Learn the scaling secrets of a 1-person ML stock picking engine
Learn the scaling secrets of a 1-person ML stock picking engine
Further below are 6 job roles including Senior roles in Data Science and Data Engineering at organisations like Causaly, Cultivate and Trust Power.
Further below I pull out some insights from the a review article on a 1-person ML stock picking engine (which self-reportedly was good) for tools for scaling and share some notes on the latest HoloViz visualisation tool.
I'm looking forward to getting along to the next PyDataLondon meetup on Tues 1st November at the usual venue, it'll be good to talk to folk face to face again (well, I'll be masked, but talking).
Sorry to be slow with this issue, between training, client coaching and planning some volunteer activities in the PyData world, plus an infant (potty training now - what times!), I just ran out of hours.
Executives at PyDataGlobal for Dec 1st
Are you a data science leader? Would you like to raise leadership questions in a like-minded group to get answers and share your hard-won process solutions? I'm organising another of my Executives at PyData sessions for the upcoming PyDataGlobal (virtual, wordwide) conference for December 1-3. On Thursday Dec 1st I'll run a session over a couple of hours focused on leaders, anyone who is approaching leadership or who runs a team is welcome to join.
I have a plan to make this more problem-solving focused than previous sessions, with a write-up to be shared after the conference so there's something to take away. Attendance for these sessions is free if you have a Global ticket. This builds on the sessions I've volunteered to run in the past and the Success calls I've organised via this newsletter earlier this year.
Reply to this (or write to me - ian at ianozsvald com) if you'd like to be added to a reminder and a GCal calendar entry (there's no obligation, these just remind you and set it in your calendar).
The anatomy of an ML-powered stock picking engine
There was an interesting write-up on Didact AI (linked with comments via hn), on an automated stock-picking engine. I'm less interested in the quant aspect and more on the automation behind a live high-risk ML system and the tools used (mostly Python as it happens).
Through this essay, I hope to convey an idea of how productionized ML systems work in a real-world setting.
The overall data processing diagram is pretty clear, I think for teams starting on a new DS journey maybe having a diagram like this, to discuss with the bosses to show just how much data and process has to be corralled, could be useful:
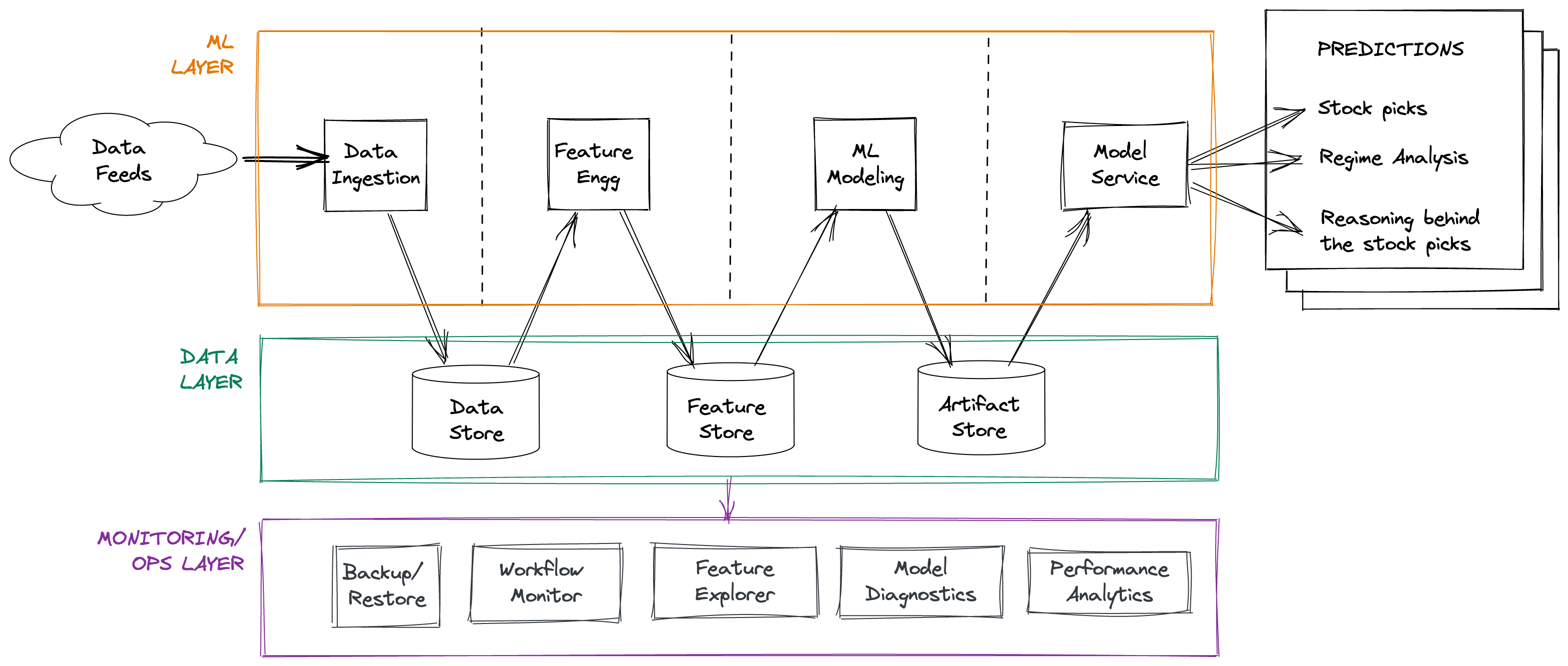
I've been involved in quant work a little bit during my 20 years so I can follow the arguments for market patterns, market regimes, regime shift and sentiment as a basis for pattern recognition and prediction systems. The author makes a nice point about features over any particular ML approach:
...an insight I have always kept in mind is that feature engineering is almost always the key difference between success and failure...the choice of ML model is no longer a critical step.
The volume of data (for a 1-person operation) is pretty crazy. Scraping feeds and reports (often text), building features, models on the timeseries numbers and the text reports, then combining it all in a testable way leads to a lot of moving parts.
The author notes that DuckDB with Arrow and Parquet beats Postgres, Redis is the feature store, Python glues it all together, Pandas and numpy are used, Airflow builds the dependency-based data. xgboost is used as the main ML tool to glue the data together, DNN tools are used to generate features. Have you had success with DuckDB? I'm always keen to hear stories and I see it increasingly (albeit from a slow start) now.
GreatExpectations is used for data quality tests, generally I teach and use Pandera but I think I need to look at GreatExpectations again, it seems to have grown a whole new base of useful extra tools beyond what's available in Pandera. Have you had particular wins with either library? I'd love to hear back (just reply) if so?
For the data crunching interestingly along with Pandas the author uses Polars (see my interviews 1 and 2 ), joblib and bottleneck. I'll be teaching faster Pandas in a private run of my Higher Performance Python course tomorrow. I'll show how bottleneck makes Pandas faster (it is an optional but highly recommended addition to Pandas), but I rarely see it used directly to improve performance. Polars is a late entrant as a "better Pandas" but it has legs - a cleaner design and built-in parallelism. I'm always on the look-out for success stories - have you used Polars or bottleneck (directly) with success?
The summary of performance improvements is a nice read, benefits came from replacing Postgres with DuckDB, replacing Pandas with DuckDB and Arrow, replacing numpy with bottleneck, replacing Pandas with Polars and finally scaling up with multiprocessing. That's a nice summary of wins which might help you prioritise some of your engineering scalability work?
Open source - some links
HoloViz has a new 0.8 demo page and 2 minute release video (which is worth a watch) - thanks for the notification Sophia. This visualisation project has been growing for years:
hvPlot is an open-source library that offers powerful high-level functionality for data exploration and visualization that doesn't require you to learn a new API. For instance, if you have a Pandas or Xarray data pipeline already, you can turn it into a simple data-exploration app by starting the pipeline with .interactive and replacing method arguments with widgets. Or you can get powerful interactive and compositional Bokeh, Plotly, or Matplotlib plots by simply replacing
.plotwith.hvplot
The .interactive interface has looked nice for a while, it lets you simply build an interactive interface into your data. On top of this is the more enticing .explorer tool which builds an interactive (yeah, you guess it) exploration interface showing your fields with some options for how two axis are displayed, grouped and drawn. From here you can request .plot_code and it'll give you the programmatic code to generate the same interface, so you can mock-up investigations very quickly and then build out your own interface.
It isn't a replacement for tools like pandas profiling (javascript plots) or lux (using altair), but gives you an on-ramp to dive deeper into the tool.
Bonus - whilst checking for alternative libraries I came across DTale from the Man Group (who wonderfully host our PyDataLondon meetups), it is another interactive exploration tools and this looks pretty powerful. It shows column descriptions, histograms, correlations, duplications and more. There's a bunch of animated gifs down the page showing how it works. I've no prior experience - have you tried it? Did it enable you to learn about your data faster?
Have you got a library or seen a new release that I might want to mention here? Just reply and let me know if so.
Footnotes
See recent issues of this newsletter for a dive back in time. Subscribe via the NotANumber site.
About Ian Ozsvald - author of High Performance Python (2nd edition), trainer for Higher Performance Python, Successful Data Science Projects and Software Engineering for Data Scientists, team coach and strategic advisor. I'm also on twitter, LinkedIn and GitHub.
Now some jobs…
Jobs are provided by readers, if you’re growing your team then reply to this and we can add a relevant job here. This list has 1,500+ subscribers. Your first job listing is free and it'll go to all 1,500 subscribers 3 times over 6 weeks, subsequent posts are charged.
Senior Cloud Platform Applications Engineer, Medidata
our team at Medidata is hiring a Senior Cloud Platform Applications Engineer in the London office. Medidata is a massive software company for clinical trials and our team focus on developing the Sensor Cloud, a technology with capabilities in ingesting, normalizing, and analyzing physiological data collected from wearable sensors and remote devices. We offer a good salary and great benefits !!
- Rate:
- Location: Hammersmith, London
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link
Natural Language Processing Engineer
In this role, NLP engineers will:
Collaborate with a multicultural team of engineers whose focus is in building information extraction pipelines operating on various biomedical texts Leverage a wide variety of techniques ranging from linguistic rules to transformers and deep neural networks in their day to day work Research, experiment with and implement state of the art approaches to named entity recognition, relationship extraction entity linking and document classification Work with professionally curated biomedical text data to both evaluate and continuously iterate on NLP solutions Produce performant and production quality code following best practices adopted by the team Improve (in performance, accuracy, scalability, security etc...) existing solutions to NLP problems
Successful candidates will have:
Master’s degree in Computer Science, Mathematics or a related technical field 2+ years experience working as an NLP or ML Engineer solving problems related to text processing Excellent knowledge of Python and related libraries for working with data and training models (e.g. pandas, PyTorch) Solid understanding of modern software development practices (testing, version control, documentation, etc…) Excellent knowledge of modern natural language processing tools and techniques Excellent understanding of the fundamentals of machine learning A product and user-centric mindset
- Rate:
- Location: London/Hybrid
- Contact: [email protected] 07730 893 999 (please mention this list when you get in touch)
- Side reading: link, link
Senior Data Engineer at Causaly
We are looking for a Senior Data Engineer to join our Applied AI team.
Gather and understand data based on business requirements. Import big data (millions of records) from various formats (e.g. CSV, XML, SQL, JSON) to BigQuery. Process data on BigQuery using SQL, i.e. sanitize fields, aggregate records, combine with external data sources. Implement and maintain highly performant data pipelines with the industry’s best practices and technologies for scalability, fault tolerance and reliability. Build the necessary tools for monitoring, auditing, exporting and gleaning insights from our data pipelines Work with multiple stakeholders including software, machine learning, NLP and knowledge engineers, data curation specialists, and product owners to ensure all teams have a good understanding of the data and are using them in the right way.
Successful candidates will have:
Master’s degree in Computer Science, Mathematics or a related technical field 5+ years experience in backend data processing and data pipelines Excellent knowledge of Python and related libraries for working with data (e.g. pandas, Airflow) Solid understanding of modern software development practices (testing, version control, documentation, etc…) Excellent knowledge of data processing principles A product and user-centric mindset Proficiency in Git version control
- Rate:
- Location: London/Hybrid
- Contact: [email protected] 07730 893 999 (please mention this list when you get in touch)
- Side reading: link, link
Data Engineering Lead - Purpose
This is an exciting opportunity to join a diverse team of strategists, campaigners and creatives to tackle some of the world's most pressing challenges at an impressive scale.
- Rate:
- Location: London OR Remote
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link
Mid/Senior Python Software Engineer at an iGambling Startup (via recruiter: Difference Digital)
This role is for a software start-up, although is a part of a much larger established group, so they have solid finance behind them. You would be working on iGaming/online Gambling products. As well as working on the product itself you would also work on improving the backend application architecture for performance, scalability and robustness, reducing complexity and making development easier.
Alongside Python, experience of one or more of the following would be useful: Flask, REST, APIs, OOP, TDD, databases (Datastore, MySQL, Postgres, MongoDB), Git, Microservices, Websocket, Go, Java, PHP, Javascript, GCP.
- Rate: Up to £90k
- Location: Hybrid - 2 days per week in office opposite Victoria station
- Contact: [email protected] (please mention this list when you get in touch)
Data Scientist at Trust Power, Permanent
Trust Power is an energy data startup. Our app, "Loop", connects to a home's smart meters, collects half-hourly usage data and combines with contextual data to provide personalised advice on how to reduce costs and carbon emissions. We have a rapidly growing customer base and lots of interesting data challenges to overcome. You'll be working in a highly skilled team, fully empowered to use your skills to help our customers through the current energy crisis and beyond; transforming UK homes into the low carbon homes of the future. We're looking for a mid to senior level data scientist with a bias for action and great communication skills.
- Rate:
- Location: Oxford on site or hybrid (~1 day/week in office minimum)
- Contact: [email protected] 07986740195 (please mention this list when you get in touch)
- Side reading: link