|
|
MODEL
MAJOR
2026-05-18
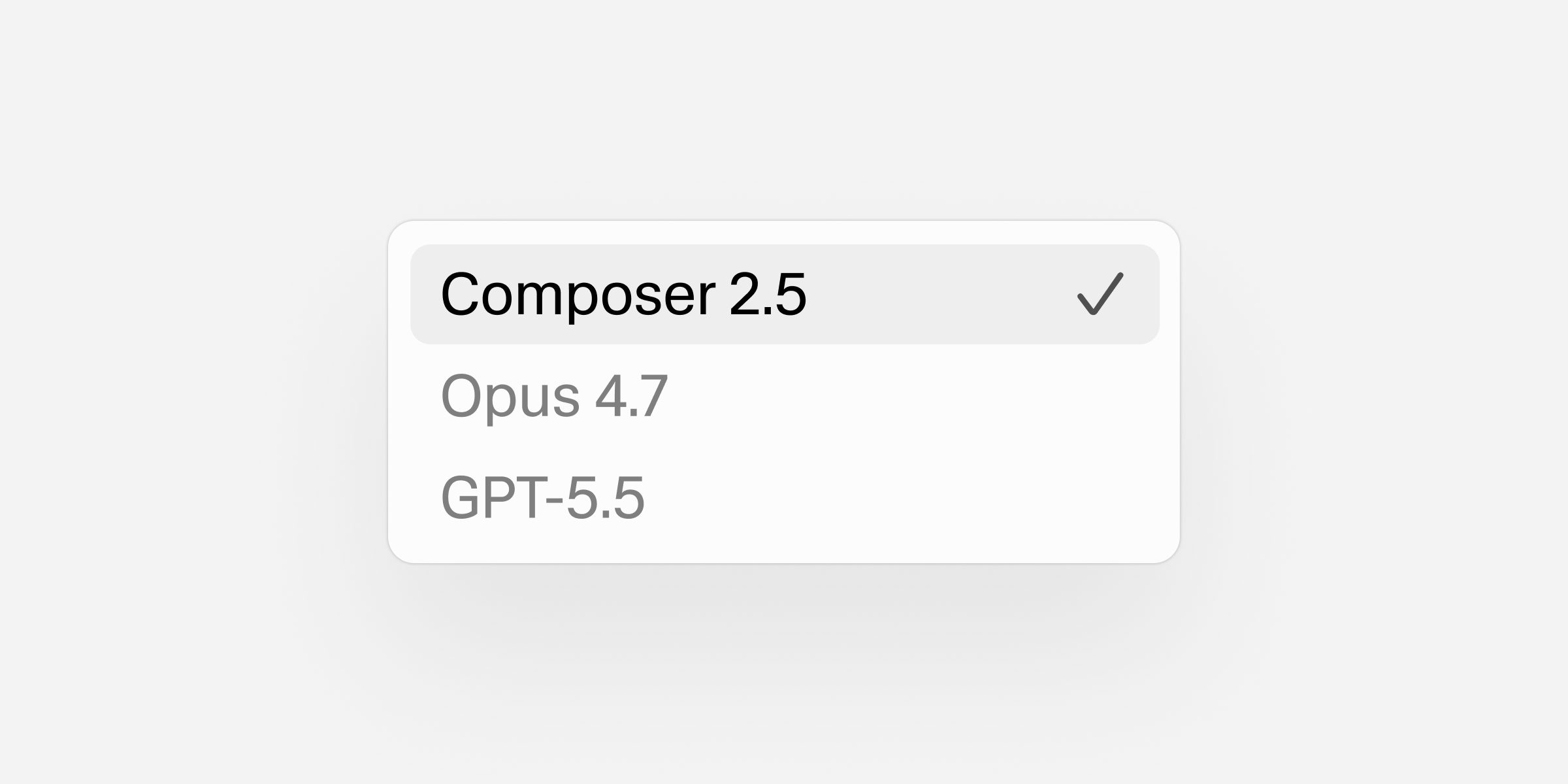
Cursor Composer 2.5 — Coding Model Matches Opus 4.7 and GPT-5.5 on SWE-Bench at a Fraction of the Cost
Cursor's in-house coding model now matches frontier models on coding benchmarks at a fraction of the price.
What is it?
Composer 2.5 is the latest version of Cursor's own coding model, built into the Cursor editor. It is tuned for sustained work on long-running tasks and for following complex instructions, and replaces Composer 2 as Cursor's default agent model.
How does it work?
It is built on Moonshot's open-source Kimi K2.5 checkpoint, with 85% of the compute budget spent on additional training and reinforcement learning. Cursor trained it on 25x more synthetic tasks than Composer 2, using targeted textual feedback inserted at the exact point in a trajectory where the model went wrong.
Why does it matter?
On SWE-Bench Multilingual (79.8%) and CursorBench v3.1 (63.2%), Composer 2.5 matches Opus 4.7 and GPT-5.5 while charging $0.50/$2.50 per million input/output tokens — well below what Anthropic and OpenAI charge. Cursor says a typical task runs under a dollar versus up to eleven for rival models.
Who is it for?
Developers using Cursor who want frontier-level coding performance without paying frontier-level API prices.
|
|

|
|
ECOSYSTEM
MAJOR
2026-05-18
Jury Throws Out Elon Musk's Lawsuit Against OpenAI and Sam Altman — Unanimous Verdict Finds Claims Filed Too Late
A federal jury unanimously dismissed Elon Musk's long-running lawsuit over OpenAI's for-profit conversion.
What is it?
Elon Musk sued OpenAI, Sam Altman, and Greg Brockman in 2024, claiming they "stole a charity" by restructuring the nonprofit AI lab into one with a for-profit arm. He sought to unwind the conversion and remove Altman from leadership.
How does it work?
A nine-member advisory jury deliberated for under two hours and found Musk filed too late — he had three years to sue and was aware of the conduct as early as 2021. Judge Yvonne Gonzalez Rogers agreed and dismissed the case on statute-of-limitations grounds.
Why does it matter?
The verdict clears a major legal cloud over OpenAI's restructuring, removing a threat that could have unwound its for-profit arm and forced out its CEO. Musk's lead attorney said the team will appeal, so the dispute is not fully settled.
Who is it for?
Anyone tracking OpenAI's corporate structure, its planned IPO, or the broader governance debate around AI labs.
|
|

|
|
SECURITY
MAJOR
2026-05-18
Cloudflare Publishes Project Glasswing Findings — Anthropic's Mythos Preview Chained Exploits Across 50+ Repos but Needed a Seven-Stage Harness
Cloudflare shares hands-on results from using Anthropic's Mythos Preview to hunt vulnerabilities in its own code.
What is it?
Cloudflare is a partner in Project Glasswing, Anthropic's program giving select companies access to Claude Mythos Preview — an unreleased frontier model strong at finding and weaponizing software vulnerabilities. This post reports what Cloudflare learned scanning more than 50 of its own repositories.
How does it work?
Mythos Preview excels at exploit-chain construction, combining several bugs into a working proof-of-concept by iteratively writing, compiling, and testing exploit code. But it gave inconsistent safety refusals and produced more false positives in C/C++, so Cloudflare built a seven-stage pipeline: Recon, parallel-agent Hunt, adversarial Validate, Gapfill, Dedupe, Trace, and Report.
Why does it matter?
It is one of the first detailed outside accounts of running a Mythos-class model against real production code, and it gives security teams a concrete orchestration blueprint — showing that a single agent is not enough to keep signal-to-noise usable at scale.
Who is it for?
Security engineers and vulnerability researchers exploring how to operationalize AI-assisted exploit research in production environments.
|
|

|
|
REPO
MAJOR
2026-05-17
Semble — Code Search for AI Agents Uses ~98% Fewer Tokens Than grep+read, Hits the Hacker News Front Page
A CPU-only code-search MCP server that cuts the tokens an agent burns hunting through a repo.
What is it?
Semble is an open-source code-search library built for AI coding agents. Instead of an agent running grep and reading whole files into its context window, Semble returns only the specific snippets that match a query. It runs as an MCP server, so Claude Code, Cursor, and other MCP clients can call it directly.
How does it work?
It combines semantic search using Model2Vec static embeddings with BM25 lexical matching for identifiers and API names. Results are merged with Reciprocal Rank Fusion and re-ranked with code-aware signals. Everything runs on CPU with no API keys, GPU, or external services.
Why does it matter?
The project reports indexing a repo in about 250ms and answering queries in about 1.5ms on CPU while using roughly 98% fewer tokens than a grep-and-read loop — leaving more of an agent's context window for actual reasoning. It reached 2.3K GitHub stars and 417 points on Hacker News.
Who is it for?
Developers building or running coding agents who want to reduce token costs and context bloat during large-codebase exploration.
|
|

|
|
PAPER
NOTABLE
2026-05-18
LongLive-2.0 — NVIDIA's NVFP4 Parallel Infrastructure Generates Minute-Long Interactive Video at 45.7 FPS
A 4-bit training and inference stack that makes minute-long interactive video generation fast enough for real time.
What is it?
LongLive-2.0 is an infrastructure update to NVIDIA's LongLive project for generating long, multi-shot, interactive videos. It targets the speed and memory bottlenecks that appear as generated videos get longer, and ships code, models, and demos under Apache 2.0.
How does it work?
Training uses Balanced SP, a sequence-parallel autoregressive scheme combined with NVFP4 4-bit precision to cut memory and speed up matrix multiplies. Inference on Blackwell GPUs uses W4A4 NVFP4 compute, an NVFP4-quantized KV cache, and asynchronous streaming VAE decoding.
Why does it matter?
The LongLive-2.0-5B model hits 45.7 FPS with 2.15x faster training and 1.84x faster inference — fast enough for real-time, interactive long-video generation, at a scale previously requiring much larger industrial systems.
Who is it for?
Video-generation researchers and teams building interactive or embodied-AI systems who need efficient long-video generation at production speed.
|
|

|
|
ARTICLE
NOTABLE
2026-05-19
Simon Willison — The Last Six Months in LLMs, in Five Minutes
A five-minute tour of what changed in large language models between late 2025 and May 2026.
What is it?
A written version of Simon Willison's lightning talk at PyCon US 2026. Willison is the creator of Datasette and the LLM CLI and writes one of the most-followed running commentaries on LLM developments.
How does it work?
The post walks through three themes: multiple frontier labs (Anthropic, OpenAI, Google) alternating at the top, coding agents maturing from unreliable to daily-driver tools via reinforcement learning, and open-weight models like Gemma 4 and Qwen becoming strong enough to run on consumer laptops.
Why does it matter?
It is a fast, opinionated catch-up from a source known for verifying claims and avoiding hype — useful for anyone who needs a concise briefing on where the field stands today without wading through six months of announcement posts.
Who is it for?
Developers and practitioners who want a quick, trustworthy summary of LLM progress without the marketing spin.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|