
|
|
MODEL
MAJOR
2026-06-30
LongCat-2.0 — Meituan's 1.6T open-source MoE for agentic coding
Meituan's first frontier-tier open-source coding model — 1.6T parameters with 48B active, trained without a single NVIDIA chip.
What is it?
LongCat-2.0 packs 1.6 trillion total parameters into a mixture-of-experts layout that activates roughly 48 billion per token. Meituan, the Chinese super-app group, released it under the MIT license on June 30, 2026, with a chat interface at longcat.ai and weights coming to Hugging Face.
How does it work?
Three innovations drive it: "LongCat Sparse Attention" for a 1M-token context window, a 135B N-gram Embedding module for extra capacity, and dynamic activation ranging from 33B to 56B parameters per query — all pretrained on 50,000+ domestic Chinese AI ASICs across 35 trillion tokens.
Why does it matter?
Open-weight coding agents now have a Chinese-chip-trained option in the same league as leading closed models (59.5 on SWE-bench Pro, 70.8 on Terminal-Bench 2.1) — with an MIT license for unrestricted self-hosting and fine-tuning, and no NVIDIA hardware required.
Who is it for?
Agentic-coding teams, Chinese-stack adopters, and export-controlled groups needing a frontier-class model they can fully self-host.
|
|
|
|
TOOL
MAJOR
2026-06-29
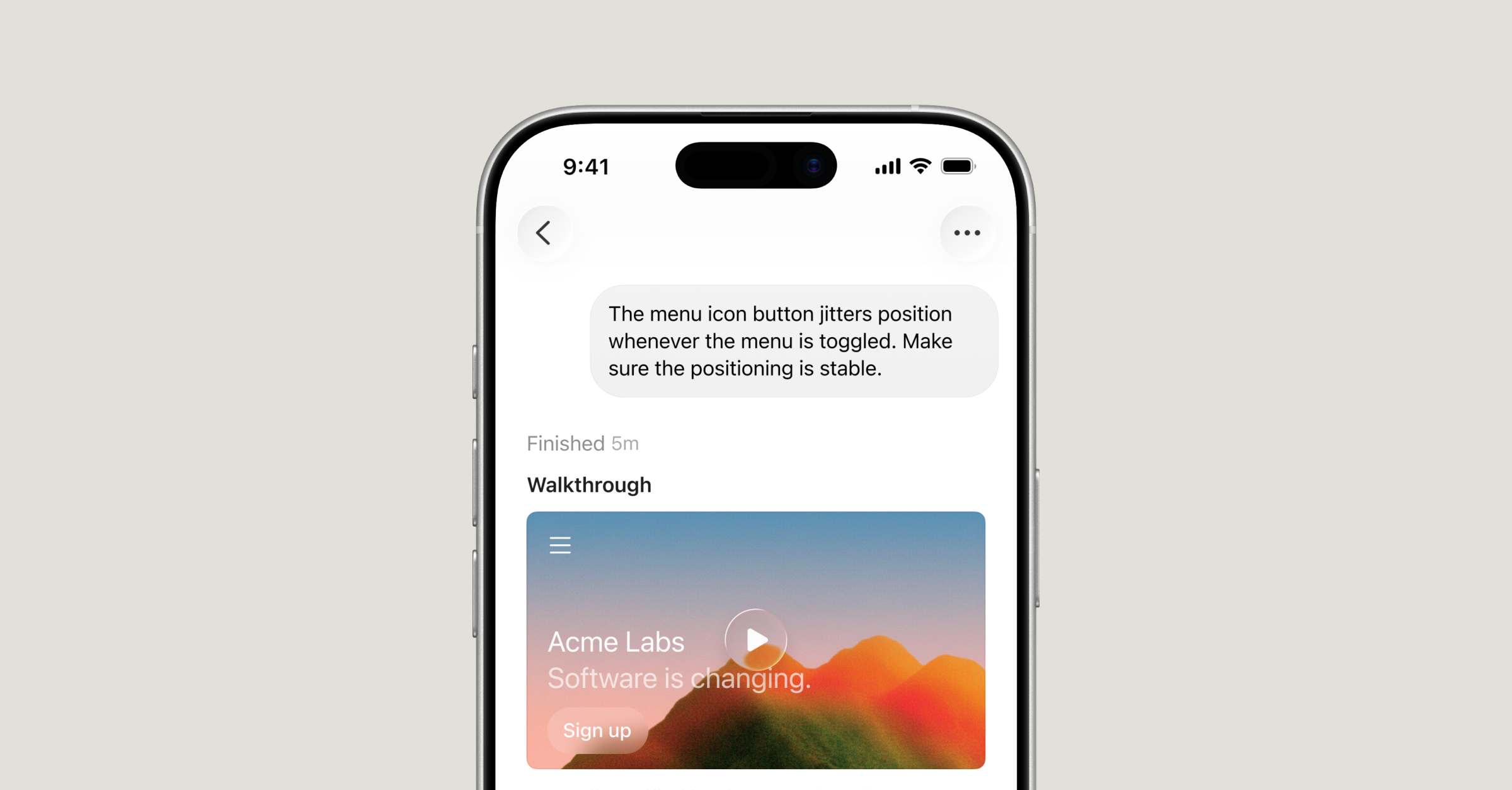
Cursor for iOS — native mobile app for cloud and remote coding agents
Cursor's coding agent now ships as a native iOS app so you can dispatch cloud runs, control your desktop, and merge PRs from a phone.
What is it?
Cursor for iOS is a public-beta native iPhone app that lets paid Cursor subscribers start cloud agents, remote-control their desktop Cursor, and ship pull requests without opening a laptop. It's free to download with any paid Cursor plan, with 75% off Composer 2.5 runs through July 5, 2026.
How does it work?
Two modes share one chat surface: Cloud Agents run in isolated VMs that iterate toward merge-ready PRs unattended, while Remote Control pipes commands to your awake desktop Cursor over the network — both with voice input, screenshot context, and lock-screen Live Activities.
Why does it matter?
Mobile coding shifts when you can dispatch, monitor, and merge agent work from a phone. Cursor built this for the on-call engineer, the founder triaging a Slack escalation, and the reviewer who wants to merge a green PR away from a desk.
Who is it for?
Cursor subscribers who want to start, watch, or merge agent work from their iPhone — search "Cursor" on the App Store.
|
|

|
|
PAPER
MAJOR
2026-06-29
Brain2Qwerty v2 — Meta non-invasive brain-to-text hits 61% word accuracy
Meta's Brain2Qwerty v2 reads typed sentences off MEG brain scans at 61% word accuracy — without surgery.
What is it?
Brain2Qwerty v2 is Meta AI's pipeline for decoding what a person is typing from non-invasive MEG brain recordings — no surgery, no implanted electrodes. It was trained on 22,000 sentences from 9 volunteers, and the full training code is open-sourced on GitHub.
How does it work?
Raw MEG signals flow through a convolutional encoder, a transformer, and a character-level language model fine-tuned on neural data — fully end-to-end, replacing the hand-coded event detection in v1. Meta also used AI agents to search the pipeline configuration space.
Why does it matter?
Non-invasive brain-to-text just jumped from 8% to 61% word accuracy (78% for the best participant), putting no-surgery BCIs on the same improvement trajectory as implanted devices. This matters especially for people who can't undergo neurosurgery.
Who is it for?
Neuroscience and BCI researchers, and accessibility engineers building on Meta's open-source pipeline.
|
|

|
|
TOOL
MAJOR
2026-06-26
Cline 4.0 — SDK rewrite rolled back to 3.89 two days after launch
Cline shipped a major SDK rewrite as 4.0.0, then rolled it back two days later as 4.0.1 after launch-day regressions.
What is it?
Cline 4.0.0 rewrote the 64k-star open-source coding agent's VS Code extension on a shared SDK session layer, adding a Customize marketplace (Skills, MCP servers, Plugins), ClinePass billing, and queued chat — then 4.0.1 reverted to the pre-migration 3.89.2 codebase two days later.
How does it work?
The SDK layer consolidates turns, tools, MCP, checkpoints, and telemetry into one shared runtime used by the VS Code extension, CLI, and SDK consumers. Cline 4.0.1 ships the 3.89.2 extension code under the higher version number so VS Code auto-pushes the rollback; SDK migration continues on main.
Why does it matter?
A rollback of a flagship coding-agent release is a public reminder that shared-runtime rewrites carry real risk — users on 4.0.1 are effectively back on 3.89.2, and builders evaluating the Cline SDK should track main rather than the stable release for the new capabilities.
Who is it for?
Developers using Cline in VS Code, and builders evaluating the Cline SDK as a foundation for custom coding agents.
|
|

|
|
MODEL
NOTABLE
2026-06-30
Agents-A1 — Shanghai AI Lab 35B MoE matches trillion-parameter agents
Open-weight 35B agent from Shanghai AI Lab posts SOTA on SEAL-0, IFBench, and FrontierScience-Research.
What is it?
Agents-A1 is a 35B Mixture-of-Experts agent model from Shanghai AI Laboratory's InternScience group, released Apache-2.0 on Hugging Face. Built on Qwen3.5-35B-A3B, it targets long-horizon search, scientific research, software engineering, and tool calling.
How does it work?
Training uses three stages: full-domain supervised fine-tuning, domain-specialist teacher models for each skill (search, code, tool use), and multi-teacher on-policy distillation to merge them back into one student — handling trajectories averaging 45K tokens with action, observation, and verification traces.
Why does it matter?
Agents-A1 claims SOTA on SEAL-0 (56.4), IFBench (80.6), and FrontierScience-Research (40.0), with the paper asserting parity with trillion-parameter systems like Kimi K2.6 — but on a single 8-GPU node with fully open Apache-2.0 weights.
Who is it for?
Open-source agent builders and scientific labs that need frontier-class agentic capability without paying frontier API rates.
|
|

|
|
ARTICLE
NOTABLE
2026-06-29
Quesma: 'Qwen3.6 27B is the sweet spot for local development'
Hands-on case that 27B-dense Qwen3.6 is now production-grade on a single laptop — 875 points on Hacker News.
What is it?
Quesma's founding engineer Piotr Migdał benchmarks Alibaba's open-weight Qwen3.6 27B running locally on a MacBook Pro with M5 Max, arguing the 27B-dense variant is the new sweet spot — small enough for consumer hardware, large enough for daily coding work.
How does it work?
On the M5 Max with multi-token prediction enabled, the model hits ~32 tokens per second using llama.cpp at 8-bit quantization, needing about 42GB of unified memory — and Migdał used it to write a playable hexagonal minesweeper from a single prompt.
Why does it matter?
A 27B-dense model that runs on one laptop at near-frontier quality changes the math for local AI development — the post hit 875 points on Hacker News with nearly 600 comments, signaling the developer community treats this as a genuine inflection point.
Who is it for?
Local AI developers on Apple Silicon and high-end Linux laptops who want production-grade inference without cloud costs.
|
|
|
All releases at ai-tldr.dev
Simple explanations • No jargon • Updated daily
|
|