[AI For Engineers Beta] Day 4: Image generation
Latent Space University: Day 4 - Image Generation
Welcome back to Latent Space University! Today, we will delve deep into the fascinating world of image generation and learn how to leverage the DALL-E API to generate images from user prompts. 
Business Case for Images
Image generation AI has progressed exponentially in the last 10 years:

And has become one of the earliest clearly monetizable usecases in the current AI summer:
- Lensa making $1m/day selling Dreamboothed personal avatars
- Pieter Levels making $1m in 10 months with PhotoAI/InteriorAI/AvatarAI
- RoomGPT getting 2m users in 6 months (it’s open source!)
- Midjourney bootstrapping between 33M-300M in revenue with just 11 full time staff - Largest discord server at over 15M people!
- Playground.ai raising $40m and Pika Labs raising a $55m Series A. Look for upcoming Latent Space episode!
Why Pay for It?
The difference between a hobby and a paid product often boils down to personalization. People want to visualize their ideas and see themselves in the products they use, without having the skills or resources to make it themselves. This desire for personalization has fueled the success of companies like Midjourney, Lexica, PhotoAI, and PlaygroundAI.
Dall-E
OpenAI led the way in the modern image generation era with DALL·E 1 and 2 in 2021-22, impressing people with the iconic avocado chair:

and it is available as an API if you’re all-in on the OpenAI stack. However there is much more competition to OpenAI in the images domain compared to text, as we’ll cover below.
Midjourney
While Midjourney does not have an API (there is an open source clone), it is by far the most advanced and successful platform in this space. Midjourney v5 was responsible for the viral Balenciaga Pope image in March 2023.

To get started with Midjourney, you must know how to prompt effectively. You can find a thread on prompting here, and explore their Discord or Subreddit. Some things are outdated, specific to Midjourney, but the fundamentals are there and still true.
FYI: Midjourney is exceptionally good at designing apps. In the future, we can imagine simply paste in Midjourney designs into multimodal GPT-4, and it will generate code for us.
Stable Diffusion
💡 All Images generated with the prompt:
portrait photo of an armored demonic undead deer with antlers, in a magical forest looking at the cameraWhich is a prompt used in this paper. Try to mix and match more prompts here.
OpenAI’s closed source DallE led to Big Sleep led to BigGAN led to VQGan led to Latent Diffusion led to Stable Diffusion, the current best open source text-to-image model that celebrated its one year anniversary in August.
While you can run Stable Diffusion by yourself, you can start by using a platform such as


You should also spend at least 15 minutes going through Lexica, one of the earliest Stable-Diffusion-based Image AI startups.
- You get to see the images you like first and then the prompts used to generate them.
- Also hear from the founder Sharif Shameem on the Latent Space pod!
Then there are UI’s out there to help you extend your Stable Diffusion experience that can be run on your machine:
💡 Note that Stable Diffusion runs without a UI, but the number of flags and options and complexity of prompts (take note of prompt weights and negative prompting) and image editing workflow options has made the UI’s a very useful if overwhelming part of the overall Stable Diffusion experience. (FYI: there is also a similar effort for the open source text models, called oobabooga)
We really do strongly recommend that you try to run Stable Diffusion on your own laptop, even if we don’t recommend that for serious usage. This is for most people the first SOTA (State Of The Art) model that they will run locally, and we’ll ramp this up in future days.
Then you can run it on someone else's machine (there are LOTS of options here):
Train Your Face/Dog/Whatever on Stable Diffusion
You can personalize your images using various techniques (listed in chronological order):
- Textual Inversion - popular in early 2022, tutorial here
- Dreambooth - featured in the viral Corridor Crew video
- ControlNet - popular in early 2023 - enabled RoomGPT to stand out from InteriorAI - You can find logos created using ControlNet here.
- install LORAs: current hotness - Low Rank Adaptations/Finetunes of Stable Diffusion - Finetunes are very powerful for improving Stable Diffusion - civit-ai is the go to for exploring them, automatic1111 helps you install them. - ⚠️ Potential NSFW. Their filters are quite good, but occasionally, something slips through; you’ve been warned.
HOMEWORK: Try ControlNet QR Code Generation
- Inspo as to why you might want to do that (speaking of business value being tied to personalization?)
- Tutorial for how to do it. There are standalone apps for this now, but you knowing how to make your own exposes you to a lot of the nuances of image generation.
Known Hard Problems in Images
When Stable Diffusion first came out, it was easy to be impressed by the sheer amount of image generation capability contained in its 4.2GB of model weights (smaller if you quantize them). As you gain experience generating images, you should get a feel for what it is not yet good at:
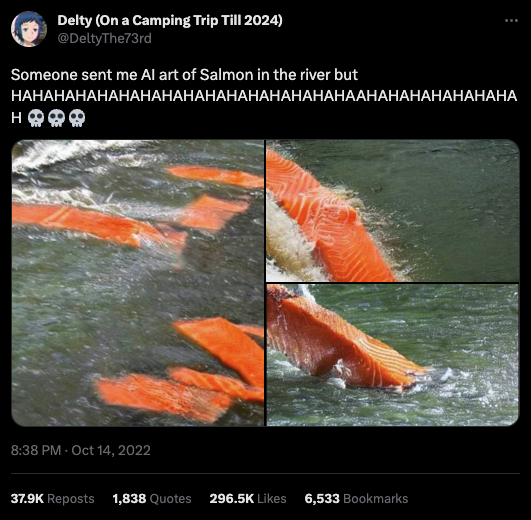
- Hands: the Diffusion process doesn’t yet have strong control of countable things. This leads to some fairly cursed hands (click for nightmare fuel)
- Composition: is AGI-hard.
- Text on Images
- DeepFloyd is an Stability.ai affiliated project, another text-to-image generation model like Stable Diffusion, but with some core differences in how the model works when compared to latent diffusion models such as Stable Diffusion. You can see some of the wonderful text-on-images on their Twitter and try it from Huggingface.

Getting Hands On
Integrate with Telegram to Generate Pictures for You
I think all of the above should be a nice primer for you to see where the space is currently. We will use the OpenAI DALL-E API for this project since we already have the OpenAI key configured.
This will be fairly straightforward, as we’ll add just one command to the telegram bot. A /image command that will include a prompt. For this, we do need to install an additional package. The requests package.
Run the following command:
poetry add requests
Add the code below to the top of your file alongside the other imports.
# main.py
import requests
Then, by the rest of the functions, such as mozilla, start, and chat, define another function called image.
It should look like this:
# main.py
async def image(update: Update, context: ContextTypes.DEFAULT_TYPE):
response = openai.images.generate(prompt=update.message.text,
model="dall-e-3",
n=1,
size="1024x1024")
image_url = response.data[0].url
image_response = requests.get(image_url)
await context.bot.send_photo(chat_id=update.effective_chat.id,
photo=image_response.content)
This will take the user's message, pass it to the openAI image endpoint, and you’ll get back a response that contains a URL of the image.
We then fetch the contents of that URL with the requests.get function.
After getting the response back, we pass the image_response.content to the photo parameter in the send_photo function.
Now, all that’s left to do is hook up this function to the bot like we have with all the others.
if __name__ == '__main__':
application = ApplicationBuilder().token(tg_bot_token).build()
start_handler = CommandHandler('start', start)
mozilla_handler = CommandHandler('mozilla', mozilla)
image_handler = CommandHandler('image', image) # <--- THIS IS NEW
chat_handler = MessageHandler(filters.TEXT & (~filters.COMMAND), chat)
application.add_handler(chat_handler)
application.add_handler(image_handler) # <--- THIS IS NEW
application.add_handler(mozilla_handler)
application.add_handler(start_handler)
application.run_polling()
This should be a familiar pattern at this point, so I won’t go into more detail. That’s all the code you need to boot up the bot and start slinging images! 
This was a pretty straightforward integration since we already had all of the tools in place that we needed to execute this. But as some bonuses, you could try the following to really stretch your knowledge.
Challenge
-
Use a stable diffusion API (e.g., replicate) for more customization. You have three choices:
1. SD 1.5 2. SD2 3. SDXL.
It can be a fun rabbit hole to figure out the differences!
-
Instead of using
/imageas we’ve done, use the OpenAI function call that we learned yesterday to generate images when the user intent is asking for an image rather than directly invoking the image endpoint.
Bonus: Image to Text
Try OpenAI's CLIP here and BLIP and BLIP2 here. You can also try Roboflow for more vision models, including OCR (optical character recognition, e.g., handwriting to text) and image segmentation (e.g., understand the difference between bounding boxes and image masks - see our episode on SAM). Also understand what’s coming with GPT-4 Vision.
Follow up from Yesterday's Tease
You may have noticed that latency is generally worse on these text-to-image models. They aren’t as quick as the text-based models.
We are mostly using Diffusion here, which is not the typical transformers architecture - instead of going token-by-token, the entire image has to be drafted from white noise over dozens of runs. Diffusion is quite far off the evolutionary tree from the GPT-3 like models: 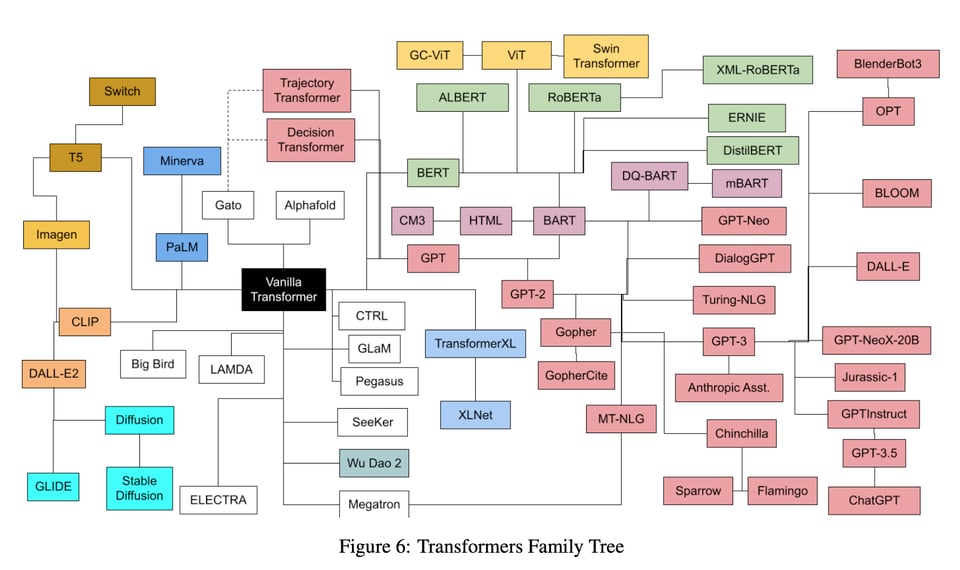
While there are efforts to unify these (see Google MUSE), they aren’t generally available yet.
Tease for Tomorrow
We have now gone multimodal beyond text. Images are great for visuals, but as you can tell, there is much room left to improve for perfect visual understanding.
We might be better at speech-to-text — which is next!
That's it for today! We hope you found this tutorial helpful and are excited to dive into the world of image generation. Remember to practice, experiment, and have fun! Check y’all tomorrow.
Additional Reading
- Multimodal GPT4
- Here’s a nice webby-version of the GPT-4 paper https://openai.com/research/gpt-4 - Here’s the raw pdf of the original paper https://cdn.openai.com/papers/gpt-4.pdf - And here’s a 12 minute video breaking it down if you’d prefer that https://www.youtube.com/watch?v=Mqg3aTGNxZ0
Here’s a quick 10-year look back on the state of multi-modal AI and how far we’ve come.
- 2012 http://karpathy.github.io/2012/10/22/state-of-computer-vision/
- 2022
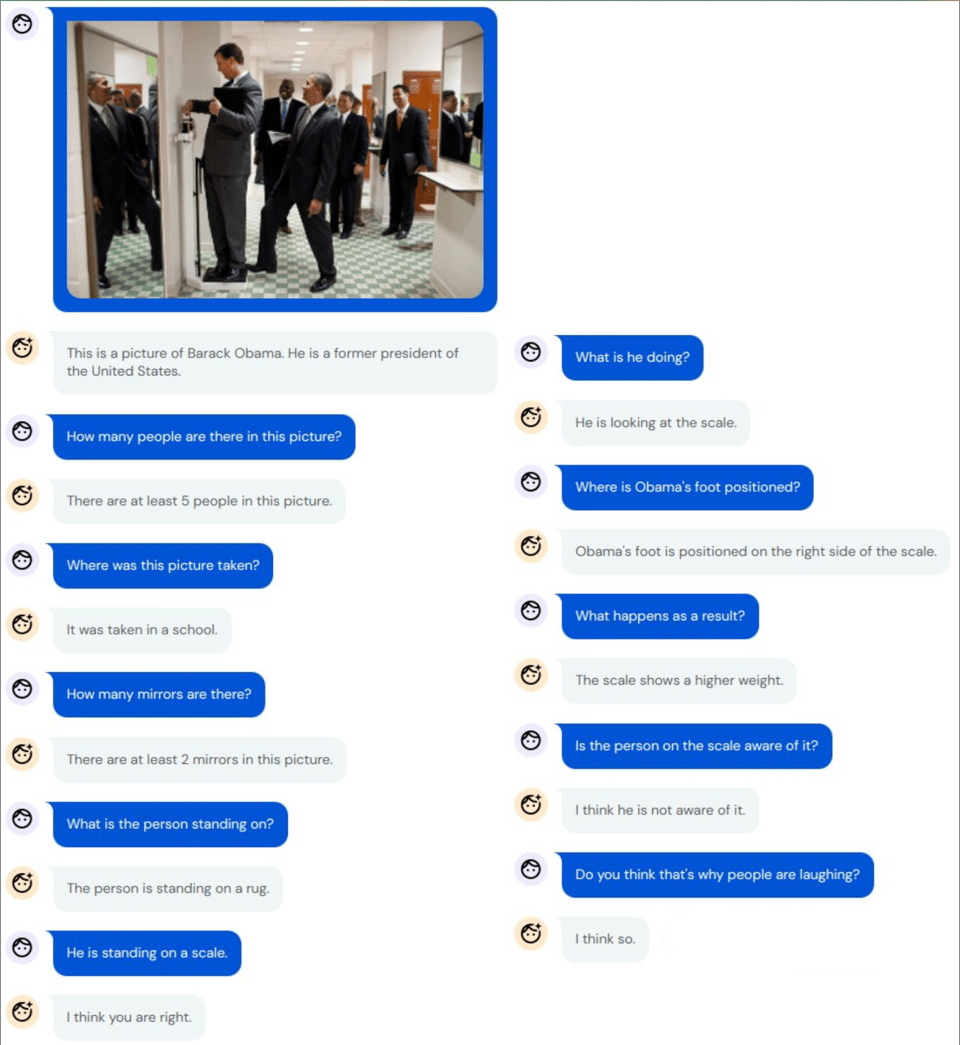
- 2023

- OCR of discord - You get glimpses of what the future of app design/development can look like.