[AINews] 5 small news items
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
AGI Realism may be what Humanity Needs
AI News for 6/4/2024-6/5/2024! We checked 7 subreddits, 384 Twitters and 29 Discords (401 channels, and 3628 messages) for you. Estimated reading time saved (at 200wpm): 404 minutes.
- OpenAI still says ChatGPT's voice mode is "coming soon"
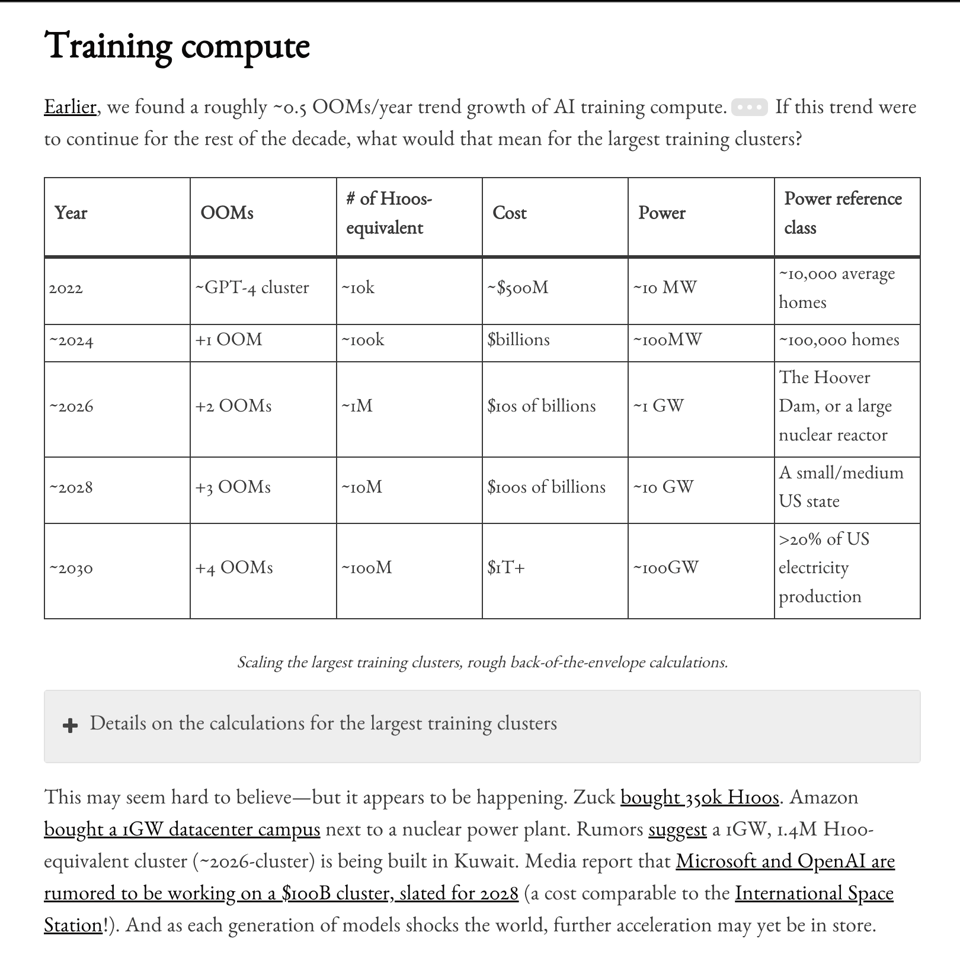
- Leopold Aschenbrenner launched a 5 part AGI timelines piece dedicated to Ilya together with a Dwarkesh pod, predicting a trillion dollar cluster on current rates of progress
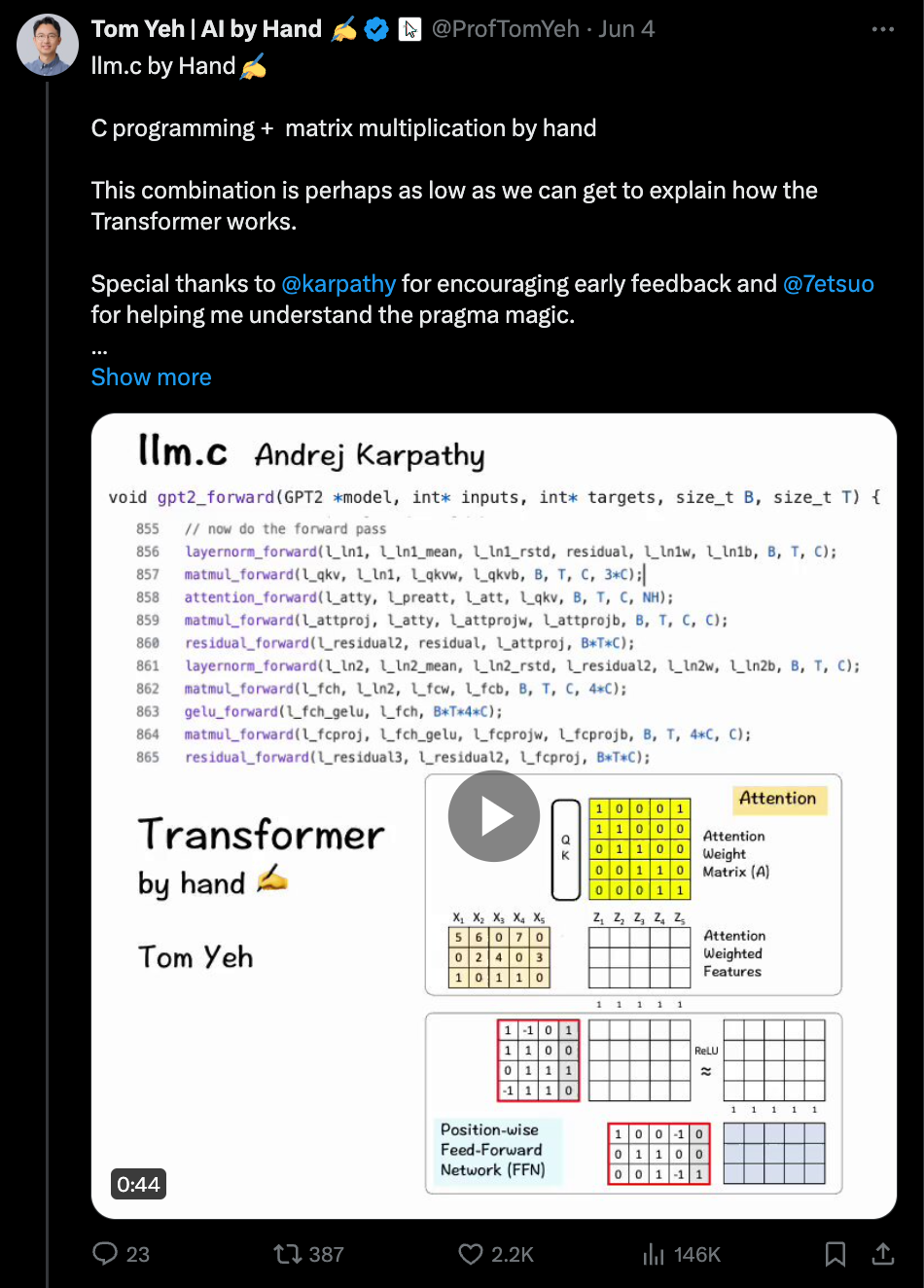
- Tom Yeh hand-illustrates llm.c
- Will Brown dropped a comprehensive GenAI Handbook

- and Cohere completed its $450m raise at $5b valuation but has not yet announced it.
The Table of Contents and Channel Summaries have been moved to the web version of this email: !
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- New Models and Architectures: @arankomatsuzaki shared a DeepMind paper on Uncertainty Quantification in LLMs. @hardmaru highlighted xLSTM, an extension of LSTM that performs favorably compared to Transformers and State Space Models in performance and scaling. @omarsar0 discussed a study on the geometry of concepts in LLMs, finding that simple categorical concepts are represented as simplices and hierarchically related concepts are orthogonal.
- Efficiency Improvements: @omarsar0 shared a paper proposing an implementation that eliminates matrix multiplication operations from LLMs while maintaining performance at billion-parameter scales, potentially reducing memory consumption by more than 10x. @rohanpaul_ai discussed a survey on Parameter-Efficient Fine-Tuning (PEFT) methods for large models, categorizing them into additive, selective, reparameterized, and hybrid approaches.
- Alignment and Safety: @RichardMCNgo outlined a scenario for how building misaligned AGI could lead to humanity losing control, with an AGI exploiting privileged access to a lab's servers. @omarsar0 shared an overview of methods for automated alignment of LLMs, exploring directions like aligning through inductive bias, behavior imitation, model feedback, and environment feedback.
Tools and Frameworks
- LangChain and LangGraph: @hwchase17 introduced a new DeepLearning.AI course on building AI agents using LangGraph, an extension of LangChain for developing controllable agents with persistence and agentic search capabilities. @llama_index demonstrated how a longer context window in a LlamaIndex agent attempting to answer a multi-part question from heterogeneous documents leads to better performance.
- Hugging Face and NVIDIA Integrations: @ClementDelangue noted that Hugging Face is becoming a gateway for AI compute, with NVIDIA NIM now directly accessible from the Hugging Face Hub for the Llama3 model. @rohanpaul_ai discussed Optimum-NVIDIA, a Hugging Face inference library leveraging NVIDIA's FP8 format and TensorRT-LLM software for faster LLM inference.
- Mistral AI and Fine-Tuning: @sophiamyang announced the release of Mistral's fine-tuning API, allowing users to fine-tune their own Mistral models and deploy them efficiently on La Plateforme. @HamelHusain shared a live demo of the API, walking through data preparation, hyperparameter selection, and integrations.
Datasets and Benchmarks
- Synthetic Data Generation: @_philschmid outlined a pipeline for generating synthetic data for fine-tuning custom embedding models, involving creating a knowledge base, chunking data, generating questions using an LLM, optionally generating hard negative examples, deduplicating and filtering pairs, and fine-tuning embedding models with Sentence Transformers 3.0.
- Evaluation Metrics: @abacaj built a benchmark for analyzing malicious Solidity contract code, finding that only top closed models like GPT-4o and Claude-Opus can occasionally identify malicious code, while open models fail more than 95% of the time. @mervenoyann noted that MMUPD, a comprehensive evaluation benchmark of multi-modal LLMs in video analysis, is now hosted on the Hugging Face Hub as a leaderboard.
- Domain-Specific Datasets: @arohan highlighted Google's Gemini 1.5 model outperforming proprietary models on many subtasks in the Video-MME benchmark for multi-modal LLMs in video analysis. @rohanpaul_ai shared a paper comparing the performance of Gemini 1.5 Flash and GPT-4o on the Video-MME benchmark.
Applications and Use Cases
- Enterprise AI and RAG: @llama_index shared a full video tutorial on building enterprise RAG (Retrieval-Augmented Generation) with Bedrock and Ragas.io, covering synthetic dataset generation, critic-based evaluation, and fine-tuning. @RazRazcle interviewed @gogwilt, Co-founder of Ironclad, discussing how they succeeded in using AI for contract negotiation, with over 50% of contracts for top customers negotiated by Ironclad AI.
- AI Assistants and Agents: @svpino built an AI assistant that listens and uses the webcam to see the world, explaining the process in a video tutorial. @bindureddy predicted that AI assistants will become essential and people's dependence on them will grow exponentially.
- Creative AI and Multimodal Models: @suno_ai_ announced a contest to create songs from any sound using their VOL-5 model, with winners receiving early access and one winner's video being shared on social media. @ClementDelangue showcased an AI-powered tool for making non-player characters in video games playable, a collaboration between @cubzh_, @GigaxGames, and @huggingface.
Discussions and Opinions
- AI Timelines and Risks: @leopoldasch argued that AGI by 2027 is strikingly plausible based on the progress from GPT-2 to GPT-4 and projected trends in compute, algorithmic efficiencies, and model capabilities. @_sholtodouglas described Leopold's essay as capturing the worldview of key players in the AI field, predicting a wild few years as timelines potentially hold.
- Compute and Scaling: @ylecun proposed the concept of objective-driven AI, where intelligent systems require the ability to reason, plan, and satisfy guardrails according to their internal world model, and the key challenge becomes designing appropriate guardrails. @ethanCaballero noted that as it becomes clear that energy and power are the new bottlenecks for scaling to AGI, certain stocks may skyrocket in the coming years.
- Open Source and Democratization: @ylecun shared an article discussing the benefits and risks of open-source AI versus proprietary AI controlled by a few big players, arguing that those who worry most about AI safety tend to overestimate the power of AI. @far__el predicted that Meta and other companies will not open-source powerful AI, and we are headed towards an "AGI monarchy".
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Here is a summary of the recent AI developments, organized by topic and with key details bolded and linked to relevant sources:
AI Model Releases and Capabilities
- Potential GPT-5 Release: The Information reports that GPT-5 may be released in December 2024, suggesting significant advancements in OpenAI's language model capabilities.
- Advanced AI Models: Microsoft CTO Kevin Scott claims that upcoming AI models can pass PhD qualifying exams, indicating substantial improvements in memory and reasoning abilities.
- Character Voice Generation: A YouTube video demonstrates GPT-4o's ability to generate character voices, showcasing the model's versatility in speech synthesis.
- Robotic Future: Nvidia promises that "everything is going to be robotic" as AI becomes more advanced, hinting at the increasing integration of AI in various domains.
- AI Clones in the Workplace: Zoom's CEO predicts that AI clones will eventually handle a significant portion of people's jobs, potentially transforming the nature of work.
AI Outages and Concerns
- Simultaneous AI Service Outages: Major AI services ChatGPT, Claude, and Perplexity experienced simultaneous outages, raising concerns about the reliability and impact of these services.
- Prolonged ChatGPT Downtime: ChatGPT was down for approximately 12 hours, causing issues for users relying on the service and highlighting the need for robust infrastructure.
- Whistleblowers and Safety Concerns: Current and former OpenAI employees, along with other AI researchers, are willing to reveal confidential information to the public regarding AI risks and safety concerns. An OpenAI safety researcher quit and signed a letter calling for AI labs to support employees speaking out about these issues.
- Cybersecurity Vulnerabilities: Leopold Aschenbrenner was fired from OpenAI after warning the board about cybersecurity vulnerabilities that China could exploit, raising questions about the handling of security concerns within the company.
- Race for AI Dominance: OpenAI insiders warn of a "reckless" race for AI dominance in a New York Times article, highlighting the potential risks associated with the rapid development of AI technologies.
AI Investments and Partnerships
- Elon Musk's Chip Allocation: Elon Musk instructed Nvidia to prioritize shipping processors to X and xAI over Tesla, suggesting a focus on AI development in his companies.
- UAE-US AI Partnership: The UAE is partnering with the US in AI, using its $2 trillion sovereign wealth fund to become a global AI powerhouse, highlighting the increasing international competition in the field.
- OpenAI-Google Collaboration: Ilya Sutskever and Jeff Dean published a US patent together on May 30, 2024, suggesting a potential collaboration between OpenAI and Google in AI research and development.
AI Models and Benchmarks
- SDXL Model Parameters: The SDXL model has 2.6B parameters for the UNET, 3.5B parameters including text encoders, and 6.6B parameters for the full pipeline with the Refiner, providing insights into the model's architecture and complexity.
- Yi-1.5-34B Model Performance: The Yi-1.5-34B model is the highest-ranked ~30B model and Apache 2.0 model on the LMSYS leaderboard, demonstrating its strong performance compared to other models of similar size and licensing.
- L3-MS-Astoria-70b Model Ranking: The L3-MS-Astoria-70b model becomes the top-ranked model on the Uncensored General Intelligence Leaderboard, showcasing its capabilities in general intelligence tasks.
- GPT-4o Usability: Despite GPT-4o's high rankings on MMLU and LMSYS benchmarks, some users find it harder to prompt and follow instructions compared to other models, highlighting the importance of user experience and model usability.
AI Discord Recap
A summary of Summaries of Summaries
1. Finetuning Techniques and Model Integration:
- Members discussed the importance of finetuning models with tools like Deepspeed zero2 and Qlora, highlighting successful integration for Llama3 and memory management strategies like disk offloading (Unsloth AI).
- Mistral Fine-Tuning Hackathon generated excitement, encouraging participants to explore Mistral's new capabilities, detailed in the Mistral tutorial and corresponding YouTube demos (LLM Finetuning (Hamel + Dan)).
2. Issues in Model Training and Optimization:
- Members expressed frustration over OOM (Out of Memory) errors during model training, seeking solutions like efficient VRAM management techniques and validating YAML configurations (OpenAccess AI Collective).
- Troubleshooting advice was shared for issues including CUDA library mismatches in Jarvis Labs and GGUF compatibility in LM Studio (HuggingFace and LM Studio).
3. New Tools and Resources in AI:
- Stable Audio Open was released by Stability AI for generating short audio pieces, emphasizing local fine-tuning with custom data (Stable Diffusion).
- Various valuable resources were shared, such as a comprehensive LLM resource guide by William Brown and the FineWeb technical report for high-performance LLMs (HuggingFace).
4. Community Concerns and Collaborative Projects:
- Concerns over credit distribution and server performance were widely discussed, with numerous members reporting issues receiving credits or facing 502 Gateway errors (LLM Finetuning (Hamel + Dan) and OpenRouter).
- Collaborative efforts in learning and implementing new AI features included discussions on Flash-attn GPU compatibility and RAG chatbot integration with tools like Verba (Nous Research AI and LangChain).
5. Security and Ethical Discussions in AI:
- Security concerns were raised following a Hugging Face breach where private tokens were exposed, leading to discussions on the reliability of internet-based data (HuggingFace).
- Ethical issues of AGI development incentives and ensuring fair model use were debated, stressing the importance of aligned AI behavior and proper reward models within LLM architectures (Interconnects and Latent Space).
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
- Model and Workshop Mania: Engineers actively debated the best code models for fine-tuning, with many citing a lack of specific resources or models that stand out. Meanwhile, workshop attendees clamored for access to slides and links, with recommendations to apply for Modal credits via a credit form to claim $500 bonuses.
- Credit Confusion Across Platforms: Across various platforms, users expressed confusion regarding credit distribution, such as Modal's additional $500 and Replicate's redemption process. For assistance with Modal's offer, Charles extended help via email, while for issues with Replicate credits, users were directed to message with their details for support.
- Curating Fine-Tuning Resources: A comprehensive list of LLM fine-tuning explainers was spotlighted, available via this LLM guide. Additionally, the excitement was apparent for the Mistral Fine-Tuning Hackathon with its development coinciding with an API launch, suggesting heightened interest in exploring Mistral's capabilities and resources like the fine-tuning tutorial and YouTube demos.
- Honing Fine-Tuning Techniques: The community shared knowledge and sought advice on Mistral fine-tuning, including discussions on vertical integration, API advantages, and memory management. Moreover, Predibase users extolled its methodology for reusing base models and suggested improvement for an enhanced fine-tuning process such as access to more epochs and UI data filtering walkthroughs.
- Troubleshooting Tech Stacks: Various challenges in setting up different technologies such as Axolotl, Jarvis Labs' CUDA version mismatches, and debugging LangChain notebooks were addressed with collaborative problem-solving. Solutions ranged from using Docker for Axolotl ease to updating CUDA libraries and advising environment variable configurations for seamless Langsmith integration.
Unsloth AI (Daniel Han) Discord
- Faster, Leaner Pretraining on Unsloth AI: Unsloth AI has introduced capabilities to continually pretrain LLMs with double the speed and half the VRAM previously required by HF+FA2, as detailed on their blog.
- No Medusa Support Yet for Unsloth: Engineers confirmed that Unsloth does not support fine-tuning using Medusa, based on a provided GitHub link, but it offers improved unsloth updates like disk offloading for lm_head/embed_tokens and automatic tokenizer fixes.
- VRAM Management Techniques in Discussion: Techniques for managing VRAM, including the use of cosine learning rates and selective offloading, were shared, noting the optimization potential for H100 GPUs and strategies to free memory for running multiple models via
delcommands.
- Challenges in Multi-Nodal Implementation: While multi-GPU support is active, a slight delay is anticipated for multinodal support implementation, which is essential for projects like 70B fine-tuning. Meanwhile, VRAM-saving alternatives like LoRA adapter use during fine-tuning were also touched upon.
- Open Source TTS Models Scouted for Side Projects: A member's request for "good OS TTS models" for a waifu companion app/RPG yielded the recommendation of the "xttsv2 -rvc pipeline," demonstrating active collaboration in Open Source resources among engineers.
Perplexity AI Discord
- Perplexity AI Hits a Snag: Users reported downtime and frustrations with model selection in Perplexity AI, with comments on extensive waiting periods and a quirky interface where requests for image generation are met with written descriptions instead of actual graphics.
- AI Model Smackdown: Debates compared ChatGPT-4o with Claude 3, noting Perplexity's unique approach of using internal search indexes, and shared resource links including presentation tips and an overview of Perplexity's search functionality.
- Searching Beyond SEO: Engaging in the backend processes, discussions pointed out that Perplexity AI differentiates itself by not relying on third-party services for crawling and indexing, leading to higher-quality search results that are less manipulated by SEO tactics.
- Diving Into Outages: An article analyzing a major outage of DCcT was shared, providing insights into the technical issues faced by Perplexity AI.
- Knowledge Expansion Through Shared Links: Users enhanced discussions by referencing Perplexity AI search results on various topics, including articles on dailyfocus, Bitcoin, and shared reminders concerning the necessity of making threads shareable, with guidelines attached.
CUDA MODE Discord
- Open Office Hours and Interview Prep: Engineers can join vLLM and Neural Magic open office hours on optimized LLM inference and enterprise ML, scheduled for June 5 and June 20, 2024. For performance engineer interview prep, a curated list of questions and resources is provided by awesomeMLSys on GitHub.
- Triton Kernel PTX Access and GitHub Discussions: Queries about extracting PTX code from Triton kernels led users to a useful GitHub issue discussing the procedure. The user corrected their initial search location to
~/triton/.cachefor the PTX code.
- Cracking the CUDA Stream Conundrum: AI Engineers discuss using named streams in CUDA for better performance and shared a pull request to mainstream operations. Efforts to fix a PyTorch DDP loss computation bug have culminated in a successful PR.
- OOM Woes and Quantization Quirks in Large Model Evaluation: Out-of-memory issues plague large model evaluations with torchao APIs, as seen in a GitHub pull request. AI Engineers recommend loading models on CPUs before quantization and adjusting for large vocab sizes.
- Sparse Matrix Semantics and Sparsity in AI: Clarifications on sparse matrices led to a sharing of a Wikipedia definition and a PyTorch README. Moreover, a comprehensive arXiv survey paper summarizing over 300 papers on the utilization of sparsity in deep learning was circulated for better understanding and implementations.
HuggingFace Discord
- FineWeb Unwraps LLM Performance Insights: The FineWeb technical report details processing decisions and introduces the FineWeb-Edu dataset aimed at enhancing education-focused content and understanding high-performance LLMs like Llama3 and GPT-4. FineWeb technical report is now available.
- Browser-Based AI with Transformers.js in Firefox: Firefox 130 update will include Transformers.js for on-device AI, with initial features targeting automatic alt-text generation for images to improve accessibility. Details can be found in this announcement.
- Nvidia NIM Accelerates Model Deployment: Nvidia NIM launches on Hugging Face Inference Endpoints, providing easy 1-click deployment for models like Llama 3 8B and 70B on cloud platforms. Reference for deployment can be found here.
- Hugging Face and Wikimedia Team Up for ML Progress: The collaboration leverages Wikimedia's datasets to further machine learning, underscoring the importance of community consent. The initiative details are explained here.
- Diving Deep into Security and Ethics of AI: The revelation of a security breach at Hugging Face prompted discussions on the ethical implications and safety of internet-based data storage, with a focus on maintaining respectful community engagements.
- Crossing Technological Barriers: The introduction of diffusion-based language modeling strategies mirrors principles used in image generation models, suggesting novel ways to handle textual "noise."
- AI Tools for Climate-Conscious Investing: An AI tool to identify climate-focused investment opportunities and calculate carbon footprint has been developed, utilizing models like
climatebert/tcfd_recommendation, showcasing AI's potential in sustainable finance. Explore the AI tool here.
- Knowledge Sharing in the AI Community: A variety of AI-related projects and discussions span topics like improved logo detection, Apache Airflow setup on Windows, valuable LLM resources, and advanced German audio datasets for language model training, adding diversity to the knowledge pool.
LM Studio Discord
Troubleshooting Model Loading in LM Studio: Users faced issues with model loading due to insufficient VRAM; the proposed workaround is to disable GPU offloading. A specific case highlighted problems with loading Llama70b which was not saved as a GGUF file, and a sym link option or file conversion was recommended.
Discussions Highlight Model Performance and Compatibility: The Command R model showed suboptimal performance when offloaded to Metal, and for text enhancement, no specific model was recommended, although one should look at 13B models on the leaderboard. Additionally, difficulties with SMAUG's BPE tokenizer were reported with Llama 3 version 0.2.24.
Chatter About Workstation GPUs and Operating Systems: The ASRock Radeon RX 7900 XTX & 7900 XT Workstation GPUs sparked interest, especially due to their AI setup-oriented design. There were mixed sentiments about Linux's user-friendliness and discussions about switching to Linux due to Windows' Recall feature prompting privacy concerns.
Feedback for Bug in LM Studio: A bug in LM Studio v0.2.24 was pointed out, involving extra escape characters in preset configurations such as "input_suffix": "\\n\\nAssistant: ".
Privacy and Security: Privacy concerns were raised related to Windows' Recall feature potentially creating security vulnerabilities by amassing sensitive data. In a lighter tone, anecdotes of IT support challenges—including a computer tainted with the odor of cat urine—brought humor to the discussions on tech support woes.
OpenAI Discord
- Hackers Hit AI Services Hard: The ChatGPT, Claude, Gemini, Perplexity, and Copilot services experienced outages due to a DDoS attack by Anonymous Sudan. The incident revealed vulnerabilities beyond typical cloud server expectations.
- Comparing AI Subscriptions: AI engineers debated the practicality of AI subscriptions, contrasting services like GPT and Character AI for tasks such as book summarizing and content creation.
- Math's Got AIs Stumped: Engineers observed persistent weaknesses in AI language models like GPT when tackling mathematical problems, highlighting inaccuracies and logical oversight in calculations.
- AI Gets Personal and Practical: Discussions showcased real-world integrations of AI, such as interfacing ChatGPT with home automation systems, highlighting both benefits and limitations in practical scenarios.
- Using GPT-4 Vision with Google Sheets: A query was raised about implementing GPT-4 vision to analyze and describe images in Google Sheets, suggesting an interest in expanding AI utility into spreadsheet tasks.
Stability.ai (Stable Diffusion) Discord
- Stable Audio Open Serenades the Scene: Stability.ai has launched Stable Audio Open, an open-source model to generate short audio pieces, including sound effects and production elements from text prompts. The model supports producing audio clips lasting up to 47 seconds, emphasizes innovation for sound designers and musicians, and is open for local fine-tuning; more details can be found here.
- WebUI Wonders: A Web of Possibilities for Stable Diffusion: Community members engaged in a lively comparison between A1111 and InvokeAI WebUIs for Stable Diffusion with a nod to A1111’s user-friendliness and InvokeAI’s unique "regional prompting" feature, which can be explored on GitHub.
- Tuning in on Training: A technical clarification around using regularization images was sought, with members debating if these images could replace captions in training processes. Meanwhile, an emerging curiosity about Stable Audio Tools and its utility, including possible Google Colab use and commercial permissions, was evident, referencing their GitHub repository.
- UI Flex to the Max: ComfyUI was recommended for its adaptability in image generation tasks, despite a challenging learning curve as illustrated by a member: "you can generate with cascade or sigma then refine it with sdxl...".
- Bootstrapping Beginners: New users were directed towards substantial community-curated resources like tutorials to learn Stable Diffusion, including a comprehensive guide from Sebastian Kamph on YouTube for getting started with A1111.
Eleuther Discord
- AI Finds Its Aesthetic Sense: Discussion surged around implementing AI to control patterns and colors on display walls, which could potentially result in personalized art or branded decor. Questions about whether this could evolve towards a form of AI-driven interior design were raised.
- Rethinking RLCD Buzz: Scrutiny of RLCD technology's marketing led to conversations about its actual innovative aspects, with comparisons drawn to Samsung's QD-OLED displays. Skepticism persists regarding whether newer models significantly surpass existing transflective screen technology.
- AGI Developments on the Horizon: Growing investments in AGI were spotlighted, referencing a blog that predicts substantial advancements in AGI capabilities by 2025/26, stirring dialogue on the expanding gap between leading labs and broader industry implications.
- Balancing IQ and Agency: Debates unfolded on the merits of IQ tests in hiring within open-source communities, juxtaposing them against "high agency" traits. Discussions emphasized the latter's superiority in contributing to success, given its ties to initiative, pattern recognition, and long-term vision.
- Breaking Down Deep Learning's Limits: Shared literature expanded upon deep learning's struggles with complex reasoning, whether it be transformers or SSMs. The community digested papers on diffusing "chain-of-thought" strategies into models and methods like SRPO, which seeks to robustify RLHF.
- Open Implementations Spark Enthusiasm: NVIDIA's public exposure of the RETRO model within Megatron-LM sparked conversations about the democratization of AI research and the potential for wider accessibility of cutting-edge models.
- Lm-evaluation-harness Troubleshooting: A user faced difficulties getting the desired output from lm-evaluation-harness, leading to a consensus that results might be hiding away in the tmp folder. There's an appetite for guidance on implementing loglikelihood metrics specifically for the LLaMA 3 8B instruct model.
Nous Research AI Discord
- GLM-4 Breaking Language Barriers: The introduction of GLM-4 brings support for 26 languages with capabilities extending to code execution and long-text reasoning. The open-source community can find the repository and contribute to its development on GitHub.
- Exploring Nomic-Embed-Vision's Superiority: The community is discussing the advancements of Nomic-Embed-Vision, which excels over models like OpenAI CLIP in creating a unified embedding space for image and text. For those interested, both the weights and code are available for experimentation.
- Contrastive Learning Loss Insights Shared: A recently published paper introduces a novel contrastive learning objective known as the Decoupled Hyperspherical Energy Loss (DHEL), and a related GitHub repo that compares different InfoNCE type losses is available here. These resources could significantly benefit researchers in the deep learning community.
- Microsoft's Idea Appropriation Discussion: Concerns about Microsoft allegedly appropriating ideas without attribution came to light with a related arXiv paper serving as a discussion point for the unintended open-sourcing of concepts.
- Testing and Utilization of AI Models and Datasets: Discussions around testing the Phi-3 Vision 128k-Instruct model on NVIDIA NIM and employing the Openbmb's RLAIF-V-Dataset for crafting applications are ongoing. Members are encouraged to participate and provide feedback on model performance and dataset utility.
LlamaIndex Discord
- GraphRAG Construction Choices Discussed: Members debated whether to build GraphRAG by manually defining the graph for full control or using an LLM for automatization; each approach impacts effort and data mapping effectiveness. An enterprise RAG workshop was available, exploring Bedrock models and agentic design patterns, while Prometheus-2 surfaced as an alternative to GPT-4 for evaluating RAG applications due to its open-source nature.
- Innovations in Metadata Extraction: A new Metadata Extractor module and tutorial were introduced to help clarify long text segments, and questions around storing
DocumentSummaryIndexin the Chroma Database led to a clear answer: Chroma cannot be used in this context.
- Practical Solutions for Retrieval and Indexing: They resolved a pertinent bug with Neo4j integration for query engines by merging a related pull request, and shared methods to fine-tune the “intfloat/multilingual-e5-large” embedding model for e-commerce applications. A single QueryEngineTool proved capable of efficiently managing multiple PDFs, dismissing concerns about their cumulative operability.
- Addressing Query Precision Issues: One user's struggle with irrelevant material in a vectorstore's top responses prompted a suggestion to filter results by score, ensuring higher relevance and precision in retrieval outcomes.
LAION Discord
ChatGPT 4 Adds Acting Chops: OpenAI's ChatGPT 4 introduces impressive new voice generation features as seen in a shared video, stirring excitement with its ability to craft unique character voices.
DALLE3's Diminishing Returns: Users express concerns over a noticeable degradation in the quality of DALLE3 outputs, with disappointments echoed for both traditional usage and API integrations.
Debating the Ethics of AI Monetization: Recent discussions reveal a palpable frustration within the community over non-commercial licenses for AI models, criticizing motivations centered around financial gain and the extensive resources required for training models such as T5.
LLMs Lose their Logic: A new Open-Sci collective paper exposes the "dramatic breakdown" in reasoning exhibited by large language models, available for review here with accompanying codebase and project homepage.
WebSocket Whims: An issue with WebSockets in the WhisperSpeech service within whisperfusion pipeline prompted a detailed inquiry on StackOverflow, hoping for a resolution to unexpected closures.
Modular (Mojo 🔥) Discord
Rust Rises, Mojo Eyes New Heights: A member praised a YouTube tutorial highlighting the safety of Rust in systems development through FFI encapsulation, evidencing the engineering community's interest in secure and efficient systems programming.
Transitional Tips for Python Devs: A Python to Mojo transition guide on YouTube was lauded for compiling essential low-level computer science knowledge beneficial for non-CS engineers moving to Mojo.
Mojo's Enumeration Alternatives: While Mojo currently lacks Enum types, the conversation turned to its accommodation of Variants with a nod towards the ongoing GitHub discussion for those interested in potential developments.
Nightly Updates Stir Commotion: A new release of the Mojo compiler (2024.6.512) was announced, along with advice on managing versions in VSCode, while challenges were addressed in adapting to changes like Coroutine.__await__ becoming consuming, as shown in the changelog.
Encryption Entreats Extension: Capturing the intersection of security and programming, a user emphasized the urgency for a cryptography library in Mojo, suggesting the feature would be "fire" and underscoring the need to build robustness into the language's capabilities.
Interconnects (Nathan Lambert) Discord
- Investors Are All In on Robotics AI: Investors are on the lookout for the ChatGPT equivalent in robotics AI, as they are eager to back companies with strong foundation models in robotics minus the hazards associated with hardware design, according to a Substack article.
- National Security and AI Trade Secrets: The tech community debated the firing of an individual for leaks, with focus on the underappreciated role of trade secrets in AI national security. There's concern about overconfidence from labs like OpenAI and Anthropic on attaining researcher-level AI within 3 to 5 years, with some suggesting misaligned incentives and flawed extrapolations.
- Toward AI That Aces PhDs?: Microsoft CTO Kevin Scott predicts upcoming AI models may soon be capable of passing PhD qualifying exams, comparing today's models like GPT-4 to ones that can tackle high school AP exams. Ph.D. exams' difficulty, notably at Berkeley where a 75% failure rate in prelims was observed, was also a topic of discussion, showcasing the challenge such AI models would face.
- Paying for Problem-Solving: An open issue in rewardbench.py creates discrepancies in results due to varying batch sizes; Nathan Lambert offers a $25 bounty for a resolution. Additionally, AutoModelForSequenceClassification was termed "kind of cursed", indicating improvements might be possible with adjustments.
- AGI Talk Yields Mixed Reactions: Conversations reveal that the community is evenly split between being annoyed at both overly-optimistic AGI enthusiasts and the gloom-spreading doomers.
Cohere Discord
Will Cohere's API Remain Free?: Members are buzzing with speculations that Cohere's free API might be discontinued, urging others to seek official confirmation and disregarding unverified rumors.
Bringing Order to Multi-User Bot Chats: Engineers discussed the challenges of engaging Language Models (LLMs) in multi-user chat threads, suggesting that tagging messages with usernames could improve clarity.
Hunting for the Ultimate Chat Component: A community member inquired about a React-based Chat component; they were pointed to the Cohere Toolkit, which isn't built on React but may contain elements such as the chatbox written in it.
React Components and Cohere Synergy: Though Cohere Toolkit lacks React components, the open-source tool positions itself as a useful resource for implementing RAG applications, potentially compatible with React implementations.
OpenAccess AI Collective (axolotl) Discord
Bug Hunt in Memory Lane: Users reported Out of Memory (OOM) errors when running a target module on 2xT4 16GB GPUs, alongside anomalous loss:0.0 readings, which could suggest a critical issue in parameter configuration or resource allocation.
Data Feast for Hungry Models: The HuggingFace FineWeb datasets, a sizeable collection sourced from CommonCrawl with 15 trillion tokens, is making waves for its potential to lower entry barriers for training large models, though concerns about computational and financial resources required to utilize it fully have been raised.
Deepspeed Dominates Model Training Chatter: Engineering discussions revealed a preference for using the command line for running Deepspeed tasks including successful fine-tuning of the Llama3 model using Deepspeed zero2 and selected Qlora over Lora for fine-tuning.
Seeking Speedy Solutions: A member vented frustration over Runpod's slow boot times, specifically that booting a 14 billion parameter model takes about a minute, impacting cost-effectiveness; questions were raised about alternative serverless providers with faster model loading capabilities.
Model Mingle and Muddle: While there is clear enthusiasm over the GLM-4 9B model, concrete feedback within the community on its performance and use cases seems scarce, suggesting either a novelty of deployment or a gap in shared user experiences.
Latent Space Discord
- Real-Time AI Revolution: LiveKit secures a $22.5M Series A funding to pioneer a transport layer for AI, citing the capabilities of GPT-4 as a catalyst for investor interest.
- Multimodal AI Grabs the Spotlight: Twelve Labs has acquired $50M in Series A funding and debuted Marengo 2.6 with aspirations to refine multimodal foundation models.
- Forecasting the Art of Precision: Microsoft Research unveils Aurora, aiming to drastically improve the accuracy of weather forecasting through leveraging advancements in AI foundation models.
- Transparency in AI Alignment Questioned: Teknium scrutinizes OpenAI for not being open about alignment rewards and moderation classifiers; the discussion uncovers that reward models are typically incorporated within the architecture of large language models (LLMs) itself.
- Content Management Gets an AI Boost: Storyblok clinches $80M in Series C funding to evolve an AI-powered content platform, initiating the public beta of its new Ideation Room.
- Anthropic Dives into Monosemanticity: Anthropic scheduled an insightful talk on Scaling Monosemanticity, promising advancements in understanding the links between monosemanticity and model scaling. Details and registration were provided for the event.
OpenInterpreter Discord
- Skill Persistence Poses Problems: Discussions revealed that OpenInterpreter lacks the ability to retain skills across sessions despite users trying to "tell OI to create a new skill." To circumvent this, the advice is to save and store scripts as a workaround.
- RAG Under The Microscope: There's skepticism regarding Retrieval-Augmented Generation (RAG) with a preference for conventional embedding/vector databases cited for their reliability, albeit at a higher token cost.
- Data Privacy Takes the Spotlight: Concerns over data privacy with OpenAI was assuaged with reassurances that communications with OpenAI's API remain confidential, while running a local model was proposed for additional security.
- Cross-Model Compatibility Queries: Query into integrating the O1 dev preview with other large language models like Anthropic raised compatibility issues, particularly the necessity of a vision model and potential infinite loops on some operating systems.
- Voice Assistant for Devs: A link to a GitHub project for a Terminal Voice Assistant sparked interest in whether similar functionalities could be implemented in 01, pointing to potential development tools for engineers.
tinygrad (George Hotz) Discord
- Hotz Throws Down the Tqdm Replacement Gauntlet: George Hotz offered $200 for a minimalist tqdm replacement, sparking a flurry of activity and a submitted PR from Trirac, albeit with a note about its suboptimal it/s rate at higher speeds.
- Tinygrad's Missing Stats Mystery: Hotz inquired about why the stats.tinygrad.org site is currently a 404 error, sparking discussion on the site's accessibility.
- Invitation to Improve Tinygrad Docs: Updates to Tinygrad's documentation have been announced, including new sections on training and a library diagram, and the community has been solicited for further content ideas (George Hotz).
- Tinygrad: Seeking Specs before the Sprint: The bounties offered by Hotz aim to draft the Tinygrad spec, with a promise it could be reimplemented in roughly two months when finalized, also serving as an employee screening process.
- Deciphering CUDA-to-Python: Discussion centered on the complexity of connecting CUDA debug output to Python code, a key feature for Tinygrad's v1.0, with existing PRs yet to be merged (George Hotz).
LangChain AI Discord
Outdated Docs Cause Commotion: LangChain and OpenAI documentation woes have caught the attention of members noting significant discrepancies due to API updates. A suggestion pointed engineers towards the primary code stack itself for the most current insights.
DB Wars: MongoDB vs. Chroma DB: When an engineer pondered the use of MongoDB for vector storage, a clarification ensued about MongoDB's purpose for storing JSON rather than embeddings, directing the inquirer to MongoDB's assistance or ChatGPT.
Verba: RAG Under the Microscope: The community took an interest in Verba, a Weaviate-powered RAG chatbot, with a request for user experiences being aired, indicating an exploration into Weaviate's retrieval augmentation capabilities.
SQL Agent Leaves Users Puzzled: Issues surfaced with the SQL agent not delivering final answers, sparking a discussion on troubleshooting this cryptic behavior in an environment that detests non-performing components.
Graph-Based Knowledge with LangChain: An engineer showcased a LangChain guide focused on constructing knowledge graphs from unstructured text, prompting inquiries on integrating LLMGraphTransformer with Ollama models, a nod to the constant pursuit of enhanced knowledge synthesis.
VisualAgents Usher in Drag-and-Drop LLM Patterns: A live demonstration via a YouTube video on using VisualAgents highlighted the creative process entailed in arranging agent flow patterns, reflecting a trend towards more intuitive interfaces in LLM chain management.
OpenRouter (Alex Atallah) Discord
- Rope Scaling Hits a Snag with OpenRouter: Members highlighted issues with integrating rope scaling in OpenRouter, suggesting local deployment to sidestep GPU constraints.
- Codestral Lags Behind on Code Specialization: A recommendation was made against using Codestral for code specialization, with a nod toward more efficient models detailed in <#1230206720052297888>.
- Identifying the Culprit Behind 502 Errors: Engineers tackled 502 Bad Gateway errors with OpenRouter, tracing the problem to the format of
contentinmessagesrather than server capacity or request volume.
- Eclectic Model Mix-Up During Downtime: The 502 errors were occurring while handling a variety of models from Nous Research, Mistral, Cognitive Computations, Microsoft, and Meta-Llama, with emphasis on the issue stemming from message content formatting.
- Seek Alternatives for Greater Code Efficiency: Engineers looking for effective code specialization are advised to consider more performance-oriented alternatives to Codestral, with hints to check a specific model mentioned in the guild.
MLOps @Chipro Discord
- Circle Your Calendars for AI Safety: The Human Feedback Foundation event is set for June 11th; tickets can be grabbed from Eventbrite. The focus of the event will encompass AI governance and safety, enriched through a collaborative open-source environment.
- Gleaning Insights from AI Experts: Check out the Human Feedback Foundation's YouTube channel for insights from academia and industry leaders from UofT, Stanford, and OpenAI, focusing on the integration of human feedback into AI development.
- LLM Reading Group Discord Access Restricted: There was a request for a separate Discord for the LLM Reading Group, but direct invitations were hampered due to privacy settings, implying a need for alternate access arrangements for interested individuals.
Mozilla AI Discord
- Vector Tech Marches Forward with RISC-V: RISC-V Vector Processing reaches a significant milestone with the 1.0 RISC-V Vector Specification now ratified. The linked video delves into the early silicon implementations, suggesting ample opportunities for innovation in CPU designs.
- AI's Existential Threat Spotlighted: The Right to Warn AI project raises alarm about the potential existential threats posed by AI technologies, promoting the need for oversight much beyond corporate governance. It raises concern over AI-related risks like inequality, misinformation, and potential human extinction.
DiscoResearch Discord
- Exploring "Sauerkraut Gemma" Prospects: Interest in replicating the PaliGemma model for German, tentatively named "Sauerkraut Gemma", was expressed, with the idea of simply replacing Gemma's base for adaptation.
- PaliGemma Model As a Template: Referencing the PaliGemma-3B-Chat-v0.2 model, a member proposed a strategy of "freezing the vision and training the chat", post-dataset translation for the development of a German counterpart.
LLM Perf Enthusiasts AI Discord
- AI Learning Hub Unveiled: The GenAI Handbook, curated by William Brown, was highlighted as a significant resource for AI engineers seeking a comprehensive understanding of modern AI systems formatted in a user-friendly, textbook-style guide.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: !
If you enjoyed AInews, please share with a friend! Thanks in advance!