[AI For Engineers Beta] Day 7: Agents!
The Emergence of AI Agents and Their Potential
Everyone gets into AI with the dream of building AGI - and in practice these are called “agents” - not killer Terminator bots, but helpful/honest/harmless AI Agents that autonomously augment/automate the boring parts of our lives.
It's not just us saying it:
- Bill Gates thinks agents are going to change how you use computers
- Sam Altman is guiding OpenAI towards agents
- Why Karpathy thinks YOU should work on Agents
Today, we will be building our first AI agent! It will take all the skills we’ve learned and achieve interoperability between all of our existing tools:
So far you’ve gotten to most of the modalities that AI’s are being used in the mainstream tech world:
- Text - Code Generation - Retrieval Augmented Generation
- Image
- Audio - TTS & STT (aka ASR aka Whisper)
In the last day of Latent Space University, we will delve into AI agents, their definition, various agent models, and how to build your own AI agent.
The Evolution of AI Agents
Agents as a concept have evolved significantly. The dream of autonomous non-human assistants trace back hundreds of years to golems and homunculi. The 1956 Dartmouth workshop where AI was born called out self-improvement as a top level focus, and the next half-century of work on blackboard architectures and multiagent systems are now considered GOFAI.
Post ChatGPT (2022)the Voyager paper (mandatory reading) introduced the idea of a curriculum, an iterative prompting mechanism and a skills library.
⚠️ (Taken directly from Voyager paper, formatted for brevity)
Automatic Curriculum
Automatic curriculum takes into account the exploration progress and the agent's state to maximize exploration. The curriculum is generated by GPT-4 based on the overarching goal of "discovering as many diverse things as possible". This approach can be perceived as an in-context form of novelty search.
- Iterative Prompting Mechanism
Iterative prompting mechanism that generates executable code for embodied control
Skills Library

Top: Adding a new skill. Each skill is indexed by the embedding of its description, which can be retrieved in similar situations in the future.
Bottom: Skill retrieval. When faced with a new task proposed by the automatic curriculum, we perform querying to identify the top-5 relevant skills. Complex skills can be synthesized by composing simpler programs, which compounds Voyager's capabilities rapidly over time and alleviates catastrophic forgetting.
With the idea of a curriculum and a skill library, you can start to see where the Code Core mental model for agents comes from.

There are various architectures around — and while we’ll dive deeper, at a high level, people have thought of agents as being human-esque. Naturally, analogies have tried to follow, giving us the Anatomy of Autonomy

- Foundation models:
- Everything starts with the evolution and widespread availability of massive LLMs (via API or Open Source). The sheer size of these models finally allow for 3 major features:
- Perfect natural language understanding and generation
- World knowledge (175B Parameters can store 320GB, which is 15 Wikipedia’s)
- Emergence of major capabilities like in-context learning
- This leads to the rise of the early prompt engineers, like Gwern Branwern and Riley Goodside who explored creative single-shot prompts.
- Everything starts with the evolution and widespread availability of massive LLMs (via API or Open Source). The sheer size of these models finally allow for 3 major features:
- Capability 1: Metacognition (self improvement of pure reasoning)
- Kojima et al (2022) found that simply adding “let’s think step by step” to a prompt dramatically raised the performance of GPT3 on benchmarks, later found to be effective due to externalizing the working memory for harder tasks.
- Wei et al (2022) formalized the technique of Chain of Thought prompting that further improved benchmark performance.
- Wang et al (2022) found that taking a majority vote of multiple Chains of Thought worked even where regular CoT was found to be ineffective.
- More and more techniques like Calibrate Before Use, Self-Asking, Recursively Criticize and Improve, Automatic Prompt Engineering, appear.
- Capability 2: External Memory (reading from mostly static external data)
- The capability of in-context/few shot learning could be used to cheaply update a foundation model beyond its’ knowledge cutoff date and focus attention on domain specific, private data.
- (This should sound familiar, because we’ve implemented RAG to do just that!)
- The constraints of limited context length lead to the need for embedding, chunking and chaining frameworks like LangChain, and vector databases like Pinecone (now worth $700m), Weaviate ($200m), and Chroma ($75m).
- Another way of using natural language to access and answer questions form relational databases are the Text to SQL companies, which included Perplexity AI ($26m Series A), Seek AI ($7.5m Seed), and a long tail of other approaches including CensusGPT and OSS Insight.
- The capability of in-context/few shot learning could be used to cheaply update a foundation model beyond its’ knowledge cutoff date and focus attention on domain specific, private data.
- Capability 3: Browser Automation (sandboxed read-and-write in a browser)
- Sharif Shameem (listen to him on the pod) first demoed GPT-3 automating Chrome to buy Airpods in 2021.
- Adept raised a Series A with an all-star team of Transformer paper authors and launching the ACT-1 Action Transformer (now with a hefty $350m Series B despite the departure of Vaswani et al)
- Nat Friedman’s NatBot brought browser utomation back into the zeitgeist a year later, showing how an agent can make a restaurant reservation across google search and maps from a single natural language instruction.
- Capability 4: Tool making and Tool use (server-side, hooked up to everything)
- Search. Generated answers from memorized world knowledge, or retrieved and stuff into context from a database, will never be as up to date as just searching the web.
- Writing Code to be Run. We knew that GPT-3 could write code, but it took a certain kind of brave soul like Riley Goodside to ask it to generate code for known bad capabilities (like math) and to run the code that was generated. Replit turned out to be the perfect hosting platform for this style of capability augmentation (another example here). GPT-4 is strictly better at this, and this trend will only continue over time with fine-tunes for coding specific models such as Replit’s code completion model(blog, hugging face).
- ReAct. Yao et all (2022) coined the ReAct pattern which introduced a delightfully simple prompt template for enabling LLMs to make reliable tool choices for Reasoning + Acting given a set of tools.
- And while useful and worth noting, remember ReAct when compared to voyager for certain tasks such as exploration. Tools for the job.
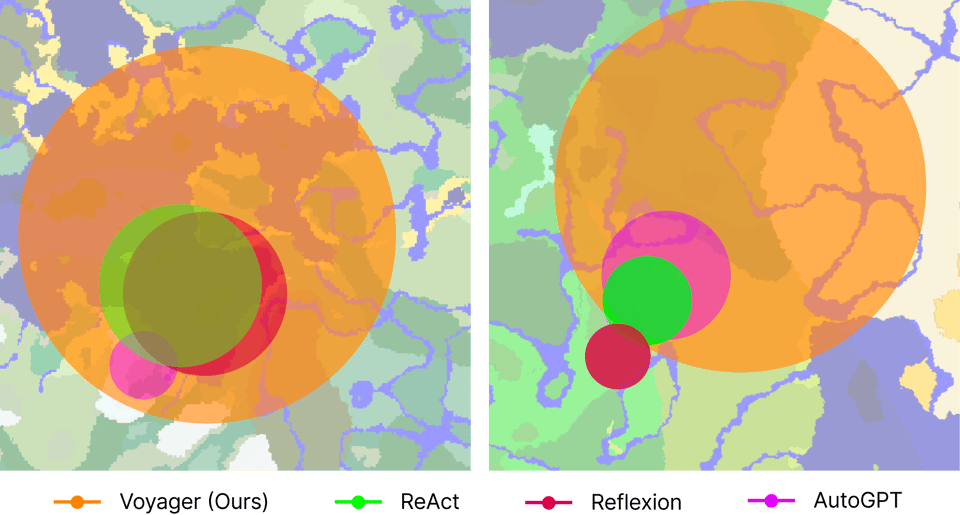
- And while useful and worth noting, remember ReAct when compared to voyager for certain tasks such as exploration. Tools for the job.
- Multi-model Approaches. Models calling other models with capabilities they don’t have. Think about STT combined with GPT4 to build products like AudioPen, or using Vision + TTS to narrate your life as it happens.
-
Self-Learning. Self-Learning Agent for Performing APIs (SLAPA) searches for API documentation to teach itself HOW to use tools, not just WHEN.
- Again, refer to how this is relevant with the voyager curriculum.
At this point it is worth calling out that we have pretty much reached the full vision laid out by this excellent post from John McDonnell from 2022.
- Capability 5: Planning, reflexion, and prioritization
- Shinn et al (2023) showed that Reflexion - an autonomous agent with dynamic memory and self-reflection, could dramatically improve on GPT-4 benchmarks.
- Shoggoth the Coder won the a ChatGPT Plugins (Now known as GPTs) Hackathon as an independent agent capable of proposing and submitting PR fixes to open source projects.
- Meta’s Simulacra paper showed the entertaining potential of autonomous NPC agents interacting with each other in a game-like setting.
- Regardless of use case, autonomous agents will be expected to plan further and further ahead, prioritizing task lists, reflecting on mistakes and keeping all relevant context in memory. The “Sparks of AGI” paper specifically called planning out as a notable weakness of GPT-4, meaning we will likely need further foundation model advancement before this is reliable.
- The LangChain Agents webinar discussion also highlighted the need for the ability to stack agents and coordinate between them.
And while the Anatomy of Autonomy is useful, this is a square peg trying to fit a round hole, as machines are decidedly Not Human. Swyx calls this abandonment of human anatomy analogies in favor of computing ones the Sour Lesson.
For those aforementioned computing analogies, Karpathy introduces the LLM OS, where you can take the more fleshed out concepts from above, and map them to this.

This diagram maps out a bit differently than the Anatomy of Autonomy, but there are the various higher-level concepts we’ve seen as a recurring theme such as:
- Stacking Multiple LLMs/agents
- Using external memory (embeddings)
- Various modalities
- Different tools - Browser - Calculator - Terminal - Code Interpreter
While all these architectures are high level concepts, it is important to reference these before we drop down several levels to start implementing things as these mental models are how experts begin to think about agents and the directions that they will go in over the coming years.
Ask yourself:
- What design spaces do each of these various analogies/architectures lend themselves to?
- What differences would agents built with these two system designs be?
And while this section is a background on agents, since we’ll be building one we need to get really clear one one particular question.
What IS an agent?
Defining an AI Agent
An agent, as defined by Lilian Weng:
Agent = LLM + Memory + Planning Skills + Tool Use

Photo From Lilian Weng’s blog: LLM Powered Autonomous Agents
This provides you the Minimum Viable Agent. Please note that for more popular agents that blew up last year such as AutoGPT, you may think an infinite loop is required to meet the agent status. This is purposefully missing from this definition we chose, as I don’t believe that’s a requisite. You’ll see all of the different models in a later section, but it’s worth addressing now.
This definition gets you 90% of the way there, and is where I believe the bar begins for agents; but there are still a few things missing here that are important to address:
- Context & Search (subtly different than memory)
- context = what you know (eg knowledge base, pdf, whatver)
- memory = what you’ve done (eg conversation history, action history, user preferences)
- search = what you don’t yet know but can find on the internet
- Skills Library (see Voyager above, again subtly different than tool use)
- Instead of giving predefined tools, can agent make its own tool and then use it going forward
- Nested agents (can agents call agents?)
- Multiple Systems of Agents
-
MetaGPT paper
- Code/Github
-
MetaGPT is a meta-programming framework that allows one to build multi-agent collaborations through an intertwining of efficient human workflows and encoded SOPs for LLMs to follow.
- These SOPs allow you to chain agents together without some of the classic issues like cascading hallucinations from a naively implemented chain of LLMS. SOPs require a structured output, allowing for clear separation between agents, and the jobs to do.
- It also provides clear starting and stopping points for a human to check in on the progress of the task.

Figure 1 from the MetaGPT paper
- MetaGPT implements a PubSub style architecture with a shared messaging pool, that utilizes the structured outputs from each agent, and allows agents to subscribe to what’s happening. Then they decide on whether or not it’s a relevant based on their profile. This allows the memory to stay fairly clean, as there aren’t long 1:1 threads where agents go back and forth on a topic and get stuck on a loop.

Figure 2 from the MetaGPT paper
-
- Similar to MetaGPT in that it’s a way to organize a multi-agent workflow. This is a higher-level implementation, as it has it’s own IDE/GUI that you can use to orchestrate the whole thing.
-
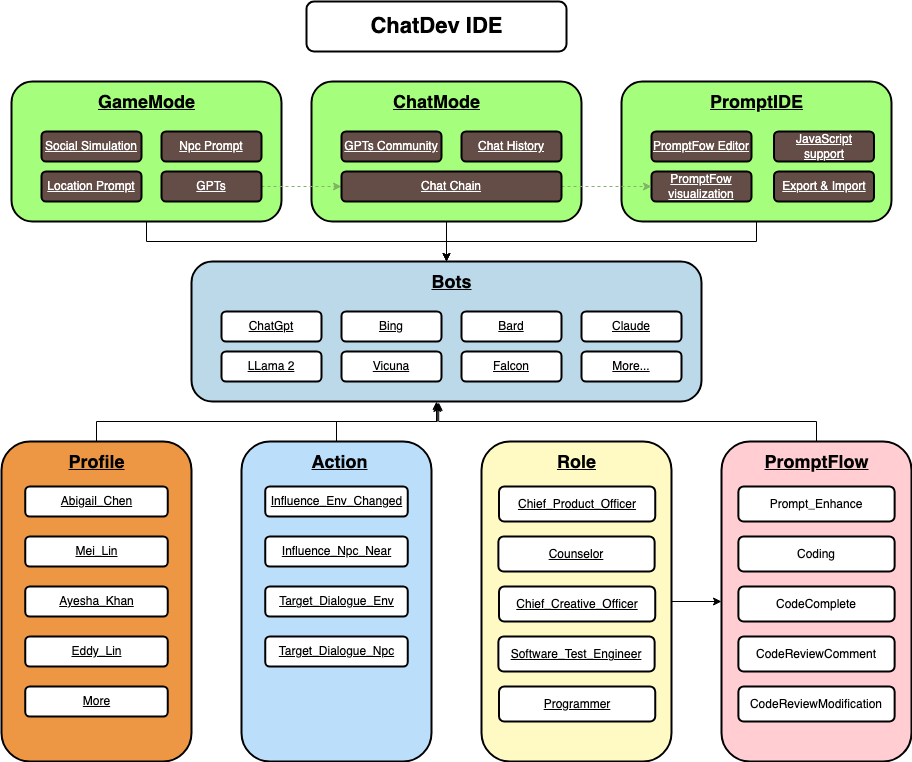
With all of these concepts tied together, we can define agents as LLMs that have various bolt-ons to enhance their capabilities such as:
- Memory = What you’ve done
- Planning Skill = What is the task at hand and how will you execute it
- Tool Use = Can I effectively use tools at my disposal
- Skills Library = Can I generate new tools, or combine tools for novel problems
- Context = What do you know (embeddings, pre-training, fine-tune, etc)
- Search = What you don’t know, but think you can figure out from internet (another tool)
- Recursive Agent Management (RAM) = Nested Agents
- Note Recursive Agent Management isn’t recognized lingo (yet!) let me know what you think of the term, feedback is always appreciated.
For all of these different capabilities that are being built out, there is also the idea of what level of automation you are going for. Most agents currently are synchronous, meaning you (the human) are involved actively in achieving the provided goal.
You can compare/contrast the levels of autonomy that have been around for a while, such as self driving:

And then you can look at the agents equivalent that’s provided in Codium’s ‘6 levels of autonomous unit testing’ post.
And with all of these various knobs to turn, and levels to measure, it’s important that agents are evaluated holistically and constantly.
Agent Benchmarks
With The definition of Agents firmly solidified, we can go on to the last stage before we implement our own, which is benchmarks.
Benchmarks are incredibly important in the space, but doubly so for agents. Since there are so many moving parts, it’s important to keep the end goal in mind, as tweaks in one area may make gains in one column, and regressions in another. Benchmarks are how you’ll keep the north star in mind when developing an agent.
- Mind2Web is a dataset for developing and evaluating generalist agents for the web that can follow language instructions to complete complex tasks on any website. Mind2Web contains 2,350 tasks from 137 websites spanning 31 domains that:
- Reflect diverse and practical use cases on the web.
- Provide challenging yet realistic environments with real-world websites.
- Test generalization ability across tasks and environments.
- CogEval for LLMs is a paper written by some Microsoft researchers that took a look at using CogEval for use in large language model testing/benchmarking. This benchmark is designed to:
- Evaluate a wide range of cognitive capabilities in LLMs, including memory, reasoning, and planning.
- Utilize cognitive science principles to create a systematic and comprehensive testing protocol.
- Provide a basis for comparing different models' performance on tasks that require higher-order cognitive functions.
- Highlight the strengths and weaknesses of current LLMs in understanding and generating human-like responses.
There are many different benchmarks and testing methods out there, and many are still being developed. With the space being so new, things are changing frequently. Keep up to date by following Open source AI agents, and seeing what tests and benchmarks they’re using.
Building Your Own Agent
For today’s code portion, we’ll be consolidating the functionality we’ve built so far into an AI agent by using OpenAI’s assistant API
OpenAI Assistants are in Beta, things are subject to rapid change. If you find something isn’t working, be sure to email us! We want to keep this up to date for you and future students.
I hope with the information about agents above, that you have the confidence and terminology to map how we can move our existing functionality into this agent model.
Breaking down our current app’s functionality we have augmented, or otherwise stitched together an AI app with the following:
- Retrieval Augmented Generation from MDN docs (Day 2)
- Transcription (Day 5)
- Image Generation (day 4)
- Code Generation (day 3, few shot prompting)
- Code Interpreter (day 3, function calling for math)
This will go off of the code we had for day 5. Since day 6 was Open Source Models, they aren’t compatible with the OpenAI’s Assistant API.
If you didn’t store your code in a way that’s easy to revert, the only changes you should need to make is changing your chat function to be this.
Don’t spend too much time here. This is just a reference, we’ll be moving to an entirely new architecture with the assistants api.
# Main.py
async def chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Append the user's message to the messages list
messages.append({"role": "user", "content": update.message.text})
# Generate an initial response using GPT-3.5 model
initial_response = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=messages,
functions=functions)
initial_response_message = initial_response.get('choices',
[{}])[0].get('message')
final_response = None
# Check if the initial response contains a function call
if initial_response_message and initial_response_message.get(
'function_call'):
# Extract the function name and arguments
name = initial_response_message['function_call']['name']
args = json.loads(initial_response_message['function_call']['arguments'])
# Run the corresponding function
function_response = run_function(name, args)
# if 'svg_to_png_bytes' function, send a photo and return as there's nothing else to do
if name == 'svg_to_png_bytes':
await context.bot.send_photo(chat_id=update.effective_chat.id,
photo=function_response)
return
# Generate the final response
final_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[
*messages,
initial_response_message,
{
"role": "function",
"name": initial_response_message['function_call']['name'],
"content": json.dumps(function_response),
},
],
)
final_answer = final_response['choices'][0]['message']['content']
# Send the final response if it exists
if (final_answer):
messages.append({"role": "assistant", "content": final_answer})
await context.bot.send_message(chat_id=update.effective_chat.id,
text=final_answer)
else:
# Send an error message if something went wrong
await context.bot.send_message(
chat_id=update.effective_chat.id,
text='something wrong happened, please try again')
else:
# If no function call, send the initial response
messages.append(initial_response_message)
await context.bot.send_message(chat_id=update.effective_chat.id,
text=initial_response_message["content"])
await context.bot.send_message(chat_id=update.effective_chat.id,
text="I'm a bot, please talk to me!")
# --- Old chat function (OSS version)
async def old_chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Add User Message
message_history.append({"isUser": True, "text": update.message.text})
prompt = generate_prompt(message_history)
prediction = client.predictions.create(version=version,
input={"prompt": prompt})
await context.bot.send_message(chat_id=update.effective_chat.id,
text=prediction.status)
prediction.wait()
await context.bot.send_message(chat_id=update.effective_chat.id,
text=prediction.status)
output = prediction.output
human_readable_output = ''.join(output).strip()
await context.bot.send_message(chat_id=update.effective_chat.id,
text=human_readable_output)
#Add AI Message
message_history.append({"isUser": False, "text": human_readable_output})
Step 0: Initialization
For this new iteration of our Telegram bot, we’ll be stuffing all of the functionality we have into the chat function. All of the users intent, whether they want to generate an image, do some math, or ask about files we have downloaded, will be intuited by the assistant.
To begin, lets create a new function called assistant_chat, which we’ll set up like our old chat function. It should have a function signature like this
async def assistant_chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
#This is where our business logic will go, just pass for now
pass
Set this up to the Message handler the same way you did for the original chat_handler function, and either delete or comment out the existing one. So now your bot code should look something like this
# main.py
application = ApplicationBuilder().token(tg_bot_token).build()
chat_handler = MessageHandler(filters.TEXT & (~filters.COMMAND), assistant_chat)
#.. other handlers
application.add_handler(chat_handler)
#.. other handlers
application.run_polling()
Now we can begin implementing our assistant. Before we start in the assistant_chat function, we need to do a bit of setup above. The same we we instantiated the openai client, we’re going to have to initialize an assistant for us to call. you should do this right under wherever you’ve already got the openai client.
It looks like this
# main.py
openai = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
assistant = openai.beta.assistants.create(
name="Telegram Bot",
instructions=CODE_PROMPT,
model="gpt-4-0125-preview",
)
This creates the assistant that we’ll be interfacing with in the function. We’ll be starting simple, but as we add additional functionality, we’ll return to this object in order to do that. Worth noting here the CODE_PROMPT that we established in our day of code generation can be plopped straight into here to keep our code generation in that css-in-js jsx flavoring.
The other thing we’ll need to create is a thread. Threads are the assistants version of the message history. OpenAI manages the message history, and truncating it for us with the assistants api. Less control, but more convenience.
So for each user, we want to immediately spin up a thread for them. This keeps things slightly more composable, as you can have many assistants with many threads, and interchange them since they’re standalone, 1st class citizens in the API.
To spin up a thread, you make this call
# main.py
THREAD = openai.beta.threads.create()
I would put this right under the assistant initialization.
All in all it should look like this
# main.py
openai = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
assistant = openai.beta.assistants.create(
name="Telegram Bot",
instructions=CODE_PROMPT,
model="gpt-4-0125-preview",
)
THREAD = openai.beta.threads.create()
With all of that out of the way, we can now start work on our function
Step 1: Implementation
To begin the chat history with the user, we’ll need to create a message and a run
Messages are the smaller units within a thread. So each time a user sends some text to our app, we’ll be wrapping their text in a message, and passing that to the thread. This alone doesn’t do anything. We need to start a run in order to actually get a response back from the model.
Again, the whole idea is to remain composable and asynchronous. You can start many runs all at the same time, all with the same thread of messages.
To create our message and runs, we’ll create them like this:
# main.py
async def assistant_chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
message = openai.beta.threads.messages.create(
thread_id=THREAD.id, role="user", content=update.message.text
)
run = openai.beta.threads.runs.create(
thread_id=THREAD.id, assistant_id=assistant.id
)
With this, we’ll have added the users message to our thread, and kicked off a run.
Since runs are async, we’ll have to poll them for their status. Assistants as of the time of writing do not support streaming, although it is on their roadmap.
This is quite different than the completions api, which starts responding immediately, and will stream back its response.
To create a polling mechanism, we’ll create a new function
# main.py
import time # add this at the top with the rest of your imports
def wait_on_run(run, thread):
while run.status in ("queued", "in_progress"):
print(run.status)
run = openai.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
time.sleep(0.5)
return run
This function will continously retrieve our current run’s status, and if it’s still “queued” or “in progress”, it will sleep for half a second, and then fetch the run’s status again. Once it’s either succeeded or failed, it will return the run back to us.
This will handle all we need for our basic implementation.
But there are many different statuses, which you can find listed on their docs here.
Moving back to our function, we’ll now call this to wait for our run to complete.
After it’s completed, we’ll extract the response, and send a message back to our user.
# main.py
async def assistant_chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
message = openai.beta.threads.messages.create(
thread_id=THREAD.id, role="user", content=update.message.text
)
run = openai.beta.threads.runs.create(
thread_id=THREAD.id, assistant_id=assistant.id
)
run = wait_on_run(run, THREAD)
# Grab all of our message history
messages = openai.beta.threads.messages.list(
thread_id=THREAD.id, order="asc", after=message.id
)
# Extract the message content
message_content = messages.data[0].content[0].text
await context.bot.send_message(
chat_id=update.effective_chat.id, text=message_content.value
)
So getting the response back is certainly more cumbersome than it was before.
- Several API calls, having to poll for the responses. And instead of our most recent result being last, it’s now first.
- This helps OpenAI since it’s going to continuously truncate the chat as the user continues talking, we we always want the most recent messages to be first.
This has now does exactly what we were doing before. We get a request from the user, and we send them a response from the LLM.
But assistants are a bit more powerful than what we had before. Let’s take a look
Step 2: Adding Code Interpreter & Retrieval
The telegram chat bot is cool and call, but let’s give it a bit more juice.
Go back to where we initialized it and add the following
# main.py
current_dir = os.path.dirname(os.path.abspath(__file__))
scraped_csv_path = os.path.join(current_dir, "processed", "scraped.csv")
mdn_scrape_file = openai.files.create(
file=open(scraped_csv_path, "rb"), purpose="assistants"
)
assistant = openai.beta.assistants.create(
name="Telegram Bot",
instructions=CODE_PROMPT,
tools=[
{"type": "code_interpreter"},
{"type": "retrieval"},
],
model="gpt-4-0125-preview",
file_ids=[
mdn_scrape_file.id,
],
)
With this, we’ve now added code interpreter, so our LLM can generate and run code, as well as RAG. We give our assistant the scraped.csv file with all of our MDN scrape in a structured format by using the openai.files.create method. From there, we add the tools and the file_ids that we need to get it going.
You don’t need to change anything else. If you restart the script, you should be able to get some answers the document, as well as getting it to generate code!
While RAG and code interpreter are quite cool, and it’s awesome to get it so easily, the real power comes from us being able to create our own functionality and plug it in.
Step 3: Adding Functions
Previously we had function calling with our chat completion. Let’s add it into our assistant.
We need to tweak the functions a bit however. Go over to your functions.py file and make the following adjustments
# Functions.py
functions = [
{
"name": "svg_to_png_bytes",
"description": "Generate a PNG from an SVG",
"parameters": {
"type": "object",
"properties": {
"svg_string": {
"type": "string",
"description": "A fully formed SVG element in the form of a string",
},
},
"required": ["svg_string"],
},
},
]
A few things here:
- we removed the previously needed
typeandfunctionkeys. That means we’re only left with the object that was withinfunctionthat we needed for chat completion are no longer needed. - We’ve also removed the
python_math_executionfunction, as it’s just a worse version of the code interpreter we just added, and the UX is cumbersome to get it to actually execute this function as the overlap was so significant.
To add this to our assistant, we’ll go back to where we instantiate it
# main.py
assistant = openai.beta.assistants.create(
name="Telegram Bot",
instructions=CODE_PROMPT,
tools=[
{"type": "code_interpreter"},
{"type": "retrieval"},
{"type": "function", "function": functions[0]}, # <-- This line here
],
model="gpt-4-0125-preview",
file_ids=[
mdn_scrape_file.id,
],
)
Now our assistant has the ability to interpret a message, and execute this function if the AI determines that the user would benefit from the output of this function.
But there’s some code to change here to handle this case
Currently the status that we’re polling successfully returns a response after a period of time. However, whenever it executes a function, it stops the run with a status of requires_action , along with the name of the function to execute, and the generated arguments.
Its up to us to actually execute the function with the generated arguments, and then pass back the response from that function, back into the run. it should look like this
graph LR
A(Run) --> B(Function Argument Generation)
B --> C(Actually Calling the Function)
C --> D(Plugging That Back Into Run)
For the telegram function, we’ll update our code accordingly:
# main.py
async def assistant_chat(update: Update, context: ContextTypes.DEFAULT_TYPE):
message = openai.beta.threads.messages.create(
thread_id=THREAD.id, role="user", content=update.message.text
)
run = openai.beta.threads.runs.create(
thread_id=THREAD.id, assistant_id=assistant.id
)
run = wait_on_run(run, THREAD)
# if we did a function call, run the function and update the thread's state
if run.status == "requires_action":
print(run.required_action.submit_tool_outputs.tool_calls)
tool_call = run.required_action.submit_tool_outputs.tool_calls[0]
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
response = run_function(name, args)
if name in ("svg_to_png_bytes"):
await context.bot.send_photo(
chat_id=update.effective_chat.id, photo=response
)
run = openai.beta.threads.runs.submit_tool_outputs(
thread_id=THREAD.id,
run_id=run.id,
tool_outputs=[
{"tool_call_id": tool_call.id, "output": json.dumps(str(response))}
],
)
run = wait_on_run(run, THREAD)
# Retrieve the message object
messages = openai.beta.threads.messages.list(
thread_id=THREAD.id, order="asc", after=message.id
)
# Extract the message content
message_content = messages.data[0].content[0].text
await context.bot.send_message(
chat_id=update.effective_chat.id, text=message_content.value
)
So here we wait on our run just as before. But we’ve added an if block that triggers upon the requires_action status.
- We pull the tool call object. In our case we know it’s the first item since we’re only calling 1 function. However multiple functions can be called at once, which you can see on this page of OAI docs.
- We pull the name, and arguments from the tool call object
- We use our previously defined
run_functionto invoke the function with the generated arguments - Then we pull out logic for different functions into matching if statements
1. in our case, we want to send a photo that we got back from the
svg_to_png_bytesfunction back to the user 2. In this case it’s just one, but we’ll add another one later! - After getting the response back from the function, we give it back to our existing
runobject, letting it know we want to get another response back from it, informed with the context of the tool call / response life cycle. - We then poll again, waiting for the final response to send to the user.
We’ve just augmented our capabilities again with this function call. If you compare it to our previous example, this is less code since we no longer have to keep track of the message history in addition to our function calling like we did in the previous iteration of our bot.
So now we have almost all of our slash command functionality — baked right into our chat.
But we still have the /image command handler.
Let’s convert that into a function!
Step 3.5: Image Function Calling
We can start by deleting all of code associated with the /image command currently.
- The
imagefunction - The image command handler
- Connecting the handler to the application
Then, we can open up our functions file again, and add an additional definition there.
# functions.py
functions = [
{
"name": "svg_to_png_bytes",
"description": "Generate a PNG from an SVG",
"parameters": {
"type": "object",
"properties": {
"svg_string": {
"type": "string",
"description": "A fully formed SVG element in the form of a string",
},
},
"required": ["svg_string"],
},
},
{
"name": "generate_image",
"description": "generate an image using the dalle api from a prompt",
"parameters": {
"type": "object",
"properties": {
"prompt": {
"type": "string",
"description": "an image generation prompt",
},
},
"required": ["prompt"],
},
},
]
We take the same approach as the previous function, as it has the same shape. It takes one parameter that is a string, and we want it to be a required.
Then we need to take the functionality that was in our image function and move it into here.
It’s the same function, so I won’t explain it again, we’re just moving it into another file.
# functions.py
from openai import OpenAI
openai = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
def generate_image(prompt: str):
response = openai.images.generate(
prompt=prompt, model="dall-e-3", n=1, size="1024x1024"
)
image_url = response.data[0].url
image_response = requests.get(image_url)
return image_response
And then the last bit we need to do in this file is add the ability to invoke this function from our run_function function.
# functions.py
def run_function(name: str, args: dict):
if name == "svg_to_png_bytes":
return svg_to_png_bytes(args["svg_string"])
if name == "generate_image":
return generate_image(args["prompt"])
return None
Remember we also want to get rid of all of the python_math_execution stuff.
Checkpoint
To quickly recap, your entire file should look like this now.
Okay, with all of that done, we can add this into our assistant.
That will consist of two portions
- Adding the function to our tools upon initialization
- Adding Logic to our chat function to handle that function call
Moving back over to main.py our new assistant should look like this
# main.py
assistant = openai.beta.assistants.create(
name="Telegram Bot",
instructions=CODE_PROMPT,
tools=[
{"type": "code_interpreter"},
{"type": "retrieval"},
{"type": "function", "function": functions[0]},
{"type": "function", "function": functions[1]}, # <---- new line
],
model="gpt-4-0125-preview",
file_ids=[
mdn_scrape_file.id,
],
)
And then for our logic, I want to show you how to gracefully exit out of a run without mucking up your state. So instead of passing the response back to our run after executing the function, we’re going to send the picture to the user, and then quit out.
Here’s how that looks like at a close look.
# main.py
if name in ("generate_image"):
run = openai.beta.threads.runs.cancel(thread_id=THREAD.id, run_id=run.id)
run = wait_on_run(run, THREAD)
await context.bot.send_photo(
chat_id=update.effective_chat.id, photo=response.content
)
return
So here, if we enter the generate_image clause of our function, the first thing we do is fire off a cancel request. Then we wait to hear back from it. And THEN we send the photo to the user, and exit out of the function.
Your first intuition may be to send the photo to the user as quickly as possible.
However, if you do that, the user is still locked out of sending new messages, as the run is still processing, and will cause unpredictable state for the user.
This way, as soon as the user sees an image, they are free to send another request.
That’s all for today on covering the assistant API!
Step 4: But what about voice?
However, we still have the transcription service that isn’t integrated.
It wasn’t a slash command, but we already have everything set up to take a piece of text from the user, and have a bunch of different functionality from just the one message.
So let’s have that message come from somebody’s voice instead of the keyboard!
This is the same logic we already have, so you can just update the whole transcribe_message function like so:
# main.py
async def transcribe_message(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Safety Check
voice_id = update.message.voice.file_id
if voice_id:
file = await context.bot.get_file(voice_id)
await file.download_to_drive(f"voice_note_{voice_id}.ogg")
await update.message.reply_text("Voice note downloaded, transcribing now")
audio_file = open(f"voice_note_{voice_id}.ogg", "rb")
transcript = openai.audio.transcriptions.create(
model="whisper-1", file=audio_file
)
message = openai.beta.threads.messages.create(
thread_id=THREAD.id, role="user", content=transcript.text
)
run = openai.beta.threads.runs.create(
thread_id=THREAD.id, assistant_id=assistant.id
)
await update.message.reply_text(
f"Transcript finished:\n {transcript.text}\n processing request"
)
run = wait_on_run(run, THREAD)
# if we did a function call, run the function and update the thread's state
if run.status == "requires_action":
print(run.required_action.submit_tool_outputs.tool_calls)
tool_call = run.required_action.submit_tool_outputs.tool_calls[0]
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
response = run_function(name, args)
if name in ("svg_to_png_bytes"):
await context.bot.send_photo(
chat_id=update.effective_chat.id, photo=response
)
if name in ("generate_image"):
await context.bot.send_photo(
chat_id=update.effective_chat.id, photo=response.content
)
run = openai.beta.threads.runs.cancel(
thread_id=THREAD.id, run_id=run.id
)
run = wait_on_run(run, THREAD)
return
run = openai.beta.threads.runs.submit_tool_outputs(
thread_id=THREAD.id,
run_id=run.id,
tool_outputs=[
{"tool_call_id": tool_call.id, "output": json.dumps(str(response))}
],
)
run = wait_on_run(run, THREAD)
# Retrieve the message object
messages = openai.beta.threads.messages.list(
thread_id=THREAD.id, order="asc", after=message.id
)
# Extract the message content
message_content = messages.data[0].content[0].text
await context.bot.send_message(
chat_id=update.effective_chat.id, text=message_content.value
)
Now if you spin up the bot, you can talk to it and ask it to generate images and things for you like so!

You can see, things are perfect. For example on the bottom request, it didn’t output my base64 encoded version. It did sometimes, but I didn’t want to cherrypick on the examples. This technology is still quite early, and we certainly aren’t anywhere near it’s final iteration.
Conclusion
That wraps up latent space university!
You went from potentially knowing nothing about AI, to building a fully functioning, multi-modal, AI agent!
While you certainly won’t have learned everything you need to know to be successful writing production software in the field, you now have a vocabulary to begin learning more complex topis on your own, coming up with your own ideas, and building out your own projects!
I hope this was useful to you, and I would love to hear as much from you!
Reply to the email sequences; those go straight to my inbox, or tag me on Twitter/X.
I always want to hear from you!