
|
|
ECOSYSTEM
MAJOR
2026-05-14
Anthropic Puts the Claude Agent SDK on a Separate Monthly Credit Pool — $20 for Pro, $100 for Max 5x, $200 for Max 20x, Starting June 15
Programmatic Claude usage moves to its own monthly credit pool on June 15, sized to the subscription price and billed at API rates.
What is it?
Anthropic is separating chat-driven Claude usage from programmatic usage on every paid subscription tier. Each plan gets a dedicated Agent SDK credit that refreshes monthly, sized roughly to the subscription's monthly price, and burned down at standard Claude API token rates.
How does it work?
The credit covers Claude Agent SDK usage in Python or TypeScript, the headless claude -p command, Claude Code GitHub Actions, and third-party apps that authenticate through the Agent SDK. Unused credit does not roll over; overflow lands on extra-usage rates rather than the interactive subscription bucket.
Why does it matter?
It re-legitimises third-party agent frameworks like OpenClaw on Claude subscriptions after April's lockout — but at API economics. Power users are noting that $20 of API tokens does not last a day of serious agent work. Sam Altman responded the same day with two months of free Codex for businesses willing to switch.
Who is it for?
Anyone running Claude Code at scale, Agent SDK apps, or third-party agent frameworks on a paid Claude plan.
|
|

|
|
ECOSYSTEM
MAJOR
2026-05-14
OpenAI Hires Outside Counsel to Mull Breach-of-Contract Action Against Apple — ChatGPT-Siri Deal Frays Over 'Buried' Integration
OpenAI quietly retained outside counsel to weigh a breach-of-contract claim against Apple over the long-strained ChatGPT-in-Siri integration.
What is it?
Bloomberg reports OpenAI executives have grown frustrated that the ChatGPT-Siri partnership announced at WWDC 2024 has produced a tiny fraction of the projected billions in annual subscription revenue. OpenAI has enlisted an outside law firm to explore its options, potentially starting with a formal breach-of-contract notice.
How does it work?
OpenAI's complaint is that the integration is buried — users must explicitly say "ChatGPT," Siri's replies are truncated versus the standalone app, and Apple has marketed the feature minimally. Apple's counter-grievances include privacy concerns and frustration over OpenAI's hardware push with former Apple design chief Jony Ive.
Why does it matter?
It signals a public rupture between OpenAI and one of its highest-profile distribution partners, exactly as Apple prepares to unveil a Gemini-powered next-gen Siri at WWDC and open iOS 27 to outside models including Claude. This sets the template for how AI labs negotiate platform integrations going forward.
Who is it for?
AI partnership watchers, Apple platform developers, and regulators tracking AI distribution power.
|
|

|
|
TOOL
MAJOR
2026-05-14
OpenAI Codex Lands in ChatGPT Mobile — Drive Coding Sessions From iOS or Android With a Secure Relay to Your Mac, Free Tier Included
Codex now rides shotgun in the ChatGPT mobile app, so you can babysit long-running coding sessions from anywhere.
What is it?
Codex is OpenAI's agentic coding tool. The mobile rollout puts the same session controls that used to live in the CLI and Chrome extension into the ChatGPT app on iOS and Android. Coding still runs on a paired Mac (Windows coming soon), but the phone becomes the cockpit.
How does it work?
A secure relay layer brokers traffic between the ChatGPT app and the user's trusted machine without exposing that machine to the public internet. Session state stays synced across every device, so a task started on the desktop can be reviewed, approved, or branched from the phone.
Why does it matter?
Codex sessions can stretch over hours. Putting the controls on a phone closes a gap that Claude Code, Cursor's cloud agents, and Google's Jules have all been pushing into. Free tier inclusion makes it a default workflow rather than a Pro luxury.
Who is it for?
Developers running Codex sessions on a Mac and frequent context-switchers who want to triage runs away from a desktop.
|
|

|
|
TOOL
MAJOR
2026-05-14
Grok Build — xAI's CLI Coding Agent Runs 8 Parallel Subagents With Plan Mode, Worktree Integration, and Local-First Privacy
xAI launches a CLI coding agent that splits work across eight concurrent subagents and lands diffs through plan mode.
What is it?
Grok Build is xAI's new terminal-based coding agent, designed for professional software engineering. It runs locally as a CLI, takes high-level tasks, and breaks them across parallel subagents that plan, search docs, and write code together. The early beta is gated to SuperGrok Heavy subscribers.
How does it work?
For complex tasks, Grok Build enters plan mode: it lays out a multi-step plan the user can approve or rewrite before any code is touched. Once approved, edits arrive as clean diffs. Larger jobs are split across specialized subagents running in their own git worktrees in parallel, powered by grok-code-fast-1.
Why does it matter?
This is xAI's direct shot at Claude Code, Codex CLI, and Gemini CLI — but instead of one sequential agent, Grok Build runs up to eight in parallel. Local-first execution keeps source code, credentials, and project data on the developer's machine.
Who is it for?
Software engineers and SuperGrok Heavy subscribers comparing CLI coding agents.
|
|

|
|
ECOSYSTEM
MAJOR
2026-05-14
Anthropic Forms $200M, Four-Year Partnership With the Gates Foundation — Global Health, Education, and Economic Mobility
Anthropic's biggest non-commercial commitment yet: $200M, four years, and engineering time aimed at deploying Claude inside global-health, education, and economic-mobility programs.
What is it?
A multi-year commitment that bundles Gates Foundation grant funding, Claude usage credits, and embedded Anthropic engineers from the Beneficial Deployments team. Priority sectors are global health, life sciences, education, and economic mobility, with programs spanning the US, sub-Saharan Africa, and India.
How does it work?
Rather than a pure grant, the partnership pairs Gates Foundation domain teams with Anthropic engineers to ship Claude-powered workflows: vaccine research, faster health-data analysis, math-tutoring, and college-advising tools. A separate workstream funds African language data collection, with resulting datasets released publicly for any model maker to use.
Why does it matter?
It's the first time a top frontier lab has put nine-figure money, model access, and forward-deployed engineers behind a single non-profit's portfolio. The public African language corpora directly attack the data scarcity that has kept frontier models weak on most languages spoken by 4.6 billion people in low- and middle-income countries.
Who is it for?
Global-health programs, education ministries, and AI teams working on African languages.
|
|

|
|
ECOSYSTEM
MAJOR
2026-05-13
Anthropic Surpasses OpenAI in Business Adoption for the First Time — Ramp AI Index Shows 34.4% vs 32.3% in April 2026
Ramp's monthly index of corporate-card spend shows Anthropic edging past OpenAI in B2B paid adoption for the first time.
What is it?
The Ramp AI Index is a monthly read on which AI vendors paying businesses are actually swiping cards for. The May 2026 edition covers April spending across more than 50,000 Ramp-using companies. Anthropic landed at 34.4% adoption versus OpenAI's 32.3% — the first crossover the index has recorded.
How does it work?
Ramp counts a company as 'adopting' a vendor if it pays via Ramp corporate card or invoiced billing in the period. Year over year, Anthropic climbed from 9% to 34.4% while OpenAI moved 0.3 points; April alone saw Anthropic +3.8 and OpenAI -2.9.
Why does it matter?
Business-card spend is the closest public proxy for which model providers are showing up on real expense reports — and the gap had been the durable Anthropic-vs-OpenAI talking point for two years. Three headwinds could erase the lead: Anthropic's incentive to push more expensive tiers, recent service degradation, and pricing changes that tripled image-prompt token costs.
Who is it for?
AI vendor strategists, investors, and enterprise buyers benchmarking peer adoption.
|
|
|
|
TOOL
MAJOR
2026-05-13
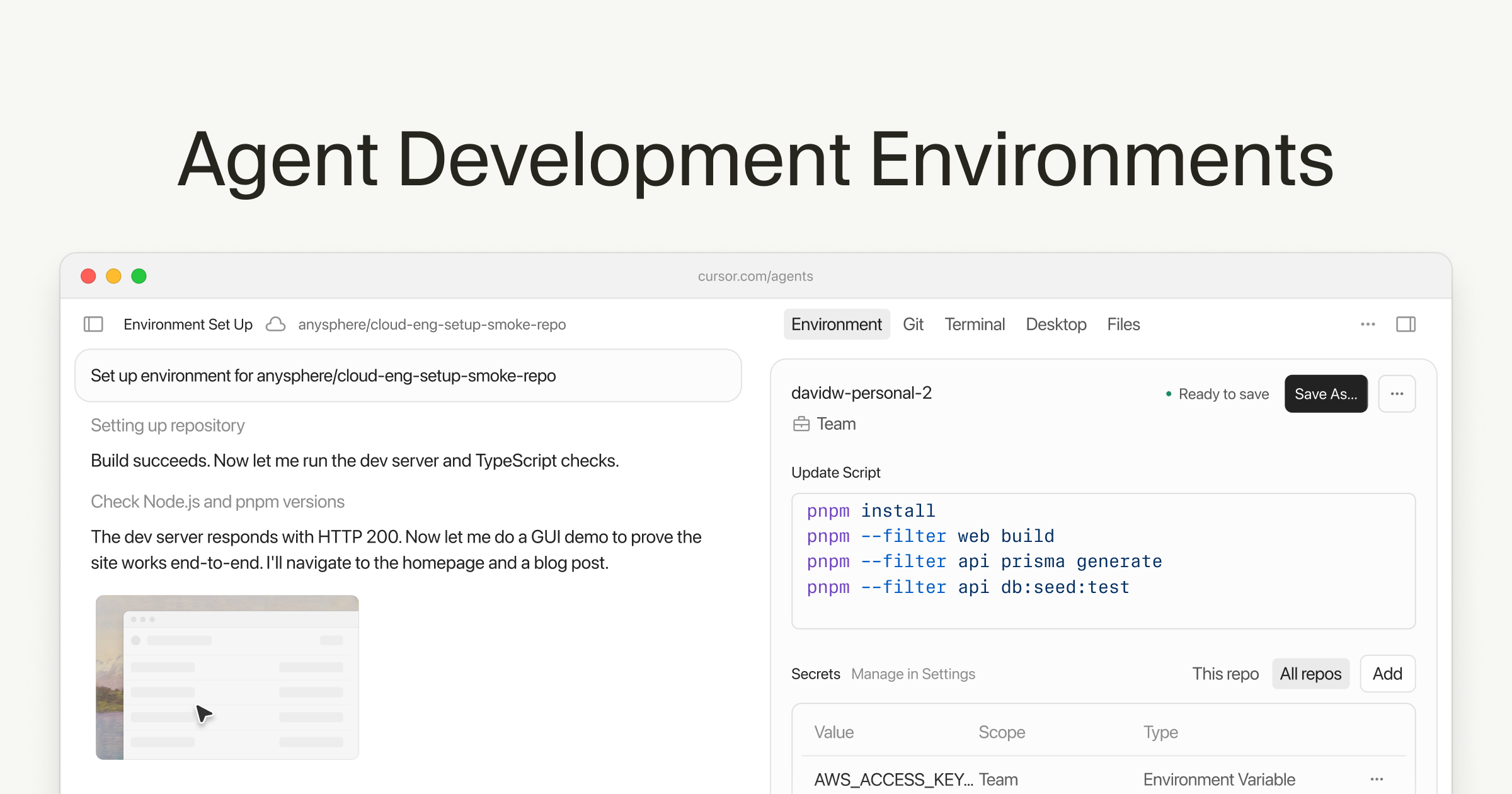
Cursor Cloud Agents Get Real Dev Environments — Multi-Repo Workspaces, Auto-Generated Dockerfiles, Build Secrets, and 70% Faster Cached Builds With Audit-Logged Rollbacks
Cloud Agents now ship with the same kind of provisioning, secrets, and audit controls platform teams expect from CI — and they can span multiple repos at once.
What is it?
A platform-team-flavored upgrade to Cursor's Cloud Agents. One environment can now bundle several repositories, a Dockerfile, build secrets, and the credentials an agent needs to actually run, then be reused across sessions with full version history.
How does it work?
Environments are configured as code through Dockerfiles, with build secrets scoped to the build step only so they never leak into the running agent process. Layer caching was rebuilt so cached layers rebuild 70% faster after Dockerfile edits. Every member action is captured in an audit log; admins can restrict rollback to themselves; secrets are scoped per environment.
Why does it matter?
Before this drop, Cursor's Cloud Agents were powerful but opaque to security teams — credentials lived in ad-hoc places, builds were slow on cache misses, and there was no per-environment audit trail. By matching the Dockerfile + secrets + audit-log model that CI tools already provide, Cursor removes the main blockers enterprise security teams raised for production rollout.
Who is it for?
Platform engineers, security reviewers, and large engineering teams deploying Cursor Cloud Agents at scale.
|
|

|
|
SECURITY
MAJOR
2026-05-12
Microsoft MDASH — Multi-Model Agentic Scanning Harness Finds 16 Windows Flaws Including Four Critical RCEs, Tops CyberGym at 88.45%
Microsoft's new agentic vulnerability discovery system orchestrates 100+ AI agents across frontier and distilled models, and just topped CyberGym.
What is it?
MDASH (multi-model agentic scanning harness) is a model-agnostic system that uses bespoke agents for different vulnerability classes to autonomously discover, validate, and prove exploitable defects in complex codebases like Windows. On its first production run it surfaced 16 previously unknown Windows vulnerabilities, including four critical RCEs — all shipped in this month's Patch Tuesday.
How does it work?
The harness pipelines five sequential stages — Prepare, Scan, Validate, Dedup, and Prove — across more than 100 specialized agents drawn from an ensemble of frontier and distilled models. Debater agents argue findings for or against; a Prove stage constructs and executes triggering inputs before anything reaches a human engineer.
Why does it matter?
MDASH lands in the same lane as Anthropic's Project Glasswing and OpenAI's Daybreak, but Microsoft is publishing the first end-to-end benchmark numbers any of them has shared. The 88.45% CyberGym score is roughly five points ahead of the next-best published system; 96–100% recall on five years of historical MSRC cases means it can rediscover bugs that took human teams years to chase.
Who is it for?
Security engineers, vulnerability researchers, and blue teams.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|