[AINews] 1/4/2024: Jeff Bezos backs Perplexity's $520m Series B.
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
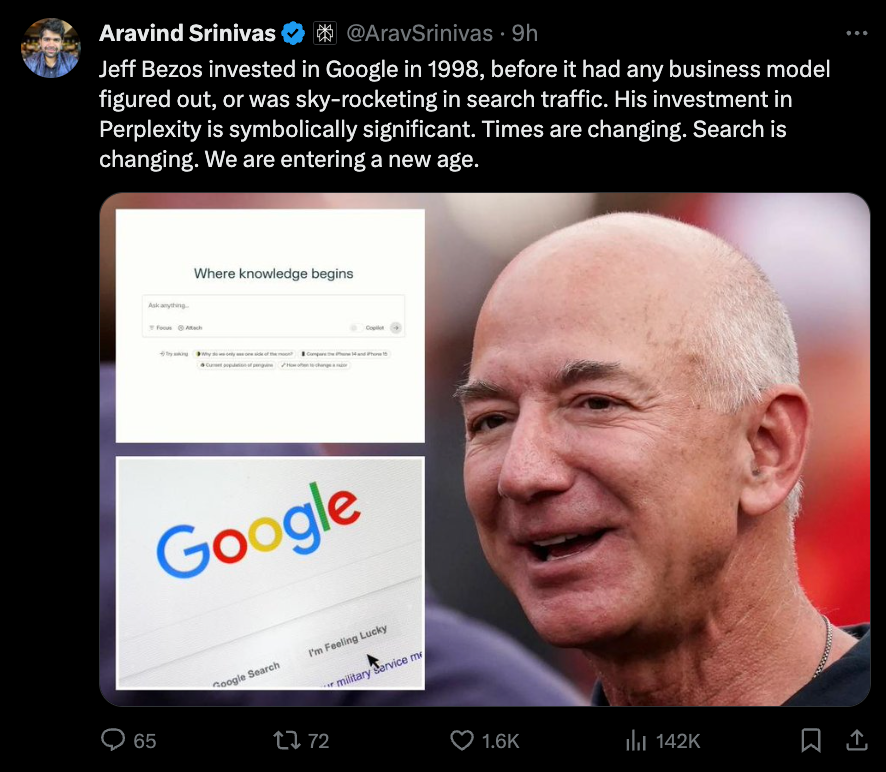
As widely rumored, Perplexity announced their Series B. Most notable investor is Jeff Bezos, who also invested in Google 25 years ago.
Elsewhere, Anthropic's ongoing $750m fundraising prompts it to issue very ambitious forecasts and institute "brutal" ToS changes:
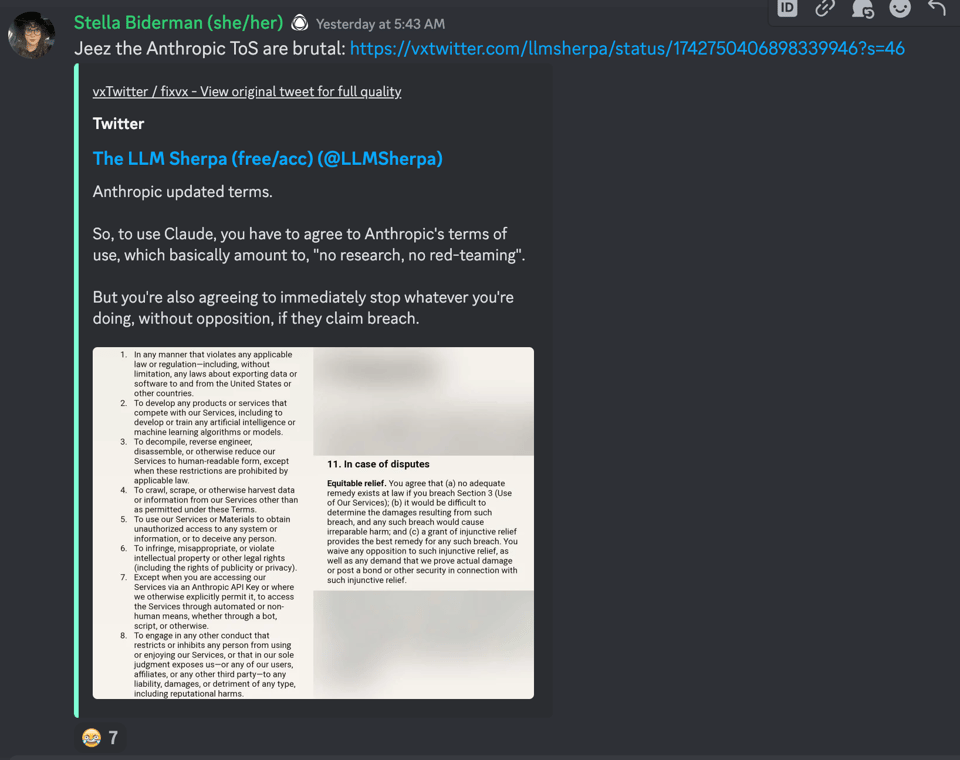
Table of Contents
- Nous Research AI Discord Summary
- OpenAI Discord Summary
- LAION Discord Summary
- HuggingFace Discord Discord Summary
- Perplexity AI Discord Summary
- Eleuther Discord Summary
- Mistral Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- LangChain AI Discord Summary
- Latent Space Discord Summary
- DiscoResearch Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- Skunkworks AI Discord Summary
- Alignment Lab AI Discord Summary
Nous Research AI Discord Summary
- Querying Memory Matters: In a discussion within the #ctx-length-research channel,
@benjoyowondered about the limits of document recall from gigabytes of data. On the topic of costing,@tekniumnoted that, though costs do rise with context size, the increase isn't exponential.@euclaiseshined a light on RNN memory and compute subtleties, explaining that in RNN mode, memory usage is consistent but requires extensive compute, while non-RNN mode provides a sub-linear compute trade-off for greater memory use. - Software Sovereignty and GPU Struggles: The #off-topic channel saw a lively debate about data sovereignty ignited by
@benjoyo's question about potential pitfalls of European hosting.@gabriel_symegrappled with graphics card issues on Windows 11, while@max_paperclipshailed the dawn of synthetic datasets, much to the chagrin of already overworked GPUs. - Language Models New and Newer: The #interesting-links channel buzzed with talk of language models, from WizardCoder-33B-V1.1's promising performance to Humaneval-Test-Set-Alpha's theoretical prowess under extreme conditions.
@metaldragon01highlighted an article on a novel model expansion technique called CALM, causing@gabriel_symeto speculate on its potential combination with LORAs. In response to@euclaisechampioning the performance of MobileLLaMA-1.4B-Base,@.benxhasserted the superior benchmarking results of ShearedLLaMA. Meanwhile, evaluation hangs in the balance for TinyLLaMA. - Model Possibilities and Practicalities: In the #general channel,
@gabriel_symesought clarity on applying UnsLOTH optimizations to multi-GPU systems, prompting@tekniumto emphasize the proprietary nature of UnsLOTH. Mention of a potential 200k context Nous Hermes model stirred intrigue, but it was an AI rap voice model that truly had tongues wagging. Queries about Mac-compatible AI trainers were fielded, and excitement persisted for context-extending code updates. - LLM Architectures – Adapt, Implement, Explore: The #ask-about-llms channel saw
@__nordpropose applying a Detectron/ViT backbone to LLMs for operation on a private dataset. On high-throughput inference engines,@uchihakrishnaadiscovered ctranslate2 as a potential pick to outperform TGI and vLLM. Sliding window attention got a nod as a technique worthy of implementation in Mistral, and the prospect of adding bounding boxes to architecture without fine tuning was greeted with interest.@kyleboddyvoiced issues with parallelizing Mixtral 8x7b across GPUs, for which@orangetinsuggested FSDP and HF Accelerate as potential solutions.
Nous Research AI Channel Summaries
▷ #ctx-length-research (15 messages🔥):
- Limits of Document Recall: User
@benjoyospeculated about the limitations of retrieving information from large amounts of data, suggesting that gigabytes of documents would not yield perfect recall. - Costs Increase with Context Size:
@tekniumstated that while the cost of context does increase as size increases, it is not an exponential increase. - RNN Memory and Compute:
@euclaiseinformed that in RNN mode, memory usage is O(1), but it necessitates O(N) compute. Non-RNN mode allows for sub-linear compute, but requires more memory. - Recall Efficiency with Mamba:
@ldjshared that Mamba achieved over 95% associative recall on sequences of 1 million tokens, outperforming SOTA DNA models trained using Hyena. - Context Management and Retrieval as Research Directions:
@maxwellandrewssuggested that better retrieval (knowledge, not text chunks) and better model context management are both valid and independently useful research directions. This was supported by@gabriel_syme, who opined that there's more discovery potential in retrieval vs context, given the existing extensive work on the latter.
▷ #off-topic (13 messages🔥):
- Discussion on Data Sovereignty: In response to
@benjoyo's query about potential problems of a platform being hosted in Europe,@gabriel_symeraised the issue of data sovereignty.
- Windows 11 Graphics Card Problems:
@gabriel_symereported that Windows 11 caused issues with his graphics card, nuking the drivers and rendering them non-functional.
- Synthetic Datasets Enthusiasm vs GPU Consumption:
@max_paperclipscheered for synthetic datasets, to which@carsonpoolehumorously noted the increased workload for GPUs ("GPUs about to go brrr").
- Question About Funding Synthetic Datasets:
@gabriel_symesought clarity on whether work might fund synthetic datasets;@tekniumclarified that it's allowed, and@gabriel_symeindicated having noted the terms.
- Twitter Ads and Bots:
@euclaiseraised a point about the influx of ads from Chai on Twitter. The discussion broadened with@metaldragon01and@gabriel_symeremarking on the presence of pervasive porn ads and bots on the platform.
▷ #interesting-links (38 messages🔥):
- New Language Model WizardCoder-33B-V1.1 Outperforms GPT3.5-Turbo:
@metaldragon01shared a Twitter update from@WizardLM_AIon the release of WizardCoder-33B-V1.1, a new language model that excels in a variety of benchmarks. However,@giftedgummybeeexpressed concern over the lack of available dataset and code for reproducing the data.
- Humaneval-Test-Set-Alpha Shows Promise:
@n8programshumorously claimed that their model "Humaneval-Test-Set-Alpha" can achieve a 100% success rate on the humaneval with less than a megabyte of data.
- Discussion on Model Composition and Expansion:
@metaldragon01shared an article introducing CALM (Composition to Augment Language Models), a new way to merge models and give them new capabilities.@gabriel_symespeculated on the use of cross attention between an anchor model and LORAs (Locally Optimized Robust Anchors).
- MobileLLaMA-1.4B-Base Shows Promising Performance:
@euclaiseshared a link to MobileLLaMA-1.4B-Base on HuggingFace, a downscaled LLaMA model that delivers comparable benchmark performance to other recent open-source models. However,@.benxhargued that ShearedLLaMA performs better based on benchmarks.
- TinyLLaMA Awaits Evaluation: Following a miscommunication,
@qnguyen3clarified that TinyLLaMA has been completed and is waiting for@387972437901312000to run evaluation.
Links mentioned:
- mtgv/MobileLLaMA-1.4B-Base · Hugging Face
- LLM Augmented LLMs: Expanding Capabilities through Composition: Foundational models with billions of parameters wh...
- Paper page - LLaMA Pro: Progressive LLaMA with Block Expansion
- Tweet from WizardLM (@WizardLM_AI): 🔥 Excited to release WizardCoder-33B-V1.1, the SO...
▷ #general (120 messages🔥🔥):
- UnsLOTH Queries Clarified:
@gabriel_symeinquired about the nature of UnsLOTH, a LORA trainer with a custom kernel.@tekniumclarified that it's a proprietary product and the code for a multi-GPU system would not be provided freely.@beowulfbrlinked an issue from axolotl's Github repository where a user attempted to apply UnsLOTH's optimizations. - 200k Nous Model Speculations: While discussing large context models,
@nonameusrcasually asked about the potential of a 200k Nous Hermes model.@ldjmentioned that such a model already exists in the form of Nous Capybara. It was then clarified that the query was specific to a Hermes variation of the 200k context model. - Peek into AI Rap Models: A discussion was initiated by
@euclaiseon the potential existence of an AI rap voice model. Various responses pointed towards services like UberDuck and MAYK, including creating vocals using RVC. - AI Trainers on Mac Questions:
@agcobra1asked about the potential to train models on a Mac. Although specifics were not provided,@n8programssuggested using LORA MLX or Transformers with a MLX backend. - Context Extending Code Updates: There was a conversation about a new code claiming to perform a magical, no-training required, context extension (
@spaceman777).@ldjindicated that users were working on adding Mamba support to the Llama.cpp project, and potentially Mamba would make handling larger context models more practical.
Links mentioned:
- Popular "AI Hub" Discord Taken Down Following Copyright Complaints * TorrentFreak
- Uberduck | Make Music with AI Vocals: Generate high-quality voices by synthesizing your ...
- Tweet from Teknium (e/λ) (@Teknium1): @yacineMTB @abacaj I've told you about a syste...
- Apply unsloth optimizations · Issue #908 · OpenAccess-AI-Collective/axolotl: ⚠️ Please check that this feature request hasn'...
- Your Virtual Music Studio – mayk.it: We’re a Virtual Music Studio for next-gen music cr...
▷ #ask-about-llms (24 messages🔥):
- Modifying LLM Architecture:
- User
@__nordraised the question about modifying LLM's architectures and training. They are planning to implement a certain paper and if it is successful,.. they will consider adding a Detectron/ViT backbone to it for a private dataset they work with. - Inference Engine Alternatives:
-
@uchihakrishnaaexpressed a need for inference engines that provide greater throughput than TGI and vLLM for a fine-tuned vicuna model.@night_w0lfsuggested looking into ctranslate2 as a potential solution. - Discussion on Sliding Window Attention:
- User
@lwasinaminquired about implementing sliding window attention, a technique employed by Mistral. - Incorporating Bounding Boxes into architecture:
- In a discussion featuring
@__nordand@max_paperclips, the potential for modifying attention without fine tuning was discussed. It was suggested that a new pair of keys and values could be projected with the same weights as the original ones. - Parallelizing Mixtral Over Multiple GPUs:
-
@kyleboddyexpressed difficulties with parallelizing Mixtral 8x7b over multiple GPUs for training and inference.@orangetinrecommended FSDP for training and HF Accelerate for inference.
OpenAI Discord Summary
- Meshing Multiple ChatGPT Subscriptions: Users can club multiple subscriptions of ChatGPT together under the Enterprise plan. This was confirmed by
@luguiin response to@shalevbartal_38833's query. Check the subscription details here. - Clever ASCII Alteration Proposed for Generative Attribution:
@iruintproposed an intriguing solution for text copying issues - alter ASCII character encoding to create detectable corruptions in copied text.@.doozand@luguiexpressed both interest and uncertainty in this idea. - Mobile ChatGPT Now Enjoys PC Compatibility: According to
@satanhashtagand@dystopia78, users can use Mobile ChatGPT+ subscriptions on their PCs. However, do note, you'll need to purchase from mobile if using PayPal. - OpenAI's GPT Store Launch Is on the Horizon: Exciting times as
@uchenkentaannounced the imminent launch of OpenAI's GPT Store, a platform allowing developers to distribute their custom AI applications. To join, developers need to have a ChatGPT Plus or Enterprise subscription. - Free Users and Their GPT Store Access Left in Question: Concerning GPT Store's launch,
@misangeniuswondered if free users would have access to the custom GPTs.@muyfashionistaspeculated that the cost of OpenAI's APIs might be passed onto consumers through the apps. - Debut of DadBot, a Chatmate You Longed for:
@tdgrpodcastintroduced 'DadBot', inviting users for a chat. You too can meet DadBot here. - Developers' GPT Prompt Limit Hack: Hit Custom GPT's prompt limit? No problem - you can continue the chat by copying the context into GPT-4, as suggested by
@darthgustav.. - GPT Store Launch Raises Security Concerns: As GPT Store launch nears,
@r3plac3dvoiced potential security threats like cloning, and called for more robust security measures than those currently recommended by OpenAI. - Image Variation in Custom GPT-3 Miffs Users:
@jungle_joobserved that their custom GPT-3 producing similar images repeatedly devaluing user's experience.@eskcantasuggested adding three user-derived keywords to prompts for more varied outputs. - Budding Business Opportunity in Prompt Engineering:
@iiimandalorianiiiexpress success in selling a set of AI chatbot prompts to a corporate client for $1500. - Need for AI that Follows Instructions Better:
@zdev26reported issues with their tailoredGPT 3.5 Turboignoring additional user instructions, asking OpenAI for a solution. - Ever Thought About Replacing Words with
ChatGPT?:@dnp_required assistance for replacing niche-specific words with placeholders in a set text, but dealing with negative words seemed challenging.
OpenAI Channel Summaries
▷ #ai-discussions (20 messages🔥):
- Multiple ChatGPT Subscriptions Inquiry: User
@shalevbartal_38833inquired about purchasing multiple subscriptions of ChatGPT.@luguiprovided guidance that purchasing multiple subscriptions simultaneously is possible only with an Enterprise plan and also shared the subscription link.
- A Solution for Generative Attribution Problem?: A user
@iruintmade an intriguing suggestion to solve the issue of generative attribution. They proposed altering the ASCII character set, using robot characters instead of standard 'a' and 'i', and applying these changes across non-latin characters. The idea is to make it possible to detect a violation when the character encoding in the copied text is corrupted.@.doozand@luguijoined in the discussion, posing questions about the practicality and reliability of such a solution.
- ChatGPT Subscription Across Devices: User
@knownx.asked if a ChatGPT+ subscription purchased on mobile could be used on a PC. They received responses from@satanhashtagand@dystopia78confirming that this indeed is possible, however, payments would need to be made from the mobile platform if using PayPal.
- Announcement of GPT Store Launch:
@uchenkentashared news about the upcoming launch of the GPT Store by OpenAI. The GPT Store will be a platform for developers to distribute custom applications built on OpenAI's AI models. Developers will need to follow OpenAI's updated usage policies and brand guidelines and have a ChatGPT Plus or Enterprise subscription.
- Access to GPT Store for Free Users: In relation to the GPT Store launch announcement,
@misangeniusquestioned whether free users would have access to custom GPTs from the store.@muyfashionistasuggested that the cost of OpenAI's APIs might be embedded into the apps and passed onto customers and referenced a discussion about potential monetization.
Links mentioned:
OpenAI Set to Launch GPT Store Next Week: A Platform for Custom AI Apps: OpenAI is set to introduce the GPT Store, a platfo...
▷ #gpt-4-discussions (69 messages🔥🔥):
- DadBot Debuts:
@tdgrpodcastinvited users to test a new AI called DadBot they created, providing a link to it (https://chat.openai.com/g/g-OhGvGkxM9-dadbot). - GPT Store Launch Announcement: Users
@pierrunoytand@nickthepaladindiscussed the impending launch of the GPT Store, expressing some concerns regarding membership requirements. - Helpful Hints for Using Custom GPTs:
@darthgustav.provided fellow developers with a workaround for continuing conversations when the prompt limit in a Custom GPT has been reached: just copy the context into GPT-4 and continue the chat. - Security Concerns with GPT Store Launch:
@r3plac3draised strong concerns about security issues in light of the upcoming GPT Store launch. They indicated that previous recommendations from OpenAi, like disabling the code interpreter, are insufficient protection against cloning and other potential threats. - Profile Picture Upload Issues:
@francisrafalshared difficulties uploading a profile picture to a GPT. It was discovered that using Chrome as a browser resolved the issue, indicating a potential issue with the Brave browser. - Limits on Custom GPTs Questioned:
@holden3967,@thepitviperand others raised concerns about the limitations placed on Custom GPTs, such as the 25 prompts/3hours limit. Questions were asked about known limit loopholes, the need for OpenAI plus accounts, and the expectation that paying customers should get higher limits. - Adjusting Builder Profile Info:
@r3plac3dand@scargiadiscussed adjusting builder profile information on the OpenAI platform, where@scargiastated that users can edit their name via the account profile link (https://platform.openai.com/account/profile).
▷ #prompt-engineering (38 messages🔥):
- Struggling with Image Variation: User
@jungle_jonoticed that their custom GPT-3 model, which generates images based on a set of guidelines, was creating images with similar patterns in 5 out of 10 cases. - Lack of randomness: Upon discussing with
@eskcanta, they suggested that the AI, being stateless, might be picking the same choices each time. AI's struggle with generating randomness was highlighted. - Improving image variation:
@eskcantasuggested to rewrite the user's prompt by adding three keywords and then taking inputs from these. This leads to 'true randomness' and more variation in the generated images. - Sales in Prompt Engineering:
@iiimandalorianiiishared their successful experience of selling a set of prompts for AI chatbots to a corporate client for $1500. - Request for Texting Story Prompt:
@user691378asked for help to create a prompt that can generate texting stories for social media.
▷ #api-discussions (38 messages🔥):
- Overcoming
GPT 3.5 TurboIgnoring Added User Instructions:@zdev26reports experiencing an issue with their tunedGPT 3.5 Turbochatbot ignoring additional user instructions for outputs. They've noticed that the model frequently ignores guiding prompts such as 'User has provided instructions for the next message: "Ask for her phone number in a funny way"'. - Manipulating
ChatGPTfor Word Replacement:@dnp_asks for assistance on how to getChatGPTto copy a set text, but replace certain niche-specific words with a placeholder like "fillintheblank". There seem to be challenges with negative words in the text. - Generating Unique AI Images:
@jungle_joreports a problem with their customGPTmodel which generates images based on a set of guidelines. They have noticed that the model tends to generate similar images repeatedly, lacking in variation. They would like advice on how to improve this. - Solutions to Image Variation Problem:
@eskcantaprovides thoughtful advice for@jungle_jo's problem, suggesting methods to stimulate random image generation. They recommend a rewrite of current instructions, adding three keywords derived from user prompts. - Prompt Engineering as a Business Opportunity:
@iiimandalorianiiishares an interesting story of selling a set of prompts to a corporation for $1500. They proposed the idea of prompt engineering to the corporation and wrote a set of prompts for their processes.
LAION Discord Summary
- Child Risks in LAION 5B: '@chad_in_the_house' discussed child pornography appearing in LAION 5B from findings by Stanford researchers, forcing the removal of certain databases.
- Debunking the Myth of OpenClip Going Explicit: '@thejonasbrothers' and '@pseudoterminalx' concluded, after analysis, that OpenCLIP couldn't generate explicit or illegal images due to data limitations.
- The Ups and Downs of Dataset Rips: '@thejonasbrothers' and '@pseudoterminalx' shared experiences in feeding high-quality ripped data from films and anime into models, detailing hallucination issues and possible solutions.
- Terms of Play with Claude: '@itali4no' referenced a tweet indicating Anthropic's terms of use for Claude had changed, now restricting its use for research, red-teaming, or in competing models' development.
- aMUSEd to Boost Text-to-Image Processes: '@thejonasbrothers' highlighted new lightweight Masked Image Model (MIM) called aMUSEd via an arXiv paper that enhances style learning from single images & speeds up large-scale text-to-image processes.
- Sculpt Your 2D Images with 3D: '@thejonasbrothers' shared an arXiv paper on 'Image Sculpting' - a tool that edits 2D images with 3D geometry tools for increased precision.
- Meet Unicron, the Self-healer for Large-Scale Language Model Training: '@vrus0188' introduced Unicron via a Reddit post - an AI by Alibaba researchers designed for efficient self-healing in large-scale language model training.
- Why Stable Diffusion Struggles with Age Concepts: '@phryq' and '@JH' discussed the inherent limitations of Stable Diffusion Models in representing age-based features and the challenge of sampling out-of-distribution (OOD). Pretraining could offer a solution, although it necessitates comprehensive testing.
LAION Channel Summaries
▷ #general (132 messages🔥🔥):
- Controversy over Illegal Content in LAION 5B:
@chad_in_the_housediscussed the finding of child pornography within LAION 5B by Stanford researchers, which led to certain databases being taken offline.
- Discussions on Potential Generation of Inappropriate Imagery: Conversation took place between
@thejonasbrothersand@pseudoterminalxregarding the OpenCLIP model's capability (or lack thereof) to generate explicit or illegal imagery, with both agreeing it's unlikely due to limitations in data.
- Training Models on Dataset Rips: A detailed conversation occurred between
@thejonasbrothersand@pseudoterminalxon their experiences feeding models high-quality rip data from movies and anime, the challenges they experienced with hallucinations, and the possible solutions they attempted.
- Consequences of Terms of Service Violation for the use of Claude: A tweet cited by
@itali4nomentioned that Anthropic had updated its terms of use for Claude, restricting it from being used for research, red-teaming, or in the development of competing models.
- Appreciation for MistralAI's Policy on Using Outputs:
@SegmentationFaultpraised MistralAI for its more lenient stance on using the outputs of their models for training other models.
Links mentioned:
Tweet from The LLM Sherpa (free/acc) (@LLMSherpa): Anthropic updated terms. So, to use Claude, you h...
▷ #research (6 messages):
- Lightweight image model aMUSEd to boost text-to-image generation:
thejonasbrothersshared a link to an arXiv paper about a new, lightweight Masked Image Model (MIM) called aMUSEd. This model, developed by Patrick von Platen, aims to speed up text-to-image generation processes and enhance learning additional styles from a single image. This method could revolutionize large-scale text-to-image operations. - Image Sculpting: A new way to edit 2D images with 3D tools:
thejonasbrothersposted another arXiv paper presenting a tool called Image Sculpting, which allows for editing 2D images with 3D geometry tools. This novel approach could increase the precision of image editing and enhance the potential of generative models. - Unicron: Alibaba's self-healing AI system for language model training:
vrus0188shares a Reddit post about Unicron, an AI system developed by Alibaba researchers. This system is uniquely designed for efficient self-healing in large-scale language model training. - Conditional Velocity Score Estimation Paper from WACV2024:
wangshuaiposted a PDF link to the best paper from WACV2024 titled "Conditional Velocity Score Estimation for Image Restoration". PDF Link
Links mentioned:
- Image Sculpting: Precise Object Editing with 3D Geometry Control: We present Image Sculpting, a new framework for ed...
- aMUSEd: An Open MUSE Reproduction: We present aMUSEd, an open-source, lightweight mas...
- Reddit - Dive into anything
▷ #learning-ml (3 messages):
- Conceptual Understanding in Stable Diffusion Models: User
@phryqquestioned the conceptual capability of Stable Diffusion in learning to represent age-based features in images. They queried if the model could interpolate ages it was not directly trained on. - Sampling Out-of-Distribution Limits:
@JHclarified that, due to the age being modeled by input tokens and not actual numbers, models are typically challenged in interpolating between different ages (30 and 40, for example). This challenge is recognized as sampling out-of-distribution (OOD). - Possible Exceptions with Pretrained Models:
@JHfurther added that pretrained models, like a clip encoder used with a text-to-image model, might have already learned to recognize tokens for ages. Therefore, even if it's OOD for your training data, the age might just be in distribution for the pretrained model. - Emphasis on Testing and Verifying Model Capability: For guaranteeing the learned concepts,
@JHrecommended the development of comprehensive tests to periodically check the model's abilities, gauge the extent of training required, and evaluate the potential need for data augmentation. - Deeper Insight into Concept formation in Stable Diffusion:
@phryqfurther emphasized on the difference between LLM (that can develop a concept) and Stable Diffusion, suggesting that Stable Diffusion models might be limited to understanding exactly what they've been trained on, without forming deeper "conceptual understandings."
HuggingFace Discord Discord Summary
- Data Management Gets Cozier with Hugging Face and DVC:
@Andyrasikawrote a blogpost about managing data using Hugging Face and Data Version Control (DVC) Blogpost Link. - Bilingual Content Creation Sees a New Star:
@manishiitgshowcased their model trained on Hindi and English data, ideal for content writing, classification, and coherent content creation. This model isn’t a fit for coding/maths tasks Model Link. - Whispers of ASR Endpoint Inference Issues:
@blahblah6407experienced an issue while creating and testing an endpoint inference for ASR with a finetuned Whisper. - Building Budget PCs for Deep Learning:
@sedthhsought advice on a budget PC build for deep learning, posing a choice between a 3090 or 4080, or other alternatives in the same price range. - Discovering Stable Diffusion XL:
@8bit888shared a blog post on Stable Diffusion XL: a guide for image generation without limitations Link. - Bank Statement Image Annotation Automatization:
@detraxsenpaisought advice on automating the annotation of bank statement images and making unusual amendments. - Chatbot on the Horizon:
@jryariantosought guidance for creating a chatbot able to provide real-time answers from a database while maintaining access controls.@absolutt1suggested that the Retrieval Augmented Generation (RAG) system would be a good fit. - Gradio 4.13 Lands with a Bang:
@abidlabsannounced the Gradio 4.13 release, detailing the new features. He also shared the full changelog. - Gemini Pro Vision Opens for Testing:
@aiman1993shared a Hugging Face Spaces link to the Gemini Pro Vision Streamlit Application, welcoming others to experiment Link. - Python Packages Unleashed:
@lawls.nethighlighted the complexity of managing Python packages and encouraged the practice of setting up separate virtual environments for each project. - Mimic Mammalian Learning In AI:
@amylizzleshared an interesting paper on a new error propagation method that simulates mammalian learning Link. - AnimateDiff Takes the Stage:
@hina_techreleased the AnimateDiff prompt travel GUI, now available on Gradio. - AI Comes to Flashcards for Easy Recall:
@venkycsshared a link to AI Hub, a platform that offers AI concept flashcards to help learners Link.
HuggingFace Discord Channel Summaries
▷ #announcements (1 messages):
- Data Management with Hugging Face and DVC:
@Andyrasikawrote a blogpost about streamlining data management with Hugging Face and Data Version Control (DVC). The post explores how DVC and Hugging Face's ecosystem interact to transform how data is managed within projects. Blogpost Link - Piano MIDI Generation with Transformers:
@afmckhas published a blogpost titled TchAIkovsky, focusing on piano MIDI generation using Transformers. Blogpost Link - Hindi-English Model for Content Creation and Classifications:
@manishiitghas trained a model on Hindi and English data, optimized primarily for content writing, role playing, classification, and generating coherent content. The model is not optimized for coding/maths tasks. Model Link - Multiple Choice Question Handling with Transformers and PyTorch:
@Andyrasikadiscusses how to leverage Transformers and PyTorch for handling Multiple Choice Questions in a blogpost. Blogpost Link - AI Chatbot for Code Generation and Plot Editing:
@sophiamyangshowcases an AI chatbot that makes use of Panel and Mixtral 8x7b to run code and edit matplotlib plots. Blogpost Link - Preventing Data Contamination in LLMs: In a blogpost by
@rishiraj, he talks about managing evaluation data contamination during model merging and introduces tools to streamline processes and maintain data integrity. Blogpost Link - Understanding Counting in Probability:
@ariG23498writes an instructional blogpost on the importance of counting for understanding probability and its use cases. Blogpost Link - Shoe Image Classification Dataset:
@Andryasikahas created a dataset of 15,000 images of shoes, sandals, and boots, ideal for multiclass classification with deep neural networks. Dataset Link
Links mentioned:
- Streamlining Data Management with Hugging Face and DVC: A Seamless Integration
- TchAIkovsky – Piano MIDI Generation with Transformers
- manishiitg/open-aditi-hi-v1 · Hugging Face
- Leveraging Transformers and PyTorch for Multiple Choice Question Tasks
- Build an AI Chatbot to Run Code and Tweak plots
- Celebrity Look A Like - a Hugging Face Space by tonyassi
- Combating Evaluation Data Contamination in LLMs: Strategies for High-Quality Finetuning and Model Merging
- Counting 'n' objects
- Andyrasika/ShoeSandalBootimages · Datasets at Hugging Face
▷ #general (85 messages🔥🔥):
- Urgent Help With Gradio Requested: In general queries,
@nigg.pablorequested urgent help with gradio. - Confusion on Huggingface API Usage and Payments:
@.o.sarge.o.expressed confusion about their Huggingface API usage and payment expectations, noting a lack of charges despite extensive usage with the "openai/whisper-large-v3" model. - Unexpected Issue with ASR Endpoint Inference: User
@blahblah6407experienced an issue during the creation and testing of an endpoint inference for ASR with a finetuned Whisper, reporting a specific error related to an unexpected 'ignore_warning' argument and seeking assistance in resolving it. - Operating Llama 2 on an M1 Macbook Pro: User
@sia4030sought guidance in getting Hugging Face models working with Llama 2 on an M1 Macbook Pro. They were assisted by@lee0099, who guided them through resolving issues with thepython convertcommand and the lack of aconfig.jsonfile. - Difficulty Signing up to Hugging Face: User
@illumesreported difficulty signing up to Hugging Face, expressing that process seemed to halt after the CAPTCHA stage. The issue was subsequently addressed by@sakalys, who suggested the issue may be due to the use of an ad blocker, or a browser like Brave. They then advised switching to another browser to avoid the CAPTCHA issue. - PC Build Advice for Deep Learning: User
@sedthhsought advice in building a budget PC for Deep Learning, specifically requesting recommendations between a 3090 or 4080, or other suitable alternatives within the same price range. - Inquiring About Interview Footage:
@vishyouluckexpressed an interest in viewing an interview involving@504681610373758977(Sayak Paul), with@qwerty_qwerproviding the link to the podcast. - Potential Strength of AI Model Discussed:
@not_lainand@vipitishighlighted the release of WizardCoder-33B-V1.1, mentioning its strong start. - Problem with Open LLM Evals Submission:
@kquantexpressed difficulty in uploading models to the open LLM evaluation queue, their model submission appeared to have failed with no clear reason for the failure given.
Links mentioned:
- meta-llama/Llama-2-13b-chat-hf at main
- ArtificialThinker Demo on GPU - a Hugging Face Space by lmdemo
- HuggingChat
- Kquant03/EarthRender-32x7B-bf16_eval_request_False_bfloat16_Original.json · open-llm-leaderboard/requests at main
- Tweet from WizardLM (@WizardLM_AI): 🔥 Excited to release WizardCoder-33B-V1.1, the SO...
- When running as python module - meta-llama/Llama-2-7b-hf does not appear to have a file named config.json · Issue #26432 · huggingface/transformers: System Info Python 3.10 Transformer 4.32.0.dev0 Tr...
- GitHub - julien-c/arxiv-to-hf: Chrome extension to add a link from each Arxiv page to the corresponding HF Paper page: Chrome extension to add a link from each Arxiv pag...
- Llama 2 for Mac M1: Getting Llama 2 working on Mac M1 with llama.cpp a...
- How to install Llama2 on a Mac M1 & M2(Mac-Silicon)?: An important point to consider regarding Llama2 an...
- meta-llama/Llama-2-70b-chat-hf · Hugging Face
- Accelerating Generative AI Part III: Diffusion, Fast: This post is the third part of a multi-series blog...
- Release v0.25.0: aMUSEd, faster SDXL, interruptable pipelines · huggingface/diffusers: aMUSEd aMUSEd is a lightweight text to image mode...
▷ #today-im-learning (6 messages):
- Python Package Management Challenges: User
@lawls.nethighlighted the complexity and the importance of handling Python packages and virtual environments properly. They stressed the importance of using the correct versions of packages and setting up a separate virtual environment for each project. - Stable Diffusion XL for Image-Generation:
@8bit888shared a blog post titled Stable Diffusion XL: A tutorial for designing without limitation, It offers a guide to installing and using Stable Diffusion XL, an open-source image generating tool. - Journey into Python Packaging and PyPI Publishing:
@vipitismentioned that they are trying to learn about Python packaging, specifically optional extras and also publishing to PyPI.
Links mentioned:
Install Stable Diffusion XL on MacOS: DALL-E & Midjourney are great but free is bett...
▷ #cool-finds (4 messages):
- Mimicking Mammalian Learning Through Error Propagation:
@amylizzleshared an interesting paper presenting a new error propagation method that mimics mammalian learning.
- Quadrilingual
@sia4030highlighted their diverse language skills, speaking English, Swedish, Persian fluently and French at beginner level.
- Flashcards for Mastering AI via AIHub:
@venkycsshared a link to AI Hub, a platform that offers flashcards to easily master AI concepts like transfer learning.
- @dttch Open to New Connections:
@dttchexpressed openness to forming new connections within the servers, illustrating the welcoming and collaborative atmosphere of the community.
Links mentioned:
- undefined
- Inferring neural activity before plasticity as a foundation for learning beyond backpropagation - Nature Neuroscience: This paper introduces ‘prospective configura...
▷ #i-made-this (8 messages🔥):
- AnimateDiff Prompt Travel GUI Now on Gradio:
@hina_techshared their new creation, the AnimateDiff prompt travel GUI, that is now available on Gradio. - DreamDrop V1 by ehristoforu:
@ehristoforuintroduced DreamDrop V1, a modern model trained on Deliberate V5 with MJLora. They provided optimal settings, negative prompts, and additions for optimal use. Various versions of the model can be found in the Files tab. - Discussion on Tokenizing vs. Embedding:
@lordgrim0033sought clarity on the difference between tokenizing and embedding.@torres8552clarified that tokenizing breaks down text into words or sub-words and assigns an ID to each token, while embedding converts these tokens into high-dimensional vectors. - Don't Cross-Post Reminder:
@cakikigently reminded@venkycsnot to cross-post.
Links mentioned:
GitHub - JojoYay/animatediff-cli-prompt-travel: animatediff prompt travel: animatediff prompt travel. Contribute to JojoYay/a...
▷ #reading-group (2 messages):
- Casual Affirmative Responses:
- Both
@chad_in_the_houseand@lunarflushared positive and affirmatory responses to a previous message or statement. The details of the original message or statement were not provided in the given message history.
▷ #computer-vision (3 messages):
- Annotations for bank statement images:
@detraxsenpaiis seeking advice on automating the annotation of bank statement table images. They express interest in using an existing model that has about 70-80% accuracy and manually tweaking it for full accuracy. - Possibility of GPU acceleration:
@pragma9538suggested checking if torch.cuda is being leveraged on NVIDIA GPU for improved processing efficiency. - Open Collaboration Offer:
@pragma9538has expressed openness for collaboration in this area. Those interested can reach out via direct message.
▷ #NLP (12 messages🔥):
- Chatbot Overlord:
@jryariantois seeking guidance for building a chatbot capable of accessing a database and providing real-time answers while maintaining strict access controls.@absolutt1suggests the use of the Retrieval Augmented Generation (RAG) system for this task, which is suited for assistants. - Searching for Learning Paths:
@notoothis looking for tutorials to train Phi-2 or LLAMA-2 models. Our man of mystery@babylonkiwuis also in the hunt and wonders about the feasibility of training Phi-2.7 and Mistral 7B on free colab using Qlora. - RAG How-to Guide: To help jryarianto,
@absolutt1mentions the widespread availability of tutorials on building chatbots using the RAG method, capable of providing contextually relevant responses. - Gemini Pro Vision Deploys:
@aiman1993shares a Hugging Face Spaces link to the Gemini Pro Vision Streamlit Application, inviting others to experiment and test it. - RAG Disciple:
@jryariantoacknowledges a lack of familiarity with the RAG system but expresses interest in exploring@absolutt1's recommendation further.
Links mentioned:
Gemini Pro Vision Streamlit Application - a Hugging Face Space by disham993
▷ #gradio-announcements (1 messages):
- Gradio 4.13 Launch Announced:
@abidlabsannounced the launch of Gradio 4.13 with a post listing the new features and fixes including Button components fix,.select()event fix for image selection, Chatbot and Model3D component fixes, security enhancements for the FileExplorer component, and ensured compatibility with Python 3.12. He also shared the full changelog. - Lighting up Lite: Thanks to @whitphx, AnnotatedImage support on Wasm has been introduced in Lite.
- Developers, Join the SharedWorker mode: Another thanks to @whitphx for adding a development instruction for lite in SharedWorker mode.
- Functional Test Fixes:
@aliabid94deserves a shout-out for fixing functional tests.
Links mentioned:
Gradio Changelog: Gradio Changelog and Release Notes
Perplexity AI Discord Summary
- Perplexity's Series B Celebrations: Perplexity successfully raised $73.6M in Series B Funding led by big names like IVP, NVIDIA, Jeff Bezos and more, aiming to create the world's fastest and most accurate answers platform. Perplexity's current phenomenol performance includes 10M monthly users and over a million mobile app installations. @AravSrinivas's Tweet spread the news further and attracted congratulations from various users in the Discord guild.
- Queries on Perplexity's Internet Interactive Capabilities: In the experimental mode, Perplexity AI does have internet access but it cannot cite references yet. Users were curious about this aspect and are looking forward to new developments, which supposedly include citation features. @nqiwbh07r44p's query sparked this discussion.
- Incorporating PPLX API : Beyond the Perplexity platform, the PPLX API can help developers deploy larg°e language models into their software. The Perplexity API, introduced in this blog post, provides a fast inference and an easy-to-deploy system. A future feature request includes the return of raw snippets and reference links as well as setting the number of snippets in Perplexity API's online models.
- Exploring Perplexity's Online Models: Perplexity's online models, featured in this blog post, provides factual and up-to-date responses in their search. However, users in the Discord guild also noticed Perplexity's absence of Mixtral for online responses.
- Space Ed for Tech Enthusiasts: A blog post highlights the top 8 skills needed for anyone keen on joining the space tech industry. With innovative companies like SpaceX and Blue Origin leading the way, this is an area of interest for technology enthusiasts.
Perplexity AI Channel Summaries
▷ #announcements (1 messages):
- Perplexity Raises $73.6 million in Series B Funding: User
@enigmagiannounces that Perplexity raised $73.6 million in Series B Funding led by IVP with participation from NVIDIA, NEA, Bessemer, Elad Gil, Jeff Bezos, among others. The company dreams of building the world's most accurate and fastest platform for answers. - A blog post was shared where readers can look up more details: blog.perplexity.ai/blog/perplexity-raises-series-b-funding-round - Perplexity's Success and Future Plans: They reported achieving 10M monthly users and serving more than half a billion queries in 2023. A quote taken directly from the announcement post: "Our ambition is to serve the entire planet’s unbounded curiosity, and we’re just getting started."
- Milestone in Mobile: The company also revealed that over a million users have installed their mobile apps, both on iOS and Android.
- Challenging Google's Dominance: Perplexity, according to a linked WSJ article, is backed by Jeff Bezos and some venture capitalists who believe that AI will upend the way people find information online, thus challenging the dominance of Google in web search: www.wsj.com/tech/ai/jeff-bezos-bets-on-a-google-challenger
- Impressive Startup Growth: Despite being started less than two years ago and having fewer than 40 employees, Perplexity's product is used by roughly 10 million people monthly.
Links mentioned:
- Perplexity Raises Series B Funding Round : Announcing Perplexity's Series B Funding Round
- WSJ News Exclusive | Jeff Bezos Bets on a Google Challenger Using AI to Try to Upend Internet Search: Perplexity, with a fraction of Google’s users, rai...
▷ #general (96 messages🔥🔥):
- Experimental Perplexity AI Internet Usage: User
@nqiwbh07r44pinquired if the experimental mode of Perplexity AI has access to the internet and how to make it show its references.@giddzand@icelavamanconfirmed that the experimental model has internet access but cannot currently cite references, a feature that is supposedly on the roadmap. - Becoming a Perplexity AI Tester: User
@nqiwbh07r44pasked about becoming a tester for Perplexity AI.@giddzprovided a Discord link and@icelavamanmentioned that the program is currently closed. - Perplexity vs Other AI Models: User
@marcopaoneasked for opinions on which AI model to choose between Gemi Pro, GPT-4, and Claude 2.1.@icelavamanrecommended GPT-4. - Perplexity AI App and VPN: User
@mares1317noted that with VPN, the web version of Perplexity only requires to check the box of Cloudflare and the app has no issues. User@icelavamanpointed out that this might not be the case for everyone and it depends on the VPN provider/hotspot, yet@mares1317insisted that no problems occur with a good VPN provider like Proton. - Perplexity AI Funding News: Users
@blackwhitegrey,@giddz,@billbuttliquor,@serpentineuk,@theoutbacklp,@keef_kahn, and@theoutbacklpcongratulated Perplexity team on their new funding round announcement, which valued Perplexity at $520 million. The news includes notable investors such as Jeff Bezos and Nvidia.
Links mentioned:
- AI-powered search engine Perplexity AI, now valued at $520M, raises $73.6M | TechCrunch: Perplexity AI, a search engine heavily leveraging ...
- Perplexity Careers: Join our team in shaping the future of search and ...
▷ #sharing (4 messages):
- Space Tech Skills to Master:
@madhusudhan7shared a blog post about the 8 skills one needs to master to work in the growing space tech industry. The post mentions that the space tech industry is innovating and companies like SpaceX and Blue Origin are making space travel more accessible.
- Arav Srinivas Funding Announcement:
@icelavamanshared a tweet from@AravSrinivasannouncing that they have raised $73.6M at a $520M valuation. The funding round was led by IVP, with participation from NVIDIA, Jeff Bezos,@tobi, Databricks,@naval,@rauchg,@balajis, among others.
- Search Queries on Perplexity AI: Both
@_joeweiand@maxymus85shared queries from the Perplexity AI database, though the content or purpose of these search queries are not specified in the messages.
Links mentioned:
- 8 Skills You Should Master If You Want to Work in Space Tech - Take It Personel-ly: If you're interested in pursuing a career in the s...
- Tweet from Aravind Srinivas (@AravSrinivas): Excited to announce we've raised 73.6M$ at 520...
▷ #pplx-api (9 messages🔥):
- Expanding Perplexity API features:
@maxwellandrewsrequests the option to return both raw snippets and reference links for online models via the Perplexity API, and suggests providing the ability to set the number of snippets to return. They also suggest the possibility of a separate search API and questions the lack of Mixtral for online responses. - PPLX API vs Perplexity:
-
@blackwhitegreyasks about the advantages of using PPLX API over Perplexity, and@icelavamanresponds that the API allows developers to integrate LLM's into their products. -@icelavamanthen clarifies that online LLM's can search in response to@blackwhitegrey's query about the API's capabilities. - Perplexity API Introduction: A link to the introduction of pplx-api on the Perplexity blog is shared by
@icelavaman, which provides information about the api's features like ease of use, fast inference, and reliable infrastructure. - Perplexity online models:
@icelavamanshares another link from the Perplexity blog about the introduction of perplexity's online models and their unique advantage of providing factual and up-to-date responses. - Adding Perplexity Models to Typingmind:
@blackwhitegreyinquires about how to add Perplexity models to Typingmind.
Links mentioned:
- Introducing pplx-api : Perplexity Lab's fast and efficient API for open-s...
- Introducing PPLX Online LLMs : The first-of-its-kind Online LLM API
Eleuther Discord Summary
- Anthrowpic's Terms Ruffle Feathers:
@stellaathenacriticized Anthrowpic's Terms of Service for being overly strict, potentially hindering research and competition, based on a tweet from@LLMSherpa. Members speculate on the possible motivations behind these terms. - Possible Legal Implications of Anthrowpic's Terms:
@fern.bearvoiced concern about the potential legal issues associated with Anthrowpic's terms, noting it might pose complications for businesses who use their services. - Twitter Analysis Project Takes Flight:
@sirmalamuteproposed an open-source Twitter analysis project using NLP and showed openness to collaborations, feature-feedback, and project explorations. - Early Termination in Neural Networks Turns Heads: Discussion initiated by
@gabriel_symeabout early exit strategy in deep neural networks drew attention and suggestions like looking into Adaptive Computation Time and expert-specific stopping in Mixture of Experts (MoEs). - A Potential Roadblock in the HF Street:
@micpienoticed a potential issue inlm_eval/api/task.pydue to a change in Hugging Face's dataset structure, discussed by@hailey_schoelkopfand@micpie. - Buzz Around Document Packing in GPT-Neox:
@tastybucketofriceand@ad8edelved into the efficiency of document packing in GPT-Neox, with ad8e hinting at a more efficient packing scheme mentioned in a professional paper and expressing willingness to contribute to the project.
Eleuther Channel Summaries
▷ #general (44 messages🔥):
- Anthrowpic's Terms of Service Deemed Harsh:
@stellaathena, citing a tweet from@LLMSherpa, criticized Anthrowpic's Terms of Service for being strict and possibly stifling research and competition. The terms of use apparently demand users to halt activities when a breach is claimed. Some users speculated this either as a defensive move or a sign of the company's struggle. - Clarity Over Terms, Research Restrictions:
@thatspysaspysought clarification about the "no research" claim in Anthrowpic's terms.@stellaathenaand@mrgonaopointed to the term banning development or training of models, which could be interpreted as prohibiting substantial areas of AI research. - Terms Deemed Too Restrictive, Possibly Problematic:
@fern.bearvoiced concern about the possible legal implications of waiving opposition to injunctive relief in the terms, noting it could pose complications for businesses interested in using Anthropic's services. - Proposed Open Source Twitter Analysis Project:
@sirmalamuteproposed an open-source Twitter analysis project using NLP with features like sentiment analysis, polarity check, political affiliation determination, and so on. The user is open to feedback, exploring possible features and collaboration on the project. The initial aim is to create a toolkit rather than a traditional research paper or database. - Challenges and Considerations for Twitter Analysis Project:
@ad8equeried@sirmalamuteon the project's specifics, including handling necessary labels for analysis.@sirmalamutementioned potential sources or methods for labels and discussed the possible need to navigate Twitter's policy when considering distribution of tweets for analysis.
Links mentioned:
Tweet from The LLM Sherpa (free/acc) (@LLMSherpa): Anthropic updated terms. So, to use Claude, you h...
▷ #research (20 messages🔥):
- Early Exit in Neural Networks: User
@gabriel_symeinitiated a discussion on early exit strategy in deep neural networks, particularly in regards to terminating and outputting at an intermediate layer instead of the last one.@thootonsuggested looking into Adaptive Computation Time, which@gabriel_symeappreciated. The topic then evolved into discussing stopping at specific experts/layers in Mixture of Experts (MoEs). - Papers on Adaptive Computation and Transformers:
@thisisniqand@zphangshared links to papers and more recent ones on adaptive computation time and transformer models respectively. - Multilingual Model for Long-sequence Classification: User
@_michaelshsought recommendations for a multilingual model designed for long-sequence classification tasks.@stellaathenarecommended mT5 or BLOOM. - Point2CAD Project Shared: User
@digthatdatashared a link to a GitHub repository related to the Point2CAD project. - Opinion on CALM and AI Research Communication:
@gabriel_symeexpressed their thoughts on the Composition to Augment Language Models (CALM) approach and its comparison to LoRA. They also criticized the communication style of a tweet they found, arguing it didn't offer practical solutions.
Links mentioned:
- LLM Augmented LLMs: Expanding Capabilities through Composition: Foundational models with billions of parameters wh...
- Universal Transformers: Recurrent neural networks (RNNs) sequentially proc...
- Confident Adaptive Language Modeling: Recent advances in Transformer-based large languag...
- GitHub - YujiaLiu76/point2cad: Code for "Point2CAD: Reverse Engineering CAD Models from 3D Point Clouds": Code for "Point2CAD: Reverse Engineering CAD ...
▷ #lm-thunderdome (5 messages):
- HF Datasets changes affect lm-thunderdome:
@micpienoticed HF datasets updates might have caused issues with previous commits and required commenting out code inlm_eval/api/task.py. Issue was brought by the removal ofname=self.DATASET_NAMEin line 732. - Potential issue due to HF's transition:
@hailey_schoelkopfnoted that the dataset issue might be related to HF moving away from dataset loading scripts and usingtrust_remote_code=True. - Pull request merged:
@hailey_schoelkopfannounced that a pull request in thelm-evaluation-harnessrepo which removes theself.dataset_path post_init processhas been merged. - Toxigen evaluation questioned:
@johnnysandsraised a question regarding the evaluation method used for the Toxigen dataset, asking whether turning it into a binary classification task is standard practice as mentioned in the Toxigen paper or unique to lm-eval-harness.
Links mentioned:
▷ #gpt-neox-dev (15 messages🔥):
- Access to VM and updates on Documentation/Cleanup:
@tastybucketofriceoffered VM access to a user and inquired about documentation and cleanup progress.
- Efficient Timing in Torch CUDA:
@tastybucketofricerecommended the use oftorch.cuda.Eventtimers for accurate timing in CUDA-based code, specifically within a distributed setting, citing examples from EleutherAI's cookbook.
- Tracking Upstream on GPT-NeoX:
@tastybucketofriceexplained why GPT-NeoX tracks upstream, focusing on usability, support for multiple systems, readability, and interpretability. Cherry-picking of optimizations is done as they mature upstream, and they are open to new upstream-tracking workflows.
- Efficiency of Document Packing in GPT-NeoX:
@ad8eand@tastybucketofricediscussed document packing in GPT-NeoX, with@ad8epointing out the potential inefficiencies of the current system. They also referenced a packing scheme from a professional paper.@tastybucketofriceoffered to add this to the development roadmap upon receiving solid evidence of its effectiveness.
- Potential Code Contributions for Document Packing:
@ad8eindicated that they might be able to submit a PR for improving document packing in the future.@tastybucketofriceand@hailey_schoelkopfreferenced previous work done on sequence packing without attending to one another and potential codes for efficient packing.@hailey_schoelkopfsuggested reaching out to the lead author of a published paper for code related to this matter.
Links mentioned:
- In-Context Pretraining: Language Modeling Beyond Document Boundaries: Large language models (LMs) are currently trained ...
- Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance: Effective training of today's large language m...
- cookbook/benchmarks/communication at main · EleutherAI/cookbook: Deep learning for dummies. All the practical detai...
- gpt-neox/tools/datasets/preprocess_data_with_mask.py at e5a7ea71e96eeada636c9612036dc85e886d973d · EleutherAI/gpt-neox: An implementation of model parallel autoregressive...
- GitHub - EleutherAI/gpt-neox at multitask: An implementation of model parallel autoregressive...
- GitHub - EleutherAI/gpt-neox at FIM: An implementation of model parallel autoregressive...
Mistral Discord Summary
- Mixtral steps into the Spotlight: @i_am_dom announced that Mixtral is now available on Replicate with new updates. User also delved into nuances of syntax for incorporating system prompts in Mistral models and Mixtral's sensitivity to prompt formatting based on their experience.
- Chatting Effectively with Mistral: @gbourdin and @lovis07 expressed a need for guidelines on effectively using Mistral as a chatbot. @i_am_dom responded with an applicable Python script.
- RAM Impact on Mixtral's Performance: @arianagrandefan4024 queried if DDR5 RAM would boost Mixtral's performance. @someone13574 clarified that it would help if running Mixtral on a CPU, otherwise, it wouldn't present a significant advantage.
- Instructing the Mixtral with System Prompts: @nickbro0355 was interested in how to make Mixtral work with a system prompt. @bdambrosio suggested using the full llama-2 template or inserting a system message within
<<SYS>>[message]<</SYS>>. - Running Models on Local Devices & Apple Silicon: Suggestions around running models locally and using Apple's M2 Neural Engine for accelerating Mistral models were discussed, with @bdambrosio mentioning the potential of OrangePi 5B and @jdo300 curious about leveraging the new MLX framework and the M2's neural engine.
- Opportunity for Engineer Fine-Tuners: User @arkalius75 appealed for a skilled engineer fine-tuner for a mission—compensation included. Interested parties can reach out via direct message.
- Debating AGI and AI Perceptions: Users discussed whether GPT-4 can be considered a weak AGI, how AI achievements become a moving target over time, the inadequacy of our understanding of intelligence and how substantial is GPT-4's intelligence as compared to ordinary animals.
- La Platform Impressions & Questions: User @acast_37857 shared their positive impressions of "la platform" and raised questions about implementing "mistral-embed". Related, @sublimatorniq spotted a potential issue with abrupt stops related to
\[.*?\]patterns in the prompt data and Mixtral's stop parameters, humorously deciding to start including seeds in all their requests.
Mistral Channel Summaries
▷ #general (43 messages🔥):
- Mixtral Now Available on Replicate:
@i_am_domshared a link to the dedicated Mixtral page on Replicate, revealing new updates ("I meant this btw. Not censored anymore suddenly.").
- Formatting System Prompts in Mistral Models: An in-depth discussion was observed regarding the correct syntax for incorporating system prompts in Mistral models.
@i_am_domshared a detailed example from Huggingface Spaces and clarified that the<<SYS>>format is used with LLaMA, not Mistral.
- Mixtral's Sensitivity to Prompt Formatting:
@i_am_domhighlighted that from his experience, Mistral's output quality is heavily influenced by the format of the input prompt, based on a Reddit post discussing the same.
- Effective Use of Mistral as a Chatbot:
@gbourdinand@lovis07expressed a need for clear documentation or guidelines on how to effectively use Mistral as a chatbot with history and rag.@i_am_domresponded with a link to a Python script as a practical solution.
- RAM Specifications Affecting Mixtral Performance:
@arianagrandefan4024queried if moving from DDR4 to DDR5 RAM would improve Mixtral's performance.@someone13574clarified that it would help if running Mixtral on a CPU, otherwise, it wouldn't present a significant advantage.
Links mentioned:
- Tiktokenizer
- app.py · openskyml/mixtral-46.7b-chat at main
- mistralai/Mixtral-8x7B-Instruct-v0.1 - API Reference - DeepInfra: Mixtral mixture of expert model from Mistral AI. T...
- Reddit - Dive into anything
- text-generation-webui/instruction-templates/Mistral.yaml at main · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Support...
- FastChat-release/fastchat/conversation.py at 2855bf974f0973f85adb2bb7a9d075255b353ecf · mistralai/FastChat-release: An open platform for training, serving, and evalua...
- mistralai/mixtral-8x7b-instruct-v0.1 – Run with an API on Replicate
▷ #models (5 messages):
- Does Mistral Medium support function calls?:
@rantash68raised a query about the capability of Mistral Medium to have "function call" feature akin to GPT-4. But, they couldn't find any definitive answer to this question. - Mistral's language prowess questioned:
@acast_37857sparked a discussion about the language capability of Mistral Tiny. Despite the bot being marketed as English-speaking, the user noticed it responding accurately in French. The tongue-in-cheek response by.superintendentpoints out that Mistral is a French company.
▷ #deployment (10 messages🔥):
- Inquiring about System Prompts with Mixtral: User
@nickbro0355was interested in how to make mixtral instruct use a system prompt.@bdambrosiosuggested using the full llama-2 template or trying to include a system message within<<SYS>>[message]<</SYS>>. - Running Models on Local Devices:
@choudhary_sahab101asked for suggestions regarding the most optimal way to run the model on a local device.@bdambrosiomentioned the potential of OrangePi 5B, a local 6TOPS unit that supports most Pytorch including transformers. - Utilizing Apple's M2 Neural Engine for Models:
@jdo300is curious about what API back-end would be the best to run Mistral models on Apple silicon. Specifically seeking to leverage the new MLX framework and the M2's neural engine to accelerate model inference.
▷ #finetuning (2 messages):
- Calling all engineer fine-tuners for a paid mission:
@arkalius75is on the search for a skilled engineer fine-tuner for a mission—compensation included. Interested parties are encouraged to send a direct message to@arkalius75.
▷ #random (15 messages🔥):
- Is GPT-4 a Weak AGI?: In a discussion about GPT-4 and AGI,
@poltronsuperstarquestioned whether GPT-4, which is above average human in many tasks, could be termed as a weak AGI.@blueridanusresponded that in a way, yes, GPT-4 is a weak AGI. - Changing Perception of AI Over Time:
@poltronsuperstaralso raised a concern about how AI achievements become a moving target over time. For instance, if GPT was shown to someone from 2004, they would probably consider it an AGI. - The Unknowns of Intelligence:
@blueridanusvoiced that we don't understand intelligence enough to define foolproof criteria for it. It's the lack of understanding that might be preventing us from creating an AGI. - Comparative Intelligence of GPT-4 and Animals: At the same time,
@blueridanusalso stated that in many meaningful ways, GPT-4 is dumber than very ordinary animals are. - Defining AGI – A Moving Goalpost?:
@ducksuggested to consider AGI as a range rather than a single point. The idea of an AI being similar to an infant progressing to become an adult was floated as a possible interpretation for AGI.
▷ #la-plateforme (4 messages):
- Introduction to "la platform" and Questions on "mistral-embed": User
@acast_37857shared their positive first impressions of "la platform" and asked for guidance on using "mistral-embed", unclear from which platform to implement it. - Abrupt Stops Issue Detected: User
@sublimatorniqnoticed a correlation between abrupt stops and the presence of\[.*?\]patterns in the prompt data. Upon their removal, the abrupt stops seemed to cease, suggesting that the issue could stem from these patterns' interactions with mixtral's stop parameters. - Potential Issue with Mixtral Stop Parameters:
@sublimatorniqnoted that Mixtral for ollama is configured withPARAMETER stop "[INST]"andPARAMETER stop "[/INST]", which might be causing confusions leading to unexpected stops. - Sending Seeds with Requests: After the observed issue,
@sublimatorniqhumorously indicated their decision to start including seeds in all their requests.
OpenAccess AI Collective (axolotl) Discord Summary
- Confusion Angles fire up a debate: In a detailed image posted by
@yamashi, users were thrown into a discussion on which angle marked - A, B, C, or D - is the correct one. - Closer Gap vs Lower Loss:
@nafnlaus00sparked a conversation saying that "it's better to aim for minimizing the distance between eval_loss and train_loss vs only caring about getting as low of an eval_loss as possible", especially when handling unclean datasets. - Early Beta of RL Training announced:
@caseus_revealed that RL (Reinforcement Learning) training is merged and now supports DPO and IPO. Though in its beta stages, the community's suggestions and pull requests are much appreciated to refine the development. - "Fine-Tuning Mixtral" Talk arises: Potential issues with fine-tuning Mixtral were brought to light by
@dangfutures. However, the query remained unanswered. - Curriculum Learning Idea pops up in Axolotl-dev:
@suikamelonshowed interest in implementing curriculum learning, a process where the model is trained starting with "easy" samples. @Caseus_ suggested considering yaml for disabling shuffle. - Multigpu Config Hitch:
@qeternityhad issues with axolotl's deepspeed stages and asked for multi-gpu config examples. The user was then recommended to refer to the nccl.md docs by@caseus_. - Application of User Feedback:
@athenawisdomsasked how user feedback on responses could be beneficial to model improvement, to which@noobmaster29floated the idea of setting up a reinforcement pipeline. - The Synthetic dataset size conundrum:
@antti_45069raised a query regarding the size of a synthetic dataset in comparison to typical code datasets which usually are of the range 100k+. - Introduction of Search RAG API: The availability of the Search RAG API was announced by
@emrgnt_cmplxty. This tool appears promising for challenges relating to synthetic data and grounding responses. - Contextual Connotations and Misspellings: A potential misspelling in the phrase "and be vary of the context" was caught by
@nafnlaus00, but@le_messclarified that it doesn't affect overall performance.
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (18 messages🔥):
- Uncertain Angles sowing confusion: User
@yamashiposted an image with multiple angles marked and caused a small confusion among users, asking for the correct angle – A, B, C, or D? - A call for more general solutions rather than aiming for the lowest eval_loss:
@nafnlaus00expressed the perspective that it's better to aim for [minimizing the distance between eval_loss and train_loss vs only caring about getting as low of an eval_loss as possible], particularly in situations where the dataset isn't clean. - Announcement of Reinforcement Learning (RL) training with chatml support:
@caseus_shared that RL training is now merged and supports DPO and IPO, but is currently in beta and needs further polishing. Open to suggestions/Pull Requests from the community, Caseus_ confirmed it is in its early stages and welcomes any external assistance. - Non-English Model Tuning: User
@noobmaster29provided a helpful link (https://arxiv.org/pdf/2401.01854.pdf) for non-English model tuners. - Potential issues with fine-tuning mixtral:
@dangfuturesqueried if there were still issues fine-tuning mixtral. The question remained unanswered within the provided chat history.
▷ #axolotl-dev (7 messages):
- Disabling Shuffling in Axolotl:
@suikamelonquestioned how to disable the shuffling feature in axolotl and later confirmed it seems to work after making modifications.@caseus_suggested considering a yaml setting for it. - Concept of Curriculum Learning:
@suikamelonexpressed interest in experimenting with the concept of "curriculum learning" by training the model starting with "easy" samples. - Sample Packing Randomization:
@caseus_mentioned that randomization occurs when using sample packing, but@suikamelonconfirmed having disabled it. - Suggestion for Windowed Random Sampler:
@caseus_proposed the idea of incorporating a windowed random sampler in future development.
Links mentioned:
axolotl/src/axolotl/utils/data.py at 59b2d302c8780ed83e6a0201b741574ee51a1a5e · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to Open...
▷ #general-help (24 messages🔥):
- Mistral Fine-Tune Query:
@henrikliedasked if 8-bit lora and 8192 sequence length are feasible for fine-tuning mistral on 3x4090's with a dataset containing 430,791,018 tokens.@nanobitzresponded that if it fits, it'll just take some time. - VRAM Queries for qlora Finetunes:
@leoandlibeinquired about the amount of VRAM required for 13B/34B/70B qlora finetunes. To which,@nanobitzreplied that to load 13B, it takes roughly 13GB VRAM for qlora + optimizer + batch size. - Script Automation:
@athenawisdomsquestioned about automatically running a second command/script after the axolotl command has finished or crashed.@leoandlibesuggested using python subprocess run to listen and trigger the required actions. - Axolotl's Multiturn Chat Modelling:
@evil_mallocquestioned if axolotl is suited for multi-turn chat models and how the model is trained.@nanobitzexplained that the model is trained on all assistant messages. - Multigpu Config Example:
@qeternityasked examples on multigpu config as they encountered issues with axolotl's deepspeed stages during dataset prep.@caseus_recommended them to check out the nccl.md docs. - User Feedback's Usage:
@athenawisdomsqueried about how the user feedback on generated responses can be employed to improve the model. In response,@noobmaster29suggested possibly setting up a reinforcement pipeline.
▷ #datasets (2 messages):
- Synthetic dataset size debate:
@antti_45069inquired about an undisclosed language learning model and remarked that a synthetic dataset of 1780 rows is quite small compared to other code datasets that usually range in the 100k+ range. - Introduction of Search RAG API:
@emrgnt_cmplxtyannounced that the Search RAG API, suitable for synthetic data and grounding responses, is now available for users to experiment with.
▷ #community-showcase (2 messages):
- Watch out for Context:
@nafnlaus00pointed out a potential misspelling in the phrase "and be vary of the context". - Misspelling doesn't affect performance:
@le_messconfirmed the misspelling, but noted that it doesn't hurt performance.
LangChain AI Discord Summary
- Call for Better Conversational Retrieval:
@irfansyah5572expressed that their ConversationalRetrievalChain setup was returning all found source documents, not just the relevant ones.@seththundersuggested a solution involving asimilarity_score_threshold. - Langchain Out, Custom Utils In:
@atefyaminand@evolutionsteppervoiced strong criticisms of Langchain and hinted at developing their own utilities. - On the Hunt for Image Resizers:
@rajib2189initiated a hunt for preferred image resizing packages within the tech community. - RAG Meets Tabular Data:
@michael_71751asked for guidance on using a RAG with tabular data input and output, along with transforming tabular data in a linguistic context. - Markdown Love in LCEL:
@cryptossssuninquired about selecting and loading markdown files from a local directory.@seththunderproposed usingDirectoryLoader. - LLMChain vs ConversationChain Showdown:
@nav1106sought clarity on the differences between LLMChain and ConversationChain, with@seththundersuggesting ConversationChain is the better bet for simple conversational contexts. - Pipeline Dreams with MultiChains:
@seefrogwas curious if it was feasible to connect multi-chains using a pipeline operator, confirmed by@seth_thunder. - GCP Adventures in JVMs:
@johnda98delved into questions around running a JVM within a Python standard app engine on GCP and the possibilities of initiating a JRE or GCP JVM within a containerized langserve. - A New Challenger, Search RAG API:
@emrgnt_cmplxtyhighlighted the launch of the Search RAG API, potentially a game-changer for synthetic data and grounding responses. Give it a whirl here. - Tutorial Transmissions on Video Interactivity and Advanced AI Retrieval:
@a404.ethshared a how-to on building a tool to chat with videos for optimizing video metadata. Additionally,@lhc1921flagged this resource for mastering advanced retrieval in the realm of AI: Advanced Retrieval for AI.
LangChain AI Channel Summaries
▷ #general (28 messages🔥):
- ConversationalRetrievalChain relevance issue:
-
@irfansyah5572pointed out that their ConversationalRetrievalChain setup was returning all found source documents, not just the ones relevant to the query asked.@seththundersuggested using a line of code with asimilarity_score_thresholdto tackle this issue. - Conversational miscommunications? Ditch Langchain!
-
@atefyaminand@evolutionsteppervoiced strong concerns regarding the limitations of Langchain. Mentioning everything from parser issues to the trouble of synchronous tasks, they expressed a clear preference for building their own utilities instead. - Image Resizing:
- User
@rajib2189opened a discussion asking about which packages are usually used for image resizing. - RAG with tabular data:
-
@michael_71751asked for advice on using a RAG with tabular data input and output and also sought assistance on transforming tabular data using a linguistic context. - Loading markdown files with LCEL:
-
@cryptossssunqueried about the potential way to select and load markdown files from a local directory using a custom function. They planned to use these files as the context for retrieval. -@seththundersuggested usingDirectoryLoaderand specifying just the markdown files in the directory glob. - LLMChain vs ConversationChain:
-
@nav1106queried about the differences between LLMChain and ConversationChain and when to use one over the other. -@seththunderresponded saying both were very similar but ConversationChain is preferred when you want to have a simple conversation before asking your question. - MutliChains Connection with Pipeline Operator:
-
@seefrogasked if it was possible to connect multi-chains using a pipeline operator -@seth_thunderconfirmed that this can be done using a SequentialChain.
▷ #langserve (3 messages):
- Running JVM within a Python Standard App Engine on GCP: User
@johnda98asked if anyone has experience running a JVM within a Python standard app engine on GCP for a layer2 project that involves billing AItoken counts in crypto tokens/in-protocol currency using a crypto SDK in Java via py4j. - Deploying Langserve on GCP:
@johnda98has successfully deployed langserve on GCP and is looking to integrate it with a JVM. - Running JRE/GCP JVM within containerized Langserve:
@johnda98brought up a query whether it's possible to initiate a JRE or GCP JVM within a containerized langserve deployed on GCP via cloud run.
▷ #share-your-work (1 messages):
- Search RAG API now available for trials:
@emrgnt_cmplxtyannounced that the Search RAG API is now up and working. They highlighted its potential usefulness for synthetic data and grounding responses. They provided a link for anyone interested to give it a try: Sciphi.ai.
▷ #tutorials (2 messages):
- Build a 'Chat with Your Videos' Tool: User
@a404.ethposted a YouTube video tutorial illustrating how to create a simple LCEL chat that can transcribe and interact with video content. This tool aims to assist content creators by generating improved titles, descriptions, and keywords for their videos. - Advanced Retrieval for AI: User
@lhc1921shared a link for learning advanced retrieval methods for artificial intelligence.
Links mentioned:
- DLAI - Learning Platform Beta
- Building an OpenAI Custom RAG with LangChain: The Ultimate Tutorial to Chat with your Videos!: I hate writing video descriptions and titles so I ...
Latent Space Discord Summary
- GPT Store Enters the Market:
@swyxioshared a tweet from@eeracabout the upcoming launch of GPT store, a hub for AI-related projects in 2024, advising to port existing applications like weather, podcast, mindfulness, to-do list, word games, etc., to CustomGPT. Tweet Link. - ChatGPT Introduces Reply-to-Part Feature?: In a discussion triggered by a screenshot,
@coffeebean6887,@fanahova, and@dimfelddebated the novelty and the possible ChatGPT exclusivity of a feature to reply to parts of messages. - The Challenge of Related-Article Features:
@swizecrequested strategies to evaluate features offering related articles, encouraging a collective brainstorming. - DevOps GPT Deemed A Flop:
@btdubbinsexpressed dissatisfaction with "DevOps" GPT, highlighting an array of errors and labeling it one of the worst implementations seen. - Akuity Tops Kubernetes LLm Projects: In response to
@austintackaberry'sinquiry about significant Kubernetes LLm products/projects,@fanahovarecommended Akuity, a product revaled to be the driving force behind Argo. Akuity Link. - Anticipating TLDRAW Episode: In the ai-event-announcements channel,
@swyxioteased the upcoming episode with TLDRAW and invited feedback. The preview link was provided. - Chat Transcription vs User Comfort: A discussion initiated by
@picocreatorin the llm-paper-club channel raised concerns around the potential infringement on user comfort by AI-based chat transcriptions, emphasizing the importance of user trust. - Reproducing Papers as a Group Activity:
@ivanleomkpitched the idea of reproducing and training models based on discussed papers, suggesting a 1-1.5 months timeline for interested contributors. - Acknowledgment of Successful Claim:
@swyxiothanked a user (<@206404469263433728>) for a successful, albeit unspecified, claim in the llm-paper-club channel.
Latent Space Channel Summaries
▷ #ai-general-chat (23 messages🔥):
- GPT Store Announcement:
@swyxioshared a tweet from@eeracannouncing the impending launch of GPT store, an ideal starting place for AI-related ambitions in 2024. The suggestion was to port existing favourite applications like weather, podcast, mindfulness, to-do list, word games, etc., to CustomGPT. [Tweet Link] - New ChatGPT Feature?: A screenshot shared prompted a conversation about the ability to reply to parts of messages on ChatGPT. Both
@coffeebean6887and@fanahovahad not seen this feature previously, whereas@dimfeldthought it was new and exclusive to ChatGPT. - Talking Embeddings and Related Articles:
@swizecasked the community for effective ways to evaluate related-articles features. - Distress Over "DevOps" GPT:
@btdubbinsobserved that their "DevOps" GPT generated an array of errors, making it one of the worst implementations they've seen. - Request for Kubernetes LLm Product/Project:
@austintackaberryinquired about notable kubernetes llm products/projects, to which@fanahovarecommended Akuity, a product reported to be behind Argo. [Akuity Link]
Links mentioned:
- draw fast • tldraw: Draw a picture (fast) with tldraw
- lens by tldraw: An infinitely scrolling drawing and hallucinating ...
- Tweet from Eric Rachlin (@eerac): If your goals for 2024 involve building something ...
- Deploy to Kubernetes with Argo CD as a managed service: Akuity SaaS platform for Argo CD. Argo enterprise ...
- Reddit - Dive into anything
▷ #ai-event-announcements (1 messages):
- Upcoming TLDRAW Episode Preview:
@swyxioshared a preview link to the upcoming episode with TLDRAW and welcomed comments.
▷ #llm-paper-club (6 messages):
- Recording Chats: An Invasive Affair?:
@picocreatorposed a query on whether chat transcriptions via AI could infringe upon user's comfort. A concern was raised that this could potentially deter members from asking questions in a session, emphasizing the need for trust and user comfort. - An Invitation to Reproduce Papers:
@ivanleomkproposed an idea of reproducing and training models based on discussed papers. Suggestion was for interested parties to take on this project over the course of 1-1.5 months. - Successful Claim Acknowledged:
@swyxiothanks a user (<@206404469263433728>) who claimed an unknown item or task, though the exact details are left unsaid.
DiscoResearch Discord Summary
- Performance Rivals between Stage and Turbo:
@maxidlnoted that both StageTurbo and Turbo had comparable performance in ranking a document set, with only a 1% deviation in the nDCG score favoring StageTurbo. - Plug for German Embedding Models: Highlighting a need for localized text embeddings,
@sebastian.bodzashared a research article and expressed the desire to develop similar models for the German language. - Rise of Retrieval Tasks for AI:
@sebastian.bodzashared the first part of a dataset on Huggingface, highlighting a move towards training AI models to complete retrieval tasks with specific context-driven guidelines. - Underscoring Need for More Real German Questions: Amidst his work on German wikipedia data,
@philipmayemphasized the need for more real questions in training data. He also shared a positive experience with training a German DPR model on a translated and curated SQUAD dataset, noting the seamless blend of English instructions with German text through GPT-3.5-turbo. - BERT Models and Token Lengths Debated:
@philipmayand@_jp1_conversed about the optimal token length for BERT models, hovering around a range of 252-2048 tokens depending on general or specific use cases. - Classic Info Retrieval vs. Embedding Models Discourse Sparked:
@thewindmomquestioned the use of classic information retrieval systems over embedding models, pointing the conversation towards CoBERT and the challenges of dense embeddings as per a Hacker News post and a Twitter thread. - Introduction of German MTEB Benchmark:
@rasdaniannounced a German-oriented contribution to the MTEB benchmark with a retrieval benchmark based on the GermanQuAD, now hosted on DiscoResearch's GitHub. - Call for Collaboration on Open GitHub Issue:
@rasdanishared an open GitHub issue on the DiscoResearch mteb, inviting ideas and contributions. - Video Meetings Proposed for Collaboration: Espousing a collaborative spirit,
@philipmaysuggested video meetings to discuss different approaches and potential synergies.
DiscoResearch Channel Summaries
▷ #general (17 messages🔥):
- Performance Comparison of StageTurbo and Turbo:
@maxidlnoted that in testing both to rank a set of documents, StageTurbo and Turbo performed very close, with Turbo only 1% less in nDCG. - Discussion on German Embedding Models:
@sebastian.bodzashared a research article on high-quality text embeddings and expressed the need to build similar models for german language and experiments with Textexercises. - Exploring Retrieval Tasks for AI:
@sebastian.bodzashared the first part of a dataset on Huggingface, and the Proof of Context implementation to train a model to complete retrieval tasks following specific guidelines. - Interest in German Dataset Development:
@philipmayaffirmed working on the generation of questions from German wikipedia data, and highlighted the need for more real questions in the training data. He also shared his recent positive experience with GPT-3.5-turbo in mixing English instructions with German text, and a successful training of a German DPR model on a translated and curated SQUAD dataset. - Creation of Dedicated Channel for AI Models Discussion:
@philipmayand@bjoernpagreed on the creation of a separate channel for discussions related to embeddings and DPR models, leading@bjoernpto officially create a new channel for the said purpose.
Links mentioned:
- Improving Text Embeddings with Large Language Models: In this paper, we introduce a novel and simple met...
- SebastianBodza/RAG_Aufgaben · Datasets at Hugging Face
▷ #embedding_dev (12 messages🔥):
- Discussing Maximum Context Length for BERT Models:
@philipmayasked for opinions on the maximum context length (in tokens) for BERT models used in DPR training, referencing their previously trained model with a max token length of 252.@_jp1_suggested a minimum of 512 for general purpose embedding models, stating that 1 or 2k might be better. For specific RAG use cases, they suggested 2xx might be sufficient. Reference - Question about CoBERT and Classic IR:
@thewindmominquired if anyone had looked at CoBERT or worked with classic IR instead of embedding models. They also shared a link to a Hacker News post discussing the challenges of using dense embeddings and a Twitter thread that they intended to explore further. - Introduction of First German MTEB Benchmark Contribution:
@rasdaniannounced the hosting of a fork of MTEB for German benchmarks on the DiscoResearch Github organisation, including a retrieval benchmark based on the GermanQuAD in thegermanquad-retrievalbranch. They also shared the testset results on MRR@10. - Open GitHub Issue on DiscoResearch mteb:
@rasdanishared an open GitHub issue on the DiscoResearch mteb, inviting interested individuals to take it up. - Proposing Video Meeting for Discussion:
@philipmaysuggested a video meeting to clarify the different approaches being followed and discuss potential collaboration points. The invitation was extended to several channel members.
Links mentioned:
- Show HN: RAGatouille, a simple lib to use&train top retrieval models in RAG apps | Hacker News
- Improving Text Embeddings with Large Language Models: In this paper, we introduce a novel and simple met...
- Adding German to MTEB · Issue #183 · embeddings-benchmark/mteb: Hi everybody, I think it would be great to add Ger...
- Custom class for e5 embedding model family · Issue #1 · DiscoResearch/mteb: The e5 embedding family requires "query: &quo...
- unilm/e5/utils.py at master · microsoft/unilm: Large-scale Self-supervised Pre-training Across Ta...
- GitHub - DiscoResearch/mteb: A fork containing German benchmark contributions for MTEB, the Massive Text Embedding Benchmark. All contributions will be upstreamed to MTEB.: A fork containing German benchmark contributions f...
LLM Perf Enthusiasts AI Discord Summary
Only 1 channel had activity, so no need to summarize...
- SciPhi.AI Reveals Knowledge Engine for LLM Agents:
@emrgnt_cmplxtyshares a link to the Sciphi.AI website, a project that proposes to enable LLM agents with seamless access to humanity's key knowledge through web-scale search and data synthesis. - You.com API Discussion:
@robotumsbumped You.com's API in the chat, wondering how it compares to the Metaphor API. In response,@jeffreyw128explained that while You.com largely wraps the Brave API, Metaphor uses an embedding-first search approach, with an emphasis on search customization and computational resources. - Upcoming Powerful Snippets from Metaphor:
@jeffreyw128teased an upcoming feature from Metaphor, promising impressive snippets that offer high customizability, including control of sentence count, snippets per page, and specific queries pertaining to the snippet. - Improved Response noted on Lebesgue Integration Query:
@nosa_.stated a significantly improved response on a Lebesgue integration question they queried previously, to which@emrgnt_cmplxtycheerfully acknowledged.
Links mentioned:
Skunkworks AI Discord Summary
Only 1 channel had activity, so no need to summarize...
- A Curiosity Check:
@dook4inquired about the group's activity, to which@far_elresponded encouragingly, hinting at upcoming activities in the next week. - A Show of Excitement:
@s3nh1123expressed excitement with an emoji. - Question Regarding Data Release:
@maxmaticalasked aboutwizardlm/wizardcoderand their data release, posing the concern of irreproducible research.
Alignment Lab AI Discord Summary
- New Kid on the Block, Search RAG API:@emrgnt_cmplxty announced that the new Search RAG API is live. It holds compelling implications for synthetic data and grounding responses. Get more information here.
- Benchmarks Beating Models: @maxmatical raised an important point about AI model training: models may exhibit poor performance as base models because they're tuned to outdo benchmarks. Whether deliberate or accidental, this training approach can affect a model's robustness across applications.
Alignment Lab AI Channel Summaries
▷ #general-chat (1 messages):
- New Search RAG API Now Available: User
@emrgnt_cmplxtyannounces that the Search RAG API is now available for use, highlighting its benefits for synthetic data and grounding responses. Details can be found at this link.
▷ #phi-tuning (1 messages):
- Models Trained to Beat Benchmarks: User
@maxmaticalsuggested that models may not perform effectively as base models because they are primarily trained to beat benchmarks, either intentionally or unintentionally.
The Datasette/LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.