
The 2019 version of me would have been shocked and horrified at what I’m about to say: Nancy Krieger is incredibly fucking tedious to read. I’m so over it. I’m particularly tired today (and particularly exhausted lately), but today is not the problem. I’ve been incubating an idea for this essay for months at this point — a take on Krieger’s arid 50-page 2012 paper “Who and what is a ‘population’? Historical debates, current controversies, and implications for understanding ‘population health’ and rectifying health inequities.” I haven’t published anything yet because I simply can’t get through the fucking thing. Even trying to say the title out loud is tiresome to the jaw muscles, like trying to break down a Tootsie pop. Not that I don’t have a high tolerance for boring text. (I’m a Marxist, after all. Ask me how many yards of linen to make a coat.)
I can barely even even bring myself to open the document again, honestly. It’s not even really necessary. Like all Krieger papers, the “argument,” if we can call it that, is an extremely pedestrian non-point buried under a sludge of dictionary definitions. (Literally. And if that’s not annoying enough, she archly close-reads dictionary entries for “population” according to a completely arbitrary and occult set of criteria — Miriam-Webster defines population this way, but they don’t specify exactly what a population is, that kind of grating vibe.) Here’s a quote from the paper: “Consequently, apart from specifying that entities comprising a population individually possess some attribute qualifying them to be a member of that population, none of the conventional definitions offers systematic criteria by which to decide, in theoretical or practical terms, who and what is a population, let alone whether and, if so, why their mean value or rate (or any statistical parameter) might have any substantive meaning.” Okay? What I want to get into here is… what are the epistemic assumptions, or the system of thought, behind the idea that having “systematic criteria” to decide “who and what is a population” is something that we really need.
At issue is the concept of population, “core to epidemiology” (as Krieger says) or some such nonsense, and a rather interesting story.
Have you ever thought much about what an average really is? It’s kind of a funny joke about the “average American” with 2.5 kids, which of course corresponds to no actual person, living or dead. The joke, which makes fractional children possible, is that the average is an abstraction, a reified statistical object, that we nevertheless endow with some kind of meaning or authority as a representation of a group of things. How did we get here?
The reason we confer averages with kind of meaning is because of a fairly obscure Belgian guy named Adolphe Quetelet. The abbreviated version of the story is as follows. For a long time, observational astronomers struggled to figure out a problem having to do with measurement error. Different people at different positions on planet Earth, attempting to record the position of celestial bodies from their locations, will tend to record a value that is the true location of the body plus or minus some error. Different observers all “miss the mark” somehow. Galileo recognized this, as did others. After a long time of trying, a method was finally cracked to combine different measurements of the same quantity (each made with some amount of error) to arrive at the optimal estimate of the true value — daps to Adrien-Marie Legendre. This method is the method of least squares, which will be familiar to anybody with a passing knowledge of statistical regression. The optimal estimate of the true position of a star or planet is, it turns out, the average of all the observations made with error. (For anybody who is unfamiliar, to take the average, you add up the values of all the observations, then divide by the number of observations.) A German scientist, Carl Friedrich Gauss, figured out how to combine this least-squares method for obtaining the true value with a distribution of the errors themselves. This is the bell-shaped, or normal curve. (This is a gross oversimplification — I’m trying to leave out a bunch of technical detail that a casual reader really does not need.)
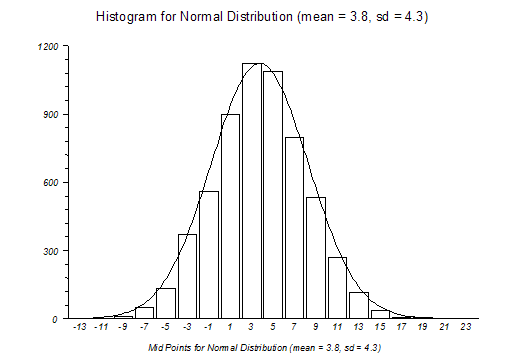
I’m including this little pictorial illustration because I think it helps develop some intuition about what’s going on. The mean, or average, of the distribution pictured above is 3.8, meaning that this is the best estimate of the true value of all the observations of this quantity (whatever it is) made with some error. The bars represent the frequency of measurements made with some error — the higher the bar, the more frequent the measurement. It makes sense that more frequent errors are closer to the true value, and more extreme errors are less frequent — there are many more measurements of about 5 or about 2 than there are measurements of -7 or 17. Because the measurement errors are more or less random (not generated by some kind of systematic distortion in the measurement process), some of the measurement errors will be greater than and some will be less than the true value. As the number of observations increases, these errors will tend to cancel each other out, yielding this symmetrical bell-shaped distribution.
Observational astronomers used this “law of error” to reconcile different, error-ridden measurements of the same quantity. Adolphe Quetelet trained as an astronomer in Paris before returning to his native Belgium; for reasons that are complex, interesting, and too much to get into here, Quetelet (an astronomer but also a proto-social scientist) was fairly obsessed with how chance, seemingly random phenomena (like crimes, or suicide) show stable regularities when observed at the aggregate level. The famous story is that Quetelet looked at a frequency distribution of chest girths among Scottish conscripts, noticed that they showed a similar bell-shaped pattern to the image above, and had the idea for which is famous: the average man. The average man (l’homme moyenne) was a huge conceptual leap. Instead of the average of a number of observations of the same object, Quetelet translated this into a different context — measurements of different people. The “average man,” for Quetelet, was sort of the platonic ideal of a group (or population), of which actually-existing human beings are imperfect copies. (There’s an extended metaphor in one of Quetelet’s writings about bronze casts of Michelangelo’s David or some such, but I can’t find it right now.) Quetelet really cared a lot about the average and the truth he believed an average expressed about a group of people or, in a proto-eugenicist way, of a race. This idea would be extended into actual eugenics by Francis Galton, who combined the average with the normal curve as a measure of “deviation” around the average, to rank people according to (supposed) intellectual ability and other traits. (Recall Foucault, that the norm is what articulates the individual in the population? This is how.)
Krieger’s main point of contention is that we, as 21st-century population health researchers, treat populations as “statistical rather than substantive.” She views this as a problem and pins the whole thing (rather unfairly, in my opinion) on Quetelet, who she charges with the transition to, improperly in her view, viewing population characteristics as reflective of innate characteristics of population elements (i.e., individual people). Her big rebuttal to this, which will come as absolutely no surprise to anyone familiar with her oeuvre of repetitive papers that boil down to “social conditions affect health,” is that “social relations, not just individual traits, shape population distributions of health” (p. 647). You don’t say! Her recommended course of action is, as always, to use the conceptual framework she developed (the ecosocial theory of disease distribution) to treat populations as “substantive” and “relational” rather than merely “statistical.” Her argument is kind of hard to follow because, again, it’s simply not very good or very well developed. But it’s ironic that she’s trying to pillory ol’ Quetelet for making us think like this, when in fact, she and Quetelet are exactly in agreement: populations are substantive and the average of some quantity describing a substantive population is meaningful.
Maybe who she would really want to take issue with is experimental psychology researchers of the early 20th century. Kurt Danziger, a historian of psychology, has written extensively about the confluence of factors leading to the enthusiastic uptake of statistical methods in experimental psych. One of the consequences of this uptake was the shift in objective of psychological experimentation from attempting to characterize individual mental processes to describing aggregate descriptors (like average IQ scores) of groups of subjects. From Danziger’s article “Research Practice in American Psychology” (in The Probabilistic Revolution: Volume 2):
“The original Galtonian groups were natrual groups; that is to say, they were drawn from actual socially defined populations, men and women, sophomores and freshmen, nine-year-olds and ten-year-olds, etc., and the only problems that could arise about their constitution were relatively technical problems of the representativeness of the sample. But in due course psychologists began to constitute research groups on the basis of psychological measurements, the prototypical example being groups differing in intelligence. These groups were then compared in terms of their performance on some other psychological measure. It was not uncommon to give a completely unwarranted causal interpretation to the group differences obtained in such studies — for example, to regard a difference in intelligence as the cause of differences in other psychological characteristics… [much later] What is involved here is a kind of modeling in which the statistical structure of data based on the responses of many individuals is assumed to conform to the structure of the relevant psychological processes operating on the individual level.”
The statistical populations that Krieger decries emerged as a byproduct of social scientific practice — in epidemiology, too, not just in psychology. The structure of inquiry Danziger describes is similar in epidemiology — the statistical structure of population health data, however we define the “population,” is meant to conform to the structure of the relevant physiological processes in the individual body. This is whence we get the interminable confusion between population- and individual-level risk, and the whole farcical framework of “evidence based medicine,” which hinges on exactly this kind of assumption — that if, at the group/aggregate/population level, we observe that a given characteristic is associated with a given outcome, we assume that an individual with this characteristic carries a greater “risk” of the outcome. Surely, there are situations where this makes sense to assume. But it is a little bit peculiar as an approach to clinical medicine, or to trying to understand the inner workings of the mind.
And now I’m gonna bring this to a rushed conclusion because I need to go do things before my evening commitments (including going to take a walk, I fucked up my lower back and walking followed by some gentle yoga is the only thing that is helping).
The unaddressed question in all of this is: what makes population possible? This answer was supplied for me by a new book that I’ve been skimming, Biopolitics as a System of Thought by Serene Richards. It’s way too much heady critical theory-speak for me, but there are really interesting questions and problematics in it. Richards argues that biopolitics is a system of thought as well as a mode of governance. I’m rushing, there’s a lot that could be said here, but here’s a passage:
“For Lyotard, the turn to positivism as the only mode of knowledge conducive to the organization of the social is problematic and symptomatic of the decline in faith in the idea of grand narratives. One effect of this shift is that we no longer know for the sake of knowing, ‘knowledge is and will be produced in order to be sold, it is and will be consumed in order to be valorised in a new production: in both cases, the goal is exchange.’ A cyclical relation is in play where this knowledge is also produced in order to govern and governing as such can only take place or ‘govern’ through this knowledge.” (p. 18)
Krieger’s preoccupation is the calculation of meaningful means that characterize substantive populations because, in her mind, this will lead to better research which will in turn lead to strategies for remedying the many health inequalities that plague the United States (and the world). Biopolitics as a mode of thought is what makes the concept of population possible, that makes it possible for us to conceptualize and quantify groups of individuals as populations in order to administer and govern them… it is worth wondering out loud whether biopolitics as a system of thought and as a mode of governance might in fact have some kind of constitutive, underpinning relation to the health inequalities themselves, as well as the statistical tools that we use to quantify and manage them.
You just read issue #40 of Closed Form. You can also browse the full archives of this newsletter.