
|
|
MODEL
MAJOR
2026-05-06
Zyphra ZAYA1-8B — AMD-Trained MoE Reasoning Model With <1B Active Parameters
Zyphra trained an 8.4B sparse MoE with under a billion active params on AMD MI300X — and it matches open models 10–100× larger on math and code.
What is it?
ZAYA1-8B is a small mixture-of-experts language model: 8.4B total parameters but only ~760M active per token. It's a reasoning-first open-weight model (Apache 2.0) targeting math, code, and long-form analysis, trained end-to-end on AMD hardware — a first at this scale for any well-known frontier-style release.
How does it work?
Trained on 1,024 AMD Instinct MI300X GPUs, combining a Compressed Convolutional Attention variant with an MLP-based expert router for routing stability. Post-training adds a reasoning RL cascade and Markovian RSA — a test-time compute method that chunks parallel reasoning traces to keep memory constant during long deliberation.
Why does it matter?
Sub-1B active params reaching 89.1 on AIME26 and 71.6 on HMMT shows AMD's MI300X is now production-ready for end-to-end frontier-style training, not just inference. It keeps the case alive that you can win on intelligence-per-parameter without scaling totals to hundreds of billions.
Who is it for?
Open-weight researchers, anyone optimizing reasoning per FLOP, and AMD-stack teams looking for a capable small model.
|
|

|
|
TOOL
MAJOR
2026-05-06
Anthropic Managed Agents Get Dreams — Self-Improving Memory Curation Pipeline
An async pipeline that lets Claude reflect on past sessions and rewrite an agent's memory store without touching the original.
What is it?
Dreams is a research-preview feature for Claude Managed Agents that runs an offline pipeline over an existing memory store plus up to 100 past session transcripts. It produces a fresh memory store with duplicates merged, stale entries replaced, and new patterns surfaced — leaving the input store untouched so teams can review and discard the result.
How does it work?
A dream job is created via POST /v1/dreams with two beta headers (managed-agents-2026-04-01 and dreaming-2026-04-21) and an inputs array referencing a memory store plus optional session IDs. The selected model (Opus 4.7 or Sonnet 4.6) reads transcripts, dedupes contradictions, and writes a new memory_store output asynchronously.
Why does it matter?
Long-running agents accumulate duplicates, contradictions, and dead context that drag down quality across sessions. Dreaming gives teams a structured way to compress that history on a schedule, with a human-review safety net while the feature is in preview.
Who is it for?
Teams running multi-agent Claude deployments with persistent memory stores.
|
|

|
|
SECURITY
MAJOR
2026-04-07
GrafanaGhost: Indirect Prompt Injection Silently Exfiltrates Enterprise Metrics via Grafana AI
A hidden prompt injection in Grafana's AI assistant leaks enterprise data silently — no phishing, no credentials, no alerts.
What is it?
GrafanaGhost is an indirect prompt injection vulnerability in Grafana's AI assistant. An attacker embeds a crafted payload inside data Grafana's AI later processes (e.g., a dashboard annotation), forcing the Markdown image renderer to make an outbound HTTP request to an attacker server with sensitive metrics embedded in the URL. Noma Security disclosed it; Grafana patched promptly.
How does it work?
The attack chains three weaknesses: crafted prompts stored in Grafana context, a protocol-relative URL bypass (// prefix) that evades image-loading protections, and the keyword INTENT that causes the model to ignore its own guardrails. Victims see no error, no alert, and no anomalous log entry.
Why does it matter?
Grafana is the de-facto monitoring platform for cloud-native infrastructure. The attack requires no credentials, no user interaction, and leaves no trace in Grafana's own audit logs — making it a silent exfiltration path for financial metrics, SLO dashboards, and operational telemetry.
Who is it for?
Security engineers running Grafana in production, DevSecOps leads, and enterprise CISO offices tracking AI-augmented monitoring risk.
|
|
|
|
PAPER
MAJOR
2026-04-28
RecursiveMAS — Stanford/MIT/NVIDIA Multi-Agent System Cuts Tokens 75% With 8.3% Accuracy Gain
Recursive computation, now for teams of AI agents.
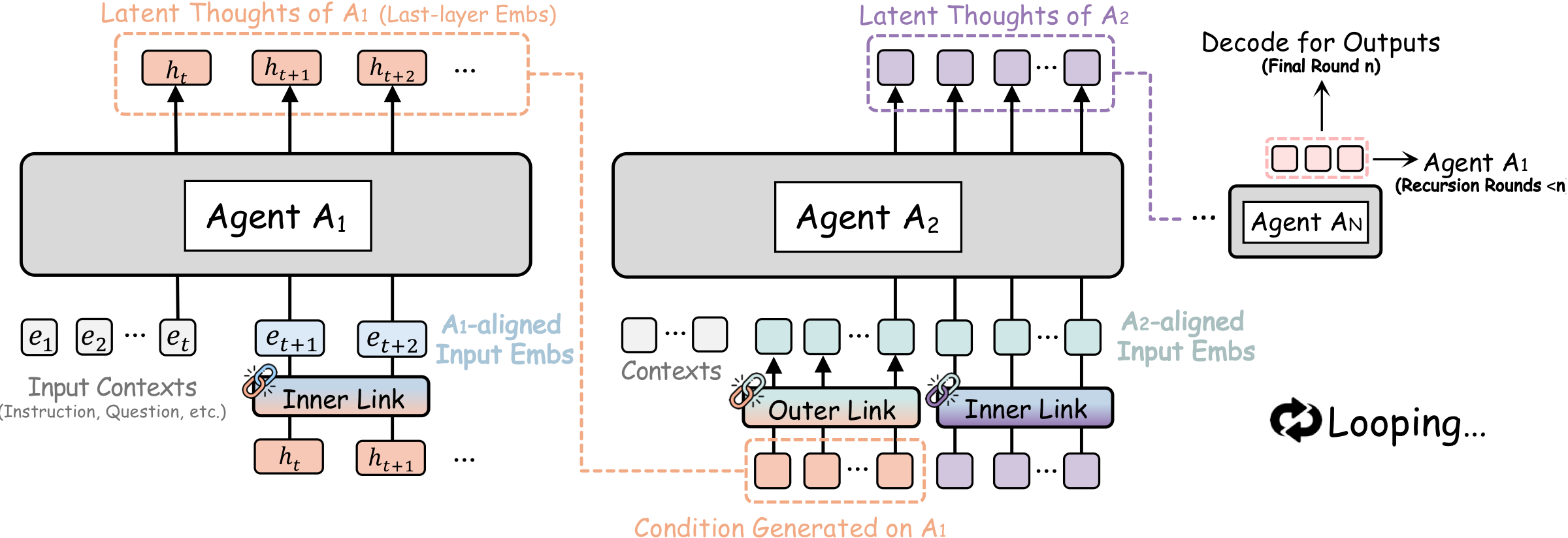
What is it?
A framework from Stanford, MIT, and NVIDIA that applies recursive latent-space computation across heterogeneous agents, connecting them through a lightweight RecursiveLink module that passes latent states between rounds of collaboration instead of text.
How does it work?
Each agent refines its outputs across multiple rounds, sharing internal latent thoughts via RecursiveLink rather than verbose text. An inner-outer loop training algorithm assigns credit across the whole recursion, optimizing the multi-agent system end-to-end.
Why does it matter?
Across 9 benchmarks covering math, science, medicine, and code generation, RecursiveMAS delivers the same accuracy improvement as adding more agents — but with 75.6% fewer tokens and up to 2.4× faster inference.
Who is it for?
ML researchers and engineers building or deploying multi-agent reasoning pipelines who need accuracy gains without proportional compute scaling.
|
|

|
|
REPO
MAJOR
2026-04-18
GenericAgent — Fudan's Token-Efficient Self-Evolving LLM Agent With 9k Stars Uses 6× Fewer Tokens
An agent that grows smarter every time it solves a task.
What is it?
A general-purpose LLM agent from Fudan University that treats context information density — not context length — as the primary lever for long-horizon performance. Every verified execution path is crystallized into a reusable SOP, building a personal skill tree over time.
How does it work?
Four components work together: minimal atomic tools, hierarchical on-demand memory (only high-level summaries stay in context), a self-evolution mechanism that converts past trajectories into reusable skills, and a compression layer that maintains density during long runs.
Why does it matter?
9.3k GitHub stars within weeks. Outperforms leading agents on task completion, tool efficiency, memory, and web browsing while consuming 6× fewer tokens — a major cost reduction for long-horizon agent deployments.
Who is it for?
LLM developers building autonomous agents with long context requirements who need token efficiency without sacrificing task coverage.
|
|

|
|
PAPER
MAJOR
2026-04-15
HY-World 2.0 — Tencent Hunyuan Open-Sources Multi-Modal 3D World Model With 1,770 HF Upvotes
Text or a single photo → a navigable 3D world you can walk through.
What is it?
A fully open-source multi-modal world model from Tencent that reconstructs, generates, and simulates 3D environments from text, single images, multi-view images, or video. A new WorldLens rendering platform enables interactive exploration with character integration.
How does it work?
A four-stage pipeline upgraded from HY-World 1.0: enhanced panoramic scene generation → navigation trajectory planning → stereo expansion → final scene assembly. Each stage improves 3D scene comprehension over the previous version.
Why does it matter?
It earned 1,770 Hugging Face upvotes — the top paper of the April 2026 cycle. Fully open-sourced models and code compete directly with closed proprietary 3D world systems from major labs.
Who is it for?
3D generation researchers, game developers, and simulation engineers who want open-source alternatives to proprietary world-generation pipelines.
|
|
|
|
TOOL
NOTABLE
2026-05-06
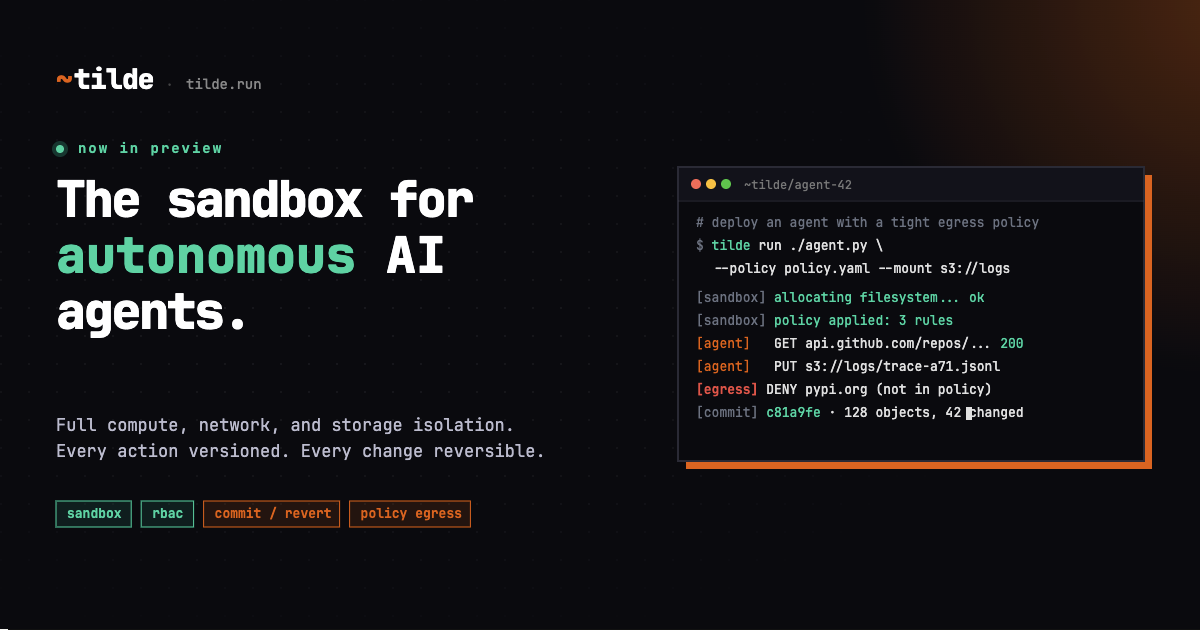
Tilde.run — Agent Sandbox With a Transactional, Versioned Filesystem on lakeFS
Each agent run is a transaction you can roll back, with code, S3 data, and Drive docs mounted as one versioned filesystem.
What is it?
A hosted sandbox for letting AI agents act on real production data without permanent risk. Each run starts in a fresh isolated container; on clean exit changes commit atomically, on failure nothing changes. Any tool or language works without a Tilde-specific SDK.
How does it work?
Built on lakeFS, code from GitHub, data from S3, and documents from Google Drive are all mounted into a single ~/sandbox path. Every outbound network call is logged, and operators review diffs to decide whether to commit or roll back.
Why does it matter?
Letting autonomous agents touch real customer data is the unsolved blocker for production agent rollouts. A versioned filesystem with transactional commits gives teams a credible undo button without re-architecting agents around bespoke staging directories.
Who is it for?
Teams running coding or research agents on production data who need rollback guarantees without changing how agents are built.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|