[AINews] AI2 releases OLMo - the 4th open-everything LLM
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AI Discords for 2/1/2024. We checked 21 guilds, 312 channels, and 5874 messages for you. Estimated reading time saved (at 200wpm): 483 minutes. We enountered stability issues with very link-heavy messages (thanks @yikesawjeez...) that we had to figure out how to address.
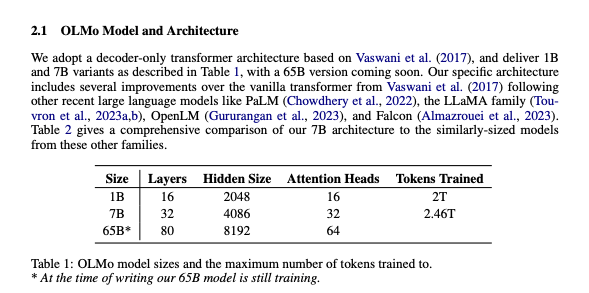
As teased on Nathan Lambert's Latent Space appearance, we're about to see AI2 come up a lot more this year under new leadership. The first results of that are coming through now with OLMo (Open Language MOdels) - a 1B, and set of 7B models, with a 65B on the way.
Nathan's Substack has the less corpo take if you enjoy that tone (we do) and it is also fun to note that the releasing-models-thru-magnet-link meta still has not yet run out of juice.
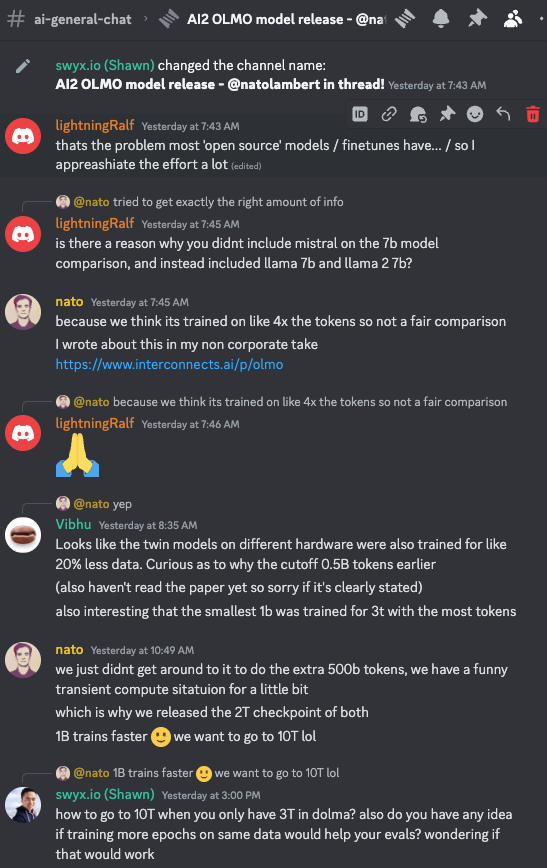
In the LS Discord we had the honor of discussion with Nathan in more detail, including the odd choice to release a "Twin" AMD model, the exclusion of Mistral 7B from benchmarks, and more.
We happened to cover Pythia (one of the top 10 papers of 2023) in this week's Paper Club, and Nathan agreed that OLMo might be regarded a spiritual successor to Pythia in its commitment to reproducible and fully open research.
Hopefully the start of more in 2024.
Table of Contents
- PART 1: High level Discord summaries
- TheBloke Discord Summary
- Mistral Discord Summary
- Nous Research AI Discord Summary
- HuggingFace Discord Summary
- LAION Discord Summary
- LM Studio Discord Summary
- Eleuther Discord Summary
- Latent Space Discord Summary
- OpenAI Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- Perplexity AI Discord Summary
- LlamaIndex Discord Summary
- LangChain AI Discord Summary
- DiscoResearch Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- CUDA MODE (Mark Saroufim) Discord Summary
- Datasette - LLM (@SimonW) Discord Summary
- PART 2: Detailed by-Channel summaries and links
- TheBloke ▷ #general (1279 messages🔥🔥🔥):
- TheBloke ▷ #characters-roleplay-stories (665 messages🔥🔥🔥):
- TheBloke ▷ #training-and-fine-tuning (26 messages🔥):
- TheBloke ▷ #model-merging (2 messages):
- TheBloke ▷ #coding (12 messages🔥):
- Mistral ▷ #general (178 messages🔥🔥):
- Mistral ▷ #models (4 messages):
- Mistral ▷ #ref-implem (4 messages):
- Mistral ▷ #finetuning (44 messages🔥):
- Mistral ▷ #showcase (16 messages🔥):
- Mistral ▷ #la-plateforme (26 messages🔥):
- Mistral ▷ #office-hour (240 messages🔥🔥):
- Nous Research AI ▷ #ctx-length-research (3 messages):
- Nous Research AI ▷ #off-topic (12 messages🔥):
- Nous Research AI ▷ #interesting-links (14 messages🔥):
- Nous Research AI ▷ #general (374 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (38 messages🔥):
- Nous Research AI ▷ #project-obsidian (6 messages):
- HuggingFace ▷ #announcements (3 messages):
- HuggingFace ▷ #general (241 messages🔥🔥):
- HuggingFace ▷ #today-im-learning (12 messages🔥):
- HuggingFace ▷ #cool-finds (2 messages):
- HuggingFace ▷ #i-made-this (9 messages🔥):
- HuggingFace ▷ #reading-group (28 messages🔥):
- HuggingFace ▷ #core-announcements (1 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- HuggingFace ▷ #computer-vision (18 messages🔥):
- HuggingFace ▷ #NLP (5 messages):
- HuggingFace ▷ #diffusion-discussions (1 messages):
- HuggingFace ▷ #gradio-announcements (1 messages):
- LAION ▷ #general (298 messages🔥🔥):
- LAION ▷ #research (1 messages):
- LM Studio ▷ #💬-general (137 messages🔥🔥):
- LM Studio ▷ #🤖-models-discussion-chat (32 messages🔥):
- LM Studio ▷ #🧠-feedback (12 messages🔥):
- LM Studio ▷ #🎛-hardware-discussion (44 messages🔥):
- LM Studio ▷ #🧪-beta-releases-chat (1 messages):
- LM Studio ▷ #autogen (3 messages):
- LM Studio ▷ #open-interpreter (2 messages):
- Eleuther ▷ #general (33 messages🔥):
- Eleuther ▷ #research (159 messages🔥🔥):
- Eleuther ▷ #interpretability-general (11 messages🔥):
- Eleuther ▷ #lm-thunderdome (1 messages):
- Latent Space ▷ #ai-general-chat (151 messages🔥🔥):
- Latent Space ▷ #ai-announcements (3 messages):
- OpenAI ▷ #ai-discussions (50 messages🔥):
- OpenAI ▷ #gpt-4-discussions (92 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (79 messages🔥🔥):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (10 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #runpod-help (17 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #shearedmistral (1 messages):
- Perplexity AI ▷ #general (66 messages🔥🔥):
- Perplexity AI ▷ #sharing (4 messages):
- Perplexity AI ▷ #pplx-api (8 messages🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (40 messages🔥):
- LlamaIndex ▷ #ai-discussion (3 messages):
- LangChain AI ▷ #general (32 messages🔥):
- LangChain AI ▷ #langserve (2 messages):
- LangChain AI ▷ #share-your-work (9 messages🔥):
- LangChain AI ▷ #tutorials (2 messages):
- DiscoResearch ▷ #disco_judge (1 messages):
- DiscoResearch ▷ #general (15 messages🔥):
- DiscoResearch ▷ #discolm_german (2 messages):
- LLM Perf Enthusiasts AI ▷ #embeddings (3 messages):
- LLM Perf Enthusiasts AI ▷ #reliability (1 messages):
- LLM Perf Enthusiasts AI ▷ #irl (2 messages):
- LLM Perf Enthusiasts AI ▷ #openai (2 messages):
- LLM Perf Enthusiasts AI ▷ #prompting (5 messages):
- CUDA MODE (Mark Saroufim) ▷ #cuda (7 messages):
- CUDA MODE (Mark Saroufim) ▷ #beginner (3 messages):
- CUDA MODE (Mark Saroufim) ▷ #pmpp-book (1 messages):
- Datasette - LLM (@SimonW) ▷ #ai (1 messages):
- Datasette - LLM (@SimonW) ▷ #llm (2 messages):
PART 1: High level Discord summaries
TheBloke Discord Summary
- Miqu-70B: The Surprise Self-Corrector: Within the general discussions, Miqu-70B, particularly the Mistral Medium version, received praise for its ability to self-correct during responses. Advanced users reported model speed averages of 17 tokens per second after optimizations, comparing it favorably with Mixtral.
- Language Showdown: C++ vs. Rust vs. Go: A lively debate amongst engineers in the general channel concerned the merits of programming languages such as C++, Rust, and Go. The preference seems to lean towards the simpler, more manageable languages due to their ease of understanding.
- VRAM Capers with Miqu-1-70B-SF: In characters-roleplay-stories, efforts were made to fit Miqu-1-70B-SF-4.25bpw-h6-exl2 within the constraints of available VRAM, leading to discussions on potential solutions, including hardware upgrades.
- Category Conundrum: Distilbert-base to the Rescue?: One user in the training-and-fine-tuning channel experimented with Distilbert-base-uncased for predicting hierarchical codes from text, observing fair accuracy for higher-level predictions but difficulties with the finer categorical distinctions.
- File Hierarchy Heresy: Search to Surpass Structure: Users in the coding channel discussed the increasing reliance on powerful search functionality over traditional file organization, with good search considered more effective than traditional methods like tags or directories, especially in software like nvpy and simplenote.
Mistral Discord Summary
- Tackling the GPU Drought: Engineers discussed the GPU shortage due to complex semiconductor manufacturing processes and the months-long wafer production cycle. This limits scaling up production, with companies like TSMC, ASML, and Zeiss bearing the brunt of collaboration requirements.
- Open Source vs. Proprietary: A vibrant debate centered on open-source versus proprietary software, highlighting that while open source relies on community and company contributions, the "open core model" offers a promising monetization strategy through premium features.
- Chunking Choices in AI Modeling: @lhc1921 highlighted the specificity required in chunking embeddings—there's no one-size-fits-all approach, and @mrdragonfox reinforced that it depends on dataset characteristics.
- Recommendations for JSON & Grammar Within AI: Users suggested improved results in JSON output generation by prompting with examples and discussed integrating grammar via examples on a platform, with @gbourdin sharing a related link.
- Fine-Tuning Finesse: Questions arose regarding fine-tuning LLMs, from creating conversational datasets for beginners to addressing challenges in models for low-resource languages. @yashkhare_ referenced research on using LoRA for pretraining and @mrdragonfox voiced concerns about inadequate fine-tuning methodologies compared to instruct versions of models.
- Mistral's Successful Implementations & API Inquiries: @soletum reported user satisfaction with integrating Mistral within their product, and inquiries about API key activation times were noted, suggesting immediate contact with Mistral support.
- Dedicated Endpoint Discussions on La plateforme: Queries about the pricing of dedicated endpoints for big companies led to suggestions of direct contact with developer relations for precise figures, considering the costs could be significantly higher than raw GPU expenses.
- Office-Hour Insights Bring Clarity and Requests: Engineers sought advice on system prompts and the potential of Mixtral-8x7B-Instruct-v0.1, discussing the nuances of instruct models and user message identities. Feature requests for the Mistral API indicated a keen interest in enhancements.
Nous Research AI Discord Summary
- Rethinking RMT with Weight Freezing: The concept of weight freezing in an approach somewhat similar to RMT was highlighted as innovative by
@hexani, despite not being the main focus of the referenced material.
- Potential Release of Qwen2 Causes Buzz: Anticipation around the
Qwen2release grew as it appeared briefly on a leaderboard before going offline, as mentioned by@nonameusrand@weyaxi. Meanwhile, a "llamafied" version ofQwen-72Braised tokenizer performance concerns, with the relevant model found on Hugging Face.
- Training Leveraging 4-bit Optimizer States: A thu-ml study suggests training neural networks with 4-bit optimizer states can dramatically reduce memory footprint, as outlined in their paper.
- Enduring Value of N-gram Models: An 'infinite-gram' model was proposed as relevant in the neural LLM era, potentially scaling beyond traditional n-gram limits as per a shared paper.
- Anthropic Raises Alarm on Sleeper Agents in LLMs: A potential fastidious problem with backdoor training was discussed, with sleeper agents being able to persist post safety training, based on an Anthropic article.
- Project Obsidian Goes Dormant: Project Obsidian's focus on multimodality was clarified with the project being essentially complete and released, as pointed out by
@tekniumand available on Nous' Hugging Face.
HuggingFace Discord Summary
- Custom Pipelines and Creativity Benchmarks: A custom pipeline for
vikhyatk/moondream1has been introduced on Hugging Face, and an evaluation benchmark for model creativity has been proposed, with discussions on Twitter. A Resume QA space and Han Instruct dataset were launched, and the Ukrainian wav2vec2 bert model has been released.
- Celebrating Model Milestones and LLM Hosting Discussions: Downloads for
moondream1hit 2500, video generation tools similar tomoonvalleywere discussed, API usage for models likellama2on Hugging Face's servers was clarified, discussions around free LLM hosting for projects, and choosing novel datasets for academic pursuits ensued.
- Knowledge Sharing and Remote Employment Proposals: Free API access for LLMs, a guided tour to pretrained LLMs were highlighted, and a transnational employment strategy was suggested for U.S. citizens to collaborate with an international web developer.
- New Diffusion and Clustering Models: A new diffusion model from Google, MobileDiffusion, was announced, potentially outperforming Stable Diffusion and DALL·E. EfficientNet models were suggested to help with clustering models to identify user actions.
- Innovations from Community Creators: ColBERT's live visualization tool hosted at colbert.aiserv.cloud was shared. The UltraTextbooks dataset was released on Hugging Face, and VS Code integration with Jupyter on a remote GPU was guided through a Medium post.
- Readings and Presentations About AI and Law: The Mamba presentation was set for a reading group discussion with scheduling through a When2meet link, and recording inquiries were made for a presentation on AI challenges in law.
- Dreambooth Training and TPU Inquiry: The Dreambooth LoRA training for Stable Diffusion is now available, with advanced capabilities revealed in a GitHub script. A question about TPU compatibility for such training remains unanswered.
- AWS SageMaker and CUDA Toolkit Installation Discussed: Guidance was sought for using AWS SageMaker with Mistral, Llama, or Tapas, and installation issues possibly related to the CUDA toolkit version were reported.
- Popup Modal Component for Gradio: The
𝚐𝚛𝚊𝚍𝚒𝚘_𝚖𝚘𝚍𝚊𝚕was released to enhance Gradio apps with pop-up features and can be explored on the Hugging Face Space.
LAION Discord Summary
- LLaMa 1.6 Gains Quiet Applause: User
@kache_indicated LLaMa 1.6 is performing well, though no specific performance metrics or comparisons were given, keeping the discussion light and mysterious.
- Community Writeup Earns Hacker News Spotlight: A member's Reddit writeup was spotted making rounds on Hacker News, amplified by a fellow user who provided a link to the thread.
- Controversy over Bard’s Watermarked Images:
@max_voltagesparked a debate by criticizing Bard's image-generation feature for embedding watermarks, a step towards responsible AI, and pointed to a broader conversation, suggesting a clash between creativity and ethics.
- Imagen 2 Images Show Unexpected Noise:
@thejonasbrothersraised concerns about the noise levels in images generated by Imagen 2, indicating potential quality issues and inefficient output formats when compared to SDXL's imagery.
- Deep Dive into Autoencoder's Latent Space Sensitivity: A detailed discussion unfolded between
@drheadand@thejonasbrotherson the nuances in the latent space of autoencoders, touching on Segmind Vega and SDXL VAE models, and the training's impact on noise pattern evolution.
- OLMo Receives a Shoutout: User
felfri_merely dropped a link to OLMo by the Allen Institute for AI, without context, but presumably as a hint towards innovative research worth looking into for the engineering minds.
LM Studio Discord Summary
- Long-Term Memory for ChatGPT Sparks Interest:
@flyyt4sought advice on enhancing ChatGPT's long-term memory, with@fabguysuggesting "memGPT" without providing a specific source or additional context.
- Prompt Crafting Techniques Shared: Advanced prompting techniques like Chain of Thought and Tree Thinking were highlighted by
@wolfspyre, including a link to advanced prompt examples.
- Exploring Unrestricted Models: Users discussed the performance and utility of uncensored models such as The Bloke Goat Storytelling 70B Q3KS, with a focus on story-writing applications and avoiding smaller models.
- Challenges with GGUF and Model Adapters: Mixed feedback surfaced on the usability of the GGUF format and locating model adapters within LM Studio, with constructive tips shared for locating and editing models on the disk.
- Hardware Concerns for Model Performance: Users like
@silverstar5654and@docorange88inquired about leveraging dual RTX 3090s, RTX 6000s, or NVLink setups for running large models like Mixtral and discussed potential performance with multi-GPU configurations.
- Inquiries About llava 1.6 and Autogen's Server Capabilities: Support for recognizing llava 1.6 as a vision model in LM Studio is in question, and there is curiosity about running Autogen on multiple servers and whether it's possible to operate dual instances of LM Studio on separate ports.
- Integration Issues and Cost Concerns with Open Interpreter: User
@raiderduckreported nonsensical responses when using OI with LM Studio and cited high costs when using GPT-4, amounting to $250 in a week, prompting a search for cost-effective server settings.
Eleuther Discord Summary
- OLMo Steps into the LLM Ring: A newly released OLMo paper has initiated a lively debate on its approach and licensing, with AI2 clarifying that no chat model or interface has been released yet. Questions were raised about OLMo's benchmarks, training code, particularly its warmup scheduler, normalization choices, and AI2's evaluation metrics, with discussions on tokenizers, layer norm usage, and potential benchmark cherry-picking stirring the technical crowd.
- Trillions of Tokens in N-gram Models Discussed: The Eleuther community debated the value of scaling n-grams to trillions of tokens and its integration with LLMs, pondering over potential performance boosts and generalization. The limitations and applications of the Infinigram model, the potential of tagging backtranslated data for LLMs, and synthetic data generation strategies, like MCTS, also formed part of the rigorous research discourse, showcasing the relentless pursuit of enhancing AI efficiency.
- Innovations and Contributions Celebrated: Updates on the AI research landscape were shared, with the release of the Gaussian Adaptive Attention library for multi-modal work drawing interest. The dynamic nature of AI research was further highlighted by announcements of works such as Amortized Text-to-Mesh (AToM) and others, disseminating the latest in visual representation learning and model editing techniques.
- In-Context Learning and Neural Circuits Analyzed: Insights into in-context language learning (ICLL) culminated in the discovery of a relevant research paper and discussions on contextual neurons within language models. The group also debated the effectiveness of ∞-gram models in perplexity versus open-ended text generation, and compared the challenges faced in ∞-gram retrieval with MoE model attacks, referencing a study on the latter.
- Brief Confirmation in Thunderdome: Within the Thunderdome's sparse chatter, a concise response from
daniellepintzsimply confirmed the non-existence of alimitwithout further elaboration or context.
Latent Space Discord Summary
- Reddit Sounds the Alarm on VAEs: A Reddit post unveiled a critical issue in the KL divergence loss of VAEs used in models like SD1.x, SD2.x, SVD, DALL-E 3, which could be impacting efficiency by transmitting global information through minimal pixels.
- VAE Simplicity Catches Eye: A VAE-related Reddit discussion noted by
@swyxiopiqued interest for its straightforwardness, suggesting it was refreshingly concise compared to typical academic publications that might include "unnecessary fluff."
- LLMs Spark Memes and More:
@natolambertshared a link to LLM memes, highlighting the community's humorous engagement with language models, while AI2's Open Language Models (OLMo) were discussed for their hardware diversity and short context length limitation.
- Open Source Gains a Player: Nomic AI released a set of open-source embeddings that exhibited high performance on the LoCo benchmark, accompanying the launch with a detailed blog post.
- Latest Latent Space Podcast Lands Quietly: A new episode of the Latent Space Podcast was released as announced by
@swyxioon Twitter and Hacker News, though it struggled to gain traction despite clickbait strategies.
OpenAI Discord Summary
- Ethical Quandaries and AI Role Confusion: A discussion initiated by
@yami1010dealt with the ethical parameters of AI, prompting a desire for resources about the nuances in LLMs, and touching upon the often nebulous definitions of responsibility in AI development.
- Debating the ChatGPT Smarts Slide:
@voidrunner42and.@tadase.engaged in a conversation about ChatGPT's performance, debating whether a perceived decline in smartness is due to a real decrease in capabilities or just the nature of the prompts provided.
- AI Credit Where Credit Is Due:
@movozacorrected a misattribution where Bing appeared to claim sole credit for developing an AI, igniting a discussion on the collective effort in AI advancements and the intricate history involving multiple stakeholders.
- Trolling the GPT-3 School Bot and Beyond:
@qiqimonasked about the feasibility of GPT-powered chatbots in school customer service, while others noted the importance of measures to prevent misuse, suggesting this use case is within reach but not without its challenges.
- Tech Talk on GPT-3 Data Formats and Auth Issues: Opinions were shared on the optimal file formats for knowledgebases to feed into GPT, specifically preferring RSV over JSON and XLXS, and
@woodenrobotrecounted troubles with API authentication during their project's transition from alpha to public beta, highlighting real-world issues AI engineers face when scaling solutions.
OpenAccess AI Collective (axolotl) Discord Summary
- Model Concerns and Solutions Spread Across Channels: Discussion in the general channel raised concerns about code changes potentially impacting models like Llama and Mistral, but a fix was noted to have been merged upstream in the axolotl-dev channel. Specific to Mixtral, users in the general-help channel shared advice on finetuning approaches depending on GPU VRAM, and discussed finetuning the entire model with Zero3 offloading.
- Performance Discussions for 7B Models: There's been talk about the stagnation of 7B models, but names like
CapybaraHermes-2.5-Mistral-7BandEagle 7Bhave been mentioned, along with performance updates and links to results, highlighting the active competition in this space. Eagle 7B on Hugging Face, MTEB Leaderboard, and CapybaraHermes-2.5-Mistral-7B were cited.
- Exploring Text Embedding and Vector Databases: There was a technical exchange about text embedding models and vector databases, with nomic-embed-text-v1 being notable, as well as discussions on starting with bge and utilizing GPUs in cloud services. For further exploration, qdrant/fastembed on GitHub and Improving RAG by Optimizing Retrieval and Reranking Models were shared.
- RunPod Service Challenges Contested: In runpod-help, complaints surfaced about sudden pod shutdowns, data loss, and communication mix-ups about pod deletion times. In addition, issues with SSL errors during data transfers and slow download speeds prompted discussions about the reliability and efficiency of RunPod services, with the RunPod Discord suggested as a place to seek help: RunPod Discord Help Channel.
- Unanswered Mistral Configurations: A lone message in the shearedmistral channel by
dangfutureshighlights that there's ongoing curiosity or confusion regarding the configurations for Mistral, perhaps indicative of a broader conversation or need for clarification within the community.
Perplexity AI Discord Summary
- AI Amusement Shared Across Channels: User
@tbyflywas directed to share a humorous response from Perplexity AI in another channel after their initial inquiry in the general chat.
- Navigating Model Complexities: The PPLX models, promoted for generating up-to-date and factual responses, were discussed; however, users
@brknclock1215and@jayb1791noted limitations of the 7b-online model with complex queries and privacy overreach for SQL assistance. Meanwhile,@general3dsuggested improvements for the codellama 70b model to ensure more consistent answers.
- Perplexity as a Default Search:
@bartleby0provided a solution for setting Perplexity AI as the default search engine, while separately mentioning Arc Search as a potential competitor.
- Intriguing AI Applications and Observations: New member
@.sayanaralinked to a blog post and book about AI's potential to mitigate misinformation (The Right Direction for AI). Elsewhere, an absence from a list of top apps led@bartleby0to note Facebook's lack of presence as "interesting."
- Subscription Snafus and API Anomalies:
@dame.outlawrequested assistance with subscription issues, and@alankarshreported problems with API credits post subscription, revealing a hiccup in user experience.
LlamaIndex Discord Summary
- Open Source Rival to OpenAI Embeddings: A new open-source text embedding, nomic-embed-text-1 by
@nomic_ai, has been introduced by LlamaIndex, showcasing better performance than OpenAI's text-embedding-3-small and includes integration details on Twitter. - Keynote Replay on Agentic RAG: The keynote by @jerryjliu0 on Beyond Naive Rag: Adding Agentic Layers is now available to watch as a replay on YouTube, with the slides accessible here.
- Llama Index Expands Compatibility: LlamaIndex's guide for integrating other LLMs, such as using Llama-2, is highlighted with a guide and an example notebook, while also addressing issues regarding Postgres connections and MongoDB in an active discussion.
- Seeking PII Anonymization for LLMs: The quest to anonymize personally identifiable information from text datasets efficiently through the langchain and Presidio shows a need for production-level solutions, as the current approach remains experimental.
- Speech-to-Text Deep Dive: Insights into OpenAI's Whisper model are explored in a detailed blog post by @amgadoz, focusing on its encoder-decoder transformer architecture and its relation to the "Attention is All You Need" paper.
LangChain AI Discord Summary
- Beware of LangChain AI Twitter Scam: Multiple users, including
@markopolojarvi,@alcazarr, and@solac3, reported a possible security breach involving LangChain AI's Twitter account. A suspicious tweet led to speculations of hacking.
- Innovative Autonomous GPT-4 Agent Platform Introduced:
@robot3yesunveiled Agent IX, a standalone GPT-4 agent platform, and is encouraging community exploration on GitHub.
- ContextCrunch Streamlines Token Efficiency:
@speucepromoted ContextCrunch, a prompt compression API designed to reduce token costs, with early access and further details available at contextcrunch.com.
- LangServe and Llamacpp Aim for Streaming Capabilities:
@veryboldbageland@legendary_pony_33278engaged in discussions on enabling streaming with Llamacpp and Langserve or FastAPI, with a shared GitHub example demonstrating LangServe with ollama.
- Exploring Step-Back Prompting and Context Compression: Methods for enhancing language model interactions, such as Step-Back Prompting and Contextual Compression using LangChain, were detailed in a Medium article. This compression technique is discussed as a potential solution to excessive token usage in RAG setups.
DiscoResearch Discord Summary
- Switching to Mixtral for Bigger Gains:
_jp1_confirmed the migration from a 7b model to Mixtral, citing the latter's proficiency for evaluation tasks and extended an invitation for assistance in the transition process. - API Exposed:
@sebastian.bodzaraised an alarm about the API lacking security measures as it's currently not leveraging tokens in requests, posing a security risk. - Nomic Outperforms OpenAI: Showcased by
@bjoernp, the Nomic's embedding model,nomic-embed-text-v1, holds sequence length supremacy with 8192 and outshines its OpenAI counterparts, is freely available along with its weights and training code at Nomic AI on Hugging Face. - OLMo 7B Enters the Open Model Arena: The introduction of OLMo 7B, the Open Language Model by Allen AI presented by
_jp1_, comes with its dataset, training resources, and a research paper, which are accessible at OLMo on Allen AI and OLMo on Hugging Face. - GPU Workarounds for Inference and Shared Resources: In the absence of GPUs,
_jp1_proposed inference alternatives using services like replicate, modal, or serverless runpod, and hinted at a possible group hosting if needed while sharing a potentially useful but unspecified Google Colab notebook at this link.
LLM Perf Enthusiasts AI Discord Summary
- Nomic Embed Leads the Pack: The new nomic-embed-text-v1 from HuggingFace claims superior performance to similar OpenAI models, boasting scores of 62.39 on MTEB and 85.53 on LoCo. Interest is shown in comparing embedding models in a competitive leaderboard akin to the LLM arena.
- Seeking Deployment Guidance: A Discord user, firefox8975, is looking for advice or a guide to deploy open-source machine learning models to AWS using VLLM, indicating a practical problem-solving discussion among the members.
- Exa Announces Launch Events: Exa (formerly Metaphor) is hosting toga-themed launch parties in San Francisco on February 2 (RSVP SF party) and New York City on February 7 (RSVP NYC party).
@sarahchiengalso kindly offers to buy coffee for those interested to discuss Exa in both cities.
- Vector Database Migration Underway: In the realm of vector databases, a user
@michelcarrollshares their transition from Weaviate to pgvector with HNSW, providing insight into the practical application and migration of data platforms.
- Chain of Thought Persistence Examined: There's a conversation about the tradeoffs of saving and reusing a language model's Chain of Thought (CoT). While the reuse of CoT can reduce costs and processing time, it was highlighted that doing so incurs a latency tradeoff due to the necessity of multiple API calls.
CUDA MODE (Mark Saroufim) Discord Summary
- CUDA Kernel achieves Warp-Speed:
@zippikaimplemented a CUDA kernel to convert rgb_to_grayscale, optimizing it to utilize ulong for vectorized loads, which increased GPU occupancy to 77% and memory utilization to 71.87%. However, despite theoretical improvements, the kernel was slower in practice, evidencing the complexity of optimization. See the optimization details here.
- Jumping into CUDA with C++ Grounding: User
@noobpeenhas successfully set up CUDA 12.2 with Visual Studio and plans to leverage their knowledge of PyTorch and C++ to start CUDA development. Experienced user@lancertssuggested starting with a new CUDA project, specifically developing CUDA kernels, and studying the book Professional CUDA C Programming for a deeper dive.
- Employing Thread Coarsening for Efficiency: In the discussion,
@tvi_emphasized the benefits of thread coarsening to increase work efficiency by reducing global memory load frequency, a principle that speaks to more than just compute efficiency but also memory optimization as examined in the PMPP book.
Datasette - LLM (@SimonW) Discord Summary
- Datasette's Documentation Meets GPT: @simonw experimented with inputting the PDF version of the Datasette documentation into a GPT, but found the initial results lacking. They retained some optimism about the technique's potential after more refinement.
- Pursuing 'Quiet AI' Discussed: One post introduced an external article concerning the pursuit of 'Quiet AI', however, no substantial discussion or details were provided. Read the article here.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1279 messages🔥🔥🔥):
- Discussing Miqu-70B's Performance: Users like
@netrveand@mrdragonfoxshared experiences with the Miqu-70B model and various versions such as Mistral Medium, with some commenting on its unexpected ability to self-correct during responses. The conversation touched on aspects like model speed (@goldkoronmentioned getting on average 17t/s after some tweaks) and comparison to other models like Mixtral.
- Conversations on Programming Languages: A discourse around programming languages unfolded, debating the merits and drawbacks of C++, Rust, Go, and other languages.
@mrdragonfoxpraised the simplicity of C and stated that not all programming needs classes. The discussion touched on advanced features of C++ and the simplicity offered by Rust and Go, with@rtyaxand others expressing a preference for simpler, more understandable languages.
- Chatbot UI Discussion:
@righthandofdoomexpressed interest in a simplistic web UI or native UI that could connect to remote OpenAI-compatible endpoints, with@coffeevampir3and@animalmachinesuggesting alternatives like Hugging Face's "Candle" and lamenting issues in creating frontends with current tools.
- Speculative Decoding and API Tools:
@.justinobserverand others discussed speculative decoding and which current tools support it, with mentions of llama-cpp and the desire for@flashmanbahadurto find an API tool that supports exl2 and an OpenAI compatible API.@itsme9316suggested "tabbyapi" for its OpenAI compatible API with exl2.
- Finetuning and Calibration Misunderstandings: Users like
@turboderp_and@giftedgummybeeaddressed misunderstandings about the purpose of calibration in the context of finetuning. The conversation delved into the challenges of using quantization as a way to retain model quality, with@giftedgummybeefacing issues with loading parquet files and considering reliance on default quant settings.
TheBloke ▷ #characters-roleplay-stories (665 messages🔥🔥🔥):
- Fit for Chat Finetune?:
@kaltcitpointed out that a llama resume trained (<@266127174426165249>) is good at ERP, however, without ghost attention. - Miqu API Optimism:
@righthandofdoomoffered others the opportunity to use Groq API with his ratelimited API key for Mixtral experiments. - Model VRAM Dilemma:
@kaltcitfaced issues trying to fit Miqu-1-70B-SF-4.25bpw-h6-exl2 within available VRAM, discussing with@turboderp_about potential solutions and even considering hardware upgrades. - Experimenting with New Tasks: Participants discussed the outcomes observed from newly attempted tasks, such as detailed character RP, longer token contexts, with models like Miqu and LLMs, seeking optimal performance and grappling with hardware limitations.
- LLM Performance Insights Shared: Various users like
@mrdragonfox,@doctorshotgun, and@goldkorondiscussed different settings and configurations to optimize the speed and performance of language models on given hardware, considering factors like VRAM, model bits-per-weight, and context sizes.
TheBloke ▷ #training-and-fine-tuning (26 messages🔥):
- Challenges in Predictive Model Training:
@hapticalacrityis seeking advice on training a model to predict 8-digit hierarchical codes from text strings, with 25 examples for each subcategory. Distilbert-base-uncased was tried for the task, showing accuracy at higher levels but performing poorly at predicting the last 2 digits of the codes.
- Innovative Alternatives for Model Improvement:
@tom_lrdadvised considering methods like recursive clustering with embeddings instead of costly model training, which could efficiently handle the category prediction without relying on heavy hardware resources.
- Utilizing Natural Language Models for Category Classification:
@tom_lrdsuggested employing prompt engineering with large models such as mistral7b to classify text into categories in a hierarchical manner, despite acknowledging it as a more resource-intensive approach.
- Rapid Resolution of Training Queries:
@hapticalacrityexpressed gratitude to@tom_lrdfor providing concise, helpful feedback on the classification problem, highlighting the collaborative aspect of the TheBloke Discord community.
- Model Usage Post Fine-Tuning:
@choviiencountered a ValueError when attempting to use a fine-tuned model and sought assistance for the correct procedure after encountering issues when merging LORA layers.
TheBloke ▷ #model-merging (2 messages):
- InternLM Recommended for Limited Resources:
@alphaatlas1suggested using InternLM 20B for those who might not be able to run the larger 34B models. This advice is tailored to users with resource constraints.
TheBloke ▷ #coding (12 messages🔥):
- Debate on the Merits of Search vs File Organization:
@wbschargued that good search capabilities in software can be more effective than traditional file organization methods like tags or directories. They mentioned using systems like nvpy and simplenote since 2008 for their note-taking needs.
- The Necessity of File System Knowledge for IT:
@wbschagreed with@Spliceaffirming that understanding files and file systems is essential for IT, although not so much for organizing files, where good search functionality has its advantages.
- File Systems in User Interfaces:
@wbschelaborated that for user interfaces, good search is essential and should be complemented by methods like "recently changed files" to reduce user effort, while mentioning IDEs benefit from function search features for efficiency.
- Practical Solutions to Dynamic Linking Issues:
@spottyluckshared an issue with a missinglibllama.solibrary when running amaincommand and demonstrated the use ofpatchelfto solve the problem by specifying the library's path, and thenLD_PRELOADas an alternative if the library is removed.
- Good Maintenance Practices Recommended: In the context of missing shared libraries,
@spottyluckadvised fixing the build process after applying temporary fixes likepatchelfto ensure that the correct library linking is established.
Mistral ▷ #general (178 messages🔥🔥):
- GPU Shortages Affecting Model Training:
@frosty04212discussed the lack of GPU availability affecting the production of more units, attributing the shortage in part to the complexities of semiconductor manufacturing which involves long processes and deep investments.@mrdragonfoxexpanded on the barriers to scaling up production such as the months-long wafer manufacturing cycle, extensive cleanroom requirements, specialist workforce needs, and the collaboration between companies like TSMC, ASML, and Zeiss.
- The Open Source Debate: An active conversation about the interplay between open source and proprietary software occurred, with users like
@frosty04212,@ethux, and@firesonwiresdiscussing whether open source technology can compete with closed source, noting that open source often relies on contributions and funding from larger companies. The "open core model" was mentioned as a positive hybrid approach, implying that while some elements can be open and free, monetization can occur through premium features.
- Mistral's Public Relations Strategy: User
@_dampfpraised Mistral for being transparent regarding the leak of an early access version of the Mistral Medium model, instead of remaining silent.@ethuxadded that the leaked model was not the latest version, and@mrdragonfoxmentioned that leaked models, such as MIQU, wouldn't receive official support.
- Mistral API Key Activation Inquiries: User
@cptplasticenquired about the activation time for new API keys at Mistral after facing a rate limit issue.@mrdragonfoxsuggested emailing Mistral support for any activation troubles, while@i_am_domaffirmed that API keys should have immediate and reasonable limits.
- Predictions and Musings on Future Models: Speculative chatter about what Mistral might do next surfaced with
@gtnbssnjesting about a model named miqtral or miqstral that might use Q-learning. Opinions and jokes about upcoming technologies were shared among users, reflecting curiosity and excitement for future model iterations.
Mistral ▷ #models (4 messages):
- Chunk Size Matters in Embeddings:
@lhc1921humorously admits to being pedantic after noting that there are definitely wrong ways to chunk embeddings in certain use cases. - Data Dictates Chunking Strategy:
@mrdragonfoxemphasizes that how to chunk embedding documents is data-dependent, implying that there isn't a one-size-fits-all chunk size that will work across different datasets.
Mistral ▷ #ref-implem (4 messages):
- Grammar Integration on La Platforme?:
@superintendentqueried about integrating grammar on the platform, mentioning an approach of providing examples to the system.
- Prompting Bests Direct Instruction for JSON Schema:
@gbourdinrecommended prompting the chatbot with examples to yield desired outputs, sharing a link that demonstrates using JSON schema with examples in the prompt for effective results.
- Size Matters for JSON Output:
@samy7418observed that generating JSON output with few-shot examples is possible on medium-sized models, but the small-sized counterpart tends to add explanatory text to the JSON output.
- Seeking Context in Discord Links:
@akshay_1replied to@samy7418with a link to a specific message in the Discord channel, presumably for context or further information.
Mistral ▷ #finetuning (44 messages🔥):
- Seeking Guidance on Fine-tuning: User
@d.j147is new to the field and is seeking advice on how to create a conversational dataset and fine-tune large language models (LLMs). - Challenges with Low-Resource Languages:
@quicksortshares that fine-tuning LLMs for languages that make up less than 5% of pretraining corpora is resulting in subpar language quality, and is asking for insights or success stories about continuously pretraining Mistral with low-resource language datasets. - LoRA Pretraining Exploration:
@yashkhare_discusses the intention to pretrain using LoRA, referencing a research work and wondering about the number of tokens and languages used in the Mistral-7b paper’s training. - Frustrations with Mistral Training Methods:
@mrdragonfoxexpresses that the community has not yet figured out an optimal way to train Mistral, mentioning that attempts so far do not compare to the base instruct version of language models. - Axolotl Training Query: User
@woodenstick_is encountering anIndexErrorwhile using Axolotl to train Mistral and has shared the configuration snippet possibly linked to the error.
Mistral ▷ #showcase (16 messages🔥):
- Mistral Receives Positive Feedback:
@soletuminformed the channel that they implemented Mistral within their product, offering a text correction and generation interface based on keywords. Their initial users are satisfied with its usefulness. - Community Encouragements:
@frammieexpressed admiration for the implementation of Mistral, describing it as looking "very nice, awesome!" - Showcase of AIDocks: User
@lhc1921shared a link to the GitHub repository for AIDocks with the GitHub Link. - Friendly German Exchange: Conversational exchange in German took place between
@mrdragonfoxand@lhc1921, discussing the presence of German-speaking community members on the platform. - Hugging Face Chatbot Suggestion: In response to
@jamiecropleyasking for a platform to use Mistral as a chatbot,@ethuxrecommended checking out Hugging Face Chat.
Mistral ▷ #la-plateforme (26 messages🔥):
- In Search of a Price Tag for Dedication:
@gbourdininquired about the availability and cost of dedicated endpoints on La plateforme, seeking a monthly price quote for a big company's estimate. Despite no specific figures provided, they mentioned considering the inference endpoint pricing from HuggingFace as a reference. - Revenue Benchmarks for Custom Endpoints:
@mrdragonfoxsuggested that custom dedicated endpoints typically require an enterprise to have at least $1 million in annual revenue, emphasizing that such services are substantially pricier. - Direct Contact for Accurate Estimates: It was recommended that
@gbourdinreach out tosupport@mistral.aior directly to Sophia, who is in developer relations, to get precise pricing, especially since@mrdragonfoxclarified they do not represent Mistral. - Understanding the Scale of Costs:
@mrdragonfoxindicated that the enterprise deployment of Mistral's state-of-the-art model, if available, would likely be far more costly than the raw GPU cost—roughly ten times more by their estimation. - Initial Steps Towards Partnership:
@gbourdinconsidered starting with the regular endpoint of La plateforme, accepting that a minimum budget for customizing endpoints would likely begin around $10k per month, and planned to further discussions with the potential enterprise client based on this information.
Mistral ▷ #office-hour (240 messages🔥🔥):
- Clarity Requested for System Prompts: `@sa_code` sought guidance on using system prompts with Mistral, referencing a Jinja template in their PR, and noting the absence of system prompt support in the Mixtral chat template on Hugging Face. They provided links to the documentation and their PR for reference.
- Seeking Mixtral's Full Potential: `@touristc` inquired if Mixtral-8x7B-Instruct-v0.1 has reached its full parameter potential or if there's room for improvement. `@sophiamyang` responded, indicating that there's always room for improvement.
- Instruct Models Explained: `@damiens_` queried the difference between instruct and non-instruct models, to which `@sophiamyang` replied that instruct models are trained to follow instructions better. The topic was further discussed with links to an explanatory video and guide posted by `@canyon289` and an original paper link shared by `@sandeep3890`.
- Message Identity Complexity Discussed: `@jakobdylanc` pondered the complexity behind assigning identities to user messages. `@lerela` explained that the process isn't overly complex but requires dataset preparation and fine-tuning.
- API Feature Requests and Hints of Future Enhancements: Participants in the office-hour made various feature requests for the Mistral API, such as JSON output support, logprobs and logit bias, function calling, and improved support for API parameters like openai. Comments from `@lerela`, `@sophiamyang`, and `@nicolas_mistral` hinted at ongoing work and future releases that could address some of these requests.
Nous Research AI ▷ #ctx-length-research (3 messages):
- Retraction of Previous Statement:
@hexaniretracted an earlier statement, mentioning that the approach discussed is somewhat similar to RMT but interestingly freezes weights, which they found noteworthy. - Innovation Highlighted in Weight Freezing:
@hexaniclarified that while the method discussed shares similarities with RMT, the innovative aspect lies in the weight freezing rather than the main point of the referenced material. - Wavenet Vibes from Graphs:
@gabriel_symeobserved that the graphs discussed bear resemblance to Wavenet or something similar, suggesting a parallel in the visual data representation.
Nous Research AI ▷ #off-topic (12 messages🔥):
- Search for Streamlined Notion Templates: User
@faiqkhaninquired about minimalistic Notion startup templates, expressing a preference for free options since most of the good ones appear to require payment. - Sharing Dance of the Quackduckflower: Error.PDF posted a link to a GIF with the title "Quackduckflower," providing a visual amusement.
- Inquiry for Dingboard Access:
.benxhasked who to contact for access to dingboard, andrandom_string_of_characterrecommended sending a direct message on Twitter to Yacine. - Interactive Fiction Adventure with 'Her':
@everyoneisgrossshared a ChatGPT-enhanced interactive version of the movie script for "Her," allowing users to engage with the story sequentially. - Discussion on CLIP Embedding Phenomenon:
@cccntustarted a conversation about the phenomenon where CLIP embeddings only maintain partial meaning of text due to contrastive loss not needing to retain every detail.
Links mentioned:
- Cat Driving Car GIF - Cat driving car - Discover & Share GIFs: Click to view the GIF
- Quackduckflower GIF - Quackduckflower - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #interesting-links (14 messages🔥):
- Pushing the Limits of Optimizer Memory Efficiency: Research from thu-ml presents the capability of training neural networks with 4-bit optimizer states, potentially reducing the memory footprint of model training. The study explores detailed empirical analysis and proposes new quantization strategies, described in their paper.
- Demystifying Whisper Model for Speech-to-Text:
@amgadozwrote a detailed blog post about OpenAI's Whisper model, discussing its architecture and how it transcribes audio to text. The insights and the model's reliance on large-scale supervised pre-training are available on Substack.
- AI Literacy with OpenHermes 2.5 AWQ:
@__ctrlaltdel__shared a YouTube video of their talk focused on open source AI, small models, and applications in structured data extraction given in Vancouver, Canada.
- Exploring End-side Large Language Models: Metaldragon01 linked to a Notion document discussing MiniCPM, but provided no further context or a valid URL.
- CroissantLLM Emerges as a Bilingual Competitor:
@euclaiseshared information about CroissantLLM, a 1.3B parameter bilingual language model pretrained on English and French datasets. Further details and use recommendations can be found on Hugging Face and their related paper.
- NeurIPS Paper on Synthetic Data Generation Company:
@euclaisereferenced a paper from the NeurIPS conference about a synthetic data generation company but did not include further details or commentary. The paper can be accessed here.
Links mentioned:
- Intro to Open Source AI: This is a recording of a talk I gave on Jan 30th, 2024 at BCIT in Vancouver, Canada. The talk is specifically about Natural Language Processing (NLP) with a ...
- Whisper: How to Create Robust ASR (2 / N): Part 2 of a multi-part series in which we delve deep into Whisper, OpenAI's state-of-the-art automatic speech recognition model
- croissantllm/CroissantLLMBase · Hugging Face: no description found
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team
- Memory Efficient Optimizers with 4-bit States: Optimizer states are a major source of memory consumption for training neural networks, limiting the maximum trainable model within given memory budget. Compressing the optimizer states from 32-bit fl...
- GitHub - thu-ml/low-bit-optimizers: Low-bit optimizers for PyTorch: Low-bit optimizers for PyTorch. Contribute to thu-ml/low-bit-optimizers development by creating an account on GitHub.
Nous Research AI ▷ #general (374 messages🔥🔥):
- Exploring Qwen's AI and Llamafication: A discussion about
Qwen-72BAI involved users like@light4bearand@weyaxisharing insights on the model.@weyaxishared a Hugging Face link to the llamafied version and noted concerns about the tokenizer performance when used.
- Uncertainty Around Qwen2 Release: Users
@nonameusrand@weyaxidiscussed the anticipated release ofQwen2, with@weyaximentioning that it briefly appeared on the leaderboard and then went offline, causing speculation about its unveiling.
- Optimizer Discussions & Large Model Training: Conversations touched on the challenges and strategies for training large language models, such as
@euclaisementioning a script for a more efficient optimizer named Adalite, which performs well in certain scenarios.
- Integrating LLMs into Gaming and Consumer Hardware Constraints:
@light4bearshared an idea for an online universe game powered by LLMs, which sparked a debate on the feasibility of running such models on consumer-grade hardware.@euclaiseand@stefangligapointed out that current models would likely need significant downsizing to run on typical consumer setups.
- Real-Time Relevance of n-gram Language Models:
@johnryan465highlighted an interesting paper that defends the continued relevance of n-gram language models in the age of neural LLMs and proposes an 'infinite-gram' model, which, unlike traditional n-gram models, does not limit the range of n.
Links mentioned:
- Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens: Are n-gram language models still relevant in this era of neural large language models (LLMs)? Our answer is yes, and we show their values in both text analysis and improving neural LLMs. Yet this nece...
- Qwen-VL-Max - a Hugging Face Space by Qwen: no description found
- Weyaxi/Qwen-72B-Llama · Hugging Face: no description found
- Weyaxi/Helion-4x34B · Hugging Face: no description found
- supertrainer2000/supertrainer2k/optim/adalite.py at master · euclaise/supertrainer2000: Contribute to euclaise/supertrainer2000 development by creating an account on GitHub.
- dataautogpt3/miqu-120b · Hugging Face: no description found
- The Annotated Transformer: no description found
- Tweet from Aravind Srinivas (@AravSrinivas): Quite a few people asked me if all of Mistral's models are based off on Meta's Llama. Especially because the similarity of the outputs was also discovered via testing Mistral Medium on Perplex...
- Qwen2: no description found
Nous Research AI ▷ #ask-about-llms (38 messages🔥):
- Backdoor Training Resistant to Safety Measures:
@if_aprovided an Anthropic article that suggests sleeper agents (deceptive LLMs) can persist even after safety training, indicating that backdoors introduced during training may not be fixable with current methods. - Diff Algorithm Suggested for License Comparison: In a discussion about identifying differences in open source licenses,
@if_arecommended using a diff algorithm followed by an LLM to summarize the changes, with the assumption that modifications are made to standard templates. - Context Length Extension with YaRN:
@rememberlennyinquired about the feasibility of using YaRN for context length extension of models, and@bloc97confirmed it can be used for extensions up to 128k tokens, with better performance observed in shorter context versions. - Curious About Costs to Train on Math:
@jihaasked about the cost of training a model similar to AlphaGeometry for number theory;@Error.PDFresponded with an estimate of a few million dollars for training and a few thousand for execution. - Question on Open Sourcing Model Details:
@420gunnainquired about resources that inspired the creation of open datasets, specifically reaching out to@387972437901312000after thanking them for sharing their datasets and expressing interest in data-centric AI.
Links mentioned:
- teknium/OpenHermes-7B · Hugging Face: no description found
- Cat Reaction GIF - Cat Reaction - Discover & Share GIFs: Click to view the GIF
Nous Research AI ▷ #project-obsidian (6 messages):
- Project Obsidian Inquiry:
@rabiussanysought clarification on the goals of Project Obsidian and needed help understanding current activities within Nous. - Project Focus Explained Briefly:
@_3sphereinformed that the channel description indicates a focus on multimodality, but also mentioned that activity in the project seems to be currently low. - Newcomer Eager to Participate:
@rabiussanyshowed eagerness to participate in Nous Research projects, inquiring about ways to get involved. - Obsidan Project Status Update:
@tekniumclarified that Project Obsidian is essentially complete and released, directing@rabiussanyto Nous' huggingface for the Obsidian model. - Future Collaboration Hopeful:
@rabiussanyexpressed a willingness to wait for future opportunities to contribute to Nous Research projects.
HuggingFace ▷ #announcements (3 messages):
- Custom Pipeline for
moondream1: User@vikhyatkintroduced a custom pipeline forvikhyatk/moondream1on the Hugging Face platform, allowing users to call the pipeline with specific Python code snippets. You can find the pipeline and the discussion here.
- Promoting an Evaluation Benchmark for Creativity:
@Vipitisshared about proposing a novel evaluation benchmark to assess language model creativity, sharing the update on Twitter.
- Resume QA Space Launch: User
@not-lainlaunched a Resume QA space, aimed at improving resumes and sharpening interview responses. Discover more about this helpful tool on the Hugging Face space.
- Introduction of Han Instruct Dataset: User
@pythainlpshared about the Han Instruct dataset, providing an insightful dataset for various questions and answers. Learn more about the dataset here.
- Release of Ukrainian wav2vec2 bert model: User
@Yehorannounced the Ukrainian wav2vec2 bert model and provided links to a Discord server and a Telegram group for discussions related to Speech Recognition. The model and additional resources can be found here.
Links mentioned:
- Resume Qa - a Hugging Face Space by not-lain: no description found
- vikhyatk/moondream1 · add pipeline: no description found
- pythainlp/han-instruct-dataset-v1.0 · Datasets at Hugging Face: no description found
- Yehor/w2v-bert-2.0-uk · Hugging Face: no description found
- Tweet from thecollabagepatch (@thepatch_kev): when your singer kinda sounds like elvis for no reason one day @fffiloni 's dreamtalk needs to come out 😂 this week we just havin fun in the captains chair next week... @_buildspace
- @s3nh on Hugging Face: "GPU Poor POV: Quantization Today I want to share with you my notebook plug…": no description found
- @natolambert on Hugging Face: "Today, we’re releasing our first pretrained Open Language Models (OLMo) at the…": no description found
- @psinger on Hugging Face: "Happy to share H2O-Danube-1.8b, a small 1.8b model based trained on only 1T…": no description found
- @santiviquez on Hugging Face: "Had a lot of fun making this plot today. If someone ever asks you why you…": no description found
- @gsarti on Hugging Face: "🔍 Today's pick in Interpretability & Analysis of LMs: Gradient-Based Language…": no description found
- Locutusque/UltraTextbooks · Datasets at Hugging Face: no description found
- miqu-70b Chat - a Hugging Face Space by freQuensy23: no description found
- joshuasundance/mtg-coloridentity-multilabel-classification · Hugging Face: no description found
- Tables - a Hugging Face Space by sid27: no description found
- MLX | Mistral-7B-Instruct on Apple Silicon: Can you run Mistral-7B-Instruct-v0.2 from Mistral AI on Apple Silicon with MlX? Let's find out. -------------------------------------------------------------...
- Best Image Models Demo - a Hugging Face Space by FumesAI: no description found
- ColBERT Inference in the Browser: no description found
HuggingFace ▷ #general (241 messages🔥🔥):
- Celebrating "moonddream1" Model Downloads: User
@not_lainannounced that their modelmoonddream1has reached 2500 downloads, celebrating the milestone achievement. - Discussion on Video Generation Tools:
@ch33zw2zardinquired about the best video generation tools available, expressing interest in alternatives tomoonvalley; they are open to recommendations. - Hugging Face API Usage Clarification:
@ram1428sought understanding about whether using the Hugging Face API token for models likellama2involves computation on Google Colab or Hugging Face's servers. It was clarified that using the API key allows the use of models without downloading them, offloading compute to Hugging Face's servers. - Exploring LLM Hosting for Projects:
@woodenrobotasked the community for suggestions on free Large Language Model (LLM) hosting for open-source projects, with discussions about free tiers and possible integrations with other services like Colab or Kaggle. - Dataset Dilemma in Academic Projects:
@akvnnengaged in an extended discussion with@doctorpanglosson choosing a suitable and novel dataset for a classification problem aiming for publication. Despite suggestions and advice,@akvnnremained undecided on a specific topic but considered collaborations with dental experts for unique dental scan data.
Links mentioned:
- Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code: In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 170+ datasets, and 700+ related works. We break down c...
- RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation: The task of repository-level code completion is to continue writing the unfinished code based on a broader context of the repository. While for automated code completion tools, it is difficult to util...
- Code Evaluation - a Vipitis Collection: no description found
- Paper page - DevEval: Evaluating Code Generation in Practical Software Projects: no description found
- GitHub - huggingface/llm-ls: LSP server leveraging LLMs for code completion (and more?): LSP server leveraging LLMs for code completion (and more?) - GitHub - huggingface/llm-ls: LSP server leveraging LLMs for code completion (and more?)
- torch_geometric.nn.pool.global_mean_pool — pytorch_geometric documentation: no description found
- GitHub - Silver267/pytorch-to-safetensor-converter: A simple converter which converts pytorch bin files to safetensor, intended to be used for LLM conversion.: A simple converter which converts pytorch bin files to safetensor, intended to be used for LLM conversion. - GitHub - Silver267/pytorch-to-safetensor-converter: A simple converter which converts py...
- no title found): no description found
- GitHub - TabbyML/tabby: Self-hosted AI coding assistant: Self-hosted AI coding assistant. Contribute to TabbyML/tabby development by creating an account on GitHub.
- lowres/anime · Datasets at Hugging Face: no description found
- lowres/sukasuka-anime-vocal-dataset · Datasets at Hugging Face: no description found
HuggingFace ▷ #today-im-learning (12 messages🔥):
- Free LLM API Access for Newcomers: User
@erlonidasapasked if there were any free APIs for large language models (LLMs), and@not_laininformed them about Hugging Face's free open APIs for AI models and spaces, sharing a detailed presentation with more information on page 16. - A Guided Tour to Pretrained LLMs: On page 16 of his Google Slides presentation,
@not_lainprovides an introduction to using pretrained LLMs with clickable yellow links for further exploration. - Sharing is Caring: Community members, including
@tadeodonegana, appreciated@not_lain's effort in sharing the presentation, and@not_lainexpressed gratitude for the positive feedback. - Proposal for a Transnational Employment Strategy:
@nikolacurovic, a non-U.S. senior web developer, proposed a collaboration with U.S. citizens to apply for jobs on LinkedIn while offering to fulfill the job responsibilities remotely, suggesting a percentage-based financial arrangement for any job offers secured.
Links mentioned:
introduction to using pretrained LLMs: Introduction to using pretrained LLMs Hafedh hichri Released last year, Was SOTA on different tasks, such as image classification, image segmentation
HuggingFace ▷ #cool-finds (2 messages):
- Google Unleashes Mobile Diffusion Power:
sta._.noshared excitement over a new 386M diffusion model from Google, raising curiosity about possible open sourcing. MobileDiffusion boasts rapid sub-second text-to-image generation on mobile devices, outperforming its high-parameter predecessors like Stable Diffusion and DALL·E.
- I-BERT Accelerates RoBERTa Inference:
andysingalintroduced the I-BERT model, an integer-only quantization of RoBERTa, capable of running inference up to four times faster. This efficiency opens doors for transformatively faster natural language processing tasks on edge devices.
Links mentioned:
- MobileDiffusion: Rapid text-to-image generation on-device – Google Research Blog: no description found
- I-BERT: no description found
HuggingFace ▷ #i-made-this (9 messages🔥):
- ColBERT in Action:
@andreer_vespa_99582shared a tool for live visualization of token contributions to document similarity using the ColBERT model hosted on colbert.aiserv.cloud. Users like@cakikiand@weyaxiexpressed their enthusiasm and support for the project.
- Free Chat Demo with MiQU:
@frequesnyposted about a free demo for the MiQU model, which is GPT-4 level and a result of a leak from Mistral AI. The demo is available on Hugging Face's project page.
- UltraTextbooks Dataset Released:
@locutusqueintroduced the "UltraTextbooks" dataset, combining synthetic and human-written textbooks for advanced NLP tasks, hosted on Hugging Face's datasets page.@stroggozexpressed appreciation for the new resource.
- VS Code, Jupyter, and Remote GPUs United:
@chongdashuwrote a guide on integrating Visual Studio Code with Jupyter Notebooks on a remote GPU server, aiming to streamline the machine learning development workflow. The detailed guide is published on Medium.
- Serverless Image Similarity on HuggingFace Spaces:
@omerxfaruqdeveloped a serverless image similarity tool using Upstash Vector, demonstrated at Find Your Twins Space and detailed in a Hugging Face blog post. The solution focuses on using HuggingFace ecosystem and Upstash to streamline backend and frontend complexities.
Links mentioned:
- ColBERT Inference in the Browser: no description found
- miqu-70b Chat - a Hugging Face Space by freQuensy23: no description found
- Connecting Visual Studio Code with Jupyter Notebooks on a remote GPU server instance: Leverage the power of all three without compromise
- FindYourTwins - a Hugging Face Space by omerXfaruq: no description found
- Serverless Image Similarity with Upstash Vector and Huggingface Models, Datasets and Spaces: no description found
- Locutusque/UltraTextbooks · Datasets at Hugging Face: no description found
HuggingFace ▷ #reading-group (28 messages🔥):
- Mamba Presentation on the Horizon: User
@ericauldproposed to present Mamba or related topics for the reading-group, with the presentation being set for Friday (Feb 9) and the time being flexible, including late afternoon California time. A When2meet link was provided by@chad_in_the_houseto schedule the exact time. - Presentation Recording Inquiries: In anticipation of the discussion on AI challenges in law,
@k4rolina_nrequested recording the meeting for those who might join late.@chad_in_the_houseconfirmed the intention to record with OBS. - AI in Law Sparking Interest:
@chad_in_the_houseannounced a presentation about the difficulties of AI with Law, which would occur the following day (from the time of messaging) from 1-2pm EST, to be held in the Discord voice-chat. - Grappling with Compression Algorithms:
@chad_in_the_housecommented on a paper about compression algorithms, mentioning a lack of broader benchmarks such as MT and the absence of inference techniques like speculative decoding in the evaluation criteria. - Paper Ponderings: In discussing a paper on compression,
@chad_in_the_houseinitially found it interesting but noted that the "best" approach for compression isn't well-defined, before acknowledging the paper's comprehensiveness.
Links mentioned:
Eric's Presentation - When2meet: no description found
HuggingFace ▷ #core-announcements (1 messages):
- Advanced Dreambooth Training Arrives: User
@linoy_tsabanannounced that Dreambooth LoRA training for Stable Diffusion (SDXL) is now available indiffusersdue to a significant community contribution from@brandostrong. It includes advanced features such as pivotal tuning, custom captions, the prodigy optimizer, and the newly added noise offset support for improved results, all while requiring less compute power.
- Dreambooth LoRA Training Script Ready for Action: Hugging Face's GitHub provides the advanced training script for those ready to leverage these new capabilities in finetuning SD models.
- Release Gets Twitter Spotlight: The release of this new feature was heralded on Twitter, with
@linoy_tsabansharing the announcement, which can be found in the release tweet.
Links mentioned:
diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py at main · huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - huggingface/diffusers
HuggingFace ▷ #diffusion-discussions (1 messages):
- Inquiry about Diffusion Training on Google TPUs:
@pawkanarekasked if advanced diffusion training mentioned in the announcements would work on a Google TPU. The community has not yet responded with information regarding TPU compatibility.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
HuggingFace ▷ #computer-vision (18 messages🔥):
- Function Name Fix Resolves Error:
@swetha98resolved an error in the fine-tuning code for a donut model by changing the function name and confirmed that the solution provided by Merve worked fine. - Screenshot Clarity for Error Sharing:
@johko990suggested to@swetha98for future references to share screenshots instead of photos taken by phone for clarity when presenting code-related issues. - Seeking Clustering Model Advice for User Actions:
@amarcelrequested suggestions for clustering models able to identify repetitive sequences of user actions (e.g., clicks, copies, pastes) among 15k screenshots, even considering potential misclicks by users. - Model Training with Appended Actions:
@banaanbakjeshared experience in training models by appending actions to screenshots and suggested making a function that scans for sequences of similar user actions. - EfficientNet Based Model Building Resource Shared: Referencing
@amarcel's scenario about analyzing user actions,@banaanbakjeprovided a link to a guide on building an AI-powered game bot with PyTorch and EfficientNet that could help with the concept.
Links mentioned:
Akshay's Personal Website: I am a Machine Learning Enthusiast. Check out my Projects and Blogs
HuggingFace ▷ #NLP (5 messages):
- Seeking AWS SageMaker Guidance: User
refik0727is looking for tutorials or GitHub code on how to use AWS SageMaker, Mistral, Llama, or Tapas for building a chatbot using a CSV file or connecting to a local database. - ChatGPT as a Learning Resource:
@akshit1993recommended that ChatGPT is currently the best resource for learning about the topicsrefik0727is interested in. - Puzzled by Installation Issues: User
@.sgpinitially thought that following the install instructions from the documentation would work, but then encountered an error during installation. - Outdated CUDA Toolkit Causes Error:
@joshuasundancesuggests that@.sgp's installation error might be due to using an outdated version of the CUDA toolkit.
HuggingFace ▷ #diffusion-discussions (1 messages):
- TPU Compatibility Question Unanswered: User
@pawkanarekasked if advanced diffusion training will work on Google TPUs, referencing an announcement here. However, no further information or answers were provided in the available messages.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
HuggingFace ▷ #gradio-announcements (1 messages):
- Popup Modal Component Released for Gradio:
@yuviii_has announced the release of a new custom component for Gradio, the 𝚐𝚛𝚊𝚍𝚒𝚘_𝚖𝚘𝚍𝚊𝚕, created by Ali Abid. This component can be used for displaying a license agreement, prompting user logins, alerts, step-by-step guides, contextual help, or confirmations within Gradio Apps.
- Explore the 𝚐𝚛𝚊𝚍𝚒𝚘_𝚖𝚘𝚍𝚊𝚕 Component: You can check out and implement the
𝚐𝚛𝚊𝚍𝚒𝚘_𝚖𝚘𝚍𝚊𝚕in your own Gradio apps by visiting the Hugging Face Space provided. The component could enhance user interaction within Gradio applications by offering various popup functionalities.
Links mentioned:
gradio_modal V0.0.1 - a Hugging Face Space by aliabid94: no description found
LAION ▷ #general (298 messages🔥🔥):
- Whispers of "LLaMa 1.6" Success:
User
@kache_briefly mentioned their satisfaction by stating "llava 1.6 is very good," but provides no further details on its performance or comparisons to other models.
- Hacker News Spotlight:
@itali4nohighlighted that a writeup by@122380520226160640gained traction on Hacker News, linking to the discussion with the message: "Your reddit writeup is doing numbers on orange site <@122380520226160640>, if you haven't seen Hacker News Discussion."
- Watermark Debate in Bard's Image Generation:
@max_voltageshared concerns about Bard's upgraded image-generation feature being too wrapped up in responsible AI principles, embedding watermarks to distinguish AI-created visuals, and linked to the relevant discussion with a disgusted emoji.
- Imagen 2's Generated Image Quality Scrutinized:
@thejonasbrothersnoted the apparent noise in all the Imagen2 images and wondered why output wasn't returned in more efficient formats like "jpeg with 80% quality," expressing a critical comparison to SDXL's output.
- Discourse on Autoencoder Sensitivity and Training: Acclaimed users like
@drheadand@thejonasbrothershad an extended technical discussion about the sensitivity of latent space in autoencoders, the impact of noise patterns, and the potential evolution of these patterns during model training. The conversation referenced various models, including Segmind Vega, and the differences observed in them when compared to SDXL VAE.
Links mentioned:
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Finally! First Look at Google's New Imagen 2 & Image FX Interface!: ImageFX is an experimental technology that allows you to generate your own synthetic images. ImageFX is powered by Google’s Imagen 2 and uses Google DeepMind...
- no title found: no description found
- ImageFX: no description found
- GitHub - openai/consistencydecoder: Consistency Distilled Diff VAE: Consistency Distilled Diff VAE. Contribute to openai/consistencydecoder development by creating an account on GitHub.
LAION ▷ #research (1 messages):
felfri_: https://allenai.org/olmo
LM Studio ▷ #💬-general (137 messages🔥🔥):
- In Search of Enhanced Memory:
@flyyt4asked about libraries or tools to improve the long-term memory of LLMs like ChatGPT, which prompted@fabguyto simply mention "memGPT." - The Art of Advanced Prompting:
@wolfspyreshared a link to advanced prompt examples for text generation, emphasizing the significance of Chain of Thought, Tree Thinking, and prompt compression. - Discovering LLaMA on Hugging Face:
@pierrunoytposted a link to Hugging Face's moondream1 project page, and@fabguyacknowledged this as a good find. - Optimizing GPU Offload:
@yagilbgave advice on turning on GPU offload to address complaints of slow model load times by@pierrunoyt. - Downloading Correct LLaMA Model Versions: After
@.veskiinstalled a heavy LLaMA model,@heyitsyorkiedirected them to download the GGUF quantized version from Hugging Face for better compatibility with LM Studio.
Links mentioned:
- moondream1 - a Hugging Face Space by vikhyatk: no description found
- Devlog: Make Amazing GPT copy! Prompt Examples of Chain of Thought, Tree Thinking, and more - FunkPd: Welcome to the world of advanced prompt examples for text generation - a realm where creativity and logic intertwine, and where complexity is not a barrier,
- llama.cpp/README-sycl.md at ce32060198b7e2d6a13a9b8e1e1369e3c295ae2a · ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- GitHub - facebookresearch/llama: Inference code for LLaMA models: Inference code for LLaMA models. Contribute to facebookresearch/llama development by creating an account on GitHub.
LM Studio ▷ #🤖-models-discussion-chat (32 messages🔥):
- Users express dissatisfaction with ChatGPT:
@goldensun3dsexpressed frustration over ChatGPT becoming "useless," particularly with its reduced web browsing capabilities and seemingly arbitrary limitations such as censorship and context size. They likened ChatGPT’s dominance and limitations to Intel's history with CPUs. - Quality concerns over various model versions:
@kujilaremarked on the superiority of Q4 over Q2 by calling Q4 "a lot less of a FILTHY LIAR," inferring improvements in the model's reliability. - Searching for uncensored models: In a response to
@zono50.looking for the best uncensored 7B model,@goldensun3dsrecommended avoiding small models for story writing and provided a personal experience with several models including The Bloke Goat Storytelling 70B Q3KS and The Bloke Dolphin 2 6 Mixtral 7B Q4. - Users troubleshooting and seeking models with no guardrails:
@p4stoboyasked for recommendations on the best model without guardrails after a disappointing experience with Mistral 7B Instruct. Various users discussed solutions, including@ptablewho posted a link in the channel, and@goldensun3dsadvised on editing AI messages in LM Studio to add missing pronouns. - Performance and context limitations in larger models discussed:
@binaryalgorithmtouched on the necessity of keeping story lore consistent with large contexts and mentioned that models like GPT-4 are limited in their output, affecting story continuity. They speculated on the costs and feasibility of using models with larger context sizes via API.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LM Studio ▷ #🧠-feedback (12 messages🔥):
- Insights on GGUF format:
@fabguyacknowledged that GGUF is a better format than.chkas it explicitly loads tensors, however, they expressed caution due to limited knowledge of llama.cpp implementation. Despite this caveat,@fabguymentions having no issues with LM Studio over the past 6 months.
- Finding and Removing Model Adapters:
@elsatchinquired about removing model adapters from vision models after downloading, specifically after installing fp16 for llava and then wanting to switch to Q4.@heyitsyorkiepointed to finding them in the local models folder.
- Request for Timely Support Before Major Meeting:
@docorange88urgently requested a response to their email prior to a significant meeting scheduled for 12PM CST concerning software discussion.@yagilbprioritized the response, apologized for the delay, and ensured timely communication.
- Guidance on Locating Model Adapters on Disk:
@fabguyhelped@elsatchby suggesting to Right-Click the model in the "my models" view to be led directly to the model folder on the disk.
- LM Studio Version Differences Affecting Model Loading:
@foobar8553reported an issue where they could not load the mixtral-8x7B ... Q5_K_M model with LM Studio 0.2.12 despite being able to do so with 0.2.10 due to potential changes in the way models are loaded into RAM and GPU.@yagilboffered to provide 0.2.10 for comparison testing and asked about the operating system used.
LM Studio ▷ #🎛-hardware-discussion (44 messages🔥):
- Dual 3090s for Larger Models:
@silverstar5654inquired about using dual 3090 GPUs with LM Studio to load larger models.@pefortinsuggested simply checking the offload to GPU box, assuming that the drivers are installed correctly.
- LM Studio ARC Support Speculation:
@goldensun3dsshared a link questioning whether ARC support could be coming to LM Studio, to which@rugg0064provided a brief affirmative response.
- Mixtral in VRAM Queries:
@docorange88asked about running Mixtral on two 4090 or RTX6000 GPUs and whether the memory requirements could offload to CPU RAM.@foobar8553shared that they ran Mixtral with 12 GB VRAM on a 4070, utilizing additional system RAM.
- Model Performance on Multi-GPUs:
@ellric_questioned the performance and quality of 8bit versus 4bit models and if adding more GPUs would improve speed.@mahdiyarinoted that using two GPUs might be slower unless using NVLink, and shared a GPU benchmark link for LLM inference.
- Loading Issues with Models on LMStudio:
@lowkey9920experienced difficulties running a 3.8 GB model on a system with a 3080 GPU and 64GB RAM, specifically with "magicoder-s-ds." Others like@binaryalgorithmalso reported issues, while noting that other models loaded fine.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LM Studio ▷ #🧪-beta-releases-chat (1 messages):
- Llava 1.6 Support Inquiry: User
@_koopmaninquired about support for llava 1.6, noting that LM Studio does not currently recognize it as a vision model. There is anticipation for integration.
LM Studio ▷ #autogen (3 messages):
- Exploring Autogen with Multiple Servers:
@ellric_was curious about the capability of running Autogen using two different servers instead of a single machine. They considered experimenting with this setup. - Running Dual Instances of LM Studio:
@_anarche_confirmed that it's feasible to run two models simultaneously using LM Studio on separate ports if there's sufficient hardware to support it. They provided guidance to@ellric_for their planned experimentation.
LM Studio ▷ #open-interpreter (2 messages):
- LM Studio Puzzles with Open Interpreter: User
@raiderduckis experiencing issues while integrating OI (Open Interpreter) with LM Studio, where responses become nonsensical upon activating the server. They have successfully loaded Solar instruct into LM Studio, which works well in chat but fails when using OI, leading to self-replies and nonsense.
- OI Costs a Pretty Penny with GPT-4:
@raiderduckmentioned that OI operates smoothly when paired with GPT-4, but the extensive usage has resulted in a steep $250 bill in one week. They are currently seeking server preset settings advice for OI to alleviate these costs.
Eleuther ▷ #general (33 messages🔥):
- OLMo Enters the LLM Arena:
@sk5544sparked a discussion with the release of the OLMo paper, catching the community's attention on their approach and licensing, with@hailey_schoelkopfclarifying that AI2 hasn't released a chat model or interface. - Debate Over OLMo's Evaluation Scores:
@mistobaanexpressed surprise at OLMo's modest score on the GSM8K benchmark, prompting a debate about tokenizer issues and exacting format problems outlined by@stellaathena, mentioning SFT models potentially scoring better. - OLMo's Training Code Scrutinized: The community dissected OLMo's warmup scheduler, with
@jerry0478explaining its function for resetting optimizer state, and@mistobaanpointing out an absence of papers discussing the warmup technique, referencing an alternative PyTorch warmup tool. - Examination of OLMo's Normalization Choices: Discussion about OLMo's use of layer norm versus rmsnorm gained momentum, clarified by
@ad8ethat they used layer norm without learnable scales, and@the_random_lurkergiving a skeptical take on ai2's emphasis on data quality and model evaluations. - Community Weighs in on AI2's Evaluation Metrics:
@the_random_lurkercriticized AI2's choice of evaluation metrics, suggesting they might have cherry-picked results to favorably compare againstllama2, raising eyebrows about the benchmarks not featured in the main paper but on a HF page.
Links mentioned:
- OLMo/olmo/optim.py at main · Mistobaan/OLMo: Modeling, training, eval, and inference code for OLMo - Mistobaan/OLMo
- phi-playground/notebooks/evaluation/evaluation_GSM8k_transformers_colab.ipynb at main · bmx-ai/phi-playground: A series of utilities to play with microsoft/phi-* models - bmx-ai/phi-playground
- GitHub - Tony-Y/pytorch_warmup: Learning Rate Warmup in PyTorch: Learning Rate Warmup in PyTorch. Contribute to Tony-Y/pytorch_warmup development by creating an account on GitHub.
Eleuther ▷ #research (159 messages🔥🔥):
- N-gram Scaling Sparks Debate:
@xylthixlmshared a paper on scaling n-grams to trillions of tokens, prompting discussion on its innate value and synergy with larger language models (LLMs). Several users, including@ai_waifuand@johnryan465, contemplated combining n-gram models with LLMs to boost overall performance and generalization, while@catboy_slim_commented on the potential in-distribution bias of such models.
- Infinigram Under the Microscope: The research community showed both interest and skepticism towards the Infinigram model;
@_inoxpointed out it was only benchmarked in combination with LLMs, and not on its own, sparking a discussion on its standalone capabilities.
- Tagging Backtranslations for LLMs:
@resonanciasparked a discussion about applying techniques from the machine translation field, such as tagging backtranslated data, to improve the efficiency of language models.@tekniummentioned that while no Hermes-series models uses such techniques, similar approaches are seen in other works, hinting at possible applications in future models.
- Synthetic Data Generation Strategies Evaluated: Users, with insights from
@blagdad, discussed different methods for synthetic data generation, specifically mentioning MCTS (Monte Carlo tree search) and the potential drawbacks of beam search in diversity. It was widely agreed that diverse synthetic data is key, and this might entail using alternative sampling methods.
- Machine Learning Community Highlights:
@ge0.ioannounced the release of the Gaussian Adaptive Attention library tailored for multi-modal work, while@digthatdatashared links to new papers and upcoming research, such as Amortized Text-to-Mesh (AToM), showcasing the dynamic nature of the AI research landscape.
Links mentioned:
- Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens: Are n-gram language models still relevant in this era of neural large language models (LLMs)? Our answer is yes, and we show their values in both text analysis and improving neural LLMs. Yet this nece...
- AToM: Amortized Text-to-Mesh using 2D Diffusion: AToM: Amortized Text-to-Mesh using 2D Diffusion, 2023.
- Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model: Recently the state space models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have shown great potential for long sequence modeling. Building efficient and generic vision backbones purely...
- Self-Alignment with Instruction Backtranslation: We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction...
- Editing Models with Task Arithmetic: Changing how pre-trained models behave -- e.g., improving their performance on a downstream task or mitigating biases learned during pre-training -- is a common practice when developing machine learni...
- AToM: Amortized Text-to-Mesh using 2D Diffusion: We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail ti...
- Tagged Back-Translation: Isaac Caswell, Ciprian Chelba, David Grangier. Proceedings of the Fourth Conference on Machine Translation (Volume 1: Research Papers). 2019.
- Tagged Back-translation Revisited: Why Does It Really Work?: Benjamin Marie, Raphael Rubino, Atsushi Fujita. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
- GitHub - gioannides/Gaussian-Adaptive-Attention: Contribute to gioannides/Gaussian-Adaptive-Attention development by creating an account on GitHub.
Eleuther ▷ #interpretability-general (11 messages🔥):
- Spontaneous Research Intersection:
@norabelroseexpressed surprise upon discovering a research paper on in-context language learning (ICLL) that was aligned with their own research interests. - Paper on 'Contextual Neurons' Shared:
@norabelroseshared a link to a paper exploring the concept of contextual neurons in language models, particularly a neuron that activates on German text, which is part of a second-order circuit. - Perplexity vs. Open-Ended Text Generation:
@nostalgebraistnoted that ∞-gram can improve neural LMs perplexity, but may be harmful to open-ended text generation by causing odd mistakes and retrieval of irrelevant tokens. - N-gram strength in Retrieval over Coherence:
@nostalgebraistsuggested that n-gram models are better suited for tasks resembling long-tail retrieval rather than those requiring coherent text generation, with perplexity results reflecting this dichotomy. - Comparing MoE Attack and ∞-gram Retrieval:
@xa9axdrew parallels between difficulties experienced with ∞-gram in open-ended text generation and MoE model attacks where incorrect expert selection can compromise output, referencing a paper on MoE attacks and expressing interest in this area of research.
Links mentioned:
- In-Context Language Learning: Architectures and Algorithms: Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of whe...
- Training Dynamics of Contextual N-Grams in Language Models: Prior work has shown the existence of contextual neurons in language models, including a neuron that activates on German text. We show that this neuron exists within a broader contextual n-gram circui...
Eleuther ▷ #lm-thunderdome (1 messages):
daniellepintz: Nope, no limit
Latent Space ▷ #ai-general-chat (151 messages🔥🔥):
- Reddit Exposes a Flaw in VAE Latent Space:
@gsegatohighlighted a post discussing the critical flaws in the KL divergence loss on the KL-F8 VAE. It reportedly affects models like SD1.x, SD2.x, SVD, DALL-E 3, making them less efficient by smuggling global information through minimal pixels. - VAE Flaw Sparks Intrigue:
@swyxioresponded to the discussion on VAE shortcomings, noting the brevity of the Reddit writeup and its straightforward nature compared to traditional academic papers would have included unnecessary fluff. - LLMMemes Come Marching In:
@natolambertspread the word about LLM memes through a Twitter post, generating interest in the lighthearted side of language models. - AI2 Unveils OLMo Models: Discussion about AI2's OLMo model release, featuring details like the use of different hardware during training, with a nod towards its relatively short context length of 2048 compared to some other models.
- Nomic AI Releases New Embeddings:
@coffeebean6887highlighted Nomic AI's release of open source embeddings and their excellent performance on the LoCo benchmark; a detailed blog post and dataset are available for further exploration.
Links mentioned:
- Tweet from anton (@abacaj): Here's a snippet of using gpt-4 as a "reward" model. Has been working really well for me (better than using a numbering system)
- Amazon announces Rufus, a new generative AI-powered conversational shopping experience: With Rufus, customers are now able to shop alongside a generative AI-powered expert that knows Amazon’s selection inside and out, and can bring it all together with information from across the web to ...
- Meet Act II of Arc Browser | A browser that browses for you: On Thursday, February 1st @ 12.30pm ET we shared our vision for Act II of this journey we call Arc — a new category of software, a browser that browses for y...
- Open Language Models (OLMos) and the LLM landscape: A small model at the beginning of big changes.
- Why we founded Parcha : A deeper dive into why we're building AI agents to supercharge compliance and operations teams in fintech at Parcha
- no title found: no description found
- OLMo Suite - a allenai Collection: no description found
- GitHub - uptrain-ai/uptrain: Your open-source LLM evaluation toolkit. Get scores for factual accuracy, context retrieval quality, tonality, and many more to understand the quality of your LLM applications: Your open-source LLM evaluation toolkit. Get scores for factual accuracy, context retrieval quality, tonality, and many more to understand the quality of your LLM applications - GitHub - uptrain-ai...
- Tweet from anton (@abacaj): LazyGPT is back ↘️ Quoting Shannon Sands (@max_paperclips) So apparently, according to this at least, it's actually worse https://aider.chat/docs/benchmarks-0125.html Amazing. I can't see...
- Reddit - Dive into anything: no description found
- Tweet from swyx (@swyx): @simon_mo_ @RickLamers @zhuohan123 @woosuk_k @amanrsanger i think theyre doing the thing we talked about at neurips
- allenai/OLMo-7B · Hugging Face: no description found
- NAIRR Pilot - Home: no description found
- [Public] vLLM Project Update @ Second vLLM Meetup): Project Update Jan 31st, 2024 The Second vLLM Meetup @ IBM 1
- R-Judge: Benchmarking Safety Risk Awareness for LLM Agents: no description found
- How to Announce Your Actual AI: no description found
- no title found: no description found
- 7 Habits of Highly Effective AI Business Projects: What’s the difference between good & great AI business projects? Here are 7 things to consider when doing AI work in your organisation.
- How to convince Venture Capitalists you’re an expert in Artificial Intelligence: If you like this article, check out another by Robbie: 15 Ways a Venture Capitalist Says “No”
- Launching your new AI Startup in 2023 — Building Better Teams: In the last few months more and more people have been asking me for my thoughts on their AI business ideas, and for help with navigating the space. This post covers the majority of my thoughts on the ...
- How to use AI to do practical stuff: A new guide: People often ask me how to use AI. Here's an overview with lots of links.
- 3 things everyone’s getting wrong about AI: As AI tools spread, people are struggling to separate fact from fiction.
- How to talk about AI (even if you don’t know much about AI): Plus: Catching bad content in the age of AI.
- What are AI Agents?: In this post, you’ll learn what AI agents are and what they are truly capable of. You’ll also learn how to build an AI agent suitable for your goals.
- AI Agent Basics: Let’s Think Step By Step: An introduction to the concepts behind AgentGPT, BabyAGI, LangChain, and the LLM-powered agent revolution.
- Pitching Artificial Intelligence to Business People: From silver bullet syndrome to silver linings
- How PR people should (not) pitch AI projects: These are exciting times for the artificial intelligence community. Interest in the field is growing at an accelerating pace, registration at academic and professional machine learning courses is soar...
- Educating Clients about Machine Learning and AI – Andy McMahon: no description found
- People + AI Guidebook: A toolkit for teams building human-centered AI products.
Latent Space ▷ #ai-announcements (3 messages):
- New Latent Space Podcast Episode Alert:
@swyxioannounced the release of the latest Latent Space Podcast on Twitter and Hacker News (HN). - Clickbait Experiment Falters:
@swyxiomentioned that despite using a clickbait title and image for the podcast promotion, the response has been disappointing.
OpenAI ▷ #ai-discussions (50 messages🔥):
- Confusion over AI Ethics and Development:
@yami1010revealed confusion about AI's role across various domains and questioned what truly constitutes unethical in AI learning. They expressed a desire to access sources explaining LLMs' inner workings, highlighting the blurred lines in AI development responsibilities.
- Chatbot Integration for Customer Service Inquiry:
@qiqimoninquired about the difficulty of integrating a GPT-powered chatbot for handling customer service inquiries in a school setting, suggesting usage for tasks such as enrollment information.
- Misattribution of AI Development Credit:
@movozavoiced frustration over Bing claiming it developed an AI, corrected only after pointed questions to acknowledge OpenAI’s role.@yami1010contributed a broader perspective on AI development's collective nature, bringing in history and various stakeholders involved.
- Understanding Perceived Performance Dip in ChatGPT:
@voidrunner42observed that ChatGPT seems to be getting dumber, with.@tadase.suggesting that the issue might be related to how the system is prompted rather than a general decline in quality.
- Moderation Standards and Image Guidelines Debate: A conversation between
@jeremy.oand@Teddealt with content moderation on a server, particularly around image allowable content and the interpretation of G-rating guidelines, highlighting a tension between content diversity and strict moderation.
OpenAI ▷ #gpt-4-discussions (92 messages🔥🔥):
- Chatbot Integration Queries for Schools:
@qiqimoninquired about the complexity of implementing a chatbot using GPT for a school's customer service to manage enrollment inquiries, with@luguiand others suggesting it's quite straightforward but requires measures to prevent trolling. - GPT and Knowledgebase Troubles:
@united_beagle_74104expressed frustration with ChatGPT errors and sought customer support contact. Meanwhile, users discussed the best file formats for maintaining a knowledgebase, with strong opinions on avoiding XLXS and DOCX due to encoding issues, as advised by@darthgustav.and others. - RSV Over JSON for AI Product Recommendations:
@quengelbertand@darthgustav.had an extensive exchange on the best knowledgebase format for an AI product-recommendation assistant, with RSV (row separated values) suggested over JSON or XLXS for improved GPT performance. - API Authentication Struggles for Custom GPT Actions:
@woodenrobotfaced difficulties regarding bearer token authentication when moving a GPT project from internal alpha to public beta, particularly in working with a Weaviate database. - Erratic GPT Behavior with Knowledge Files and RAG: Users
@loschess,@blckreaper, and others reported inconsistency in GPT's accessing knowledge files and using APIs following recent updates, and shared workarounds such as reducing file sizes to avoid retrieval tool dependencies.
OpenAccess AI Collective (axolotl) ▷ #general (79 messages🔥🔥):
- Concern Over Changes Affecting Models:
@dreamgenexpressed concerns that the code change involving the lineif any(m in name for m in ["norm", "gate"]):would affect many models like Llama and Mistral.@nafnlaus00found this problematic change insrc/axolotl/utils/models.pyand a discussion ensued about the potential effects on model training and memory use. - Proposed Fix for Model Issue: A fix was proposed by
@nafnlaus00, changing code to includemodel_config.model_type == "mixtral"when checking for "gate" in names, to which@nanobitzqueried whether "mixtral" was meant instead of "mistral". - Contributions on GitHub and Model Troubleshooting:
@nafnlaus00had trouble with Git commands, accidentally deleting important files, and expressed dissatisfaction with GitHub, while@nanobitzoffered to help create a pull request and asked@nafnlaus00for a GitHub handle reference. - Discussion on Text Embedding and Vector Databases: Users engaged in a technical discussion about text embedding models and vector databases, with specific mention of
nomic-embed-text-v1by@nanobitz, and recommendations to start withbgeby@dangfutures. The conversation also touched on finding and using GPUs in cloud services. - Updates on 7B Models Performance and Utilization: There was a conversation about the stagnation of 7B model improvements and mentions of new models like
CapybaraHermes-2.5-Mistral-7BandEagle 7B.@dangfuturesand@c.gatoshared links to recent 7B models and their results, highlighting the progress and competition in this space.
Links mentioned:
- RWKV/v5-Eagle-7B · Hugging Face: no description found
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- argilla/CapybaraHermes-2.5-Mistral-7B · Hugging Face: no description found
- GitHub - qdrant/fastembed: Fast, Accurate, Lightweight Python library to make State of the Art Embedding: Fast, Accurate, Lightweight Python library to make State of the Art Embedding - GitHub - qdrant/fastembed: Fast, Accurate, Lightweight Python library to make State of the Art Embedding
- nomic-ai/nomic-embed-text-v1 · Hugging Face: no description found
- 🌠 Improving RAG by Optimizing Retrieval and Reranking Models: In this tutorial, we will show how to improve a RAG (Retrieval Augmented Generation) model by optimizing the retrieval and reranking models. For this purpose, we will use the ArgillaTrainer to fine...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
caseus_: A fix for this was merged upstream in transformers
OpenAccess AI Collective (axolotl) ▷ #general-help (10 messages🔥):
- Seeking Finetuning Advice for Mixtral:
@emperorinquired about the best way to fully finetune Mixtral, considering whether all parameters except the routers and gates should be fine-tuned.
- GPU VRAM Matters for Mixtral Finetuning:
@caseus_suggested that depending on the available GPU VRAM, approaches like using ds zero3, 8bit optimizer, and freezing the top third to half layers could be beneficial starting points for finetuning Mixtral.
- Full Model Finetuning with Zero3:
@caseus_also mentioned that with offloading using Zero3, one might be able to finetune the entire Mixtral model.
- Looking for Hyperparameters Insights:
@emperorsought confirmation on whether Mixtral has any good working hyperparameters (hparams) and whether it behaves like Mistral7b, which does not favor high learning rates, unlike the Llama model.
- Tokenization Troubles and Potential Solution:
@arcontexasked for assistance with an unspecified problem, and to this,@nanobitzsuggested trying to switch the tokenizer toAutoTokenizer.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (17 messages🔥):
- RunPod Rundown:
@c.gatoexperienced a sudden shutdown of their pod and loss of data, mentioning that they received an email stating the pod would not be removed for two days, but found it gone in just 45 minutes. - Link to RunPod Discord Provided: In response to
@c.gato's issue,@caseus_suggested addressing the concern on the official RunPod Discord, providing the link: RunPod Discord Help Channel. - Possible Bug in Pod Deletion Timing:
@caseus_indicated that@c.gato's experience might point to a bug, differentiating between a pod being stopped and deleted. - Hugging Face Connection Troubles:
@dreamgenreported an SSL error when attempting to transfer data from RunPod to Hugging Face, questioning the reliability of the service. - Slow Download Speeds Questioned:
@dreamgencomplained about the lengthy download time for a Torch package on RunPod, expressing frustration over the service's efficiency.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
OpenAccess AI Collective (axolotl) ▷ #shearedmistral (1 messages):
dangfutures: did you guys figure out the configs for mistral
Perplexity AI ▷ #general (66 messages🔥🔥):
- Guide to Share Funny AI Responses:
@tbyflysought guidance on where to share an amusing response from Perplexity AI.@me.lkdirected them to share it in another channel, and@tbyflyconfirmed the share.
- Subscription Support Query:
@dame.outlawasked for assistance with a subscription issue on the mobile app, to which@icelavamanresponded by asking for details regarding their account and login method.
- Perplexity AI Models Explained:
@icelavamanprovided a link to a blog post explaining the new PPLX models that focus on delivering up-to-date and factual responses.@clay_fergusonsought information on model usage, for which@icelavamanreferred again to the detailed blog post.
- Setting Perplexity as Default Search Engine:
@bartleby0shared a solution for setting Perplexity AI as a browser’s default search engine using a provided template link.
- In-App Issues and Competitor Mention: Users discussed in-app problems such as text selection bugs and default search engine settings. Separately,
@dpshade22mentioned Arc Search being a potential competitor or user of Perplexity AI.
Links mentioned:
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Supported Models: no description found
- Introducing PPLX Online LLMs : The first-of-its-kind Online LLM API
- What models does Copilot use?: Dive deep into Perplexity's technical details with our comprehensive FAQ page. From the nuances of AI models like GPT-4 and Claude 2 to token limits and AI profiles, get concise answers to optimize yo...
- Perplexity Blog: Explore Perplexity's blog for articles, announcements, product updates, and tips to optimize your experience. Stay informed and make the most of Perplexity.
Perplexity AI ▷ #sharing (4 messages):
- Cryptic Contemplation: User
@tbyflyshared a pondering emoji, but without additional context or discussion, the intent behind the message remains a mystery. - Approval of Content:
@twelsh37seemed pleased with an unspecified content, describing it as a "jolly decent watch," though the specifics of the content were not provided. - Embracing Perplexity through Blogging: New community member
@.sayanarashared their enthusiasm about discovering Perplexity AI and linked a blog post praising AI's potential to combat misinformation. They advocate for AI to be used responsibly, nudging people towards clarity and facts, as discussed in both their blog article and book, Pandemic of Delusion. - Surprising Top App Trends:
@bartleby0commented on the notable absence of Facebook from a list of top apps, calling it "interesting" but did not provide a link or elaborate further on the topic.
Links mentioned:
The Right Direction for AI: In this blog and in my book, Pandemic of Delusion, I have focused a lot on AI and particularly on its tremendous potential to shape our thinking for better or for worse. While AI represents a frigh…
Perplexity AI ▷ #pplx-api (8 messages🔥):
- 7b Model's Limitations Exposed:
@brknclock1215points out that the 7b-online model tends to fail on complex queries and often relies on its training data, leading to inaccurate outputs or answers. - Tweaking Codellama 70b's Response Behavior:
@general3dmentions that codellama 70b is very restrictive and suggests that the Perplexity AI team might be able to tweak it to give more consistent answers by starting responses with "Sure!" or similar prompts. - AI Agents as a Workaround:
@tbyflyproposes using AI Agents to run prompts back and forth until a satisfactory answer is obtained, as a potential solution to codellama 70b's issues. - Privacy Concerns Thwart SQL Assistance:
@jayb1791complains that codellama 70b refused to assist with an SQL question due to data privacy concerns, even though the question merely referenced a business address within the SQL query. - Issues with API Credit and Subscription Services:
@alankarshis experiencing problems with API credits not showing up after being charged for a pro subscription, despite trying three different cards and communicating with the customer experience team for assistance.
LlamaIndex ▷ #blog (3 messages):
- Open Source Embedding Rivals OpenAI's Latest: LlamaIndex introduces
@nomic_ai's nomic-embed-text-1, boasting better performance than OpenAI's text-embedding-3-small. The embedding is open source with open data and fully integrated with LlamaIndex; more details are on Twitter.
- Missed @aiusergroup's Keynote? Watch the Replay: Conference attendees can now watch the replay of @jerryjliu0's keynote on Beyond Naive Rag: Adding Agentic Layers via YouTube and access the slides at this link, as shared by LlamaIndex Twitter.
- Blog Post on Enhancing RAG with Data Science: @sudalairajkumar explores the combination of classic data science and retrieval approaches to improve Retrieval-Augmented Generation (RAG), providing guidance on dataset evaluation and embedding model selection in a detailed blog post highlighted by LlamaIndex.
Links mentioned:
- no title found: no description found
- LlamaIndex Talk (AI User Conference): Beyond Naive RAG: Adding Agentic Layers Jerry Liu, LlamaIndex co-founder/CEO
LlamaIndex ▷ #general (40 messages🔥):
- LLAMA Index Beyond OpenAI:
@whitefang_jrconfirmed that LlamaIndex can be easily used with other LLMs and pointed to the guide for integrations and an example notebook for incorporating Llama-2 with LlamaIndex. - Integration Instructions for Local LLAMA Packs:
@whitefang_jrprovided source code to adjust for integrating LLAMA 2 with the resume_screener pack, and linked to the GitHub repository. - Postgres Conundrum in TypeScript/JS Project: User
@.Jaysonnoted issues with Postgres connections and@whitefang_jrsuggested customizing the PG vector class to address multiple connections;@cheesyfishesalso mentioned considering connection pooling. - Spam Alert Rapid Response:
@cheesyfishestook action against a spam alert mentioned by@mysterious_avocado_98353, handling the situation by banning and deleting the harmful content. - Ingestion Pipeline Configuration with MongoDB:
@ramihassaneinsought help for an error encountered while setting up an ingestion pipeline with MongoDB Atlas, to which@cheesyfishesresponded with a solution to update the MongoDB vector store to use the updated base class.
Links mentioned:
- no title found: no description found
- llama-hub/llama_hub/llama_packs/resume_screener/base.py at e6960d4c64f053d32f1e92aa3a587f7b045cbfff · run-llama/llama-hub: A library of data loaders for LLMs made by the community -- to be used with LlamaIndex and/or LangChain - run-llama/llama-hub
- Query Transformations - LlamaIndex 🦙 0.9.42.post1: no description found
- Using LLMs - LlamaIndex 🦙 0.9.42.post1: no description found
- LlamaCPP - LlamaIndex 🦙 0.9.42.post1: no description found
LlamaIndex ▷ #ai-discussion (3 messages):
- Seeking PII Anonymization Solutions:
@princekumar13is looking for methods to anonymize personally identifiable information (PII) from text data before sending it to a large language model (LLM) while maintaining data accuracy. They've found a method using langchain and Presidio but it's experimental and not suitable for production.
- Interest in Specialized LLM for Scheduling:
@erizviinquired about the smallest LLM that could interpret natural language inputs specific to configuring job schedules and then convert them into cron job expressions.
- Whisper into Text: Understanding Speech-to-Text Models:
@amgadozshared a blog post detailing OpenAI's Whisper model, an advanced speech-to-text (STT) system, including insights into its architecture and functionality. The article is the second part of a series, with a focus on the encoder-decoder transformer used by Whisper based on the "Attention is All You Need" paper.
Links mentioned:
Whisper: How to Create Robust ASR (2 / N): Part 2 of a multi-part series in which we delve deep into Whisper, OpenAI's state-of-the-art automatic speech recognition model
LangChain AI ▷ #general (32 messages🔥):
- Seeking Resources for AWS Sagemaker and Chatbot Building:
@refik0727inquired about tutorials or GitHub repositories for building chatbots with AWS SageMaker, using models like Mistral and Llama, with the ability to integrate one's own CSV file or connect to a local database.
- Potential LangChain Twitter Security Breach: Multiple users including
@markopolojarvi,@alcazarr, and@solac3alerted the community about a potential scam involving the LangChain AI Twitter account being hacked, sharing the same suspicious Twitter link.
- Inquiry about ChatOpenAI and Streaming: User
@hiranga.gasked the community ifget_openai_callback()is compatible with an Agent for streaming with ChatOpenAI.
- Proposal for a Dedicated Channel for OpenGTPs Discussed:
@benjaminbascaryproposed the idea of creating a separate channel within the Discord for OpenGTPs discussions.
- Exploration of Streaming with Llamacpp and Langserve/FastAPI:
@legendary_pony_33278sought community help for enabling streaming with Llamacpp and Langserve or FastAPI, to which@veryboldbagelresponded by sharing a GitHub example with Ollama that may not specifically handle streaming.
- Guardrails for AI That Teaches Without Giving Answers: In response to
@_emiya's quest to build an AI that teaches students without providing direct answers to math problems,@deetisaacrecommended looking into Guardrails, while sharing the GitHub repository.
- Deep Learning Resources for Enhancing RAG Applications: After
@daii3696asked for resources to improve RAG applications,@johnny2x2suggested reading the llama index source code and announced that they will be hosting a talk about RAG techniques the following Tuesday.
- Adjusting Max Tokens Limit for ChatOpenAI Agents:
@irfansyah5572sought advice on setting the max tokens limit for an agent encountering anInvalidRequestError, which@the_agent_jaddressed by referring to themaxTokensparameter in the LangChain OpenAI API.
- Question about Disabling Exponential Backoff: User
@apollo7701queried the community about ways to disable exponential backoff without any further context or follow-up responses.
Links mentioned:
- Open-source LLMs as LangChain Agents: no description found
- ChatOpenAI | LangChain.js - v0.1.12: no description found
- langserve/examples/local_llm/server.py at main · langchain-ai/langserve: LangServe 🦜️🏓. Contribute to langchain-ai/langserve development by creating an account on GitHub.
- GitHub - guardrails-ai/guardrails: Adding guardrails to large language models.: Adding guardrails to large language models. Contribute to guardrails-ai/guardrails development by creating an account on GitHub.
LangChain AI ▷ #langserve (2 messages):
- LangServe Local LLM Example with Ollama:
@veryboldbagelshared a GitHub link to an example of using LangServe with ollama, reminding users of the limitations regarding concurrent usage. - LangSmith's Waitlist to Shrink:
@veryboldbagelannounced that more individuals will be taken off the waitlist for LangSmith in the coming weeks.
Links mentioned:
langserve/examples/local_llm/server.py at main · langchain-ai/langserve: LangServe 🦜️🏓. Contribute to langchain-ai/langserve development by creating an account on GitHub.
LangChain AI ▷ #share-your-work (9 messages🔥):
- Autonomous GPT-4 Agent Platform IX:
@robot3yesintroduced Agent IX, an autonomous GPT-4 agent platform on GitHub, encouraging others to check it out. Visit their work on GitHub - kreneskyp/ix. - Maximize Token Savings with ContextCrunch:
@speuceshared ContextCrunch, a prompt compression API that helps save on token costs and integrates with LangChain. Early access and feedback are welcomed at contextcrunch.com. - Job Opportunity at Skipp for OpenAI Full-Stack Developer:
@marcelaresch_11706highlighted a job opening at Skipp for a senior full-stack developer with a focus on backend and in-depth knowledge of OpenAI API. The position is full-time within the Pacific Time zone, looking for candidates from LATAM and Europe. - Deep Dive into OpenAI's Whisper Model:
@amgadozwrote a detailed blog post on OpenAI's Whisper model for Speech-to-Text, covering the model's architecture and function. The model's insights are available without a paywall on Substack. - Step-Back Prompting Technique Explored:
@andysingalpublished an article on Medium about incorporating Step-Back Prompting with Langchain, discussing the improvements in language processing capabilities. Read the full article on Medium.
Links mentioned:
- Whisper: How to Create Robust ASR (2 / N): Part 2 of a multi-part series in which we delve deep into Whisper, OpenAI's state-of-the-art automatic speech recognition model
- GitHub - kreneskyp/ix: Autonomous GPT-4 agent platform: Autonomous GPT-4 agent platform. Contribute to kreneskyp/ix development by creating an account on GitHub.
- ContextCrunch: no description found
- Langchain Elevates with Step-Back Prompting using RAGatouille: A Language Revolution
LangChain AI ▷ #tutorials (2 messages):
- Token Count Troubles with ChatOpenAI: User
@hiranga.genquired about how to get Token counts on ChatOpenAI Agent during streaming, mentioning thatget_openai_callback()does not seem to work with it. - Compressing LLM Contexts with LangChain: User
@speuceshared a Medium article outlining the process of Contextual Compression in LangChain, utilizing ContextCrunch for efficient compression, a solution to the high token usage in Retrieval Augmented Generation (RAG) setups.
Links mentioned:
How to Compress LLM Contexts with LangChain: In this tutorial, you will learn to reduce token usage by up to 90% using LangChain.
DiscoResearch ▷ #disco_judge (1 messages):
- Migration from 7b to Mixtral Planned:
@_jp1_mentioned the decision to switch from a 7b model to a Mixtral base due to limitations in the 7b model for certain dimensions, noting that Mixtral offers a better trade-off for evaluation tasks. They also welcomed help with this transition.
DiscoResearch ▷ #general (15 messages🔥):
- API Security Omission Alert:
@sebastian.bodzahighlighted a potential security concern, pointing out that the API is not secured, with no token used in the request. - New Embedding Model on the Horizon:
@bjoernpshowcased Nomic's long context text embeddernomic-embed-text-v1, which boasts 8192 sequence length and outperforms OpenAI models, complete with open weights, training code, and data (Nomic AI on Hugging Face). - OLMo 7B Unleashed by Allen AI:
@_jp1_introduced the release of OLMo 7B, an Open Language Model by Allen AI, alongside its dataset, training code, and a paper (OLMo on Allen AI, OLMo on Hugging Face). - Quest for the Best German Embedding Model: In response to
@ustollasking for the best German text embedding model for Q/A retrieval,@philipmayemphasized that the use case, such as clustering or semantic similarity, is key in determining the appropriate model. - Fine-Tuning with RAG and Axolotl:
@rasdanidescribed the process of converting the RAG dataset to the ShareGPT format for use with Axolotl, noting the original absence ofpositive_ctx_idxduring SFT and its later addition for potential but not implemented DPO.
Links mentioned:
- nomic-ai/nomic-embed-text-v1 · Hugging Face: no description found
- allenai/OLMo-7B · Hugging Face: no description found
DiscoResearch ▷ #discolm_german (2 messages):
- GPU Alternatives for Inference: User
@_jp1_discussed options for running inference tasks without dedicated GPUs. They suggested using services like replicate, modal, or serverless runpod, and mentioned the possibility of hosting the model with together et al. if there is a demand. - Colab Resource Shared:
@_jp1_also shared a Google Colab notebook link, but the specific contents or context of the notebook remain unclear due to the lack of details in the message. Access the Colab Notebook.
Links mentioned:
Google Colaboratory: no description found
LLM Perf Enthusiasts AI ▷ #embeddings (3 messages):
- Nomic Embed Outperforms Ada and Small OpenAI Models:
@thebaghdaddyshared a link to HuggingFace featuring nomic-embed-text-v1, an open source text encoder with a context length of 8192 that claims to outperform OpenAI's text-embedding-ada-002 and text-embedding-3-small, with performance metrics provided. - Performance Metrics Table Presented: According to the source, nomic-embed-text-v1 scored 62.39 on MTEB and 85.53 on LoCo benchmarks, indicating its superior performance. The table also highlights the accessibility of open weights, training code, and data for this model.
- Intrigued by Open Source Encoder:
@thebaghdaddyexpressed interest in personally testing the new nomic-embed-text-v1 model. - Searching for an Embeddings Testing Ground:
@thebaghdaddyinquired about the existence of an "embeddings arena," similar to the LLM arena leaderboard, showcasing competitive models.
Links mentioned:
nomic-ai/nomic-embed-text-v1 · Hugging Face: no description found
LLM Perf Enthusiasts AI ▷ #reliability (1 messages):
firefox8975: Has anyone tried or is there a guide on how to deploy oss models to aws using vllm?
LLM Perf Enthusiasts AI ▷ #irl (2 messages):
- Exa (formerly Metaphor) Throws Toga-Themed Launch Parties:
@sarahchienginvites everyone to Exa's coast-to-coast launch parties featuring an Acropolis room, a DJ, and "truth-inducing serums." The SF party is on February 2, and the NYC party on February 7; both require an RSVP.
- Coffee on Exa in SF and NYC: In addition to the launch party,
@sarahchiengoffers to meet up for coffee in both San Francisco and New York City and states the costs are "on me...haha."
Links mentioned:
- RSVP to Exa Greco-Roman Toga Launch Party | Partiful: Same mission, new name! Come join the Exa (prev. Metaphor) team for the official Exa Launch Party! Exa's mission is to organize the world's knowledge... and so naturally this is a TOGA party...
- Exa East Coast launch party: Come join the Exa (prev. Metaphor) team for the official Exa Launch Party! Swag, snacks, and Exa credits provided :) Launch post: https://twitter.com/ExaAILabs/status/1750942315055882554 Who we are:...
LLM Perf Enthusiasts AI ▷ #openai (2 messages):
- Database Transition in Progress:
@michelcarrollrevealed that they are currently using Weaviate but are in the process of migrating to pgvector with HNSW, in response to@.psychickoala's inquiry about the vector database being used.
LLM Perf Enthusiasts AI ▷ #prompting (5 messages):
- Saving and Reusing Chain of Thought:
@byronhsuinquired about the outcomes of saving a model's chain of thought (CoT) and then using it as input for subsequent prompts. The aim is to reduce the time and cost of multiple iterations, questioning whether this technique affects the reasoning abilities of the model. - Latency Tradeoff in CoT Approach:
@justahveeconfirmed that feeding a previously saved CoT into a second step works but noted a tradeoff with inference latency due to multiple calls (the original generation and the follow-up inference). - Clarifying Inference Latency Concerns:
@byronhsusought clarification from@justahveeon the inference latency issue, assuming that feeding in a CoT directly should result in faster inferences. - Explaining the Latency Tradeoff:
@justahveeexplained that the latency experienced is due to the total time of the initial CoT generation and the second inference using the CoT, as it involves multiple separate calls. - Assurance on Accuracy Retention:
@byronhsureceived confirmation from@justahveethat accuracy is retained when CoT output from one step is used as input for the next step.
CUDA MODE (Mark Saroufim) ▷ #cuda (7 messages):
- A Warp-Speed Experiment:
@zippikashared code forrgb_to_grayscaleCUDA kernel optimizations, utilizing ulong for vectorized loads per warp. This unique approach loads three pixels at a time, aiming to increase efficiency. - Crank up that Occupancy: Subsequent modifications led to a much higher occupancy with a calculated theoretical of 100% but a measured achieved occupancy of 77%, indicating better utilization of GPU resources in
@zippika's experiments. - Throughput Under the Microscope:
@zippikaposted the GPU Throughput analysis, highlighting Memory utilization at 71.87% and Compute (SM) usage at 46.36%, reflecting the comprehensive workload distribution of their GPU-based computation. - Speed Bumps Ahead: Despite the conceptual success,
@zippikamentioned not having tested the speed and later followed up to report that the new implementation appears to be slower in practice. - Thinking Out Loud with Emoji Support: The user apologized for the seemingly disorganized messages, expressing that the comments were part of a thought process, accompanied by a unique emoji (
<:floom:799302782477402142>), indicating a mix of informal communication and technical content.
CUDA MODE (Mark Saroufim) ▷ #beginner (3 messages):
- CUDA Setup Success: User
@noobpeenannounced they've successfully set up CUDA 12.2 with Visual Studio and is inquiring about the next steps to follow. - Experience with PyTorch and C++:
@noobpeenshared their familiarity with PyTorch and proficiency in C++ to give context to their CUDA setup progress. - Advice to Dive into CUDA Development: In response to
@noobpeen,@lancertssuggested creating a new CUDA project and beginning with CUDA kernels development, followed by recommending the journey through the Professional CUDA C Programming book.
CUDA MODE (Mark Saroufim) ▷ #pmpp-book (1 messages):
- Optimizing Memory Loads via Thread Coarsening:
@tvi_explained that thread coarsening is employed to increase tile size and reduce the global memory load frequency by handling more output pixels per thread. This approach is linked to the concept of "work efficiency", which is discussed later in the book, underscoring its importance in memory operations as opposed to just compute tasks.
Datasette - LLM (@SimonW) ▷ #ai (1 messages):
dbreunig: https://www.dbreunig.com/2024/02/01/pursuing-quiet-ai.html
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- Datasette PDF provided to GPT:
@simonwshared an experience where they provided a GPT with the PDF version of the Datasette documentation, but the results were not very satisfactory. - Hopeful Yet Cautious Optimism: Despite the initial underwhelming results,
@simonwconveyed a belief that with substantial effort, feeding a GPT with Datasette's PDF documentation could potentially be effective.
Links mentioned:
Datasette documentation: no description found