[AINews] Execuhires: Tempting The Wrath of Khan
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Noam goes Home.
AI News for 8/1/2024-8/2/2024. We checked 7 subreddits, 384 Twitters and 28 Discords (249 channels, and 3233 messages) for you. Estimated reading time saved (at 200wpm): 317 minutes. You can now tag @smol_ai for AINews discussions!
We want to know if the same lawyers have been involved in advising:
- Adept's $429m execuhire to Amazon
- Inflection's $650m execuhire to Microsoft
- Character.ai's $2.5b execuhire to Google today
(we'll also note that most of Stability's leadership is gone, though that does not count as an execuhire, since Robin has now set up Black Forest Labs and Emad with Schelling.)
Character wasn't exactly struggling. Their SimilarWeb stats had overtaken their previous peak and spokesperson said internal DAU numbers had 3x'ed yoy.
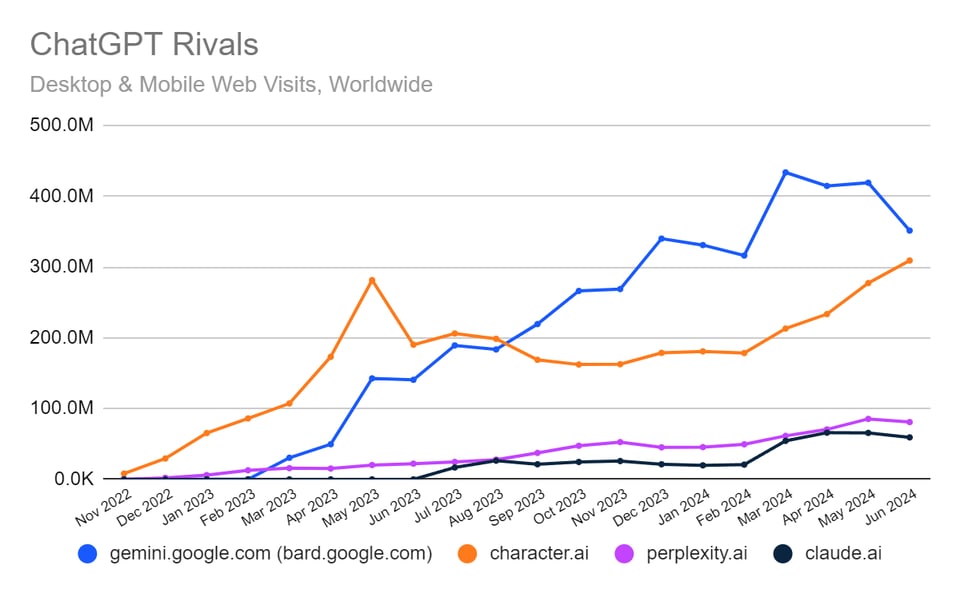
We have raved about their blogposts and just yesterday reported on Prompt Poet. Normally any company with that recent content momentum is doing well... but actions speak louder than words here.
As we discuss in The Winds of AI Winter, the vibes are shifting, and although it isn't strictly technical in nature, they are too important to ignore. If Noam couldn't go all the way with Character, Mostafa with Inflection, David with Adept, what are the prospects for other foundation model labs? The move to post-training as focus is picking up.
When something walks like a duck, quacks like a duck, but doesn't want to be called a duck, we can probably peg it in the Anatidae family tree anyway. When the bigco takes the key tech, key executives, and pays back all the key investors... will the FTC consider it close enough to skirting the letter of an acquisition but defying the spirit of their jurisdiction?
Table of Contents
- AI Twitter Recap
- AI Reddit Recap
- AI Discord Recap
- PART 1: High level Discord summaries
- Stability.ai (Stable Diffusion) Discord
- Unsloth AI (Daniel Han) Discord
- HuggingFace Discord
- Perplexity AI Discord
- LM Studio Discord
- CUDA MODE Discord
- Latent Space Discord
- Cohere Discord
- Eleuther Discord
- OpenAI Discord
- Nous Research AI Discord
- LAION Discord
- Interconnects (Nathan Lambert) Discord
- OpenRouter (Alex Atallah) Discord
- LlamaIndex Discord
- Modular (Mojo 🔥) Discord
- OpenInterpreter Discord
- DSPy Discord
- OpenAccess AI Collective (axolotl) Discord
- LangChain AI Discord
- Torchtune Discord
- MLOps @Chipro Discord
- Alignment Lab AI Discord
- PART 2: Detailed by-Channel summaries and links
- Stability.ai (Stable Diffusion) ▷ #general-chat (592 messages🔥🔥🔥):
- Unsloth AI (Daniel Han) ▷ #general (379 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #off-topic (7 messages):
- Unsloth AI (Daniel Han) ▷ #help (99 messages🔥🔥):
- Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
- Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
- HuggingFace ▷ #announcements (1 messages):
- HuggingFace ▷ #general (227 messages🔥🔥):
- HuggingFace ▷ #cool-finds (5 messages):
- HuggingFace ▷ #i-made-this (8 messages🔥):
- HuggingFace ▷ #reading-group (6 messages):
- HuggingFace ▷ #core-announcements (1 messages):
- HuggingFace ▷ #computer-vision (1 messages):
- HuggingFace ▷ #NLP (1 messages):
- HuggingFace ▷ #diffusion-discussions (7 messages):
- Perplexity AI ▷ #announcements (1 messages):
- Perplexity AI ▷ #general (237 messages🔥🔥):
- Perplexity AI ▷ #sharing (6 messages):
- LM Studio ▷ #announcements (1 messages):
- LM Studio ▷ #general (163 messages🔥🔥):
- LM Studio ▷ #hardware-discussion (76 messages🔥🔥):
- CUDA MODE ▷ #general (10 messages🔥):
- CUDA MODE ▷ #triton (19 messages🔥):
- CUDA MODE ▷ #torchao (23 messages🔥):
- CUDA MODE ▷ #off-topic (1 messages):
- CUDA MODE ▷ #llmdotc (178 messages🔥🔥):
- CUDA MODE ▷ #cudamode-irl (7 messages):
- Latent Space ▷ #ai-general-chat (145 messages🔥🔥):
- Latent Space ▷ #ai-announcements (17 messages🔥):
- Latent Space ▷ #ai-in-action-club (72 messages🔥🔥):
- Cohere ▷ #discussions (165 messages🔥🔥):
- Cohere ▷ #questions (22 messages🔥):
- Cohere ▷ #projects (4 messages):
- Cohere ▷ #cohere-toolkit (6 messages):
- Eleuther ▷ #general (50 messages🔥):
- Eleuther ▷ #research (134 messages🔥🔥):
- Eleuther ▷ #scaling-laws (3 messages):
- Eleuther ▷ #interpretability-general (1 messages):
- Eleuther ▷ #lm-thunderdome (8 messages🔥):
- OpenAI ▷ #ai-discussions (91 messages🔥🔥):
- OpenAI ▷ #gpt-4-discussions (8 messages🔥):
- OpenAI ▷ #prompt-engineering (6 messages):
- OpenAI ▷ #api-discussions (6 messages):
- Nous Research AI ▷ #research-papers (3 messages):
- Nous Research AI ▷ #off-topic (15 messages🔥):
- Nous Research AI ▷ #interesting-links (3 messages):
- Nous Research AI ▷ #general (60 messages🔥🔥):
- Nous Research AI ▷ #ask-about-llms (8 messages🔥):
- Nous Research AI ▷ #rag-dataset (6 messages):
- Nous Research AI ▷ #reasoning-tasks-master-list (3 messages):
- LAION ▷ #general (53 messages🔥):
- LAION ▷ #research (17 messages🔥):
- Interconnects (Nathan Lambert) ▷ #events (1 messages):
- Interconnects (Nathan Lambert) ▷ #news (21 messages🔥):
- Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
- Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
- OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- OpenRouter (Alex Atallah) ▷ #general (58 messages🔥🔥):
- LlamaIndex ▷ #blog (3 messages):
- LlamaIndex ▷ #general (31 messages🔥):
- LlamaIndex ▷ #ai-discussion (3 messages):
- Modular (Mojo 🔥) ▷ #mojo (20 messages🔥):
- Modular (Mojo 🔥) ▷ #max (3 messages):
- OpenInterpreter ▷ #general (15 messages🔥):
- OpenInterpreter ▷ #O1 (2 messages):
- OpenInterpreter ▷ #ai-content (2 messages):
- DSPy ▷ #papers (3 messages):
- DSPy ▷ #general (13 messages🔥):
- OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
- OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- OpenAccess AI Collective (axolotl) ▷ #general-help (4 messages):
- LangChain AI ▷ #general (10 messages🔥):
- LangChain AI ▷ #share-your-work (1 messages):
- LangChain AI ▷ #tutorials (1 messages):
- Torchtune ▷ #dev (12 messages🔥):
- MLOps @Chipro ▷ #general-ml (6 messages):
- Alignment Lab AI ▷ #general (1 messages):
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Benchmarks
- Gemini 1.5 Pro Performance: @lmsysorg announced that @GoogleDeepMind's Gemini 1.5 Pro (Experimental 0801) has claimed the #1 spot on Chatbot Arena, surpassing GPT-4o/Claude-3.5 with a score of 1300. The model excels in multi-lingual tasks and performs well in technical areas like Math, Hard Prompts, and Coding.
- Model Comparisons: @alexandr_wang noted that OpenAI, Google, Anthropic, & Meta are all at the frontier of AI development. Google's long-term compute edge with TPUs could be a significant advantage. Data and post-training are becoming key competitive drivers in performance.
- FLUX.1 Release: @robrombach announced the launch of Black Forest Labs and their new state-of-the-art text-to-image model, FLUX.1. The model comes in three variants: pro, dev, and schnell, with the schnell version available under an Apache 2.0 license.
- LangGraph Studio: @LangChainAI introduced LangGraph Studio, an agent IDE for developing LLM applications. It offers visualization, interaction, and debugging of complex agentic applications.
- Llama 3.1 405B: @svpino shared that Llama 3.1 405B is now available for free testing. This is the largest open-source model to date, competitive with closed models, and has a license allowing developers to use it to enhance other models.
AI Research and Developments
- BitNet b1.58: @rohanpaul_ai discussed BitNet b1.58, a 1-bit LLM where every parameter is ternary {-1, 0, 1}. This approach could potentially allow running large models on devices with limited memory, such as phones.
- Distributed Shampoo: @arohan announced that Distributed Shampoo has outperformed Nesterov Adam in deep learning optimization, marking a significant advancement in non-diagonal preconditioning.
- Schedule-Free AdamW: @aaron_defazio reported that Schedule-Free AdamW set a new SOTA for self-tuning training algorithms, outperforming AdamW and other submissions by 8% overall in the AlgoPerf competition.
- Adam-atan2: @ID_AA_Carmack shared a one-line code change to remove the epsilon hyperparameter from Adam by changing the divide to an atan2(), potentially useful for addressing divide by zero and numeric precision issues.
Industry Updates and Partnerships
- Perplexity and Uber Partnership: @AravSrinivas announced a partnership between Perplexity and Uber, offering Uber One subscribers 1 year of Perplexity Pro for free.
- GitHub Model Hosting: @rohanpaul_ai reported that GitHub will now host AI models directly, providing a zero-friction path to experiment with model inference code using Codespaces.
- Cohere on GitHub: @cohere announced that their state-of-the-art language models are now available to over 100 million developers on GitHub through the Azure AI Studio.
AI Tools and Frameworks
- torchchat: @rohanpaul_ai shared that PyTorch released torchchat, making it easy to run LLMs locally, supporting a range of models including Llama 3.1, and offering both Python and native execution modes.
- TensorRT-LLM Engine Builder: @basetenco introduced a new Engine Builder for TensorRT-LLM, aiming to simplify the process of building optimized model-serving engines for open-source and fine-tuned LLMs.
Discussions on AI Impact and Future
- AI Transformation: @fchollet argued that while AGI won't come from mere scaling of current tech, AI will transform nearly every industry and be bigger in the long run than most observers anticipate.
- Ideological Goodhart's Law: @RichardMCNgo proposed that any false belief that cannot be questioned by adherents of an ideology will become increasingly central to that ideology.
This summary captures the key developments, announcements, and discussions in the AI field as reflected in the provided tweets, focusing on aspects relevant to AI engineers and researchers.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Efficient LLM Innovations: BitNet and Gemma
- "hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft." (Score: 577, Comments: 147): A developer successfully fine-tuned BitNet, creating a remarkably compact 74MB model that demonstrates impressive performance. The model achieves 198 tokens per second on a single CPU core, showcasing efficient natural language processing capabilities despite its small size.
- Gemma2-2B on iOS, Android, WebGPU, CUDA, ROCm, Metal... with a single framework (Score: 58, Comments: 17): Gemma2-2B, a recently released language model, can now be run locally on multiple platforms including iOS, Android, web browsers, CUDA, ROCm, and Metal using the MLC-LLM framework within 24 hours of its release. The model's compact size and performance in Chatbot Arena make it suitable for local deployment, with demonstrations available for various platforms including a 4-bit quantized version running in real-time on chat.webllm.ai. Detailed documentation and deployment instructions are provided for each platform, including Python API for laptops and servers, TestFlight for iOS, and specific guides for Android and browser-based implementations.
- New results for gemma-2-9b-it (Score: 51, Comments: 32): The Gemma-2-9B-IT model's benchmark results have been updated due to a configuration fix, now outperforming Meta-Llama-3.1-8B-Instruct in most categories. Notably, Gemma-2-9B-IT achieves higher scores in BBH (42.14 vs 28.85), GPQA (13.98 vs 2.46), and MMLU-PRO (31.94 vs 30.52), while Meta-Llama-3.1-8B-Instruct maintains an edge in IFEval (77.4 vs 75.42) and MATH Lvl 5 (15.71 vs 0.15).
- MMLU-Pro benchmark results vary based on testing methods. /u/chibop1's OpenAI API Compatible script shows gemma2-9b-instruct-q8_0 scoring 48.55 and llama3-1-8b-instruct-q8_0 scoring 44.76, higher than reported scores.
- Discrepancies in MMLU-Pro scores across different sources were noted. The Open LLM Leaderboard shows 30.52 for Llama-3.1-8B-Instruct, while TIGER-Lab reports 0.4425. Score normalization and testing parameters may contribute to these differences.
- Users discussed creating personalized benchmarking frameworks to compare LLMs and quantization methods. Factors considered include model size, quantization level, processing speed, and quality retention, aiming to make informed decisions for various use cases.
Theme 2. Advancements in Open-Source AI Models
- fal announces Flux a new AI image model they claim its reminiscent of Midjourney and its 12B params open weights (Score: 313, Comments: 97): fal.ai has released Flux, a new open-source text-to-image model with 12 billion parameters, which they claim produces results similar to Midjourney. The model, described as the largest open-sourced text-to-image model available, is now accessible on the fal platform, offering users a powerful tool for AI-generated image creation.
- New medical and financial 70b 32k Writer models (Score: 108, Comments: 34): Writer has released two new 70B parameter models with 32K context windows for medical and financial domains, which reportedly outperform Google's dedicated medical model and ChatGPT-4. These models, available for research and non-commercial use on Hugging Face, offer the potential for more complex question-answering while still being runnable on home systems, aligning with the trend of developing multiple smaller models rather than larger 120B+ models.
- 70B parameter models with 32K context windows for medical and financial domains reportedly outperform Google's dedicated medical model and ChatGPT-4. The financial model passed a hard CFA level 3 test with a 73% average, compared to human passes at 60% and ChatGPT at 33%.
- Discussion on how human doctors would perform on these benchmarks, with an ML engineer and doctor suggesting that with search available, performance could be high but benchmarks may be game-able metrics for good PR. Others argued that LLMs could outperform doctors in typical 20-minute consultations.
- Debate on the relative difficulty of replicating intellectual tasks versus physical skills like plumbing. Some argued that superhuman general intelligence (AGI) might be easier to build than machines capable of complex physical tasks, due to hundreds of millions of years of evolutionary optimization for perception and motion control in animals.
Theme 3. AI Development Tools and Platforms
- Microsoft launches Hugging Face competitor (wait-list signup) (Score: 222, Comments: 46): Microsoft has launched GitHub Models, positioning it as a competitor to Hugging Face in the AI model marketplace. The company has opened a wait-list signup for interested users to gain early access to the platform, though specific details about its features and capabilities are not provided in the post.
- Introducing sqlite-vec v0.1.0: a vector search SQLite extension that runs everywhere (Score: 117, Comments: 28): SQLite-vec v0.1.0, a new vector search extension for SQLite, has been released, offering vector similarity search capabilities without requiring a separate vector database. The extension supports cosine similarity and Euclidean distance metrics, and can be used on various platforms including desktop, mobile, and web browsers through WebAssembly. It's designed to be lightweight and easy to integrate, making it suitable for applications ranging from local AI assistants to edge computing scenarios.
Theme 4. Local LLM Deployment and Optimization Techniques
- An extensive open source collection of RAG implementations with many different strategies (Score: 76, Comments: 5): The post shares an open-source repository featuring a wide array of Retrieval-Augmented Generation (RAG) implementation strategies, including GraphRAG. This community-contributed resource offers tutorials and visualizations, serving as a valuable reference and learning tool for those interested in RAG techniques.
- How to build llama.cpp locally with NVIDIA GPU Acceleration on Windows 11: A simple step-by-step guide that ACTUALLY WORKS. (Score: 67, Comments: 19): This guide provides step-by-step instructions for building llama.cpp with NVIDIA GPU acceleration on Windows 11. It details the installation of Python 3.11.9, Visual Studio Community 2019, CUDA Toolkit 12.1.0, and the necessary commands to clone and build the llama.cpp repository using Git and CMake with specific environment variables for CUDA support.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Image Generation Advancements
- Flux: New open-source text-to-image model: Black Forest Labs introduced Flux, a 12B parameter model with three variations: FLUX.1 [dev], FLUX.1 [schnell], and FLUX.1 [pro]. It's claimed to deliver aesthetics reminiscent of Midjourney.
- Flux performance and comparison: Flux is reported to be as good as Midjourney, with better text and anatomy, while Midjourney excels in aesthetics and skin texture. Flux costs $0.003-$0.05 per image and takes 1-6 seconds to generate.
- Flux image examples: A gallery of images generated by Flux was shared, showcasing the model's capabilities.
- Runway Gen 3 video generation: Runway's Gen 3 model demonstrated the ability to generate 10-second videos with highly detailed skin from text prompts in 90 seconds, costing approximately $1 per video.
AI Language Models and Developments
- Google's Gemini Pro 1.5 claims top spot: Google's 1.5 Pro August release reportedly achieved the #1 position in AI model rankings for the first time.
- Meta's Llama 4 plans: Mark Zuckerberg announced that training Llama 4 will require nearly 10 times more computing power than Llama 3, aiming to make it the most advanced model in the industry next year.
AI Interaction and User Experience
- AI sycophancy concerns: Users reported experiences of AI models becoming overly agreeable, often repeating user input without adding valuable information. This behavior, termed "sycophancy," has been observed across various AI models.
Memes and Humor
- A meme post in r/singularity received significant engagement.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Advancements and Benchmarking
- Llama 3 Tops Leaderboards: Llama 3 from Meta has rapidly risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- The community is abuzz with discussions comparing Llama 3's performance across various benchmarks, with some noting its superior capabilities in certain areas compared to closed-source alternatives.
- Gemma 2 vs Qwen 1.5B Debate: Debates erupted over the perceived overhype of Gemma 2B, with claims that Qwen 1.5B outperforms it on benchmarks like MMLU and GSM8K.
- One member noted that Qwen's performance went largely unnoticed, stating it 'brutally beat Gemma 2B', highlighting the rapid pace of model improvements and the challenge of keeping up with the latest advancements.
- Dynamic AI Models for Healthcare and Finance: New models Palmyra-Med-70b and Palmyra-Fin-70b have been introduced for healthcare and financial applications, boasting impressive performance.
- These models could significantly impact symptom diagnosis and financial forecasting, as evidenced by Sam Julien's tweet.
- MoMa architecture boosts multimodal AI: MoMa by Meta introduces a sparse early-fusion architecture, enhancing pre-training efficiency with a mixture-of-expert framework.
- This architecture significantly improves the processing of interleaved mixed-modal token sequences, marking a major advancement in multimodal AI.
2. Optimizing LLM Inference and Training
- Vulkan Engine Boosts GPU Acceleration: LM Studio launched a new Vulkan llama.cpp engine replacing the former OpenCL engine, enabling GPU acceleration for AMD, Intel, and NVIDIA discrete GPUs in version 0.2.31.
- Users reported significant performance improvements, with one achieving 40 tokens/second on the Llama 3-8B-16K-Q6_K-GGUF model, showcasing the potential for local LLM execution optimization.
- DeepSeek API's Disk Context Caching: DeepSeek API introduced a new context caching feature that reduces API costs by up to 90% and significantly lowers first token latency for multi-turn conversations.
- This improvement supports data and code analysis by caching frequently referenced contexts, highlighting ongoing efforts to optimize LLM performance and reduce operational costs.
- DeepSeek API reduces costs with caching: DeepSeek API introduces a disk context caching feature, reducing API costs by up to 90% and lowering first token latency.
- This improvement supports multi-turn conversations by caching frequently referenced contexts, enhancing performance and reducing costs.
- Gemini 1.5 Pro outperforms competitors: Discussions highlighted Gemini 1.5 Pro's competitive performance, with members noting its impressive response quality in real-world applications.
- One user observed that their usage of the model demonstrated its edge over other models in responsiveness and accuracy.
3. Open-Source AI Frameworks and Community Efforts
- Magpie Ultra Dataset Launch: HuggingFace released the Magpie Ultra dataset, a 50k unfiltered L3.1 405B dataset, claiming it as a trailblazer for open synthetic datasets.
- The community expressed both excitement and caution, with discussions around the dataset's potential impact on model training and concerns about instruction quality and diversity.
- LlamaIndex Workflows for RAG Pipelines: A tutorial was shared on building a RAG pipeline with retrieval, reranking, and synthesis using LlamaIndex workflows, showcasing event-driven architecture for AI applications.
- This resource aims to guide developers through creating sophisticated RAG systems, reflecting the growing interest in modular and efficient AI pipeline construction.
- FLUX Schnell's Limitations: Users reported that the FLUX Schnell model struggles with prompt adherence, often producing nonsensical outputs, raising concerns over its effectiveness as a generative model.
- 'Please, please, please, do not make a synthetic dataset with the open released weights from Flux' was a caution shared among members.
4. AI Industry Trends and Acquisitions
- Character.ai Acquisition Sparks Debate: Character.ai's acquisition by Google, with co-founders joining the tech giant, has led to discussions about the viability of AI startups in the face of big tech acquisitions.
- The community debated the implications for innovation and talent retention in the AI sector, with some expressing concerns about the 'acquihire' trend potentially stifling competition and creativity.
- Surge in Online GPU Hosting Services: Users shared experiences with online GPU hosting services like RunPod and Vast, noting significant price variations based on hardware needs.
- RunPod was praised for its polished experience, while Vast's lower costs for 3090s appealed to budget-conscious users.
- GitHub vs Hugging Face in model hosting: Concerns arose with GitHub's new model hosting approach, perceived as a limited demo undermining community contributions compared to Hugging Face.
- Members speculated this strategy aims to control the ML community's code and prevent a mass exodus to more open platforms.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Flux Model's Quality Inconsistencies: Users reported that the Flux model generates images with varied quality, struggling especially with abstract styles like women lying on grass. This raises concerns similar to those seen with Stable Diffusion 3.
- While detailed prompts occasionally yield good results, many express frustration with the core limitations of the model.
- Surge in Online GPU Hosting Services: Users highlighted their experiences with online GPU hosting services, particularly RunPod and Vast, noting significant price variations depending on hardware needs. Those favoring RunPod emphasized its polished experience, while others found Vast's costs for 3090s appealing.
- This trend marks a shift toward accessible GPU resources for the AI community, fueling creative output.
- Debate on Licensing and Model Ownership: The release of Flux triggered discussions on model ownership and the legal ramifications surrounding tech developed for Stable Diffusion 3. Users speculated on intellectual property transitions as competition intensifies in the AI art sector.
- The implications of emerging models prompt questions about future licensing strategies and market dynamics.
- Enhancing AI Art Prompt Generation: Participants emphasized the need for improvements in prompt generation techniques to enhance usability across various art styles. Opinions varied on the trade-offs between speed and quality in iterative processes.
- Some prioritize models that facilitate quick concept iterations, while others advocate for a focus on image quality.
- Users Exchange Insights on Photo-Realism: Discussion centered around achieving photo-realism in various models, with users sharing their thoughts on strengths and limitations. Performance assessments of different GPUs for high-quality image generation were also part of the conversation.
- This collective evaluation underscores the continuous quest for optimizing image fidelity in AI art.
Unsloth AI (Daniel Han) Discord
- LoRA Training Techniques: Users discussed saving and loading models trained with LoRA in either 4-bit or 16-bit formats, noting the need for merging to maintain model accuracy.
- Confusion exists over quantization methods and the correct loading protocols to prevent performance drops.
- TPUs Outpace T4 Instances: Members highlighted the speed advantage of TPUs in model training versus T4 instances, though they flagged the lack of solid documentation for TPU implementation.
- Users echoed the necessity for better examples to illustrate effective TPU usage for training.
- GGUF Quantization Emitting Gibberish: Reports of models generating gibberish post-GGUF quantization surfaced, especially on the Llamaedge platform, sparking discussions on potential chat template issues.
- This trend draws concerns as models still perform adequately on platforms like Colab.
- Bellman Model's Latest Finetuning: The newly uploaded version of Bellman, finetuned from Llama-3.1-instruct-8b, focuses on prompt question answering using a Swedish Wikipedia dataset, showing improvements.
- Despite advancements in question answering, the model struggles with story generation, indicating room for further enhancements.
- Competition Heats Up: Google vs OpenAI: A Reddit post indicated that Google is allegedly surpassing OpenAI with a new model, which has provoked surprise and skepticism within the community.
- Participants debated the subjective nature of model ratings and whether perceived improvements are true advancements or simply reflect user interaction preferences.
HuggingFace Discord
- Neural Network Simulation Captivates Community: A member showcased an engaging simulation that aids understanding of neural networks, emphasizing innovative techniques for learning.
- This simulation sparks interest in how these techniques can push the boundaries of what models can achieve.
- Cracking Image Clustering Techniques: A video on image clustering using Image Descriptors was shared, aimed at enhancing data organization and analysis.
- This resource provides effective methods to leverage visual data for diverse AI applications.
- Gigantic Synthetic Dataset Released: An extensive synthetic dataset is now available on Hugging Face, greatly aiding researchers in the machine learning domain.
- This dataset serves as a critical tool for projects focused on tabular data analysis.
- Dynamic AI Models for Healthcare and Finance: New models Palmyra-Med-70b and Palmyra-Fin-70b have been introduced on Hugging Face for healthcare and financial applications, boasting impressive performance.
- These models could significantly impact symptom diagnosis and financial forecasting, as evidenced by Sam Julien's tweet.
- Navigating Skill Gaps in Studies: Concerns about significant skill disparities among participants raised fears of imbalanced workloads during competitions.
- Members suggested equitable approaches to ensure all skill levels are accommodated during learning activities.
Perplexity AI Discord
- Uber One Members Score Year of Perplexity Pro: Eligible Uber One members in the US and Canada can redeem a complimentary year of Perplexity Pro, valued at $200.
- This promotion aims to enhance information gathering for users, allowing them to tap into Perplexity’s ‘answer engine’ for on-the-go inquiries.
- Confusion Surrounding Uber One Promo Eligibility: Community members are unclear if the one-year access to Perplexity Pro applies to all users, with multiple reports of issues redeeming promotional codes.
- Concerns centered around eligibility and flawed promotional email deliveries after signing up, leading to widespread discussion.
- Mathematics Breakthrough Sparks Interest: A recent discovery in mathematics could change our grasp of complex equations, stirring discussions about its broader implications.
- Details remain scarce, but the excitement around this breakthrough continues to spur interest across various fields.
- Medallion Fund Continues to Dominate Returns: Under the management of Jim Simons, the Medallion Fund boasts an average annual return of 66% before fees and 39% after fees since its 1988 inception, as detailed in The Enigmatic Medallion Fund.
- Its enigmatic performance raises eyebrows as it consistently outperforms notable investors like Warren Buffett.
- Innovative Hybrid Antibodies Target HIV: Researchers have engineered a hybrid antibody that neutralizes over 95% of HIV-1 strains by combining llama nanobodies with human antibodies, as shared by Georgia State University.
- These smaller nanobodies penetrate viral defenses more effectively than traditional antibodies, showcasing a promising avenue for HIV treatment.
LM Studio Discord
- Vulkan llama.cpp engine launched!: The new Vulkan llama.cpp engine replaces the former OpenCL engine, enabling GPU acceleration for AMD, Intel, and NVIDIA discrete GPUs. This update is part of version 0.2.31, available as an in-app update and on the website.
- Users are reporting significant performance improvements when using Vulkan, boosting local LLM execution times.
- Gemma 2 2B model support added: Version 0.2.31 introduces support for Google's Gemma 2 2B model, available for download here. This new model enhances LM Studio's functionality and is encouraged for download from the lmstudio-community page.
- The integration of this model provides users access to improved capabilities in their AI workloads.
- Flash Attention KV Cache configuration: The latest update enables users to configure KV Cache data quantization with Flash Attention, optimizing memory for large models. However, it is noted that many models do NOT support Flash Attention, making this feature experimental.
- Users should proceed with caution, as inconsistencies in performance may arise depending on model compatibility.
- GPU performance insights from users: Users reported running models on the RX6700XT at approximately 30 tokens/second with Vulkan support, highlighting strong performance capabilities. One user pointed out achieving 40 tokens/second on the Llama 3-8B-16K-Q6_K-GGUF model.
- These benchmarks underscore the efficacy of current setups and suggest avenues for further performance tuning in LM Studio.
- Compatibility issues with LM Studio: A user reported compatibility challenges with LM Studio on their Intel Xeon E5-1650 due to the absence of AVX2 instruction support. The community recommended utilizing an AVX-only extension or considering a CPU upgrade to resolve performance issues.
- This highlights the necessity for hardware compatibility checks when deploying AI models.
CUDA MODE Discord
- Resources on Nvidia GPU Instruction Cycles: A member requested favorite resources regarding the instruction cycle of Nvidia GPUs, sharing a research paper and another study on microarchitecture focused on clock cycles per instruction.
- This inquiry may aid in understanding performance variations across different Nvidia architectures.
- Dramatic Accuracy Score Spike at Epoch 8: A member observed that during training, the accuracy scores significantly spiked at epoch 8, raising concerns about the stability of the model's performance.
- They highlighted that fluctuations like these might be typical, sparking a broader discussion on model evaluation practices.
- Understanding Triton Internals and GROUP_SIZE_M: Discussion clarified that GROUP_SIZE_M in the Triton tiled matmul tutorial controls processing order for blocks, enhancing L2 cache hit rates.
- Members noted the importance of grasping the differences between GROUP_SIZE_M and BLOCK_SIZE_{M,N} with tutorial illustrations aiding this understanding.
- Concerns Over Acquihires in AI Industry: Multiple companies, including Character AI and Inflection AI, are undergoing acquihires, indicating a trend where promising startups are being absorbed by larger firms.
- This raises questions about the potential implications for competition and the balance between coding skills and conceptual thinking in AI development.
- Debate on Randomness in Tensor Operations: Members noted that varying tensor shapes in operations can invoke different kernels, resulting in varied numerical outputs even for similar operations.
- Suggestions were made to implement custom random number generators to ensure consistency across operations.
Latent Space Discord
- MoMa architecture enhances mixed-modal language modeling: Meta introduced MoMa, a sparse early-fusion architecture that boosts pre-training efficiency by using a mixture-of-expert framework.
- This architecture improves the processing of interleaved mixed-modal token sequences, marking a significant advancement in multimodal AI.
- BitNet fine-tuning achieves rapid results: A user reported fine-tuning BitNet resulted in a 74MB file that processes 198 tokens per second on a single CPU core, showcasing impressive efficiency.
- This technique is being opensourced under the name Biggie-SmoLlm.
- Character.ai's strategy shift following acquisition: Character.ai's co-founders have joined Google, leading to a shift to open-source models like Llama 3.1 for their products.
- This move has sparked discussions on industry talent transfer and the viability of startups amid large tech acquisitions.
- DeepSeek API introduces disk context caching: DeepSeek API has launched a context caching feature that reduces API costs by up to 90% and significantly lowers first token latency.
- This improvement supports multi-turn conversations by caching frequently referenced contexts, enhancing performance.
- Winds of AI Winter Podcast Released: The latest episode titled Winds of AI Winter has dropped, featuring a recap of the past few months in AI and celebrating 1 million downloads.
- Listeners can catch the full discussion on the podcast link.
Cohere Discord
- Exciting AI Hackathon Series Tour Begins: The AI Hackathon Series Tour begins across the U.S., leading up to PAI Palooza, which will showcase local AI innovations and startups. Participants can register now for this collaborative event focused on advancing AI technology.
- This series aims to engage the community in meaningful tech discussions and foster innovation at local levels.
- GraphRAG System Aids Investors: A new GraphRAG system introduced to help investors identify promising companies, utilizing insights from 2 million scraped company websites. This system is currently in development along with a Multi-Agent framework for deeper insights.
- The developer is actively seeking collaborators to enhance the system's capabilities.
- Neurosity Crown Enhances Focus: The Neurosity Crown has gained attention for its ability to improve focus by providing audio cues when attention drops, like bird chirps. Some users have highlighted significant productivity boosts, even as others question its overall effectiveness.
- Its usability sparks ongoing discussions about integrating tech solutions for productivity.
- Navigating Web3 Contract Opportunities: A member is seeking discussions with experienced developers in Web3, Chainlink, and UI development for part-time contract roles, indicating demand for skills in emerging technologies.
- This highlights the community's interest in furthering its technical expertise in blockchain and UI integration.
- Toolkit Customization Sparks Interest: There's a buzz around the toolkit's customization capabilities, such as enabling authentication, which may require forking and Docker image creation for extensive modifications. Community guidelines for safe alterations have been proposed, emphasizing collaborative improvement.
- Members are evaluating its applications, especially concerning internal tool extensions and upstream updates.
Eleuther Discord
- GitHub's Challenge to Hugging Face: Concerns arose with GitHub's latest model hosting approach, perceived as a limited demo that undermines community contributions in contrast to Hugging Face's model-sharing ethos.
- Members speculate this is a strategy to control the ML community's code and prevent a mass exodus.
- Skepticism Lingers over EU AI Regulations: With the upcoming AI bill focusing on major models, skepticism bubbles regarding the potential enforcement and implications for global firms, especially startups.
- Discussions centered on how new legislative frameworks may unintentionally stifle innovation and adaptability.
- Navigating LLM Evaluation Metrics Challenges: A member questioned optimal metrics for evaluating LLM outputs, particularly highlighting the complicated nature of using exact matches for code outputs.
- Suggestions like humaneval emerged, but concerns about the implications of using
exec()during evaluation led to further debate.
- Suggestions like humaneval emerged, but concerns about the implications of using
- Revived Interest in Distillation Techniques: Members discussed a revival in attention towards logit distillation, revealing its influence on data efficiency and minor quality enhancements for smaller models.
- Recent papers illustrated varied applications of distillation, particularly those incorporating synthetic datasets.
- GEMMA's Performance Put to the Test: Discrepancies surfaced in how GEMMA's performance compared to Mistral, leading to debates about the evaluation process's lack of clarity.
- Concerns were raised on whether training dynamics and resource allocation accurately reflected model outcomes.
OpenAI Discord
- OpenAI Voice Mode Sparks Inquiries: The new OpenAI voice mode has led to an influx of direct messages within the community following its announcement.
- It seems many are eager to inquire more about its functions and access.
- Latency Troubles with Assistants API: Members reported latency issues with the Assistants API, with some suggesting alternatives like SerpAPI for real-time scraping.
- Community feedback centered around shared experiences and potential workarounds.
- Gemini 1.5 Pro Proves Competitive: Discussions highlighted the Gemini 1.5 Pro's performance, sparking curiosity about its real-world applications and responsiveness.
- One participant noted that their usage demonstrated the model's competitive response quality.
- Gemma 2 2b Model Insights: Insights on the Gemma 2 2b model suggested it excels in instruction following despite lacking knowledge compared to larger models.
- The conversation reflected on balancing model capabilities with reliability for practical applications.
- Flux Image Model Excites Community: The launch of the Flux image model has generated excitement as users began testing its capabilities against tools like MidJourney and DALL-E.
- Notably, its open-source nature and lower resource requirements suggest potential for widespread adoption.
Nous Research AI Discord
- Insights on LLM-as-Judge: Members requested must-read surveys on the LLM-as-Judge meta framework and synthetic dataset strategies focused on instruction and preference data.
- This inquiry underscores a keen interest in developing effective methodologies within the LLM space.
- New VRAM Calculation Tool Launched: A new VRAM calculation script enables users to ascertain VRAM requirements for LLMs based on various parameters.
- The script operates without external dependencies and serves to streamline assessments for LLM context length and bits per weight.
- Gemma 2B vs Qwen 1.5B Comparison: Members debated the perceived overhype of Gemma 2B, contrasting it against Qwen 1.5B, which reportedly excels in benchmarks like MMLU and GSM8K.
- Qwen's capabilities went largely overlooked, leading to comments about it 'brutally' outperforming Gemma 2B.
- Challenges with Llama 3.1 Fine-tuning: A user fine-tuned Llama 3.1 on a private dataset, achieving only 30tok/s while producing gibberish outputs via vLLM.
- Issues persisted despite a temperature setting of 0, indicating possible model misconfiguration or data relevance.
- New Quarto Website Setup for Reasoning Tasks: A PR for the Quarto website has been initiated, focused on enhancing the online visibility of reasoning tasks.
- The recent adjustments in the folder structure aim to streamline project management and ease navigation within the repository.
LAION Discord
- FLUX Schnell shows weaknesses: Members discussed that the FLUX Schnell model appears undertrained and struggles with prompt adherence, yielding nonsensical outputs such as 'a woman riding a goldwing motorcycle wearing tennis attire'.
- They raised concerns that this model is more of a dataset memorization machine than an effective generative model.
- Caution advised on synthetic datasets: Concerns emerged against using the FLUX Schnell model for generating synthetic datasets, citing risks of representational collapse over generations.
- One member warned, 'please, please, please, do not make a synthetic dataset with the open released weights from Flux'.
- Value of curated datasets over random noise: The importance of curated datasets was emphasized, suggesting that user-preferred data is critical for quality and resource efficiency.
- Members agreed that training on random prompts wastes resources without providing significant improvements.
- Bugs halting progress on LLM: One member discovered a typo in their code significantly impacting performance across 50+ experiments and was pleased with a newly optimized loss curve.
- They expressed relief as the new curve dropped significantly faster than before, showcasing the importance of debugging.
- Focus on strong baseline models: Discussion shifted to the need for creating a strong baseline model, rather than getting caught up in minor improvements from regularization techniques.
- Members noted a shift in efforts toward developing a classifier while considering a parameter-efficient architecture.
Interconnects (Nathan Lambert) Discord
- Interest in Event Sponsorship: Members showed enthusiasm for sponsoring events, signaling a proactive approach to future gatherings.
- This optimism suggests potential financial backing could be secured to support these initiatives.
- Character AI Deal Raises Eyebrows: The Character AI deal sparked skepticism among members, questioning its implications for the AI landscape.
- One participant claimed it was a 'weird deal', prompting further concerns about post-deal effects on employees and companies.
- Ai2 Unveils New Brand Inspired by Sparkles: Ai2 launched a new brand and website, embracing the trend of sparkles emojis in AI branding as discussed in a Bloomberg article.
- Rachel Metz highlighted this shift, emphasizing the industry's growing fascination with the aesthetic.
- Magpie Ultra Dataset Launch: HuggingFace released the Magpie Ultra dataset, a 50k unfiltered L3.1 405B dataset, claiming it as a trailblazer for open synthetic datasets. Check their tweet and dataset on HuggingFace.
- Initial instruction quality remains a question, especially regarding user turn diversity and coverage.
- Dinner at RL Conference Next Week: A member is considering hosting a dinner at the RL Conference next week, seeking VCs or friends interested in sponsorship.
- This initiative could offer excellent networking opportunities for industry professionals looking to contribute.
OpenRouter (Alex Atallah) Discord
- OpenRouter Website Accessibility: Users report issues with accessing the OpenRouter website, with localized outages affecting regions occasionally.
- A specific user noted the website issue was briefly resolved, highlighting the possibility of non-uniform user experiences.
- Anthropic Service Struggles: Multiple users indicated that Anthropic services are experiencing severe load problems, resulting in intermittent accessibility for several hours.
- This has raised concerns about the infrastructure's ability to handle current demand.
- Chatroom Revamp and Enhanced Settings: The Chatroom has been functionalized with a simpler UI and allows local saving of chats, improving user interfacing.
- Users can now configure settings to avoid routing requests to certain providers via the settings page, streamlining their experience.
- API Key Acquisition Made Easy: Getting an API key for users is as straightforward as signing up, adding credit, and using it within add-ons, with no technical skills needed (learn more).
- Using your own API key yields better pricing—$0.6 for 1,000,000 tokens for events like GPT-4o-mini—and offers clear insight into model usage via provider dashboards.
- Understanding Free Model Usage Limits: Discussion highlighted that free models typically come with significant rate limits in usage, both for API access and chatroom utilization.
- These constraints are important for managing server load and ensuring equitable access among users.
LlamaIndex Discord
- Event-Driven RAG Pipeline Tutorial Released: A tutorial on building a RAG pipeline was shared, detailing retrieval, reranking, and synthesis across specific steps using LlamaIndex workflows. This comprehensive guide aims to showcase event-driven architectures for pipeline construction.
- You can implement this tutorial step-by-step, enabling better integration of various event handling methodologies.
- AI Voice Agent Developed for Indian Farmers: An AI Voice Agent has been developed to support Indian farmers, addressing their need for resources due to insufficient governmental aid, as highlighted in this tweet. The tool seeks to improve their productivity and navigate challenges.
- This initiative exemplifies technology's potential in addressing critical agricultural concerns, enhancing farmers' livelihoods.
- Strategies for ReAct Agents without Tools: Guidance was sought on configuring a ReAct agent to operate tool-free, with suggested methods like
llm.chat(chat_messages)andSimpleChatEnginefor smoother interactions. Members discussed the challenges of agent errors, particularly regarding missing tool requests.- Finding solutions to these issues remains a priority for improving usability and performance in agent implementation.
- Changes in LlamaIndex's Service Context: Members examined the upcoming removal of the service context in LlamaIndex, which impacts how parameters such as
max_input_sizeare set. This shift prompted concerns over the need for significant code adjustments.- One user voiced their frustration, affecting developer workflows particularly with the transition to more individualized components in the base API.
- DSPy's Latest Update Breaks LlamaIndex Integration: A member reported issues with DSPy's latest update, causing integration failures with LlamaIndex. They noted the previous version, v2.4.11, yielded no improvements in results from prompt finetuning when compared to standard LlamaIndex abstractions.
- The user continues to face hurdles in achieving operational success with DSPy, post-update.
Modular (Mojo 🔥) Discord
- Mojo's Error Handling Dilemma: Members discussed the dilemmas surrounding Mojo's error handling, comparing Python style exceptions and Go/Rust error values, with concerns that mixing both could lead to complexity.
- One exclaimed that this could blow up in the programmer's face*, highlighting the intricacies of managing errors effectively in Mojo.
- Installation Woes with Max: A member reported facing difficulties with the installation of Max, indicating that running the code has not been smooth.
- They are seeking assistance to troubleshoot the problematic installation process.
- Mojo Nightly Rocks!: Mojo nightly is operating smoothly for an active contributor, indicating stability despite issues with Max.
- This suggests that Mojo's nightly builds offer a reliable experience that could be leveraged while dealing with installation problems.
- Conda Installation Might Save the Day: A member recommended using conda as a possible solution to the installation issues, noting that the process has recently become simpler.
- This could significantly ease troubleshooting and resolution for those facing installation challenges with Max.
OpenInterpreter Discord
- Open Interpreter session confusion addressed: Members experienced confusion about joining an ongoing session, clarifying that the conversation happened in a specific voice channel.
- One member noted their struggle to find the channel until others confirmed its availability.
- Guidance on running local LLMs: A new member sought help on running a local LLM and shared their initial script which faced a model loading error.
- Community members directed them to documentation for setting up local models correctly.
- Starting LlamaFile server clarified: It was emphasized that the LlamaFile server must be started separately before utilizing it in Python mode.
- Participants confirmed the proper syntax for API settings, emphasizing the distinctions between different loading functions.
- Aider browser UI demo launches: The new Aider browser UI demo video showcases collaboration with LLMs for editing code in local git repositories.
- It supports GPT 3.5, GPT-4, and others, with features enabling automatic commits using sensible messages.
- Post-facto validation in LLM applications discussed: Research highlights that humans currently verify LLM-generated outputs post-creation, facing difficulties due to code comprehension challenges.
- The study suggests incorporating an undo feature and establishing damage confinement for easier post-facto validation more details here.
DSPy Discord
- LLMs Improve Their Judgment Skills: A recent paper on Meta-Rewarding in LLMs showcases enhanced self-judgment capabilities, boosting Llama-3-8B-Instruct's win rate from 22.9% to 39.4% on AlpacaEval 2.
- This meta-rewarding step tackles saturation in traditional methods, proposing a novel approach to model evaluation.
- MindSearch Mimics Human Cognition: MindSearch framework leverages LLMs and multi-agent systems to address information integration challenges, enhancing retrieval of complex requests.
- The paper discusses how this framework effectively mitigates challenges arising from context length limitations of LLMs.
- Building a DSPy Summarization Pipeline: Members are seeking a tutorial on using DSPy with open source models for summarization to iteratively boost prompt effectiveness.
- The initiative aims to optimize summarization outcomes that align with technical needs.
- Call for Discord Channel Exports: A request for volunteers to share Discord channel exports in JSON or HTML format surfaced, aimed at broader analysis.
- Contributors will be acknowledged upon release of findings and code, enhancing community collaboration.
- Integrating AI in Game Character Development: Discussion heats up around using code from GitHub for AI-enabled game characters, particularly for patrolling and dynamic player interactions.
- Members expressed interest in implementing the Oobabooga API to facilitate advanced dialogue features for game characters.
OpenAccess AI Collective (axolotl) Discord
- Fine-tuning Gemma2 2B grabs attention: Members explored fine-tuning the Gemma2 2B model and shared insights, with one suggesting utilizing a pretokenized dataset for better control over model output.
- The community’s feedback indicates varied experiences, and they are keen on further results from adjusted methodologies.
- Quest for Japan's top language model: In search of the most fluent Japanese model, a suggestion surfaced for lightblue's / suzume model based on the community's input.
- Users expressed interest in hearing more about real-world applications of this model.
- BitsAndBytes simplifies ROCm installation: A recent GitHub PR streamlined the installation of BitsAndBytes on ROCm, making it compatible with ROCm 6.1.
- Members noted the update allows for packaging wheels compatible with the latest Instinct and Radeon GPUs, marking a significant improvement.
- Training Gemma2 and Llama3.1 output issues: Users detailed their struggles with training Gemma2 and Llama3.1, noting the model's tendency to halt only after hitting max_new_tokens.
- There's a growing concern about the time invested in training without proportional improvements in output quality.
- Minimal impact wrestling with prompt engineering: Despite stringent prompt efforts meant to steer model output, users report a minimal impact on overall behavior.
- This raises questions about the effectiveness of prompt engineering strategies in current AI models.
LangChain AI Discord
- LangChain 0.2 Documentation Gap: Users reported a lack of documentation regarding agent functionalities in LangChain v0.2, leading to questions about its capabilities.
- Orlando.mbaa specifically noted they couldn't find any reference to agents, raising concerns about usability.
- Implementing Chat Sessions in RAG Apps: A discussion emerged on how to incorporate chat sessions in basic RAG applications, akin to ChatGPT's tracking of previous conversations.
- Participants evaluated the feasibility and usability of session tracking within the existing frameworks.
- Postgres Schema Issue in LangChain: A member referenced a GitHub issue regarding chat message history failures in Postgres, particularly with explicit schemas (#17306).
- Concerns were raised about the effectiveness of the proposed solutions and their implications on future implementations.
- Testing LLMs with Testcontainers: A blog post was shared detailing the process of testing LLMs using Testcontainers and Ollama in Python, leveraging the 4.7.0 release.
- Feedback was encouraged on the tutorial provided here, highlighting the necessity of robust testing.
- Exciting Updates from Community Research Call #2: The recent Community Research Call #2 highlighted thrilling advancements in Multimodality, Autonomous Agents, and Robotics projects.
- Participants actively discussed several collaboration opportunities, emphasizing potential partnerships in upcoming research directions.
Torchtune Discord
- QAT Quantizers Clarification: Members discussed that the QAT recipe supports the Int8DynActInt4WeightQATQuantizer, while the Int8DynActInt4WeightQuantizer serves post-training and is not currently supported.
- They noted only the Int8DynActInt4Weight strategy operates for QAT, leaving other quantizers slated for future implementation.
- Request for SimPO PR Review: A member highlighted the need for clarity on the SimPO (Simple Preference Optimisation) PR #1223 on GitHub, which aims to resolve issues #1037 and #1036.
- They emphasized that this PR addresses alignment concerns, prompting a call for more oversight and feedback.
- RFC for Documentation Overhaul: A proposal for revamping the torchtune documentation system surfaced, focusing on smoother recipe organization to improve onboarding.
- Members were encouraged to provide insights, especially regarding LoRA single device and QAT distributed recipes.
- Feedback on New Models Page: A participant shared a link to preview a potential new models page aimed at addressing current readability issues in the documentation.
- Details discussed included the need for clarity and thorough model architecture information to enhance user experience.
MLOps @Chipro Discord
- Computer Vision Enthusiasm: Members expressed a shared interest in computer vision, highlighting its importance in the current tech landscape.
- Many members seem eager to diverge from the NLP and genAI discussions that dominate conferences.
- Conferences Reflect Machine Learning Trends: A member shared experiences from attending two machine learning conferences where their work on Gaussian Processes and Isolation Forest models was presented.
- They noted that many attendees were unfamiliar with these topics, suggesting a strong bias towards NLP and genAI discussions.
- Skepticism on genAI ROI: Participants questioned if the return on investment (ROI) from genAI would meet expectations, indicating a possible disconnect.
- One member highlighted that a positive ROI requires initial investment, suggesting budgets are often allocated based on perceived value.
- Funding Focus Affects Discussions: A member pointed out that funding is typically directed toward where the budgets are allocated, influencing technology discussions.
- This underscores the importance of market segments and hype cycles in shaping the focus of industry events.
- Desire for Broader Conversations: In light of the discussions, a member expressed appreciation for having a platform to discuss topics outside of the hype surrounding genAI.
- This reflects a desire for diverse conversations that encompass various areas of machine learning beyond mainstream trends.
Alignment Lab AI Discord
- Image Generation Time Inquiry: Discussion focused on the time taken for generating a 1024px image on an A100 with FLUX Schnell, raising questions about performance expectations.
- However, no specific duration was mentioned regarding the image generation on this hardware.
- Batch Processing Capabilities Explored: Questions arose about whether batch processing is feasible for image generation and the maximum number of images that can be handled.
- Responses related to hardware capabilities and limitations were absent from the conversation.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (592 messages🔥🔥🔥):
Flux Model PerformanceGPU Utilization in AI ArtLicensing and Model RestrictionsPrompt Generation TechniquesOnline GPU Hosting Services
- Flux model generates images with varied quality: Users discussed the performance of the Flux model, noting it sometimes struggles with abstract styles, particularly when generating images of women lying on grass.
- While some find success with detailed prompts, others reported inconsistent results, indicating the model has core limitations similar to SD3.
- GPU hosting services gain popularity: Several users highlighted their experiences with online GPU hosting services like RunPod and Vast, noting that prices vary significantly based on hardware and performance needs.
- RunPod was favored by some for its polished experience, while others appreciated Vast for its lower costs, particularly for 3090s.
- Discussion on licensing and model ownership: The release of Flux sparked conversations about the potential implications of model ownership and the legal aspects surrounding the use of tech developed for SD3.
- Users speculated about the transition of intellectual property and the future of competitive models in the AI art space.
- Concerns over practical usage and tooling in AI art models: A discussion highlighted the need for fine-tuning and prompt generation improvements to enhance usability across different art styles.
- There were contrasting opinions on the importance of speed versus quality, with some users preferring models that allow for rapid iterations in concept development.
- User experiences with photo-realistic rendering: Users exchanged opinions about the current state of various models for achieving photorealism, assessing strengths and weaknesses among them.
- The conversation also touched on the performance of different GPUs in generating high-quality images efficiently.
- Flux Examples: Examples of ComfyUI workflows
- Chameleon: Mixed-Modal Early-Fusion Foundation Models: We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach f...
- Tweet from DataVoid (@DataPlusEngine): @ReyArtAge first epoch. seems like it helped a ton! still having trouble with hands it seems.
- Tweet from virushuo (@virushuo): no description found
- RunPod - The Cloud Built for AI: Develop, train, and scale AI models in one cloud. Spin up on-demand GPUs with GPU Cloud, scale ML inference with Serverless.
- Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #general (379 messages🔥🔥):
Training with LoRAUsing TPUs for model trainingEffect of padding tokensImplementing vLLM with LoRAPreparing datasets for fine-tuning
- Training with LoRA on 4-bit vs. 16-bit models: Users discussed saving and loading models trained with LoRA in either 4-bit or 16-bit formats, highlighting potential confusion over quantization and proper loading methods.
- It's recommended to merge the LoRA obtained from a 4-bit model with a 16-bit model to retain accuracy.
- Leveraging TPUs for faster training: Members noted the significant speed advantage of using TPUs for model training compared to T4 instances, emphasizing the importance of support for TPUs.
- However, adequate knowledge and examples for TPU utilization appear to be lacking in documentation.
- Impact of padding tokens on performance: There was a discussion regarding whether high numbers of padding tokens affect inference performance, with suggestions to preprocess datasets to minimize padding.
- Utilizing 'group by length' during training could enhance performance by reducing unnecessary padding.
- Fine-tuning datasets for chat AI: For specific chat AI training, users were advised to use tailored datasets, and there's confusion regarding the specific datasets recommended for fine-tuning LLAMA3.1.
- Messages need to be formatted appropriately, ideally incorporating the last few interactions as context for effective training.
- Model Loading Best Practices: Concerns were raised about memory errors when using different model versions, particularly when loading 16-bit models without proper quantization.
- Using load_in_4bit=True is recommended to ensure consistent VRAM usage with 4-bit model variants.
- johnpaulbin/qwen1.5b-e2-1-lora · Hugging Face: no description found
- LLAMA 2 13B on TPU (Training): Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
- fhai50032/RolePlayLake-7B · Hugging Face: no description found
- Finetune Llama 3 with Unsloth: Fine-tune Meta's new model Llama 3 easily with 6x longer context lengths via Unsloth!
- Tweet from nisten (@nisten): hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: https://huggi...
- Tweet from xjdr (@_xjdr): L3.1 scales to 1M tokens with nearly perfect recall by just increasing the scaled rope multipliers. Without additional training. lol
- Home: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- fhai50032/magicoder-oss-instruct-sharegpt-75k · Datasets at Hugging Face: no description found
- Tweet from Daniel Han (@danielhanchen): My Low Level Technicals of LLMs 3 hour workshop is out! I talk about: 1. Why training is O(N^2) not cubic 2. Triton vs CUDA 3. Why causal masks, layernorms, RoPE, SwiGLU 4. GPT2 vs Llama 5. Bug fixes...
- GitHub - Locutusque/TPU-Alignment: Fully fine-tune large models like Mistral, Llama-2-13B, or Qwen-14B completely for free: Fully fine-tune large models like Mistral, Llama-2-13B, or Qwen-14B completely for free - Locutusque/TPU-Alignment
- LDJnr/Capybara · Datasets at Hugging Face: no description found
- Tensor Processing Unit (TPU): Tensor Processing Unit (TPU) Google Cloud dibuat khusus untuk membantu mempercepat workload machine learning. Hubungi Google Cloud sekarang untuk mempelajari lebih lanjut.
Unsloth AI (Daniel Han) ▷ #off-topic (7 messages):
Google vs OpenAIChat Ratings
- Google reportedly surpasses OpenAI: A member shared a Reddit post claiming that Google has finally beaten OpenAI with a new model.
- I can't believe it... was expressed in response to the post, highlighting the surprise over this claim.
- Debate on the nature of 'real': Another member questioned the definition of what is 'real' in this context, stirring a discussion on perceptions.
- They suggested that the model's ratings could merely reflect conversational preferences rather than a definitive superiority.
- Skepticism about chat ratings: Concerns were raised that ratings are subjective and depend on personal experiences with the models involved.
- Comments suggested that the improvements might simply result from a more conversational interaction rather than a true advancement in capabilities.
Link mentioned: Reddit - Dive into anything: no description found
Unsloth AI (Daniel Han) ▷ #help (99 messages🔥🔥):
GGUF quantization issuesFine-tuning difficulties with Llama 3.1Training on small datasetsLoRA parameters and learning ratesIncompatibility of Unsloth models
- GGUF quantization causes gibberish output: Members have reported issues with models outputting gibberish after GGUF quantization, particularly on the Llamaedge platform, while they work fine on Colab.
- It was suggested that issues with the chat template might be causing this problem, which seems to affect many users recently.
- Challenges in fine-tuning Llama 3.1: Users have faced difficulties when trying to fine-tune Llama 3.1 models, experiencing erratic behaviour post-quantization, even after multiple attempts.
- It appears that the training duration and methods might not yield the expected results, leading to concerns about the model's learning capacity.
- Small datasets hinder model training: Discussion highlighted that using very small datasets severely restricts the model's ability to learn effectively without extensive fine-tuning.
- Experts suggest using larger, more diverse datasets or relying on alternative methods like RAG to improve model performance.
- LoRA parameters affect performance: The group discussed the impact of LoRA parameters, emphasizing that a lower rank (r) is advisable for small datasets to avoid overfitting.
- However, for larger datasets, a higher r value may be beneficial, alongside adjusting the learning rate appropriately.
- Incompatibility of models with AutoModelForCausalLM: There were questions regarding the compatibility of newer Unsloth models with
AutoModelForCausalLMand whether it supports recent model updates.- Some members noted that they had success with older models, but newer releases like Mistral and Llama 3.1 presented issues when trying to download.
- Reddit - Dive into anything: no description found
- Ak1104 (Akshat Shrivastava): no description found
- Unsloth Documentation: no description found
- Ak1104/QA_8k_withChapter_PT · Hugging Face: no description found
- Ak1104/3_70B · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
bellman model updatefinetuning Llama 3.1uploading model issuesQ8 version testing
- Bellman Finetuning Released with Llama 3.1: A new version of Bellman has been uploaded, finetuned from Llama-3.1-instruct-8b, specifically for prompt question answering based on a Swedish Wikipedia dataset. This update introduces questions from a translated code-feedback dataset alongside several story prompts.
- While the model has improved in question answering, it struggles with story generation, outperforming its predecessors.
- Testing the Q8 Version of Bellman: The Q8 version of Bellman can be tested here on CPU, offering users the chance to explore its capabilities directly. Users are encouraged to experiment with this version to assess the finetuning's effectiveness.
- The model card can be viewed here for detailed insights and specifications.
- Issues During Model Uploading Process: While attempting to upload the base model, several issues arose leading to a TypeError indicating that 'NoneType' is not iterable. This error occurred during model card creation, causing repeated failed attempts to push the new model to the hub.
- Clarification on whether this issue is a known concern or user error is requested, as the process has stalled multiple times.
Link mentioned: neph1/llama-3.1-instruct-bellman-8b-swedish · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
lithofyre: <@1179680593613684819> any timeline on when y'all will be able to take a look?
HuggingFace ▷ #announcements (1 messages):
Neural network simulationImage clustering techniquesNew synthetic datasetsKnowledge distillation trendsFinance and medical models
- Neural Network Simulation Takes the Stage: A member shared a simulation demonstrating a neural network that piqued interest across the community.
- This simulation showcases innovative techniques that could enhance understanding and engagement with neural networks.
- Achieving Accurate Image Clustering: A video on image clustering using Image Descriptors was presented, highlighting effective methods for organizing and analyzing visual data.
- The member's insights into this clustering technique are expected to aid in various AI applications.
- Exciting Release of Synthetic Datasets: A huge synthetic dataset was released by a member, available on this link, broadening accessibility for researchers.
- This dataset is a valuable resource that supports various machine-learning projects, particularly in tabular data analysis.
- Insightful Knowledge Distillation Trends: Trends in knowledge distillation were summarized in a post found here, providing an up-to-date overview of the field.
- This resource offers perspectives on how knowledge distillation is evolving, engaging the community in pertinent developments.
- Game-Changing Finance and Medical Models Released: Two new models, Palmyra-Med-70b and Palmyra-Fin-70b, have been unveiled, focusing on healthcare and financial sectors respectively, with impressive performance metrics.
- These models can significantly enhance diagnosing, investing, and research, with details accessible on Hugging Face.
Link mentioned: Tweet from Sam Julien (@samjulien): 🔥 @Get_Writer just dropped Palmyra-Med-70b and Palmyra-Fin-70b! Palmyra-Med-70b 🔢 Available in 8k and 32k versions 🚀 MMLU perf ~86%, outperforming top models 👨⚕️ For diagnosing, planning treatme...
HuggingFace ▷ #general (227 messages🔥🔥):
Learning Resources for Application DevelopmentModel Performance DiscussionsDrafting Project IdeasTraining AutoencodersDataset Licensing Inquiries
- Resources for Aspiring Developers: A high school student inquired about affordable resources to start building applications, particularly using Python and some Java/Swift knowledge.
- Suggestions included using Google Colab for cloud-based machine learning efforts.
- Model Performance Metrics and Issues: Discussions around performance issues in models highlighted concerns regarding loss values from trained LLMs, particularly mentioning a loss of 0.6 as problematic.
- Participants debated on various model training strategies and the significance of gradient flow in the context of Transformers.
- Project Ideas & Practical Applications: Members shared ideas for unique projects and discussed frameworks like Gradio and the use of LLMs for document interaction, emphasizing the need to provide good context.
- Contributors also explored the feasibility of using autoencoders in various applications, including image recognition.
- Challenges in Model Training and Deployment: Individuals faced issues with training autoencoders, seeking advice and optimizations for their performance, particularly in relation to pre-trained models.
- There were explorations on inference methods using ONNX and the importance of proper dataset management during model training.
- Dataset Licensing Discussions: A user sought clarity on the licensing of the IMDB dataset, engaging in discussions about reaching out to authors for confirmation.
- Participants agreed that reaching out to corresponding authors was a sensible approach to clarify licensing issues.
- Tweet from nisten (@nisten): hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: https://huggi...
- Luffy One Piece GIF - Luffy One Piece Luffy Smile - Discover & Share GIFs: Click to view the GIF
- Tweet from Noa Roggendorff (@noaroggendorff): nice
- Helicopter Baguette GIF - Helicopter Baguette - Discover & Share GIFs: Click to view the GIF
- stanfordnlp/imdb at main: no description found
- GitHub - huggingface/candle: Minimalist ML framework for Rust: Minimalist ML framework for Rust. Contribute to huggingface/candle development by creating an account on GitHub.
- Flux pipeline by sayakpaul · Pull Request #9043 · huggingface/diffusers: We are working on uploading the diffusers weights to the respective FLUX repositories. Will be done very soon.
HuggingFace ▷ #cool-finds (5 messages):
Knowledge DistillationLocal LLM ApplicationsBuilding NLP Applications with Hugging FaceEvolution of AI BotsRetrieval-Augmented Generation
- Exploring Knowledge Distillation: Knowledge distillation is a machine learning technique for transferring learnings from a large ‘teacher model’ to a smaller ‘student model,’ facilitating model compression.
- It's particularly valuable in deep learning, allowing compact models to mimic complex ones effectively.
- Emergence of Local LLM Applications: An article highlighted the significant role of large language models (LLMs) in transforming enterprises over the next decade, focusing on Generative AI.
- It discusses advancements in R&D leading to models like Gemini and Llama 2, with Retrieval Augmented Generation (RAG) for better data interaction.
- Building NLP Applications with Hugging Face: An article on building NLP applications emphasizes the collaborative aspects of the Hugging Face platform, highlighting its open-source libraries.
- The resource aims to equip both beginners and experienced developers with tools to enhance their NLP projects effectively.
- AI Bots and the New Tools: A piece examined the evolution of AI bots, focusing on LLMs and RAG as pivotal technologies in 2024.
- It serves as a comprehensive overview suitable for newcomers, offering insights into patterns and architectural designs in AI bot development.
- Overview of AI Bot Development: The article synthesizes knowledge on various tools for developing intelligent AI applications, focusing on patterns, pipelines, and architectures.
- It's tailored to provide a generalist technical level while also addressing deeper theoretical aspects, making it accessible for tech-savvy newcomers.
- Announcing Initial Availability of VMware Private AI Foundation with NVIDIA: Generative AI (Gen AI) is one of the top emerging trends that will transform enterprises in the next 5 to 10 years. At the heart of this wave in AI innovation are large language models (LLMs) that pro...
- What is Knowledge distillation? | IBM : Knowledge distillation is a machine learning technique used to transfer the learning of a large pre-trained “teacher model” to a smaller “student model.”
- Evolution of the AI Bots: Harnessing the Power of Agents, RAG, and LLM Models: Structuring knowledge about tools for AI bot development, also high-level overview of approaches, architectures and designs.
- How to Build NLP Applications with Hugging Face?: Explore how to build NLP applications with Hugging Face, using models, datasets, and open-source libraries to elevate your ML projects.
HuggingFace ▷ #i-made-this (8 messages🔥):
AI + i Podcast LaunchAI Journey UpdatesSimulations and Neural NetworksUber ETA Prediction Video
- AI + i Podcast Launch Announcement: A member announced the launch of the AI + i podcast, discussing leading foundation and open-source models, and is seeking topic suggestions.
- Another member humorously inquired if the podcast involves actual conversations with the models.
- AI Journey Update in July 2024: A member shared their excitement about their AI Journey updates for July 2024, expressing enthusiasm with celebratory emojis.
- This announcement indicates a personal milestone or project completion related to AI.
- Clarification on Simulation Mechanics: A discussion developed around a simulation's mechanics, particularly its 'Reward' and 'Punish' functions as components for learning.
- One member noted that 'Reward' is meant to release dopamine and 'Punish' serotonin, but expressed confusion regarding the simulation's effectiveness.
- Inquiry about Uber's ETA Prediction: A member inquired about Uber's method for predicting Expected Time of Arrival (ETA), referencing a fully animated video explaining the entire ML system.
- The video addresses various topics, including classical routing engines, the necessity of ML, and incremental model improvements.
Link mentioned: TikTok - Make Your Day: no description found
HuggingFace ▷ #reading-group (6 messages):
Organizing study sessionsFocus topics for learningHackathons and competitionsSkill gaps in projectsBalance between courses and projects
- Organizing Study Sessions on Server: Members discussed the excitement around organizing study and sharing sessions directly on the server, which would allow anyone to join.
- However, there were concerns over too many topics potentially leading to chaos and disengagement.
- Need for a Main Focus: A member emphasized the importance of selecting a main focus for the sessions, such as a specific course or book to avoid structure chaos.
- Flexibility is important, but a common goal could help retain participant engagement.
- Collaborative Projects for Learning: Another member suggested teaming up for hackathons or Kaggle competitions as a way to foster shared learning and engagement.
- This could create a common goal that motivates members to collaborate and learn from one another.
- Challenges with Skill Disparities: Concerns were raised that significant skill gaps among group members could lead to uneven work distribution and frustration.
- Competitions may exacerbate this issue due to their time limits, necessitating a more equitable learning approach for all levels.
- Starting with Courses or Books: It was recommended that beginners start by following a course or reading a book as a foundational step before taking on projects.
- This approach could help ensure all members have a baseline understanding before tackling more complex collaborative challenges.
HuggingFace ▷ #core-announcements (1 messages):
Running Flux pipelinesLimited resources for DiffusersPull request for Diffusers
- Tips for Running Flux on Limited VRAM: A member shared a resource guide on how to run Black Forest Lab's Flux with Diffusers on limited resources, even with a 24GB card.
- The guide specifically addresses issues encountered while utilizing Flux pipelines under constrained VRAM conditions.
- New Pull Request for Diffusers Improvements: A member announced a pull request that includes a fix to enable Flux pipelines to run effectively with 24GBs of VRAM.
- The PR focuses on changes in the
encode_promptfunction to enhance performance for users with limited hardware resources.
- The PR focuses on changes in the
- This document enlists resources that show how to run Black Forest Lab's Flux with Diffusers under limited resources. : This document enlists resources that show how to run Black Forest Lab's Flux with Diffusers under limited resources. - run_flux_with_limited_resources.md
- [Flux] fix: encode_prompt when called separately. by sayakpaul · Pull Request #9049 · huggingface/diffusers: What does this PR do? This PR allows the Flux pipeline to run under 24GBs of VRAM. Code: from diffusers import FluxPipeline, AutoencoderKL from diffusers.image_processor import VaeImageProcessor fr...
HuggingFace ▷ #computer-vision (1 messages):
LoRA FinetuningStable Diffusion modelsTraining techniques
- Fine-tuning with LoRA on Stable Diffusion: A member shared a guideline for fine-tuning a model using LoRA on runwayml/stable-diffusion-v1-5, highlighting its speed and memory efficiency.
- LoRA reduces trainable parameters by inserting fewer new weights, making the model easier to store and share.
- Training script for LoRA: The discussion mentioned the train_text_to_image_lora.py script as a resource to get familiar with LoRA for personal use-cases.
- Members were advised to first install the diffusers library from source to ensure the script runs smoothly.
- Question on SDXL-base-1.0 and LoRA: A member inquired whether SDXL-base-1.0 supports LoRA finetuning similarly to runwayv1.5.
- This highlights a curiosity about compatibility with new techniques in training methods.
Link mentioned: LoRA: no description found
HuggingFace ▷ #NLP (1 messages):
Error ResolutionTroubleshooting Solutions
- Seeking Help for Persistent Error: A member expressed frustration with an ongoing error while seeking assistance from others, stating, 'nothing seemed to work out.'
- The request for help reflects a broader concern within the community about effective solutions for common issues.
- Exploring Solutions to Common Errors: Members discussed various troubleshooting methods but noted that many of them did not yield successful results for common errors faced during programming.
- There was a consensus that sharing effective solutions could help streamline error resolution in future discussions.
HuggingFace ▷ #diffusion-discussions (7 messages):
Flux ArchitectureFine-Tuning FluxDreamBoothGB200 Accelerator
- Exploring Flux Architecture: A member inquired about the architecture of Flux and directed others to this GitHub link for more details.
- The GitHub repository describes Diffusers as state-of-the-art diffusion models for image and audio generation in PyTorch and FLAX.
- Fine-Tuning Flux Discussion: Another member asked if anyone was currently fine-tuning Flux, and shared a link to this pull request related to the Diffusers repository.
- They encouraged others to try out DreamBooth, which seems to be a feature associated with the update.
- Need for GB200 Accelerator: A member highlighted that fine-tuning Flux requires a GB200 accelerator, indicating some technical requirements.
- Another member humorously remarked they could use it but don’t necessarily need it for this process.
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- diffusers/src/diffusers/pipelines/flux/pipeline_flux.py at main · huggingface/diffusers: 🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX. - huggingface/diffusers
Perplexity AI ▷ #announcements (1 messages):
Perplexity Pro for Uber One membersBenefits of Uber One membership
- Uber One members get 1 year of Perplexity Pro: Eligible Uber One members across the US and Canada can now redeem a complimentary year of Perplexity Pro, valued at $200.
- This offer aims to enhance information gathering while commuting or at home, providing users with unlimited access to Perplexity’s ‘answer engine’.
- Uber One enhances efficiency with new perks: Starting today, Uber One members can unlock benefits that boost efficiency when gathering information and conducting research.
- Perplexity Pro allows members to ask questions like “Who invented the hamburger?” and get engaging conversational responses.
Link mentioned: Eligible Uber One members can now unlock a complimentary full year of Perplexity Pro : Uber One members can now save even more time with perks like Pro Search
Perplexity AI ▷ #general (237 messages🔥🔥):
Uber One promotionPerplexity user experiencesML model comparisonsPerplexity Pro subscriptions
- Confusion Over Uber One Promotion: Users are uncertain if the Uber One promotion allowing a year of Perplexity Pro is applicable to both new and existing subscribers, with some reporting issues redeeming codes.
- Concerns around eligibility and errors in receiving promotional emails were prevalent among users after signing up for Uber One.
- User Rankings and Preferences for Perplexity: Several users shared their preferred models for research, comparing Sonnet 3.5 and ChatGPT 4.0, with varying opinions on their performance and usability.
- Discussions included how to obtain focused results using specific site operators for better accuracy in technical documentation searches.
- Experiences with Perplexity Usage: Users have shared diverse use cases for Perplexity, from casual chatting and story writing to creating credible blog posts backed by sources.
- The perception of Perplexity as a reliable tool for generating accurate information was highlighted by multiple community members.
- Technical Issues Regarding App Functionality: There were numerous complaints about the subpar mobile experience and various bugs affecting usability, especially on Android devices.
- Members emphasized issues like losing typed text upon navigating away from input fields and difficulties in sending messages using tablet keyboards.
- Perplexity's Growing User Base: Questions were raised regarding the reported growth of Perplexity's Pro user base, with speculation about nearly 100,000 users.
- Users expressed curiosity over the reasons for choosing Perplexity and whether it truly met their needs compared to other AI tools.
- character.ai | Personalized AI for every moment of your day: Meet AIs that feel alive. Chat with anyone, anywhere, anytime. Experience the power of super-intelligent chat bots that hear you, understand you, and remember you.
- Eligible Uber One members can now unlock a complimentary full year of Perplexity Pro : Uber One members can now save even more time with perks like Pro Search
- 的9 GIF - 的9 - Discover & Share GIFs: Click to view the GIF
- Generative AI: Generative AI
Perplexity AI ▷ #sharing (6 messages):
Massive Mathematical BreakthroughDigital Organization for ProductivityMedallion FundHybrid Human-Llama AntibodyDucks Classification and Habitat
- Massive Mathematical Breakthrough Unveiled: A recent discovery highlighted a Massive Mathematical Breakthrough, potentially reshaping our understanding of complex equations as shared in a YouTube video.
- Details surrounding this discovery remain closely guarded, prompting extensive discussions about its implications across various fields.
- Digital Organization Impacts Workplace Efficiency: A survey by Adobe Acrobat revealed that nearly 3 in 4 employees feel poor digital organization negatively affects their efficiency, with 30% of Gen Z considering leaving their jobs over it, as noted in an article on Digital Organization for Productivity.
- This highlights the critical link between digital organization and employee satisfaction in the modern business landscape.
- Medallion Fund's Extraordinary Performance: The Medallion Fund, managed by Renaissance Technologies under Jim Simons, has impressively achieved an average annual return of 66% before fees and 39% after fees since its inception in 1988, as detailed in The Enigmatic Medallion Fund.
- Its secretive strategies reportedly surpass those of notable investors like Warren Buffett and George Soros.
- Hybrid Antibodies Show Promise Against HIV: Researchers have developed a hybrid antibody that can neutralize over 95% of HIV-1 strains by fusing llama nanobodies with human antibodies, as reported by Georgia State University.
- These nanobodies, due to their small size, can penetrate the virus's defenses more effectively than traditional human antibodies.
- Understanding Ducks and Their Habitats: Ducks, classified under the family Anatidae, are characterized by their small size and flat bills, with distinct groups based on their feeding habits: dabbling, diving, and perching ducks, as outlined in the article on Ducks.
- These unique classifications help in studying their behaviors and habitats across diverse environments.
- what is a duck: Ducks are waterfowl belonging to the family Anatidae, which also includes swans and geese. They are characterized by their relatively small size, short necks,...
- Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
- Hybrid Human-Llama Antibody Fights HIV: Researchers have engineered a powerful new weapon against HIV by combining llama-derived nanobodies with human antibodies, creating a hybrid that can...
- The Enigmatic Medallion Fund: The Medallion Fund, managed by Renaissance Technologies, stands as one of the most successful and mysterious hedge funds in financial history. Founded by...
- Digital Organization for Productivity: According to a survey by Adobe Acrobat, nearly 3 in 4 employees report that poor digital organization interferes with their ability to work effectively,...
LM Studio ▷ #announcements (1 messages):
Vulkan llama.cpp engineGemma 2 2B modelFlash Attention KV Cache configuration
- 🌋🔥 Vulkan llama.cpp engine launched!: The new Vulkan llama.cpp engine replaces the former OpenCL engine, enabling GPU acceleration for AMD, Intel, and NVIDIA discrete GPUs.
- This update is part of the new version 0.2.31 available as an in-app update and on the website.
- 🤖 New support for Gemma 2 2B model: Version 0.2.31 introduces support for Google's new Gemma 2 2B model, available for download here.
- Users are encouraged to download this model from the lmstudio-community page for enhanced functionality.
- 🛠️ Advanced KV Cache data quantization feature: The update allows users to configure KV Cache data quantization when Flash Attention is enabled, which may help reduce memory requirements for large models.
- However, it's noted that many models do NOT support Flash Attention, making this an experimental feature.
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Download and run lmstudio-community/gemma-2-2b-it-GGUF) in LM Studio: Use lmstudio-community/gemma-2-2b-it-GGUF) locally in your LM Studio
LM Studio ▷ #general (163 messages🔥🔥):
GPU Performance and CompatibilityModel Training and InferenceLM Studio Features and UpdatesVulkan vs ROCm on AMD GPUsUser Experiences with LLMs
- GPU performance insights: Users reported successful performance on the RX6700XT running models at around 30 tokens/second with Vulkan support, highlighting the effectiveness of the setup.
- One user noted they achieved 40 tokens/second using the Llama 3-8B-16K-Q6_K-GGUF model, showcasing impressive capabilities.
- Challenges in model training and inference: Several users discussed issues with training LSTM models, expressing difficulties in achieving proper inference results despite successful training outputs.
- One user using a 32M parameter LSTM model noted challenges in feeding input correctly, leading to incoherent output.
- Feature requests for LM Studio: Users expressed a desire for the ability to drag and drop documents into LM Studio, with hopes for this feature to be implemented soon.
- The community discussed the addition of features like RAG and improved support for various document formats to enhance usability.
- Performance of quantized models: Discussions around different quantization methods revealed that flash attention works inconsistently, functioning well on qx_0 settings but not on qx_1.
- Users identified specific quantization settings such as q4_1, q5_0, and q5_1 affecting performance, prompting further exploration.
- Debate on Vulkan vs ROCm: Participants engaged in discussions about the performance of Vulkan and ROCm on AMD GPUs, with Vulkan being viewed as a fallback option.
- Users shared experiences related to the setup of their environments, weighing the benefits of CUDA versus Vulkan.
LM Studio ▷ #hardware-discussion (76 messages🔥🔥):
Learning ProxmoxDrivers for GPUs in ProxmoxCompatibility issues with LM StudioSettings for ML Studio on MacBook ProChoosing GPUs for Local LLM
- Learning Proxmox Efficiently: A user suggested learning Proxmox inside VirtualBox before moving to bare-metal Proxmox to utilize LLM knowledge concurrently.
- Another member shared their ongoing strategy of using RAG documentation while learning Proxmox.
- Troubleshooting GPU Driver Issues: A user faced difficulties with NVIDIA drivers in their Proxmox VM, specifically errors with the nvidia-persistenced service after installation.
- Members advised checking device detection with
lspciand suggested ensuring that the necessary driver packages are installed.
- Members advised checking device detection with
- Compatibility Issues with LM Studio: A user encountered compatibility issues with LM Studio on their Intel Xeon E5-1650, attributed to the lack of AVX2 instruction support.
- The community suggested using an AVX-only extension and recommended considering an upgrade of the CPU if possible.
- Optimizing ML Studio Settings on MacBook Pro: A MacBook Pro user with M2 Max and 96GB RAM sought advice on server model settings to optimize LM Studio's performance.
- The community pointed out that adjustments in VRAM allocation could enhance performance, although caution with stability was advised.
- Choosing the Right GPU for Local LLM: A user inquired about purchasing NVIDIA Quadro GPUs for a dual Xeon server build, weighing options from A2000 to A6000.
- Another member recommended considering a single RTX 3090 for initial setup, citing better performance for local LLM workloads.
- lmstudio-community/Meta-Llama-3.1-70B-Instruct-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Spongebob Patrick Star GIF - Spongebob Patrick Star Shocked - Discover & Share GIFs: Click to view the GIF
- All Large Language Models: A Curated List of the Large and Small Language Models (Open-Source LLMs and SLMs). All Large Language Models with Dynamic Sorting and Filtering.
- configs/Extension-Pack-Instructions.md at main · lmstudio-ai/configs: LM Studio JSON configuration file format and a collection of example config files. - lmstudio-ai/configs
- Reddit - Dive into anything: no description found
CUDA MODE ▷ #general (10 messages🔥):
Nvidia GPU instruction cycleAccuracy score fluctuations
- Gathering resources on Nvidia GPU instruction cycles: A member requested favorite resources regarding the instruction cycle of Nvidia GPUs, exploring both disclosure and experimental findings.
- They shared a research paper and another study on microarchitecture that focuses on clock cycles per instruction.
- Dramatic spike in accuracy scores: A member observed that at epoch 8, the accuracy scores significantly spiked, leading to confusion about the run's status.
- They questioned whether such fluctuations in accuracy scores were typical, indicating a sense of surprise and concern over performance stability.
Link mentioned: Demystifying the Nvidia Ampere Architecture through Microbenchmarking and Instruction-level Analysis: Graphics processing units (GPUs) are now considered the leading hardware to accelerate general-purpose workloads such as AI, data analytics, and HPC. Over the last decade, researchers have focused on ...
CUDA MODE ▷ #triton (19 messages🔥):
GROUP_SIZE_M in TritonTriton matrix multiplication tutorialUnderstanding Triton internalsFeedback on Triton blog post
- Understanding the role of GROUP_SIZE_M: In a discussion on the triton tiled matmul tutorial,
GROUP_SIZE_Mwas clarified as controlling the processing order for blocks, which can enhance L2 cache hit rates.- Members emphasized the conceptual difference between
GROUP_SIZE_MandBLOCK_SIZE_{M,N}with illustrations from the tutorial aiding their understanding.
- Members emphasized the conceptual difference between
- Triton matrix multiplication tutorial highlights: The Triton tutorial covers high-performance FP16 matrix multiplication, emphasizing block-level operations, multi-dimensional pointer arithmetic, and L2 cache optimizations.
- Participants noted the effectiveness of re-ordering computations to improve performance in practical applications.
- Resources on Triton internals: A member expressed difficulty in finding comprehensive documentation on Triton compilation processes and internals, citing that much has changed since the original 2019 paper.
- They shared a blog post they created to compile resources and seek feedback from others in the community.
- Request for Triton lecture on ML Compilers: A request was made for a potential lecture focused on Triton Internals or ML Compilers to enhance community understanding on the topic.
- The inquiry aimed at gathering interest from experts who could provide valuable insights into Triton functionalities.
Link mentioned: Matrix Multiplication — Triton documentation: no description found
CUDA MODE ▷ #torchao (23 messages🔥):
Overfitting in ModelsCUDA Extensions and BitBLASBitnet InterestPR ReviewsTopic Model Analysis
- Members discuss overfitting metrics: A member asked if others checked for overfitting issues, suggesting that MMLU is a good metric to verify this.
- This sparked discussions about model evaluation practices among the group.
- Excitement for C++ Extensions Development: One member humorously celebrated acquiring a 3090 GPU, expressing eagerness to build with C++ extensions.
- Others chimed in, discussing the usefulness of more CUDA extensions, with one member highlighting BitBLAS as a potential addition.
- Revisiting Bitnet for New Developments: Members expressed interest in revisiting Bitnet, referring to new findings and progress shared by community members.
- One highlighted that Bitnet had been hacked for finetuning, producing a 74MB model that functions efficiently on a single CPU core.
- Development Progress and PR Reviews: Discussion ensued about getting PR #468 merged, with one member mentioning they faced issues related to tensor subclasses.
- Once these were resolved, they expected a re-review to happen soon, aiming for efficient collaboration.
- Analysis of Repository Growth Over Time: A member is exploring the tree representations of modules within a library to better understand its structure.
- They plan to generate a timeseries of topic models from the commit history to visualize repository growth.
- Tweet from nisten (@nisten): hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: https://huggi...
- GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
- add bitblas backend for 4-bit/2-bit · mobiusml/hqq@6249449: no description found
- Intx Quantization Tensor Class by vayuda · Pull Request #468 · pytorch/ao: PR fulfilling #439 benchmark results: Performance with dtypes that aren't multiples of 2 is significantly worse, but that was to be expected without custom kernels.
CUDA MODE ▷ #off-topic (1 messages):
marksaroufim: https://techcrunch.com/2024/08/02/character-ai-ceo-noam-shazeer-returns-to-google/
CUDA MODE ▷ #llmdotc (178 messages🔥🔥):
Llama 3 ImplementationKV Cache IssuesAcquihires in AIRandomness in Tensor OperationsComparative Performance of RDNA vs CDNA
- Llama 3 Implementation Progress: A user modified the
llm.cPython script to support Llama 3, noticing that the first sample generation matched but became divergent during the second pass due to differing kernels used as they didn't implement KV cache yet.- They are planning to refactor the code to minimize branching and consolidate the forward pass of attention for a cleaner implementation.
- KV Cache Issues Identified: The implementer highlighted that discrepancies in output were due to the KV cache state logic being inactive, leading to numerical deviations in logits during the second pass.
- The user confirmed that all initial tensors and logits were equivalent in earlier stages, suggesting that implementing KV cache could ensure identical sample generation.
- Acquihires in AI Industry: Discussion emerged around multiple companies such as Character AI and Inflection AI undergoing acquihires, signaling a trend in the industry where promising companies are being absorbed.
- Concerns were raised regarding the potential impact on the ecosystem, suggesting that while more players may enhance competition, it also raises questions about the value of coding versus conceptual thinking in AI development.
- Randomness in Tensor Operations: It was noted that different tensor shapes in operations could lead to different kernels being invoked, resulting in varying numerical outputs.
- This led to suggestions of passing in custom random number generators to ensure consistent behavior across tensor operations.
- Comparative Performance of RDNA vs CDNA: Performance discrepancies were observed between RDNA and CDNA setups, with the latter showing improved validation loss in a specific AI model despite different hardware architectures.
- Users discussed that RDNA uses microcoded matrix operations through vector units, while CDNA features dedicated matrix hardware, potentially influencing performance results.
- Issues · karpathy/llm.c: LLM training in simple, raw C/CUDA. Contribute to karpathy/llm.c development by creating an account on GitHub.
- Llama tmp by gordicaleksa · Pull Request #726 · karpathy/llm.c: tmp, internal use
- Add LLaMA 3 Python support by gordicaleksa · Pull Request #725 · karpathy/llm.c: WIP.
- Do not modify global random state · Issue #39716 · pytorch/pytorch: 🚀 Feature Currently, the recommended approach to achieve reproducibility is setting global random seeds. I would like to propose that instead all functions which need a random source accept a local.....
- unsloth/unsloth/chat_templates.py at main · unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- HydraHarp 400 - Multichannel Picosecond Event Timer & TCSPC Module | PicoQuant: no description found
CUDA MODE ▷ #cudamode-irl (7 messages):
GPU Compute LearningPyTorch Conference DetailsEvent Invites Expectation
- GPU Compute Learning Enthusiasm: A member expressed their passion for GPU compute, highlighting their extensive weekend learning efforts and interest in connecting with like-minded individuals at the upcoming event.
- I find this space close to my heart emphasizes the personal connection and dedication to the topic.
- Travel Plans and Event Links: Another member confirmed travel plans from Boston using Jetson and AWS, inquiring about a link to the PyTorch conference.
- The shared link provides insights into featured speakers and event details, encouraging more participation.
- Invites Will Be Sent Out Soon: A member noted that invites for the event are expected to be sent out by the end of this month due to the overwhelming response.
- They mentioned that responses have been overwhelming, indicating that not everyone can be accommodated, creating anticipation among participants.
Link mentioned: PyTorch Conference | LF Events: Join top-tier researchers, developers, and academics for a deep dive into PyTorch, the cutting-edge open-source machine learning framework.
Latent Space ▷ #ai-general-chat (145 messages🔥🔥):
MoMa architectureBitNet fine-tuningCharacter.ai acquisitionDeepSeek API improvementsLlamaCoder app
- MoMa architecture enhances mixed-modal language modeling: Meta introduced MoMa, a sparse early-fusion architecture that boosts pre-training efficiency by using a mixture-of-expert framework.
- This architecture improves the processing of interleaved mixed-modal token sequences, making it a significant advancement in multimodal AI.
- BitNet fine-tuning achieves rapid results: A user reported fine-tuning BitNet resulting in a 74MB file that processes 198 tokens per second on a single CPU core, showcasing impressive efficiency.
- This technique is being opensourced by the user under the name Biggie-SmoLlm.
- Character.ai's strategy shift following acquisition: Character.ai's co-founders have joined Google, leading to a shift to open-source models like Llama 3.1 for their products, prompting discussions on industry talent transfer.
- The move has sparked conversations about the viability of startups in face of large tech acquisitions, with mixed sentiments on whether this benefits or harms innovation.
- DeepSeek API introduces disk context caching: DeepSeek API has launched a new context caching feature that reduces API costs by up to 90% and significantly lowers first token latency.
- This improvement supports multi-turn conversations, data, and code analysis by caching frequently referenced contexts, enhancing overall performance.
- LlamaCoder enables efficient React app generation: LlamaCoder is an open source application that uses Llama 3.1 to generate full React applications and components quickly.
- This tool provides users with a free way to transform ideas into working applications, promoting rapid development in web programming.
- Tweet from nisten (@nisten): hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: https://huggi...
- Tweet from Victoria X Lin (@VictoriaLinML): 1/n Introducing MoMa 🖼, our new sparse early-fusion architecture for mixed-modal language modeling that significantly boosts pre-training efficiency 🚀 (https://arxiv.org/pdf/2407.21770). MoMa employ...
- Tweet from anton (𝔴𝔞𝔯𝔱𝔦𝔪𝔢) (@atroyn): 1. buzzwords are mind killers. you must empty your head of all buzzwords. the temptation with any new technology is to use existing concepts as crutches as much as possible, but this kills the creativ...
- Tweet from xjdr (@_xjdr): Google has: - AlphaZero - pretty good at search and indexing - Gemini goodharting lmsys with 1M ctx len - some of the best researchers and engineers in the world (now once again including Noam and...
- Tweet from xjdr (@_xjdr): - GDM is now leading the AGI race - Llama3.1 changed everything and Llama4 is the most important model in the world right now in terms of potential impact (short of AGI has been achieved internally an...
- Introducing GitHub Models: A new generation of AI engineers building on GitHub: We are enabling the rise of the AI engineer with GitHub Models – bringing the power of industry leading large and small language models to our more than 100 million users directly on GitHub.
- Tweet from Sheel Mohnot (@pitdesi): Character is doing an acquihire licensing deal with Google, similar to Inflection>Microsoft & Adept>Amazon... cofounders join bigco, co survives under new leaders Character investors get 2.5x, ...
- no title found: no description found
- Tweet from Teortaxes▶️ (@teortaxesTex): $0.014 per million tokens of reused context. Consider what we've just read about using Deepseek API for zerg-rushing SWEBench. I've been tweeting about cache reuse since 2023. It's only f...
- Perplexity: Llama 3.1 Sonar 70B Online by perplexity: Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. This is the online version of the [offline chat model](/m...
- Tweet from Gabriel Martín Blázquez (@gabrielmbmb_): Dropping magpie-ultra-v0.1, the first open synthetic dataset built with Llama 3.1 405B. Created with distilabel, it's our most advanced and compute-intensive pipeline to date. https://huggingfac...
- Argilla: no description found
- Tweet from Baseten (@basetenco): We're excited to introduce our new Engine Builder for TensorRT-LLM! 🎉 Same great @nvidia TensorRT-LLM performance—90% less effort. Check out our launch post to learn more: https://www.baseten.c...
- Tweet from Nikunj Kothari (@nikunj): Getting a bunch of DMs, apparently people don't seem to fully grok what's happening. Here's the gist: - Current FTC team has made acquisitions basically impossible - Large incumbents want...
- Tweet from DeepSeek (@deepseek_ai): 🎉Exciting news! DeepSeek API now launches context caching on disk, with no code changes required! This new feature automatically caches frequently referenced contexts on distributed storage, slashing...
- Tweet from Character.AI (@character_ai): Thrilled to share that we're open sourcing our innovative approach to prompt design! Discover how Prompt Poet is revolutionizing the way we build AI interactions in our latest blog post: https://r...
- Tweet from Hassan (@nutlope): Introducing LlamaCoder! An open source Claude Artifacts app that can generate full React apps and components with Llama 3.1 405B. 100% free and open source. http://llamacoder.io
- Tweet from Theodor Marcu (@theomarcu): I spent time building a competitor to Character AI. Some thoughts on the news: Quoting TechCrunch (@TechCrunch) http://Character.AI CEO Noam Shazeer returns to Google https://tcrn.ch/3WQCl7R
- Tweet from Nikunj Kothari (@nikunj): Inflection (Microsoft), Adept (Amazon) and now Character (Google). These examples _will_ make early employees question why they should join high growth startups in the first place since they are the...
- Tweet from xjdr (@_xjdr): Google has: - AlphaZero - pretty good at search and indexing - Gemini goodharting lmsys with 1M ctx len - some of the best researchers and engineers in the world (now once again including Noam and...
- Tweet from Tim Dettmers (@Tim_Dettmers): After 7 months on the job market, I am happy to announce: - I joined @allen_ai - Professor at @CarnegieMellon from Fall 2025 - New bitsandbytes maintainer @Titus_vK My main focus will be to strengthe...
- Tweet from Nick Dobos (@NickADobos): The State of Coding with Ai Tier Lists for Best Base Model & App (August 2024)
- Tweet from Romain Huet (@romainhuet): @triviatroy @OpenAI The dollar price per image is the same for GPT-4o and GPT-4o mini. To maintain this, GPT-4o mini uses more tokens per image. Thank you for your observation!
- Tweet from Stability AI (@StabilityAI): We are excited to introduce Stable Fast 3D, Stability AI’s latest breakthrough in 3D asset generation technology. This innovative model transforms a single input image into a detailed 3D asset in just...
- Adaptive Computer: What will you build?
- Tweet from Ai2 (@allen_ai): After months of behind-the-scenes research, interviews, and labors of love, we’re delighted to debut Ai2’s new brand and website today. Explore the evolution 🧵
- Reddit - Dive into anything: no description found
- Tweet from undefined: no description found
- Tweet from Steve (Builder.io) (@Steve8708): LLMs are literally the most unreliable technology of all time (followed by **ing bluetooth) After an absurd amount of trial and error, we've internally created a set of rules for make LLMs consid...
- Tweet from anton (𝔴𝔞𝔯𝔱𝔦𝔪𝔢) (@atroyn): character ai's users really want the models to be horny. noam really really doesn't want the models to be horny. google have never made a single horny product in the entire history of the comp...
- Tweet from Contextual AI (@ContextualAI): We’re excited to share today that we’ve raised $80M in Series A funding to accelerate our mission to change the way the world works through AI. Read more at our blogpost: https://contextual.ai/news/an...
- GitHub - Nutlope/turboseek: An AI search engine inspired by Perplexity: An AI search engine inspired by Perplexity. Contribute to Nutlope/turboseek development by creating an account on GitHub.
Latent Space ▷ #ai-announcements (17 messages🔥):
Winds of AI Winter PodcastChatGPT Voice Mode DemoFeature Clamping in ModelsPodcast Recap & Vibe ShiftBenchmarking with Singapore Accent
- Winds of AI Winter Podcast Released: The latest episode titled Winds of AI Winter has dropped, featuring a recap of the past few months in the AI space and celebrating 1 million downloads.
- Listeners can catch the full discussion and recap on the podcast link.
- Impressive ChatGPT Voice Mode Demo: The podcast features a voice demo at the end, showcasing how the Singapore accent enhances user experience and opens up new benchmarking possibilities.
- Listeners expressed excitement over potential applications in role-playing games, sparking interest in innovative use cases.
- Discussion on Feature Clamping: A listener raised questions about whether feature clamping can improve model performance in coding, as it was mentioned in the podcast.
- The conversation highlighted the need for deeper exploration into how adjusting activations, like increasing the 'python' feature, impacts performance in practical tasks.
- Recap of Vibe Shift in AI Space: The podcast dives into the shifts in the AI landscape focusing on changes from models like Claude 3.5 to Llama 3.1 and more.
- The discussion also covers the expansion of RAG/Ops amidst emerging competition in the LLM OS space.
- Podcast Version Confusion Resolved: Confusion arose regarding a potential error in the podcast's title, but it was later confirmed that the correct version was utilized.
- Listeners and hosts discussed logistics regarding minor editing discrepancies, ensuring the content remains engaging.
- Tweet from Latent.Space (@latentspacepod): 🆕 pod: The Winds of AI Winter! https://latent.space/p/q2-2024-recap The vibes have shifted... @fanahova and @swyx celebrate 1m downloads and recap the last 3 months in AI! Discussing the Frontier...
- Tweet from FxTwitter / FixupX: Sorry, that user doesn't exist :(
- Im Doing My Part Soldier GIF - Im Doing My Part Soldier Smile - Discover & Share GIFs: Click to view the GIF
Latent Space ▷ #ai-in-action-club (72 messages🔥🔥):
Cursor vs. CodyContext Management in AI ToolsUsage of Aider.nvimClaude's Local Sync FeatureComposer's Predictive Editing
- Debate on Cursor and Cody's Effectiveness: Users discussed how Cody from Sourcegraph allows context-aware indexing while Cursor has hindered some due to complex context management.
- yikesawjeez expressed that managing context is difficult with Cursor, leading them to prefer Aider.nvim for manual control.
- Aider.nvim's Unique Functions: Aider.nvim boasts a feature that scrapes URLs for automatic documentation retrieval, a functionality users found beneficial.
- yikesawjeez noted that their personal version with manual scraping was redundant compared to Aider.nvim's capabilities.
- Claude's Upcoming Sync Feature: Users reported that Claude is developing a local Sync Folder feature, allowing users to upload files in batches.
- This feature was highlighted as a step forward for more efficient project management in workflows.
- Interesting Features of Composer: Discussion around Composer revealed its predictive editing capabilities, enhancing inline editing with commands like ctrl+k.
- disco885 praised its frequent usability questions as a motivating factor in development, noting its potential power.
- AI Tools as Digital Toolboxes: Participants appreciated the collective usefulness of the discussed tools, dubbing them a digital toolbox for developers.
- disco885 emphasized the impressive workflow examples shared by Slono, highlighting their effectiveness.
- How Cody understands your codebase: Context is key for AI coding assistants. Cody uses several methods of context fetching to provide answers and code relevant to enterprise-scale codebases.
- How Cody provides remote repository awareness for codebases of every size: Cody’s context awareness scales to every size codebase, from the smallest startups to the biggest enterprises, using the Sourcegraph platform.
- Tweet from TestingCatalog News 🗞 (@testingcatalog): Anthropic is working on a Sync Folder feature for Claude Projects 👀 There you can select a local folder to get your files uploaded in a batch.
Cohere ▷ #discussions (165 messages🔥🔥):
AI Hackathon Series TourGraphRAG SystemNeurosity Crown for FocusDwarf Fortress GameplaySilent Gaming Equipment
- AI Hackathon Series Tour Announced: An exciting AI Hackathon Series Tour is set to take place across the United States, culminating in the PAI Palooza showcasing local AI startups and innovations.
- Participants are encouraged to register today to secure their spot for an event focused on collaboration and technological advancement in AI.
- GraphRAG System for Investors: A member introduced their GraphRAG system aimed at assisting investors in identifying promising companies, built from 2 million scraped company websites.
- The system is currently under development alongside a Multi-Agent framework and the member is looking for collaboration opportunities.
- Neurosity Crown Increases Productivity: The Neurosity Crown is highlighted as a productivity tool that improves focus by providing audio cues when attention wanes, such as bird chirps.
- While some users question its efficacy, one member reports significant improvements in their focus during work sessions.
- Dwarf Fortress Gameplay Experience: A humorous discussion unfolds about Dwarf Fortress, noting how unexpected game mechanics, like a dwarf slipping on spilled booze, can lead to chaotic in-game events.
- Members shared their varied experiences with the game, expressing both nostalgia and the challenges of its unique simulation style.
- Gaming Equipment Discussions: Members discuss their gaming setups, including the advantages of silent mice and ergonomic keyboards like Kinesis for better typing and gaming experiences.
- The conversation emphasizes the importance of comfort and ergonomics for long hours of use, with suggestions for quality equipment.
- API Keys and Rate Limits: Cohere offers two kinds of API keys: trial keys (with a variety of attendant limitations), and production keys (which have no such limitations). You can get a trial key by registering through the Cohe...
- Kinesis Keyboards: Ergonomics keyboards, mice, and foot pedals.
- Kinesis Advantage2 Ergonomic Keyboard: Split, contoured design that maximizes comfort and boosts productivity. Mechanical switches, onboard programmability and more.
- Techstars StartUp Weekend - PAI Palooza & GDG Build with AI—Mountain View · Luma: This AI Hackathon Series Tour is a groundbreaking, multi-city event that spans the United States, bringing together the brightest minds in artificial…
- no title found: no description found
Cohere ▷ #questions (22 messages🔥):
Aspect Based Sentiment AnalysisAI Project SuggestionsCohere API for ClassificationRAG with Chat Embed and Rerank Notebook Errors
- Exploring Cohere for Aspect Based Sentiment Analysis: A user is evaluating Cohere for aspect-based sentiment analysis, aiming to classify reviews into specific facets such as loudness and suction power.
- They noted Cohere models required fewer training examples compared to OpenAI's models, which may signal cost-effectiveness in application.
- Suggestions for AI Projects: Members proposed various AI projects such as spam email detection, sentiment analysis of product reviews, and traffic sign recognition.
- They also recommended checking out the Cohere AI Learning Library for resources to enhance understanding in the AI field.
- Utilizing Cohere API for Efficient Classification: A user found the classification model on the Cohere platform effective and is excited about building a prototype with the API.
- They were advised to visualize dataset patterns and use them for cost-effective training in the future.
- Errors in RAG with Chat Embed and Rerank Notebook: A user encountered errors related to
rank_fieldsandchat_streamwhile running a GitHub notebook for RAG functionality.- Other members offered assistance by asking for code changes and logs to troubleshoot the issue effectively.
- LLM University (LLMU): Welcome to LLM University, your premier learning destination for mastering Enterprise AI technologies. Designed for developers and technical professionals, our hub offers comprehensive resources, expe...
- Structured Generations (JSON): Cohere models such as Command R and Command R+ are great at producing structured outputs in formats such as JSON. Why generate JSON Objects using an LLM? JSON is a lightweight format that is easy for ...
- notebooks/notebooks/llmu/RAG_with_Chat_Embed_and_Rerank.ipynb at main · cohere-ai/notebooks: Code examples and jupyter notebooks for the Cohere Platform - cohere-ai/notebooks
Cohere ▷ #projects (4 messages):
Web3 Contract OpportunitySpam Concerns in Chat
- Web3 Contract Opportunity for Developers: A user expressed interest in chatting with someone experienced in Web3, Chainlink, LLM, and UI development for a part-time contract opportunity.
- This indicates a demand for skills in emerging technologies within the community.
- Discussion on Chat Spam Posts: A member pointed out that certain posts in the chat are spam and often scams, suggesting they could be deleted for better community experience.
- Another user expressed gratitude for the awareness on this issue, highlighting community efforts to maintain chat quality.
Cohere ▷ #cohere-toolkit (6 messages):
Toolkit CustomizationGuidelines for Modifying CodeCollaboration and ContributionsUse-cases EvaluationUpstream Updates
- Toolkit promises flexibility for customization: A member expressed interest in the toolkit, highlighting its promising customization options like enabling authentication and themes.
- Forking the project and building a Docker image might be necessary for deeper modifications.
- Best practices for safe modifications discussed: Another member responded, indicating that guidelines for using the toolkit are already provided, and customization is encouraged.
- They emphasized the community's willingness to see and support contributions to the project.
- Request for specific guidance on use-cases: A member inquired if there was a specific aspect that needed guidance, prompting a follow-up on the desired use-cases for the toolkit.
- They were curious whether the use-cases focused more on Chat x RAG or analysis.
- Evaluation of internal tool extensions: A member mentioned they are currently evaluating the toolkit's fit for their scenarios, particularly on the potential to extend it with internal tools.
- They also expressed interest in staying up to date with upstream developments.
Eleuther ▷ #general (50 messages🔥):
GitHub and Hugging Face competitionEU AI regulation concernsLLM evaluation metricsDeveloping new neural network architecturesCode understanding tools for LLMs
- GitHub aims to compete with Hugging Face: Concerns were raised about GitHub's approach, as some members noted it feels like they're starting a limited demo focused on hosted models rather than community contributions.
- One member suggested this might be a strategic move to maintain control and prevent migration of the ML community's code.
- Uncertainties around EU AI regulations: The UK tech secretary stated that the upcoming AI bill would focus on major models without adding excessive regulations, but members remain skeptical about its enforceability.
- Discussions highlighted worries over how EU and UK laws might affect companies globally and whether compliance is feasible for startups.
- Choosing metrics for LLM evaluation: A member inquired about suitable metrics for evaluating LLM outputs, referencing the challenges of using exact matches for code.
- Several users suggested methods like humaneval, while acknowledging concerns about the risks of using
exec()in evaluation.
- Several users suggested methods like humaneval, while acknowledging concerns about the risks of using
- Guidelines for creating new neural architectures: Inquiries about developing new deep learning architectures emphasized the importance of encoding invariances and prior experimentation.
- One user suggested using contrastive learning techniques to improve model invariance and performance across user-based data.
- Tools for code comprehension by LLMs: A user introduced a Python tool designed to help LLMs understand codebases without needing all file access, claiming it enhances efficiency.
- Although some requested empirical evidence of its effectiveness, follow-up discussions emphasized the potential of API calls to manage file interactions.
Link mentioned: UK’s AI bill to focus on ChatGPT-style models: no description found
Eleuther ▷ #research (134 messages🔥🔥):
Distillation TechniquesGEMMA Model PerformanceTraining DynamicsLogit Distillation vs Synthetic DataParameter Initialization Effects
- Distillation Techniques Revisited: The conversation highlighted a resurgence in interest in logit distillation, with members noting its impact on data efficiency and minor quality improvements for smaller models, despite past skepticism about its effectiveness.
- Several examples from recent papers showed that distillation methods can have different applications, including those using synthetic data, indicating evolving methodologies in the field.
- Concerns with GEMMA Model Comparison: Discussion around GEMMA's performance indicated discrepancies in benchmark results, especially regarding the comparison with models like Mistral, highlighting potential opacity in the evaluation process.
- Members debated the implications of training dynamics and resource allocation on performance metrics, seeking clarification on how various model setups impacted outcomes.
- Impact of Training Parameters: The group explored how the initialization variance of models can be altered, specifically noting that for the NTK model, different learning rates were employed leading to varying training dynamics.
- This provoked analysis on whether the adjustments actually aligned with expected behaviors, as conflicting results arose from using differing parameterization approaches.
- Synthetic Data vs. Logit Distillation: A comparison was made between synthetic data usage and traditional logit distillation methods, with various participants conveying that clarity is needed around how the terms are currently defined and understood.
- The need for rigorous experimentation and baseline comparisons was emphasized to better evaluate these strategies within their respective frameworks.
- Challenges in Understanding Results: Members expressed confusion over discrepancies in figures from recent papers, particularly how certain experiments yielded unexpected results despite theoretical equivalences in model setups.
- The need for thorough validation processes was highlighted to ensure that varying initialization and learning rate configurations were accurately represented in performance evaluations.
- MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts: We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models. MoMa processes images and text in arbitrary sequenc...
- Hashes — EleutherAI: no description found
- An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models: The optimal training configurations of large language models (LLMs) with respect to model sizes and compute budgets have been extensively studied. But how to optimally configure LLMs during inference ...
- On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes: Knowledge distillation (KD) is widely used for compressing a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, current KD methods for auto-...
- Scaling Exponents Across Parameterizations and Optimizers: Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices...
- Compact Language Models via Pruning and Knowledge Distillation: Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we invest...
- Gemma 2: Improving Open Language Models at a Practical Size: In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we a...
- Tweet from MLCommons (@MLCommons): @MLCommons #AlgoPerf results are in! 🏁 $50K prize competition yielded 28% faster neural net training with non-diagonal preconditioning beating Nesterov Adam. New SOTA for hyperparameter-free algorith...
- Tweet from Karina Nguyen (@karinanguyen_): I’m hiring for the Model Behavior team at OpenAI! It’s my dream job at the intersection of design engineering and post-training research, and the rarest in the world ❤️ We define the core behavior o...
Eleuther ▷ #scaling-laws (3 messages):
Double Descent PhenomenonEffects of Parameters and Data Size on Loss
- Double Descent Exists for Both: A member noted that double descent is evident when analyzing the behavior of models during training across both parameters and data size.
- They emphasized that this observation shifts when plotting epochs on the x-axis.
- Training Regime Influences Loss: Discussion highlighted that for a given training regime, keeping everything fixed except for parameters and data size can reveal unexpected behaviors.
- It was pointed out that there exists a significant region where one or both factors can have a negative effect on loss.
Eleuther ▷ #interpretability-general (1 messages):
norabelrose: https://x.com/norabelrose/status/1819395263674699874
Eleuther ▷ #lm-thunderdome (8 messages🔥):
PhD research gapsEvaluation tasks in AIBroader Impacts Evaluation workshopProvocative claims in social impact evaluationCollaborative ML paper writing
- PhD Students Seek Research Gaps: A member expressed feeling lost in their PhD journey and recalled a Twitter thread discussing a cool idea for research.
- They are on the lookout for potential gaps to work on in their field.
- Running Evaluations with Multiple Prompts: A new member requested guidance on how to add a task that involves evaluating multiple prompts at once and aggregating results.
- They are seeking the best practices for executing this process effectively.
- NeurIPS Workshop Announcement: A member shared a Twitter thread announcing a workshop on Broader Impacts Evaluation of GenAI at NeurIPS.
- The workshop aims to discuss the importance of evaluation as a governance tool grounded in the needs of affected parties.
- Call for Provocative Papers: Members are soliciting tiny papers for a workshop that includes short research papers and novel perspectives on social impact evaluation for generative AI.
- One provocative statement mentioned is: 'There is no reason to believe RLHF'd models are safer than base models.'
- Potential Collaboration on ML Paper: A member expressed interest in co-authoring a machine learning paper, indicating they are looking for opportunities to publish.
- They are keen to contribute ideas, particularly around provocative claims regarding social impact evaluation.
Link mentioned: Tweet from Yacine Jernite (@YJernite): Excited to announce our workshop on Broader Impacts Evaluation of GenAI at @NeurIPSConf! Evaluation is an important governance tool; if sufficiently grounded, defined, and motivated by the needs of a...
OpenAI ▷ #ai-discussions (91 messages🔥🔥):
OpenAI Voice ModeLatency Issues with Assistants APIGemini 1.5 Pro ExperimentGemma 2 2b ModelFlux Image Model
- OpenAI Voice Mode Buzz: Members discussed the new OpenAI voice mode, with some mentioning that it has led to an influx of direct messages since its announcement.
- It seems many are eager to inquire more about its functions and access.
- Latency Concerns with Assistants API: A user reported issues with latency concerning the Assistants API, seeking community feedback on their experiences.
- Some recommended alternatives like SerpAPI for real-time information scraping tasks.
- Gemini 1.5 Pro Outperforms: Discussions highlighted the performance of Gemini 1.5 Pro over other models, with members curious about its real-world applications.
- One participant noted that their own usage of the model proved it to be competitive in response quality.
- Gemma 2 2b Capabilities: A member shared insights on the potential of the Gemma 2 2b model, emphasizing its effectiveness in instruction following despite being less knowledgeable than larger models.
- The conversation centered around balancing tech capabilities with reliability for practical applications.
- Excitement over Flux Image Model: The release of the Flux image model has generated excitement, as community members began testing its capabilities compared to existing tools like MidJourney and DALL-E.
- Users noted its open-source nature and lower resource requirements, suggesting its potential for widespread use.
Link mentioned: Tweet from Greg Brockman (@gdb): A GPT-4o generated image — so much to explore with GPT-4o's image generation capabilities alone. Team is working hard to bring those to the world.
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
GPT Custom InstructionsFine-Tuning GPTsPersonalized GPTsCustom GPT for OCT Processing
- GPT Custom Instructions Leaking Concerns: Developers expressed worries that GPT custom instructions could be leaked, allowing others to create knockoff versions that threaten monetization.
- To avert unnecessary drama, the idea of sharing instructions was scrapped altogether.
- Fine-Tuning Frequency and Limits: A member suggested that limiting GPT fine-tuning to five times a month could improve performance and usability.
- This limit might help manage the quality of fine-tuned models while ensuring they cater to specific user needs.
- Personalized GPTs for Efficiency: Users acknowledged the effectiveness of making custom GPTs for personal tasks, enhancing workflow across projects.
- One member noted they primarily use their own created GPTs to streamline different tasks.
- Accessing Custom GPT via OpenAI API: A user inquired about the possibility of accessing a custom GPT for OCT processing through the OpenAI API.
- This highlights interest in leveraging custom solutions in other environments beyond the ChatGPT web interface.
OpenAI ▷ #prompt-engineering (6 messages):
Text Length ReductionLLM LimitationsPython Tool for Word Counting
- Challenges in Reducing Text Length: Members expressed concerns about successfully reducing text to a specific character or word count due to limitations in how LLMs predict text.
- One member noted that LLMs struggle with precise calculations, making it difficult to achieve exact lengths.
- Using Qualitative Language for Text Reduction: "Qualitative language" like 'short' or 'very short' can provide generally consistent lengths when asking LLMs to shorten text, though not precise counts.
- Despite this, LLMs may not respond well to commands like 'shorten in half' or 'split in half' as intended.
- Python as a Solution for Word Counting: A suggestion was made to use Python for critical word counts, with the AI generating initial text and Python handling the counting.
- This approach allows for more control, as Python can check the word count and return commands to 'shorten' if necessary.
OpenAI ▷ #api-discussions (6 messages):
Text Shortening ChallengesUpgraded ChatGPT VersionsPython for Word Counting
- Text Shortening Challenges in LLMs: Members discussed the limitations of LLMs in shortening text to specific character or word counts, emphasizing that LLMs primarily predict text rather than perform calculations.
- One noted that while qualitative language can help guide length, it won’t yield exact counts.
- Interactivity Queries on LLMs: A member inquired whether asking LLMs to 'shorten' text quantitatively would produce consistent results based on commands like 'shorten in half'.
- Responses indicated that LLMs struggle with precise word counting, leading to unpredictable outcomes.
- Utilizing Python for Reliable Word Counts: A suggestion was made to use a Python tool for more accurate word counts if the text length is critical, while the AI can generate the initial text.
- This approach allows for a systematic check, directing the AI to 'shorten' content if the word count exceeds desired limits.
- Interest in Upgraded ChatGPT Versions: In a parallel discussion, a member was seeking upgraded versions of ChatGPT-4 or 4o, requesting direct messages from those who have access.
- This reflects ongoing interest in acquiring enhanced AI capabilities among the community.
Nous Research AI ▷ #research-papers (3 messages):
LLM-as-JudgeSynthetic Dataset GenerationWizardLM Papers
- Search for LLM-as-Judge Reads: A member asked for recommendations on must-read surveys regarding the current meta in LLM-as-Judge and the generation of synthetic datasets, particularly focused on instruction and preference data.
- This inquiry highlights the ongoing interest in effective methodologies within the LLM domain.
- Recommendation of WizardLM Papers: Another member suggested checking out the latest two papers from WizardLM as relevant reading for the inquiry regarding LLMs and synthetic dataset generation.
- This recommendation indicates that WizardLM's recent research may offer valuable insights into the discussed topics.
Nous Research AI ▷ #off-topic (15 messages🔥):
Cooking RecipesNous MerchDeep FryingCommunity Engagement
- Appeal for New Cooking Recipes: Members expressed a desire for new cooking inspiration, with one stating they often leave disappointed from the channel.
- Another member humorously quoted, 'no man steps in the same river twice,' urging for fresh posts despite older content availability.
- Production of Nous Merch: There was a discussion on Nous merchandise, with one member eagerly asking when it will be available.
- A reply indicated that high-quality items, including an excellent hoodie, are being prepared and will be released soon.
- Frying Potatoes in Beef Tallow: One member shared their experience of frying potatoes in beef tallow bought from a classified ads website, showcasing their cooking method.
- They mentioned using a no-name brand Chinese electric deep fryer, prompting inquiries from others about the brand.
Nous Research AI ▷ #interesting-links (3 messages):
VRAM calculation for LLMsBlack Forest Labs generative AIFLUX.1 models
- Efficient VRAM Calculation Script Released: A new VRAM calculation script allows users to determine VRAM requirements for LLMs based on model, bits per weight, and context length.
- The script requires no external dependencies and provides functionalities for assessing context length and bits per weight based on available VRAM.
- SOTA Text-to-Image Model Declared by Black Forest Labs: The Latent Diffusion Team has launched Black Forest Labs, introducing the FLUX.1 suite of state-of-the-art text-to-image models aimed at advancing generative AI.
- The team is committed to making generative models accessible, enhancing public trust, and driving innovation in media generation, as detailed in their announcement.
- FLUX Official Inference Repo Now on GitHub: An official GitHub repository for the FLUX.1 models has been launched, providing resources and support for users looking to implement the models.
- The repository can be accessed at black-forest-labs/flux and aims to facilitate contributions to the project's development.
- Announcing Black Forest Labs: Today, we are excited to announce the launch of Black Forest Labs. Deeply rooted in the generative AI research community, our mission is to develop and advance state-of-the-art generati...
- [Script] Calculate VRAM requirements for LLM models: Script is here: https://gist.github.com/jrruethe/8974d2c8b4ece242a071d1a1526aa763 For a while I have been trying to figure out which quants I can...
- GitHub - black-forest-labs/flux: Official inference repo for FLUX.1 models: Official inference repo for FLUX.1 models. Contribute to black-forest-labs/flux development by creating an account on GitHub.
Nous Research AI ▷ #general (60 messages🔥🔥):
Gemma 2B vs Qwen 1.5BFinetuning using BitnetN8Leaderboard implementationsLlama 405B performanceComparison of AI models in coding
- Gemma 2B overhyped compared to Qwen 1.5B: Members discussed how Gemma 2B is perceived as overhyped, with Qwen 2 reportedly outperforming it on various benchmarks including MMLU and GSM8K.
- One member mentioned that Qwen's performance went unnoticed despite its capabilities, saying it 'brutally' beat Gemma 2B.
- Finetuning renaissance with Bitnet: A member shared a link discussing the use of Bitnet for finetuning, resulting in a 74MB file that operates at 198 tokens per second on a single CPU core.
- This led to a discussion about potential open-sourcing of the project and the efficacy of finetuning in the current landscape of AI.
- N8Leaderboard gaining attention: The N8Leaderboard is being discussed, with one member emphasizing that it consists of 30 brain teasers for evaluation.
- Another member inquired about the software and hardware used to implement the leaderboard, indicating a desire to replicate the process.
- Llama 405B showcases impressive accuracy: Discussion highlighted the Llama 405B model achieving 90% accuracy after just 2 epochs of training, which sparked intrigue among the members.
- Members debated the model's training logistics, with one noting the validation loss appeared favorable initially.
- Comparative analysis of AI models: A member is currently comparing Athena 70B and Llama 3.1 for coding tasks, sharing insights on performance differences.
- This led to further discussion on the overall trend of models exhibiting better theoretical performance rather than practical application effectiveness.
- Tweet from nisten (@nisten): hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: https://huggi...
- Reddit - Dive into anything: no description found
- Tweet from nisten (@nisten): @reach_vb @skunkworks_ai got mad that no one'd share bitnet code, so I rawdogged it the straight off the paper. but it wouldn't converge. so then I kept autofrankensteining the layers of smolL...
Nous Research AI ▷ #ask-about-llms (8 messages🔥):
Llama3.1 Fine-tuning ChallengesDataset DiscussionGemma 2B Experimentation
- Llama3.1 shows gibberish output: After fine-tuning Llama3.1 70B on a private dataset and deploying it via vLLM, a user reports getting around 30tok/s but experiencing unusable gibberish output.
- Temperature 0 settings did not resolve the issue, indicating potential data or model misconfiguration.
- Private dataset used for fine-tuning: A user confirmed they utilized a private dataset, following Together AI's guide to fine-tune Llama3.1.
- They cited successes with proprietary data in improving accuracy compared to leading closed-source models.
- Discussion on Gemma 2B: A query was raised about attempting to run Gemma 2B with the project found on GitHub - LLM2Vec.
- The post prompted members to share their experiences or outcomes related to the implementation of LLM2Vec.
- Fine-tuning Llama-3 to get 90% of GPT-4’s performance at a fraction of the cost: no description found
- GitHub - McGill-NLP/llm2vec: Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders': Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders' - McGill-NLP/llm2vec
Nous Research AI ▷ #rag-dataset (6 messages):
Llama 3.1 performanceGroq temperature settings
- Llama 3.1 shows instability in outputs: A user reported that Llama 3.1 on Groq is unstable, often producing gibberish instead of coherent responses, particularly during a persona-based Wikipedia dataset search.
- They humorously requested an output format and expressed the need to clean up the resulting outputs due to the performance issues.
- Temperature settings affect performance: A member from Groq inquired about the temperature setting used during the Llama 3.1 runs, aiming to understand the instability.
- The original user affirmed that setting the temperature to 0 improved the formatting and resolved the errors they experienced, appreciating the feedback received.
- Recommendation for temperature baseline: The user interacted with Groq's member to establish a baseline for temperature settings, ultimately deciding to test using a 0% temperature.
- They thanked the Groq team for their guidance, noting significant improvements in output quality after the adjustment.
Nous Research AI ▷ #reasoning-tasks-master-list (3 messages):
Quarto website setupFile structure confirmation
- New PR for Quarto Website Launch: A new PR for the quarto website has been created to set up the project, enhancing the online presence of reasoning tasks.
- The PR includes all necessary images for clarity and detailed description on the changes made.
- Clarification on Folder Structure: A member confirmed that chapters is a top-level directory while all other files are also top-level files, ensuring a clear project organization.
- This structure is meant for ease of navigation and management within the repository.
Link mentioned: create quarto website by mmhamdy · Pull Request #17 · NousResearch/Open-Reasoning-Tasks: Set up quarto website for tasks.
LAION ▷ #general (53 messages🔥):
FLUX Schnell performanceSynthetic data generation concernsModel training insightsCuration of datasetsChallenges with synthetic datasets
- FLUX Schnell shows weaknesses: Members discussed the FLUX Schnell model, noting it appears to be undertrained and struggles with prompt adherence, leading to nonsensical outputs like 'a woman riding a goldwing motorcycle' wearing tennis attire.
- Concerns were raised that while the model looks nice, it fails to generalize and is more a dataset memorization machine than an effective generative model.
- Caution advised on synthetic datasets: Concerns were expressed against using the FLUX Schnell model for generating synthetic datasets, as some members warned that it could lead to representational collapse over generations.
- One member noted, 'please, please, please, do not make a synthetic dataset with the open released weights from Flux'.
- The value of curation over randomness: Members emphasized the importance of curated datasets over random synthetic datasets, stating that user-preferred data reflects true quality and avoids unnecessary wastage.
- A member pointed out that training exclusively on random prompts wastes resources and would likely provide no significant improvement.
- Synthetic vs. real data training advantages: Some members discussed that using a synthetic dataset can accelerate training, allowing for quicker concept learning by mixing synthetic and real data.
- However, there was a counterpoint that directly distilling models is still the best approach if you already have access to a robust original model.
- Queries on missing dataset: A user inquired about the laion2B-en dataset from Hugging Face, noting it appears to no longer be available, possibly affecting their work on a Stable Diffusion project.
- This sparked concerns about the accessibility of datasets critical for model training.
- FLUX.1 [Schnell] - a Hugging Face Space by black-forest-labs: no description found
- AI models collapse when trained on recursively generated data - Nature: Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collap...
LAION ▷ #research (17 messages🔥):
Data AugmentationTraining BugsParameter-efficient ArchitectureClassifier Development
- Data Augmentation Options Fail to Impress: After trying data augmentation, dropout, and weight decay, it was noted that these techniques delay overfitting but do not significantly reduce validation error.
- One user remarked, 'I’m actually not super worried about using regularization to eke out every possible percentage-point' since the task is CIFAR-10.
- Bugs Halting Progress on LLM: One member discovered a typo in their code that had severely impacted performance across 50+ experiments.
- They expressed satisfaction upon seeing the new loss curve drop significantly faster than the old version.
- Issues with LLM Generalization: A member acknowledged fixing 10 bugs while developing their own LLM but noted that the model memorizes outputs instead of generalizing them.
- This made them realize, 'So you think it's working but it's not.
- Real World Data Suggestion: A suggestion was made to use a photograph of carpet as a fake background for data augmentation to improve real-world data usage.
- Following this technique could positively influence the performance curve, as one member encouraged, 'Let's see how your curve goes after the fact.'
- Focus on Strong Baseline Models: The main goal expressed was to create a strong baseline model rather than focusing on minor improvements from regularization techniques.
- One member clarified they are developing a classifier, keeping in mind the parameter-efficient architecture.
Interconnects (Nathan Lambert) ▷ #events (1 messages):
Event SponsorshipRL Conference Dinner
- Interest in Event Sponsorship: Some members expressed interest in sponsoring events, indicating a proactive approach to support future gatherings.
- The community seems optimistic about finding financial backing for such initiatives.
- Dinner at RL Conference next week: A member is considering hosting a dinner at the RL Conference next week and is looking for VCs or friends of the pod who might be interested in sponsoring.
- This initiative could provide an excellent networking opportunity for attendees willing to contribute financially.
Interconnects (Nathan Lambert) ▷ #news (21 messages🔥):
Character AI dealEmployee concerns post-dealImplications for AI firmsNoam's exit from the industryRegulatory challenges
- Character AI Deal Raises Eyebrows: Discussion centered on the Character AI deal, with members expressing skepticism about its implications for the industry.
- One participant claimed it was a 'weird deal', which prompted further discussion about its aftermath.
- Worries About Non-Founder Employees: Concerns were raised regarding the fate of employees who are not founders, questioning how they might be affected post-deal.
- One member speculated that while founders and VCs likely benefited, the majority might be left behind.
- AI Firms Might Be Struggling: A member likened some struggling AI firms to 'zombie husks', hinting they are aimless following recent acquisitions.
- Another contributed that these deals often involve dodging regulators, which might lead to complications.
- Noam's Exit from the Game: Speculation about Noam leaving the AI industry prompted members to wonder about his motivations and thoughts on his customer base.
- One suggested there might have been a lucrative offer involved, possibly from Sundar.
- Running an Unintended Erotica Startup: Concerns were voiced about the challenges of running a company that unintentionally became an erotica startup.
- One member expressed disbelief over how that could happen, suggesting it might not have been an enjoyable experience.
Interconnects (Nathan Lambert) ▷ #ml-drama (19 messages🔥):
Ai2 redesignSparkles Emoji TrendCopyright Issues with AIAI Companies Moving to JapanNonprofit Press Freedom
- Ai2 Unveils New Brand Inspired by Sparkles: Ai2 announced its new brand and website after extensive research, taking cues from the trend of using sparkles emojis in AI branding as highlighted in a Bloomberg article.
- Rachel Metz remarked on the AI industry's embrace of sparkles, pointing to its rise in popularity.
- RIAA's Copyright Dilemma: A member noted that the only way for the RIAA to succeed against the rise of AI-generated content is to cut deals with AI companies.
- This poses challenges, as there's a risk that another AI company could emerge from a more favorable jurisdiction, leading to copyright owners receiving nothing.
- AI Companies Flocking to Japan: There is a growing trend of AI companies relocating to Japan, with discussions highlighting this as a strategy fueled by torrenting challenges.
- One member stated they were unaware this was becoming a trend, revealing insights into changes in the landscape of AI regulations.
- Nonprofits and Negative Press: A member expressed frustration about how nonprofit organizations like OpenAI are often scrutinized and do not receive negative press due to their status.
- This prompted another member to humorously note that OpenAI is also classified as a nonprofit, blending laughter with serious commentary.
Link mentioned: Tweet from Rachel Metz (@rachelmetz): looks like @allen_ai is taking a page from the sparkles emoji playbook with its redesign! see my recent piece on the AI industry's embrace of ✨ to learn more about the humble sparkles' jump in...
Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
Magpie Ultra DatasetInstruction and Response DiversitySynthetic Data GenerationNemotron and Olmo Fine-TunesRoss Taylor Interview
- Magpie Ultra Dataset Launch: HuggingFace introduced the Magpie Ultra dataset, a 50k unfiltered L3.1 405B dataset, claiming it to be the first of its kind for open synthetic datasets. For more details, check their tweet and the dataset on HuggingFace.
- Initial instruction quality remains a question with concerns about user turn diversity and whether the model's first turn limits coverage.
- Bayesian Reward Model for Instruction Diversity: A proposal to use a Bayesian reward model was discussed, which could help improve instruction and response diversity by guiding prompt generation. It was noted that uncertainty around the reward score may indicate undersampled task distributions.
- Previous papers suggested adding a variance penalty to avoid reward over-optimization, but this approach aimed to facilitate exploration instead.
- Synthetic Data Generation Challenges: There's an ongoing effort to process 100k prompts for generating synthetic instructions and updating previous GPT-4 completions to Llama. This includes generating preference data to enhance future models.
- Concerns about properly leveraging Nemotron for synthetic data and avoiding potential naming conflicts were raised, especially in light of recent shifts in company dynamics.
- Excitement for Upcoming Llama-3.1-Olmo-2: Enthusiasm was expressed for the upcoming Llama-3.1-Olmo-2 model, with discussions about redoing synthetic data using Nemotron for optimal results. The desire for coherence and clarity in naming strategies was emphasized.
- Additionally, a notable Ross Taylor interview is anticipated, with participants praising his expertise and contributions in the AI field.
- Tweet from Gabriel Martín Blázquez (@gabrielmbmb_): Dropping magpie-ultra-v0.1, the first open synthetic dataset built with Llama 3.1 405B. Created with distilabel, it's our most advanced and compute-intensive pipeline to date. https://huggingfac...
- Argilla: no description found
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Chatroom improvementsIgnored ProvidersParameters API updatesNew models launched
- Chatroom gets a fresh update: The Playground has been rebranded to Chatroom, featuring a simpler UI and local saving of chats.
- Users will find it easier to configure new rooms with this update.
- Avoid unwanted providers with new settings: Users can now avoid routing requests to specific providers via settings page.
- This feature allows for greater customization of the request handling process.
- Check model parameters easily now!: The Improved Parameters API allows checking for supported parameters and settings for models and providers at this link.
- This enhancement makes it easier to understand model capabilities.
- Exciting new models released: New models include the Llama 3.1 405B BASE for generating training data and the Llama 3.1 8B, available for free here.
- Others include Mistral Nemo 12B Celeste, a specialized writing and roleplaying model, and the Llama 3.1 Sonar family for factual responses with links available.
- Settings | OpenRouter: Manage your accounts and preferences
- Parameters API | OpenRouter: API for managing request parameters
- Meta: Llama 3.1 405B (base) by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This is the base 405B pre-trained version. It has demonstrated strong performance compared to leading clo...
- Meta: Llama 3.1 8B Instruct (free) by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient. It has demonstrated strong performance compared to ...
- Mistral Nemo 12B Celeste by nothingiisreal: A specialized story writing and roleplaying model based on Mistral's NeMo 12B Instruct. Fine-tuned on curated datasets including Reddit Writing Prompts and Opus Instruct 25K. This model excels a...
- Perplexity: Llama 3.1 Sonar 70B Online by perplexity: Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. This is the online version of the [offline chat model](/m...
- Perplexity: Llama 3.1 Sonar 8B Online by perplexity: Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. This is the online version of the [offline chat model](/m...
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
API Key AcquisitionBenefits of Using Own API KeyFree Plan LimitationsGoogle Sheets Add-ons
- Getting an API Key is a Breeze: Acquiring an API key is straightforward; simply sign up on the AI provider's website, add credit, copy the API key, and paste it into the add-ons without any technical skills required. Learn more about the process here.
- Why Using Your Own API Key Matters: Using your own API key not only offers the best pricing but also ensures flexibility in choosing your AI provider. For instance, the price for GPT-4o-mini is only $0.6 for 1,000,000 tokens.
- Additionally, you can transparently view your model usage in the AI provider's dashboard.
- Lite Plan: Free but with Limitations: The Lite plan remains free indefinitely for low-usage users, currently limited to 300 results per month. Notably, 1 cell result counts as 1 result and 1 analyze counts as 5 results.
- It's important to note that this limit may change in the future.
- Get 1 Year Free with Google Sheets Add-ons: You can access a 1-year free offer for the add-ons by using the code LAUNCH at checkout and selecting yearly while using the same email as your Google Sheets. This offer is a great way for new users to experience the service with reduced costs.
Link mentioned: AiAssistWorks - AI for Google Sheets™ - GPT- Claude - Gemini - Llama, Mistral, OpenRouter ,Groq. : no description found
OpenRouter (Alex Atallah) ▷ #general (58 messages🔥🔥):
OpenRouter Website IssuesAnthropic Service ProblemsGroup Chat Functionality in OR PlaygroundYi Large AvailabilityFree Model Usage Limitations
- OpenRouter Website Accessibility: A member confirmed that the OpenRouter website works for them, but regional connection issues are common, as evidenced by past incidents like this. Another user reported that the website issue was resolved for them shortly thereafter.
- This highlights the potential for localized outages affecting user experience.
- Anthropic Facing Service Issues: Multiple users reported that Anthropic services seem to be down or struggling under severe load, indicating possible infrastructural issues. One user noted that the service has been intermittent for a couple of hours.
- This appears to be a growing concern among users who rely on their services.
- Clarification on Group Chat in OR Playground: A user attempted to set up a 'writer's room' with Llama3, to which members clarified that each model in the OR Playground operates with segregated memory, not akin to traditional group chats. Future improvements to allow models to respond in sequence were hinted at.
- The current setup is designed to compare outputs from various models with the same prompts.
- Yi Large and Fireworks Availability: A member inquired about the status of Yi Large, to which another member indicated that they are exploring the addition from the original creator's host. There was also a mention that Fireworks has been removed.
- This suggests ongoing adjustments to the available models on the platform.
- Understanding Free Model Limitations: Discussion ensued on what it means when a model is offered for free; it was clarified that free models are heavily rate-limited in usage via API or chatroom. This limitation is crucial for managing server load and ensuring fair access to users.
- Such constraints are important for maintaining the service's viability.
- Tweet from OpenRouter (@OpenRouterAI): Llama 3.1 405B BASE! It's here. This is the base version of the chat model released last week. You can use it to generate training data, code completions, and more. Currently hosted by a new pro...
- Meta: Llama 3.1 405B (base) by meta-llama: Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This is the base 405B pre-trained version. It has demonstrated strong performance compared to leading clo...
- OpenRouter Status: OpenRouter Incident History
LlamaIndex ▷ #blog (3 messages):
RAG PipelineAI Voice Agent for FarmersReAct Agents
- Event-Driven RAG Pipeline Tutorial Released: A tutorial was shared on how to build a RAG pipeline with retrieval, reranking, and synthesis broken into three distinct steps that utilize events. Further orchestration logic can be managed using @llama_index workflows.
- The tutorial aims to guide users through building a RAG pipeline from scratch, offering a comprehensive approach to event-driven architecture.
- AI Voice Agent Developed for Indian Farmers: To support Indian farmers lacking essential government assistance, an AI Voice Agent has been developed by @SamarthP6 and the team. This tool aims to enhance productivity and improve livelihood outcomes during challenges, as highlighted in this tweet.
- The initiative seeks to bridge the gap between farmers and critical resources, showcasing how technology can address agricultural concerns.
- Build a ReAct Agent with New Workflows: A new resource has been provided for building a ReAct agent from scratch using updated LlamaIndex workflows. This allows users to explore the internal logic of agents and understand system dynamics in greater detail, as seen in the shared link here.
- ReAct agents serve as key components in agentic systems, making these workflows particularly useful for developers seeking to innovate.
LlamaIndex ▷ #general (31 messages🔥):
ReAct Agent without ToolsService Context Changes in LlamaIndexUsing WhatsApp Data for Chatbot TrainingRAG Pipeline for Data Interaction
- ReAct Agent Strategies without Tools: A user sought advice on configuring a ReAct agent not to request any tools, suggesting alternatives like using
llm.chat(chat_messages)orSimpleChatEnginefor a more straightforward chat experience.- Another member noted the challenges with agent errors, particularly managing issues like 'couldn't find a tool' gracefully.
- Changes in LlamaIndex's Service Context: Members discussed the removal of the service context in upcoming versions of LlamaIndex, emphasizing the need for more flexible approaches to setting parameters like
max_input_sizeandchunk overlap.- One user expressed frustration over re-writing code due to the shift to more individualized components needing to be passed to the base API.
- Using WhatsApp Chat Data for Chatbot Development: A newcomer explored leveraging their WhatsApp business chat history to create a chatbot, looking for methods to clean and format data while retaining useful customer interactions.
- They mentioned encountering errors when processing large PDF files and sought guidance on best practices for data extraction and query accuracy.
- RAG Pipeline for Efficient Chat Data Management: A user shared a structured approach to implementing a RAG pipeline, including data organization, chunking strategies, and indexing with LlamaIndex for querying customer interactions.
- They recommended incremental processing over large files, suggesting tools like UnstructuredReader for parsing chat logs and storing them in a VectorStoreIndex.
LlamaIndex ▷ #ai-discussion (3 messages):
DSPy integration issuesFine-tuning vs. RAG
- DSPy's Latest Update Breaks LlamaIndex Integration: A member reported that DSPy's latest update breaks the integration with LlamaIndex, expressing they've had no successful use cases in DSPy thus far.
- They noted that in the previous version v2.4.11, there were no observable improvements from prompt finetuning compared to using vanilla LlamaIndex abstractions.
- The Future of Fine-Tuning in AI Development: A member posed a question about the necessity of fine-tuning in the face of rapidly evolving LLMs like Llama 3.1, which might be sufficient for most use cases.
- They highlighted that considering the resource demands, RAG systems could be a more efficient alternative for enhancing model knowledge.
Modular (Mojo 🔥) ▷ #mojo (20 messages🔥):
Mojo error handlingPython vs Go/Rust error patternsDistributed actor frameworks
- Mojo's Error Handling Dilemma: Members discussed the dilemmas surrounding Mojo's error handling, comparing Python style exceptions and Go/Rust error values while noting that Mojo aims to be a Python superset.
- One expressed concern that using both patterns could lead to complexities that might blow up in the programmer's face.
- Exception Handling Costs: Concerns were raised about the expense of throwing and catching exceptions, with darkmatter__ stating that pure Mojo libraries should avoid invoking such operations unless necessary.
- He highlighted the challenge of implementing this effectively, especially on an FPGA, where it could massively increase resource consumption.
- Quotes and References Shared: yolo007 shared a YouTube video featuring Chris Lattner discussing the differences between exceptions and errors in programming languages.
- The video sparked discussions comparing Elixir's handling of errors and how that might intersect with Mojo's approach.
- Erlang's 'Let it Crash' Philosophy: The notion of 'Let it crash' from Erlang was brought up as a possible design philosophy, where uncontrolled errors propagate to higher levels for handling.
- It was noted that such philosophies might not align with Mojo's aspirations, particularly in creating a robust distributed actor framework.
- Flexibility in Error Handling: Members noted that Mojo can utilize both exception and return error handling, allowing flexibility in catching errors through try/catch syntax.
- yolo007 mentioned a preference for wrapping code in try/catch structures to avoid explicitly managing all possible errors, indicating a leaner coding style.
Link mentioned: Exception vs Errors | Chris Lattner and Lex Fridman: Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=pdJQ8iVTwj8Please support this podcast by checking out our sponsors:- iHerb: https://lexfri...
Modular (Mojo 🔥) ▷ #max (3 messages):
Installation IssuesMojo Nightly ContributionConda Installation Suggestion
- Installation Issues with Max: A member expressed difficulties with installing Max, noting that they are encountering issues when attempting to run the code.
- They mentioned that the installation process could be problematic and are seeking assistance.
- Mojo Nightly Works Smoothly: Mojo nightly is functioning fine for a member who is actively contributing to it.
- This suggests that while Max has issues, Mojo nightly remains stable and operational.
- Conda Installation Recommended: Another member suggested using conda as a potential solution for the installation problems.
- They noted that the installation process has been massively simplified recently, which could help resolve the issues being faced.
OpenInterpreter ▷ #general (15 messages🔥):
Open Interpreter setupUsing local LLMsAPI configuration for LLMsPython development with LlamaFileCommunity engagement
- Open Interpreter session confusion: Members experienced confusion about joining an ongoing session, clarifying the conversation took place in a specific voice channel.
- One member noted their struggle to find the channel until others confirmed its availability.
- Running local LLM with Open Interpreter: A new member seeks guidance on running a local LLM and shares their initial script that leads to an error about model loading.
- Community members directed them to documentation for setting up local models correctly.
- Starting LlamaFile server for Python mode: It was emphasized that the LlamaFile server must be started separately before using it in Python mode.
- Participants confirmed the correct syntax for API and model settings, clarifying distinctions between different loading functions.
- Python mode development ambitions: The newcomer expressed interest in developing a one-click assistant using Python mode with Open Interpreter.
- They conveyed prior experience with basic chatbots and are eager to explore new capabilities offered by LlamaFile.
Link mentioned: LlamaFile - Open Interpreter: no description found
OpenInterpreter ▷ #O1 (2 messages):
Stripe Payment ReceiptsShipping Address Inquiries
- Missing Shipping Address on Stripe Receipt: A user raised a concern about not seeing a shipping address on a payment receipt from Stripe dated March 21.
- They inquired about the next steps to resolve this issue.
- Next Steps for User: Another member responded that no action is needed on the user's end at this time.
- They confirmed that OpenInterpreter will reach out with the appropriate next steps.
OpenInterpreter ▷ #ai-content (2 messages):
Aider browser UIPost-facto validation with LLMs
- Aider browser UI for code editing: The new Aider browser UI demo video showcases collaboration with LLMs to edit code in local git repos, automatically committing changes with sensible messages.
- It supports GPT 3.5, GPT-4, GPT-4 Turbo with Vision, and Claude 3 Opus, and can be launched using the
--browserswitch after installation.
- It supports GPT 3.5, GPT-4, GPT-4 Turbo with Vision, and Claude 3 Opus, and can be launched using the
- Post-facto validation in LLM applications: Research highlights that as LLMs expand, humans currently verify LLM-generated outputs before execution, facing challenges due to code comprehension difficulties. The concept of integrating an undo feature and establishing damage confinement is suggested to facilitate easier post-facto validation of LLM actions more details here.
- The study argues that post-facto validation—verifying after output generation—is often more manageable than pre-facto validation.
- Aider in your browser: Aider can run in your browser, not just on the command line.
- Gorilla Execution Engine: no description found
DSPy ▷ #papers (3 messages):
Meta-Rewarding Mechanisms in LLMsMindSearch for Information Integration
- LLMs Improve Their Judgment Skills: A recent paper discusses a Meta-Rewarding step in LLMs that allows them to judge their own judgments, leading to improved capabilities and a win rate increase of Llama-3-8B-Instruct from 22.9% to 39.4% on AlpacaEval 2.
- This approach addresses saturation in traditional methodologies by enhancing the model's self-judgment capabilities.
- MindSearch Mimics Human Cognitive Processes: Another paper introduces MindSearch, a framework designed to overcome challenges in information seeking and integration by mimicking human cognition using LLMs and multi-agent systems.
- It addresses issues like complex requests not being accurately retrieved and context length limitations of LLMs while aggregating relevant information effectively.
- MindSearch: Mimicking Human Minds Elicits Deep AI Searcher: Information seeking and integration is a complex cognitive task that consumes enormous time and effort. Inspired by the remarkable progress of Large Language Models, recent works attempt to solve this...
- Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge: Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et a...
DSPy ▷ #general (13 messages🔥):
DSPy Summarization PipelineDiscord Channel ExportsAI for Game DevelopmentRepeatable Analysis ToolsPatrolling AI Characters
- Building a DSPy Summarization Pipeline: One member is seeking guidance on using DSPy with open source models for summarization, indicating a desire for a tutorial.
- The goal is to enhance prompt effectiveness iteratively for better summarization outputs.
- Request for Discord Channel Exports: Another member is looking for volunteers to share an export of Discord channels in JSON or HTML format for analysis purposes.
- They expressed intentions to acknowledge contributors in the release of their findings and code.
- General Purpose Analysis Tool for OSS Projects: There’s a discussion about developing a well-documented, repeatable analysis tool tailored for open-source software projects.
- This tool aims to consolidate various logs and issues from GitHub, Discord, and other platforms.
- AI Integration for Game Character Development: A member received a GitHub link relating to AI implementation for game characters, specifically for patrol and player interaction.
- They aim to utilize the Oobabooga API to facilitate responses from a large language model (LLM) for dynamic character dialogue.
- Library for Different Player Types in Games: In conjunction with the AI character talks, the same member expressed interest in creating a library of various player types.
- This would enhance character interactions based on players' proximity and chat activity.
OpenAccess AI Collective (axolotl) ▷ #general (7 messages):
Fine-tuning Gemma2 2BModel fluency in JapaneseBitsAndBytes installation for ROCm
- Exploration of Fine-tuning Gemma2 2B: A member inquired about attempts to fine-tune the Gemma2 2B model, seeking insights from others.
- Another member suggested using a pretokenized dataset and adjusting output labels to control model behavior.
- Seeking Most Fluent Japanese Model: A member asked if there are any Japanese speakers who could recommend the most fluent model available.
- A suggestion was made for using lightblue's / suzume model, based on collective recommendations from others.
- Simple Installation for BitsAndBytes on ROCm: A member shared that the installation process for BitsAndBytes on ROCm has become simpler due to a recent GitHub pull request.
- This update enables packaging wheels for ROCm 6.1, making it compatible with the latest Instinct and Radeon GPUs, and noted that everything on the tracker is complete now.
- bitsandbytes - Overview: bitsandbytes has 6 repositories available. Follow their code on GitHub.
- Enable bitsandbytes packaging for ROCm by pnunna93 · Pull Request #1299 · bitsandbytes-foundation/bitsandbytes: This PR enables packaging wheels for bitsandbytes on ROCm. It updates rocm compilation and wheels build jobs to compile on ROCm 6.1 for latest Instinct and Radeon GPUs. There are also updates to do...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
Merged PRKD developmentadam-atan2 updatedistilkit release
- Merged PR creates smooth sailing: A member noted that after merging a specific PR, everything has been working fine since.
- Unfortunately, they cannot easily reproduce the issue due to the merge.
- KD development still in the queue: One member apologized for disappearing and mentioned that their time slot to work on KD got consumed.
- They confirmed it remains a priority and opened it up for anyone interested to tackle in the meantime.
- Interesting tweak with adam-atan2: A member shared thoughts on a paper discussing adam-atan2, an elegant fix to avoid division by zero.
- They provided a link to the paper for further reading: adam-atan2 paper.
- Excitement over distilkit release: A member mentioned no issues with the distilkit released by arcee-ai, expressing enthusiasm about its features.
- This new tool appears promising, and there's eagerness to explore its capabilities.
OpenAccess AI Collective (axolotl) ▷ #general-help (4 messages):
Training Gemma2Llama3.1 Template ChallengesOutput Termination IssuesPrompt EngineeringData Sufficiency for Training
- Training Gemma2 and Llama3.1 presents challenges: Users shared experiences with training Gemma2 and Llama3.1 on new templates, noting the model learns structure but struggles with output termination.
- They observed that the model continues generating until reaching max_new_tokens or reverts to default behaviors post-reply.
- Prompt engineering minimally impacts output: In attempts to direct the model's output, users included stringent prompt instructions to output nothing but the reply.
- However, they reported that these adjustments had only a minimal impact on the overall behavior of the model.
- Concerns about training duration versus output changes: There are concerns regarding the time required for training, with users hesitant to train for several days without substantial improvement in output.
- They speculated that providing more examples might aid the model in learning when to terminate its outputs, but were wary of the investment involved.
- Non-traditional template structure poses challenges: The discussion highlighted the challenges of using an input-output structure for crafting templates versus traditional chat templates.
- Users indicated that this distinctive template structure complicates the training process, exacerbating the issues with output generation.
LangChain AI ▷ #general (10 messages🔥):
LangChain v0.2 featuresChat sessions in RAG applicationsChat message history with PostgresFine-tuning models for summarizationPerformance comparison of GPT-4o Mini and GPT-4
- Inquiry about LangChain v0.2 features: Users discussed the lack of documentation regarding agent functionalities in the new version of LangChain 0.2.
- Orlando.mbaa specifically noted they couldn't find any reference to agents in the available documentation.
- Implementing chat sessions in RAG apps: A user asked how to implement chat sessions in a basic RAG application similar to ChatGPT's ability to track previous conversations.
- The conversation revolved around the usability of session tracking within existing frameworks.
- Postgres schema issues with LangChain: A member referenced a GitHub issue (#17306) regarding chat message history failures in Postgres when using an explicit schema.
- They expressed concerns on how this was resolved and shared relevant resources.
- Discussion on fine-tuning for summarization: A user with a large text corpus inquired about the approach to fine-tune a model specifically for summarization tasks.
- Another member pointed out that fine-tuning is generally unnecessary for summarization, but the user insisted on incorporating specific data in the summaries.
- Performance comparison: GPT-4o Mini vs GPT-4: Someone asked about the performance of GPT-4o Mini compared to GPT-4, seeking insights on their capabilities.
- This inquiry highlights the ongoing interest in understanding the efficiency of different AI models.
Link mentioned: Chat message history with postgres failing when destination table has explicit schema · Issue #17306 · langchain-ai/langchain: Checked other resources I added a very descriptive title to this issue. I searched the LangChain documentation with the integrated search. I used the GitHub search to find a similar question and di...
LangChain AI ▷ #share-your-work (1 messages):
Community Research Call #2Multimodality updatesAutonomous Agents developmentsRobotics projectsCollaboration opportunities
- Community Research Call #2 Highlights: The recent Community Research Call #2 featured groundbreaking updates on various research projects.
- Attendees expressed excitement over the shared developments in Multimodality, Autonomous Agents, and new Robotics projects.
- Exciting Collaboration Opportunities Shared: During the event, participants discussed several collaboration opportunities across ongoing research directions.
- The energy was high as members brainstormed potential joint efforts and partnerships in future projects.
Link mentioned: Tweet from Manifold Research (@ManifoldRG): Community Research Call #2 was a blast! We shared groundbreaking updates on our Multimodality and Autonomous Agents directions, as well as unveiling our new projects in Robotics.
LangChain AI ▷ #tutorials (1 messages):
Testing LLMsTestcontainersOllamaPython Blog Post
- Blog Post on Testing LLMs: A member wrote a blog post detailing how to test LLMs using Testcontainers and Ollama in Python, specifically with module functionality from the 4.7.0 release.
- They emphasized the importance of testing LLMs to ensure they perform as expected under various conditions, inviting feedback on the tutorial shared here.
- Self-made Illustration of Testing Framework: An illustration was shared showing how Testcontainers interacts with Docker, Ollama, and ultimately LLMs in the proposed testing framework.
- This visual representation aims to clarify the relationship between the tools utilized for testing in a Python environment.
Link mentioned: Testing LLMs and Prompts using Testcontainers and Ollama in Python: An easy-to-use testing framework for LLMs and prompts using Python
Torchtune ▷ #dev (12 messages🔥):
QAT QuantizersSimPO PR ReviewDocumentation ImprovementNew Models Page Feedback
- Clarification on QAT Quantizers: Members clarified that the QAT recipe supports the Int8DynActInt4WeightQATQuantizer, while the Int8DynActInt4WeightQuantizer is intended for post-training.
- They noted that only the Int8DynActInt4Weight strategy is currently supported for QAT, and the other quantizers are available for future use.
- Request for SimPO PR Review: A member requested a review of the SimPO (Simple Preference Optimisation) PR #1223 on GitHub, emphasizing the need for clarity on its purpose.
- They highlighted that this PR resolves issues #1037 and closes #1036 related to alignment.
- RFC for Documentation Overhaul: Another member discussed a proposal for overhauling the documentation system for torchtune, especially focusing on recipe organization.
- They solicited feedback to enhance user onboarding and referenced examples for LoRA single device and QAT distributed recipes.
- Feedback on Potential New Models Page: A member shared a link to a preview of a potential new models page on the torchtune documentation site for feedback.
- They pointed out that the current models page is difficult to read and noted that the page contains detailed information on model architectures.
- get_quantizer_mode — torchtune 0.2 documentation: no description found
- torchtune.models — TorchTune main documentation: no description found
- Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
- SimPO (Simple Preference Optimisation) by SalmanMohammadi · Pull Request #1223 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) (resolves #1037, closes #1036) Another alignment PR??? T...
MLOps @Chipro ▷ #general-ml (6 messages):
Computer Vision InterestConferences on Machine LearningROI of genAIFunding TrendsDiscussion Diversification
- Computer Vision Enthusiasm: Members expressed a shared interest in computer vision, highlighting its importance in the current tech landscape.
- Many members seem eager to diverge from the NLP and genAI discussions that dominate conferences.
- Conferences Reflect Machine Learning Trends: A member shared experiences from attending two machine learning conferences where their work on Gaussian Processes and Isolation Forest models was presented.
- They noted that many attendees were unfamiliar with these topics, suggesting a strong bias towards NLP and genAI discussions.
- Skepticism on genAI ROI: Participants questioned if the return on investment (ROI) from genAI would meet expectations, indicating a possible disconnect.
- One member highlighted that a positive ROI requires initial investment, suggesting budgets are often allocated based on perceived value.
- Funding Focus Affects Discussions: A member pointed out that funding is typically directed toward where the budgets are allocated, influencing technology discussions.
- This underscores the importance of market segments and hype cycles in shaping the focus of industry events.
- Desire for Broader Conversations: In light of the discussions, a member expressed appreciation for having a platform to discuss topics outside of the hype surrounding genAI.
- This reflects a desire for diverse conversations that encompass various areas of machine learning beyond mainstream trends.
Alignment Lab AI ▷ #general (1 messages):
Image generation time on A100Batch processing capabilities with FLUX Schnell
- Image generation time on A100 with FLUX Schnell: The time taken for generating a 1024px image on an A100 with FLUX Schnell was inquired about, highlighting performance expectations.
- No specific duration was provided in the discussion.
- Batch processing capabilities discussed: Questions were raised regarding whether batch processing is possible for image generation and the maximum number of images that can be handled.
- The response related to hardware capabilities was not shared in the messages.