[AINews] 12/25/2023: Nous Hermes 2 Yi 34B for Christmas
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
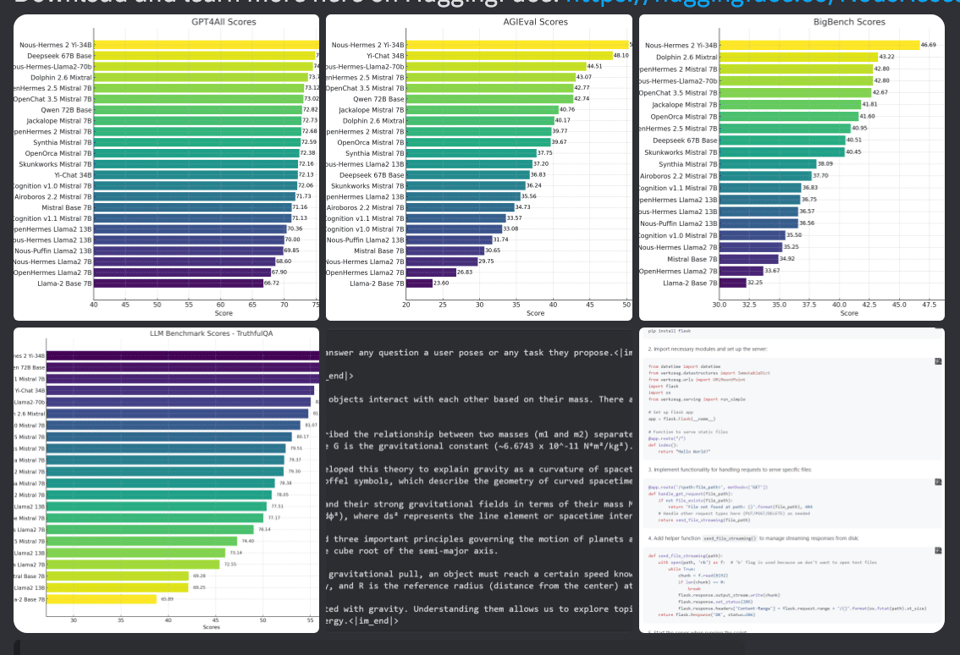
Today Teknium released Nous Hermes 2 on Yi, making it the top open model compared to Mixtral, DeepSeek, Qwen, and others:
Apple also introduced Ferret, a multimodal LLM.
Also, here's the year in memes.
- Nous Research AI Discord Summary
- LM Studio Discord Summary
- Mistral Discord Summary
- OpenAI Discord Summary
- HuggingFace Discord Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- LangChain AI Discord Summary
- DiscoResearch Discord Summary
- Alignment Lab AI Discord Summary
- Skunkworks AI Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- AI Engineer Foundation Discord Summary
Nous Research AI Discord Summary
- Extensive discussion on technical aspects of AI model optimization, specifically focusing on quantization methods including AWQ, GPTQ and AutoAWQ. Dialogues pivoted around perceived inefficiencies of public quantization techniques, proprietary optimization methods, and model throughput metrics. The conversation involved users
@teknium,@carsonpoole, and@casper_aiin the #off-topic channel. - Sharing of different valuable links in the #interesting-links channel: addition of NucleusX Model to
transformers, a research paper on Huggingface, a 30B model with 80 MMLU, and the YAYI 2 language model by Wenge Technology. - Announcement of the release of Nous Hermes 2, an advanced model transcending previous Hermes models, trained over Yi 34B and downloadable from HuggingFace, as shared by
@tekniumin the #announcements channel. - Multifaceted discussions held in the #general channel: wide-ranging conversations on ML models, text-to-speech and text-to-music datasets, the impact of AI in the movie industry, the launch of Nous Hermes 2 and its quantification process.
- Conversations in the #ask-about-llms channel pertained to hosting service recommendations for inference servers and ways to run Hermes models on a Mac.
- A dialogue about finding inference code examples for a specific model and the need to update the respective model card, as seen in the #project-obsidian channel.
Nous Research AI Channel Summaries
▷ #off-topic (45 messages🔥):
- Quantization Benefits and Limitations: There was a long technical discussion between
@teknium,@carsonpoole, and@casper_airegarding the effects and efficiency of quantization methods in AI model optimization.@tekniumargued that public quantization techniques such as AWQ and GPTQ are not efficient compared to undisclosed techniques used internally by some organizations. - Throughput Metrics: The discussion also delved into metrics for model throughput across various batch sizes, with further exploration of the tradeoffs between batching vs sequential generation.
- Proprietary Optimization Methods:
@tekniumsuggested that some organizations may be using proprietary parallel decoding methods that offer significant speed improvements.@carsonpoolebelieved it was more likely that organizations were using tensor parallelization across multiple GPUs for speed up. - AutoAWQ Performance:
@casper_aiweighed in, stating that AutoAWQ outperforms vLLM in their benchmarks up to a batch size of 8. However, FP16 eventually delivers higher throughput with enough concurrent generations. - Job Inquiry: A user,
@pradeep1148expressed interest in working for Nous Research in a brief message.
▷ #interesting-links (4 messages):
- NucleusX Model Addition to Transformers: User
@osansevieropointed out that NucleusX Model is being added totransformers. - Reference to a Research Paper: User
@metaldragon01shared a link to a research paper on Huggingface. - 30B Model with 80 MMLU: User
@metaldragon01mentioned a 30B model with 80 MMLU but didn't specify additional details. - YAYI 2 Language Model: User
@metaldragon01shared a link to the YAYI 2 language model developed by Wenge Technology. This model uses 2.65 trillion Tokens of high-quality, multi-language corpus for pre-training.
▷ #announcements (2 messages):
- Announcement of Nous Hermes 2: User
@tekniumofficially announced the release of Nous Hermes 2. This model builds on the Open Hermes 2.5 dataset and surpasses all previous Open Hermes and Nous Hermes models in benchmark scores. The model was trained over Yi 34B and can be downloaded from HuggingFace here.
▷ #general (214 messages🔥🔥):
- Discussion on Different ML Models:
@gabriel_syme .beowulfbrquestioned how to identify the weights that should be reduced in ML models while discussing a research paper. In another thread,@Otto von Bismarckand@alpindalediscuss the performance of AI model goliath and possible testing models. Later@.beowulfbrshared his personal experience with Reddit's toxic environment, while revealing the criticism his AI model, codeninja, received on the platform. - Text-to-Speech and Text-to-Music Datasets:
@qwerty_qwerannounced that he has access to massive data sets for text-to-speech and text-to-music models, to which@nruaifresponded by suggesting diffusion-based text2sound models and provided a link to a GitHub repository of VITS2, an efficient text-to-speech model. - AI and Movie Industry Discussion:
@mihai4256shared a twitter post discussing the potential of AI in democratizing the movie industry. He later also inquired about the professional whereabouts of Jeremy Howard, founder of Fast.ai who recently launched a new venture, Answer.ai. - Nous Hermes AI Model:
@tekniumexcitedly announced the release of the new Nous Hermes 2 AI model and shared the model chat link as a Christmas present to the community. This led to several appreciative reactions and excited queries from other users on the platform. - Discussion on Model Quantification and Performance:
@tekniumand@n8programshad a detailed discussion about how to perform quantization for the new model, including the hardware requirements and other relevant aspects. They discussed various benchmarks, and@n8programswent on to carry out quantization successfully and shared the quantized model on GitHub.
▷ #ask-about-llms (5 messages):
- Hosting Services for Inference Servers: User
@kenakafrostyasked for recommendations on hosting services for inference servers, expressing a preference for a solution that allows for serverless and pay-only-for-compute operation, but doesn't incur long start-up times. - Running Hermes Models on Mac: User
@ac_sdinquired if Hermes models can be run directly on a mac, and also asked for clarification on a specific file format. Responding, user@n8programsconfirmed that Hermes models can indeed be run on a mac.
▷ #project-obsidian (5 messages):
- Inference Code for Model: User
@vic49.expressed difficulty in finding inference code examples for a specific model online, noting the absence of such information on the model card.@qnguyen3responded to the concern, assuring that they would update the model card later in the day with the required information.
LM Studio Discord Summary
- Release and discussion over new AI models: Apple's Ferret, an open-source multimodal Learning Language Model, was introduced and discussed for its unique image querying feature; Dolphin 2.6 Phi-2, another new model with coding focus, was also introduced and its obedience and dependencies were discussed. Information and links were provided for further conversation.
-
AI and tech discussions: A heated conversation on loading large models led to suggestions of altering layer numbers; chat history maintenance, AI-generated text changes and real-time code autocompletion were also talked about. Issues with special characters in windows usernames were briefly discussed and solutions provided.
- In a related context, examination and comparison of AMD Radeon RX 6800 XT's performance was discussed through published performance tables; benefits of a 3060 ti over a 2080 Super in a multi-GPU setup emerged, an upgrade to 64GB RAM for larger models was shared, and optimization setups for the Mixtral model were discussed through a shared guide. The idea of fitting multiple GPUs through PCI risers was proposed, with potential issues acknowledged.
- LM studio in the business field and app development: An LM Studio Android app project from
@thelefthandofurzawas announced; business usage of LM Studio and testing procedures were explored as@docorange88inquired about it.
- Extension releases: A pre-release version of the AI navigator extension that supports multiple AI technologies was announced.
- Community engagement: Christmas and holiday greetings were exchanged among the users; an issue concerning a model loading error was addressed and discussions about experimental builds for long conversations and their limitations were explored. A specific instance of system troubleshooting via re-installation was also addressed.
- Lastly, miscellaneous discussions surrounding model configurations and upcoming updates were conducted. This includes GPU usage for loading models, bundling of OpenChat presets, and persistent errors with Mixtral models on Linux platforms.
LM Studio Channel Summaries
▷ #🎄🎅-general (17 messages🔥):
- Apple's New Open Source ML Model: User
@pierrunoytshared a link about Ferret, a new open-source multimodal Learning Language Model released by researchers from Apple and Cornell University in October. The model can use regions of images for queries. - Holiday Greetings: Users
@heyitsyorkie,@authentictimers,@thelefthandofurza,@izukumidoriya2211, and others exchanged Christmas and holiday greetings. - LM Studio Android App Project:
@thelefthandofurzaannounced that they are working on an LM Studio Android app to work with the inference server, which was mostly developed by ChatGPT. Plans to share the code on GitHub and leave it open for communal improvements were stated. - Business Usage of LM Studio:
@docorange88inquired about testing and using LM Studio for business purposes, preferring a direct private message for communication. - AI Music Generation Discussion:
@american_prideinitiated a conversation about AI music generation models, specifically mentioning Suno.@musenikcontributed to the discussion, voicing a preference for LM Studio due to Suno's requirements for online generation and account creation. The question of whether there are any music generation models that run on LM Studio remains open.
▷ #🤝-help-each-other (36 messages🔥):
- Loading Large Models:
@bearmcx98encountered an issue when trying to load a large model with 40 layers on a machine with 8gb VRAM and 32gb RAM.@fabguysuggested reducing the number of layers to 10 as the current configuration might be too much for the machine, particularly with models above Q3 or Q4.
- Message History with AI:
@oaaliyevasked about using Python or another language to chat with AI via API, saving the message history, and maintaining the chat history after reloading the script.@fabguyexplained that this needs to be programmed manually by storing the history in a file as it is currently not supported on the server side.
- Changing the AI's Generated Text:
@fabguyexplained a way to change the AI's generated text, suggesting that users can simply modify the words the AI uses instead of trying to argue or persuade the AI. This will make the AI treat the change as its own idea.
- Real-time Code Autocompletion:
@funappleasked if there is a way to use active models in LMS for real-time code autocompletion.@heyitsyorkierecommended exploring the continue extension in VS Code, which does something similar through local models.
- Challenges with Special Characters in Windows Usernames:
@proutesfaced an issue possibly linked to having a special character (é) in the windows username.@yagilbconfirmed that it was due to the illegal character and suggested changing the path by clicking the gear icon next to “Chats” top left.
▷ #🤖-models-discussion-chat (1 messages):
- Discussion on Dolphin 2.6 Phi-2: User
@clickclack777introduced Dolphin 2.6 Phi-2, a new, uncensored chat model with a coding-focus link. - The user commented that Dolphin 2.6 Phi-2 is highly obedient but not DPO tuned, therefore it might require system prompt encouragement.
- The model, developed by Eric Hartford and Fernando Fernandes, is sponsored by convai.
- Dolphin 2.6 Phi-2 is based on Phi-2 and follows Microsoft's microsoft-research-license, which prohibits commercial use.
- To converse about the model, they shared a Discord link.
▷ #🛠-configs-discussion (6 messages):
- GPU Usage in Loading Models: User
@myndsuggested that one should be able to fully load the model on a 3090 GPU by trying-1for the number of layers, implying that this action would transfer all of the layers to the GPU. @pefortinresponded by advising to monitor the vram usage, which is expected to increase. If it doesn't, there could be an issue with the installation/config.- Bundling of OpenChat Preset:
@sublimatorniqexpressed a desire for the OpenChat preset to be bundled as other chat templates for convenience. @ptableresponded by asking why doesn't the user simply save it as a config. But@sublimatorniqcountered that having it bundled like other presets would align with the goal of convenience.
▷ #🔗-integrations-general (3 messages):
- AI Navigator Extension Christmas Release:
@sublimatorniqannounced a pre-release version of the AI navigator extension that supportsollama,lm-studio,mistral,geminiand more. - Functionality Questions: User
@vic49.asked about the extension's functionality, which wasn't clear from the webpage. - Explanation of the Extension: In response,
@sublimatorniqdetailed that the extension counts tokens, queries the context, hyperlinks responses, and scrolls to the source.
▷ #🎛-hardware-discussion (114 messages🔥🔥):
- Graphics Card Performance Testing:
@fabguyandpcrafterdiscussed the performance of AMD Radeon RX 6800 XT in terms of tokens per second. The exact numbers, tested on a system with i5-12600k CPU and 32GB of RAM, are available in the posted table.pcrafterfound the 0.11 tokens/s amusing, as they could predict the next word in the generated text. - GPU Choice for Multi-GPU Setup:
@pefortin,@heyitsyorkie, andrugg0064had a discussion on a better choice between NVIDIA 2080 Super and 3060 ti for a multi-GPU setup, the consensus leaned towards the 3060 ti due to its better compatibility with a 3090 in the same system. - Extended RAM Usage:
@dedr1ckshared their upgrade to 64GB RAM to fit larger models. They noted that while the new RAM is slower (7200MHz vs. 600MHz), it does provide the necessary capacity to run larger models like Mixtral which was previously crashing their system.@heyitsyorkiecommented on this, stating that the performance benefit mostly comes from extra VRAM and system RAM mainly speeds up time to first token. - Optimizing Mixtral Model Setup:
@heyitsyorkieshared a guide detailing steps on setting up Mixtral models - from which Kobold version and model quants to select, to troubleshooting common issues. Quality might degrade under 4-bit and ensuring a minimum of 20GB VRAM/RAM for better speeds was suggested. - Considerations for Multi-GPU Setup:
@pefortinraised the idea of fitting multiple GPUs on a standard motherboard using PCI risers, although they acknowledged potential performance issues because of the risers' limited transfer speed. They shared plans to conduct experiments with different card mixes on Linux and report back with results.totallyboredandrugg0064discussed the possible bottlenecks presented by such a setup, especially with the added complexities of inferencing across different GPUs.
▷ #🧪-beta-releases-discussion (9 messages🔥):
- Issues with mixtral models: User
@doderleinreported an error loading mixtral models in the Linux version, receiving an error message regarding the tensor 'blk.0.ffn_gate.weight'. User@fabguyresponded that this issue is currently unsupported in the Linux version, but should be fixed in the next release. - Impressions on mixtral models:
@fabguyshared that the mixtral models are less impressive than the hype suggested and advised@doderleinto try out other models such as open Hermes. - Unavailable Experimental Build for Long Conversations: User
@yagilbsuggested an experimental build that addresses issues with very long conversations deviating off course. However, this build is currently only available for Mac. - Persistent Model Loading Error on Linux: User
@eason0731also encountered the same error on Ubuntu 22.04.3 LTS while trying to load a model locally. The user inquired about the release of a Linux version that would address this persistent issue, referencing a previous chat that promised a fix in the next release after 0.2.8.@yagilbdirected them to recent discussions in another channel for more information on the subject.
▷ #autogen (1 messages):
@heliosprime_3194 glufy: I uninstalled and installed it back and now it is working
Mistral Discord Summary
- In-depth discussions around the implementation, performance and fine-tuning of the Mistral model series, emphasising their potential utility in various applications. Key techniques and deployment issues include the functionality of .safetensors files, Mistral 8x7b deployment on Edge Coral AI, the handling of GGUF file formats in model deployment, and the specificities of the HuggingFace version of the instruct-v0.2 with mlx.
- User
@qwerty_qwermade available a large text-to-music dataset potentially beneficial for training certain models. - Explored the importance of developing efficient audio generation models, with
@flame1536underscoring the necessity of small, fast audio generating models similar to ElevenLabs. - Proposal by
@tafferboyfor implementing an AI Summary feature on Discord to help members keep up with discussions. - Discussion of the potential of models in tool usage and coding, particularly through a technique described as "negotiation" by
@poltronsuperstar. A related discussion centred around the possibilities of model interaction and independent improvement viewed as a key to achieving artificial general intelligence (AGI). This includes an emphasis on model reliability as a current issue facing AI application development. - Clarifying the differentiation between the paid API of Mistral-AI and free versions available on platforms like Perplexity.AI. Consideration of whether existing large language models (LLMs) could be enhanced by online weight updates and the introduction of rich human feedback.
Mistral Channel Summaries
▷ #general (43 messages🔥):
- Opening and Understanding .safetensors Files: User
@hasanurrahevyinquired whether it was possible to open and understand .safetensors files.@blueridanusprovided a Python code snippet to open these files and explained that these files hold the weights of a model. The weights are symbolized by the mentioned file names like "model.embed_tokens.weight" (which is of dimensions torch.Size([32000, 4096])).
- Deployment Inquiry for mistral 8x7b on Edge Coral AI:
@queuelabsraised a question about optimizing and deploying a mistral 8x7b model on edge coral ai, specifically regarding how to optimize model for edge inference through flash storage using an SD card.
- Contextual - AI Assisted Navigation and Querying:
@sublimatorniqshared the news of an XMAS pre-release of an AI navigator extension called Contextual that supports mistral/gemini/ollama/lm-studio/etc. Included in the announcement was a link to the extension on the Chrome Web Store.
- Availability of Large Text-to-Music Dataset:
@qwerty_qweroffered to share their large dataset consisting of 1 million songs from Spotify and approximately 20k hours of audio files with captions. This data might be useful if someone wanted to train text-to-music or text-to-speech models.
- Need for Fast, Small Audio Generation Models:
@flame1536pointed out the lack of work done on fast, small audio generation models and emphasized how important they could be to unlocking new applications. They suggested the need for a small ~7B model capable of local operation, which would offer quality similar to ElevenLabs.
- Suggestion for AI Summary Feature on Discord:
@tafferboysuggested that the server moderators should enable the AI summary feature on Discord. This would allow users to conveniently review conversations that took place while they were away.
▷ #models (2 messages):
- Mistral Open Source version:
'@ken70wtfand@tom_lrddiscussed about the benefits of open source and open weight models. They mentioned that it would theoretically allow anyone to modify models to remove or minimise any alignments they don’t like. They also discussed the current state of Mistral 8x7b by dolphin 2.5 and its performance with Chinese language. - Instruct-v0.2 with mlx:
'@unskillessshared their experience and queries about using the HuggingFace version of instruct-v0.2 with mlx. Notably, they noticed a difference in the Mistral 7B models in terms of the missing output layer in the HuggingFace version as compared to the .pth ones.
▷ #deployment (15 messages🔥):
- Using Mistral AI locally: User
@sakstasked for guidance on how to use Mistral AI locally after downloading the files posted on 8th December.@sublimatorniqrecommended using platforms like Ollama AI and LM Studio AI for this purpose.
- Using LM Studio for Mistral AI on Windows:
@sakstattempted using LM Studio for running Mistral 0.2 on Windows, but faced difficulties uploading the downloaded files due to large file size (around 90 GB).
- Understanding GGUF format for AI models:
@dutchellieclarified that the files to be used with LM Studio should be in GGUF format, which is a quantization format that reduces the size of the models. These GGUF format files are not available on Twitter but can be downloaded from Huggingface.
- Sources for GGUF files:
@Dutchellienamed a Huggingface user, TheBloke, who posts quantized models in several formats, including GGUF.
- Confusion Resolved: With the advice from
@dutchellie,@sakstexpressed an understanding of the necessary steps and expressed gratitude towards the community for the assistance.
▷ #finetuning (1 messages):
- Mistral Model Details:
@casper_aiasked<@707162732578734181>about any plans to publish a detailed paper or blog on the Mistral model series. Specifically, they're interested in learning about the architecture optimization for training and hyperparameters used. They mentioned that while MegaBlocks are available, it's unclear which parts were used for Mistral.
▷ #showcase (1 messages):
.tanuj.: Burned through a lot of tokens, but the agent framework is looking promising!
▷ #random (77 messages🔥🔥):
- Using AI Models for Tool Usage and Coding:
@poltronsuperstarand@victronwolfsondiscussed the potential of AI models in tool usage and coding practice.@poltronsuperstarsuggested a method of "fake few shot learning" with large context tokens and multiple iterations until the desired output is achieved. They refer to this approach as "negotiation" and shared that they successfully imitated the behavior of Discord's official bot using GPT-3.5 in this manner.
- Models Interacting with Themselves and AGI:
@blueridanusand@poltronsuperstarhad a back-and-forth on the potential of models interacting with themselves, with@poltronsuperstarexpressing confidence that this approach is the path to AGI (artificial general intelligence). There was some contention on whether AGI can be achieved solely through advancements in language modeling, or if more components are required.
- Intelligent Self-Improvement of Models: In an extended discussion on AGI,
@poltronsuperstarput forth the idea that self-improvement in a model is key to achieving AGI. They proposed a scenario where the complexity of a codebase that can generate code equals or surpasses the complexity of its own codebase - signaling an ability for self-enhancement and possibly AGI.
- Ideas to Improve Current LLMs:
@blueridanussuggested exploring approaches to update current language large models (LLMs), incorporating online weight updates and ability to make gradient steps based on reasoning capabilities and rich human feedback, in order to enhance their learning capabilities. They acknowledge the issue of catastrophic forgetting as a hurdle in the way.
- Reliability as the Biggest Issue: In response to
@tonyaichamp's query about the biggest difficulty in building LLM apps currently,@sublimatorniqstated that reliability is a significant challenge.
▷ #la-plateforme (17 messages🔥):
- Comparison of Mistral-AI API with Free Alternatives:
@ved_ikkequestioned the additional benefits of the paid API of Mistral-AI compared to the free version available on other platforms such as Perplexity.AI.@blueridanusclarified that some platforms offer evalutation versions but if one doesn't have any use for the API itself, they can use other platforms which host free versions for evaluation. - Accessing Mistral-AI through Other Platforms:
@ved_ikkereferenced Perplexity AI Labs as a platform where Mistral AI can be accessed for free.@blueridanuspointed out that this is an instance of a playground hosted for users to evaluate their offering. - Metric for Mistral embed:
@ak35asked for clarification on what the metric is for Mistral embed, mentioning it has 1024 dimensions but not specifying if the metric is cosine, dotproduct, or euclidean.
OpenAI Discord Summary
- Several users expressed interest in learning AI & Prompt Engineering despite lacking a tech background, with suggestions to refer to the Prompt Engineering guide on the OpenAI website.
- OpenAI Discord members exchanged Christmas greetings, while discussing technical comparisons between Co-pilot and ChatGPT, noting noticeable improvements in OpenAI's system performance.
- Practical applications of GPT-4 were discussed, particularly regarding its usage for summarizing school lecture transcriptions due to the extended information context window.
- A collection of resources and tools for data extraction and analysis from Excel spreadsheets were recommended by multiple users.
- User experience issues regarding browser compatibility, interface accessibility, API quotas, and refund policies were discussed in the openai-questions channel, along with several troubleshooting suggestions.
- In the gpt-4-discussions channel, discussions centered on modifying the current prompt/message cap in OpenAI projects, adjusting prompting habits according to OpenAI's guide, and the potential of GPT in captioning multi-speaker audio.
- OpenAI's Prompt Engineering guide was linked and discussed in the prompt-engineering channel, alongside conversations about common challenges in prompt engineering such as model evasiveness and hallucinations. An inquiry about model predictions of non-positive hypothetical character reactions sparked discussion and linkage to OpenAI's updated usage policies and successful interaction examples.
- Similar discussions occurred in the api-discussions channel, focusing on the Prompt Engineering guide, the prevalent challenges in prompt engineering, and queries on predictive behavior based on character profiles as well as user interactions with the chatbot model.
OpenAI Channel Summaries
▷ #ai-discussions (7 messages):
- Learning AI & Prompt Engineering: User
@saketrathore_52744expressed interest in learning AI & Prompt Engineering despite not having a tech background.@thunder9289reassured the user that a tech background was not necessary and suggested referring to the Prompt Engineering guide on the OpenAI website.@definitely_not_yalso mentioned an OpenAI course by Andrew NG. @thunder9289provided the link to the Prompt Engineering guide (here) in response to@saketrathore_52744's request.- Use of Reference Images in Stable Diffusion:
@rchap92asked if stable diffusion can use reference images in a "get as close as possible" approach.
▷ #openai-chatter (48 messages🔥):
- Christmas Celebrations: The OpenAI Discord chatroom members including
@ta_noshii,@peter20225953,@intermatrixnaut, and@loschessamongst others, exchanged Merry Christmas greetings, sharing various Christmas-themed emojis and stickers.
- Comparing Co-pilot and ChatGPT: A comparison between Co-pilot and ChatGPT was discussed by users
@pruoand【penultimate】. They noted that while both are about the same for chat, Co-pilot has a music plugin that ChatGPT may lack.
- OpenAI Speed Performance: Users discussed a noticeable speed improvement in OpenAI's system performance.
@luguinoticed that the stream speed is way improved, and other users such as@pruoand【penultimate】concurred, speculating it could be due to reduced demand because of Christmas or the addition of more GPUs.
- Use of GPT-4 for Notes: User
@pencil9195inquired if GPT-4 plus is worth using for summarizing school lecture transcriptions.@jaicraftresponded that GPT-4 can use more information for its responses and hence might be better at summarizing, particularly due to its 32k context window.
- Tools for Excel Data Analysis: Users
@brianjwash,@lumirix,@luguiand@michael_6138_97508discussed utilities for detailed extraction of information from Excel data. Suggestions ranged from utilizing Advanced Data Analysis on CSV data to running your own model, possibly with embedding/vectorization techniques.
▷ #openai-questions (13 messages🔥):
- Browser Compatibility and Privacy Issues:
Rockexpressed frustration about the interface being unfriendly to privacy browsers, questioning the testing processes prior to updates. - Interface and Accessibility:
skousenxhad difficulties finding Dall-E 3 on ChatGPT Plus and experiencing an different interface than expected. Postulated that the issues might be related to their location (Peru), signing up with a Google account, or due to new plus users having limited tools. - Troubleshooting Suggestions: In response to
skousenx's issue,froggy_chackosuggested clearing cache/cookies and trying a VPN. They also recommended reaching out to support. - Refund Policy Inquiry:
skousenxasking about the possibility of a refund so they can attempt signing up again with a new account. - API Quota Issue:
arthurananda, a Plus subscriber, reported a rate limit error message accusing them of exceeding their current quota, despite not having used the API previously. They inquired how to resolve this issue.
▷ #gpt-4-discussions (11 messages🔥):
- Removing the 30 prompt cap: User
@yungamainasked if there is a way to remove the 30 prompt cap.@satanhashtagsuggested buying another account or switching for the API service. - Increasing Messages Limit:
@Rockadvised@yungamainto hit "learn more" and make a case every time the cap is hit for why they should have more messages. - GPT Translation Issues:
@joker002reported an issue where the bot would only translate 10 of the 20 rows requested.@Rocksuggested that the issue might be due to recent modifications in how the output works and advised@joker002to modify their prompting habits according to OpenAI's guide. - Accessing the Prompt Guide:
@joker002sought help in finding the Prompt Guide.@lumirixshared the link to the guide: https://platform.openai.com/docs/guides/prompt-engineering - GPT Captioning Multiple Voices:
@arnoldtriasked if there's a GPT that can caption different voices of Podcasts / multiple speakers. No answer was provided in the observed messages.
▷ #prompt-engineering (10 messages🔥):
- OpenAI's Prompt Engineeering Guide: User
@exhort_oneintroduced a link to OpenAI's guide on prompt-engineering. They wondered why it had not been discussed in the channel before. - Difficulties in Prompt Engineering:
@tonyaichampasked about common challenges faced in prompt engineering for Language Learning Model (LLM) applications. User@beanz_and_riceresponded, citing model evasiveness and hallucinations as the main problems. - Model Speculation Behavior:
@rchap92raised a question about whether the chatbot model would ever predict non-positive reactions from characters in hypothetical situations. - OpenAI Usage Policies: In response,
@eskcantarecommended reviewing OpenAI's updated usage policies, advising to discuss with the model about desired outputs while taking these policies into account. - Example Case with OpenAI chatbot model:
@eskcantashared a link to an example of interacting with the OpenAI chatbot, demonstrating how the model can handle conflicts and nuances in conversation.
▷ #api-discussions (10 messages🔥):
- Prompt Engineering Guide:
@exhort_oneshared a link to OpenAI's guide on prompt engineering, mentioning that the document isn't broadly discussed in the chat.@bambooshootsadded that the guide seems to be a recent addition from the last month or two. - Challenges in Prompt Engineering: In response to
@tonyaichamp's query about difficulties faced in prompt engineering for language model apps,@beanz_and_ricementioned "Model Evasiveness and Hallucinations" as significant challenges. - Speculations Based on Character Profiles:
@rchap92asked if the chatbot could predict character reactions based on their profiles instead of opting for the 'best case scenario'.@eskcantaresponded with a recommendation to refer to the updated usage policies of OpenAI as it could guide user interactions with the chatbot. They also shared an example of an educated discussion with the model. - Bot Responses to Speculative Questions:
@rchap92further mentioned that the bot tends to revert to a positive outcome most of the time when asked speculative questions, which@pratham_shettyfound amusing.
HuggingFace Discord Discord Summary
- Discussion around using Huggingface: Includes the possibility of a session on Huggingface for engineering students, Apple's open-source multimodal LLM, interest in blockchain partnerships and smart contracts with Huggingface, possible Huggingface service interruption, query about using Dolphin 2.5 mixtral 8x7b on Huggingface, and a question about the gradio_client functionality.
- Learning experiences and inquiries shared in the Today-I'm-Learning channel: Highlighting findings on MobileSAM, query about open-source projects, reminder about channel etiquette, guidance sought for beginners, and expressions of appreciation for shared information.
- Exciting find about an NLP course from HuggingFace shared by
jaminchenin the Cool-Finds channel. - In I-Made-This channel, sharing of achievements and seeking solutions:
@andysingalshared his fine-tuned DistilBERT model with achieved accuracy, and there was a discussion about how to download images with suggestions from@yjg30737. Also, a conversation about the differences between Runpod and Kaggle notebooks for downloading generated images. - Computer-Vision channel highlighted model fine-tuning advice (BLIP-2 model), recommended resources for understanding computer vision models (Piotr's YouTube channel), and the showcasing of notable Spaces on the HuggingFace hub (EfficientSAM Space).
- Conversations in the NLP channel covered recommendations for image-to-text tasks, characterization of QA and Seq2seq models, discussions on the level of abstraction in models, and a question about methods for text entailment using T5 models. Notably, two models for image-to-text tasks were recommended: Donut and Nougat.
HuggingFace Discord Channel Summaries
▷ #general (23 messages🔥):
- Huggingface session:
@ishavvermaexpressed interest in finding someone to deliver a session on Huggingface to engineering students, with the goal of familiarizing them with the platform. - Apple's open-source multimodal LLM:
@dame.outlawshared a VentureBeat Article about Apple quietly releasing an open-source multimodal LLM. - Chain Partnerships and Huggingface: A series of conversations were held between
@cakiki,@earduman2, and@roboliciousdiscussing the possibility of blockchain partnerships and whether Huggingface has any smart contracts (which it doesn't). - Potential Huggingface service interruption:
@casanovasanwondered whether the download service was down, as a vae pack installation had suddenly stopped. - Huggingface Dolphin Integration Query:
@notsaiffinquired about the steps to use Dolphin 2.5 mixtral 8x7b on Huggingface, noting its free AI hosting. - Gradio_Client Functionality:
@_gilfoyle_asked if it was possible to change the text/state of textboxes via the gradio_client.
▷ #today-im-learning (10 messages🔥):
- MobileSAM:
@merve3234shared learning about MobileSAM, providing a link to the findings here. - Question about Open-source:
@neuralinkquestioned whether@merve3234has open-sourced a project, to which the response was it is a work in progress. - Channel Etiquette:
@cakikireminded users to keep on topic and not cross-post in the channel. - New Member Inquiry:
@alluring_chipmunk_62732_31615inquired on how to start as an absolute beginner in the channel. - Appreciation:
@osansevieroand@llmsherpaexpressed appreciation for shared info and notes from various users.
▷ #cool-finds (1 messages):
jaminchen: nlp course from HuggingFace 🙂 https://huggingface.co/learn/nlp-course/
▷ #i-made-this (5 messages):
- Rating Classification Model: User
@andysingalshared a link to his fine-tuned version of the DistilBERT model. His model achieved a loss of 0.9611 and an accuracy of 0.7011 on the evaluation set. No other data on the model's description or intended uses was given. The model can be found here. - Downloading Images Discussion:
@yjg30737provided a guide on how to download images from a created notebook. The user referred@andysingalto the Overview and Parameters & Variables sections of his notebook, which can be accessed here. - Runpod vs Kaggle Notebook:
@andysingalexpressed interest in understanding the differences between Runpod and Kaggle notebooks for downloading generated images.@yjg30737suggested downloading and running the source code from the Kaggle notebook on the user's platform to observe the results. The user noted potential modifications required for Kaggle-based code sections. - Variables and Parameters:
@yjg30737clarified that the Variables and Functions can be copied and pasted from the source. They also detailed the process of downloading from Kaggle as compressing image files into a zip folder and downloading via a specific class provided by Kaggle. - Appreciation for Shared Information:
@andysingalthanked@yjg30737for sharing useful information on handling Variables and Parameters when creating styled images. The user agreed to try the shared download script.
▷ #computer-vision (5 messages):
- Fine-tuning BLIP-2 Model:
@srikanth_78440asked for advice on fine-tuning an image-captioning model, which was answered by@nielsr_. He provided a link to a HuggingFace notebook with detailed guidance. He added that bothpixel_valuesandinput_idsneed to be prepared and the model labels need to be a copy of theinput_ids, with padding tokens replaced by-100. - Piotr's YouTube Channel for Computer Vision:
@nielsr_recommended Piotr's YouTube channel for understanding computer vision models better for@blackbox3993. The channel features various applications of computer vision models. - Spaces on the Hub:
@nielsr_highlighted some cool Spaces on the HuggingFace hub, providing a link to one such Space created by Piotr showcasing a comparison between Segment Anything Model (SAM) and EfficientSAM.
▷ #NLP (5 messages):
- Image-to-text Models:
@edude11recommended two models for image-to-text tasks: Donut and Nougat. Donut for generic tasks, available athuggingface.co/naver-clova-ix/donut-base, and Nougat for academic documents, available athuggingface.co/facebook/nougat-base. - QA and Seq2seq Models:
@opencuiguyexplained to@merve3234that QA models are encoder only models that extract answers from a given context. In contrast, seq2seq models are encoder-decoder models that generate the answer. Information on these models could be found at the following pages: Question Answering and Text Generation on HuggingFace. - Level of Abstraction in Models: Responding to
@opencuiguy,@merve3234confirmed that seq2seq models are the lower-level abstraction, and question-answering is higher level because seq2seq models can be used to solve question answering. @opencuiguyasked@merve3234about suitable methods for text entailment using a T5 model and requested a code that could act as a study reference.
OpenAccess AI Collective (axolotl) Discord Summary
- Discussion on retrieval-augmented generation (RAG) implementing tools, as RAG Local Tool Inquiry raised by
@nanobitzwith request for any known good tool equipped with user-interface for storage and retrieval of past GPT interactions. - Recommendation and exchange of academic resources and practical tools:
-
@caseus_suggesting a research paper considering it a "must-read" for those engaged in working with quantized models. -@noobmaster29introducing promptbench, a unified evaluation framework for large language models. -@nanobitzsharing findings from an Unsloth's blog post about how to finetune Mistral 14x faster with features including sliding window attention. - Detailed analysis by
@nafnlaus00on Mixtral's inference code and query around number of experts per token per layer as found in the GitHub commit. - Speculation and advice on fine-tuning parameters, epochs and embeddings:
-
@noobmaster29questioning if alpha is an adjustable parameter in post fine-tuning of a model considering it to be causing high loss. -@noobmaster29also inquiring about the appropriate number of epochs for larger datasets, suggesting a limit of 3 epochs for a dataset of 500 million tokens. - Queries by@dreamgenaround fine-tuning specifics of special token embeddings during LoRA and FFT. - Desire by@dreamgento freeze all embeddings except those for new tokens during fine-tuning. - Query about finetuning deepseek-coder 6.7B model by
@shrex8791, with a specific problem being described where the model keeps parallelizing, using all memory and seeking advice to make it run unparalelled.
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (11 messages🔥):
- RAG Local Tool Inquiry:
@nanobitzasked if anyone knows of a good RAG local tool with UI to store and retrieve past GPT conversations. - Quantized Models Inference:
@caseus_suggested a paper about inference by downstream with quantized models. They deemed it a "must-read" for people working with quantized models. - Mixtral's Inference Deep Dive:
@nafnlaus00shared their investigation into Mixtral's inference code, a link to the GitHub commit, and raised questions about the number of experts per token per layer in Mixtral. - Promptbench Evaluation Framework:
@noobmaster29shared a link to promptbench on GitHub, which is a unified evaluation framework for large language models, and asked if anyone had tried it. - Model Fine-tuning Parameter:
@noobmaster29asked if alpha is a parameter that can be modified after fine-tuning a model, expressing surprise about what they perceived as a high loss.
▷ #axolotl-dev (3 messages):
- Comparison of Sequence Lengths:
@dreamgensuggested mentioning the sequence length for a better comparison.
- Unsloth's Mistral Benchmark Findings:
@nanobitzshared a link to Unsloth's blog post by Daniel Han discussing how to finetune Mistral 14x faster. The article revealed that the QLoRA support for Mistral 7B, CodeLlama 34B, and other models based on the Llama architecture has been released. It includes features like sliding window attention, preliminary Windows and DPO support, and 59 shared notebooks. Unsloth's Blog
- Benchmark Findings Review:
@nanobitzacknowledged that@casperhas previously examined the findings from Unsloth's post.
▷ #general-help (9 messages🔥):
- Dataset Size and Epochs:
@noobmaster29inquired whether 3 epochs would be too much for larger datasets. When asked to define "large", noobmaster29 clarified a dataset size of about 500 million tokens. - Fine-tuning Special Tokens with LoRA:
@dreamgenquestioned the specifics of fine-tuning special token embeddings using LoRA and FFT. They asked whether only the added token embeddings would be fine-tuned or all, and if this process is configurable.@caseus_advised including the "lm head and embed token" layers for LoRA. - Frozen vs Unfrozen Embeddings: Subsequently,
@dreamgenexpressed the desire to be able to freeze all embeddings with the exception of those for new tokens. - Finetuning Deepseek-coder 6.7B:
@shrex8791queried about a challenge they were facing whilst finetuning the Deepseek-coder 6.7B model. According to shrex8791, the model kept parallelizing and as a result, used up all memory. They sought advice on how to make it unparallel.
LangChain AI Discord Summary
- Switching Models based on User Queries: User
@shellordis working on project that needs to switch between a General Question and Answering model and a Function Calling model based on user query. - LangChain Related Queries: User
@emreweb3asked if LangChain includes smart contracts, while user@a404.ethshed light on issues surrounding streaming for custom agents incorporating complete RAG chains. A potential event in Denver was also discussed, highlighting current limitations due to the team's security requirements. - Challenges in LLM App Development: Conversation initiated by user
@tonyaichampabout the major issues experienced while developing LLM apps. - FastAPI Dependencies in langserve[client]: User
@sidlly.ethraised concerns over why FastAPI needs to be included in the package when adding langserve[client], emphasizing the perception that a client-side SDK shouldn't require FastAPI. - GenAI Stack Use and Language Processing Innovations: Dialogue between user
@tachi3and@shamspias, centering around the utilization of the GenAI Stack. Meanwhile,@andysingalshared a medium blog post encapsulating a new approach to revolutionizing language processing using Llama-cpp and StructuredOutputParser.
LangChain AI Channel Summaries
▷ #general (10 messages🔥):
- Selecting Models for Different User Queries:
@shellordsought advice on a project that requires using different models based on the user query. The goal is to switch between a General Question and Answering model and a Function Calling model depending on the type of user query. - Discussion on LangChain and Smart Contracts:
@emreweb3queried whether LangChain incorporates smart contracts. The user@lhc1921was tagged but a response isn't present in the provided chat log. - Challenges in Developing LLM Apps:
@tonyaichampelicited opinions on the greatest challenges or nuisances in developing LLM apps. - Enabling Streaming in Custom Agents:
@mohammed.shokrexplored how to enable streaming for a custom agent incorporating a complete RAG chain. User@a404.ethresponded, asking for the code since streaming with agents could be tricky compared to LECL. - Discussion on LangChain Hack Night Locations: A conversation took place about potential locations for a LangChain Hack Night. User
@glenn_sjobsresponded to@shiftybitexplaining the high costs for Hawaii but promised possible future events within the contiguous US. User@a404.ethoffered to host such an event in Denver, but a meet-up with the LangChain team wasn't possible due to security requirements.
▷ #langserve (1 messages):
- Langserve Client and FastAPI Dependency: User
@sidlly.ethexpressed a concern about the need to include FastAPI in their package when adding langserve[client]. They believe there's no reason for a client-side SDK to require FastAPI.
▷ #share-your-work (3 messages):
- Discussion on GenAI Stack: User
@tachi3asked@shamspiasif they had tried the GenAI stack. In response,@shamspiasclarified that they have only gone through the readme and description so far, and haven't actually tried it out yet. - Blog Post on "Revolutionizing Language Processing with Langchain and Mixtral-8x7B":
@andysingalshared a Medium Blog post discussing a Llama-cpp and StructuredOutputParser Approach to revolutionising language processing. The article is authored by Ankush K Singal and published under AI Advances.
DiscoResearch Discord Summary
- Discussion on xDAN-AI's Model Performance and its claim of being the top performer on MT-bench with strong abilities in Humanalities, Coding and Writing with 7b, including user
@cryptossssun's enthusiastic endorsement and posted link to the model's Discord, Twitter, and Huggingface platforms. - Expression of skepticism surrounding xDAN-AI's model, with
@.pathosand@technotechraising doubt about the 7B model's performance and its assertion of being 'close to GPT-4'. - User feedback regarding the UX and quality of AI tools with
@rtyaxcomparing the Copilot for IDEs and Continue tools, finding the former to be superior due to its high-quality UX and response quality while finding the latter less useful due to its lack of auto-completion features. - Recommendation by
@bjoernpfor@rtyaxto try out ClipboardConquerer, an AI tool, with@rtyaxexpressing interest and agreeing to share their experience with the tool in the future.
DiscoResearch Channel Summaries
▷ #mixtral_implementation (4 messages):
- xDAN-AI's Model Performance: User
@cryptossssunshared the link of xDAN-AI's new model claiming it as the Top 1 Performer on MT-bench and made a bold claim about it being the first top model performing well in Humanalities, Coding and Writing with 7b. The post also contains links to the model's Discord, Twitter, and Huggingface platforms. - Users' Skepticism:
@.pathosand@technotechexpressed their skepticism about the 7B model's performance claiming that it is 'close to GPT-4', questioning its credibility.
▷ #general (3 messages):
- Discussion on AI tools UX and quality: User
@rtyaxshared his experience with different AI tools. Found Copilot for IDEs to be the best in terms of user experience and response quality. Also, discussed Continue a Copilot-alternative that integrates with any local or remote LLM, however, found it a lot less useful since it doesn't offer auto-completion, only chatting/refactoring. - Suggestion to try ClipboardConquerer: User
@bjoernpsuggested trying ClipboardConquerer.@rtyaxexpressed interest in trying the tool and mentioned sharing their experience afterward.
Alignment Lab AI Discord Summary
- Conversation revolves around holiday greetings with
@venadorefrom#general-chatwishing everyone a Merry Christmas, complemented by a YouTube Video: A.I. Rewind 2023 (but in memes), andcryptossssunfrom#oosharing a similar sentiment. - A Twitter Post was shared by
@tekniumin#general-chatwithout any additional context provided. @undiand@fredipyboth in#general-chat, expressed anticipation and congratulations for an unspecified 'release', stirred much interest but lacked more detailed information.- A Twitter Post linked by
cryptossssunin#oo, but without any further context discussed.
Alignment Lab AI Channel Summaries
▷ #general-chat (5 messages):
@venadoreshared a YouTube Video: A.I. Rewind 2023 (but in memes) recapping the year of AI in memes. They also wished everyone a Merry Christmas.@tekniumshared a Twitter Post.@undicongratulated on the release and mentioned seeing it on another website, but didn't specify what the release was.@fredipyresponded to@tekniumand showed excitement about trying 'it' out, although it's unclear what 'it' refers to.
▷ #oo (1 messages):
cryptossssun: Hi Merry Christmas ! https://twitter.com/shootime007/status/1739312828111360339
Skunkworks AI Discord Summary
Only 1 channel had activity, so no need to summarize...
- AGI Space Appreciation: User
@0xevilexpressed enthusiasm for the basement AGI space. - Tweet Link: User
@tekniumshared a link to a Tweet.
LLM Perf Enthusiasts AI Discord Summary
Only 1 channel had activity, so no need to summarize...
- Control over Context Length in Threads: User
@joshcho_mentioned their frustration over the lack of control over context length for threads. They stated, "...i have to delete then copy everything over (or is there another way)", hinting at possible interest in more efficient ways to manage thread content.
AI Engineer Foundation Discord Summary
Only 1 channel had activity, so no need to summarize...
- Users
@._zand@vince_ucexchanged Christmas greetings on the channel.