[AINews] 1/11/2024: Mixing Experts vs Merging Models
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it 🔜
We checked 18 guilds, 277 channels, and 1342 messages for you. Estimated reading time saved (at 200wpm): 187 minutes. New: we also switched to GPT-4 turbo today. Let us know how it feels vs previous days (GPT-4-32k)!
A bunch of MoE models have sprung up since the Mixtral architecture has been published - DeepSeekMOE, Phixtral. But equally interesting is the practice of "model merging" - from naive (spherical) linear interpolation to "frankenmerges" used by SOLAR and Goliath. It seems that these techniques have created a new growth spurt in the open leaderboards as even relatively naive implementations are handily beating vanilla incumbents from the big labs.
https://huggingface.co/blog/mlabonne/merge-models
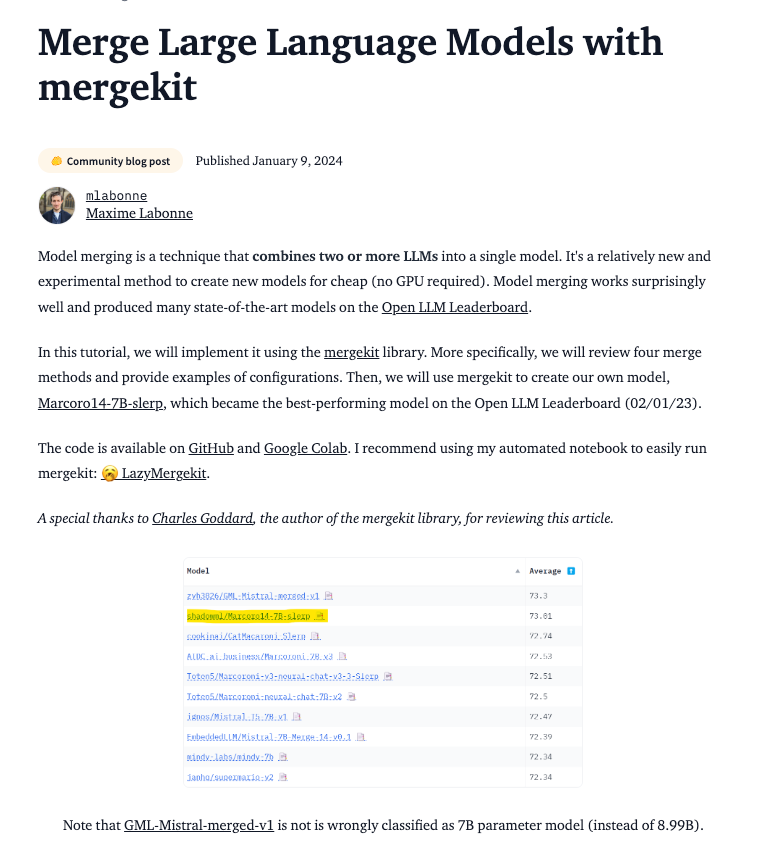
--
Table of Contents
- Nous Research AI Discord Summary
- OpenAI Discord Summary
- LM Studio Discord Summary
- HuggingFace Discord Discord Summary
- ▷ #announcements (1 messages):
- ▷ #general (54 messages🔥):
- ▷ #today-im-learning (6 messages):
- ▷ #cool-finds (22 messages🔥):
- ▷ #i-made-this (7 messages):
- ▷ #reading-group (10 messages🔥):
- ▷ #diffusion-discussions (5 messages):
- ▷ #computer-vision (2 messages):
- ▷ #NLP (8 messages🔥):
- ▷ #diffusion-discussions (5 messages):
- OpenAccess AI Collective (axolotl) Discord Summary
- Eleuther Discord Summary
- LAION Discord Summary
- Mistral Discord Summary
- Latent Space Discord Summary
- LlamaIndex Discord Discord Summary
- DiscoResearch Discord Summary
- LangChain AI Discord Summary
- LLM Perf Enthusiasts AI Discord Summary
- Alignment Lab AI Discord Summary
- YAIG (a16z Infra) Discord Summary
Nous Research AI Discord Summary
- AI Sandbox Exploration:
@ash_prabakeris looking for AI playgrounds that accommodate various prompt/llm parameters and support file uploads, recommended to try LangFlow or langchain with DATA ANALYSIS and GPT-4 by@everyoneisgross.
- Scroll Wheel Functionality Curiosity:
@shacrwponders the usage of the scroll wheel on the Rabbit r1, highlighting the juvenile form factor of some AI gadgets amidst a larger discourse on their usability.
- Security in Third-Party Cloud Concerns:
@tekniumvoices apprehension regarding the security of having their Discord account active on someone else's cloud, referring to a technology comparison involving RPA on cloud environments matched to Mighty.
- Bots vs. Discord TOS:
@0xeviland@tekniumdebate potential infractions of Discord's TOS by bots managing actual user accounts, contemplating the possibility of locally executed actions through vision models and TTS.
- TE's Cloud LLM Skepticism:
@everyoneisgrossexpresses doubt over Teenage Engineering's cloud hosted LLM, critiquing its potential inability to meet the company's marketing claims.
- AI Model Performance Gap:
@ldjdiscusses a notable performance gap between GPT-4 0613 and GPT-4-turbo, as per ELO scores, with the latter preferred for conversational and creative undertakings.
- AI Training Delays: The AI research community is abuzz with talk of project setbacks, such as the anticipated Pile 2, and the misuse of "open-source" by firms imposing extensive license restrictions.
- Fine-tuning LLM Strategies: Discussion on fine-tuning LLMs emerges with suggestions like exploring beta hyperparameters with DPO, alongside the complexities involved in adjusting a fine-tuning pipeline including mlx, lora, and safetensors.
- Integrating RAG with API Calls:
@pramod8481seeks guidance on integrating RAG for specifying API sequences, with@mgreg_42266proposing models that emit function calls based on JSON specs, and the potential use of grammars.
- MoE Models Versus Dense LLMs: Dialogue on the diverging communication styles of MoE models like Mixtral compared to dense LLMs, where MoE models seemingly display distinct semantic handling.
- Seeking Supreme RAG Data Framework: Discussion considers the llama index as a leading choice for RAG data architecture, while
@georgejrjrjrrecommends SciPhi-AI's synthesizer for simpler backend needs or creating a personalized framework.
- Anomalous Characters in Fine-Tuning Responses:
@kenakafrostyencounters unusual characters during fine-tuning, prompting inquiries into whether this represents a rule the model learned or an overfitting glitch.
Nous Research AI Channel Summaries
▷ #off-topic (32 messages🔥):
- Seeking Advanced AI Playgrounds:
@ash_prabakeris looking for AI playgrounds that allow for experimentation with prompt/llm parameters as well as rag+rag parameters including file upload capabilities, chunk size, and overlap adjustments.@everyoneisgrossrecommended trying LangFlow or using langchain with DATA ANALYSIS and GPT-4 for setting up common RAG python tools.
- Curiosity about Rabbit r1 Scroll Wheel:
@shacrwasked about the function of the scroll wheel on the Rabbit r1 and shared thoughts on the toy form factor of AI devices despite a blundered demo, mentioning plans to write a post on the topic.
- Concern Over Remote Cloud Actions:
@tekniumexpressed concerns over the security implications of having their Discord account logged in on a third party's cloud as per a conversation they linked and speculated about the technology behind a video recording being used for task learning.
- Discord's Terms of Service Discussed:
@0xeviland@tekniumdiscussed the potential issues with bots accessing real user accounts on Discord, considering the Discord TOS which prohibits such actions. They mused over the possibilities of locally executed actions using a vision model and TTS.
- Skepticism on TE's Oncloud LLM:
@everyoneisgrossshowed skepticism towards Teenage Engineering's cloud hosted LLM in conjunction with their hardware product, suggesting that it may not live up to the marketing pitches made by the company.
Links mentioned:
Tweet from Rajesh Karmani -- acting fast and slow (@rkarmani): @Teknium1 @amasad Found the answer here. They use RPA on their cloud in virtual environments... similar to Mighty.
▷ #interesting-links (18 messages🔥):
- A New Market for AI Solutions: User
@nonameusrshares about The Arbius network, a platform where solvers compete to provide solutions to user tasks, optimizing software for speed to increase profitability. - Key aspects: It offers secure generation by honest solvers, integration with various applications like NFTs and gaming, and DeFi AI, allowing model creators to earn from model invocations. - Questioning GSM8K Data Integrity:
@euclaiseexpresses skepticism over claims of contamination between the train and test sets of the GSM8K dataset, despite others referencing issues brought up by@teortaxestex. - Exploring LoRA's Nuances:
@romaincosentinoelaborates on LoRA's weight perturbation in large language models, suggesting that while it may differ from the full model fine-tuning, there’s not a huge difference for early layers as compared to LM-cocktail. - New Datasets and Merging Techniques for LLMs: User
@metaldragon01shares a link to a blog post announcing the creation of MetaMathFewShot and stacked LLM merges that are open-sourced on Hugging Face. Referenced link to tweet: FXTwitter - Bindu Reddy tweet, and the blog post: Open Sourcing Datasets and Merged/Stacked LLM - Abacus.AI Blog. - New Contributions to Self-Correcting LLMs: User
@metaldragon01also highlights a Google Research blog post regarding large language models (LLMs) and their capabilities in self-correction, particularly in mistake finding and output correction. Google Research Blog Post.
Links mentioned:
- Arbius
- Can large language models identify and correct their mistakes? – Google Research Blog
- Tweet from Bindu Reddy (@bindureddy): Improving LLM Performance - Open-Sourcing Datasets And A New Merged / Stacked LLM We are excited to announce several open-source AI contributions. MetaMathFewShot - open-source LLMs don't perfor...
- Add qwen2 by JustinLin610 · Pull Request #28436 · huggingface/transformers: Adding Qwen2 This PR adds the support of codes for the coming Qwen2 models. For information about Qwen, please visit https://github.com/QwenLM/Qwen. @ArthurZucker
▷ #general (204 messages🔥🔥):
- MMLU: Measure of Intelligence or Not?:
@gabriel_symeexpresses skepticism about using MMLU as a measure of AI intelligence, having observed that some tasks seem "pretty dumb." In a later conversation,@n8programsadds that MMLU is the only benchmark that really matters, sparking a discussion on the difference in AI capabilities at varying levels of the metric.
- Turbo Charged AI Gaps:
@ldjdiscusses the significant preference gaps between AI versions based on ELO scores, noting an 89 point gap between GPT-4 0613 and GPT-4-turbo, and@ldjadds that GPT-4-turbo is considered the superior model for conversational and creative tasks.
- AI Training Tensions and Terminology: Users like
@erichallahanand@proprietaryengage in a discussion about tensions in the AI research community, concerning the delays in projects like Pile 2 and the use of terms like "open-source" by companies with restrictive licenses.
- Building Better with Open Source:
@everyoneisgrossadvises the use of search capabilities, sharing their approach of building an agent using a 160 MB JSON and a 300 MB embedding pickle file from an OpenAI archive.
- Fine-tuning Finesse for AI Models: Users
@decruzand@n8programsdiscuss strategies for fine-tuning AI models, with@decruzsuggesting exploration of beta hyperparameters with DPO and@n8programssharing the complexities in their fine-tuning pipeline involving mlx, lora, and safetensors.
Links mentioned:
- fblgit/UNA-TheBeagle-7b-v1 · Hugging Face
- Fine-Tuning Language Models Using Direct Preference Optimization - Cerebras: An Alternative to RLHF to get a human preferred chat model.
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks. - GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.
▷ #ask-about-llms (30 messages🔥):
- RAG and API Conundrum:
@pramod8481explains they're tackling the challenge of figuring out the sequence of API calls through a RAG, while@mgreg_42266suggests that current models might emulate RAG by having models return function calls when provided with a JSON function spec, hinting at the use of grammars for better responses.
- MoE Experience Debated:
@adjectiveallisonseeks to understand why MoE models like Mixtral feel different in communication style or token choice compared to dense LLMs, despite literature suggesting otherwise.@tekniumshares their experience, indicating semantics play a role, particularly with semantically unique tasks like coding.
- Pursuit of the Ideal Re-ranker Model:
@pogpunkinquires about the best reranking model for RAG, expressing dissatisfaction with BGE, and@georgejrjrjrpoints them to the MTEB leaderboard, where e5-Mistral takes the lead.
- In Search of the Best Data Framework for RAG: While
@bigdatamikeasks if llama index is the supreme choice for a RAG data framework,@orabazesand@jaredquekendorse it, and@georgejrjrjrsuggests checking out SciPhi-AI's synthesizer if llama index's extensive backend adapters aren't a necessity.@decruzraises the idea of building one's own framework.
- Funky Degradations Puzzle:
@kenakafrostydescribes encountering odd characters in responses during fine-tuning and seeks insights into this anomaly, wondering if it's a learned rule rather than an overfitting issue.
Links mentioned:
GitHub - SciPhi-AI/synthesizer: A multi-purpose LLM framework for RAG and data creation.: A multi-purpose LLM framework for RAG and data creation. - GitHub - SciPhi-AI/synthesizer: A multi-purpose LLM framework for RAG and data creation.
OpenAI Discord Summary
- Outages and Errors on OpenAI: Users such as
@pavoldobiasand others reported experiencing technical issues with OpenAI services, with complaints including errors on account pages and complete outages of ChatGPT. - AI Bias and Content Avoidance Concerns: Discussions surfaced around how training data biases AI systems; users were concerned about AIs unintentionally mirroring ideological leanings or avoiding certain content types.
- Medical Advice from AI - A Bad Idea?: The community engaged in a debate on the reliability of LLMs for medical advice, with a consensus forming on the importance of consulting healthcare professionals over AI.
- The Nuts and Bolts of File Handling in GPT: Clarifications were made that GPTs can understand uploaded files, yet guidance helps the AI to reference them effectively. Moreover, file format efficiency for GPT training was scrutinized, with .txt being recommended over .docx for better processing times.
- Image Recognition Selection for the Classroom: A discussion occurred concerning choosing the right image recognition model for a school project, where accuracy and resource balance were key considerations for classifying fruits.
Additional Points & Community Inquiries:
- Seeking Feedback for AI SEO GPT: @kalle97 shared their GPT tailored for writing AI SEO articles and is looking for community feedback: Best AI Writer GPT-1 AI Text Generator.
- Tracking Prompt-Output Pairs: @boomboom68 sought out and @aidudeperfect recommended using Promthub and GIT for managing prompt-output pairs.
- Effective Education Content Extraction with GPT: @mischasimpson discussed generating customizable reading materials for education and was advised to consider a peer review process for prompt optimization.
OpenAI Channel Summaries
▷ #ai-discussions (80 messages🔥🔥):
- Technical Issues Plague Users: Numerous users, including
@pavoldobias,.australiaball,@areaboy_, and@marla.nettle, reported issues with the OpenAI service, ranging from errors on account management pages to complete outages of ChatGPT. - Understanding GPT File Handling: In a discussion sparked by
@tetsujin2295, users including@steve_03454,@7877, and@luguiclarified that files uploaded to GPTs are indeed read and understood by the AI, although instructing the AI on when to reference specific files can be beneficial. - The Bias Behind AI: A dialogue about AI biasing emerged with
@badapau,@7877, and@lugui. It focused on how taining data can introduce biases into AI systems, such as avoiding certain types of content or reflecting ideological leanings. - Concern About AI for Medical Advice: A conversation regarding the unsuitability of LLMs in providing medical advice unfolded between
@luguiand@you.wish. Lugui emphasized the need to consult qualified professionals rather than relying on AI for health-related decisions. - Image Recognition Model Debate:
@calamityn1njaand@luguidiscussed the selection of the appropriate image recognition model for a school project, with a focus on balancing accuracy with processing resources for a fruit classification task.
Links mentioned:
Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
▷ #gpt-4-discussions (128 messages🔥🔥):
- User Expresses Confusion over GPT Promotions:
@offlinequeried if promoting one's Patreon or Ko-fi is permissible through a GPT.@elektronisaderesponded indicating to reporter such instances through the report menu. - Potential Trademark Issues in GPT Store: Multiple users, including
@shira4888and@sayhelloai, discussed having their GPTs removed or flagged for possible trademark violations with names like "Code Copilot" or "Handy". - How Does Name Trademark Affect GPTs?:
@eligumpand@n8programsengaged in a conversation about the potential of using public domain characters or avoiding names like "copilot" due to Microsoft's trademark. - Concerns Over GPT Query Limits:
@encryptshawnlamented the limit on GPT-4 queries, claiming it hampers the development and testing of complex GPTs.@drinkoblog.weebly.comsuggested using the Team subscription to bypass these limits, attesting to the ability to perform 69 prompts in under an hour without getting locked out. - Explaining Plus Subscription Limitations: New subscribers like
@soy_reoinquired about the GPT Plus message cap.@han_hideoclarified that every message counts towards the 40 message/3-hour quota, including simple queries like greetings.
Links mentioned:
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Brand guidelines: Language and assets for using the OpenAI brand in your marketing and communications.
▷ #prompt-engineering (25 messages🔥):
- Seeking Feedback on AI SEO Content Creation: User
@kalle97shared a link to their GPT for writing AI SEO articles, asking for feedback from the community: Best AI Writer GPT-1 AI Text Generator. - Query About Message Counter:
@homesick9458inquired about the purpose of a message counter and whether it's to keep track of reaching a limit, but did not receive a response. - Tracking Prompt-Output Pairs: User
@boomboom68sought recommendations for tools to track, version, and analyze prompt-output pairs.@aidudeperfectmentioned using Promthub and GIT repositories for this purpose. - File Formats for GPT Training Knowledge Files:
@johnz999questioned the best file format for knowledge files in GPT Builder, sharing concerns about processing times and suggesting that .docx may be inefficient.@madame_architectrecommended avoiding .rtf and stated a preference for .txt, while acknowledging good OCR on PDFs. - Extracting Education Content for GPT Prompts:
@mischasimpson, an elementary teacher, discussed creating prompts for customizable reading material and considering whether to use trial and error in GPT-3.5 or GPT-4.@darthgustav.advised using a powerful model and peer review for optimization while noting that Bing, which uses GPT-4 Turbo, is also free. - Best Practices for Feeding Examples to GPT-4:
@jkyleasked how to best provide explicit examples to GPT-4, whether to include them in the initial prompt or as a message thread, and if reinforcement for example replies is necessary. No responses to the query were provided. - Boosting GPT Syntax Variation: User
@eligumpwas curious about keywords that could alter GPT's syntax significantly, to which@eskcantareplied by suggesting using high linguistic levels in input and asking the model to mirror that. An example of a custom instruction was also shared. - Concerns Over GPT's Recent Performance:
@nefariousapeexpressed that ChatGPT responses have become less effective and sought advice on prompts to improve its language output, but no direct solutions were offered in response.
▷ #api-discussions (25 messages🔥):
- SEO Article Writing Using GPT: User
@kalle97seeks feedback on their GPT for creating AI SEO articles, sharing a link https://chat.openai.com/g/g-oNyW1YcOI-best-ai-writer-gpt-1-ai-text-generator. - Inquiry about message counters: User
@homesick9458questions the use of message counters for tracking the limit on message-length or number in the chat. - Tracking Prompts and Outputs Quest:
@boomboom68asks the community for tools to track, version and analyze prompt-output pairs, with@aidudeperfectsuggesting Promthub and GIT, and@madame_architectreflecting on the need for a systematic solution. - Optimal File Formats for GPT Builder Revealed:
@johnz999inquires about the most efficient file format for knowledge files in GPT Builder, receiving advice from@madame_architectto avoid .rtf, favor .txt, and consider the quality of OCR on PDFs. - Peer Review for Custom Educational Prompts:
@mischasimpson, an elementary teacher, discusses creating specific prompts for a reading program and receives suggestions from@darthgustav.on using powerful models and peer review to ensure effectiveness.
LM Studio Discord Summary
- LM Studio API Limitations and Options:
@esraa_45467questioned whether LM Studio can automatically select the correct API for user actions.@fabguyclarified that API calls are not natively supported; users must build the functionality using an API server with LLM as the backend. Additionally,@fabguyconfirmed the ability to connect LM Studio to SillyTavern, suggesting a search within the Discord for existing tutorials.
- VRAM Hunger of 20B Models: Memory constraints are a common issue when running 20B models, as shared by
@letrangegwho faced difficulties with these models on a 24GB VRAM GPU. Tips were exchanged, including using smaller quants to prevent OOM errors (@heyitsyorkie) and reducing GPU layers to rely more on system RAM (@fabguy).
- Challenges of AI Model Compression Revealed: Discussions by
@drawless111and others brought to light the impact of model compression techniques like GGUF and EXL2 on performance, with anecdotal humor on GGUFing an EXL2_2bit model not working out. These conversations underscore the evolving nature of AI model compression techniques.
- High RAM and VRAM Specifications Shared:
@pwrresetdetailed specs of their powerful machine, which starkly contrasts with queries about operating LLMs on 8GB RAM systems. The machine featured an i9-11900k CPU, 128GB RAM, and a 4090 GPU with 24G VRAM.
- Falcon 180B Loading Issues in Latest Beta:
@pwrresetfaced a memory error when trying to load Falcon 180B on the latest beta, a problem they did not experience in previous versions. They proposed that a RAM paging feature might have been disabled, causing the issue, and noted after rolling back to version 0.2.10, the model loaded successfully.
LM Studio Channel Summaries
▷ #💬-general (123 messages🔥🔥):
- Debunking LM Studio 'Action' Misconceptions:
@esraa_45467inquired whether the app could automatically determine the correct API for a user action, such as booking a hotel room.@fabguyclarified that function calls aren't supported, and users would need to build that functionality themselves using the API server as the LLM backend. - SillyTavern Connection Clarification:
@messycabbage42asked about connecting LM Studio to SillyTavern like oobabooga, to which@fabguyconfirmed it's possible and advised searching the discord, as others have done it previously. - UI Troubleshooting in LM Studio: When
@.wotevafaced a UI issue,@fabguysuggested to change the screen size and close the "Conversation Notes" to prevent overlapping and reveal hidden buttons. - LM Studio Lacks Image Generation:
@esraa_45467was curious about using LM Studio for image generation and@fabguyresponded with a definitive no, recommending they look into Fooocus instead. - Good News for Config Seekers:
@systemsculptasked about optimal presets for models, and@fabguydirected to the pinned messages in a specific Discord channel for resources.
Please note that the above summary does not include every single message due to content and summary length restrictions.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Download GIF - Download - Discover & Share GIFs: Click to view the GIF
- CultriX/MistralTrix-v1 · Hugging Face
- Mixtral of Experts: We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (...
- Mixtral of experts: A high quality Sparse Mixture-of-Experts.
- Agent Tools: Framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. - joaomdmoura/cr...
- Don't ask to ask, just ask
- GitHub - danny-avila/LibreChat: Enhanced ChatGPT Clone: Features OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure Multi-User System, Presets, completely open-source for self-hosting. More features in development: Enhanced ChatGPT Clone: Features OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure...
- GitHub - mckaywrigley/chatbot-ui: The open-source AI chat app for everyone.: The open-source AI chat app for everyone. Contribute to mckaywrigley/chatbot-ui development by creating an account on GitHub.
- SillyTavern - LLM Frontend for Power Users
▷ #🤖-models-discussion-chat (54 messages🔥):
- Discussing VRAM and System RAM for Large Models:
@letrangegmentioned memory issues with 20B models on a 24GB VRAM GPU, considering if increasing system RAM could help.@heyitsyorkieadvised using smaller quants to avoid out-of-memory (OOM) errors, and@fabguyrecommended reducing GPU layers to utilize system RAM. - Model Performance Variations by Compression:
@drawless111shared insights on model compression techniques affecting performance, drawing attention to significant differences between GGUF, AWQ, GPTQ, and EXL2 models at the 1B level. This could inform better model results through improved compression methodologies. - Small LLM Loads on Low RAM Machines: A user,
@haseeb_heaven, asked for coding-based LLM recommendations that could run on 8GB RAM.@fabguysuggested DeepSeek Coder and highlighted that 8GB of RAM is generally not sufficient for AI tech, recommending an upgrade. - AI Model Compression Is a Field in Flux:
@dagbsand@drawless111discussed the potential for improvement in GGUF compression, while also teasing the idea of GGUFing an EXL2_2bit model, which did not work out humorously. Attention is drawn to the continuous learning and change in the AI model compression space. - Sharing Rig Details:
@pwrresetshared the specs of a powerful machine boasting an i9-11900k CPU, 128GB RAM, and a 4090 GPU with 24G VRAM, which stands in contrast to previous discussions about lower-end configurations.
Links mentioned:
- 3d Chess Star Trek GIF - 3d Chess Star Trek Tng - Discover & Share GIFs: Click to view the GIF
- GitHub - deepseek-ai/DeepSeek-MoE: Contribute to deepseek-ai/DeepSeek-MoE development by creating an account on GitHub.
▷ #🧠-feedback (1 messages):
- Channel Etiquette Reminder:
@heyitsyorkieadvised a user to move their post to another channel, stating "<#1111440136287297637> this channel is for feedback only, not help posts."
▷ #🧪-beta-releases-chat (9 messages🔥):
- Falcon 180B Loading Issues Hit a Wall:
@pwrresetreported encountering a memory error when trying to load Falcon 180B in the latest beta, despite having sufficient RAM available. They mentioned that previous versions did not have this problem and speculated it might be a vRam calculation error. - Rebooting Doesn't Revive the Falcon: In response to
@dagbs's suggestion to reboot to kill any potential zombie processes,@pwrresetconfirmed they had already rebooted three times to no avail. - Windows Version Display Mismatch:
@pwrresetpointed out an inconsistency with the OS version in the error message, stating they're on Windows 11, whereas the log displays Windows version as "10.0.22621". - Potential RAM Paging Issue Suggested:
@pwrresethypothesized that the latest beta might have disabled RAM paging, connecting this change to their inability to load the model. - Rollback Resolves Model Load Issue:
@pwrresetnoted that after rolling back to version 0.2.10, they were able to load the model fine with 14 GB of RAM left, indicating the problem may be specific to the latest beta update. - Intrigue Peaks with yagilb’s Discovery:
@yagilbchimed in, finding the situation interesting and inquired if mlock was enabled, observing the stats below the chat box.
HuggingFace Discord Discord Summary
- Phoenix Ascends with German Precision: A new German chat model, Phoenix, introduced by
@DRXD1000using Direct Preference Optimization (DPO) and based on datasets like the German translation ofHuggingFaceH4/ultrachat_200kandHuggingFaceH4/ultrafeedback_binarized. Check out Phoenix.
- Open Source Giant OpenChat 3.5 Takes the Stage: The announcement of OpenChat-3.5, a 7B parameter open-source language model claimed to be unrivaled, introduced and backed by RunPod. Detailed information available here.
- LiteLlama Makes Its Mobile Move:
@Toniclaunches an on-device model named LiteLlama, streamlining access to AI capabilities. More info found here.
- Community Eager for PyEmber’s Educational Wave: PyEmber—an accessible deep learning framework based on PyTorch—is introduced by
@emperorws, aiming to educate AI newcomers with ease. Find this valuable learning tool on GitHub and support its spread on LinkedIn.
- Reading Group Rendezvous: The reading group event, set for the next day with the possibility of a co-author's appearance, has been successfully creating a buzz while accommodating global members with a YouTube recording. Join the event.
- Mixtral's Mysteries and AI Education Insights: Discussions highlight the respected standing of Mixtral's AI capabilities relative to others in the AI hierarchy and share valuable insights on AI and Deep Learning educational resources, favoring PyTorch and course recommendations such as FastAI and Zero To Mastery for varying levels of learners.
- Kosmos-2’s Visual Aptitude Gets a Nod: Presentation of Microsoft's Kosmos-2, capable of object localization and interrogation within images, sparks interest for its 'grounded' nature, avoiding hallucinations while interacting with visuals. Demonstrations can be seen here. For pure object detection tasks, trending models on Hugging Face are recommended.
- Inpaint Patch Requests and Text Gen Challenges: An inquiry about the applicability of fooocus inpaint patch to diffusers was raised by
@waterknight98, with@lunarfluhighlighting the complexity of communication between text generation models and hardware, and@sayakpauldiscussing a preference for fine-tuning over training base models from scratch. A user experienced randomness in image generation despite fixed seed usage.
HuggingFace Discord Channel Summaries
▷ #announcements (1 messages):
- Phoenix Rises with DPO: User
@DRXD1000trained a new German chat model named Phoenix using Direct Preference Optimization (DPO). This model, designed for the German language, operates on the back of datasets such as the German translation ofHuggingFaceH4/ultrachat_200kandHuggingFaceH4/ultrafeedback_binarized. Check out the model here. - OpenChat 3.5 Stuns the Crowd: An open-source 7B LLM called OpenChat-3.5, claimed to be the best in the world, is introduced and sponsored by RunPod. Details of the model can be found via the following link.
- LiteLlama on Your Device:
@Tonichas released an on-device model named LiteLlama. You can find more about it and run the model from this space. - Artificial Thinker Seeks Feedback: A new demo called Artificialthinker by user
@687955585647247372has been launched, with a call for community feedback written all over it. Interact with the demo here. - Catch’em All with Pokemon Classifier: A new Pokemon classifier was developed by
@AgastyaPatel, making it easy for enthusiasts to identify various Pokémon. Discover the classifier here. - DreamDrop V1 Dreams Big: From OpenSkyML,
DreamDrop V1has been meticulously trained on Deliberate V5 with LoRA - MJLora for unique generative capabilities. Dive into DreamDrop here.
Note: The additional content on community discussions, blog posts, and acknowledgments of contributors was not included as bullet points due to the 5 bullet point constraint.
Links mentioned:
- DRXD1000/Phoenix · Hugging Face
- openchat/openchat-3.5-0106 · Hugging Face
- Chatbot UI
- LiteLlama - a Hugging Face Space by Tonic
- ArtificialThinker Demo on GPU - a Hugging Face Space by lmdemo
- Pokemon Classifier - a Hugging Face Space by AgastyaPatel
- openskyml/dreamdrop · Hugging Face
- Join the Hugging Face Discord Server!: We're working to democratize good machine learning 🤗Join us! hf.co/jobs | 66758 members
- Merge Large Language Models with mergekit
- Temporal Scene Generation w/ Stable Diffusion
- Unveiling TinyLlama: An Inspiring Dive into a Revolutionary Small-Scale Language Model
- Multi-Label Classification Model From Scratch: Step-by-Step Tutorial
- Multimodal IDEFICS: Unveiling the Transparency & Power of Open Visual Language Models
- 4D masks support in Transformers
- Understanding Mixtral-8x7b
▷ #general (54 messages🔥):
- AI outperforms Human Art?: User
@acidgrimponders if a certain quality in "really good" AI images sets them apart from human-created art.@lunarfluadds that small detailed imperfections could be the giveaway, despite overall thematic accuracy. - Mixtral's Place in AI Hierarchy Clarified:
@Cubie | Tomprovides insights, explaining Mixtral's relative performance compared to other models like Llama2-70b on various leaderboards and the human-evaluated LMSYS where Mixtral ranks 7th. - Concurrent Celery and Transformers Struggles:
@_barrel_of_lube_seeks help for an issue with concurrency in Celery when implementing transformers, as models are loaded multiple times. - Launching Medical Model 'biohack' on Huggingface:
@khalidschoolhackshares an upcoming launch of their finetuned medical model 'biohack' on Mixtral 7B and is looking for influencers to market and review it. - Hugging Chat TTS Feature Desired:
@green_eyeexpresses a wish for a TTS mode in Hugging Chat for a more accessible user experience.
▷ #today-im-learning (6 messages):
- Choosing the Right Learning Path: User
@merve3234suggests that the domain of interest should guide the learning choice, implying the importance of domain-specific knowledge in AI education. - PyTorch Over TensorFlow:
@kxonlineexpresses a preference for PyTorch over TensorFlow and plans to take more courses on PyTorch, indicating a perceived usability difference between the two frameworks. - FastAI for Beginners; Zero to Mastery for a Deeper Dive:
@kxonlinerecommends the FastAI course for beginners due to its abstraction level, and mentions Zero To Mastery as a decent PyTorch course for those starting out. - It's Not Just About Programming:
@sebastian3079shares that the course they are taking focuses more on the specifics of AI architectures/algorithms rather than the programming aspect, highlighting the diverse nature of AI education. - Embarking on a New AI Project:
@mad_cat__discusses their plans to refine AIs for a new system they are developing, though uncertain of how it will measure up against something called Sunspot, showing the exploratory and competitive nature of AI projects.
▷ #cool-finds (22 messages🔥):
- Innovative Uses of Face Recognition in Image Synthesis:
_vargolshared the IP-Adapter-FaceID Model Card which claims to generate images based on face ID embedding, but mentioned experiencing subpar results, describing them as "CGI version of a puppet". - Laughter in the Face of Grinch-like Proportions:
_vargoland@merve3234discussed facial proportions generated by the model, likening them to the Grinch, suggesting some humorous mishaps in image outputs. - Gravitating Towards More Realistic Models:
@chad_in_the_housecommented on the challenges of getting good results with default Stable Diffusion (SD) and indicated that using realistic models might yield better results. - GUI for Image Generation in the Works:
@meatfuckerreferenced a simple Windows-based GUI for image generation they are developing and shared the GitHub repository link: goobworkshop. - Quick Fixes for Configurable Faces:
@meatfuckeradvised that users currently have to manually replaceimage.pngin assets to change the face and noted that the tool should work on Linux, although the setup script is for Windows with NVIDIA.
Links mentioned:
- h94/IP-Adapter-FaceID · Hugging Face
- GitHub - Meatfucker/goobworkshop: Goob Workshop: Goob Workshop. Contribute to Meatfucker/goobworkshop development by creating an account on GitHub.
▷ #i-made-this (7 messages):
- Introducing PyEmber for Deep Learning Newbies:
@emperorwsshared their project PyEmber, an educational framework based on PyTorch, designed for beginners in AI and DL to understand the workings of a DL framework. Find it here: PyEmber on GitHub and help him spread the word on LinkedIn.
- Speedy 2x Image Upscaling Space Unveiled:
@helamancreated a fast image upscaling space using their latest models, able to upscale an image from 256x256 to 512x512 in ~1 second on a T4 Small GPU. Check it out: fast2xupscale.
- Quick Music Generation Demo:
.bigdookieshared a Twitter post showcasing music generated using a newly built Chrome extension for musicgen, which outputs 5-8 seconds of music, shorter than the usual 30 seconds.
- Back-End Auto-Crops Music Samples:
.bigdookiementioned that there's no need to crop manually because their backend attempts to do it automatically.
- Offer to Use Music Generation Tool:
.bigdookieinvited others to use their tool, though noted minor issues with howler.play instances that may affect playback but not the exported mp3 quality.
Links mentioned:
- Fast 2x Upscale Image - a Hugging Face Space by Phips
- GitHub - Emperor-WS/PyEmber: An Educational Framework Based on PyTorch for Deep Learning Education and Exploration: An Educational Framework Based on PyTorch for Deep Learning Education and Exploration - GitHub - Emperor-WS/PyEmber: An Educational Framework Based on PyTorch for Deep Learning Education and Explor...
▷ #reading-group (10 messages🔥):
- Event Reminder and YouTube Announcement:
@lunarfluannounced that the reading group event is set for tomorrow and confirmed that a YouTube recording will be available. They also express willingness to adjust meeting times for future events and ask for paper suggestions Join the event. - Cozy Timezone Challenges for Global Members:
@hamster.uwuappreciates the YouTube recordings, as the event's timing aligns with 4:30 AM in Australia, making live participation challenging. - Co-author's Participation Excites Reading Group:
@mr.osophyshares that one of the co-authors might join the event at 1:45 PM ET to answer questions, adding an exciting element for attendees. - Reading Group Gathers Steam & Support:
@ironman5769humorously alludes to the meeting time fitting within standard startup hours.@pier1337and@mad_cat__express enthusiasm for the reading group initiative, with@mad_cat__humorously accepting the challenge of being too late to learn.
Links mentioned:
Join the Hugging Face Discord Server!: We're working to democratize good machine learning 🤗Join us! hf.co/jobs | 66758 members
▷ #diffusion-discussions (5 messages):
- Inpaint Integration Curiosity:
@waterknight98inquired about the usage of fooocus inpaint patch with diffusers. - Text Generation Over Hardware Control:
@lunarflupointed out that while there are examples for text generation found in previous channel posts (<#1119313248056004729>, <#1147210106321256508>, <#1162396480825462935>), having such systems to communicate with a computer on a hardware level would be more complex. - Finetuning Over Base Training Preference: In response to
@chad_in_the_house,@sayakpaulconfirmed a preference for finetuning methods rather than training a base model from scratch like pixart alpha. - Unexpected Randomness in Image Generation:
@felixsanzexpressed confusion about why setting a manual seed (generator.manual_seed(2240851815)) still resulted in a random image being generated.
▷ #computer-vision (2 messages):
- Kosmos-2 Brings Object Localization and LLM Together:
@merve3234highlighted Microsoft's Kosmos-2 as an underrated model that can localize objects in images and answer questions about them. They provided a user's tweet as a reference to the model's capabilities and a code snippet for easy use. - Kosmos-2 as a Grounded Alternative:
@merve3234emphasized that Kosmos-2 is grounded and doesn’t hallucinate, posting a HuggingFace demo link for practical demonstrations. - Suggestion for Pure Tracking: For tasks strictly related to object tracking,
@merve3234recommended using specialized object detection models, sharing a link to trending models on HuggingFace, including microsoft/table-transformer-detection. - Balancing Novelty with Practicality:
@meatfuckeracknowledged the attractiveness of Kosmos-2 but agreed that for certain use cases, traditional object detection methods might prove more effective.
Links mentioned:
- Tweet from merve (@mervenoyann): Think of an LLM that can find entities in a given image, describe the image and answers questions about it, without hallucinating ✨ Kosmos-2 released by @Microsoft is a very underrated model that ca...
- Kosmos 2 - a Hugging Face Space by ydshieh
- Models - Hugging Face
▷ #NLP (8 messages🔥):
- Tensor Weights Need to Stick Together!: User
@merve3234offers a solution to non-contiguous tensor errors during training by explicitly making specific tensor weights contiguous using a code snippet. They also point to a range of T5 models and resources on Hugging Face. - No Difference Between
cuda:0andcudafor Single GPU Use:@merve3234clarifies that usingcuda:0orcudais essentially the same when working on a single GPU device, as it defaults to the 0th GPU. - Apple Silicon GPU Support Inquiry:
@pippopluto_96741asks whether Hugging Face supports Apple Silicon GPUs like m2/m3 since they've only worked with NVIDIA GPUs previously. - Leaderboard Prompt Formatting:
@latentfogposes a question about the prompt format used by the leaderboard for models, particularly regarding models trained in different formats or multi-formats. - Seeking Summarization Pipeline for Office Desktops:
@n278jmseeks advice on creating a summarization pipeline that includes speaker diarization and does not impose heavy loads on tier hardware office desktops, all while avoiding the use of external services for legal and ethical reasons. - Discussion on Application-Level Patches for Transformer Library:
@opencuiguymentions the expectation that the transformer library should handle issues like non-contiguous tensors without the need for patching at the application level and seeks feedback from the user with handle@697163495170375891.
Links mentioned:
▷ #diffusion-discussions (5 messages):
- Inpaint Patch Inquiry: User
@waterknight98inquired if anyone has used fooocus inpaint patch with diffusers. No direct responses regarding their question were given in the provided messages. - Complexity of Text Gen Communication: User
@lunarfluaddressed the complexities of having text generation models communicate with computers at a certain level. Specific examples were hinted at with message references<#1119313248056004729>,<#1147210106321256508>,<#1162396480825462935>. - Focus on Fine-tuning Over Base Model Training: In response to an observation made by
@chad_in_the_house,@sayakpaulconfirmed focusing on fine-tuning pre-trained base models to generate high-quality results, rather than training from the alpha stage. - Seed Confusion:
@felixsanzreported an issue with generating a random image despite using a fixed seedgenerator.manual_seed(2240851815), expressing confusion over the unexpected result.
OpenAccess AI Collective (axolotl) Discord Summary
- Memory Struggles and Training Challenges: Users discussed difficulties with controlling memory usage during model training, specifically comparing the behavior of
E5-mistral-7b-instructto Llama2 13b. The conversation highlighted issues with handling lower max_tokens with the new model. This sparked further discourse on finetuning practices, such as finetuning LLaVA 1.5 with image inputs on Axolotl, supported by reference to a previous PR and a shared debugging tutorial video. Additionally, discussions emerged about MoE (Mixture of Experts) models and their efficiency, particularly referencing DeepSeekMoE's claim of matching Llama2's performance with significantly lower computational demands.
- Advanced Configuration Conversations: Engineers debated finer technical details, like keeping the gate on fp32 for LoRA, and deliberations on the naming of configuration settings for autounwrap functionality, favorably settling on
rl_adapter_ref_model. Discussion of a potential Axolotl 0.4.0 release was informed by integration of a Mixtral loss fix into Hugging Face transformers, and user@dctannershared Hugging Face's intentions of adding default system prompts to model tokenizers.
- Data Handling Issues and Tips: Engineers exchanged insights on data manipulation and system interactions. One helpful hint shared was that wandb logs can be utilized to retrieve stack traces post-closure of the command box. Queries about configurations for Mistral with LoRA suggested 4bit pairing with qlora. There's a looming anticipation for simplified configurations in the future. Community members inquired about the structure and uniqueness of CommonCrawl dumps as well as efficient sample packing methodologies for large datasets to conserve RAM.
- Dataset Discoveries and Queries: Participants recommended datasets, such as the Tested 22k Python Alpaca for code generation enthusiasts. Methods for configuring datasets to train specific models like Mistral Instruct were also queried, and no location was given for the sought
dolphin201.jsonldataset. The community evaluated dataset quality, sharing links to datasets like ultrafeedback_binarized_cleaned, and discussed the significance of response quality in DPO datasets.
- Updates on Docker Reinforcement Learning: The
#rlhfchannel confirmed the merging of a dpo PR for Docker optimization, indicating a direction towards efficiency and resource management in the containerized environment, which may influence use cases and development within the community.
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (16 messages🔥):
- E5-Mistral-7B Instruct Challenges:
@tostinoexpresses difficulty in controlling memory usage while training[E5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct)and compares it to their previous experience with Llama2 13b where they could train with 6144 max_tokens but now can only handle 480 max_tokens with the current model. - Enthusiasm for Axolotl Collaboration:
@leoandlibeinquires about finetuning LLaVA 1.5 with image inputs on Axolotl, and@caseus_shows interest in collaborating on this feature, directing to a prior pull request[PR #781](https://github.com/OpenAccess-AI-Collective/axolotl/pull/781/files)for pretraining the LLaVA projector model as a potential starting point. - VSCode Debugging Tutorial for Axolotl:
@hamelhshares a video walkthrough to help users set up VSCode for debugging Axolotl, available at[https://youtu.be/xUUB11yeMmc](https://youtu.be/xUUB11yeMmc). - Exploring DeepSeekMoE's Efficiency:
@b_ryan0brings attention to DeepSeekMoE 16B, which claims to match Llama2's performance with 40% less computation, and@leoandlibeconfirms that MoE models generally have greater memory demands but reduce compute by only activating a subset of experts.@emrgnt_cmplxtyqueries about the possibility of extending context length with Rope, showing curiosity towards the capabilities of the model.
Links mentioned:
- How to debug Axolotl (for fine tuning LLMs): This is a detailed guide on debugging Axolotl, a project that helps you fine-tune LLMs. Specifically, I show you how to configure VSCode for debugging. Res...
- GitHub - deepseek-ai/DeepSeek-MoE: Contribute to deepseek-ai/DeepSeek-MoE development by creating an account on GitHub.
- intfloat/e5-mistral-7b-instruct · Hugging Face
- Integrate LLaVA for multimodal pre-training by winglian · Pull Request #781 · OpenAccess-AI-Collective/axolotl: you'll need to download the images.zip from https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/tree/main into a llava folder to use this this PR simply mostly reimplements this file htt...
▷ #axolotl-dev (30 messages🔥):
- FF32 vs LoRA:
@caseus_suggests keeping the gate on fp32 for LoRA while discussing a DeepSeek-MoE finetune script. - Assistance Requested for Testing PR:
@caseus_enquires if@208256080092856321tested the PR yet, referencing Pull Request #1060 to enable autounwrap in TRL. - Struggle for the Right Name:
@caseus_and@nanobitzdiscuss potential configuration names for their autounwrap functionality, settling onrl_adapter_ref_modelwhich implies passing the reference model when set to true. - Axolotl Preparing for a New Release:
@caseus_announces the merge of Mixtral loss fix into transformers and plans a new 0.4.0 Axolotl release after the imminent new release of transformers, informed by the recent accelerate 0.26.1 release related PR on GitHub. - Hugging Face to Add Default System Prompts:
@dctannershares a Hugging Face community post about adding support for system and chat prompts to model tokenizers, aimed at improving model evaluations as chat agents, with the feature planned for the next quarter Hugging Face Discussion #459.
Links mentioned:
- jondurbin/bagel-dpo-8x7b-v0.2 · Hugging Face
- DeepSeek-MoE/finetune/finetune.py at main · deepseek-ai/DeepSeek-MoE: Contribute to deepseek-ai/DeepSeek-MoE development by creating an account on GitHub.
- Codestyle.co: Code standards and guidelines for a variety of programming languages.
- axolotl/.github/CONTRIBUTING.md at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- HuggingFaceH4/open_llm_leaderboard · Future feature: system prompt and chat support
- feat: enable trl's autounwrap by NanoCode012 · Pull Request #1060 · OpenAccess-AI-Collective/axolotl: For testing currently! Tested working by Teknium. Based on this https://github.com/huggingface/trl/blob/104a02d207b63a4a062882aaff68f2d275493399/trl/trainer/dpo_trainer.py#L691 , trl would unwrap t...
- Fix load balancing loss func for mixtral by liangxuZhang · Pull Request #28256 · huggingface/transformers: What does this PR do? Fixes #28255 Before submitting This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). Did you read the contributor guideline, P...
▷ #general-help (16 messages🔥):
- Helpful Hint on Wandb Logs:
@c.gatoshared a tip that wandb logs can be used to retrieve stack traces even after closing the box.@leoandlibeappreciated this useful info.
- Config Queries for LoRA Finetuning:
@ragingwater_asked for advice on finetuning Mistral with LoRA, referencing a config file. Further,@ragingwater_inquired about theload_in_8bitandload_in_4bitsettings, to which@caseus_replied that 4bit should be paired with qlora and@nanobitzconfirmed the same.
- Anticipation for Configuration Simplification:
@caseus_indicated a plan to simplify the configuration process soon, while@ragingwater_shared their experience with the config.yml and possible unintended full-finetuning.
- Inquiries on Data Uniqueness in CommonCrawl:
@emperorqueried if CommonCrawl dumps are unique or cumulative, looking for clarity on the dataset's structure.
- Sample Packing for Large Datasets Discussed:
@jinwon_kasked about the implementation of sample packing for large datasets and suggested potential improvements to avoid wasting RAM.@nanobitzresponded with a recommendation to check the preprocessing section in the docs for processing datasets efficiently.
Links mentioned:
- axolotl/examples/mistral/qlora.yml at 44ba616da2e5007837361bd727d6ea1fe07b3a0e · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- axolotl/examples/mistral/config.yml at 44ba616da2e5007837361bd727d6ea1fe07b3a0e · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
▷ #datasets (12 messages🔥):
- Latest Code Dataset for Alpaca Enthusiasts:
@dreamgenrecommended the Tested 22k Python Alpaca dataset by Nicolas Mejia Petit for those interested in code generation and analysis, which features 22,600 examples of Python code verified as working. - Configuring Mistral Instruct:
@dinonst74queried about the dataset definition fordnovak232/sql_create_context-v4-mssql-instruct-revinconfig.yamlto train Mistral Instruct, to which@ragingwater_responded that the Alpaca format should work, requiringinstruction,output, andinputvalues. - Dolphin201.jsonl Sought for Training:
@athenawisdomssearched for thedolphin201.jsonldataset used to train thedolphin-2.1-mistral-7b, but no direct responses were provided regarding its location. - Dataset Utilized for
ultrafeedback_binarized_cleaned:@noobmaster29shared a link to the ultrafeedback_binarized_cleaned dataset on Hugging Face, soliciting opinions on its quality. - Insights on DPO Dataset Quality:
@noobmaster29sought insight on the importance of the quality of chosen responses in a DPO dataset and factors that contribute to a good DPO dataset.@xzuynsuggested that chosen responses should be of at least the same quality as those for a regular SFT response.
Links mentioned:
- Vezora/Tested-22k-Python-Alpaca · Datasets at Hugging Face
- dnovak232/sql_create_context-v4-mssql-instruct-rev · Datasets at Hugging Face
- allenai/ultrafeedback_binarized_cleaned · Datasets at Hugging Face
▷ #rlhf (3 messages):
- Docker Power Optimization Merged:
@caseus_confirmed that the dpo PR has been merged a few days ago, which@jaredquekwas keen to use in Docker.
Eleuther Discord Summary
- A Sour Take on ML Terms:
@stellaathenahumorously declared all ML names bad and misleading, terming it the "sour lesson." - Optimizing Scaling Laws in Large Language Models: A debate sparked by
@maxmaticalon new scaling laws in DeepSeek's LLM paper, with@stellaathenafinding some of the data representation choices questionable. - Challenges for Generative AI Compiled:
@stellaathenashared an extensive list of open problems in generative AI, fostering a discussion on overlapping questions in the field. - Vision Transformers Get a Makeover:
@digthatdatapresented Denoising Vision Transformers, an approach to enhancing ViT features with a denoiser. - LLaMA's Books3 Reveal & Huggingface Clarifications:
@stellaathenaconfirmed Meta's transparent use of Books3 dataset in LLaMA training, while also separating EleutherAI's lm-evaluation-harness from Huggingface's evaluate library.
Eleuther Channel Summaries
▷ #general (28 messages🔥):
- Clarification on Huggingface's Evaluate Library:
@joe5729_00015inquired about the connection between Huggingface's Evaluate library and EleutherAI's lm-evaluation-harness, pondering if the latter was a wrapper for the former. However,@stellaathenaclarified that there is no relationship between the two, and that the evaluation harness runs separately from evaluate-on-the-hub LF's primary revenue stream.
- Meta's LLaMA Training Dataset Disclosure:
@digthatdatapointed out a document indicating that Meta used parts of Books3 for training LLaMA models.@stellaathenaresponded, confirming that the dataset usage for LLaMA 1 was openly disclosed and it was unsurprising for LLaMA 2.
- Lack of Spiking Neural Network Training:
@sentialxquestioned the lack of engagement in training spiking neural networks suggesting they appear more efficient. However, `@thatspysaspy** responded discussing the hardware compatibility issues, with current technology being optimized for conventional neural networks rather than spiking ones.
- Legal Trends in AI Training Data:
@eirairaised a point about the future of AI training data becoming obscured for legal reasons, to which@avi.aiadded that this trend is evident when comparing the LLaMA 1 and 2 reports. The discussion extended with@clock.work_speculating on the potential requirements for using GPT-4 synthetic data and the involvement of regulatory checks for plagiarism.
- No Recording of OpenAI QA Event:
@jbustterasked about a recording of an OpenAI QA event, to which@boneamputeeclarified that no broadcast was made, and the event consisted only of messages being answered via a Discord bot.
Links mentioned:
GitHub - wzzheng/OccWorld: 3D World Model for Autonomous Driving: 3D World Model for Autonomous Driving. Contribute to wzzheng/OccWorld development by creating an account on GitHub.
▷ #research (15 messages🔥):
- Deciphering the Latent Space: User
@aloftyfound a paper discussing the mapping from nonlinear to linear geometry in latent spaces fascinating but admitted to not grasping all the details. - Generative AI Challenges Compiled:
@stellaathenashared A large list of open problems in generative AI, which sparked several members to discuss specific questions and potential overlaps, such as between questions 51, 33, and 59. - Contemplating Gradient Schedules and Optimizations:
@ad8eexpressed disdain for the inv sqrt gradient schedule and discussed the merits of using spectral norm as a gradient scaling method. - RNNs and Transformers, A Shared Pedigree: User
@pizza_joelinked several papers discussing the relationship between RNNs and transformer models, elaborating on new approaches in model efficiency and caching techniques for large language models. - Reimagining Vision Transformers:
@digthatdatashared the GitHub page Denoising Vision Transformers and explained it entails training a denoiser to enhance intermediate ViT features. A related teaser image was also provided: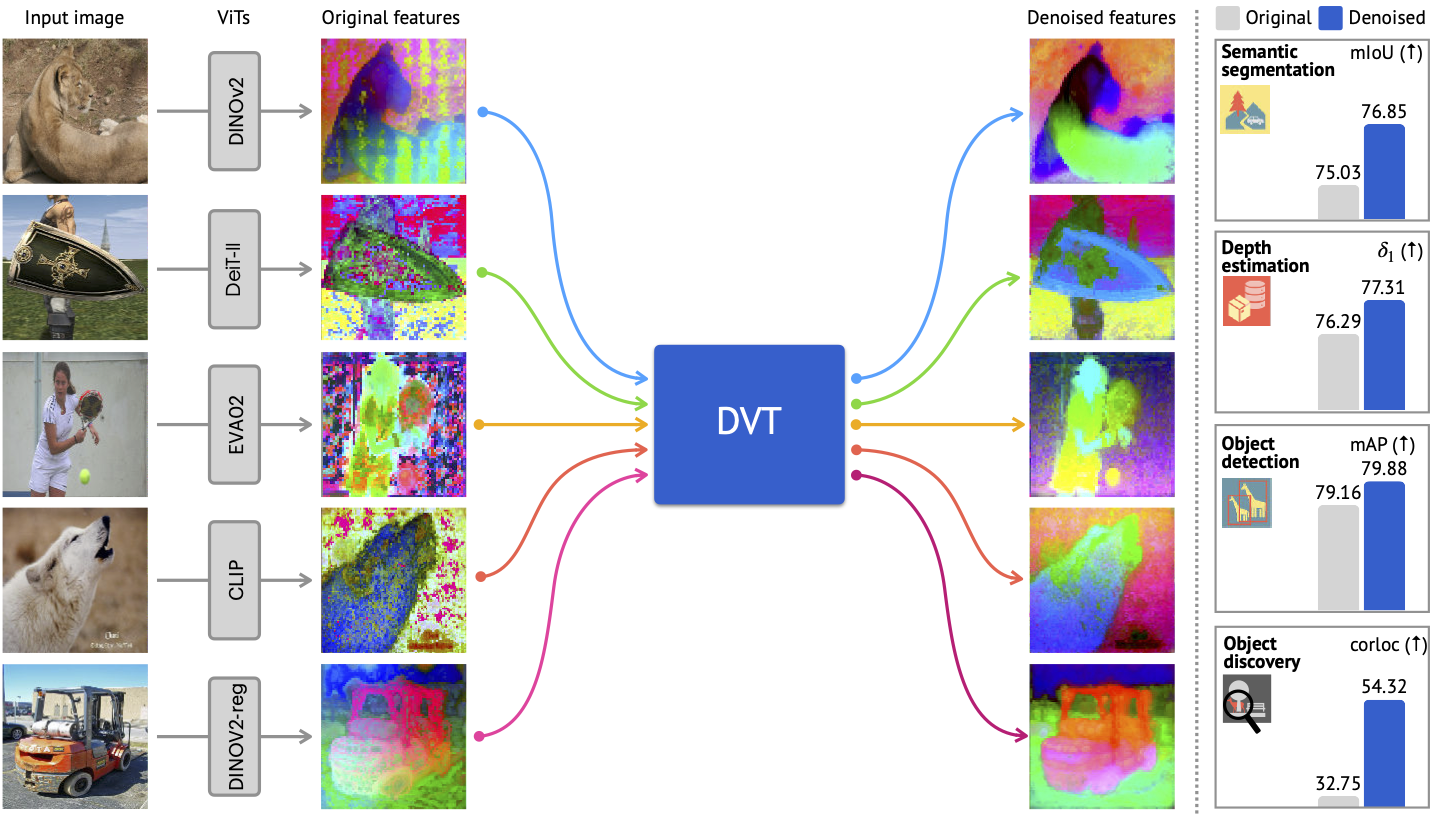 .
.
Links mentioned:
- Transformers are Multi-State RNNs: Transformers are considered conceptually different compared to the previous generation of state-of-the-art NLP models - recurrent neural networks (RNNs). In this work, we demonstrate that decoder-only...
- Efficient LLM inference solution on Intel GPU: Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly...
- Distilling Vision-Language Models on Millions of Videos: The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human...
- Finetuning Pretrained Transformers into RNNs: Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, Noah A. Smith. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Pro...
- GitHub - Jiawei-Yang/Denoising-ViT: This is the official code release for our work, Denoising Vision Transformers.: This is the official code release for our work, Denoising Vision Transformers. - GitHub - Jiawei-Yang/Denoising-ViT: This is the official code release for our work, Denoising Vision Transformers.
▷ #scaling-laws (6 messages):
- Debating Scaling Laws in DeepSeek LLMs:
@maxmaticalsparked a conversation on the scaling laws presented in DeepSeek LLM papers, highlighting a significant difference from Kaplan 2020: critical batch size in DeepSeek is much larger and dependent on compute rather than the number of layers (L). The paper details these scaling laws aslr_opt = 0.3118 * (c ** -0.125)andbs_opt = 0.292 * (c ** 0.3271). - Nothing Unreasonable Found:
@stellaathenaresponded with an assessment that nothing seems unreasonable regarding the new scaling laws discussed. - Raises Questions About the Data Plot: In subsequent messages,
@stellaathenapointed out concerns about the data representation in the discussed paper, finding it strange that raw parameters rather than the number of tokens are plotted on the x-axis, and noting that the plot is not logarithmically scaled, ultimately stating that it is "just a bad plot".
Links mentioned:
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism: The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark ...
▷ #interpretability-general (12 messages🔥):
- Sour Lesson Debate:
@stellaathenahumorously suggested that all names for things in ML are bad and misleading, which they dubbed the "sour lesson." - Neural Nets and Human Brains Similarity Discussion:
@norabelrosecountered the "sour lesson" argument by pointing out research suggesting similarities between neural nets and human brains. - The Salty Lesson in Interpretability:
@nsaphraproposed the "salty lesson": interpretability work is only meaningful when time is spent with the data. - Transformers Reign Supreme: In a spicy turn of events,
@stellaathenastated that transformers are better than RNNs, acknowledging that this take is six years too late to be considered spicy. - Request and Sharing of Interpretability Paper:
@epicxexpressed a desire to access a certain IEEE paper on improving interpretability of DNNs through model transformation, which was subsequently shared by@suhasia.@epicxresponded playfully, referencing Team Four Star's requests to support the official release.
Links mentioned:
Interpreting Deep Neural Networks through Model Transformation: Literature Review: Machine learning especially deep learning models have achieved state-of-the-art performances in many fields such as automatic driving, speech recognition, facial expression recognition and so on. Howe...
▷ #lm-thunderdome (9 messages🔥):
- Inquiry about Meta-Templates Support:
@stellaathenaasked if there's a way to support the formatting of BigBench tasks for any multiple-choice question and answer (MCQA) task without needing to reformat each time.@hailey_schoelkopfreplied that they can use promptsource templates, but the idea of a "prompt library" has not been prioritized yet. - Bug Fix Leads to Unexpected Accuracy Drop:
@baber_expressed shock that fixing a bug resulted in a 20-point decrease in accuracy, initially thinking a new sampling method had been discovered. - Correction on Accuracy Statistics:
@hailey_schoelkopfclarified that accuracy improved from 7% to 52% after fixing the bug, dispelling@baber_'s initial misunderstanding of the accuracy percentages. - Confusion and Realization:
@baber_acknowledged the confusion, having mistaken 7% for 70% and thinking the fix was a downgrade, eventually realizing the mistake and showing relief. - Concern Over Finetune Methods:
@cubic27expressed alarm over the implications of the accuracy discussion, suggesting they might need to re-evaluate their work with llama finetunes due to the unexpected developments.
▷ #multimodal-general (1 messages):
- Seeking Multimodal LLMs Foundation:
@clams_and_beansis looking for a repository for a multimodal LLM research project, explicitly stating a desire to work with modalities beyond images. They asked for guidance to a basic implementation to start building upon.
LAION Discord Summary
- LAION-coco Dataset MIA: User
@chatdiablosearched for the missing LAION-coco dataset, and despite challenges in locating it, they were pointed towards Datacomp on HuggingFace by@thejonasbrothersas an alternative amidst concerns over potential illegal content in the dataset.
- Mistral Models Under Scrutiny: A comparison between Mistral-medium and Mixtral highlighted that Mistral-medium tends to hallucinate more, though sometimes it delivers detailed answers, indicating a quality trade-off as observed by
@nx5668.
- Wacom's AI Art Outrage:
@thejonasbrothersand@astropulsedove into the controversy over Wacom's use of AI-generated art in marketing and@.undeletedraised the possibility of the art originating from Adobe Stock. The incident underlined the sensitivity within the art community regarding AI artwork, as detailed in Boing Boing's coverage.
- PIXART-Delta Shakes Up Image Gen: The announcement of PIXART-Delta, a framework capable of generating 1024px images in 0.5 seconds, spurred discussions around image quality and the effectiveness of training data, with complimentary links shared including the PIXART-Delta technical paper.
- The Quest for Superior Captioning: Ongoing discussions on whether humans or AIs make better captioners invoked the mention of GPT4-V and CogVLM as leading examples for AI-based solutions in the captioning arena. Debates emphasized the nuances and capabilities of both proprietary and open-source models in this domain.
- Innovations in AI-Driven Video Generation: A development in high-aesthetic video generation technology highlighted by
@nodjaled to the sharing of MagicVideo-V2's project page and its corresponding research paper, illustrating advancements in producing imaginative and high-quality video content from textual prompts.
LAION Channel Summaries
▷ #general (46 messages🔥):
- LAION-coco dataset lost in the digital shuffle: User
@chatdiabloinquired about accessing the LAION-coco dataset for research purposes, but it was noted by@pseudoterminalxthat it's probably not coming back due to potentially illegal content.@thejonasbrotherssuggested to use Datacomp as an alternative and provided the link: Datacomp on HuggingFace.
- Mistral-medium vs Mixtral: In the LAION discussions,
@nx5668commented on Mistral-medium hallucinating more than Mixtral, despite giving detailed answers at times, noting a quality trade-off.
- Wacom walks into an AI controversy:
@thejonasbrothersshared a link about Wacom's marketing misstep using AI-generated art, sparking debates and artist community backlash. The original ads have been removed, adding fuel to the controversy. Boing Boing coverage of Wacom's AI art fiasco.
- Backlash over poorly chosen AI art in ads:
@astropulsecriticized companies like Wacom for advertising with obvious AI-generated images, stating it's "insulting to AI art" due to glaring mistakes, and pondering the disregard shown by such a significant artist tool company.
- Wacom's AI art - an adobe stock journey?: Amidst the discussion of Wacom's AI art controversy,
@.undeletedsuggested the images might originate from Adobe Stock, adding another twist to the unfolding story.
Links mentioned:
Artists upset after Wacom uses AI art to market artist gear: Who needs a Wacom Intuos or Cintiq when you can have Midjourney crank it out? Well, you can use them to edit out the AI's hallucinations, mistakes and do compositing…
▷ #research (23 messages🔥):
- LAION-coco Data Hunt: User
@chatdiablois looking for assistance to download the LAION-coco dataset as Hugging Face seems to have issues. They are appealing for someone who has the dataset to share it. - PIXART-Delta Makes Waves with Speed: A new framework called PIXART-Delta is introduced by
@thejonasbrothers, which generates high-quality 1024px images in just 0.5 seconds. A link to the technical paper is shared, discussing its impressive features over PIXART-Alpha. - Debate on PIXART-Delta's Image Quality: Following the introduction of PIXART-Delta,
@thejonasbrotherscriticizes the demo outputs, stating they ignore half the prompt and are a result of training on low-quality llava captions.@qwerty_qwerpresents a counter-point, highlighting the artistic aspect of the outputs. - Human vs AI Captioning: Opinions are shared about the best captioning method with
@nodjahumorously stating that humans are the best captioners, and@qwerty_qwerretorts that humans can be lazy.@thejonasbrothersmentions GPT4-V as the best, with@progamergovadding that CogVLM is the best open-source while GPT-4V is the best proprietary. - High-Aesthetic Video Generation:
@nodjashares a link to a project on multi-stage video generation, which includes a wide range of imaginative prompts. A project page is provided, but with a warning of numerous gifs, and a link to the authors' research paper.
Links mentioned:
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation: The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-i...
- PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models: This technical report introduces PIXART-δ, a text-to-image synthesis framework that integrates the Latent Consistency Model (LCM) and ControlNet into the advanced PIXART-α model. PIXART-α is recognize...
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Mistral Discord Summary
- New Paper Drop: @sophiamyang highlighted the release of a new paper available at arXiv for review by peers.
- Mistral or Dense? The MoE dilemma: @yiakwyxpumlframeworkteam_03391 sparked a debate about MoE's generation quality in domain-specific datasets vs traditional dense models, prompting a knowledge exchange with @sophiamyang.
- Cloud Training Platforms Compared: @damiens_ sought opinions on user-friendly cloud services for training Mistral models, mentioning SkyPilot, SageMaker, and Hugging Face as potential contenders.
- API Parameters Shift: Updates in Mistral API parameters from
safe_modetosafe_prompttripped up users @freqai and @nftsmasher, leading @lerela to provide a clarifying explanation and apology. - Custom Decoding with Mistral 7B: @michaelwechner requested a Python code example for a custom decoding strategy implementation using Mistral's 7B model.
Emphasis on Technical Precision and Clarifications: Maintained a technical focus, ensuring to include specific model names, API parameters, and user handles for precision and direct follow-ups within the engineering audience.
Mistral Channel Summaries
▷ #general (23 messages🔥):
- New Paper Alert: User
@sophiamyangannounced the publication of a new paper on https://arxiv.org/pdf/2401.04088.pdf. - Mistral vs Dense Models: User
@yiakwyxpumlframeworkteam_03391discussed concerns that MoE has bad generation in domain dataset compared to dense models and sought insights from@sophiamyang. - Training on Cloud Question:
@damiens_queried the community on the best and user-friendly cloud service for training and fine-tuning a Mistral model, mentioning SkyPilot, SageMaker, and Hugging Face. - Typescript Inquiry and Clarification:
@derastatknutredinquired about TypeScript support for the API. It was clarified by@sublimatorniqthat TypeScript is already supported, and@derastatknutredrealized the issue lay with the Vercel AI SDK. - API Parameter Update Causes Confusion:
@freqaiand@nftsmasherreported an error with the Mistral API.@coheehighlighted the update fromsafe_modetosafe_prompt, while@lerelaprovided an explanation and apology for the inconvenience caused by the documentation error.
Links mentioned:
- Mistral AI API | Mistral AI Large Language Models: Chat Completion and Embeddings APIs
▷ #models (9 messages🔥):
- GitHub Copilot with @workspace keyword:
@kim_techmentioned that GitHub Copilot's recent update allows prioritizing your current git repo using the@workspacekeyword. - Search for Custom Model for Editable Diagrams:
@m1sol_44558is looking for a custom model to generate editable diagrams. - Issues with Mistral and Local Deployment:
@gbourdinreported problems withmixtral-8x7b-instruct-v0.1.Q2_K.ggufon a localllama.cppserver, getting 0.0 series in response to/embeddingrequests. - Introducing Mermaid for Generating Diagrams: In response to
@m1sol_44558,@kim_techrecommended investigating the Mermaid programming language for generating editable diagrams. - Mistral Medium Potentially Experiencing Downtime:
@theunholymessiahinquired about potential downtime of Mistral Medium as it was unresponsive on their end.
Links mentioned:
Kquant03/Hippolyta-7B-bf16 · Hugging Face
▷ #finetuning (1 messages):
- Confusion over Llama-index usage with OpenAI models: User
@dinonst74inquired whether it's necessary to tune OpenAI-like models to include</s>at the end, as it seems unnecessary when using regular Mistral models. They ponder if they should adjust their dataset and omit</s>for better learning outcomes.
▷ #random (3 messages):
- Request for Decoding Strategy Example:
@michaelwechneris looking for a python code example to implement a custom decoding strategy using Mistral 7B as LLM. - The Inner Voice as C3PO:
@king_sleezeoffers an analogy comparing the inner voice to C3PO, referring to it as a protocol droid script that narrates and affirms. - Bicameral Theory of Consciousness Discussed:
@cognitivetechexpresses relief in agreement that the bicameral theory of consciousness can't be proven or disproven, yet it might be useful for contemplating the essence of consciousness.
▷ #la-plateforme (19 messages🔥):
- Kudos and Speed Concerns for Mistral 8x7B:
@c_bonadiopraises the Mistral Team's work on Mistral 8x7B, but raises a concern regarding slow response times (16s) compared to fireworks.ai. They seek assistance for speed improvement.@lerelaacknowledges the issue and commits to working on faster response times. - API
safe_modeParameter Confusion:@gimaldi_75953encounters a 422 Unprocessable Entity error when usingsafe_modeparameter in API calls, regardless of itstrueorfalsesetting.@lerelaclarifies that the API documentation had an error wheresafe_promptwas incorrectly referred to assafe_mode, promising that the change in documentation should fix the issue.@gimaldi_75953later confirms the solution works. - Go vs Python API Clients:
@gimaldi_75953reports issues when using the Go client and plans to try out Python client for comparison;@c_bonadiosuggests that 422 might be related to parameter formatting. - Updated Guardrailing Documentation:
@lerelashares a link to the updated documentation clarifying the previously misnamedsafe_modeAPI parameter, urging users to update their code accordingly with the correctsafe_promptflag. The update is located at: Mistral Documentation on Guardrailing. - GPU Curiosity and Jokes: Users in the channel joke about the number of GPUs required to run la plateforme, with guesses including A100s, H100s, and at least "3 GPUs" according to
@standardunit's calculations.
Links mentioned:
Guardrailing | Mistral AI Large Language Models: System prompt to enforce guardrails
Latent Space Discord Summary
- Bubbling Up with Event-driven Chat UIs:
@slonodiscussed the creation of a bubbletea-powered TUI for agent frameworks, focusing on the nuances of handling streaming, live updates, and async responses in a tabbed interface designed for agent interactions. This evolving discussion touches on UI's role in multi-agent system communication dynamics.
- Debating UI's Role in AI Memory:
@swizecignited a debate by questioning if UI containing a conversation's state could be viewed as a memory layer for AI agents, sparking a reflection on the impact of UI design on AI-based "business logic".
- AI Research at the Forefront: The community focused on various AI topics like Andrew Ng's tweet about Direct Preference Optimization (DPO) research and Bill Gates' podcast with Sam Altman on AI leadership.
@decruzshared interest in applications of distilled Orca datasets and running DPO finetunes on Modal, hinting at a broader conversation on AI research direction and implementation.
- Synergy Between AI and Raspberry Pi: Experiments with hosting models like Phi and TinyLLaMA on Raspberry Pi were detailed by
@decruz, with findings shared on a Reddit thread. This exploration reveals the potential of combining accessible hardware with advanced AI models.
- MOE Models: Fast Trainers but Finicky Tuners: In the LLM Paper Club,
@swyxiosummarized@ivanleomk's insights on MOE models, noting their propensity for overfitting despite faster training speeds, specifically citing MOE-Mamba's training efficiency. Fine-tuning these models remains a challenge, with the potential upside of distillation. The full discussion is available in a tweet.
Latent Space Channel Summaries
▷ #ai-general-chat (52 messages🔥):
- Slono's Quest for a Dynamic Chat UI:
@slonodelved into the intricacies of building a bubbletea-powered, event-driven TUI for agent frameworks, discussing the challenges of streaming, live updates, and the coordination of async responses with UI rendering. This UI targets to accommodate multiple completion events for agent interactions in a tabbed view.
- Swizec's Skepticism on UI as Agent Memory: In a thoughtful exchange,
@swizecquestioned whether the UI containing conversational state could be considered a form of agent memory, indicating a concern for the control that UI has over agents in a system where AI acts as "business logic".
- Deep Learning and AI Talk Take Center Stage: New ventures in AI were highlighted, including Andrew Ng's tweet about the Direct Preference Optimization (DPO) research paper,
@decruzmentioning the usage of distilled Orca datasets for DPO, and Bill Gates' new podcast episode with Sam Altman that@swyxioshared, sparking discussions on company sizes and Gates’ online presence.
- Paper Club and DPO Experiments:
@ivanleomkinvited peers to join a paper club discussion, while@decruzalso asked for examples of running DPO finetunes on Modal, showing interest in cutting-edge AI research practices.
- GitHub and Raspberry Pi Experiments:
@swyxiolinked to a collection of synthetic datasets, and@decruzdetailed experiments running models like Phi and TinyLLaMA on a Raspberry Pi, with posted results on a Reddit thread.
Links mentioned:
- deepseek-ai (DeepSeek)
- Reddit - Dive into anything
- Tweet from Howie Xu (@H0wie_Xu): At @ycombinator W24 kickoff today, @sama suggested ppl build w/ the mindset GPT-5 and AGI will be achieved "relatively soon"; most GPT-4 limitations will get fixed in GPT-5, per YC founder Ric...
- Episode 6: Sam Altman: If you ask people to name leaders in artificial intelligence, there’s one name you’ll probably hear more than any other: Sam Altman. His team at OpenAI is pu...
- Reddit - Dive into anything
- GitHub - jondurbin/bagel: A bagel, with everything.: A bagel, with everything. Contribute to jondurbin/bagel development by creating an account on GitHub.
▷ #llm-paper-club (1 messages):
- Faster Training but Challenging Fine-tuning for MOE Models:
@swyxioshared a recap from@ivanleomkhighlighting that MOE models, like MOE-Mamba, tend to overfit more than dense counterparts but benefit from significantly faster training times—about 2.2x faster. However, fine-tuning these models poses challenges. The upside, however, is the potential to distil an MOE model. The full discussion can be read here.
Links mentioned:
Tweet from Ivan Leo (@ivanleomk): MOE models seem to overfit more heavily than their dense counterparts but train significantly faster. MOE-Mamba for instance trained ~2.2x faster. This means that training is fast but fine-tuning is ...
LlamaIndex Discord Discord Summary
- Semantic Strategies for RAG on Long Texts:
@GregKamradtintroduced a new semantic-based method for splitting long documents in RAG. Further insights and discussion are available through the shared tweet. - New Course Alert: Activeloop & IFTTT Offer Free Certification: A course collaboration between IFTTT and Activeloop promises to impart real-world use case knowledge with a free certification. Participants can explore more on this opportunity here.
- Launch Time: Together Embeddings Meets Mistral AI: Together AI released a guide on building retrieval-augmented generation apps with Mistral AI and its new Together Embeddings endpoint. Instructions are detailed in the announcement found here.
- LlamaIndex.TS Leveling Up: An update to the
LlamaIndex.TSTypeScript library brought new embeddings, vector databases, multiple language models, and multimodal support. More information can be found in the update announcement here.
- LLM Integration Conundrums and Solutions:
@syblus_queried about switching from OpenAI API to Together AI Llama-2. Helpful information and reference code were made available through Together LLM documentation, and LlamaIndexTS GitHub repository. - Pushing the Boundaries of Document Summarization:
@emrgnt_cmplxtyis looking to fine-tune a document summarization model to deliver structured outputs, with prior work accessible on HuggingFace. - Debugging ReAct Agent Prompt Peculiarities: Issues with
system_promptin ReAct Agent were discussed, and@7levenpointed out that customizingReActChatFormatterwas needed and plans to contribute to the LlamaIndex project were indicated. - Discrepancy Woes in Agent Testing:
@vedtamreported mismatches between console verbose outputs and results in Postman, hinting at agent behavior with chat history. - SageMaker Meets Llama_Index Challenges:
@cd_chandraasked about integrating Amazon SageMaker model endpoints with llama_index. Although not directly possible,@cheesyfishesdiscussed a workaround involving LangChain's LLM and embeddings compatibility with llama_index.
LlamaIndex Discord Channel Summaries
▷ #blog (4 messages):
- Semantic Split for Longer Documents:
@GregKamradtsuggested a new method for splitting long documents for RAG, focusing on the semantic connections between sentences, and shared a tweet with further details and relevant links. - Activeloop Course Hits Popularity: The course by IFTTT and Activeloop is gaining traction. Interested participants can dive in and receive a free certification by working through real-world use cases. More information can be found here.
- Launch of Together Embeddings with Mistral AI and LlamaIndex: Together AI has announced a guide for building retrieval-augmented generation apps using @MistralAI and the new Together Embeddings endpoint. The blog post offers step-by-step instructions and can be accessed here.
- Exciting Updates to LlamaIndex.TS: The TypeScript library
LlamaIndex.TSjust had a major update with new embeddings and vector databases, as well as multiple language models and multimodal support. Check out the announcement and more details here.
Links mentioned:
Building your own RAG application using Together AI and LlamaIndex
▷ #general (48 messages🔥):
- Switching LLMs in LlamaIndex Discord Bot:
@syblus_asked how to transition from using the default OpenAI API to Together AI Llama-2 in a Node.js environment.@whitefang_jrreplied with a link to the Together LLM documentation and provided sample code for Colab, but acknowledged Together AI is not present in the TypeScript (TS) version and directed to LlamaIndexTS GitHub repository. For further discussion, they also pointed to a specific TS channel.
- Fine-Tuning a Summarization Model:
@emrgnt_cmplxtyexpressed interest in fine-tuning a document summarization model instructable to return structured outputs, linking their previous related work on HuggingFace.
- ReAct Agent's Use of System Prompt:
@7levenbrought up issues with thesystem_promptargument not influencing a ReAct Agent as expected.@cheesyfishesconfirmed that thefrom_tools()method does not utilize thesystem_prompt, and that the ReActChatFormatter needs customization to alter prompts. Later,@7levenmentioned successfully monkeypatching aContextReActChatFormatterand indicated plans to contribute to the LlamaIndex project.
- Inconsistent Results Between Console and Postman:
@vedtamexperienced discrepancies between verbose output seen in the console and the final message in Postman when testing.@cheesyfishesresponded that the agent might reinterpret the tool's response in the context of chat history.
- Utilizing SageMaker Model Endpoints with Llama_Index:
@cd_chandrainquired if it's possible to use Amazon SageMaker model endpoints with llama_index.@cheesyfishesrelayed that llama_index lacks a SageMaker integration but mentioned its presence in LangChain, providing a code snippet to work with LangChain's LLM and embeddings within llama_index.
Links mentioned:
- Togather AI LLM - LlamaIndex 🦙 0.9.30
- LlamaIndexTS/packages/core/src/llm at main · run-llama/LlamaIndexTS: LlamaIndex is a data framework for your LLM applications - run-llama/LlamaIndexTS
DiscoResearch Discord Summary
- MergeKit Merges into the Spotlight: Technical discussions highlighted the potential of using MergeKit for combining language models. An informative blog post on Model Merging Simplified was shared by
@thewindmom, along with a collection of model-merging papers on Hugging Face.@philipmayand@remek1972engaged in discussions about the feasibility of merging two Llama2-70B models, whereas@rasdanipointed to DiscoLM-120B as an example.
- The Birth of a Bilingual AI: A significant update in the AI community was introduced by
@hammadkhan, sharing that Jina AI released the world's first bilingual Chinese-English model, with more details found on Jina AI's embeddings page. This led to@philipmayraising questions about whether the model was open-source or limited to an API, prompting further investigation from the community.
- Benchmark Deep Dive into Min P Sampling: The conversation in the benchmark development community was sparked by
@.calytrix's inquiry about implementations of Min P sampling for benchmark comparisons.@kalomazeprovided a comprehensive response with multiple implementations and discussed the methodology, including insights into the temperature's impact on model outputs, with detailed analysis on Reddit.
- First Embedding Community Meeting Afoot: An announcement by
@philipmayabout the first embedding community meeting generated interaction, confirming Discord's suitability for group calls. This was tied to a shared tweet hinting at the advancement in the embedding development domain by@thewindmom, while_jp1_introduced lengthy-context retrieval models, sharing the work from Hazy Research on the Monarch Mixer and their GitHub repository.
DiscoResearch Channel Summaries
▷ #mixtral_implementation (8 messages🔥):
- In Search of MergeKit Insights: User
@philipmayinquired about resources on the "mergekit" method for combining models. They questioned if it's akin to MoE in Mixtral but with just two models instead of eight. - TheWindMom Shares MergeKit Knowledge:
@thewindmomposted a link to a Hugging Face blog about model merging with mergekit: “Model Merging Simplified”. They clarified that it's not the same as MoE and provided another link to related papers, including one from 2014 about characterizing neural network optimization. - Merger of Llama2-70Bs questioned:
@philipmaypondered over the feasibility and practicality of combining two Llama2-70B models using mergekit. - MoE Merging Method Clarification: User
@remek1972responded to@philipmaypointing them to a specific branch of mergekit that uses MoE merging methods, different from the standard approach. - DiscoLM-120B's Two-Part Tango:
@rasdanijoined the dialogue, referencing DiscoLM-120B as a merge of two Llama2-70B tunes. They mentioned operational challenges and speculated on its potential to top the Hugging Face leaderboard with sufficient compute power. - Chuckles Over MergeKit:
@thewindmomshared a humorous tweet from @osanseviero regarding the mergekit conversation.
Links mentioned:
▷ #general (5 messages):
- Bilingual Models Break Language Barriers:
@hammadkhanshared a tweet from@bo_wangbo, announcing that a Chinese-English bilingual model is now available via API, with a German-English model expected next week. Jina AI confirmed the release of the world's first bilingual Chinese-English embedding model with an extensive 8192 token-length on Jina AI's embeddings page, and further details can be found on Jina AI's news. - Anticipation for Open-Source Code: In response,
@philipmayquestioned whether the model by Jina AI is an open-source or just an API/black box service.@hammadkhanindicated uncertainty regarding its openness. - Direct Outreach for Clarity:
@thewindmomexpressed concern about the potential lack of open-source access and mentioned reaching out directly to the official source for more information.
Links mentioned:
Tweet from Bo (@bo_wangbo): Chinese-English bilingual model available on API, German-English model coming next week, and we are syncing with HF team to make both models seamless integrated into the upcoming long waited sbert rel...
▷ #benchmark_dev (15 messages🔥):
- Seeking Min P Implementations:
@.calytrixasked if Min P sampling had been implemented anywhere for comparison benchmarks.@kalomazeresponded with several implementations: llama.cpp, exllama2, text-generation-webui's HF loaders, vllm, koboldcpp (a fork of llama.cpp), and tabbyAPI, a lightweight API fork of exllama2. - Dissecting Sampling Methods:
@kalomazeshared a Reddit post detailing their breakdown of how the order of Temperature settings can heavily impact a model's output and underscored how Min P behaves differently than other sampling methods like Top P at higher temperatures. - Min P vs. Other Sampling Parameters: In a further explanation,
@kalomazediscussed how Min P does not break down at higher temperatures as compared to other sampling methods such as Top K and Top P, stressing on their consistent behavior across models and backends. - Benchmarking Results with Min P:
@.calytrixshared benchmark results demonstrating that scores remained consistent when using Min P with temperature set to 1 through 4. However, they noted the benchmark's focus on assigning numerical values to emotion states may not be the best way to evaluate the sampler. - Temperature's Impact on Min P Usage:
@.calytrixhighlighted that it could be useful to have benchmarks of Min P at various temperatures and asked if there were other parameters worth comparing.@kalomazementioned that temperature, Top K, and Top P are conventional methods for controlling language model determinism.
Links mentioned:
▷ #embedding_dev (5 messages):
- Embedding Community's First Meeting Scheduled: User
@philipmayannounced that the first embedding community meeting is set for tomorrow at 4pm German time on Discord, querying the platform's suitability for such an event. - Discord Confirmed for Group Calls: In response,
@rasdaniconfirmed the feasibility, mentioning their positive experience with group calls on Discord. - The Tweet Heard 'Round the World: User
@thewindmomshared a tweet from @realDanFu without additional commentary. - Multilingual Performance Speculation: Following that tweet,
@bjoernpexpressed curiosity about the multilingual performance and the competitiveness of Jina in that space. - The Next Level of Text Embeddings:
_jp1_highlighted the advanced work on long-context retrieval models with a link to Hazy Research's detailed blog and shared their GitHub repository for Monarch Mixer (M2) models that support up to 32K context length, which could be applicable to other languages. Visit M2 GitHub repo.
Links mentioned:
- Long-Context Retrieval Models with Monarch Mixer: Long-Context Retrieval Models with Monarch Mixer
- GitHub - HazyResearch/m2: Repo for "Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture": Repo for "Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture" - GitHub - HazyResearch/m2: Repo for "Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture"
LangChain AI Discord Summary
- Local LLM Plugin Quest for VS Code and IntelliJ:
@zwaragis on the lookout for a Visual Studio Code or IntelliJ plugin that interfaces with a local Large Language Model for direct development support.
- Scraper Libraries Sought for Image Harvesting:
@gomfe_52955polled the guild for preferences in libraries adept at scraping images from the web.
- Vector DB Enthusiasts Talk Local: The conversation between
@manskipand@schtiphtouched on utilizing vector databases like MongoDB on local machines, with a pro tip to consider "persist" in the context of MongoDB documentation.
- Linux Libmagic Lamentations: User
@Eminemis dealing with difficulties with Libmagic on Linux, requesting assistance from anyone familiar with troubleshooting the tool.
- RAG Chatbot Speaker Identification Struggle:
@bennybladerdiscussed challenges related to a RAG chatbot, contemplating using a JSON structure to pass context and improve the bot's ability to differentiate conversation participants.
- LangServe Discussions Get Technical on GitHub:
@veryboldbageland@cryptossssunengaged in a dialogue over handling input variables in LangServe functionalities, with a situation needing attention in setting input variables and a GitHub Discussion suggested as the venue for a more in-depth conversation.
- The Bartender: A GPT that Raps and Sings: In a striking showcase,
@hat_tr1ckintroduced The Bartender, a GPT creation that not only crafts rap lyrics but also delivers them in an MP3 format, found via a Twitter post.
LangChain AI Channel Summaries
▷ #general (17 messages🔥):
- Seeking Local LLM Plugin for IDE: User
@zwaraginquired about a Visual Studio Code or IntelliJ plugin that integrates with a local Large Language Model (LLM). - Scraping Images with Web Scraper Libraries:
@gomfe_52955asked the community about preferred libraries for scraping images with a web scraper. - Vector Databases on Local Machines:
@manskipand@schtiphdiscussed the possibility of using a vector database like MongoDB locally, with @schtiph hinting to search for "persist" as a keyword in the MongoDB context. - Troubles with Libmagic on Linux: User
@Eminemsought assistance for issues encountered with Libmagic on Linux, looking for someone with experience in fixing it. - Challenges with RAG Chatbot Speaker Differentiation:
@bennybladeris working on structuring conversation data for a RAG chatbot and sought advice on whether to pass the context as a JSON structure, facing difficulties with the chatbot differentiating speakers within the conversation.
▷ #langserve (10 messages🔥):
- GitHub Discussion Redirect:
@veryboldbagelmoved a question regarding how to make new variables available via the query method in LangServe to a GitHub discussion, providing a link for further help: Discussion #394. - In Search of a Detailed Explanation:
@cryptossssunsought clarification on how to have input variables passed correctly within a chain wrapper in LangServe'sRunnableWithMessageHistoryfunction. - Code Snippet Shared:
@cryptossssunshared a code snippet as an example of setting input variables which seems to not work as expected:"{"lession": RunnablePassthrough(), "affection": RunnablePassthrough(), "question": RunnablePassthrough()}". - Direct Call to Help:
@cryptossssuntagged a specific user for assistance with the issue regarding setting input variables. - Continued GitHub Discussion Recommended:
@veryboldbageladvised@cryptossssunto continue their technical discussion on GitHub for a more thorough examination of the issue.
Links mentioned:
How to make the new variables input available via query method? · langchain-ai/langserve · Discussion #394: Question: If I create the new varialbels: input_variables=["history", "input","lession", "affection"], and setting like the below code. I cant make the right qu...
▷ #share-your-work (1 messages):
- GPT that sings:
@hat_tr1ckshared a new GPT found on Twitter which not only generates rap lyrics but also creates an MP3 file of the finished song, claiming it's a first. Here's the bot called The Bartender.
LLM Perf Enthusiasts AI Discord Summary
- In Search of Expanded Queries:
@robhaisfieldis seeking out excellent resources on query expansion. Join the discussion. - No Limits Hit Yet on Team Messages:
@joshcho_inquired about the message cap for teams with intentions to implement upcoming changes and observed no speed improvements post-update. - GPT Shift Feels Like Turbo: There's chatter around a significant shift in GPT's model, with
@joshcho_comparing the latest experience to a turbocharged version. - Skepticism Surrounds the GPT Store's Path:
@justahveeexpressed doubts about the GPT store's strategy, contrasting its transactional nature against apps that build long-standing user bases. - Debate Over Custom GPT Utility:
@thebaghdaddyis critical of custom GPTs, suggesting they lack uniqueness, while@nosa_.provided a counterpoint, sharing positive outcomes using a research-focused GPT for enhanced task performance. - Worry Over GPTs' Incentive Structures: Concerns were raised by
@nosa_.about the reward system for creating engaging GPTs, with the potential for dystopian user manipulation. They cited a Twitter thread by @metaviv which questions the implications of OpenAI's incentive structure.
LLM Perf Enthusiasts AI Channel Summaries
▷ #rag (1 messages):
robhaisfield: Anyone have great resources on query expansion?
▷ #openai (24 messages🔥):
- Querying Message Cap for Teams:
@joshcho_is looking for information on the message cap for teams as they plan to incorporate changes immediately. - No Speed Boost for Teams Detected: According to
@joshcho_, there has been no noticeable difference in speed for teams despite changes. - Shift in GPTs Model Observed:
@joshcho_also mentioned what seems to be a massive model change in GPTs, stating it feels similar to turbo now. - Concerns over GPT Store’s Future:
@justahveeexpressed skepticism about the GPT store, pointing out the differences with other app stores and how it may be too transactional compared to apps that earn long-term users. - Critical View on Value of Custom GPTs:
@thebaghdaddycritically pointed out that most custom GPTs are just 1-2 paragraph instructions with no real moat or compelling reason to use over others, while@nosa_.expressed a positive experience with a research-focused GPT, suggesting they can provide a performance boost for specific tasks. - Potential Dystopian Incentives in GPTs:
@nosa_.linked to a Twitter thread by @metaviv discussing the risk of dystopian outcomes due to the incentives provided by OpenAI to create engaging GPTs, raising concerns about GPTs' potential for user manipulation.
Links mentioned:
Tweet from Aviv Ovadya 🥦 (@metaviv): Uh oh. This looks bad. OpenAI will pay those who create the most engaging GPT's. This makes their incentives very close to those of social media—capturing attention. This could get dystopian very ...
Alignment Lab AI Discord Summary
- Trouble in Compile Town: @stormchaser9939 reported build issues with the latest llama.cpp on Windows, with a sudden spike in errors compared to previous, problem-free builds.
- Quest for Orca Replication: @ming.l.linoracle.com is seeking assistance with Mistral-7B-SlimOrca to replicate its results, looking for reference code or training settings and provided a Hugging Face link to the mentioned model.
Alignment Lab AI Channel Summaries
▷ #general-chat (1 messages):
- Llama.cpp Build Errors on Windows: User
@stormchaser9939is experiencing issues building the latest code from the master branch of llama.cpp on Windows, mentioning that previous builds were fine but the current one is producing a lot of errors.
▷ #open-orca-community-chat (1 messages):
- Seeking Mistral-7B-SlimOrca Reproduction Guidance: User
@ming.l.linoracle.cominquired about reproducing results on Mistral-7B-SlimOrca and is looking for reference code or training settings. They thanked everyone in advance for any assistance and referenced the model on Hugging Face (Mistral-7B-SlimOrca).
YAIG (a16z Infra) Discord Summary
Only 1 channel had activity, so no need to summarize...
- GCP Waives Egress Fees Due to New EU Regulation:
@stevekammanhighlighted that Google Cloud Platform (GCP) is eliminating egress fees for data transfer to other clouds as a response to a new EU regulation. He expects Azure and AWS to follow suit. This change is intended to make it cheaper to switch cloud providers, although it does not simplify the complex economics of data transfer pricing. An attached diagram illustrates this complexity, but the diagram was not included in the message.
- Examining Groq's Approach to AI Hardware:
@stevekammanshared links discussing Groq's hardware capabilities, specifically the LLAMA7B model running on Groq's architecture. A general architecture paper outlines their "Superlane" concept and clocking variance. For those seeking a simpler explanation, he shared a plain-english explainer on how Groq's technology innovates neural network processing, but also noted a lack of signs of adoption in practical settings.
Links mentioned:
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.