[AI For Engineers Beta] Day 5: Whisper (Audio)
Day 5 - Whisper (Audio)
Here's a quick demo of what we'll be building today!
Speech-to-text AI models, commonly called Automatic Speech Recognition (ASR) systems, serve as the bedrock of many modern applications such as:
- Voice assistants
- Transcriptions services
- Voice-controlled devices
- Alexa, Hey Google, Siri, etc
Once audio is converted to text, you can plug them straight into the rest of your text based LLM stack, as Text is the Universal Interface. (You can also think about the same for image-to-text, or consider the inverse with text-to-audio).
At their core, these models convert spoken language into written text by analyzing audio waveforms by:
-
Extracting features from the raw audio
-
transforms the complex waveforms into a more digestible format for the model.
-
The model we’re using, OpenAI’s Whisper-1 (both Whisper v2 and v3 are currently available in open source, but not in API), then employs the use of Transformers (previous ASR models used Recurrent Neural Networks— RNNs ) to decipher and transcribe the audio into the corresponding textual output.
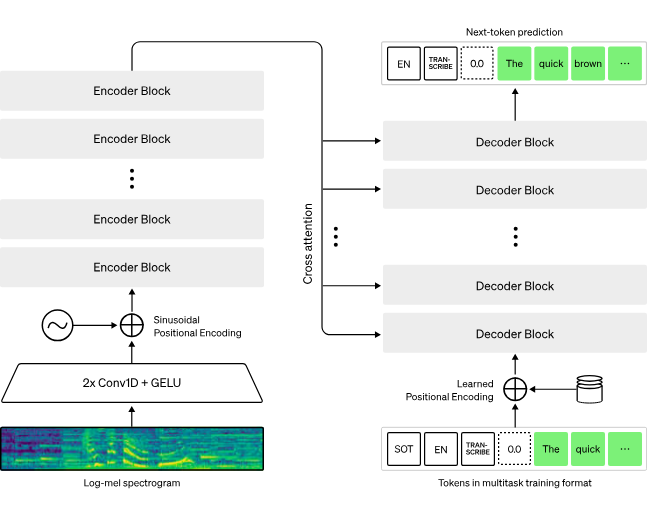
The accuracy of these models is enhanced through training on vast amounts of labeled audio data, enabling them to better understand diverse accents, languages, intonations, and even noisy backgrounds.

In terms of hardware, speech-to-text models and text-based Large Language Models (LLMs) like GPT-4 (rumored to be a mixture of 8 models each with 220B parameters) usually must be run on Nvidia H100 GPUs or TPUs for training. The specific requirements can differ based on the model's architecture and size. However, ASR models like OpenAI’s Whisper are small enough (ranging from tiny (39m) to large (1.6b) params) to be run on your own machine.
📖 Homework: — read the paper and/or watch the video from Yannic Kilcher
Exploring the ASR Landscape
Familiarize yourself with the many options for running the Whisper models - this is our first tentative step into running models rather than calling APIs, which we’ll increasingly ramp up in future steps.
HuggingFace Spaces with Whisper: If you're dipping your toes in the text-to-speech waters for the first time, you might want to start with Whisper on HuggingFace Spaces. It offers a nice platform to just try out the capabilities of Whisper with zero setup.
Whisper Model from OpenAI: Taking a step further, the full-fledged Whisper from OpenAI can be a bit of a rabbit hole. If you've ever run it, you'd probably know the nuances - it's relatively slower and a bit cumbersome to use. Not the greatest experience out there.
At OpenAI Devday they announced Whisper3, but it isn't supported by their own API yet.
Whisper API from OpenAI: We’ll be using this in the code portion today. Since we already have our key configured, it will be very easy for us to integrate this into our current codebase. It does well with performance and accuracy. But worth noting that if you were running a production project, you would probably want to explore one of the self-hosted options such as whisper.cpp.
Whisper.cpp: This is pretty much a straight upgrade for the average consumer of an ASR. This is because it’s a CPU-optimized version of the Whisper model, rewritten in C++. A good piece of homework would be to call out to a whisper.cpp model running on your machine instead of the OpenAI API that we’re going to use in the tutorial portion.
WhisperX with Diarization: Diarization is the practice of distinguishing speakers in an audio file. This capability takes transcription to a new level. With improved timestamps and speaker identification, WhisperX showcases breakthrough capabilities. You can checkout the repo to see how to run it if you’re inclined to try it out. For the Latent Space Pod transcripts, we use thomasmol/whisper-diarization hosted by Replicate.
Distil-Whisper and Insanely-Fast-Whisper: HuggingFace distilled a smaller version of Whisper that runs at a much higher speed for a small but acceptable loss in quality. Insanely-Fast-Whisper is the CLI for Distil-Whisper that also supports Diarization. You can checkout the deep dive in this video.
A Few More Tools Worth Exploring:
-
MacWhisper: A polished tool that streamlines the transcription process. More details can be found here.
-
Text to Speech Options:
- OpenAI: OpenAI announced at their dev day that they now offer TTS support via their audio API. It is much cheaper than the paid options below as of this writing.
- Eleven Labs: Offering a blend of quality and performance. (We have a podcast with Wondercraft.ai exploring AI podcasting!)
- play.ht: A simple yet efficient text-to-speech platform - Eleven Labs' main competitor.
- Tortoise-tts: The leading open source alternative.
This field moves all the time - Meta recently released the AudioBox model which is capable of generating both voice and sounds much faster than traditional models because of a diffusion process.
📖 Homework: — Try to add text-to-speech on top of the code after you’re done today
The Perennial Question: With the array of models available, how do you decide which one to use? If you're looking for a sweet spot between performance and accuracy, the Whisper.cpp small model is the standout in the category. For a more detailed analysis, you can check out this comparison article.

While Whisper.cpp and WhisperX are currently hailed as the SOTA models, it's a rewarding experience to explore various tools in this domain. You can also check HuggingFace Leaderboards for alternative models like AssemblyAI’s Conformer-1.
With all of that context out of the way, let's write up the code to unlock speech-to-text in the Telegram bot.
Getting Hands On
We will leverage Whisper to take the user’s speech, recorded via telegram, and send them back a transcription of what they said.
Fortunately for us we already have all of the tools we need already installed. This only requires the OpenAI/Telegram Bot APIs. In your main.py file, add another function called transcribe_message.
This is where we will put all of the logic of:
-
downloading the voice file
-
passing it to the Whisper model
-
returning the text transcription back to the user
# main.py
async def transcribe_message(update: Update, context: ContextTypes.DEFAULT_TYPE):
# Make sure we have a voice file to transcribe
voice_id = update.message.voice.file_id
if voice_id:
file = await context.bot.get_file(voice_id)
await file.download_to_drive(f"voice_note_{voice_id}.ogg")
await update.message.reply_text("Voice note downloaded, transcribing now")
audio_file = open(f"voice_note_{voice_id}.ogg", "rb")
transcript = openai.audio.transcriptions.create(
model="whisper-1", file=audio_file
)
await update.message.reply_text(
f"Transcript finished:\n {transcript.text}"
)
1. Get Voice File ID:
voice_id = update.message.voice.file_id
- This extracts the file ID of the voice message from the incoming update. If there's no voice message,
voice_idwill beNone.
2. Check if Voice ID Exists:
if voice_id:
- This conditional ensures the subsequent code only runs if there's a voice message in the update.
3. Get and Download Voice File:
file = await context.bot.get_file(voice_id)
await file.download_to_drive(f"voice_note_{voice_id}.ogg")
- The bot fetches the voice file from the messaging platform using the provided voice ID.
- The voice note is then downloaded and saved with a filename formatted as
voice_note_[VOICE_ID].ogg.
4. Send a Message:
await update.message.reply_text("Voice note downloaded, transcribing now")
- Sends a reply to the original message saying the voice note has been downloaded and the transcription process will begin.
5. Open Audio File and Transcribe:
audio_file = open(f"voice_note_{voice_id}.ogg", "rb")
transcript = openai.audio.transcriptions.create(
model="whisper-1", file=audio_file
)
- Opens the downloaded audio file in binary read mode.
- Uses
openai.audtio.transcriptions.create, to transcribe the audio. The first argument "whisper-1" defines the model to use. Currently “whisper-1” is the only model available to use for this API.
6. Send Transcription:
await update.message.reply_text( f"Transcript finished:\n {transcript.text}")
- Sends a reply to the original message with the transcribed text.
With that function written, we can now follow the established pattern of creating a handler, and then passing that handler to our bot. Edit your handler logic to add these two lines of code
# main.py
# This handler will be triggered for voice messages
voice_handler = MessageHandler(filters.VOICE, transcribe_message)
application.add_handler(voice_handler)
All-in-all, your entire code block should look like this on the bottom:
# main.py
if __name__ == '__main__':
application = ApplicationBuilder().token(tg_bot_token).build()
start_handler = CommandHandler('start', start)
mozilla_handler = CommandHandler('mozilla', mozilla)
image_handler = CommandHandler('image', image)
chat_handler = MessageHandler(filters.TEXT & (~filters.COMMAND), chat)
# This handler will be triggered for voice messages
voice_handler = MessageHandler(filters.VOICE, transcribe_message) # <--- New line
application.add_handler(chat_handler)
application.add_handler(voice_handler) # <--- New line
application.add_handler(image_handler)
application.add_handler(mozilla_handler)
application.add_handler(start_handler)
application.run_polling()
With all of that code written, you can now record audio and get the transcription back, just like in demo video at the beginning!
Stretch Goals
For fun, you can keep your ASR running in an infinite loop as an always-on voice assistant
Conclusion
The realm of Automatic Speech Recognition (ASR) has grown exponentially, paving the way for advanced and efficient transcription tools. With models like Whisper, the process of converting spoken language into written text has been refined, resulting in a more accurate and adaptable system.
As developers, this allows us to tap into a wide range of tools, from basic implementations on HuggingFace Spaces to more intricate solutions like WhisperX with Diarization.
You’ve seen firsthand how easy it can be to add a SOTA transcription service to your already-existing app. Making something that used to be an entire service a simple tack-on feature.
While we have delved deep into the current state-of-the-art models and tools in the ASR domain, it's worth noting that things are moving quickly. As we stand on the cusp of further advancements, it's crucial for us to remain curious, experiment with available tools, and anticipate the next leap in ASR technology if we’re to stay ahead of the curve.
Tease for day 6
With Whisper we have taken our first step into the wild and complex ecosystem of self-hosting and locally running models. This is primarily important for data security/privacy, increased control, circumventing OpenAI/Anthropic censorship, and lower per-token cost (though not necessarily total cost of ownership).
There is a wild mass of options here - can you write up a list of the most important factors to consider when hosting/running OSS models?
We’ll provide our list tomorrow, and you can check if your intuition is correct.