Fixing your data science projects, valuation, rubber ducking and new ML tools
Tips for fixing Data Science projects from our Global conference, valuation, rubber ducking
Further below are 9 jobs including Senior and Research Data Science and Data Engineering positions at companies like (the very lovely) Coefficient Systems, Ocado and the Metropolitan Police
Slowly I catch up on my silly backlog. Infants truly suck all of your time (I'm finding the 2+4+6am interruptions to be the most costly right now, sigh). But they're also so much fun! Watching my child try to reason through whether the thing up ahead is a train or a tram (pantograph? 2 rails? carriages? what's the difference!) is wonderful.
Our monthly PyDataLondon meetup (RT it) is on next Tuesday, my buddy Nick will be speaking on "functional team embedding" (he's got a ton of experience between running teams at Google, Facebook and startups) - you should attend.
I'll be talking at PyDataCambridge in 2 weeks on Building Successful Data Science Projects - this is an updated run from my well-received PyDataLondon talk earlier last year. I'll also be talking a tiny bit about my ideas on building a forum for data science leaders to talk about what-goes-wrong-and-how-to-avoid-it. I'd love to see you there in person.
The CfP is open for PyDataLondon 2023 conference on June 2-4. You should get your talk proposals in and think about whether your organisation will want to sponsor to get in front of great DS and DEng candidates. I'll run another of my Executives at PyData discussion sessions alongside the usual wide range of talks and workshops.
Further below you'll see the jobs section - note that Coefficient Systems are hiring a Senior Data Scientist and co-organiser John is a PyDataLondon organiser (ex PyDataBristol organiser) and they run a very nice company. If you're in the market, definitely check the job ad.
New courses - Software Engineering and Higher Performance
I've (finally - did I mention I have an infant?) re-listed two of my public courses.
On April 12-14 with Zoom I'll run my Software Engineering for Data Scientists course - you should attend if you need to write tests and move from Notebooks to building maintainable library code.
On May 3-5 with Zoom I'll run my Higher Performance Python course - you should attend if your scientific code is slow and scales poorly. We'll cover profiling so you know what's slow, then we'll cover all the ways to make it faster including speeding-up Pandas and scaling to bigger-than-Pandas datasets.
Reply directly to this email if you've got questions.
Data science project techniques
I'll add a couple of notes below from our virtual Global conference discussion session and a perhaps-thought-provoking valuation example below.
Executives at PyData Global 2022 write-up
I noted recently that I ran a session with colleagues Lauren Oldja (of PyDataNYC) and Douglas Squirrel (who runs the SquirrelSquadron) at our virtual PyDataGlobal conference. We had a 2 hour discussion stretching between curated questions and then free-form problems. We wrote this up and we got it published on the NumFOCUS account just a couple of weeks back. Having run these sessions for 6 years, this is the first time I've tried to make an "asset" as an outcome from the session, now there's something to build upon for future iterations.
The write-up has a link to the 2 hour video if you'd rather listen along.
We talk through:
- What tools and processes support a remote-first culture?
- How do you get good projects for your backlog?
- Is the T-shaped team (deep specialism & broad shallow knowledge) the ideal? Is there a better profile for a team?
- How do you get DS to work with other business units?
- Which tools help data science teams?
- In what sort of organizations does DS work well?
On remote-first:
Onboarding is surprisingly important. If the new hire gets to meet the bosses and has a “buddy” outside their direct reporting structure, they’ll feel closer to the team very quickly and will be more self-sufficient in navigating remote work.
On the back-log:
A useful technique is to hold co-creation workshops with potential clients. If one simply asks “what do you want,” the answer is likely to be something like “more reporting” or “a better dashboard”, which potentially reflects a gap in understanding what business value data science solutions can bring. Instead, focus your requirements gathering on building empathy for their pain points or soliciting their big ideas. Try to figure out what’s really valuable to them; an automated report or dashboard may still be the first step towards building rapport with your team.
On T-shaped teams:
From those who had experience working in the T-shape model, there was consensus that it can work well. Coupling a data scientist with a good data engineer is “a joy” — the complementary skills become a force multiplier to help both members achieve a larger goal far more efficiently.
On collaboration:
If a business unit focuses on “value streams” rather than fixed traditional business units, it can form around problems. (This is a very enlightened view of agile team organization!) These value-stream teams might use data science (or any other specialization) to solve the teams they encounter.
One must avoid having data science team members disappear for three months to write a solution. Instead focus on regular client collaboration with regular deployments of new value, starting from whatever’s the easiest thing to deliver to show progress. This unlocks new learning and builds confidence, delivering value while tightening the feedback loop.
If management has set bad priorities or under-resourced a team, it is very acceptable to point this out. It is ok to “be the bad person and pour water on the fire” if the project is at risk; it is in fact your professional obligation.
Read the full write-up here.
Project valuation
With each client engagement I try to get smarter at assigning a value to project components, both to flush out "what we're ignorant about" and to figure out "is the potential value worth the risks we know?". Putting a price on stuff (i.e. money or time) really helps with prioritisation and I'm keyed up about "asking the right questions" and "choosing the most sensible tasks to solve" - at least for R&D on early stage projects.
This screenshot caught my eye on twitter where the "dollar hourly cost" of participants is included in a calendar entry, so the "assumed free" cost of the call is $600 (I'm guessing this is just a mock-up, but maybe you know differently?). Surfacing the price-cost of the call, and watching it balloon as the participant-count rises, could really help people think about the consequences of just adding lots of folk. Do you do the same when figuring out the value and cost of stages of your data science project?
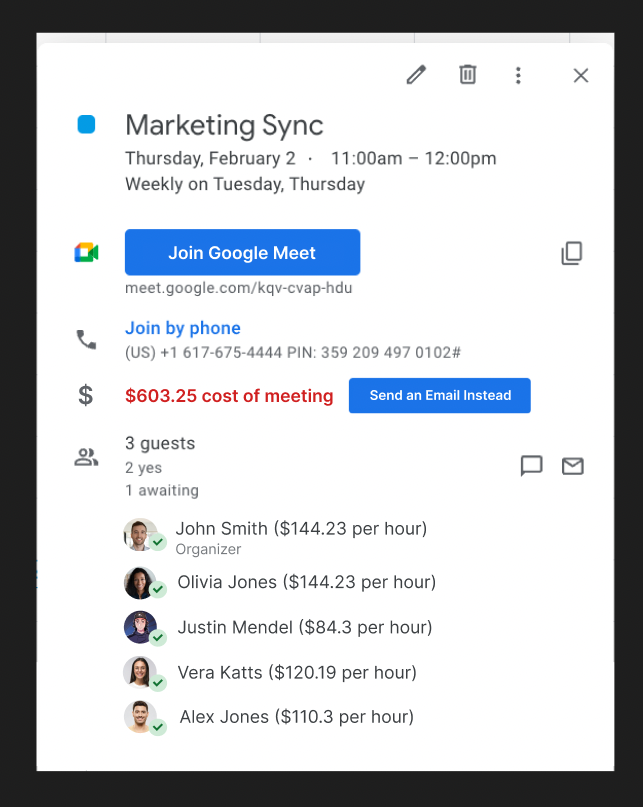
Now I know that "that's the cost of the call" and that's not the same as the cost or value of stages in a data science project. Many DS folks I coach haven't thought about "the cost" or "the value" of our outcomes, they're just "the end result of my clever thinking". Adding a price to the outcome really helps you focus on what's important to the wider business.
Surfacing the true cost of positive and negative outcomes from projects is normally hard, but once you've got an idea on it (do we make money? save time? reduce churn so reducing the need for acquisition?) it is very powerful when prioritising and choosing how chunks of a year will be spent. Do you have any interesting examples to share from your data projects?
Open source
Bulk labeling
The prolific Vincent Warmerdam has updated his bulk-labelling tool for (I believe light) labelling jobs. Have any of you tried it? There's a video showing the selection of examples on a dimensionality-reduction plot which collects the right sentences together for eyeballing prior to assigning a label. I think in the right situation this could be pretty sweet for quick data preparation. Images are supported too and the comments list some alternative tools.
Embetter
Vincent's embetter (RT) helps you
...quickly get sentence/image embeddings working in scikit-learn pipelines.
# make a pipeline that consumes the `text` DataFrame column
# use the Huggingface sentence transformer->384d vector
text_emb_pipeline = make_pipeline(
ColumnGrabber("text"),
SentenceEncoder('all-MiniLM-L6-v2')
)
# add it to an ML pipeline
text_clf_pipeline = make_pipeline(
text_emb_pipeline,
LogisticRegression()
)
The text example is nice to read - specify how to grab a text column in a DataFrame, make 1-liner embedding transform from an off-the-shelf model, then add a classifier that feeds off of the embedding result and train. Pretty sweet. There's an image example too. Have you tried this? Any joy?
Do you know someone who might save time and iterate quicker if they tried it?
NLTK and NetworkX updates
NLTK 3.8.1 has been released to include Python 3.11 support plus a bunch of improvements. NetworkX 3.0 has Python 3.11 support and has reworked the internal numpy usage so numpy.matrix has been replaced and scipy.sparse arrays are supported plus numpy.random.Generator support. Also there's a new plugin-based architecture for computational backends and new TikZ LaTeX graph support.
Random
fosstodon account on Mastodon - finding who to follow
Given the latest announce that Twitter is cutting off the free API, I'm reminded that my Mastodon account is very lonely (and underused, but that's for me to fix). I searched in Twitter for "mastodon" and clicked the People link, that lists a bunch of people I follow who have "mastodon" visible in their bio. A example is Gael Varoquaux or Andreas Muller both of sklearn.
Back at my https://fosstodon.org/@ianozsvald Mastodon page I can search for their mastodon links (copy/pasting from their profiles) and then easily follow them in my fosstodon account. Similarly I've updated my Twitter profile to mention both mastodon and with my fosstodon address.
Rubber ducking
Štefan makes an interesting point about rubber ducking - the art of talking to something inanimate which lets you figure out your own answer, without needing to interrupt a colleague:
ChatGPT is an excellent rubber duck. It is so hopeless for even slightly complex problems, it forces you to explain the problem to it like to a child. As It progresses and you clarify and rephrase your questions, a solution appears in your mind. You talk to yourself - through It.
Talking with various friends I'm sort-of open to the idea that ChatGPT and friends have value if you know the domain so you can tell when it is confidently lying, but that makes it much less useful for anything you don't know. One buddy used it to help them figure out how to solve a statistics problem including code, by building up the problem and asking for solutions. They could verify the solution and "it worked". It feels just useful enough to be dangerous.
Footnotes
See recent issues of this newsletter for a dive back in time. Subscribe via the NotANumber site.
About Ian Ozsvald - author of High Performance Python (2nd edition), trainer for Higher Performance Python, Successful Data Science Projects and Software Engineering for Data Scientists, team coach and strategic advisor. I'm also on twitter, LinkedIn and GitHub.
Now some jobs…
Jobs are provided by readers, if you’re growing your team then reply to this and we can add a relevant job here. This list has 1,500+ subscribers. Your first job listing is free and it'll go to all 1,500 subscribers 3 times over 6 weeks, subsequent posts are charged.
Data Scientist
M&G plc is an international savings and investments business, as at 30 June 2022, we had £348.9 billion of assets under management and administration.
Analytics – Data Science Team is looking for a Data Scientist to work on projects ranging from Quantitative Finance to NLP. Some recent projects include: - ML applications in ESG data - Topic modelling and sentiment analysis - Portfolio Optimization
The work will revolve around the following: - Build data ingestion pipelines (with data sourced from SFTP & third party APIs) - Explore data and extract insights using Machine Learning models like Random Forest, XGBoost and (sometimes) Neural Networks - Productionize the solution (build CI/CD pipelines with the help of friendly DevOps engineer)
- Rate:
- Location: London
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link
Senior Data Scientist at Coefficient Systems Ltd
We are looking for an enthusiastic and pragmatic Senior Data Scientist with 5+ years’ experience to join the Coefficient team full-time. We are a “full-stack” data consultancy delivering end-to-end data science, engineering and ML solutions. We’re passionate about open source, open data, agile delivery and building a culture of excellence.
This is our first Senior Data Science role, so you can expect to work closely with the CEO and to take a tech lead role for some of our projects. You'll be at the heart of project delivery including hands-on coding, code reviews, delivering Python workshops, and mentoring others. You'll be working on projects with multiple clients across different industries, including clients in the UK public sector, financial services, healthcare, app startups and beyond.
Our goal is to promote a diverse, inclusive and empowering culture at Coefficient with people who enjoy sharing their knowledge and passion with others. We aim to be best-in-class at what we do, and we want to work with people who share that same attitude.
- Rate: £80-90K
- Location: London/remote (we meet in London several times per month)
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link, link, link
(Senior) Data Scientist, Ocado Technology, Permanent, Hatfield UK
Ocado technology has developed an end-to-end retail solution, the Ocado Smart Platform (OSP) which it serves a growing list of major partner organisations across the globe. We currently have three open roles in the ecommerce stream.
Our team focuses on machine learning and optimisation problems for the web shop - from recommending products to customers, to ranking optimisation and intelligent substitutions. Our data is stored in Google BigQuery, we work primarily in Python for machine learning and use frameworks such as Apache Beam and TensorFlow. We are looking for someone with experience in developing and optimising data science products as we seek to improve the personalisation capabilities and their performance for OSP.
- Rate:
- Location: Hatfield, UK
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link, link, link
Request for proposals – Database Integration Project
Global Canopy is looking for a consultancy that will work with us on the second phase of development of our Forest IQ database. This groundbreaking project brings together a number of leading environmental organisations, and the best available data on corporate performance on deforestation, to help financial institutions understand their exposure and move rapidly towards deforestation-free portfolios.
- Rate: The maximum budget available for this work is NOK 1,000,000 (including VAT)., approximately £80,000 GBP.
- Location: Oxford/Remote
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link
Machine Learning Researcher - Ocado Technology, Permanent
We are looking for a Machine Learning Scientist specialised in Reinforcement Learning who can help us improve our autonomous bot control systems through the development of novel algorithms. The ideal candidate will draw on previous expertise from academia or equivalent practical experience. The role will report to the Head of Data in Fulfilment but will be given the appropriate latitude and autonomy to focus purely on this outcome. Roles and responsibilities will include:
- Rate:
- Location: London | Hybrid (2 days office)
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link, link
Analyst and Lead Analyst at the Metropolitan Police Strategic Insight Unit
The Met is recruiting a data analyst and a lead analyst to join its Strategic Insight Unit (SIU). We are looking for people who are keen on working with large datasets using Python, R, SQL or similar software. The SIU is a small, multi-disciplinary team that combines advanced data analytics and social research skills with expertise in operational policing to empirically answer questions linked with public safety, good governance, and the effectiveness of policing methods.
- Rate: £32,194 to £34,452 (Analyst) / £39,469 to £47,089 (Lead Analyst), plus location allowance
- Location: Hybrid, at least one day per week at New Scotland Yard, London
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link, link
Web Scraper/Data Engineer
Looking to a hire a full time Web Scraper to join our Data Engineering team, scrapy and SQL are desired skills, as a bonus you'll have an interest in art.
- Rate:
- Location: London, Remote
- Contact: [email protected] (please mention this list when you get in touch)
- Side reading: link
Data Scientist at Kantar - Media Division
Our data science team (~15 people in London ~5 in Brazil) is hiring a Data Scientist to work on data science and machine learning projects in the media industry, working with broadcasters and advertisers, media agencies and industry committees. A major area of focus for this role involves the integration of multiple data sources, with a view of creating new Hybrid Datasets that leverage and extract the best out of the original ones.
The role requires advance programming skills with Python and related data science libraries (pandas, numpy, scipy, sklearn, etc) to develop new and enhance existing mathematical, statistical and machine learning algorithms; assist our integration to cloud-based computing and storage solutions, through Databricks and Azure; take the lead in data science projects, run independent project management; interact with colleagues, clients, and partners as appropriate to identify product requirements.
- Rate: £40k - £50K plus benefits
- Location: Hybrid remote and in Farringdon/Clerkenwell offices
- Contact: [email protected] 07856089264 (please mention this list when you get in touch)
- Side reading: link
Data Scientist at Kantar - Media Division in London
Our data science team (~15 people in London ~5 in Brazil) is hiring a Data Scientist to work on cross-media audience measurement, consumer targeting, market research and in-depth intelligence into paid, owned and earned media. Redefining client requests into concrete items and best modelling choices is a crucial part of this job. Attention to details, critical thinking, and clear communication are vital skills.
The role requires advance programming skills with Python and related data science libraries (pandas, numpy, scipy, etc) to develop new and enhance existing mathematical, statistical and machine learning algorithms; assist our integration to cloud-based computing and storage solutions, through Databricks and Azure; take the lead in data science projects, run independent project management; interact with colleagues, clients, and partners as appropriate to identify product requirements.
- Rate: £40K-£50K + benefits
- Location: Hybrid remote and in Clerkenwell/Farringdon offices
- Contact: [email protected] 07856089264 (please mention this list when you get in touch)
- Side reading: link