[AINews] a quiet weekend
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
Patience is all you need.
AI News for 9/13/2024-9/16/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (220 channels, and 6976 messages) for you. Estimated reading time saved (at 200wpm): 757 minutes. You can now tag @smol_ai for AINews discussions!
Everyone spent the weekend exploring o1 and opinions are quite mixed so far:
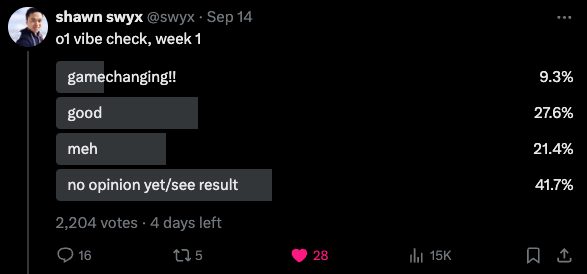
Astrophysics PhDs and George Hotz and Terence Tao like it, and someone manually graded it with an IQ of 120 on a custom IQ quiz.
In other news:
- Supermaven announced their $12m seed with Bessemer
- 11x announced their $24m series A with Benchmark
- Luma Labs launched an API for Dream Machine
- Cohere and Anthropic and Latent Space University launched courses.
One has to wonder just how good the upcoming Gemini 2 will have to be to compare with o1...
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Industry Updates
- OpenAI's o1 Model: OpenAI released a new model called "o1" (also known as Project Strawberry/Q*), which uses reinforcement learning and chain-of-thought to "think" before responding. @adcock_brett noted it smashes reasoning benchmarks. The model achieved 25 out of 35 correct answers on IQ questions, surpassing most humans, according to @rohanpaul_ai.
- Google DeepMind Developments:
- Google introduced DataGemma, designed to connect large language models with real-world data, aiming to reduce AI hallucinations @adcock_brett.
- DeepMind unveiled two new AI systems, ALOHA and DemoStart, advancing robot dexterity using diffusion methods @adcock_brett.
- Other Industry Updates:
- Adobe previewed its Firefly AI Video Model with features like Text to Video, Image to Video, and Generative Extend @adcock_brett.
- French AI startup Mistral released Pixtral 12B, a multimodal model capable of processing both images and text @adcock_brett.
- Tencent presented GameGen-O, an 'Open-world Video Game Generation' model @adcock_brett.
AI Research and Papers
- Several papers were highlighted as potentially relevant to understanding OpenAI's o1 model, including:
- "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking" from Stanford
- "Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents" from MultiOn/Stanford
- "Let's Verify Step by Step" from OpenAI
- "V-STaR: Training Verifiers for Self-Taught Reasoners" from Microsoft, Mila
- "Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning" from Notre Dame, Tencent @_philschmid
- A paper on "Selective Reflection-Tuning" was mentioned, describing an improved version of the 2023 Reflection-Tuning approach @rohanpaul_ai.
AI Capabilities and Benchmarks
- @bindureddy claimed AI has reached an IQ of 120, surpassing most humans, but noted it still lacks in perception and environmental understanding.
- @fchollet commented that while AI can generalize, it does so only locally and still breaks down on simple problem modifications or novel problems.
- Terence Tao, a renowned mathematician, provided commentary on o1's math capabilities, with mixed but overall optimistic takeaways @mathemagic1an.
Industry Perspectives and Debates
- There was discussion about the terminology "Large Language Models" (LLMs), with some arguing it's becoming a misnomer @karpathy.
- @ylecun criticized auto-regressive prediction for non-temporal sequences as "a pure abomination."
- Sam Altman commented that o1 marks the beginning of a significant new paradigm and stated "We have the next few years in the bag" regarding AI progress @rohanpaul_ai.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama 3.1 405B: Open-Source Rival to GPT-4
- Llama 405B running locally! (Score: 81, Comments: 23): The post demonstrates Llama 405B running locally on Apple Silicon hardware, specifically a Mac Studio M2 Ultra and a Macbook Pro M3 Max, achieving a speed of 2.5 tokens/sec. The setup is powered by Exo (https://github.com/exo-explore) and Apple MLX as the backend engine, with an important optimization trick shared by the Apple MLX creator involving setting specific sysctl parameters for improved performance.
- Llama 405B performance was further improved by adding a Linux system with 3090 GPU to the cluster, achieving 153.56 TFLOPS. The setup uses wifi for connectivity between devices.
- The project utilizes 4-bit quantization, pushing nearly 500GB/sec through the GPUs. The developer is exploring integration of an Nvidia 3090 using tinygrad.
- While the 2.5 tokens/sec speed is considered playable, the 30.43 seconds to first token with only 6 tokens in the prompt was noted as a limitation. Users can try the setup using the Exo GitHub repository.
- I ran o1-preview through my small-scale benchmark, and it scored nearly identical to Llama 3.1 405B (Score: 169, Comments: 52): Llama 3.1 405B and OpenAI's o1-preview model achieved nearly identical scores in a small-scale benchmark test. The benchmark results suggest that o1-preview might be a fine-tuned version of Llama 3.1 405B, potentially indicating a collaboration between Meta and OpenAI. This performance parity also implies that o1-preview could be matching GPT-4's capabilities in certain tasks.
- The benchmark creator, dubesor86, shared the full benchmark results and noted that testing was expensive due to harsh caps. The pricing difference between models is attributed to the base cost multiplied by the number of invisible tokens used.
- Several users questioned the unexpectedly low performance of Claude 3.5 Sonnet in the coding benchmark, particularly compared to popular consensus and personal experiences. The benchmark creator emphasized that results vary based on specific use cases and skill levels.
- Users discussed the potential for improving Llama's performance on reasoning tasks by using Chain of Thought (CoT) prompting, similar to o1. The benchmark creator expressed interest but preferred to maintain default model behavior in the official results.
Theme 2. O1 Model's Advanced Reasoning Capabilities
- Inspired by the new o1 model, Benjamin Klieger hacked together g1, powered by Llama-3.1 on @GroqInc (Score: 260, Comments: 58): Benjamin Klieger developed g1, a model inspired by O1 and powered by Llama-3.1 on Groq's hardware. This implementation aims to replicate O1's reasoning capabilities using the Llama-3.1 architecture, potentially offering similar performance on alternative infrastructure.
- The infinite bookshelf project by Benjamin Klieger garnered interest, with discussions on its Groq dependency and potential for local implementation. A user shared an intriguing simulation of a dinner with historical figures and an AI from the future.
- Users debated the effectiveness of replicating O1's performance using prompts alone, questioning if reinforcement learning with multi-step training data was crucial for O1's capabilities. Some suggested using Chain of Thought (CoT) output for further model fine-tuning.
- The proposed reasoning prompt using JSON format for step-by-step explanations was criticized, with users noting that forcing models to respond in JSON can degrade answer quality, especially for smaller models like Llamas.
- Is this a way to reveal o1's thinking steps? (Score: 92, Comments: 41): The post discusses a potential method to reveal O1's thinking steps by using a prompt engineering technique. The technique involves asking O1 to explain its reasoning for each step of a task, with the goal of understanding the AI's decision-making process. However, the effectiveness of this approach in truly revealing O1's internal thought process remains uncertain.
- Users suggest O1's thinking steps may be summarized by a smaller LLM, making it difficult to reveal true internal processes. Some speculate about an agentic system or specialized agents coordinating tasks.
- Attempts to reveal O1's chain of thought may result in threats from OpenAI to remove access to O1. Users report receiving emails warning against such attempts, leading to reduced probing of the model.
- Theories about O1's capabilities include a potential algorithm with reflection tokens allowing for recursive loops during inference, and training to recognize and avoid responding to "bad" instructions while maintaining an internal model of them.
Theme 3. Comparing Online LLM Providers and Services
- Large LLM providers, which one do you use and why? (Score: 46, Comments: 39): The post discusses the various Large Language Model (LLM) providers available for users who cannot run large models locally, mentioning options like Together, Poe, You.com, Groq, OpenRouter, and Fireworks. The author expresses frustration with Poe's reduced output length compared to original models and seeks recommendations for other providers, asking about criteria for choosing paid services and how to identify providers that use unmodified LLMs without artificially shortened outputs.
- OpenRouter is highly recommended for its wide variety of models, pricing options, and free choices. Users appreciate its load balancing feature and the ability to switch between supported models without changing API requests.
- Several users prefer a combination of providers, including OpenAI, Anthropic, Google, Together.AI, and vast.AI/RunPod. This approach allows for SOTA performance, free options, and the ability to run unique models, with monthly costs typically under $15.
- Google Gemini and Cohere are popular for their free plans, while some users opt for local solutions like Ollama or open-source alternatives like open-webui to avoid subscription fees and maintain data control.
- I ran o1-preview through my small-scale benchmark, and it scored nearly identical to Llama 3.1 405B (Score: 169, Comments: 52): O1-preview performed nearly identically to Llama 3.1 405B in a small-scale benchmark test. The benchmark included various tasks such as arithmetic, common sense reasoning, and language understanding, with both models achieving similar scores across the board. This suggests that O1-preview may be a competitive alternative to Llama 3.1 405B, though further testing on larger benchmarks would be needed to confirm these initial findings.
- The benchmark's creator, dubesor86, shared the full benchmark results and noted that testing was expensive due to harsh caps and invisible tokens. The pricing difference between models is attributed to base cost multiplied by token usage.
- Users questioned the underperformance of Claude 3.5 Sonnet in coding tasks, contrasting with their personal experiences. The benchmark creator emphasized that results vary based on specific use cases and that "coding" is a broad term with diverse requirements.
- The benchmark cost for O1-preview was approximately 52 times more expensive than testing Llama 3.1 405B. Users expressed interest in the testing methodology, including local builds, rented instances, and API usage.
Theme 4. Advancements in Local LLM Tools and Applications
- Sharing my Screen Analysis Overlay app (Score: 58, Comments: 10): The post introduces a Screen Analysis Overlay app designed to work with local LLMs for real-time screen analysis. The app captures the screen, processes it through a local LLM, and displays the results as an overlay, allowing users to interact with their computer while receiving AI-powered insights about on-screen content. The developer mentions plans to open-source the project and seeks feedback on potential use cases and improvements.
- I massively updated my python program that allows local LLMs running via llama.cpp to look things up on the internet, it now fully web scrapes the most relevant results! (Score: 133, Comments: 19): The author has significantly updated their Python program that enables local LLMs running via llama.cpp to access internet information, now featuring full web scraping of the most relevant search results. The program allows the LLM to select a search query, choose the 2 most relevant results out of 10, gather information from those results, and either conduct further searches or answer the user's question, with the update also including an llm_config.py file for customizing llama.cpp settings and enabling GPU support. The updated project is available on GitHub.
- Users praised the project, with one suggesting the addition of OpenAI compatible API endpoints to increase usability. The author agreed to work on implementing this feature, noting it would take "a few weeks".
- Discussion revealed that llama-cpp-python has a built-in OpenAI compatible API, which could be a starting point for integrating the project into larger personal assistant efforts. Users highlighted the potential performance benefits of running llama.cpp on a server with OpenAI API.
- A detailed implementation suggestion was provided, including steps to spin up the server, modularize the code, and refactor get_llm_response() to query the API endpoint. The commenter praised the project's simplicity and approach.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Capabilities
- OpenAI's o1 model demonstrates significant improvements in reasoning and coding abilities: Multiple posts highlight o1's capabilities, including creating video games from scratch, generating complex animations, and performing large-scale code refactoring. The model shows particular strength in tasks requiring extended reasoning.
- Rapid progress in AI capabilities: Posts discuss how o1 has reportedly increased by 30 IQ points to 120 IQ, surpassing 90% of humans. Another post mentions OpenAI's roadmap suggesting models will soon reach PhD-level reasoning and have agent-like capabilities.
- Improvements in multimodal AI: A Google Deepmind paper demonstrates advancements in multimodal learning through joint example selection.
AI Research and Infrastructure
- Massive computational requirements for frontier AI models: Larry Ellison of Oracle discusses plans to build nuclear reactors to power large GPU clusters, estimating costs of $100 billion over 3 years to stay competitive in AI development.
- Advancements in AI inference speed: Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy.
- Novel approaches to synthetic data creation: A paper on scaling synthetic data creation leverages diverse perspectives within large language models to generate data from 1 billion web-curated personas.
AI Model Releases and Comparisons
- Salesforce releases xLAM-1b: This 1 billion parameter model achieves 70% accuracy in function calling, surpassing GPT 3.5 despite its relatively small size.
- Updates to existing models: Rubra AI released an updated Phi-3 Mini model with function calling capabilities, competitive with Mistral-7b v3.
- Comparisons between models: A detailed comparison between o1-mini and Claude Sonnet 3.5 for coding tasks highlights strengths and weaknesses of each model.
Societal and Economic Impacts of AI
- Potential job market disruption: A report suggests AI will affect 60 million US and Mexican jobs within a year.
- Debates on AI's impact on various professions: Discussions around how AI advancements might affect software development and other knowledge work.
AI Applications and Tools
- AI-generated content creation: Examples include miniature people LoRA for image generation and affirmation cards for mental health support.
- AI-assisted coding and development: Multiple posts demonstrate AI's ability to generate complex applications and assist in large-scale refactoring tasks.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1: OpenAI's O1 Models Ignite Debate in AI Community
- O1 Models Impress and Disappoint in Equal Measure: OpenAI's new O1 models (o1-preview and o1-mini) are causing a stir, with some users praising their reasoning capabilities while others find their responses mechanical and underwhelming. The models' mixed reception highlights ongoing challenges in advancing AI reasoning.
- Community Questions O1's Advantage Over Existing Models: Users are comparing O1 to models like GPT-4o, debating whether O1's chain-of-thought reasoning offers significant improvements or is just hype. Discussions focus on O1's performance in complex tasks and its real-world applicability.
- Speculations Arise Over O1's Development and Data Usage: Enthusiasts are reverse engineering O1 to understand its training and reliance on user interaction data. Concerns about privacy and the feasibility of replicating O1's capabilities in open-source models are fueling heated debates.
Theme 2: AI Coding Tools Transform Development Workflows
- Aider and O1 Outshine Competitors in Bug Fixing: Developers are celebrating Aider and OpenAI's O1 for their superior performance in bug fixing over models like Claude. These tools deliver detailed, step-by-step outputs that streamline troubleshooting in complex codebases.
- Cursor AI Tackles Large Codebase Edits with Ease: Cursor AI is addressing challenges with large-scale code edits that stymie models like O1. Their specialized coding assistant enhances productivity by handling big changes more efficiently.
- AI's Growing Role in Coding Sparks Job Market Concerns: Discussions are intensifying around AI potentially replacing junior developers, prompting conversations about the future of human roles in programming. The emphasis is on fostering AI-human collaboration to keep experienced developers relevant.
Theme 3: Fine-Tuning and Training Models Remain Complex
- Frustration Mounts Over Underperforming Models: Models like Gemma2, Mistral, and Phi 3.5 are underperforming during training, leading to user exasperation. Challenges include high VRAM usage and unsatisfactory outputs, highlighting the need for better training solutions.
- LLama 3.1 Emerges as a Bright Spot: Amidst widespread training issues, LLama 3.1 stands out for its robust performance. Users report better results compared to other models, though they still face configuration hurdles due to its complexity.
- INT8 Mixed-Precision Training Offers Significant Speedups: The introduction of INT8 mixed-precision training promises up to 70% speedup on NVIDIA 4090 GPUs. This advancement allows for faster training without sacrificing accuracy, particularly on consumer-grade hardware.
Theme 4: Creative Applications of AI Gain Traction
- GameGen-O Opens New Frontiers in Game Development: Tencent's GameGen-O introduces a diffusion transformer model that generates open-world video games. This innovation excites developers eager to harness AI for accelerated game creation.
- Artists Leverage AI for Character Design and Animation: Creatives are using Stable Diffusion, ControlNet, and LoRA training to produce stunning character designs and animations. These tools are revolutionizing artistic workflows and expanding possibilities in digital art.
- Diffusion Illusions Captivate with Mind-Bending Art: The Diffusion Illusions project showcases interactive optical illusions generated through diffusion models. Accepted at SIGGRAPH 2024, it pushes the boundaries of AI-generated art and visual perception.
Theme 5: Security and Ethical Concerns Surrounding AI Technologies
- StealC Malware Exploits Chrome to Phish Passwords: The new StealC malware traps Chrome users in full-screen mode, coercing them into revealing their Google passwords via fake login screens. This sophisticated attack raises alarms about browser security vulnerabilities.
- Debates Heat Up Over AI Model Censorship: Users are clashing over the heavy censorship in models like Phi 3.5, which hampers technical tasks and coding assistance. The community is calling for a balance between necessary moderation and the practical utility of AI models.
- 'Humanity's Last Exam' Initiative Sparks Controversy: Dan Hendrycks announced a $500,000 prize pool for challenging AI with tough questions in Humanity's Last Exam. While some applaud the effort to advance AI, others express concern about its implications for AI regulation and policy influence.
PART 1: High level Discord summaries
aider (Paul Gauthier) Discord
- O1 Shines in Bug Fixing over Claude: O1 excelled in bug fixing, outperforming Claude models like Sonnet in speed and accuracy, especially in coding contexts.
- Users highlighted O1's ability to deliver detailed outputs, aiding in complex code troubleshooting.
- Sonnet 3.5 Faces Compatibility Issues: Sonnet 3.5 struggles with larger contexts and misinterprets instructions, frustrating users in complex coding tasks.
- In contrast, O1's outputs have been described as straightforward and effective, minimizing confusion.
- Aider Scripting Automates Workflows: Aider users can streamline tasks using the command line
--messageargument, sending commands directly to automate processes.- This method allows for easier batch processing through simple shell scripts across multiple files.
- Game Gen - O Revolutionizes Game Development: The introduction of Game Gen - O offers new capabilities for open-world video game creation based on diffusion-transformer models.
- This tool has ignited excitement in the community as it promises to accelerate AI-driven game development.
- The Big Prompt Library Launches: The Big Prompt Library repository provides a collection of prompts and LLM instructions, aiding users in effective prompt crafting.
- This resource is essential for developers utilizing systems like ChatGPT and Claude, enhancing user experiences.
Unsloth AI (Daniel Han) Discord
- Underperformance of Gemma2 and Mistral Models: Users flagged Gemma2 and Mistral for underperformance in training, especially in comparison to LLama 3.1, amidst frustrations over VRAM limitations.
- Concerns were raised on the necessary configurations for successful training, complicating the workflow.
- LLama 3.1 Shines in Performance: Excitement brewed as users found LLama 3.1 to outperform other models tried, while Gemma 2 9B also showed potential with proper settings.
- Members noted the need to adjust settings due to the larger size of Gemma 2, inviting a discussion on optimizations.
- Job Hunting is the New Black: With job hunting in full swing, members noted investments like LinkedIn Premium as they seek opportunities amid an uptick in the machine learning market.
- One PhD holder is navigating the transition from academia to enterprise due to a contracting postdoc role in machine learning.
- Debates on Recruitment Processes: Conversations revolved around advocating for a fair recruitment process, challenging traditional methods that favor memorization over skill evaluation.
- Emphasis was placed on skills and potential growth over mere connections in hiring, aiming for a revamped model.
- DPO Skepticism Leads to Alternative Suggestions: A member expressed skepticism over Direct Preference Optimization (DPO), hinting at exploring alternatives like KTO for their work.
- Ongoing discussions surrounding DPO loss types and the desire for shared experiences surfaced among attendees.
OpenRouter (Alex Atallah) Discord
- Users debate context limits on OpenRouter models: Concerns arose over the displayed context lengths for various models on OpenRouter, particularly with discrepancies in supported sizes in extended versions compared to what's stated.
- This sparked a call for increased transparency and communication updates on model capabilities for clearer user understanding.
- Performance woes lead to model review: Users reported bizarre outputs and responses getting cut off with models like Venus Chub AI and WizardLM-2, raising alarms over consistency across different providers.
- The ongoing discussions aimed to gather user experiences to pinpoint whether these issues were widespread or isolated incidents.
- Effective prompt engineering techniques share spotlight: Prominent discussions surfaced regarding XML tag usage for improved model responses and educational resources for optimizing prompt engineering.
- Shared tutorials focused on prompt manipulation methods, providing insight into increasing user engagement in AI interactions.
- Integrations and API configuration confusion alert: Reports emerged about a hyperbolic key being linked to an unintended chargeable provider, stirring discussions on naming conventions and integration clarity.
- Users expressed the need for more robust error handling in JSON configurations, notably requesting to enforce integration key presence for improved setup reliability.
- Need for failure feedback during provider configuration: Discussion highlighted user frustrations over the inability to view failure details when configuring providers, complicating troubleshooting efforts.
- Users sought clearer mechanisms from OpenRouter to effectively identify and resolve integration issues, enhancing overall setup success.
Perplexity AI Discord
- Perplexity AI's Performance Challenges: Users reported Perplexity AI experiencing significant lag and service outages, raising concerns about high traffic on the platform which caused delayed responses.
- This ongoing issue prompted queries about the reliability of their service during peak usage times.
- API Errors Storming In: Members noted that API calls are returning errors like 500 and 524, leading to suspicions of widespread problems affecting operations.
- Concerns escalated when users discussed inconsistencies in citation outputs and timeout issues, calling for improved handling of API interactions.
- Comparative Analysis of AI Models: Users compared various AI models, observing that the original OpenAI model outperformed alternatives like You.com and Monica in notable scenarios.
- The upcoming Opus 3.5 model was highlighted as a potential game-changer, expected to surpass existing performance benchmarks.
- Emergence of Korean Emotion Video Dataset: Interest in the Korean Emotion Video Dataset peaked as it aims to enhance AI's emotional recognition capabilities, opening avenues for practical application.
- Discussions emphasized the excitement around its implications for both research and the emotional intelligence of AI systems.
- Microstrategy's Bold Bet on Cryptocurrency: Conversations centered on Microstrategy's billion-dollar investment, analyzing its potential impact on cryptocurrency markets.
- Members debated the strategic maneuvering from the company, evaluating risks associated with market stability.
HuggingFace Discord
- Challenges in Fine-tuning LLMs: Users are facing high GPU memory usage of 29G while fine-tuning models like Llama 8b using FSDP and BF16 AMP, prompting some to revert to raw PyTorch calls for debugging.
- This issue brings attention to resource management in LLM training and highlights the ongoing pursuit of optimizing memory consumption.
- Revamped Inference API Documentation: The Hugging Face Inference API documentation has been improved based on user feedback, featuring clearer rate limits and better code examples. The updates aim to simplify AI deployment, making it more user-friendly.
- This move shows Hugging Face's commitment to enhancing user experience as indicated in this announcement.
- New Medical LLMs and their Impact: The Chai-1 Foundation model excels in predicting molecular structures, contributing to advancements in medical AI, as noted in a recent update.
- Innovative models like BrainWave and DS-ViT are advancing evaluation techniques in diagnostics, pushing for greater transparency in model training datasets.
- Efficient Tokenizer Training for Multilingual Models: Discussion around retraining tokenizers highlights the flexibility to incorporate multiple languages while maintaining original data performance, though concerns about increased ambiguity arose.
- Suggestions for continued pretraining emerged as a method to mitigate these challenges, indicating the community's engagement with multilingual capabilities in NLP.
- Nitro Giveaway Sparks Interest: A member announced a Nitro giveaway, inviting participants to engage with the server, generating light-hearted interest among the community.
- Despite the humor, this announcement showcases the community's efforts in fostering interaction and connectivity.
Nous Research AI Discord
- StealC Malware Targets Chrome Users: A newly discovered malware called StealC restricts Chrome users by locking their browser and forcing them to reveal their Google passwords through a deceptive login screen, raising major security concerns.
- The malware utilizes a full-screen kiosk mode to trap users into submitting sensitive information, drawing logical parallels to traditional phishing methods.
- Tencent's GameGen-O Revolutionizes Video Games: Tencent introduced GameGen-O, a diffusion transformer model designed for generating open-world video games, leveraging extensive data from over a hundred next-generation games.
- The model trains on the OGameData, enabling more interactive gameplay and raising the bar for video game development through advanced simulation techniques.
- Innovative Approaches to Drag-based Image Editing: The InstantDrag pipeline enhances drag-based image editing by eliminating the need for masks or text prompts, utilizing a two-network system to achieve real-time, photo-realistic edits.
- By leveraging motion dynamics from real-world video datasets, this method significantly speeds up the editing process, showcasing potential for creative applications.
- Exploring Precision Annealing in AI Training: A member raised inquiries about precision annealing, suggesting pre-training at FP8 and switching to BF16 or FP32 to maximize throughput during the final training phase.
- They highlighted that this approach could optimize resource utilization in training regimes as it mitigates memory constraints.
- Evaluation Metrics & Performance Insights: In evaluations, QLoRA has shown improved performance over traditional LoRA methods, suggesting advantages in tuning efficiency.
- Members engaged in a comparative analysis of performance metrics across QLoRA, full fine-tuning, and original models, debating the percentage differences observed.
OpenAI Discord
- O1 Writes Extensive Essays: A member showcased O1's capability by generating a detailed essay covering major Minecraft updates from indev to 1.21, exciting the community.
- This highlights O1's advanced writing proficiency and its potential for creative applications.
- Fine-tuning Models presents Challenges: Users expressed concerns about fine-tuning results, reporting lack of improvement and wiggly training loss, prompting advice on model selection.
- The conversation underscored that fine-tuning may not always yield effective outcomes, prompting calls for strategic adjustments.
- Custom GPT Features Spark Questions: Inquiries about Custom GPTs' functionality revealed variability depending on the model used, with a request for clarity in model selection.
- Insights shared included potential links for references, emphasizing the need for clearer guidance on initiating conversations.
- Issues with ChatGPT Response Consistency: Users tackled the challenge of ChatGPT's inconsistency in following predetermined sequences, especially for battles in RPGs.
- Suggestions included a Discord bot format to gather responses before feeding them to ChatGPT for analysis, aiming to streamline interactions.
- Exploring Game Mechanics with ChatGPT: A scenario involving a 60% losing chance game was dissected, pointing out ChatGPT's tendency towards misleading interpretations.
- This discussion revealed the complexities in wealth accumulation strategy and the model's performance variability when addressing gaming contexts.
CUDA MODE Discord
- CUDA-MODE Hackathon Gains Remote Interest: A proposal for remote participation in the upcoming CUDA-MODE hackathon sparked mixed discussions regarding its feasibility and organization.
- While some members support a remote track, others noted challenges with large in-person events.
- Triton Kernel Launch Overhead Issues: Concerns were raised about kernel launch overhead in Triton, with reports that it consumes 10-20% of execution time for mid-sized matrices.
- A GitHub issue detailed that kernel execution takes 80us but launching it takes 220us.
- Significant Boosts from INT8 Mixed-Precision Training: The latest torchao 0.5 release showcases INT8 mixed-precision training yielding up to 70% speedup on NVIDIA 4090 GPUs without noticeable accuracy loss.
- This progress highlights enhanced training efficiency particularly beneficial for consumer GPUs with maintained convergence.
- Liger-Kernel v0.3.0 Is Now Live!: Liger-Kernel v0.3.0 launched with major advancements and community appreciation for their support.
- The team invites the community to experiment with the new features and provide feedback.
- BitNet Training Faces Efficiency Challenges: Recent discussions indicate ongoing struggles with BitNet model training, with no significant progress reported in recent trials.
- Members raised concerns about GPU inefficiencies linked to bitwise operations, emphasizing the need for custom hardware approaches.
LM Studio Discord
- GPU Acceleration Troubles Persist: Users reported issues with GPU acceleration not being utilized in LM Studio, prompting checks under Developer > LM Runtimes. A successful update led to one user's GPU usage climbing significantly.
- Troubleshooting practices revealed potential configuration misunderstandings, leading to better setups for increased efficiency.
- Model Compatibility Woes: LM Studio predominantly supports GGUF models, but not all listed models function as expected, particularly in multimodal tasks. This limitation raised concerns about model performance and feature accessibility.
- Participants shared insights into features that remain unusable, indicating a gap between expectations and reality in utilizing LM Studio.
- Strix Halo APU Capability Hype: The Strix Halo APU's potential for running large AI models was debated, with claims of allocating up to 20GB to its iGPU. Support for ROCm was noted, although concerns about offloading tasks affecting performance arose.
- Competing views on processing efficiency surfaced, stressing the importance of balancing CPU and GPU tasks.
- RTX 4090 Speeds Up AI Queries: With three RTX 4090 cards, one member reported achieving 110 tokens per second during queries. This sparked conversations about power supply setups to harness such performance effectively.
- Discussions centered around optimizing configurations for improved power efficiency and GPU performance.
- Optimizing RAM for LLMs: The need for sufficient system RAM to run large models led to anecdotes suggesting 192GB DDR5 could support models like Llama 3.1. However, it was argued that 64GB might be sufficient if models are well-optimized.
- Participants exchanged optimization strategies, balancing between RAM capacity and model requirements.
Latent Space Discord
- OpenAI's o1 Models Introduced: OpenAI has released o1 models designed for improved reasoning on complex tasks, attracting attention for their potential in scientific and coding applications.
- The new models reportedly outperform older versions but still struggle with large edits, a challenge Cursor AI is addressing with their specialized coding assistant.
- Funding for AI Startups Soars: 11x AI raised 24 million in Series A funding, highlighting their rapid growth with a 15x increase in ARR and the launch of new digital workers.
- Similarly, Supermaven AI secured 12 million to develop an AI-focused text editor that integrates seamlessly with their models.
- HTEC's report on AI copilots: The nearshore consultancy HTEC published a report on their experiences with 26 AI coding tools, although access requires signing up.
- Members discussed whether the brief usage and limitations noted in the report truly reflected the tools' capabilities.
- Voice Mode API Discussion: The episode delves into the new Voice Mode API, which allows for more interactive and dynamic conversation capabilities.
- It emphasizes how this feature can transform user interactions with AI on various platforms.
- ChatGPT Scaling Strategies: Strategies for scaling ChatGPT were discussed, particularly focusing on increased latency and prompt/schema caching techniques for optimization.
- The team addressed concerns over model reproducibility and evolving tiering and rate limiting strategies for the API.
Interconnects (Nathan Lambert) Discord
- OpenAI's o1 models raise eyebrows: OpenAI's recent release of o1-preview and o1-mini models has sparked discussions regarding their intriguing reasoning patterns and the possible influence of user interaction data on model development.
- A user highlighted a surprising finding that mini does not reason longer than preview, yet generates lengthier responses, challenging expectations.
- Humanity's Last Exam Launch Announced: Dan Hendrycks introduced Humanity's Last Exam, inviting submissions for tough AI questions with a $500,000 prize pool due by November 1, 2024, igniting mixed responses concerning its implications for AI regulation.
- Concerns emerged over Hendrycks' lobbying efforts and connections to politics, potentially influencing future AI policies based on performance metrics.
- Reverse Curriculum Learning discussed among RL enthusiasts: Emerging papers on Reverse Curriculum Learning in LLMs have prompted discussions about its limited use in the RL community, with users noting it has not gained widespread acceptance.
- Members identified Reverse Curriculum Learning as clunky and suitable primarily for niche applications, contributing to its rarity in broader contexts.
- Excitement Over LLM Model Developments: Anticipation is growing for future LLM advancements scheduled for 2025, with discussions reflecting increased enthusiasm over potential breakthroughs in model capabilities.
- Members recognized a significant shift in sentiment, noting that the landscape has shifted, marking potential milestones akin to past advancements.
- Poe Subscription Service Evaluation: Users debated their experiences with the Poe subscription service, expressing mixed feelings about its usability despite $20 granting access to all available LLMs.
- Concerns over interface design were raised, indicating a preference for more appealing aesthetics compared to competitors like Claude and ChatGPT.
Cohere Discord
- Fei-Fei Li's Reasoning Method Explored: Members expressed curiosity about Fei-Fei Li’s techniques for solving reasoning problems, aiming to gather insights on her approaches in the AI context.
- There’s a notable desire for deeper understanding among engineers about methodologies like hers that could inform ongoing AI advancements.
- Command-R-Plus-08-2024 Output Issues: A user reported that the Command-R-Plus-08-2024 model is producing more repetitive outputs compared to previous versions, particularly in creative tasks.
- This led to discussions on how extended prompts could further impact performance, urging exploration of alternative models.
- Cohere Developer Office Hours Announced: Cohere hosts Developer Office Hours today at 1 PM ET, discussing updates in the Command model family including new features in RAG and Safety Modes.
- Attendees can expect insights into the significant improvements in model efficiency and practical applications.
- Implementing Safety Modes for Enhanced Control: Cohere introduced Safety Modes aimed at giving enterprise customers better control over model usage and interactions.
- This update reinforces governance while ensuring that model effectiveness remains intact.
- Job Posting Concerns and Community Focus: A member called for removing non-Cohere related job postings from discussions, emphasizing the need for relevance in community topics.
- This reflects a commitment to keeping discussions tightly aligned with the interests and purposes of the Cohere community.
Stability.ai (Stable Diffusion) Discord
- Users Struggle with FLUX Models: Members reported issues with running FLUX models, specifically regarding formats like
.sftand.safetensor, as well as compatibility with tools like Forge.- It was recommended to switch to ComfyUI for better support, with users sharing experiences around specific model sizes.
- Creating Characters with Style: A user sought advice on generating a character similar to Cheetara using Stable Diffusion checkpoints and prompt phrasing techniques.
- Discussion included successful checkpoints for character art tailored for later 3D modeling, referencing a Cheetara GIF for inspiration.
- Mastering Image Editing: Recommendations emerged for techniques in removing text from images and utilizing inpainting methods, with tools like GIMP being highlighted.
- Users discussed various AI tools for enhancing images while preserving quality, including tutorials by Piximperfect.
- Animating Characters with ControlNet: Insights flowed about leveraging ControlNet and LoRA training for creating vector-style character animations, emphasizing the use of proper training examples.
- Contributors shared tips on employing ControlNet technologies for improving character posing and structure in artistic renderings.
- Tech Support Woes: A user encountered errors during Stable Diffusion installation and was advised to share their error logs in the support channel for troubleshooting.
- Helpful links to installation guides were shared, stressing the importance of detailed logs.
Modular (Mojo 🔥) Discord
- User Verification Process Goes Live: The Discord server has implemented a user verification process requiring members to submit their email addresses through a bot in the #verify channel, allowing continued read access for unverified users.
- Members opting out of verification will face limited messaging capabilities, emphasizing the importance of this new step.
- Onboarding Questions Introduced to Streamline Experience: After email verification, users will answer two multiple-choice onboarding questions aimed at enhancing their server experience.
- This initiative reflects an effort to improve the onboarding process for both new and current members.
- Mojo Struggles with Python Interoperability: Discussions revealed that Mojo currently cannot import Python modules or call its functions, hindering effective interoperability, which is crucial for seamless integration.
- Participants are keen on methods for achieving zero-copy data exchanges between Mojo and Python, particularly in performance-sensitive contexts.
- Count Leading Zeros Faces Compile-Time Limitations: Users reported that the
clzfunction struggles to operate at compile time due to dependency on LLVM intrinsics, which are not executable at this stage.- An alternative implementation for counting leading zeros was proposed, highlighting the need for better compile-time capabilities within the standard library.
- New Channel for Server Changes Discussion: A dedicated channel for discussing upcoming server changes has been established, allowing members to share suggestions and pose questions.
- This move signifies a commitment to enhancing the user experience through community input and dialogue.
Eleuther Discord
- Understanding Mixed Precision Training Challenges: While mixed precision training can enhance performance by storing models in both fp32 and fp16, it also doubles the computational load during the forward pass—a noteworthy trade-off.
- Members emphasized the importance of balancing speed and resource utilization amidst budget constraints.
- CoreWeave's Significant Valuation: CoreWeave is in negotiations to sell shares that value the company at $23 billion, reflecting its prominent status in the AI-driven cloud computing sector.
- This move has generated substantial interest from notable financial media, highlighting the competitive landscape in the industry.
- AI's Societal Implications Explored: Discussions reflected on how OpenAI has effectively enabled greater access to information, likening it to placing a 'PhD in everyone's pocket' with minimal public reaction to these changes.
- Members underscored a need for deeper conversations about the transformative effects and ongoing integration of AI into daily life.
- RWKV team pushes RNN boundaries: The RWKV team is making waves in RNN architecture advancements, with contributions recognized particularly from Smerky and others.
- This innovative push has garnered attention and praise for its potential impacts within the community.
- Concerns about Overfitting Models on Small Datasets: A member expressed difficulty overfitting a model using only 9 images, sparking discussions about possible learning issues when working with larger datasets.
- The consensus was that failure to overfit such a small sample could indicate even larger struggles ahead.
LlamaIndex Discord
- LlamaParse excels in parsing Excel data: In a recent video, advanced Excel parsing abilities in LlamaParse are showcased, including handling multiple sheets and complex tables. LlamaParse utilizes recursive retrieval to summarize complex tables automatically, enhancing efficiency.
- This feature provides a significant improvement in usability, especially for users dealing with intricate Excel files.
- TypeScript workflows introduced in LlamaIndex: LlamaIndex has now integrated workflows into TypeScript, as noted in this announcement. This new feature aims to streamline development processes for TypeScript users.
- The integration aids in making the framework more accessible and efficient for developers working with TypeScript.
- Importance of Unit Testing in LLM applications: Unit testing is emphasized as crucial for mitigating stochasticity in LLM applications, highlighted in a blog post detailing building and testing a RAG app with CircleCI. Proper unit testing is vital to prevent unexpected behaviors in AI applications.
- The discussion underlines a commitment to quality and reliability in AI-driven projects.
- Vectara-Agentic library simplifies RAG implementation: Check out vectara-agentic by a member, a library that simplifies building agentic RAG powered by LlamaIndex and Vectara. It provides tools to construct agents capable of planning and tool use compatible with various model providers.
- This flexibility allows developers to implement RAG solutions more efficiently.
- Local LLM offers cost optimization: Members discussed that running a Local LLM can significantly reduce costs compared to OpenAI services. The total cost of ownership (TCOS) was noted as an important factor when choosing between OpenAI and local models.
- This consideration emphasizes the growing trend of optimizing AI solutions for better cost efficiency.
OpenInterpreter Discord
- Understanding GPU Diminishing Returns: The point of diminishing returns for GPUs shows up after 2-3 GPUs for gaming and 4-6 GPUs for rendering, largely due to PCIe bandwidth limitations.
- Documentation issues were cited as a concern that's affecting user experience with GPU setups.
- Non-Streaming Responses in Open Interpreter: Members discussed how to stop streaming responses in command line mode; options included using the --plain flag or
claude-3.5model.- This feedback aims to improve usability and comfort while interacting with the command line.
- Confusion Over ChatGPT O1 Model Release: Concerns arose regarding ChatGPT's O1 model, with speculation that its release could undermine existing alternatives, although this was challenged by another member.
- While O1 shines in reasoning, critiques noted its inability to execute code tasks as effectively as earlier models like model 4.
- Livekit Setup Errors Alert: Around 90% of users reported issues with Livekit setup, attributing their struggles to inadequate documentation.
- A proposal was made to create a comprehensive setup guide to enhance user support.
- Exciting MoA LLM Library for Orchestration: The MoA LLM library introduces a way to orchestrate LLMs in a neural network-inspired architecture, aimed at improved model collaboration.
- This open-source initiative provides a framework for integrating multiple LLMs efficiently.
OpenAccess AI Collective (axolotl) Discord
- Debate on O1 Model's Effectiveness: There's a mixed reception around the O1 model; while some celebrate its Chain of Thought interface, others find its mechanical responses disappointing.
- One member mentioned that despite its solid UI, the overall performance still leaves much to be desired.
- OpenAI's O1 Development Timeline Clarified: A member revealed that OpenAI has been developing O1 (Strawberry/Q*) for a long time, contrary to claims of it being a rapid result.
- They pointed out that O1 employs an agentic chain of thought, showing resilience against common pitfalls like hallucination.
- Tokenization Errors from Masking Issues: A member reported a tokenization error emerging from new per-turn masking strategies that obscure the last end of turn token.
- They linked the issue to a comprehensive bug report they filed on GitHub.
- Phi 3.5's Frustrations in Classification: Members expressed their struggles with developing a Phi 3.5 sentence classifier that fails to produce the correct classification output.
- One opted to share their dumb sentence classifier and confessed to potentially giving up for now.
- vLLM and Adapter Compatibility Issues: A discussion emerged surrounding vLLM's failure to properly interpret the
qkv_projlayer, impacting models trained with Axolotl’s adapters.- Interestingly, while a LORA model showed no learning during merging, it performed well as a standalone adapter atop the base model.
LangChain AI Discord
- GenAI/RAG/CV Consultations Available: A member announced offering consultation services in GenAI, RAG, and CV to assist startups in prototype development.
- Interested members can reach out directly for collaboration opportunities.
- OpenAI Sparks Societal Reflections: Concerns were raised regarding OpenAI's influence on access to knowledge while society appears unchanged.
- Discussion included thoughts on how accelerated automation might lead us into a post-scarcity era.
- LangGraph Cloud Pricing Uncertainty: A member inquired about potential costs for LangGraph Cloud post-beta phase, considering whether to develop a custom FastAPI wrapper.
- Concerns about feasible long-term pricing models were a key point of discussion.
- Streaming LLM Output Parsing Problems: Parsing issues with incomplete JSON strings during streaming LLM output were discussed, particularly with Pydantic parsers.
- Switching from
parse_resulttoparsemethods yielded better results despite initial skepticism.
- Switching from
- Chat History Management Challenges: Users expressed difficulties in managing chat history with LangChain, especially in tracking app-specific messages.
- They highlighted issues in maintaining transactional integrity when integrating this data.
DSPy Discord
- Optimize RAG Query Structure: A member suggested optimizing RAG in a singular module by packing a 'context' field with data from memory and prompts to enhance results. This approach received confirmation with reference to this simple RAG example.
- Another member acknowledged the practical nature of this strategy, noting advantages in data handling.
- Visual LLM Use Case in DSPy: A query arose about the potential of using visual LLM models in DSPy for image descriptions, which another member speculated could be available by next week. A promising pull request for GPT-4 Vision API was cited, hinting at ongoing integrations.
- The anticipated feature triggered enthusiastic anticipation of the upcoming capabilities.
- Seeking GitHub Contributions: Discussion sparked when a member expressed interest in contributing to the DSPy project and inquired about available bounties. Insights revealed that additional integration changes are on the horizon, with an expected completion timeline of 7-10 days.
- The prospect of contributions generated excitement within the community, indicating a collective eagerness for collaborative development.
tinygrad (George Hotz) Discord
- Runtime Type Checking Added to Tinygrad: George Hotz announced
TYPED=1support for runtime type checking in Tinygrad, revealing type errors during testing withpython3 test/test_ops.py. A GitHub pull request proposes a fix for most type errors, leaving one unresolved.- The community feedback highlights the importance of robust type checking, reinforcing the necessity for clean coding practices.
- Tinygrad Fails Tests on AMD with 0.9.2: A user reported issues upgrading Tinygrad from version 0.9.0 to 0.9.2, encountering an AttributeError related to
struct_kfd_ioctl_criu_args. The suspected root cause is a potential mismatch between the kernel version and the library's requirements.- Diagnostics indicate a possible gap in Tinygrad's compatibility documentation and troubleshooting guidance for AMD users.
- Tinygrad Libraries Discussion Sparks: Members discussed the development of libraries within the tinygrad ecosystem, specifically mentioning timm and torchvision as candidates. This conversation prompted inquiries about the practical necessity and current implementations of such libraries.
- Discussion escalated when a user questioned the actual utility of these libraries with tinygrad, signaling a need for clarity in integration.
- Investigating VRAM Allocation Spikes: A member sought advice on diagnosing spikes in VRAM allocation during Tinygrad operations, highlighting a knowledge gap in memory monitoring tools within the framework. This inquiry underscores the need for more robust diagnostics.
- Understanding VRAM behavior is crucial for optimizing performance and preventing crashes during intensive processing tasks.
- Tensor Modification Error Reported: A user encountered an error when modifying a Tensor in Tinygrad, especially during element incrementation. They referenced an open GitHub issue that aligns with their problem, focusing on the contiguous property.
- The findings from this user reinforce the importance of comprehensive testing and documentation regarding tensor operations.
Torchtune Discord
- Mastering Checkpoints Management: To implement checkpoints at specific token counts, utilize the
num_tokensfield while filtering padding tokens as detailed here. Adjustments in the saving logic are crucial for accurate tracking and resuming from saved states.- Members emphasized the necessity of an all gather to account for totals across ranks during training.
- Cosine Learning Rate Decay Introduced: The integration of
torchtune.modules.get_cosine_schedule_with_warmupfor cosine decay in learning rates is discussed among members, currently applied in LoRA recipes. It's suggested to bypass deriving steps from epoch number for mid-epoch resumes for smoother transitions.- Members are advised to follow these implementations closely for their inclusion in the full finetune recipe.
- Debate on CUDA vs CPU Operations: A query on whether token operations could be conducted on CPUs was raised, with confirmation that
num_tokensare not CUDA tensors advising CUDA use instead. The preference for CUDA processes persists while questions about CPU efficiency remain.- Discussions reveal uncertainty but show a clear inclination towards optimal performance using CUDA for these operations.
- Online Packing Support on the Horizon: The team is set to implement online packing as soon as they add support for iterable datasets. This move promises to enhance efficiency for bulk data processing.
- Members expressed excitement about the improved capabilities this will bring to future projects.
- CI GPU Test Failures Cause Concern: Ongoing issues with CI related to GPU tests, especially
test_eleuther_eval.py, stem from import errors in transformers.pipelines, with 504 tests passing but significant errors halting completion. This has raised alarms regarding overall system stability.- Members are actively discussing potential fixes and investigating anomalies to ensure smoother CI operations.
LAION Discord
- Generative AI crafts art instantly: A member showcased an artwork crafted with NotebookLM, fully generated in just 2 minutes. They shared a thrilling YouTube video capturing this rapid creation.
- What a time to be alive was their enthusiastic remark regarding the capabilities of generative AI.
- Steve Mould’s Illusion Exploration: A member shared This new type of illusion is really hard to make on YouTube, which dives into AI-generated illusions. The video includes insights about the Jane Street internship, watch it here.
- They noted that generative AI creates images that shift under varying lighting conditions.
- Diffusion Illusions Take Center Stage: A member introduced the Diffusion Illusions website, featuring interactive optical illusions produced via diffusion models. The site is linked to their project accepted at SIGGRAPH 2024, including a YouTube talk.
- Key contributors include Ryan Burgert and Xiang Li, showcasing compelling applications of diffusion models.
- Quest for Text in Images: A member sought advice on efficiently embedding text within images to create a comprehensive dataset, with aspirations of scaling to millions of images.
- This discussion highlights the demand for automating text-embedded image dataset creation for AI applications.
MLOps @Chipro Discord
- Pretrained VLMs Require Serious Compute: A member raised concerns about lacking compute resources for using pretrained vision-language models (VLMs), which by nature demand substantial computing power.
- Discussions emphasized that the efficacy of these models heavily relies on having appropriate hardware to handle their intensive processing requirements.
- Anomaly Detection Needs Clarification: One member questioned if anomaly detection should focus on logs or actual time-series data, prompting a dive into data types.
- Several suggested methodologies for time-series analysis were shared, including transformer models, Kalman Filters, and isolation forests, with recommendations to use z-scores for error evaluation.
Gorilla LLM (Berkeley Function Calling) Discord
- Model Struggles with Function Calling: Discussions revealed that the model is currently only capable of chatting and scores a 1 in relevance, failing to execute any function calls and receiving a 0 in other capabilities.
- This bug limits the model's functionality significantly, hampering user experience and expectations.
- Model Produces Chat Instead of Function Call: Members raised concerns that the model outputted conversational responses instead of executing function calls, causing miscommunication and incorrect markings.
- This results in an automatic marking of the attempt as incorrect, affecting accuracy in processing responses.
- Invalid Syntax Triggers AST Decoder Failure: An error message flagged 'Invalid syntax', leading to a failure in decoding the Abstract Syntax Tree (AST), categorized as 'ast_decoder:decoder_failed'.
- This issue indicates a critical problem in interpreting the model's output, posing challenges for troubleshooting.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!