open-source community provides valuable insights, use-cases, and problem-solving, creating a symbiotic relationship between companies and developers. This approach may be more effective than closed methods in advancing AI technology.
- Despite rapid improvements in open models, some users express concerns about potential diminishing returns in transformer architecture optimization. However, others argue that progress remains exponential, citing examples like Llama 3.1 8B outperforming earlier, much larger models like GPT-3.5 (175 billion parameters).
Theme 2. Breakthroughs in Specialized AI Capabilities
- DeepSeek-Coder-V2-0724 released today, 2nd place in aider leaderboard (Score: 87, Comments: 15): DeepSeek has released DeepSeek-Coder-V2-0724, which has achieved 2nd place in the aider leaderboard for coding assistants. This new version demonstrates improved performance in coding tasks, positioning it as a strong competitor in the field of AI-powered programming tools.
- Users appreciate DeepSeek's frequent updates and performance gains, with some expressing a desire for similar rapid iterations from other models like "Llama-3.2 next month, and 3.3 the month after".
- The API for DeepSeek-Coder-V2-0724 is described as "dirt cheap" and offers tools+json capability. However, some users report issues with the model generating full code blocks despite prompts asking otherwise.
- There's interest in the model's availability on Hugging Face, with the developer noting that release of weights might take some time, similar to the previous version (Deepseek-V2-0628).
- Introducing InternLM-Step-Prover. A SOTA math prover on MiniF2F, Proofnet, and Putnam benchmarks. (Score: 68, Comments: 8): InternLM-Step-Prover achieves state-of-the-art performance on math proving benchmarks including MiniF2F, Proofnet, and Putnam, solving 3 IMO problems in MiniF2F, including one (IMO1983P6) never before solved by ATP. The model and its training dataset, which includes Lean-Github data, have been open-sourced and are available on Hugging Face and GitHub, with the full research paper accessible on arXiv.
- The discussion highlights the shifting goalposts for defining AI intelligence, with users noting how proving mathematical theorems, once considered a benchmark for true intelligence, is now achievable by LLMs. This shift mirrors the abandonment of the Turing test as a standard.
- A user points out that according to pre-2010 definitions, current LLMs would be considered intelligent, while more recent definitions have made the term "intelligence" nearly meaningless. The rapid progress in ARC (Abstract Reasoning Corpus) scores is cited as an example.
- Some comments suggest that the constant redefinition of AI intelligence may be driven by fear among intellectuals of being surpassed by machines, leading to denial and attempts to delay acknowledging AI's capabilities.
Theme 3. Uncensored AI Models and Ethical Considerations
- Mistral Nemo is uncensored (Score: 131, Comments: 40): Mistral Nemo, a highly performant and uncensored model, outperforms other ~13b models on the UGI leaderboard, with its instruct version being more uncensored than the base model. Despite limited benchmarks, Mistral's track record suggests it will compete with larger models, and a Dolphin finetune has been released by Cognitive Computations, potentially making it even more uncensored.
- Mistral Nemo 12b is praised as the best model in its size category, with users reporting no refusals even with "gnarly" prompts. However, it still exhibits limitations due to its 12b size, including common GPT-isms and difficulty with complex instructions.
- Users compare Mistral Nemo 12b favorably to larger models, describing it as a "Gemma 2 27b lite" version. It performs well in roleplaying scenarios, maintaining coherence and character tracking even when quantized (Q8_0).
- The model is noted for being highly "open-minded," with a temperature of 0.3 producing wild results. It's now available in GGUF format, compatible with llama.cpp, making it accessible for users with limited hardware.
- Multimodal Llama 3 will not be available in the EU, we need to thank this guy. (Score: 164, Comments: 78): The post criticizes Thierry Breton, the EU Commissioner for Internal Market, for potentially restricting the release of multimodal Llama 3 in the European Union. The author suggests that Breton's actions, including a tweet about AI regulation, may lead to Meta not making the multimodal version of Llama 3 available in the EU, similar to how GPT-4V is currently unavailable in the region.
- Users discussed the practical implications of EU restrictions, noting that individuals can still access models via VPNs or self-hosting. However, EU businesses may face legal challenges in using these models commercially, potentially leading to an "AI colony" situation.
- The irony of Mark Zuckerberg becoming a "savior" for open AI access was noted, contrasting with Sam Altman's previous efforts to restrict open-source models. Users in Germany reported successfully downloading Llama 3.1 models using LM Studio.
- Criticism was directed at Thierry Breton and the EU's approach to AI regulation, with some calling it "dysfunctional" and potentially causing the EU to fall behind in AI development. Users questioned the effectiveness of blocking access to models trained on European data.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Benchmarks
- Llama 405B achieves SOTA performance: In /r/singularity, a post discusses how Llama 405B's success challenges the notion that OpenAI has proprietary techniques, achieving comparable performance without novel methods.
- "AI Explained" channel's Simple Bench results: A comparison of Llama 405B against other models on a private 100-question benchmark called "Simple Bench" is shared on /r/singularity.
- Open-source model surpasses GPT-4: /r/singularity reports on a second open-source model outperforming GPT-4, highlighting rapid progress in publicly available AI.
- Mistral Large 2 announced: Mistral AI introduces Mistral Large 2, a new model in their lineup, as reported on /r/singularity.
AI Applications and Improvements
- Udio 1.5 audio quality enhancement: Udio releases version 1.5 with significantly improved audio quality, as shared on /r/singularity.
AI Generation Challenges
-
Stable Diffusion prompt struggles: A humorous post on /r/StableDiffusion illustrates the challenges of generating specific content without unwanted elements, particularly in character generation.
- Comments suggest using
rating_safein positive prompts andrating_questionable, rating_explicitin negative prompts for better control. - Discussion touches on model biases, tagging systems, and the importance of careful prompt engineering.
- Comments suggest using
AI Discord Recap
A summary of Summaries of Summaries
1. AI Model Releases and Benchmarks
- Mistral Large 2 Takes on Llama 3.1: Mistral AI unveiled Mistral Large 2, a 123 billion parameter model with a 128k context window, outperforming competitors like Llama 3.1 70B by an average of 6.3% on multilingual benchmarks.
- The model excels in code generation, mathematics, and supports multiple languages, designed for efficient single-node inference. This release highlights the rapid advancements in open-source AI models competing with proprietary offerings.
- DeepMind's AlphaProof Scores Silver at IMO: Google DeepMind announced that their AlphaProof system, combined with AlphaGeometry 2, achieved silver medal level performance at the International Mathematical Olympiad, solving 4 out of 6 problems.
- This breakthrough demonstrates AI's growing capabilities in formal reasoning and mathematics, though it required significantly more time than human competitors. The achievement sparked discussions about AI's potential impact on mathematical research and education.
2. AI Search and Information Retrieval
- OpenAI Unveils SearchGPT Prototype: OpenAI announced testing for SearchGPT, a new AI search feature aimed at providing fast, relevant answers with clear source attribution, initially involving 10,000 users.
- This move signals OpenAI's entry into the search market, potentially challenging traditional search engines. The community expressed both excitement and skepticism, with discussions on its impact on existing AI-powered search tools like Perplexity.
- Reddit's Exclusive Deal with Google Raises Concerns: Reddit implemented a policy to block most search engines except Google from indexing its content, tied to a $60 million annual agreement between the two companies.
- This decision has sparked controversy regarding open internet practices and data accessibility, particularly concerning its impact on AI training datasets and the broader implications for information retrieval and model development.
3. Open Source AI and Community Efforts
- Llama 3.1 Sparks Optimization Efforts: The release of Llama 3.1 by Meta, especially the 405B parameter version, has prompted discussions and efforts in the open-source community to optimize its deployment and fine-tuning across various hardware setups.
- Developers are exploring techniques like quantization, distributed inference, and memory optimizations to run these large models efficiently. Platforms like Hugging Face are facilitating access and implementation of these models.
- Collaborative Tools for AI Development: New tools and libraries are emerging to support collaborative AI development, such as stack-pr for managing stacked pull requests, and discussions around sharing optimized kernels for GPU efficiency.
- These initiatives highlight the community's focus on improving development workflows and resource utilization in AI projects. There's growing interest in peer-to-peer sharing of optimizations and caches to leverage collective efforts in model training and inference.
4. AI Ethics and Data Usage
- Runway AI's Training Data Controversy: A leak revealed that Runway's AI video generation tool was trained on scraped content from YouTube and pirated films, raising ethical questions about data usage in AI training.
- This revelation sparked intense debate within the AI community about the ethics of using publicly available but potentially copyrighted content for training AI models, highlighting the ongoing challenges in balancing innovation with intellectual property rights.
- Condé Nast's Legal Action Against Perplexity: Condé Nast issued a cease-and-desist letter to AI search engine Perplexity, demanding they stop using content from Condé Nast publications in their AI responses.
- This legal action underscores the growing tensions between traditional media companies and AI-powered platforms over content usage rights, potentially setting precedents for how AI companies can use and cite published material.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Data Privacy Fears in Discord AI Training: Concerns emerged regarding using Discord logs for AI training under GDPR regulations, indicating that public data reuse may still require permission.
- Participants agreed that disregarding privacy rights could lead to significant violations, despite the perceived accessibility of public messages.
- Llama 3's Fine-Tuning Challenges: Users reported Out-Of-Memory (OOM) errors and inference quality issues while fine-tuning Llama 3, emphasizing the need for dataset sanitization.
- Advice included switching to instruct models to enhance response quality and addressing formatting inconsistencies in datasets.
- The Importance of Batching for Inference Speed: Participants stressed that batching data effectively can dramatically accelerate inference speed, noting that not using HF transformers can hinder performance.
- Discussion highlighted that many users experience negligible speeds, averaging 30-100 tokens/sec, due to mismanagement of batching.
- Inference Process Sluggishness Unpacked: A participant explained how the autoregressive inference process leads to slower response generation, as it computes each token sequentially.
- This sequential generation was critiqued for its inefficiency, prompting calls for improved methodologies for real-time applications.
- AI's Job Security Debate Heats Up: Discussion arose on the potential job displacement caused by AI, particularly in software engineering, revealing varied opinions on the urgency of these impacts.
- Participants reflected on both anxiety and acceptance regarding AI's integration into the workforce, questioning legislative responses to the fast-evolving landscape.
LM Studio Discord
- LM Studio 0.2.28 Supports Llama 3.1: The latest version of LM Studio, 0.2.28, is essential for utilizing Llama 3.1 effectively, as noted by users who have encountered limitations with previous versions.
- It seems upgrading is crucial for accessing new features, especially since auto-updater lacks this version.
- Understanding LLaMA's Pretraining Dataset: The LLaMA model's pretraining dataset comprises 50% general knowledge, 25% math reasoning, 17% code, and 8% multilingual, critical for its overall performance.
- This data mix's significance was shared through a data mix summary.
- Beta 1 Faces Performance Issues: Users are reporting significant CPU spikes in Beta 1, leading to sluggish performance during chat interactions, with one individual experiencing crashes.
- The general sentiment echoed among users is a keen interest in resolving these performance bottlenecks before the anticipated Beta 2 release.
- Mistral Large Model Is Here: Mistral Large, characterized by its imatrix design for size management, is now available with capabilities scaling up to 70GB.
- Users are urged to experiment with this model via its Hugging Face page, as it promises robust performance.
- Optimizing GPU Configurations for LLMs: Discussions highlighted various GPU setups, notably the P40 compared to newer models like the RTX 3090, revealing stark contrasts in speed and heat management.
- Notably, users have recorded speeds of 3.75 tokens/s with Llama 3.1 on the P40, but thermal issues demand cooling solutions for sustained performance.
HuggingFace Discord
- Llama 3.1 Hits the Scene: The much-anticipated Llama 3.1 is now available, enhancing the community's favorite AI chat models. Explore its capabilities on the official blogpost and utilize it via this link.
- Interested users can follow the Hugging Face recipes on GitHub for implementation details.
- Hugging Face Access Stumbles in China: Discussion highlighted the challenges of accessing Hugging Face in China, where the site is blocked, leading some developers to rely on VPNs for model access.
- Suggestions include negotiating with Chinese regulators to restore access, as well as promoting localized content.
- Dolphin 2.9.3 Model Revolutionizes AI: The newly released Dolphin 2.9.3 Mistral Nemo 12b model, curated by Eric Hartford, features a 128K context and an 8192 sequence length.
- This enhancement stems from the Mistral-Nemo-Base-2407 model, promising improved performance.
- Open Source Bounty Programs Flourish: Members shared that several open-source bounty programs are available encouraging contributions to implement various models.
- Such programs not only provide compensation for completed work but also facilitate skill development and collaboration.
- Optimizing with Quantized Diffusers: A new feature supporting quantized Diffusers models via Quanto offers a 50% reduction in memory usage, as detailed in this GitHub PR.
- Moreover, the Orig PixArt Sigma checkpoint size dropped significantly, from 2.44GB to 587MB, enhancing model access and processing speed.
Nous Research AI Discord
- Hermes 2 Theta 70B Surpasses Llama-3: Nous Research released Hermes 2 Theta 70B, which surpasses benchmarks set by Llama-3 Instruct and matches performance with GPT-4. This model features capabilities such as function calling and feature extraction.
- The launch reflects significant advances in model architecture, indicating a competitive edge in versatile AI applications.
- Mistral Large 2 Revolutionizes AI: On July 24, 2024, Mistral AI unveiled Mistral Large 2, boasting 123 billion parameters and a 128,000-token context window. This model excels in code generation and mathematics, edging out Llama 3.1.
- The introduction of this model is a step forward in scaling AI applications, possibly nearing parity with leading benchmarks like GPT-4.
- Reddit's New Indexing Policy: Reddit's update to block most search engines except Google sparked controversy linked to a $60 million agreement with Google. This change prevents unauthorized indexing, raising questions about open internet practices.
- Members debated the implications of restricted access to data, illuminating concerns over content availability in a rapidly evolving digital landscape.
- Condé Nast's Legal Action Against Perplexity: Condé Nast issued a cease-and-desist letter to Perplexity, demanding an end to content use from its publications. This escalates tensions between conventional media and AI-powered search engines amid Perplexity’s rise in valuation.
- The move reflects broader issues of content ownership and usage rights in an era of AI-driven information retrieval.
- LLaMA 3.1 under Scrutiny: Users reported disappointing results from the LLaMA 3.1 instruct model, which performed worse than LLaMA 3.0 in knowledge benchmarks. Discussions centered on the impact of RoPE on performances, suggesting it may be detrimental.
- Members noted that turning off RoPE could lead to better outcomes, especially for smaller models, indicating potential areas for optimization.
Modular (Mojo 🔥) Discord
- Modular releases new Git tool - stack-pr: Modular introduced a new open-source tool called stack-pr designed for managing stacked pull requests on GitHub, aimed at streamlining integration for developers.
- This tool supports smaller contributions, benefitting code reviews by enabling smoother updates during the PR evaluation process.
- Interest in Posits for AI applications: Discussion around the role of posits in AI revealed interest in implementations like Gosit and the llvm-xposit, with potential integration into MLIR on the horizon.
- However, members noted that transitioning from traditional floating-point systems to posits could pose significant challenges.
- Open sourcing Mojo matrix multiplication: A member announced the open-sourcing of their matrix multiplication implementation in Mojo, inviting others to share their performance benchmarks on their setups.
- This initiative aims to foster collaboration and technical discussions surrounding the performance metrics utilized.
- Discussions on SIMD Comparisons: The community engaged in discussions on SIMD comparisons, debating between preserving both element-wise and total comparison results to accommodate various functionalities.
- There is a push to ensure SIMD performance remains robust without compromising its integration with list behaviors, especially for databases.
- Introducing Llama 3.1 with enhanced capabilities: Meta unveiled its Llama 3.1 model, now featuring a 128K context length and support for eight languages, pushing the boundaries of open intelligence advancements.
- This model provides unique capabilities that match those of leading closed-source models, expanding potential AI applications.
Perplexity AI Discord
- Perplexity AI Scheduled Downtime Alert: Perplexity announced a 10-minute scheduled downtime on
- The team expressed gratitude to users for their patience during this crucial maintenance period.
- Mistral Large 2 Gains Ground in AI: On July 24, 2024, Mistral AI introduced Mistral Large 2, enhancing capabilities with 123 billion parameters and a 128,000-token context window, significantly outperforming the Llama 3.1 70B in multilingual MMLU benchmarks.
- Mistral Large 2 demonstrated an average improvement of 6.3% over its competitors, especially in code generation and mathematics.
- Reddit Places Search Engine Restrictions: Reddit's recent move blocks most search engines from indexing its content, granting access only to Google due to a $60 million annual agreement.
- This decision has sparked debates about data access implications for the scraping and training of AI models.
- Condé Nast Challenges AI Search Practices: Condé Nast has issued a cease-and-desist against Perplexity for allegedly using its publications without approval, indicating escalating tensions in media-AI content usage.
- This legal action puts a spotlight on the complexities of content rights as AI tools proliferate and seek to monetize information.
- Microsoft Teams Connector Error Reported: A user encountered an unspecified error message while attempting to upload a Perplexity Connector ZIP file into Microsoft Teams.
- This prompted inquiries about successful integration experiences and potential workarounds within the community.
OpenRouter (Alex Atallah) Discord
- Llama 405B gets a 10% price cut: The price of Llama 405B has been reduced by 10% as announced by OpenRouterAI, part of ongoing competitive strategies in the market.
- This trend suggests a filtering mechanism for user choice amid aggressive pricing tactics in AI model offerings.
- Middle-out transform to be turned off by default: Starting August 1, the middle-out transform will be turned off by default, shifting from its historical setting to enhance user control.
- Users reliant on this feature should refer to the documentation to adjust their requests accordingly.
- Traffic surge causes database strain: OpenRouter experienced a 5x traffic surge, leading to a scheduled downtime at 10:05 PM ET for database upgrades.
- Post-upgrade services were reported to be back online promptly, but with unresolved performance concerns due to recurrent database issues.
- Llama 3.1 exhibits variable performance: Reports indicate inconsistent outputs from Llama 3.1, particularly during high context loads, with some responses being off-topic.
- Users noted that switching providers sometimes improved output quality, indicating a potential issue with inference engine effectiveness.
- Mistral Large 2 showcases multilingual prowess: Mistral Large 2 excels in multiple languages, demonstrating substantial capability in languages including English, Spanish, and Mandarin.
- The performance positions it as a significant contender in multilingual language processing domains.
OpenAI Discord
- OpenAI tests SearchGPT Prototype: OpenAI introduces SearchGPT, a prototype aimed at enhancing search capabilities with fast, relevant answers and clear sourcing, rolling out initially to select users for feedback. More info can be found at OpenAI's SearchGPT page.
- User feedback during testing will be crucial for refining SearchGPT before its fully integrated into ChatGPT.
- Long Downloads for Mistral Model: Users reported lengthy download times for the Mistral Large model, with one noting a download duration of 2.5 hours and achieving 18 tk/s on their MacBook Pro performance. Despite slow downloads, the MacBook Pro M2 Max's capabilities with 96GB RAM generated excitement for future improvements.
- Anticipation for internet upgrades was palpable, as one user plans to boost their speed to 1 Gbps in December, essential for optimizing download times.
- Users Frustrated with GPT-4o Performance: After upgrading to GPT-4o, users expressed disappointment, noting frequent inaccuracies and lack of sourced responses, with one lamenting, 'I felt the wise friend was long gone, only its dumb twin brother stayed.'
- Concerns about the SearchGPT API suggested that general access might take months, with users prioritizing functional improvements over API specifics.
- Challenges with Chatbot Memory Functions: Developers discussed difficulties in implementing function calls for chatbot memory creation, editing, and removal, currently hitting accuracy rates of around 60%. Clear guidance is deemed necessary for improving memory storage decisions.
- Suggestions included saving user preferences alongside important events, while emphasizing the need for specificity in memory input instructions.
- Issues with File Upload to OpenAI: A user encountered a 400 error while trying to upload a txt file to OpenAI, citing unsupported file extensions and referring to the OpenAI documentation.
- Despite following detailed documentation for file uploads using Python and FastAPI, the user faced challenges with vector store configurations linked to file upload failures.
Stability.ai (Stable Diffusion) Discord
- Stable Video 4D Shakes Up Video Generation: Stability AI introduced Stable Video 4D, a pioneering video-to-video generation model that creates dynamic multi-angle videos from a single input video in about 40 seconds.
- With the ability to generate 5 frames across 8 views, this tool enhances the creative process for users aiming for quality video production.
- Stable Assistant Gains New Powers: Stable Assistant now features Inpaint and Erase tools, allowing users to clean up generated content and iterate effortlessly within a 3-day free trial.
- These updates enable fine-tuning of output, catering to users seeking precision in their creative workflows.
- Debate Rages on Model Performance: Discussions heated up around model efficiency, with members claiming that a certain model outperforms SDXL while others noted the increasing competition from models like Kolors and Auraflow.
- The emphasis was placed on staying current with releases due to the rapidly shifting landscape of model performance.
- Mastering Lora Training for Better Outputs: Community members exchanged insights on the best practices for Lora training, emphasizing whether to use full or cropped images for different features.
- This discourse highlighted critical strategies for crafting detailed training datasets to enhance results effectively.
- Inpainting Techniques Explored in Detail: Users explored various inpainting methods, with recommendations to leverage img2img processes and pertinent tutorial resources for optimal results.
- The community reinforced using context-rich prompts as essential for successfully integrating objects into scenes.
Eleuther Discord
- Flash Attention Optimizes VRAM but Not Time: Flash Attention helps achieve linear VRAM usage, particularly during inference, but it does not lessen time complexity, which remains quadratic. One member observed that using Flash Attention with a long cache and a single query could actually slow down performance due to reduced parallelization.
- The impact of strategies like KV-Cache was discussed in terms of linear increases with sequence length, affecting VRAM without a significant change in compute time.
- Debate on Inference Costs for Model Providers: Members argued that inference for models like Mistral should be available for free at scale, emphasizing the efficiency of utilizing either single layers or MoE frameworks. Concerns were raised that inefficiencies in batch inference could undermine the benefits of MoE due to heightened complexity.
- Discussions touched on the minimal understanding of Meta's operational tactics, challenging the operational efficiency that seems to be neglected in favor of optimization of lines of code.
- Scrutiny on Meta's Scaling Laws: Users questioned if Meta's scaling laws are affected by data superposition, suggesting non-linear scaling of optimal data amounts via exponential functions. This led to dialogue about calculating and understanding optimal data quantities in relation to model performance.
- Generalization of Chinchilla to 20 tokens per parameter was mentioned, revealing that scaling perceptions seem distorted yet rational at a deeper level.
- Explore the Awesome Interpretability Repository: The Awesome Interpretability in Large Language Models GitHub repository serves as an essential compilation for researchers focused on LLM interpretability. It functions as a key resource for digging into the complexities of large language model behaviors.
- Participation in the NDIF initiative allows access to Llama3-405b for audacious experiments, where participants will receive substantial GPU resources and support—a novel opportunity for meaningful research collaboration documented here.
- MMLU Evaluation on External APIs: A member is seeking guidance on testing MMLU performance with external APIs reflective of OpenAI’s setup, especially regarding log_probs in the model evaluation process. A related GitHub PR was mentioned that introduces a superclass aimed at API modularity.
- Concerns about calculating necessary VRAM for model evaluations arose, emphasizing the understanding of VRAM capabilities' implications on experimental outcomes.
CUDA MODE Discord
- NCCL Overlap Challenges: A user raised concerns about achieving computation overlap with NCCL during the backward pass in their training setup using NCCL Issue #338. They noted that implementing what was suggested in lectures proved to be more complex than expected.
- This highlights ongoing challenges in effectively utilizing NCCL for optimized GPU workloads in training.
- Flute Matrix Multiplications Introduced: A member shared the repository for Flute, focused on fast matrix multiplications for lookup table-quantized LLMs. This aims to enhance performance in LLM processing applications.
- This tool could potentially streamline operations for models requiring efficient matrix handling, crucial for large-scale deployments.
- Analyzing Triton Kernels with CUDA Tools: You can analyze triton kernels just like other CUDA kernels using tools like Nsight Compute for detailed profiling. Nsight Compute provides comprehensive analysis capabilities to optimize GPU throughput.
- This profiling tool is essential for developers aiming to enhance performance and efficiency in GPU applications.
- Memory Limitations with FP16 Execution: A user expressed frustration regarding insufficient memory to run the model at fp16 precision, highlighting a common issue faced by developers. This prompted discussions on exploring alternative solutions to optimize memory usage.
- Addressing this issue is crucial for improving the feasibility of deploying large models in memory-constrained environments.
- Exploring Quantization Techniques with BnB: Another user recommended investigating quantization techniques using the bitsandbytes (BnB) library as a potential workaround for memory issues. This sparked confusion, with some questioning the concept of quantization itself.
- Understanding the implications of quantization is vital for leveraging model efficiencies, especially in large language models.
Interconnects (Nathan Lambert) Discord
- DeepMind AI achieves Silver at IMO 2024: A recent discussion centered around Google DeepMind AI earning a silver medal at the IMO 2024, according to Google's blog stating it meets 'silver-medal standard.'
- Skeptics questioned the criteria's clarity, suggesting Google may have influenced challenges to showcase its AI's performance.
- Runway AI's training data sources exposed: A leak revealed that Runway's AI video generation tool was trained on scraped YouTube content and pirated films, which has raised ethical concerns.
- The controversy sparked intense discussion, hinting at heated debates over the implications for content creators.
- OpenAI enters search market with SearchGPT: OpenAI announced testing for SearchGPT, aimed at delivering quick answers and will initially involve 10,000 users.
- Feedback from this testing is expected to shape integrations into ChatGPT, generating excitement for improvements in AI search features.
- Recommendations for Books on Modern Architectures: In the search for resources on Diffusion and Transformers, a community member sought book recommendations for an ML course, highlighting the need for more focused reading materials.
- One suggestion was the book from rasbt, Building LLMs from scratch, but members are looking for more comprehensive titles on modern architectures.
- Understanding LLAMA 3.1 Annealing: Discussion focused on the LLAMA 3.1 technical report, particularly how lowering the learning rate to 0 aids in training without overshooting optimal points.
- This tactic could enhance model performance on leaderboards through meticulous pretraining strategies.
Latent Space Discord
- OpenAI's SearchGPT Prototype Takes Off: OpenAI announced the launch of the SearchGPT prototype, designed to enhance search capabilities beyond current options, starting with a select user group for feedback.
- This initial phase aims to gather insights before integrating the prototype into ChatGPT for real-time operations.
- AI Shines at the International Mathematical Olympiad: A hybrid AI system developed by Google DeepMind secured silver medal level performance at the International Mathematical Olympiad (IMO), solving 4 out of 6 problems using AlphaProof and AlphaGeometry 2.
- This achievement highlights significant progress in AI's capability to tackle complex mathematical challenges, although it took longer than human competitors.
- OpenAI's Rule-Based Rewards for Safer AI: OpenAI released Rule-Based Rewards (RBRs) aimed at improving AI safety by aligning behavior without requiring extensive human data collection.
- This approach allows for quicker adjustments to safety protocols with fewer manually labeled examples, promoting a more adaptable safety model.
- LLMs Step Up as Judges with Grading Notes: Databricks introduced Grading Notes to improve the reliability of LLMs in judgment roles by creating structured evaluation rubrics.
- The incorporation of these notes enhances domain-specific applications by providing clear guidelines for LLMs in specialized assessments.
- Synthetic Data in AI Training Faces Criticism: Concerns were raised in a recent paper about the over-reliance on synthetic data for AI training, warning that it could lead to model collapse after multiple generations.
- Experts emphasize maintaining diversity in training inputs to uphold information quality and mitigate performance degradation.
LlamaIndex Discord
- Structured Extraction Capabilities Launch: A new release enables structured extraction capabilities in any LLM-powered ETL, RAG, or agent pipeline, fully supporting async and streaming functionalities.
- Users can now define a Pydantic object and attach it to their LLM using
as_structured_llm(…)for streamlined implementation.
- Users can now define a Pydantic object and attach it to their LLM using
- Introducing LlamaExtract for Efficient Data Extraction: An early preview of LlamaExtract, a managed service for extracting structured data from unstructured documents, was revealed.
- This service infers a human-editable schema from documents, enabling user-defined criteria for structured extraction.
- OpenAI Calls Duplication Confusion: Users raised concerns about seeing duplicate OpenAI calls in
MultiStepQueryEngine, leading to discussions about logging issues with Arize.- Clarifications confirmed that these are not actual duplicates and progress continues on structured text extraction.
- RAG Chatbot Update Plans Shared: A user shared plans to upgrade their earlier RAG chatbot built with LlamaIndex, including a link to the GitHub repo for developers.
- They highlighted their eagerness to enhance the chatbot's functionality now that RAG is much more popular.
- Monitoring Llama Agents Article Gains Praise: Members discussed an article titled Monitoring Llama Agents: Unlocking Visibility with LlamaIndex and Portkey, found here.
- One member remarked that it's a nice article, emphasizing its significance to the community.
Cohere Discord
- Cohere compares well against OpenAI: Cohere provides language model solutions focused on natural language processing via API, allowing developers to create tools like conversational agents and summarizers. For comprehensive information, visit the Cohere API documentation.
- Their pricing is usage-based, eliminating the need for subscriptions, which differentiates it from other competitors in the market.
- Guidance for Writing Research Papers: Members discussed tips on writing research papers, emphasizing the role of university advisors for newcomers in academia. They pointed to the Cohere For AI community as a resource for collaborative support.
- The community offers essential guidance, helping to bolster the early stages of academic research for new authors.
- Understanding Langchain's optional_variables: Clarifications about 'optional_variables' in Langchain's ChatPromptTemplate surfaced, highlighting its function to permit non-required variables in prompts. This flexibility is crucial for creating adaptive user queries.
- However, confusion arose regarding how it differs from 'partial_variables', which also offers handling of optional metadata in prompt designs.
OpenAccess AI Collective (axolotl) Discord
- Mistral Large 2 sets new benchmarks: Mistral Large 2 is reported to outperform 405 billion parameter models with a 123 billion parameters and a 128k context window, making it suitable for long context applications.
- This model supports multiple languages and coding languages, designed for efficient single-node inference, raising excitement about its performance potential.
- Exploring Multi-token Predictions: Members expressed curiosity about multi-token predictions, noting its potential in making byte-level models more feasible and efficient during training.
- There's enthusiasm about possible annotations in datasets to specify token predictions, aligning thoughts with methodologies discussed in related papers.
- Training Data Modification Strategies: The discussion revolved around improving the efficiency of training by masking simpler words that don't add value, akin to concepts from the Microsoft Rho paper.
- Members considered strategies to augment training data, like analyzing perplexity spots and enhancing context with tags to boost training effectiveness.
- Confusion Over Mistral Releases: There was confusion about the release details of Mistral Large vs Mistral Large 2, with members questioning the open-source status and the improvement claims.
- Some expressed concern over the relative performance metrics compared to existing models like Claude 3.5 and whether this model would eventually be open-sourced.
- Challenges loading 405B with FSDP and Zero3: A user reported difficulties getting the 405B model to load using FSDP or Zero3 with QLoRA.
- They expressed uncertainty about the specific issues causing these loading failures.
tinygrad (George Hotz) Discord
- Kernel Sharing Enhances GPU Efficiency: Members discussed the potential of peer-to-peer (p2p) kernel sharing to improve GPU efficiency after searching for optimal kernels.
- Previous discussions highlighted the effectiveness of p2p searches and sharing tinygrad caches.
- Need for Multiple Backpropagation Support: The community emphasized the necessity for a consistent method to backpropagate multiple times in tinygrad to implement neural network potentials.
- While some felt combining losses for backward calls would suffice, many sought a solution that retains the computation graph for complex gradient calculations.
- Random Tensor Generation Gives Repeated Results: A user reported issues with get_random_sum() returning the same output repeatedly due to TinyJit's output overwriting behavior.
- It was advised that using
.numpy()before repeat calls would resolve this, ensuring unique outputs.
- It was advised that using
- Optimization in NumPy Conversion Process: A user reported cutting the NumPy conversion time from 6 seconds to 3 seconds by removing
.to('CLANG')in the tensor conversion method.- While questions about correctness arose, they verified that the resulting NumPy array remained accurate.
OpenInterpreter Discord
- Mistral-Large-Instruct-2407 offers speed: Mistral-Large-Instruct-2407 (128B) is approximately 3x smaller than the 405B model, resulting in reduced inference time.
- This reduction might appeal to those looking for efficient models.
- Llama 3.1 output token maximum inquiry: A member inquired about the maximum output tokens for Llama 3.1, indicating a need for more information in the community.
- Understanding these limits could optimize users' experience with Llama 3.1.
- Concerns over outdated Ubuntu installation: Discussions arose about the installation instructions for Ubuntu potentially being outdated.
- It was noted that the current instructions do not work anymore.
- Fine-tuning GPT-4o-mini for optimization: A question was raised about fine-tuning GPT-4o-mini for better performance within the Open Interpreter framework.
- This discussion reflects an interest in capitalizing on the free fine-tuning quota available.
- Deepseek coder shows promising update: There was excitement over the recent update for the Deepseek coder, with promising performance specs shared.
- The affordability of Deepseek at 14-28 cents per mil was highlighted as a significant advantage.
Torchtune Discord
- Llama 3.1 approaches testing completion: Members indicated they’re finalizing tests for the Llama 3.1 patch, focusing on integrating 405B QLoRA on a single node. One participant flagged difficulties in saving checkpoints for such a large model.
- The current efforts reflect significant advancements, but challenges remain, especially in memory management while dealing with heavier models.
- Explore multi-GPU production challenges for Llama 3/3.1: Inquiries arose about distributed generation for Llama 3/3.1 70B, with pointers that current capabilities don't support it natively; members suggested checking a repo for workarounds. Additionally, single GPU fitting was problematic, and users were directed towards quantizing the model to int4.
- Ongoing discussions indicated that while multi-GPU inference support isn't prioritized, development is underway in the torchchat library.
- Snowflake enhances fine-tuning memory management: A member highlighted a blog post outlining memory optimizations for finetuning Llama 3.1, noting peak usage of 66GB on A100s using bfloat16. They shared that the lack of FP8 kernels forced this choice.
- The insights seem to set the stage for more efficient AI deployment as they share techniques for working with large model architectures.
- RFC proposes Transformer mod upgrades for cross attention: An RFC proposal seeks to modify TransformerDecoderLayer for cross attention in multimodal applications. It projects considerable implications for existing custom builders due to changes detailed in a pull request.
- Members were warned about the need for updates, emphasizing the comprehensive nature of the changes to maintain compatibility.
- Experimentation with distributed generation scripts: A user suggested that the existing generate.py could be adapted into generate_distributed.py for those adept with FSDP integration techniques. They recommended leveraging distributed finetuning recipes for smoother transitions.
- This approach could streamline multi-GPU implementations and enhance collaborative efforts as they aim to maximize efficiency in distributed environments.
LAION Discord
- Mistral Large 2 sets new AI benchmarks: Mistral Large 2 features a 128k context window and supports over a dozen languages, boasting 123 billion parameters for enhanced AI applications.
- Single-node inference capabilities allow for extensive throughput in long-context tasks.
- DFT Vision Transformer reshapes image processing: The new DFT Vision Transformer employs a Fourier transform, MLP, and inverse Fourier transform in each block to enhance image quality without bottlenecking data.
- This architecture also integrates image-wide norm layers efficiently, maintaining detailed information throughout.
- Complex numbers take center stage: The DFT Vision Transformer operates entirely with complex number parameters, enhancing computational dynamics within the network.
- This allows for an effective merging with rotary position encoding, refining overall performance.
- Rotary Position Encoding improves training speed: Switching to rotary position encoding resulted in a marked improvement in the loss curve's decline rate, showing positive effects on training.
- Participants found this enhancement quite satisfying, confirming the method's efficacy.
- Streamlined design boosts performance: The DFT Vision Transformer features a straight pipeline structure through equally sized blocks, completing with a global average pool and a linear layer.
- This ensures the image is never downsampled, preserving all information throughout processing.
DSPy Discord
- SymbolicAgentLearner merges RAG with symbolic learning: A member developed a SymbolicAgentLearner using DSPy that integrates Retrieval-Augmented Generation (RAG) and symbolic techniques for question answering and citation generation.
- The SymbolicLearningProcedure class enables multi-hop retrieval and auto-added citations, significantly enhancing information richness.
- Plans for a shared GitHub repository: In response to interest, it was mentioned that plans are in place to create a new public GitHub repository to share developments with the broader community.
- Currently, the existing code repository remains private, but this change aims to increase accessibility and collaboration.
- litellm proxy achieves flawless integration: Members reported using a litellm proxy across all models, noting it works like a charm for integrating with DSPy by redirecting OpenAI's
api_base.- This solution simplifies model interactions, enhancing the usability of DSPy.
- Function calling across models requires extra effort: A member successfully enabled function calling across various models, though it requires additional workaround steps.
- Specific methods employed were discussed but not detailed, highlighting the effort needed for cross-model functionality.
- DSPy's new approach to news categorization: A newly implemented news categorization system uses DSPy and OpenAI's GPT-3.5-turbo to classify articles as 'fake' or 'real' via a Chain of Thought mechanism.
- The method employs ColBERTv2 for retrieval and MIPRO for optimization, showcasing a custom F1 score for effectiveness in evaluating misinformation.
LangChain AI Discord
- LangChain Agents struggle with consistency: Users voiced frustration with LangChain agents that utilize open-source models, citing inconsistent performance and improper tool selection.
- Multiple testers reported similarly disappointing results when evaluating local LLMs.
- Community explores Multi Agents functionality: A user sought guidance on implementing multi agents, spurring the community to discuss specific functionalities of interest.
- This exchange prompted further questions about the potential applications and configurations of these agents.
- Inquiry to use ConversationSummary with Database Agents: A user wondered if they could integrate ConversationSummary with their own database agent, asking for implementation advice.
- They showed openness to suggestions, especially if direct usage presented challenges.
- LangChain and Ollama drop a useful video: A member highlighted a YouTube video called 'Fully local tool calling with Ollama' that discusses local LLM tools and their usage.
- The video aims to clarify tool selection and maintains that agents can function consistently if set up correctly; watch it here.
- LangGraph looks for persistent options: A user requested updates on potential enhancements to LangGraph persistence beyond existing SqliteSaver options.
- Community members shared interest in alternative storage solutions that could improve data handling.
AI Stack Devs (Yoko Li) Discord
- Excitement for AI Raspberry Pi: In a recent exchange, a user expressed enthusiasm over the AI Raspberry Pi project, prompting curiosity about its specifics.
- The request for more details suggests potential interest in its capabilities and applications within low-cost AI deployment.
- Inquiry for More Details: A member requested further information, stating, this is cool, tell us more regarding the AI Raspberry Pi discussions.
- This indicates an active engagement in the community around innovative AI projects using Raspberry Pi, likely looking to explore technical intricacies.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!