[AINews] 12/11/2023: Mixtral beats GPT3.5 and Llama2-70B
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
These are the key results from the Mixtral blogpost:
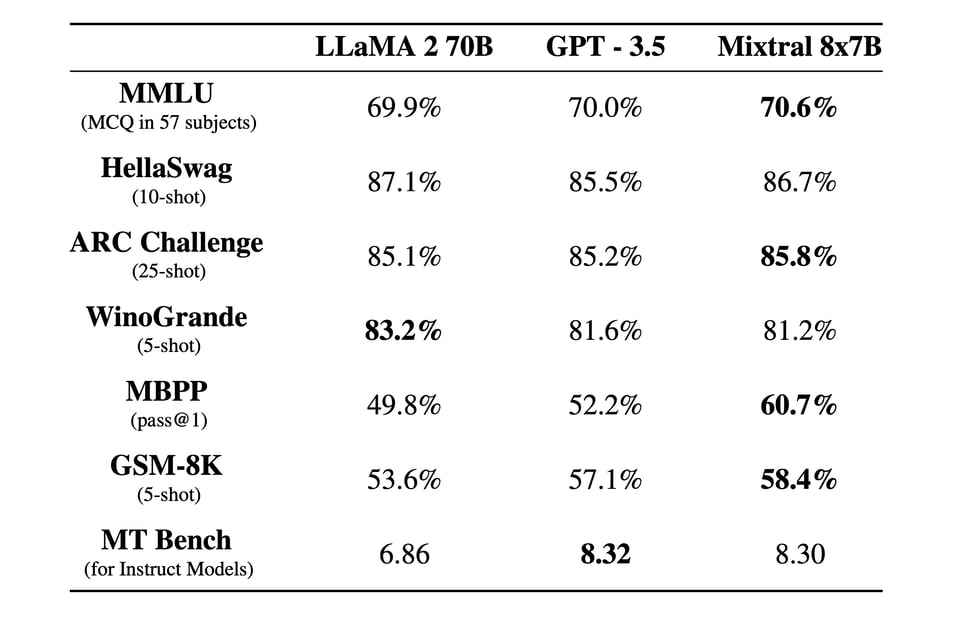
And people are rightfully cheering. They also announced their API platform today.
- Nous Research AI Discord Summary
- OpenAI Discord Summary
- DiscoResearch Discord Summary
- HuggingFace Discord Discord Summary
- OpenAccess AI Collective (axolotl) Discord Summary
- LangChain AI Discord Summary
- Latent Space Discord Summary
- Alignment Lab AI Discord Summary
- Skunkworks AI Discord Summary
- MLOps @Chipro Discord Summary
Nous Research AI Discord Summary
- The guild discussed options for GPU hardware for training transformer models and fine-tuning language models, considering options like two RTX 4070s, a single A4500 or RTX 3090s with an nvlink, with a YouTube video showcasing running a Mistral 8x7B Language Learning Model on an A100 GPU being shared.
- There were key conversations on whether the Mixtral model by Mistral AI could rival GPT-4 due to its high-quality Sparse Mixture of Experts (SMoE) output, and on fine-tuning Mixtral and generating quantized versions of the model.
- An interest in curating a high-quality coding dataset was expressed, with potential tasks ranging from generating code to debugging, translating, commenting, explaining, and expanding/cleaning/transforming it.
- Guild members shared and discussed key resources: a YouTube video discussing the deployment of open source models, an Arxiv paper, GitHub resources, a blog post on the Mixture-of-Experts (MoE), and a link to a GGUF format model file for Mistral's Mixtral 8X7B v0.1.
- Discussions concerning potential future releases like an open-source version of GPT-3.5 Turbo by OpenAI and LLama-3, with sources hinting towards such developments being shared, such as tweets from (@futuristflower), (@apples_jimmy), and The Information article.
- Clarifications regarding running OpenHermes 2.5 with fine-tuning on a Mac M3 Pro, and the VRAM requirements for running Mixtral 8x7b, alongside the sharing of an HuggingFace link to the Llava v1.5 13B - GPTQ model.
Nous Research AI Channel Summaries
▷ #off-topic (13 messages🔥):
- Hardware Discussion: User
@airpods69asked the community for advice on selecting GPU hardware for training transformer models and fine-tuning language models. The discussion revolved around the choice between two RTX 4070s or a single A4500, the former arising due to concerns about the high price of the A4500. The idea of sourcing an RTX 4090 was also floated by@giftedgummybee. - Alternative GPU Options:
@giftedgummybeeproposed the possibility of two RTX 3090s with an nvlink as an alternative, and pointed out that the A4500 seemed overpriced in comparison to these options. - Nvidia's EULA: User
@kazamimichirubrought up that Nvidia's EULA restricts the use of RTX series GPUs in data centers, but this was refuted by@airpods69who clarified that the setup would be at a home location, not a much stricter data center environment. - Running Mistral on A100:
@pradeep1148shared a YouTube video showcasing the processes of running a Mistral 8x7B Language Learning Model (LLM) on an A100 GPU. - Open Source AI Web Development:
@.plotoffered to help build a website for the community, showing interest in the open source AI niche and mentioning past projects such as open-neuromorphic.org and aimodels.org.
▷ #interesting-links (13 messages🔥):
- Should You Use Open Source Large Language Models?:
@tekniumshared a YouTube video discussing the deployment of open source models on WatsonX. - Arxiv Paper -
@euclaiseshared a link to a research paper though its specifics weren't discussed. - Awesome-llm-role-playing-with-persona:
@kazamimichirupointed out a GitHub repository providing resources for using large language models for role-playing with assigned personas. - Mixture-of-Experts Discussion:
@.beowulfbrshared their blog post discussing the Mixture-of-Experts (MoE) as the future of Large Language Models. - Mistral's Mixtral 8X7B v0.1 - GGUF:
@cyborgdreamshared a link to a GGUF format model file for Mistral's Mixtral 8X7B v0.1. They mentioned the model can be run on one 3090 or on any CPU with 32GB of CPU RAM.
▷ #general (545 messages🔥🔥🔥):
- There is an ongoing discussion about the performance and potential of the Mixtral model, a high-quality Sparse Mixture of Experts (SMoE) model recently released by Mistral AI. Users are particularly interested in its fine-tuning capabilities, multilingual support, and potential to rival GPT-4 in performance.
- Various users express their intentions to experiment with fine-tuning Mixtral and generating quantized versions of the model. Challenges and issues regarding quantization are mentioned, with a particular focus on understanding the VRAM requirements of Mixtral.
@nagaraj_arvinddiscusses the router auxiliary loss in mixture of experts models and points to a recent PR in huggingface transformers that adds mixtral moe support. This PR reportedly includes a setting that automatically calculates the auxiliary loss which according to@euclaisehelps balance the use of experts in MoE models.@wlrdproposes the idea of curating a high-quality coding dataset.@tekniumsupports the idea and outlines the types of tasks that such a dataset could contain, including generating code, translating code to other programming languages, debugging code, commenting code, explaining code, and expanding/cleaning/transforming code.- Kenshin9000's thread claiming that GPT-4 beats Stockfish (the best chess engine) is discussed. The user said they will post evidence for this claim in two weeks.
▷ #ask-about-llms (50 messages🔥):
- Future Open Sourcing of GPT-3.5 Turbo: User
@cyborgdreamshared several leaks hinting towards the possibility of OpenAI releasing an open source version of GPT-3.5 Turbo. Some sources include tweets from (@futuristflower), (@apples_jimmy), and The Information article. The discussion indicated that such a release could boost OpenAI's reputation amongst developers. - LLama-3: User
@cyborgdreammentioned LLama-3, a model predicted to outperform GPT-4 and expected to be multimodal. The release of this model is reportedly set for February. - Inference and Fine-tuning on a Mac M3 Pro: Users
@tekniumand@night_w0lfresponded to@httpslinus' question on whether the M3 Pro machine could run OpenHermes 2.5. Both suggested that the computer could run it via inference but not fine-tuning. - Inference with Mixtral and Llava 13B: User
@chhilleeinquired about the best tokens/sec achieved with Mixtral.@papr_airplaneshared an HuggingFace link to the Llava v1.5 13B - GPTQ model during a discussion on running inference with Llava 13B model. - VRAM Requirement for Mixtral 8x7b: User
@gerredasked if 96GB VRAM would be sufficient to run Mixtral 8x7b. The conversation didn't provide a concrete answer.
OpenAI Discord Summary
- Extensive discussions pertaining to the philosophy of truth in scientific communities, fairness metrics, and algorithmic biases in AI methodology. Debate initiated by
@light.grey.labswith contributions from@whynot66k20ni,@lhc1921,@solbus, among others. - Shared concerns and issues regarding the performance and functionality of OpenAI's services, including ChatGPT message limit, GPT4 subscriptions, and video color grading. Users
@robg2718,@rjkmelb,@lyrionex,@marcelaze,@lumirix,@croc_cosmos,@null_of_gehenna,@thunder9289,@prncsgateau,@solbus,@gd2x,@elektronisade,@swedikplay, and@luguiparticipated in these discussions. - Various concerns about GPT-4, including long waitlist, issues with contextual understanding and inconsistent performance.
@kyper,@eveiw,@Rock,@.pywiz,@drcapyahhbara,@pietman,@solbus,@chotes,@napoleonbonaparte0396added to the discussion. - Extensive queries and issues related to prompt engineering, focusing on improvement of model performance, instruction comprehension, censorship issues, the understanding of markup languages, and metrics for measuring success in prompt engineering. This line of discussion saw contributions from
@m0bsta,@cat.hemlock,@tp1910,@you.wish,@madame_architect,@exhort_one,@pfakanator, and@bambooshoots. - Various technical issues related to GPT-4, including problems with donations for access, network issues, dissatisfaction over performance and functionalities, possible account suspension, and frustrations over creating custom GPTs were reported by
@strange073,@inspectorux,@lucianah,@slo_it_down,@kurailabs,@lumirix,@michaelyungkk,@rjkmelb,@maledizioni,@panospro,@maticboncina,@chealol,@digitallywired, and@mfer.pirx. - AI art was a notable topic of discussion, with debates over modifying rules, evaluation of AI art tools such as
BardandGemini Pro, and resources for AI news suggested by users like@rchap92,@lugui,@fluffy_dog__,@staniscraft,@avalani,@thunder9289, and@julien1310. - Concerns over potential copyright violation raised by
@swedikplay, with@luguiconfirming OpenAI's awareness of the issue and urging the forwarding of additional information. - Heated debates and diverse viewpoints on matters relating to prompt style, DALLe policy, AI performance, expanded AI context, resulting in significant interactions among channels, with
@m0bsta,@cat.hemlock,@pfakanator,@mysticmarks1,@fluffy_dog__,@bambooshoots,@madame_architect,@eskcantaamongst others contributing to the discussion.
OpenAI Channel Summaries
▷ #ai-discussions (69 messages🔥🔥):
- Philosophy of Truth in Science: Conversation started by
@light.grey.labsquestioning the motivation behind the quest for truth in the scientific community. The conversation evolved into a broader discussion about reality, observability, and the nature of quantum physics, with contributions from@whynot66k20ni,@lhc1921,@solbus, and others. - Fairness Metrics and Algorithmic Bias: Offhand remarks made by
@whynot66k20nirelated to algorithmic fairness and bias, with no detailed discussion on the topic. - AI Art Modification Rules: A short discussion between
@rchap92and@luguiabout the guidelines for generating images of real people using AI tools, with mention of various platforms like BING AI and Krea.ai. - Evaluation of AI Art Tools: Positive comments about
BardandGemini Proby@fluffy_dog__and@staniscraftrespectively, as well as a brief interaction about Grok AI between@avalani,@lugui, and@thunder9289. - Resources for AI News:
@julien1310inquires about best resources for AI news, to which multiple users suggested sources like Ycombinator, Perplexity, and arXiv. In particular,@shadowoftheturingshared direct links to recent submissions on arXiv in the fields of Computational Linguistics (cs.CL) and Artificial Intelligence (cs.AI). - Upscaling AI Art: Concluded with a discussion initiated by
@sgsd_about upscaling AI art, with several suggestions from@elektronisadeincluding free and paid services like Stable Diffusion, Magnific AI, and Topaz.
▷ #openai-chatter (131 messages🔥🔥):
- Speech Feature on Android: User
@gd2xasked about the absence of a speech feature for ChatGPT on Android devices.@elektronisadesuggested that ad blocker DNS or services might be intervening, after disabling which,@gd2xconfirmed the issue was resolved.
- Various Issues and Discussons about OpenAI: Numerous users brought up their concerns and discussions about various aspects of OpenAI's services. The topics included unclear information about the ChatGPT message limit over time (
@robg2718,@rjkmelb,@lyrionex), the waitlist and availability of GPT4 subscription (@marcelaze,@lumirix,@satanhashtag), the possibility of using GPT4 for video color grading (@croc_cosmos,@null_of_gehenna,@thunder9289), and concerns about accessibility issues on the iOS app for voiceover users (@prncsgateau,@solbus). In these discussions, various users, including@lugui,@offline, and@mrcrack_provided information or referred to appropriate help resources.
- Potential Copyright Violation:
@swedikplaydiscussed their concern about a third-party bot on Discord that potentially violates OpenAI's identity.@luguiconfirmed OpenAI's awareness of the issue and encouraged@swedikplayto pass any supporting information via DM.
- Features and Updates on OpenAI: Various users inquired about the rumored upcoming announcements (
@merpnderp), ability to upgrade to ChatGPT Plus through iOS (@alpha33589), and the awaited launch of the GPT store (@emiliaaaaa_). However, definitive responses were not available.
- Confusion and Complaints About GPT Usage and Performance: Users
@becausereasons,@mrcrack_, and@Meme Popperzexpressed dissatisfaction with the performance of GPT services, bringing up issues with instruction following, decreasing creativity, limiting message quotas, and website lagging during use.
▷ #openai-questions (97 messages🔥🔥):
- Accessing GPT-4:
@strange073and@inspectoruxdiscussed about donation criteria for accessing GPT-4. However, there was no clarification provided in the chat about how to make a $1 donation for access. - Performance Issues:
@lucianahand@inspectoruxexpressed frustration with network errors and slow processing times, with@lucianahsuspicious of possible usage throttling due to high numbers of Plus users.@slo_it_downalso mentioned recurring error messages, especially after file inputs. Minimal troubleshooting was provided by the the chat community. - Use of Custom GPT for complex tasks:
@kurailabsexpressed frustration over GPT-4's reticence to fully generate law papers in response to specific instructions, compared to GPT-3.5's willingness to do so.@lumirixprovided some explanation and shared OpenAI's usage policies concerning high risk government decision-making. - Subscription issues:
@michaelyungkkreported problems with multiple credit card denials during attempted subscription.@rjkmelbsuggested subscribing via the iPhone App, then recommended contacting OpenAI support via their website when this didn't work. - Account suspension:
@maledizionirequested urgent help for account reactivation after a mistaken age verification error, but was redirected to openai support by@rjkmelb. - Creating Custom GPT: Questions and issues with creating custom GPTs were raised by
@panospro,@maticboncina,@chealol,@digitallywired, and@mfer.pirx. Assistance was provided by@mysticmarks1. - Corrupted and long chat threads:
@maf2829discussed an issue of getting a "message in conversation not found" error.@elektronisadesuggested the possibility of thread corruption and asked if@maf2829was using any unofficial browser extensions for ChatGPT. The issue remained unresolved.
▷ #gpt-4-discussions (69 messages🔥🔥):
- Limitations on Tools for Custom GPT:
@kyperraised a question about the limitations on the number of functions a custom GPT can handle and whether including tools consumes tokens. - Issues with GPT-4: Several users including
@eveiw,@Rock,@.pywiz, and@drcapyahhbaraexpressed concerns about the performance of GPT-4 including difficulty in remembering context, inconsistent performance and a long waitlist. - Instructions in a Custom GPT: There was a discussion about whether it's better to include instructions in the config of a custom GPT or in the file placed in knowledge, with suggested strategies from
@smilebedaand@offline. - Creating a Variable in GPT:
@pietmanasked for advice on creating variables in a GPT to reference in instructions.@solbusand@chotesoffered strategies and resources to read in order to achieve this. - Limits on Creating GPTs:
@napoleonbonaparte0396asked whether there was a limit on how many GPTs one can create.
▷ #prompt-engineering (93 messages🔥🔥):
- Prompts and Model Performance:
@mysticmarks1shared their concerns over bias and issues with the DALLE3 model and suggested that they've tweaked certain codes to improve its performance. However, not everyone agreed with their viewpoints. There was a discussion about how instruction prompts can be modified to get more accurate results, as articulated by@pfakanatorand@bambooshoots.@cat.hemlockalso shared a detailed guide on markdown format for instructing models.
- GPT's Understanding of Instruction:
@tp1910asked about the difference between adding instructions to the configuration or knowledge section of a custom GPT. There was no clear answer given in the chat.
- OpenAI GPT's Gaming Queries:
@you.wishasked for advice on tweaking a game-related query (Dead by Daylight) that was being censored by OpenAI.@madame_architectprovided a suggestion that appeared to suit the user's needs.
- Markup Language Inquiry:
@exhort_onesought clarification about Markdown, a markup language.
- Measurement of Prompt Engineering Success:
@madame_architectinitiated a discussion on metrics for measuring success in prompt engineering, concentrating on converting qualitative aspects of language into quantitative metrics.@cat.hemlocksuggested evaluating consistency for measuring success.
▷ #api-discussions (93 messages🔥🔥):
- Discussion about Prompt Style:
@m0bstaexpressed difficulties with creating effective prompts due to comprehension issues, while@cat.hemlockprovided examples of how to create effective prompts using Markdown and suggested not to delay this process. - Dalle Policy:
@cat.hemlockshared detailed instructions for the DALLe (a tool for image generation) usage policy. These instructions covered various points, such as its image generation limitations along with contextual restrictions and ethical guidelines.@cat.hemlockfurther provided an example of a default prompt for DALLe in TypeScript, asking for user@215370453945024513's thoughts. - Feedback and Interactions about AI Performance:
@pfakanatorshared that instructing the agent to "understand things in a way that makes sense" improved responses.@mysticmarks1expressed dissatisfaction with current prompt set-ups and shared an improved version.@fluffy_dog__asked for thoughts on the performance of Bard compared to ChatGPT, which@eskcantaredirected to a different channel. - Expanded AI Context:
@bambooshootsdiscussed the implementation of cross-conversation context management for more coherent and extended conversations with the AI. - Intense Personal Interactions:
@bambooshootsand@mysticmarks1engaged in a heated debate, with different viewpoints expressed regarding code contribution and personality traits. - Quantitative Measures for Prompt Engineering:
@madame_architectwas trying to understand how to convert qualitative aspects of language into quantitative metrics for measuring prompt engineering success, and solicited advice/input from others.
DiscoResearch Discord Summary
- Discussion primarily revolved around the implementation, performance, and future expectations of the Mixtral model, with various technical issues and proposed solutions being discussed. Key topics included output issues, VRAM requirements, multi-GPU compatibility, model quantization, and auxiliary losses, as found in Mixtral on Huggingface. "
@nagaraj_arvindpointed out that base MoE models use the standard language model loss function..." - Users shared varying experiences regarding Mixtral's performance, with consensus around its capable handling of extensive contexts, despite its inferior translating ability. "
@goldkoronmentioned that the model's translation abilities were inferior to other models like GPT-3.5." - Technical updates included Huggingface's addition of Mixtral model support with a pull request, and the report of an in-progress pull-request on the vllm from the Mistral side in the #benchmark_dev channel.
- Individuals in the #general channel discussed the differences between LeoLM 70b Chat and DiscoLM 70b. "
@bjoernpclarified that Leo 70b chat is finetuned on only German instruction data, while DiscoLM includes mostly English instructions." - The spotting of a refined version of the Mistral-7B model dubbed "Mistral-7B-v0.2" elicited community interest. "
_jp1_spotted "Mistral-7B-v0.2" on the Mistral AI models page..." - A callout was made by
@tarikoctapmfor potential collaborators on a distributed computing project focused on training an LLM during idle periods. - The community also engaged in more casual discussions, such as celebrating the birthday of
@fernando.fernandesin the #mixtral_implementation channel.
DiscoResearch Channel Summaries
▷ #disco_judge (1 messages):
nagaraj_arvind: They are the same
▷ #mixtral_implementation (322 messages🔥🔥):
- Mixtral Implementation Issues and Resolutions: Users in the channel faced various issues in implementing the Mixtral model. Some of the issues were related to model performance, VRAM requirements, multi-GPU compatibility and the need for model quantization. Several solutions, including the use of specific versions of libraries and the inclusion of auxiliary losses, were proposed to tackle these problems.
-
@goldkoronstated that running the DiscoLM Mixtral model was causing output issues but found disablingexllamamight solve it. ErrorResponse issues about memory allocation were also reported by@goldkoron.-
@nagaraj_arvindpointed out that base MoE models use the standard language model loss function, and if you setoutput_router_logits = True, aux loss is calculated automatically. If you want to add your own losses, you can import from the switch transformer and use returned logits to compute it, as seen in this section of the Mixtral model on the Huggingface repository.-
@datarevisednoted that Mixtral currently lacks multi-GPU support for inference but this issue is being addressed as seen in this pull request.-
@armifer91indicated that they are trying to run Mixtral using the LLaMa implementation provided here.-
@fernando.fernandessuggested that Mixtral v0.1 can work in low contexts of RAM like 8k using 4-bit quantization as seen in here, where GGUF format model files with instructions like 'python -m venv venv' can be installed.
- Mixtral Performance Evaluation: Users have shared their experiences with Mixtral's performance, with
@goldkoronmentioning that the model's translation abilities were inferior to other models like GPT-3.5. The model's capability to handle more extensive context has been valued by users like@goldkoronand@fernando.fernandes.
- Mixtral on Huggingface Transformers: Discussion about a Mixtral pull request on Huggingface was shared by
@flozi00. It added support for the Mixtral model to Transformers. The PR has been merged into Transformers as reported by@le_mess.
- Birthday Celebration:
@fernando.fernandesstated that it is his birthday week and members of the channel, such as@datarevisedand.grey_, wished him a happy birthday.
- Mixtral Model Size Speculations and Future Expectations:
@dyngnosissparked a discussion about the size of experts in the future release of the Mixtral model. Users speculated the size could range from 30 to 70.@fernando.fernandesmentioned that a "all-in-one" model like Mixtral 7B could be very beneficial for specific tasks.
▷ #general (15 messages🔥):
- DiscoResearch Discord Link Fix:
@philpaxreported that the Discord invite link on the DiscoResearch page on HuggingFace had expired. This issue was resolved by_jp1_. - Difference Between LeoLM 70b Chat and DiscoLM 70b:
@apepperinquired about the differences between LeoLM 70b Chat and DiscoLM 70b.@bjoernpclarified that Leo 70b chat is finetuned on only German instruction data, while DiscoLM includes mostly English instructions. - Translation Models Recommendation:
@apepperasked which model would be suitable for translation from English to German.@bjoernpsuggested that both LeoLM and DiscoLM might not be the best fit as translation data isn't explicitly included in datasets. However,@noobmaster29shared a link to a GitHub resource which might be helpful for finetuning translation. - Mistral-7B-v0.2 Spotting:
_jp1_spotted "Mistral-7B-v0.2" on the Mistral AI models page, and noted that although this is not an improved 7b base, it is a better fine-tuning of the initial Mistral-7B. - Collaboration Inquiry:
@tarikoctapmdid a callout for potential collaborators in their distributed computing project, where they plan to train an LLM when nodes are idle and not being rented.
▷ #benchmark_dev (2 messages):
- Adding Backend for llama.cpp:
@rtyaxreported that adding a backend for llama.cpp to run models is straightforward, but integrating with other backends poses a challenge due to their utilization of Hugging Face configuration and tokenizer features. - Progress on the vllm PR:
@flozi00mentioned that there is a work in progress on the vllm pull request from the Mistral side, according to the documentation.
HuggingFace Discord Discord Summary
- Graph Extension using Fuyu: User
@heumasfaced challenges in extending graphs.@doctorpanglossproposed usingFuyuand provided a demonstration through a Google Colab link. - Audio Classification Models:
@doctorpanglosssuggestedaudioclipandwav2vecfor audio classification in response to@vara2096's query. - Accelerate Framework on Mistral:
@ghimiresunilshared an error encountered when using the Accelerate framework on Mistral model and shared the error along with a code sample via a GitHub Gist. - Decentralized Pre-training: user 'neuralink' shared about implementing 0.01% of DiLoCo decentralized pre-training.
- Webinar on LLM-based Apps & Their Risks:
@kizzy_kayannounced a webinar by Philip Tannor on 'Evaluating LLM-based Apps & Mitigating Their Risks'.Registration link shared. - HuggingFace Summarization Models: User
@kaycebasquesshared experience of using HuggingFace summarization models for Sphinx site pages via a blog post. - TV Show Quote Scraping: 'joshuasundance' shared a TV quote dataset available on HuggingFace link here.
- AI Model Badging System: User
@.plotsuggested an open-source badging system for AI models available here. - Reading group discussions focused on Magvit2, Eliciting Latent Knowledge (ELK) paper here, and Text-to-image (T2I) diffusion models paper here .
- Difficulties Running mm_sdxl_v10_beta.ckpt with Animatediff:
@happy.jreported difficulties running this implementation and had to resort to using the implementation from the animatediff GitHub repo. - Computer Vision Discussions: Topics included excessive text extraction from bounding boxes, photogrammetry, and mesh extraction Link to Sugar project.
- Chatbot Architecture, LLM on Amazon EC2 G5g, and Sentiment Analysis were main topics in the NLP channel. Issues such as CUDA incompatibility and memory errors were addressed.
HuggingFace Discord Channel Summaries
▷ #general (70 messages🔥🔥):
- Use of Fuyu for Graph Extension: User
@heumaswas having problems extending or creating graphs using AI models.@doctorpanglosssuggested usingFuyuto extract data from graphs, although it doesn't have the capability of adding new image data to graphs coherently. He also offered a demonstration through Google Colab. - Discussion on Audio Classification Models: User
@vara2096asked for an open source model that can use raw vocal audio as input effectively, with the aim to classify a large pile of audio files.@doctorpanglosssuggested tryingaudiocliporwav2vec. - Issues with Accelerate Framework on Mistral Model: User
@ghimiresunilposted problem about an error he encountered while using the Accelerate framework to train the Mistral model across seven A100 GPUs, seeking help to fix this error. The error and code sample were shared via GitHub Gist. - Compression of Large Datasets: User
@guactheguacsought advice on using ML/DL for compression of large datasets collected from LiDAR, large format photogrammetry, and multispectral.@doctorpanglossreplied saying the expectations for neural approaches should be moderate, but provided no specific suggestions or resources. - Fine-tuning Llama-2 with PPO: User
@harrison_2kmentioned he was using PPO for fine-tuning theLlama-2, and was looking for suggestions or documentation regarding the appropriate reward range for this process.
▷ #today-im-learning (1 messages):
neuralink: the last three days i learned: implemented 0.01% of DiLoCo decentralized pre-training
▷ #cool-finds (1 messages):
- Upcoming Webinar on LLM-based Apps & Mitigating Their Risks:
@kizzy_kayfrom the Data Phoenix team announced a free webinar titled "GPT on a Leash: Evaluating LLM-based Apps & Mitigating Their Risks". The speaker for this webinar is Philip Tannor, Co-founder and CEO of Deepchecks. - Webinar Date and Time: The event is scheduled for December 12, at 10 am PST.
- Learning Opportunities: Attendees can expect to learn about evaluating and mitigating risks in LLM-based applications, testing AI systems involving text and unstructured data, and how to navigate the complexities of providing contextually appropriate responses.
- Registration: Interested parties are encouraged to register before the event to secure a spot.
- Q&A Session: The webinar will also include a Q&A session for attendees to explore specific concerns relating to the topic.
▷ #i-made-this (6 messages):
- Page Summarization for Sphinx Sites:
@kaycebasquesshared his exploration of using HuggingFace summarization models to generate summaries for Sphinx site pages. Based on his experimentation, the endeavor seems promising but inconclusive. The blog post explains the potential advantages of implementing page summarization on technical documentation sites. - TV Show Quote Scraping:
@joshuasundancehas scraped quotes from TV shows from wikiquote.org. These quotes are available on HuggingFace as a datasetjoshuasundance/wikiquote_tvand contain 103,886 rows of data available here. - AI Model Badging System: User
@.plotsuggested a badge-style open-source information system for AI models, similar to Creative Commons badges, and sought public feedback. The proposed system consists of badges such asOpen Model (OM)andOpen Model - Open Weights (OM-OW), among others, to foster transparency and collaboration. - Positive Reception: The AI model badging system received positive feedback from
@tonic_1. - Possibilities with TV Show Quotes:
@joshuasundanceand@tonic_1brainstormed potential applications for the scraped quotes, such as fine-tuning language models or creating a 'Rag-type' bot that can assume any character from TV shows.
▷ #reading-group (2 messages):
- Magvit2 Discussion:
@chad_in_the_housesuggests presenting on Magvit2 and shares the paper link here. - ELK Research:
@chad_in_the_housealso considers discussing a paper on Eliciting Latent Knowledge (ELK). The abstract indicates research on 'quirky' language models and the paper is accessible here. - Text-to-image Diffusion Models: Finally,
@chad_in_the_houseshows interest in a paper on Text-to-image (T2I) diffusion models which talks about the computational costs of these models. The paper can be accessed here.
▷ #diffusion-discussions (1 messages):
- Difficulty Running mm_sdxl_v10_beta.ckpt with Animatediff:
@happy.jreported difficulties running mm_sdxl_v10_beta.ckpt with the diffusers animatediff implementation and had to resort to the implementation from the animatediff GitHub repo.
▷ #computer-vision (15 messages🔥):
- Extracting Text from Bounding Boxes:
@navinaananthaninquired about how to extract text from a set of bounding boxes, specifically from a newspaper.@boriselanimal7suggested using Optical Character Recognition (OCR) and provided a Medium article as a resource.@merve3234also highlighted that text extraction is the objective and recommended@947993236755054633for professional guidance.
- Photogrammetry and Mesh Extraction:
@n278jmand@individualkexdiscussed the use of photogrammetry for 3D modeling, especially concerning interior design applications for non-local or budget-conscious clients.@n278jmdemonstrated concerns over the level of precision attainable without lidar. They later shared a link to a project named Sugar focusing on precise and fast mesh extraction from 3D Gaussian Splatting.
- Machine Learning/Deep Learning in Computer Vision:
@guactheguacasked if anyone was using machine/deep learning in computer vision, sparking potential further discussion in the channel.
▷ #NLP (34 messages🔥):
- Discussion on Chatbot Architecture:
@ppros666and@vipitisdiscussed about transformers in chatbot implementation, where@ppros666clarified that the paper they referred to mentioned a transformer with some modifications, not "dropping the encoder" as in many chatbot applications. - Running LLM Application on Amazon EC2 G5g Instances:
@lokendra_71926inquired about running an LLM application on Amazon EC2 G5g instances using auto-gptq.@merve3234clarified that auto-gptq can be used to quantize the model if it's too big to fit into the EC2 instance. - Troubleshooting GPU Availability on Torch:
@lokendra_71926faced an issue wheretorch.cuda.is_available()returned false, despite the GPU being visible with thenvidia-smicommand.@merve3234suggested that there might be a mismatch between CUDA-related packages and GPU requirements, or the GPU might not be CUDA-compatible. - Sentiment Analysis with TinyBERT Model:
@blood_bender64sought advice for a sentiment analysis problem using a TinyBERT model, which was performing poorly on the validation set despite various learning rate adjustments.@merve3234and@9alxsuggested checking the distribution of data in validation and test sets, investigating class noise, and monitoring loss changes from epoch to epoch to understand if the model was underfitting. - RuntimeError: CUDA out of memory:
@blood_bender64encountered a CUDA out of memory issue during training.@vipitissuggested checking if optimizer states were kept on the GPU and inquired about the number of batches and gradient accumulation steps.
▷ #diffusion-discussions (1 messages):
- Running mm_sdxl_v10_beta.ckpt with animatediff: User
@happy.jenquired about difficulties in runningmm_sdxl_v10_beta.ckptwith thediffusersanimatediff implementation. They mentioned that various attempts were unsuccessful and they had to revert to using the implementation from the animatediff GitHub repository.
OpenAccess AI Collective (axolotl) Discord Summary
- Concerning the Axolotl project, a work-in-progress branch that centers on Mixtral Sharded was shared by
@caseus_. View the specifics of the branch here. - Questions surrounding Distributed Policy Optimization (DPO) and Reinforcement Learning with Human Feedback (RLHF) were raised. The Hugging Face TRL DPO Trainer documentation was cited as evidence that the two closely relate.
- Queries on hosting a LLava 13b model on a server or on VLLM were broached, having trouble making a Python request to pass the image to the API.
- The feasibility of training the Mixtral-MoE model from Axolotl using qLora on a singular, 24GB GPU was debated, citing ~27GB as the requirement to infer it in 4 bits.
- A comparison was drawn between V100s and 3080s, evaluating how a finetune of opt-350m on a single GPU results in about 3.5 iterations per second (it/s) on a 3080 and 2it/s on the V100.
- The script to train Mixtral using tinygrad was shared, as was related conversation about training mixtral with openorca on 3xA40, specifically using the DiscoResearch model.
- Updates on Mistral's Mixtral 8x7B release, a high-quality sparse mixture of experts model (SMoE) with open weights, were mentioned here.
- Queries about the high VRAM requirements for Mixtral were addressed, and it was shared that with adequate quantization and optimization, it should align to the resources needed to run a 12B model.
- Transformers now support llava natively, simplifying integration processes.
- Questions about multipack usage and clarity in relation to token packing, positional encoding, loss computation were raised — a documentation page was offered for reference.
- Members encountered a FileNotFoundError issue during a mixtral training run involving checkpoints — in response to this, a potential solution mgan were shared and was advised to monkeypatch the local file in the virtual environment.
- Lastly,
@joshuasundancecreated a dataset of more than 103,886 rows of quotes from various TV shows, accessible here.
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (64 messages🔥🔥):
- Axolotl Work-In-Progress Branch:
@caseus_shared a link to a work-in-progress branch of the Axolotl project on GitHub related to Mixtral Sharded. The details of the branch can be seen at this link. - DPO and RLHF:
@noobmaster29was curious if DPO is a form of RLHF.@nanobitzpointed to the Hugging Face TRL DPO Trainer documentation as proof that they might be the same thing. - Hosting LLava 13b Model on a Server: Responding to
@papr_airplane, who inquired on hosting LLava 13b model either on a server or on VLLM but was having trouble doing a Python request to pass the image to the API. - Axolotl Training of Mixtral-MoE:
@gururisewondered if the Mixtral-MoE model from Axolotl can be trained using qLora in a single 24GB GPU.@whiskeywhiskeydoubted it's possible, as it took ~27GB to infer it in 4 bits. - Training Speeds of V100s: In a discussion with
@gururiseabout training speeds,@whiskeywhiskeymentioned that a finetune of opt-350m on a single GPU results in about 3.5 iterations per second (it/s) on a 3080 and 2it/s on the V100.
▷ #axolotl-dev (16 messages🔥):
- Mixtral with Tinygrad:
@caseus_shares the script for training Mixtral using tinygrad from its official GitHub page mixtral.py at mixtral · tinygrad/tinygrad. - Training Mixtral with Openorca:
@whiskeywhiskeydiscusses about training mixtral with openorca on 3xA40. He further mentions that he has used the DiscoResearch model that works with transformers@main. - Mistral Mixtral Release:
@jaredquekand@nanobitzdiscuss about Mistral's release of Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights Mixtral of Experts. - VRAM Requirement and Optimization:
@jaredquekexpresses concerns over high VRAM requirement (~28GB from Lelio).@_dampfassures that with quantization and optimization, the resources needed would be more aligned with handling a 12B model, which should allow users to run Mixtral if they can operate 13B models. - Native Llava Support in Transformers:
@caseus_informs that transformers now support llava natively which could make integration easier.
▷ #general-help (9 messages🔥):
- Multipack Understanding:
@tim9422asked for clarification on how multipack works in relation to token packing, positional encoding, and loss computation, referencing a documentation page on the topic. - Mixtral Training Issue:
@colejhunterencountered a FileNotFoundError during a mixtral training run involving checkpoints.@nanobitzmentioned that another user had a similar issue previously. - Possible Solution for FileNotFoundError:
@caseus_suggested a potential solution to the FileNotFoundError, referencing a GitHub issue and advising that the user monkeypatch the local file in their virtual environment.@colejhunterand@whiskeywhiskeyshowed appreciation for the advice.
▷ #datasets (1 messages):
- TV Show Quotes Dataset:
@joshuasundancescraped quotes from TV shows from wikiquote.org and compiled them into a dataset, which is publicly available on Hugging Face under the name 'wikiquote_tv'. The dataset contains quotes from various TV series, and comprises more than 103,886 rows. Dataset link: huggingface.co/datasets/joshuasundance/wikiquote_tv.
LangChain AI Discord Summary
- Implementation of kork package in pandas: User
@xstepzengaged in discussions on how to incorporate the kork package to limit the functions of pandas accessed by bots. - Integration of LangChain with React.js and Python: Queries about the importance of Python in AI development while using LangChain with React.js, with an active project on diagnosing plant diseases in agri-tech being discussed. Suggested resource for learning PythonLangChain: deeplearning.ai courses.
- Criticism on using LangChain: user
@philipsmanshared a Reddit post, illustrating criticism about LangChain implementation, advising caution. - Issues with
ChatOpenAIAPI:@a404.ethexpressed difficulty regarding theChatOpenAIAPI when usingConversationalChatAgent.from_llm_and_toolsalong with customTools. - Model performance measurement methodologies:
@martinmueller.devinitiated discussion on approaches to gauge model performance changes and specific codes with automation in view. - Connection timeouts with
Chroma.from_documents()API:@wei5519reported connection timeout errors when using theChroma.from_documents()API. - Avoiding redundancy in RAG responses:
@b0otablediscussed ways to eliminate repeated phrases in RAG responses, suggesting prompt hints as a potential solution. - Understanding
AgentExecutoroperation:@egeressought understanding on the functioning ofAgentExecutor- if actions were planned ahead or chosen in real time. - Use of Tracers in LangChain:
@lhc1921recommended using tracers like LangSmith and Langfuse in LangChain for clearer understanding over console logs. - Performance comparison of models:
@_egeresraised a query about times when a 7B model outperforms larger models (34B/70B), asking whether it was due to evasion of evaluation processes or unique fine-tuning techniques. - TV Show Quote Scraping for Deep Learning:
@joshuasundanceshared about scraping TV show quotes for deep learning, making the dataset with approximately 103,886 rows available on Hugging Face with samples from the TV series "10 Things I Hate About You".
LangChain AI Channel Summaries
▷ #general (69 messages🔥🔥):
- Implementing kork package for limiting pandas functions: User
@xstepzrequested examples on how to implement the kork package to restrict the pandas functions accessed by the bot. - Discussion about Using LangChain with React.js:
@yasuke007raised a question about the necessity of Python in AI development when using LangChain with React.js. The discussion extended to include a project on agricultural tech for diagnosing plant diseases using AI.@lhc1921suggested resources for learning PythonLangChain: deeplearning.ai courses. - LangChain Critique on Reddit:
@philipsmanshared a Reddit post, criticizing LangChain implementation and advised caution. - Issues with the
ChatOpenAIAPI:@a404.ethexpressed confusion over using theChatOpenAIAPI withConversationalChatAgent.from_llm_and_toolsand customTools. - Bedrock API Calls and Model Performance Measurement:
@martinmueller.devinquired about methodologies to measure the performance of models and specific codes as they evolve, with the aim of automating the process. - Error with
Chroma.from_documents()API:@wei5519experienced errors related to connection timeouts when using theChroma.from_documents()API. - Eliminating Redundancies in RAG Responses:
@b0otablediscussed an issue regarding redundant phrases in the responses from a RAG workflow, and shared a potential prompt hint as a solution. - Understanding the Operation of
AgentExecutor:@egeressought clarification on how theAgentExecutoroperates - whether it first makes a plan of the actions to take, or chooses actions on the go. - Utilizing Tracers in LangChain:
@lhc1921suggested the use of tracers like LangSmith and Langfuse in LangChain for better comprehension instead of console logs. - Discussion on Model Performance:
@_egeresposed a question about the instances when a 7B model beats larger models like 34B/70B, inquiring whether this could be attributed to tricking the evaluation process or innovative fine-tuning approaches.
▷ #share-your-work (1 messages):
- Scraping Quotes from TV Shows for Deep Learning: User
@joshuasundanceshared that they have scraped quotes from TV shows from wikiquote.org. The dataset, containing around 103,886 rows, is available on Hugging Face. They provided several examples from the TV series "10 Things I Hate About You".
Latent Space Discord Summary
- Discussion regarding various topics in the AI field, including the popular theme of efficiency at the NeurIPS Expo Day, as shared by
@swyxioin a recap. - A question by
@aristokratic.ethon creating personal datasets for fine-tuning ML models, but without any evident responses. - Sharing of a Twitter post by
@swyxiothat provided insights into Mixtral, sparking a discussion. - Positive feedback from
@kaycebasqueson the utility of Latent Space Benchmarks 101, with requests for the future 101 series. Response from@fanahovaindicating Algorithms 101 may be the next topic. - A tweet shared by
@swyxioon November recap of AI events. - Mention of Humanloop by
@swyxioin an unclear context, leading to a discussion without many specifics.
Latent Space Channel Summaries
▷ #ai-general-chat (8 messages🔥):
- NeurIPS Expo Day Recap: User
@swyxioshared a recap of NeurIPS expo day 0, highlighting the popular theme of efficiency during the event. - Humanloop Inquiry: User
@swyxiostarted a discussion about Humanloop but didn't provide any specific question or context. - Creating Own Datasets:
@aristokratic.ethposed a question to the community about creating own datasets for fine-tuning ML models. - Mixtral Breakdown:
@swyxioshared a Twitter post from Guillaume Lample providing a breakdown of Mixtral. - Latent Space Benchmarks 101 Feedback and Future 101s:
@kaycebasquesfound the Latent Space Benchmarks 101 useful and inquired about future 101 releases.@fanahovareplied they'll send out a survey for 101 requests, considering Algorithms 101 as the next topic.
▷ #ai-event-announcements (1 messages):
swyxio: Nov recap here! https://fxtwitter.com/latentspacepod/status/1734245367817093479
Alignment Lab AI Discord Summary
- Conversation about a Mixtral-based OpenOrca Test initiated by
@lightningralf, with the reference to a related fxtwitter post from the OpenOrca's development team. - Speculation on the speed of the machine learning process, proposed solution includes using server 72 8h100 to enhance performance.
@teknium'sdeclaration of testing an unidentified model and the need for further clarification of the said model.- Inquiry from
@mister_poodleon ways to extend or fine-tune Mistral-OpenOrca for specific tasks, namely boosting NER task performance using their datasets and generating JSON outputs.
Alignment Lab AI Channel Summaries
▷ #oo (5 messages):
- Discussion about a Mixtral-based OpenOrca Test:
@lightningralfasked@387972437901312000if they tested Mixtral based on OpenOrca, linking a fxtwitter post - Question about Process Speed:
@nanobitzexpressed surprise about the speed of the process, with@lightningralfsuggesting the use of server 72 8h100. - Unidentified Model Testing:
@tekniummentioned testing some model, but being uncertain about which one.
▷ #open-orca-community-chat (1 messages):
- Extending/Fine-tuning Mistral-OpenOrca for Specific Tasks: User
@mister_poodleexpressed interest in using their datasets to boost Mistral-OpenOrca's performance on an NER task with JSON outputs. They sought examples or suggestions for extending or fine-tuning Mistral-OpenOrca to achieve this goal.
Skunkworks AI Discord Summary
- Discussion occurred about the potential exploration of instructing tune mixtral, mentioned by zq_dev.
- @lightningralf shared a Tweet about the development of a fine-tuned chat version built on slim openorca.
- A YouTube link was shared by pradeep1148 without providing additional context.
Skunkworks AI Channel Summaries
▷ #finetune-experts (1 messages):
zq_dev: Anybody attempting to instruction tune mixtral yet?
▷ #moe-main (1 messages):
- Fine-tuned Chat Version Based on Slim openorca:
@lightningralfshared a Tweet about a fine-tuned chat version based on slim openorca.
▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=yKwRf8IwTNI
MLOps @Chipro Discord Summary
- An event notification was shared by user ty.x.202. in #events channel, with an invitation link: https://discord.gg/FKYww6Fn?event=1183435830711296032
- User fehir in #general-ml channel mentioned a new EU legislation without providing further details or context. This topic will be omitted due to insufficient context provided.
MLOps @Chipro Channel Summaries
▷ #events (1 messages):
ty.x.202.: @everyone https://discord.gg/FKYww6Fn?event=1183435830711296032
▷ #general-ml (1 messages):
fehir: New EU legislation in nutshell
The Ontocord (MDEL discord) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Engineer Foundation Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Perplexity AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it