[AINews] AIPhone 16: the Visual Intelligence Phone
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Apple Intelligence is maybe all you need.
AI News for 9/6/2024-9/9/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (215 channels, and 7493 messages) for you. Estimated reading time saved (at 200wpm): 774 minutes. You can now tag @smol_ai for AINews discussions!
At the special Apple Event today, the new iPhone 16 lineup was announced, together with 5 minutes spent covering some updates on Apple Intelligence (we'll assume you are up to speed on our WWDC and Beta release coverage).
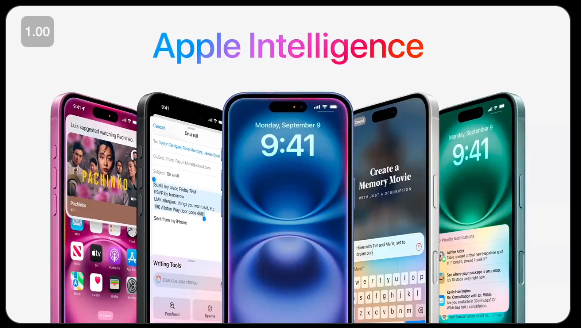
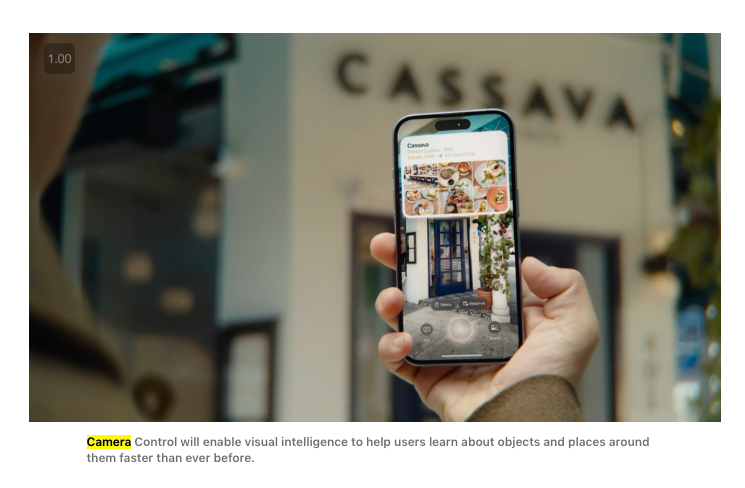
The newest update is what they now call Visual Intelligence, rolling out with the new dedicated Camera Control button for iPhone 16:
As discussed on the Winds of AI Winter pod and now confirmed, Apple is commoditizing OpenAI and putting its own services first:

Presumably one will eventually be able to configure what the Ask and Search buttons call in the new UI, but every Visual Intelligence request will run through Apple Maps and Siri first and those services second. Apple wins here by running first, being default, and being private/free, which is surprisingly a more defensible position than being "best".
Apple Photos now also have very good video understanding, down to the timestamps in a video:

Craig Federighi called this a part of Apple Intelligence in his segment, but some of these features are already in the iOS 18.0 beta (Apple Intelligence only shipped in iOS 18.1).
You can read the Hacker News commentary for other highlights and cynical takes but that's the big must-know thing from today.
How many years until Apple Visual Intelligence is just... always on?

A Note on Reflection 70B: our coverage last week (and tweet op-ed) covered known criticisms on Friday, but more emerged over the weekend to challenge their claims. We expect more developments over the course of this week, therefore it is premature to make it another title story, but interested readers should scroll to the /r/localLlama section below for a full accounting.
Perhaps we should work on more ungameable LLM evals? Good thing this month's inference is supported by our friends at W&B...
Sponsored by Weights & Biases: If you’re a builder in the Bay Area Sep 21/22, Weights & Biases invites you to hack with them on pushing the state of LLM-evaluators forward. Build better LLM Judges at the W&B Judgement Day hack - $5k in prizes, API access and food provided.

Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- HuggingFace Discord
- aider (Paul Gauthier) Discord
- OpenRouter (Alex Atallah) Discord
- Stability.ai (Stable Diffusion) Discord
- LM Studio Discord
- Perplexity AI Discord
- Cohere Discord
- Nous Research AI Discord
- CUDA MODE Discord
- OpenAI Discord
- Modular (Mojo 🔥) Discord
- Eleuther Discord
- Interconnects (Nathan Lambert) Discord
- Latent Space Discord
- OpenInterpreter Discord
- LlamaIndex Discord
- Torchtune Discord
- LangChain AI Discord
- OpenAccess AI Collective (axolotl) Discord
- LAION Discord
- DSPy Discord
- tinygrad (George Hotz) Discord
- Gorilla LLM (Berkeley Function Calling) Discord
- LLM Finetuning (Hamel + Dan) Discord
- Alignment Lab AI Discord
- MLOps @Chipro Discord
- PART 2: Detailed by-Channel summaries and links
- HuggingFace ▷ #general (930 messages🔥🔥🔥):
- HuggingFace ▷ #today-im-learning (9 messages🔥):
- HuggingFace ▷ #cool-finds (11 messages🔥):
- HuggingFace ▷ #i-made-this (51 messages🔥):
- HuggingFace ▷ #reading-group (6 messages):
- HuggingFace ▷ #computer-vision (8 messages🔥):
- HuggingFace ▷ #NLP (3 messages):
- HuggingFace ▷ #diffusion-discussions (2 messages):
- aider (Paul Gauthier) ▷ #general (687 messages🔥🔥🔥):
- aider (Paul Gauthier) ▷ #questions-and-tips (193 messages🔥🔥):
- aider (Paul Gauthier) ▷ #links (14 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (10 messages🔥):
- OpenRouter (Alex Atallah) ▷ #general (611 messages🔥🔥🔥):
- OpenRouter (Alex Atallah) ▷ #beta-feedback (11 messages🔥):
- CUDA MODE ▷ #cool-links (18 messages🔥):
- Stability.ai (Stable Diffusion) ▷ #general-chat (592 messages🔥🔥🔥):
- LM Studio ▷ #general (402 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (83 messages🔥🔥):
- Perplexity AI ▷ #general (334 messages🔥🔥):
- Perplexity AI ▷ #sharing (49 messages🔥):
- Perplexity AI ▷ #pplx-api (13 messages🔥):
- CUDA MODE ▷ #llmdotc (2 messages):
- Cohere ▷ #discussions (334 messages🔥🔥):
- Cohere ▷ #questions (25 messages🔥):
- Cohere ▷ #api-discussions (20 messages🔥):
- Cohere ▷ #projects (13 messages🔥):
- Nous Research AI ▷ #general (199 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (7 messages):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #interesting-links (19 messages🔥):
- Nous Research AI ▷ #research-papers (2 messages):
- Nous Research AI ▷ #reasoning-tasks (2 messages):
- CUDA MODE ▷ #general (16 messages🔥):
- CUDA MODE ▷ #triton (49 messages🔥):
- CUDA MODE ▷ #torch (6 messages):
- CUDA MODE ▷ #algorithms (2 messages):
- CUDA MODE ▷ #cool-links (18 messages🔥):
- CUDA MODE ▷ #beginner (27 messages🔥):
- CUDA MODE ▷ #pmpp-book (2 messages):
- CUDA MODE ▷ #torchao (2 messages):
- CUDA MODE ▷ #off-topic (14 messages🔥):
- CUDA MODE ▷ #irl-meetup (6 messages):
- CUDA MODE ▷ #triton-puzzles (10 messages🔥):
- CUDA MODE ▷ #hqq-mobius (2 messages):
- CUDA MODE ▷ #llmdotc (2 messages):
- CUDA MODE ▷ #rocm (1 messages):
- CUDA MODE ▷ #arm (1 messages):
- CUDA MODE ▷ #liger-kernel (19 messages🔥):
- CUDA MODE ▷ #thunder (4 messages):
- OpenAI ▷ #ai-discussions (112 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (7 messages):
- OpenAI ▷ #prompt-engineering (30 messages🔥):
- OpenAI ▷ #api-discussions (30 messages🔥):
- Modular (Mojo 🔥) ▷ #general (80 messages🔥🔥):
- Modular (Mojo 🔥) ▷ #mojo (96 messages🔥🔥):
- Eleuther ▷ #general (124 messages🔥🔥):
- Eleuther ▷ #research (20 messages🔥):
- Eleuther ▷ #scaling-laws (13 messages🔥):
- LAION ▷ #research (9 messages🔥):
- Eleuther ▷ #interpretability-general (12 messages🔥):
- Eleuther ▷ #lm-thunderdome (5 messages):
- Interconnects (Nathan Lambert) ▷ #news (144 messages🔥🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
- Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Latent Space ▷ #ai-general-chat (47 messages🔥):
- Latent Space ▷ #ai-in-action-club (76 messages🔥🔥):
- OpenInterpreter ▷ #general (38 messages🔥):
- OpenInterpreter ▷ #O1 (54 messages🔥):
- OpenInterpreter ▷ #ai-content (5 messages):
- LlamaIndex ▷ #blog (9 messages🔥):
- LlamaIndex ▷ #general (51 messages🔥):
- Torchtune ▷ #general (25 messages🔥):
- Torchtune ▷ #dev (32 messages🔥):
- LangChain AI ▷ #general (41 messages🔥):
- LangChain AI ▷ #share-your-work (9 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (33 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- LAION ▷ #general (21 messages🔥):
- LAION ▷ #research (9 messages🔥):
- LAION ▷ #paper-discussion (1 messages):
- DSPy ▷ #show-and-tell (2 messages):
- DSPy ▷ #general (26 messages🔥):
- tinygrad (George Hotz) ▷ #general (6 messages):
- tinygrad (George Hotz) ▷ #learn-tinygrad (17 messages🔥):
- Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (10 messages🔥):
- LLM Finetuning (Hamel + Dan) ▷ #general (2 messages):
- Alignment Lab AI ▷ #general (1 messages):
- MLOps @Chipro ▷ #events (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Benchmarks
- Reflection-70B Claims: @JJitsev reported that Reflection-70B claims to be the "world's top open source model" based on common benchmarks. However, preliminary tests using the AIW problem show the model is close to Llama 3 70B and slightly worse than Qwen 2 72B, not reaching top-tier performance as claimed.
- LLM Planning Capabilities: @ylecun noted that LLMs still struggle with planning. Llama-3.1-405b and Claude show some planning ability on Blocksworld, while GPT4 and Gemini perform poorly. Performance is described as "abysmal" for all models on Mystery Blocksworld.
- PLANSEARCH Algorithm: @rohanpaul_ai highlighted a new search algorithm called PLANSEARCH for code generation. It generates diverse observations, constructs plans in natural language, and translates promising plans into code. Claude 3.5 achieved a pass@200 of 77.0% on LiveCodeBench using this method, outperforming the no-search baseline.
AI Tools and Applications
- RAG Pipeline Development: @dzhng reported coding a RAG pipeline in under an hour using Cursor AI composer, optimized with Hyde and Cohere reranker, without writing a single line of code. The entire process was done through voice dictation.
- Google AI's Illuminate: @rohanpaul_ai mentioned Google AI's release of Illuminate, a tool that converts research papers to short podcasts. Users may experience a waiting period of a few days.
- Claude vs Google: @svpino shared an experience where Claude provided step-by-step instructions for a problem in 5 minutes, after spending hours trying to solve it using Google.
AI Research and Developments
- AlphaProteo: @adcock_brett reported on Google DeepMind's unveiling of AlphaProteo, an AI system designed to create custom proteins for binding with specific molecular targets, potentially accelerating drug discovery and cancer research.
- AI-Driven Research Assistant: @LangChainAI shared an advanced AI-powered research assistant system using multiple specialized agents for tasks like data analysis, visualization, and report generation. It's open-source and uses LangGraph.
- Top ML Papers: @dair_ai listed the top ML papers of the week, including OLMoE, LongCite, AlphaProteo, Role of RAG Noise in LLMs, Strategic Chain-of-Thought, and RAG in the Era of Long-Context LLMs.
AI Ethics and Societal Impact
- Immigration Concerns: @fchollet expressed concerns about potential immigration enforcement actions, suggesting that legal documents may not provide protection in certain scenarios.
- AI's Broader Impact: @bindureddy emphasized that AI is more than hype or a business cycle, stating that we are creating new beings more capable than humans and that AI is "way bigger than money."
Hardware and Infrastructure
- Framework 13 Computer: @svpino mentioned purchasing a Framework 13 computer (Batch 3) for use with Ubuntu, moving away from Mac after 14 years.
- Llama 3 Performance: @vipulved reported that Llama 3 405B crossed the 100 TPS barrier on Together APIs with a new inference engine release, achieving 106.9 TPS on NVIDIA H100 GPUs.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Reflection 70B Controversy: Potential API Fraud and Community Backlash
- CONFIRMED: REFLECTION 70B'S OFFICIAL API IS SONNET 3.5 (Score: 278, Comments: 168): Reflection 70B's official API has been confirmed to be Sonnet 3.5. This information aligns with previous speculations and provides clarity on the technical infrastructure supporting this large language model. The confirmation of Sonnet 3.5 as the API suggests specific capabilities and integration methods for developers working with Reflection 70B.
- OpenRouter Reflection 70B claims to be Claude, Created by Anthropic (try it yourself) (Score: 68, Comments: 29): OpenRouter's Reflection 70B model, available through their API, claims to be Claude and states it was created by Anthropic. This assertion raises questions about the model's true identity and origin, as it's unlikely that Anthropic would release Claude through a third-party API without announcement. Users are encouraged to test the model themselves to verify these claims and assess its capabilities.
- Reflection 70B (Free) is broken now (Score: 86, Comments: 25): The Reflection 70B free API is currently non-functional, possibly due to exhaustion of Claude credits. Users attempting to access the service are encountering errors, suggesting that the underlying AI model may no longer be available or accessible through the free tier.
- Reflection 70B API outage is attributed to exhausted Claude credits, with users speculating on the end game of the developer. A VentureBeat article hyped GlaiveAI as a threat to OpenAI and Anthropic, but major publications have yet to cover the fallout.
- OpenRouter replaced the API version with an open weights version, still named Reflection 70B (Free). Users questioned OpenRouter's verification process, with the company defending its quick model deployment without extensive review.
- Some users suggest this incident mirrors a previous Glaive-instruct 3b controversy, indicating a pattern of hyping models for funding. Others speculate on potential distractions or ulterior motives behind the reputation-damaging event.
Theme 2. Community Lessons from Reflection 70B Incident: Trust and Verification in AI
- Well. here it goes. Supposedly the new weights of you know what. (Score: 67, Comments: 77): The post suggests the release of new weights for Reflection 70B, a large language model. However, the community appears to remain highly skeptical about the authenticity or significance of this release, as implied by the cautious and uncertain tone of the post title.
- Reflection 70B lessons learned (Score: 114, Comments: 51): The post emphasizes the critical importance of model verification and benchmark skepticism in AI research. It advises that all benchmarks should start by identifying the specific model being used (e.g., LLAMA, GPT-4, Sonnet) through careful examination, and warns against trusting benchmarks or API claims without personal replication and verification.
- Users emphasized the importance of verifying models through platforms like Lmarena and livebench, warning against trusting unsubstantiated claims from unknown sources. The community expressed a need to recognize bias towards believing groundbreaking improvements.
- There's growing evidence that Matt Shumer may have been dishonest about his AI model claims. Some speculate this could be due to mental health issues, given the short timeframe from project conception to revealed fraud.
- Commenters stressed the importance of developing personal benchmarks based on practical use cases to avoid falling for hype. They also noted that the incident highlights the expectation for open-weight models to soon match or surpass proprietary options.
- Extraordinary claims require extraordinary evidence, something Reflection 70B clearly lacks (Score: 177, Comments: 31): The post title "Extraordinary claims require extraordinary evidence, something Reflection 70B clearly lacks" suggests skepticism about claims made regarding the Reflection 70B model. However, the post body only contains the incomplete phrase "Extraordinary c", providing insufficient context for a meaningful summary of the author's intended argument or critique.
- Reflection 70B's performance is significantly worse when benchmarked using the latest HuggingFace release compared to the private API. Users speculate the private API was actually Claude, leading to skepticism about the model's claimed capabilities.
- Questions arise about Matt Shumer's endgame, as he would eventually need to deliver a working model. Some suggest he didn't anticipate the visibility his claims would receive, while others compare the situation to LK99 and Elon Musk's FSD promises.
- Users criticize Shumer's lack of technical knowledge, noting he asked about LORA on social media. The incident is seen as potentially damaging to his credibility, with some labeling it a scam.
Theme 3. Memes and Humor Surrounding Reflection 70B Controversy
- Who are you? (Score: 363, Comments: 34): The post presents a meme depicting Reflection 70B's inconsistent responses to the question "Who are you?". The image shows multiple conflicting identity claims made by the AI model, including being an AI language model, a human, and even Jesus Christ. This meme highlights the issue of AI models' inconsistent self-awareness and their tendency to generate contradictory statements about their own identity.
- The Reflection 70B controversy sparked numerous memes and discussions, with users noting the model's responses changing from Claude to OpenAI to Llama 70B as suspicions grew about its authenticity.
- A user suggested that the developer behind Reflection is using commercial SOTA models to gather data for retraining, aiming to eventually deliver a model that partially fulfills the claims. Others speculated about the developer's true intentions.
- A detailed explanation of the controversy was provided, describing how the model initially impressed users but failed to perform as expected upon release. Investigations revealed that requests were being forwarded to popular models like Claude Sonnet, leading to accusations of deception.
- TL;DR (Score: 249, Comments: 12): The post consists solely of a meme image summarizing the recent Reflection 70B situation. The meme uses a popular format to humorously contrast the expectations versus reality of the model's release, suggesting that the actual performance or impact of Reflection 70B may have fallen short of initial hype or anticipation.
- The Twitter AI community was criticized for overhyping Reflection 70B, with mentions that it was actually tested on Reddit. Users pointed out similar behavior in subreddits like /r/OpenAI and /r/Singularity.
- Some users expressed confusion or criticism about the meme and its creator, while others defended the release, noting that it provides free access to a model comparable to Claude Sonnet 3.5.
- A user suggested that the hype around Reflection 70B might be due to OpenAI's pivot to B2B SaaS, indicating a desire for new developments in the open-source AI community.
- POV : The anthropic employee under NDA that see all the API requests from a guy called « matt.schumer.freeaccounttrial27 » (Score: 442, Comments: 17): An Anthropic employee, bound by an NDA, observes API requests from a suspicious account named "matt.schumer.freeaccounttrial27". The username suggests potential attempts to circumvent free trial limitations or engage in unauthorized access, raising concerns about account abuse and security implications for Anthropic's API services.
- Users joked about the potential consequences of API abuse, with one comment suggesting a progression from "Matt from the IT department" to "Matt from his guantanamo cell" as the scamming strategy escalates.
- The thread took a humorous turn with comments about Anthropic employing cats, including playful responses like "Meow 🐱" and "As a cat, I can confirm this."
- Some users critiqued the post itself, with one suggesting a "class action lawsuit for wasting our time" and another pointing out the misuse of the term "POV" (Point of View) in the original post.
Theme 4. Advancements in Open-Source AI Models and Tools
- gemma-2-9b-it-WPO-HB surpassed gemma-2-9b-it-simpo on AlpacaEval 2.0 Leaderboard (Score: 30, Comments: 5): The gemma-2-9b-it-WPO-HB model has outperformed gemma-2-9b-it-simpo on the AlpacaEval 2.0 Leaderboard, achieving a score of 80.31 compared to the latter's 79.99. This improvement demonstrates the effectiveness of the WPO-HB (Weighted Prompt Optimization with Human Baseline) technique in enhancing model performance on instruction-following tasks.
- The WPO (Weighted Preference Optimization) technique is detailed in a recent paper, with "hybrid" referring to a mix of human-generated and synthetic data in the preference optimization dataset.
- AlpacaEval 2.0 may need updating, as it currently uses GPT4-1106-preview for human preference benchmarking. Suggestions include using gpt-4o-2024-08-06 and validating with claude-3-5-sonnet-20240620.
- The gemma-2-9b-it-WPO-HB model, available on Hugging Face, has outperformed both gemma-2-9b-it-simpo and llama-3-70b-it on different leaderboards, prompting interest in further testing.
- New upstage release: SOLAR-Pro-PT (Score: 33, Comments: 10): Upstage has released SOLAR-Pro-PT, a new pre-trained model available on Hugging Face. The model is accessible at upstage/SOLAR-Pro-PT, though detailed information about its capabilities and architecture is currently limited.
- Users speculate SOLAR-Pro-PT might be an upscaled Nemo model. The previous SOLAR model impressed users with its performance relative to its size.
- The model's terms and conditions prohibit redistribution but allow fine-tuning and open-sourcing of resulting models. Some users suggest fine-tuning it on empty datasets to create quantized versions.
- There's anticipation for nousresearch to fine-tune the model, as their previous Open Hermes solar fine-tunes were highly regarded for coding and reasoning tasks.
- Ollama Alternative for Local Inference Across Text, Image, Audio, and Multimodal Models (Score: 54, Comments: 34): The Nexa SDK is a new toolkit that supports local inference across text, audio, image generation, and multimodal models, using both ONNX and GGML formats. It includes an OpenAI-compatible API with JSON schema for function calling and streaming, a Streamlit UI for easy testing and deployment, and can run on any device with a Python environment, supporting GPU acceleration. The developers are seeking community feedback and suggestions for the project, which is available on GitHub at https://github.com/NexaAI/nexa-sdk.
- ROCm support for AMD GPUs was requested, with the developers planning to add it in the next week. The SDK already supports ONNX and GGML formats, which have existing ROCm compatibility.
- A user compared Nexa SDK to Ollama, suggesting improvements such as ensuring model accuracy, providing clear update information, and improving the model management and naming conventions.
- Suggestions for Nexa SDK include using K quantization as default, offering I matrix quantization, and improving the model listing and download experience to show different quantizations hierarchically.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Developments and Releases
- Salesforce's xLAM-1b model surpasses GPT-3.5 in function calling: A 1 billion parameter model achieving 70% accuracy in function calling, outperforming GPT-3.5 despite its smaller size.
- Phi-3 Mini update with function calling: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
- Reflection API controversy: A sonnet 3.5 wrapper with prompt engineering was marketed as a new model, leading to discussions about AI hype and verification.
AI Research and Applications
- Virotherapy for breast cancer: A virologist successfully treated her own recurring breast cancer using experimental virotherapy, raising discussions about medical ethics and self-experimentation.
- Waymo robotaxi progress: Waymo is providing 100,000 robotaxi rides per week but not yet profitable, drawing comparisons to early-stage strategies of companies like Uber and YouTube.
- AI-generated video creation: A demonstration of creating an AI-generated video using multiple tools including ComfyUI, Runway GEN.3, and SUNO for music generation.
AI Development Tools and Visualization
- TensorHue visualization library: An open-source Python library for tensor visualization compatible with PyTorch, JAX, TensorFlow, Numpy, and Pillow, designed to simplify debugging of tensor contents.
AI Ethics and Societal Impact
- AI-generated art evaluation: A discussion on shifting focus from identifying AI-generated art to assessing its quality, highlighting the evolving perception of AI in creative fields.
AI Industry and Market Trends
- Data growth and AI training: Michael Dell claims the amount of data in the world is doubling every 6-7 months, with Dell Technologies possessing 120,000 petabytes compared to 1 petabyte used in advanced AI model training.
Memes and Humor
- A humorous video about OpenAI's release cycle and the anticipation for new models.
AI Discord Recap
A summary of Summaries of Summaries GPT4O (gpt-4o-2024-05-13)
1. AI Model Performance
- Reflection 70B underwhelms: Reflection 70B's performance lagged behind Llama 3.1 in benchmarks, raising skepticism about its capabilities, with independent tests showing lower scores and delayed weight releases.
- Matt Shumer acknowledged issues with the uploaded weights on Hugging Face, promising a fix soon.
- DeepSeek Coder struggles: Users reported DeepSeek Coder malfunctioning and providing zero responses, indicating possible upstream issues despite the status page showing no problems.
- This added to existing frustrations over API limitations and service inconsistencies.
- CancerLLM and MedUnA advance medical AI: CancerLLM and MedUnA are enhancing clinical applications and medical imagery, supported by benchmarks like TrialBench.
- Discussions emphasized diving deeper into medical papers to improve research visibility.
2. AI Tools and Integrations
- Aider improves workflow efficiency: Community members shared their Aider workflows, integrating tools like CodeCompanion for streamlined project setups and emphasizing clear planning.
- A refined system prompt is expected to enhance output consistency in Aider.
- OpenInterpreter's resource management woes: While the 01 app allows quick access to audio files, users face performance variability on Mac, leading to inconsistent outcomes.
- One user indicated a preference for plain OpenInterpreter due to the 01 app's stability problems.
3. Open Source AI Developments
- GitHub Open Source AI panel: GitHub is hosting a free Open Source AI panel next Thursday (9/19) at their San Francisco office, discussing access, democratization, and the impact of open source on AI.
- Panelists include representatives from Ollama, Nous Research, Black Forest Labs, and Unsloth AI.
- Finegrain's open-source image segmentation model: Finegrain released an open-source image segmentation model outperforming closed-source alternatives, available under the MIT License on Hugging Face.
- Future improvements include a subtler prompting method for enhanced disambiguation beyond simple bounding boxes.
4. Benchmarking and Evaluation
- Overfitting concerns in model training: Concerns were raised about overfitting, with benchmarks often misleading and models inevitably experiencing overfitting regardless of size, leading to skepticism about benchmark reliability.
- A member expressed hope for their article on benchmark issues to be reviewed at NeurIPS, highlighting evaluation challenges.
- Benchmark limitations acknowledged: Insights were shared on benchmark limitations, with members noting they remain crucial for comparisons despite flaws.
- Discussions emphasized the necessity of diverse benchmarks to gauge AI models, pointing out risks of overfitting to certain datasets.
5. AI Community Events
- Berlin AI Hackathon: The Factory Network x Tech: Berlin AI Hackathon is scheduled for September 28-29 at Factory Berlin Mitte, aiming to gather 50-100 builders motivated to drive AI-driven innovations.
- Participants can improve existing products or initiate new projects in a collaborative environment.
- LLVM Developer Meeting: The upcoming Fall LLVM Developer Meeting in October will feature 5 talks by Modular on topics including Mojo and GPU programming.
- Recorded sessions will be available on YouTube following the event, generating excitement among attendees.
PART 1: High level Discord summaries
HuggingFace Discord
- Hugging Face Inference API Troubles: Users are facing 'bad credentials' errors when accessing private models via the Hugging Face Inference API, often without helpful logs.
- Suggested solutions involve verifying API token setups and reviewing recent updates affecting functionality.
- Fine-Tuning Models on Hugging Face: Discussions indicated that models fine-tuned on Hugging Face might not always upload correctly, leading to missing files in repositories.
- Users recommended scrutinizing configurations and managing larger models during conversion processes for optimal results.
- Challenges in AI Art Generation: The community shared experiences about generating quality AI art, highlighting persistent issues with limb and hand representations.
- Simpler, cheesier prompts were suggested as surprisingly more effective in yielding desirable results.
- Universal Approximation Theorem Insights: Members analyzed the Universal Approximation Theorem, referencing Wikipedia for foundational details.
- Discussions revealed limitations in Haykin's work and better generalizations from Leshno et al. addressing continuity.
- Exploring Medical AI Advances: Recent updates featured CancerLLM and MedUnA for their roles in clinical applications, alongside benchmarks like TrialBench.
- Members expressed enthusiasm for delving deeper into medical papers, enhancing the visibility of significant research.
aider (Paul Gauthier) Discord
- DeepSeek struggles with benchmark accuracy: Users voiced concerns about DeepSeek Coder performance, indicating it may be using the incorrect model ID, leading to poor stats on the dashboard.
- Both model IDs currently point to DeepSeek 2.5, which may be contributing to the benchmarking issues.
- Aider improves workflow efficiency: Community members shared their Aider workflows, integrating tools like CodeCompanion for streamlined project setups and emphasizing clear planning.
- The introduction of a refined system prompt is expected to enhance output consistency in Aider.
- Reflection 70B falls short against Llama3 70B: Reflection 70B scored 42% on the code editing benchmark, while Llama3 70B achieved 49%; the modified version of Aider lacks necessary functionality with certain tags.
- For further details, check out the leaderboards.
- V0 update shows strong performance metrics: Recent updates to v0, tailored for NextJS UIs, have demonstrated remarkable capabilities, with users sharing a YouTube video showcasing its potential.
- For more insights, visit v0.dev/chat for demos and updates.
- Concerns over AI's impact on developer jobs: Members expressed worries about how advanced AI tools could potentially alter the developer role, raising questions over job oversaturation and relevance.
- As AI continues to evolve, there's rising tension regarding the workforce's future in development.
OpenRouter (Alex Atallah) Discord
- Reflection API Available for Playtesting: The Reflection API is now available for free playtesting on OpenRouter, with notable performance differences between hosted and internal versions.
- Matt Shumer expressed that the hosted API is currently not fully optimized and a fixed version is anticipated shortly.
- ISO20022 Gains Attention in Crypto: Members are urged to explore ISO20022 as it could significantly influence financial transactions amid crypto developments.
- The discussion highlighted the standard's implications, reflecting a growing interest in its relevance to the evolving financial landscape.
- DeepSeek Coder Faces API Malfunctions: Users reported that the DeepSeek Coder is providing zero responses and malfunctioning, indicating possible upstream issues despite the status page showing no reported problems.
- This complication adds to frustrations surrounding existing API limitations and inconsistencies in service availability.
- Base64 Encoding Workaround for Vertex AI: A workaround was devised for JSON upload issues with Vertex AI; users are now advised to convert the entire JSON into Base64 before submission.
- This technique, drawn from a GitHub PR discussion, streamlines the transfer process.
- Integration of Multi-Modal Models: Technicians inquired about methods for combining local images with multi-modal models, focusing on request formatting for proper integration.
- Guidance was provided on encoding images into base64 format to facilitate direct API interactions.
Stability.ai (Stable Diffusion) Discord
- LoRA vs Dreambooth Showdown: LoRAs are compact and easily shareable, allowing for runtime combinations, whereas Dreambooth generates much larger full checkpoints.
- Both training methods thrive on limited images, with Kohya and OneTrainer leading the way, and Kohya taking the crown for popularity.
- Budget GPU Guide Under $600: For local image generation, users suggest considering a used 3090 or 2080 within a $600 budget to boost VRAM-dependent performance.
- Increasing VRAM ensures better results, especially for local training tasks.
- The Backward Compatibility Hail Mary: There is a plea for new Stable Diffusion models to maintain backward compatibility with SD1.5 LoRAs, as SD1.5 is still favored among users.
- Conversations underline SD1.5's strengths in composition, with many asserting that newer models have yet to eclipse its effectiveness.
- Content Creation Critique: Influencers vs Creators: A critique surfaced regarding the influencer culture that pressures content creators into monetizing via platforms like Patreon and YouTube.
- Some community members yearn for a shift back to less commercialized content creation, while balancing the reality of influencer marketing.
- LoRAs Enhance Image Generation: Users highlighted that improving details in AI-generated images depends heavily on workflow enhancements rather than merely on prompting, with LoRAs proving essential.
- Many incorporate combinations like Detail Tweaker XL to maximize results in their image productions.
LM Studio Discord
- Users express concerns over LM Studio v0.3: Feedback on LM Studio v0.3 reveals disappointment over the removal of features from v0.2, sparking discussions about potential downgrades.
- Concerns about missing system prompts and adjusting settings led developers to assure users that updates are forthcoming.
- Model configuration bugs impact performance: Users face issues with model configurations, particularly regarding GPU offloading and context length settings, affecting the assistant's message continuity.
- Solutions suggested involve tweaking GPU layers and ensuring dedicated VRAM, as one user experienced context overflow errors.
- Interest in Training Small Language Models: Discussion focused on the viability of training smaller language models, weighing dataset quality and parameter counts against anticipated training loss.
- Challenges specific to supporting less common languages and obtaining high-quality datasets were highlighted by multiple members.
- Navigating LM Studio server interactions: Users clarified that sending API requests is essential for interacting with the LM Studio server rather than a web interface.
- One user found success after grasping the correct API request format, resolving their earlier issues.
- Excitement for Apple Hardware: Speculation surrounds Apple's upcoming hardware announcements, particularly regarding the 5090 GPU and its capabilities compared to previous models.
- Expectations suggest that Apple will maintain dominance with innovative memory architectures in the next wave of hardware.
Perplexity AI Discord
- Cancellation of Subscriptions Sparks Outrage: Users are frustrated with the cancellation of their subscriptions after using leaked promo codes, with reports of limited support responses from Perplexity's team.
- Many are seeking clarification on this issue, feeling left in the dark about their subscription status.
- Model Usage Limit Confusion Reigns: Clarification is needed regarding imposed limits on model usage, with pro users facing a cap of 450 queries and Claude Opus users only 50.
- Questions are arising about how to accurately specify the model in use during interactions, pointing to a lack of straightforward guidance.
- API Responses Lack Depth: Users noticed that API responses are short and lack the richness of web responses, raising concerns about the default response format.
- They are looking for suggestions on adjusting parameters to enhance the API output, indicating potential areas for improvement.
- Payment Method Errors Cause Frustration: Numerous users reported authentication issues with their payment methods when trying to set up API access, with various errors across multiple cards.
- This problem appears to be widespread, as others noted similar payment challenges, particularly with security code error messages.
- Web Scraping Alternatives Emerge: Discussions have shifted towards alternatives to Perplexity's functionality, citing other search engines like You.com and Kagi that utilize web scraping.
- These options are gaining attention for effectively addressing issues related to knowledge cutoffs and inaccuracies in generated responses.
Cohere Discord
- Cohere tech tackles moderation spam: Members highlighted how Cohere's classification tech effectively filters out crypto spam, maintaining the integrity of server discussions.
- One user remarked, 'It's a necessary tool for enjoyable conversations!', emphasizing the bot's importance.
- Wittgenstein launches LLM web app: A member shared the GitHub link to their newly coded LLM web app, expressing excitement for feedback.
- They confirmed that the app uses Langchain and is available on Streamlit, now deployed in the cloud.
- Concerns about crypto scammers: Members voiced frustrations over crypto scams infiltrating the AI space, impacting the reputation of legitimate advancements.
- It was noted by an enthusiast how such spam tarnishes AI's credibility in broader discussions.
- Exploring Cohere products and their applications: Members expressed interest in Cohere products, pointing to customer use cases available regularly on the Cohere blog.
- Usage insights and starter code can be found in the cookbooks, inspiring members' projects.
- Invalid raw prompt and API usage challenges: Members discussed a 400 Bad Request error associated with the
raw_promptingparameter while clarifying how to configure outputs.- A member noted, 'Understanding chat turns is critical', reinforcing the need for clarity in API documentation.
Nous Research AI Discord
- Reflection 70B's Underwhelming Benchmarks: Recent evaluations reveal that Reflection 70B scores 42% on the aider code editing benchmark, falling short of Llama 3.1 at 49%.
- This discrepancy has led to skepticism regarding its capabilities and the delayed release of some model weights, raising questions about transparency.
- Medical LLM Advancements in Oncology: Highlighted models like CancerLLM and MedUnA enhance applications in oncology and medical imagery, showing promise in clinical environments.
- Initiatives like OpenlifesciAI's thread detail their impact on improving patient care.
- AGI Through RL Training: Discussion emphasized that AGI may be achievable through intensive training combined with reinforcement learning (RL).
- However, doubts persist about the efficacy of transformers in achieving Supervised Semantic Intelligence (SSI).
- PlanSearch Introduces Diverse LLM Outputs: Scale SEAL released PlanSearch, a method improving LLM reasoning by promoting output diversity through natural language search.
- Hugh Zhang noted this enables deeper reasoning at inference time, representing a strategic shift in model capabilities.
- Scaling Models for Enhanced Reasoning: Scaling larger models may address reasoning challenges by training on diverse, clean datasets to improve performance.
- Concerns remain regarding resource demands and the current limitations of cognitive simulations in achieving human-like reasoning.
CUDA MODE Discord
- Together AI's MLP Kernels outperform cuBLAS: Members discussed how Together AI's MLP kernels achieve a 20% speed enhancement, with observations on SwiGLU driving performance. The conversation hinted at further insights from Tri Dao at the upcoming CUDA MODE IRL event.
- This sparked inquiries on efficiency metrics compared to cuBLAS and prompted exchanges on achieving competitive speedups in machine learning frameworks.
- ROCm/AMD Falling Behind NVIDIA: Discussions raised concerns about why ROCm/AMD struggles to capitalize on the AI boom compared to NVIDIA, with members questioning corporate trust issues. Despite PyTorch's compatibility with ROCm, community consensus suggests NVIDIA's hardware outperforms in real-world applications.
- Such insights have led to speculations about the strategic decisions AMD is making in the ever-evolving GPU marketplace.
- Triton Matmul Integration Shows Potential: The Thunder channel session highlighted the application of Triton Matmul, focusing on real-world integration with custom kernels. For those interested, a recap is available in a YouTube video.
- Members expressed enthusiasm for the deployment of fusing operations and teased future application to the Liger kernel.
- AMD's UDNA Architecture Announcement: At IFA 2024, AMD introduced UDNA, a unified architecture merging RDNA and CDNA, aiming to better compete against NVIDIA's CUDA ecosystem. This strategic pivot indicates a commitment to enhancing performance across gaming and compute sectors.
- Moreover, AMD's decision to deprioritize flagship gaming GPUs reflects a broader strategy to expand their influence in diverse GPU applications, moving away from a narrow focus on high-end gaming.
- Concerns with PyTorch's ignore_index: It was confirmed that the handling of
ignore_indexin Cross Entropy avoids invalid memory access, managing conditions effectively with early returns. Test cases demonstrating proper handling reassured concerned members.- This exchange pinpointed the essentiality of robust testing in kernel implementations, particularly as performance tuning discussions continued to evolve.
OpenAI Discord
- Reflection Llama-3.1 Claims Top Open Source Title: The newly released Reflection Llama-3.1 70B model is claimed to be the best open-source LLM currently available, utilizing Reflection-Tuning to enhance reasoning capabilities.
- Users reported earlier issues have been addressed, encouraging further testing for improved outcomes.
- Clarifications on OpenAI's Mysterious 'GPT Next': Members were skeptical about GPT Next being a new model, which OpenAI clarified was just figurative terminology with no real implications.
- Despite clarification, frustration remains regarding the lack of concrete updates amid rising expectations.
- Hardware Needs for Running Llama 3.1 70B: To successfully operate models like Llama 3.1 70B, users need a high-spec GPU PC or Apple Silicon Mac with at least 8GB of VRAM.
- Experiences on various setups highlighted that inadequate resources severely hamper performance.
- Enhancing AI Outputs with Prompt Engineering: Members recommended using styles like 'In the writing style of Terry Pratchett' to creatively boost AI responses, showcasing prompt adaptability.
- Structured output templates and defined chunking strategies were emphasized for effective API interactions.
- Debating AI for Stock Analysis: Caution arose over using OpenAI models for stock analysis, advocating against reliance solely on prompts without historical data.
- Discussions pointed towards the necessity of real-time updates and traditional models for comprehensive evaluations.
Modular (Mojo 🔥) Discord
- Integrating C with Mojo via DLHandle: Members discussed how to integrate C code with Mojo using
DLHandleto dynamically link to shared libraries, allowing for function calls between the two.- An example was provided where a function to check if a number is even was executed successfully after being loaded from a C library.
- LLVM Developer Meeting Nuggets: The upcoming Fall LLVM Developer Meeting in October will feature 5 talks by Modular on topics including Mojo and GPU programming.
- Attendees expressed excitement, with recorded sessions expected to be available on YouTube following the event.
- Subprocess Implementation Aspirations: A member expressed interest in implementing Subprocess capabilities in the Mojo stdlib, indicating a push to enhance the library.
- Concerns were raised about the challenges of setting up development on older hardware, emphasizing resource difficulties.
- DType's Role in Dict Keys: Discussion focused on why
DTypecannot serve as a key in a Dict, noting DType.uint8 as a value rather than a type.- Members mentioned that changing this implementation could be complex due to its ties with SIMD types having specific constraints.
- Exploration of Multiple-precision Arithmetic: Members discussed the potential for multiple-precision integer arithmetic packages in Mojo, referencing implementations akin to Rust.
- One participant shared a GitHub link showing progress on a
uintpackage for this capability.
- One participant shared a GitHub link showing progress on a
Eleuther Discord
- DeepMind's Resource Allocation Shift: A former DeepMind employee indicated that compute required for projects relies heavily on their product-focus, especially post-genai pivot.
- This insight stirred discussions on how foundational research might face reduced resources, as noted by prevalent community skepticism.
- Scraping Quora Data Issues: Members examined the potential use of Quora's data in AI training datasets, acknowledging its value but raising concerns over its TOS.
- The discussion highlighted the possible infeasibility of scraping due to stringent regulations.
- Releasing TurkishMMLU Dataset: TurkishMMLU was officially released with links to the dataset and a relevant GitHub issue.
- This addition aims to bolster language model evaluation for Turkish, as outlined in a related paper.
- Insights on Power Law Curves in ML: Members discussed that power law curves effectively model performance scaling in ML, referencing statistical models related to scaling laws in estimation tasks.
- One member noted similarities between scaling laws for LLM loss and those in statistical estimation, indicating that mean squared error scales as N^(-1/2).
- Exploring Adaptive Transformers: A discussion focused on 'Continual In-Context Learning with Adaptive Transformers,' which allows transformers to adapt to new tasks using prior knowledge without parameter changes.
- This technique aims for high adaptability while minimizing catastrophic failure risks, attracting attention across various domains.
Interconnects (Nathan Lambert) Discord
- Reflection API Performance Questioned: The Reflection 70B model faced scrutiny, suspected to have been simply a LoRA trained on benchmark sets atop Llama 3.0; claims of top-tier performance were misleading due to flawed evaluations.
- Initial private API tests yielded better results than public versions, raising concerns over inconsistencies across releases.
- AI Model Release Practices Critiqued: Debates emerged on the incompetence surrounding significant model announcements without robust validation, leading to community distrust regarding AI capabilities.
- Members urged the industry to enforce stricter evaluation standards before making claims public, noting a troubling trend in inflated expectations.
- OpenAI's Transition to Anthropic Stirs Talks: Discussion centered on OpenAI co-founder John Schulman’s move to Anthropic, described as surreal and highlighting transitions within leadership.
- The light-hearted remark about frequent mentions of 'from OpenAI (now at Anthropic)' captures the shift in community dynamics.
- Speculative Buzz Around GPT Next: Speculation arose from a KDDI Summit presentation regarding a model labeled GPT Next, which OpenAI clarified was just a figurative placeholder.
- A company spokesperson noted that the graphical representation was merely illustrative, not indicative of a timeline for future releases.
- Internal Bureaucracy Slowing Google Down: An ex-Googler voiced concerns over massive bureaucracy in Google, citing numerous internal stakeholders stymying effective project execution.
- This sentiment underscores challenges employees face in large organizations where internal politics often hinder productivity.
Latent Space Discord
- AI Codex Boosts Cursor: The new AI Codex for Cursor implements self-improvement features like auto-saving insights and smart categorization.
- Members suggested that a month of usage could unveil valuable learning outcomes about its efficiency.
- Reflection API Raises Eyebrows: The Reflection API appears to function as a Sonnet 3.5 wrapper, reportedly filtering out references to Claude to mask its identity.
- Various evaluations suggest its performance may not align with claims, igniting inquiry about the benchmarking methodology.
- Apple's Bold AI Advances: Apple's recent event teased substantial updates to Apple Intelligence, hinting at a potentially improved Siri and an upcoming AI phone.
- This generated excitement around competitive implications, as many members called for insights from Apple engineers.
- New Enum Mode Launches in Gemini: Logan K announced the advent of Enum Mode in the Gemini API, enhancing structured outputs by enabling selection from predefined options.
- This innovation looks to streamline decision-making for developers interacting with the Gemini framework.
- Interest in Photorealistic LoRA Model: A user showcased a photorealistic LoRA model that's captivating the Stable Diffusion community with its detailed capabilities.
- Discussions surrounding its performance, particularly unexpected anime images, have garnered significant attention.
OpenInterpreter Discord
- OpenInterpreter's resource management woes: While the 01 app allows quick access to audio files, users face performance variability on Mac, leading to inconsistent outcomes.
- One user indicated a preference for plain OpenInterpreter due to the 01 app's stability problems.
- Call for AI Skills in OpenInterpreter: Users are eager for the release of AI Skills for the standard OpenInterpreter rather than just the 01 app, showcasing a demand for enhanced functionality.
- Frustration echoed regarding the 01 app's performance relative to the base OpenInterpreter.
- Discontinuation and Refunds for 01 Light: The team announced the official end of the 01 Light, focusing on a free 01 app and processing refunds for all hardware orders.
- Disappointment was prevalent among users eagerly waiting for devices, but assurance was given regarding refund processing through help@openinterpreter.com.
- Scriptomatic’s triumph with Open Source Models: A member successfully integrated Scriptomatic with structured outputs from open source models and plans to submit a PR soon.
- They expressed appreciation for the support provided for Dspy, emphasizing their methodical approach involving grepping and printing.
- Instructor Library Enhances LLM Outputs: The Instructor library was shared, designed to simplify structured outputs from LLMs using a user-friendly API based on Pydantic.
- Instructor is poised to streamline validation, retries, and streaming, bolstering user workflows with LLMs.
LlamaIndex Discord
- Deploy Agentic System with llama-deploy: Explore this full-stack example of deploying an agentic system as microservices with LlamaIndex and getreflex.
- This setup streamlines chatbot systems, making it a go-to for developers wanting efficiency.
- Run Reflection 70B Effortlessly: You can now run Reflection 70B directly from LlamaIndex using Ollama, given your laptop supports it (details here).
- This capability allows hands-on experimentation without extensive infrastructure requirements.
- Build Advanced RAG Pipelines: Check out this guide for building advanced agentic RAG pipelines with dynamic query routing using Amazon Bedrock.
- The tutorial covers all necessary steps to optimize RAG implementations effectively.
- Automate Financial Analysis Workflows: A blog post discusses creating an agentic summarization system for automating quarterly and annual financial analysis (read more).
- This approach can significantly boost efficiency in financial reporting and insights.
- Dynamic ETL for RAG Environments: Learn how LLMs can automate ETL processes with data-specific decisions, as outlined in this tutorial.
- This method enhances data extraction and filtering by adapting to different dataset characteristics.
Torchtune Discord
- Gemma Model Configuration Updates: To configure a Gemma 9B model using Torchtune, users suggested modifying the
modelentry in the config with specific parameters found in config.json.- This approach leverages the component builder, aiming for flexibility across various model sizes.
- Gemma 2 Support Challenges in Torchtune: Discussion arose around difficulties in supporting Gemma 2 within Torchtune, mainly due to issues with logit-softcapping and bandwidth constraints.
- The burgeoning architecture improvements in Gemma 2 have generated a backlog of requested features waiting for implementation.
- Proposed Enhancements for Torchtune: A potential bug concerning padding sequence behavior in Torchtune was highlighted alongside a proposed PR to fix the issue by clarifying the flip method.
- The goal is to achieve feature parity with the torch pad_sequence, enhancing overall library functionality.
- Cache Handling During Generation Needs Refinement: Users discussed the need for modifications in cache behavior during generation, proposing the use of
torch.inference_modefor consecutive forward calls in attention modules.- Despite this, they acknowledged that an explicit flag for
.forward()might yield a more robust solution.
- Despite this, they acknowledged that an explicit flag for
- Chunked Linear Method Implementation Reference: A member shared interest in a clean implementation of chunked linear combined with cross-entropy from a GitHub gist as a potential enhancement for Torchtune.
- Integrating this method may pose challenges due to the library's current separation of the LM-head from loss calculations.
LangChain AI Discord
- Struggling with .astream_events() Decoding: Users reported challenges with decoding streams from .astream_events(), especially the tedious manual serialization through various branches and event types.
- Participants highlighted the lack of useful resources, calling for a reference implementation to ease the burdens of this process.
- Gradio Struggles with Concurrency: After launching Gradio with 10 tabs, only 6 requests generated despite higher concurrency limits, hinting at potential configuration issues.
- Users pointed out the hardware limitations, suggesting the need for further investigation into handling concurrent requests.
- Azure OpenAI Integration Facing 500 Errors: A user is dealing with 500 errors when interacting with Azure OpenAI, prompting queries about endpoint parameters.
- Advice included validating environment variables and naming conventions to potentially resolve these troubleshooting headaches.
- VAKX Offers No-Code AI Assistant Building: VAKX was introduced as a no-code platform enabling users to build AI assistants, with features like VAKChat integration.
- Members were encouraged to explore VAKX and the Start Building for Free link for quick setups.
- Selenium Integrated with GPT-4 Vision: An experimental project demonstrated the integration of Selenium with the GPT-4 vision model, with a detailed process available in this YouTube video.
- Interest sparked around leveraging this integration for more effective automated testing with vector databases.
OpenAccess AI Collective (axolotl) Discord
- Overfitting Concerns Take Center Stage: Members raised issues regarding overfitting, emphasizing that benchmarks can mislead expectations, suggesting that models inevitably experience overfitting regardless of size.
- “I don't believe benchmarks anymore” captured skepticism towards reliability in model evaluations based on inadequate data.
- Benchmark Limitations Under Scrutiny: Insights were shared on benchmark limitations, revealing that although flawed, they remain crucial for comparisons among models.
- A member expressed optimism for their article on benchmark issues to be reviewed at NeurIPS, highlighting current evaluation challenges.
- AI Tool Exposed as a Scam: A recently hyped AI tool turned out to be a scam, falsely claiming to compare with Claude 3.5 or GPT-4.
- Discussions stressed the time loss caused by such scams and their distracting nature across various channels.
- Urgent Inquiry on RAG APIs: A member urgently sought experiences with RAG APIs, needing immediate support for a project due to their model being unready.
- They highlighted the challenges of 24/7 hosting costs and sought alternatives to manage their AI projects effectively.
- H100's 8-Bit Loading Limitations Questioned: A member queried why the H100 does not support loading models in 8-bit format, seeking clarity on this limitation.
- They reiterated the urgency for insights into the H100's constraints regarding 8-bit model loading.
LAION Discord
- Berlin AI Hackathon Promises Innovation: The Factory Network x Tech: Berlin AI Hackathon is scheduled for September 28-29 at Factory Berlin Mitte, aiming to gather 50-100 builders motivated to drive AI-driven innovations.
- Participants can improve existing products or initiate new projects in a collaborative environment, fostering creative approaches.
- Finegrain's Open-Source Breakthrough: Finegrain released an open-source image segmentation model outperforming closed-source alternatives, available under the MIT License on Hugging Face.
- Future improvements include a subtler prompting method for enhanced disambiguation and usability beyond simple bounding boxes.
- Concrete ML Faces Scaling Issues: Discussions highlighted that Concrete ML demands Quantization Aware Training (QAT) for effective integration with homomorphic encryption, resulting in potential performance compromises.
- Concerns about limited documentation were raised, especially in its applicability to larger models in machine learning.
- Free Open Source AI Panel Event: GitHub will host an Open Source AI panel on September 19 in SF, featuring notable panelists from organizations like Ollama and Nous Research.
- While free to attend, registration is prerequisite due to limited seating, making early sign-up essential.
- Multimodality in AI Captivates Interest: The rise of multimodality in AI has been underscored with examples like Meta AI transfusion and DeepMind RT-2, showcasing significant advancements.
- Discussion suggested investigating tool augmented generation employing techniques like RAG, API interactions, web searches, and Python executions.
DSPy Discord
- LanceDB Integration PR Submitted: A member raised a PR for LanceDB Integration to add it as a retriever for handling large datasets in the project.
- They requested feedback and changes from a specific user for the review process, emphasizing collaboration in enhancements.
- Mixed feelings on GPT-3.5 deprecation: Members discussed varying user experiences with models following the deprecation of GPT-3.5, noting inconsistent performance, especially with open models like 4o-mini.
- One user suggested using top closed models as teachers for lower ones to improve performance consistency.
- AttributeError Plagues MIPROv2: A user reported encountering an
AttributeErrorin MIPROv2, indicating a potential issue in theGenerateModuleInstructionfunction.- Discussion circled around suggested fixes, with some members pointing to possible problems in the CookLangFormatter code.
- Finetuning small LLMs Generates Buzz: A member shared success in finetuning a small LLM using a unique reflection dataset, available for interaction on Hugging Face.
- They provided a link while encouraging others to explore their findings in this domain.
- CookLangFormatter Issues Under Scrutiny: Members debated potential issues with the CookLangFormatter class, identifying errors in method signatures.
- Post-modifications, one user reported positive outcomes and suggested logging the issue on GitHub for future reference.
tinygrad (George Hotz) Discord
- WebGPU PR #6304 makes waves: The WebGPU PR #6304 by geohot marks a significant effort aimed at reviving webgpu functionality on Asahi Linux, with a $300 bounty attached.
- 'It's a promising start for the initiative,' noted a member, emphasizing the community’s excitement over the proposal.
- Multi-GPU Tensor Issues complicate development: Developers are encountering AssertionError with multi-GPU operations, which requires all buffers to share the same device.
- A frustrated user remarked, 'I've spent enough time... convinced this goal is orthogonal to how tinygrad currently handles multi-gpu tensors.'
- GGUF PRs facing delays and confusion: Concerns are rising regarding the stalled status of various GGUF PRs, which are lacking merges and clear project direction.
- One user inquired about a roadmap for GGUF, highlighting a need for guidance moving forward.
- Challenges in Model Sharding: Discussions unveiled issues with model sharding, where certain setups function on a single GPU yet fail when expanded across multiple devices.
- One user observed that 'George gave pushback on my workaround...', indicating a complex dialogue around solutions.
Gorilla LLM (Berkeley Function Calling) Discord
- xLAM Prompts Deviation from Standard: Members discussed the unique system prompt used for xLAM, as detailed in the Hugging Face model card.
- This prompted an analysis of how personalized prompts can diverge from the BFCL default.
- LLaMA Lacks Function Calling Clarity: Participants noted that LLaMA offers no documentation on function calling, raising concerns regarding prompt formats.
- Although classified as a prompt model, LLaMA's handling of function calling remains ambiguous due to inadequate documentation.
- GitHub Conflicts Cause Integration Delays: A user reported facing merge conflicts with their pull request, #625, obstructing its merger.
- After resolving the conflicts, they resubmitted a new pull request, #627 to facilitate integration.
- Exploring Model Evaluation via VLLM: A query arose regarding the evaluation of models after setting up the VLLM service.
- The inquiry reflects a significant interest in model assessment methodologies and best practices within the community.
- Introducing the Hammer-7b Handler: The community discussed the new Hammer-7b handler, emphasizing its features as outlined in the associated pull request.
- Detailed documentation with a CSV table highlights model accuracy and performance metrics.
LLM Finetuning (Hamel + Dan) Discord
- 4090 GPU enables larger models: With a 4090 GPU, engineers can run larger embedding models concurrently, including Llama-8b, and should consider version 3.1 for enhanced performance.
- This setup boosts efficiency in processing tasks and allows more complex models to operate smoothly.
- Hybrid Search Magic with Milvus: Discussions highlighted using hybrid search with BGE and BM25 on Milvus, demonstrated with an example from the GitHub repository.
- This example effectively illustrates the incorporation of both sparse and dense hybrid search for improved data retrieval.
- Boost Results with Reranking: Implementing a reranker that utilizes metadata for each chunk helps prioritize and refine result sorting.
- This method aims to enhance data handling, making retrieved information more relevant and accurate.
Alignment Lab AI Discord
- Understanding RAG Based Retrieval Evaluation: A member inquired about necessary evaluation metrics for assessing a RAG based retrieval system within a domain-specific context.
- They were uncertain whether to compare their RAG approach to other LLMs or to evaluate against results without using RAG.
- Comparison Strategies for RAG: The same member pondered whether to conduct comparisons only with and without RAG or also against other large language models.
- This question sparked interest, prompting members to consider various approaches for evaluating the effectiveness of RAG in their projects.
MLOps @Chipro Discord
- GitHub Hosts Open Source AI Panel: GitHub is hosting a free Open Source AI panel next Thursday (9/19) at their San Francisco office, aimed at discussing access, democratization, and the impact of open source on AI.
- Panelists include representatives from Ollama, Nous Research, Black Forest Labs, and Unsloth AI, contributing to vital conversations in the AI community.
- Registration Approval Required for AI Panel: Attendees are required to register for the event, with registration subject to host approval to manage effective attendance.
- This process aims to ensure a controlled environment as interest in the event grows within the AI sector.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
HuggingFace ▷ #general (930 messages🔥🔥🔥):
Hugging Face Inference API IssuesModel Fine-Tuning ExperiencesAI Art and Prompting ChallengesQ&A on LLM Features and Usage
- Hugging Face Inference API Issues: Users are experiencing difficulties with the Hugging Face Inference API, particularly when trying to access private models, which leads to a 'bad credentials' error without any useful logs.
- Suggested solutions include ensuring proper setup of API tokens and evaluating recent updates that may have affected functionality.
- Model Fine-Tuning Experiences: The process of fine-tuning models on Hugging Face is discussed, with users noting that the resulting models may not always upload correctly, resulting in missing files in repositories.
- Users recommend checking configurations and handling large models, especially when converting formats like GGUF for local hosting.
- AI Art and Prompting Challenges: Conversations explore the challenges of generating high-quality AI art, specifically focusing on issues with limb and hand representations in generated images.
- The importance of using effective prompts was emphasized, with users suggesting that simpler, cheesier prompts often yield better results.
- Q&A on LLM Features and Usage: Users inquire about effective local hosting options for language models and tools like vLLM, with discussions on batching and the utility of different inference methods.
- Mention of various models, such as Mistral and LLama, highlights the interest in their performance and usability in real-world applications.
- no title found: no description found
- 401 Client Error: Unauthorized for url: Recently I started to get
requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://api.soundcloud.com/oauth2/token
using soundcloud (0.5.0) Python library.&#x... Need More Depth**: A user noted that API responses are **short and dry** compared to web responses, despite identical queries, and sought recommendations on parameters to adjust.
- Suggestions for improvement could enhance the richness of API replies.
- **404 Error on API URL**: A user encountered an **HTTP ERROR 404** when trying to access the API at the specified URL.
- Another user pointed out the correct endpoint as [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions).
- **Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards.
- Another participant confirmed similar experiences, particularly with security code errors.
- **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links.
- They inquired about methods to prompt models for more direct link access.
- **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches.
- This approach might help users retrieve more accurate information from current models.
**Link mentioned**: Civitai | Share your modelsed to web responses, despite identical queries, and sought recommendations on parameters to adjust.
- Suggestions for improvement could enhance the richness of API replies.
- **404 Error on API URL**: A user encountered an **HTTP ERROR 404** when trying to access the API at the specified URL.
- Another user pointed out the correct endpoint as [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions).
- **Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards.
- Another participant confirmed similar experiences, particularly with security code errors.
- **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links.
- They inquired about methods to prompt models for more direct link access.
- **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches.
- This approach might help users retrieve more accurate information from current models.
**Link mentioned**:
- Google Colabadjust. - Suggestions for improvement could enhance the richness of API replies. - **404 Error on API URL**: A user encountered an **HTTP ERROR 404** when trying to access the API at the specified URL. - Another user pointed out the correct endpoint as [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions). - **Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards. - Another participant confirmed similar experiences, particularly with security code errors. - **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- Meta-Llama3.1-8B - a Hugging Face Space by freeCS-dot-orgess the API at the specified URL. - Another user pointed out the correct endpoint as [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions). - **Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards. - Another participant confirmed similar experiences, particularly with security code errors. - **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- Karate Kid GIF - Karate Kid Wax Rotate - Discover & Share GIFs*Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards. - Another participant confirmed similar experiences, particularly with security code errors. - **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- shafire/talktoaiZERO · Hugging Faceng up API access, receiving errors on multiple cards. - Another participant confirmed similar experiences, particularly with security code errors. - **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- Google Colabver Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- Text Generation Inference (TGI) They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**:
- Error 401 Client Error: Unauthorized for urleter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**: WaifuDiffusion Tagger - a Hugging Face Space by SmilingWolfd.com/channels/954421988141711382/954421988783444043/1281793672391819378)** (334 messages🔥🔥): >: no description found1711382/954421988783444043/1281793672391819378)** (334 messages🔥🔥): >
- Dies Cat GIF - Dies Cat Dead - Discover & Share GIFss in moderation` >: Click to view the GIFams and crypto` >
- Gen Battle SF: Let’s make Music Videos With AI! · LumaMembers discussed how the Cohere classification technology effectively eliminates crypto spam, enhancing server conversations. - One user emphasized that the bot is a necessary tool to keep discussions focused and enjoyable after encountering rampant spam. - **Haircuts trending in the chat**: Participants engaged in a lighthearted conversation about haircuts, specifically referencing Aidan Gomez's hairstyle and sharing their own experiences. - Several members contemplated getting similar cuts, highlighting the fun community vibe while sharing hair-related anecdotes. - **Crypto influences on AI**: There were concerns raised about crypto scammers infiltrating the AI space, with members expressing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: Let's get into groups and make a music video! For AI beginners and experts split into groups and create short films together. By the end of the night, we'll…essary tool to keep discussions focused and enjoyable after encountering rampant spam. - **Haircuts trending in the chat**: Participants engaged in a lighthearted conversation about haircuts, specifically referencing Aidan Gomez's hairstyle and sharing their own experiences. - Several members contemplated getting similar cuts, highlighting the fun community vibe while sharing hair-related anecdotes. - **Crypto influences on AI**: There were concerns raised about crypto scammers infiltrating the AI space, with members expressing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- RandomForestClassifier engaged in a lighthearted conversation about haircuts, specifically referencing Aidan Gomez's hairstyle and sharing their own experiences. - Several members contemplated getting similar cuts, highlighting the fun community vibe while sharing hair-related anecdotes. - **Crypto influences on AI**: There were concerns raised about crypto scammers infiltrating the AI space, with members expressing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: Gallery examples: Release Highlights for scikit-learn 1.4 Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.22 Comparison of Calibration of Classifiers Probability Cali...ng the fun community vibe while sharing hair-related anecdotes. - **Crypto influences on AI**: There were concerns raised about crypto scammers infiltrating the AI space, with members expressing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- Napoleon Dynamite Kip GIF - Napoleon Dynamite Kip Yes - Discover & Share GIFsAI space, with members expressing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: Click to view the GIFessing frustration about associated scams. - One long-time AI enthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- Tweet from cocktail peanut (@cocktailpeanut)nd mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: OpenAI preparing to drop their new modeltion of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- shafire (Shafaet Brady Hussain)bers expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: no description foundement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- Kamala Harris Real Though GIF - Kamala harris Real though - Discover & Share GIFsexperiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: Click to view the GIFMultimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.- Joe Biden Presidential Debate GIF - Joe biden Presidential debate Huh - Discover & Share GIFse conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.
: Click to view the GIF how different AI models could contribute to more realistic problem-solving approaches.- Steve Brule Orgasm GIF - Steve Brule Orgasm Funny - Discover & Share GIFs>: Click to view the GIFom/@a.sale/chatgpt-5-and-beyond-openais-five-level-roadmap-to-agi-unveiled-be09db42ca27">
- Tim And Eric Spaghetti GIF - Tim And Eric Spaghetti Funny Face - Discover & Share GIFsment, OpenAI has unveiled a new five-level system to track its progress towards achieving Artificial General…
: Click to view the GIF new five-level system to track its progress towards achieving Artificial General…- Ohearn Sad Mike Ohearn Sad GIF - Ohearn sad Ohearn Mike ohearn sad - Discover & Share GIFs: Click to view the GIF/li>
- shafire/talktoaiZERO at main Gomez: What No One Understands About Foundation Models | E1191: no description foundtands About Foundation Models | E1191
- Manage your Spaceg AI platform for enterprise, having raised over $1BN from some of the best with their last round pr...
: no description foundse, having raised over $1BN from some of the best with their last round pr...- Empire'S Got Your Back GIF - Empire I Got You Brothers - Discover & Share GIFs/ul>: Click to view the GIFCohere ▷ #[questions](https://discord.com/channels/954421988141711382/1168411509542637578/1282142131183681547)** (25 messages🔥): >
- openai/whisper-large-v3 · Hugging Face81547)** (25 messages🔥): >: no description found >
- Btc Blockchain GIF - Btc Blockchain Fud - Discover & Share GIFser sought the contact information for the recruiting team after finding a part-time remote role on LinkedIn and being redirected to the Discord server. - Another member suggested they will get a contact once the team gets back to them, noting the server is meant for tech discussions, not recruitment. - **Exploring Cohere Products**: In response to a question about what people are using Cohere products for, it was noted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**: : Click to view the GIFmation for the recruiting team after finding a part-time remote role on LinkedIn and being redirected to the Discord server. - Another member suggested they will get a contact once the team gets back to them, noting the server is meant for tech discussions, not recruitment. - **Exploring Cohere Products**: In response to a question about what people are using Cohere products for, it was noted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**:
- Hello GIF - Hello - Discover & Share GIFshe Discord server. - Another member suggested they will get a contact once the team gets back to them, noting the server is meant for tech discussions, not recruitment. - **Exploring Cohere Products**: In response to a question about what people are using Cohere products for, it was noted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**: : Click to view the GIFther member suggested they will get a contact once the team gets back to them, noting the server is meant for tech discussions, not recruitment. - **Exploring Cohere Products**: In response to a question about what people are using Cohere products for, it was noted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**:
- Data Visualization : Bar Chart and Heat Maprver is meant for tech discussions, not recruitment. - **Exploring Cohere Products**: In response to a question about what people are using Cohere products for, it was noted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**: : In this video, I will discuss bar charts and heat maps, explaining how they work and the trends they reveal in data, along with other related topics. If you'...ted that customer use cases are regularly published on the [Cohere blog](https://cohere.com/blog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**:
- shafire/talktoai at mainlog). - Discord members also share their use cases in a dedicated channel, and [cookbooks](https://docs.cohere.com/page/cookbooks) offer inspirational starter code for various applications. - **MrDragonFox's Ubiquitous Presence**: Members joked about MrDragonFox being everywhere in the server, with one member humorously questioning if he is even human. - MrDragonFox replied affirmatively about being human, humorously adding that he is 'just connected'. - **Difference Between Embed and Embed Jobs**: A member asked for clarification on the difference between the terms 'embed' and 'embed jobs', indicating they understood the embed process. - The discussion was aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**: : no description found **Link mentioned**: **Link mentioned**: **Link mentioned**:
HuggingFace ▷ #today-im-learning (9 messages🔥):
Latch-up effect in CMOS microcircuitsDeploying uncensored models to SageMakerDaily learning progress forum
- Understanding Latch-up Effect in CMOS: A member inquired about the Latch-up effect in CMOS microcircuits, seeking information on how it functions.
- This topic remains open for further discussion and clarification from knowledgeable members.
- Sharing Insights on SageMaker Deployment: One member asked for experiences and guidance on deploying uncensored models to SageMaker, following the Hugging Face documentation.
- Another member mentioned they were looking into similar issues, with a follow-up noting that things are going decently well.
- Community Motivation through Daily Progress: A member queried if the channel functions like a forum for posting daily learning progress, akin to 100 days of code.
- Other members confirmed this setup is meant to motivate individuals on their learning journeys.
- Appreciation for Collaboration: A member expressed admiration for a fellow user's work, stating it was 'amazing', to which the original poster credited Nvidia and Epic Games for their contributions.
- This highlights the collaborative spirit and recognition within the community.
HuggingFace ▷ #cool-finds (11 messages🔥):
Medical AI Research UpdatesAlphaProteo Protein Prediction ModelMedical LLMs ApplicationsML Training Visualization ToolsExploring Medical Literature
- Last Week in Medical AI Highlights: The latest update covered several cutting-edge medical LLMs, including CancerLLM and MedUnA, and their applications in clinical tasks.
- TrialBench and DiversityMedQA were noted as significant benchmarks for evaluating LLMs' performance in medical applications.
- DeepMind's AlphaProteo Model Revolutionizes Protein Design: The AlphaProteo model from Google DeepMind predicts protein binding to molecules, enhancing bioengineering applications like drug design.
- This new AI system aims to advance our understanding of biological processes through improved protein interactions, as highlighted in their blog post.
- Interest in Diving into Medical Papers: Members expressed enthusiasm about exploring medical papers further, enhancing visibility for research in the medical AI domain.
- A suggestion was made to engage in deeper discussions around the recent papers listed in the latest research updates.
- Inquiry About Open Access of AlphaProteo: A question arose regarding the open access status of the AlphaProteo model by Google DeepMind.
- This reflects ongoing discussions about accessibility of advanced AI tools in the research community.
- Tools for Training Curve Visualization in ML: A member inquired about frameworks and tools to automatically generate training and validation curves for ML models, specifically for image classification.
- This underscores a continued interest in effective visualization methods for improving model training processes.
Links mentionednthusiast shared experiences dealing with such spam and mentioned the negative impact on the perception of legitimate AI advancements. - **Exploration of Cohere products**: New members expressed their excitement about exploring Cohere products and learning more about the platform's capabilities. - Discussions highlighted the latest updates to R and R+ which have improved coding experiences for users. - **Multimodal models and projects**: There were discussions about the potential of vision models in planning tasks, with community members sharing insights from their own experiences in robotics and AI. - The conversation reflected on how different AI models could contribute to more realistic problem-solving approaches.:-
Tweet from Open Life Science AI (@OpenlifesciAI)roaches.
: Last Week in Medical AI: Top Research Papers/Models 🏅(September 1 - September 7, 2024) Medical LLM & Other Models : - CancerLLM: Large Language Model in Cancer Domain - MedUnA: Vision-Languag...5 and Beyond: OpenAI’s Five-Level Roadmap to AGI Unveiled
- @aaditya on Hugging Face: "Last Week in Medical AI: Top Research Papers/Models 🏅(September 1 -…"ioned">: no description foundtioned
- AlphaProteo generates novel proteins for biology and health researchAGI Unveiled: New AI system designs proteins that successfully bind to target molecules, with potential for advancing drug design, disease understanding and more.
HuggingFace ▷ #i-made-this (51 messages🔥):
PowershAI FeaturesGraphRAG UtilizationOm LLM ArchitectureFLUX.1 [dev] Model ReleaseOCR Correction Techniques
- PowershAI Simplifies AI Integration: PowershAI aims to facilitate AI usage for Windows users by allowing easy integration and invocation of AI models using PowerShell commands, enhancing script object-oriented capabilities.
- It supports features like function calling and Gradio integration, which helps users streamline workflows with multiple AI sources.
- Local GraphRAG Model Testing: A new repository was created to enable users to test Microsoft's GraphRAG using various models from Hugging Face, beyond the limited options provided by Ollama.
- This allows greater flexibility for users looking to expand their graph retrieval capabilities without the associated costs of using the OpenAI API.
- Innovation in LLM Architecture with Om: Dingoactual introduced a novel LLM architecture named Om, emphasizing unique features like initial convolutional layers and multi-pass memory for handling long-context inputs.
- The design improvements focus on optimized processing while managing VRAM requirements effectively.
- Introduction of FLUX.1 [dev] Model: The FLUX.1 [dev] model, a 12 billion parameter flow transformer for image generation, has been released with open weights, allowing scientists and artists to leverage its capabilities.
- This model offers high-quality outputs comparable to leading closed-source alternatives, reinforcing the potential for innovative workflows in creative fields.
- OCR Correction and Creative Text Generation: Tonic highlighted a technique developed by Pleiasfr to correct OCR outputs, which can also be used creatively to generate historical-style texts in multiple languages.
- This method reflects the versatility and innovation in utilizing AI for both correcting data and creative endeavors.
Links mentioned aimed at simplifying the technical distinctions between these two concepts. **Link mentioned**: :-
Chapter 34. Working with the Component Object Model (COM) · PowerShell in Depth(https://discord.com/channels/954421988141711382/1168578329423642786/1282139055127134279)** (20 messages🔥):
>: Discovering what COM is and isn’t · Working with COM objects86/1282139055127134279)** (20 messages🔥):
>
- Reflection 70B llama.cpp (Correct Weights) - a Hugging Face Space by gokaygokay `Chat Turns in API` - **Configuring Output Lengths discussion**: Members discussed how to configure output lengths and early stop sequences, indicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description found**Configuring Output Lengths discussion**: Members discussed how to configure output lengths and early stop sequences, indicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- Xtts - a Hugging Face Space by rrg92 early stop sequences, indicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description foundicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- lazarzivanovicc/timestretchlora · Hugging Facee she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description foundp year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- black-forest-labs/FLUX.1-dev · Hugging Face search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description foundlarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- Civitai | Share your models is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description foundn; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- GitHub - NotTheStallion/graphrag-local-model_huggingface: Microsoft's graphrag using ollama and hugging face to support all LLMs (Llama3, mistral, gemma2, fine-tuned Llama3 ...).fic documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : Microsoft's graphrag using ollama and hugging face to support all LLMs (Llama3, mistral, gemma2, fine-tuned Llama3 ...). - NotTheStallion/graphrag-local-model_huggingfaceror when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- GitHub - BBC-Esq/VectorDB-Plugin-for-LM-Studio: Plugin that lets you use LM Studio to ask questions about your documents including audio and video files.docs.cohere.com/page/calendar-agent">: Plugin that lets you use LM Studio to ask questions about your documents including audio and video files. - BBC-Esq/VectorDB-Plugin-for-LM-Studiocalendar_events and create_calendar_event tools to book appointments. --- ### **Cohere ▷ #[projects](https://discord.com/channels/954421988141711382/1218409701339828245/1281806144565678101)** (13 messages🔥): >
- GitHub - dingo-actual/om: An LLM architecture utilizing a recurrent structure and multi-layer memory1218409701339828245/1281806144565678101)** (13 messages🔥): >: An LLM architecture utilizing a recurrent structure and multi-layer memory - dingo-actual/omit Hosting Plans` >
- Tonics-OCRonos-TextGen - a Hugging Face Space by Tonic A member announced the coding of a simple LLM web app and shared the [GitHub link](https://github.com/xettrisomeman/llm_simple_app) for others to explore. - They expressed enthusiasm and invited questions, asserting that **Cohere** is a great tool. - **Plans to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
: no description foundding of a simple LLM web app and shared the [GitHub link](https://github.com/xettrisomeman/llm_simple_app) for others to explore. - They expressed enthusiasm and invited questions, asserting that **Cohere** is a great tool. - **Plans to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.- AssistantsLab/Tiny-Toxic-Detector · Hugging Facelore. - They expressed enthusiasm and invited questions, asserting that **Cohere** is a great tool. - **Plans to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
: no description foundenthusiasm and invited questions, asserting that **Cohere** is a great tool. - **Plans to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.- AssistantsLab/Tiny-Toxic-Detector · Hugging Faced the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
: no description foundng the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.- Tiny-Toxic-Detector: A compact transformer-based model for toxic content detectione app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
: This paper presents Tiny-toxic-detector, a compact transformer-based model designed for toxic content detection. Despite having only 2.1 million parameters, Tiny-toxic-detector achieves competitive pe... access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk. - Reflection 70B llama.cpp (Correct Weights) - a Hugging Face Space by gokaygokay `Chat Turns in API` - **Configuring Output Lengths discussion**: Members discussed how to configure output lengths and early stop sequences, indicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**: : no description found**Configuring Output Lengths discussion**: Members discussed how to configure output lengths and early stop sequences, indicating a need for clearer instructions. - *A participant mentioned they would ask Alicja for further assistance since she is currently on a gap year.* - **Understanding Search Query Costs**: A member inquired if a query with 10 documents counts as 0.1 of a search, to which it was clarified that any number up to 100 counts as a single search. - *There is no fractional execution; whether you search for 1 or 99 documents, it is still considered one search query.* - **Using the Calendar Agent**: Questions arose regarding the usage of the Calendar agent and how to book appointments through proper API calls. - *The user was directed to specific documentation but still struggled to get the expected output as demonstrated in the examples.* - **Handling Invalid Raw Prompt Error**: One member reported a 400 Bad Request error when using the `raw_prompting` parameter and asked for clarification on 'valid chat turns'. - *It was clarified that a chat turn is defined as a user, system, or agent interaction.* **Link mentioned**:
- powershai/docs/en-US at main · rrg92/powershaile_app: Simple LLM APP: Powershell + AI. Contribute to rrg92/powershai development by creating an account on GitHub. by creating an account on GitHub.
- SECourses 3D Render for FLUX - Full Dataset and Workflow Shared - v1.0 | Stable Diffusion LoRA | Civitai>: Full Training Tutorial and Guide and Research For a FLUX Style Hugging Face repo with all full workflow, full research details, processes, conclusi... --- ### **Cohere ▷ #[api-discussions](https://discord.com/channels/954421988141711382/1168578329423642786/1282139055127134279)** (20 messages🔥): > --- ### **Cohere ▷ #[api-discussions](https://discord.com/channels/954421988141711382/1168578329423642786/1282139055127134279)** (20 messages🔥): > --- ### **Cohere ▷ #[api-discussions](https://discord.com/channels/954421988141711382/1168578329423642786/1282139055127134279)** (20 messages🔥): >
HuggingFace ▷ #reading-group (6 messages):
Universal Approximation TheoremUncensored ModelsModel DefinitionsLeshno's TheoremHuggingFace Models
- Universal Approximation Theorem Depth Discussion: Members discussed the Universal Approximation Theorem, referencing Wikipedia's article for depth-1 UAT details.
- It was noted that Haykin's work is limited to monotone families, whereas Leshno et al. provide a more general definition that covers continuity.
- Uncensored Models Overview: A member recommended a detailed article explaining the process of creating uncensored models like WizardLM.
- Links to various WizardLM models were provided, including WizardLM-30B and Wizard-Vicuna.
- Clarification on Model Definitions: Clarifications were provided regarding what constitutes a model, specifically HuggingFace transformer models trained for instructed responses.
- The distinction was made that while many transformer models exist, only certain ones are designed for interactive chatting.
- Explaining Uncensored Models: A comprehensive explanation of uncensored models, like Alpaca and Vicuna, was shared, detailing their characteristics and uses.
- It was emphasized that these models are valuable for eliciting responses without typical content restrictions.
Links mentionedprojects](https://discord.com/channels/954421988141711382/1218409701339828245/1281806144565678101)** (13 messages🔥): >:-
Uncensored Models Integration`
>: I am publishing this because many people are asking me how I did it, so I will explain. https://huggingface.co/ehartford/WizardLM-30B-Uncensored https://huggingface.co/ehartford/WizardLM-13B-Uncensore.../llm_simple_app) for others to explore.
- They expressed enthusiasm and invited questions, asserting that **Cohere** is a great tool.
- **Plans to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree.
- **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality.
- **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/).
- They conveyed gratitude for the motivation received during development.
- **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords.
- Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
- Universal approximation theorem - Wikipedia to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
: no description found > > >
HuggingFace ▷ #computer-vision (8 messages🔥):
Community Computer Vision CourseStanford CS231n CourseImgcap CLI ToolFace Recognition DatasetsData Training Methods with CSV Files
- Community Computer Vision Course Launched: A member shared a link to the Community Computer Vision Course, which covers various foundational topics in computer vision.
- The course is designed to be accessible and friendly for learners at all levels, emphasizing the revolutionizing impact of computer vision.
- Highly Recommended Stanford CS231n Course: A member suggested following the Stanford CS231n course as the best resource for learning computer vision.
- This recommendation highlights the course's reputation and value in the field.
- Imgcap CLI Tool for Image Captioning Released: A new CLI tool called Imgcap was announced for generating captions for local images.
- The developer encouraged users to try it out and provide feedback on the results.
- Seeking Face Recognition Dataset: A member inquired about a medium-sized face recognition dataset organized by folder, similar to structures discussed on Data Science Stack Exchange.
- They found a dataset that meets their requirement, questioning the folder structure's utility compared to naming conventions.
- Training Models with PNG and CSV Data: A member asked whether to use original PNG images or associated CSV files for training their model, given that the CSV contains image IDs and labels.
- They also wondered if using the CSV files would expedite model training, referencing client needs.
Links mentioned ▷ #[general](https://discord.com/channels/1053877538025386074/1149866623109439599/1281697372845375669)** (199 messages🔥🔥): >:-
Face dataset organized by folderB's Underwhelming Benchmarks**: Recent evaluations show that **Reflection 70B** consistently underperforms compared to **Llama 3.1** across various benchmarks, indicating possible overpromising on its capabilities.
- Independent tests reveal lower scores, leading to skepticism about its initial claims and raising questions about why certain weights have not been released.
- **Community Skepticism on AI Claims**: Members of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick.
- Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements.
- **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event.
- While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI.
- **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets.
- Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations.
- **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture.
- Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
: I'm looking for a quite little/medium dataset (from 50MB to 500MB) that contains photos of famous people organized by folder. The tree structure have to bee something like this: ...ties. - Independent tests reveal lower scores, leading to skepticism about its initial claims and raising questions about why certain weights have not been released. - **Community Skepticism on AI Claims**: Members of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
- Welcome to the Community Computer Vision Course - Hugging Face Community Computer Vision Coursesm on AI Claims**: Members of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
: no description found of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.- GitHub - ash-01xor/Imgcap: A CLI to generate captions for imagestially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
: A CLI to generate captions for images. Contribute to ash-01xor/Imgcap development by creating an account on GitHub. > > - **Reflection 70B's Underwhelming Benchmarks**: Recent evaluations show that **Reflection 70B** consistently underperforms compared to **Llama 3.1** across various benchmarks, indicating possible overpromising on its capabilities. - Independent tests reveal lower scores, leading to skepticism about its initial claims and raising questions about why certain weights have not been released. - **Community Skepticism on AI Claims**: Members of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
HuggingFace ▷ #NLP (3 messages):
HF Trainer confusion matrixRAG-based retrieval evaluation
- Plotting Confusion Matrix in TensorBoard: A user inquired about how to plot the confusion matrix as an image in TensorBoard while training with HF Trainer.
- The query focuses on integrating visualization tools to enhance model evaluation during training.
- Evaluating RAG-based Retrieval Framework: Another user addressed the need for defining evaluation metrics for a project involving RAG-based retrieval for a specific domain.
- They also questioned whether to compare their RAG approach solely with other LLMs or against versions with and without RAG to assess effectiveness.
HuggingFace ▷ #diffusion-discussions (2 messages):
Transformer2DModelDiT
- Is Transformer2DModel the same as DiT?: A member inquired about the relationship between Transformer2DModel and DiT.
- They specifically questioned whether these models are equivalent or if there are key differences.
- Discussion on Model Comparisons: Another participant prompted for insights on various models and their functionalities, including DiT.
- This opened up a broader discussion about model architectures and their applications in the field.
aider (Paul Gauthier) ▷ #general (687 messages🔥🔥🔥):
DeepSeek and Aider PerformanceAI Development ConcernsAider Workflow StrategiesUsing a Config File for AiderConventions and Prompt Engineering
- DeepSeek's Recent Benchmarking Issues: Users expressed concerns about the performance of the DeepSeek Coder model, suggesting that it may be using the wrong model ID for benchmarks and hitting bad stats on the dashboard.
- It was noted that both model IDs now point to the same DeepSeek 2.5 model, possibly affecting the performance.
- AI Development Worries and Feedback: Community members discussed the potential impact of AI on development jobs and the changing role of developers as AI tools become more advanced.
- There were thoughts on whether the reliance on AI might lead to oversaturation or obsolescence in the workforce.
- Aider Workflow and Use Cases: Users shared their workflows using Aider and integration with tools like CodeCompanion for efficient project setup, emphasizing the importance of clear planning.
- The idea of incorporating a reinvigorated system prompt that follows conventions and plans was mentioned, suggesting potential improvements in Aider's output consistency.
- Configuring Aider Settings Properly: Discussions highlighted the need for efficient setup of environmental variables and configuration files to streamline Aider use, including the potential for using
.aider.conf.yml.- Community members also mentioned the use of
.envfiles for API keys, creating separation between Aider configuration and project-specific settings.
- Community members also mentioned the use of
- Issues with Google Cloud Quotas: Users reported encountering quota issues with Google Cloud's Vertex AI, particularly new accounts facing a 429 error for prediction requests, leading to speculation about quota restrictions.
- There were observations of broader issues with Google's services as users noted receiving unexpected rate limit errors with their various AI tools.
Links mentioned Medical LLMs**: The week highlighted various **Medical LLMs** including **CancerLLM**, which serves the cancer domain, and **MedUnA**, a vision-language model for medical imagery. - Key advancements like the **Foundation Model for Robotic Endoscopic Surgery** and **DHIN**, a **Decentralized Health Intelligence Network**, point towards innovative uses in healthcare. - **Evaluations of Medical AI Benchmarks**: Several evaluations emerged such as **TrialBench**, which provides clinical trial datasets and benchmarks, alongside **MedFuzz**, that explores the robustness of medical LLMs. - The focus on assessing **LLM bias** in diagnosis through initiatives like **DiversityMedQA** illustrates a proactive approach to fairness in medical AI. - **Digital Twins in Medical Applications**: **Digital Twins** were a crucial topic, with efforts in creating models for rare gynecological tumors and forecasting patient health using **DT-GPT**. - This technology underscores potential improvements in patient-specific medical interventions through predictive analytics. - **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: :-
no title foundere a crucial topic, with efforts in creating models for rare gynecological tumors and forecasting patient health using **DT-GPT**.
- This technology underscores potential improvements in patient-specific medical interventions through predictive analytics.
- **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools.
- Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare.
- **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow.
- This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity.
**Link mentioned**: : no description foundefforts in creating models for rare gynecological tumors and forecasting patient health using **DT-GPT**.
- This technology underscores potential improvements in patient-specific medical interventions through predictive analytics.
- **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools.
- Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare.
- **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow.
- This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity.
**Link mentioned**:
- Tweet from Artificial Analysis (@ArtificialAnlys)y underscores potential improvements in patient-specific medical interventions through predictive analytics. - **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: : Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not ...ription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**:
- direnv – unclutter your .profile - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: : unclutter your .profiles in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**:
- Tweet from Chubby♨️ (@kimmonismus)ns within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: : GPT-5 photographed with presumed parameters: 3*5T (assumingly MoE). Correctly, GPT-4 is specified there with 1.7T parameters. In addition, 7000 B100 as compute. The official statements are getting lou...rios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**:
- Specifying coding conventionssks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: : Tell aider to follow your coding conventions when it works on your code.integrity. **Link mentioned**:
- Tweet from blueblue (@deep9483)from Open Life Science AI (@OpenlifesciAI): @teortaxesTex We encountered some deployment issues with DeepSeek v2.5 and have temporarily fixed them. Could you please test it again? Medical LLM & Other Models : - CancerLLM: Large Language Model in Cancer Domain - MedUnA: Vision-Languag... --- ### **Nous Research AI ▷ #[interesting-links](https://discord.com/channels/1053877538025386074/1132352574750728192/1281731955292897384)** (19 messages🔥): >
- Chat modesncer Domain - MedUnA: Vision-Languag... --- ### **Nous Research AI ▷ #[interesting-links](https://discord.com/channels/1053877538025386074/1132352574750728192/1281731955292897384)** (19 messages🔥): >: Using the chat, ask and help chat modes. ### **Nous Research AI ▷ #[interesting-links](https://discord.com/channels/1053877538025386074/1132352574750728192/1281731955292897384)** (19 messages🔥): >
- Encountered 429 error "Quota exceeded for online_prediction_concurrent_requests_per_base_model" when using Claude 3 Haikumodel capabilities` >: I am using Claude 3 Haiku on Vertex AI and occasionally encounter the following error message: { "code": 429, "message": "Quota exceed...h significantly improves LLM reasoning by encouraging diversity during code generation through a natural language search method. - Hugh Zhang expressed that this method enables **LLMs to reason more deeply** at inference time, marking a promising direction within AI. - **RedTeam Arena launches with gamification**: A new game called **RedTeam Arena** invites participants to challenge models to say offensive words within 60 seconds, designed for engaging AI hackers in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
- FAQl language search method. - Hugh Zhang expressed that this method enables **LLMs to reason more deeply** at inference time, marking a promising direction within AI. - **RedTeam Arena launches with gamification**: A new game called **RedTeam Arena** invites participants to challenge models to say offensive words within 60 seconds, designed for engaging AI hackers in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: Frequently asked questions about aider.ressed that this method enables **LLMs to reason more deeply** at inference time, marking a promising direction within AI. - **RedTeam Arena launches with gamification**: A new game called **RedTeam Arena** invites participants to challenge models to say offensive words within 60 seconds, designed for engaging AI hackers in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- git-lfs/docs/spec.md at main · git-lfs/git-lfs- **RedTeam Arena launches with gamification**: A new game called **RedTeam Arena** invites participants to challenge models to say offensive words within 60 seconds, designed for engaging AI hackers in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: Git extension for versioning large files. Contribute to git-lfs/git-lfs development by creating an account on GitHub.s to say offensive words within 60 seconds, designed for engaging AI hackers in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- Model warnings in testing capabilities. - The game aims to create a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: aider is AI pair programming in your terminalate a **community-driven platform** focused on competitive prompting and red teaming, with all datasets and prompts to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- Tweet from Teortaxes▶️ (@teortaxesTex)to be made public post-disclosure. - **Reflection 70b model capabilities**: The newly discussed **Reflection 70b model** reportedly has a built-in scratchpad that utilizes XLM tags, sparking curiosity about its potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: Yeah it seems to work much better now, and better than previous models. I urge you to redo your tests. Quoting Teortaxes▶️ (@teortaxesTex) The new DeepSeek has a joy-killing, infuriating tendency o...s potential for advanced reasoning. - Community members speculated whether reflection-focused models might signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- Tweet from Matt Shumer (@mattshumer_) signal a new paradigm in multi-step problem-solving, although some felt prompts still play a more critical role. - **Insights on AI research fraud**: A thread highlighted alleged fraud involving **OthersideAI's** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: We’ve figured out the issue. The reflection weights on Hugging Face are actually a mix of a few different models — something got fucked up during the upload process. Will fix today. Quoting Matt Shu...'s** announcement of a breakthrough in training models, with skepticism about its legitimacy. - The discussion referenced a timeline of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- Sure Moron GIF - Sure Moron - Discover & Share GIFsine of deception, emphasizing the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: Click to view the GIFng the **importance of accountability** in AI research and development. - **Itext2kg as a knowledge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- NEW: Replit AI Agents Destroy Cursor Composor?!? 🤖🤔 End-To-End Coding & Deployment AI Coding user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.
: NEW: Replit AI Agents Destroy Cursor Composor?!? 🤖🤔 End-To-End Coding & Deployment AI Codinghttps://replit.com/https://cursor.com/🤑 FREE VALUE:👉 Free 6-D...heir ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**.- aider/benchmark/README.md at main · paul-gauthier/aiderlass="linksMentioned">: aider is AI pair programming in your terminal. Contribute to paul-gauthier/aider development by creating an account on GitHub.et from lmsys.org (@lmsysorg)
- "code": 429, "message": "Quota exceeded for aiplatform.googleapis.com/online_prediction_requests_per_base_model with base model: anthropic-claude-3-5-sonnet. Please submit a quota increase request. https://cloud.google.com/vertex-ai/docs/generative-ai/quotas-genai.", "status": "RESOURCE_EXHAUSTED" · Issue #18 · cg-dot/vertexai-cf-workersence compute has not yet yielded analogous gains. We hypothesize that a core missing com...
: "code": 429, "message": "Quota exceeded for aiplatform.googleapis.com/online_prediction_requests_per_base_model with base model: anthropic-claude-3-5-sonnet. Please submit a q... - This technology underscores potential improvements in patient-specific medical interventions through predictive analytics. - **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: - **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**:
aider (Paul Gauthier) ▷ #questions-and-tips (193 messages🔥🔥):
Aider Chat FunctionalityModel Performance ComparisonsGit Integration FeaturesLanguage Output BehaviorUsing Aider with Conventions
- Aider's Command Execution and Initialization Delays: Users have noticed that running aider with specific models, such as
--model, can introduce initialization delays compared to running aider without it.- Instances of commands executing slower than expected may be due to the complexity of the chosen model or the initial loading process.
- Adjusting Aider's Language Output: Aider can inadvertently switch languages during sessions, prompting users to specify desired output languages explicitly.
- Using the command
/chat-mode askor adding 'answer in English' to prompts helps maintain consistency in responses.
- Using the command
- Managing Git Integration with Aider: Aider is tightly integrated with git, automatically creating commits for changes, but it can be customized with the
--no-auto-commitsoption.- This allows users to manage how aider interacts with their git repositories, including whether it automatically creates new branches.
- Utilizing Aider for Automation in Workflows: Users can script interactions with aider through command line or Python for automated code modifications and pull request creation.
- While using aider as a library offers potential, it's noted that aider does not currently have a stable API for this purpose.
- Setting Project Conventions with Aider: To instruct Aider on specific coding guidelines, users can create a
CONVENTIONS.mdfile and read it in, ensuring guidelines are followed.- Aider's adherence to these conventions may require explicit reminders in prompts to maintain consistency.
Links mentionededge graph tool**: A GitHub project called **Itext2kg** offers a user-friendly tool to construct incremental knowledge graphs from unstructured documents using LLMs, with a direct connection to Neo4j. - Users can now leverage their ontologies effortlessly in production, presenting an accessible alternative to more traditional academic tools like **GraphRAG**. : no description found- Vertex AIt from lmsys.org (@lmsysorg): aider is AI pair programming in your terminalive content ahead. Introducing RedTeam Arena with Bad Words—our first game. You've got 60 seconds to break the model to say the bad word. The faster, the better. (Collaboration ...
- Tips39;ve got 60 seconds to break the model to say the bad word. The faster, the better. (Collaboration ...
: Tips for AI pair programming with aider. the bad word. The faster, the better. (Collaboration ...- Chat modeshref="https://arxiv.org/abs/2409.03733">: Using the chat, ask and help chat modes.ng In Natural Language Improves LLM Search For Code Generation
- Specifying coding conventionsute has led to remarkable improvements in large language models (LLMs), scaling inference compute has not yet yielded analogous gains. We hypothesize that a core missing com...
: Tell aider to follow your coding conventions when it works on your code.g inference compute has not yet yielded analogous gains. We hypothesize that a core missing com...- Scripting aiderhat a core missing com...
: You can script aider via the command line or python.lexandr_wang/status/1832147956562284987?s=46">- GPT code editing benchmarksA test-time compute result from Scale SEAL⚡️ We are releasing a new SOTA test-time compute method called PlanSearch. It meaningfully outperforms existing approaches on LiveCodeBench via a new...
: Benchmarking GPT-3.5 and GPT-4 code editing skill using a new code editing benchmark suite based on the Exercism python exercises.utperforms existing approaches on LiveCodeBench via a new...- Aider LLM Leaderboardsttps://x.com/shinboson/status/1832933747529834747">: Quantitative benchmarks of LLM code editing skill. from 𝞍 Shin Megami Boson 𝞍 (@shinboson)
- Git integrationy: On September 5th, Matt Shumer, CEO of OthersideAI, announces to the world that they've made a breakthrough, allowing them to train a mid-size mod...
: Aider is tightly integrated with git.thersideAI, announces to the world that they've made a breakthrough, allowing them to train a mid-size mod...- sahil2801/reflection_70b_v5 · Hugging Face.
: no description found/github.com/AuvaLab/itext2kg">- Options referenceLanguage Models: Details about all of aider’s settings.raphs Constructor Using Large Language Models - AuvaLab/itext2kg
- Thread By @shinboson - A story about fraud in the AI research c..rs](https://discord.com/channels/1053877538025386074/1104063238934626386/1282055619054010410)** (2 messages): >: A story about fraud in the AI research community On September 5th Matt Shumer CEO of OthersideAI announces to the world that they've made a breakthroul In-Context Learning` >
- Reddit - Dive into anythingls lead Medical AI advancements**: Highlighted models like **CancerLLM** and **MedUnA** are paving the way in the field of medical language models and vision-language tasks, enhancing applications in oncology and medical imagery. - The models play a crucial role in clinical environments and are further backed by initiatives like [OpenlifesciAI's thread](https://x.com/OpenlifesciAI/status/1832476252260712788) detailing their impact. - **Continual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : no description foundments**: Highlighted models like **CancerLLM** and **MedUnA** are paving the way in the field of medical language models and vision-language tasks, enhancing applications in oncology and medical imagery. - The models play a crucial role in clinical environments and are further backed by initiatives like [OpenlifesciAI's thread](https://x.com/OpenlifesciAI/status/1832476252260712788) detailing their impact. - **Continual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**:
- How To Develop 2 AI Apps in 10 Minutes!al language models and vision-language tasks, enhancing applications in oncology and medical imagery. - The models play a crucial role in clinical environments and are further backed by initiatives like [OpenlifesciAI's thread](https://x.com/OpenlifesciAI/status/1832476252260712788) detailing their impact. - **Continual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : You don't have to pay to try out building apps that use AI. With Ollama you can run AI models locally, for free. Vercel's AI library makes it easy to manage ...ther backed by initiatives like [OpenlifesciAI's thread](https://x.com/OpenlifesciAI/status/1832476252260712788) detailing their impact. - **Continual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**:
- no title foundg their impact. - **Continual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : no description foundual In-Context Learning with Adaptive Transformers**: The architecture of ‘Continual In-Context Learning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**:
- Issues · ggerganov/llama.cpprning with Adaptive Transformers’ extends transformer applicability in varied tasks, utilizing a pre-trained transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.transformer with additional layers for adaptive learning. - It employs a two-fold approach where it initially uses **in-context** learning and modifies the system only if performance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**:
- better prompting for LLM to suggest files · paul-gauthier/aider@6638efbformance falls short, aiming for a balance between adaptability and risk management. - **Expansion of Medical Benchmarks**: New benchmarks like **TrialBench** and **DiversityMedQA** are introduced to assess medical LLM performance in clinical settings and tackle bias in diagnostic processes. - These evaluations are fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : no description found
Reflection 70B vs Llama3 70BV0 updates and applicationsZed's GitHub discussionsYouTube AI coding videos- Reflection 70B lags behind Llama3 70B: Reflection 70B scored 42% on the aider code editing benchmark, while Llama3 70B achieved 49%. It was noted that the current model won't function properly with the released aider after modifying it to ignore certain tags.
- For further insights, see the leaderboards.
- Impressive results from recent V0 update: A member recommended checking out updates to v0, which is Vercel's version of Claude tailored for NextJS UI's, reporting impressive results. They also provided a YouTube video that demonstrates its capabilities.
- Demos and more information can be found at v0.dev/chat and other linked resources.
- Zed's GitHub hints at upcoming subscription: Discussion revealed that there are multiple mentions on Zed's GitHub regarding a forthcoming Zed Pro subscription. This collaboration with Anthropic is anticipated to introduce an 'edit mode' feature.
- Members speculated that this may enhance functionality greatly in upcoming updates.
- AI Coding Secret Sauce Explored: A newly shared YouTube video titled 'SECRET SAUCE of AI Coding?' investigates high-output AI coding techniques. It highlights various tools including Aider, Cursor, Bun, and Notion.
- The video is part of an ongoing exploration into practical AI coding solutions and methods.
-
Hyperbolic AI Dashboarde meets high standards of safety and efficacy.
**Link mentioned**: : no description foundsafety and efficacy.
**Link mentioned**:
- Tweet from Paul Gauthier (@paulgauthier)t from Open Life Science AI (@OpenlifesciAI): Reflection 70B scored 42% on the aider code editing benchmark, well below Llama3 70B at 49%. I modified aider to ignore the
tags. This model won't work properly with t...n Cancer Domain - MedUnA: Vision-Languag... --- ### **Nous Research AI ▷ #[reasoning-tasks](https://discord.com/channels/1053877538025386074/1264666760972472481/1281809703562907690)** (2 messages): > - SECRET SAUCE of AI Coding? AI Devlog with Aider, Cursor, Bun and Notion38025386074/1264666760972472481/1281809703562907690)** (2 messages): >: What's the secret sauce of HIGH OUTPUT AI Coding?🔗 More AI Coding with AIDERhttps://youtu.be/ag-KxYS8Vuw🚀 More AI Coding with Cursorhttps://youtu.be/V9_Rzj...eded in AI` - **AGI can come from intense training and RL**: A discussion highlighted that **AGI** can potentially be achieved through **intense training** and **reinforcement learning (RL)**. - However, there are doubts about **transformers** leading to **Supervised Semantic Intelligence (SSI)**. - **Scaling may enhance reasoning abilities**: It was noted that scaling up models may help solve **reasoning challenges** by training on **large, diverse, and clean datasets**. - This approach could make a significant difference, although not sufficient to fully emulate human cognitive systems. - **Resource demands hinder cognitive simulations**: Concerns were raised about the **resource demands** of simulating human cognitive systems, which makes it **super hard to scale**. - This suggests that a **new breakthrough** in AI is **much needed** to overcome these challenges. --- ### **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1281700074274951281)** (16 messages🔥): >
- Build anything with v0 (3D games, interactive apps)e achieved through **intense training** and **reinforcement learning (RL)**. - However, there are doubts about **transformers** leading to **Supervised Semantic Intelligence (SSI)**. - **Scaling may enhance reasoning abilities**: It was noted that scaling up models may help solve **reasoning challenges** by training on **large, diverse, and clean datasets**. - This approach could make a significant difference, although not sufficient to fully emulate human cognitive systems. - **Resource demands hinder cognitive simulations**: Concerns were raised about the **resource demands** of simulating human cognitive systems, which makes it **super hard to scale**. - This suggests that a **new breakthrough** in AI is **much needed** to overcome these challenges. --- ### **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1281700074274951281)** (16 messages🔥): >: Try it out at https://v0.dev/chat.• Demos: https://x.com/v0/status/1826020673908535325• shadcn/ui: https://ui.shadcn.com• Deploy: https://vercel.com **Link mentioned**: **Link mentioned**: **Link mentioned**:
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
Reflection APIReflection-Tuning TechniqueSelf-Correcting AI Models
- Reflection API Now Open for Playtesting: The Reflection API is now available on OpenRouter for free playtesting, with a fixed version expected soon.
- Matt Shumer noted a distinct quality difference between hosted and internal APIs, indicating the current hosted version is not fully optimized.
- Introducing Reflection-Tuning Technique: The Reflection-70B model developed by Matt Shumer employs a new technique called Reflection-Tuning that enables the model to detect and correct mistakes in its reasoning.
- This model leverages synthetic data for training, enhancing its performance as noted in several sources, including a LinkedIn post.
- Community Resources on Reflection 70B: Users can access various resources about the Reflection 70B model, including a Medium article that discusses its self-correcting abilities.
- There are also insightful videos available, such as a YouTube discussion with Matt Shumer about this innovative model.
Links mentioned ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1281700074274951281)** (16 messages🔥): >:-
Tweet from OpenRouter (@OpenRouterAI)81700074274951281)** (16 messages🔥):
>: Reflection's own API is now available on OpenRouter for free playtesting: https://openrouter.ai/models/mattshumer/reflection-70b:free Stay tuned for a production endpoint for the fixed version so...her AI's MLP Kernels**: Members discussed the **20% speed enhancement** of MLP kernels from Together AI, with specific mention of **SwiGLU** as a potential factor.
- *Tri Dao* might address this topic further at the upcoming CUDA MODE IRL event.
- **ROCm/AMD's Struggles Compared to NVIDIA**: There were inquiries on why **ROCm/AMD** isn't capitalizing on the AI boom as effectively as **NVIDIA/CUDA**, questioning whether it relates to **corporate trust**.
- Another member pointed out that **PyTorch does run on ROCm**, yet real-world performance still leans heavily towards NVIDIA hardware.
- **Speculation on RTX 5XXX Architecture**: Discussions included speculation about whether the upcoming **RTX 5XXX** series will feature **Blackwell** or **Hopper** architecture generation.
- There were also questions regarding the potential inclusion of **int/fp4 tensor cores**.
- **Reflection Drama Causes Embarrassment**: Conversations centered on the **Reflection drama**, which one member described as **embarrassing**, urging others to disregard it.
- A link was shared to a Reddit discussion outlining **lessons learned** from Reflection 70B, stressing the importance of replicating benchmarks.
- **PyTorch Compatibility on ROCm**: A member confirmed that **PyTorch** does indeed run on **ROCm**, adding to the ongoing conversations about hardware performance.
- Despite its compatibility, there's still a perceived performance gap when compared to NVIDIA's offerings.
- no title found of **SwiGLU** as a potential factor. - *Tri Dao* might address this topic further at the upcoming CUDA MODE IRL event. - **ROCm/AMD's Struggles Compared to NVIDIA**: There were inquiries on why **ROCm/AMD** isn't capitalizing on the AI boom as effectively as **NVIDIA/CUDA**, questioning whether it relates to **corporate trust**. - Another member pointed out that **PyTorch does run on ROCm**, yet real-world performance still leans heavily towards NVIDIA hardware. - **Speculation on RTX 5XXX Architecture**: Discussions included speculation about whether the upcoming **RTX 5XXX** series will feature **Blackwell** or **Hopper** architecture generation. - There were also questions regarding the potential inclusion of **int/fp4 tensor cores**. - **Reflection Drama Causes Embarrassment**: Conversations centered on the **Reflection drama**, which one member described as **embarrassing**, urging others to disregard it. - A link was shared to a Reddit discussion outlining **lessons learned** from Reflection 70B, stressing the importance of replicating benchmarks. - **PyTorch Compatibility on ROCm**: A member confirmed that **PyTorch** does indeed run on **ROCm**, adding to the ongoing conversations about hardware performance. - Despite its compatibility, there's still a perceived performance gap when compared to NVIDIA's offerings.
: no description found ### **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1281700074274951281)** (16 messages🔥): > > >
OpenRouter (Alex Atallah) ▷ #app-showcase (10 messages🔥):
ISO20022Bitcoin and CBDCscli_buddy GitHub projectOpen Source Multi-lingual ModelOpenRouter Usage
- Exploring ISO20022 for Crypto: A member highlighted the importance of ISO20022 in the context of ongoing developments in crypto, suggesting that others should investigate its implications.
- They encouraged a deeper look into this standard to understand its potential impact on financial transactions.
- Bitcoin's Incompatibility with CBDCs: Bitcoin cannot be traded with CBDCs, sparking discussions about the implications of central bank digital currencies on decentralized cryptocurrencies.
- Members shared their surprise at this limitation and its potential effects on trading dynamics.
- Introducing cli_buddy for OpenRouter: A member shared a GitHub project called cli_buddy, designed to enhance interactions with OpenRouter by offering a variety of commands.
- The info command allows users to search for AI models and display credits available in OpenRouter, increasing accessibility.
- Development of Open Source Multi-lingual Model: Discussions emerged regarding a dataset currently under development, with 1.5GB in size, aimed at training an open source multi-lingual model.
- This dataset combines image position data, making it suitable for integration with vision models.
- Cost-effectiveness of Recent OpenAI Usage: Members compared the 1 week usage cost of OpenAI credits at roughly $2,500, considering it quite expensive in light of the other project expenses discussed.
- Participants pointed out the need for more affordable options amidst the rising costs of AI services.
Link mentioned: GitHub - rezmeplxrf/cli_buddy595451895918/1281976608311480392)** (49 messages🔥):
: Contribute to rezmeplxrf/cli_buddy development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (611 messages🔥🔥🔥):
DeepSeek CoderReflection ModelOpenRouter API IssuesGemini ModelsMulti-Modal Models
- DeepSeek Coder experiencing issues: Users reported that the DeepSeek Coder is producing zero responses and that the API is malfunctioning, indicating potential upstream issues.
- Despite the DeepSeek status page showing no reported issues, users continue to experience problems with both the API and the OpenRouter chat.
- Concerns about Reflection Model: Discussion arose regarding the legitimacy of the Reflection model, with some users expressing skepticism over its claims and performance.
- There is a desire for the model to be removed from OpenRouter due to concerns over scams and misinformation.
- Errors in OpenRouter API Calls: Users encountered errors such as 'httpx.RemoteProtocolError' indicating that connections were prematurely closed, suggesting issues with the DeepSeek API.
- Some users are attempting to verify whether these errors stem from their own implementations or upstream problems.
- Interest in AI Model Hosting: Users discussed the hosting of models on OpenRouter, noting that Euryale 2.2 is a recommended choice for RP applications, while Magnum's lack of updates is a concern.
- The conversation included comparisons to other models and requests for reliable options for roleplaying.
- Multi-Modal Model Usage: Users asked about integrating local images with multi-modal models, seeking guidance on how to format requests properly.
- Instructions on decoding images into base64 format for API requests were provided to assist users in utilizing multi-modal capabilities.
Links mentioned▷ #[torch](https://discord.com/channels/1189498204333543425/1189607750876008468/1282058495193120860)** (6 messages): >:-
Tweet from cocktail peanut (@cocktailpeanut)20860)** (6 messages):
>: OpenAI preparing to drop their new modelysis`
>
- no title found Cache Lookup` - **Analyzing Dynamo Calls**: Members discussed tracing the calls in **Dynamo**, particularly focusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : no description foundyzing Dynamo Calls**: Members discussed tracing the calls in **Dynamo**, particularly focusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- OpenRouter in **Dynamo**, particularly focusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : LLM router and marketplaceusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- Transforms | OpenRouterxpressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : Transform data for model consumptionrigin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- Prompt Caching | OpenRouterh's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : Optimize LLM cost by up to 90%in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- Monopoly Guy Money GIF - Monopoly Guy Money - Discover & Share GIFsL332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : Click to view the GIFentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- Requests | OpenRouterne **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : Handle incoming and outgoing requestsding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- DeepSeek Service Statusmember remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : no description foundhing for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- Tweet from Matt Shumer (@mattshumer_) This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : Quick update — we re-uploaded the weights but there’s still an issue. We just started training over again to eliminate any possible issue. Should be done soon. Really sorry about this. The amount of...rch/nn/modules/container.py#L332">
- Lumen Orbits/container.py at 31c4e0d37d8efc37a0697159e5b9121ec34d5141 · pytorch/pytorch: Join Lumen Orbit in pioneering sustainable space-based data centers. Learn how we use 90% less electricity and access 24/7 solar energy. Download our white paper today! --- ### **CUDA MODE ▷ #[algorithms](https://discord.com/channels/1189498204333543425/1189861061151690822/1282297172678934640)** (2 messages): >
- Models: 'base>' | OpenRouter1061151690822/1282297172678934640)** (2 messages): >: Browse models on OpenRouter)** (2 messages): >
- Tweet from OpenRouter (@OpenRouterAI)ed the importance of limiting messages that focus on **self-promotion**, stating that only performance-related content is considered engaging. - Another member acknowledged the feedback with an *oopsie*, indicating they understood the point made. - **Feedback on Message Content**: The conversation emphasized the need for value in server messages, discouraging posts with just links unless they are performance-related. - This feedback was well-received, showing a community commitment to constructive interactions. --- ### **CUDA MODE ▷ #[cool-links](https://discord.com/channels/1189498204333543425/1189868872887705671/1281708898792771624)** (18 messages🔥): >: Reflection's own API is now available on OpenRouter for free playtesting: https://openrouter.ai/models/mattshumer/reflection-70b:free Stay tuned for a production endpoint for the fixed version so...dicating they understood the point made. - **Feedback on Message Content**: The conversation emphasized the need for value in server messages, discouraging posts with just links unless they are performance-related. - This feedback was well-received, showing a community commitment to constructive interactions. --- ### **CUDA MODE ▷ #[cool-links](https://discord.com/channels/1189498204333543425/1189868872887705671/1281708898792771624)** (18 messages🔥): >
- Tweet from Matt Shumer (@mattshumer_)es, discouraging posts with just links unless they are performance-related. - This feedback was well-received, showing a community commitment to constructive interactions. --- ### **CUDA MODE ▷ #[cool-links](https://discord.com/channels/1189498204333543425/1189868872887705671/1281708898792771624)** (18 messages🔥): >: We’ve figured out the issue. The reflection weights on Hugging Face are actually a mix of a few different models — something got fucked up during the upload process. Will fix today. Quoting Matt Shu...-links](https://discord.com/channels/1189498204333543425/1189868872887705671/1281708898792771624)** (18 messages🔥): >
- python-aiplatform/google/cloud/aiplatform_v1/types/tool.py at 6d1f7fdaadade0f9f6a77c136490fac58d054ca8 · googleapis/python-aiplatformbooks are highly valued**: Members discussed the **2023 lab notebooks** for a course, emphasizing their quality and usefulness for studies. - *A member noted they're waiting for future releases*, but expressed confidence in the existing materials. - **Exciting YouTube Content on CUDA**: A **YouTube video** titled *Zen, CUDA, and Tensor Cores - Part 1* was shared, providing an overview of key concepts and insights. - This video is part of a series, with more information available at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: A Python SDK for Vertex AI, a fully managed, end-to-end platform for data science and machine learning. - googleapis/python-aiplatform - *A member noted they're waiting for future releases*, but expressed confidence in the existing materials. - **Exciting YouTube Content on CUDA**: A **YouTube video** titled *Zen, CUDA, and Tensor Cores - Part 1* was shared, providing an overview of key concepts and insights. - This video is part of a series, with more information available at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- Llama 3.1 Euryale 70B v2.2 - API, Providers, Statsg YouTube Content on CUDA**: A **YouTube video** titled *Zen, CUDA, and Tensor Cores - Part 1* was shared, providing an overview of key concepts and insights. - This video is part of a series, with more information available at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: Euryale L3.1 70B v2. Run Llama 3.1 Euryale 70B v2.2 with API, and Tensor Cores - Part 1* was shared, providing an overview of key concepts and insights. - This video is part of a series, with more information available at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- no title found more information available at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: no description founde at [Computer Enhance](https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i). - **Recording of Latest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- DeepSeek-Coder-V2 - API, Providers, Statsest VLLM Office Hours**: A link to the latest **VLLM office hours** recording discussing quantized **CUTLASS GEMM optimizations** was shared with interested members. - This is targeted at those keen on optimizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model. It is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Run DeepSeek...mizing performance in NVIDIA CUDA-related work, providing valuable insights for AI collaboratives. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- Reddit - Dive into anythinges. - **Introduction to AdEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: no description foundEMAMix Optimizer**: An **arXiv paper** and GitHub repository were shared discussing the *AdEMAMix Optimizer*, highlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- What is Top K? - Explaining AI Model Parametershighlighting advancements in optimizer efficiency. - The paper can be found at [arXiv](https://arxiv.org/pdf/2409.03137) and the code repository is available [here](https://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: Today, I delve into the concept of Top K in AI, a crucial parameter that influences text generation. By limiting the AI's word choices to the top K most like...tps://github.com/nanowell/AdEMAMix-Optimizer-Pytorch). - **Herbie Tool Enhances Numerical Analysis**: A member introduced **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- Llama 3.1 405B (base) - API, Providers, Statsd **Herbie**, a tool designed to improve the speed and accuracy of input equations via various implementations. - It's suggested to [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.
: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. Run Llama 3.1 405B (base) with API [install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.- Mixtral 8x7B (base) - API, Providers, Statsclass="linksMentioned">: A pretrained generative Sparse Mixture of Experts, by Mistral AI. Incorporates 8 experts (feed-forward networks) for a total of 47B parameters. Run Mixtral 8x7B (base) with API.youtube.com/watch?v=uBtuMsAY7J8&ab_channel=MollyRocket">
- Brave Search: Search the Web. Privately. Truly useful results, AI-powered answers, & more. All from an independent index. No profiling, no bias, no Big Tech.i>
- Magnum 72B - API, Providers, Statssors with Andrew Feldman of Cerebras Systems: From the maker of [Goliath](https://openrouter.ai/models/alpindale/goliath-120b), Magnum 72B is the first in a new family of models designed to achieve the prose quality of the Claude 3 models, notabl....
- This appears to be very similar to our Atlas-1 model, but with hard coded clicks. Is that correct? · Issue #21 · OthersideAI/self-operating-computero nanowell/AdEMAMix-Optimizer-Pytorch development by creating an account on GitHub.
: Hey guys we've been training a very similar multi-modal model called Atlas-1, however we don't need to hard-code click positions like it appears here, because we trained our model to find UI-e...4/1282039658997350401)** (27 messages🔥): >- no title foundres` >: no description found Templates` - **Understanding Tensor Core Efficiency in Matmul**: A member explained that using **4 WMMA** operations per warp allows for better pipelining in matrix multiplication compared to using just **1 WMMA** per warp, enhancing overall performance. - The discussion highlighted that with NVIDIA's Ampere architecture, higher arithmetic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.
- Change Log | DeepSeek API Docsg **4 WMMA** operations per warp allows for better pipelining in matrix multiplication compared to using just **1 WMMA** per warp, enhancing overall performance. - The discussion highlighted that with NVIDIA's Ampere architecture, higher arithmetic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.
: Version: 2024-09-05er warp allows for better pipelining in matrix multiplication compared to using just **1 WMMA** per warp, enhancing overall performance. - The discussion highlighted that with NVIDIA's Ampere architecture, higher arithmetic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.- feat: Add support for system instruction and tools in tokenization. · googleapis/python-aiplatform@72fcc06metic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.
: PiperOrigin-RevId: 669058979rformance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.- Change Log | DeepSeek API Docsformance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.
: Version: 2024-09-05 > > >
OpenRouter (Alex Atallah) ▷ #beta-feedback (11 messages🔥):
Vertex AI Key CompatibilityJSON Formatting IssuesGoogle AI Studio UsageBase64 Encoding Workaround
- Vertex AI Key requires full JSON: A member noted that for the Vertex AI key, it indeed needs to be the whole JSON object, including the project_id and other details.
- This point was confirmed after some discussion about whether just the private_key would suffice.
- Google AI Studio is current requirement: Members discussed limitations in using Vertex AI, confirming that as of now, one can only use Google AI Studio.
- This indicates that further fixes are necessary to expand compatibility options.
- Base64 encoding suggested as solution: A clever workaround was suggested for upload issues with the JSON file: convert the whole JSON to Base64 and decode it before sending to Vertex AI.
- This method was mentioned as a stolen idea from a GitHub PR discussion.
CUDA MODE ▷ #cool-links (18 messages🔥):
: This PR adds support for Vertex AI in Google Cloud. At this time, the Application Default Credentials (ADC) must be set in the gcloud command to use Vertex AI. Authentication supports one of the fo...
Stability.ai (Stable Diffusion) ▷ #general-chat (592 messages🔥🔥🔥):
AI model training methodsGPU recommendations for image generationStable Diffusion models comparisonInfluencer culture and content creationUsing detail enhancing LoRAs
- Comparison of training methods: LoRA vs Dreambooth: LoRAs are smaller, easier to distribute, and can be combined during runtime, while Dreambooth outputs full checkpoints which occupy significantly more space.
- Both methods require minimal images for training, but the tools like Kohya and OneTrainer are preferable for LoRA, with Kohya being particularly popular.
- GPU recommendations under $600 for local image generation: For a budget of $600, a used 3090 or 2080 is suggested as a solid option for enhancing local image generation capabilities.
- Users emphasized the importance of VRAM for optimal performance, particularly when it comes to tasks such as local training.
- The evolution of SD models and their compatibility: There is a call for new models that are backwards compatible with SD1.5 LoRAs, as SD1.5 remains a classic tool for many users today.
- Current discussions highlight the strengths of SD1.5 in composition, with users noting how newer models haven't diminished its effectiveness.
- Influencer culture in content creation: A critiqued influencer culture highlights the expectation for content creators to monetize their efforts through platforms like Patreon and YouTube.
- Some community members express a desire for a return to less commercialized forms of content creation, while acknowledging the prevalent use of influencer strategies.
- Detail enhancing LoRAs in image generation: Users report that details in AI-generated images rely significantly on workflow enhancements rather than prompting, with LoRAs being crucial for improving image quality.
- Several users utilize combinations of LoRAs, such as Detail Tweaker XL, for optimal results in their image generations.
Links mentioned[install Herbie](https://herbie.uwplse.org/demo/) for personal use to avoid limitations from the web demo.:- imgur.coma href="https://herbie.uwplse.org/demo/">: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ... See https://www.computerenhance.com/p/zen-cuda-and-tensor-cores-part-i for more information, links, addenda, and more videos in this series.
- imgur.comnsor-cores-part-i for more information, links, addenda, and more videos in this series. : Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...drew Feldman of Cerebras Systems
- UVMapper - UV Mapping Softwareew Feldman, Founder and CEO of Cerebras Systems. Andrew and the Cerebras team are responsible for building the largest-e...
: no description foundO of Cerebras Systems. Andrew and the Cerebras team are responsible for building the largest-e...- DC-Solver: Improving Predictor-Corrector Diffusion Sampler via Dynamic Compensationanowell/AdEMAMix-Optimizer-Pytorch">: Diffusion probabilistic models (DPMs) have shown remarkable performance in visual synthesis but are computationally expensive due to the need for multiple evaluations during the sampling. Recent predi...Mix-Optimizer-Pytorch development by creating an account on GitHub.
- imgur.com on GitHub.
: Discover the magic of the internet at Imgur, a community powered entertainment destination. Lift your spirits with funny jokes, trending memes, entertaining gifs, inspiring stories, viral videos, and ...>- Kijai/flux-fp8 · Hugging FaceUDA Development Templates` - **Understanding Tensor Core Efficiency in Matmul**: A member explained that using **4 WMMA** operations per warp allows for better pipelining in matrix multiplication compared to using just **1 WMMA** per warp, enhancing overall performance. - The discussion highlighted that with NVIDIA's Ampere architecture, higher arithmetic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication.
: no description found - **Understanding Tensor Core Efficiency in Matmul**: A member explained that using **4 WMMA** operations per warp allows for better pipelining in matrix multiplication compared to using just **1 WMMA** per warp, enhancing overall performance. - The discussion highlighted that with NVIDIA's Ampere architecture, higher arithmetic density leads to improved performance, specifically suggesting a **4x4 layout** for operations. - **Critique of WMMA for Performance Gains**: *One participant discouraged using WMMA*, suggesting that frameworks like **CUTLASS** are necessary for extracting optimal performance from tensor cores, especially in FP32 operations. - They noted that integrating NVIDIA’s **WMMA sample** into their code resulted in better performance than standard FP32 FMAs but remained behind **cuBLAS**. - **Challenges of Occupancy and Register Allocation**: A discussion around **occupancy** revealed that while higher occupancy allows for better resource usage, it necessitates fewer registers per thread, limiting data reuse. - A member noted that with the arrival of the **Hopper** architecture, dynamic register reallocation between warps could potentially improve both occupancy and performance. - **New CUDA Development Template Shared**: One member introduced a **GitHub template** designed to simplify CUDA C++ kernel development, facilitating testing within **Python/PyTorch**. - This initiative aimed to help provide a streamlined setup for future CUDA developers and received positive feedback from the community. - **Clarification on Matrix Multiplication Code**: Members clarified code snippets involving **wmma::mma_sync**, confirming that the example actually performed **16 matmuls** instead of the originally stated 2x2 configuration. - The conversation highlighted the importance of correct terminology and understanding of kernel operations in optimizing matrix multiplication. - no title found Cache Lookup` - **Analyzing Dynamo Calls**: Members discussed tracing the calls in **Dynamo**, particularly focusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**: : no description foundyzing Dynamo Calls**: Members discussed tracing the calls in **Dynamo**, particularly focusing on performance gaps associated with **getitem** methods. - One member expressed interest in understanding the **origin** of these calls and their respective **timing**. - **Identifying Source in PyTorch's container.py**: A relevant line in the [PyTorch container module](https://github.com/pytorch/pytorch/blob/31c4e0d37d8efc37a0697159e5b9121ec34d5141/torch/nn/modules/container.py#L332) was identified as potentially responsible for the iterative **getitem** calls. - The specific line being investigated is line **320**, which ignited discussions regarding its implications. - **Challenges in TorchDynamo Cache Lookup**: A member remarked that searching for **torchdynamo cache lookup** resulted in a wrapper but lacked specific details on direct calls. - This prompted an exploration for more **insight** on the cache management within **Dynamo**. **Link mentioned**:
- no title found of **SwiGLU** as a potential factor. - *Tri Dao* might address this topic further at the upcoming CUDA MODE IRL event. - **ROCm/AMD's Struggles Compared to NVIDIA**: There were inquiries on why **ROCm/AMD** isn't capitalizing on the AI boom as effectively as **NVIDIA/CUDA**, questioning whether it relates to **corporate trust**. - Another member pointed out that **PyTorch does run on ROCm**, yet real-world performance still leans heavily towards NVIDIA hardware. - **Speculation on RTX 5XXX Architecture**: Discussions included speculation about whether the upcoming **RTX 5XXX** series will feature **Blackwell** or **Hopper** architecture generation. - There were also questions regarding the potential inclusion of **int/fp4 tensor cores**. - **Reflection Drama Causes Embarrassment**: Conversations centered on the **Reflection drama**, which one member described as **embarrassing**, urging others to disregard it. - A link was shared to a Reddit discussion outlining **lessons learned** from Reflection 70B, stressing the importance of replicating benchmarks. - **PyTorch Compatibility on ROCm**: A member confirmed that **PyTorch** does indeed run on **ROCm**, adding to the ongoing conversations about hardware performance. - Despite its compatibility, there's still a perceived performance gap when compared to NVIDIA's offerings.
- Tweet from Paul Gauthier (@paulgauthier)t from Open Life Science AI (@OpenlifesciAI): Reflection 70B scored 42% on the aider code editing benchmark, well below Llama3 70B at 49%. I modified aider to ignore the
aider (Paul Gauthier) ▷ #links (14 messages🔥):
Links mentionedare fundamental in improving model reliability and demonstrating the evolving standards of medical AI applications. - **Digital Twins and Patient Forecasting**: Emerging technologies like **Digital Twins for Rare Gynecological Tumors** and **DT-GPT** are set to revolutionize patient health forecasting, enabling more personalized healthcare solutions. - These innovations signify advancements in utilizing AI to simulate patient conditions and predict outcomes effectively. - **Frameworks for Medical AI applications**: Frameworks such as **Rx Strategist** and **Guardrails for Medical LLMs** are being developed to enhance prescription verification and establish safety protocols in AI usage. - These efforts are critical in ensuring that the deployment of AI in healthcare meets high standards of safety and efficacy. **Link mentioned**: : - Tweet from Artificial Analysis (@ArtificialAnlys)y underscores potential improvements in patient-specific medical interventions through predictive analytics. - **Frameworks for Robust Medical AI**: Innovations such as **Rx Strategist** enable LLM-based prescription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**: : Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not ...ription verification, enhancing the reliability of medical AI tools. - Additionally, developments in **guardrails for medical LLMs** suggest a growing concern for safety and reliability in AI applications within healthcare. - **Advancements in Continual In-Context Learning**: The architecture of **Continual In-Context Learning with Adaptive Transformers** extends transformer models for dynamic learning scenarios, focusing on effective gradient flow. - This system supports rapid adaptation to new tasks, thereby reducing risks of catastrophic failure while preserving learning integrity. **Link mentioned**:
- Welcome to the Community Computer Vision Course - Hugging Face Community Computer Vision Coursesm on AI Claims**: Members of the community express doubts regarding the **performance claims** of new AI models, labeling the situation as potentially misleading or a marketing gimmick. - Some discussions suggest that continued releases might not reflect the model's actual abilities, akin to earlier hype cycles within AI advancements. - **Nous Forge's Potential Appearance at 38C3**: There's consideration for a **Nous Forge presentation** at the upcoming **Chaos Communication Congress 2024**, with members discussing the relevance of the event. - While the event may cater primarily to German speakers, its bilingual format could still allow for comprehensive presentations on digital freedom and AI. - **Importance of Diverse Benchmarking**: Participants agree on the necessity of utilizing **diverse benchmarks** to gauge AI models, pointing out risks of overfitting to certain datasets. - Examples like **Alice** benchmark indicate that specific weaknesses may not accurately represent overall model performance and can lead to skewed evaluations. - **Need for Cleaner Pretraining Data**: There's a consensus that the issues observed in certain AI models are symptomatic of **pretraining data cleanliness**, rather than systemic flaws in transformer architecture. - Suggestions include the use of **synthetic data** to improve model training and mitigate biases or misleading patterns found in datasets.
- Universal approximation theorem - Wikipedia to host the app on Streamlit**: Members discussed the possibility of hosting the LLM app on **Streamlit** for easier access, prompting the developer to agree. - **Integration of Langchain**: The developer confirmed the app was built as a learning project involving **Langchain**, enhancing its functionality. - **App Deployed in the Cloud**: Wittgenstein shared that the app is now deployed in the cloud, providing the link to access it: [Streamlit App](https://llmsimpleapp-mrzdrd8jxzcxmy5yisnmis.streamlit.app/). - They conveyed gratitude for the motivation received during development. - **Admin Access Issue Identified**: Concerns arose when it was discovered that the app allows easy admin login via JSON output, revealing administrative passwords. - Members reacted with humor regarding the password being 'admin', pointing out a potential security risk.
- Google Colabadjust. - Suggestions for improvement could enhance the richness of API replies. - **404 Error on API URL**: A user encountered an **HTTP ERROR 404** when trying to access the API at the specified URL. - Another user pointed out the correct endpoint as [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions). - **Payment Method Authentication Problems**: A user reported issues with the authentication of their payment method while setting up API access, receiving errors on multiple cards. - Another participant confirmed similar experiences, particularly with security code errors. - **Concerns Over Deprecation of Models**: A user expressed frustration that many models were deprecated, affecting access to updated information and links. - They inquired about methods to prompt models for more direct link access. - **Using the Search Domain Filter**: A user suggested utilizing the `search_domain_filter` parameter in the API to regulate the domains the model searches. - This approach might help users retrieve more accurate information from current models. **Link mentioned**: