Experiment with local LLMs with llama.cpp
Experiment with local LLMs with llama.cpp
Further below are 6 jobs including: AI and Cloud Engineers at the Incubator for Artificial Intelligence, UK wide, Data Science Intern at Coefficient, Data Scientist at Coefficient Systems Ltd, Data Science Educator - FourthRev with the University of Cambridge, Data Scientist Insights (Customer Experience & Product) at Catawiki, Permanent, Amsterdam, Senior machine learning engineer - NLP/DL
So this issue is a bit more explorative - I've been playing with my local GPU (NVIDIA 3050Ti on my laptop) with a view to running an external GPU (NVIDIA RTX 3090) for both accelerated Pandas and LLM experimentation. I've got some notes on an LLM-for-coding paper, CuDF for Pandas and llama.cpp which is a CPU-based LLM runner. Next issue maybe I'll have done some benchmarking with CuDF.
My RebelAI leadership peer group is growing, I've got another reflection from a "crit" call below.
Successful Data Science Projects and NEW Fast Pandas course coming in February
If you're interesting in being notified of any of my upcoming courses (plus receiving a 10% discount code) please fill in my course survey and I'll email you back.
In February I run another of my Successful Data Science Projects courses virtually, aimed at anyone who sets up their own projects, who has had failures and who wants to turn these into successes. We deconstruct failures, talk about best practice and set you up with new techniques for success.
- Successful Data Science Projects (22-23rd February)
- Fast Pandas (date TBC in March) - lots of ways to make your Pandas run faster - reply to this for details
- Higher Performance Python (date TBC in March) - profile to find bottlenecks, compile, make Pandas faster and scale with Dask and even to accelerate on GPUs
- Software Engineering for Data Scientists (date TBC in March)
- Scientific Python Profiling (in-house only) - focused on quants who want to profile to find opportunities for speed-ups
RebelAI - running outsourced DS teams
Last issue I talked on my RebelAI peer leadership - a private group of excellent data scientists turned leaders who have challenges to solve (reply to this if you want to hear more).
In a recent conversation we talked through the challenge of running an outsourced data science team.
One difficulty raised is when an outsourced provider drives the hiring, leading to a mix of quality levels in the resulting team. One suggestions was to get far more involved in the hiring process, the more interesting challenge back was to ask "but could you bring it in-house instead?".
Faced with the issue of cultural barriers leading to suboptimal outcomes - notably a people-heavy remote process, we talked about having an accountability plan and pairing the outsourced team with an on-site team. Going beyond more-detailed-monitoring we talked about having 1-on-1 calls that help the out-sourced devs - letting them explain what's good and bad from their point of view.
These approaches had worked well for others on the call, leading to an improvement in quality and greater visibility on where potential automation might be being missed, so it could be fixed, plus reporting to note where the provider was falling down for accountability.
This week we ran a brainstorm session (called "cake" - you bring cake of course) on LLMs to figure out what we're doing with them, what works and what's dangerous. I'll write up some notes in a future issue.
If you think you could benefit from joining this peer-supported leadership group to help you through the challenges you face, reply to this newsletter. I'm looking to add a small second group to my original 10 from February.
LLMs and GPUs
Running an LLM locally with llama.cpp on the CPU
I gave a lightning talk at PyDataLondon this week on the very interesting llama.cpp (tweet). If you give it an LLM it'll run it on the CPU (at a reasonable-enough speed) without sending any data off the machine. You can prototype ideas on company data, on your laptop, without any negotiated agreements. That feels pretty powerful.
The slides show me running live demos of the llama2 text chat model, the large 34B parameter WizardCoder Python coding model and the 7B parameter llava multi-modal image model. WizardCoder wrote some re code and llava queried an image for car make, registration and details (I was thinking about a PoC for an image-upload verifier for insurance use).
The two critical things are:
llama.cppwas created a year back - prior to that you had to run a large LLM on a big GPU (note that an H100 costs £30,000)llama.cppcan run quantised models (think: compression - smaller files, but less detailed knowledge and higher chance of word vomit)
In my example I was running Q4 and Q5 quantised models - these drop the 16bit or so original parameter weights to circa 5 bits, dramatically shrinking the model size without reducing model perplexity too much. As a consequence it runs pretty quick (semi-real-time) on a multi-core laptop just on the CPU.
llama.cpp partially on the GPU
In addition you can offload some of the work to a GPU. I've recompiled to support cuBLAS on my laptop's nvidia 3050Ti and I get a 30-50% speed improvement.
Using $ ./main -m models/llama-2-7b-chat.Q5_K_M.gguf -i --color -n 256 --repeat_penalty 1.0 -ngl 22 the -ngl 22 says to send 22 layers to the VRAM for GPU processing, this just about fills my 4GB of built-in GPU VRAM.
The llama-2-7b Q5 model goes from 5 tokens/sec to 10 tokens/sec when I move it to the GPU. The much larger 34B parameter wizardcoder doesn't change much as only a few layers fit on this small GPU.
Next I need to figure out how to get my external GPU running.
Profiling GPUs
Working with llama.cpp with GPU support got me thinking about profiling the GPU and this pointed me at nvtop:
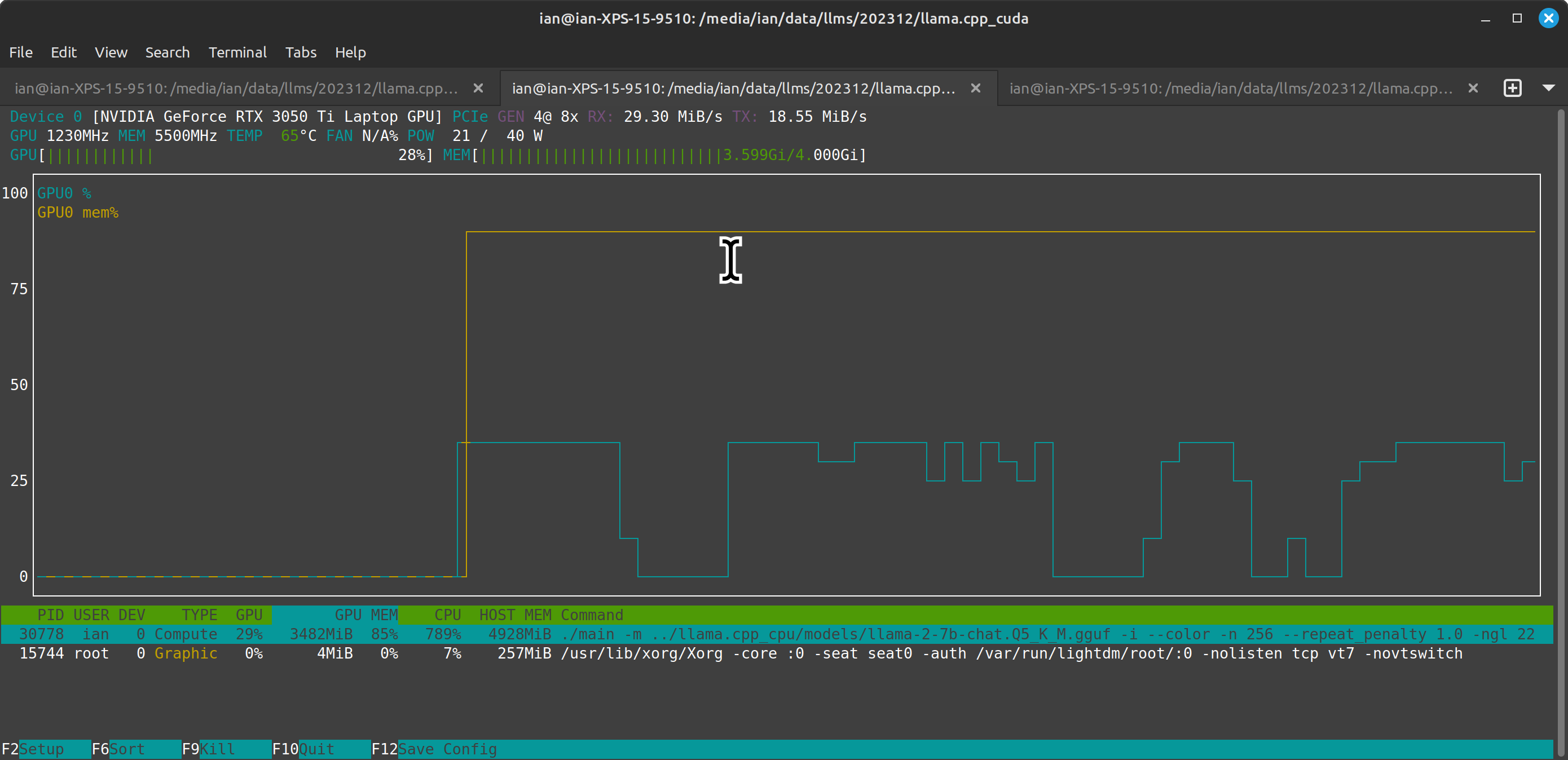
Above (tweet) you can see a trace of GPU-based calculation and memory utilisation (scaled as a percentage), with a list of the processes on the GPU+CPU and some details of your card. We can see that main running llama.cpp is mostly on the CPU with a little bit of work using all the VRAM on the GPU.
When I first tried the cuBLAS GPU compilation of llama.cpp it segfaulted (I hardcoded the wrong cuda capability), then I compiled without GPU support by mistake and it didn't run any faster - nvtop showed the process clearly wasn't touching the GPU. After that I recompiled and got the above trace.
LLMs - Program Synthesis
I'm looking back at a paper from 2021 on "Program Synthesis with Large Language Models" (arxiv), one of the early ground breaking papers that showed how custom LLMs (244M-137B parameter models) performed writing Python code.
Section 4.4 was interesting which talks on asking the model to "Write a python function to remove first and last occurrence of a given character from the string". The paper notes:
All of the solutions emitted by our best model pass all three test cases, but the test cases do not fully test the function's semantics. None of the test cases use strings which contain more than two of the specified character. Upon inspection, we realized that all of the sampled solutions would simply delete all occurrences of the specified character. ... Thus, we can roughly estimate that something like 12% of what we are counting as solutions would fail to satisfy adversarially generated test cases.
They're noting that if they ask a clear question and give assert-based test cases, they can get back code that "looks right" but isn't solving the problem as a human might solve it. They build a set of adversarial tests (designed to poke holes against the existing tests) and that exposes a deeper issue.
When I teach my Software Engineer for Data Scientists course we talk about using ChatGPT and CoPilot and what we've seen. I think learning to build good tests (which we might do with an LLM) is going to be a growing requirement as we use LLMs (e.g. CoPilot) to write our code, alongside pair-programming with a human and using defensive techniques like code reviews. I cover all of this in my course because...it feels like we need all these checks and balances whilst we experiment with these new tools. Times continue to be interesting.
Have you faced issues with auto-generated code looking ok...but really not doing the right job in a subtle way? Reply and let me know if so, I'm always keen to gain new stories.
Trialling CuDF for faster Pandas along with PyTorch for LLMs
This is just a first note - getting CuDF installed to use an NVIDIA GPU to accelerate Pandas is a bit of a pain. I'll give you a tip - you may want to avoid the suggested pip installation notes and go straight to using conda as described below.
In PyPI the default cudf package points in a roundabout way to the installer. If you try cudf-cu12 you get different guidance. cu12 is good for Driver 525.60.13 - this is documented on their proper installation page, if you install e.g. cu11 when you need cu12 then you just get unhelpful error messages. Overall I spent 30+ minutes failing to use pip to install a working Python environment.
Next I tried conda and "it just worked". That's the first time I've gone back to a full-on conda install in a bunch of years.
Assuming the GPU is correctly visible the in Jupyter or IPython n [1]: %load_ext cudf.pandas or import cudf (in a plain Python shell) should succeed, else I get an CUDARuntimeError: cudaErrorUnknown: unknown error. Not the most helpful error message. Sometimes after sleeping the GPU seemed to disappear (but maybe that issue has gone away now).
I had a similar issue with PyTorch losing visibility on the GPU, this was easily tested in the activated environment with $ python -c "import torch; print(torch.cuda.is_available())" (which either prints True or fails with a long trace). A reboot seemed to be needed.
More next time when I've done something useful with these :-) Once upon a time I used to do a lot of GPU experimentation - and getting them working was just as tricky back then.
Have you had joy with cudf for Pandas? I'd love to hear if so!
libmamba
Wanting to experiment with CuDF from the RAPIDS NVIDIA project (for faster Pandas) I used their installation guide to install using conda. However RAPIDS uses libmamba and that required a little update to my setup.
This post from 2022 details making libmamba the default resolution engine. There are details here to undo the change if you needed it.
The update was easy:
conda update -n base conda
conda install -n base conda-libmamba-solver
conda config --set solver libmamba
and then the installation process suggested by RAPIDS for CuDF worked just fine:
conda create --solver=libmamba -n rapids-23.12 -c rapidsai -c conda-forge -c nvidia \
cudf=23.12 python=3.10 cuda-version=12.0
Plotting in Polars
I see Marco Gorelli posting that plotting is enabled in Polars via hvplot:

Footnotes
See recent issues of this newsletter for a dive back in time. Subscribe via the NotANumber site.
About Ian Ozsvald - author of High Performance Python (2nd edition), trainer for Higher Performance Python, Successful Data Science Projects and Software Engineering for Data Scientists, team coach and strategic advisor. I'm also on twitter, LinkedIn and GitHub.
Now some jobs…
Jobs are provided by readers, if you’re growing your team then reply to this and we can add a relevant job here. This list has 1,600+ subscribers. Your first job listing is free and it'll go to all 1,600 subscribers 3 times over 6 weeks, subsequent posts are charged.
AI and Cloud Engineers at the Incubator for Artificial Intelligence, UK wide
The Government is establishing an elite team of highly empowered technical experts at the heart of government. Their mission is to help departments harness the potential of AI to improve lives and the delivery of public services.
We're looking for AI, cloud and data engineers to help build the tools and infrastructure for AI across the public sector.
- Rate: £64,700 - £149,990
- Location: Bristol, Glasgow, London, Manchester, York
- Contact: ai@no10.gov.uk (please mention this list when you get in touch)
- Side reading: link
Data Science Intern at Coefficient
We are looking for a Data Science Intern to join the Coefficient team full-time for 3 months. A permanent role at Coefficient may be offered depending on performance. You'll be working on projects with multiple clients across different industries, including the UK public sector, financial services, healthcare, app startups and beyond. You can expect hands-on experience delivering data science & engineering projects for our clients as well as working on our own products. You can also expect plenty of mentoring and guidance along the way: we aim to be best-in-class at what we do, and we want to work with people who share that same attitude.
We'd love to hear from you if you: Are comfortable using Python and SQL for data analysis, data science, and/or machine learning. Have used any libraries in the Python Open Data Science Stack (e.g. pandas, NumPy, matplotlib, Seaborn, scikit-learn). Enjoy sharing your knowledge, experience, and passion. Have great communication skills. You will be expected to write and contribute towards presentation slide decks to showcase our work during sprint reviews and client project demos.
- Rate: £28,000
- Location: London, Hybrid
- Contact: jobs@coefficient.ai (please mention this list when you get in touch)
- Side reading: link, link, link
Data Scientist at Coefficient Systems Ltd
We are looking for a Data Scientist to join the Coefficient team full-time. You can expect hands-on experience delivering data science & engineering projects for our clients across multiple industries, from financial services to healthcare to app startups and beyond. This is no ordinary Data Scientist role. You will also be delivering Python workshops, mentoring junior developers and taking a lead on some of our own product ideas. We aim to be best in class at what we do, and we want to work with people who share the same attitude.
You may be a fit for this role if you: Have at least 1-2 years of experience as a Data Analyst or Data Scientist, using tools such as Python for data analysis, data science, and/or machine learning. Have used any libraries in the Python Open Data Science Stack (e.g. pandas, NumPy, matplotlib, Seaborn, scikit-learn). Can suggest how to solve someone’s problem using good analytical skills e.g. SQL. Have previous consulting experience. Have experience with teaching and great communication skills. Enjoy sharing your knowledge, experience, and passion with others.
- Rate: £40,000-£45,000 depending on experience
- Location: London, Hybrid
- Contact: jobs@coefficient.ai (please mention this list when you get in touch)
- Side reading: link, link, link
Data Science Educator - FourthRev with the University of Cambridge
As a Data Science Educator / Subject Matter Expert at FourthRev, you will leverage your expertise to shape a transformative online learning experience. You will work at the forefront of curriculum development, ensuring that every learner is equipped with industry-relevant skills, setting them on a path to success in the digital economy. You’ll collaborate in the creation of content from written materials and storyboards to real-world case studies and screen-captured tutorials.
If you have expertise in subjects like time series analysis, NLP, machine learning concepts, linear/polynomial/logistic regression, decision trees, random forest, ensemble methods: bagging and boosting, XGBoost, neural networks, deep learning (Tensorflow) and model tuning - and a passion for teaching the next generation of business-focused Data Scientists, we would love to hear from you.
- Rate: Approx. £200 per day
- Location: Remote
- Contact: Apply here (https://jobs.workable.com/view/1VhytY2jfjB3SQeB75SUu1/remote-subject-matter-expert---data-science-(6-month-contract)-in-london-at-fourthrev) or contact d.avery@fourthrev.com to discuss (please mention this list when you get in touch)
- Side reading: link, link, link
Data Scientist Insights (Customer Experience & Product) at Catawiki, Permanent, Amsterdam
We are looking for a Data Scientist to work with our Customer Experience (CX) and Product teams to enable them to make operational and strategic decisions backed by data. You will help them not only to define and measure their success metrics but also to provide insights and improvement opportunities.
You will be part of the Data Science Insights team, helping us make sense of our data, finding actionable insights and creating self-service opportunities by combining data from multiple sources and working closely together with your colleagues in other departments.
- Rate: -
- Location: Amsterdam, The Netherlands
- Contact: Iria Kidricki i.kidricki@catawiki.nl (please mention this list when you get in touch)
- Side reading: link, link
Senior machine learning engineer - NLP/DL
You will be part of the ML team at Mavenoid, shaping the next product features to help people around the world get better support for their hardware devices. The core of your work will be to understand users’ questions and problems to fill the semantic gap.
The incoming data consists mostly of textual conversations, search queries (more than 600Ks conversations or 2Ms of search queries per month), and documents. You will help to process this data and assess new NLP models to build and improve the set of ML features in the product.
- Rate: 90K+ euros
- Location: remote - EU
- Contact: gdupont@mavenoid.com (please mention this list when you get in touch)
- Side reading: link